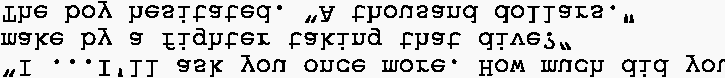No es una ciencia exacta:
Interpreting Figurative Language in Narratives
Tuhin Chakrabarty1∗ Yejin Choi2,3 Vered Shwartz4∗
1Columbia University, USA 2Allen Institute for Artificial Intelligence, EE.UU
3Paul G. Allen School of Computer Science & Ingeniería, University of Washington, EE.UU
4University of British Columbia, Canada
tuhin.chakr@cs.columbia.edu, yejinc@allenai.org, vshwartz@cs.ubc.ca
Abstracto
Figurative language is ubiquitous in English.
Todavía, the vast majority of NLP research focuses
on literal language. Existing text representa-
tions by design rely on compositionality,
while figurative language is often non-
compositivo. en este documento, we study the
interpretation of two non-compositional fig-
urative languages (idioms and similes). Nosotros
collected datasets of fictional narratives con-
taining a figurative expression along with
crowd-sourced plausible and implausible con-
tinuations relying on the correct interpretation
of the expression. We then trained models
to choose or generate the plausible contin-
uation. Our experiments show that models
based solely on pre-trained language mod-
els perform substantially worse than humans
on these tasks. We additionally propose
knowledge-enhanced models, adopting human
strategies for interpreting figurative language
types:
inferring meaning from the context
and relying on the constituent words’ literal
meanings. The knowledge-enhanced models
improve the performance on both the discrim-
inative and generative tasks, further bridging
the gap from human performance.
1
Introducción
Figurative language is a medium for mak-
ing language expressive, communicating ab-
stract ideas otherwise difficult to visualize, y
provoking emotions (Roberts and Kreuz, 1994;
Fussell and Moss, 1998). Despite the ubiquity of
figurative language across various forms of speech
y escribiendo, the vast majority of NLP research fo-
cuses primarily on literal language. Figurative
language is often more challenging due to its
implicit nature and is seen as ‘‘a bottleneck in
automatic text understanding’’ (Shutova, 2011).
∗Work done at the Allen Institute for AI.
589
En años recientes,
transformer-based language
modelos (LMs) achieved substantial performance
gains across various NLP tasks, sin embargo, they still
struggle with figurative language. En particular,
one of the challenges is that figurative expres-
sions are often non-compositional, eso es, el
phrase meaning deviates from the literal mean-
ings of its constituents. Por ejemplo, the idiom
‘‘chicken feed’’ in Figure 1 denotes ‘‘a ridicu-
lously small sum of money’’ instead of ‘‘food
for poultry’’. By design, transformer-based LMs
compute a word representation as a function
of the representation of its context. LM-based
phrase representations encode the meanings of the
constituent words but hardly capture any mean-
ing that is introduced by the composition itself
(Yu and Ettinger, 2020). Even though LMs may
recognize when a word is used non-literally, y
potentially attend to it less, they still struggle to
represent the implied, non-literal meaning of such
phrases (Shwartz and Dagan, 2019).
While LMs potentially memorize familiar id-
ioms, we can expect them to further struggle
with similes, which are often created ad hoc
(Carston and Wearing, 2011). Por ejemplo, en
Cifra 1, the person is compared to ‘‘a high
mountain lake without a wind stirring it’’ to imply
calmness. Many such figurative expressions com-
pose in a non-trivial way, and introduce implicit
meaning that requires multiple reasoning steps
to interpret.
In this paper we work on interpreting idioms
and similes in narratives, where they are es-
pecially abundant. Existing work on narrative
understanding focuses on literal stories,
prueba-
ing models on their ability to answer questions
about a narrative (Koˇcisk´y et al., 2018) or con-
tinue an incomplete narrative (Story Cloze Test;
Mostafazadeh et al., 2016). We follow the latter
Transacciones de la Asociación de Lingüística Computacional, volumen. 10, páginas. 589–606, 2022. https://doi.org/10.1162/tacl a 00478
Editor de acciones: Tim Baldwin. Lote de envío: 0/2021; Lote de revisión: 12/2021; Publicado 5/2022.
C(cid:3) 2022 Asociación de Lingüística Computacional. Distribuido bajo CC-BY 4.0 licencia.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 1: Example narratives from our datasets, containing an idiom (arriba) or a simile (abajo), junto con
human-written plausible and implausible continuations.
setup. We extracted short narratives from the
Toronto Book corpus (Zhu et al., 2015), cada
containing a figurative expression, and crowd-
sourced plausible and implausible continuations
that rely on correct interpretation of the figurative
expresión. We defined two tasks: a discrimi-
native setting, where the goal is to choose the
plausible continuation among two candidates, y
a generative setting, where the goal is to generate
a plausible continuation that is coherent with the
narrative and complies with the meaning of the
figurative expression.
We report the performance of an extensive
number of state-of-the-art LMs on both tasks,
en tiro cero, few-shot, and supervised settings.
Our results show that pre-trained LMs including
GPT-3 (Brown y cols., 2020) perform poorly in the
zero-shot and few-shot settings. While the super-
vised model’s performance is closer to humans,
the gap is still substantial: In the discriminative
tareas, the gap from human performance was 10
y 14.6 points in accuracy for idioms and sim-
iles, respectivamente. In the generative tasks, allá
was a striking 24 y 28 points difference in hu-
man evaluation of the plausibility of generated
continuations.
To further close this gap, we developed
knowledge-enhanced models inspired by two hu-
man strategies for interpreting unknown idioms,
as studied by Cooper (1999) and discussed in
Shwartz and Dagan (2019). The first strategy is to
infer the expression’s meaning from its context,
for which we incorporate event-centered infer-
ences from ParaCOMET (Gabriel et al., 2021b).
The second relies on the literal meanings of the
constituent words, using concept-centered knowl-
edge from COMET-ConceptNET (Hwang et al.,
2021). Additionally similes are often interpreted
by humans using the literal property of the ve-
hicle or object of comparison and thus we use
concept-centered knowledge here as well. El
knowledge-enhanced models consistently outper-
formed other models on both datasets and settings,
with a substantial gap on the generative tasks.
Además, different strategies were favored
for each case: The generative context model
performed well on idioms, in line with Cooper’s
findings, while the literal model was favored
for similes, which are by design based on a
constituent’s literal attribute (p.ej., calm lake).
The knowledge-enhanced models leave room for
improvement on our dataset. We hope that future
work will use additional techniques inspired by
the properties of figurative language and human
processing of it. Our code and data are available
at https://github.com/tuhinjubcse
/FigurativeNarrativeBenchmark and
leaderboard is available at https://
nuestro
leaderboard.allenai.org/idiom-simile/.
2 Fondo
2.1 Idioms
instancia,
‘‘break a leg’’
Idioms are figurative expressions with a non-literal
significado. Para
es un
good luck greeting before a performance and
shouldn’t be taken literally as wishing someone
to injure themselves. Idioms are typically non-
compositivo (es decir., the meaning of an idiom is not
derived from the meanings of its constituents) y
fixed (es decir., allowing little variance in syntax and
lexical choice).1 Idiomatic expressions include
1The meaning of some idioms may be derived from the
non-literal meanings of their constituents. Por ejemplo, en
‘‘spill the beans’’, the non-literal meaning of spill is ‘‘reveal’’
and the beans signify the secret (Sag et al., 2002).
590
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
proverbs (‘‘actions speak louder than words’’),
clich´es (‘‘what goes around comes around’’),
euphemisms (‘‘rest in peace’’), y más.
Prior work on idioms largely focused on identi-
fying the idiomaticity of a multi-word expression.
This is a classification task, defined either at the
token-level (is the phrase idiomatic within a given
contexto?), or the type-level (may the phrase be
idiomatic in some context?) (Fazly et al., 2009;
Li and Sporleder, 2009; Verma and Vuppuluri,
2015; Peng and Feldman, 2016; Salton et al.,
2016; Liu and Hwa, 2017). Compared to iden-
tification, the interpretation of idioms has been
less explored. Approaches for representing id-
iomatic expressions include substituting idioms
with literal paraphrases (Liu and Hwa, 2016; zhou
et al., 2021), representing them as a single token,
or learning to compose them at the character level
rather than the word level (Liu et al., 2017).
With the rising popularity of pre-trained LMs,
several recent papers studied their capacity to
accurately represent idioms. Shwartz and Dagan
(2019) found that while LMs excelled at detect-
ing non-literal word usage (p.ej., ‘‘flea’’ in ‘‘flea
market’’), the representation of idiomatic expres-
sions was of lower quality than that of literal ones.
Yu and Ettinger (2020) showed that LMs en-
code the words that appear in a given text,
but capture little information regarding phrase
significado. Finalmente, Garcia et al. (2021) studied
the compositionality of noun compounds in En-
glish and Portuguese, and found that LM-based
models did not perform well on detecting com-
positionality, and represented idiomaticity differ-
ently from humans.
2.2 Similes
Similes are a figure of speech that compares two
cosas, usually with the intent to make the de-
scription more emphatic or vivid, and spark the
reader’s imagination (Paul et al., 1970). simí-
les may either be explicit, a saber, specify the
topic, vehicle, and similarity property, as in ‘‘The
house was cold like Antarctica’’ (where the topic
the vehicle is ‘‘Antarctica’’ and
is ‘‘house’’,
the property of comparison is ‘‘cold’’), or im-
plicit, a saber, omitting the property, as in ‘‘the
house was like Antarctica’’ (Sección 3.2). Mayoría
work in NLP has focused on simile detection,
eso es, distinguishing literal from figurative com-
parisons. Earlier work relied on semantic and
syntactic characteristics, a saber, higher semantic
similarity between the topic and the vehicle in
literal comparisons than in figurative comparisons
(Niculae and Danescu-Niculescu-Mizil, 2014;
Qadir et al., 2015; Mpouli, 2017), and dictionary
definitions (Qadir et al., 2016), while more recent
work is based on neural methods (Liu et al., 2018;
Zeng et al., 2020). Simile interpretation focused
on inferring the implicit property (Qadir et al.,
2016). In other lines of work, Chakrabarty et al.
(2020b) and Zhang et al.
(2021) propuesto
methods for generating similes from their literal
counterparts, while Chakrabarty et al. (2021a)
showed that state-of-the-art NLI models fail on
pragmatic inferences involving similes.
2.3 Human Processing of Figurative Language
The ways in which humans process figurative
language may inspire computational work on fig-
urative language interpretation. Cooper (1999)
studied how L2 English speakers interpret un-
familiar English idioms. He found that the leading
strategy was to infer the meaning from the given
contexto, which led to successful interpretation
57% of the time, followed by relying on the literal
meaning of the constituent words (22% success
tasa). Por ejemplo, a participant asked to inter-
pret ‘‘robbing the cradle’’ in the context ‘‘Robert
knew that he was robbing the cradle by dating
a sixteen-year-old girl’’ used the literal meaning
of cradle to associate the meaning with babies
and indirectly with young age, and along with
the context inferred that it meant to ‘‘date a very
young person’’. Asl (2013) repeated the same ex-
periment with stories, and concluded that longer
contexts improved people’s ability to interpret un-
known idioms. With respect to novel similes and
metaphors, they are interpreted through shared
literal attributes between the topic and vehicle
(p.ej., ‘‘Antarctica is cold, can a house also be
cold?'') (Wolff and Gentner, 2000; Carston and
Wearing, 2011).
2.4 Narrative Understanding
Early computational work on narrative un-
derstanding extracted chains of subevents and
their participants from narratives (Chambers and
Jurafsky, 2009). An alternative task is ma-
chine reading comprehension, eso es, answering
multiple-choice questions based on a narrative,
591
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
such as MCTest (Richardson et al., 2013) y
NarrativeQA (Koˇcisk´y et al., 2018).
The most commonly used benchmark for
narrative understanding today is ROCStories
(Mostafazadeh et al., 2016), a collection of 50k
five-sentence commonsense stories pertaining to
everyday life. The story cloze task requires mod-
els to identify the plausible continuation sentence
among two candidate continuations in its discrimi-
native form, or generate a plausible sentence, in its
generative form. Since the release of this dataset,
many computational approaches for the task have
been developed (Chaturvedi et al., 2017; Schwartz
et al., 2017b; Cai et al., 2017; Srinivasan et al.,
2018; Le et al., 2019; Cui et al., 2020; Brown y cols.,
2020, inter alia). en este documento, we follow the story
cloze benchmark setup, and collect benchmarks
particularly aimed at testing the comprehension of
figurative language in narratives.
2.5 Commonsense Knowledge Models
Many language tasks require relying on implicit
commonsense knowledge that is never mentioned
explicitly because it is assumed to be known by
everyone. Con ese fin, commonsense knowledge
bases (KB) record such facts. Notablemente, Concept-
Net (Speer et al., 2017) is a large-scale concept-
centric KB, while ATOMIC (Sap et al., 2019)
contains event-centric knowledge about causes,
efectos, and the mental states of the participants.
To overcome the sparsity of KBs, conocimiento
models such as COMET (Bosselut et al., 2019;
Hwang et al., 2021) fine-tuned an LM on struc-
tured KB triplets. COMET is capable of providing
inferences for new events or concepts. Para-
COMET (Gabriel et al., 2021a) is an extension
of ATOMIC-COMET that works at the paragraph
level and generates discourse-aware common-
sense knowledge. Recientemente, several works have
used such commonsense knowledge models for
improved natural language understanding or gen-
eration such as Bhagavatula et al. (2019) para
abductive reasoning, Shwartz et al. (2020) para
control de calidad, Guan et al. (2019), and Ammanabrolu et al.
(2020) for story generation, Majumder et al.
(2020) for dialog generation, and Chakrabarty
et al. (2020a; 2020b; 2021b) for creative text
generación.
In our work we use the knowledge models
COMET (Hwang et al., 2021) and ParaCOMET
(Gabriel et al., 2021a), respectivamente, to provide
Idioms
Similes
any port in a storm
been there, done that
slap on the wrist
no time like the present
lay a finger on
walk the plank
curry favour
not to be sneezed at
no peace for the wicked
like a psychic whirlpool
like a moth-eaten curtain
like a first date
like a train barreling of control
like a sodden landscape of melting snow
like a Bunsen burner flame
like a moldy old basement
like a street-bought Rolex
like an endless string of rosary beads
Mesa 1: Examples of idioms and similes present
in the narratives in our datasets.
more information about the literal meaning of
constituent words or the narrative context useful
to infer the figurative expressions meaning.
3 Datos
We build datasets aimed at testing the understand-
ing of figurative language in narratives, focusing
on idioms (Sección 3.1) and similes (Sección 3.2).
We posit that a model that truly understands the
meaning of a figurative expression, like humans
hacer, should be able to infer or decide what happens
next in the context of a narrative. De este modo, nosotros estafamos-
struct a dataset in the form of the story-cloze test.
3.1 Idioms
We compile a list of idioms, automatically find
narratives containing these idioms, and then elicit
plausible and implausible continuations from
crowdsourcing workers, como sigue.
Collecting Idioms. We compile a list of 554
English idioms along with their definitions from
online idiom lexicons.2 Table 1 presents a sample
of the collected idioms.
Collecting Narratives. We use the Toronto
Book corpus (Zhu et al., 2015), a collec-
ción de 11,038 indie ebooks extracted from
smashwords.com. We extract sentences from
the corpus containing an idiom from our list, y
prepend the 4 preceding sentences to create a nar-
rative. We manually discarded paragraphs that did
not form a coherent narrative. We extracted 1,455
narratives with an average length of 80 palabras,
spanning 554 distinct idioms.
2www.theidioms.com, idioms.thefreedictionary.com.
592
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Collecting Continuations. We collected plausi-
ble and implausible continuations to the narrative.
We used Amazon Mechanical Turk to recruit 117
workers. We provided these workers with the
narrative along with the idiom definition, and in-
structed them to write plausible and implausible
continuations that are pertinent to the context, de-
pend on the correct interpretation of the idiom,
but that don’t explicitly give away the meaning of
the idiom. We collected continuations from 3 a
4 workers for each narrative. The average plau-
sible continuation contained 12 palabras, mientras que la
implausible continuations contained 11 palabras.
To ensure the quality of annotations, we re-
quired that workers have an acceptance rate of
al menos 99% para 10,000 prior HITs (Amazonas
Mechanical Turk tasks), and pass a qualification
prueba. We then manually inspected the annotations
to identify workers who performed poorly in
the initial batches, disqualified them from fur-
ther working on the task, and discarded their
anotaciones.
Our automatic approach for collecting narra-
tives does not account for expressions that may be
used figuratively in some contexts but literally in
otros. Por ejemplo, the idiom ‘‘run a mile’’ (es decir.,
avoiding something in any way possible) may
also be used literally to denote running a distance
of one mile. To avoid including literal usages,
we instructed the workers to flag such examples,
which we discard from the dataset. We further
manually verified all the collected data. En general,
we removed 12 such narratives.
idiom dataset
contiene 5,101
the top part of Figure 1. We split the examples to
train (3,204), validation (355), and test (1,542)
conjuntos. To test models’ ability to generalize to
unseen idioms, we split the data such that there
are no overlaps in idioms between train and test.
final
El
3.2 Similes
A simile is a figure of speech that usually consists
of a topic and a vehicle (typically noun phrases)
that are compared along a certain property using
comparators such as ‘‘like’’ or ‘‘as’’ (Hanks,
2013; Niculae and Danescu-Niculescu-Mizil,
2014). The property may be mentioned (explicit
simile) or hidden and left for the reader to infer
(implicit simile). We focus on implicit similes,
which are less trivial to interpret than their ex-
593
plicit counterparts (Qadir et al., 2016), and test a
model’s ability to recover the implicit property.
Collecting Similes. Because there are no reli-
able methods for automatically detecting implicit
similes, we first identify explicit similes based on
syntactic cues, and then deterministically convert
them to implicit similes. We look for sentences
in the Toronto Book corpus containing one of
the syntactic structures ‘‘as ADJ/ADV as’’ or
‘‘ADJ/ADV like’’ as a heuristic for identifying
explicit similes. We additionally add the con-
straint of the vehicle being a noun phrase to avoid
examples like ‘‘I worked as hard as him’’. We re-
move the adjectival property to convert the simile
to implicit, as demonstrated below:
Explicit:
He feels calm, like a high mountain lake without a wind
stirring it.
He feels as calm as a high mountain lake without a wind
stirring it.
Implicit:
He feels like a high mountain lake without a wind stirring it.
We collected 520 similes along with their as-
sociated property. We asked workers to flag any
expression that was not a simile, and manually
verified all the collected data. Mesa 1 presents
a sample of the collected similes. Many of the
similes are original, such as ‘‘like a street-
bought Rolex’’ which implies that the subject is
fake or cheap.
Collecting Narratives. Once we identified the
explicit simile and converted it to its implicit
forma, we similarly prepend the 4 previous sen-
tences to form narratives. The average length of
the narrative was 80 palabras.
Collecting Continuations. We repeat the same
crowdsourcing setup as for idioms, providing the
explicit simile property as the definition. Each nar-
rative was annotated by 10 workers. el promedio
length of continuations was identical to the idiom
conjunto de datos (12 for plausible and 11 for implausible).
The simile dataset contains 4,996
part of Figure 1. We split the examples to train
(3,100), validation (376), and test (1,520) sets with
no simile overlaps between the different sets.
4 Discriminative Task
The first task we derive from our dataset is of dis-
criminative nature in the setup of the story cloze
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
tarea. Given a narrative N and two candidate con-
tinuations {C1, C2}, the goal is to choose which
of the continuations is more plausible.
4.1 Métodos
For both idioms and similes, we report the per-
formance of several zero-shot, few-shot, y
supervised methods as outlined below. Most of
our experiments were implemented using the
transformers package (Wolf et al., 2020).
Zero-shot. The first
type of zero-shot mod-
els is based on standard language model score
as a proxy for plausibility. We use GPT-2 XL
(Radford et al., 2019) y GPT-3 (Brown y cols.,
2020) to compute the normalized log-likelihood
score of each continuation given the narra-
tivo, predicting the continuation with the highest
probabilidad: argmaxi PLM (Ci|norte).
We also use UnifiedQA (Khashabi et al., 2020),
a T5-3B model (Rafael y col., 2020) trained on 20
QA datasets in diverse formats. We don’t fine-tune
it on our dataset, but instead use it in a zero-shot
manner, with the assumption that the model’s
familiarity with QA format and with the narra-
tive domain through training on the NarrativeQA
conjunto de datos (Koˇcisk´y et al., 2018) would be useful. A
cast our task as a QA problem we format the input
such that the question is ‘‘Which is more plausible
between the two based on the context?''.
Few-shot. Language models like GPT-3 have
shown impressive performance
after being
prompted with a small number of labelled exam-
ples. A prompting example in which the correct
continuation is the first is given in the following
format: q: norte (1) C1 (2) C2 A: (1).
We provided the model with as many prompting
examples as possible within the GPT-3 API limit
de 2,048 tokens, cual es 6 examples. The test
examples are provided without the answer and the
model is expected to generate (1) o (2).
We also use the recently proposed Pattern
Exploiting Training model (PET; Schick and
Sch¨utze, 2021). PET reformulates the tasks as
a cloze question and fine-tunes smaller masked
LMs to solve it using a few training examples.3
3Específicamente, it uses ALBERT XXL V2 (Lan et al., 2020),
cual es 784 times smaller than GPT-3.
We use the following input pattern: ‘‘N. C1.
You are ’’ for idioms and ‘‘N. C1. Eso
was ’’ for similes. PET predicts the masked
token and maps it to the label inventory using
the verbalizer {‘‘right’’, ‘‘wrong’’} for idioms
y {‘‘expected’’, ‘‘unexpected’’} for similes
respectively mapping them to {TRUE, FALSE}.4 Nosotros
provide each model 100 training examples, train
it for 3 epochs, and select the model that yields
the best validation accuracy.
Supervised. Nosotros
fine-tune RoBERTa-large
(Liu et al., 2019) as a multiple-choice model. Para
a given instance, we feed each combination of
the narrative and a continuation separately to the
model in the following format: norte < s/ > Ci.
We pool the representation of the start token to
get a single vector representing each continuation,
and feed it into a classifier that predicts the contin-
uation score. The model predicts the continuation
with the higher score. We fine-tune the model for
10 epochs with a learning rate of 1e−5 and a batch
tamaño de 8, and save the best checkpoint based on
validation accuracy.
Knowledge-Enhanced.
Inspired by how hu-
mans process figurative language, we develop
RoBERTa-based models enhanced with common-
sense knowledge. We develop two models: El
first model obtains additional knowledge to bet-
ter understand the narrative (contexto), mientras que la
second seeks knowledge pertaining to the literal
meaning of the constituents of the figurative ex-
presion (Sección 2.3). In both cases, in addition
to the narrative and candidate continuations, el
model is also provided with a set of inferences:
{Inf1, . . . , Infn} that follow from the narrative,
as detailed below and demonstrated in Figure 2.
The literal model uses the COMET model
(Hwang et al., 2021), a BART-based language
model trained to complete incomplete tuples from
ConceptNet. As opposed to extracting knowledge
from ConceptNet directly, COMET can gener-
ate inferences on demand for any textual input.
For an idiom, we retrieve knowledge pertain-
ing to the content words among its constituents,
4We also experimented with the pattern and verba-
lizer used by Schick and Sch¨utze (2021) for MultiRC
(Khashabi et al., 2018), with the pattern: ‘‘N. Question:
Based on the previous passage is C1 a plau-
sible next sentence? .’’ and the verbalizer {‘‘yes’’,
‘‘no’’}, but it performed worse.
594
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 2: Extracting inferences from COMET regarding the context (previous sentences in the narrative) y el
literal meaning of the content words among the idiom constituents.
Cifra 3: Integrating commonsense inferences into a RoBERTa-based discriminative model.
focusing on the following relations: UsedFor,
Desires, HasProperty, MadeUpOf, En-
Location, and CapableOf. For each content
palabra, we extract the top 2 inferences for each
relation using beam search. Por ejemplo, given
the idiom ‘‘run the gauntlet’’, we obtain infer-
ences for ‘‘run’’ and ‘‘gauntlet’’. We convert the
inferences to natural language format based on
the templates in Guan et al. (2019). Given the
nature of the simile task, we focused solely on
the vehicle’s HasProperty relation and ob-
tain the top 12 inferences. Por ejemplo, given
the simile ‘‘like a psychic whirlpool’’, we obtain
inferences for the phrase ‘‘psychic whirlpool’’.
The context model is enhanced with knowledge
from ParaCOMET (Gabriel et al., 2021a), entrenado
on ATOMIC. We feed into ParaCOMET all but
the last sentence from the narrative, a excepción de
the sentence containing the figurative expres-
sión. We generate inferences along ATOMIC
dimensions pertaining to the narrator (PersonX),
a saber: xIntent, xNeed, xAttr, xWant,
xEffect, and xReact. De nuevo, we extract
the top 2 inferences for every relation using
beam search.
In both models, como se demuestra en la figura 3,
the input format Xi,j for continuation Ci and
inference Infj is: Infj < s/ > norte Ci.
We compute the score of each of these state-
ments separately, and sum the scores across
inferences to get a continuation score:
12(cid:2)
12(cid:2)
si =
si,j =
scorer(RoBERTa(Xi,j))
j=1
j=1
where scorer is a dropout layer with dropout
probability of 0.1 followed by a linear classifier.
Finalmente, the model predicts the continuations with
the higher score. We fine-tune the context and
literal models for 10 epochs with a learning rate of
1e−5 and an effective batch size of 16 for idioms
y 64 for similes, and save the best checkpoint
based on validation accuracy.
4.2 Resultados
Mesa 2 shows the performance of all models
on the discriminative tasks. For both similes and
idioms, supervised models perform substantially
better than few-shot and zero-shot models, pero
still leave a gap of several points of accuracy
behind human performance. Human performance
is the average accuracy of two native English
speakers on the task. We did not provide them
with the idiom definition, and we assume they
were familiar with the more common idioms. El
models performed somewhat better on idioms
595
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Modelo
Idiom
Simile
Método
Majority
Zero-shot
Few-shot
Supervised
Knowledge
Enhanced
GPT2-XL
GPT3
UnifiedQA
GPT3
PET
RoBERTa
-narrative
Context
Literal
Human Performance
50.0
53.6
60.2
67.7
54.1
66.1
82.0
65.0
82.8
83.5*
92.0
50.8
53.7
62.4
60.6
51.7
55.2
80.4
67.9
79.9
80.6
95.0
Mesa 2: Model performance (exactitud) sobre el
idiom and simile discriminative tasks. ∗ Differ-
ence is significant (a < 0.07) between the super-
vised and knowledge-enhanced models via t-test.
than on similes, possibly due to the LMs’ famil-
iarity with some common idioms as opposed to
the novel similes.
Among the zero-shot models, GPT-2 performed
worse than GPT-3 and UnifiedQA, each of which
performed best on one of the tasks. In particu-
lar, UnifiedQA performed well on idioms, likely
thanks to its familiarity with the QA format and
with the narrative domain.
In the idiom task, PET outperformed few-shot
GPT-3 by a large margin of 12 points in accuracy
for idioms and 3.5 points for simile, which we
conjecture is attributed to the different number of
training examples: 6 for GPT-3 vs. 100 for PET.
The small number of examples used to prompt
GPT-3 is a result of the API limit on the number
of tokens (2,048) as well as the setup in which
all prompting examples are concatenated as a
single input.
Overall, few-shot models performed worse than
zero-shot models on both datasets. We conjecture
that this is due to two advantages of the zero-shot
models. First, the GPT-2 and GPT-3 models per-
formed better than the majority baseline thanks to
the similarity between the task (determining which
continuation is more plausible) and the language
model objective (guessing the next word). Second,
the UnifiedQA model performed particularly well
thanks to its relevant training. At the same time,
both few-shot models had to learn a new task from
just a few examples.
The supervised models leave some room for
improvement, and the knowledge-enhanced mod-
596
els narrow the gap for idioms. For similes we
see a minor drop in the context model and nearly
comparable performance for the literal model.
Annotation Artifacts. Human-elicited texts of-
ten contain stylistic attributes (e.g., sentiment,
lexical choice) that make it easy for models to
distinguish correct from incorrect answers with-
out solving the actual
task (Schwartz et al.,
2017a; Cai et al., 2017; Gururangan et al., 2018;
Poliak et al., 2018). Following previous work,
we trained a continuation-only baseline, which
that
is a RoBERTa-based supervised model
was trained only on the candidate continuations
without
the narrative. The results in Table 2
(-narrative) show that the performance is
above majority baseline, indicating the existence
of some bias. However, the performance of this
baseline is still substantially worse than the su-
pervised baseline that has access to the full input,
with a gap of 17 points for idioms and 12 points
for similes, indicating that this bias alone is not
enough for solving the task.
4.3 Analysis
The knowledge-enhanced models provide vari-
ous types of inferences corresponding to different
relations in ConceptNet and ATOMIC. We are
interested in understanding the source of improve-
ments from the knowledge-enhanced models over
the supervised baseline, by identifying the re-
lations that were more helpful than others. To
that end, we analyze the test examples that
were incorrectly predicted by the supervised
baseline but correctly predicted by each of the
knowledge-enhanced models. We split the ex-
amples such that every example consists of a
single inference, and feed the following input
into the model to predict the plausible continua-
tion: Inf norte C. We focus on the
idiom dataset, since for the literal model for sim-
iles the only used relation was HasProperty
and the context model performed slightly worse
than the baseline.
Mesa 3 shows the percents of successful test set
predictions for each relation type. The relations
in the context model perform similarly, con el
best relation xReact performing as well as all
of the relations (Mesa 2). In the literal model, él
seems that the combination of all relations is ben-
eficial, whereas the best relation, CapableOf,
performs slightly worse than the full model. Para
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Literal
HasProperty
CapableOf
Desires
AtLocation
UsedFor
MadeUpOf
Context
xNeed
xIntent
xWant
xReact
xEffect
xAttr
82.2
82.6
82.2
82.8
82.5
82.5
82.3
83.2
82.5
82.7
82.4
82.8
Mesa 3: Percents of successful predictions for
each relation type for the test set examples.
a narrative snippet ‘‘Since Dominic isn’t up for
grabs anymore, I figure that I will concentrate on
something else, Carmen declares’’, the inference
‘‘grabs is capable of hold on to’’ was compliant
with the meaning of ‘‘up for grabs’’ (disponible
or obtainable), and led to the correct prediction
of the plausible continuation ‘‘The good news is
that there are many other available bachelors out
there’’. En cambio, the inference corresponding
to the Desires relation was ‘‘grab desires mak-
ing money’’ which was irrelevant and led to an
incorrect prediction.
5 Generative Task
In the generative task, given a narrative N, el
is to generate a plausible next sentence
meta
that is coherent with the context and consistent
with the meaning of the figurative expression.
Each instance consists of a reference plausible
continuation C.
5.1 Métodos
We similarly experiment with zero-shot, few-shot,
and supervised models.
Zero-shot. We use standard LMs, GPT-2 XL
y GPT-3, to generate the next sentence fol-
lowing the narrative. We let the models generate
hasta 20 tokens, stopping when an end of sen-
tence token was generated. Following preliminary
experimentos, for GPT-2 XL and the rest of the
models we use top-k sampling (Fan et al., 2018)
as the decoding strategy with k = 5 and a softmax
temperature of 0.7, while for GPT-3 we use the
method provided in the API which is nucleus sam-
pling (Holtzman et al., 2020) with a cumulative
probability of p = 0.9.
Few-shot. We prompt GPT-3 with 4 training
examples of the form Q: N A: C followed
by each individual
the answer.
test example, and decode
Supervised. We fine-tune GPT-2 XL with a
language model objective for 3 epochs with a batch
tamaño de 2. We also trained T5 large (Rafael y col.,
2020) and BART large (Lewis et al., 2020) como
encoder-decoder models. Both were trained for 5
epochs for idioms and 20 epochs for similes, con
an effective batch size of 64. For each model, nosotros
kept the best checkpoint based on the validation
set perplexity, and used top-k decoding with k = 5
and a temperature of 0.7.
Knowledge-Enhanced. We followed the same
intuition and inferences we used for the knowledge-
enhanced discriminative models (Sección 4.1). Nosotros
fine-tune the models for one epoch as the effective
data size is multiplied by the number of inferences
per sample. The overall architecture of the gen-
erative knowledge-enhanced model is depicted in
Cifra 4. The models are based on GPT-2 XL
and trained with a language model objective to
predict the next sentence given the narrative and
a single inference. The input format for infer-
ence Infj is: Infj
the expected output is the plausible continuation
C. During inference, we combine the generations
from all inferences pertaining to a given narra-
tivo. Inspired by Liu et al. (2021), who ensemble
logits from multiple LMs, we ensemble the logits
predicted for multiple input prompts using the
same model.
A standard decoding process gets at each time
step an input prompt text x
12
We sum the logits vectors to obtain zt =
j=1 ztj,
from which we decode the next token as usual.
(cid:3)
597
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 4: Integrating commonsense inferences into a GPT2-based generative model.
Método
Modelo
Zero-shot
Few-shot
GPT2-XL
GPT3
GPT3
GPT2-XL
Supervised
T5-large
BART-large
Knowledge Context
Enhanced
Literal
Idiom
Simile
R-L
B-S
R-L
B-S
6.2
8.2
12.8
15.9
12.9
12.4
15.4
13.6
40.2
33.6
51.2
54.2
51.0
48.8
52.6
51.4
17.0
13.9
23.1
26.2
22.9
26.7
20.5
28.9
47.7
40.2
56.1
59.0
54.9
58.4
55.1
59.1
Mesa 4: Model performance on the generative
tasks in terms of automatic metrics. R-L denotes
Rouge-L and B-S denotes BERT-Score.
5.2 Resultados
Automatic Evaluation. Mesa 4 shows the per-
formance of all the models on the generative
tasks in terms of automatic metrics. reportamos el
performance of the recall-oriented n-gram over-
lap metric Rouge-L (lin, 2004), typically used
for summarization tasks, and the similarity-based
BERT-Score (Zhang et al., 2019). We use the lat-
est implementation to date, which replaces BERT
with deberta-large-mnli—a DeBERTa
modelo (He et al., 2021) fine-tuned on MNLI
(Williams et al., 2018). In terms of automatic eval-
uation, the best-performing knowledge-enhanced
modelo (context for idioms and literal for similes)
performs similarly to the GPT-2 XL supervised
base, with slight preference to the baseline for
idioms and to the knowledge-enhanced model
for similes. Both types of supervised models
outperform the zero-shot and few-shot models.
Human Evaluation. Although automatic met-
rics provides an estimate of
relative model
actuación, these metrics were often found to
have very little correlation with human judgments
(Novikova et al., 2017; Krishna et al., 2021). A
account for this we also performed human eval-
uation of the generated texts for a sample of the
598
Modelo
Absoluto
Idiom Simile
Comparative
Idiom Simile
GPT2-XL
+Context
+Literal
Humano
Todo
Neither
56
68
48
80
−
−
60
68
76
88
−
−
15
45
13
−
8
17
18.6
16
46.7
−
12
6.7
Mesa 5: Percent of times that the generation
from each of the models and human-written
references was chosen as plausible (absolute)
or preferred (comparative) by the majority of
workers.
test narratives. The human judgments were col-
lected using Amazon Mechanical Turk. Workers
were shown a narrative, the meaning of the id-
iom (or the property of the simile), and a list of
3 generated continuations, one from each of the
supervised GPT-2 model, the context model, y
the literal model. We performed two types of eval-
uations. In the absolute evaluation, we randomly
muestreado 50 narratives for each task, and asked
workers to determine for each of the generated
continuations along with the human references
whether it is plausible or not. In the comparative
evaluación, we randomly sampled 100 narratives
for idioms and 75 for similes, and presented the
workers with a randomly shuffled list of continu-
ations, asking them to choose the most plausible
uno (or indicate that ‘‘neither of the genera-
tions were good’’ or ‘‘all are equally good’’).
In both evaluations, workers were instructed to
consider whether the generation is sensical, co-
herent, follows the narrative, and consistent with
the meaning of the figurative expression. Cada
example was judged by 3 workers and aggregated
using majority voting. The inter-annotator agree-
ment was moderate with Krippendorff’s α = 0.68
and α = 0.63 for the absolute and comparative
evaluations, respectivamente (Krippendorff, 2011).
In both absolute and comparative performance,
the tasks,
Mesa 5 shows that
for each of
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Cifra 5: Narratives ending in an idiom (arriba) or a simile (abajo) with the continuations generated by the baseline
GPT-2 model and a knowledge-enhanced model, as preferred by human judges.
Modelo
Category
Ejemplo
Literal
(Simile)
Context
(Idiom)
1(cid:3)
2(cid:3)
1(cid:3)
3(cid:3)
Is that how you got those bruises on your face? They colored her pure white skin like
a sloppily designed ink blot test It was as if her skin was smudged with a brownie.
We stand there munching next to the evening sun-swept grass and whispering trees of
Duboce Park, where a bunch of happy-ass dogs are sprinting around in circles while
their owners stand there like a scarecrow convention. The humans were having a
great time, jumping and barking and running around.
She could hold some of her thoughts while she was a wolf.Better than the rest of us.
Not as well as Sam, but better than me.She and Derrick were thick as thieves They
would always be looking for opportunities to steal
That’s why I packed the heat. Just in case I needed some motivation for him to calm
down should he be inclined to go ballistic on me. : because I was thinking of ways to
solve this problem in a peaceful way
Mesa 6: An example for each error category. Each example consists of a narrative, with the figurative
expression in bold and the continuation in italic.
a knowledge-enhanced model outperformed the
baseline GPT-2 model. What makes a more com-
pelling case is that the context model was favored
for idioms while the literal model was favored for
similes, complying with prior theoretical ground-
ing on these figurative language types. Cifra 5
shows examples generated by the baseline and the
best model for each task. We note that 80% del
human-written continuations for idioms and 88%
of those in the simile task were judged as plausible.
Based on our analysis, the gap from 100% may be
explained by the ambiguity of the narratives that
leaves room for subjective interpretation.
5.3 Análisis de errores
We analyze the continuations labeled as implau-
sible by the annotators, for the best model in
each task: context for idioms and literal for
similes. We found the following error catego-
ries, with percent details in Table 7 and exem-
plified in Table 6:
Cat. Literal (Simile) Context (Idioms)
1(cid:3)
2(cid:3)
3(cid:3)
50
33
17
72
14
14
Mesa 7: Error categories along with their
proportion (en %) among the implausible
continuations.
1(cid:3) Inconsistent with the figurative expression:
The continuation is inconsistent or contradic-
tory to the figurative expression. Por ejemplo,
the simile in the first row in Table 6 is ‘‘like a
sloppily designed ink blot test’’, for which the
property of comparison is ‘‘a pattern of dark blue,
purple, and black’’, but the generated continua-
tion mentions brownie, which has a brown color.
Similarly for the idiom ‘‘thick as thieves’’ the
model generates a literal continuation without
599
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
understanding its actual meaning ‘‘closest of
friends’’.
2(cid:3) Inconsistent with the narrative: The con-
tinuation is inconsistent or contradictory to the
flow of the narrative. Por ejemplo, the narrative in
the second row in Table 6 states that ‘‘the owners
who are humans are standing’’, while the contin-
uation states they are jumping. The model further
predicts that the humans are barking, instead of
the dogs. En general, across multiple examples we
have found that models tend to confuse the various
characters in the narrative.
3(cid:3) Spelling or grammar errors: Some gener-
ations contained spelling mistakes or introduced
grammar errors such as starting with a punc-
tuation or having extra blank spaces. A pesar de
we instructed the crowdsourcing workers to ig-
nore such errors, they may have affected their
plausibility judgments.
6 Conclusión
We introduced a narrative understanding bench-
mark focused on interpreting figurative language,
specifically idioms and similes. Following the
story cloze test, we designed discriminative and
generative tasks with the goal of continuing a
narrative. We found that pre-trained LMs irre-
spective of their size struggle to perform well
in zero-shot and few-shot setting, and that the
supervised models while competitive are still
behind human performance by a significant mar-
gin. We further bridged some of this gap with
knowledge-enhanced models that are inspired by
the way humans interpret figurative expressions.
Our analysis reassessed known findings that al-
though LMs generate grammatical human-like
textos, they are often inconsistent and the model’s
ability to distinguish characters in a story is lim-
ited. We hope this work will spark additional
interest in the research community to further ad-
vance the representations and modeling of fig-
urative language, which is too common to ignore.
Acknowledgment
Referencias
Prithviraj Ammanabrolu, Wesley Cheung,
William Broniec, and Mark O. Riedl. 2020. Au-
tomated storytelling via causal, commonsense
plot ordering. arXiv preimpresión arXiv:2009.00829.
Fatemeh Mohamadi Asl. 2013. The impact of con-
text on learning idioms in EFL classes. TESOL
Diario, 37(1):2.
Chandra Bhagavatula, Ronan Le Bras, Chaitanya
Malaviya, Keisuke Sakaguchi, Ari Holtzman,
Hannah Rashkin, Doug Downey, Scott
Wen-tau Yih, and Yejin Choi. 2019. Abduc-
tive commonsense reasoning. arXiv preprint
arXiv:1908.05739.
Antoine Bosselut, Hannah Rashkin, Maarten
Sap, Chaitanya Malaviya, Asli Celikyilmaz,
and Yejin Choi. 2019. COMET: Common-
sense transformers for automatic knowledge
el
graph construction.
57ª Reunión Anual de la Asociación de
Ligüística computacional, pages 4762–4779,
Italia. Asociación de Computación-
Florencia,
lingüística nacional. https://doi.org/10
.18653/v1/P19-1470
En procedimientos de
Tom B. Marrón, Benjamín Mann, Nick Ryder,
Melanie Subbiah,
Jared Kaplan, Prafulla
Dhariwal, Arvind Neelakantan, Pranav Shyam,
Girish Sastry, Amanda Askell, et al. 2020.
Language models are few-shot learners. arXiv
preprint arXiv:2005.14165.
Zheng Cai, Lifu Tu, and Kevin Gimpel. 2017.
Pay attention to the ending:strong neural
baselines for the ROC story cloze task. En
Proceedings of the 55th Annual Meeting of
la Asociación de Lingüística Computacional
(Volumen 2: Artículos breves), pages 616–622,
vancouver, Canada. Asociación de Computación-
lingüística nacional. https://doi.org/10
.18653/v1/P17-2097
Robyn Carston and Catherine Wearing. 2011.
Metaphor, hyperbole and simile: A prag-
and Cogni-
matic
ción, 3(2):283–312. https://doi.org/10
.1515/langcog.2011.010
acercarse. Idioma
This research was supported in part by DARPA
under the MCS program through NIWC Pacific
(N66001-19-2- 4031), Google Cloud computing,
and the Allen Institute for AI (AI2).
Tuhin Chakrabarty, Debanjan Ghosh, Smaranda
Muresan, and Nanyun Peng. 2020a. Rˆ3:
Reverse, retrieve, and rank for sarcasm gen-
En
eration with commonsense knowledge.
600
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Actas de
the 58th Annual Meeting
de la Asociación de Linguis Computacional-
tics, pages 7976–7986, En línea. Asociación
para Lingüística Computacional. https://doi
.org/10.18653/v1/2020.acl-main.711
en
idioma
recognizing
and Smaranda Muresan.
Tuhin Chakrabarty, Debanjan Ghosh, Adán
2021a.
Poliak,
tex-
Figurative
the As-
tual entailment.
sociation
para Lingüística Computacional:
ACL-IJCNLP 2021, pages 3354–3361, On-
line. Association for Computational Linguis-
tics. https://doi.org/10.18653/v1
/2021.findings-acl.297
En hallazgos de
Tuhin Chakrabarty, Smaranda Muresan, y
Nanyun Peng. 2020b. Generating similes
effortlessly like a pro: A style transfer
approach for simile generation. En curso-
el 2020 Conferencia sobre Empirismo
cosas de
Métodos
in Natural Language Process-
En g (EMNLP), pages 6455–6469, En línea.
Asociación
for Computational Linguis-
tics. https://doi.org/10.18653/v1
/2020.emnlp-main.524
el 2021 Conference of
Tuhin Chakrabarty, Xurui Zhang, Smaranda
Muresan, and Nanyun Peng. 2021b. MER-
MAID: Metaphor generation with symbolism
En curso-
and discriminative decoding.
cosas de
the North
Asociación
American Chapter
para Lingüística Computacional: Human Lan-
guage Technologies, pages 4250–4261, En línea.
Asociación de Lingüística Computacional.
https://doi.org/10.18653/v1/2021
.naacl-main.336
el
de
Nathanael Chambers and Dan Jurafsky. 2009.
Unsupervised learning of narrative schemas
En procedimientos de
and their participants.
the Joint Conference of
the 47th Annual
the ACL and the 4th Interna-
reunión de
tional Joint Conference on Natural Language
Processing of the AFNLP, pages 602–610, Sol-
tec, Singapur. Asociación de Computación
Lingüística. https://doi.org/10.3115
/1690219.1690231
Snigdha Chaturvedi, Haoruo Peng, and Dan Roth.
2017. Story comprehension for predicting what
happens next. En procedimientos de
el 2017
Jornada sobre Métodos Empíricos en Natu-
601
Procesamiento del lenguaje oral, pages 1603–1614,
Copenhague, Dinamarca. Asociación para Com-
Lingüística putacional. https://doi.org
/10.18653/v1/D17-1168
Tomas C.. Cooper. 1999. Processing of idioms
by L2 learners of english. TESOL Quar-
terly, 33(2):233–262. https://doi.org
/10.2307/3587719
Yiming Cui, Wanxiang Che, Wei-Nan Zhang,
Ting Liu, Shijin Wang, and Guoping Hu.
2020. Discriminative sentence modeling for
story ending prediction. En procedimientos de
the AAAI Conference on Artificial Intelligence,
volumen 34, pages 7602–7609. https://doi
.org/10.1609/aaai.v34i05.6260
Angela Fan, mike lewis, and Yann Dauphin.
2018. Hierarchical neural story generation. En
Proceedings of the 56th Annual Meeting of
the Association for Computational Linguis-
tics (Volumen 1: Artículos largos), pages 889–898,
Melbourne, Australia. Asociación de Computación-
lingüística nacional.
Afsaneh Fazly, Paul Cook,
and Suzanne
stevenson. 2009. Unsupervised type
y
token identification of idiomatic expressions.
computacional
Lingüística,
35(1):61–103.
https://doi.org/10.1162/coli.08
-010-R1-07-048
Susan R. Fussell and Mallie M. Moss. 1998.
Figurative language in emotional communi-
catión. Social and Cognitive Approaches to
Interpersonal Communication, pages 113–141.
Saadia Gabriel, Chandra Bhagavatula, Vered
Shwartz, Ronan Le Bras, Maxwell Forbes, y
Yejin Choi. 2021a. Paragraph-level common-
sense transformers with recurrent memory. En
AAAI.
Saadia Gabriel, Antoine Bosselut, Jeff Da, Ari
Holtzman, Jan Buys, Kyle Lo, Asli Celikyilmaz,
and Yejin Choi. 2021b. Discourse under-
standing and factual consistency in abstractive
summarization. In Proceedings of the 16th Con-
ference of the European Chapter of the Asso-
ciation for Computational Linguistics: Main
Volumen, pages 435–447, En línea. Asociación
para Lingüística Computacional. https://doi
.org/10.18653/v1/2021.eacl-main.34
Marcos Garcia, Tiago Kramer Vieira, Carolina
Scarton, Marco Idiart, and Aline Villavicencio.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
2021. Assessing the representations of idio-
maticity in vector models with a noun com-
pound dataset labeled at type and token levels.
En procedimientos de
the 59th Annual Meet-
ing of
the Association for Computational
Linguistics and the 11th International Joint
Conferencia sobre procesamiento del lenguaje natural
(Volumen 1: Artículos largos), pages 2730–2741,
En línea. Association for Computational Linguis-
tics. https://doi.org/10.18653/v1
/2021.acl-long.212
Jian Guan, Yansen Wang, and Minlie Huang.
2019. Story ending generation with incremental
encoding and commonsense knowledge. En profesional-
ceedings of the AAAI Conference on Artificial
Inteligencia, volumen 33, pages 6473–6480.
https://doi.org/10.1609/aaai.v33i01
.33016473
Suchin Gururangan, Swabha Swayamdipta, Omer
Exacción, Roy Schwartz, Samuel Bowman, y
Noah A. Herrero. 2018. Annotation artifacts in
natural language inference data. En procedimientos
del 2018 Conference of the North American
Chapter of the Association for Computational
Lingüística: Tecnologías del lenguaje humano,
Volumen 2 (Artículos breves), pages 107–112, Nuevo
Orleans, Luisiana. Asociación de Computación-
lingüística nacional. https://doi.org/10
.18653/v1/N18-2017
Patrick Hanks. 2013. Lexical analysis: Norms
and exploitations. CON prensa. https://doi
.org/10.7551/mitpress/9780262018579
.001.0001
Liu,
Pengcheng He, Xiao Dong
Jianfeng
gao, and Weizhu Chen. 2021. Deberta:
Decoding-enhanced bert with disentangled
In International Conference on
atención.
Learning Representations.
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes,
and Yejin Choi. 2020. The curious case
of neural text degeneration. En internacional
Conferencia sobre Representaciones del Aprendizaje.
Jena D. Hwang, Chandra Bhagavatula, Ronan
Le Bras, Jeff Da, Keisuke Sakaguchi, Antoine
Bosselut, and Yejin Choi. 2021. COMET-
ATOMIC 2020: On symbolic and neural
commonsense knowledge graphs. En AAAI.
Daniel Khashabi, Snigdha Chaturvedi, Miguel
Roth, Shyam Upadhyay, and Dan Roth. 2018.
602
Looking beyond the surface: A challenge
set for reading comprehension over multi-
ple sentences. En procedimientos de
el 2018
the North American Chap-
Conference of
ter of
the Association for Computational
Lingüística: Tecnologías del lenguaje humano,
Volumen 1 (Artículos largos), pages 252–262, Nuevo
Orleans, Luisiana. Asociación de Computación-
lingüística nacional. https://doi.org/10
.18653/v1/N18-1023
Daniel Khashabi, Sewon Min, Tushar Khot,
Ashish Sabharwal, Oyvind Tafjord, Peter
clark, and Hannaneh Hajishirzi. 2020. UNI-
FIEDQA: Crossing format boundaries with a
single QA system. In Findings of the Asso-
ciation for Computational Linguistics: EMNLP
2020, pages 1896–1907, En línea. Asociación
para Lingüística Computacional. https://doi
.org/10.18653/v1/2020.findings-emnlp
.171
Tom´aˇs Koˇcisk´y, Jonathan Schwarz, Phil Blunsom,
Chris Dyer, Karl Moritz Hermann, G´abor
Melis, and Edward Grefenstette. 2018. The Nar-
rativeQA reading comprehension challenge.
Transactions of the Association for Computa-
lingüística nacional, 6:317–328. https://doi
.org/10.1162/tacl_a_00023
Klaus
Krippendorff.
Informática
Krippendorff’s alpha-reliability. Informática,
1:25–2011.
2011.
Kalpesh Krishna, Aurko Roy, and Mohit Iyyer.
2021. Hurdles to progress in long-form question
answering. En Actas de la 2021 Conferir-
ence of the North American Chapter of the Asso-
ciation for Computational Linguistics: Humano
Language Technologies, pages 4940–4957,
En línea. Association for Computational Linguis-
tics. https://doi.org/10.18653/v1
/2021.naacl-main.393
Zhenzhong Lan, Mingda Chen, Sebastian
Buen hombre, Kevin Gimpel, Piyush Sharma, y
Radu Soricut. 2020. AlBERT: A lite BERT for
self supervised learning of language represen-
taciones. https://arxiv.org/abs/1909
.11942v3.
mike lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer
Exacción, Veselin Stoyanov, and Luke Zettlemoyer.
2020. BART: Denoising sequence-to-sequence
pre-training for natural language generation,
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
the 58th Annual Meeting of
traducción, and comprehension. En curso-
el
cosas de
Asociación de Lingüística Computacional,
pages 7871–7880, En línea. Asociación para
Ligüística computacional. https://doi.org
/10.18653/v1/2020.acl-main.703
Linlin Li and Caroline Sporleder. 2009. Classi-
fier combination for contextual idiom detection
without labelled data. En Actas de la
2009 Conference on Empirical Methods in Nat-
ural Language Processing, pages 315–323,
Singapur. Asociación de Computación
Lingüística. https://doi.org/10.3115
/1699510.1699552
Zhongyang Li, Xiao Ding, and Ting Liu.
2019. Story ending prediction by transferable
BERT. In Proceedings of the Twenty-Eighth
International Joint Conference on Artificial
Inteligencia, IJCAI-19, pages 1800–1806. En-
ternational Joint Conferences on Artificial
Intelligence Organization.
Chin-Yew Lin. 2004. ROUGE: A package for
automatic evaluation of summaries. In Text
Summarization Branches Out, pages 74–81,
Barcelona, España. Asociación de Computación-
lingüística nacional.
texto
the 59th Annual Meeting of
Alisa Liu, Maarten Sap, Ximing Lu, Swabha
Swayamdipta, Chandra Bhagavatula, Noah
A. Herrero, and Yejin Choi. 2021. DExperts:
generación
controlled
Decoding-time
with experts and anti-experts. En procedimientos
de
the Asso-
ciation for Computational Linguistics and
the 11th International Joint Conference on
Natural Language Processing (Volumen 1:
Artículos largos), pages 6691–6706, En línea.
Asociación de Lingüística Computacional.
https://doi.org/10.18653/v1/2021.acl
-long.522
Changsheng Liu and Rebecca Hwa. 2016. Phrasal
substitution of idiomatic expressions. En profesional-
cesiones de la 2016 Conference of the North
American Chapter of
la Asociación para
Ligüística computacional: Human Language
Technologies, pages 363–373, San Diego,
California. Asociación de Computación
Lingüística.
Changsheng Liu and Rebecca Hwa. 2017. Rep-
resentations of context
in recognizing the
figurative and literal usages of idioms. En
603
Thirty-First AAAI Conference on Artificial
Inteligencia.
Lizhen Liu, Xiao Hu, Wei Song, Ruiji Fu,
Ting Liu, and Guoping Hu. 2018. nuevo-
ral multitask learning for simile recognition.
En procedimientos de
el 2018 Conferencia sobre
Métodos empíricos en Natural Language Pro-
cesando, pages 1543–1553, Bruselas, Bélgica.
Asociación de Lingüística Computacional.
Pengfei Liu, Kaiyu Qian, Xipeng Qiu, y
Xuanjing Huang. 2017.
Idiom-aware com-
positional distributed semantics. En curso-
cosas de
el 2017 Conferencia sobre Empirismo
Métodos en el procesamiento del lenguaje natural,
pages 1204–1213, Copenhague, Dinamarca.
Asociación de Lingüística Computacional.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei
Du, Mandar Joshi, Danqi Chen, Omer Levy,
mike lewis, Lucas Zettlemoyer, and Veselin
Stoyanov. 2019. RoBERTa: A robustly opti-
mized bert pretraining approach. arXiv preprint
arXiv:1907.11692.
Bodhisattwa Prasad Majumder, Harsh Jhamtani,
Taylor Berg-Kirkpatrick, and Julian McAuley.
2020. Like hiking? You probably enjoy
naturaleza: Persona-grounded dialog with com-
En procedimientos de
monsense
el 2020 Conferencia sobre métodos empíricos
en procesamiento del lenguaje natural (EMNLP),
pages 9194–9206, En línea. Asociación para
Ligüística computacional.
expansions.
Nasrin Mostafazadeh, Nathanael Chambers,
Xiaodong He, Devi Parikh, Dhruv Batra, Lucy
Vanderwende, Pushmeet Kohli, and James
allen. 2016. A corpus and cloze evaluation
for deeper understanding of commonsense sto-
ries. En Actas de la 2016 Conferencia
of the North American Chapter of the Asso-
ciation for Computational Linguistics: Humano
Language Technologies, pages 839–849, san
diego, California. Asociación de Computación-
lingüística nacional. https://doi.org/10
.18653/v1/N16-1098
Suzanne Mpouli. 2017. Annotating similes in lit-
erary texts. In Proceedings of the 13th Joint
ISO-ACL Workshop on Interoperable Semantic
Annotation (ISA-13).
Vlad
Niculae
Cristian
Niculescu-Mizil. 2014. Brighter
y
Danescu-
than gold:
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Figurative language in user generated compar-
isons. En Actas de la 2014 Conferencia
sobre métodos empíricos en lenguaje natural
Procesando
2008–2018,
Doha, Qatar. Asociación de Computación
Lingüística. https://doi.org/10.3115
/v1/D14-1215
(EMNLP),
paginas
Jekaterina Novikova, Ondˇrej Duˇsek, Amanda
Cercas Curry, and Verena Rieser. 2017.
Why we need new evaluation metrics for
el 2017 Estafa-
En procedimientos de
NLG.
ference on Empirical Methods
in Natu-
Procesamiento del lenguaje oral, pages 2241–2252,
Copenhague, Dinamarca. Asociación para Com-
Lingüística putacional. https://doi.org
/10.18653/v1/D17-1238
Anthony M. Pablo, Salim Roukos, Todd Ward, y
Wei-Jing Zhu. 1970. Figurative language. En
Philosophy & Rhetoric, pages 225–248.
Jing Peng and Anna Feldman. 2016. experimentos
in idiom recognition. In Proceedings of COL-
ING 2016, the 26th International Conference on
Ligüística computacional: Technical Papers,
pages 2752–2761, Osaka, Japón. The COLING
2016 Organizing Committee.
Adam Poliak,
Jason Naradowsky, Aparajita
Haldar, Rachel Rudinger, and Benjamin Van
Durme. 2018. Hypothesis only baselines in
natural language inference. En procedimientos de
the Seventh Joint Conference on Lexical and
Computational Semantics, pages 180–191, Nuevo
Orleans, Luisiana. Asociación de Computación-
lingüística nacional. https://doi.org/10
.18653/v1/S18-2023
Ashequl Qadir, Ellen Riloff, and Marilyn Walker.
2015. Learning to recognize affective polar-
el 2015
ity in similes. En procedimientos de
Conference on Empirical Methods in Nat-
ural Language Processing, pages 190–200,
Lisbon, Portugal. Asociación de Computación-
lingüística nacional. https://doi.org/10
.18653/v1/D15-1019
Ashequl Qadir, Ellen Riloff, and Marilyn A.
Caminante. 2016. Automatically inferring implicit
properties in similes. En Actas de la
2016 Conference of
the North American
Chapter of the Association for Computational
Lingüística: Tecnologías del lenguaje humano,
pages 1223–1232, San Diego, California.
Asociación de Lingüística Computacional.
604
https://doi.org/10.18653/v1/N16
-1146
Alec Radford, Jeff Wu, R. Child, David Luan,
Dario Amodei, and Ilya Sutskever. 2019. En
Language models are unsupervised multitask
learners.
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, Miguel
mañana, Yanqi Zhou, wei li, y Pedro J.. Liu.
2020. Explorando los límites del aprendizaje por transferencia
con un transformador unificado de texto a texto. Diario
de Investigación sobre Aprendizaje Automático, 21:1–67.
Matthew Richardson, Christopher J. C. Burges,
and Erin Renshaw. 2013. MCTest: A chal-
lenge dataset for the open-domain machine
comprehension of text. En Actas de la
2013 Conference on Empirical Methods in Nat-
ural Language Processing, pages 193–203,
seattle, Washington, EE.UU. Asociación para
Ligüística computacional.
Richard M.. Roberts and Roger J. Kreuz. 1994.
Why do people use figurative language? Psy-
chological Science, 5(3):159–163. https://
doi.org/10.1111/j.1467-9280.1994
.tb00653.x
Ivan A. Sag, Timothy Baldwin, Francis Bond,
Ann Copestake, and Dan Flickinger. 2002.
Multiword expressions: A pain in the neck for
NLP. In International Conference on Intelligent
Text Processing and Computational Linguis-
tics, pages 1–15. Saltador. https://doi
.org/10.1007/3-540-45715-1_1
Giancarlo Salton, Robert Ross, and John Kelleher.
2016. Idiom token classification using senten-
tial distributed semantics. En procedimientos de
the 54th Annual Meeting of the Association for
Ligüística computacional (Volumen 1: Largo
Documentos), pages 194–204, Berlina, Alemania.
Asociación de Lingüística Computacional.
https://doi.org/10.18653/v1/P16
-1019
Maarten Sap, Ronan Le Bras, Emily Allaway,
Chandra Bhagavatula, Nicholas Lourie, hanna
Celos, Brendan Roof, Noah A. Herrero, y
Yejin Choi. 2019. Atomic: An atlas of machine
commonsense for if-then reasoning. Proceed-
ings of the AAAI Conference on Artificial In-
inteligencia, 33(01):3027–3035. https://doi
.org/10.1609/aaai.v33i01.33013027
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
el 2021 Conference of
just size that matters: Pequeño
Timo Schick and Hinrich Sch¨utze. 2021. It’s
idioma
no
learners. En profesional-
models are also few-shot
el
cesiones de
North American Chapter of
the Associa-
ción para la Lingüística Computacional: Humano
Language Technologies, pages 2339–2352,
En línea. Association for Computational Linguis-
tics. https://doi.org/10.18653/v1
/2021.naacl-main.185
Roy Schwartz, Maarten Sap, Ioannis Konstas,
Leila Zilles, Yejin Choi, y Noé A.. Herrero.
2017a. The effect of different writing tasks
on linguistic style: A case study of the ROC
story cloze task. In Proceedings of the 21st
Conference on Computational Natural Lan-
guage Learning (CONLL 2017), pages 15–25,
vancouver, Canada. Asociación de Computación-
lingüística nacional. https://doi.org/10
.18653/v1/K17-1004
Roy Schwartz, Maarten Sap, Ioannis Konstas,
Leila Zilles, Yejin Choi, y Noé A.. Herrero.
2017b. Story cloze task: UW NLP sys-
the 2nd Workshop
tema. En procedimientos de
on Linking Models of Lexical, Sentential
and Discourse-level Semantics, pages 52–55,
Valencia, España. Asociación de Computación-
lingüística nacional. https://doi.org/10
.18653/v1/W17-0907
Ekaterina V. Shutova. 2011. Computational ap-
proaches to figurative language. Técnico
informe, University of Cambridge, Computadora
Laboratory. https://doi.org/10.1162
/tacl_a_00277
Vered Shwartz and Ido Dagan. 2019. Still a
pain in the neck: Evaluating text represen-
tations on lexical composition. Transactions
de la Asociación de Linguis Computacional-
tics, 7:403–419. https://doi.org/10
.18653/v1/2020.emnlp-main.373
Vered Shwartz, Peter West, Ronan Le Bras,
Chandra Bhagavatula, and Yejin Choi. 2020.
Unsupervised commonsense question answer-
el
ing with self-talk.
2020 Conferencia sobre métodos empíricos
en procesamiento del lenguaje natural (EMNLP),
pages 4615–4629, En línea. Asociación para
Ligüística computacional.
En procedimientos de
Robyn Speer, Joshua Chin, and Catherine Havasi.
2017. Conceptnet 5.5: An open multilingual
605
graph of general knowledge. In Thirty-first
Conferencia AAAI sobre Inteligencia Artificial.
Siddarth Srinivasan, Richa Arora, and Mark
Riedl. 2018. A simple and effective approach
to the story cloze test. En procedimientos de
el 2018 Conference of the North American
Chapter of the Association for Computational
Lingüística: Tecnologías del lenguaje humano,
Volumen 2 (Artículos breves), pages 92–96, Nuevo
Orleans, Luisiana. Asociación de Computación-
lingüística nacional. https://doi.org/10
.18653/v1/N18-2015
Rakesh Verma and Vasanthi Vuppuluri. 2015. A
new approach for idiom identification using
meanings and the web. En Actas de la
International Conference Recent Advances in
Natural Language Processing, pages 681–687,
Hissar, Bulgaria. INCOMA Ltd. Shoumen,
BULGARIA.
Adina Williams, Nikita Nangia, and Samuel
Bowman. 2018. A broad-coverage challenge
corpus for sentence understanding through in-
ference. En Actas de la 2018 Conferir-
ence of the North American Chapter of the
Asociación de Lingüística Computacional: Hu-
man Language Technologies, Volumen 1 (Largo
Documentos), pages 1112–1122, Nueva Orleans,
Luisiana. Asociación de Lin Computacional-
guísticos. https://doi.org/10.18653
/v1/N18-1101
Tomás Lobo, Debut de Lysandre, Víctor Sanh,
Julien Chaumond, Clemente Delangue, Antonio
moi, Pierric Cistac, Tim Rault, Remi Louf,
Morgan Funtowicz, Joe Davison, Sam Shleifer,
Patrick von Platen, Clara Ma, Yacine Jernite,
Julien Plu, Canwen Xu, Teven Le Scao, Sylvain
Gugger, Mariama Drama, Quentin Lhoest, y
Alexander Rush. 2020. transformadores: State-of-
the-art natural language processing. En curso-
el 2020 Conferencia sobre Empirismo
cosas de
Métodos en el procesamiento del lenguaje natural:
Demostraciones del sistema, páginas 38–45, En línea.
Asociación de Lingüística Computacional.
https://doi.org/10.18653/v1/2020
.emnlp-demos.6
PAG. Wolff and D. Gentner. 2000. Evidence for
initial processing of metaphors.
role-neutral
Revista de Psicología Experimental. Aprendiendo,
Memoria, and Cognition, 26 2:529–41.
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Lang Yu and Allyson Ettinger. 2020. evaluando
phrasal representation and composition in trans-
formadores. En Actas de la 2020 Conferencia
sobre métodos empíricos en lenguaje natural
Procesando (EMNLP), pages 4896–4907, En línea.
Asociación de Lingüística Computacional.
Jiali Zeng, Linfeng Song, Jinsong Su, Jun Xie,
Wei Song, and Jiebo Luo. 2020. Neural sim-
ile recognition with cyclic multitask learning
and local attention. En procedimientos de
el
Conferencia AAAI sobre Inteligencia Artificial,
volumen 34, pages 9515–9522. https://doi
.org/10.1609/aaai.v34i05.6496
Jiayi Zhang, Zhi Cui, Xiaoqiang Xia, Ya-Long
guo, Yanran Li, Chen Wei, and Jianwei Cui.
2021. Writing polishment with simile: Tarea,
dataset and a neural approach. En AAAI.
Tianyi Zhang, Varsha Kishore, Felix Wu,
Kilian Q. Weinberger, and Yoav Artzi. 2019.
BERTscore: Evaluating text generation with
BERT. In International Conference on Learn-
ing Representations.
Jianing Zhou, Hongyu Gong, and Suma Bhat.
idiomatic expression
2021. PIE: A parallel
corpus for idiomatic sentence generation and
paraphrasing. In Proceedings of the 17th Work-
shop on Multiword Expressions (MWE 2021),
pages 33–48, En línea. Asociación de Computación-
lingüística nacional. https://doi.org/10
.18653/v1/2021.mwe-1.5
Yukun Zhu, Jamie Kiros, Rich Zemel, Ruslan
Salakhutdinov, Raquel Urtasun, Antonio
Torralba, and Sanja Fidler. 2015. Aligning
books and movies: Towards story-like vi-
sual explanations by watching movies and
reading books. In Proceedings of the IEEE
International Conference on Computer Vi-
sión, pages 19–27. https://doi.org/10
.1109/ICCV.2015.11
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
4
7
8
2
0
2
2
9
5
8
/
/
t
yo
a
C
_
a
_
0
0
4
7
8
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
7
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
606