Sound Synthesis with
Auditory Distortion
Products
Gary S. Kendall,∗ Christopher Haworth,†
and Rodrigo F. C ´adiz∗∗
∗Artillerigatan 40
114 45 Stockholm, Suecia
garyskendall@me.com
†Faculty of Music
Universidad de Oxford
Calle. Aldate’s,
Oxford, OX1 1 DB, Reino Unido
christopher.p.haworth@gmail.com
∗∗Center for Research in Audio Technologies,
Music Institute
Pontificia Universidad Cat ´olica de Chile
Av. Jaime Guzm ´an E. 3300
Providencia, Santiago, Chile 7511261
rcadiz@uc.cl
Abstracto: This article describes methods of sound synthesis based on auditory distortion products, often called
combination tones. En 1856, Helmholtz was the first to identify sum and difference tones as products of auditory
distorsión. Today this phenomenon is well studied in the context of otoacoustic emissions, and the “distortion” is
understood as a product of what is termed the cochlear amplifier. These tones have had a rich history in the music
of improvisers and drone artists. Until now, the use of distortion tones in technological music has largely been
rudimentary and dependent on very high amplitudes in order for the distortion products to be heard by audiences.
Discussed here are synthesis methods to render these tones more easily audible and lend them the dynamic properties
of traditional acoustic sound, thus making auditory distortion a practical domain for sound synthesis. An adaptation
of single-sideband synthesis is particularly effective for capturing the dynamic properties of audio inputs in real time.
Also presented is an analytic solution for matching up to four harmonics of a target spectrum. Most interestingly, el
spatial imagery produced by these techniques is very distinctive, and over loudspeakers the normal assumptions of
spatial hearing do not apply. Audio examples are provided that illustrate the discussion.
This article describes methods of sound synthesis
based on auditory distortion products, often called
combination tones—methods that create controlled
auditory illusions of sound sources that are not
present in the physical signals reaching the lis-
tener’s ears. These illusions are, En realidad, products
of the neuromechanics of the listener’s auditory
system when stimulated by particular properties of
the physical sound. Numerous composers have used
auditory distortion products in their work, y el
effects of these distortion products—often described
as buzzing, ghostly tones located near to the head—
have been experienced by many concert audiences.
Históricamente, the technology for generating auditory
distortion tones in musical contexts has been rather
rudimentary, initially constrained by the limita-
tions of analog equipment and always requiring high
sound levels that are uncomfortable for most listen-
ers. In this article, we describe methods of sound
synthesis that both exploit the precision of digital
Computer Music Journal, 38:4, páginas. 5–23, Invierno 2014
doi:10.1162/COMJ a 00265
C(cid:2) 2014 Instituto de Tecnología de Massachusetts.
signal processing and require only moderate sound
levels to produce controlled auditory illusions. Nuestro
goal is to open up the domain of sound synthesis
with auditory distortion products for significant
compositional exploration.
Auditory Distortion Products
There is a long history of research into what has
commonly been called combination tones (CTs).
Most studies of combination tones have used two
pure tones (es decir., sinusoids) as stimuli and stud-
ied the listener’s perception of a third tone, no
present in the original stimulus, but clearly audible
to the listener. En 1856 Hermann von Helmholtz
was the first to identify sum and difference tones
(von Helmholtz 1954). For two sinusoidal sig-
nals with frequencies f1 and f2 such that f2 >
f1, the sum and difference tones have the fre-
quencies f1 + f2 and f2 – f1 respectively. Más tarde,
Plomp (1965) identified many additional combi-
nation tones with the frequencies f1 + norte( f2 − f1)
Originally, it was thought that CTs occurred only at
Kendall et al.
5
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
5
1
9
7
1
6
7
5
/
C
oh
metro
_
a
_
0
0
2
6
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
high intensity levels that then drove the essentially
linear mechanics of the physical auditory system
into a nonlinear region. The original theory was that
a mechanical nonlinearity was located in the middle
ear or in the basilar membrane.
Goldstein (1967) provided a particularly thorough
investigation of CTs produced by two pure tones.
The frequency, amplitude, and phase of the dis-
tortion tones were determined using a method of
acoustic cancellation, first introduced by Zwicker
(1955). En tono rimbombante, Goldstein demonstrated that
CTs were present at even low stimulus levels and
thus could not be products of mechanical nonlinear-
ity in the way they were originally conceived.
The theory of mechanical nonlinearity has been
displaced after the recognition that parts of the
inner ear, específicamente, the outer hair cells of the
basilar membrane, act as an active amplification
sistema. So, rather than being a passive system
with nonlinearities, the ear is an active one, y
these nonlinearities are best explained in terms of
the workings of the cochlear amplifier (Gold 1948;
Kemp 1978). Seen from this perspective, CTs can
best be understood as subjective sounds that are
evoked by physical acoustic signals and generated
by the active components of the cochlea. Combi-
nation tones are exactly the same as otoacoustic
emissions, o, more specifically, distortion product
otoacoustic emissions. De paso, distortion prod-
uct otoacoustic emissions propagate back through
the middle ear and can be measured in the ear
canal. They are typical of healthy hearing systems
and their testing has become a common diagnostic
tool for identifying hearing disorders (Kemp 1978;
Johnsen and Elberling 1983). To be perfectly clear,
sin embargo, when experiencing distortion products as
a listener, it is the direct stimulation of the basilar
membrane that gives rise to the perception of sound,
not the acoustic emission in the ear canal. Esto es
why we use the term “distortion products” to refer
to the general phenomena throughout this article.
Of the many distortion products, two types are
particularly useful for music and sound synthesis
due to the ease with which listeners can hear and rec-
ognize them: the quadratic difference tone ( f2 – f1),
QDT, which obeys a square-law distortion and the
cubic difference tone (2 f1 – f2), CDT, which obeys
cubic-law distortion. Despite the commonalities
of their origins, there are considerable differences
between the two. The CDT is the most intense
distortion product and is directly observable to the
listener even when acoustic stimuli are at relatively
low intensity levels. Sin embargo, because the tone’s
frequency (2 f1 – f2) generally lies relatively close
to f1, it has seldom been commented on in mu-
sical contexts (a significant exception being Jean
Sibelius’s First Symphony, cf. Campbell and Greated
1994). The level of the CDT is highly dependent on
the ratio of the frequencies of the pure tones, f2 / f1,
with the highest level resulting from the lowest
ratio and thereafter quickly falling off (Goldstein
1967). There is a loss of over 20 dB between the
ratios of 1.1 y 1.3.
The QDT ( f2 – f1) requires a higher stimulus in-
tensity to be audible, but because the resultant tone’s
frequency generally lies far below the stimulus fre-
quencies and thus can be more easily recognized,
it has been a topic of musical discourse since its
discovery by Tartini in 1754. The QDT shows little
dependence on the ratio of the frequencies of the
pure tones; levels are again highest with the lowest
ratios and there is a roughly 10 dB loss between ratios
de 1.1 y 1.8 (Goldstein 1967). Even simple charac-
terizations of the differences between the CDT and
QDT are subject to debate, and our understanding is
frequently being updated by research.
A Study with Musical Tones
In a study easily related to musical tones, Pressnitzer
and Patterson (2001) focused on the contribution of
CTs to pitch, especially to the missing fundamental.
They utilized a harmonic tone complex instead
of the usual pair of pure tones. In their first
experimento, they used a series of in-phase pure
tones between 1.5 kHz and 2.5 kHz with a spacing
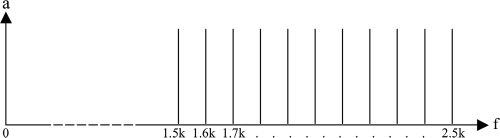
de 100 Hz, as shown in Figure 1. Using the same
cancellation technique as Goldstein, they measured
the resulting amplitude and phase of the first
four simultaneous distortion products at 100 Hz,
200 Hz, 300 Hz, y 400 Hz.
One consequence of employing the complex
of pure tones was that each adjacent pair of
6
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
5
1
9
7
1
6
7
5
/
C
oh
metro
_
a
_
0
0
2
6
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 1. Representation of
the harmonic tone
complex used
by Pressnitzer and
Patterson (2001) in their
Experimento 1 to measure
distortion products. El
signal is comprised of 11
pure tones separated by
frequency internals of 100
Hz between 1.5 kHz and
2.5 kHz.
sinusoids contributed to the gain of the resulting
fundamental (which was verified in their subse-
quent experiments). They report that “an harmonic
complex tone . . . can produce a sizeable DS [dis-
tortion spectrum], even at moderate to low sound
levels.” They go on to establish that the level of
the fundamental is essentially “the vector sum of
the quadratic distortion tones . . . produced by all
possible pairs of primaries.” (This is a good first
approximation in which the influence of CDTs is ig-
nored.) Another consequence was that the resulting
distortion products contained multiple harmon-
ics of the fundamental (1,700 – 1,500 = 200 Hz;
1,800 – 1,500 = 300 Hz; etc.). These too were ap-
proximately vector sums of the corresponding pairs
of pure tones. Y, de modo significativo, phase has a critical
influence on these vector products because out-of-
phase pure-tone pairs create out-of-phase distortion
products that can cancel out the in-phase products
when summed together. Por lo tanto, to create dis-
tortion products with the highest gain, all acoustic
components should be in phase with each other.
Además, Pressnitzer and Patterson verified that
there was relatively little intersubject variability.
The predictability of QDTs and distortion spectra
provides a practical foundation for the synthesis of
more complex tones and dynamic sound sources
that are heard by the listener yet are completely
absent from the acoustic sound. De hecho, desde el
listener’s perspective, QDTs might just as well be
externally generated sound, albeit a sound with
some illusive perceptual properties.
The Missing Fundamental versus
Combination Tones
(Refer also to Audio Examples 1 and 2a–b in
Apéndice 1.)
The “missing fundamental” is a perceptual phe-
nomenon that is superficially related to CTs. En el
psychoacoustic literature, the missing fundamental
is most commonly referred to as “residue pitch,"
where “residue” refers to how the perceived pitch of
a harmonic complex corresponds to the fundamental
frequency even when the fundamental component
is missing from the acoustic signal. The simplest
way to illustrate the phenomenon is to imagine a
100-Hz periodic impulse train passing through a
high-pass filter. Unfiltered, the sound will clearly
have a perceived pitch corresponding to the 100-Hz
fundamental as well as harmonics at integer mul-
tiple frequencies. But setting the high-pass filter’s
cutoff so that the 100-Hz component is removed
does not cause the pitch to disappear; what changes,
bastante, is the perceived timbre of the tone. Cuando
raising the cutoff frequency even further, the pitch
persists until all but a small group of mid-frequency
harmonics remains (Ritsma 1962). Ahora, relating
this back to Pressnitzer and Patterson’s experiment
with the harmonics of a 100-Hz fundamental, nosotros
might ask whether residue pitch and combination
tones are essentially the same phenomenon.
It is true that the missing fundamental and
combination tones have an intertwined history.
Early researchers (Schaefer and Abraham 1904;
Fletcher 1924) assumed that residue pitch was
itself a form of nonlinear distortion, reintroduced
by the ear when the fundamental was removed
(Smoorenburg 1970). Schouten (1940) disproved
este, sin embargo, by showing that the residue is not
masked by an additional acoustic signal. Esto es
illustrated in Audio Examples 1a–d (Apéndice 1)
where the residue is not masked by noise, mientras
the combination tone is. This is a very important
point for composers, because for CTs to be easily
perceived by the listener, other sounds must not
mask the distortion spectrum.
En tono rimbombante, Houtsma and Goldstein (1972)
established that residue pitch is not dependent
upon interaction of components on the basilar
membrane. But recall that Goldstein (1967) como
well as Pressnitzer and Patterson (2001) measured
the properties of combination tones by cancelling
them with acoustic tones. Combination tones
require the interaction of components on the basilar
Kendall et al.
7
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
5
1
9
7
1
6
7
5
/
C
oh
metro
_
a
_
0
0
2
6
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
membrane while residue pitch is then the product of
a higher auditory “pattern recognition” mechanism
(Houtsma and Goldstein 1972).
An equally compelling difference is illustrated
in Audio Examples 2a and 2b, where each set of
acoustic tones produces combination tones with
the same subjective pitch. In Audio Example 2a the
acoustic tones are higher harmonics of the perceived
fundamental, f1 = 10 F . In Audio Example 2b the
acoustic tones are inharmonic to the fundamental,
f1 = 10.7 F , while still maintaining a frequency
separation of the fundamental frequency, F . El
subjective impression of the combination tones is
essentially the same. This illustrates that CTs do
not depend on harmonic ratios. En suma, a pesar de
CTs and the missing fundamental may appear to be
related, their underlying neurological mechanisms
must be quite different.
Musical Applications
Although auditory scientists have expanded our
knowledge of CTs, it was a musician who first
discovered them, and the many composers and per-
formers who have utilized the phenomena in their
work inherit Giuseppe Tartini’s early fascination
with what he called the terzo suono [third tone].
As we will see, the computer musician is techno-
logically better equipped to exploit the phenomena,
given the exacting control one can exert upon all
aspects of the acoustic sound. For historical reasons,
sin embargo, it has tended to be improvisation that
has afforded creative experimentation with auditory
distorsión. This is reflected by the many instrumen-
tal improvisers—for example, Yoshi Wada, Mate
Ingalls, John Butcher, Pauline Oliveros, and Tony
Conrad—who describe the role of the phenomena
in their practice. Conrad has described his Theatre
of Eternal Music improvisations with La Monte
Young and others as a practice of working “on”
the sound from “inside” the sound (Conrad 2002,
pag. 20), and his characterization indirectly illustrates
why auditory distortion flourishes in this context.
Where accidents and artifacts can be accepted or
rejected, or enhanced or attenuated immediately,
the opportunity for a subjectively heard “musical
layer” to be developed is greatest; greatest, eso es,
when the performer is free of a score. Evan Parker’s
Monoceros (1978) is a great example of a work
in this tradition. Recorded from the microphone
directly to the vinyl master using the “direct-cut”
técnica, the album comprises four solo soprano
saxophone improvisations that explore a range of
performance techniques including circular breath-
ing and overblowing. These enable him to achieve a
kind of polyphony from the instrument, con tres
or more registers explored simultaneously. When lis-
tened to at a high enough volume, the rapid cascades
of notes in the altissimo range of the saxophone
create fluttery distortion tones in the listeners’ ears.
The sheer melodic density of the piece, sin embargo,
lends the distortion products a fleeting quality here:
Listeners who do not know to listen for them could
easily miss them. This is perhaps emblematic of
the overall status of auditory distortion products
in musical history—more “happy accidents” than
directly controlled musical material.
Jonathan Kirk (2010) and Christopher Haworth
(2011) have both described several instances in
20th-century music where this is not the case, y
the auditory distortion product has been treated as
a musical material in itself. Artists like Maryanne
Amacher and Jacob Kierkegaard achieved this with
the aid of computers, and for accurate control of the
distortion product, the use of a pure-tone generator,
at the very least, is essential. Phill Niblock is
particularly worthy of note in this context, an artist
whose approach falls squarely between the ear-
guided instrumental work of Parker and the more
exacting approach of somebody like Amacher. Su
work is composed of dense layers of electronically
treated instrumental drones. He applies microtonal
pitch shifts and spectral alterations in order to
enhance the audibility and predominance of the
naturally occurring combination tones, as well as to
introduce new ones. Volker Straebel (2008), in his
analysis of works by Niblock, counted as many as
21 CTs of different frequencies in 3 a 7 – 196 para
cello and tape (Niblock 1974).
Niblock’s drone music illustrates an important
point concerning combination tones and perceptual
saliency. A formally static, apparently stationary
composition can reveal a multiplicity of acoustic
8
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
5
1
9
7
1
6
7
5
/
C
oh
metro
_
a
_
0
0
2
6
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
detail when listened to intently, and auditory distor-
tion may often be noticed in this situation. Freely
moving the head, one can easily recognize how this
movement changes the intensity and localization of
the resultant distortion products. Were the musical
form rapidly changing and developing, this kind of
comparison would not be possible, and so in many
cases auditory distortion may simply go unrecog-
nized. Niblock’s approach therefore magnifies the
conditions for the discrimination of auditory dis-
tortion from acoustic sound. Engineered during the
editing process, the serendipitous quality of auditory
distortion in music performance is, por lo tanto, subtly
effaced.
Like most techniques for creating auditory
distorsión, Niblock’s approach can be considered to
be “inside out,” that is, he starts with the acoustic
sound and manipulates it until the distortion
product is rendered audible. Whether one is (como
Tartini) playing the violin, o (like Niblock) digitally
pushing partials to within close ratios, the fact
remains that the distortion product as a musical
material is fundamentally elusive here, controllable
only in terms of its pitch and loudness. In order to
achieve fine-grained control, one needs to reduce the
acoustic variables to just those that are necessary.
Electronic musicians were quick to see the
musical possibilities of the evolving notions of
auditory nonlinearity. Por ejemplo, the British
Radiophonic Workshop composer Daphne Oram
devotes two chapters to the consideration of sum
and difference tones in her book, An Individual Note
(Oram 1972). Some years later these ideas were born
into fruition by the late Maryanne Amacher, OMS
made the solicitation of auditory distortion into an
art form in its own right. Her sound installations
and live performances became notorious for their
utilization of interlocking patterns of short sine tone
melodies reproduced at very high volumes, cual
induced prominent distortion tones in the ears of
listeners. In the liner notes to Sound Characters
(Making of the Third Ear), Amacher gives a vivid
description of the subjective experience of these
tones:
When played at the right sound level, cual es
quite high and exciting, the tones in this music
will cause your ears to act as neurophonic
instruments that emit sounds that will seem
to be issuing directly from your head . . .
[my audiences] discover they are producing
a tonal dimension of the music which interacts
melodically, rhythmically, and spatially with
the tones in the room. Tones “dance” in the
immediate space of their body, around them
like a sonic wrap, cascade inside ears, and out
to space in front of their eyes . . . Do not be
alarmed! Your ears are not behaving strange or
being damaged! . . . These virtual tones are a
natural and very real physical aspect of auditory
percepción, similar to the fusing of two images
resulting in a third three dimensional image in
binocular perception . . . I want to release this
music which is produced by the listener . . .
(Amacher 1999, liner notes).
The tones Amacher used to produce these effects
were generated using the Triadex Muse, a digital
sequencer instrument built by Edward Fredkin
and Marvin Minsky at MIT. Amacher’s is the first
sound work to elicit a truly separate musical stream
from the auditory distortion, a subjective “third
capa,” which she sometimes referred to as the
“third ear” (Amacher 2004). This objectification of
these previously ignored, subliminal sounds is very
successful in Amacher’s work, and is the point that
we have taken forward in this research.
Practical Observations
In order for auditory distortion products to be
musically meaningful, the listener must be able to
distinguish them from acoustic sounds; de lo contrario,
why not simply use ordinary acoustic signals? Como
already stated, fixed combinations of acoustic pure
tones will produce sustained distortion tones with
fixed frequencies. In this situation, the listener’s
head and body movements will produce important
streaming cues for segregating the two sound sources
(see the Spatial Imagery section, subsequently).
For musical purposes, sin embargo, we may want to
create sequences of pure tone complexes, thereby
producing distortion-tone patterns that change over
Kendall et al.
9
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
5
1
9
7
1
6
7
5
/
C
oh
metro
_
a
_
0
0
2
6
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
tiempo. Musically speaking, sequences of tones are
more noticeable, as is illustrated by Amacher’s
1999 piece “Head Rhythm/Plaything.” The piece
features a repetitive sequence of crude, pure-tone
chirps that elicit a disorientating, subtly shifting
rhythmic pattern of distortion tones at different
frecuencias; easily distinguishable from the tones
used to generate them. But among the musical
properties that have not been synthesized in any
systematic way are dynamic properties of tones
such as tremolo, vibrato, dynamic spectra, spatial
ubicación, etc.. Computer synthesis enables the
exploration of these possibilities in a way that was
not available to the early practitioners, and has not
been previously exploited in music synthesis.
amplitude of the quadratic distortion, C ≈ 130 dB
(Fastl and Zwicker 2007). Experimental data in
which a cancellation tone is used to determine
the amplitude of the QDT exhibit a fairly regular
comportamiento. The auditory QDT is well modeled as a
quadratic distortion. With increasing L1 or L2 the
cancellation level is almost exactly what is predicted
and this happens whether the difference between the
frequencies of the acoustic signals is large or small.
Por ejemplo, for L1 = L2 = 90 dB, the level of the
cancellation tone is approximately 50 dB. (There is
a percentage of listeners for whom this observation
breaks down, see Fastl and Zwicker 2007, páginas. 280–
281.) For our purposes, variances in the effective
amplitudes will have a relatively small effect on
perceived timbres, especially dynamic ones.
Modeling Auditory Distortion as a
Nonlinear System
The exact relationship between physical acoustic
stimuli and the resulting auditory distortion prod-
ucts is quite complex, but in developing a systematic
approach for synthesis, a good first approximation is
to model the production of the distortion products as
a general nonlinear system. We start with a classical
power series representation (von Helmholtz 1954):
y − a0 + a1x + a2x2 + · · · + anx2
(1)
where x is the input and y the output of the system.
The an are constants. The nonlinearity of the output
increases as the gain of the input level, X, aumenta.
Quadratic Difference Tone
The quadratic component, a2x2, contributes the
difference tone, f2 – f1, and also components at
2 f1, f1 + f2, y 2 f2, although at lower subjective
niveles. The level of the quadratic distortion tone (como
measured by the acoustic cancellation method) es
given by
l( f2− f1) − L1 + L2 − c
(2)
where L1 and L2 represent the levels of the acoustic
signals in decibels and C depends on the relative
The QDT as Distortion Product
Modeling the QDT as a nonlinear product is quite
straightforward. If we consider the situation in
which there are two sinusoidal inputs to the simple
quadratic equation:
y − x2,
(3)
we find:
y(t) = (A1 sin(ω1t) + A2 sin(ω2t))2
2 pecado2(ω2t)
1 pecado2(ω1t) + A1
= A2
+ 2A1 A2 sin(ω1t) sin(ω2t)
(4)
where ω1 and ω2are the sinusoidal frequencies and
A1and A2 their respective amplitudes. In expanding
Ecuación 4, one finds that the first two terms yield
a direct current (corriente continua) component, and the third term
supplies the important combination tones:
y(t) =
−
A2
1
2
porque(2ω1t) +
A2
A2
2
1
2
2
+ A1 A2 cos((ω1 − ω2)t) − A1 A2 cos((ω1 + ω2)t),
porque(2ωt)
A2
2
2
−
dónde (ω1 + ω2)y (ω1 − ω2) are the sum and
difference frequencies. The gain of the difference
frequency is A1 A2 (in decibels: L1 + L2). Además
(5)
10
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
5
1
9
7
1
6
7
5
/
C
oh
metro
_
a
_
0
0
2
6
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Mesa 1. Chords Evoked by Two Pure Tones and CDT
f2/f1
1.25
1.2
1.166
1.1428
1.125
1.111
f1: f2
4:5
5:6
6:7
7:8
8:9
9:10
Interval
2f1-f2: f1: f2
Resulting chord
Major third
Minor third
∼Minor third
∼Major second
Major second
Major second
3:4:5
4:5:6
5:6:7
6:7:8
7:8:9
8:9:10
Major triad
Major triad
∼Diminished triad
Non-tertian triad
∼Whole-tone cluster
Whole-tone cluster
The frequencies f1 and f2 generate a third tone, the CDT, at the frequency 2f1 − f2, supplying the lowest note of a three-note
chord. The table gives the interval between the first two tones and the kind of chord resulting. Intervals and chords marked with
the tilde (∼) are slightly out of tune.
to the sum and difference frequencies, the complete
output signal of the squarer contains DC and com-
ponents at twice the input frequencies, componentes
that are inaudible.
Cubic Difference Tone
The cubic component, a3x3, contributes the cubic
difference tone, 2 f1 – f2and also 2 f2 – f1, 3 f1, etc..
Experimental test data do not conform well to what
would be predicted for regular cubic distortions.
Por ejemplo, the level of the CDT is strongly
dependent on the frequency separation between the
pure tones, f2 – f1 (Fastl and Zwicker 2007). Este
means that the auditory CDT is not well modeled as
a regular cubic distortion. Its characteristics under
varying circumstances are far more idiosyncratic
than the QDT. En particular, the level’s dependency
on both frequency separation and frequency range
is another reason why CDTs are difficult to use
in a controlled way for synthesis, even though
under ideal circumstances the level of the CDT is
significantly higher than the QDT.
CDT Ratios
The CDT is most clearly audible when the ratio
of the acoustic signals, f2/ f1, lies between 1.1 y
1.25. Ratios within this range coincide with musical
intervals between a major second and a major third.
Y, as we expect with musical intervals, ratios
abajo 1.14 produce auditory roughness (or disso-
nance from the musical perspective). Además,
the CDT itself falls so close to f1 and f2 that what
one typically perceives is a three-tone aggregate.
As the example from Sibelius’s First Symphony
ilustra (Cambpell and Greated 1994), if the ratio,
f2 / f1, forms a musical interval, the CDT will form
another musical interval to yield a three-note chord.
These relationships are summarized in Table 1
using simple integer ratios for illustration.
Synthesis Techniques
For the purposes of sound synthesis, the direct
generation of quadratic and cubic difference tones
from a pair of pure tones suffers from important lim-
itations. As noted earlier, the CDT is comparatively
louder than the QDT, but the close proximity of the
CDT’s frequency to the acoustic stimuli limits the
circumstances in which the listener can easily dis-
tinguish it from the acoustic tones. In order to create
QDTs at levels that the listener can recognize, el
acoustic pure tones have to be presented at a level
that is uncomfortable for most listeners, especially
for any extended period of time.
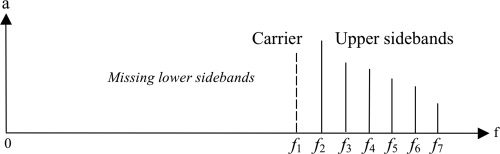
Haworth solved the problem for QDTs in concert
settings by utilizing a sinusoidal complex with
constant difference frequencies, akin to the stimuli
of Pressnitzer and Patterson discussed earlier. En
the composition “Correlation Number One” (2010),
each adjacent pair of sinusoids produces the identi-
cal QDT frequency, adding linearly to its total gain
y, thereby, increasing the level of the distortion
Kendall et al.
11
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
5
1
9
7
1
6
7
5
/
C
oh
metro
_
a
_
0
0
2
6
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
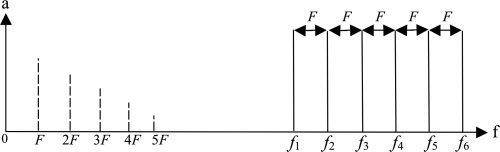
Cifra 2. Quadratic
difference tone (QDT)
spectrum (dashed lines)
produced by pure tones
(solid lines) con un
constant frequency
interval of F.
tono (Haworth 2011). Not only did the combination
of acoustic sinusoids increase gain, but it also
produced components that were harmonics of the
primary QDT. En tono rimbombante, increasing the number
of acoustic tones (and consequently spreading them
over a wider frequency range) permits the subjective
level of the acoustic tones to be reduced, de este modo
greatly diminishing the problem of listener fatigue.
Claramente, the musical context in which auditory
distortion products are used dictates to a large
degree how successful the effects will be. Tenemos
noted that the listener must be able to distinguish
the distortion products from the acoustic tones,
and for this to happen careful attention must
be paid to the frequency spectrum. Generally,
researchers have focused on QDTs below 1 kHz
with pure tones between 1 y 5 kHz. This gives
some guidance to the most practical frequency
ranges to use when there are no competing sounds.
Recognition of the presence of auditory distortion
products requires that they be aurally separable from
acoustic sounds by pitch or by other means. Este
has an important impact on the choice of synthesis
methods. Other high-frequency acoustic signals
overlapping the frequency range of the acoustic
signals stimulating the auditory distortion tones
can produce unintended side effects and weaken the
impact of the distortion products. También, the presence
of other acoustic signals overlapping the range
of the distortion products themselves can mask
and destroy their effect. It may be obvious to say,
but auditory distortion products, like many other
aspects of synthesis, are best adjusted and optimized
by ear. Many imaginative effects can be achieved
through creative use of synthesis. We summarize
the most important synthesis methods here.
Direct Additive Synthesis
(Refer also to Audio Example Group 2 in Appendix 1.)
Pressnitzer and Patterson (2001) demonstrated
that multiple pure tones synthesized at sequential
upper harmonics of a fundamental, F , produce a
harmonic QDT spectrum with the fundamental F .
The gains of the individual harmonic components
of that spectrum are a summation of the QDT
contributions produced by each pair of pure tones.
Por ejemplo, they demonstrated that harmonics
15 a 25 of a 100-Hz fundamental, each at 54 dB
SPL, produces a harmonic QDT spectrum with a
fundamental only 10–15 dB lower than the gain of
the acoustic tones.
But to produce a QDT harmonic spectrum, el
acoustic pure tones ( f1, f2, f3, etc.) do not need to be
harmonics of the QDT fundamental, they only need
to be separated by the constant frequency interval
F (F = f2 – f1 = f3 – f2, etc.). This produces a
QDT spectrum with a fundamental of F as shown in
Cifra 2. The exact quality of the resulting distortion
tones experience depends on the choice of f1 and
the number of acoustic, sinusoidal components.
By itself, this technique can produce QDT spectra
that are clearly audible in typical loudspeaker
reproduction at moderate sound levels. And from
this starting point, many classic time-domain
synthesis processes can be introduced with trivial
ease, por ejemplo, amplitude modulation (AM).
There are two possibilities for AM that each yield
slightly different results depending on how many
acoustic signals are producing the effect. Modulating
all pure tones together produces a single, amplitude-
modulated sound. Modulating all pure tones except
for the lowest, f1, enhances the effect of a sustained
pure tone plus an amplitude-modulated distortion
product. The latter case provides better subjective
timbral segregation between the acoustic tones and
the distortion tone, whereas in the former case the
two tend to fuse. Altering the modulation rate has
predictable results. A pleasant tremolo effect occurs
up to approximately 15 Hz, and then “roughness”
entre 20 Hz and 30 Hz. Increasing the modulation
rate much further introduces sidebands in the
acoustic signals that may interfere with the intended
distortion spectrum.
12
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
5
1
9
7
1
6
7
5
/
C
oh
metro
_
a
_
0
0
2
6
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Applying the same principles to the frequencies of
the acoustic signals produces frequency modulation
of the QDT spectrum. In the simplest case, the f1
frequency best remains static, and the modulation
is applied to the frequency separation between
the other components ( f2– f1, f3– f2, etc.). En esto
way, the frequency modulation of the fundamental,
F , is easily audible, while the modulation of the
acoustic components is less distinct because the
pitch interval of their deviation is much smaller
than for the acoustic tones.
The rates of both AM and FM require subtle
adjustment, otherwise the roughness caused by
beating of the acoustic frequencies will interfere
with the segregation of the QDT spectrum. The FM
rate parameter, En particular, offers a few additional
possibilities. If it is set sufficiently high, even at
relatively small frequency deviations the pitch
sensation of the distortion tone will be lost. En
sí mismo, this gives a fairly dull, static sound, bastante
like narrowband noise. But if one applies a repeating
sequence of short time windows to the sound stream,
akin to synchronous granular synthesis, then the
results become more interesting. If we choose a slow
frequency modulation rate (<12 Hz) and a repeating
envelope with sharp attack sloping decay,
then, due to the closeness of distortion tone
and its unresolved pitch, one perceives fluttery,
wind-like sound that appears bristle against the
ear. The techniques described here are employed
in Haworth’s compositions “Correlation Number
One” (2011) “Vertizontal Hearing (Up & Down,
I then II)” (2012).
Dynamic Sinusoidal Synthesis
(Refer also Audio Example Group 3 in Appendix 1.)
The basic processes this article
can be applied situations which the
fundamental frequency overall amplitude
are dynamically changing. Most importantly, the
pitch amplitude QDT spectrum can be
made follow characteristics model signal,
including recorded or real-time performance.
Again, order for tone heard
clearly by listener, synthesis must again rely
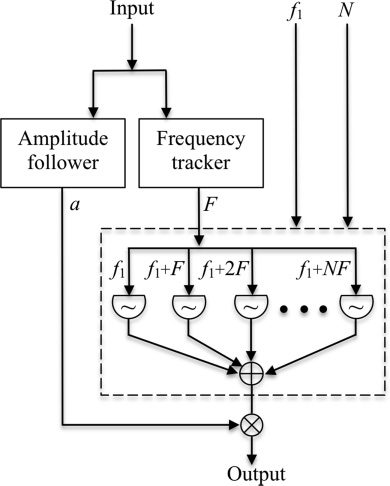
Figure 3. Dynamic
sinusoidal a
QDT based on
an audio signal input. The
frequency lowest
acoustic component is f1,
and N number of
additional sinusoids
synthesized.
on multiple pure tones constant frequency
offset.
Consider algorithm illustrated Figure 3.
Here input fed frequency
tracker an follower dynamically
extract fundamental, F , amplitude, a.
Then, sinusoidal oscillator bank along
with two values set user: f1, frequency
of lowest sinusoid, N, sinusoids synthesize. will determine
the strength spectrum’s fundamental
and possible harmonics. Typically
one f1 remains constant,
while additional oscillators follow
the value at integral offsets from
f1, + 2F . NF sum sinu-
soids produced multiplied
by output follower, a, recre-
ate original envelope. result synthesis
will like shown 2, only dynamic.
In way, mimic the
dynamic character live prerecorded sound.
Of course, success depends on nature of
the material degree there
is fundamental extract. Then too,
the same oscillator-bank technique used
Kendall et al.
13
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
> 6.
Abel’s impossibility theorem states that, en general,
polynomial equations higher than fourth degree are
incapable of algebraic solutions in terms of a finite
number of additions, subtractions, multiplications,
divisions, and root extractions operating on the co-
efficients (Cheney and Kincaid 2009, páginas. 705). Este
does not mean that high-degree polynomials are not
solvable, because the fundamental theory of algebra
guarantees that at least one complex solution exists.
What this really means is that the solutions cannot
be always expressed in radicals.
Por lo tanto, as seeking an algebraic expression
for any N is impractical; if we want to specify s(t)
with more than four harmonics by calculating the
coefficients of x(t), the only way of doing that is by
numerical methods such as the Newton-Rhapson,
Laguerre, or the Lin-Bairstrow algorithm (Rosloniec
2008, páginas. 29–47). This is the main reason why a
numerical rather than an algebraic solution is the
correct approach for this problem when a high
number of harmonics in the target signal is desired.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
4
5
1
9
7
1
6
7
5
/
C
oh
metro
_
a
_
0
0
2
6
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Kendall et al.
23