INFORME
Speech Segmentation and Cross-Situational
Word Learning in Parallel
Rodrigo Dal Ben1
Débora de Hollanda Souza1
, Isabella Toselli Prequero1,
, and Jessica F. Hay2
un acceso abierto
diario
Palabras clave: statistical learning, speech segmentation, cross-situational word learning, word learning
1Universidade Federal de São Carlos, São Carlos, São Paulo, Brasil
2University of Tennessee, Knoxville, Knoxville, TN, EE.UU
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
.
/
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
ABSTRACTO
Language learners track conditional probabilities to find words in continuous speech and to
map words and objects across ambiguous contexts. It remains unclear, sin embargo, si
learners can leverage the structure of the linguistic input to do both tasks at the same time. A
explore this question, we combined speech segmentation and cross-situational word learning
into a single task. In Experiment 1, when adults (norte = 60) simultaneously segmented continuous
speech and mapped the newly segmented words to objects, they demonstrated better
performance than when either task was performed alone. Sin embargo, when the speech stream
had conflicting statistics, participants were able to correctly map words to objects, but were at
chance level on speech segmentation. In Experiment 2, we used a more sensitive speech
segmentation measure to find that adults (norte = 35), exposed to the same conflicting speech
stream, correctly identified non-words as such, but were still unable to discriminate between
words and part-words. De nuevo, mapping was above chance. Our study suggests that learners
can track multiple sources of statistical information to find and map words to objects in noisy
entornos. It also prompts questions on how to effectively measure the knowledge arising
from these learning experiences.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
INTRODUCCIÓN
Learning a new language requires mastering several complex tasks. Las investigaciones han demostrado que
language learners can use statistical cues from their linguistic environment to overcome some
of these challenges. Por ejemplo, learners can track conditional probabilities between sylla-
bles to discover words from continuous speech and between words and objects to learn the
meaning of novel words across ambiguous situations. The present study explores how tracking
conditional probabilities in audiovisual input may help learners to solve both tasks simulta-
neously. We combine two well established statistical learning tasks—speech segmentation
(p.ej., Romberg & Saffran, 2010; Saffran et al., 1996) and cross-situational word learning
(p.ej., Herrero & Yu, 2008; Yu & Herrero, 2007)—into a single paradigm.
Faced with continuous speech and only a few words in isolation (∼10%; Brent & Siskind,
2001), one of the crucial challenges for language learners is to segment streams of words into
discrete units. Conditional probabilities between syllables (es decir., transitional probabilities; Krogh
et al., 2013; Romberg & Saffran, 2010; Saffran et al., 1996) provide one cue that aids segmen-
tation (for evidence of other cues, see Hay & Saffran, 2012; Johnson et al., 2014). In natural
Citación: Dal Ben, r., Prequero, I. T.,
Souza, D. de H., & Hay, j. F. (2023).
Speech Segmentation and Cross-
Situational Word Learning in Parallel.
Mente abierta: Discoveries in Cognitive
Ciencia, 7, 510–533. https://doi.org/10
.1162/opmi_a_00095
DOI:
https://doi.org/10.1162/opmi_a_00095
Recibió: 6 Julio 2023
Aceptado: 6 Julio 2023
Conflicto de intereses: Los autores
declare no conflict of interests.
Autor correspondiente:
Rodrigo Dal Ben
dalbenwork@gmail.com
Derechos de autor: © 2023
Instituto de Tecnología de Massachusetts
Publicado bajo Creative Commons
Atribución 4.0 Internacional
(CC POR 4.0) licencia
La prensa del MIT
Segmentation and Word Learning Dal Ben et al.
speech, syllables that form words tend to have higher likelihood of co-occurrence (más alto
Transitional Probabilities, TPs) in comparison to syllables across word boundaries (Swingley,
1999; but see Yang, 2004), which provides a potential cue to segmentation. Por ejemplo, en
the sequence pretty#baby the TP of pre to ty is greater than the TP of ty to ba, this difference in
TP could signal a word boundary for learners (Saffran et al., 1996). There is now a vast empirical
literature showing that language learners can track differences in TPs across syllable sequences
to segment continuous speech into discrete words (for reviews see Cannistraci et al., 2019;
Cunillera & Guilera, 2018; but see Black & Bergmann, 2017). The experimental task in these
studies usually starts by familiarizing participants with a continuous speech stream in which TP
is the main cue to word boundaries. Por ejemplo, some syllables always occur together
(creating a word), sometimes occur together (creating a part-word or a low TP word), o
never occur together (creating a non-word). Following familiarization, participants’ preferences
for words, part-words, or non-words are measured. By and large participants differentiate words
from foils (part-words or non-words), suggesting that they successfully tracked TP information to
find words in the continuous speech stream.
Phonotactic probability (PÁGINAS), the conditional probability of a syllable occurring in a given
position of a word from a given language ( Vitevitch & Luce, 2004), is another statistical cue to
word boundaries (Benitez & Saffran, 2021; Mattys & Jusczyk, 2001; Mattys et al., 1999). Para
instancia, in the same sound sequence pretty#baby, the English PPs1 of the words pretty and
baby are comparable (≈ 0.0440, ≈ 0.0050, respectivamente) and both are higher than the PP of
the part-word ty#ba (≈ 0.0022), which could signal word boundaries to language learners. El
combined information of TPs and PPs can promote—when both cues point to word
boundaries—or impair speech segmentation—when they provide conflicting information
about word boundaries. Evidence suggests that this happens when TP is combined with legal
versus illegal PPs (Finn & Hudson Kam, 2008), with high versus low PPs (Mersad & Nazzi,
2011), and even with subtle differences in high PPs (Dal Ben et al., 2021). In previous work,
we argued that careful consideration of phonotactics from participants’ natural languages
should be an integral part of the stimuli design of statistical speech segmentation studies
(Dal Ben et al., 2021). This is especially true when studying adults, who will promptly bring
their extensive learning history and expectations from their natural languages’ PPs to the
experimental task (Steber & Rossi, 2020; Sundara et al., 2022).
Assigning meaning to words is another challenge for language learners. There is evidence
eso, early in development, recently segmented words (with stronger TPs) are treated as better
candidate labels on subsequent mapping tasks (Graf Estes et al., 2007; Hay et al., 2011). Mientras
the benefit of high TP sequences during word learning appears to diminish across develop-
mento (Mirman et al., 2008; Shoaib et al., 2018), learners continue to be remarkably successful
both at segmenting speech using TP information (Saffran et al., 1996; but see Black &
Bergmann, 2017) and at making one-to-one mappings between labels and referents (Graf
Estes, 2009; Graf Estes et al., 2007; Lany & Saffran, 2010). Además, a lo largo de la vida,
language learners rely on phonotactics from their natural languages when learning novel
palabras, with words with stronger PPs being learned faster and more accurately than words with
weaker PPs (Graf Estes et al., 2011; Storkel et al., 2013; but see Cristia 2018). Sin embargo, este
might not be true when learning novel words in ambiguous situations (Dal Ben et al., 2022).
In everyday life, several words are presented with several potential referents at the same
tiempo, creating ambiguous learning experiences (Quine, 1960). A growing empirical literature
1 Phonotactic probabilities calculated using Vitevitch and Luce (2004) online calculator.
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
511
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
.
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
shows that learners can track word-object co-occurrences across ambiguous situations to find
the meaning of words (for a recent meta-analysis, see Dal Ben et al., 2019; but see Smith et al.,
2014). The experimental task in these studies usually familiarizes participants with a series of
ambiguous trials. On each trial, two (or more) words are presented with two (or more) objects.
On any given trial, there is insufficient information to solve the ambiguity. Sin embargo, if partic-
ipants compare word-object conditional probabilities across trials, word-object relations can
be learned2 (Herrero & Yu, 2008; Yu & Herrero, 2007).
The evidence that statistical information can promote both speech segmentation and cross-
situational word learning prompts the question of whether these processes unfold in sequence
or in parallel. Related evidence for the latter is reported by Cunillera, Laine, et al. (2010).
Adults were familiarized with a continuous speech stream and, at the same time, with a stream
of objects. When the first word was being played, its corresponding object was displayed on
the screen; when the second word started, its corresponding object replaced the previous one,
Etcétera. From this dynamic presentation, participants were able to segment words from
the continuous speech and to map them to its corresponding objects in parallel. Además, en
a follow-up study, François et al. (2017) replicated the findings and showed neurophysiolog-
ical markers for online simultaneous speech segmentation and mapping. Although these stud-
ies have shown that segmentation and mapping can happen in parallel (see also Shukla et al.,
2011 for a related task with infants), both used non-ambiguous word learning tasks.
Intuitivamente, adding mapping ambiguity could make the simultaneous task too challenging.
Sin embargo, Yurovsky et al. (2012) have shown that adults can simultaneously segment labels
from phrases and map them to objects across ambiguous presentations. Using an adaptation
of the cross-situational word learning paradigm ( Yu & Herrero, 2007), adults were exposed to
scenes with two novel objects. On each trial, they would see only one object and hear a
sentence that included a word labeling it among other function words. When the position
and the onset of labels in the sentences matched the patterns of their natural language (es decir.,
final position, label preceded by a small set of words), participants were able to segment the
labels and to map them to objects. Despite the additional demands that ambiguity might
impose, the authors argued that the parallel solution of segmentation and mapping might hap-
pen in continuous iterations, as even partial speech segmentation would reduce mapping
ambiguity and vice-versa (for similar evidence with multilingual adults see Tachakourt,
2023; for related evidence with other linguistic cues, see Feldman, Griffiths, et al., 2013;
Feldman, miers, et al., 2013). This is in line with proposals by Räsänen and Rasilo (2015).
In a comprehensive combination of computational simulations and reanalyses of empirical
datos, the authors argue that tracking cross-modal conditional probabilities between words
and objects in ambiguous situations may boost both speech perception and word learning,
in comparison to tracking only TPs or word-object co-occurrences (for a similar argument,
see Jones et al., 2010). Además, recent meta-analytic findings show that infants effectively
integrate audio and visual information, from a variety of sources, when learning language (p.ej.,
Cox et al., 2022; but see Frank et al., 2007, Johnson & tyler, 2010, and Thiessen, 2010 para
potential limits of this integration).
Here we further explore whether the integration of transitional probabilities, phonotactic
probabilities, and word-object co-occurrences would promote speech segmentation and word
2 Here we do not join the productive debate between hypothesis-testing and aggregation as learning mech-
anisms for cross-situational word learning (p.ej., Yurovsky & Franco, 2015), as we believe it is beyond the scope of
nuestro estudio.
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
512
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
.
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
learning across ambiguous presentations. Our study is guided by three main questions. Primero,
we ask whether words can be segmented and mapped at the same time across dynamic
ambiguous presentations. To answer this question, we adapted the design by Cunillera, Laine,
et al. (2010) to combine a speech stream with several new objects in an ambiguous fashion.
Segundo, we ask whether phonotactic properties of our stimuli would impact speech segmen-
tation and cross-situational word learning in parallel. Answering this question allows us to bet-
ter understand how multiple linguistic statistics can be combined when learning novel words
across ambiguous situations (Saffran, 2020; Smith et al., 2018). Tercero, we ask whether this joint
task would improve segmentation and mapping in comparison to separate tasks. To answer
this question, we compared our current findings to data from our previous studies testing
speech segmentation (Dal Ben et al., 2021) and cross-situational word learning (Dal Ben
et al., 2022) separately, but using the same stimuli (same TP and phonotactic properties)
and population.
EXPERIMENT 1
To investigate whether words can be segmented and mapped simultaneously and whether dif-
ferences in phonotactics would impact this joint performance, we exposed participants to con-
tinuous speech streams with varying distributions of phonotactics and TPs. Al mismo tiempo,
we also presented them with a series of objects, two at a time, that corresponded to the words
in the speech streams. críticamente, one of the languages had TPs and phonotactics aligned,
consistently pointing to word boundaries. In another language, words and part-words had
balanced phonotactics, with TPs being the only informative statistic to word boundaries. En
a third language, TPs and phonotactics were in conflict: TPs pointed to word boundaries
and phonotactic information pointed to syllables within-words (part-words).
To investigate whether the joint task would improve segmentation and mapping in compar-
ison to separate tasks, we compared segmentation and mapping performance in the present
combined task with performance in the individual tasks (es decir., speech segmentation only and
cross-situational word learning only; Dal Ben et al., 2021, 2022, respectivamente).
Método
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
.
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
/
.
i
Participantes. Sixty native Brazilian-Portuguese-speaking adults (Mage = 21.37 años, ± 3.27
Dakota del Sur, 32 femenino) participó. None of the participants reported any visual or auditory impair-
ments that could interfere with the task. Participants were recruited online at the official Face-
book group of Universidade Federal de São Carlos, where data was collected. They received
no compensation for their in-person participation. The study was conducted according to the
Declaration of Helsinki and the Ethics Committee of the host university approved the research
(#1.484.847). Participants were randomly assigned to one of three groups.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Stimuli and Design
Auditory Stimuli. Three frequency-balanced languages from Dal Ben et al. (2021) were used
(ver tabla 1). Each language contained six statistically defined disyllabic pseudo-words
(TP = 1), which served as labels in our task. Test words and part-words in all Languages were
frequency balanced (Aslin et al., 1998). In each language, half of the words were repeated
300 veces (labeled H on Table 1) and the other half were repeated 150 veces (labeled L on
Mesa 1). The recombination of syllables from the words with higher frequency generated three
part-words, used during test phase, that had lower TPs (TP = 0.5), but that were balanced in
frequency with the test words (150 repetitions each; Aslin et al., 1998).
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
513
Segmentation and Word Learning Dal Ben et al.
Mesa 1. Words and Part-words (grapheme and IPA) and their Phonotactic Probabilities (PP+ or PP−) and Frequency (High or Low) para el
Balanced, and Aligned, Conflict Languages
Idioma
Balanced
Aligned
Conflicto
Words
Familiarization
PÁGINAS
H+
[sute]
sute
viko
bara
nipe
tadi
[viko]
[baʁa]
[nipe]
[tad͡ʒi]
mide
[mide]
dini
deta
[d͡ʒini]
[deta]
pemi
[pemi]
sute
viko
bara
teba
kosu
ravi
nipe
tadi
[sute]
[viko]
[baʁa]
[teba]
[kosu]
[ʁavi]
[nipe]
[tad͡ʒi]
mide
[mide]
H+
H+
H−
H−
H−
H+
H+
H+
H+
H+
H+
H−
H−
H−
H−
H−
H−
Words
nipe
tadi
[nipe]
[tad͡ʒi]
mide
[mide]
sute
viko
bara
[sute]
[viko]
[baʁa]
nipe
tadi
[nipe]
[tad͡ʒi]
mide
[mide]
PÁGINAS
H−
H−
H−
H+
H+
H+
H−
H−
H−
TP
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0
Prueba
Part-words
teba
kosu
ravi
[teba]
[kosu]
[ʁavi]
nipe
tadi
[nipe]
[tad͡ʒi]
mide
[mide]
sute
viko
bara
[sute]
[viko]
[baʁa]
PÁGINAS
H−
H−
H−
H−
H−
H−
H+
H+
H+
TP
0.5
0.5
0.5
0.5
0.5
0.5
0.5
0.5
0.5
Freq
h
h
h
l
l
l
h
h
h
l
l
l
h
h
h
l
l
l
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
.
/
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Además, all words and part-words had legal and high phonotactic probabilities in
Brazilian-Portuguese. Following previous research (Dal Ben et al., 2021), we decided to use
only syllable sequences with high phonotactics (instead of legal vs. illegal or high vs. bajo; Finn
& Hudson Kam, 2008; Mersad & Nazzi 2011) so that all syllable sequences would be phono-
tactically plausible in the participants’ native language. Sin embargo, some syllable sequences
had higher phonotactic probability than others (Mesa 1, PP+ or PP−). Phonotactics were cal-
culated using Vitevitch and Luce’s (2004) algorithm and Estivalet and Meunier (2015) database
of Brazilian-Portuguese biphones. Brevemente, we divided the sum of the log (base 10) of token
frequency of each biphone on each word position by the total log frequency of words with
biphones in that given position (p.ej., /mæ/ in the third biphone divided by the total log fre-
quency of all words with at least three biphones). Entonces, using a custom search engine, nosotros
created six novel disyllabic words with consonant–vowel structure (CVCV) and with the high-
est possible phonotactic probability before becoming actual words in Brazilian-Portuguese
(labeled PP+; Mesa 1). Por último, we recombined their biphones to create six other novel words
that had slightly less probable, but still high, phonotactic probabilities (labeled PP−; Mesa 1).
For a full description of the phonotactic calculations, see Dal Ben et al. (2021) and Vitevitch
and Luce (2004).
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
514
Segmentation and Word Learning Dal Ben et al.
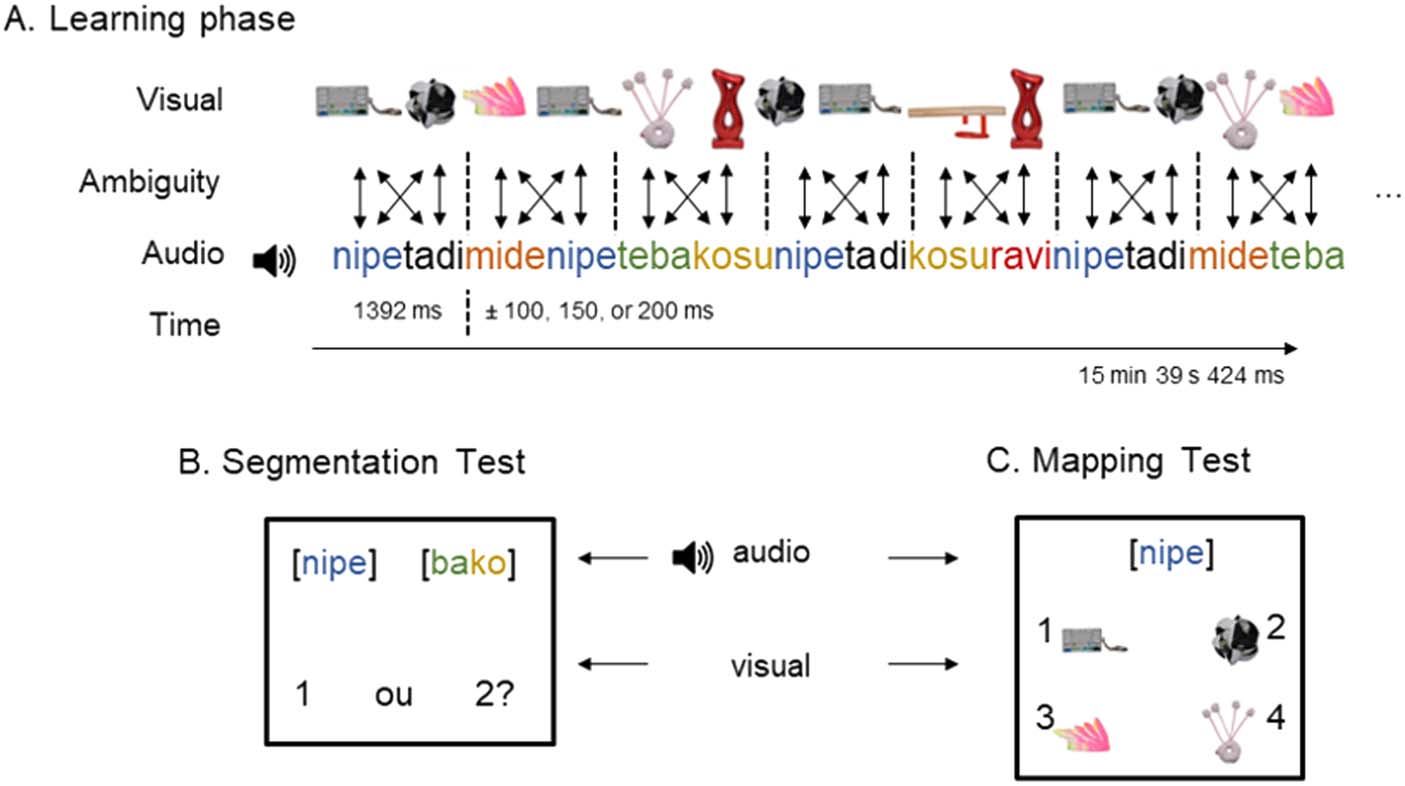
(A) Displays the Familiarization phase, with dynamic trials combining the continuous
Cifra 1.
speech stream with two objects at a time. (B) Displays a trial of the speech segmentation test (two-
alternative forced-choice). (C) Displays a trial of the mapping test (four-alternative forced-choice).
Languages were synthesized using the MBROLA speech synthesizer with a Portuguese
female voice3 (Dutoit et al., 1996). Prosodic cues were minimized by setting the pitch constant
en 180 Hz, the intensity at 77 dB, and the duration of each word to 696 EM (cf. Cunillera,
Laine, et al., 2010). The total duration of each language was 15 mín. 39 s and 424 EM.
Following our previous studies, TPs and phonotactics were combined to create three lan-
calibres. The Balanced language had test words (TP = 1.0) and part-words (TP = 0.5) with bal-
anced phonotactic probabilities (Mwords = 0.0072, Mpart-words = 0.0075; Mesa 1); this language
served as a control. The Aligned language had test words with higher phonotactic probabilities
in comparison to part-words (Mwords = 0.0085, Mpart-words = 0.0072; Mesa 1). De este modo, both TPs
and phonotactics signaled word boundaries. Finalmente, in the Conflict language: test words had
lower phonotactic probabilities in comparison to part-words (Mwords = 0.0072, Mpart-words =
0.0085; Mesa 1). De este modo, TPs highlighted word boundaries whereas phonotactics highlighted
part-words.
Visual Stimuli. Six novel objects, used by Dal Ben et al. (2022), were also used in the present
experimento. They were realistic, colorful, 3D objects that are part of the NOUN object base
(Horst & Hout, 2016) and were chosen based on their high degree of novelty (m = 77%) y
discriminability (m = 90%). For each language, objects and words were randomly paired,
forming six word-object pairs. All stimuli are openly available at https://osf.io/rs2bm/.
Diseño. Our paradigm (Cifra 1) was an adaptation of Cunillera, Laine, et al. (2010) and com-
bined speech segmentation and cross-situational word learning in the same task. It had two
phases: familiarization and test. During familiarization, one of the languages (Balanced,
Aligned, Conflicto) was played while objects were displayed on the computer screen. Nosotros
matched words from the speech stream and objects on the screen in such a way that, en
any given time, two objects were displayed while their corresponding words were presented
(ffi 1392 EM; Cifra 1). Por ejemplo, when the first word was first presented, the objects
3 We used the MBROLA database br4 (available at: https://github.com/numediart/ MBROLA-voices).
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
515
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
.
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
/
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
corresponding to the first and second words were displayed; when the third word was played,
the first two objects were replaced by two other objects and so on. This created a highly
dynamic adaptation of the classic 2 × 2 cross-situational word learning arrangement (for a
video sample, see https://osf.io/rs2bm/; cf. Herrero & Yu, 2008). En tono rimbombante, the onset and offset
of the words and objects were desynchronized (± 100, ± 150, or ± 200 EM) to avoid additional
cues to speech segmentation (Cunillera, Càmara, et al., 2010). Además, the entire audio
stream had a fade-in and fade-out effect of 500 ms to minimize cues for the initial and final
words’ boundaries. Finalmente, to minimize fatigue from this extensive exposure (a total of 1350
word-object presentations, o 675 2 × 2 “trials”, over ffi 15 minutos), we divided the familiar-
ization into five blocks. Each block had 270 word-object presentations—60 for each high
frequency word-object pair and 30 for each low frequency pair—and lasted a little over
3 minutos. Between blocks, participants were given a 5-second pause on a screen displaying
the task progress (p.ej., “Block 2 of 5”).
Following familiarization, two tests were performed, always in the same order: segmenta-
tion and mapping. The segmentation test followed a two-alternative forced-choice structure.
On each trial, a frequency-balanced word (es decir., a low frequency word, TP = 1, 150 repetitions)
and a part-word (TP = 0.5, 150 repetitions) were played with a pause of 500 ms between them.
Participants were prompted to indicate which one was a word from the speech stream they
had just heard. The order of presentation of words and part-words was counterbalanced across
ensayos. Each of the three low frequency words were tested six times across 18 test trials, con
each word being tested against each part-word twice4.
The mapping test followed a four-alternative forced-choice structure. Each trial began with
four objects displayed in the corners of the screen: one target object (co-occurrence probabil-
ity = 1 with target word) and three distractors (co-occurrence probability = 0.2 with target
palabra). Después 1 segundo, a target word was played and participants were prompted to select
the matching object. Each of the 6 word-object pairs (3 high frequency words and 3 low fre-
quency words) were tested twice across 12 ensayos.
Procedimiento. The experiment was conducted in a sound-attenuated room and was computer
administered using Psychopy2 (Peirce et al., 2019). Auditory stimuli were played on high-
definition neutral headphones (AKG K240 powered by Fiio e10K dac/amp). All responses were
entered on an adapted numeric keyboard with only the keys: 1, 2, 3, 4, Return, +, and − (a
increase or decrease the audio volume). At the beginning of the experiment, music with the
same intensity as the experimental stimuli (77 dB) was played and participants were instructed
to adjust the volume to a comfortable level.
Próximo, they were instructed that they would hear a new language and see new objects and
that their task was to discover which words corresponded to which objects. Following famil-
iarization, they were tested on segmentation and mapping. The first two trials of each testing
phase were warm-up trials used to familiarize participants with the structure of the tasks. Para
ejemplo, before the segmentation test trials began, participants were presented with two prac-
tice trials with a common word from Brazilian-Portuguese versus a nonsense word (p.ej., pato
[duck] vs. tafi). Similarmente, before the mapping test trials began, participants were presented with
two practice trials during which they heard a familiar word and were presented with 4 familiar
4 The decision to test each word six times was based on our previous investigation of speech segmentation
solo (Dal Ben et al., 2021). Whereas this number of repetitions is higher in comparison to similar studies (p.ej.,
Cunillera, Laine, et al., 2010; François et al., 2017), follow-up analyses revealed that trial number did not pre-
dict performance on neither Experiment 1 nor 2. Full analysis available at: https://osf.io/rs2bm/.
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
516
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
.
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
objects (p.ej., “pato” + picture of a duck, house, cat, ball). Además, after each test phase,
participants were asked to estimate their performance by indicating if the percentage of correct
responses was between 0–25%, 25–50%, 50–75%, or 75–100%. Participants’ compliance to
instructions was continuously assessed using a CCTV system. At the end, Participantes
answered a questionnaire about their educational background and language abilities.
Análisis de los datos. After excluding inattentive responses, defined as test trials with reaction times
greater than 3 SDs away from the mean (segmentation: 15 ensayos, 1% of the data; mapping: 17
ensayos, 2% of the data), we fitted mixed-effects logistic regressions using the lme4 package for R
(Bates et al., 2015; R Core Team, 2021) and Spearmans’ correlations, also in R, to explore
speech segmentation performance, cross-situational word learning performance, relaciones
between them, and self-evaluation. Specific models, resultados, and predictors are described
in the next section. Given the exploratory nature of our investigation, we report effect size
estimations and confidence intervals, but not p-values (Scheel et al., 2021). All scripts and data
are openly available at https://osf.io/rs2bm/.
Results and Discussion
Speech Segmentation. To analyze speech segmentation performance, our mixed-effects logistic
regression had selection of the target word (either correct or incorrect) as our outcome variable
and chance level (logit of 0.5) and language (Balanced, Aligned, Conflicto, respectivamente) as pre-
dictor variables. Our initial model had a maximal random structure with stimuli as random
slopes and participants as random intercepts5 (Barr et al., 2013), but this model did not con-
verge. We then pruned it to include only random intercepts for stimuli and participants6.
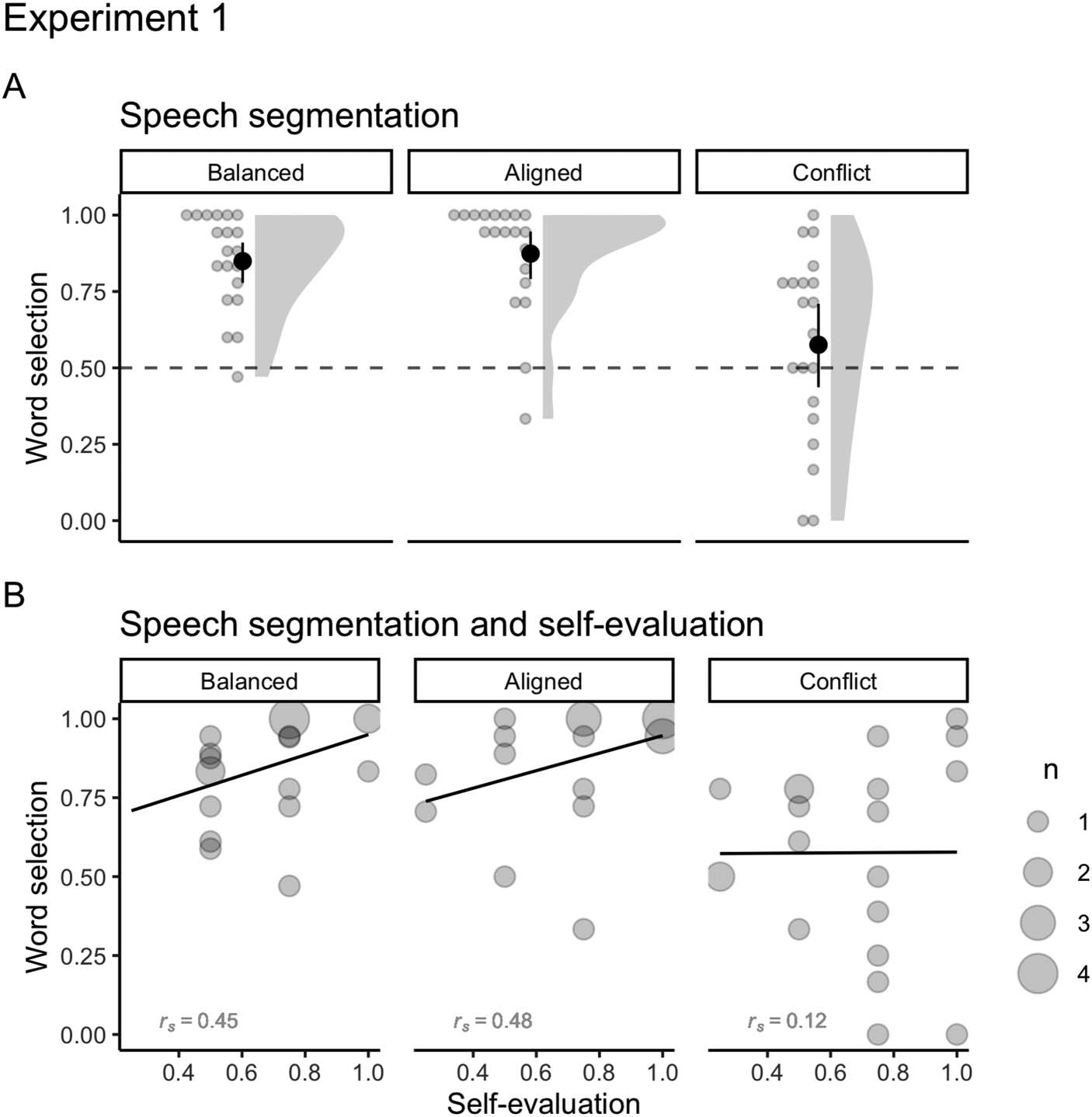
Participants from the Balanced language were much more likely to select the words over
the part-words at test (Odds Ratio = 10.95, 95% CI [4.19, 28.57]7; m = 0.85, DE = 0.16;
Cifra 2). Participants from the Aligned language, in which both TP and phonotactic proba-
bility pointed to word boundaries, were even more likely to select words over part-words
(change in OR = 1.61, 95% CI [0.41, 6.27]; m = 0.87, DE = 0.18). Por otro lado, par-
ticipants from the Conflict language, in which TP and phonotactic probabilities worked against
entre sí, were equally likely to select words and part-words (change in OR = 0.13, 95% CI
[0.04, 0.42]; m = 0.57, DE = 0.3). These results are in line with our previous findings that
adults not only track both TP and PP at the same time, but that these statistics can be combined
to improve (es decir., Aligned language) or impair (es decir., Conflict language) speech segmentation (Dal
Ben et al., 2021).
Además, segmentation performance and self-evaluation (Cifra 2) were positively cor-
related for the Balanced (rs = 0.45) and Aligned (rs = 0.48) idiomas, but not for the Conflict
idioma (rs = 0.12). This suggests that being exposed to a continuous speech in which TPs
and PPs were either aligned or balanced within words formed clearer word representations,
which allowed participants to estimate their knowledge of the words more accurately from the
speech.
To explore whether our joint task impacts speech segmentation, we compared the present
data with data from a previous investigation testing speech segmentation only (Dal Ben et al.,
2021). Because we used the exact same languages as previous studies, we fit separate
5 lme4 syntax: selection ∼ chance level + idioma + (estímulos|partícipe).
6 lme4 syntax: selection ∼ chance level + idioma + (1|estímulos) + (1|partícipe).
7 Regression tables are available at https://osf.io/rs2bm/.
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
517
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
.
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
.
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
(A) Mean number of correct word selections for Balanced (m = 0.84, DE = 0.15), Aligned
Cifra 2.
(m = 0.87, DE = 0.18), and Conflict (m = 0.57, DE = 0.3) languages on segmentation test of
Experimento 1. Solid points represent the overall mean, error bars represent 95% CIs (non-parametric
bootstrap). Points represent the mean for each participant. Shaded areas depict the distribution of
individual responses. The dashed line displays the chance level (0.5). Grupo B: Correlations between
segmentation and self-evaluation (upper panel; rs Balanced = 0.45; rs Aligned = 0.48; rs Conflict = 0.12)
for Balanced, Aligned, and Conflict languages on Experiment 1. The size of dots indicates the
number of participants that overlap in given coordinates (de 1 a 4).
mixed-effects logistic regressions8 for each language (Balanced, Aligned, Conflicto), teniendo
the selection of target words (correct or incorrect) as our outcome variable, experimento
(segmentation only or simultaneous task) as a predictor variable, and participants as random
intercepts.
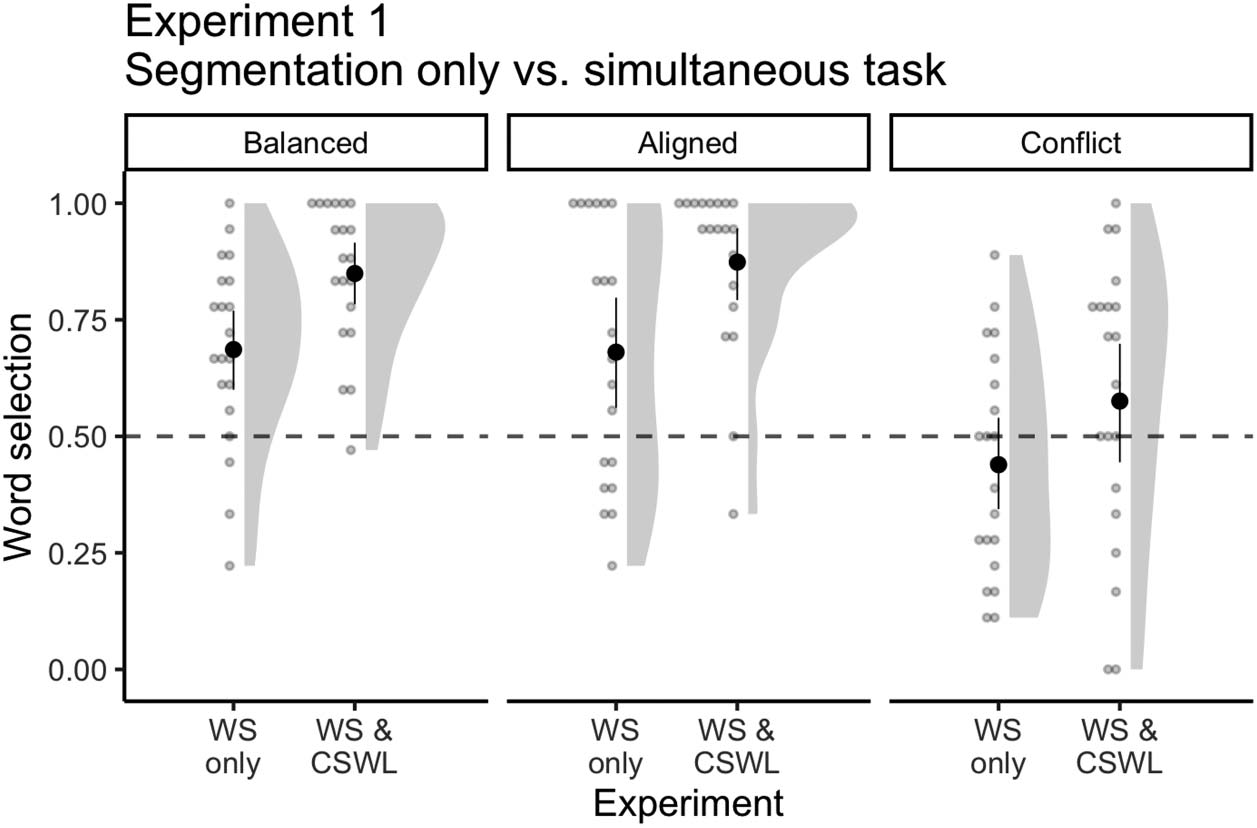
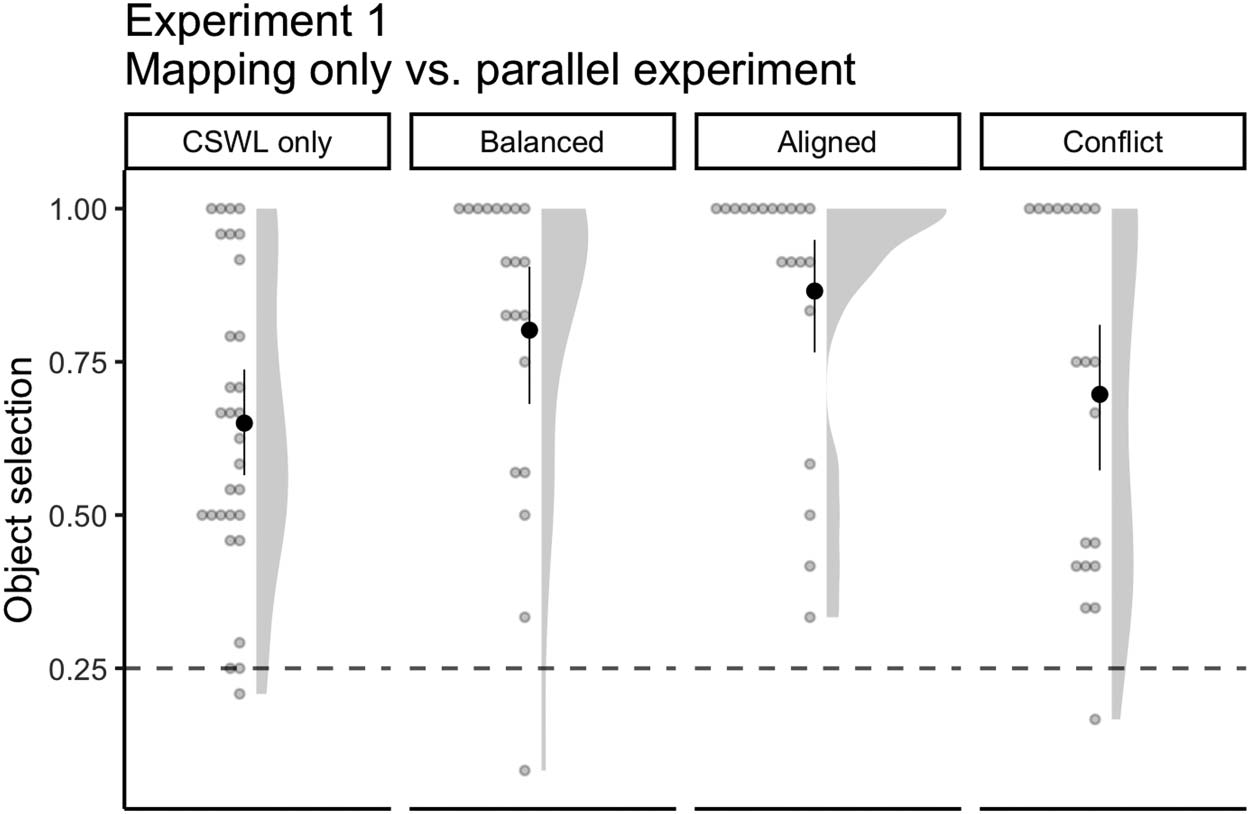
For the Balanced language, participants in the simultaneous task were approximately three
times more likely to choose the target word compared to the separate task (change in OR =
3.21, 95% CI [1.50, 6.88]; Cifra 3). The difference was even higher for the Aligned language,
participants from the simultaneous task were almost five times more likely to make correct
selections in comparison to the separate task (change in OR = 4.93, 95% CI [1.34, 18.16]).
Por otro lado, in the Conflict language, although participants in the simultaneous task still
8 lm4 syntax for each language: word selection ∼ experiment + (1|partícipe).
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
518
Segmentation and Word Learning Dal Ben et al.
Cifra 3. Mean number of correct word selections for Balanced (separate: m = 0.68, DE = 0.2;
simultaneous: m = 0.84, DE = 0.15), Aligned (separate: m = 0.68, DE = 0.27; simultaneous: m =
0.87, DE = 0.18), and Conflict (separate: m = 0.43, DE = 0.23; simultaneous: m = 0.57, DE = 0.3)
languages for an experiment testing speech segmentation only ( WS only; Dal Ben et al., 2021)
and on our current simultaneous task ( WS & CSWL). Solid points represent the overall mean,
error bars represent 95% CIs (non-parametric bootstrap). Points represent the mean for each partic-
ipant. Shaded areas depict the distribution of individual responses. Dashed line displays the chance
nivel (0.5).
outperformed participants from the separate task, the improvement was much less pronounced
(change in OR = 1.96, 95% CI [0.83, 4.64]).
These results show that adults will use any statistic available–phonetic and audiovisual co-
occurrences–to find words in continuous speech. Además, the improvement in segmentation
in our current task indicates that adults benefit from tracking multiple statistical sources. Este
provides initial empirical support for the model proposed by Räsänen and Rasilo (2015) and is
in line with recent research on language development in natural environments (Clerkin et al.,
2017; Smith et al., 2018; Yu et al., 2021).
Cross-situational Word Learning. To analyze cross-situational word learning, our mixed-effects
logistic regression9 had selection of the target object (either correct or incorrect) como el
outcome variable, chance level (logit of 0.25), idioma (Balanced, Aligned, Conflicto, respetar-
activamente), the frequency of word-object pairs (low or high), and their interaction as predictor
variables, and stimuli and participants as random intercepts.
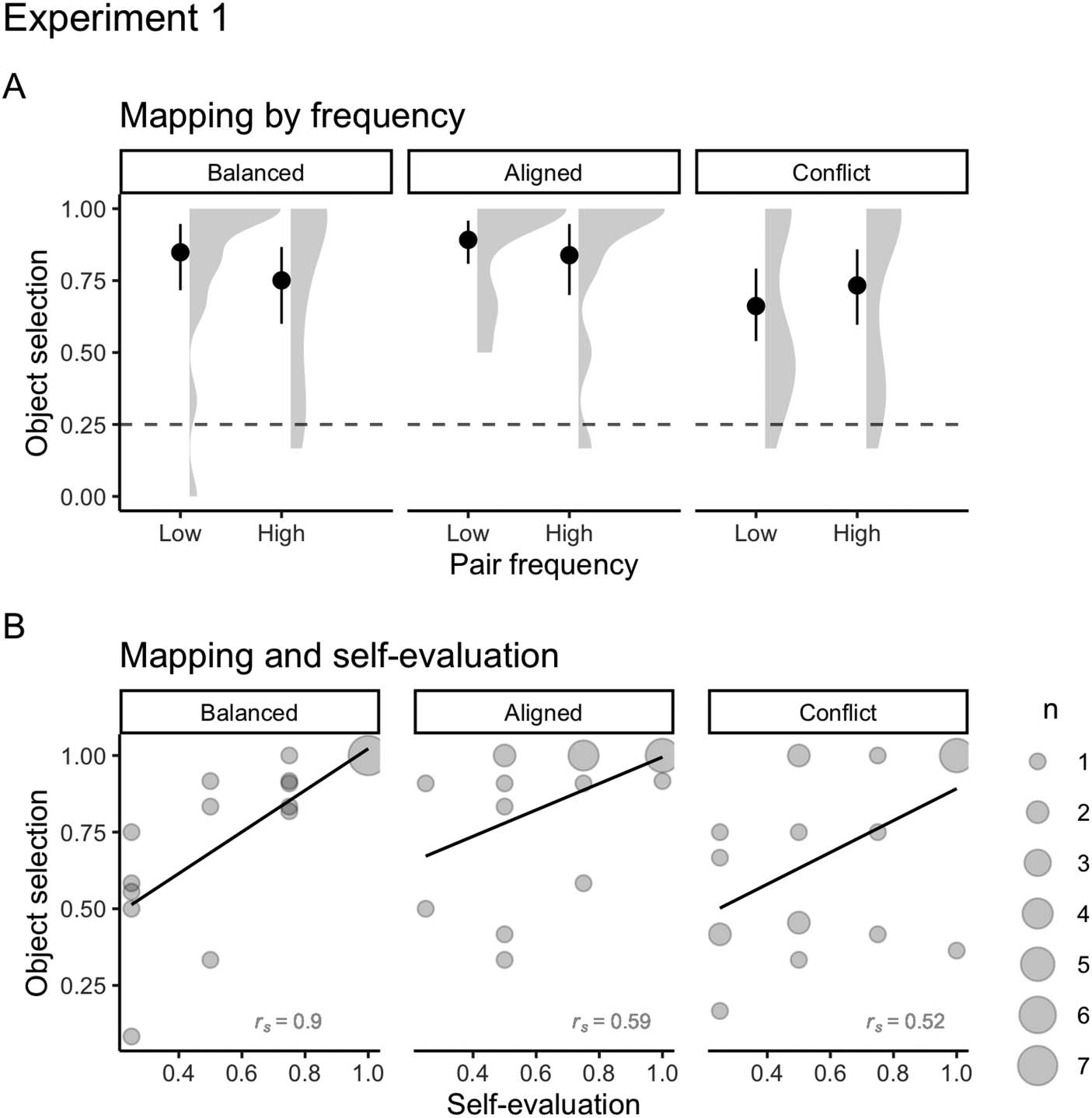
Across all languages and pair frequencies, participants were much more likely to select the
correct object in comparison to the distractors (Cifra 4; full regression table available at
https://osf.io/rs2bm/). Mapping and self-evaluation (Cifra 4) were positively correlated for
all languages. They were strongly correlated for the Balanced language (rs = 0.9), and moder-
ately for the Aligned (rs = 0.59) and the Conflict languages (rs = 0.53). This suggests that
9 lm4 syntax: object selection ∼ chance level + idioma * pair frequency + (1|estímulos) + (1|partícipe).
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
519
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
.
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
/
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
.
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
(A) Mean number of correct high and low frequency object selections for Balanced,
Cifra 4.
Aligned, and Conflict languages on cross-situational word learning test of Experiment 1 (Balanced:
Mlow = 0.85, DE = 0.26, Mhigh = 0.75, DE = 0.3; Aligned: Mlow = 0.89, DE = 0.18, Mhigh = 0.84,
DE = 0.28; Conflicto: Mlow = 0.49, DE = 0.31, Mhigh = 0.56, DE = 0.32). Solid points represent the
overall mean, error bars represent 95% CIs (non-parametric bootstrap). Shaded areas depict the dis-
tribution of individual responses. The dashed line displays the chance level (0.25). (B) Correlations
between cross-situational word learning and self-evaluation for Balanced, Aligned, and Conflict
idiomas (rs Balanced = 0.9; rs Aligned = 0.59; rs Conflict = 0.52) on Experiment 1. The size of dots
indicates the number of participants that overlap in given coordinates (de 1 a 7).
participants from all languages were able to form clear word-object relationships. It was sur-
prising to see that participants from the Conflict language, who performed at chance on the
speech segmentation task, were able to form strong word-object relationships—a point to
which we return later.
To explore whether our simultaneous task impacts mapping performance, we compared the
present data with data from a previous experiment that only tested cross-situational word
learning but using the same stimuli and population (Dal Ben et al., 2022). We fitted one
mixed-effect logistic model that had mapping (correct or incorrect) as the outcome variable,
the interaction between experiment (separate or simultaneous task) and language (Balanced,
Aligned, Conflicto) as a predictor, and participants as random intercepts10.
10 lme4 syntax: object selection ∼ experiment:idioma + (1|partícipe).
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
520
Segmentation and Word Learning Dal Ben et al.
Cifra 5. Mean number of correct object selections in an experiment testing cross-situational
word learning only—CSWL only (m = 0.65, DE = 0.24; Dal Ben et al., 2022)—and in the Balanced
(m = 0.79, DE = 0.28), Aligned (m = 0.86, DE = 0.23), and Conflict (m = 0.69, DE = 0.3) idiomas
from the present, simultaneous, experimento. Solid points represent the overall mean, error bars
representar 95% CIs (non-parametric bootstrap). Points represent the mean for each participant.
Shaded areas depict the distribution of individual responses. Dashed line displays the chance
nivel (0.25).
En general, cross-situational word learning improved for all languages during the parallel task
in comparison to the separate task (Cifra 5). The improvement was greater for participants
from the Aligned language (change in OR = 7.39, 95% CI [2.10, 25.98]), followed by partic-
ipants from the Balanced language (change in OR = 3.34, 95% CI [1.37, 5.52]). Although less
pronounced, there was also an improvement for the Conflict language (change in OR = 1.60,
95% CI [0.50, 5.05]), which indicates that participants can benefit from word-object co-
occurrence even when TP and phonotactics point to different word boundaries.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
.
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
/
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Relationship Between Speech Segmentation and Word Mapping. To explore potential relationships
between speech segmentation and word mapping, we ran Spearmans’ correlations between
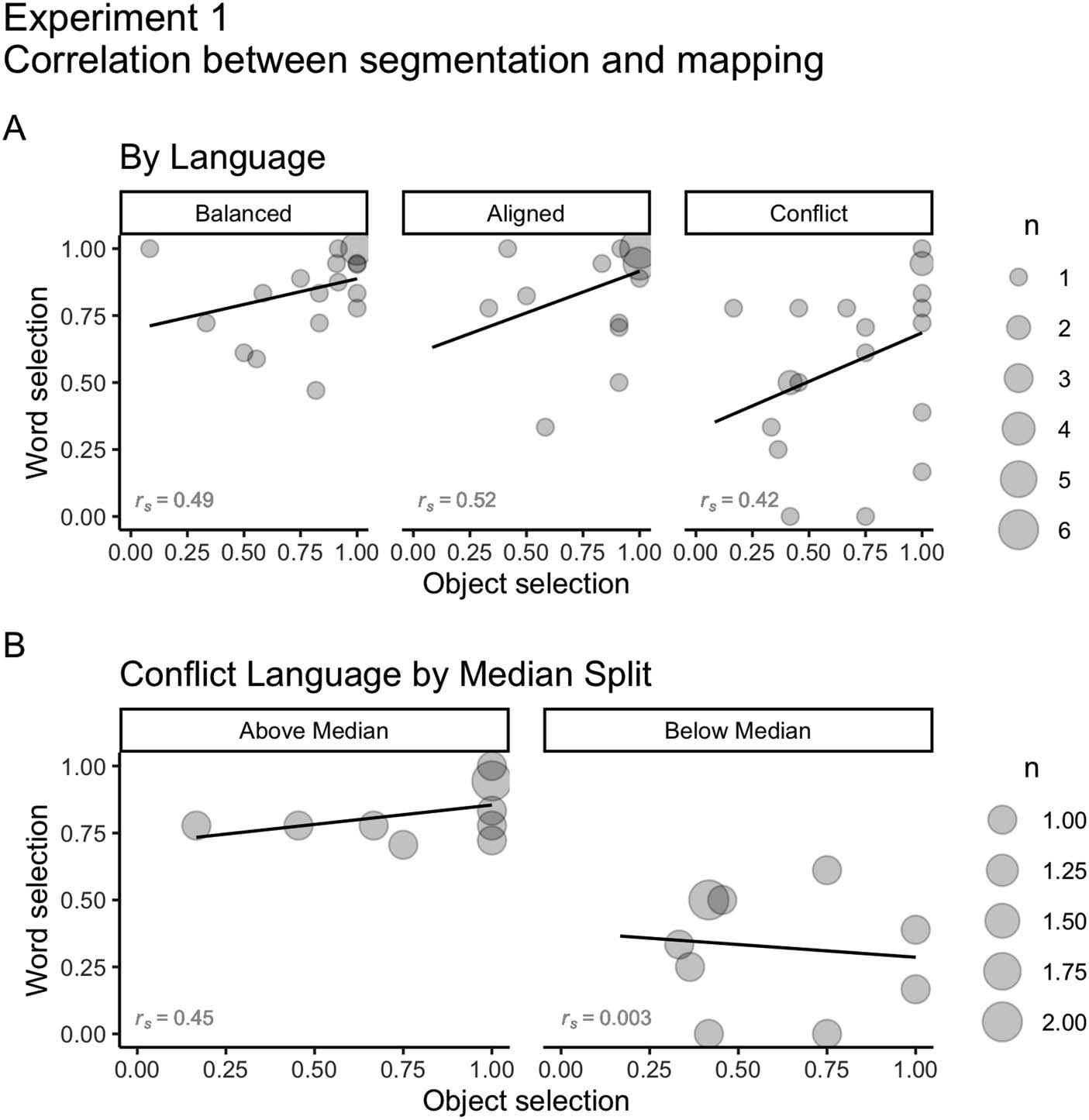
words’ and objects’ selections (average scores per participant) for each Language. Encontramos
moderate positive correlations between segmentation and mapping for all Languages (rs Balanced =
0.49; rs Aligned = 0.52; rs Conflict = 0.42; Figure 6A). En general, participants that were better at
segmentation were also better at mapping. To further explore if that was true for participants
from the Conflict Language, we performed a median split of segmentation performance
(Mdn = 0.66, IQR = 0.4) and ran Spearman correlation tests for each group separately
(Figure 6B). Participants that successfully segmented the speech (above median) were also suc-
cessful in mapping words to objects (rs = 0.46). Sin embargo, we found no relationship between
segmentation and mapping for those who performed poorly on segmentation (below the
median; rs = 0.003).
Our design does not inform us about potential learning sequences. Intuitivamente, strong
speech segmentation skills should lead to strong word mapping, which is confirmed to some
extent by the positive correlation between word and object selections for participants above
the median in the Conflict language, but not for those below the median. Curiosamente,
simulations by Räsänen and Rasilo (2015) favor a simultaneous performance in which speech
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
521
Segmentation and Word Learning Dal Ben et al.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
.
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
/
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
(A) Correlations between speech segmentation and mapping for Balanced, Aligned,
Cifra 6.
and Conflict Languages on Experiment 1 (rs Balanced = 0.49; rs Aligned = 0.52; rs Conflict = 0.42).
The size of dots indicates the number of participants that overlap in each coordinate (de 1 a
6). (B) Correlations between speech segmentation and mapping in the Conflict Language for partic-
ipants with speech segmentation above the median (Mdn = 0.66, IQR = 0.4; rs = 0.45) and below
the median (rs = 0.003). The size of dots indicates the number of participants that overlap in each
coordinate (de 1 a 2).
segmentation and mapping retrofeed each other, driving performance on both tasks. En esto
regard, the absence of a relationship between segmentation and mapping for participants
below the median in the Conflict Language indicates that these performances could be
independent from one another.
En general, results from the present experiment suggest that not only can adults simultaneously
track conditional probabilities between audio and visual stimuli to segment words from
continuous speech streams and map them to referents under ambiguous learning contexts,
but that both segmentation and mapping improve when a greater set of cues, even from dif-
ferent modalities, are available (Figures 3 y 5). Such results provide preliminary empirical
evidence to the model of simultaneous segmentation and ambiguous mapping proposed by
Räsänen and Rasilo (2015) and Jones et al. (2010).
Our results also indicate that phonotactic probabilities, or how familiar syllables’ positional
probabilities are in the native language of the participants, also impact such joint performance.
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
522
Segmentation and Word Learning Dal Ben et al.
When transitional and phonotactic probabilities worked together to signal word boundaries,
segmentation and mapping improved (Aligned language) in contrast to when the phonotactic
probabilities were balanced among test items (Balanced language). Sin embargo, the impact of
phonotactics was most pronounced when it conflicted with TP information. In the Conflict
idioma, en general, participants failed to show a preference for words when compared to
part-words at test (Cifra 2). Sin embargo, they were able to map words and objects (Cifra 4).
How could this happen?
If we assume that segmentation is a necessary pre-step to cross-situational mapping, entonces
this result is hard to explain. Sin embargo, if adults use whatever informative statistics they have at
hand to solve linguistic ambiguity, they would take advantage of both transitional and phono-
tactic statistics and word-object co-occurrences in the Aligned and Balanced languages. On
the other hand, in the Conflict language, statistics were not consistent enough to promote seg-
mentation, but co-occurrences between word syllables and objects were consistent enough to
promote mapping and, hasta cierto punto, speech segmentation—even without clear and explicit
word representations. It is worth noting that objects were consistently paired with words only,
and not with part-words. This might have provided some participants with enough information
for speech segmentation. It might also have decreased the influence of statistical cues on seg-
mentation (both TPs and PPs). Sin embargo, if word-object co-occurrence was the main source
of information for speech segmentation, we should have seen similar levels of segmentation in
all languages.
Además, our two-alternative forced-choice test might not have been sensitive enough to
capture the weaker and implicit word representations that might have arisen in the Conflict
idioma, providing us a partial picture of participants’ speech segmentation. Our two-
alternative-forced-choice trials contrasted words with stronger TPs and weaker phonotactic
probabilidad, or part-words with weaker TPs but stronger phonotactic probability. The contrast
between recently acquired TP knowledge, and language specific phonotactic knowledge
learned across the lifespan, may have impaired word selection (Finn & Hudson Kam,
2008). Teniendo esto en cuenta, we replicate the current experiment, but using an arguably more
sensitive speech segmentation measurement.
Finalmente, it is worth noting that our careful selection and combination of syllables to create
disyllabic words with varying TP and PP contrasts introduced an important confound to our
estudiar: none of our words shared syllables. As all syllables were unique to a given word, track-
ing co-occurrences between individual syllables and objects would be enough to solve the
mapping task—but not the segmentation task. This learning strategy would greatly reduce
mapping complexity: participants could ignore half of the syllables and all linguistic regular-
ities (es decir., TP and PP). Whereas this strategy may be computationally most simplistic, it seems
como, como un grupo, participants in the Balanced and Aligned languages did track word-level sta-
tistics, as indicated by their segmentation performance. Sin embargo, when faced with conflicting
linguistic regularities, participants in the Conflict language might have defaulted to this more
simplistic learning strategy and solved the mapping task without relying on word represen-
taciones. En tono rimbombante, this confound extends to Experiment 2 and we further discuss it in the
General Discussion.
EXPERIMENT 2
In an attempt to capture the potentially nuanced word form knowledge implicitly arising from
experience with the Conflict language, in the current experiment we use a more sensitive word
segmentation test: go/no-go (François et al., 2017). In this test, each item is presented and
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
523
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
.
/
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
evaluated separately, one at a time. By avoiding the contrast between stimuli (es decir., palabra, part-
palabra, non-word) with different statistics (TP and phonotactics) at test and by adding a new
stimuli type (es decir., non-words), we aim for a more fine-grained understanding of word represen-
tations in the Conflict language. The mapping test is the same as in Experiment 1.
Método
This experiment was a replication of Experiment 1, but it was fully online due to the COVID-
19 pandemic. Differences in methodology are described below.
Participantes. Forty-five adults, all native speakers of Brazilian-Portuguese, with no reported
visual or auditory impairment that could interfere with the task, participó. Sin embargo, 10
participants were excluded from the final analyses because they failed or missed attention
check questions, reported using their mobile phones or taking notes during the experiment
(see Data analysis for further details). The final sample consisted of 35 adultos (Mage = 23.51,
± 4.01 Dakota del Sur, 22 femenino). As in Experiment 1, participants were recruited at the official Facebook
group of the Universidade Federal de São Carlos and received no compensation for their par-
ticipation. The study was conducted according to the Declaration of Helsinki and the Ethics
Committee of the host university approved the research (#3.085.914).
Stimuli and Design. We used the Conflict language from Experiment 1, with the same word-
object pairs. As a brief reminder, in this Language, words had high TPs (TP = 1; Mesa 1) y
lower phonotactic probabilities (Mwords = 0.0072), while part-words had lower TPs (TP = 0.5)
and higher phonotactic probabilities (Mpart-words = 0.0085). Además, we created three addi-
tional non-words with balanced phonotactic by recombining the initial syllables of words (es decir.,
/visu/, /tami/, /rako/; PPs = 0.0080, 0.0074, 0.0069, respectivamente). Because their syllables never
occurred together in the Language, their TP was zero.
A similar design from Experiment 1 was used here, with four main differences. Primero, given
the online nature of the study, before beginning the experimental task, participants were
instructed to move to a quiet room, to turn off any electronic devices (p.ej., cellphone, TV),
to wear earphones, and not to take notes during the experiment. Segundo, the segmentation
test followed a go/no-go structure: test words (es decir., /nipe/, /tadi/, /mide/), part-words (es decir.,
/sute/, /viko/, /bara/), and non-words (es decir., /visu/, /tami/, /rako/) were presented one at a time
and participants were instructed to indicate whether they were or were not words from the
language they had just heard (by pressing to “s” or “n”, corresponding to “sim” [Sí] o
“não” [No] in Portuguese). Each stimuli was tested 6 veces (total of 54 ensayos). Tercero, atención
checks were conducted during the familiarization and segmentation test. At each familiariza-
tion block, participants were prompted to answer five simple questions (es decir., “Are you alive?",
“Are you sleeping?", “Are you breathing?", “Are you dead?", “Are you awake?"). Between seg-
mentation test trials, attention checks displayed either a Portuguese word or a made-up word
(p.ej., “mesa” [mesa], “drevo”) printed on the screen and participants were prompted to indi-
cate if the word existed in Portuguese or not. During both familiarization and test, Participantes
indicated their answers for attention checks by pressing the “s” or “n” keys on the keyboard.
Cuatro, at the end of the experiment, we checked for compliance to instructions by asking
participants whether they had used the cellphone or if they had taken notes during the
experimento.
Procedimiento. The experiment was entirely online, hosted on Pavlovia and programmed using
Psychopy3 (Bridges et al., 2020). After agreeing to participate, participants were instructed
to avoid distractions (see previous section), answered a questionnaire about their educational
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
524
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
.
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
/
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
background and language abilities, and then started the experimental task. As in Experiment 1,
they were exposed to three phases: familiarization, segmentation test, and mapping test (mismo
as Experiment 1). Además, attention checks (described before) were presented between
familiarization blocks and between trials during the segmentation test.
Análisis de los datos. We followed similar analytical steps from Experiment 1. We first excluded
participants who reported using their mobile phones during the experiment (norte = 3) and those
(norte = 2) who failed two or more attention checks (out of five questions) during familiarization.
Another five participants were excluded because their reaction times to attention checks in the
familiarization or segmentation tests were greater than 3 SDs from the mean. For the remaining
Participantes (norte = 35), we excluded trials with reaction times greater than 3 SDs away from the
significar (segmentation: 32 trials overall, 1% of the data; mapping: 7 trials overall, 1% del
datos). The final data was entered in mixed-effect logistic regressions. The outcome, predictors,
and random effects for each model is described in the next section.
Results and Discussion
Speech Segmentation. To analyze speech segmentation, we fitted a mixed-effects logistic
regression with words’, part-words’, and non-words’ evaluations as the outcome variable.
Selection of words and rejections of part-words and non-words were coded as correct
respuestas. Predictors were the chance level (logit of 0.5) and stimuli type (palabras, part-words,
non-words), stimuli and participants were random intercepts11.
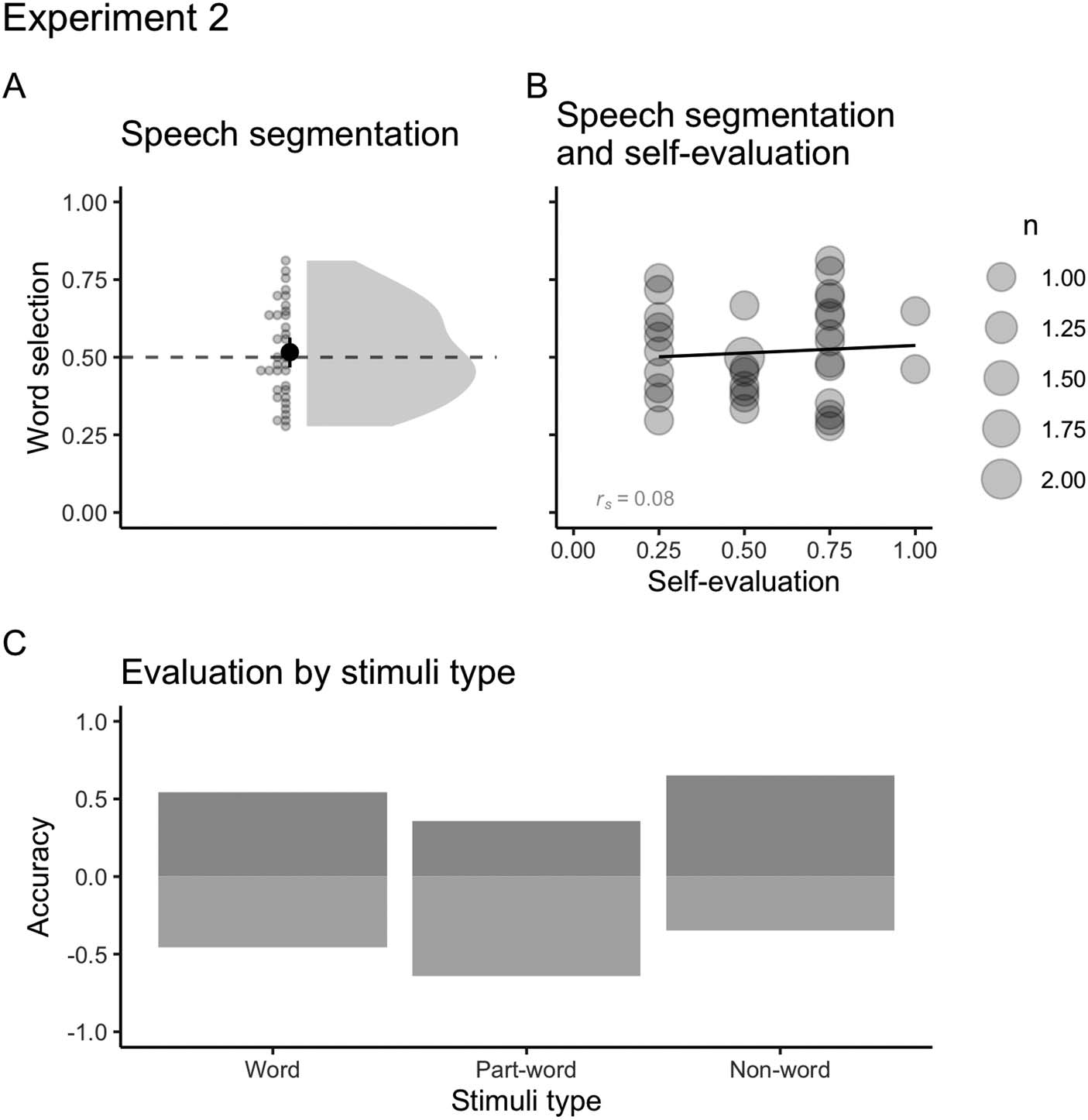
We replicated the results from Experiment 1 – Conflict language. En general, participants’ per-
formance was at chance level (m = 0.51, DE = 0.15; Figure 7A). The analyses by stimuli type
(Figure 7C) reveal a slight tendency for evaluating words as such (OR = 1.21, 95% CI [0.61,
2.4]), a stronger tendency for correctly rejecting non-words (change in OR = 1.68, 95%
CI [0.67, 4.2]), and a much less accurate judgment when rejecting part-words (change in
OR = 0.41, 95% CI [0.16, 1.03]). As in Experiment 1, there was no correlation between speech
segmentation and self-evaluation (rs Conflict = 0.08).
These results indicate that participants might have tracked both transitional and phonotactic
statistics from familiarization, but used them differently when evaluating stimuli during test. Para
instancia, they might have relied on TP information when evaluating words (higher TP and
lower phonotactics) and phonotactic information when evaluating part-words (lower TP
and higher phonotactics). Finalmente, the lack of familiarity with non-words (no TP information),
and the balanced phonotactic statistics, might have generated correct non-word rejections.
En general, our nuanced results could indicate that the go/no-go procedure is not sensitive
enough to capture implicit word representation arising from speech segmentation of a lan-
guage with conflicting statistics—a point we return to in the General Discussion.
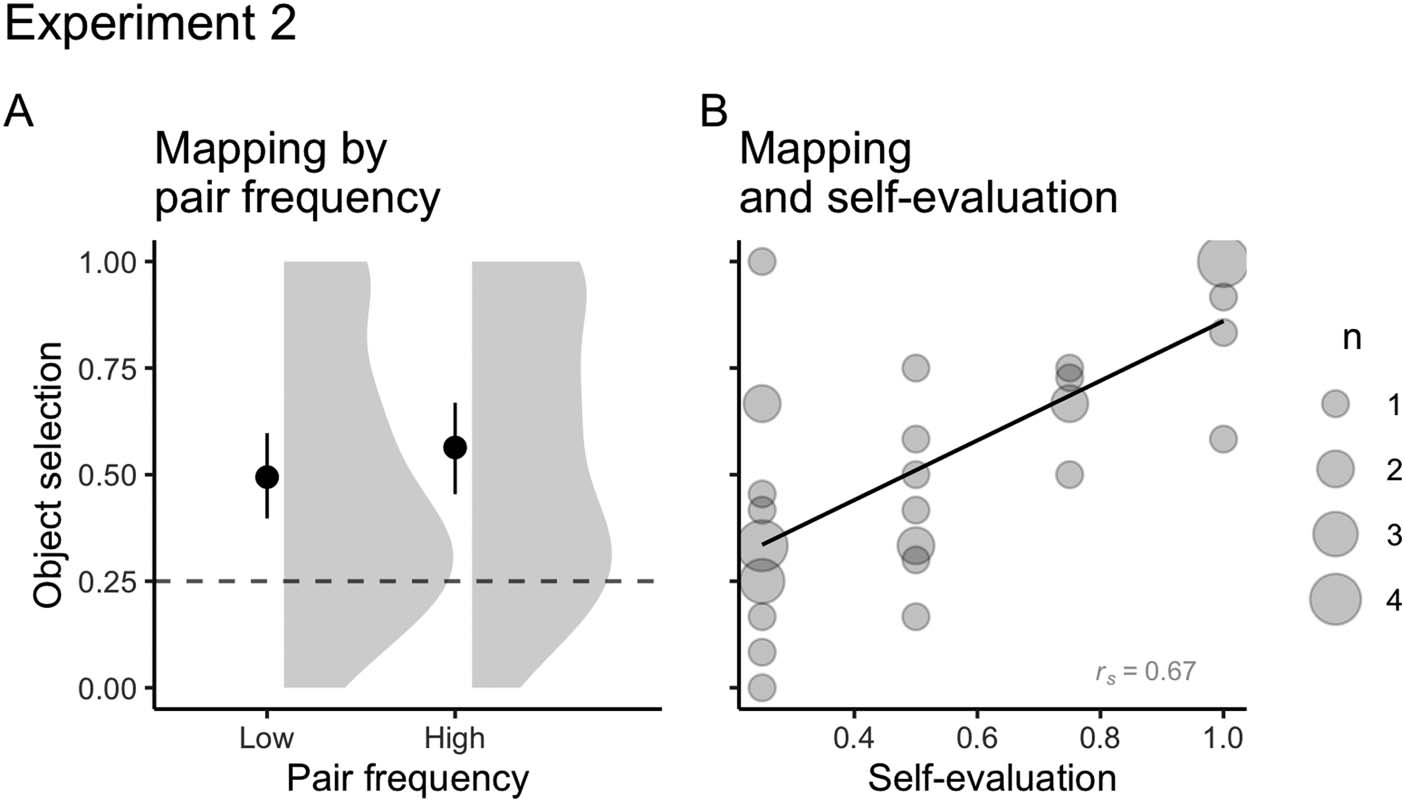
Cross-situational Word Learning. To model mapping performance, our mixed-effect logistic
regression had object selection (correct or incorrect) as the outcome variable, chance level
(logit of 0.25) and target stimuli frequency (150 o 300 repetitions) as predictors, and stimuli
and participants as random intercepts12. As in Experiment 1, participants correctly mapped
both high and low frequency words above chance level (Mhigh = 0.56, SDhigh = 0.31; Mlow =
0.49, SDlow = 0.31; Cifra 8), with small differences in the likelihood of correctly selecting
high or low frequency word-object pairs (ORhigh = 1.51, 95% CI [0.75, 3.02]; change in
11 lme4 syntax: selection ∼ chance level + stimuli type + (1|estímulos) + (1|partícipe).
12 lme4 syntax: selection ∼ chance level + target frequency + (1|estímulos) + (1|partícipe).
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
525
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
.
/
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
/
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
.
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
(A) Mean number of correct word selections and part-word and non-word rejections on
Cifra 7.
Experimento 2 (m = 0.51, DE = 0.15). The solid point represents the overall mean, error bars
representar 95% CIs (non-parametric bootstrap). Points represent the mean for each participant.
The shaded area depicts the distribution of individual responses. The dashed line displays the
chance level (0.5). (B) Correlations between segmentation and self-evaluation (rs Conflict = 0.08)
on Experiment 2. The size of dots indicates the number of participants that overlap in given coor-
dinates (de 1 a 2). (C) Evaluation by stimuli type (palabra, part-word, non-word). Positive scores
represent correct selection of words (m = 0.54, DE = 0.28) and rejection of part-words (m =
0.35, DE = 0.25) and non-words (m = 0.65, DE = 0.27). Negative scores represent incorrect rejec-
tions of words and selection of part-words and non-words.
ORlow = 0.68, 95% CI [0.35, 1.36]). De nuevo, we found a moderate positive correlation between
mapping and self-evaluation (rs = 0.67; Cifra 8).
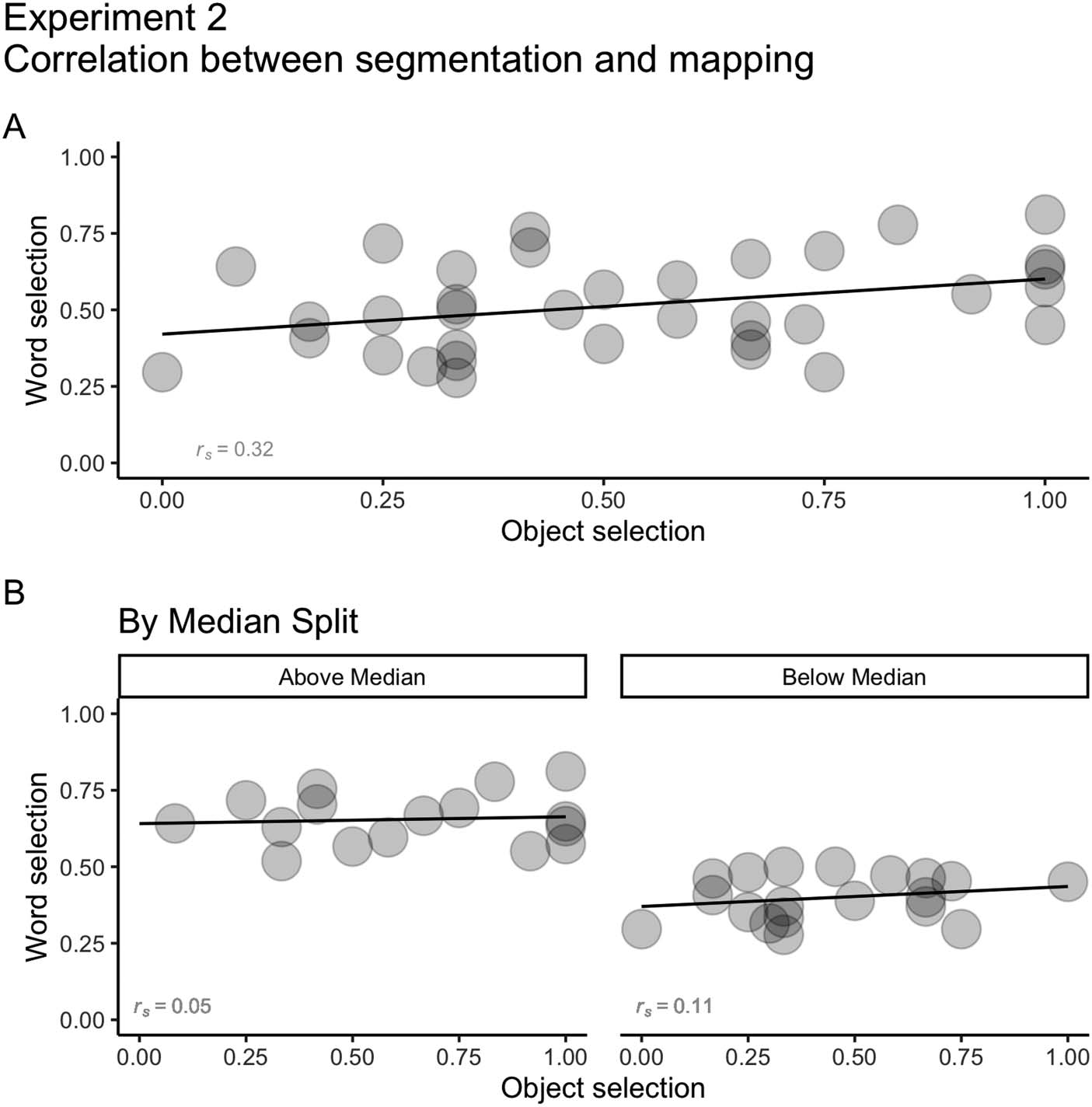
Relationship Between Speech Segmentation and Word Mapping. As in Experiment 1, we ran Spear-
mans’ correlation tests between words’ and objects’ selections (average scores per participant)
to explore potential relationships between speech segmentation and word mapping. Encontramos
a weak positive correlation between segmentation and mapping (rs = 0.32; Cifra 9). De nuevo,
en general, participants that were better at segmentation were also better at mapping. Más
exploration by speech segmentation median split (Mdn = 0.5, IQR = 0.24) revealed little dif-
ference between participants above the median (rs = 0.05) and below the median (rs = 0.11),
with no correlation between segmentation and mapping for both groups.
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
526
Segmentation and Word Learning Dal Ben et al.
(A) Mean number of correct object selections for high (m = 0.56, DE = 0.31) and low
Cifra 8.
(m = 0.49, DE = 0.31) frequency pairs on Experiment 2. The solid point represents the overall
significar, error bars represent 95% CIs (non-parametric bootstrap). The shaded area depicts the distri-
bution of individual responses. The dashed line displays the chance level (0.25). (B) Correlations
between mapping and self-evaluation (rs Conflict = 0.67) on Experiment 2. The size of dots indicates
the number of participants that overlap in given coordinates (de 1 a 4).
The current experiment was designed to further evaluate the effects of the conflict between
transitional and phonotactic statistics on simultaneous speech segmentation and cross-
situational word learning. En general, we replicated Experiment 1: speech segmentation, as mea-
sured by a go/no-go test, was at chance level, but word-object mapping performance was
above chance. Sin embargo, our more sensitive word segmentation test provided some
nuanced information about stimulus representations.
We found that participants were likely to correctly evaluate non-words as such. This indi-
cates that how participants represented words and part-words was most likely the result of the
interplay between phonotactic and transitional probabilities. Por ejemplo, stronger phonotac-
tics combined with a probabilistic transitional probability (TP = 0.5) lead participants to incor-
rectly evaluate part-words as words. Por otro lado, the weaker phonotactics combined
with deterministic transitional information (TP = 1) prompt only a slight tendency to correctly
evaluate words as such.
As in Experiment 1, speech segmentation performance and self-evaluation indicate that the
conflict between transitional and phonotactic probabilities impaired the formation of clear
word representations, which could have impaired participants’ accuracy when estimating their
knowledge of words from speech. De nuevo, sin embargo, despite the absence of clear word repre-
sentaciones, participants were able to map words to objects. Consistent word-object
co-occurrences might have provided sufficient information to promote mapping and some
level of segmentation, despite conflicting phonetic information (Räsänen & Rasilo, 2015).
Además, as in Experiment 1, syllables were not shared between words. Participants could
have tracked co-occurrences between individual syllables and objects to solve the mapping
tarea, without relying on any word-level phonetic information. Whereas using this strategy
would allow participants to solve the mapping task, it wouldn’t allow them to gain any
word-level information. De este modo, if this was the entirety of the explanation, speech segmentation
performance should have been at chance level for words, part-words, and non-words.
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
527
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
.
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
.
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
(A) Correlation between segmentation and mapping (rs = 0.32) on Experiment 2. (B)
Cifra 9.
Correlations between speech segmentation and mapping for participants with speech segmentation
above the median (Mdn = 0.5, IQR = 0.24; rs = 0.05) and below the median (rs = 0.11).
Sin embargo, during the go/no-go test, participants were more likely to correctly select words as
such and to correctly reject non-words, indicating that they tracked word-level statistics to
some degree.
Próximo, we discuss a possible design to overcome this important confound as well as some of
the limitations of our study. Además, nosotros, discuss how our preliminary findings broaden our
understanding of statistical learning from multiple cues and prompt further research on the
sujeto.
GENERAL DISCUSSION
En el presente estudio, we explored whether adults could segment speech streams into words
and map them to objects simultaneously by tracking conditional probabilities across ambigu-
ous presentations. We also investigated the effects of word-level phonotactics in segmentation
and mapping. Phonotactics were either balanced, aligned, or in conflict with transitional prob-
abilities. We found that participants were successful at both the segmentation and mapping
tasks when transitional and phonotactic probabilities were either aligned or balanced across
palabras. A diferencia de, when transitional and phonotactic probabilities were in conflict, we did not
find evidence for speech segmentation, but we still found evidence for mapping.
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
528
Segmentation and Word Learning Dal Ben et al.
Our results offer preliminary support for the idea that a greater set of cues, even in different
modalities, supports speech segmentation and word learning in ambiguous situations ( jones
et al., 2010; Räsänen & Rasilo, 2015). Not only were participants able to segment and map
words simultaneously by tracking conditional probabilities, but their overall performance was
stronger in this simultaneous task in comparison to separate tasks of segmentation and
cross-situational word learning. This adds to the evidence showing that language learners
benefit from combining several sources of linguistic information when learning a new
idioma (Choi et al., 2018; Johnson, 2016; Saffran, 2020; Smith et al., 2018; Tachakourt,
2023; Yurovsky et al., 2012). This combination might be especially useful when dealing with
ambiguity, as even a partial solution to one linguistic challenge could reduce ambiguity in
other linguistic challenges (for related evidence, see Feldman, Griffiths, et al., 2013; Feldman,
miers, et al., 2013).
Our design does not provide insights into specific learning strategies used by our partici-
pants. Por ejemplo, they could have used an aggregation strategy, gradually segmenting
speech and using the segmented words as anchors for further segmentation and mapping.
Or they could have used hypothesis testing from the start, electing syllable sequences and
testing their co-occurrence with each other and with objects over time. Participants might
have also used a blend of these strategies depending on the level of ambiguity they were fac-
En g ( Yurovsky & Franco, 2015). Además, our selection of unique syllables for each word
introduced an important confound to our study. Participants could have solved the mapping
task even when ignoring half of the syllables and all word-level statistics. A diferencia de, más
efficient segmentation performance for all languages (except for the Conflict language on
Experimento 1) suggests that participants tracked word-level statistics to some degree. Más-
más, the positive correlation between segmentation and mapping, found in all languages of
both experiments, suggests that both speech segmentation, that relied on word-level statistics,
and cross-situational mapping were in close interaction, potentially retro feeding each other
con el tiempo (in line with proposals by Räsänen & Rasilo, 2015).
Curiosamente, the conflict between phonotactics and transitional information might have
impaired the formation of clear and explicit word representations, but not the formation
of strong word-object relationships. Whereas this could point to independent processing
of phonetic and audiovisual statistics, it could also be that participants did form clear, pero
implicit, word representations that our explicit measurements (either a two-alternative
forced-choice or go/no-go) were not able to capture. Por ejemplo, despite the conflict
between transitional and phonotactic statistics, participants were still able to consistently
reject non-words during Experiment 2, showing that stimuli with different degrees of statis-
tical information were treated differently. It is worth reinforcing that we manipulated TPs and
PPs differently. Whereas TPs were determined when designing the experimental stimuli, PPs
were estimated from participants’ native language. This led to differences in strength
between cues that might have had different effects on participants’ processing. Por ejemplo,
they could have relied more on TP to find word boundaries and on PPs to form strong word
representaciones. A more direct way to assess these implicit processes and to overcome the
confound of not repeating syllables across words may be to use EEG measures during the
passive familiarization phase.
Recording neural activity during familiarization could inform us about how the alignment
or conflict between TP and PP are processed and what happens when these statistics are
violated (p.ej., Elmer et al., 2021; François et al., 2017). Además, the use of neural entrain-
ment analysis could provide direct evidence to whether participants track word-level statistics
(disyllabic words) or individual syllables (p.ej., Batterink & Paller, 2017; Choi et al., 2020). En
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
529
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
.
/
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
an ongoing EEG study in one of our labs, we are measuring: a) whether participants will show
similar ERPs to violations of transitional and phonotactic information presented in the
Balanced and in the Conflict languages and b) the temporal entrainment of their neural activity
during familiarization.
Another invaluable source of information on the learning mechanisms involved in the
simultaneous speech segmentation and mapping are the cognitive processes underlying such
performances. Por ejemplo, auditory and visual memory have been shown to predict cross-
situational word learning ( Vlach & DeBrock, 2017; Vlach & Johnson, 2013). Differences in
attention have also been found to impact statistical learning (Herrero & Yu, 2013; Yurovsky
et al., 2013). Future research could measure these and other cognitive processes to better
understand their role in statistical language learning.
Our study was exploratory in nature. Building on our promising initial findings, future
replications should put our findings to the test. They could also address some of the short-
comings of the present investigation. Future investigations could, Por ejemplo, manipulate
both TPs and PPs in a similar way, leading to a finer control of their contrast. Both cues
could be defined experimentally (p.ej., Benitez & Saffran, 2021), or estimated directly from
participants’ natural language. The latter estimation could lead to the design of natural con-
tinuous speech (in line with Hay et al., 2011) that comprises the variability in transitional
and phonotactic probabilities that learners face in the wild, increasing the ecological validity
of statistical learning findings (cf. Smith et al., 2014). Future research could also have par-
ticipants from more heterogeneous backgrounds, Por ejemplo, by recruiting participants from
different ages, in different countries, with different socioeconomic status. We tested fairly
homogenous samples of young college students from a single language background. El
trends we found may not generalize to other populations (Simons et al., 2017). También, it could
be that the statistical learning mechanisms involved in this simultaneous task may have
different roles across development (Choi et al., 2018; Danielson et al., 2017; Smith et al.,
2018). Future research could investigate simultaneous statistical language learning across
development to bridge the gaps between young adults, infantes, and older adults. Finalmente,
although highly dynamic, our task comprises only a small sampling of the challenges
(es decir., segmentation and mapping) and statistics (es decir., conditional probabilities) available for
language learners in natural environments. Future studies could improve ecological validity
por, por ejemplo, combining statistical, prosodic, and semantic information (Hay et al., 2011;
Karaman & Hay, 2018), or diving into natural environments (Bogaerts et al., 2022; Yu et al.,
2021).
Learning languages is difficult. To overcome many linguistic challenges, learners can rely
on several cues. Here we provide preliminary evidence that adults can track conditional prob-
abilities to simultaneously find words in continuous speech and map them to objects across
ambiguous situations. We also show that the level of pre-experimental familiarity with words
can impact their representation. By doing so, we contribute to a more nuanced understanding
of how statistical cues interact to promote language learning.
EXPRESIONES DE GRATITUD
This work was supported by grants from FAPESP (#2015/26389-7, #2018/04226-7) and CAPES
(#001) to RDB; FAPESP (#2018/18748-5) to ITP; from INCT-ECCE (National Institute on
Cognición, Behavior and Teaching; CNPq #573972/2008-7, #465686/2014-1, FAPESP
#2008/57705-8, #2014/50909-8) to DHS; and from the NICHD (#R01HD083312) to JFH.
RDB is now at Ambrose University.
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
530
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
.
/
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
CONTRIBUCIONES DE AUTOR
RDB: Conceptualización, Metodología, Software, Investigación, Visualización, Data Formal
Análisis, Writing – Original Draft; ITP: Investigación, Data Formal Analysis, Writing – Original
Draft; DHS & JFH: Conceptualización, Writing – Revisar & Editing, Supervisión, Proyecto
administración, Adquisición de financiación.
DATA AVAILABILITY STATEMENT
The materials, código, and data from this study are openly available on Open Science Frame-
work at https://osf.io/rs2bm/.
REFERENCIAS
Aslin, R. NORTE., Saffran, j. r., & Newport, mi. l. (1998). Computation of
conditional probability statistics by 8-month-old infants. Psycho-
logical Science, 9(4), 321–324. https://doi.org/10.1111/1467
-9280.00063
barr, D. J., Exacción, r., Transportistas, C., & Teja, h. j. (2013). Aleatorio
effects structure for confirmatory hypothesis testing: Keep it
maximal. Journal of Memory and Language, 68(3), 255–278.
https://doi.org/10.1016/j.jml.2012.11.001, PubMed: 24403724
Bates, D., Mächler, METRO., Bolker, B., & Caminante, S. (2015). Fitting linear
mixed-effects models using lme4. Journal of Statistical Software,
67(1), 1–48. https://doi.org/10.18637/jss.v067.i01
Batterink, l. J., & Paller, k. A. (2017). Online neural monitoring of
statistical learning. Corteza, 90, 31–45. https://doi.org/10.1016/j
.cortex.2017.02.004, PubMed: 28324696
Benitez, V. l., & Saffran, j. R. (2021). Two for the price of one:
Concurrent learning of words and phonotactic regularities from
continuous speech. PLoS ONE, 16(6), Article e0253039. https://
doi.org/10.1371/journal.pone.0253039, PubMed: 34115799
Negro, A., & Bergmann, C. (2017). Quantifying infants’ statistical
word segmentation: A meta-analysis. In G. Gunzelmann, A.
Howes, t. Tenbrink, & mi. j. Davelaar (Editores.), Actas de la
39th Annual Conference of
the Cognitive Science Society
(páginas. 124–129). Sociedad de ciencia cognitiva.
Bogaerts, l., Siegelman, NORTE., Christiansen, METRO. h., & Frost, R. (2022).
Is there such a thing as a ‘good statistical learner’? Tendencias en
Cognitive Sciences, 26(1), 25–37. https://doi.org/10.1016/j.tics
.2021.10.012, PubMed: 34810076
Brent, METRO. r., & Siskind, j. METRO. (2001). The role of exposure to
isolated words in early vocabulary development. Cognición,
81(2), B33–B44. https://doi.org/10.1016/S0010-0277(01)00122
-6, PubMed: 11376642
Bridges, D., Pitiot, A., MacAskill, METRO. r., & Peirce, j. W.. (2020). El
timing mega-study: Comparing a range of experiment generators,
both lab-based and online. PeerJ, 8, Article e9414. https://doi.org
/10.7717/peerj.9414, PubMed: 33005482
Cannistraci, R. A., Dal Ben, r., Karaman, F., Esfahani, S. PAG., & Hay,
j. F. (2019). Statistical learning approaches to studying language
desarrollo. In J. S. Horst & j. von Koss Torkildsen (Editores.),
International handbook of language acquisition (páginas. 51–75).
Routledge. https://doi.org/10.4324/9781315110622-4
Choi, D., Batterink, l. J., Negro, A. K., Paller, k. A., & Werker, j. F.
(2020). Preverbal infants discover statistical word patterns at
similar rates as adults: Evidence from neural entrainment. Psy-
chological Science, 31(9), 1161–1173. https://doi.org/10.1177
/0956797620933237, PubMed: 32865487
Choi, D., Negro, A. K., & Werker, j. F. (2018). Cascading and
multisensory influences on speech perception development.
Mente, Cerebro, and Education, 12(4), 212–223. https://doi.org/10
.1111/mbe.12162
Clerkin, mi. METRO., Hart, MI., Rehg,
j. METRO., Yu, C., & Herrero, l. B.
(2017). Real-world visual statistics and infants’ first-learned
object names. Philosophical Transactions of the Royal Society
of London, Serie B: Ciencias Biologicas, 372(1711), Article
20160055. https://doi.org/10.1098/rstb.2016.0055, PubMed:
27872373
Cox, C. METRO. METRO., Keren-Portnoy, T., Roepstorff, A., & Fusaroli, R.
(2022). A Bayesian meta-analysis of infants’ ability to perceive
audio–visual congruence for speech. Infancy, 27(1), 67–96.
https://doi.org/10.1111/infa.12436, PubMed: 34542230
Cristia, A. (2018). Can infants learn phonology in the lab? A
meta-analytic answer. Cognición, 170, 312–327. https://doi.org
/10.1016/j.cognition.2017.09.016, PubMed: 29102857
Cunillera, T., Càmara, MI., Laine, METRO., & Rodríguez-Fornells, A.
(2010). Speech segmentation is facilitated by visual cues.
Revista trimestral de psicología experimental, 63(2), 260–274.
https://doi.org/10.1080/17470210902888809, PubMed:
19526435
Cunillera, T., & Guilera, GRAMO. (2018). Twenty years of statistical learning:
From language, back to machine learning. cienciometria, 117(1),
1–8. https://doi.org/10.1007/s11192-018-2856-x
Cunillera, T., Laine, METRO., Càmara, MI., & Rodríguez-Fornells, A. (2010).
Bridging the gap between speech segmentation and word-to-
world mappings: Evidence from an audiovisual statistical learning
tarea. Journal of Memory and Language, 63(3), 295–305. https://doi
.org/10.1016/j.jml.2010.05.003
Dal Ben, r., Souza, D. d. h, & Hay, j. F. (2019). Cross-situational
word learning: Systematic review and meta-analysis. Manuscript
in preparation. https://doi.org/10.17605/OSF.IO/GU9RB
Dal Ben, r., Souza, D. d. h, & Hay, j. F. (2021). When statistics
collide: The use of transitional and phonotactic probability cues
to word boundaries. Memoria & Cognición, 49(7), 1300–1310.
https://doi.org/10.3758/s13421-021-01163-4, PubMed: 33751490
Dal Ben, r., Souza, D. d. h, & Hay, j. F. (2022). Combining statis-
tics: The role of phonotactics on cross-situational word learning.
Psicologia: Reflexao e Critica, 35(1), Article 30. https://doi.org/10
.1186/s41155-022-00234-y, PubMed: 36169750
Danielson, D. K., Bruderer, A. GRAMO., Kandhadai, PAG., Vatikiotis-Bateson,
MI., & Werker, j. F. (2017). The organization and reorganization of
audiovisual speech perception in the first year of life. Cognitivo
Desarrollo, 42, 37–48. https://doi.org/10.1016/j.cogdev.2017
.02.004, PubMed: 28970650
Dutoit, T., Pagel, v., Pierret, NORTE., Bataille, F., & van der Vrecken, oh.
(1996). The MBROLA project: Towards a set of high quality
speech synthesizers free of use for non commercial purposes.
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
531
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
.
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
/
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
In Proceedings of Fourth International Conference on Spoken
Procesamiento del lenguaje (volumen. 3, páginas. 1393–1396). IEEE. https://doi
.org/10.1109/ICSLP.1996.607874
Elmer, S., Valizadeh, S. A., Cunillera, T., & Rodriguez-Fornells, A.
(2021). Statistical learning and prosodic bootstrapping differen-
tially affect neural synchronization during speech segmentation.
NeuroImagen, 235, Article 118051. https://doi.org/10.1016/j
.neuroimage.2021.118051, PubMed: 33848624
Estivalet, GRAMO. l., & Meunier, F. (2015). The Brazilian Portuguese
Lexicon: An instrument for psycholinguistic research. PLoS ONE,
10(12), Article e0144016. https://doi.org/10.1371/journal.pone
.0144016, PubMed: 26630138
Feldman, norte. h., Griffiths, t. l., Goldwater, S., & morgan, j. l.
(2013). A role for the developing lexicon in phonetic category
adquisición. Revisión psicológica, 120(4), 751–778. https://doi
.org/10.1037/a0034245, PubMed: 24219848
Feldman, norte. h., miers, mi. B., Blanco, k. S., Griffiths, t. l., &
morgan, j. l. (2013). Word-level information influences phonetic
learning in adults and infants. Cognición, 127(3), 427–438.
https://doi.org/10.1016/j.cognition.2013.02.007, PubMed:
23562941
Finn, A. S., & Hudson Kam, C. l. (2008). The curse of knowledge:
First language knowledge impairs adult learners’ use of novel
statistics for word segmentation. Cognición, 108(2), 477–499.
https://doi.org/10.1016/j.cognition.2008.04.002, PubMed:
18533142
François, C., Cunillera, T., Garcia, MI., Laine, METRO., & Rodriguez-
Fornells, A. (2017). Neurophysiological evidence for the inter-
play of speech segmentation and word-referent mapping during
novel word learning. Neuropsicología, 98, 56–67. https://doi
.org/10.1016/j.neuropsychologia.2016.10.006, PubMed:
27732869
Franco, METRO. C., Mansinghka, v., Gibson, MI., & Tenenbaum, j. B.
(2007). Word segmentation as word learning: Integrating stress
and meaning with distributional cues. En H. Caunt-Nulton, S.
Kulatilake, & I. Cortejar (Editores.), Proceedings of the 31st Annual
Boston University Conference on Language Development
(páginas. 218–229). Boston University.
Graf Estes, k. (2009). From tracking statistics to learning words: Sta-
tistical learning and lexical acquisition. Linguistics and Language
Compass, 3(6), 1379–1389. https://doi.org/10.1111/j.1749-818X
.2009.00164.X
Graf Estes, K., Edwards, J., & Saffran, j. R. (2011). Phonotactic con-
straints on infant word learning. Infancy, 16(2), 180–197. https://
doi.org/10.1111/j.1532-7078.2010.00046.x , PubMed:
21297877
Graf Estes, K., evans, j. l., Alibali, METRO. w., & Saffran, j. R. (2007).
Can infants map meaning to newly segmented words? Statistical
segmentation and word learning. ciencia psicológica, 18(3),
254–260. https://doi.org/10.1111/j.1467-9280.2007.01885.x,
PubMed: 17444923
Hay, j. F., Pelucchi, B., Graf Estes, K., & Saffran, j. R. (2011). Enlace
sounds to meanings: Infant statistical learning in a natural lan-
guage. Psicología cognitiva, 63(2), 93–106. https://doi.org/10
.1016/j.cogpsych.2011.06.002, PubMed: 21762650
Hay, j. F., & Saffran, j. R. (2012). Rhythmic grouping biases constrain
infant statistical learning. Infancy, 17(6), 610–641. https://doi.org
/10.1111/j.1532-7078.2011.00110.x, PubMed: 23730217
Horst, j. S., & Hout, METRO. C. (2016). The Novel Object and Unusual
Nombre (NOUN) Database: A collection of novel images for use
in experimental research. Behavior Research Methods, 48(4),
1393–1409. https://doi.org/10.3758/s13428-015-0647-3,
PubMed: 26424438
Johnson, mi. k. (2016). Constructing a proto-lexicon: An integrative
view of infant language development. Annual Review of Linguis-
tics, 2, 391–412. https://doi.org/10.1146/annurev-linguistics
-011415-040616
Johnson, mi. K., Seidl, A., & tyler, METRO. D. (2014). The edge factor in
early word segmentation: Utterance-level prosody enables word
form extraction by 6-month-olds. PLoS ONE, 9(1), Article
e83546, https://doi.org/10.1371/journal.pone.0083546,
PubMed: 24421892
Johnson, mi. K., & tyler, METRO. D. (2010). Testing the limits of statistical
learning for word segmentation. Developmental Science 13(2),
339–345. https://doi.org/10.1111/j.1467-7687.2009.00886.x,
PubMed: 20136930
jones, B. K., Johnson, METRO., & Franco, METRO. C. (2010). Learning words
and their meanings from unsegmented child-directed speech.
In Human Language Technologies: The Annual Conference of
the North American Chapter of the Association for Computational
Lingüística (páginas. 501–509). Asociación de Lin Computacional-
guísticos. https://aclanthology.org/N10-1074/
Karaman, F., & Hay, j. F. (2018). The longevity of statistical learning:
When infant memory decays, isolated words come to the rescue.
Revista de Psicología Experimental: Aprendiendo, Memoria, and Cog-
nition, 44(2), 221–232. https://doi.org/10.1037/xlm0000448,
PubMed: 28782968
Krogh, l., Vlach, h. A., & Johnson, S. PAG. (2013). Statistical learning
across development: Flexible yet constrained. Frontiers in Psy-
chology, 3, Article 598. https://doi.org/10.3389/fpsyg.2012
.00598, PubMed: 23430452
Lany, J., & Saffran, j. R. (2010). From statistics to meaning: Infants’
acquisition of lexical categories. ciencia psicológica, 21(2),
284–291. https://doi.org/10.1177/0956797609358570,
PubMed: 20424058
Mattys, S. l., & Jusczyk, PAG. W.. (2001). Do infants segment words or
recurring contiguous patterns? Journal of Experimental Psychol-
ogia: Percepción y desempeño humanos, 27(3), 644–655.
https://doi.org/10.1037/0096-1523.27.3.644, PubMed:
11424651
Mattys, S. l., Jusczyk, PAG. w., Luce, PAG. A., & morgan, j. l. (1999).
Phonotactic and prosodic effects on word segmentation in
infantes. Psicología cognitiva, 38(4), 465–494. https://doi.org
/10.1006/cogp.1999.0721, PubMed: 10334878
Mersad, K., & Nazzi, t. (2011). Transitional probabilities and posi-
tional frequency phonotactics in a hierarchical model of speech
segmentation. Memoria & Cognición, 39(6), 1085–1093. https://
doi.org/10.3758/s13421-011-0074-3, PubMed: 21312017
Mirman, D., Magnuson, j. S., Graf Estes, K., & dixon, j. A. (2008).
The link between statistical segmentation and word learning in
adultos. Cognición, 108(1), 271–280. https://doi.org/10.1016/j
.cognition.2008.02.003, PubMed: 18355803
Peirce, J., Gray, j. r., Simpson, S., MacAskill, METRO., Höchenberger, r.,
Sogo, h., Kastman, MI., & Lindeløv, j. k. (2019). PsychoPy2:
Experiments in behavior made easy. Behavior Research Methods,
51(1), 195–203. https://doi.org/10.3758/s13428-018-01193-y,
PubMed: 30734206
Quine, W.. V. oh. (1960). Word and object. CON prensa.
R Core Team. (2021). R: A language and environment for statistical
computing. R Foundation for Statistical Computing.
Räsänen, o., & Rasilo, h. (2015). A joint model of word segmenta-
tion and meaning acquisition through cross-situational learning.
Revisión psicológica, 122(4), 792–829. https://doi.org/10.1037
/a0039702, PubMed: 26437151
Romberg, A. r., & Saffran, j. R. (2010). Statistical learning and
language acquisition. Wiley Interdisciplinary Reviews: Cognitivo
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
532
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
/
.
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
/
.
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Segmentation and Word Learning Dal Ben et al.
Ciencia, 1(6), 906–914. https://doi.org/10.1002/wcs.78,
PubMed: 21666883
Saffran, j. R. (2020). Statistical language learning in infancy. Child
Development Perspectives, 14(1), 49–54. https://doi.org/10.1111
/cdep.12355, PubMed: 33912228
Saffran, j. r., Aslin, R. NORTE., & Newport, mi. l. (1996). Statistical
learning by 8-month-old infants. Ciencia, 274(5294), 1926–1928.
https://doi.org/10.1126/science.274.5294.1926, PubMed:
8943209
Scheel, A. METRO., Tiokhin, l., Isager, PAG. METRO., & Lakens, D. (2021). Por qué
hypothesis testers should spend less time testing hypotheses. Por-
spectives on Psychological Science, 16(4), 744–755. https://doi
.org/10.1177/1745691620966795, PubMed: 33326363
Shoaib, A., Wang, T., Hay, j. F., & Lany, j. (2018). Do infants learn
words from statistics? Evidence from English-learning infants
hearing Italian. Ciencia cognitiva, 42(8), 3083–3099. https://
doi.org/10.1111/cogs.12673, PubMed: 30136301
Shukla, METRO., Blanco, k. S., & Aslin, R. norte. (2011). Prosody guides the
rapid mapping of auditory word forms onto visual objects in
6-mo-old infants. Actas de la Academia Nacional de
Ciencias de los Estados Unidos de América, 108(15), 6038–6043.
https://doi.org/10.1073/pnas.1017617108, PubMed: 21444800
simons, D. J., Shoda, y., & lindsay, D. S. (2017). Constraints on
Generality (COG): A proposed addition to all empirical papers.
Perspectives on Psychological Science, 12(6), 1123–1128. https://
doi.org/10.1177/1745691617708630, PubMed: 28853993
Herrero, l. B, Jayaraman, S., Clerkin, MI., & Yu, C. (2018). The devel-
oping infant creates a curriculum for statistical learning. Tendencias en
Cognitive Sciences, 22(4), 325–336. https://doi.org/10.1016/j.tics
.2018.02.004, PubMed: 29519675
Herrero, l. B., Suanda, S. h., & Yu, C. (2014). The unrealized promise
of infant statistical word-referent learning. Tendencias en Cognitivo
Ciencias, 18(5), 251–258. https://doi.org/10.1016/j.tics.2014.02
.007, PubMed: 24637154
Herrero, l. B., & Yu, C. (2008). Infants rapidly learn word-referent
mappings via cross-situational statistics. Cognición, 106(3),
1558–1568. https://doi.org/10.1016/j.cognition.2007.06.010,
PubMed: 17692305
Herrero, l. B., & Yu, C. (2013). Visual attention is not enough: Indi-
vidual differences in statistical word-referent learning in infants.
Language Learning and Development, 9(1), 25–49. https://doi.org
/10.1080/15475441.2012.707104, PubMed: 24403867
Steber, S., & Rossi, S. (2020). So young, yet so mature? Electrophys-
iological and vascular correlates of phonotactic processing in
18-month-olds. Developmental Cognitive Neuroscience, 43,
Article 100784. https://doi.org/10.1016/j.dcn.2020.100784,
PubMed: 32510350
Storkel, h. l., Bontempo, D. MI., Aschenbrenner, A. J., Maekawa, J.,
& Sotavento, S.-Y. (2013). The effect of incremental changes in phono-
tactic probability and neighborhood density on word learning by
preschool children. Journal of Speech, Idioma, and Hearing
Investigación, 56(5), 1689–1700. https://doi.org/10.1044/1092
-4388(2013/12-0245), PubMed: 23882005
Sundara, METRO., zhou, z. l., Breiss, C., Katsuda, h., & Steffman, j.
(2022). Infants’ developing sensitivity to native language
phonotactics: A meta-analysis. Cognición, 221, Article 104993.
https://doi.org/10.1016/j.cognition.2021.104993, PubMed:
34953268
Swingley, D. (1999). Conditional probability and word discovery: A
corpus analysis of speech to infants. En m. Hahn & S. C. Stoness
(Editores.), Proceedings of the 21st Annual Conference of the Cogni-
tive Science Society (páginas. 724–729). Prensa de Psicología. https://doi
.org/10.4324/9781410603494-131
Tachakourt, Y. (2023). Simultaneous speech segmentation and
cross-situational statistical learning in monolinguals, bilinguals,
and multilinguals. Journal of Applied Language and Cultural
Estudios, 6(1), 110–134. https://revues.imist.ma/index.php/JALCS
/article/view/36374/18533
Thiessen, mi. D. (2010). Effects of visual information on adults’ and
infants’ auditory statistical learning. Ciencia cognitiva, 34(6),
1093–1106. https://doi.org/10.1111/j.1551-6709.2010.01118.x,
PubMed: 21564244
Vitevitch, METRO. S., & Luce, PAG. A. (2004). A Web-based interface to
calculate phonotactic probability for words and nonwords in
Inglés. Behavior Research Methods, Instrumentos, & Computadoras,
36(3), 481–487. https://doi.org/10.3758/BF03195594, PubMed:
15641436
Vlach, h. A., & DeBrock, C. A. (2017). Remember dax? Relaciones
between children’s cross-situational word learning, memory, y
language abilities. Journal of Memory and Language, 93,
217–230. https://doi.org/10.1016/j.jml.2016.10.001, PubMed:
28503024
Vlach, h. A., & Johnson, S. PAG. (2013). Memory constraints on
infants’ cross-situational statistical learning. Cognición, 127(3),
375–382. https://doi.org/10.1016/j.cognition.2013.02.015,
PubMed: 23545387
Cual, C. D. (2004). Universal Grammar, statistics or both? Tendencias en
Cognitive Sciences, 8(10), 451–456. https://doi.org/10.1016/j.tics
.2004.08.006, PubMed: 15450509
Yu, C., & Herrero, l. B. (2007). Rapid word learning under uncer-
tainty via cross-situational statistics. ciencia psicológica,
18(5), 414–420. https://doi.org/10.1111/j.1467-9280.2007
.01915.X, PubMed: 17576281
Yu, C., zhang, y., Slone, l. K., & Herrero, l. B. (2021). The infant’s
view redefines the problem of referential uncertainty in early
word learning. procedimientos de la Academia Nacional de Ciencias
of the United States of America, 118(52), Article e2107019118.
https://doi.org/10.1073/pnas.2107019118, PubMed: 34933998
Yurovsky, D., & Franco, METRO. C. (2015). An integrative account of
constraints on cross-situational learning. Cognición, 145, 53–62.
https://doi.org/10.1016/j.cognition.2015.07.013, PubMed:
26302052
Yurovsky, D., Yu, C., & Herrero, l. B. (2012). Statistical speech seg-
mentation and word learning in parallel: Scaffolding from
child-directed speech. Fronteras en psicología, 3, Article 374.
https://doi.org/10.3389/fpsyg.2012.00374, PubMed: 23162487
Yurovsky, D., Yu, C., & Herrero, l. B. (2013). Competitive processes
in cross-situational word learning. Ciencia cognitiva, 37(5),
891–921. https://doi.org/10.1111/cogs.12035, PubMed:
23607610
MENTE ABIERTA: Descubrimientos en ciencia cognitiva
533
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
/
mi
d
tu
oh
pag
metro
i
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
i
/
.
/
1
0
1
1
6
2
oh
pag
metro
_
a
_
0
0
0
9
5
2
1
5
0
9
6
1
oh
pag
metro
_
a
_
0
0
0
9
5
pag
d
.
/
i
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3