ARTÍCULO DE INVESTIGACIÓN
Understanding the Effects of Constraint and
Predictability in ERP
Kate Stone1
, Bruno Nicenboim2,3
, Shravan Vasishth3
, and Frank Rösler4
1Department of Psychology, University of Potsdam, Potsdam, Alemania
2Department of Cognitive Science and Artificial Intelligence, Tilburg University, Tilburg, Países Bajos
3Department of Linguistics, University of Potsdam, Potsdam, Alemania
4Department of Biological Psychology and Neuropsychology, University of Hamburg, Hamburg, Alemania
Palabras clave: N400, anterior PNP, posterior P600, probabilistic processing, constraint, predictability,
entropy
ABSTRACTO
Intuitivamente, strongly constraining contexts should lead to stronger probabilistic representations
of sentences in memory. Encountering unexpected words could therefore be expected to
trigger costlier shifts in these representations than expected words. Sin embargo, psycholinguistic
measures commonly used to study probabilistic processing, such as the N400 event-related
potencial (ERP) component, are sensitive to word predictability but not to contextual
constraint. Some research suggests that constraint-related processing cost may be measurable
via an ERP positivity following the N400, known as the anterior post-N400 positivity (PNP).
The PNP is argued to reflect update of a sentence representation and to be distinct from
the posterior P600, which reflects conflict detection and reanalysis. Sin embargo, constraint-
related PNP findings are inconsistent. We sought to conceptually replicate Federmeier et al.
(2007) and Kuperberg et al. (2020), who observed that the PNP, but not the N400 or the
P600, was affected by constraint at unexpected but plausible words. Using a pre-registered
design and statistical approach maximising power, we demonstrated a dissociated effect
of predictability and constraint: strong evidence for predictability but not constraint in the
N400 window, and strong evidence for constraint but not predictability in the later window.
Sin embargo, the constraint effect was consistent with a P600 and not a PNP, sugerencia
increased conflict between a strong representation and unexpected input rather than greater
update of the representation. We conclude that either a simple strong/weak constraint design
is not always sufficient to elicit the PNP, or that previous PNP constraint findings could be
an artifact of smaller sample size.
INTRODUCCIÓN
Readers can use contextual cues from words and sentences to construct a mental representa-
tion of an event. This representation can be viewed as probabilistic, with plausible upcoming
words and sentence structures preactivated in anticipation of their appearance (Kuperberg
et al., 2020; Kuperberg & Jaeger, 2016; Kutas & Federmeier, 2011). Assuming that readers gen-
erate such a representation, its probabilistic strength should depend on how constraining the
sentential context is. Por ejemplo, in sentence (1)a, the strong constraint of the context makes
un acceso abierto
diario
Citación: Piedra, K., Nicenboim, B.,
Vasishth, S., & Rösler, F. (2023).
Understanding the effects of constraint
and predictability in ERP. Neurobiología
of Language, 4(2), 221–256. https://doi
.org/10.1162/nol_a_00094
DOI:
https://doi.org/10.1162/nol_a_00094
Supporting Information:
https://doi.org/10.1162/nol_a_00094
Recibió: 30 Julio 2020
Aceptado: 5 December 2022
Conflicto de intereses: Los autores tienen
declaró que no hay intereses en competencia
existir.
Autor correspondiente:
Kate Stone
stone@uni-potsdam.de
Editor de manejo:
Kate Watkins
Derechos de autor: © 2023
Instituto de Tecnología de Massachusetts
Publicado bajo Creative Commons
Atribución 4.0 Internacional
(CC POR 4.0) licencia
La prensa del MIT
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
the word true highly predictable, whereas in (1)b, the weak contextual constraint means no
specific word is predictable (Federmeier et al., 2007):
(1)
a. Strongly constraining:
Sam could not believe her story was … true/published
b. Weakly constraining:
I was impressed by how much he … knew/published
The reader’s probabilistic representation should therefore be stronger in (1)a than (1)b, entonces
that encountering the low-predictable word published is more unexpected (in the sense that
the reader expected a different event) en (1)a, even though published is equally unpredictable
in both contexts (according to a cloze test; Federmeier et al., 2007). Sin embargo, psycholin-
guistic measures typically used to study probabilistic processing—including the N400 event-
related potential (ERP) component—have been found to correspond only to the matched
predictability of published between (1)a and (1)b, and not the mismatch in constraint
(Federmeier et al., 2007; Kuperberg et al., 2020; Kutas & Hillyard, 1984; Van Petten & Luka,
2012). En cambio, an anteriorly distributed positive deflection in the ERP after the N400, the post-
N400 positivity (PNP), may hold the key to measuring the constraint/predictability dissociation
(Brothers et al., 2020; Federmeier et al., 2007; Kuperberg et al., 2020). Sin embargo, empirical
findings involving the PNP are inconsistent (Federmeier & Kutas, 1999; Frank et al., 2015;
Lai et al., 2021; Szewczyk & Schriefers, 2013; Thornhill & Van Petten, 2012; Wlotko &
Federmeier, 2007). Given the potential importance of the PNP in studying reader’s probabi-
listic representations, in this registered report, we addressed possible sample size concerns in
previous studies by testing the PNP in a confirmatory study with a larger sample size.
The Post-N400 Positivity
An incidental finding in many studies of the N400 has been that of a late positivity beginning
at around 600 ms in the anterior scalp region. This anterior positivity appears to be spatially
and functionally distinct from the more well-known posterior P600 (Kuperberg et al., 2020).
The P600 has been variously linked to conflict detection and repair processes in a fronto-
temporal cortical circuit (Bornkessel-Schlesewsky & Schlesewsky, 2008; Brouwer et al.,
2017; Brouwer & Hoeks, 2013; Fitz & Chang, 2019; kim & Osterhout, 2005; Kuperberg
et al., 2003; Meerendonk et al., 2009; Metzner et al., 2017; Osterhout & Holcomb, 1992).
A diferencia de, the anterior PNP has been linked to the update of event representations, possibly
involving the inhibition of representations falsified by unexpected input via left prefrontal cor-
tex (Kutas, 1993). Extending this characterisation, recent research has suggested that the PNP is
only elicited when unexpected input is still plausible in the given context (DeLong et al., 2014;
Kuperberg et al., 2020). Por ejemplo, en (2) abajo, swimmers is the most expected continua-
ción, while trainees and drawer are both low probability. Sin embargo, trainees is still plausible in
the context, while drawer is not. A PNP and P600 were elicited by trainees relative to the
expected swimmers, but not by drawer, which only elicited a P600 (Kuperberg et al., 2020):
(2) The lifeguards received a report of sharks right near the beach […] Hence they cau-
tioned the swimmers/trainees/drawer
The fact that only the plausible trainees and not the implausible drawer elicited the PNP has
led some to hypothesise that the PNP reflects a change in activity associated with successfully
updating the mental representation of an event, which may include the inhibition of previous
representaciones (Kuperberg et al., 2020; Kutas, 1993; Ness & Meltzer-Asscher, 2018). Under
Neurobiology of Language
222
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
this assumption and the assumption that the P600 reflects reanalysis (kim & Osterhout,
2005; Kuperberg et al., 2003; Osterhout & Holcomb, 1992, cf. Bornkessel-Schlesewsky &
Schlesewsky, 2008; Brouwer et al., 2017; Fitz & Chang, 2019), Kuperberg et al. (2020) tener
proposed that an unexpected word (in this example trainees) triggers a large but successful
update of the readers’ representation of the event, including suppression of the more predict-
able event caution the swimmers. The magnitude of this update is reflected by the presence of
a PNP. According to Kuperberg et al. (2020), the unexpected word also engages reanalysis
processes during attempts to accommodate it, which are reflected in the presence of a
P600. A diferencia de, the implausible drawer triggers no change in the existing event representa-
ción (PNP absent), even though reanalysis processes may be engaged (P600 present).
More importantly for research on probabilistic processing, the PNP also appears to be sen-
sitive to contextual constraint. Like the N400, the PNP has been found to be larger for low
versus high probability words (Brothers et al., 2017; Brothers et al., 2020; DeLong et al.,
2011; DeLong et al., 2014; Federmeier et al., 2007; Kuperberg et al., 2020; Ness &
Meltzer-Asscher, 2018; Thornhill & Van Petten, 2012); but unlike the N400, the PNP appears
to be larger for low probability words in strongly versus weakly constraining contexts (Brothers
et al., 2020; Federmeier et al., 2007; Kuperberg et al., 2020). Returning to the example in (1)
arriba, Federmeier et al. (2007) found that the unexpected word published elicited a larger
PNP in the strongly constraining (1)a than in the weakly constraining (1)b, even though their
cloze probabilities and corresponding N400 amplitudes were the same. The PNP would there-
fore appear to suggest that a stronger probabilistic representation was built in (1)a than in (1)b,
and that the stronger representation was more costly to update.
Sin embargo, not all studies eliciting the PNP involve a constraint manipulation (Van Petten &
Luka, 2012), and thus it is difficult to attribute the PNP exclusively to the manipulation of con-
textual constraint, rather than to part of a biphasic response to low probability words following
the N400. Además, not all studies manipulating constraint show consistent effects on the
PNP. Contrary to Federmeier et al. (2007) and Kuperberg et al. (2020), Federmeier and Kutas
(1999) found that expected words elicited a larger PNP than unexpected words, and only in
low constraint sentences. It should be noted that expected words in the Federmeier and Kutas
(1999) “low” constraint condition had a mean cloze probability of 0.59 with a range 0.17 a
0.78; nonetheless, the direction of the PNP constraint effect was the opposite of that described
elsewhere. In high constraint sentences, no difference in the PNP was observed between
expected and unexpected words. More recently, Szewczyk and Schriefers (2013) noted a
más grande, centrally distributed post-N400 positivity for unexpected versus expected words, pero
in both high- and low-constraint contexts. Además, the effect was found in only two of four
conditions involving unexpected words, despite all unexpected words being plausible.
Not only is there inconsistency in how constraint affects the PNP, sometimes constraint-
based effects are not elicited at all. In an experiment using the same materials as Federmeier
et al. (2007), Wlotko and Federmeier (2007) did not find any evidence of an effect of constraint
on the PNP. The lack of a constraint effect on the PNP was perhaps particularly surprising given
that constraint was found to affect the earlier P2 component. This dissociation is interesting
given that early and late positivities may share a neural generative process, although this is
the subject of much debate (Coulson et al., 1998; Osterhout, 1999; Osterhout et al., 1996;
Sassenhagen & Fiebach, 2019). If the PNP does indeed share a generative process with the
P2, it is therefore surprising that the effect of constraint was not observed in both.
In a study more specifically investigating the PNP, Thornhill and Van Petten (2012) también
failed to find any constraint-related difference in PNP amplitude. The authors raise the
Neurobiology of Language
223
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
possibility that the concept of “weak expectation” may need close attention in designing low-
constraint experimental stimuli. Low constraint is typically measured using cloze probability;
sin embargo, the authors suggest that low cloze probability may sometimes reflect a lack of agree-
ment between cloze test participants on the best way to continue a sentence, rather than a
“weak” mental representation of the event. More recently, it has been suggested that the rich-
ness of the mental representation may also determine whether the PNP is seen at an unex-
pected word (Brothers et al., 2020). Por ejemplo, en (3)a below, expectation for the upcoming
word can only be derived from the three words immediately preceding it. A diferencia de, en (3)b, a
richer context is built across the whole of the preceding sentence. A constraint effect on the
PNP was only seen at the unexpected word in (3)b and not in (3)a, suggesting that the richer
context allowed a more committed event representation in (3)b, which required a greater
update in order to accommodate the unexpected word (Brothers et al., 2020):
(3)
a. Locally constraining:
He was thinking about what needed to be done on his way home. He finally arrived.
James unlocked the door/laptop
b. Globally constraining:
Tim really enjoyed baking apple pie for his family. He had just finished mixing the
ingredients for the crust. To proceed, he flattened the dough/foil
One possible explanation for the inconsistency among studies observing a PNP is that its
temporal proximity to the N400 makes it susceptible to component overlap (DeLong et al.,
2011; Luck, 2005a). Depending on the study design, this may mean that a difference in the
PNP is simply the result of an earlier difference in the N400. Other explanations for the incon-
sistency are that the PNP is simply a broadly distributed P600, or even a methodological
artifact. One further complication is that the PNP may have a relationship with the P3 family
of components which is as yet unclear (Coulson et al., 1998; Garnsey, 1993; Kuperberg et al.,
2020; Kutas & Hillyard, 1980; Osterhout, 1999; Osterhout et al., 1996; Sassenhagen & Fiebach,
2019; Van Petten & Luka, 2012). With these issues in mind, in the present study we treat the
N400 and PNP—with temporal and spatial signatures defined by previous research—as distinct
measures that can be used to disentangle the influence of contextual constraint. Fundamentalmente, el
PNP effect should be manipulated by constraint while the N400 should not. Even if the N400
and PNP do arise from generators that exhibit variable latency, finding evidence that they are
affected differentially by constraint will still allow conclusions about the usefulness of the PNP
in investigating readers’ probabilistic representations. Por otro lado, variable latency may
obscure any true effect and we may find no support for our hypotheses. En este caso, a null result
would provide a starting point for future designs or analyses to more explicitly address the
contribution of latency variation. Teniendo esto en cuenta, we make no claims about the possibility
of component overlap or latency variation with respect to the current study.
To summarise, while there is evidence to suggest that the PNP may be sensitive to the strength
of readers’ probabilistic sentence representations, there is still inconsistency within the PNP liter-
ature. The operationalisation of contextual constraint may also require more careful consideration.
Providing strong evidence for an association between the PNP and contextual constraint, y por lo tanto
a link between the PNP and representation strength, would provide a crucial tool for future
research into understanding how probabilistic representations are built, and how readers’ expec-
tations about the upcoming sentence influences their processing of incoming language input.
Además, providing further evidence for the PNP establishes a basis with which to inves-
tigate the neurobiology of post-N400 positive deflections, including the P600. Por ejemplo,
Neurobiology of Language
224
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
the link between the PNP and “suppression” (Kuperberg et al., 2020) or “inhibition” (Kutas,
1993; Ness & Meltzer-Asscher, 2018) suggests engagement of executive processes in the pre-
frontal cortex (p.ej., Hagoort, 2013). These executive processes are proposed to have a distinct
cortical location and function from the types of processes to which the P600 is sensitive
(Hagoort, 2013; Hagoort & Indefrey, 2014). The P600 is instead proposed to index involve-
ment of circuits between the left inferior prefrontal cortex and the temporal lobe as information
from memory is retrieved and integrated during attempts to revise a disconfirmed sentence
representación (Brouwer et al., 2017; Brouwer & Hoeks, 2013). Strong evidence for the PNP
would aid future investigations in this direction.
The Current Study
Recent research efforts have highlighted the fact that one of the critical findings in research on
probabilistic preactivation is difficult to replicate (Nieuwland et al., 2018) and that the effect
sizes of this predictability manipulation is likely much smaller than thought (Nicenboim et al.,
2020). Overestimated effect sizes and/or effects in an unexpected direction can be the result of
Type M(agnitude) and S(ign) errors in underpowered study designs with too few participants
and/or too few experimental items (Gelman & Carlin, 2014). ERP experiments are particularly
susceptible to being underpowered given that they are costly, both in terms of time, labour,
equipment maintenance, and replacement of disposable elements. Resource constraints there-
fore may prevent the recruitment of a sufficient number of participants to offset the high level
of signal-to-noise ratio inherent in ERP data (Luck, 2005a; Luck & Gaspelin, 2016). Many ERP
studies also involve the comparison of ERP components at target words that are not identical,
which may introduce additional noise through variability in frequency and lexical represen-
taciones. Investigation of the PNP would therefore greatly benefit from a confirmatory study
using a large number of participants.
We expected to show a dissociated effect of constraint on the N400 and PNP in a relatively
large number of participants (see Participants below). The key findings that we wished to rep-
licate were those of Federmeier et al. (2007) and Kuperberg et al. (2020), who found that only
the PNP and not the N400 was affected by constraint. We extended the design of Federmeier
et al. by measuring PNP and N400 effects at matching words with matching pre-critical regions,
eliminating any potential lexical- or frequency-based variation. Kuperberg et al. (2020) también
measured ERPs at matching words, but we extended their design by operationalising contextual
constraint as the continuous variable “entropy.” Entropy is a measure of uncertainty at the target
word that takes into account how the context of a sentence has affected the distribution of prob-
able words at that position (see Cloze test below for a more detailed definition). Además, nosotros
used constraint (entropy) and word predictability (log cloze probability) as continuous rather
than categorical predictors in the statistical analysis, which maximises statistical power (cohen,
1983). A discussion of the use of log cloze probability can be found in Analyses. A successful
replication would make a solid contribution to evidence that the PNP will be of great value in
future investigations of probabilistic processing.
MATERIALES Y MÉTODOS
The Introduction and Materials and Methods sections of this manuscript received Stage 1
approval as a registered report and were pre-registered at https://osf.io/bxg3n.
Participantes
In total, electroencephalography (EEG) was recorded from 74 Participantes. Seven participants
were excluded due to software problems during the recording and three because more than
Neurobiology of Language
225
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
75% of their EEG was affected by artifact. This left a final sample size of 64. The participant sample
size was determined via a stopping rule based on the inference criteria used in our statistical anal-
ysis (the Bayes factor), as well as time and resource limitations. We planned to recruit participants
either until we reached a Bayes factor of 10 in favour of the null or the alternative hypotheses, o
until we reached 150 Participantes, whichever came first. 150 participants was thought to be the
maximum feasible number that we could collect data from given limited resources and time.
Sin embargo, a major protocol deviation was made with the approval of the editor and reviewers: A
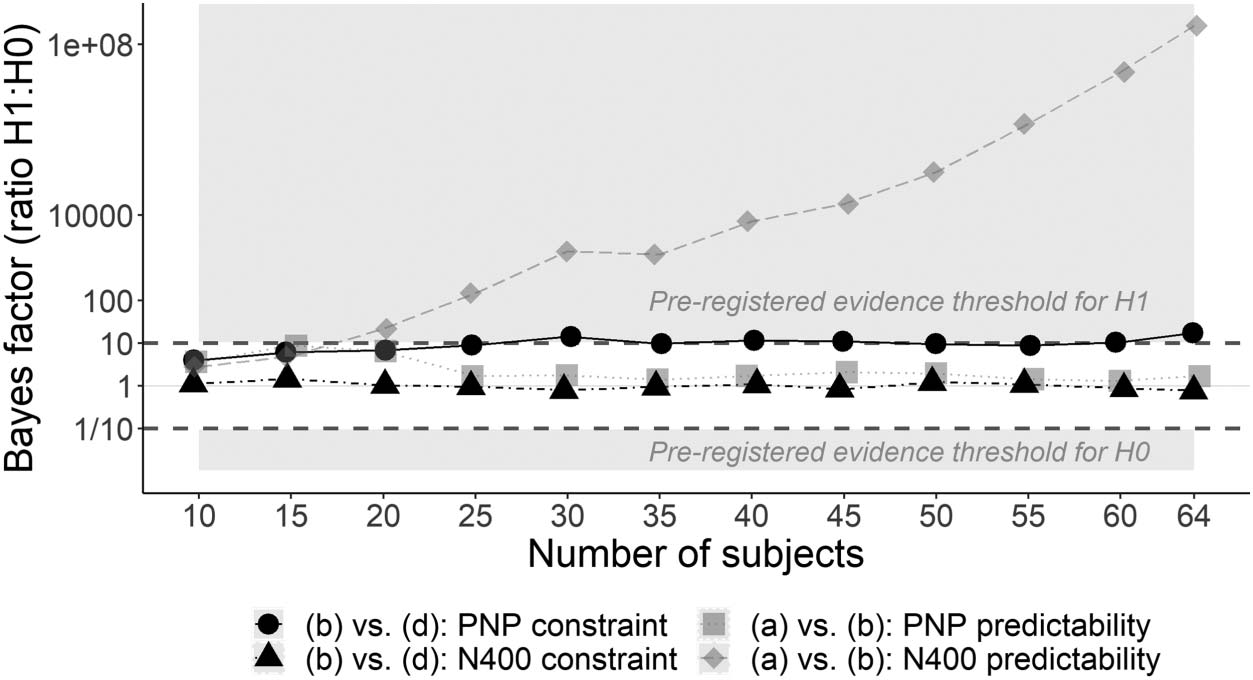
Bayes factor of 10 was exceeded for the PNP constraint effect at 40 Participantes, but the Bayes factor
for the N400 constraint effect remained stable at approximately 1, regardless of sample size. Due to
the difficulty in recruiting participants during the COVID-19 pandemic and because it seemed
unlikely that the Bayes factor for the N400 constraint effect would reach 10 incluso con 150 partícipe-
ipants, we ceased recruitment early. We discuss the inconclusive Bayes factor further in the
Results section and present a design analysis which suggests that even over 150 Participantes
would not have been sufficient to reach the pre-registered Bayes factor threshold.
More detail on the statistical analysis is provided below, but support for our hypotheses was
assessed using Bayes factors for the effect of entropy (PNP prior: a truncated normal distribu-
tion N−(0, 0.2); N400 prior: a normal distribution N(0, 0.2)), and cloze probability (PNP prior:
a truncated normal distribution N−(0, 0.2); N400 prior: a truncated normal distribution N+(0,
0.2)). Statistical Models and Predictions provides further detail and motivates the use of trun-
cated prior distributions.
Even with the protocol deviation, a nuestro conocimiento, the sample size is the largest amount of
data to date on this topic, and we reached strong evidence (a Bayes factor of at least 10, en línea
with Jeffreys, 1939) in favour of two pre-registered hypotheses without reaching the maximum
de 150 Participantes. For the hypotheses for which even 150 participants would not have yielded
strong evidence, the experiment is still informative because the estimates from our data can be
used in a future meta-analysis in order to synthesise the evidence available so far. For examples
illustrating the importance of evidence synthesis in psycholinguistics, see Bürki et al. (2022),
Jäger et al. (2017), Nicenboim et al. (2020), and Vasishth and Engelmann (2021).
The inclusion criteria for participants in the study were: native German speakers with no
other language acquired before age 6, no history of developmental or acquired reading, pro-
ducción, or hearing disorder, no history of developmental or acquired neurological disorder,
and no current need for or intake of psychopharmaceutical medication. All participants’ vision
was normal or corrected to normal. Participants were excluded from the final analysis if there
were technical problems with the EEG recording, if more than 75% of EEG segments were
badly affected by artifact, or if the attention check was failed (post-stimulus questions
answered with an accuracy of less than 70%).
Materials
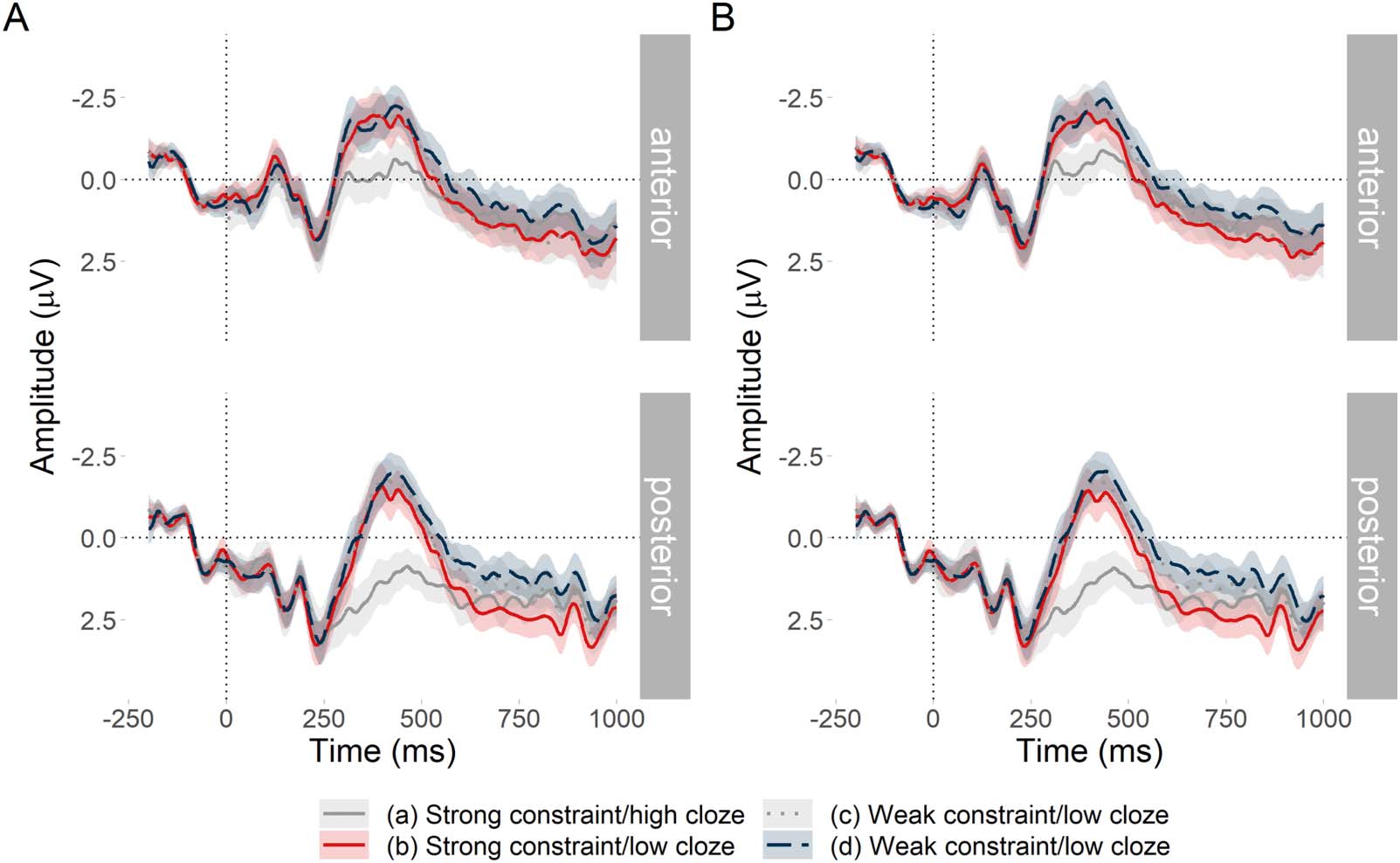
Each experimental item consisted of four sentences. An example item is below. In the exam-
por ejemplo, target nouns for the respective analyses are in bold face:
(4)
a. Strong constraint, high cloze probability noun:
Auf Annetts Terrasse schien im Sommer zu viel Sonne, um noch draußen sitzen
On Annett’s terrace shone in summer too much sun in order outside sit
zu können. Daher kaufte sie sich einen großen Schirm und …
to be able. Therefore bought she herself a.MASC large.MASC umbrella.MASC and …
Neurobiology of Language
226
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
b. Strong constraint, low cloze probability noun:
Auf Annetts Terrasse schien im Sommer zu viel Sonne, um noch draußen sitzen
On Annett’s terrace shone in summer too much sun in order outside sit
zu können. Daher kaufte sie sich einen großen Hut und …
to be able. Therefore bought she herself a.MASC large.MASC hat.MASC and …
C. Weak constraint, low cloze probability noun:
Annett mag es gerne gemütlich, wenn sie etwas Zeit für sich findet. Daher
Annett likes it really cozy when she some time for herself finds. Por lo tanto
aufte sie sich einen großen Schirm und …
bought she herself a.MASC large.MASC umbrella.MASC and …
d. Weak constraint, low cloze probability noun:
Annett mag es gerne gemütlich, wenn sie etwas Zeit für sich findet. Daher
Annett likes it really cozy when she some time for herself finds. Por lo tanto
kaufte sie sich einen großen Hut und …
bought she herself a.MASC large.MASC hat.MASC and …
Cloze test
To assess noun predictability, native German speakers completed sentences truncated after the
determiner before the target noun. For the strongly constraining conditions, we used the publicly
available stimuli from Nicenboim et al. (2020) and so the cloze procedure for the strongly constrain-
ing condition is as reported in that paper. For the weakly constraining condition, 60 new partici-
pants completed truncated sentences presented in Ibex (Drummond, 2016), either in the lab or
online via Prolific (www.prolific.co). Plural and singular forms of the same word were collapsed,
as were nouns with the same stem (p.ej., Schirm “umbrella” and Sonnenschirm “sun umbrella” or
“parasol”). The cloze probability of the target noun in each condition was computed as the propor-
tion of participants who gave that word or word stem out of the total number of participants.
To assess the contextual constraint of our conditions, we calculated entropy at the noun
site. Entropy is a measure of uncertainty in terms of how the probability mass of cloze test
responses is distributed. Por ejemplo, in a strong constraint context, nine cloze test comple-
tions may be the word “umbrella” and one may be “hat.” Probability mass is therefore con-
centrated on “umbrella” and entropy is low (high constraint). In a weak constraint context, el
cloze completions may be 10 different words; now probability mass is evenly distributed and
entropy is high (low constraint). We quantified Entropy (h) as the negative sum of cloze prob-
abilities (PAG) for all nouns provided by participants for a particular sentence in the cloze test,
multiplied by their respective logs: H = −
Xn
i¼1
Pi log Pi. Por ejemplo, if nine cloze completions
were “umbrella” and one was “hat” then: H = −(Pumbrella · log Pumbrella + Phat · log Phat) = -(0.9 ·
registro 0.9 + 0.1 · log 0.1) = 0.47. Summary statistics for cloze probability and entropy are reported
en mesa 1 as well as in Appendix B, Figure B1, in the Supporting Information, available at
https://doi.org/10.1162/nol_a_00094.
Diseño
Sentences were constructed in quartets, although the experimental design was nonfactorial,
with conditions (a) y (b), y (b) y (d) being collapsed in two respective analyses. Estafa-
condición (C) was presented for lexical balance:
a. Strong constraint, high predictable noun
b. Strong constraint, low predictable noun
Neurobiology of Language
227
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
Mesa 1.
Cloze probability and entropy descriptive statistics.
Condition
a) Strong constraint,high predictable noun
b) Strong constraint, low predictable noun
C) Weak constraint, low predictable noun
d) Weak constraint, low predictable noun
log2 cloze probability
95% range
−1.00, −0.07
Significar
−0.40
Proportion target word
95% range
50.00, 100.00
Significar
79.60
−3.71
−4.09
−4.46
−4.58, −2.50
−5.09, −1.51
−5.09, −2.34
5.47
7.49
4.93
4.17, 14.60
2.94, 34.20
2.94, 17.80
Entropy (bits)
Significar
0.68
0.68
2.44
2.44
95% range
0.00, 1.59
0.00, 1.59
1.47, 3.12
1.47, 3.12
Nota. log2 cloze probability is presented, as log2 cloze probability was used in the statistical model. Since cloze probability can only range between zero and
uno, log2 cloze probability values ranged between minus infinity and zero. El 95% range refers to the 2.5th and 97.5th percentiles of the data. Proportion
target word refers to the raw percentage of cloze completions where the target word was given. Entropy reflects contextual constraint, where low values indicate
strong constraint (low variety of completions given), and high values weak constraint (high variety of low probability completions given).
C. Weak constraint, low predictable noun
d. Weak constraint, low predictable noun
Stimuli were presented in a Latin square design such that all participants saw only one sen-
tence from each item. Había 224 items in total. The collapsed conditions meant that in
each analysis, each participant would contribute data from 112 elementos. Since all sentences
were grammatical and plausible, filler sentences were not used.
Procedimiento
Participants were tested in a single session. For the EEG recording, participants were seated in
a shielded EEG cabin at distance of approximately 60 cm from a 56 cm presentation screen.
The experimental presentation paradigm was built using OpenSesame (Mathôt et al., 2012).
Each experimental session began with instruction screens advising participants that they
would read two related sentences for each trial: The first sentence was presented several words
at a time and the second (the critical sentence) was presented word-by-word. Los participantes fueron
advised that after some sentences, they must answer a question as quickly and accurately as
posible. Each experimental session began with five practice trials.
Each trial in the experiment began with a 500 ms fixation cross in the centre of the screen
followed by a blank screen jittered with a mean of 1,000 ms and standard deviation of 250 EM.
Each sentence was presented word-by-word for a duration of 190 ms per word plus 20 ms for
each letter. The target word, sin embargo, was presented for 700 ms regardless of length so that the
segment of EEG on which we conduct our analysis would not include the onset of the follow-
ing word. The interstimulus interval was 300 EM. Después 50% of the sentences, a yes/no com-
prehension question appeared; Por ejemplo, Hat Annett eine Terrasse? (Does Annett have a
terrace?). Answering the question via a video game controller triggered the beginning of the
next trial. The order of presentation of sentences within each list was fully randomised by the
presentation software. Breaks were offered after every 30 oraciones.
Before starting the EEG experiment, participants performed a stop signal task (Lappin &
Eriksen, 1966; logan & Cowan, 1984) that closely followed the design of Verbruggen et al.
(2008). The purpose of the stop signal task was to measure individual differences in the ability
to stop an action (a button press) once they had already initiated it. This information was cor-
related with participants’ PNP responses, with the hypothesis that poorer performance on the
stop signal task may correlate with smaller constraint-related differences in the PNP; eso es, si
Neurobiology of Language
228
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
the PNP is related to suppressing the mental representation of a sentence that has been falsified
by unexpected input, people who are better at inhibiting responses on the stop signal task
might also show larger PNP constraint effects. Sin embargo, this was an exploratory analysis
and we pre-registered no specific analysis plan here. The testing session including EEG setup
lasted approximately three hours.
EEG Recording Parameters and Preprocessing Pipeline
EEG was recorded from 32 scalp sites by means of AgAgCl active electrodes mounted in an
elastic electrode cap at the standard 10–20 system (Jaspe, 1958). Eye movements and blinks
were monitored with bipolar electrodes next to the left and right outer canthus as well as
below and above the right eye. EEG and electrooculography was recorded with a TMSi Refa
amplifier with active shielding at a sampling rate of 512 Hz and a low-pass filter of 138 Hz, en
line with manufacturer recommendations. Recordings were initially referenced to the left
mastoid and re-referenced offline to the average of the left and right mastoid channels.
EEG was filtered offline using zero phase finite impulse response (FIR) filters with a band-
pass of 0.01–30 Hz on whole, unsegmented EEG blocks (es decir., continuous blocks recorded
between participants’ breaks). The width of the transition band at the low cut-off frequency
era 0.01 Hz and at the high cut-off frequency, 7.5 Hz. Data were then segmented into whole
sentences and blinks and eye movements corrected using independent component analysis
(ICA; Jung et al., 2001) with the Fast ICA algorithm (Hyvärinen & Oja, 2000). ICA compo-
nents were inspected for each participant and removed if they strongly correlated with the
ocular channels. The data were then further segmented to extract the target region, and seg-
ments were rejected if they contained a voltage difference of over 100 μV in a time window
de 150 ms or containing a voltage step of over 50 μV/ms. In total, this pipeline resulted in the
rejection of 16% of the target noun segments, leaving approximately 3,000 target segments
per condition. Corrected signal was then segmented and baseline-corrected relative to a
200 ms interval preceding the stimulus.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Analyses
The dependent variables in our planned analyses were:
(cid:129) N400: Average ERP amplitude (μV) over electrodes Cz, CP1, CP2, P3, Pz, P4, and POz
in the window 300–500 ms following target word onset.
(cid:129) PNP: Average ERP amplitude (μV) over electrodes Fpz, Fp1, Fp2, F3, Fz, F4 in the
window 600–1000 ms following target word onset.
Como se ha mencionado más arriba, constraint was operationalised as entropy, where increasing entropy
reflected decreasing constraint. Noun predictability was operationalised as smoothed cloze
probability transformed to log2. Additive smoothing was used with pseudocounts set to one
to avoid taking the log of zero (Laplace or Lidstone smoothing; Chen & Buen hombre, 1999;
Lidstone, 1920). The log transformation reflected the assumption that the effect of cloze
probability on N400 amplitude is continuous and nonlinear. En otras palabras, changes in cloze
probability at the upper end of the probability scale will not affect N400 amplitude as much as
changes at the lower end of the scale. De este modo, the model will estimate the same average change
in amplitude for a difference in cloze probability of 0.09 a 0.26 as for a change of 0.26 a
0.74, even though the latter represents a larger change in raw cloze probability. Log trans-
formed cloze probability has previously been demonstrated to give a better fit to ERP data
Neurobiology of Language
229
Constraint and predictability in ERP
(Delaney-Busch et al., 2019; Frank et al., 2015; Nicenboim et al., 2020), as well as to reading
time data (Hale, 2001; Exacción, 2008; Herrero & Exacción, 2013), is consistent with Pareto and Zipf
distributions of word frequency (Baayen, 2001), and with scaling laws in other areas of cog-
nitive research (Kello et al., 2010).
Both entropy and log cloze probability were centred according to the mean of the conditions
included in the model (see below), such that the model estimated the one-unit change in ERP ampli-
tude at average values of log cloze probability and entropy (average values are in Table 1 arriba).
Statistical models and predictions
Linear mixed effects models with correlated by-item intercept estimates and full variance-
covariance matrices for by-subject random effects were fit in the rstan/Stan wrapper brms
(Versión 2.16.3; Bürkner, 2017) in R (R Core Team, 2020). (For a complete list of the software
used in this article, see Software, below.) Only random intercepts were estimated for items
because once the conditions were collapsed to treat entropy and cloze probability as continuous
predictors, there were only two entropy/cloze values per item (corresponding to each sentence
contexto). Since this was unlikely to be sufficient to precisely calculate by-item random slopes, a
reduce computation time we included by-item intercepts only.
Our priors for the models were informed by the model estimates of previous Bayesian ERP
analiza, which suggested that intercept variability was higher than individual variability
between participants and items (Nicenboim et al., 2020). Using prior predictive checks
against simulated data, we then calibrated the priors so that they were in line with previous
findings, but not strictly informative. These regularising priors were used to ensure stable and
psycholinguistically plausible estimates (Chung et al., 2015; Gelman et al., 2008; Gelman
et al., 2017). We confirmed that the joint behaviour of these priors in the model would
generate plausible estimates using prior predictive checks (Gelman et al., 2017; Schad
et al., 2021); ver figura 3 in Prior Distributions and Predictive Check for the Statistical Models.
The priors were:
Þ
intercept ∼ Normal 0; 5d
Þ
βpredictability ∼ Normal 0; 1d
βconstraint ∼ Normal 0; 1d
Þ
σsubject;item ∼ Normalþ 0; 0:5
Þ
σresidual ∼ Normalþ 8; 2d
Þ
ρ ∼ LKJ 2ð Þ
d
Models for estimation were fit with 50,000 iterations, including a warmup of 1,000 itera-
ciones. Model convergence was assessed by ensuring that the number of bulk and tail effective
samples for every parameter estimate was at least 2,000 and that R^ values—the correlations of
entre- and within-chain variance—did not exceed 1.01. If these checks were violated, el
number of iterations for each model was increased, or sampler behaviour modified, as indi-
cated by warning messages from brms.
Support for our specific hypotheses (detailed below) was assessed using Bayes factors. Como
we had very specific, pre-registered hypotheses about the direction of these effects, the priors
used for the Bayes factor analysis were truncated such that they constitute one-sided tests. Como
discutido anteriormente, conclusions about evidence for or against our hypotheses was based on
Bayes factors computed using priors of Normal−(0, 0.2) for the effect of entropy (constraint)
and cloze probability (predictability) on the PNP, and Normal(0, 0.2) for the effect of entropy
(constraint) and Normal+(0, 0.2) for the effect of cloze probability (predictability) on the N400,
according to which of the questions (see Statistical Models and Predictions and Prior
Neurobiology of Language
230
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
Distributions and Predictive Check for the Statistical Models) was being tested. These trun-
cated priors were used for hypothesis testing, but exploratory analyses with two-sided tests
was also used to assess evidence for non-hypothesised effects.
Models for the Bayes factor analyses were fit with 50,000 iterations in line with Bürkner
(2017) recomendaciones, including a warmup of 1,000 iterations. Convergence was assessed
as for the estimation models—at least 2,000 bulk and tail effective samples for each param-
eter estimate, and R^ ≤ 1.01. Bayes factors were calculated using bridge sampling (bennett,
1976; Gronau et al., 2017; Meng & Wong, 1996). The strength of evidence for or against our
hypotheses was assessed with reference to Jeffreys (1939) escala, where a Bayes factor indi-
cating evidence at a ratio of 3:1 in favour of an effect is considered the minimum meaningful
support for that effect, y solo 10:1 or larger values are considered strong evidence. Given
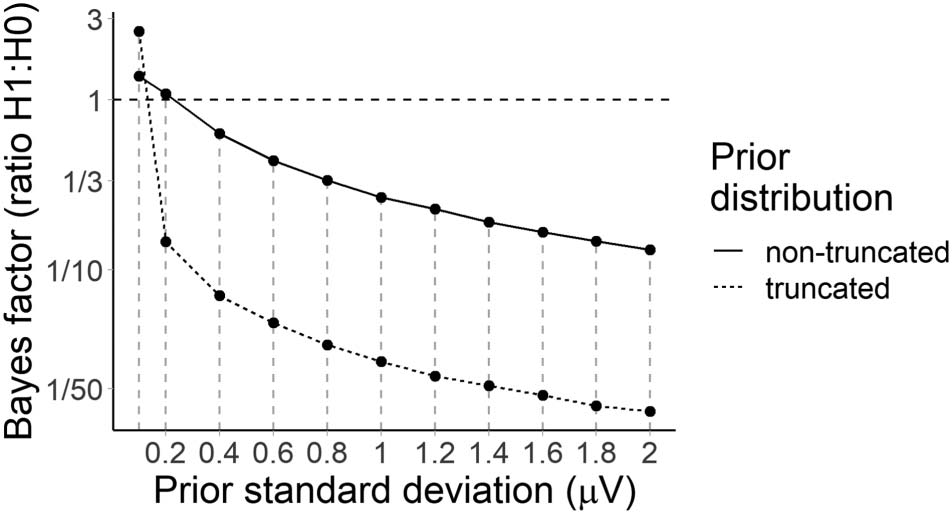
the sensitivity of the Bayes factor to the choice of prior (Sotavento & carpinteros, 2014), nosotros también
computed Bayes factors for a range of different priors on the effects of constraint (entropy) o
predictability (cloze probability) while holding all other priors (p.ej., intercept, random effects)
constant as defined above. The priors for these sensitivity analyses ranged from Normal(0, 0.2)
to Normal(0, 2), both truncated and non-truncated.
Effect of low predictability at the noun under differing constraint. Our main comparison of interest
concerned the effect of constraint when noun predictability was low. With respect to the N400,
in line with previous research we expected that words with similar cloze probabilities would
elicit N400s with similar amplitudes, regardless of how constraining their context was. Con
respect to the PNP, if it is the case that the PNP reflects the cost of revising a probabilistic event
representación (Kuperberg et al., 2020), then we should expect that low cloze probability words
elicit a PNP that is larger in contexts that are strongly constraining than in contexts that are weakly
constraining.
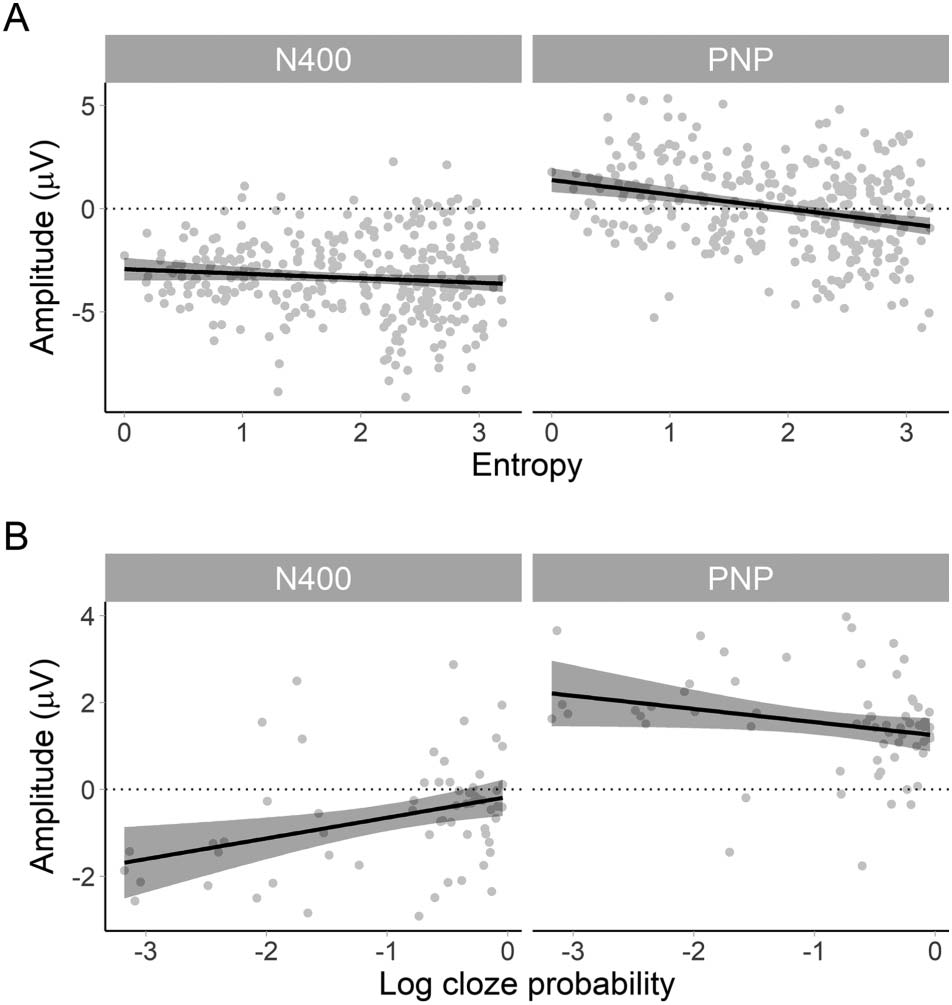
For this comparison, we took sentences from conditions (b) y (d), which both had low
cloze probability nouns but varied in entropy (high entropy = weak constraint, low entropy =
strong constraint); this can be seen in Figure 1A. Conditions (b) y (d) were collapsed together
and ERP amplitude analysed as a function of continuous entropy. Although noun cloze prob-
ability in both conditions was low, there was some variability due to the differing contexts and
thus log cloze probability was added as a continuous nuisance predictor in the models. En
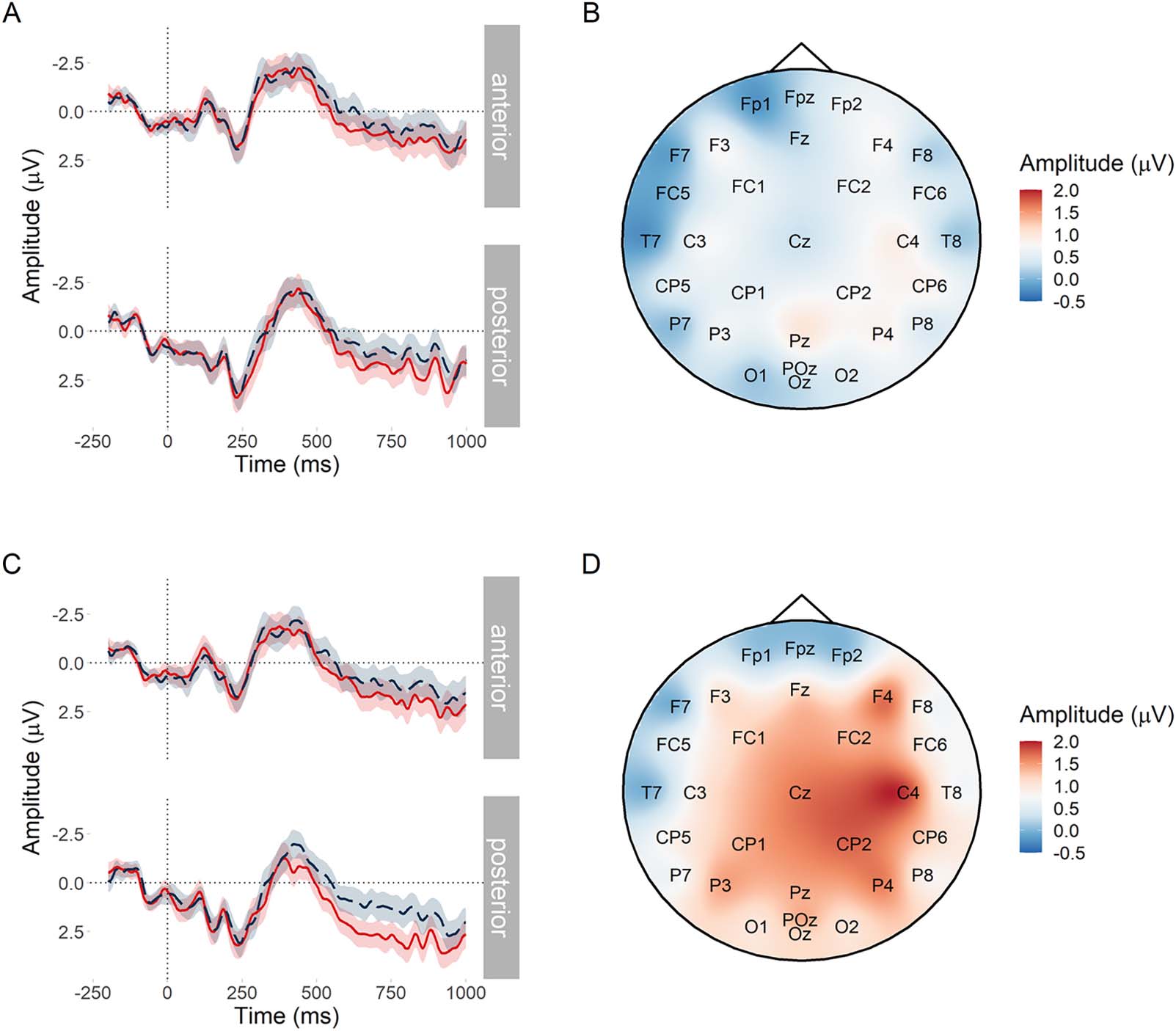
corto, Figure 1A shows our predictions that when cloze probability is low:
(cid:129) the N400 would be of equally high (negative) amplitude regardless of entropy (estafa-
straint). There may be a small effect of cloze probability;
(cid:129) the PNP would become more positive as entropy decreases (es decir., as constraint increases).
There may be a small effect of cloze probability.
Note that cloze probability and entropy are somewhat correlated (see Appendix B, Cifra
B1). This is because it is difficult to build stimuli that hold cloze probability constant while
systematically varying entropy. Sin embargo, our pre-registered hypotheses do not concern the
effect of an interaction, and adding an interaction term to the model may only estimate vari-
ance otherwise explained by entropy (or cloze probability). Por esta razón, we chose to omit
an interaction from the model.
R brms model specification:
N400 ∼ constraint þ predictability þ 1jitem
PNP ∼ constraint þ predictability þ 1jitem
d
d
Þ þ 1 þ constraint þ predictabilityjsubj
Þ
Þ
Þ þ 1 þ constraint þ predictabilityjsubj
d
d
Neurobiology of Language
231
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
Cifra 1. Simulated direction of the effect of constraint and predictability on average amplitude in
the N400 and PNP time windows. (A) In our first analysis, we collapsed conditions (b) y (d) semejante
that predictability (cloze probability) was low but constraint (entropy) varied. Increasing entropy
means decreasing constraint. De este modo, as entropy increases on the x-axis, PNP amplitude should
become less positive. En otras palabras, the PNP at unexpected words should be more positive at
low values of entropy (high constraint) than at high values of entropy (low constraint). N400 ampli-
tude should not be affected by constraint, but may be sensitive to small differences in cloze prob-
ability between conditions (b) y (d). This was accounted for in the statistical analysis by adding
cloze probability as a nuisance variable. (B) In our second analysis, we collapsed conditions (a) y
(b) such that constraint was high (low entropy), but predictability (cloze probability) varied. Cloze
probability values are negative due to the log transformation. As cloze probability increases toward
zero on the x-axis, the N400 becomes less negative and the PNP less positive. En otras palabras, como
predictability increases, the size of both the N400 and the PNP decrease.
Effect of differing predictability at the noun under strong constraint. As a sanity check, nosotros también
compared conditions (a) y (b). It is well established that decreasing cloze probability should
increase amplitude of the N400 (es decir., make it more negative; Kutas & Federmeier, 2011) y de
the PNP (es decir., make it more positive; Federmeier et al., 2007; Kuperberg et al., 2020). Under this
assumption, when constraint was matched, we expected a larger N400 and PNP for low versus
high cloze probability words. For this comparison, we took sentences from conditions (a) y
(b), which both had strong constraint but varied in cloze probability; ver Figura 1B. De este modo, estafa-
ditions (a) y (b) were collapsed and ERP amplitude analysed as a function of continuous log
cloze probability. As can be seen in Figure 1B, we expected that when constraint was strong:
(cid:129) the N400 would become more negative as cloze probability decreases;
(cid:129) the PNP would become more positive as cloze probability decreases.
R brms model specification:
N400 ∼ predictability þ 1jitem
PNP ∼ predictability þ 1jitem
d
d
Þ þ 1 þ predictabilityjsubj
Þ
Þ
Þ þ 1 þ predictabilityjsubj
d
d
Neurobiology of Language
232
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
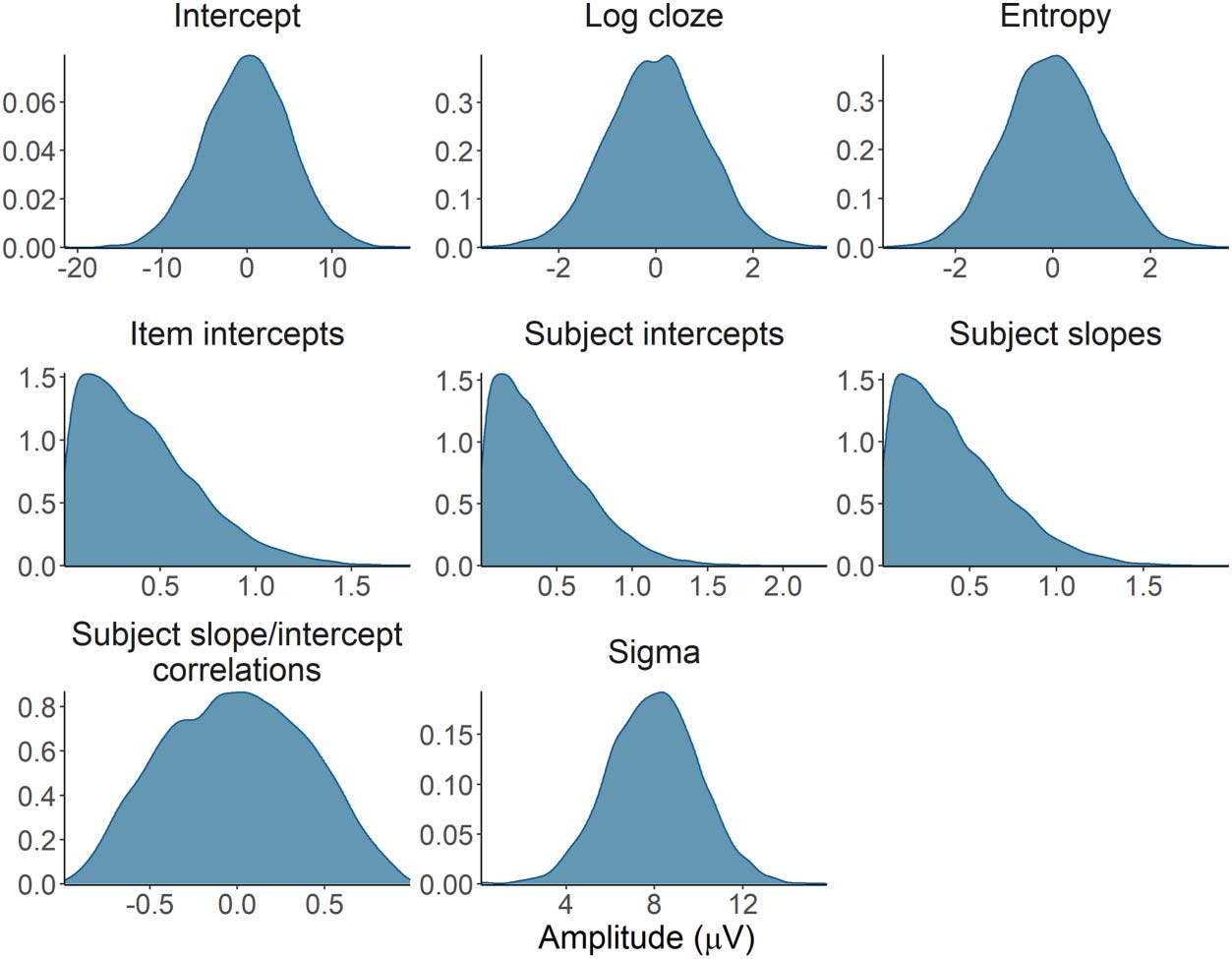
Cifra 2. Prior distributions for the model parameters.
Prior distributions and predictive check for the statistical models
As an additional check that our prior specification would result in sensible estimates for our
modelos, we conducted a prior predictive check (Gelman et al., 2017; Schad et al., 2021). En
Cifra 2, we show the prior distributions for each parameter in our statistical models. En
Cifra 3, we show the posterior distributions of a model simulating the predicted effect of
entropy on the PNP and the N400 using only the priors. The estimated effect of entropy based
on the priors (light blue lines) is plausible with respect to the effect based on simulated data
(dark blue line), confirming that the joint behaviour of our priors in the model did not lead to
implausible parameter estimates.
Cifra 3. Prior predictive check. Prior predictive distributions for the effect of entropy on the PNP
and N400 (light blue lines) based on the model priors suggests the priors generate plausible esti-
mates consistent with simulated data (dark blue lines).
Neurobiology of Language
233
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
RESULTADOS
In the following sections we report first the results of the pre-registered analyses, then the results
of our exploratory analyses. Data and code for all analyses are available at https://osf.io/fndk5.
Preregistered Analysis
Effect of low predictability at the noun under differing constraint
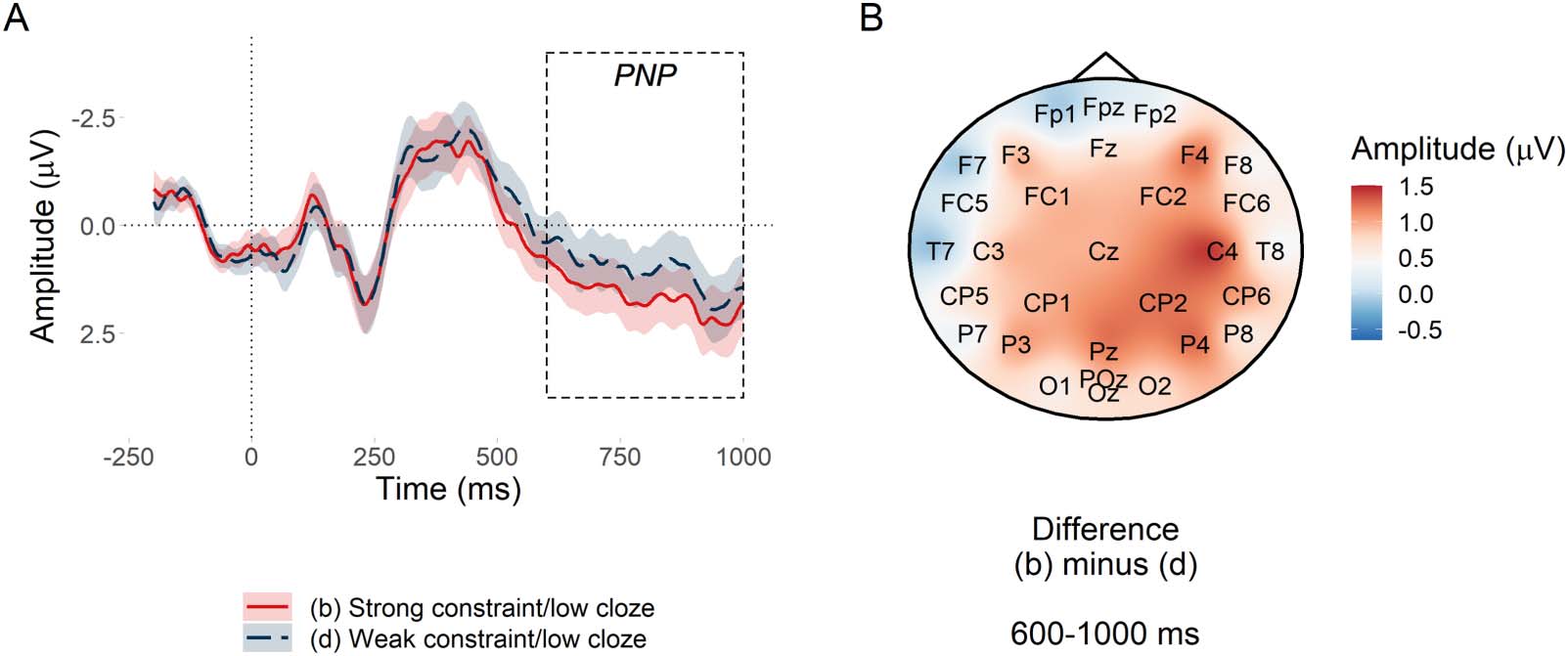
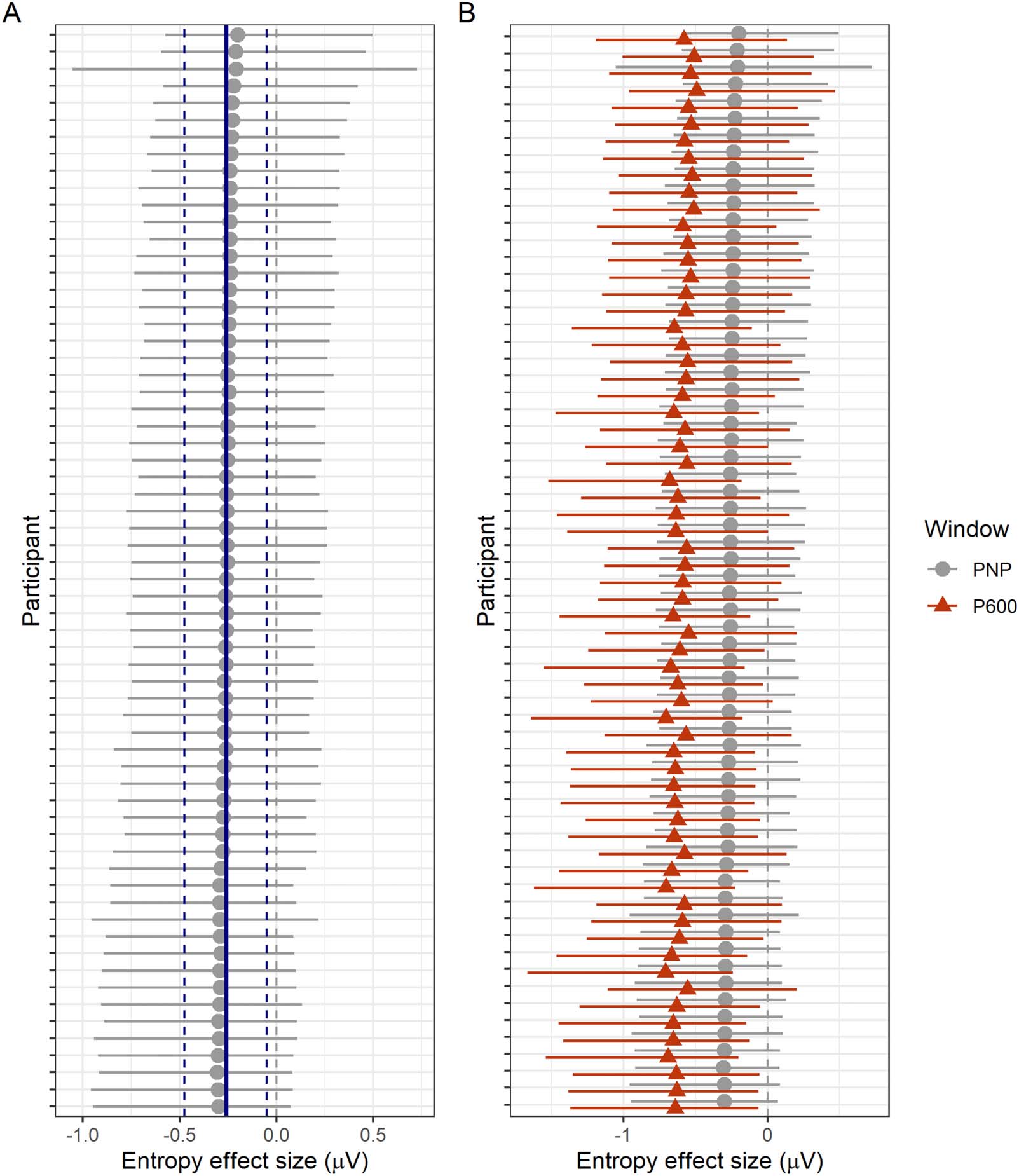
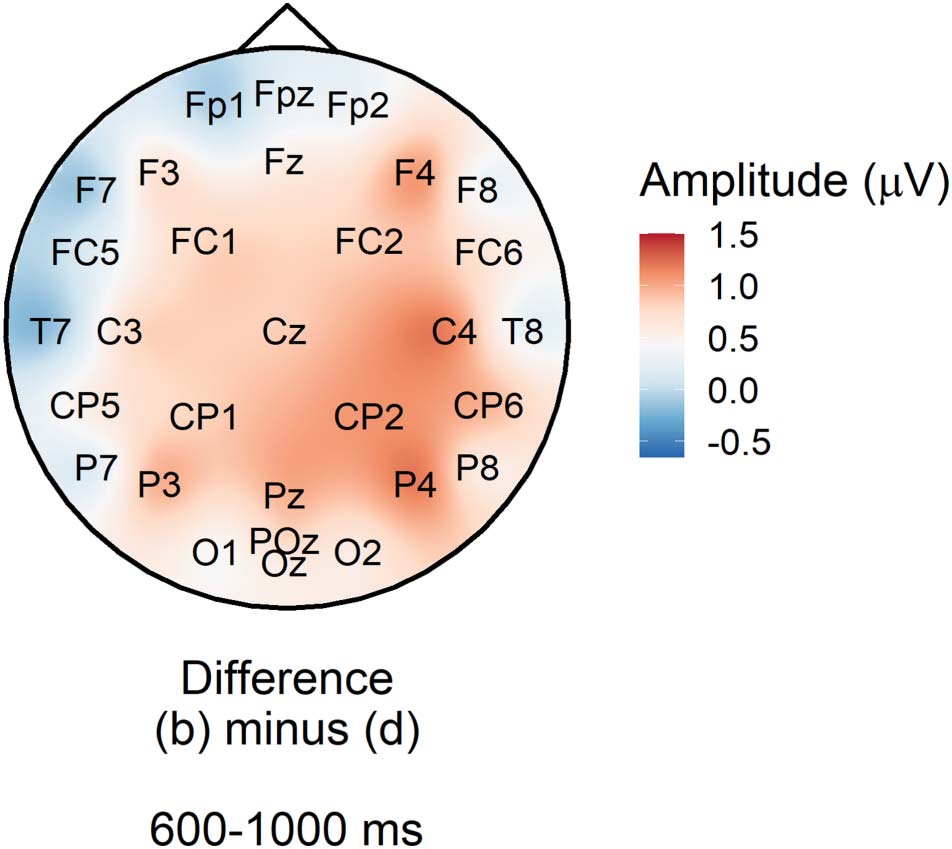
PNP window. Figure 4A plots mean amplitude at the target word in the anterior region of inter-
est. The PNP was most positive for low probability words in low entropy (strongly constraining)
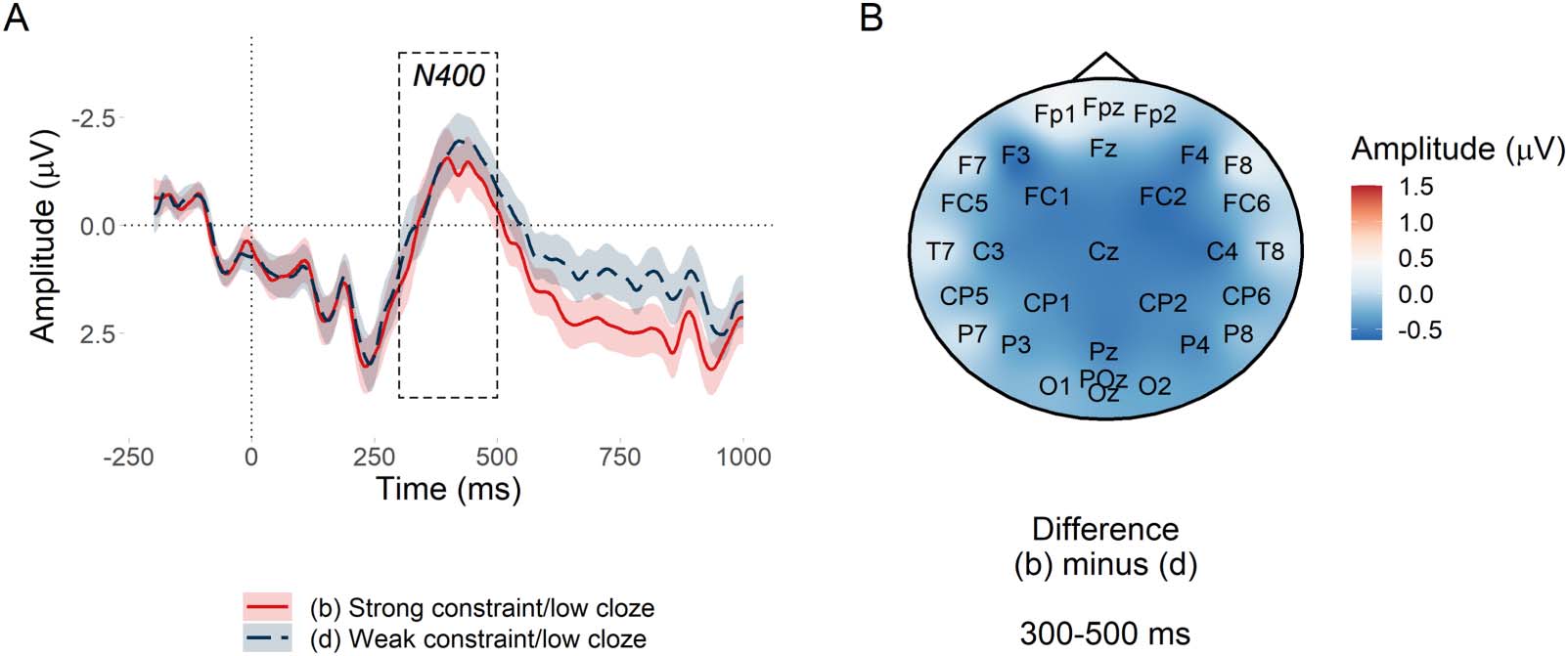
contexts and became less positive as entropy increased (constraint weakened) by a estimated
mean amplitude of −0.26 μV per bit of entropy, con un 95% credible interval of [−0.48,
−0.05] μV. Credible intervals reported throughout the manuscript are quantile-based. El
Bayes factor indicated strong evidence for H1 over H0, BF10 = 17.17, consistente con
Federmeier et al. (2007) and Kuperberg et al. (2020). Sin embargo, those studies predicted that
the effect would be centred over anterior electrodes, whereas Figure 4B suggests that in the
estudio actual, the scalp distribution of the constraint effect was centred over posterior elec-
trodes; we return to this in the exploratory analyses. Sensitivity analyses testing the sensitivity
of the Bayes factor to the choice of prior for all pre-registered analyses are presented in
Appendix C in the Supporting Information.
N400 window. Our pre-registered analysis yielded inconclusive evidence about the effect of
constraint in the N400 window, β^= −0.09 [−0.30, 0.12] μV, BF10 = 0.76. We attribute the
inconclusive result to what appears to be between-condition differences in the behaviour of
the N400 prior to and after its peak amplitude, as can be seen in Figure 5A. Prior to the peak,
there was no visible effect of constraint. Past the peak however, from about 400 EM, allá
appeared to be a small constraint effect, which could be consistent with the beginning of
post-N400 processing. Alternativamente, it could reflect differences in mean latency of the
N400 between the two conditions, with one condition peaking slightly later and thus having
a higher amplitude for longer. ( We thank a reviewer for this suggestion.) Figure 5B shows a
Cifra 4. PNP constraint effect at low predictability nouns. (A) Mean amplitude at the target low probability noun in the anterior region of
interés. Since constraint in the statistical analysis was represented by the continuous predictor entropy, condiciones (b) y (d) are divided by
the median split of their entropy values. Ribbons indicate 95% confidence intervals. (B) Subtraction plot of mean amplitude at low predict-
ability target words between high and low median split entropy.
Neurobiology of Language
234
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
Cifra 5. N400 constraint effect at low predictability nouns. (A) Mean amplitude at the target low probability noun in the posterior region of
interés. Conditions (b) y (d) are divided by the median split of their entropy values. Ribbons indicate 95% confidence intervals. (B) Sub-
traction plot of mean amplitude between the high and low constraint low predictability target words. Conditions (b) y (d) are divided by the
median split of their entropy values.
very small difference between high and low entropy in the N400 window with a topographic
distribution typical of the N400.
Effect of differing predictability at the noun under strong constraint
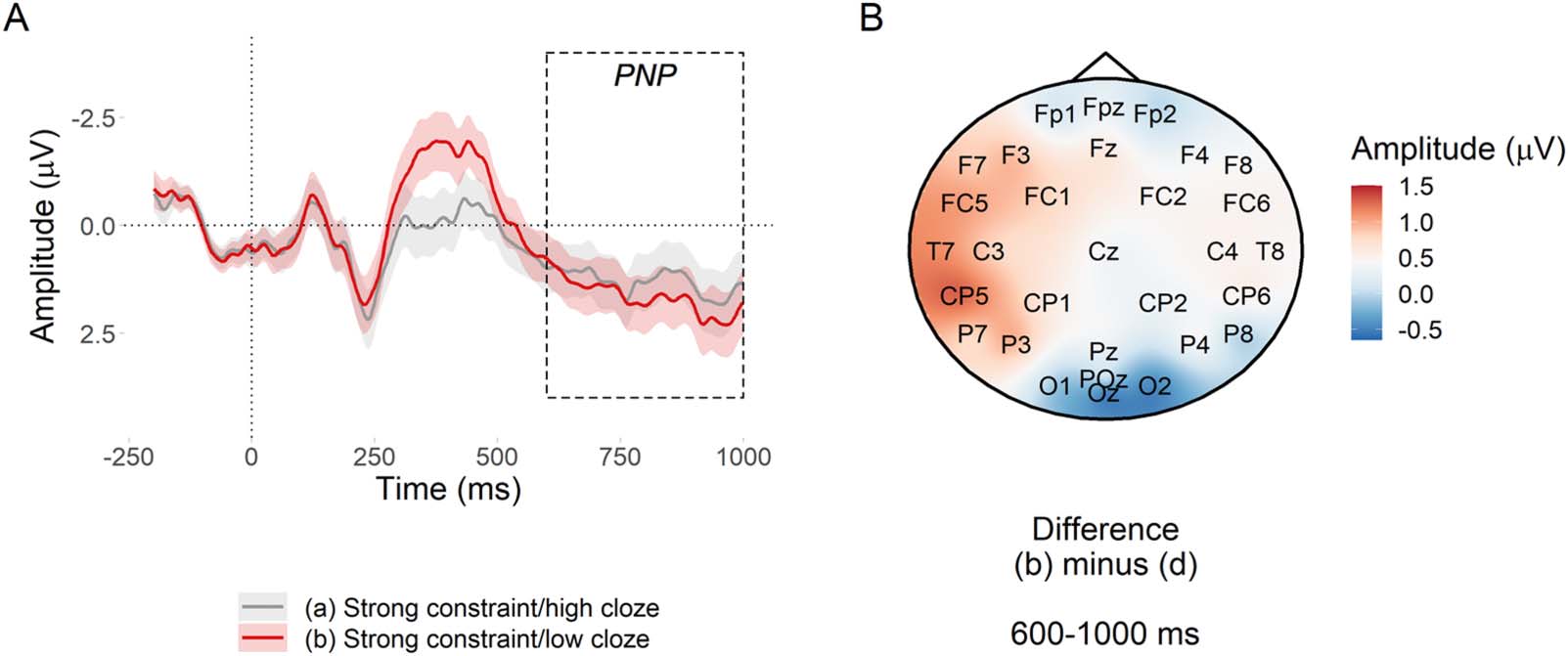
PNP window. Figure 6A suggests a small predictability effect in the expected direction with
respect to Kuperberg et al. (2020), but the evidence was inconclusive, β^= −0.11 [−0.24,
−0.01] μV, BF10 = 1.67. Sin embargo, Figure 6B suggests that there may have been a more left
lateralised predictability effect; a similar predictability effect was also observed in Kuperberg
et al. (2020) but was not analysed separately.
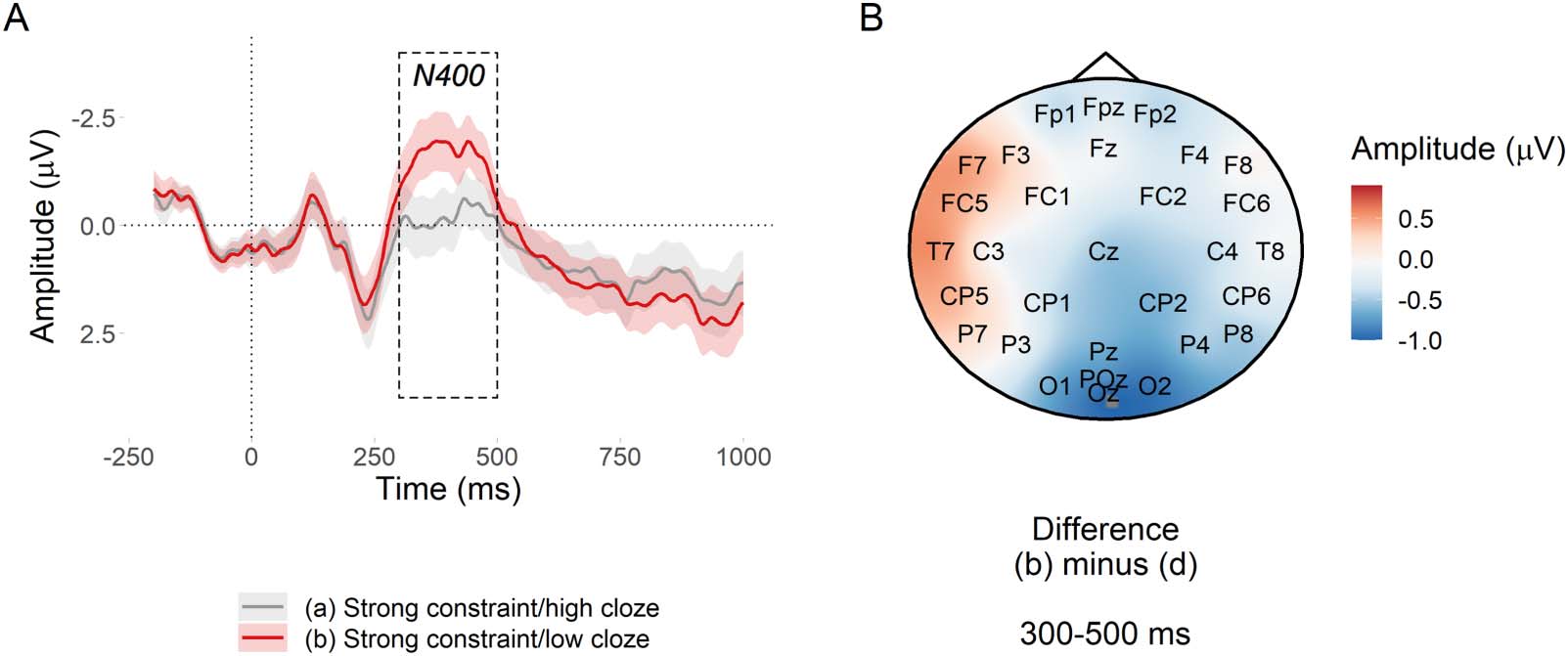
N400 window. Low probability words in strongly constraining contexts elicited a large N400
in comparison to high probability words (Cifra 7). There was extremely strong evidence for
el efecto, β^= 0.56 [0.41, 0.71] μV, BF10 > 207.
Cifra 6. PNP predictability effect at nouns in strongly constraining contexts. (A) Mean amplitude at the target noun in the posterior region
de interés. Ribbons indicate 95% confidence intervals. (B) Subtraction plot of mean amplitude between the high and low predictability
target words.
Neurobiology of Language
235
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
Cifra 7. N400 predictability effect at nouns in strongly constraining contexts. (A) Mean amplitude at the target noun in the posterior region
de interés. Ribbons indicate 95% confidence intervals. (B) Subtraction plot of mean amplitude between the high and low predictability
target words.
DISCUSIÓN
Using the pre-registered analysis plan, we observed strong evidence that low probability words
elicited more positive amplitude in the post-N400 window in strongly versus weakly con-
straining contexts. The direction of this effect was in line with previous research (Federmeier
et al., 2007; Kuperberg et al., 2020), but its scalp distribution was consistent with a posterior
P600 and not an anterior PNP. The effect of predictability in the PNP window was inconclu-
sive, which contradicts Kuperberg et al. (2020). The N400 window was more consistent with
previous research: Although between-condition differences in the behaviour of the N400
before and after its peak amplitude were apparent in the latter part of the window, it did
not appear that constraint affected the N400 (Federmeier et al., 2007; Federmeier & Kutas,
1999; Kuperberg et al., 2020; Lai et al., 2021; Szewczyk & Schriefers, 2013; Thornhill &
Van Petten, 2012) and there was strong evidence for the standard N400 predictability effect
(Kutas & Federmeier, 2011).
These findings support our hypotheses only partially. In support of our hypotheses, el
constraint effect was apparent in the post-N400 window and not in the N400 window. Este
demonstrates a dissociated effect of probabilistic representation strength as processing
progresses over time: It does not appear to affect initial semantic processing in 300–500 ms
window (Kutas & Federmeier, 2011; Rabovsky et al., 2018), but it does appear to affect the
downstream consequences of this processing in the 600–1,000 ms window. Contrary to our
hypotheses, the topography of the late positive effect was more consistent with a P600 than
with the PNP reported in the literature. The P600 has been associated with conflict monitoring
and syntactic reanalysis—a different type of processing than that proposed for the PNP
(Bornkessel-Schlesewsky & Schlesewsky, 2008; Brouwer et al., 2017; Fitz & Chang, 2019;
kim & Osterhout, 2005; Kuperberg et al., 2003; Osterhout & Holcomb, 1992).
Since a constraint effect on the P600 was unexpected in the current design, in the following
section we first establish statistical evidence for the effect. We also examine whether word
predictability affected the P600, since it was shown to affect the PNP in the previous research
we had been trying to replicate. We then present a number of exploratory analyses probing
different factors that could have resulted in the observed constraint effect being posterior
(P600) rather than anterior (PNP).
Neurobiology of Language
236
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
In other exploratory analyses, we examine the two effects for which we did not find con-
clusive evidence—the PNP predictability effect and the N400 constraint effect—and simulate
data sets with larger sample sizes to determine what a sufficient sample size would have to be
to yield conclusive evidence. Finalmente, we analyse the stop signal task to determine whether
participants who were better at suppressing motor responses also showed larger
constraint-based PNPs or P600s. We turn now to these exploratory analyses.
Exploratory Analysis
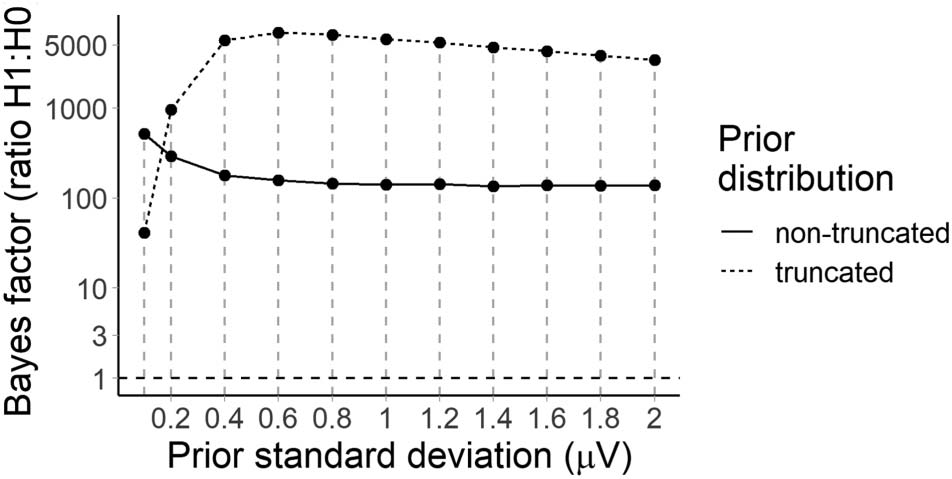
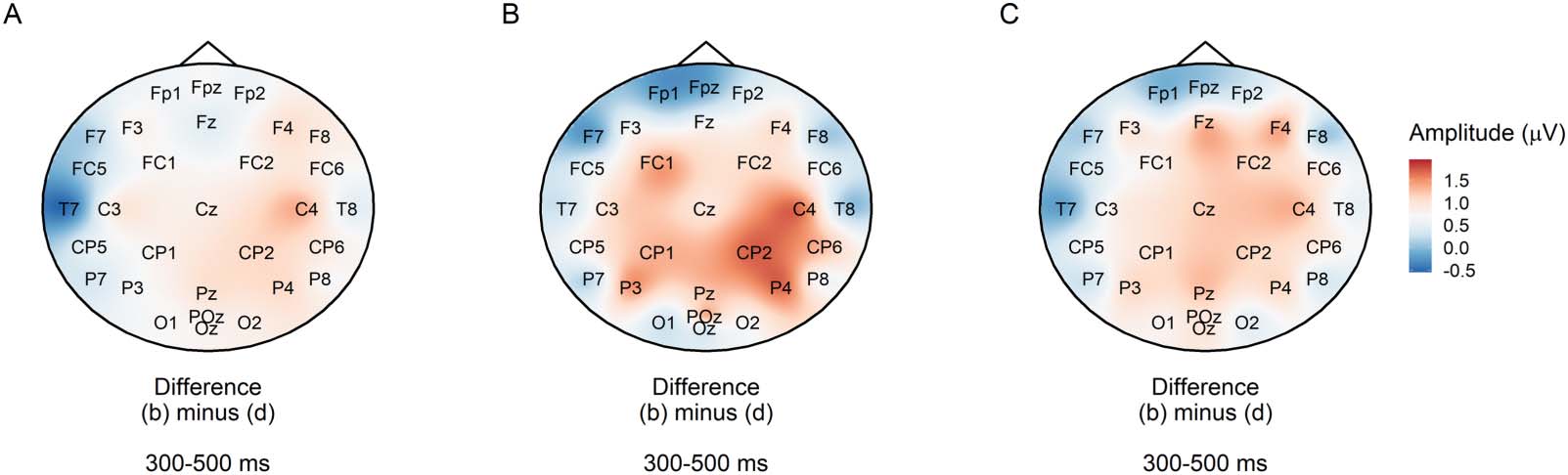
Statistical evidence for the P600 constraint effect
We analysed average amplitude in the 600–1,000 ms across the posterior region of interest
(electrodes Cz, CP1, CP2, P3, Pz, P4, and POz). The model was that used for the PNP, pero
since we did not have a priori hypotheses about the direction or magnitude of the constraint
efecto, we examined a range of priors. Cifra 8 suggests that there was strong evidence (BF10
de 41 a 5,472) that low probability words elicited a more positive P600 in strong versus
weak constraint regardless of prior, although the Bayes factor peaked around a prior standard
desviación de 0.6 μV (truncated to assume a negative effect), β^= −0.60 [−0.86, −0,34] μV.
Predictability and the posterior P600
In a previous study, both contextual constraint and word predictability affected the PNP
(Kuperberg et al., 2020). Assuming that a similar underlying process drove the P600 constraint
effect in the current study, we additionally tested the effect of predictability in the 600–1,000 ms
window. We fit the same model as used to test the PNP predictability effect, but used mean
amplitude across posterior electrodes Cz, CP1, CP2, P3, Pz, P4, and POz. We used a range
of priors and computed a Bayes factor for each. Cifra 9 suggests that for prior standard devi-
ations of 0.2 μV or more that assumed a negative effect, there was strong evidence against a
predictability effect, β^= −0.11 [−0.24, −0.01] μV, previo: β ∼ Normal−(0, 0.2). For priors that
made no assumption about the direction of the effect, evidence against a predictability effect
was weaker, but tended in the same direction as for priors assuming a positive effect.
How many subjects would have been needed to yield conclusive evidence?
Using our pre-registered analysis plan, we were unable to find conclusive evidence for two of
our four pre-registered hypotheses. Cifra 10 plots the Bayes factor for each of our four com-
parisons as sample size increased. Our two key comparisons are highlighted in black. A pesar de
the Bayes factor remaining inconclusive for one of these key comparisons—the N400
Cifra 8. Bayes factors for the P600 constraint effect under a range of priors. The dashed line at a
Bayes factor of 1 indicates equivalent evidence for H1 and H0. Bayes factors above this line indicate
evidence in favour of H1, with Bayes factors of over 10 generally considered to indicate strong evi-
dencia (Jeffreys, 1939).
Neurobiology of Language
237
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
Cifra 9. Bayes factors for the P600 predictability effect under a range of priors. The horizontal
dashed line at a Bayes factor of 1 indicates equivocal evidence for H1 and H0. Above this line,
evidence increases for H1, below this line, for H0. Evidence above 10 for H1 or below 1/10 para
H0 is generally considered to be strong. The plot panels show the estimated ratio of evidence for
H1 over H0 (BF10).
constraint effect—we ceased recruitment due to the difficulty in recruiting participants during
the COVID-19 pandemic. The post-peak N400 constraint-related differences 614 may also
have prevented the Bayes factor from ever being able to distinguish between null and alterna-
tive hypotheses, even if we had reached our pre-registered cap of 150 Participantes, cual
would have been infeasible given the poor recruitment rate.
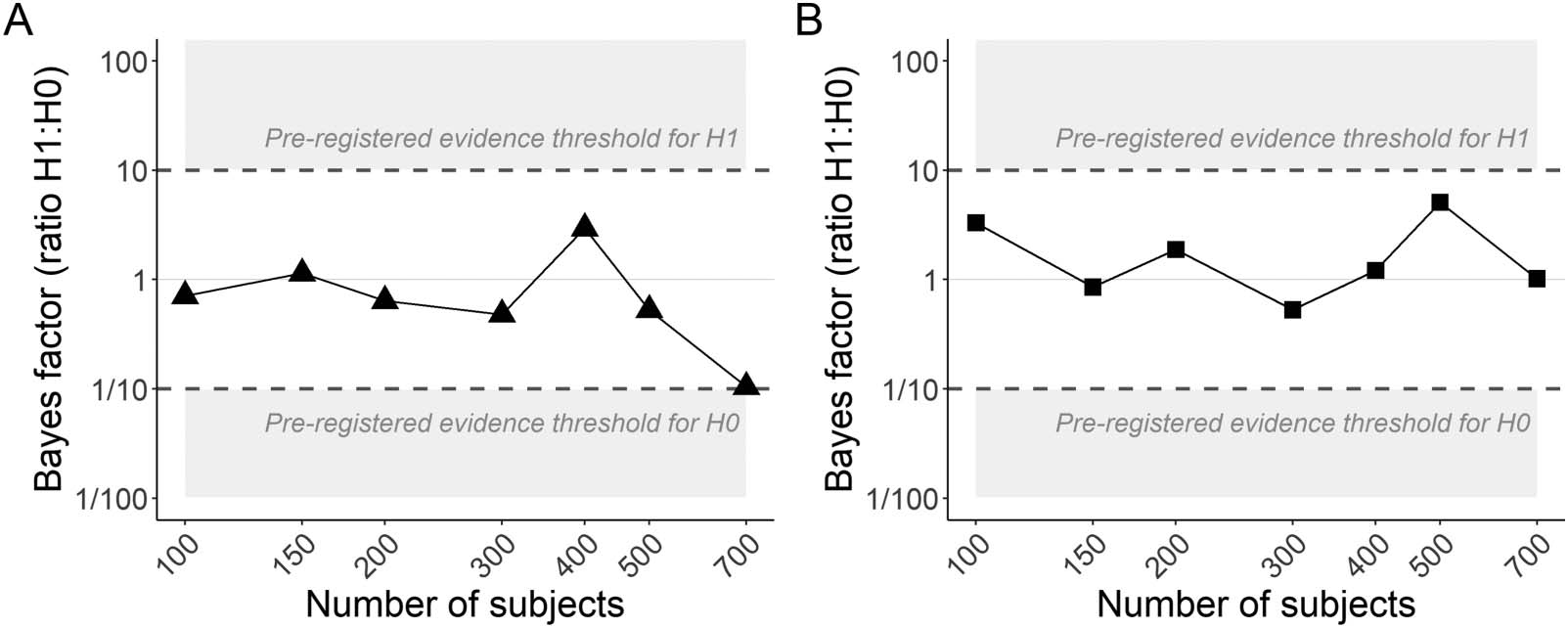
We therefore conducted a design analysis (Gelman & Carlin, 2014) to determine how many
participants would be needed in a future experiment to yield conclusive evidence for the null
hypothesis. We assumed that the estimates from the final sample of 64 participants reflected
true values and used them to simulate new data sets for between 100 y 700 Participantes. A
Bayes factor for the N400 constraint effect was computed for each sample size. Figure 11A
suggests that even with the pre-registered cap of 150 Participantes, we would not have furn-
ished strong evidence against the constraint effect on the N400 using our pre-registered
analysis plan. The analysis suggested that, assuming that the estimates obtained from the pres-
ent data are indeed the true values, al menos 700 participants would be needed to demonstrate
strong evidence against a constraint effect using the current experimental design.
Since our secondary hypothesis about the PNP predictability effect also yielded inconclu-
sive evidence with 64 Participantes, we repeated the same design analysis and noted that
Cifra 10. Ratio of evidence for H1:H0 (Bayes factor) as sample size increases. The key contrasts
regarding the effect of constraint on the PNP and N400 are in black.
Neurobiology of Language
238
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
Cifra 11. Bayes factors at simulated sample sizes. (A) N400 constraint effect: One data set was simulated for each sample size to which the
pre-registered analysis model was fit. Each point in the plot reflects the Bayes factor for that sample size. (B) PNP predictability effect: Cada
point reflects the Bayes factor for a pre-registered analysis applied to a simulated data set.
de nuevo, assuming our parameter estimates reflected the ground truth, the pre-registered cap of
150 participants would not have yielded conclusive evidence using the current design.
Figure 13B suggests that if there were a true predictability effect, not even 700 Participantes
would have been sufficient to yield conclusive evidence for it.
Factors that could have changed the scalp appearance of the constraint effect or its underlying
cognitive process
Individual variability. The scalp topography of an averaged ERP can be affected by factors such
as variability in cortical folding and skull thickness between participants (Luck, 2005a). Nosotros
examined individual variability by plotting posterior estimates of the entropy effect by partic-
ipant for the PNP (Figure 12A) and P600 (Figure 12B). Sin embargo, individual estimates largely
reflected the group mean with no obvious systematic outliers.
Another possibility is that individual participants differed in their response to the unexpected
palabra: Some may have suppressed the disconfirmed sentence parse (PNP), while others
attempted to reanalyse the sentence (P600). If this were the case and we simply had more
P600-type processors in our participant pool, one could expect a crossover effect where partic-
ipants with smaller PNP constraint effects showed larger P600 constraint effects, y viceversa.
Individual PNP estimates are plotted against P600 estimates in Figure 12B, but do not suggest a
crossover effect. To quantify the relationship between individual PNP and P600 constraint
efectos, we fit a multivariate linear mixed effects model with the same form as the constraint
models above, except that there were two response variables: mean amplitude in the PNP
and in the P600 windows/regions. A prior for the correlation of the PNP and P600 constraint
effects was also added: LKJ(2). A crossover between the PNP and P600 constraint effects would
yield a negative correlation estimate; en cambio, the model suggested a positive correlation, ^ρ = 0.61
[0.60, 0.63]. En otras palabras, participants with larger PNPs also tended to exhibit larger P600s.
The operationalisation of constraint as entropy. A major difference between the current study and
Kuperberg et al. (2020) and Federmeier et al. (2007) is the use of entropy as a continuous
measure of constraint. En cambio, as in those studies, we could have used cloze probability of
the most often given response, cual, in the high constraint condition (b) era 0.80, 95%
range = [0.50, 1.00] and in the low constraint condition (d), 0.10, 95% range = [0.06,
0.50]. To determine whether a categorical definition of constraint would have changed the
Neurobiology of Language
239
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Individual posterior estimates of the effect of entropy in the post-N400 window. (A) Individual posteriors from the pre-registered
Cifra 12.
model of the anterior PNP (grey) are plotted against the group estimate (azul). Points show posterior means and error bars the 95% credible
intervals. (B) Individual posterior estimates for the PNP (grey) are overlaid with estimates from the model fit to P600 amplitudes at the top of this
sección (naranja).
topography of the constraint effect, we re-plotted Figure 4B by subtracting condition (b) de
condición (d) as defined by their category, rather than by a median split of entropy values. Como
can be seen in Figure 13, the distribution of the constraint effect was still posteriorly focused
and was actually lower in magnitude.
Semantic association of target nouns with their context. Another difference between the current
study and Kuperberg et al. (2020) is that there was a semantic association between the target
noun and its preceding context. Kuperberg et al. (2020) deliberately kept semantic association
bajo. Assuming that low semantic association means weaker preactivation of the target word by
Neurobiology of Language
240
Constraint and predictability in ERP
Cifra 13. Subtraction plot of mean amplitude at low predictability target words between high and
low constraint as defined by category rather than entropy.
the context, it could be that readers in Kuperberg et al. had to work harder to update their
sentence representation at the unexpected noun than participants in the current study, y eso
this extra work was necessary to elicit a detectable PNP constraint effect. En ese caso, we could
expect that low semantic association is a necessary condition for eliciting the constraint effect.
En mesa 2, we compare semantic association of target nouns and their contexts across three
estudios: el estudio actual, Kuperberg et al. (2020), and Federmeier et al. (2007). For our own
estímulos, we computed cosine similarity using the LSAfun package in R ( Versión 0.6.3; Günther
et al., 2015). We used a pretrained German latent semantic analysis (LSA) space with 300
dimensions (Günther, 2022) created from the 1.7 billion-word deWaC corpus (Baroni et al.,
2009). Kuperberg et al. (2020) also computed cosine similarities using LSA, and we present the
values reported in their paper. For Federmeier et al. (2007), we computed cosine similarities
using LSAfun and a pretrained English LSA space with 300 dimensions (Günther, 2022) creado
using the British National Corpus, the ukWaC corpus (Baroni et al., 2009), y un 2009 Wiki-
pedia dump. ( We thank Kara Federmeier for providing the stimuli.)
While semantic association in the current study was notably higher than in Kuperberg et al.
(2020), it was comparable with Federmeier et al. (2007), and yet Federmeier et al. saw a dis-
tinct PNP constraint effect and no associated P600 effect. The degree of semantic association
between target noun and context thus may not explain our findings.
Mesa 2.
Cosine similarity of target nouns with their context.
Condition
a) Strong constraint, high cloze
b) Strong constraint, low cloze
C) Weak constraint, low cloze
d) Weak constraint, low cloze
Current study
Significar
0.40
0.36
0.34
0.33
95% range
0.17, 0.61
0.17, 0.58
0.13, 0.54
0.15, 0.56
Kuperberg et al. (2020)
95% CI
0.10, 0.26
Significar
0.18
Federmeier et al. (2007)
95% range
Significar
0.18, 0.64
0.40
0.01
–
0.01
−0.01, 0.03
–
−0.01, 0.03
0.33
0.36
0.34
0.17, 0.52
0.14, 0.59
0.12, 0.56
Nota. Condition names for all studies are presented in line with condition names from the current study.
Neurobiology of Language
241
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
In the current experiment, it was possible to quantify whether cosine similarity affected
whether a constraint-based anterior PNP or posterior P600 effect was seen using our model of
the potential crossover effect above. We fit the same multivariate linear mixed effects model with
the two response variables mean amplitude in the PNP and P600 windows/regions, but added
scaled and centred cosine similarity as a predictor interacting with entropy. The main effect of
cosine similarity was not consistent with a change in amplitude, β^
PNP = 0.10 [−0.11, 0.32] μV,
P600 = −0.12 [−0.35, 0.11] μV, nor was its interaction with entropy, β^
β^
PNP = 0.02 [−0.21,
0.24] μV, β^
P600 = −0.05 [−0.26, 0.17] μV. As before, the model yielded a strong positive
correlation between the PNP and the P600, ^ρ = 0.61 [0.59, 0.63], suggesting that readers who
exhibited larger PNPs still exhibited larger P600s, even after semantic relatedness was taken
into consideration.
Task-related effects. One of the factors that may play a role in the topography of positive com-
ponents in the post-N400 window is the type of task (Friederici et al., 2002; Kuperberg &
Brothers, 2019). During our experiment, participants answered a yes/no question after 50%
of sentences (28 sentences per condition). En figura 14, we compare topography and mean
ERP amplitude in the late window between target nouns that appeared in a sentence directly
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 14. Comparison of post-N400 amplitude at target nouns on trials after a trial where a question was asked versus where no question
was asked. (A) ERP amplitude in the anterior and posterior scalp regions on trials following a question. (B) Topography of the constraint com-
parison on trials following a question (strong minus weak constraint via median split entropy). (C) ERP amplitude in the anterior and posterior
scalp regions on trials following a no-question trial. (D) Topography of the constraint comparison on trials following a no-question trial (strong
minus weak constraint via median split entropy).
Neurobiology of Language
242
Constraint and predictability in ERP
following a sentence that was one of the 50% of question trials (Figure 14A and B), with nouns
that appeared after a sentence with no question (Figure 14C and D). Conditions (b) y (d)
have been collapsed and split into high and low constraint by their median entropy value.
The posterior P600 effect is markedly smaller in trials following a question (Figure 14B vs.
Figure 14D), suggesting readers behaved differently when they may have expected another
question versus when they did not.
Participants’ expectations with respect to an upcoming question could have had various
effects on their processing. Por ejemplo, although questions were randomly distributed, par-
ticipants may have thought that question trials were more likely to appear immediately after
no-question trials and focussed more on the sentences, enhancing their conflict-detection
response and eliciting the P600 constraint effect after no-question trials (Figure 14D). Alterna-
activamente, participants may have been primed to expect another question trial if they had just seen
uno, and engaged a more PNP-type of processing such as suppressing information not relevant
to answering the question. This could explain the absence of the P600 in post-question trials,
although there was no suggestion of a PNP in Figure 14B. Using the same model and priors as
for the pre-registered PNP constraint analysis, there was only inconclusive statistical evidence
for the anterior PNP constraint effect in the post-question trials, β^= −0.23 [−0.49, −0,02] μV,
BF10 = 4. When compared with the strong evidence for the same effect when all trials were
usado (see main pre-registered analysis), this finding does not suggest a functional dissociation
between the PNP and P600 on post-question and post-no-question trials.
Trial order effects. The absence of an anterior PNP may have been due to participants not
having engaged in predictive processing once they got used to or guessed the purpose of
the experiment. En ese caso, this may have been visible across the experiment, p.ej., with an anterior
PNP early on when participants were still predicting, and a posterior P600 later as prediction
stopped. Cifra 15 suggests this was not the case, with no PNP apparent at any stage of the
experimento. We quantified a trial order effect by adding trial number as an interaction with
entropy to our pre-registered constraint model. We fit two separate models, one of amplitude
in the anterior region of interest (PNP) and one of amplitude in the posterior region (P600).
There appeared to be a main effect of trial order in the anterior region, with amplitude becom-
ing less positive as the experiment progressed, β^ = −0.14 [−0.36, 0.07], but this did not
interact with entropy, β^ = 0.005 [−0.25, 0.27]. En otras palabras, there was no suggestion that
a constraint effect on the PNP differed across the experiment. In the posterior region, allá
appeared to be neither a main effect of trial order, β^ = −0.04 [−0.26, 0.16], nor an interaction
of trial order with entropy, β^ = 0.11 [−0.15, 0.37].
Cifra 15. Comparison of post-N400 amplitude at target nouns in different stages of the experiment. (A) First third of the experiment. (B)
Middle third of the experiment. (C) Final third of the experiment.
Neurobiology of Language
243
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
The choice of temporal filter. One ERP preprocessing step that can potentially alter the appear-
ance of ERP components is the choice of filter (Luck, 2005a; Tanner et al., 2015; Vanrullen,
2011). Filter choice can create artificial differences, usually in the temporal appearance of ERP
componentes, where amplitude from one time window is “smeared” into another as an artifact
of the filtering process. The degree of smear depends on various filter settings and filter types,
and can affect things like component overlap, which may have been present in our N400
window. Although smearing is more likely to affect the magnitude of an effect rather than
its topography, we compared two different filter types. For our pre-registered preprocessing
pipeline, we used FIR filters, but another common choice is infinite impulse response (IIR)
filters. We re-preprocessed the data using a Butterworth zero-phase (two-pass forward and
reverse) non-causal IIR filter with filter order 16 (effective, after forward–backward) y
cut-offs at 0.01 y 30 Hz (−6.02 dB).
ERPs after both types of preprocessing are plotted in Figure 16. Figure 16A shows the ERP
using FIR filters (Figure 4B in the main text) and Figure 16B the ERP using IIR filters. Nosotros
observed small differences in the amplitude of the ERP signal in each of our analysis windows,
but nothing of a degree that would have changed our conclusions.
Correlation of post-N400 amplitude with the stop signal task
In a final exploratory analysis, we examined whether performance on a response inhibition
task would predict the magnitude of the PNP constraint effect, with the hypothesis that better
inhibitors might elicit larger PNPs. Before undergoing the EEG recording, participants com-
pleted a stop signal task. Participants saw either a circle or a square on a screen 765 and were
instructed to press the “J” key on a keyboard as soon as they saw a circle and the “F” key as
soon as they saw a square, unless they heard a tone presented via headphones, in which case
they should not press anything. Our exploratory hypothesis was that participants who
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 16. Comparison of finite impulse response (FIR) and infinite impulse response (IIR) filters on the entropy effect in the post-N400
window. (A) Mean amplitude over time at target words after preprocessing using FIR filters. (B) Mean amplitude over time after preprocessing
using IIR filters.
Neurobiology of Language
244
Constraint and predictability in ERP
performed better at suppressing their responses after stop signals might also show larger PNP
efectos, if in fact the PNP were related to suppression. The stop signal tone was a 750 Hz sine
wave tone presented for 75 ms with no attack or decay. The stop signal varied in its delay after
the visual presentation, determined via a tracking procedure: The starting delay was 250 EM
y 50 ms was subtracted after unsuccessful stop trials (es decir., trials where a response was
made despite hearing the tone), y 50 ms added after successful stop trials. The minimum
stop signal delay was 50 ms and the maximum, 1,000 EM. The mean stop signal delay was
525 EM, 95% CI = [511, 539] EM (ver tabla 3 for further descriptive statistics).
Participants were given four practice trials. The main experiment contained eight trials per
block and three blocks. Each block contained four circles and four squares presented in ran-
orden dominante. Stop signals were presented after one of the squares and one of the circles. Cada
trial began with a fixation dot presented for 250 EM, followed by the visual presentation. A
keyboard response to the visual presentation triggered a blank screen of 500 ms duration
and the beginning of the next trial. If no response was made, the next trial began after a
timeout of 1,250 EM. At the end of each block, participants were given feedback about their
proportions of incorrect responses, missed responses, and correctly suppressed responses, como
well as their average reaction time. The duration of the feedback screen was determined by
Participantes. The task was presented using OpenSesame (Mathôt et al., 2012) en un 56 cm
monitor in a sound-insulated cabin.
Del 64 participants whose EEG was recorded, 59 had useable stop signal data: Uno
participant was excluded as they were unable to understand the stop signal task, and two
participants’ stop signal data were not saved in error. Two further participants were excluded
because their mean response time on go trials was more than two standard deviations faster or
slower than stop trials, violating the assumptions of the stop signal reaction time calculation
(Verbruggen et al., 2019). Stop signal reaction time (SSRT) was calculated via the integration
method in Verbruggen et al. (2019).
We used SSRT as a predictor of amplitude in two separate models, one for the PNP and one
for the P600. We used the same model specification as for the main analysis, but added log
transformed SSRT as a continuous predictor interacting with entropy. All predictors were
scaled and centred. Since there was only one SSRT observation per participant, random slopes
were not estimated. With respect to the prior, we had no a priori expectation about the direc-
tion in which SSRT would affect amplitude: Faster SSRTs (better response inhibition) podría
Mesa 3.
Stop signal task descriptive statistics.
Measure
Probability of no response on go trial
Probability of response on stop trial
Mean SSD
SSRT
RT on go trials
RT on stop trials
Significar
0.06
0.20
527
245
896
781
95% CI
0.04, 0.08
0.18, 0.21
514, 541
230, 260
872, 920
754, 809
Nota. Means and 95% confidence intervals are presented for the probability of (incorrectly) not responding on a
go trial, the probability of (incorrectly) making any response on a stop trial, stop signal delay after visual pre-
sentation (SSD), stop signal reaction time (SSRT), reaction time (RT) of any response on go trials, and reaction
tiempo (RT) of any response on stop trials.
Neurobiology of Language
245
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
hypothetically result in either a more marked inhibitory response to unexpected input and
higher amplitude, or a more efficient inhibitory response and lower amplitude. We also did
not expect that the effect of SSRT would be any larger than that of entropy or cloze probability.
We therefore used the same prior for SSRT as for entropy and cloze probability, only nontrun-
cated: Normal(0, 0.2) μV. Due to the mix of truncated and nontruncated priors on the predic-
tores, which brms did not allow at the time of analysis, the model was fit in the RStan R package
(Stan Development Team, 2018, 2020).
PNP = 0.09 [−0.12, 0.32] μV and β^
The posterior estimates of the interaction of entropy and SSRT on both PNP and P600 ampli-
tude were both centred around zero, β^
P600 = 0.05 [−0.18,
0.28] μV, which was not consistent with faster SSRTs being predictive of amplitude, a pesar de todo
of constraint. Estimates were also not consistent with a main effect of SSRT on amplitude in
either the anterior, β^
P600 = −0.03
[−0.30, 0.25] μV. En suma, the data were not suggestive that faster performance on the stop
signal task was associated with either PNP or P600 amplitude. Sin embargo, accuracy on the stop
signal task was too high according to guidelines set out by Verbruggen et al. (2019), cual
violates some assumptions in computing SSRT. More specifically, the probability of responding
after a stop signal should be around 0.50, or at least between 0.25 y 0.75; our participants
had a mean probability of 0.20. The finding should thus be taken with caution.
PNP = 0.11 [−0.20, 0.41] μV, or the posterior scalp region, β^
GENERAL DISCUSSION
Our study addressed the idea that encountering a low predictability noun in a context where a
different noun was highly predictable should trigger greater processing cost than a low prob-
ability noun in a context where no particular noun was predictable. We set out to conceptually
replicate the finding that a contextual constraint-based processing cost at unexpected but still
plausible words is reflected by an increase in anterior PNP amplitude (Federmeier et al., 2007;
Kuperberg et al., 2020). Using an experimental design that maximised our ability to detect
constraint effects and a sample size determined by reaching a threshold for strong evidence,
we were able to partially replicate previous findings. We observed strong evidence that low
probability words elicited more positive amplitude in the post-N400 window in strongly versus
weakly constraining contexts, but the scalp distribution of this positivity was consistent with a
posterior P600 and not an anterior PNP. Also in contrast with previous findings (Kuperberg
et al., 2020), the effect of predictability in the post-N400 window was inconclusive, ambos
for the PNP and the P600. This suggests that the critical factor in determining processing at
the target noun was not how predictable that specific noun was, but rather how strongly the
preceding context had driven expectations about the event as a whole in which the target
noun, and also other words or concepts, might be expected. Findings in the N400 window
were highly consistent with previous research: Constraint did not appear to affect the N400
(Federmeier et al., 2007; Federmeier & Kutas, 1999; Kuperberg et al., 2020; Lai et al., 2021;
Szewczyk & Schriefers, 2013; Thornhill & Van Petten, 2012), and there was strong evidence
for the standard N400 predictability effect (Kutas & Federmeier, 2011).
Is the PNP Affected by Contextual Constraint?
The anterior PNP is proposed to be a distinct ERP phenomenon reflecting the cost of shifting
the interpretation of a sentence after unexpected input, becoming larger when the preceding
context increases certainty about a particular interpretation (Federmeier et al., 2007;
Kuperberg et al., 2020). We note here an assumption: that increased ERP amplitude in one
condition relative to another can be interpreted as increased processing cost in the higher
Neurobiology of Language
246
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
amplitude condition. Sin embargo, a cost-amplitude association may not reflect the true state of
affairs since latency variability can create the appearance of artificial amplitude differences
(Luck, 2005b). The precise link between ERPs and neuronal activity is also still unclear. Cómo-
alguna vez, for the purposes of this paper, we assume a cost-amplitude link, based on the typical
pattern that more “difficult” tasks (p.ej., dealing with semantically unexpected words or odd
syntax) reliably increase the amplitude of at least the N400 and late positive components.
The mechanism underlying the PNP is proposed to be separate from that of another
post-N400 positive component—the posterior P600—since in two previous studies only the
PNP was affected by a constraint manipulation at plausible but unexpected words and not the
P600 (Federmeier et al., 2007; Kuperberg et al., 2020). In one of these studies, the reverse
observation was made for words that were anomalous in their contexts: Constraint affected
the P600 but not the PNP (Kuperberg et al., 2020). Juntos, these findings have been taken
to suggest that the PNP reflects the successful update of a sentence representation with plau-
sible input and the P600 an error signal triggered by implausible input. The current findings
contrast with Kuperberg et al. and Federmeier et al. in two ways: Primero, we did not observe a
constraint effect for plausible words in the anterior PNP but rather in the posterior P600, y
segundo, the effect on the P600 was elicited by plausible unexpected words. In this section we
examine a number of possible explanations for the contrasting findings.
With respect to the posterior rather than the anterior distribution of the constraint effect, nosotros
ruled out with exploratory analyses that the difference was related to our definition of con-
straint, or to individual variability in constraint effects. Since the type of filter used during
EEG preprocessing can also alter at least the temporal appearance of ERPs (Luck, 2005a;
Tanner et al., 2015; Vanrullen, 2011), we additionally re-preprocessed the data using a differ-
ent filter, but the topography of the constraint effect remained posterior. The combination of
filter settings and the choice of baseline can create artificial differences in ERP topography
(Tanner et al., 2016): We used average amplitude over a pre-stimulus period of 200 ms as a
baseline and a bandpass filter of 0.01–30 Hz. Of the previous studies in which constraint was
examined, all used 100 o 200 ms pre-stimulus baselines (100 ms for all but two studies), con
which effects on the PNP both were and were not observed; eso es, there was no systematic
effect of the baseline duration on whether or not a PNP constraint effect was observed. Almost
every study used different bandpass filter settings, which—while of concern for ERP research
more broadly—again does not suggest a systematic effect on the appearance of the PNP
(although we did not manipulate these settings directly and so cannot rule it out).
The type of task that participants do during the EEG recording can also affect the appear-
ance, including the topography, of late positive components (Friederici et al., 2002; Kuperberg
& Brothers, 2019; Sassenhagen & Bornkessel-Schlesewsky, 2015; Sassenhagen et al., 2014), entonces
we reviewed task types among previous studies. Participants in the current study answer
yes/no comprehension questions after 50% of sentences. In previous studies where a con-
straint effect on the anterior PNP was observed (but not on the posterior P600), Participantes
had to judge whether each sentence “made sense” and additionally answer yes/no questions
about filler sentences (Kuperberg et al., 2020), or had no task during the experiment
but were informed they would complete a word recognition task after the experiment
(Federmeier et al., 2007). Of the previous studies that have observed no or contrasting effects
of constraint on the PNP/P600, participants either had to indicate after each sentence whether
a probe word appeared in that sentence (Thornhill & Van Petten, 2012), or they were informed
they would complete a word recognition task after the experiment (Federmeier & Kutas, 1999;
Lai et al., 2021; Szewczyk & Schriefers, 2013; Wlotko & Federmeier, 2007). De este modo, there did
not appear to be systematic differences in task type between studies. Además, we did not
Neurobiology of Language
247
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
observe statistical evidence that the presence or absence of a question influenced whether
participants exhibited a PNP or P600 in the current study. Future studies directly manipulating
the effect of task type on eliciting the PNP versus the P600 would better address this question,
sin embargo.
With respect to the P600 being elicited by plausible words, this is somewhat unusual since
the target noun and context were also syntactically well formed and the P600 has traditionally
been associated with reanalysis after syntactic violations (Hagoort et al., 1993; Osterhout &
Holcomb, 1992). Sin embargo, P600s are also reliably observed at the verb in role-reversal sen-
tences which are syntactically well-formed, just semantically odd, Por ejemplo, the dog that
the man bit (kim & Osterhout, 2005; Kuperberg et al., 2003; Kuperberg et al., 2007). Van
Petten and Luka (2012) also note a number of predictability studies where a P600 was elicited
by plausible unexpected words that did not involve a role reversal. Thus rather than being lim-
ited to reanalysis after syntactic violations, the P600 has been proposed to signal a more general
conflict detection or integration process recruiting the left inferior frontal gyrus (Brouwer et al.,
2017; Brouwer & Hoeks, 2013; Fitz & Chang, 2019; van de Meerendonk et al., 2011). En nuestro
caso, it likely reflects the conflict between readers’ strong event representation and the low
probability input (Kuperberg et al., 2020; Laszlo & Federmeier, 2009; Vissers et al., 2006).
The combination of strong constraint and high semantic relationship between target words
and their contexts in the current study are known to increase the likelihood of the P600’s
appearance in syntactically well-formed sentences (Kuperberg & Brothers, 2019). Desde
semantic association was higher in our study than in Kuperberg et al. (2020), we reasoned that
this could have contributed to the difference in topography. Por ejemplo, high semantic asso-
ciation would mean that lexical preactivation of the presented target word by the context is
stronger than when semantic association is weak, even in the low predictability conditions.
Stronger semantic association and stronger preactivation in our study may not have required
the engagement of PNP-related resources when a low probability word triggered a shift in
interpretación. A diferencia de, weaker semantic association and weaker preactivation in Kuperberg
et al. (2020) may have made the shift costlier and the PNP more pronounced. Sin embargo, nosotros
compared semantic association between target words and their contexts in the current study
against Kuperberg et al. (2020) and Federmeier et al. (2007; Mesa 2) and noted that semantic
relationship in Federmeier et al.’s stimuli was comparable with our study—yet they observed a
PNP and not a P600. Future experiments comparing plausible, low probability words with
strong and weak semantic association with their contexts may yield further insights.
One likely factor contributing to the difference between the current and previous studies is
that of statistical power: Fewer participants and/or fewer critical trials in previous studies may
have led to a lower signal-to-noise ratio in the EEG recordings. It is a known issue in ERP
research that if the signal-to-noise ratio is not sufficiently high, scalp topography can be
misleading and statistical false positives can occur (Luck, 2005a; Luck & Gaspelin, 2016).
False positives occur when low power leads to an overestimate of the effect size or a type
METRO (magnitude) error (Gelman & Carlin, 2014). Type S (sign) errors may also result, explicando
why at least one previous study reports a PNP constraint effect in the opposite direction
(Federmeier & Kutas, 1999).
The current study therefore raises the possibility that the PNP constraint effect observed in
previous studies may actually be part of a broad P600 response where lower sample size has
contributed to Type M and S errors in the anterior region of the scalp. This would account for
the anterior PNP constraint effect’s inconsistent appearance in previous studies despite similar
experimental designs. If true, then our findings also suggest that the processing cost of strong
Neurobiology of Language
248
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
probabilistic representations does not always result from having to update an interpretation or
suppress disconfirmed interpretations after receiving conflicting input, but can instead be the
cost of detecting the conflict itself.
Why Was a Constraint-Based P600 Effect Not Observed in Previous Studies?
If the anterior PNP constraint effect really is just the edge of a P600 constraint effect, then one
would expect to see a P600 constraint effect in at least some previous studies. One previous
study did in fact observe a P600 constraint effect, but only at anomalous (implausible) palabras
(Kuperberg et al., 2020). For anomalous words, the P600 became more positive for anomalous
words in highly constraining contexts. This is consistent with the P600 constraint effect elicited
by syntactic violations (Gunter et al., 2000; Hoeks et al., 2004); although in Hoeks et al. el
effect was in the opposite direction and statistical evidence was not strong. One possibility
therefore is that the anomalous sentences in Kuperberg et al. encouraged participants to treat
unexpected-but-still-plausible words differently to the “real” conflict posed by anomalous
palabras (as Kuperberg et al. hypothesised it would). In the absence of anomalous words in
el estudio actual, participants may have responded to low probability words in the same
way as if they were errors. Sin embargo, this would not account for why a P600 constraint effect
was not observed in Federmeier et al. (2007)—who also did not have an anomalous
condition—nor in other previous studies without anomalous conditions who observed con-
trasting or no PNP effects. This may again be due to a power issue, but we have also made
suggestions above as to future research that could help to disentangle the PNP and P600.
Aside from the absence of anomalous words, another possibility is that features of the cur-
rent study design encouraged conflict monitoring rather than prediction in participants. generación-
erating predictions while reading is thought to be one of the necessary conditions for eliciting
the PNP (Federmeier, 2022). It is possible that the large number of sentences and simple
manipulation in the current design meant participants stopped predicting once they got used
a (or even guessed the purpose of ) the experiment. If this were the case, one might expect a
constraint-based PNP early in the experiment and a constraint-based P600 later; we examined
trial order effects and while the P600 constraint effect was visually most pronounced in the
middle of the experiment, no PNP constraint effect was obvious either visually or statistically.
Además, in order for readers to have shown a larger P600 in the strong constraint condition
at the low predictability target, with all else being equal, the strong constraint of the context
must have been used to generate some degree of expectation for a different upcoming word
relative to the weak constraint context. This would suggest that readers were indeed predicting
upcoming words. One hypothesis for a future experiment is that there is a difference between
passive expectations when participants settle into a long experiment, and active predictions in
more challenging experimental designs. One could imagine that the former encourages
conflict-monitoring and thus a P600 response and the latter, suppression of previous predic-
tions and a PNP response. There is some evidence that conscious prediction strategies mod-
ulate the PNP (Brothers et al., 2017), though not to the point of eliciting a P600 instead.
The Effect of Probabilistic Strength on Processing Cost
Topography aside, the firm conclusion from the current and previous studies is that the effect
of probabilistic representation strength on processing cost only becomes observable in the
time window after the N400. The lack of a constraint effect in the N400 window is consistent
with existing accounts of the N400 suggesting that the underlying cognitive processes are
seated in the medial temporal gyral and posterior temporal areas of the ventral stream, at a
Neurobiology of Language
249
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
time where phonetic and orthographic activation gives way to lexical retrieval and semantic
unification (Friederici, 2012; Hagoort, 2013; Hickok & Poeppel, 2007; Lau et al., 2008).
Retrieval and unification generate a probabilistic representation of the sentence, which in turn
influences the activation of related words and concepts. Under these accounts, the N400 is
only sensitive to the level of activation in this area, such that two words with the same acti-
vation level will elicit the same amplitude N400, regardless of how they came to be activated
(Fitz & Chang, 2019; Hagoort et al., 2009; Kutas & Federmeier, 2011; Lau et al., 2008;
Rabovsky et al., 2018). In our study, the low probability target in a strongly constraining con-
text would have had low activation because the context suggested it was not a likely next
palabra, whereas the low probability target in a weakly constraining context would have had
low activation because the context did not suggest any particular next word. Their respective
N400s were therefore of a similar amplitude.
Further down the ventral stream, in the post-N400 processing time window, is where we
observed the consequences of a strong probabilistic representation. En el estudio actual, a
strong representation increased sensitivity to input that conflicted with expectations (assuming
a conflict-based function of the P600). Curiosamente, low predictability lexical items seen in
strongly constraining contexts did not elicit conclusive differences in P600 amplitude relative
to high predictability lexical items, suggesting that conflict was driven by the semantic richness
of the preceding context rather than a simple unexpectedness detection. This indicates a
change in processing with respect to the previous N400 window, where word predictability
was important.
Source localisation of processing associated with the P600 has proven difficult (Friederici,
2011), however the P600 has been associated with a left inferior prefrontal-temporal cortical
circuito (Brouwer et al., 2017; Brouwer & Hoeks, 2013), which also includes areas of the frontal
inferior gyrus thought to mediate suppression of previous interpretations and possibly hints at
the involvement of executive control (Hagoort, 2013; Kutas, 1993). Thus while we interpret
our P600 constraint effect as a conflict signal, we do not believe our findings rule out that a
shift in interpretation or suppression of previous representations occurs: We simply did not
observe evidence that such a process is inevitably engaged by manipulating contextual
strength, or that it is mappable to a single ERP phenomenon (for a discussion of the difficult
“mapping problem” in behavioural neuroscience see Rösler, 2012). En efecto, if both processes
involve the same cortical circuit at the same time, they may be difficult to disentangle without
experimental methodologies better suited to spatial mapping such as magnetoencephalogra-
phy and functional magnetic imaging.
Predictability and the PNP
In contrast with constraint, word predictability is a more reliable factor in eliciting the PNP,
with low probability words triggering more positive amplitudes than high probability words
(Brothers et al., 2017; Brothers et al., 2020; DeLong et al., 2011; DeLong et al., 2014;
Federmeier et al., 2007; Hodapp & Rabovsky, 2021; Kuperberg et al., 2020; Ness &
Meltzer-Asscher, 2018; Thornhill & Van Petten, 2012). It was therefore surprising that the cur-
rent study did not find stronger evidence of a predictability effect in the anterior scalp region.
Sin embargo, we did see a left-lateralised effect (Cifra 6). Among previous studies reporting an
anterior PNP predictability effect, several observed this to be distributed across frontal and/or
left lateral electrodes (DeLong et al., 2011; DeLong et al., 2014; Federmeier et al., 2007;
Hodapp & Rabovsky, 2021; Kuperberg et al., 2020; Szewczyk & Schriefers, 2013). Uno
possibility is that the left lateralisation of the predictability effect is somehow related to the
Neurobiology of Language
250
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
presence of a constraint manipulation; sin embargo, a left-lateralised effect appears to be evenly
distributed across previous studies both with and without constraint manipulations. We thus
refrain from interpreting the finding, but make note of it as being potentially in need of future
characterisation.
Reflections on Sample Size and the Sequential Bayes Factor Design
A major concern in ERP research is how to balance the labour and financial cost of EEG
recordings with statistical power. The sequential Bayes factor design revealed that some
research questions may be answerable with relatively small samples. Por ejemplo,
Cifra 12 indicates that there was already strong evidence for the standard N400 high versus
low cloze probability effect at a sample size of 20 Participantes. Sin embargo, here we urge cau-
ción: This was a large effect size that had a clear, directional, a priori hypothesis, which we
encoded into the statistical model using a truncated prior. A truncated prior will yield strong
evidence more quickly for such a large effect, but a truncated prior must be carefully theoret-
ically motivated a priori. Truncated priors will not be suitable for all types of research ques-
tions and should be interpreted with a higher threshold for evidence. Sin embargo, designing
informative priors for effects of interest based on previous data may be useful for keeping sam-
ple size within practical limits.
Sample size must of course also be large enough to sufficiently account for the effects of
interindividual variability and prevalence (es decir., some subjects may be “non-responders”). ERP
research is particularly sensitive to interindividual effects given the limitations of the EEG
método (es decir., cortical and skull differences, low signal-to-noise ratio), and such effects are dif-
ficult to characterise in small samples (we thank an anonymous reviewer for this note). Uno
approach to deciding whether a given sample is sufficiently large when it has been determined
via a stopping rule with a narrow, truncated prior is to examine posterior estimates under a
range of priors, both truncated and nontruncated, to see how well an estimated effect “holds
up” under different assumptions (prior sensitivity analyses should be conducted regardless, pero
may be additionally useful for this question).
Sin embargo, for our research question regarding constraint, we were able to provide strong
evidence of an effect with considerably fewer participants than we had anticipated. For those
effects that remained inconclusive at our final sample size, there were reasons we had not
anticipated at the design stage of the study (p.ej., a pandemic), and we were able to demon-
strate using a design analysis that we would not have found strong evidence even with an
infeasibly large sample. We were thus able to cut our losses and conserve resources. A sequen-
tial Bayes factor design may therefore be an efficient method of sample size determination for
future EEG research.
CONCLUSIONS
In a relatively high-powered experimental design, we confirm previous research demonstrat-
ing a dissociated effect of contextual constraint on the ERP, in which the strength of a proba-
bilistic representation affects processing in the post-N400 but not the N400 window. Nosotros también
demonstrate a dissociated effect of word predictability on the ERP, in which there is a clear
effect of predictability in the N400 but not the post-N400 window. Together these findings
suggest that N400 amplitude is more sensitive to individual word predictability than context,
whereas context is more important than predictability to the processes associated with the
post-N400 window. We conclude that in the current study, the processing cost of stronger
probabilistic expectations in the post-N400 window resulted from greater conflict between
Neurobiology of Language
251
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
expectations and input, rather than from a greater shift in interpretation or suppression of pre-
vious representations. We base this conclusion on our observation of a posterior P600 rather
than an anterior PNP. While a shift in interpretation or suppression could have occurred, estos
processes may not be the inevitable result of strong contextual constraint and may not be map-
pable to a unique ERP phenomenon. We propose either that eliciting a constraint effect in the
anterior PNP requires a more complex experimental design than a straightforward strong/weak
constraint comparison or that the constraint-related PNP effect observed in previous studies
could even be an artifact of low sample size.
EXPRESIONES DE GRATITUD
We thank Johanna Thieke, Romy Leue, and Lisa Plagemann for their help with stimuli devel-
opment, and for data collection under difficult circumstances during the COVID-19 pandemic.
We also thank Trevor Brothers and Gina Kuperberg for sharing data, and Kara Federmeier for
sharing stimuli and feedback on the results. Finalmente, we thank two anonymous reviewers and
editor Kate Watkins for their help and feedback at all stages of the review process. Article pro-
cessing charges were provided by Deutsche Forschungsgemeinschaft (DFG; German Research
Base) project number 491466077.
INFORMACIÓN DE FINANCIACIÓN
Shravan Vasishth, Volkswagen Foundation, Award ID: 89953. Shravan Vasishth, Deutsche
Forschungsgemeinschaft
(DFG), Projektnummer: 325493514. Frank Rösler, Deutsche
Forschungsgemeinschaft (DFG), Projektnummer: 325493514.
CONTRIBUCIONES DE AUTOR
Kate Stone: Conceptualización: Secundario; Análisis formal: Lead; Investigación: Lead;
Metodología: Equal; Administración de proyecto: Lead; Escritura – borrador original: Lead; Writing –
revisar & edición: Lead. Bruno Nicenboim: Conceptualización: Lead; Análisis formal: Secundario;
Metodología: Equal; Administración de proyecto: Equal; Supervisión: Lead; Escritura – revisión &
edición: Secundario. Shravan Vasishth: Conceptualización: Equal; Análisis formal: Secundario;
Adquisición de financiación: Equal; Administración de proyecto: Equal; Supervisión: Equal; Escritura – revisión
& edición: Secundario. Frank Rösler: Conceptualización: Equal; Análisis formal: Secundario;
Adquisición de financiación: Equal; Administración de proyecto: Equal; Supervisión: Equal; Escritura – revisión
& edición: Secundario.
SOFTWARE
The following is a complete list of software used for this article: R ( Versión 3.6.3; R Core Team,
2020) and the R-packages bayesplot ( Versión 1.8.1; Gabry et al., 2019), brms ( Versión 2.16.3;
Bürkner, 2017), eeguana ( Versión 0.1.8.9001; Nicenboim, 2018), job ( Versión 0.3.0; Lindeløv,
2021), lme4 ( Versión 1.1-30; Bates et al., 2015), LSAfun ( Versión 0.6.3; Günther et al., 2015),
patchwork (Versión 1.1.1; Pedersen, 2022), rstan (Versión 2.21.3; Stan Development Team, 2018,
2020), tidybayes (Versión 3.0.2; kay, 2021), tidyverse (Versión 1.3.1; Wickham et al., 2019).
REFERENCIAS
Baayen, R. h. (2001). Word frequency distributions. Saltador
Ciencia & Medios comerciales. https://doi.org/10.1007/978-94-010
-0844-0
Baroni, METRO., Bernardini, S., Ferraresi, A., & Zanchetta, mi. (2009). El
WaCky wide web: A collection of very large linguistically
processed web-crawled corpora. Language Resources and Evalua-
ción, 43(3), 209–226. https://doi.org/10.1007/s10579-009-9081-4
Bates, D., Mächler, METRO., Bolker, B., & Caminante, S. (2015). Fitting linear
mixed-effects models using lme4. Journal of Statistical Software,
67(1), 1–48. https://doi.org/10.18637/jss.v067.i01
Neurobiology of Language
252
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
bennett, C. h. (1976). Efficient estimation of free energy differences
from Monte Carlo data. Journal of Computational Physics, 22(2),
245–268. https://doi.org/10.1016/0021-9991(76)90078-4
Bornkessel-Schlesewsky, I., & Schlesewsky, METRO. (2008). An alterna-
tive perspective on “semantic P600” effects in language compre-
hension. Brain Research Reviews, 59(1), 55–73. https://doi.org/10
.1016/j.brainresrev.2008.05.003, PubMed: 18617270
Brothers, T., Swaab, t. y., & Traxler, METRO. j. (2017). Goals and strategies
influence lexical prediction during sentence comprehension.
Journal of Memory and Language, 93, 203–216. https://doi.org
/10.1016/j.jml.2016.10.002
Brothers, T., Wlotko, mi. w., Warnke, l., & Kuperberg, GRAMO. R. (2020).
Going the extra mile: Effects of discourse context on two late
positivities during language comprehension. Neurobiology of
Idioma, 1(1), 135–160. https://doi.org/10.1162/nol_a_00006,
PubMed: 32582884
Brouwer, h., Crocker, METRO. w., Venhuizen, norte. J., & Hoeks, j. C. j.
(2017). A neurocomputational model of the N400 and the P600
in language processing. Ciencia cognitiva, 41(S6), 1318–1352.
https://doi.org/10.1111/cogs.12461, PubMed: 28000963
Brouwer, h., & Hoeks, j. C. j. (2013). A time and place for language
comprensión: Mapping the N400 and the P600 to a minimal
cortical network. Frontiers in Human Neuroscience, 7, Article
758. https://doi.org/10.3389/fnhum.2013.00758, PubMed:
24273505
Bürki, A., Alario, F.-X., & Vasishth, S. (2022). When words collide:
Bayesian meta-analyses of distractor and target properties in the
picture-word interference paradigm. Quarterly Journal of Experi-
mental Psychology, Article 17470218221114644. https://doi.org
/10.1177/17470218221114644, PubMed: 35818127
Bürkner, P.-C. (2017). brms: An R package for Bayesian multilevel
models using Stan. Journal of Statistical Software, 80(1), 1–28.
https://doi.org/10.18637/jss.v080.i01
Chen, S. F., & Buen hombre, j. (1999). An empirical study of smoothing
techniques for language modeling. Computer Speech & Idioma,
13(4), 359–394. https://doi.org/10.1006/csla.1999.0128
Chung, y., Gelman, A., Rabe-Hesketh, S., Liu, J., & Dorie, V. (2015).
Weakly informative prior for point estimation of covariance
matrices in hierarchical models. Journal of Educational and
Behavioral Statistics, 40(2), 136–157. https://doi.org/10.3102
/1076998615570945
cohen, j. (1983). The cost of dichotomization. Applied Psycholog-
ical Measurement, 7(3), 249–253. https://doi.org/10.1177
/014662168300700301
Coulson, S., Rey, j. w., & Kutas, METRO. (1998). Expect the unexpected:
Event-related brain response to morphosyntactic violations.
Language and Cognitive Processes, 13(1), 21–58. https://doi.org
/10.1080/016909698386582
Delaney-Busch, NORTE., morgan, MI., Lau, MI., & Kuperberg, GRAMO. R.
(2019). Neural evidence for Bayesian trial-by-trial adaptation
on the N400 during semantic priming. Cognición, 187, 10–20.
https://doi.org/10.1016/j.cognition.2019.01.001, PubMed:
30797099
DeLong, k. A., Quante, l., & Kutas, METRO. (2014). Previsibilidad, plau-
sibility, and two late ERP positivities during written sentence
comprensión. Neuropsicología, 61(1), 150–162. https://doi
.org/10.1016/j.neuropsychologia.2014.06.016, PubMed:
24953958
DeLong, k. A., Urbach, t. PAG., Groppe, D. METRO., & Kutas, METRO. (2011).
Overlapping dual ERP responses to low cloze probability sen-
tence continuations. Psychophysiology, 48(9), 1203–1207.
https://doi.org/10.1111/j.1469-8986.2011.01199.x, PubMed:
21457275
Drummond, A. (2016). Ibex: Software for psycholinguistic experi-
mentos [Software]. https://github.com/addrummond/ibex
Federmeier, k. D. (2022). Connecting and considering: Electro-
physiology provides insights into comprehension. Psychophysi-
ology, 59(1), Article e13940. https://doi.org/10.1111/psyp
.13940, PubMed: 34520568
Federmeier, k. D., & Kutas, METRO. (1999). A rose by any other name:
Long-term memory structure and sentence processing. Diario de
Memory and Language, 41(4), 469–495. https://doi.org/10.1006
/jmla.1999.2660
Federmeier, k. D., Wlotko, mi. w., Ochoa-Dewald, mi. D., & Kutas,
METRO. (2007). Multiple effects of sentential constraint on word pro-
cesando. Brain Research, 1146, 75–84. https://doi.org/10.1016/j
.brainres.2006.06.101, PubMed: 16901469
Fitz, h., & Chang, F. (2019). Language ERPs reflect learning through
prediction error propagation. Psicología cognitiva, 111, 15–52.
https://doi.org/10.1016/j.cogpsych.2019.03.002, PubMed:
30921626
Franco, S. l., Otten, l. J., Galli, GRAMO., & Vigliocco, GRAMO. (2015). The ERP
response to the amount of information conveyed by words in
oraciones. Brain and Language, 140, 1–11. https://doi.org/10
.1016/j.bandl.2014.10.006, PubMed: 25461915
Friederici, A. D. (2011). The brain basis of language processing:
From structure to function. Physiological Reviews, 91(4),
1357–1392. https://doi.org/10.1152/physrev.00006.2011,
PubMed: 22013214
Friederici, A. D. (2012). The cortical language circuit: From audi-
tory perception to sentence comprehension. Tendencias en Cognitivo
Ciencias, 16(5), 262–268. https://doi.org/10.1016/j.tics.2012.04
.001, PubMed: 22516238
Friederici, A. D., Hahne, A., & Saddy, D. (2002). Distinct neuro-
physiological patterns reflecting aspects of syntactic complexity
and syntactic repair. Journal of Psycholinguistic Research, 31(1),
45–63. https://doi.org/10.1023/A:1014376204525, PubMed:
11924839
Gabry, J., Simpson, D., Vehtari, A., Betancourt, METRO., & Gelman, A.
(2019). Visualization in Bayesian workflow. Journal of the Royal
Statistical Society Series A (Statistics in Society), 182(2), 389–402.
https://doi.org/10.1111/rssa.12378
Garnsey, S. METRO. (1993). Event-related brain potentials in the study of
idioma: An introduction. Language and Cognitive Processes,
8(4), 337–356. https://doi.org/10.1080/01690969308407581
Gelman, A., & Carlin, j. (2014). Beyond power calculations: Asses-
sing type S (sign) and type M (magnitude) errores. Perspectives on
ciencia psicológica, 9(6), 641–651. https://doi.org/10.1177
/1745691614551642, PubMed: 26186114
Gelman, A., Jakulin, A., Pittau, METRO. GRAMO., & Su, Y.-S. (2008). A weakly
informative default prior distribution for logistic and other regres-
sion models. Annals of Applied Statistics, 2(4), 1360–1383.
https://doi.org/10.1214/08-AOAS191
Gelman, A., Simpson, D., & Betancourt, METRO. (2017). The prior can
often only be understood in the context of the likelihood.
Entropy, 19(10), Article 555. https://doi.org/10.3390/e19100555
Gronau, q. F., Sarafoglou, A., Matzke, D., Ly, A., Boehm, Ud.,
Marsman, METRO., Leslie, D. S., Forster, j. J., carpinteros, E.-J., &
Steingroever, h. (2017). A tutorial on bridge sampling. Diario
of Mathematical Psychology, 81, 80–97. https://doi.org/10.1016
/j.jmp.2017.09.005, PubMed: 29200501
Gunter, t. C., Friederici, A. D., & Schriefers, h. (2000). Syntactic
gender and semantic expectancy: ERPs reveal early autonomy
and late interaction. Revista de neurociencia cognitiva, 12(4),
556–568. https://doi.org/10.1162/089892900562336, PubMed:
10936910
Neurobiology of Language
253
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
/
.
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
Günther, F. (2022). Semantic spaces. Homepage of Fritz Günther.
https://sites.google.com/site/fritzgntr/software-resources/semantic
_spaces
Günther, F., Dudschig, C., & Kaup, B. (2015). LSAfun—An R package
for computations based on Latent Semantic Analysis. Comportamiento
Research Methods, 47(4), 930–944. https://doi.org/10.3758
/s13428-014-0529-0, PubMed: 25425391
Hagoort, PAG. (2013). MUC (Memoria, Unification, Control) y
más allá de. Fronteras en psicología, 4, Article 416. https://doi.org
/10.3389/fpsyg.2013.00416, PubMed: 23874313
Hagoort, PAG., Baggio, GRAMO., & Willems, R. METRO. (2009). Semantic unifi-
catión. En m. S. Gazzaniga (Ed.), The cognitive neurosciences
(4th ed., páginas. 819–836). CON prensa. https://pure.mpg.de/pubman
/faces/ ViewItemOverviewPage.jsp?itemId=item_64579. https://
doi.org/10.7551/mitpress/8029.003.0072
Hagoort, PAG., Marrón, C., & Groothusen, j. (1993). The syntactic
positive shift (SPS) as an ERP measure of syntactic processing.
Language and Cognitive Processes, 8(4), 439–483. https://doi
.org/10.1080/01690969308407585
Hagoort, PAG., & Indefrey, PAG. (2014). The neurobiology of language
beyond single words. Revisión anual de neurociencia, 37(1),
347–362. https://doi.org/10.1146/annurev-neuro-071013
-013847, PubMed: 24905595
Hale, j. (2001). A probabilistic Earley parser as a psycholinguistic
modelo. In NAACL ’01: Proceedings of the second meeting of the
North American Chapter of the Association for Computational
Linguistics on language technologies (páginas. 1–8). Asociación para
Ligüística computacional. https://doi.org/10.3115/1073336
.1073357
Hickok, GRAMO., & Poeppel, D. (2007). The cortical organization of
speech processing. Naturaleza Reseñas Neurociencia, 8(5), 393–402.
https://doi.org/10.1038/nrn2113, PubMed: 17431404
Hodapp, A., & Rabovsky, METRO. (2021). The N400 ERP component
reflects an error-based implicit learning signal during language
comprensión. European Journal of Neuroscience, 54(9),
7125–7140. https://doi.org/10.1111/ejn.15462, PubMed:
34535935
Hoeks, j. C. J., Stowe, l. A., & Doedens, GRAMO. (2004). Seeing words
in context: The interaction of lexical and sentence level infor-
mation during reading. Cognitive Brain Research, 19(1), 59–73.
https://doi.org/10.1016/j.cogbrainres.2003.10.022, PubMed:
14972359
Hyvärinen, A., & Oja, mi. (2000). Independent component analysis:
Algorithms and applications. Neural Networks, 13(4–5),
411–430. https://doi.org/10.1016/S0893-6080(00)00026-5,
PubMed: 10946390
Jäger, l. A., Engelmann, F., & Vasishth, S. (2017). Similarity-based
interference in sentence comprehension: Literature review and
Bayesian meta-analysis. Journal of Memory and Language, 94,
316–339. https://doi.org/10.1016/j.jml.2017.01.004
Jaspe, h. (1958). Report of the committee on methods of clinical
examination in electroencephalography: 1957. EEG and Clinical
Neurofisiología, 10(2), 370–375. https://doi.org/10.1016/0013
-4694(58)90053-1
Jeffreys, h. (1939). Theory of probability. prensa de la Universidad de Oxford.
Jung, T.-P., Makeig, S., Westerfield, METRO., Townsend, J., Courchesne,
MI., & Sejnowski, t. j. (2001). Analyzing and visualizing
single-trial event-related potentials. Mapeo del cerebro humano,
14(3), 166–185. https://doi.org/10.1002/ hbm.1050, PubMed:
11559961
kay, METRO. (2021). tidybayes: Tidy data and geoms for Bayesian
modelos. R package version 3.0.2. https://mjskay.github.io
/tidybayes/. https://doi.org/10.5281/zenodo.1308151
Kello, C. T., Marrón, GRAMO. D. A., Ferrer-i-Cancho, r., Holden, j. GRAMO.,
Linkenkaer-Hansen, K., Rodas, T., & Van Orden, GRAMO. C. (2010).
Scaling laws in cognitive sciences. Tendencias en Ciencias Cognitivas,
14(5), 223–232. https://doi.org/10.1016/j.tics.2010.02.005,
PubMed: 20363176
kim, A., & Osterhout, l. (2005). The independence of combinatory
semantic processing: Evidence from event-related potentials.
Journal of Memory and Language, 52(2), 205–225. https://doi
.org/10.1016/j.jml.2004.10.002
Kuperberg, GRAMO. r., & Brothers, t. (2019). Response to reviewers: El
relationship between the late posterior positivity/P600 in lan-
guage comprehension and task demands. P600 Task Discussion.
NeuroCognition of Language Lab, Department of Psychology,
Tu f t s U n i ve r s i t y. h t t p s : / / p r o j e c t s . i q . h a r v a r d . e d u / f i l e s
/kuperberglab/files/P600_task_discussion.pdf
Kuperberg, GRAMO. r., Brothers, T., & Wlotko, mi. W.. (2020). A tale of two
positivities and the N400: Distinct neural signatures are evoked
by confirmed and violated predictions at different levels of rep-
resentimiento. Revista de neurociencia cognitiva, 32(1), 12–35.
https://doi.org/10.1162/jocn_a_01465, PubMed: 31479347
Kuperberg, GRAMO. r., & Jaeger, t. F. (2016). What do we mean by pre-
diction in language comprehension? Idioma, Cognición, &
Neurociencia, 31(1), 32–59. https://doi.org/10.1080/23273798
.2015.1102299, PubMed: 27135040
Kuperberg, GRAMO. r., Kreher, D. A., Sitnikova, T., Caplan, D. NORTE., &
Holcomb, PAG. j. (2007). The role of animacy and thematic relation-
ships in processing active English sentences: Evidencia de
event-related potentials. Brain and Language, 100(3), 223–237.
https://doi.org/10.1016/j.bandl.2005.12.006, PubMed:
16546247
Kuperberg, GRAMO. r., Sitnikova, T., Caplan, D., & Holcomb, PAG. j.
(2003). Electrophysiological distinctions in processing concep-
tual relationships within simple sentences. Cognitive Brain
Investigación, 17(1), 117–129. https://doi.org/10.1016/S0926-6410
(03)00086-7, PubMed: 12763198
Kutas, METRO. (1993). In the company of other words: Electrophysio-
logical evidence for single-word and sentence context effects.
Language and Cognitive Processes, 8(4), 533–572. https://doi
.org/10.1080/01690969308407587
Kutas, METRO., & Federmeier, k. D. (2011). Thirty years and counting:
Finding meaning in the N400 component of the event-related
brain potential (ERP). Annual Review of Psychology, 62(1),
621–647. https://doi.org/10.1146/annurev.psych.093008
.131123, PubMed: 20809790
Kutas, METRO., & Hillyard, S. A. (1980). Reading between the lines:
Event-related brain potentials during natural sentence process-
En g. Brain and Language, 11(2), 354–373. https://doi.org/10
.1016/0093-934X(80)90133-9, PubMed: 7470854
Kutas, METRO., & Hillyard, S. A. (1984). Brain potentials during reading
reflect word expectancy and semantic association. Naturaleza,
307(5947), 161–163. https://doi.org/10.1038/307161a0,
PubMed: 6690995
Dejar, METRO. K., Rommers, J., & Federmeier, k. D. (2021). The fate of
the unexpected: Consequences of misprediction assessed using
ERP repetition effects. Brain Research, 1757, Article 147290.
https://doi.org/10.1016/j.brainres.2021.147290, PubMed:
33516812
Lappin, j. S., & Eriksen, C. W.. (1966). Use of a delayed signal to
stop a visual reaction-time response. Journal of Experimental Psy-
chology, 72(6), 805–811. https://doi.org/10.1037/h0021266
Laszlo, S., & Federmeier, k. D. (2009). A beautiful day in the neigh-
borhood: An event-related potential study of lexical relationships
and prediction in context. Journal of Memory and Language,
Neurobiology of Language
254
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
61(3), 326–338. https://doi.org/10.1016/j.jml.2009.06.004,
PubMed: 20161064
Lau, MI., Phillips, C., & Poeppel, D. (2008). A cortical network for
semantics: (de)constructing the N400. Nature Reviews Neurosci-
ence, 9(12), 920–933. https://doi.org/10.1038/nrn2532, PubMed:
19020511
Sotavento, METRO., & carpinteros, E.-J. (2014). Bayesian cognitive modeling:
A practical course. Prensa de la Universidad de Cambridge. https://doi.org/10
.1017/CBO9781139087759
Exacción, R. (2008). Expectation-based syntactic comprehension.
Cognición, 106(3), 1126–1177. https://doi.org/10.1016/j
.cognition.2007.05.006, PubMed: 17662975
Lidstone, GRAMO. j. (1920). Note on the general case of the Bayes-
Laplace formula for inductive or a posteriori probabilities. Trans-
actions of the Faculty of Actuaries, 8, 182–192.
Lindeløv, j. k. (2021). Job ( Versión 0.3.0) [Software]. https://
lindeloev.github.io/job
logan, GRAMO. D., & Cowan, W.. B. (1984). On the ability to inhibit thought
and action: A theory of an act of control. Revisión psicológica,
91(3), 295–327. https://doi.org/10.1037/0033-295X.91.3.295
Luck, S. j. (2005a). An introduction to the event-related potential
técnica. CON prensa.
Luck, S. j. (2005b). Ten simple rules for designing and interpreting
ERP experiments. In T. C. Handy (Ed.), Event-related potentials:
A methods handbook (páginas. 17–32). CON prensa.
Luck, S. J., & Gaspelin, norte. (2016). How to get statistically significant
effects in any ERP experiment (and why you shouldn’t). Psycho-
physiology, 54(1), 146–157. https://doi.org/10.1111/psyp.12639,
PubMed: 28000253
Mathôt, S., Schreij, D., & Theeuwes, j. (2012). OpenSesame: Un
open-source, graphical experiment builder for the social sci-
ences. Behavior Research Methods, 44(2), 314–324. https://doi
.org/10.3758/s13428-011-0168-7, PubMed: 22083660
Meerendonk, norte. V. D., Kolk, h. h. J., Chwilla, D. J., & Vissers,
C. t. W.. METRO. (2009). Monitoring in language perception. Idioma
and Linguistics Compass, 3(5), 1211–1224. https://doi.org/10
.1111/j.1749-818X.2009.00163.x
Meng, X.-L., & Wong, W.. h. (1996). Simulating ratios of normal-
izing constants via a simple identity: A theoretical exploration.
Statistica Sinica, 6(4), 831–860.
Metzner, PAG., von der Malsburg, T., Vasishth, S., & Rösler, F. (2017).
The importance of reading naturally: Evidence from combined
recordings of eye movements and electric brain potentials. Cog-
nitive Science, 41(Suplemento. 6), 1232–1263. https://doi.org/10.1111
/cogs.12384, PubMed: 27307404
Ness, T., & Meltzer-Asscher, A. (2018). Lexical inhibition due to
failed prediction: Behavioral evidence and ERP correlates.
Revista de Psicología Experimental: Aprendiendo, Memoria, and Cog-
nition, 44(8), 1269–1285. https://doi.org/10.1037/xlm0000525,
PubMed: 29283606
Nicenboim, B. (2018). Eeguana: A package for manipulating EEG
data in R ( Versión 0.1.8.9001) [Sofware]. https://github.com
/bnicenboim/eeguana
Nicenboim, B., Vasishth, S., & Rösler, F. (2020). Are words
pre-activated probabilistically during sentence comprehension?
Evidence from new data and a Bayesian random-effects
meta-analysis using publicly available data. Neuropsicología,
142, Article 107427. https://doi.org/10.1016/j.neuropsychologia
.2020.107427, PubMed: 32251629
Nieuwland, METRO. S., Politzer-Ahles, S., Heyselaar, MI., Segaert, K.,
Darley, MI., Kazanina, NORTE., Von Grebmer Zu Wolfsthurn, S.,
Bartolozzi, F., Kogan, v., Ito, A., Mézière, D., barr, D. J., Rousselet,
GRAMO. A., Ferguson, h. J., Busch-Moreno, S., Fu, X., Tuomainen, J.,
Kulakova, MI., Husband, mi. METRO., … Huettig, F. (2018). Large-scale
replication study reveals a limit on probabilistic prediction in
language comprehension. eVida, 7, Article e33468. https://doi
.org/10.7554/eLife.33468, PubMed: 29631695
Osterhout, l. (1999). A superficial resemblance does not neces-
sarily mean you are part of the family: Counterarguments to
Coulson, King and Kutas (1998) in the P600/SPS-P300 debate.
Language and Cognitive Processes, 14(1), 1–14. https://doi.org
/10.1080/016909699386356
Osterhout, l., & Holcomb, PAG. j. (1992). Event-related brain poten-
tials elicited by syntactic anomaly. Journal of Memory and
Idioma, 31(6), 785–806. https://doi.org/10.1016/0749-596X
(92)90039-z
Osterhout, l., McKinnon, r., Bersick, METRO., & Corey, V. (1996). On
the language specificity of the brain response to syntactic anom-
alies: Is the syntactic positive shift a member of the P300 family?
Revista de neurociencia cognitiva, 8(6), 507–526. https://doi.org
/10.1162/jocn.1996.8.6.507, PubMed: 23961982
Pedersen, t. l. (2022). Patchwork: The composer of plots ( Versión
1.1.1) [Software]. https://patchwork.data-imaginist.com
Rabovsky, METRO., Hansen, S. S., & McClelland, j. l. (2018). Modelling
the N400 brain potential as change in a probabilistic representa-
tion of meaning. Nature Human Behaviour, 2(9), 693–705. https://
doi.org/10.1038/s41562-018-0406-4, PubMed: 31346278
R Core Team. (2020). R: A language and environment for statistical
computing ( Versión 3.6.3). https://www.R-project.org
Rösler, F. (2012). Some unsettled problems in behavioral neurosci-
ence research. Investigación psicológica, 76(2), 131–144. https://
doi.org/10.1007/s00426-011-0408-6, PubMed: 22231037
Sassenhagen, J., & Bornkessel-Schlesewsky, I. (2015). The P600 as
a correlate of ventral attention network reorientation. Corteza, 66,
A3–A20. https://doi.org/10.1016/j.cortex.2014.12.019, PubMed:
25791606
Sassenhagen, J., & Fiebach, C. j. (2019). Finding the P3 in the P600:
Decoding shared neural mechanisms of responses to syntactic
violations and oddball targets. NeuroImagen, 200, 425–436.
https://doi.org/10.1016/j.neuroimage.2019.06.048, PubMed:
31229659
Sassenhagen, J., Schlesewsky, METRO., & Bornkessel-Schlesewsky, I.
(2014). The P600-as-P3 hypothesis revisited: Single-trial analyses
reveal that the late EEG positivity following linguistically deviant
material is reaction time aligned. Brain and Language, 137,
29–39. https://doi.org/10.1016/j.bandl.2014.07.010, PubMed:
25151545
Schad, D. J., Betancourt, METRO., & Vasishth, S. (2021). Toward a
principled Bayesian workflow: A tutorial for cognitive science.
Psychological Methods, 26(1), 103–126. https://doi.org/10.1037
/met0000275, PubMed: 32551748
Herrero, norte. J., & Exacción, R. (2013). The effect of word predictability
on reading time is logarithmic. Cognición, 128(3), 302–319.
https://doi.org/10.1016/j.cognition.2013.02.013, PubMed:
23747651
Stan Development Team. (2018). The Stan Core Library ( Versión
2.18.0) [Software]. https://mc-stan.org
Stan Development Team. (2020). RStan: The R interface to Stan
( Versión 2.21.3) [Software]. https://mc-stan.org/
Szewczyk, j. METRO., & Schriefers, h. (2013). Prediction in language
comprehension beyond specific words: An ERP study on sentence
comprehension in Polish. Journal of Memory and Language, 68(4),
297–314. https://doi.org/10.1016/j.jml.2012.12.002
Tanner, D., Morgan-Short, K., & Luck, S. j. (2015). How inappro-
priate high-pass filters can produce artifactual effects and incor-
rect conclusions in ERP studies of language and cognition.
Neurobiology of Language
255
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Constraint and predictability in ERP
Psychophysiology, 52(8), 997–1009. https://doi.org/10.1111
/psyp.12437, PubMed: 25903295
Tanner, D., norton, j. j. S., Morgan-Short, K., & Luck, S. j. (2016).
On high-pass filter artifacts (they’re real) and baseline correction
(it’s a good idea) in ERP/ERMF analysis. Revista de neurociencia
Métodos, 266, 166–170. https://doi.org/10.1016/j.jneumeth
.2016.01.002, PubMed: 26774028
Thornhill, D. MI., & Van Petten, C. (2012). Lexical versus conceptual
anticipation during sentence processing: Frontal positivity and
N400 ERP components. International Journal of Psychophysi-
ology, 83(3), 382–392. https://doi.org/10.1016/j.ijpsycho.2011
.12.007, PubMed: 22226800
van de Meerendonk, NORTE., Indefrey, PAG., Chwilla, D. J., & Kolk, h. h. j.
(2011). Monitoring in language perception: Electrophysiological
and hemodynamic responses to spelling violations. NeuroImagen,
54(3), 2350–2363. https://doi.org/10.1016/j.neuroimage.2010
.10.022, PubMed: 20955801
Van Petten, C., & Luka, B. j. (2012). Prediction during language
comprensión: Benefits, costos, and ERP components. interna-
tional Journal of Psychophysiology, 83(2), 176–190. https://doi
.org/10.1016/j.ijpsycho.2011.09.015, PubMed: 22019481
Vanrullen, R. (2011). Four common conceptual fallacies in map-
ping the time course of recognition. Fronteras en psicología, 2,
Article 365. https://doi.org/10.3389/fpsyg.2011.00365,
PubMed: 22162973
Vasishth, S., & Engelmann, F. (2021). Sentence comprehension as
a cognitive process: A computational approach. Cambridge
Prensa universitaria. https://doi.org/10.1017/9781316459560
Verbruggen, F., a, A. r., Band, GRAMO. PAG., Beste, C., bisset, PAG. GRAMO.,
Brockett, A. T., Marrón, j. w., Chamberlain, S. r., Chambers,
C. D., Colonius, h., Colzato, l. S., Corneil, B. D., Coxon, j. PAG.,
Dupuis, A., Eagle, D. METRO., Garavan, h., Greenhouse, I., heathcote,
A., Huster, R. J., … Boehler, C. norte. (2019). A consensus guide to
capturing the ability to inhibit actions and impulsive behaviors
in the stop-signal task. eVida, 8, Article e46323. https://doi.org
/10.7554/eLife.46323, PubMed: 31033438
Verbruggen, F., logan, GRAMO. D., & stevens, METRO. A. (2008). STOP-IT:
Windows executable software for the stop-signal paradigm.
Behavior Research Methods, 40(2), 479–483. https://doi.org/10
.3758/BRM.40.2.479, PubMed: 18522058
Vissers, C. t. W.. METRO., Chwilla, D. J., & Kolk, h. h. j. (2006).
Monitoring in language perception: The effect of misspellings of
words in highly constrained sentences. Brain Research, 1106(1),
150–163. https://doi.org/10.1016/j.brainres.2006.05.012,
PubMed: 16843443
Wickham, h., Averick, METRO., Bryan, J., Chang, w., McGowan, l. D.,
François, r., Grolemund, GRAMO., Hayes, A., Henry, l., Hester, J.,
Kuhn, METRO., Pedersen, t. l., Molinero, MI., Bache, S. METRO., Müller, K.,
Ooms, J., robinson, D., Seidel, D. PAG., Spinu, v., … Yutani, h.
(2019). Welcome to the Tidyverse. Journal of Open Source Soft-
mercancía, 4(43), 1686. https://doi.org/10.21105/joss.01686
Wlotko, mi. w., & Federmeier, k. D. (2007). Finding the right
palabra: Hemispheric asymmetries in the use of sentence context
información. Neuropsicología, 45(13), 3001–3014. https://doi
.org/10.1016/j.neuropsychologia.2007.05.013, PubMed:
17659309
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
norte
oh
/
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
4
2
2
2
1
2
0
7
9
0
4
3
norte
oh
_
a
_
0
0
0
9
4
pag
d
.
/
yo
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Neurobiology of Language
256