ARTÍCULO DE INVESTIGACIÓN
Large-scale identification and characterization
of scholars on Twitter
Rodrigo Costas1,2
, Philippe Mongeon1,3
, Márcia R. Ferreira1,4,5
,
Jeroen van Honk1
, and Thomas Franssen1
1Centre for Science and Technology Studies (CWTS), Universidad de Leiden, Leiden (Los países bajos)
2Centre for Research on Evaluation, Science and Technology (CREST), Stellenbosch University, Stellenbosch (South Africa)
3Centre for Studies in Research and Research Policy (CFA), Aarhus University, Aarhus (Dinamarca)
4Complexity Science Hub Vienna, Viena (Austria)
5Institute of Information Systems Engineering, Vienna University of Technology, Viena (Austria)
Palabras clave: altmetrics, bibliometría, individual scholars, redes sociales, Twitter
ABSTRACTO
This paper presents a new method for identifying scholars who have a Twitter account from
bibliometric data from Web of Science ( WoS) and Twitter data from Altmetric.com. El
method reliably identifies matches between Twitter accounts and scholarly authors. It consists
of a matching of elements such as author names, usernames, handles, and URLs, followed by a
rule-based scoring system that weights the common occurrence of these elements related to
the activities of Twitter users and scholars. The method proceeds by matching the Twitter
accounts against a database of millions of disambiguated bibliographic profiles from WoS.
This paper describes the implementation and validation of the matching method, and performs
verification through precision-recall analysis. We also explore the geographical, disciplinary,
and demographic variations in the distribution of scholars matched to a Twitter account. Este
approach represents a step forward in the development of more advanced forms of social
media studies of science by opening up an important door for studying the interactions
between science and social media in general, and for studying the activities of scholars on
Twitter in particular.
1.
INTRODUCCIÓN
Social media have become important for scholarly communication and dissemination. Ellos
provide researchers the opportunity to make their work widely accessible, share information
with peers, and monitor the visibility of their work (Veletsianos, 2012). Popular social media
tools include Twitter and Facebook. For academics, specific tools that include a social net-
working component are ResearchGate, Mendeley, and Academia.edu (Sugimoto, Work,
et al., 2017). Some estimates indicate, por ejemplo, that approximately 21.5% of papers from
2012 indexed in Web of Science ( WoS) with a DOI have received at least one mention on
Twitter (Haustein, costas, & Larivière, 2015). Tracking and investigating social media men-
tions of scholarly articles as well as their relationship have become known as “alternative met-
rics” or altmetrics. Social media metrics have also been proposed as potentially
complementary to traditional bibliometric indicators, such as citations (p.ej., Principal &
Costello, 2010). Sin embargo, the correlations between social media indicators and bibliometric
indicators have consistently been found to be low (costas, Zahedi, & Wouters, 2015b;
un acceso abierto
diario
Citación: costas, r., Mongeon, PAG.,
Ferreira, METRO. r., van Honk, J., &
Franssen, t. (2020). Large-scale
identification and characterization of
scholars on Twitter. Quantitative
Science Studies, 1(2), 771–791. https://
doi.org/10.1162/qss_a_00047
DOI:
https://doi.org/10.1162/qss_a_00047
Recibió: 02 Octubre 2019
Aceptado: 14 Enero 2020
Autor correspondiente:
Rodrigo Costas
rcostas@cwts.leidenuniv.nl
Editor de manejo:
Staša Milojević
Derechos de autor: © 2020 Rodrigo Costas,
Philippe Mongeon, Márcia R. Ferreira,
Jeroen van Honk, and Thomas
Franssen. Published under a Creative
Commons Attribution 4.0 Internacional
(CC POR 4.0) licencia.
La prensa del MIT
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Haustein, Peters, et al., 2014; Thelwall, Haustein, et al., 2013), suggesting that social media
indicators measure an additional dimension of scholarly workflows closer to public commu-
nication, socialization, networking, and engagement with wider audiences, rather than scien-
tific impact in the narrow sense.
Despite attracting much attention, few studies have provided a comprehensive portrait of
scholars active on social media because there is no database that links scholarly authors to
their corresponding Twitter accounts, which is essential to our understanding of the use of
social media in scholarly communication. Como resultado, the demographics, scientific fields,
and geographical locations of the institutions of scholarly authors on Twitter remain poorly
comprendido (Ke, Ahn, & Sugimoto, 2016).
Recientemente, scholars have started to reconceptualize the analysis of social media activity of
research authors as part of an ambitious research agenda to study in more depth the relation-
ship between social media and scholarly entities, in what has been termed the “social media
studies of science” (costas, 2017; Wouters, Zahedi, & costas, 2019). This new perspective
aims at understanding the added value of social media interactions to the scholarly workflow,
in particular as part of communication and dissemination practices as well as network forma-
ción, rather than focusing on mere indicator development. Of particular interest is Twitter, a
popular microblogging platform that provides a means for users to communicate through short
280 character messages known as tweets. On Twitter, users are able to “follow” each other on
the platform, and thus receive notifications of their tweets, search tweets by keywords or hash-
tags, or link to other media or tweets (Sugimoto et al., 2017). Altmetric.com records the fre-
quency with which a DOI (and other scholarly outputs identifiers such as PubMed-IDs) de un
scientific article are mentioned on Twitter. The platform also collects Twitter metadata such as
user account information (p.ej., Twitter handle, username, user description, or geographical
ubicación) whenever the users have tweeted, retweeted, or mentioned a scientific article.
Many of these accounts can be linked to academic user accounts such as those of scholars,
academic institutions, and journals. The Altmetric.com database therefore offers a unique
opportunity to identify scholars with a Twitter account at a large scale.
Earlier studies matching author-level bibliometric information to Twitter user-level informa-
tion were carried out using labor-intensive approaches, such as self-identification through
surveys (collins, Shiffman, & Rock, 2016; Rowlands, Nicholas, et al., 2011; Van Noorden,
2014), or through manual verification (p.ej., Haustein, Bowman, et al., 2014; Holmberg &
Thelwall, 2014; Hwong, Oliver, et al., 2016; Lulic & Kovic, 2013; Veletsianos, 2012).
Although these studies have provided important insights into the use of Twitter by scholars
in different contexts (p.ej., conferences, educational settings, sharing preprints and publica-
ciones), limited response rates (in the case of survey research) and time-consuming manual ap-
proaches have resulted in data sets of matched authors and Twitter users that represent only a
very small fraction of the overall universe of scholars on Twitter. A few notable exceptions are
Ke et al. (2016) and Hadgu and Jäschke (2014), who used Twitter lists and conference hash-
tags, respectivamente, to identify scholars and classify similar users connected to an initial set of
seed Twitter users. Despite these approaches being automated and successful in identifying
large numbers of scholars (45,000 y 38,000 Twitter accounts respectively) on Twitter, ellos
fully rely on self-reported evidence of a user identifying as a scholar, and favor more estab-
lished scholars who are also more likely to be included in Twitter lists.
Respectivamente, the purpose of this study is to identify Twitter accounts belonging to scholars
among millions of disambiguated authors recorded in the WoS database in a fully automated
way. Al hacerlo, this paper fills a significant gap left by previous studies that depend primarily
Estudios de ciencias cuantitativas
772
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
l
a
r
gramo
mi
–
s
C
a
yo
mi
i
d
mi
norte
t
i
F
i
C
a
t
i
oh
norte
a
norte
d
C
h
a
r
a
C
t
mi
r
i
z
a
t
i
oh
norte
oh
F
s
C
h
oh
yo
a
r
s
oh
norte
t
w
i
t
t
mi
r
on manual techniques and surveys, or are limited to one scientific field. To the best of the
authors’ knowledge, no previous studies have matched Twitter accounts with scholarly biblio-
metric profiles using publications in the WoS on a large scale, as is done here. Además, este
paper also provides a more comprehensive portrait of scholars on Twitter by first creating a
large-scale data set of matched Twitter accounts with WoS authors corresponding to the
same individual, and then by characterizing these scholars on the basis of their field, aca-
demic age, country, y género. The unique connection between bibliographic data and
Twitter data opens up the possibility of studying not only the Twitter activities of scholars,
but also their scholarly activities (as captured by bibliometric analyses) (costas, 2017;
Wouters et al., 2019).
This paper is organized as follows. Sección 2 presents an overview of the literature related to
matching procedures between authors of papers indexed in the WoS database and Twitter
accounts. Sección 3 describes the matching approach, its implementation, and validation.
The results are presented in Section 4, accompanied by an empirical analysis of research au-
thors on Twitter by field, género, country, and academic age. En la sección 5 the paper draws
conclusions about our approach and discusses the method’s limitations as well as plans for
investigación futura.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
1.1. The Communication Context of Scholars on Twitter
Twitter use by scholars has been studied in various contexts, such as the sharing of scholarly
outputs on Twitter and how scholars use Twitter to develop and maintain their professional
redes. As governments and funding agencies are increasingly taking an interest in a broader
view of impact (Dinsmore, allen, & Dolby, 2014), the use of Twitter and the recording of this in
altmetric indicators are sometimes perceived as being of value in this context (El & Mishra,
2014; Principal, Cervecero, & Hemminger, 2012; Principal, Taraborelli, et al., 2010). The general pres-
ence of mentions of scholarly outputs is found to vary across different scientific disciplines
(costas, Zahedi, & Wouters, 2015a; Haustein et al., 2014; Holmberg & Thelwall, 2014), indi-
cating the existence of different thematic interests of research topics among Twitter users or
differences in the use of Twitter among different scholarly communities.
The use of Twitter by scholars shows some distinct patterns. Por ejemplo, scholars tend to
share more links and retweet more than the average Twitter user (Holmberg & Thelwall, 2014).
Recent studies have also shown that Twitter users who present themselves with academic and
scholarly terms also tend to have a stronger focus and engagement with scientific topics on
Twitter (Díaz-Faes, Bowman, & costas, 2019). Across personal and professional tweets, el
use of technological social media “affordances” on Twitter has been shown to vary based
on department, género, academic age, edad, and Twitter activity (Bowman, 2015). In a study
of Twitter accounts, it was reported that users who tweet academic articles describe them-
selves by emphasizing their occupational expertise (Vainio & Holmberg, 2017). While aca-
demic tweeters provide their full name and professional identity in their account
descripciones (Bowman, 2015; Chretien, Azar, & Kind, 2011; Hadgu & Jäschke, 2014), un gran
share of their activity is personal as opposed to professional (Bowman, 2015; Haustein et al.,
2014; Van Noorden, 2014).
When using Twitter for professional purposes, scholars discuss research-related topics and
communicate with others in the field (Van Noorden, 2014). Scholarly tweets tend to contain
links to both recent journal articles (Eysenbach, 2011; Holmberg & Thelwall, 2014; Principal &
Costello, 2010) and blogs (Letierce, Passant, et al., 2010; Principal & Costello, 2010). El contenido
of these tweets tends to be limited to the title, or part of the title of the scientific article being
Estudios de ciencias cuantitativas
773
l
a
r
gramo
mi
–
s
C
a
yo
mi
i
d
mi
norte
t
i
F
i
C
a
t
i
oh
norte
a
norte
d
C
h
a
r
a
C
t
mi
r
i
z
a
t
i
oh
norte
oh
F
s
C
h
oh
yo
a
r
s
oh
norte
t
w
i
t
t
mi
r
tweeted (Friedrich, Bowman, et al., 2015; Thelwall et al., 2013) and the level of engagement of
Twitter users with the content of publications, in terms of discussing particular details, is gen-
erally low (Robinson-Garcia, costas, et al., 2017). The use of Twitter, sin embargo, does have
effects on the dissemination of scientific papers. According to Ortega (2016), articles authored
by Twitter users are more tweeted than those of non-Twitter users. Además, the number of
followers on Twitter is found to indirectly influence the citation impact (Ortega, 2016).
1.2. Methods for Identifying Scientists on Twitter
Earlier research has studied the use of Twitter among different scientific disciplines (Holmberg
& Thelwall, 2014). The most commonly used method to identify scientists on Twitter is the
manual identification of scientists’ Twitter accounts. Veletsianos (2012) used snowball sam-
pling with an initial set of four Twitter accounts with 2,000 followers or more. He then exam-
ined these followers to identify other scholars with at least 2,000 followers, resulting in a total
sample of 46 Twitter accounts. Similarmente, Lulic and Kovic (2013) identificado 672 emergency
physicians on Twitter using a keyword, manually validating the results, and examining the
followers to identify other physicians. Holmberg and Thelwall (2014) first used the WoS da-
tabase to identify the top 10 most productive scholars for 10 disciplines, searched for these
individuals on Twitter, and complemented this data set with a keyword search and a snowball
sampling method as per Veletsianos (2012) and Lulic and Kovic (2013). Their data set com-
prised 477 Twitter accounts. Hwong et al. (2016) manually identified 60 actively maintained
Twitter accounts about space science. Past studies have also used surveys to study the Twitter
uptake and activity of scientists (p.ej., Rowlands et al., 2011; Van Noorden, 2014; Collins et al.,
2016). These methods for identifying scientists on Twitter have some important limitations.
The first is that the sample is limited by their reliance on manual selection of Twitter accounts
or on self-reported information, and the second is their relatively small scale.
Twitter lists (curated groups of Twitter accounts created by Twitter users and to which other
users can subscribe) have also been used to identify the Twitter accounts belonging to specific
groups of users (sharma, Ghosh, et al., 2012). Similarmente, Ke et al. (2016) used Twitter lists to
collect a set of 45,867 Twitter accounts belonging to scientists. The authors collected Twitter
accounts with a scientific occupation (p.ej., psychologist, economist, PhD, researcher) en el
Twitter biographies, which were part of lists that also contained a scientific occupation in their
account description. Another popular method is the use of conference hashtags or Twitter ac-
cuenta. Hadgu and Jäschke (2014) have been especially successful in this regard; they used the
Twitter accounts and hashtags of 98 computer science conferences to identify 38,368 Twitter
accounts. To identify scholars in Education, Veletsianos and Kimmons (2016) retrieved tweets
with the #aera14 hashtag. They identified 1,629 users and, after manual verification, retained
el 232 graduate students and 237 professors for their study. ross, Terras, et al. (2011) used the
hashtags of three conferences in digital humanities to identify 326 Twitter accounts. Compared
with a manual approach, these methods can identify larger sets of Twitter accounts belonging
to scholars. Sin embargo, such methods can only tell us whether a Twitter account belongs to a
scholar or not. The analyses they enable are restricted to the Twitter activities of the identified
eruditos, and they do not provide any linkage to any other features of the scholars, which is the
purpose of the present paper.
By way of summary, given the smaller scope of past methods, based on relatively small sets
of scholars and Twitter accounts, they can be seen as poorly suited for large-scale analyses of
the scientists’ Twitter activity. A second important limitation is that these methods fail to sub-
stantially connect the Twitter information identified with scientometric and demographic
Estudios de ciencias cuantitativas
774
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
l
a
r
gramo
mi
–
s
C
a
yo
mi
i
d
mi
norte
t
i
F
i
C
a
t
i
oh
norte
a
norte
d
C
h
a
r
a
C
t
mi
r
i
z
a
t
i
oh
norte
oh
F
s
C
h
oh
yo
a
r
s
oh
norte
t
w
i
t
t
mi
r
information about scholars (p.ej., publicaciones, citas, countries, affiliations, género, disci-
plines), thus limiting these studies to the analysis of Twitter activities only.
Respectivamente, the main objective of this paper is to introduce a new method to identify in-
dividual scholars on Twitter using data from the WoS database and Twitter data obtained from
Altmetric.com. The method has three main distinctive features:
1. The matching is data driven and automatic, and is thus less labor-intensive than other
2.
3.
methods and better suited for large-scale studies.
It uses various metadata elements available in the WoS database and Altmetric.com
records, facilitating the identification of a larger number of scholars on Twitter than
estudios previos.
It connects two different realms of activity in which a scholar might be active: scholarly
publishing and social media activities.
2. DATA SET AND METHODS
2.1. Data Sources
To match Twitter accounts with scholarly authors we use two data sources: the WoS-database
and the Altmetric.com database. We use the author-name disambiguation algorithm devel-
oped by Caron and Van Eck (2014) and applied to the WoS database, resulting in a set of
25,352,720 disambiguated authors with at least one publication after 2004. We extracted
todo 4,117,887 distinct Twitter accounts that have tweeted at least one DOI up to October
2017 from the Altmetric.com database.
2.2.
Identifying Possible Names of Twitter Users
Altmetric.com records three metadata fields with Twitter data related to the names of the users.
The first is the full name field, which is an optional free text field with a maximum length of 50
characters that has no restrictions on the characters used. It may not always contain the actual
name of the user and, if it does, the name can be entered in any format. We also used the
Twitter handle field, which is limited to 15 alphanumeric characters or underscores. Puede
be less likely to contain the actual name of the user, but the character set restriction can help
in cases where the users’ names are usually in a language that does not use the Roman alpha-
bet (p.ej., Arábica, Chino, and Japanese). Finalmente, when the URL field1 contains a Facebook.
com or Academia.edu URL, we extracted the part of the URL that potentially contains the
user’s name.
For each Twitter account, we created a list all of possible first names, last names, and initial(s).
After replacing all nonalphabetical characters with a space, we divided each string into distinct
componentes. Por ejemplo, “Robert J Smith” has three components: “Robert”, “J”, and “Smith”.
As the name can be concatenated (mostly in the handle or the URLs) we also parse the strings
using different uppercase and lowercase patterns. Por ejemplo, the string “RobertJSmith” is di-
vided into “Robert”, “J” and “Smith”. “RJSmith” is parsed in “R”, “J”, and “Smith”.
1 This is a field in Twitter accounts that allow users to indicate a website (p.ej., personal website, professional,
blogs, Facebook profiles, Research Gate profiles, ORCID profiles). Users can also add additional URLs in
their Twitter bios, but those URLs are not extracted or parsed.
Estudios de ciencias cuantitativas
775
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
l
a
r
gramo
mi
–
s
C
a
yo
mi
i
d
mi
norte
t
i
F
i
C
a
t
i
oh
norte
a
norte
d
C
h
a
r
a
C
t
mi
r
i
z
a
t
i
oh
norte
oh
F
s
C
h
oh
yo
a
r
s
oh
norte
t
w
i
t
t
mi
r
2.3. Matching Twitter Accounts with WoS Authors
We matched our list of names with the WoS authors’ data set using the last name and the first
initial, obtaining 1.06 billion potential matches. This means that the initial pairs of Twitter
accounts–authors must have at least a match in the last name and first initial.
Following Caron and Van Eck (2014), we use a rule-based scoring approach in which
scores are calculated (only for those pairs of Twitter accounts–authors that were matched in
the last name–first initial combination) using the information available in the Twitter account
and in the WoS records. Hay 14 normas, presented in Table 1, which can be divided into
five groups:
2.
1. Name matching rules (normas 1 a 4). These rules are based on the matches found be-
tween the authors’ names and the names extracted from the Twitter accounts. El
scores are weighted based on the frequency of the different parts of the names in
WoS2. The main rationale behind the scores is to weight uncommon names more
and common ones less, but also without allowing for a high score based on just one
of the name matching steps.
Institutional and geographical rules (normas 5 a 8). These rules are based on the matching
of different elements provided both by the authors in their papers (p.ej., affiliations,
countries, emails) and the Twitter accounts (URLs, Twitter name and Twitter handle,
and geographical or institutional information found in the Twitter accounts). The scores
are weighted based on the frequency of the different elements in WoS, using the same
method as for the name matching rules (normas 1 a 4). Among the rationales for the
choice of the scores is also to score the less common elements more highly, but again
without allowing for very high scores on just one of the institutional and geographical
normas.
3. Activity-related rules (normas 9 a 12). These are based on the publications, campos, y
journals of the authors and the publications tweeted by the Twitter account. The ratio-
nale is that the more a Twitter account has tweeted the papers of the matched author, o
papers from the research fields or journals in which the matched author has published,
the higher the chance that the author and the Twitter account are the same person.
Además, a pair is likely to be valid if a tweet contains both the handle of a
Twitter account and a link to a paper of the author matched with this Twitter account3.
These rules have the highest scores because they are expected to be more accurate than
names, institutions, y ubicaciones.
4. Name commonness rule (regla 13). If an author is only matched to one Twitter account,
the matching is weighted more positively than when the author is matched to multiple
Twitter accounts.
5. Best match rules (normas 14). We keep only the matches where the Twitter account was
the best match for the WoS author (highest score based on rule 0–13) y viceversa.
2 To calculate the weights in our methodology we have used an approach similar to the so-called
Characteristic Scores and Scales (CSS) (Glänzel & Schubert, 1988), which consists in partitioning skewed
distributions by using subsequent averages. De este modo, the first average partitions the distribution into two parts,
and the second average is calculated for the cases above the first average. Como resultado, elements can be
weighted based on whether they belong to the group below average, to the group between the first and
the second averages, and the third group above the second average. En mesa 1 we specify the specific
approaches and averages used for each rule that considers some weighting.
3 See an example here: https:// Twitter.com/wmijnhardt/status/781245999545212930.
Estudios de ciencias cuantitativas
776
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
l
a
r
gramo
mi
–
s
C
a
yo
mi
i
d
mi
norte
t
i
F
i
C
a
t
i
oh
norte
a
norte
d
C
h
a
r
a
C
t
mi
r
i
z
a
t
i
oh
norte
oh
F
s
C
h
oh
yo
a
r
s
oh
norte
t
w
i
t
t
mi
r
Mesa 1. Summary of the criteria and scores for the different elements matched
Rules
1
Matching event
Last name and initial
(es decir., author name, p.ej., “Costas, R”)
Criteria
Very common full name (es decir., full names that belong to the group of
the most common full names in the WoS disambiguated author
database as determined by the average of the distribution)
Score
1
2
First name
Common full name (es decir., full names that belong to the group of the
2
second least common full names in the WoS disambiguated author
database as determined by being between the two averages –
higher and lower – of the distribution)
Uncommon full name (es decir., full names that belong to the group of the
3
least common full names in the WoS disambiguated author
database as determined by being above the second average of the
distribución)
Very common first name (es decir., first names that belong to the group of
the most common first names in the WoS disambiguated author
database as determined by the average of the distribution)
Common first name (es decir., first names that belong to the group of the
second least common first names in the WoS disambiguated author
database as determined by being between the two averages –
higher and lower – of the distribution)
1
2
Uncommon first name (es decir., first names that belong to the group of the
3
least common first names in the WoS disambiguated author
database as determined by being above the second average of the
distribución)
3
First single name (in compound names,
Common first single name (es decir., first single names that belong to the
the first element of the name)
group of the most common first single names in the WoS
disambiguated author database as determined by being below the
average of the distribution)
Uncommon first name (es decir., first single names that belong to the group
of the least common first single names in the WoS disambiguated
author database as determined by being above the average of the
distribución)
4
5
First single name penalization
The author has a first name in the papers but it does not appear in the
Twitter name(s) at all4
Email URL (in the Twitter account
and as obtained from the email
server URL of the author)
Very common author URL (es decir., URLs that belong to the group of the
most common URLs in the Twitter database as determined by being
below the average of the distribution)
Common URL (es decir., URL that belongs to the group of the second least
common URLs in the Twitter database as determined by being
between the two averages – higher and lower – of the distribution)
Uncommon URL (es decir., URLs that belong to the group of the least
common URLs in the Twitter database as determined by being
above the second average of the distribution)
1
2
−2
1
2
3
4 We penalize when authors use their first name in their papers but use a different one (or none at all) en el
Twitter name.
Estudios de ciencias cuantitativas
777
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
l
a
r
gramo
mi
–
s
C
a
yo
mi
i
d
mi
norte
t
i
F
i
C
a
t
i
oh
norte
a
norte
d
C
h
a
r
a
C
t
mi
r
i
z
a
t
i
oh
norte
oh
F
s
C
h
oh
yo
a
r
s
oh
norte
t
w
i
t
t
mi
r
Rules
6
Matching event
Organization name (es decir., institutional
affiliations5 of the
disambiguated authors)
Mesa 1. (continued )
Criteria
Very common organization name (es decir., organization names that
belong to the group of the most common organization names in the
WoS disambiguated author database as determined by the average
of the distribution)
Common organization name (es decir., organization names that belong to
the group of the second least common organization names in the
WoS disambiguated author database as determined by being
between the two averages – higher and lower – of the distribution)
Uncommon organization name (es decir., organization names that belong
to the group of the least common organization names in the WoS
disambiguated author database as determined by being above the
second average of the distribution)
7
City (es decir., cities of the institutional
affiliations of the
disambiguated authors)
Very common city (es decir., cities that belong to the group of the most
common cities in the WoS disambiguated author database as
determined by the average of the distribution)
Common city (es decir., cities that belong to the group of the second least
common cities in the WoS disambiguated author database as
determined by being between the two averages – higher and lower –
of the distribution)
Uncommon city (es decir., cities that belong to the group of the least
common cities in the WoS disambiguated author database as
determined by being above the second average of the distribution)
8
Country (es decir., countries of the
institutional affiliations of the
disambiguated authors)
Common country (es decir., countries that belong to the group of the most
common countries in the WoS disambiguated author database as
determined by being below the average of the distribution)
Uncommon countries (es decir., countries that belong to the group of the
least common countries in the WoS disambiguated author database
as determined by being above the average of the distribution)
96
10
Tweeter has tweeted publications
from the author (es decir., self-tweeting)
Twitter user has tweeted publications
from the same micro topic(s)7
of author’s activity
(excluding self-tweeting)
Number of self-tweeted publications: 1–2
Number of self-tweeted publications: 3–5
Number of self-tweeted publications: >5
Number of overlapping topics tweeted: 1–3
Number of overlapping topics tweeted: 4–6
Number of overlapping topics tweeted: >6
Score
1
2
3
1
2
3
1
2
3
5
7
1
3
5
5 For each disambiguated author we considered the most common affiliation in which the author has pro-
duced most of their scientific output.
6 Weights for rules 9, 10, y 13 are not based on the CSS method but on rule of thumb choices.
7 Micro topics are defined as the fields obtained in the publication-level classification developed by Waltman
and Van Eck (2012).
Estudios de ciencias cuantitativas
778
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
l
a
r
gramo
mi
–
s
C
a
yo
mi
i
d
mi
norte
t
i
F
i
C
a
t
i
oh
norte
a
norte
d
C
h
a
r
a
C
t
mi
r
i
z
a
t
i
oh
norte
oh
F
s
C
h
oh
yo
a
r
s
oh
norte
t
w
i
t
t
mi
r
Matching event
Paired by co tweeted
Criteria
The tweeter has been mentioned in at least the same tweet with the
Score
5
Mesa 1. (continued )
Rules
11
12
13
Tweeter has tweeted publications
from the same journal(s) of author’s
actividad (excluding self-tweeting)
Commonness of the Twitter
account–researcher combination
paper of the author simultaneously
Number of overlapping journals tweeted: 1–5
Number of overlapping journals tweeted: >5
Combination of 1–2 scholars/Twitter
Combination of 3–6 scholars/Twitter
1
2
2
1
true/false
14
The Twitter account was the best match
for the WoS author (highest score based
on rules 0–13) y viceversa
Por ejemplo, if WoS author A is matched with Twitter account B with a score of 5. Este
is a best match only if A has no other match with a score greater than 5 and if B also has
no other match with a score greater than 5.
The matching procedure may produce ties (es decir., matches between a scholar and multiple
Twitter accounts and vice versa). De este modo, ties arise when a scholar is assigned to more than one
Twitter account with the same score, or when the same Twitter account is assigned to more
than one (disambiguated) scholar with the same score. Ties do not necessarily mean that some
of the tied pairs are invalid, because the disambiguation algorithm can sometimes split single
individuals into multiple authors; además, an individual scholar can genuinely have multiple
Twitter accounts. In the next two figures, we compare two data sets, one where we keep the
ties and one where we keep only pairs where the WoS author was a best match to a single
Twitter account and vice versa.
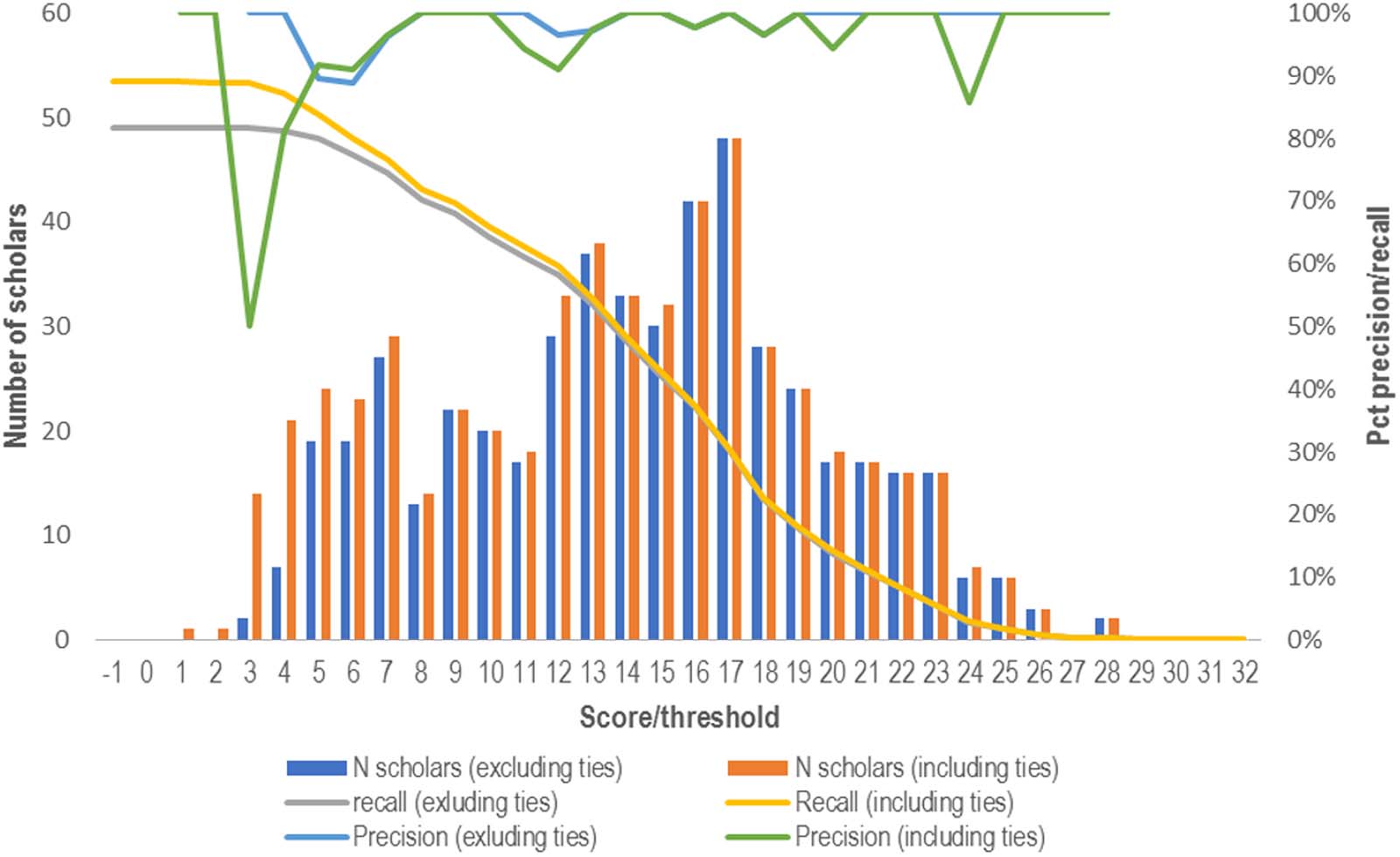
Cifra 1 presents the number of distinct scholars matched with a Twitter account for differ-
ent score thresholds for the two data sets. We notice that when including only matches with a
final score of 5 o superior, we find little difference between the data sets in terms of the number
of matches, but that below this threshold removing ties reduces the size of the data set signif-
icantly. De hecho, at a threshold score of 4, the cumulative number of scholars more than doubles
when we include ties, suggesting that a threshold below 5 may introduce a flood of false
positives.
2.3.1. Validación
We performed a precision–recall analysis using a “gold standard” of author–Twitter account
matches based on ORCID data from 2017 (Haak, Marrón, et al., 2016; Paglione, Peters, et al.,
2015). The golden set was created by following five steps:
1. Select all ORCID profiles that contain a Twitter handle from the public file of 2017.
2. Limit to Twitter handles that are found in the Altmetric.com data (es decir., Twitter users in
ORCID who have tweeted at least one paper).
3. Match the ORCID profiles with authors in the WoS database.
4. Manually verify the golden set to ensure that the Twitter handle included in the
ORCID profile is the actual scholar’s own Twitter account (es decir., removing those cases
Estudios de ciencias cuantitativas
779
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
l
a
r
gramo
mi
–
s
C
a
yo
mi
i
d
mi
norte
t
i
F
i
C
a
t
i
oh
norte
a
norte
d
C
h
a
r
a
C
t
mi
r
i
z
a
t
i
oh
norte
oh
F
s
C
h
oh
yo
a
r
s
oh
norte
t
w
i
t
t
mi
r
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 1. Number of distinct Twitter account-WoS author matches by score threshold and inclusion criteria.
in which scholars in ORCID report their group, departamento, or collective Twitter
accounts).
5. Remove the Twitter accounts that do not include the scholar’s name (either in the
Twitter handle or in the “name” field).
Como resultado, we obtain a set of 600 validated author–Twitter account pairs (550 distinto
eruditos) that we use to calculate the precision and recall of our method for different scores
and our two data sets.
Cifra 2 presents the number of scholars and the proportion of true positives (precisión) para
each score, as well as the recall for the cumulative set of scholars by score threshold of the
data set. As the results presented in Figure 1 suggested, the precision of the matching drops
significantly for scores below 5 when ties are included, suggesting a score of 5 as a reasonable
límite. At this score removing ties does not significantly affect precision but does reduce
recall significantly.
3. CHARACTERIZATION OF MATCHED SCHOLARS
3.1. Who Are the Scholars Sharing Papers on Twitter?
En esta sección, we present a descriptive analysis of 296,504 distinct scholars with at least one
publication since 2005 for whom we matched a Twitter account with a score greater than 4
and including ties. This choice was aimed at maximizing recall without compromising preci-
sion too much8.
8 Other choices could also be possible, depending on the purpose of the study. De este modo, studies that would
require a much higher level of precision in the selection of matched scholars would be possible, this being
achieved by selecting higher score values (and as a result reducing the set of matched scholars), and/or by
focusing only on those matches without ties. Apéndice 1 provides a breakdown of the number of matched
scholars that would be available depending on the choice decided.
Estudios de ciencias cuantitativas
780
l
a
r
gramo
mi
–
s
C
a
yo
mi
i
d
mi
norte
t
i
F
i
C
a
t
i
oh
norte
a
norte
d
C
h
a
r
a
C
t
mi
r
i
z
a
t
i
oh
norte
oh
F
s
C
h
oh
yo
a
r
s
oh
norte
t
w
i
t
t
mi
r
Cifra 2. Number of scholars and precision and recall for the cumulative set by score threshold.
We compare the distribution of scholars by country, discipline, academic age, number of
publicación, and gender to those distributions for the whole set of 25,352,720 disambiguated
authors in the WoS database with a publication since 2005. To check the robustness of our
análisis, we compared the results presented below with those obtained when excluding ties
(not shown). Although the proportions were slightly lower due to the reduced size of the data
colocar, we did not find any discrepancies between the two sets of results.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
3.2. Country
Cifra 3 compares the distribution by country of scholars on Twitter and of scholars in the
WoS database (see Table A2.1 in Appendix 2 for the proportion of scholars on Twitter by
country). The country of scholars is determined by their most common country derived from
the institutional affiliation(s) of each scholar as indicated in their publications. This is done not
only for the scholars matched to a Twitter account but also for those that are not matched, de este modo
allowing for homogeneous country-based comparisons among matched and not matched
investigadores.
The distribution is highly skewed, with more than 40% of the scholars active on Twitter
affiliated to an institution in the United States (26.6%) or the United Kingdom (15.1%). El
figure displays the proportion of scholars affiliated to each country in the WoS database. Este
shows which countries are over represented (p.ej., United States, Reino Unido, Canada,
Australia, España, and the Netherlands) or under represented (p.ej., Porcelana, Japón, and South
Korea) in the Twitter data set. The underrepresentation of China, Japón, and South Korea
can to some extent be explained by their use of different alphabets, which reduces our ability
to match them with WoS author names. In the case of China, this is exacerbated by the re-
strictions on Twitter in the country and the existence of local platforms comparable to Twitter,
such as Weibo (Zahedi & costas, 2017).
Estudios de ciencias cuantitativas
781
l
a
r
gramo
mi
–
s
C
a
yo
mi
i
d
mi
norte
t
i
F
i
C
a
t
i
oh
norte
a
norte
d
C
h
a
r
a
C
t
mi
r
i
z
a
t
i
oh
norte
oh
F
s
C
h
oh
yo
a
r
s
oh
norte
t
w
i
t
t
mi
r
Cifra 3. Relative frequency distribution of scholars in the WoS database, with and without a Twitter account, by country.
3.3. Discipline
Cifra 4 presents the relative frequency distributions for scholars on Twitter and the authors in
the WoS database by field (see Table A2.2 in Appendix 2 for the proportion of scholars on
Twitter by field). Individuals are assigned to one of the main fields used in the 2018 versión
of the Leiden Ranking based on their number of publications in each field, as in Larivière and
costas (2016). Sin embargo, a scholar with an equal number of publications in multiple fields is
assigned to each of these fields. Scholars without any publications classified in the Leiden
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
.
/
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 4. Relative frequency distribution of scholars in WoS with a Twitter account and overall by
campo.
Estudios de ciencias cuantitativas
782
l
a
r
gramo
mi
–
s
C
a
yo
mi
i
d
mi
norte
t
i
F
i
C
a
t
i
oh
norte
a
norte
d
C
h
a
r
a
C
t
mi
r
i
z
a
t
i
oh
norte
oh
F
s
C
h
oh
yo
a
r
s
oh
norte
t
w
i
t
t
mi
r
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
q
s
s
/
a
r
t
i
C
mi
–
pag
d
yo
F
/
/
/
/
1
2
7
7
1
1
8
8
5
9
0
6
q
s
s
_
a
_
0
0
0
4
7
pag
d
/
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
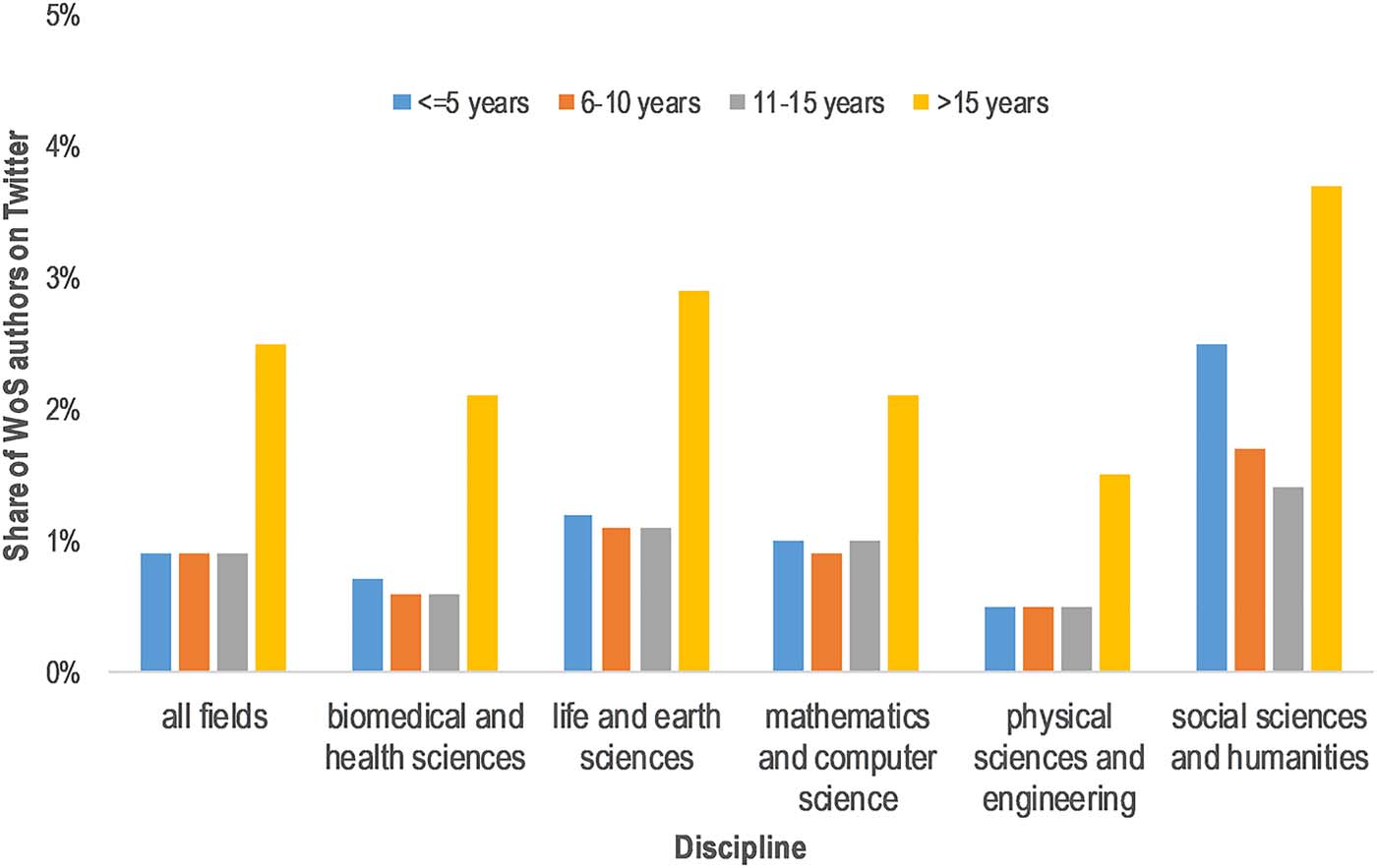
Cifra 5. Share of WoS authors with a Twitter account by discipline and academic age.
Ranking form the “Unknown” category. Results show that scholars from “Life and earth sci-
ences” and “Social sciences and humanities,” as well are those scholars that could not be as-
signed to a discipline, are overrepresented among those who share articles on Twitter.
Table A2.2 in Appendix 2 also confirms that a higher share of scholars from the “Social sci-
ences and humanities” and “Life and earth sciences” use Twitter, while “Physical sciences and
engineering” is the field with the lowest Twitter uptake.
3.4. Academic Age
Cifra 5 presents the share of scholars found on Twitter by discipline and academic age, usando
the year of first publication as a proxy for academic age (costas, Nane, & Larivière, 2015) y
subtracting the year of first publication from 2018, thus obtaining the number of years of ac-
tivity of the scholars matched on Twitter. In all fields, the older group (>15 years) has the larg-
est share of scholars found on Twitter. There is little difference between the other academic
age groups, except in “Social science and humanities,” where we observe a greater Twitter
uptake among academically younger scholars (<5 years). These results are, however, to be
interpreted with caution, as older scholars also tend have more publications in the WoS.
This may influence matching, because output are likely be
linked their Twitter account due scoring rules (particularly 9, 10, and 12) that
rely on number of scholars, well bigger chances having addi-
tional metadata elements, such email first names.
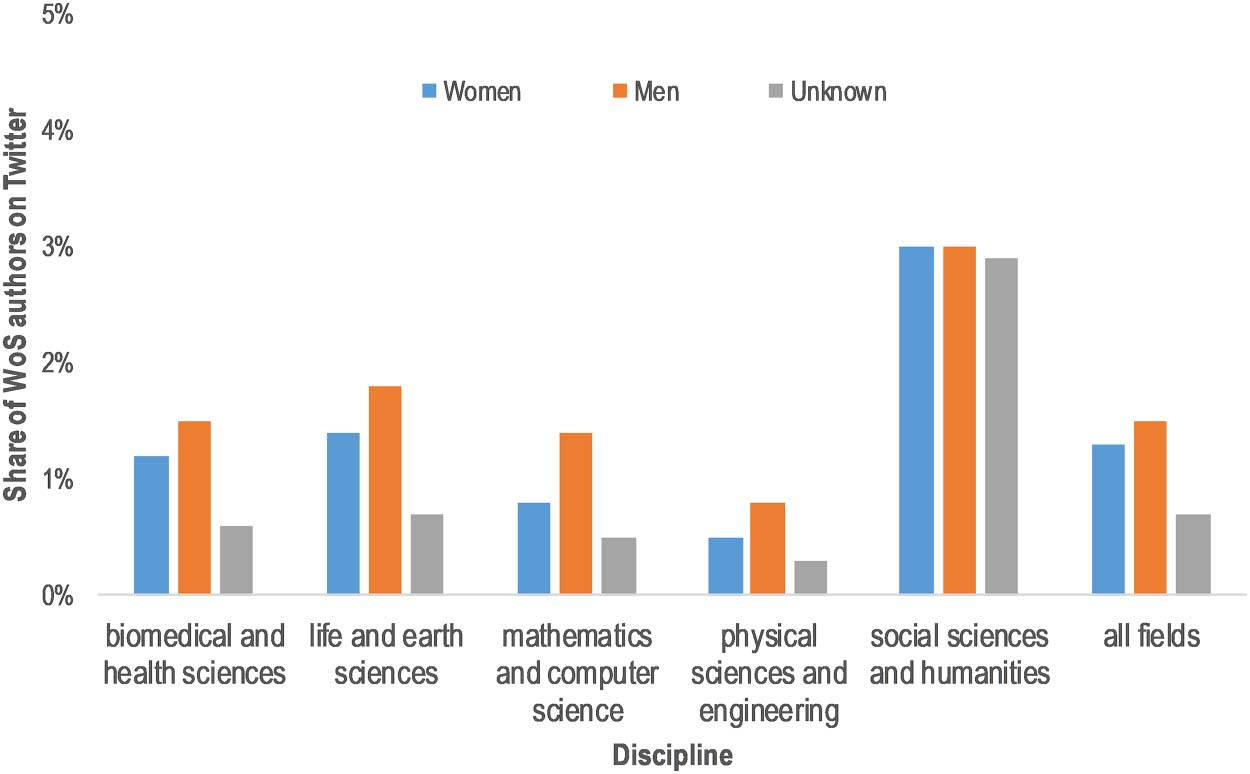
3.5. Gender
Figure 6 presents share WoS authors found by gender9 discipline. In all
fields, we find that men slightly than women be Twitter. Overall, see
that about 1.5% 1.3% overall numbers disambiguated male researchers on
Twitter, respectively.
9 Gender has been defined combining data names from Larivière, Ni, et al. (2013) data
obtained https:>