Mapping Through Listening
Baptiste Caramiaux,∗ Jules Franc¸ oise,†
Norbert Schnell,† and Fr ´ed´eric
Bevilacqua†
∗Department of Computing
Goldsmiths College
University of London
New Cross London, SE16 6NW, Reino Unido
b.caramiaux@gold.ac.uk
†STMS Lab IRCAM-CNRS-UPMC
Institut de Recherche et Coordination
Acoustique/Musique
1 place Igor Stravinsky
75004 París, Francia
{jules.francoise, norbert.schnell,
frederic.bevilacqua}@ircam.fr
Abstracto: Gesture-to-sound mapping is generally defined as the association between gestural and sound parameters.
This article describes an approach that brings forward the perception–action loop as a fundamental design principle
for gesture–sound mapping in digital music instrument. Our approach considers the processes of listening as the
foundation—and the first step—in the design of action–sound relationships. In this design process, the relationship
between action and sound is derived from actions that can be perceived in the sound. Building on previous work on
listening modes and gestural descriptions, we propose to distinguish between three mapping strategies: instantaneous,
temporal, and metaphorical. Our approach makes use of machine-learning techniques for building prototypes, de
digital music instruments to interactive installations. Four different examples of scenarios and prototypes are described
and discussed.
In digital musical instruments, gestural inputs
obtained from motion-sensing systems, imagen
análisis, or sound analysis are commonly used to
control or to interact with sound processing or
sound synthesis (Miranda and Wanderley 2006).
This has led artists, technologists, and scientists to
investigate strategies for mapping between gestural
inputs and output sound processes.
Considered as an important vector of expres-
sion in computer music performance (Rovan et al.
1997), the exploration of mapping approaches has
led to a flourishing of research work dealing with:
taxonomy (Wanderley 2002); the study of various
strategies based, Por ejemplo, on perceptual spaces
(Arfib et al. 2002), mathematical formalization (Van
Nort, Wanderley, and Depalle 2004), or dynamical
sistemas (Momeni and Henry 2006); and evaluation
procedures based on user studies and other tools
borrowed from the field of human–computer inter-
Computer Music Journal, 38:3, páginas. 34–48, Caer 2014
doi:10.1162/COMJ a 00255
C(cid:2) 2014 Instituto de Tecnología de Massachusetts.
acción (Hunt and Kirk 2000; Wanderley and Orio
2002).
It has often been discussed that for digital music
instruments, unlike most acoustic instruments
(Cadoz 1988; Wanderley and Depalle 2004), hay
no direct coupling between the gesture energy and
the acoustic energy. Más precisamente, as the mapping
is programmed in the digital realm, the relationship
between the input and output digital data streams
can be set arbitrarily. This offers unprecedented
opportunities to create various types of mapping
that can be seen as part of the creative endeavor to
build novel digital instruments.
After several years of experimentation, nosotros
have developed an approach that brings back the
perception–action loop as a fundamental design
principle. As a complement to approaches that focus
on building active haptic feedback to enhance the
action–perception loop (Castagne et al. 2004), nosotros
propose a methodology rooted in the concept of
embodied music cognition. This methodology con-
siders listening as a process from which gestures and
interactions, defining key elements for the design of
mappings, emerge.
34
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Our approach is anchored in advances in cognitive
sciences and rooted in embodied cognition (Varela,
Thompson, and Rosch 1991). The enactive point
of view on perception and the idea of embodied
cognition cover aspects of cognition as shaped
by the body, which consitute the perceptual and
motor systems (Varela, Thompson, and Rosch 1991;
No ¨e 2005). From this point of view, the action
of listening—as is the case with perception in
general—is intrinsically linked to the process of
acquiring knowledge and applying this knowledge
when interacting with our environment (Merleau-
Ponty 1945). In music-making—as well as in speech
and many other everyday activities—listening plays
a particular role in the identification, evaluación,
and execution of actions. The intrinsic relationship
between action and listening in human cognition
has been confirmed by many studies (Liberman and
Mattingly 1985; Fadiga et al. 2002; Zatorre, Chen,
and Penhune 2007). By extension, embodied music
cognition, developed by Marc Leman (2007) and Rolf
Inge Godøy (2006), tends to see music perception as
based on actions. Many situations involve people
moving while listening to music. In the framework
of embodied music cognition, these movements are
seen as conveying information about the perceived
sonic moving forms (Leman et al. 2009).
Although embodied music cognition provides
us with a theoretical framework for the study of
listening in a musical context and for the study of the
link between music perception and human actions,
digital music performance requires computational
tools to implement experimental breakthroughs.
Recent tools coming from the field of machine
learning research allow for building scenarios and
prototypes implementing concepts borrowed from
embodied music cognition. Such scenarios are,
en efecto, usually best defined from high-level gesture
and acoustic descriptions, which cannot generally
be easily programmed with other techniques. Para
ejemplo, the use of machine-learning techniques
allows one to set the gesture–sound relationships
from examples or from a database.
In this article we propose a new approach of
gesture-to-sound mapping that relies on the concept
of embodied sound cognition, and we report applica-
tions that make use of machine-learning techniques
to implement these scenarios.
The article is structured as follows. In the follow-
ing section, we review previous work characterizing
different listening modes and how they relate to
gestural descriptions of sounds. We then describe
our approach for the design of mappings inspired
by these different modes of listening. The proposed
mappings are presented as real-world applications
and stem from our past and current research in this
campo. In the final section, we discuss the different
scenarios and mapping strategies.
Describing Sound Gesturally
As mentioned previously, we are interested in
examining mapping strategies through the theory of
embodied music cognition. En particular, we focus
on listening processes that might induce gestural
representations in order to conceptually invert the
proceso, going from gesture to sound, to create
the mapping. In this section we first review work
describing different listening modes that can be
related to specific sound properties. Then we show
that these listening modes can be related to different
action strategies.
Listening Modes
Sound, as considered here, refers to recorded audio
material. Recorded sound can be played back
and processed using various techniques, cual,
importantly, leads to different listening experiences.
A vast body of work is devoted to the mechanisms of
escuchando, gathering together various research fields
such as psychoacoustics, neurosciences, auditory
scene analysis, and musicology. En esta sección, nosotros
focus on conceptual approaches of listening that
principally originated from music theory and the
theory of ecological perception. Our goal is to create
a comprehensive overview of listening modes and
their functions, which will eventually be linked, en
the next section, to gestural representations.
Caramiaux et al.
35
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Primero, in the context of musique concr `ete, Pierre
Schaeffer (1966) defined four functions of listening.
(Note that the translation of Schaeffer’s terms is far
from trivial. Por esta razón, in this article we use
both our translation and the original French term.)
These functions are: (1) escuchando ( ´ecouter), cual
focuses on the indexical value of the sound (es decir.,
the sound source); (2) perceiving (ou¨ır), the most
primitive mode, consisting of receiving the sound
through the auditory system; (3) hearing (entendre),
referring to the selective process between auditory
signals, the attention to inherent characteristics
of the perceived sound; y (4) comprehending
(comprendre), which brings semantics into sounds,
treating them as signs. These different functions
of listening are not mutually exclusive and operate
competitively.
Based on Schaeffer’s theoretical taxonomy, y
motivated by new concepts from auditory display,
Michel Chion (1983) proposed a taxonomy com-
prising three categories, called modes of listening:
(1) causal listening, consisting of listening to a
sound in order to gather information about its
causa (or source); (2) semantic listening, refering
to a code or a language to interpret a message;
y (3) reduced listening, focusing on the quali-
ties of the sound itself, independent of its cause
and of its meaning. (Note that reduced listening
is a concept that was first introduced by Schaeffer
to motivate the concept of the “sound object” in
musique concr `ete.) Por eso, Chion does not consider
the low-level aspect of perception called perceiving
(ou¨ır).
Modes of listening have also been of interest in
the ecological approach to auditory perception. Uno
important application has been the design of sounds
in human–computer interaction. In this context,
William Gaver (1993a, b) considered environmental
sounds and proposed a differentiation between two
types of listening defined as everyday listening,
in which the perception focuses on events rather
than sounds, and musical listening, en el cual
perception is centered on the sound characteristics.
As noted by Gaver (1993b, pag. 1), musical listening to
environmental sounds can be achieved by listening
“to the world as we do music.” Gaver used, como
examples, compositions by the American composer
John Cage that aim at hearing the everyday world as
música.
Recent studies have proposed to enrich these
previous taxonomies by adding an emotional di-
mension, evoked by the auditory stimulus. David
Huron (2002) proposed an analytic framework sup-
porting the idea that emotional experiences may
be usefully characterized according to a six-part
clasificación, categorized as follows: (1) reflexive,
referring to fast, automatic physiological responses;
(2) denotative, allowing the listener to identify
sound sources; (3) connotative, allowing the listener
to infer various physical properties about sound
sources such as size, proximity, energía, material,
and mode of excitation; (4) associative, referring
to arbitrary learned associations; (5) empathetic,
referring to auditory empathy that allows the lis-
tener to detect emotion from the sound (como
fear in a voice) coming from an animate agent
(be it human or animal); y, finalmente, (6) critical,
referring to conscious cognitive processes by which
the intentions of a sound-producing agent are
evaluated.
Recientemente, Kai Tuuri and colleagues proposed
an extended taxonomy of listening modes (Tuuri
and Eerola 2012). The taxonomy is hierarchical
with three levels: experiential, denotative, y
reflective. The experiential level encompasses
Huron’s reflexive and connotative modes. El
connotative mode more precisely focuses on the
relation between the action and the external world
(es decir., object, gente, and cultural context). En esto
taxonomy the experiential mode also induces a
kinaesthetic mode that refers to the inherent
movement qualities in the sound (Por ejemplo,
characterizing a sound as “wavy”). El segundo
level in the hierarchy is the denotative mode. Este
mode was first defined by Huron and extended by
Tuuri in order to separate between modes focusing
on sound sources and those focusing on sound
contextos. Finalmente, the top level is the reflective
mode, encompassing Chion’s reduced mode as well
as Huron’s critical mode.
The important point here is to realize that several
of the listening modes make reference, explicitly
or implicitly, to motor imagery or action. Ambos
Chion’s causal listening mode and the denotative
36
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 1. A simplified
taxonomy of listening
modes. Causal listening
refers to an explicit
association between sound
and its producing action.
Acoustic listening is
related to acoustic
qualities of the sound.
Semantic listening
integrates higher level
notions of meaning and
interpretación.
Causal
escuchando
Acoustic
escuchando
Semántico
escuchando
Listening (opposed to hearing,
comprehending, perceiving)
(Schaeffer 1966)
Hearing
(Schaeffer 1966)
Causal listening
(Chion 1983)
Everyday listening
(Gaver 1993)
Denotative
(Huron 2002)
Denotative (causal)
(Tuuri and Eerola 2012)
Reduced listening
(Schaeffer 1966; Chion 1983)
Musical listening
(Gaver 1993)
Connotative
(Huron 2002)
Reduced listening
Connotative (
Kinaesthetic listening
(Tuuri and Eerola 2012)
Comprehending
(Schaeffer 1966)
Semantic listening
(Chion 1983)
Associative
(Huron 2002)
Denotative (functional, semantic)
(Tuuri and Eerola 2012)
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
listening mode, used by both Huron and Tuuri, refer
to associating a sound to the action that created
the sound. Such actions are generally linked to
clear interactions and motion between objects (p.ej.,
a stick hitting a cymbal). We will keep the term
causal listening throughout this article to denote
such an association between the action and the
sound.
The reduced listening mode of Schaeffer and
Chion, Huron’s connotative mode, and Tuuri’s
kinaesthetic mode refer to acoustic properties of
the sound. We will use the term acoustic listening
throughout this article for such a type listening.
These acoustic aspects could be quantified using
a set of sound descriptors from the sound signal.
A crucial point, sin embargo, is to acknowledge that
defining the reduced listening mode is also linked
to sound descriptions such as the Schaeffer’s typo-
morphology of sonic objects (Schaeffer 1966), o
later to temporal semiotic units (unit ´es s ´emiotiques
temporelles, cf. Frey et al. 2009). As elucidated by
Godøy (2006), these descriptions can, in many cases,
be linked to notions of motions and actions.
The last mode of listening encompasses se-
mantic aspects of sound perception and is named
respectivamente. Cifra 1 summarizes the three modes
of listening—causal, acoustic, and semantic—that
we will consider in this article, with the goal of
associating them with gestural representations.
Linking Gesture and Listening
In the previous section we reviewed the listening
modes as introduced by various authors in the
literature. These were summarized as an approach
using three modes, accounting for causal, acoustic,
and semantic listening. En esta sección, we posit
that these modes of listening can be linked to
specific gestural strategies. We base this statement
on a review of important work within the field of
behavioral approaches in embodied music cognition
that reported on gestural sound description.
Interactions between sound perception and
motion have been studied either through a neuro-
scientific perspective or a behavioral perspective
(Zatorre, Chen, and Penhune 2007). Generally, el
motor–auditory interaction has been recognized as
important for describing sound perception. Neuro-
science studies have shown how listeners activate
cognitive action representations while listening to
music performances, whether they are expert musi-
cians or novices (Haueisen and Kn ¨osche 2001; Lahav
et al. 2005; Zatorre, Chen, and Penhune 2007).
Caramiaux et al.
37
In a behavioral approach, a common experimental
methodology consists of asking participants to
perform movements along with music while it
is played. The movement analysis can reveal
important insights into the underlying embodied
cognitive processes related to music perception. A
wide range of work concerns controlled tasking, para
instancia, the task of tapping on beats (Large 2000;
Large and Palmer 2002).
In systematic musicology, exploratory procedure
is more commonly used. Examples include asking
participants to spontaneously gesticulate while
listening to a sound stimulus or music. Por ejemplo,
Leman and co-workers (2009) studied participants’
movements made with a joystick while listening to
a performance of guqin music. También, Mats K ¨ussner
(2013) considered free tracing movements on a
tablet while two of Fr ´ed ´eric Chopin’s preludes were
played. Other works concern specifically designed
stimuli with well characterized musical parameters.
Como consecuencia, it is possible to investigate how the
chosen musical parameters affected the resulting
movimientos.
Godøy is one of the pioneers of this type of re-
buscar. He proposed using the morphology of sound
stimuli based on Schaeffer’s typology (impulsive,
iterative, and sustained; cf. Godøy et al. 2006).
This methodology was then used by other authors
such as Adrien Merer (2011) and Kristian Nymoen
et al. (2011). Recently K ¨ussner (2013) proposed the
use of sequences of pure tones while changing the
parameters pitch, loudness, and tempo.
This previous work provides us with a promising
methodology for the study of gestural description
of sounds. Most of these studies rely on exploring
analog relationships between gestural and sound
parámetros. We will refer to such an approach as
tracing (or analog) experimentos, where the motion
trajectories are associated with acoustic parameters.
Además, in the following we will refer to sound
morphology to designate the temporal profile of the
acoustic characteristics of sound (p.ej., amplitude,
pitch, and timbral aspects).
In prior work (Caramiaux et al. 2014), nosotros estafamos-
ducted experiments to give evidence regarding the
link between gestural description and both acoustic
and causal listening modes. We examined experi-
mentally how participants can associate different
types of motion in the acoustic and causal listening
modes. We observed two related strategies: mimick-
ing the action related to the sound source (causal
listening mode) or tracing the shape of the sound
parameter (acoustic listening mode). En particular,
we showed that the identification of sound sources
(es decir., the mode of listening) has a direct consequence
on the gestural strategies. If the participants can
identify the sound source as an action, they tend to
mimic the action. Por otro lado, a sound that
cannot be identified leads participants to trace the
profile of perceived sound features.
This experimental study showed a link between
acoustic (or causal) listening modes and analog (o
mimicking) motion strategies. This study provides
a rationale for establishing mapping strategies based
on listening modes and associated motion strategies.
Mapping strategies can stem from the reviewed
experimental findings, and they can evoke particular
links between listening modes and motion through
a scenario and design of interaction. In the next
section we describe specific examples illustrating
the link between causal, acoustic, and metaphorical
listening modes and gestural strategies.
From Listening to Controlling
In this section we describe concrete examples
that we developed and that were used in different
settings, from experiments and demonstrations to
interactive installations and performances. All these
examples are based on modeling the target sound
from a gestural perspective: a prior listening to (o
evocation of) the sound provides performers with
insights into possible strategies for gesture control.
These strategies are then made possible using
machine-learning techniques. Similar approaches
have been described by Godøy (2006), Doug Van
Nort (2009), Rebecca Fiebrink (2011), and Pieter-Jan
Maes (2012).
Our general methodology is as follows. El
first step corresponds to listening to recorded
sounds from different perceptual perspectives, como
described in the previous section. This leads one to
consider scenarios and metaphors where the motion
38
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
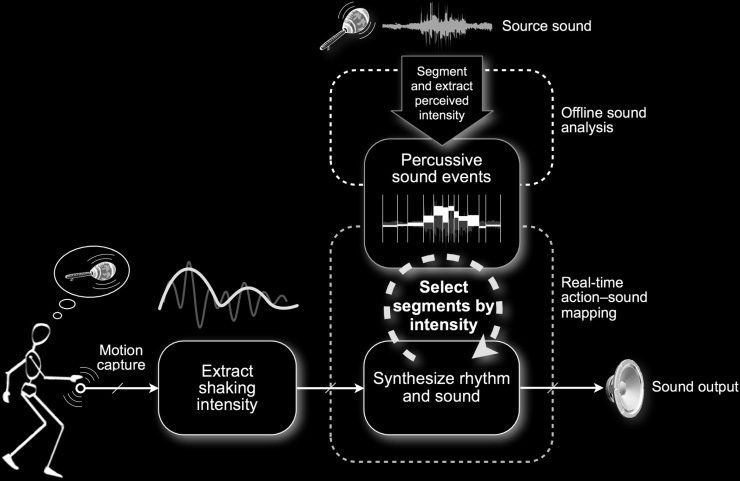
Cifra 2. The shaking
scenario. A recorded
rhythmic sound is
analyzed and segmented.
An incoming gesture is
analyzed and its energy is
computed and drives the
selection of the segment to
be played.
in interaction is linked to the targeted sounds.
Mapping strategies are then designed to implement
the interaction scenarios. In most cases, the mapping
is built using machine-learning techniques from
examples gathered during a “learning” phase, antes
the final “playing” phase.
Interaction Scenarios and Mapping Strategies
Four interactions have been created that implement
distinct mapping strategies illustrating the approach.
These four scenarios are shaking, shaping, fishing,
and shuffling.
Shaking
The action–sound mapping of this scenario emerges
from the action metaphor of shaking, associating the
performer’s shaking movement to the generation
of percussive sounds. This scenario is meant to be
related to the causal mode of listening, since the
performer mimics the gesture of shaking. A pesar de
this metaphor may refer, in music performance,
to percussion instruments such as a shaker or
maracas, it can also be associated with various
nonmusical actions and sounds. Como consecuencia, el
mapping designed for this scenario can be applied
to any sound that is composed of percussive events
of varying intensity, and it can be applied to any
movement that resembles shaking or waving (es decir.,
movements that are periodic and modulated in
intensidad).
This mapping is designed to be a direct rela-
tionship between the movement energy and the
energy of the sound played. The sound can, cómo-
alguna vez, be chosen to be any percussive recorded sound.
The mapping relies on a first phase called learn-
En g. During this phase, an offline analysis of a
sound database segments the recorded materials
into percussive events and describes each seg-
ment by its perceived intensity. Each segment is
consequently structured according to its inten-
sity level. During the second phase, playing, el
performer’s motion is analyzed in real time by
computing its energy. Sounds are then selected
from the database according to the motion’s level
of energy. The intensity of shaking has a direct
relationship to the intensity of the synthesized per-
cussive sound event whereas the performer does not
control the rhythmic pattern. Cifra 2 illustrates the
scenario.
Caramiaux et al.
39
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
We use accelerometers to sense the performer’s
movimiento. Concrete implementations were featured
in different performances using the musical object
interfaces (p.ej., performances at the 2011 Margaret
Guthman Musical Instrument Competition or the
2013 International Conference on Tangible, Embed-
ded and Embodied Interaction, cf. Rasamimanana
et al. 2011). The shaking intensity can be obtained by
integrating the variations of the measured acceler-
ation magnitude. Audio segmentation is performed
by onset detection. A mean loudness measure is
computed for each segment. Both feature spaces,
motion and sound, are normalized, so that each
sound segment can be associated with a correspond-
ing shaking intensity lying between the lowest and
highest possible values. The system used a k-nearest
neighbor (k-NN) search algorithm based on a k-
dimensional (k-D) tree to select a sound event of a
given intensity from among the available segments
(Schwarz, Schnell, and Gulluni 2009).
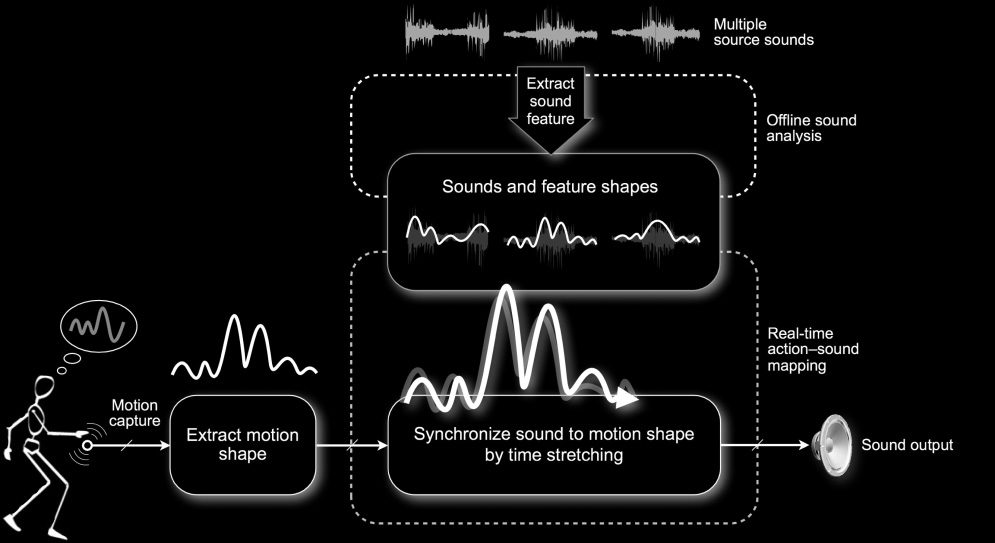
Shaping
Shaping refers to scenarios where performers control
sound morphologies by “tracing” in the air those
salient sound features they desire to control. Es
thus related to acoustic listening as we defined
previamente, where the performer pays attention to
acoustic qualities of the sound and, En particular, a
its temporal evolution.
The interaction scenario leads the performer to
design gestures related to specific recorded sound
morphologies. Rather than using a metaphor, el
link between gestures and sounds is built by analogy,
as the design of gestures needs to tightly reflect the
aspects of the sound the performer perceives and
intends to affect. De nuevo, the mapping relies on two
distinct phases: learning and playing. The learning
phase consists of a prior construction and analysis of
a database of sounds. Each sound is analyzed offline
to compute the feature representation. The playing
phase starts with a gesture executed by a performer.
The performer gesturally draws the morphology of
a particular sound and replays the sound in real
tiempo, translating the time variations of the input
gestures to sound variations. The beginning and
the end of the gesture must be marked by the
performer (p.ej., using buttons on the interface). A
sound is selected as soon as the gesture starts, usando
a real-time shape-matching algorithm that finds,
at each time step, the audio-feature morphology
closest to the gesture morphology and aligns the two
morphologies temporally. Note that the algorithm
can be configured to allow transitions between
gestures, which enables the algorithm to switch
between sounds during the execution of a gesture.
Cifra 3 illustrates the scenario.
The implementation, called the gesture follower,
is based on a machine-learning technique using
hidden Markov models (HMM) and is presented in
the Appendix. Because the sound is aligned to the
gesture in real time, it translates the variations in the
gesture morphology, such as the speed of execution,
to variation in the playback, reinterpreting the
recorded sound. In a demonstration presented at
el 2010 Sound and Music Computing Conference
(Caramiaux, Bevilacqua, and Schnell 2010a), gesture
and sound were represented by a unidimensional
time series, the energy of a gesture controlling the
loudness. The energy of a gesture was computed
as its absolute speed (an infrared camera motion
capture system was used to capture the gesture).
Being of different physical dimensions, el tiempo
series were scaled beforehand into the same range of
valores.
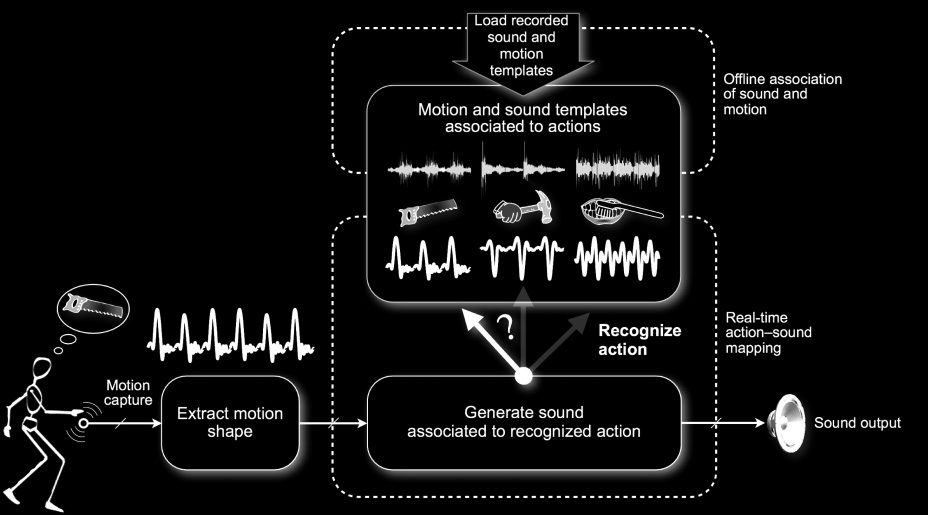
Fishing
The fishing scenario relies on a metaphor where the
performer mimics an action in order to select and
play a specific sound. En otras palabras, the performer
virtually “fishes” for the sound by mimicking the
associated action that supposedly caused the sound.
Por lo tanto, the fishing scenario is meant to be related
to the causal aspect of listening where a performer
focuses on the event that has produced the sound
and tries to mimic it.
The application is based on the recognition of the
performed action and requires a learning phase: A
database of actions is built by recording one example
of each action to be recognized. An action is a single
unit represented as a multidimensional continuous
time series of its parameters. Además, cada
action has an associated sound meant to illustrate
40
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 3. The shaping
scenario. Multiple sounds
are analyzed by computing
feature shapes. Sobre el
other hand, the motion
shape of a live gesture
performance is extracted
and used to select and
control the sound whose
feature shape is the closest
to the gesture.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
the possible sound produced by the action. During
the playing phase, the user performs a gesture that,
if recognized as an action from the database, will
trigger playback of theassociated sound. Porque
the system relies on action recognition, both the
performed and the predefined actions must have
a consistent representation, which could imply
they were performed with the same device and,
como consecuencia, with the same set of parameters
taking their values into the same range. Cifra 4
illustrates the scenario.
The system uses the same algorithm (the gesture
follower) as the shaping scenario presented in the
Apéndice. In the installation version of the system,
presented during a meeting of Sound and Music for
Everyone Everyday Everywhere Everyway project
(SAME, www.sameproject.eu/), the actions were
captured through the use of mobile phones with
embedded accelerometers. The training process is
part of the design and not seen by the performer.
The playing phase was implemented with a gaming
scenario. A set of two action–sound pairs from the
database was presented to the user in order to be
mimicked. The algorithm was set to play the sound
associated with an action as soon as this action is
Reconocido. Además, the algorithm was set to
output the time progression in the executed action.
When the user reached 90% of the recognized action,
the sound was set to be fished. The user has to do the
same with the second action. Once both sounds are
successfully fished, another set of pairs is presented.
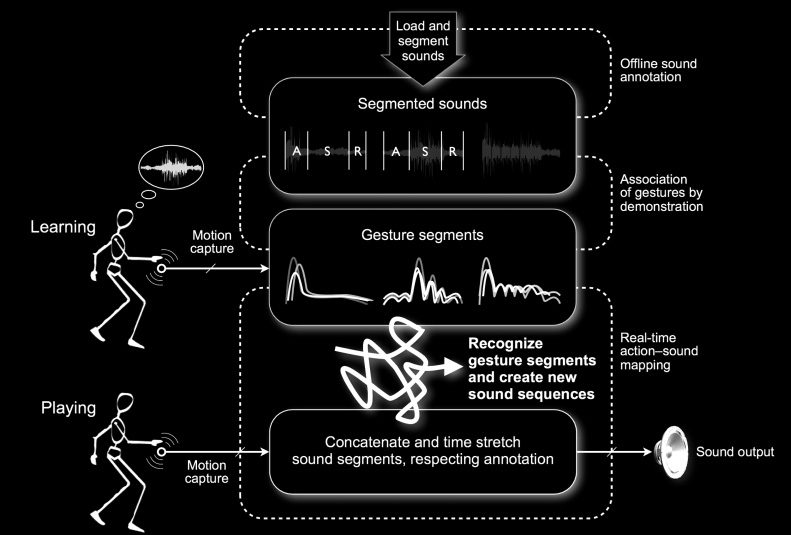
Shuffling
The shuffling scenario consists in gesturally recom-
posing and reinterpreting complex sound sequences.
This is achieved by processing short pieces of
recorded sounds put in relationships with gesture
segments. The scenario does not involve pre-
established metaphors as in the previous examples,
but defers the design choices to the performers,
allowing them to interactively implement their own
metaphors and control strategies.
The mapping is designed by demonstration: El
gestures performed by the performer in conjunc-
tion with particular sounds are used to train a
Caramiaux et al.
41
Cifra 4. The fishing
scenario. A set of recorded
sounds is loaded together
with associated actions
that represent the sound.
The incoming live gesture
performance tries to “fish»
a sound by mimicking the
associated action. Si
successful, the sound is
played.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
machine-learning model that encodes their rela-
tionships. When the performers perform a new
gesture sequence, sounds are resynthesized and
aligned in real time, using phase vocoding. En algunos
aspectos, the present scenario generalizes some of
the previous examples by allowing the performer to
mimic sound-producing actions (cf. fishing), to trace
sound features (cf. shaping), or to combine these
approaches sequentially.
Designing the mapping by demonstration in-
volves an interaction loop divided into two distinct
phases: learning and playing. During the learning
phase, the performer begins by selecting sounds
and manually defining their segmentation using
a graphical editor. Then the performer records
one or multiple gestures associated with each
sound, Por ejemplo, by recording a template gesture
synchronously while listening to a given sound.
Además, one can specify authorized transitions
between each gesture and sound segment. During
the playing phase, the performer recomposes the
original sounds by performing arbitrary sequences
of gestural segments. The gestures are recognized
and aligned to their reference in real time to dynam-
ically select and replay the appropriate sequence of
sound segments along with the gesture performance.
Cifra 5 illustrates the shuffling scenario.
The mapping is based on a hierarchical model for
continuous gesture recognition and segmentation,
called a hierarchical HMM (see the Appendix for
details). The model has two levels. The lower level
precisely encodes the time structure of the segments,
and the higher level governs their sequencing, defin-
ing the possible transitions between various points
within the gesture. The model can be built from
a single segmented example. The recognition is
performed in real time and the model estimates
the alignment of the new gesture compared with
the reference, allowing for the reinterpretation
of the sound with a fine time precision. De este modo,
the temporal variations of the live gestural perfor-
mance are translated to sound variations using a
phase vocoder (superVP in Max/MSP).
A specific implementation was introduced by
Franc¸ oise, Caramiaux, and Bevilacqua (2012). Cada
gesture and each sound morphology is segmented
42
Computer Music Journal
Cifra 5. The shuffling
scenario. A learning phase
allows the performer to
select a segmented sound
and to record one gesture
associated to it, para
example by recording
while listening to a given
sound. A playing phase
allows the performer to
recompose the original
sound by performing
arbitrary sequences of
gestural segments.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
into attack, sustain, and release segments, possibly
complemented by a preparation phase anticipating
the attack of the sound.
Two aspects of this decomposition are particularly
attack can be related to mimicking (p.ej., usando
a metaphor such as hitting an object) mientras que la
sustain and release phases can implement a tracing
gestural description.
interesante.
Primero, the consistency of the relationships between
gesture and sound can be guaranteed by specifying
constraints for the sound synthesis on particular
segments (p.ej., silence during preparation or tran-
sient conservation on attack phases). Además,
the features extracted from the performer’s gesture
in one action segment can be mapped to sound
features of the following segments. In this way, el
silent trajectory of a preparation gesture can define
the features at the beginning of the sound that,
in the following segments, can be shaped by the
performer’s gesture. (In the design of traditional in-
struments, similar possibilities are obtained through
the instrument’s geometry, allowing the performer
to interact—or not—with different parts of the
instrument responding to action in different ways.)
Segundo, this decomposition allows for designing
strategies that involve multiple gestural descriptions
related to listening: Por ejemplo, preparation and
Discusión y conclusión
We presented four mapping examples illustrating
our approach, based on a perceptual analysis of the
target sound. All examples use synthesis techniques
to gesturally “reinterpret” the recorded sounds.
Each scenario and mapping strategy can be described
by a top–down approach. En particular, each can be
linked to particular listening modes and gesture
strategies presented in the section “Describing
Sound Gesturally.”
Cifra 6 summarizes how the examples are
related to the different listening modes and gestural
strategies we have discussed. Además, we require
the different strategies of mapping that are used
in the different examples. We distinguish between
instantaneous, temporal, and metaphorical aspects
that define the relationship between gesture and
Caramiaux et al.
43
Cifra 6. Classification of
the scenarios along three
dimensions: the listening
mode, related to listening
procesos; the gestural
estrategia, which describes
how gestures derive from
escuchando; and the mapping
strategies implementing
each gestural strategy.
Listening Mode
Gestural Description Mode
Mapping Strategies
Causal
(sound source)
Acoustic
(sound features)
Mimicking
Iconic
Tracing
Analogic
Instantaneous Temporal Metaphoric
Shaking
Shaping
Fishing
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
sound. Instantaneous mapping strategies refer to the
translation of magnitudes between instantaneous
gesture and sound features or parameters. Temporal
mapping strategies refer to the translation and
adaptation of temporal morphologies (es decir., profiles,
timing, and event sequences) between the gesture
and sound data streams. Metaphorical mapping
strategies refer to relationships determined by
metaphorical or even semantic aspects, which do
not necessarily rely on morphological congruences
between gesture and sound.
The shaking scenario makes use, principally, de
an instantaneous mapping strategy between ges-
ture and sound: The shaking intensity is directly
related to the intensity of each percussive sound
evento. Curiosamente, we have observed how per-
formers spontaneously synchronize their shaking
movements to the tempo generated by the system.
This creates a direct action–perception loop: el
sound “feedback” produced is similar to a shaker
sound and encourages the player to pursue a shaking
movimiento. The listening mode is causal and there is
a metaphorical association between the action and
sound. Owing to the strong action metaphor, el
scenario can also supply completely unconventional
sounds for the performer to shake.
In the shaping scenario performers mainly focus
on “acoustic” properties of the sound. They must
“trace” the temporal profile of a sound feature
to be able to select and modify a sound whose
morphology matches the motion shape. Relying
on temporal morphologies, the mapping of this
scenario can be seen as the closest mapping example
to previous ideas developed by Godøy (2006) or Van
Nort (2009). The difference with shaking resides
in the precise control over the sound’s temporal
evolution, supporting a listening mode focussed
on acoustic sound features. Our experiments with
this scenario showed that a sonic profile must be
memorized beforehand in order to consciously target
it and, eventually, to reproduce it with temporal
variations.
The shaping scenario makes use of a temporal
mapping between gesture parameters and sound fea-
turas. This mapping allows the performer to reshape
a sound based on the temporal morphology of his or
her gesture. The general concept of temporal map-
ping was previously introduced by Bevilacqua et al.
(2011) for the cases where temporal relationships
between gesture and sound parameter profiles are
established.
The fishing scenario makes use of a mapping
that can be considered as metaphorical: Unlike the
shaking and shaping scenarios, the morphologies of
gesture and sound in this example can be incongru-
ent in some cases. The action–sound relationship
es, nevertheless, clear from the perspective of causal
escuchando. As mentioned previously, this scenario has
been shown at an installation during the EU Project
SAME. Feedback from users showed that such a
mapping was highly appreciated and characterized
as ludic. En efecto, the sounds chosen were easily iden-
tified and the action easily reproducible. A pesar de
the scenario focuses on a causal mode of listening,
44
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
an extended version comprising a metaphorical
mode of listening can be envisaged and can enrich
the scenario.
Finalmente, the shuffling scenario makes use of a
mapping strategy that can be characterized as both
temporal and metaphorical. The temporal charac-
teristic of the mapping is similar to the shaping
scenario, and the metaphorical characteristic is
enabled by the implementation of a general al-
gorithm for the recognition of actions and action
sequences. The combined mapping consequently
offers additional control opportunities and action–
perception loop feedback. It drives performers in
both causal and acoustic listening modes, haciendo
them conscious of both the sound morphologies
(as in shaping) and the control of sound segments
through iconic gesture segments (as in fishing). El
shuffling example can be seen as an unified approach
in the sense that it can be configured to activate
several modes of listening and several modes of
gestural description (and it can also easily include
the shaking scenario).
The temporal aspects of mapping are particularly
important when designing action–sound relation-
ships based on the transformation of recorded
sounds. En este caso, temporal mapping strategies
allow for adapting the temporal morphologies ini-
tially present in the recorded sounds to the actions
of the performer. Creemos, nevertheless, eso
temporal mapping strategies are equally powerful
when considering other synthesis methods. Ellos
allow one to segment the performers’ actions and
to define different action–sound relationships for
different segments. There is, Por ejemplo, a need for
a distinction between action segments that actually
produce sound or induce sound changes, and those
that do not.
One design choice in the examples presented
here concerns the motion-sensing technology. Cualquier
sensing system provides a partial gesture description,
which might impact sound controllability. En el
four scenarios presented, we used accelerometers.
Although these sensors have inherent limitations
(p.ej., they are unable to sense spatial information),
they are sensitive to small changes in orientation and
dinámica. The choice, además, has been motivated
by other advantages of this technology: low cost,
wireless, well-understood signal characteristics, y
sufficient precision for most musical applications.
The scenarios discussed in this article make
extensive use of methods based on machine learning
(k-NN, HMM, hierarchical HMM). El rol de
machine learning is to implement the top–down
approach of our scenarios based on perceptual or
metaphorical action and sound description. En efecto,
all scenarios imply implicit relationships between
sound and gestural features. As discussed by Tom
mitchell (2006), machine-learning techniques are
effective for modeling such implicit relationships.
Además, such an approach has started to be
implemented and evaluated in different cases
in computer music performance (Fiebrink 2011;
Gillian 2011; Caramiaux and Tanaka 2013). El
ongoing research in this area examines the use
of machine learning for automatically selecting
gesture and sound features (Caramiaux, Bevilacqua,
and Schnell 2010b), for jointly modeling their
interactions over time to implicitly capture their
correlations and the expressive variations emerging
in different interpretations (Franc¸ oise, Schnell, y
Bevilacqua 2013), or the use of machine learning as
a design tool (Fiebrink, Cocinar, and Trueman 2011).
The possibilities arising from the introduction
of machine-learning techniques into the interac-
tion loop are twofold. First of all, they allow the
instrument to integrate notions of recognition and
prediction that support the implementation of in-
teractions based on the performer’s listening. As the
performer always adapts his or her actions to the
behavior of the instrument—either spontaneously
or by strenuous learning—these new instruments,
for their part, adapt themselves to the performer’s
comportamiento, preferences, and playing style. It is worth
noticing that machine-learning techniques are prone
to errors or may require time to converge to an accu-
rate estimate. Latency is inherently involved, y eso
may be an issue for specific types of control. Sobre el
other hand, latency can be handled by design. Para
instancia, in the fishing scenario we chose to use the
recognition latency, namely the fact that the user
has executed 90 percent of the action, as a visual
progress bar for the user. Curiosamente, with latency
represented in this manner, it challenged the user
during the interaction, enhancing the game play.
Caramiaux et al.
45
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
En conclusión, we propose a design approach for
mapping based on the concept of embodied listening.
Building on previous work on listening modes and
gestural descriptions we propose to distinguish three
mapping strategies: instantaneous, temporal, y
metaphorical. Our approach considers the processes
of listening as the foundation—and the first step—in
the design of action–sound relationships. En esto
design process, the relationship between action and
sound is derived from actions that can be perceived
in the sound. We believe that the described examples
only scratch the surface of the possibilities arising
from this approach.
Expresiones de gratitud
This work is supported by the mixed research lab
Sciences and Technologies for Music and Sound
(STMS), the Institut de Recherche et Coordination
Acoustique/Musique (IRCAM), the Centre National
de la Recherche Scientifique (CNRS), the Universit ´e
Pierre et Marie Curie (UPMC), and the Legos project
(ANR 11 BS02 012).
Referencias
Arfib, D., et al. 2002. “Strategies of Mapping Between
Gesture Data and Synthesis Model Parameters Using
Perceptual Spaces.” Organised Sound 7(02):127–144.
Bevilacqua, F., et al. 2010. “Continuous Realtime Ges-
ture Following and Recognition.” In S. Kopp and
I. Wachsmuth, eds. Gesture in Embodied Commu-
nication and Human–Computer Interaction. Berlina:
Saltador, páginas. 73–84.
Bevilacqua, F., et al. 2011. “Online Gesture Analysis and
Control of Audio Processing.” In J. Solis and K. Ng, eds.
Musical Robots and Interactive Multimodal Systems.
Berlina: Saltador, páginas. 127–142.
Cadoz, C. 1988. “Instrumental Gesture and Musical
Composition.” In Proceedings of the International
Computer Music Conference, páginas. 1–12.
Caramiaux, B., F. Bevilacqua, y N. Schnell. 2010a.
“Analysing Gesture and Sound Similarities with a
HMM-Based Divergence Measure.” In Proceedings of
the Sound and Music Computing Conference. Disponible
online at smcnetwork.org/files/proceedings/2010/9.pdf.
Accessed March 2014.
Caramiaux, B., F. Bevilacqua, y N. Schnell. 2010b.
“Towards a Gesture–Sound Cross-Modal Analysis.” In
S. Kopp and I. Wachsmuth, eds. Gesture in Embod-
ied Communication and Human-Computer. Berlina:
Springer Verlag, páginas. 158–170.
Caramiaux, B., y un. Tanaka. 2013. “Machine Learn-
ing of Musical Gestures.” In Proceedings of the
Conference on New Interfaces for Musical Expres-
sión. Available online at baptistecaramiaux.com/blog/
wp-content/uploads/2013/05/nime2013 mlrev.pdf.
Accessed March 2014.
Caramiaux, B., et al. 2014. “The Role of Sound Source
Perception in Gestural Sound Description.” ACM
Transactions on Applied Perception 11(1):1–19.
Caramiaux, B., et al. In press. “Adaptive Gesture Recogni-
tion with Variation Estimation for Interactive Systems.”
ACM Transactions on Iterative Intelligent Systems.
Castagne, NORTE., et al. 2004. “Haptics in Computer Music:
A Paradigm Shift.” In Proceedings of the Eurohaptics
Meeting, páginas. 174–181.
Chion, METRO. 1983. Guide des objets sonores : Pierre Schaeffer
et la recherche musicale. París: Buchet/Chastel.
Fadiga, l., et al. 2002. “Speech Listening Specifically
Modulates the Excitability of Tongue Muscles: A TMS
Study.” European Journal of Neuroscience 15(2):399–
402.
Fiebrink, R. A. 2011. “Real-Time Human Interaction with
Supervised Learning Algorithms for Music Composition
and Performance.” PhD Thesis, Universidad de Princeton,
Departamento de Ciencias de la Computación.
Fiebrink, R. A., PAG. R. Cocinar, y D. Trueman. 2011.
“Human Model Evaluation in Interactive Supervised
Learning.” In Proceedings of the SIGCHI Conference
on Human Factors in Computing Systems, páginas. 147–156.
Franc¸ oise, J., B. Caramiaux, and F. Bevilacqua. 2011.
“Realtime Segmentation and Recognition of Gestures
Using Hierarchical Markov Models.” Master’s Thesis,
Universit ´e Pierre et Marie Curie (Paris VI).
Franc¸ oise, J., B. Caramiaux, and F. Bevilacqua. 2012.
“A Hierarchical Approach for the Design of Gesture-
to-Sound Mappings.” In Proceedings of the Sound
and Music Computing Conference. Available online
at smcnetwork.org/system/files/smc2012-203.pdf.
Accessed March 2014.
Franc¸ oise, J., norte. Schnell, and F. Bevilacqua. 2013. “A
Multimodal Probabilistic Model for Gesture-Based
Control of Sound Synthesis.” In Proceedings of the ACM
International Conference on Multimedia, páginas. 705–708.
Frey, A., et al. 2009. “Temporal Semiotic Units as Minimal
Meaningful Units in Music? An Electrophysiological
Approach.” Music Perception 26(3):247–256.
46
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Gaver, W.. W.. 1993a. “How Do We Hear in the World?
Explorations in Ecological Acoustics.” Ecological
Psicología 5(4):285–313.
Gaver, W.. W.. 1993b. “What in the World Do We Hear? Un
Ecological Approach to Auditory Event Perception.”
Ecological Psychology 5(1):1–29.
Merer, A. 2011. “Caract ´erisation acoustique et perceptive
du mouvement ´evoqu ´e les sons pour le contr ˆole de la
synth `ese.” PhD Dissertation, Universit ´e de Provence
Aix-Marseille 1.
Merleau-Ponty, METRO. 1945. La Ph ´enomenologie de la
Percepción. París: Gallimard.
Gillian, norte. 2011. “Gesture Recognition for Musician
Miranda, MI., y M. Wanderley. 2006. New Digital
Computer Interaction.” PhD Thesis, Queen’s Univer-
sity Belfast, School of Music and Sonic Arts.
Godøy, R. I. 2006. “Gestural–Sonorous Objects: Embodied
Extensions of Schaeffer’s Conceptual Apparatus.”
Organised Sound 11(2):149–157.
Godøy, R. I., mi. Haga, y un. R. Jensenius. 2006. “Ex-
ploring Music-Related Gestures by Sound-Tracing: A
Preliminary Study.” In Proceedings of the International
Symposium on Gesture Interfaces for Multimedia
Sistemas, páginas. 27–33.
Haueisen, J., and T. R. Kn ¨osche. 2001. “Involuntary Motor
Activity in Pianists Evoked by Music Perception.”
Revista de neurociencia cognitiva 13(6):786–792.
Hunt, A., y r. Kirk. 2000. “Mapping Strategies for Mu-
sical Performance.” In M. METRO. Wanderley and M. Battier,
eds. Trends in Gestural Control of Music. París: Institut
de Recherche et Coordination Acoustique/Musique,
páginas. 231–258.
Huron, D. 2002. “A Six-Component Theory of Auditory-
Evoked Emotion.” In Proceedings of the International
Conference on Music Perception and Cognition,
páginas. 673–676.
K ¨ussner, METRO. 2013. “Music and Shape.” Literary and
Linguistic Computing 28(3):1–8.
Lahav, A., et al. 2005. “The Power of Listening: Auditory-
Motor Interactions in Musical Training.” Annals of the
New York Academy of Sciences 1060(1):189–194.
Large, mi. W.. 2000. “On Synchronizing Movements to
Music.” Human Movement Science 19(4):527–566.
Large, mi. w., and C. Palmer. 2002. “Perceiving Temporal
Regularity in Music.” Cognitive Science 26(1):1–37.
Leman, METRO. 2007. Embodied Music Cognition and Me-
diation Technology. Cambridge, Massachusetts: CON
Prensa.
Leman, METRO., et al. 2009. “Sharing Musical Expression
Through Embodied Listening: A Case Study Based on
Chinese Guqin Music.” Music Perception 26(3):263–
278.
Liberman, A. METRO., y yo. GRAMO. Mattingly. 1985. “The Motor
Theory of Speech Perception Revised.” Cognition
21(1):1–36.
Maes, P.-J. 2012. “An Empirical Study of Embodied
Music Listening and Its Applications in Mediation
Technology.” PhD Dissertation, Ghent University.
Musical Instruments: Control and Interaction beyond
the Keyboard. Middleton, Wisconsin: A-R Editions.
mitchell, t. METRO. 2006. “The Discipline of Machine Learn-
ing.” Technical Report CMU-ML-06-108. pittsburgh,
Pensilvania: Carnegie Mellon University, School of
Computer Science, Machine Learning Department.
Momeni, A., and C. Henry. 2006. “Dynamic Independent
Mapping Layers for Concurrent Control of Audio and
Video Synthesis.” Computer Music Journal 30(1):49–66.
No ¨e, A. 2005. Action in Perception. Cambridge, Mas-
sachusetts: CON prensa.
Nymoen, K., et al. 2011. “Analyzing Sound Tracings: A
Multimodal Approach to Music Information Retrieval.”
In Proceedings of the International ACM Workshop on
Music Information Retrieval with User-centered and
Multimodal Strategies, páginas. 39–44.
Rasamimanana, NORTE., et al. 2011. “Modular Musical
Objects Towards Embodied Control of Digital Music.”
In Proceedings of the International Conference on
Tangible, Embedded, and Embodied Interaction,
páginas. 9–12.
Rovan, J., et al. 1997. “Instrumental Gestural Mapping
Strategies as Expressivity Determinants in Computer
Music Performance.” In Proceedings of Kansei: El
Technology of Emotion Workshop, páginas. 68–73.
Schaeffer, PAG. 1966. Trait ´e des Objets Musicaux. París:
´Editions du Seuil.
Schwarz, D., norte. Schnell, and S. Gulluni. 2009. “Scalability
in Content-Based Navigation of Sound Databases.” In
Proceedings of the International Computer Music
Conferencia, páginas. 13-dieciséis.
Tuuri, K., and T. Eerola. 2012. “Formulating a Revised
Taxonomy for Modes of Listening.” Journal of New
Music Research 41(2):137–152.
Van Nort, D. 2009. “Instrumental Listening: Sonic Gesture
as Design Principle.” Oganised Sound 14(02):177–
187.
Van Nort, D., METRO. METRO. Wanderley, y P. Depalle. 2004.
“On the Choice of Mappings Based on Geometric
Properties.” In Proceedings of the Conference on New
Interfaces for Musical Expression, páginas. 87–91.
Varela, F., mi. Thompson, and E. Rosch. 1991. The Embod-
ied Mind: Cognitive Science and Human Experience.
Cambridge, Massachusetts: CON prensa.
Caramiaux et al.
47
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Wanderley, METRO. METRO. 2002. “Mapping Strategies in Real-Time
Computer Music.” Organised Sound 7(2):83–84.
Wanderley, METRO. METRO., y P. Depalle. 2004. “Gestural
Control of Sound Synthesis.” Proceedings of the IEEE
92(4):632–644.
Wanderley, METRO. METRO., y N. Orio. 2002. “Evaluation of Input
Devices for Musical Expression: Borrowing Tools from
HCI.” Computer Music Journal 26(3):62–76.
Zatorre, R. J., j. l. Chen, and V. B. Penhune. 2007. "Cuando
the Brain Plays Music: Auditory–Motor Interactions
in Music Perception and Production.” Nature Reviews
Neurociencia 8(7):547–558.
Monte Carlo inference on the parameters of a non-
linear dynamic system. It allows for the continuous
adaptation to variations of gesture characteristics
(Caramiaux et al. in press). En efecto, once the ges-
ture template is recorded, a similar live gesture
can be performed with variations in speed, escala,
rotation, etc.. These characteristics can be explicitly
taken into account by the method as invariant for
the recognition. To that extent, the method con-
tinuously estimates the relative characteristics of
the gestural variations, which can then be used in
continuous interaction scenarios.
Apéndice: Algorithms
In this appendix we describe the algorithm used
in the interaction scenarios. Rather than a full
technical specification, we outline the model used
and how the model has been adapted to the context.
Gesture Follower
The gesture follower (GF, cf. Bevilacqua et al. 2010)
is a template-based gesture-recognition method
based on HMMs. The model is learned from a single
example gesture, using its whole time series as a
template. The model is built by assigning a state
to each frame, similarly to dynamic time warping.
The time structure is modeled by a left-to-right
transition structure. A causal forward inference
allows for decoding in real time and returns the
currently recognized template, así como el
time progression in the template, performing an
alignment of the live gesture to the template.
Adaptive Extension
The model has been recently extended to quantify
and adapt to gesture variations by using sequential
Hierarchical Extension
The gesture follower has been extended to com-
prehend time structures that are more complex,
allowing for the representation of gestures as or-
dered sequences of segments. The method is based
on hierarchical HMMs with a two-level structure
(Franc¸ oise, Caramiaux, and Bevilacqua 2011). El
lower level models the fine time structure of a
segment using a template-based approach identical
to the GF. The higher level governs how segments
can be sequenced by a high-level transition struc-
tura, whose probabilities constrain the possible
transitions between segments. De este modo, the model can
be built from a single demonstration of the gesture
complemented by prior annotation defining the
segmentation. The recognition is based on a for-
ward algorithm allowing for the causal estimation
of the performed segment (informed by the high-
level transition structure) and the time position
within this segment (as detailed in the the previous
sección). This representation provides both fine-
grained and high-level control possibilities, permitiendo
one to reinterpret gestures through a segment-
level decomposition that can be authored by the
performer.
48
Computer Music Journal
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
C
oh
metro
j
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
/
/
/
3
8
3
3
4
1
8
5
6
0
3
6
/
C
oh
metro
_
a
_
0
0
2
5
5
pag
d
.
j
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
8
S
mi
pag
mi
metro
b
mi
r
2
0
2
3