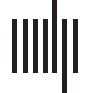ARTÍCULO DE INVESTIGACIÓN
saber: Un índice de citas inteligente que muestra la
contexto de las citas y clasifica sus
intención usando el aprendizaje profundo
un acceso abierto
diario
Domenic Rosati1
jose m. nicholson1
, Milo Mordaunt1
, Neves P.. rodrigues1
, Patrice López2
, Peter Grabitz1,3
, ashish uppala1
,
, y Sean C.. Rife1,4
1saber, Brooklyn, Nueva York, EE.UU
2minero científico, Francia
3Universidad Charité de Medicina de Berlín, Berlina, Alemania
4Universidad Estatal de Murray, Murray, Kentucky, EE.UU
Citación: nicholson, j. METRO., Mordiente,
METRO., López, PAG., Uppala, A., rosados, D.,
rodrigues, norte. PAG., Grabitz, PAG., & Abundante, S. C.
(2021). saber: Un índice de citas inteligente
que muestra el contexto de las citas
y clasifica su intención utilizando profundos
aprendiendo. Estudios de ciencias cuantitativas,
2(3), 882–898. https://doi.org/10.1162
/qss_a_00146
DOI:
https://doi.org//10.1162/qss_a_00146
Revisión por pares:
https://publons.com/publon/10.1162
/qss_a_00146
Recibió: 15 Marzo 2021
Aceptado: 29 Junio 2021
Autor correspondiente:
jose m. nicholson
josh@scite.ai
Editor de manejo:
Juego Waltman
Palabras clave: bibliometría, citas, evaluación, aprendizaje automático, publicación, cienciometría
ABSTRACTO
Los índices de citas son herramientas utilizadas por la comunidad académica para la investigación y la investigación.
evaluación que agrega la producción de literatura científica y mide el impacto mediante la recopilación de citas
cuenta. Los índices de citas ayudan a medir las interconexiones entre artículos científicos, pero caen
breves porque no comunican información contextual sobre una cita. el uso de
Las citas en la evaluación de la investigación sin considerar el contexto pueden ser problemáticas porque
una cita que presenta evidencia contrastante con un artículo se trata de la misma manera que una cita que
presenta evidencia de respaldo. Para resolver este problema, Hemos utilizado el aprendizaje automático.,
métodos tradicionales de ingesta de documentos, y una red de investigadores para desarrollar un “sistema inteligente
índice de citas” llamado scite, que clasifica las citas según el contexto. Scite muestra cómo un
La cita se utilizó mostrando el contexto textual circundante del artículo citado y un
clasificación de nuestro modelo de aprendizaje profundo que indica si la declaración proporciona
evidencia de apoyo o contraste para un trabajo referenciado, o simplemente lo menciona. Scite ha sido
desarrollado analizando más 25 millones de artículos científicos en texto completo y actualmente cuenta con una base de datos
de más de 880 millones de declaraciones de citas clasificadas. Aquí describimos cómo funciona la scite y
cómo se puede utilizar para promover la investigación y la evaluación de la investigación.
1.
INTRODUCCIÓN
Las citas son un componente crítico de la publicación científica., vincular los resultados de la investigación a lo largo del tiempo.
El primer índice de citas en ciencia., creado en 1960 por Eugene Garfield y el Instituto de
Información científica, tenía como objetivo “ser un estímulo para muchos nuevos descubrimientos científicos al servicio
de la humanidad” (garfield, 1959). Los índices de citas han facilitado el descubrimiento y la evaluación
de los hallazgos científicos en todos los campos de investigación. Los índices de citas también han llevado a establecer-
ment de nuevos campos de investigación, como la bibliometría, cienciometría, y estudios cuantitativos,
que han sido informativos para comprender mejor la ciencia como empresa. De estos campos
Han surgido una variedad de métricas basadas en citas., como el índice h, una medida del investigador
impacto (Hirsch, 2005); el factor de impacto de la revista ( JIF), una medida del impacto de la revista
(garfield, 1955, 1972); y el recuento de citas, una medida del impacto del artículo. A pesar de la
Derechos de autor: © 2021 jose m. nicholson,
Milo Mordaunt, Patricia López,
ashish uppala, Domenico Rosati,
Neves P.. rodrigues, Peter Grabitz,
y Sean C.. Abundante.
Publicado bajo Creative Commons
Atribución 4.0 Internacional
(CC POR 4.0) licencia.
La prensa del MIT
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
saber: Un índice de citas inteligente
uso generalizado de la bibliometría, Ha habido pocas mejoras en las citas y las citas.
los propios índices. Este estancamiento se debe en parte a que las citas y publicaciones son en gran medida
detrás de los muros de pago, haciendo extremadamente difícil y prohibitivamente costoso introducir
Nuevas innovaciones en citas o índices de citas.. Esta tendencia está cambiando, sin embargo, con abierto
acceder a publicaciones convirtiéndose en el estándar (Cervecero, Principal, & Orr, 2019) y organizaciones
como la Iniciativa para Citas Abiertas (Iniciativa para citas abiertas, 2017; peroni &
Shotton, 2020) ayudando a que las citas estén abiertas. Además, con millones de documentos
publicado cada año, crear un índice de citas es un desafío a gran escala que implica importantes
costos financieros y computacionales.
Históricamente, Los índices de citas solo han mostrado las conexiones entre artículos científicos.
sin más información contextual, como por qué se hizo una citación. debido a la
falta de contexto y metadatos limitados disponibles más allá de los títulos de los artículos, autores, y la fecha de
publicaciones, sólo se ha podido calcular cuántas veces ha sido citada una obra,
no analizar ampliamente cómo ha sido citado. Esto es problemático dado el papel central de las citas en
la evaluación de la investigación. En breve, no todas las citas se hacen por igual, sin embargo hemos sido limitados
a tratarlos como tales.
Aquí describimos la scite. (scite.ai), un nuevo índice de citas y una herramienta que aprovecha la re-
Avances del ciento en inteligencia artificial para producir “citas inteligentes”. Revelación de citas inteligentes
cómo se ha citado un artículo científico proporcionando el contexto de la cita y una clasificación
sistema que describe si proporciona evidencia que respalde o contraste la afirmación citada, o
si solo lo menciona.
Esta información de citas enriquecida es más informativa que un índice de citas tradicional.. Para
ejemplo, cuando vigano, por Schubert y otros. (2018) cita a Nicholson, Macedo et al.. (2015), Entre-
Los índices de citas adicionales informan esta cita mostrando el título del artículo citado y otros
información bibliográfica, como el diario, año publicado, y otros metadatos. Tradicional
citation indices do not have the capacity to examine contextual information or how the citing
paper used the citation, such as whether it was made to support or contrast the findings of the
cited paper or if it was made in the introduction or the discussion section of the citing paper.
Smart Citations display the same bibliographical information shown in traditional citation in-
dices while providing additional contextual information, such as the citation statement (el
sentence containing the in-text citation from the citing article), the citation context (the sen-
tences before and after the citation statement), the location of the citation within the citing
artículo (Introducción, Materials and Methods, Resultados, Discusión, etc.), the citation type indi-
cating intent (secundario, contrasting, or mentioning), and editorial information from Crossref
and PubMed, such as corrections and whether the article has been retracted (Cifra 1). Scite
previously relied on Retraction Watch data but moved away from this due to licensing issues.
Going forward, scite will use its own approach1 to retraction detection, as well as data from
Crossref and PubMed.
Adding such information to citation indices has been proposed before. En 1964, garfield
described an “intelligent machine” to produce “citation markers,” such as “critique” or, jokingly,
“calamity for mankind” (garfield, 1964). Citation types describing various uses of citations have
been systematically described by Peroni and Shotton in CiTO, the Citation Typing Ontology
(peroni & Shotton, 2012). Researchers have used these classifications or variations of them in
several bibliometric studies, such as the analysis of citations (Suelzer, Deal et al., 2019) made to
1 Details of how retractions and other editorial notices can be detected through an automated examination of
metadata—even when there is no explicit indication that such notice(s) exist—will be made public via a
manuscript currently in preparation.
Estudios de ciencias cuantitativas
883
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
saber: Un índice de citas inteligente
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 1. Example of scite report page. The scite report page shows citation context, citation type, and various features used to filter and
organize this information, including the section where the citation appears in the citing paper, whether or not the citation is a self-citation, y
the year of the publication. The example scite report shown in the figure can be accessed at the following link: https://scite.ai/reports/10.7554
/elife.05068.
the retracted Wakefield paper (Wakefield, Murch et al., 1998), which found most citations to be
negative in sentiment. Leung, Macdonald et al. (2017) analyzed the citations made to a five-
sentence letter purporting to show opioids as nonaddictive (Portero & Jick, 1980), finding that
most citations were uncritically citing the work. Based on these findings, the journal appended
a public health warning to the original letter. In addition to citation analyses at the individual
article level, citation analyses taking into account the citation type have also been performed on
subsets of articles or even entire fields of research. Greenberg (2009) discovered that citations
were being distorted, for example being used selectively to exclude contradictory studies to
create a false authority in a field of research, a practice carried into grant proposals. Selective
citing might be malicious, as suggested in the Greenberg study, but it might also simply reflect
sloppy citation practices or citing without reading. En efecto, Letrud and Hernes (2019) recently
documented many cases where people were citing reports for the opposite conclusions than the
original authors made.
Despite the advantages of citation types, citation classification and analysis require sub-
stantial manual effort on the part of researchers to perform even small-scale analyses (Pride,
Knoth, & Harag, 2019). Automating the classification of citation types would allow researchers
to dramatically expand the scale of citation analyses, thereby allowing researchers to quickly
assess large portions of scientific literature. PLOS Labs attempted to enhance citation analysis
with the introduction of “rich citations,” which included various additional features to tradi-
tional citations such as retraction information and where the citation appeared in the citing
paper (PLOS, 2015). Sin embargo, the project seemed to be mostly a proof of principle, and work
on rich citations stopped in 2015, although it is unclear why. Possible reasons that the project
did not mature reflect the challenges of accessing the literature at scale, finding a suitable
business model for the application, and classifying citation types with the necessary precision
Estudios de ciencias cuantitativas
884
saber: Un índice de citas inteligente
and recall for it to be accepted by users. It is only recently that machine learning techniques
have evolved to make this task possible, as we demonstrate here. Additional resources,
such as the Colil Database (Fujiwara & Yamamoto, 2015) and SciRide Finder (Volanakis &
Krawczyk, 2018) both allow users to see the citation context from open access articles
indexed in PubMed Central. Sin embargo, adoption seems to be low for both tools, presumably
due to limited coverage of only open access articles. In addition to the development of
such tools to augment citation analysis, various researchers have performed automated
citation typing. Machine learning was used in early research to identify citation intent
(Teufel, Siddharthan, & Tidhar, 2006) and recently Cohan, Ammar et al. (2019) used deep
learning techniques. Athar (2011), Yousif, Niu et al. (2019), and Yan, Chen, and Li (2020) también
used machine learning to identify positive and negative sentiments associated with the
citation contexts.
Aquí, by combining the largest citation type analysis performed to date and developing a
useful user interface that takes advantage of the extra contextual information available, nosotros
introduce scite, a smart citation index.
2. METHOD
2.1. Overview
Smart citations are created by extracting and analyzing citation statements from full-text
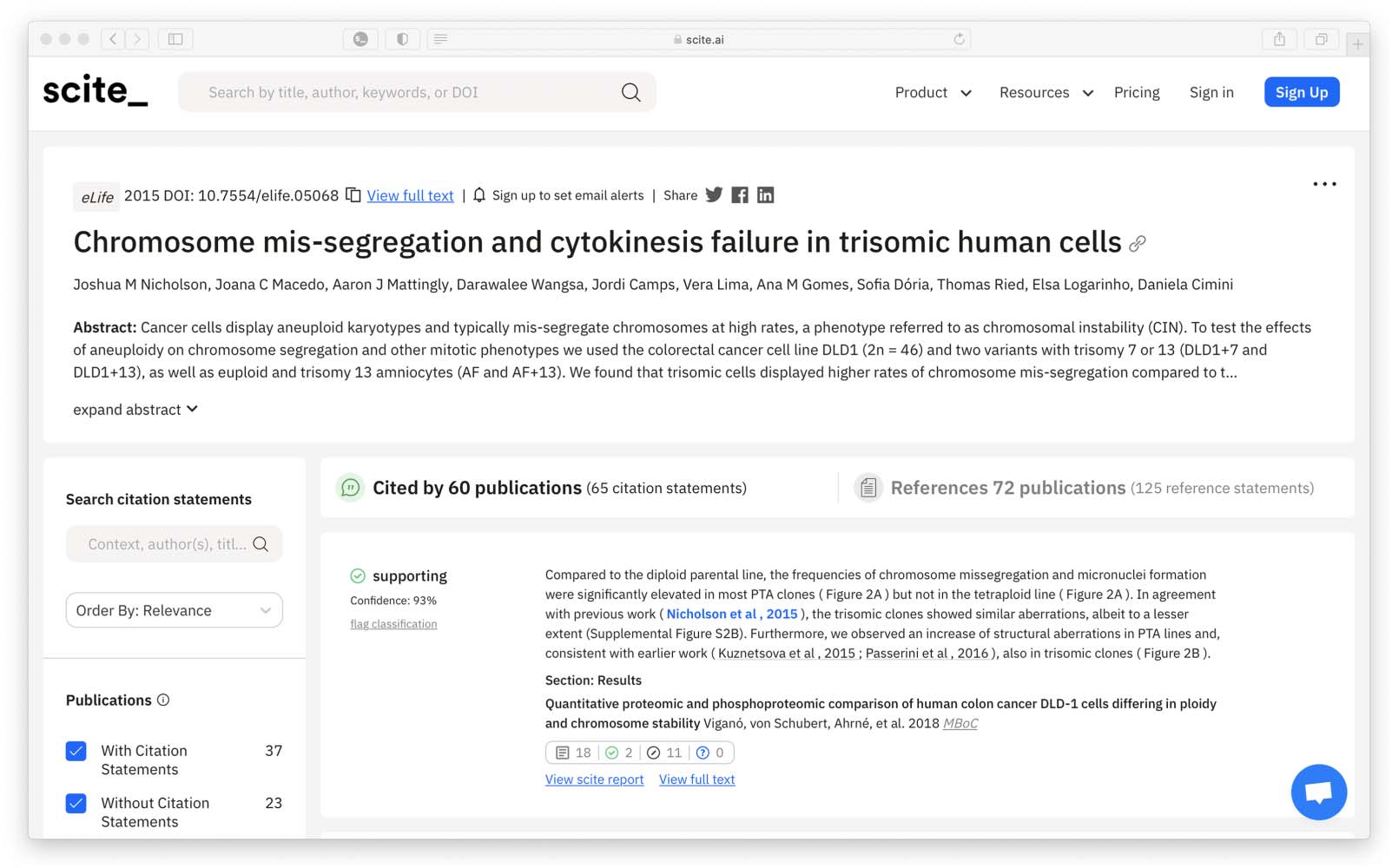
scientific articles. This process is broken into four major steps (ver figura 2):
1. The retrieval of scientific articles
2. The identification and matching of in-text citations and references within a scientific
artículo
3. The matching of references against a bibliographic database
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 2. The scite ingestion process. Documents are retrieved from the internet, as well as being received through file transfers directly from
publishers and other aggregators. They are then processed to identify citations, which are then tied to items in a paper’s reference list. Those
citations are then verified, and the information is inserted into scite’s database.
Estudios de ciencias cuantitativas
885
saber: Un índice de citas inteligente
4. The classification of the citation statements into citation types using deep learning.
We describe the four components in more detail below.
2.2. Retrieval of Scientific Documents
Access to full-text scientific articles is necessary to extract and classify citation statements and
the citation context. We utilize open access repositories such as PubMed Central and a
variety of open sources as identified by Unpaywall (Else, 2018), such as open access publishers’
websites, university repositories, and preprint repositories, to analyze open access articles.
Other relevant open access document sources, such as Crossref TDM and the Internet
Archive have been and are continually evaluated as new sources for document ingestion.
Subscription articles used in our analyses have been made available through indexing agree-
ments with over a dozen publishers, including Wiley, BMJ, Karger, Sage, Europe PMC,
Thieme, Prensa de la Universidad de Cambridge, Rockefeller University Press, IOP, Microbiology Society,
Frontiers, and other smaller publishers. Once a source of publications is established, docu-
ments are retrieved on a regular basis as new articles become available to keep the citation
record fresh. Depending on the source, documents may be retrieved and processed anywhere
between daily and monthly.
2.3.
Identification of In-Text Citations and References from PDF and XML Documents
A large majority of scientific articles are only available as PDF files2, a format designed for
visual layout and printing, not text-mining. To match and extract citation statements from
PDFs with high fidelity, an automated process for converting PDF files into reliable structured
content is required. Such conversion is challenging, as it requires identifying in-text citations
(the numerical or textual callouts that refer to a particular item in the reference list), identifying
and parsing the full bibliographical references in the reference list, linking in-text citations to
the correct items in this list, and linking these items to their digital object identifiers (DOIs) en un
bibliographic database. As our goal is to eventually process all scientific documents, este
process must be scalable and affordable. To accomplish this, we utilize GROBID, an open-
source PDF-to-XML converter tool for scientific literature (López, 2020a). The goal of GROBID
is to automatically convert scholarly PDFs into structured XML representations suitable for
large-scale analysis. The structuration process is realized by a cascade of supervised machine
learning models. The tool is highly scalable (around five PDF documents per second on a four-
core server), is robust, and includes a production-level web API, a Docker image, and bench-
marking facilities. GROBID is used by many large scientific information service providers,
such as ResearchGate, CERN, and the Internet Archive to support their ingestion and docu-
ment workflows (López, 2020a). The tool is also used for creating machine-friendly data sets of
research papers, por ejemplo, the recent CORD-19 data set (Wang, Lo et al., 2020).
Particularly relevant to scite, GROBID was benchmarked as the best open source biblio-
graphical references parser by Tkaczyk, Collins et al. (2018) and has a relatively unique focus
on citation context extraction at scale, as illustrated by its usage for building the large-scale
2 As an illustration, the ISTEX project has been an effort from the French state leading to the purchase of
23 million full text articles from the mainstream publishers (Elsevier, Springer-Nature, wiley, etc.) principalmente
published before 2005, corresponding to an investment of A55 million in acquisitions. The delivery of full
text XML when available was a contractual requirement, but an XML format with structured body could be
delivered by publishers for only around 10% of the publications.
Estudios de ciencias cuantitativas
886
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
saber: Un índice de citas inteligente
Semantic Scholar Open Research Corpus (S2ORC), a corpus of 380.5 million citations, incluir-
ing citation mentions excerpts from the full-text body (Lo, Wang y cols., 2020).
In addition to PDFs, some scientific articles are available as XML files, such as the Journal
Article Tag Suite ( JATS) format. Formatting articles in PDF and XML has become standard prac-
tice for most mainstream publishers. While structured XML can solve many issues that need to
be addressed with PDFs, XML full texts appear in a variety of different native publisher XML
formats, often incomplete and inconsistent from one to another, loosely constrained, y
evolving over time into specific versions.
To standardize the variety of XML formats we receive into a common format, we rely upon
the open-source tool Pub2TEI (López, 2020b). Pub2TEI converts various XML styles from
publishers to the same standard TEI format as the one produced by GROBID. This centralizes
our document processing across PDF and XML sources.
2.4. Matching References Against the Bibliographic Database Crossref
Once we have identified and matched the in-text citation to an item in a paper’s reference list,
this information must be validated. We use an open-source tool, biblio-glutton (López, 2020C),
which takes a raw bibliographical reference, as well as optionally parsed fields (título, author
names, etc.) and matches it against the Crossref database—widely regarded as the industry
standard source of ground truth for scholarly publications3. The matching accuracy of a raw
citation reaches an F-score of 95.4 on a set of 17,015 raw references associated with a DOI,
extracted from a data set of 1,943 PMC articles4 compiled by Constantin (2014). In an end-to-
end perspective, still based on an evaluation with the corpus of 1,943 PMC articles, combining
GROBID PDF extraction of citations and bibliographical references with biblio-glutton valida-
ciones, the pipeline successfully associates around 70% of citation contexts to cited papers with
correctly identified DOIs in a given PDF file. When the full-text XML version of an article is
available from a publisher, references and linked citation contexts are normally correctly en-
coded, and the proportion of fully solved citation contexts corresponding to the proportion of
cited paper with correctly identified DOIs is around 95% for PMC XML JATS files. The scite
platform today only ingests publications with a DOI and only matches references against bib-
liographical objects with a registered DOI. The given evaluation figures have been calculated
relative to these types of citations.
2.5. Task Modeling and Training Data
Extracted citation statements are classified into supporting, contrasting, or mentioning, to iden-
tify studies that have tested the claim and to evaluate how a scientific claim has been evalu-
ated in the literature by subsequent research.
We emphasize that scite is not doing sentiment analysis. In natural language processing,
sentiment analysis is the study of affective and subjective statements. The most common af-
fective state considered in sentiment analysis is a mere polar view from positive sentiment to
negative sentiment, which appeared to be particularly useful in business applications (p.ej.,
product reviews and movie reviews). Following this approach, a subjective polarity can be
associated with a citation to try to capture an opinion about the cited paper. la evidencia
used for sentiment classification relies on the presence of affective words in the citation
3 For more information on the history and prevalence of Crossref, see https://www.crossref.org/about/.
4 The evaluation data and scripts are available on the project GitHub repository; see biblio-glutton (López,
2020C).
Estudios de ciencias cuantitativas
887
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
saber: Un índice de citas inteligente
contexto, with an associated polarity score capturing the strength of the affective state (Athar,
2014; Halevi & Schimming, 2018; Hassan, Imran et al., 2018; Yousif et al., 2019). Yan et al.
(2020), por ejemplo, use a generic method called SenticNet to identify sentiments in citation
contexts extracted from PubMed Central XML files, without particular customization to the
scientific domain (only a preprocessing to remove the technical terms from the citation con-
texts is applied). SenticNet uses a polarity measure associated with 200,000 natural language
conceptos, propagated to the words and multiword terms realizing these concepts.
A diferencia de, scite focuses on the authors’ reasons for citing a paper. We use a discrete clas-
sification into three discursive functions relative to the scientific debate; see Murray, Lamers
et al. (2019) for an example of previous work with typing citations based on rhetorical inten-
ción. We consider that for capturing the reliability of a claim, a classification decision into
supporting or contrasting must be backed by scientific arguments. The evidence involved in
our assessment of citation intent is directed to the factual information presented in the citation
contexto, usually statements about experimental facts and reproducibility results or presentation
of a theoretical argument against or agreeing with the cited paper.
Examples of supporting, contrasting, and mentioning citation statements are given in
Mesa 1, with explanations describing why they are classified as such, including examples
where researchers have expressed confusion or disagreement with our classification.
En tono rimbombante, just as it is critical to optimize for accuracy of our deep learning model when
classifying citations, it is equally important to make sure that the right terminology is used and
understood by researchers. We have undergone multiple iterations of the design and display of
citation statements and even the words used to define our citation types, including using previ-
ous words such as refuting and disputing to describe contrasting citations and confirming to de-
scribe supporting citations. The reasons for these changes reflect user feedback expressing
confusion over certain terms as well as our intent to limit any potentially inflammatory
interpretaciones. En efecto, our aim with introducing these citation types is to highlight differences
in research findings based on evidence, not opinion. The main challenge of this classification
task is the highly imbalanced distribution of the three classes. Based on manual annotations of
different publication domains and sources, we estimate the average distribution of citation state-
ments as 92.6% mentioning, 6.5% secundario, y 0.8% contrasting statements. Obviamente, el
less frequent the class, the more valuable it is. Most of the efforts in the development of our
automatic classification system have been directed to address this imbalanced distribution.
This task has required first the creation of original training data by experts—scientists with
experience in reading and interpreting scholarly papers. Focusing on data quality, the expert
classification was realized by multiple-blind manual annotation (at least two annotators working
in parallel on the same citation), followed by a reconciliation step where the disagreements were
further discussed and analyzed by the annotators. To keep track of the progress of our automatic
classification over time, we created a holdout set of 9,708 classified citation records. To maintain
a class distribution as close as possible to the actual distribution in current scholarly publica-
ciones, we extracted the citation contexts from Open Access PDF of Unpaywall by random
sampling with a maximum of one context per document.
We separately developed a working set where we tried to oversample the two less frequent
classes (secundario, contrasting) with the objective of addressing the difficulties implied by the
imbalanced automatic classification. We exploited the classification scores of our existing
classifiers to select more likely supporting and contrasting statements for manual classification.
At the present time, this set contains 38,925 classified citation records. The automatic classi-
fication system was trained with this working set, and continuously evaluated with the
Estudios de ciencias cuantitativas
888
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Mesa 1.
Real-world examples of citation statement classifications with examples explaining why a citation type has or has not been assigned. Citation classifications
are based on the following two requirements: there needs to be a written indication that the statement supports or contrasts the cited paper; and there needs to be an
indication that it provides evidence for this assertion.
Citation statement
“In agreement with previous work (Nicholson et al., 2015), el
trisomic clones showed similar aberrations, albeit to a lesser
extent (Supplemental Figure S2B)."
“In contrast to several studies in anxious adults that examined
amygdala activation to angry faces when awareness was not
restricted (Phan, Fitzgerald, Nathan, & Tancer, 2006; piedra,
Goldin, Sareen, Zorrilla, & Marrón, 2002; piedra, Simmons,
Feinstein, & Paulus, 2007), we found no group differences in
amygdala activation.”
Classification
Secundario
Contrasting
Explanation
“In agreement with previous work” indicates support, while “the
trisomic clones showed similar aberrations, albeit to a lesser
degree (Supplemental Figure S2B)” provides evidence for this
supporting statement.
“In contrast to several studies” indicates a contrast between the
study and studies cited, while “we found no group differences
in amygdala activation” indicates a difference in findings.
“The amygdala is a key structure within a complex circuit devoted to
emotional interpretation, evaluation and response (Stein et al.,
2002; Phan et al., 2006)."
Mentioning
This citation statement refers to Phan et al. (2006) sin
providing evidence that supports or contrasts the claims made
in the cited study.
“In social cognition, the amygdala plays a central role in social
Mentioning
Aquí, the statement “consistent with these findings” sounds
reward anticipation and processing of ambiguity [87]. Coherente
with these findings, amygdala involvement has been outlined
as central in the pathophysiology of social anxiety disorders
[27], [88]."
supportive, pero, En realidad, cites two previous studies: [87] y [27]
without providing evidence for either. Such cites can be valuable,
as they establish connections between observations made by
otros, but they do not provide primary evidence to support
or contrast the cited studies. Por eso, this citation statement is
classified as mentioning.
“For example, a now-discredited article purporting a link between
Mentioning
This citation statement describes the cited paper critically and with
vaccination and autism (Wakefield et al., 1998) helped to
dissuade many parents from obtaining vaccination for their
children.”
negative sentiment but there is no indication that it presents
primary contrasting evidence, thus this statement is classified
as mentioning.
q
tu
a
norte
t
i
t
a
i
t
i
v
mi
S
C
mi
norte
C
mi
S
tu
d
mi
s
t
i
8
8
9
s
C
i
t
mi
:
A
s
metro
a
r
t
C
i
t
a
t
i
oh
norte
i
norte
d
mi
X
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
saber: Un índice de citas inteligente
immutable holdout set to avoid as much bias as possible. An n-fold cross-evaluation on the
working set, por ejemplo, would have been misleading because the distribution of the classes
in this set was artificially modified to boost the classification accuracy of the less frequent classes.
Before reconciliation, the observed average interannotator agreement percentage was
78.5% in the open domain and close to 90% for batches in biomedicine. It is unclear what
accounts for the difference. Reconciliation, further completed with expert review by core team
miembros, resulted in highly consensual classification decisions, which contrast with typical
multiround disagreement rates observed with sentiment classification. Athar (2014), para
instancia, reports Cohen’s k annotator agreement of 0.675 and Ciancarini, Di Iorio et al.
(2014) report k = 0.13 y k = 0.15 for the property groups covering confirm/supports and
critiques citation classification labels. A custom open source document annotation web appli-
catión, docanno (Nakayama, Kubo et al., 2018) was deployed to support the first round of
anotaciones.
En general, the creation of our current training and evaluation holdout data sets has been a
major 2-year effort involving up to eight expert annotators and nearly 50,000 classified citation
records. In addition to the class, each record includes the citation sentence, the full “snippet”
(citation sentence plus previous and next sentences), the source and target DOI, the reference
callout string, and the hierarchical list of section titles where the citation occurs.
2.6. Machine Learning Classifiers
Although deep learning text classifiers show very strong and stable results on imbalanced
classification tasks compared with linear classifiers (Nizzoli, Avvenuti et al., 2019), our first
experiments with an early training data set based on PLOS articles resulted in F-scores of
96.3% for mentioning citations, 55.3% for supporting, y 20.5% for contrasting. The initial
accuracy for contrasting in particular raised concerns about the feasibility of the task itself
at scale. We focused on multiple approaches to increase over time the accuracy of classifier
for the two less frequent classes:
(cid:129) Improving the classification architecture: After initial experiments with RNN (Recursive
Neural Network) architectures such as BidGRU (Bidirectional Gated Recurrent Unit, un
architecture similar to the approach of Cohan et al. (2019) for citation intent classifica-
ción), we obtained significant improvements with the more recently introduced ELMo
(Embeddings from Language Models) dynamic embeddings (Peters, Neumann et al.,
2018) and an ensemble approach. Although the first experiments with BERT
(Bidirectional Encoder Representations from Transformers) (Devlin, Chang et al.,
2019), a breakthrough architecture for NLP, were disappointing, fine-tuning SciBERT
(a science-pretrained base BERT model) (Beltagy, Lo, & Cohán, 2019) led to the best
results and is the current production architecture of the platform.
(cid:129) Using oversampling and class weighting techniques: It is known that the techniques
developed to address imbalanced classification in traditional machine learning can
be applied successfully to deep learning too (Johnson & Khoshgoftaar, 2019). Nosotros
introduced in our system oversampling of less frequent classes, class weighting, y
metaclassification with three binary classifiers. These techniques provide some
improvements, but they rely on empirical parameters that must be re-evaluated as the
training data changes.
(cid:129) Extending the training data for less frequent classes: As mentioned previously, we use an
active learning approach to select the likely less frequent citation classes based on the
Estudios de ciencias cuantitativas
890
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
saber: Un índice de citas inteligente
Mesa 2.
Progress on classification results over approximately 1 año, evaluated on a fixed holdout
set of 9,708 examples. In parallel with these various iterations on the classification algorithms, el
training data was raised from 30,665 (initial evaluation with BidGRU) a 38,925 examples (last
evaluation with SciBERT) via an active learning approach.
Acercarse
BidGRU
BidGRU + metaclassifier
BidGRU + ELMo
BidGRU + ELMo + ensemble (10 classifiers)
SciBERT
Contrasting
.206
F-score
Secundario
.554
.260
.405
.460
.590
.590
.590
.605
.648
Mentioning
.964
.964
.969
.972
.973
Observed distribution
0.8%
6.5%
92.6%
scores of the existing classifiers. By focusing on edge cases over months of manual
anotaciones, we observed significant improvements in performance for predicting con-
trasting and supporting cases.
Because deep learning today is mostly an empirical effort, the improvements using the
above-described techniques were driven experimentally and iteratively until reaching a
plateau. Mesa 2 presents the model evaluation after iterations of the classification system over
time using our fixed holdout set. Mesa 3 presents the evaluation metrics for the current
SciBERT model. Reported scores are averaged over 10 carreras. The F-score for the classification
of “contrasting” was notably improved from 20.1% a 58.97%. The precision for predicting
“contrasting” citations” in particular reaches 85.19%, a very reliable level for such a rare class.
Given the unique nature of scite, there are a number of additional considerations. Primero,
scaling is a key requirement of scite, which addresses the full corpus of scientific literature.
While providing good results, the prediction with the ELMo approach is 20 times slower than
with SciBERT, making it less attractive for our platform. Segundo, we have experimented with
using section titles to improve classifications—for example, one might expect to find supporting
and contrasting statements more often in the Results section of a paper and mentioning state-
ments in the Introduction. Counterintuitively, including section titles in our model had no impact
on F-scores, although it did slightly improve precision. It is unclear why including section titles
failed to improve F-scores. Sin embargo, it might relate to the challenge of correctly identifying and
normalizing section titles from documents. Tercero, segmenting scientific text into sentences
presents unique challenges due to the prevalence of abbreviations, nomenclatures, y
Mesa 3. Accuracy of SciBERT classifier, currently deployed on the scite platform, evaluated on a
holdout set of 9,708 examples.
Contrasting
Secundario
Mentioning
Precision
.852
.741
.962
Recordar
.451
.576
.984
F-score
.590
.648
.973
Nota: When deploying classification models in production, we balance the precision/recall so that all the clas-
ses have a precision higher than 80%.
Estudios de ciencias cuantitativas
891
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
saber: Un índice de citas inteligente
mathematical equations. Finalmente, we experimented with various context windows (es decir., el
amount of text used in the classification of a citation) but were only able to improve the F-score
for the contrasting category by eight points by manually selecting the most relevant phrases in
the context window. Automating this process might improve classifications, but doing so pre-
sents a significant technical challenge. Other possible improvements of the classifier include
multitask training, refinement of classes, increase of training data via improved active learning
técnicas, and integration of categorical features in the transformer classifier architecture.
We believe that the specificity of our evidence-based citation classes, the size and the focus
on the quality of our manually annotated data set (multiple rounds of blind annotations with
final collective reconciliation), the customization and continuous improvement of a state of
the art deep learning classifier, and finally the scale of our citation analysis distinguishes
our work from existing developments in automatic citation analysis.
2.7. Citation Statement and Classification Pipeline
TEI XML data is parsed in Python using the BeautifulSoup library and further segmented into
sentences using a combination of spaCy (Honnibal, Montani et al., 2018) and Natural
Language Toolkit’s Punkt Sentence Tokenizer (Bird, Klein, & Loper, 2009). These sentence
segmentation candidates are then postprocessed with custom rules to better fit scientific texts,
existing text structures, and inline markups. Por ejemplo, a sentence split is forbidden inside a
reference callout, around common abbreviations not supported by the general-purpose
sentence segmenters, or if it is conflicting with a list item, párrafo, or section break.
The implementation of the classifier is realized by a component we have named Veracity,
which provides a custom set of deep learning classifiers built on top of the open source DeLFT
library (López, 2020d). Veracity is written in Python and employs Keras and TensorFlow for
text classification. It runs on a single server with an NVIDIA GP102 (GeForce GTX 1080 Ti)
graphics card with 3,584 CUDA cores. This single machine is capable of classifying all citation
statements as they are processed. Veracity retrieves batches of text from the scite database that
have yet to be classified, processes them, and updates the database with the results. Cuando
deploying classification models in production, we balance the precision/recall so that all
the classes have a precision higher than 80%. For this purpose, we use the holdout data set
to adjust the class weights at the prediction level. After evaluation, we can exploit all available
labeled data to maximize the quality, and the holdout set captures a real-world distribution
adapted to this final tuning.
2.8. User Interface
The resulting classified citations are stored and made available on the scite platform. Datos
from scite can be accessed in a number of ways (downloads of citations to a particular paper;
the scite API, etc.). Sin embargo, users will most commonly access scite through its web interface.
Scite provides a number of core features, detailed below.
The scite report page (Cifra 1) displays summary information about a given paper. Todo
citations in the scite database to the paper are displayed, and users can filter results by clas-
sification (secundario, mentioning, contrasting), paper section (p.ej., Introducción, Resultados), y
the type of citing article (p.ej., preprint, libro, etc.). Users can also search for text within citation
statements and surrounding citation context. Por ejemplo, if a user wishes to examine how an
article has been cited with respect to a given concept (p.ej., miedo), they can search for citation
contexts that contain that key term. Each citation statement is accompanied by a classification
Estudios de ciencias cuantitativas
892
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
saber: Un índice de citas inteligente
label, as well as an indication of how confident the model is of said classification. Para examen-
por ejemplo, a citation statement may be classified as supporting with 90% confidence, meaning that
the model is 90% certain that the statement supports the target citation. Finalmente, each citation
statement can be flagged by individual users as incorrect, so that users can report a classifica-
tion as incorrect, as well as justify their objection. After a citation statement has been flagged
as incorrect, it will be reviewed and verified by two independent reviewers, y, if both agree,
the recommended change will be implemented. In this way, scite supplements machine
learning with human interventions to ensure that citations are accurately classified. Esto es
an important feature of scite that allows researchers to interact with the automated citation
types, correcting classifications that might otherwise be difficult for a machine to classify. Él
also opens the possibility for authors and readers to add more nuance to citation typing by
allowing them to annotate snippets.
To improve the utility and usability of the smart citation data, scite offers a wide variety of
tools common to other citation platforms, such as Scopus and Web of Science and other
information retrieval software. These include literature searching functionality for researchers
to find supported and contrasted research, visualizations to see research in context, reference
checking for automatically evaluating references with scite’s data on an uploaded manuscript
y más. Scite also offers plugins for popular web browsers and reference management soft-
mercancía (p.ej., Zotero) that allow easy access to scite reports and data in native research
entornos.
3. DISCUSIÓN
3.1. Research Applications
A number of researchers have already made use of scite for quantitative assessments of the
literature. Por ejemplo, Bordignon (2020) examined self-correction in the scientific record
and operationalized “negative” citations as those that scite classified as contrasting. Ellos
found that negative citations are rare, even among works that have been retracted. In another
example from our own group, Nicholson et al. (2020) examined scientific papers cited in
Wikipedia articles and found that—like the scientific literature as a whole—the vast majority
presented findings that have not been subsequently verified. Similar analyses could also be
applied to articles in the popular press.
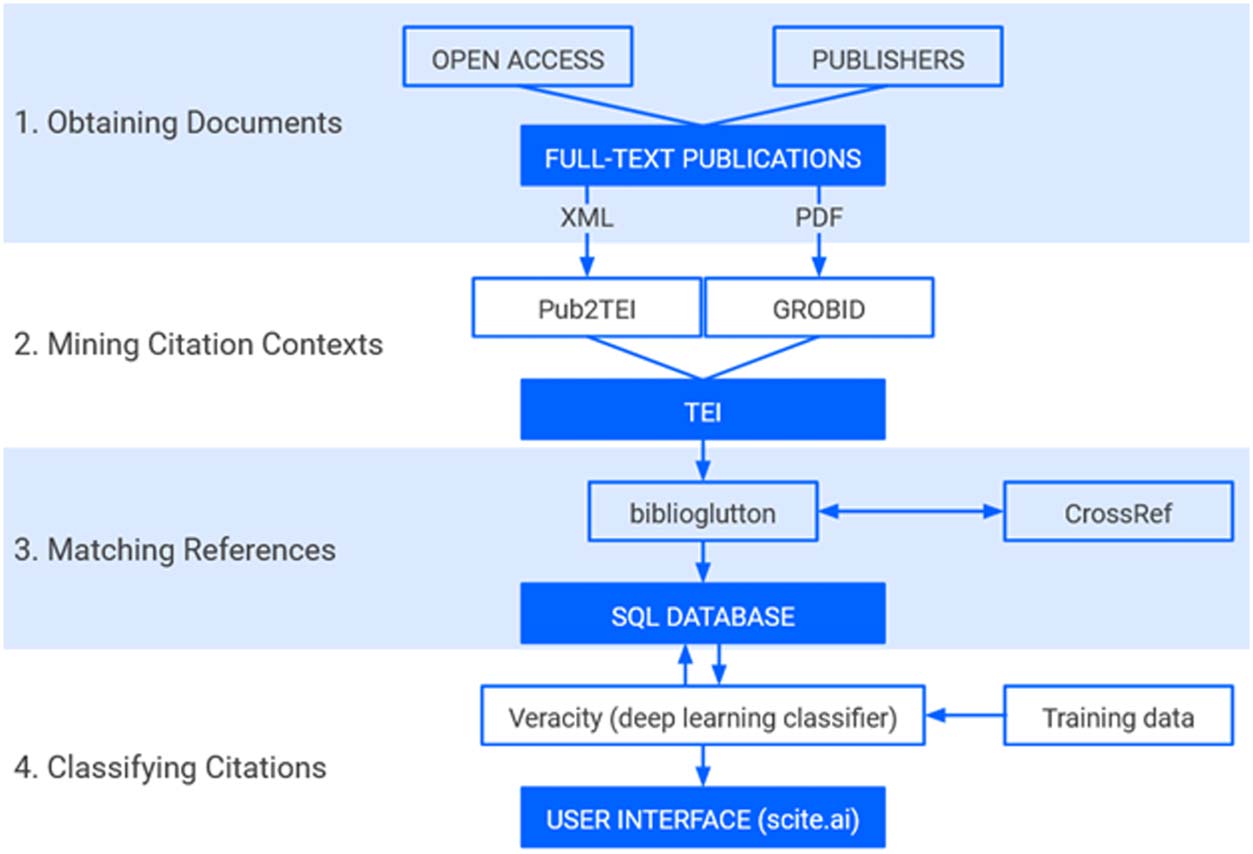
One can imagine a number of additional metascientific applications. Por ejemplo, network
analyses with directed graphs, valenced edges (by type of citation—supporting, contrasting,
and mentioning), and individual papers as nodes could aid in understanding how various
fields and subfields are related. A simplified form of this analysis is already implemented on
the scite website (ver figura 3), but more complicated analyses that assess traditional network
indices, such as centrality and clustering, could be easily implemented using standard soft-
ware libraries and exports of data using the scite API.
3.2.
Implications for Scholarly Publishers
There are a number of implications for scholarly publishers. At a very basic level, this is
evident in the features that scite provides that are of particular use to publishers. Por ejemplo,
the scite Reference Check parses the reference list of an uploaded document and produces a
report indicating how items in the list have been cited, flagging those that have been retracted
or have otherwise been the subject of editorial concern. This type of screening can help pub-
lishers and editors ensure that articles appearing in their journals do not inadvertently cite
Estudios de ciencias cuantitativas
893
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
saber: Un índice de citas inteligente
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 3. A citation network representation using the scite Visualization tool. The nodes represent individual papers, with the edges repre-
senting supporting (verde) or contrasting (azul) citation statements. The graph is interactive and can be expanded and modified for other
layouts. The interactive visualization can be accessed at the following link: https://scite.ai/visualizations/global-analysis-of-genome
-transcriptome-9L4dJr?dois%5B0%5D=10.1038%2Fmsb.2012.40&dois%5B1%5D=10.7554%2Felife.05068&focusedElement=10.7554
%2Felife.05068.
discredited works. Evidence in scite’s own database indicates that this would solve a seemingly
significant problem, as in 2019 alone nearly 6,000 published papers cited works that had been
retracted prior to 2019. Given that over 95% of citations made to retracted articles are in error
(Schneider, Ye et al., 2020), had the Reference Check tool been applied to these papers during
the review process, the majority of these mistakes could have been caught.
Sin embargo, there are additional implications for scholarly publishing that go beyond the fea-
tures provided by scite. We believe that by providing insights into how articles are cited—rather
than simply noting that the citation has occurred—scite can alter the way in which journals,
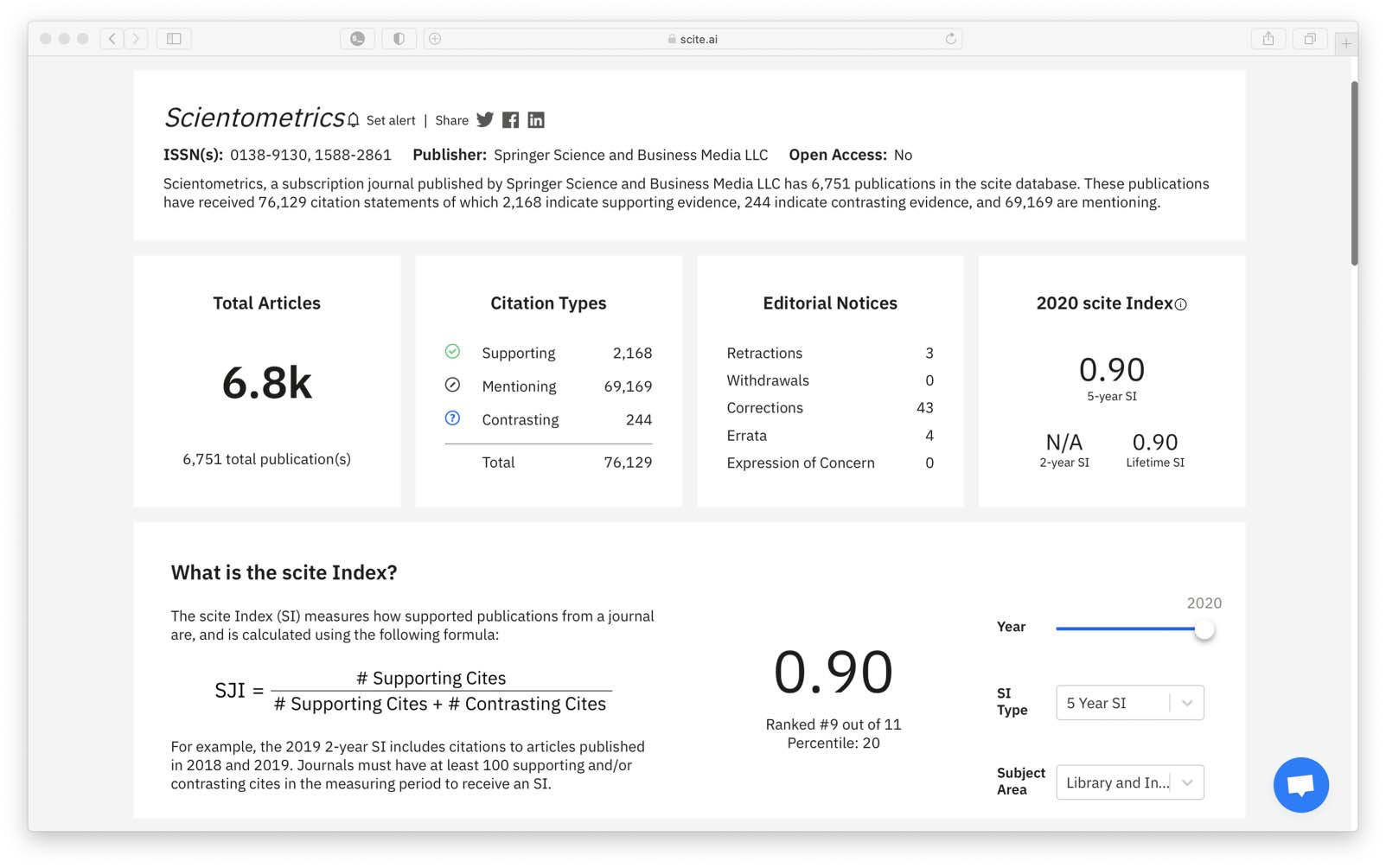
institutions, and publishers are assessed. Scite provides journals and institutions with dashboards
that indicate the extent to which papers with which they are associated have been supported or
contrasted by subsequent research (Cifra 4). Even without reliance on specific metrics, el
approach that scite provides prompts the question: What if we normalized the assessment of
journals, institutions and researchers in terms of how they were cited rather than the simple fact
that they were cited alone?
3.3.
Implications for Researchers
Given the fact that nearly 3 million scientific papers are published every year (Ware & Mabe,
2015), researchers increasingly report feeling overwhelmed by the amount of literature they
must sift through as part of their regular workflow (Landhuis, 2016). Scite can help by assisting
researchers in identifying relevant, reliable work that is narrowly tailored to their interests, como
well as better understanding how a given paper fits into the broader context of the scientific
literature. Por ejemplo, one common technique for orienting oneself to new literature is to seek
out the most highly cited papers in that area. If the context of those citations is also visible, el
Estudios de ciencias cuantitativas
894
saber: Un índice de citas inteligente
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 4. A scite Journal Dashboard showing the aggregate citation information at the journal level, including editorial notices and the scite
Index, a journal metric that shows the ratio of supporting citations over supporting plus contrasting citations. Access to the journal dashboard in
the figure and other journal dashboards is available here: https://scite.ai/journals/0138-9130.
value of a given paper can be more completely assessed and understood. Hay, sin embargo,
additional—although perhaps less obvious—implications. If citation types are easily visible, es
possible that researchers will be incentivized to make replication attempts easier (Por ejemplo,
by providing more explicit descriptions of methods or instruments) in the hope that their work
will be replicated.
3.4. Limitaciones
Actualmente, the biggest limitation for researchers using scite is the size of the database. En el
time of this writing, scite has ingested over 880 million separate citation statements from over
25 million scholarly publications. Sin embargo, there are over 70 million scientific publications in
existence (Ware & Mabe, 2015); scite is constantly ingesting new papers from established
sources and signing new licensing agreements with publishers, so this limitation should abate
con el tiempo. Sin embargo, given that the ingestion pipeline fails to identify approximately 30% de
citation statements/references in PDF files (~5% in XML), the platform will necessarily contain
fewer references than services such as Google Scholar and Web of Science, which do not rely
on ingesting the full text of papers. Even if references are reliably extracted and matched with a
DOI or directly provided by publishers, a reference is currently only visible on the scite plat-
form if it is matched with at least one citation context in the body of the article. Tal como, el
data provided by scite will necessarily miss a measurable percentage of citations to a given
paper. We are working to address these limitations in two ways: Primero, we are working toward
ingesting more full-text XML and improving our ability to detect document structure in PDFs.
Segundo, we have recently supplemented our Smart Citation data with “traditional” citation
metadata provided by Crossref (see “Without Citation Statements” shown in Figure 1), cual
surfaces references that we would otherwise miss. En efecto, this Crossref data now includes ref-
erences from publishers with previously closed references such as Elsevier and the American
Estudios de ciencias cuantitativas
895
saber: Un índice de citas inteligente
Chemical Society. These traditional citations can later be augmented to include citation con-
texts as we gain access to full text.
Another limitation is related to the classification of citations. Primero, as noted previously, el
Veracity software does not perfectly classify citations. This can partly be explained by the fact
that language in the (biomedical) sciences is little standardized (unlike law, where shepardizing
is a standing term describing the “process of using a citator to discover the history of a case or
statute to determine whether it is still good law”; see Lehman & Phelps, 2005). Sin embargo, el
accuracy of the classifier will likely increase over time as technology improves and the training
data set increases in size. Segundo, the ontology currently employed by scite (secundario,
mentioning, and contrasting) necessarily misses some nuance regarding how references are cited
in scientific papers. One key example relates to what “counts” as a contrasting citation: En
present, this category is limited to instances where new evidence is presented (p.ej., a failed
replication attempt or a difference in findings). Sin embargo, it might also be appropriate to include
conceptual and logical arguments against a given paper in this category. Además, in our system,
the evidence behind the supporting or contrasting citation statements is not being assessed; thus a
supporting citation statement might come from a paper where the experimental evidence is weak
y viceversa. We do display the citation tallies that papers have received so that users can
assess this but it would be exceedingly difficult to also classify the sample size, Estadísticas, y
other parameters that define how robust a finding is.
4. CONCLUSIONS
The automated extraction and analysis of scientific citations is a technically challenging task,
but one whose time has come. By surfacing the context of citations rather than relying on their
mere existence as an indication of a paper’s importance and impact, scite provides a novel
approach to addressing pressing questions for the scientific community, including incentiviz-
ing replicable works, assessing an increasingly large body of literature, and quantitatively
studying entire scientific fields.
EXPRESIONES DE GRATITUD
We would like to thank Yuri Lazebnik for his help in conceptualizing and building scite.
INFORMACIÓN DE FINANCIACIÓN
This work was supported by NIDA grant 4R44DA050155-02.
CONTRIBUCIONES DE AUTOR
jose m. nicholson: Conceptualización, Adquisición de datos, Analysis and interpretation of data,
Escritura: borrador original, Writing—Review and editing. Milo Mordaunt: Adquisición de datos,
Analysis and interpretation of data. Patricia López: Conceptualización, Analysis and interpre-
tation of data, Escritura: borrador original, Writing—Review and editing. ashish uppala: Análisis
and interpretation of data, Escritura: borrador original, Writing—Review and editing. Domenic
rosados: Analysis and interpretation of data, Escritura: borrador original, Writing—Review and edit-
En g. Neves P.. rodrigues: Conceptualización. Sean C. Abundante: Conceptualización, Data acquisi-
ción, Analysis and interpretation of data, Escritura: borrador original, Writing—Review and
edición. Peter Grabitz: Conceptualización, Adquisición de datos, Analysis and interpretation of
datos, Escritura: borrador original, Writing—Review and editing.
CONFLICTO DE INTERESES
The authors are shareholders and/or consultants or employees of Scite Inc.
Estudios de ciencias cuantitativas
896
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
saber: Un índice de citas inteligente
DISPONIBILIDAD DE DATOS
Code used in the ingestion of manuscripts is available at https://github.com/kermitt2/grobid,
https://github.com/kermitt2/biblio-glutton, and https://github.com/kermitt2/Pub2TEI. The clas-
sification of citation statements is performed by a modified version of DeLFT (https://github
.com/kermitt2/delft). The training data used by the scite classifier is proprietary and not pub-
licly available. El 880+ million citation statements are available at scite.ai but cannot be
shared in full due to licensing arrangements made with publishers.
REFERENCIAS
Athar, A. (2011). Sentiment analysis of citations using sentence
structure-based features. Proceedings of the ACL 2011 Alumno
Session, 81–87. Retrieved from https://www.aclweb.org
/anthology/P11-3015
Athar, A. (2014). Sentiment analysis of scientific citations. Técnico
Informe (UCAM-CL-TR-856), University of Cambridge, Computadora
Laboratory. Retrieved from https://www.cl.cam.ac.uk/techreports
/UCAM-CL-TR-856.pdf
Beltagy, I., Lo, K., & Cohán, A. (2019). SciBERT: A pretrained lan-
guage model for scientific text. ArXiv:1903.10676 [Cs]. https://
arxiv.org/abs/1903.10676. https://doi.org/10.18653/v1/ D19
-1371
Bird, S., Klein, MI., & Loper, mi. (2009). Natural language processing
with Python (1st ed). O’Reilly.
Bordignon, F. (2020). Self-correction of science: A comparative
study of negative citations and post-publication peer review.
cienciometria, 124(2), 1225–1239. https://doi.org/10.1007
/s11192-020-03536-z
Ciancarini, PAG., Di Iorio, A., Nuzzolese, A. GRAMO., peroni, S., & Vitali, F.
(2014). Evaluating citation functions in CiTO: Cognitive issues.
In V. Presutti, C. d’Amato, F. Gandon, METRO. d’Aquin, S. Staab, &
A. Tordai (Editores.), The Semantic Web: Trends and Challenges
(volumen. 8465, páginas. 580–594). Springer International Publishing.
https://doi.org/10.1007/978-3-319-07443-6_39
Cohán, A., Ammar, w., van Zuylen, METRO., & Cady, F. (2019).
Structural scaffolds for citation intent classification in scientific
publicaciones. En Actas de la 2019 Conference of the
North American Chapter of the Association for Computational
Lingüística. https://doi.org/10.18653/v1/N19-1361
Constantin, A. (2014). Automatic structure and keyphrase analysis of
publicaciones cientificas. University of Manchester. https://www
.research.manchester.ac.uk/portal/files/54553913/FULL_TEXT.PDF
Devlin, J., Chang, M.-W., Sotavento, K., & Toutanova, k. (2019). BERT:
Pre-training of deep bidirectional transformers for language
comprensión. En Actas de la 2019 Conference of the
North American Chapter of the Association for Computational
Lingüística. https://doi.org/10.18653/v1/N19-1423
Else, h. (2018). How Unpaywall is transforming open science.
Naturaleza, 560(7718), 290–291. https://doi.org/10.1038/d41586
-018-05968-3, PubMed: 30111793
Fujiwara, T., & Yamamoto, Y. (2015). Colil: A database and search
service for citation contexts in the life sciences domain. Diario
of Biomedical Semantics, 6(1), 38. https://doi.org/10.1186
/s13326-015-0037-x, PubMed: 26500753
garfield, mi. (1955). Citation indexes for science: A new dimension in
documentation through association of ideas. Ciencia, 122(3159),
108–111. https://doi.org/10.1126/science.122.3159.108,
PubMed: 14385826
garfield, mi. (1959). Letter to Dr. Joshua Lederberg, stanford
Universidad. Retrieved from https://www.garfield.library.upenn
.edu/lederberg/052159.html
garfield, mi. (1964). Can Citation Indexing be Automated? Reprinted
from M. mi. stevens, V. mi. Giuliano, & l. B. Heilprin (Editores.),
Statistical association methods for mechanized documentation,
symposium proceedings, Washington 1964 (páginas. 189–192).
National Bureau of Standards. Retrieved from https://www
.garfield.library.upenn.edu/essays/ V1p084y1962-73.pdf
garfield, mi. (1972). Citation analysis as a tool in journal evaluation:
Journals can be ranked by frequency and impact of citations for
science policy studies. Ciencia, 178(4060), 471–479. https://doi
.org/10.1126/science.178.4060.471, PubMed: 5079701
Greenberg, S. A. (2009). How citation distortions create unfounded
authority: Analysis of a citation network. BMJ, 339, b2680.
https://doi.org/10.1136/bmj.b2680, PubMed: 19622839
Halevi, GRAMO., & Schimming, l. (2018). An initiative to track senti-
ments in altmetrics. Journal of Altmetrics, 1(1), 2. https://doi.org
/10.29024/joa.1
Hassan, S. Ud., Imran, METRO., Iqbal, S., Aljohani, norte. r., & Nawaz, R.
(2018). Deep context of citations using machine-learning models
in scholarly full-text articles. cienciometria, 117(3), 1645–1662.
https://doi.org/10.1007/s11192-018-2944-y
Hirsch, j. mi. (2005). An index to quantify an individual’s scientific
research output. Actas de la Academia Nacional de
Ciencias, 102(46), 16569–16572. https://doi.org/10.1073/pnas
.0507655102, PubMed: 16275915
Honnibal, METRO., Montani, I., Honnibal, METRO., Peters, h., Samsonov, METRO.,
… Patel, A. (2018). Explosion/paCy: V2.0.11: Alpha Vietnamese
apoyo, fixes to vectors, improved errors and more. Zenodo.
https://doi.org/10.5281/ZENODO.1212304
Iniciativa para citas abiertas. (2017). https://i4oc.org/
Johnson, j. METRO., & Khoshgoftaar, t. METRO. (2019). Survey on deep learning
with class imbalance. Journal of Big Data, 6(1), 27. https://doi.org
/10.1186/s40537-019-0192-5
Landhuis, mi. (2016). Scientific literature: Information overload.
Naturaleza, 535(7612), 457–458. https://doi.org/10.1038/nj7612
-457a, PubMed: 27453968
Lehman, J., & Phelps, S. (2005). Shepardizing. In West’s encyclope-
dia of American law (2y ed., volumen. 9, pag. 162). Detroit: Thomson/
Gale.
Letrud, K., & Hernes, S. (2019). Affirmative citation bias in scientific
myth debunking: A three-in-one case study. MÁS UNO, 14(9),
e0222213. https://doi.org/10.1371/journal.pone.0222213,
PubMed: 31498834
Leung, PAG. t. METRO., macdonald, mi. METRO., Stanbrook, METRO. B., Dhalla, I. A.,
& Juurlink, D. norte. (2017). A 1980 letter on the risk of opioid
addiction. New England Journal of Medicine, 376(22), 2194–2195.
https://doi.org/10.1056/NEJMc1700150
Lo, K., Wang, l. l., Neumann, METRO., Kinney, r., & Weld, D. S.
(2020). S2ORC: The Semantic Scholar Open Research Corpus.
ArXiv:1911.02782 [Cs]. https://arxiv.org/abs/1911.02782
López, PAG. (2020a). GROBID [source code]. Retrieved from https://
github.com/kermitt2/grobid
Estudios de ciencias cuantitativas
897
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
saber: Un índice de citas inteligente
López, PAG. (2020b). Pub2TEI [source code]. Retrieved from https://
github.com/kermitt2/Pub2TEI
López, PAG. (2020C). biblio-glutton [source code]. Retrieved from
https://github.com/kermitt2/biblio-glutton
López, PAG. (2020d). delft [source code]. Retrieved from https://github
.com/kermitt2/delft
Murray, D., Lamers, w., Boyack, K., Larivière, v., & Sugimoto, C. R.
(2019). Measuring disagreement in science. 17th International
Conference on Scientometrics & Informetrics (páginas. 2370–2375).
September 2–5, 2019. Retrieved from https://crctcs.openum.ca
/files/sites/60/2019/10/ ISSI2019-measuring-disagreement-in
-science.pdf
Nakayama, h., Kubo, T., Kamura, J., Taniguchi, y., & Liang, X.
(2018). doccano: Text annotation tool for humans. https://github
.com/doccano/doccano
nicholson, j. METRO., Macedo, j. C., Mattingly, A. J., Wangsa, D.,
Camps, J., … Cimini, D. (2015). Chromosome mis-segregation
and cytokinesis failure in trisomic human cells. eVida, 4, e05068.
https://doi.org/10.7554/eLife.05068, PubMed: 25942454
nicholson, j. METRO., Uppala, A., Sieber, METRO., Grabitz, PAG., Mordiente, METRO.,
& Abundante, S. C. (2020). Measuring the quality of scientific references
in Wikipedia: An analysis of more than 115M citations to over
800 000 scientific articles. FEBS Journal, 288(14), 4242–4248.
https://doi.org/10.1111/febs.15608
Nizzoli, l., Avvenuti, METRO., Cresci, S., & Tesconi, METRO. (2019).
Extremist propaganda tweet classification with deep learning in
realistic scenarios. Proceedings of the 10th ACM Conference on
Web Science – WebSci ’19 (páginas. 203–204). https://doi.org/10
.1145/3292522.3326050
peroni, S., & Shotton, D. (2012). FaBiO and CiTO: Ontologies for
describing bibliographic resources and citations. Journal of Web
Semántica, 17, 33–43. https://doi.org/10.1016/j.websem.2012
.08.001
peroni, S., & Shotton, D. (2020). OpenCitations, an infrastructure
organization for open scholarship. Estudios de ciencias cuantitativas,
1(1), 428–444. https://doi.org/10.1162/qss_a_00023
Peters, METRO. MI., Neumann, METRO., Iyyer, METRO., jardinero, METRO., clark, C., …
Zettlemoyer, l. (2018). Deep contextualized word representations.
En Actas de la 2018 Conference of the North American
Chapter of the Association for Computational Linguistics: Humano
Language Technologies, Volumen 1 (Artículos largos) (páginas. 2227–2237).
Asociación de Lingüística Computacional. https://doi.org/10.18653
/v1/N18-1202
Phan, k. l., Fitzgerald, D. A., Nathan, PAG. J., & Tancer, METRO. mi. (2006).
Association between amygdala hyperactivity to harsh faces and
severity of social anxiety in generalized social phobia. Biológico
Psiquiatría, 59(5), 424–429. https://doi.org/10.1016/j.biopsych
.2005.08.012, PubMed: 16256956
Cervecero, h., Principal, J., & Orr, R. (2019). The future of OA: Un gran-
scale analysis projecting Open Access publication and reader-
barco [Preprint]. Scientific Communication and Education.
https://doi.org/10.1101/795310
PLOS. (2015). Rich_citations [source code]. Retrieved from https://
github.com/PLOS/rich_citations
Portero, J., & Jick, h. (1980). Addiction rare in patients treated with
narcotics. New England Journal of Medicine, 302(2), 123. https://
doi.org/10.1056/NEJM198001103020221
Pride, D., Knoth, PAG., & Harag, j. (2019). ACT: An annotation platform
for citation typing at scale. 2019 ACM/IEEE Joint Conference on
Digital Libraries ( JCDL) (páginas. 329–330). https://doi.org/10.1109
/JCDL.2019.00055
Schneider, J., S.M, D., Colina, A. METRO., & Whitehorn, A. S. (2020). Continuado
post-retraction citation of a fraudulent clinical trial report, 11 años
after it was retracted for falsifying data. cienciometria, 125(3),
2877–2913. https://doi.org/10.1007/s11192-020-03631-1
piedra, METRO. B., Goldin, PAG. r., Sareen, J., Zorrilla, l. T., & Marrón, GRAMO. GRAMO.
(2002). Increased amygdala activation to angry and contemptu-
ous faces in generalized social phobia. Archives of General
Psiquiatría, 59, 1027–1034. https://doi.org/10.1001/archpsyc.59
.11.1027, PubMed: 12418936
piedra, METRO. B., Simmons, A. NORTE., Feinstein, j. S., & Paulus, METRO. PAG. (2007).
Increased amygdala and insula activation during emotion pro-
cessing in anxiety-prone subjects. Revista americana de psiquiatría,
164(2), 318–327. https://doi.org/10.1176/ajp.2007.164.2.318
Suelzer, mi. METRO., Deal, J., Hanus, k. l., Ruggeri, B., Sieracki, r., &
Witkowski, mi. (2019). Assessment of citations of the retracted
article by Wakefield et al with fraudulent claims of an association
between vaccination and autism. JAMA Network Open, 2(11),
e1915552. https://doi.org/10.1001/jamanetworkopen.2019
.15552, PubMed: 31730183
Teufel, S., Siddharthan, A., & Tidhar, D. (2006). Automatic classifica-
tion of citation function. Actas de la 2006 Conferencia sobre
Empirical Methods in Natural Language Processing (páginas. 103–110).
https://doi.org/10.3115/1610075.1610091
Tkaczyk, D., collins, A., Sheridan, PAG., & Beel, j. (2018). Machine
learning vs. rules and out-of-the-box vs. retrained: An evaluation
of open-source bibliographic reference and citation parsers.
ArXiv:1802.01168 [Cs]. https://arxiv.org/abs/1802.01168.
https://doi.org/10.1145/3197026.3197048
Viganó, C., von Schubert, C., Ahrné, MI., Schmidt, A., Lorber, T., …
Nigg, mi. A. (2018). Quantitative proteomic and phosphoproteo-
mic comparison of human colon cancer DLD-1 cells differing in
ploidy and chromosome stability. Molecular Biology of the Cell,
29(9), 1031–1047. https://doi.org/10.1091/mbc.E17-10-0577,
PubMed: 29496963
Volanakis, A., & Krawczyk, k. (2018). SciRide Finder: A citation-based
paradigm in biomedical literature search. Informes Científicos, 8(1),
6193. https://doi.org/10.1038/s41598-018-24571-0, PubMed:
29670147
Wakefield, A., Murch, S., Antonio, A., Linnell, J., Casson, D., …
Walker-Smith, j. (1998). RETRACTED: Ileal-lymphoid-nodular
hyperplasia, non-specific colitis, and pervasive developmental
disorder in children. The Lancet, 351(9103), 637–641. https://
doi.org/10.1016/S0140-6736(97)11096-0, PubMed: 9500320
Wang, l. l., Lo, K., Chandrasekhar, y., Reas, r., Cual, J., Burdick,
D., … Kohlmeier, S. (2020). CORD-19: The COVID-19 Open
Research Dataset. ArXiv:2004.10706 [Cs]. https://arxiv.org/abs
/2004.10706
Ware, METRO., & Mabe, METRO. (2015). The STM Report: An overview of scien-
tific and scholarly journal publishing, pag. 181. The Hague: Internacional
Association of Scientific, Technical and Medical Publishers.
yan, MI., Chen, Z., & li, k. (2020). The relationship between journal
citation impact and citation sentiment: A study of 32 millón
citances in PubMed Central. Estudios de ciencias cuantitativas, 1(2),
664–674. https://doi.org/10.1162/qss_a_00040
Yousif, A., Niu, Z., Tarus, j. K., & Ahmad, A. (2019). A survey on sen-
timent analysis of scientific citations. Artificial Intelligence Review,
52(3), 1805–1838. https://doi.org/10.1007/s10462-017-9597-8
Estudios de ciencias cuantitativas
898
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
2
3
8
8
2
1
9
7
0
7
4
0
q
s
s
_
a
_
0
0
1
4
6
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3