Where’s My Head? Definition, Data Set, and Models
for Numeric Fused-Head Identification and Resolution
Yanai Elazar† and Yoav Goldberg†∗
†Computer Science Department, Bar-Ilan University, Israel
∗Allen Institute for Artificial Intelligence
{yanaiela,yoav.goldberg}@gmail.com
Astratto
We provide the first computational treatment
of fused-heads constructions (FHs), focusing
on the numeric fused-heads (NFHs). FHs con-
structions are noun phrases in which the head
noun is missing and is said to be ‘‘fused’’
with its dependent modifier. This missing
information is implicit and is important for
sentence understanding. The missing refer-
ences are easily filled in by humans but pose a
challenge for computational models. We for-
mulate the handling of FHs as a two stages
processi: Identification of the FH construc-
tion and resolution of the missing head. Noi
explore the NFH phenomena in large cor-
pora of English text and create (1) a data set
and a highly accurate method for NFH iden-
tification; (2) a 10k examples (1 M tokens)
crowd-sourced data set of NFH resolution;
E (3) a neural baseline for the NFH resolu-
tion task. We release our code and data set,
to foster further research into this challenging
problem.
In Example (1), it is clear that the sentence
refers to the age of the speaker, but this is not
stated explicitly in the sentence. Allo stesso modo, In
Esempio (2) the speaker discusses the worth of
an object in some currency. In Example (3), IL
number refers back to an object already mentioned
before—months.
All of these examples are of numeric fused
heads (NFHs), a linguistic construction that is a
subclass of the more general fused heads (FHs)
construction, limited to numbers. FHs are noun
frasi (NPs) in which the head noun is missing
and is said to be ‘‘fused’’ with its dependent
modifier (Huddleston and Pullum, 2002). Nel
examples above, the numbers ‘42’, ‘two million’,
‘three’, and ‘one’ function as FHs, whereas their
actual heads (YEARS OLD, DOLLAR, months, Chicken
Cordon Bleu) are missing and need to be inferred.
Although we focus on NFHs, FHs in general
can occur also with other categories, ad esempio
determiners and adjectives. Per esempio, in the
following sentences:
(5) Only the rich will benefit.
1
introduzione
(6)
I need some screws but can’t find any .
Many elements in language are not stated ex-
plicitly but need to be inferred from the text. Questo
is especially true in spoken language but also
holds for written text. Identifying the missing in-
formation and filling in the gap is a crucial part of
language understanding. Consider the sentences
below:
(1)
(2)
(3)
I’m 42
, Cercie.
It’s worth about two million
.
I’ve got two months left, three
at
the most.
(4)
I make an amazing Chicken Cordon Bleu.
She said she’d never had one.
the adjective ‘rich’ refers to rich PEOPLE and the
determiner ‘any’ refers to screws. In this work we
focus on the numeric fused head.
Such sentences often arise in dialog situations
as well as other genres. Numeric expressions
play an important role in various tasks, including
textual entailment (Lev et al., 2004; Dagan et al.,
2013), solving arithmetic problems (Roy and Roth,
2015), numeric reasoning (Roy et al., 2015; Trask
et al., 2018), and language modeling (Spithourakis
and Riedel, 2018).
While the inferences required for NFH con-
struction may seem trivial for a human hearer,
they are for the most part not explicitly addressed
by current natural language processing systems.
519
Operazioni dell'Associazione per la Linguistica Computazionale, vol. 7, pag. 519–535, 2019. https://doi.org/10.1162/TACL a 00280
Redattore di azioni: Yuji Matsumoto. Lotto di invio: 12/2018; Lotto di revisione: 1/2019; Pubblicato 9/2019.
C(cid:3) 2019 Associazione per la Linguistica Computazionale. Distribuito sotto CC-BY 4.0 licenza.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Index Text
Missing Head
io
ii
iii
iv
v
vi
vii
viii
ix
X
xi
xii
xiii
xiv
xv
xvi
.
O 4 brothers talkin’
of the reasons I love you
Maybe I can teach the kid a thing or two
you see like 3
When the clock strikes one. . . the Ghost of Christmas Past
My manager says I’m a perfect 10!
Vedere, that’s one
Are you two done with that helium?
No one cares, dear.
Men are like busses: If you miss one
I’d like to wish a happy 1969 to our new President.
I probably feel worse than Demi Moore did when she turned 50.
How much was it? Two hundred, but I’ll tell him it’s fifty. He doesn’t care about the gift;
Have you ever had an unexpressed thought? I’m having one
It’s a curious thing, the death of a loved one.
I’ve taken two
Sopra. Some fussy old maid and some flashy young man.
, you can be sure there’ll be soon another one
thing
brothers
O’CLOCK
SCORE
reasons
PEOPLE
PEOPLE
. . . Men | busses
YEAR
AGE
CURRENCY
unexpressed thought
PEOPLE
fussy old maid & flahy young man
now.
[non-NFH] One thing to be said about traveling by stage.
[non-NFH] After seven long years. . .
–
–
Tavolo 1: Examples of NFHs. The anchors are marked in bold, the heads are marked in italic. IL
missing heads in the last column are written in italic for Reference cases and in upper case for the
Implicit cases. The last two rows contain examples with regular numbers—which are not considered
NFHs.
Infatti, tasks such as information extraction, ma-
chine translation, question answering, and others
could greatly benefit from recovering such implicit
knowledge prior to (or in conjunction with) run-
ning the model.1
We find NFHs particularly interesting to model:
They are common (Sezione 2), easy to understand
and resolve by humans (Sezione 5), important for
language understanding, not handled by current
systems (Sezione 7), and hard for current methods
to resolve (Sezione 6).
The main contributions of this work are as
follows.
• We provide an account of NFH constructions
and their distribution in a large corpus of
English dialogues, where they account for
41.2% of the numbers. We similarly quantify
the prevalence of NFHs in other textual genres,
showing that they account for between 22.2%
E 37.5% of the mentioned numbers.
• We formulate FH identification (identifying
cases that need to be resolved) and resolution
(inferring the missing head) compiti.
1To give an example from information extraction, con-
sider a system based on syntactic patterns that needs to handle
the sentence ‘‘Carnival is expanding its ships business, con
12 to start operating next July.’’ In the context of MT, Google
Translate currently translates the English sentence ‘‘I’m in
the center lane, going about 60, and I have no choice’’ into
French as ‘‘Je suis dans la voie du centre, environ 60 ans,
et je n’ai pas le choix’’, changing the implicit speed to an
explicit time period.
• We create an annotated corpus for NFH
identification and show that the task can be
automatically solved with high accuracy.
• We create a 900,000-token annotated corpus
for NFH resolution, comprising ∼10K NFH
examples, and present a strong baseline model
for tackling the resolution task.
2 Numeric Fused Heads
Throughout the paper, we refer to the visible
number in the FH as the anchor and to the missing
head as the head.
In FH constructions the implicit heads are
missing and are said to be fused with the anchors,
which are either determiners or modifiers. Nel
case of NFH, the modifier role is realized as a
number (see examples in Table 1). The anchors
then function both as the determiner/modifier and
as the head—the parent and the other modifiers
of the original head are syntactically attached to
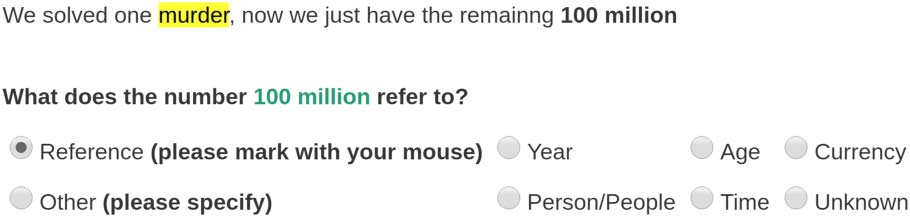
the anchor. Per esempio, in Figure 1 the phrase
the remaining 100 million contains an NFH
construction with the anchor 100 million, che è
attached to the sentence through the dotted black
dependency edges. The missing head, murders,
appears in red together with its missing depen-
dency edges.2
2An IE or QA system trying to extract or answer in-
formation about the number of murders being solved will
have a much easier time when implicit information would be
stated explicitly.
520
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Figura 1: Example for an NFH. The ‘murders’ token is missing, and fused with the ‘100 million’ numeric-span.
Distribution NFH constructions are very com-
mon in dialog situations (Infatti, we show in
Sezione 4 that they account for over 40% Di
the numbers in a large English corpus of movie
dialogs), but are also common in written text
such as product reviews or journalistic text. Using
an NFH identification model that we describe in
Sezione 4.2, we examined the distribution of NFH
in different corpora and domains. Specifically, we
examined monologues (TED talks; Cettolo et al.,
2012), Wikipedia (WikiText-2 and WikiText-103;
Merity et al., 2016), journalistic text (PTB: Marcus
et al., 1993), and product reviews (Amazon re-
views3) in which we found that more than 35.5%,
33.2%, 32.9%, 22.2%, E 37.5% of the numbers,
rispettivamente, are NFHs.
FH Types We distinguish between two kinds
of FH, which we call Reference and Implicit. In
Reference FHs, the missing head is referenced
explicitly somewhere else in the discourse, either
in the same sentence or in surrounding sentences.
In Implicit FHs, the missing head does not appear
in the text and needs to be inferred by the reader or
hearer based on the context or world knowledge.
2.1 FH vs. Other Phenomena
FH constructions are closely related to ellipsis con-
structions and are also reminiscent of coreference
resolution and other anaphora tasks.
FH vs. Ellipsis With respect to ellipsis, some of
the NFH cases we consider can be analyzed as nomi-
nal ellipsis (cf. io, ii in Table 1, and Example (3) In
the Introduction). Other cases of head-less num-
bers do not traditionally admit an ellipsis analysis.
We do not distinguish between the cases and
consider all head-less number cases as NFHs.
3https://www.kaggle.com/bittlingmayer/
amazonreviews
FH vs. Coreference With respect to corefer-
ence, some Reference FH cases may seem similar
to coreference cases. Tuttavia, we stress that these
are two different phenomena: In coreference, IL
mention and its antecedent both refer to the same
entity, whereas the NFH anchor and its head-
reference—like in ellipsis—may share a symbol
but do not refer to the same entity. Existing coref-
erence resolution data sets do consider some FH
cases, but not in a systematic way. They are also
restricted to cases where the antecedent appears
in the discourse (cioè., they do not cover any of the
NFH Implicit cases).
FH vs. Anaphora Anaphora is another similar
phenomenon. As opposed to coreference, ana-
phora (and cataphora, which are cases with a
forward rather than a backward reference) includes
mentions of the same type but different entities.
Tuttavia, the anaphora does not cover our Implicit
NFH cases, which are not anaphoric but refer
to some external context or world knowledge.
We note that anaphora/cataphora is a very broad
concept, which encompasses many different sub-
cases of specific anaphoric relations. There is
some overlap between some of these cases and the
FH constructions.
Pronimial one The word one is a very common
NFH anchor (61% of the occurrences in our
corpus), and can be used either as a number (viii)
or as a pronoun (xiii). The pronoun usage can
be replaced with someone. For consistency, we
consider the pronominal usages to be NFH, con
the implicit head PEOPLE.4
The one-anaphora phenomenon was previously
studied on its own (Gardiner, 2003; Ng et al.,
4Although the overwhelming majority of ‘one’ with an
implicit PEOPLE head are indeed pronomial, some cases are
non. Per esempio: ‘Bailey, if you don’t hate me by now you’re
a minority of one.’
521
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
2005). The work by Ng et al. (2005) divided uses
of one into six categories: Numeric (xv), Partitive
(v), Anaphoric (xii), Generic (vii), Idiomatic (xiii)
and Unclassified. We consider all of these, except
the Numeric category, as NFH constructions.
2.2 Inclusive Definition of NFH
Although our work is motivated by the linguistic
definition of FH, we take a pragramatic approach
in which we do not determine the scope of the NFH
task based on fine-grained linguistic distinctions.
Piuttosto, we take an inclusive approach that is
motivated by considering the end-user of an NFH
resolution system who we imagine is interested in
resolving all numbers that are missing a nominal
head. Therefore, we consider all cases that ‘‘look
like an NFH’’ as NFH, even if the actual linguistic
analysis would label them as gapping, ellipsis,
anaphoric pronominal-one, or other phenomena.
We believe this makes the task more consistent
and easier to understand to end users, annotators,
and model developers.
3 Computational Modeling and
Underlying Corpus
We treat the computational handling of FHs as
two related tasks: Identification and resolution.
We create annotated NFH corpora for both.
Underlying Corpus As the FH phenomenon is
prevalent in dialog situations, we base our corpus
on dialog excerpts from movies and TV-series
scripts (the IMDB corpus). The corpus contains
117,823 different episodes and movies. Every such
item may contain several scenes, with an average
Di 6.9 scenes per item. Every scene may contain
several speaker turns, each of which may span
several sentences. The average number of turns
per scene is 3.0. The majority of the scenes have
at least two participants. Some of the utterances
refer to the global movie context.5
NFH Identification In the identification stage,
we seek NFH anchors within headless NPs that
contain a number. More concretely, given a sen-
tence, we seek a list of spans corresponding to
all of the anchors within it. An NFH anchor is
restricted to a single number, but not a single
5Referring to a broader context is not restricted to movie-
based dialogues. Per esempio, online product reviews contain
examples such as ‘‘. . . I had three in total…’’, with three
referring to the purchased product, which is not explicitly
mentioned in the review.
thirty six is a two-token
token. Per esempio,
number that can serve as an NFH anchor. Noi
assume all anchors are contiguous spans. IL
identification task can be reduced to a binary de-
cision, categorizing each numeric span in the
sentence as FH/not-FH.
NFH Resolution The resolution task resolves
an NFH anchor to its missing head. Concretely,
given a text fragment w1, . . . , wn (a context) E
an NFH anchor a = (io, j) within it, we seek the
head(S) of the anchor.
For Implicit FH, the head can be any arbi-
trary expression. Although our annotated corpus
supports this (Sezione 5), in practice our modeling
(Sezione 6) as well as the annotation procedure
favor selecting one out of five prominent cate-
gories or the OTHER category.
For Reference FH, the head is selected from
the text fragment. In principle a head can span
multiple tokens (per esempio., ‘unexpected thought’ in
(Tavolo 1, xii)). This is also supported by our
annotation procedure. In practice, we take the
syntactic head of the multi-token answer to be
the single-token missing element, and defer the
boundary resolution to future work.
In cases where multiple heads are possible for
the same anchor (per esempio., viii, xiv in Table 1), Tutto
should be recovered. Hence, the resolution task is
a function from a (testo, anchor) pair to a list of
heads, where each head is either a single token in
the text or an arbitrary expression.
4 Numeric Fused-Head Identification
The FH task is composed of two sub-tasks. In
: identifying
this section, we describe the first
NFH anchors in a sentence. We begin with a
rule-based method, based on the FH definition.
We then proceed to a learning-based model, Quale
achieves better results.
Test set We create a test set for assessing the
identification methods by randomly collecting
500 dialog fragments with numbers, and labeling
each number as NFH or not NFH. We observe
that more than 41% of the test-set numbers
are FHs, strengthening the motivation for dealing
with the NFH phenomena.
4.1 Rule-based Identification
FHs are defined as NPs in which the head is
fused with a dependent element, resulting in an
522
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
NP without a noun.6 With access to an oracle
constituency tree, NFHs can be easily identified
by looking for such NPs. In practice, we resort to
using automatically produced parse-trees.
We parse the text using the Stanford constit-
uency parser (Chen and Manning, 2014) and look
for noun phrases7 that contain a number but not a
noun. This already produces reasonably accurate
risultati, but we found that we can improve further
by introducing 10 additional text-based patterns,
which were customized based on a development
set. These rules look for common cases that are
often not captured by the parser. Per esempio, UN
conjunction pattern involving a number followed
by ‘or’, such as ‘‘eight or nine clubs’’,8 Dove
‘eight’ is an NFH that refers to ‘clubs’.
Parsing errors result in false-positives. For ex-
ample in ‘‘You’ve had [one too many cosmos].’’,
the Stanford parser analyzes ‘one’ as an NP, Di-
spite the head (‘cosmos’) appearing two tokens
Dopo. We cover many such cases by consulting
with an additional parser. We use the SPACY depen-
dency parser (Honnibal and Johnson, 2015) E
filter out cases where the candidate anchor has a
noun as its syntactic head or is connected to its
parent via a nummod label. We also filter cases
where the number is followed or preceded by a
currency symbol.
Evaluation We evaluate the rule-based identi-
fication on our test set, resulting in 97.4% pre-
cision and 93.6% recall. The identification errors
are almost exclusively a result of parsing mistakes
in the underlying parsers. An example of a false-
negative error is in the sentence: ‘‘The lost six
belong in Thorn Valley’’, where the dependency
parser mistakenly labeled ‘belong’ as a noun,
resulting in a negative classification. An example
of a false-positive error is in the sentence: ‘‘our
God is the one true God’’ where the dependency
parser labeled the head of one as ‘is’.
6One exception are numbers that are part of names
(‘Appollo 11’s your secret weapon?’), which we do not con-
sider to be NFHs.
7Specifically, we consider phrases of type NP, QP, NP-TMP,
NX, and SQ.
8This phrase can be treated as a gapped coordination
construction. For consistency, we treat it and similar cases as
NFHs, as discussed in Section 2.2. Another reading is that the
entire phrase ‘‘eight or nine’’ refers to a single approximate
quantity that modifies the noun ‘‘clubs’’ as a single unit. Questo
relates to the problem of disambiguating distributive-vs-joint
reading of coordination, which we consider to be out of scope
for the current work.
train
71,821
93,785
165,606
dev
7865
10,536
18,401
test
206
294
500
Tutto
79,884
104,623
184,507
pos
neg
Tutto
Tavolo 2: NFH Identification corpus sum-
mary. The train and dev splits are noisy
and the test set are gold annotations.
4.2 Learning-based Identification
We improve the NFH identification using machine
apprendimento. We create a large but noisy data set by
considering all the numbers in the corpus and
treating the NFHs identified by the rule-based
approach as positive (79,678 examples) and all
other numbers as negative (104,329 examples).
We randomly split the data set into train and
development sets in a 90%, 10% split. Tavolo 2
reports the data set size statistics.
We train a linear support vector machine
classifier9 with four features: (1) concatenation of
the anchor-span tokens; (2) lower-cased tokens in a
3-token window surrounding the anchor span; (3)
part of speech (POS) tags of tokens in a 3-token
window surrounding the anchor span; E (4)
POS-tag of the syntactic head of the anchor. IL
features for the classifier require running a POS
tagger and a dependency parser. These can be
omitted with a small performance loss (Vedi la tabella 3
for an ablation study on the dev set).
On the manually labeled test set, the full model
achieves accuracies of 97.5% precision and 95.6%
recall, surpassing the rule-based approach.
4.3 NFH Statistics
We use the rule-based positive examples of the
data set and report some statistics regarding the
NFH phenomenon. The most common anchor of
the NFH data set with a very big gap is the
token ‘one’10 with 48,788 occurrences (61.0% Di
the data), while the second most commons is the
token ‘two’ with 6,263 occurrences (8.4%). There
is a long tail in terms of the tokens occurrences,
con 1,803 unique anchor tokens (2.2% del
NFH data set). Most of the anchors consist of a
single token (97.4%), 1.3% contain 2 gettoni, E
the longest anchor consists of 8 gettoni (‘Fifteen
million sixty one thousand and seventy six.’). IL
9sklearn implementation (Pedregosa et al., 2011) con
default parameters.
10Lower-cased.
523
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Deterministic (Test)
Full-model (Test)
Full-model (Dev)
– dep
– pos
– dep, pos
Precision Recall
93.6
95.6
97.5
97.3
97.0
96.1
97.4
97.5
96.8
96.7
96.4
95.6
F1
95.5
96.6
97.1
97.0
96.7
95.9
Tavolo 3: NFH Identification results.
numbers tend to be written as words (86.7%) E
the rest are written as digits (13.3%).
4.4 NFH Identification Data Set
The underlying corpus contains 184,507 examples
(2,803,009 gettoni), of which 500 examples are
gold-labeled and the rest are noisy. In the gold
test set, 41.2% of the numbers are NFHs. The esti-
mated quality of the corpus—based on the manual
test-set annotation—is 96.6% F1 score. The corpus
and the NFH identification models are available
at github.com/yanaiela/num fh.
5 NFH Resolution Data Set
Having the ability to identify NFH cases with high
accuracy, we turn to the more challenging task of
NFH resolution. The first step is creating a gold
annotated data set.
5.1 Corpus Candidates
Using the identification methods—which achieve
satisfying results—we identify a total of 79,884
NFH cases in the IMDB corpus. We find that a
large number of the cases follow a small set of
patterns and are easy to resolve deterministically:
Four deterministic patterns account for 28% del
NFH cases. The remaining cases are harder. Noi
randomly chose a 10,000-case subset of the harder
cases for manual annotation via crowdsourcing.
We only annotate cases where the rule-based and
learning-based identification methods agree.
Deterministic Cases The four deterministic pat-
terns along with their coverage are detailed in
Tavolo 4. The first two are straightforward string
matches for the patterns no one and you two, Quale
we find to almost exclusively resolve to PEOPLE.
The other two are dependency-based patterns for
partitive (four [children] of the children) E
copular (John is the one [John]) constructions. Noi
collected a total of 22,425 such cases. Although we
believe these cases need to be handled by any NFH
resolution system, we do not think systems should
be evaluated on them. Therefore, we provide these
cases as a separate data set.
5.2 Annotation via Crowdsourcing
The FH phenomenon is relatively common and
can be understood easily by non-experts, making
the task suitable for crowd-sourcing.
Esso
The Annotation Task For every NFH anchor,
is a
the annotator should decide whether
Reference FH or an Implicit FH. For Reference,
they should mark the relevant textual span. For
Implicit, they should specify the implicit head
from a closed list. In cases where the missing head
belongs to the implicit list, but also appears as a
span in the sentence (reference), the annotators are
instructed to treat it as a reference. To encourage
consistency, we run an initial annotation in which
we identified common implicit cases: YEAR (a cal-
endar year, Esempio (ix) in Table 1), AGE (exam-
ple x), CURRENCY (Esempio (xi); although the
source of the text suggests US dollars, we do not
commit to a specific currency), PERSON/PEOPLE
(Esempio (vi)) and TIME (a daily hour, Esempio
(iii)). The annotators are then instructed to either
choose from these five categories;
to choose
OTHER and provide free-form text; or to choose
UNKNOWN in case the intended head cannot be
reliably deduced based on the given text.11 For
the Reference cases, the annotators can mark any
contiguous span in the text. We then simplify
their annotations and consider only the syntactic
head of their marked span.12 This could be done
automatically in most cases, and was done man-
ually in the few remaining cases. The annota-
tor must choose a single span. In case the answer
includes several spans as in examples viii and xiv,
we rely on it to surface as a disagreement between
the annotators, which we then pass to further
resolution by expert annotators.
The Annotation Procedure We collected anno-
tations using Amazon Mechanical Turk (AMT).13
In every task (HIT in AMT jargon) a sentence
11This happens, Per esempio, when the resolution depends
on another modality. Per esempio, in our setup using dialogs
the speaker could refer to
from movies and TV-series,
something from the video that isn’t explicitly mentioned
in the text, such as in ‘‘Hit the deck, Pig Dog, and give me
37!’’.
12We do provide the entire span annotation as well, A
facilitate future work on boundary detection.
13To maximize the annotation quality, we restricted the
turkers with the following requirements: Complete over 5 K
524
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Tavolo 4: Example of NFHs whose heads can be resolved deterministically. The first two patterns are
the easiest to resolve. These just have to match as is and their head is the PEOPLE class. The last two
patterns depends on a dependency parser and can be resolved by following arcs on the parse tree.
Figura 2: Crowdsourcing task interface on AMT.
with the FH anchor was presented (target sen-
tence). Each target sentence was presented with
maximum two dialog turns before and one dialog
turn after it. This was the sole context that was
shown to avoid exhausting the AMT workers
(turkers) with long texts and in the vast majority
of the examined examples, the answer appeared
in that scope.
Every HIT contained a single NFH example.
In cases of more than one NFH per sentence,
it was split into 2 different HITs. The annota-
tors were presented with the question: ‘‘What
does the number [ANCHOR] refer to?’’ where
[ANCHOR] was replaced with the actual number
span, and annotaters were asked to choose from
eight possible answers: REFERENCE, YEAR, AGE,
CURRENCY, PERSON/PEOPLE, TIME, OTHER, and UNKNOWN
(See Figure 2 for a HIT example). Choosing the
REFERENCE category requires marking a span in
the text corresponding to the referred element
(the missing head). The turkers were instructed
to prefer this category over the others if possible.
Therefore, in Example (xiv) of Table 1, the Ref-
erence answers were favored over the PEOPLE
answer. Choosing the OTHER category required
entering free-form text.
Post-annotation, we unify the Other and Un-
known cases into a single OTHER category.
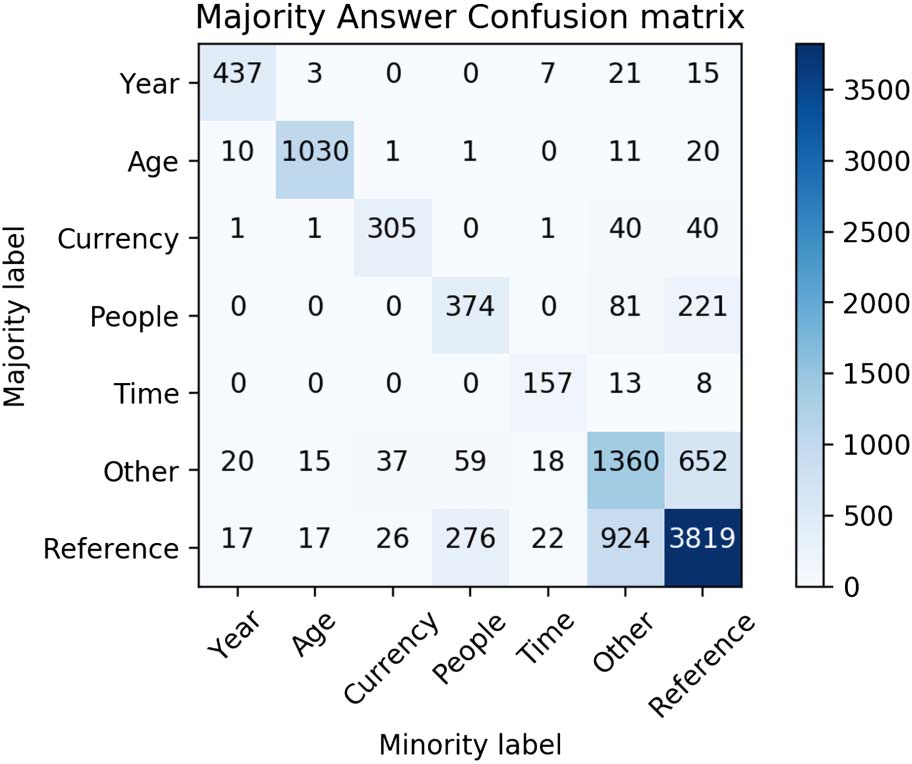
Figura 3: Confusion matrix of the majority annotators
on categorical decision.
Each example was labeled by three annotators.
On the categorical decision (just the one-of-seven
choice, without considering the spans selected for
the REFERENCE text and combining the OTHER and
UNKNOWN categories), 73.1% of the cases had a
perfect agreement (3/3), 25.6% had a majority
agreement (2/3), E 1.3% had a complete dis-
agreement. The Fleiss kappa agreement (Fleiss,
1971) is k = 0.73, a substantial agreement score.
The high agreement score suggests that the anno-
tators tend to agree on the answer for most cases.
Figura 3 shows the confusion matrix for the one-
of-seven task, excluding the cases of complete
disagreement. The more difficult cases involve
the REFERENCE class, which is often confused with
PEOPLE and OTHER.
5.3 Final Labeling Decisions
acceptable HITs, Sopra 95% of their overall HITs being
accepted, and completing a qualification for the task.
Post-annotation, we ignore the free text entry for
OTHER and unify OTHER and UNKNOWN into a
525
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
single category. Tuttavia, our data collection pro-
cess (and the corpus we distribute) contain this
informazione, allowing for more complex task
definitions in future work.
The disagreement cases surface genuinely hard
cases, such as the ones that follow:
(7) Mexicans have fifteen, Jews have thirteen,
rich girls have sweet sixteen…
(8) All her communications are to Minnesota
numbers. There’s not one from California.
(9) And I got to see Irish. I think he might
be the one that got away, or the one that
got put-a-way.
The majority of the partial category agree-
ment cases (1,576) are of REFERENCE vs. OTHER/
UNKNOWN, which are indeed quite challenging
(per esempio., Esempio (9) where two out of three turkers
selected the REFERENCE answer and marked Irish
as the head, and the third turker selected the
Person/People label, which is also true, but less
meaningful in our perspective).
The final labeling decision was carried out
in two phases. Primo, a categorical labeling was
applied using the majority label, while the 115
examples with disagreement (per esempio., Esempio (7),
which was tagged as YEAR, REFERENCE (‘birthday’
which appeared in the context), and OTHER (free
testo:‘special birthday’)) were annotated manually
by experts.
The second stage dealt with the REFERENCE
labels (5,718 cases). We associate each annotated
span with the lemma of its syntactic head, E
consider answers as equivalent if they share the
same lemma string. This results in 5,101 full-
agreement cases at the lemma level. The remain-
ing 617 disagreement cases (per esempio., Esempio (8))
were passed to further annotation by the expert
annotators. During the manual annotation we
allow also for multiple heads for a single anchor
(per esempio., for viii, xiv in Table 1).
An interesting case in Reference FHs is a con-
struction in which the referenced head is not
unique. Consider Example (viii) in Table 1: IL
word ‘one’ refers to either men or buses. Another
example of such case is Example (xiv) in Table 1
where the word ‘two’ refers both to fussy old
maid and to flashy young man. Notice that the two
cases have different interpretations: The referenced
heads in Example (viii) have an or relation be-
tween them whereas the relation in (xiv) is and.
526
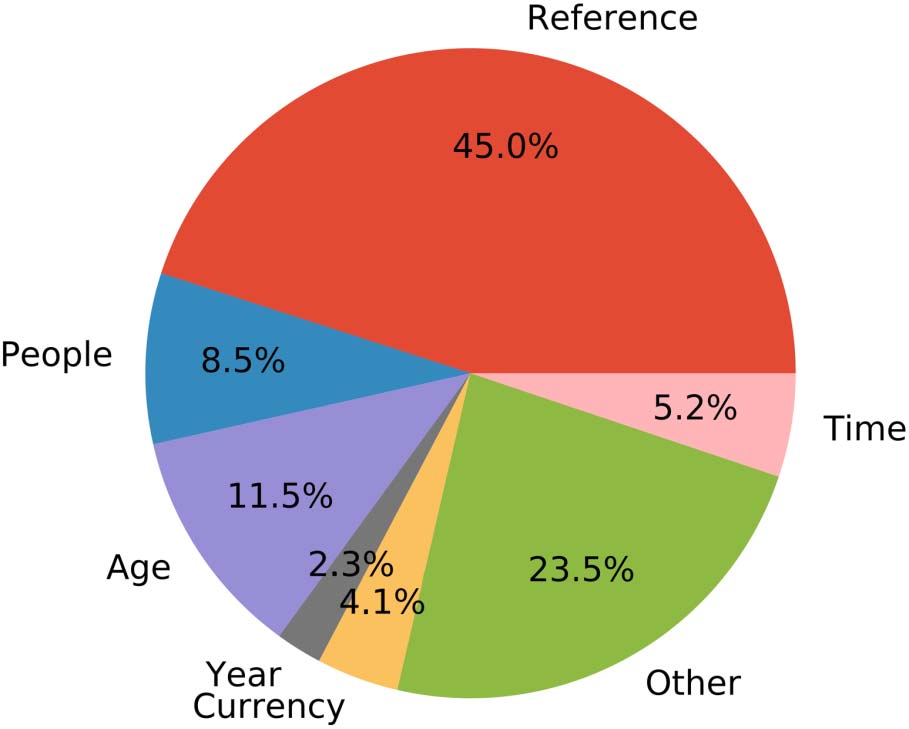
Figura 4: Distribution of NFH types in the NFH
Resolution data set.
5.4 NFH Statistics
General We collected a total of 9,412 annotated
NFHs. The most common class is REFERENCE
(45.0% of the data set). The second common class
is OTHER (23.5%), which is the union of original
OTHER class, in which turkers had to write the
missing head, and the UNKNOWN class, in which no
clear answer could be identified in the text. IL
majority of this joined class is from the UNKNOWN
label (68.3%). The rest of the five closed-class
categories account for the other 31.5% del
cases. A full breakdown is given in Figure 4. IL
anchor tokens in the data set mainly consist of
the token ‘one’ (49.0% of the data set), with the
tokens ‘two’ and ‘three’ being the second and
third most common. Additionally, 377 (3.9%) Di
the anchors are singletons, which appear only
once.
Reference Cases The data set consists of a total
Di 4,237 REFERENCE cases. The vast majority of
them (3,938 cases) were labeled with a single
referred element, 238 with two reference-heads,
E 16 with three or more.
In most of the cases, the reference span can be
found near the anchor span. In 2,019 of the cases,
the reference is in the same sentence with the
anchor, In 1,747 it appears in a previous/following
sentence. Inoltre, in most cases (82.7%), IL
reference span appears before the anchor and only
In 5.1% of the cases does it appear after it. An
example of such a case is presented in Example
(xiv) in Table 1. In the rest of the cases, references
appear both before and after the anchor.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
5.5 NFH Resolution Data Set
The final NFH Resolution data set consists of
900,777 tokens containing 9,412 instances of
gold-labeled resolved NFHs. The resolution was
done by three mechanical turk annotators per task,
with a high agreement score (k = 0.73).14 IL
REFERENCE cases are annotated with at least one
referring item. The OTHER class unifies several
other categories (None and some other scarce
Implicit classes), but we maintain the original
turker answers to allow future work to apply more
fine-grained solutions for these cases.
6 Where’s my Head? Resolution Model
We consider the following resolution task: Given
a numeric anchor and its surrounding context, we
need to assign it a single head. The head can be
either a token from the text (for Reference FH)
or one-of-six categories (IL 5 most common
categories and OTHER) for Implicit FH.15
This combines two different kinds of tasks.
The REFERENCE case requires selecting the most
adequate token over the text, suggesting a similar
formulation to coreference resolution (Di, 2010;
Lee et al., 2018) and implicit arguments iden-
tification (Gerber and Chai, 2012; Moor et al.,
2013). The implicit case requires selection from a
closed list, a similar formulation to word-tagging-
in-context tasks, where the word (in our case, span)
to be tagged is the anchor. A further complication
is the need to weigh the different decisions
(Implicit vs. Reference) against each other. Nostro
solution is closely modeled after the state-of-the-
art coreference resolution system of Lee et al.
(2017).16 Tuttavia, the coreference-centric archi-
tecture had to be adapted to the particularities of
the NFH task. Specifically, (UN) the NFH resolution
does not involve cluster assignments, E (B) Esso
14The Reference cases were treated as a single class for
computing the agreement score.
15This is a somewhat simplified version of the full task
defined in Section 3. In particular, we do not require
specification of the head in case of OTHER, and we require a
single head rather than a list of heads. Nonetheless, we find
this variant to be both useful and challenging in practice. For
the few multiple-head cases, we consider each of the items
in the gold list to be correct, and defer a fuller treatment for
future work.
16Newer systems such as Lee et al. (2018) and Zhang
et al. (2018) show improvements on the coreference task,
but use components that focus on the clustering aspect of
coreference, which are irrelevant for the NFH task.
requires handling the Implicit cases in addition to
the Reference ones.
The proposed model combines both decisions, UN
combination that resembles the copy-mechanisms
in neural MT (Gu et al., 2016) and the Pointer
Sentinel Mixture Model in neural LM (Merity
et al., 2016). As we only consider referring men-
tions as single tokens, we discarded the original
models’ features that handled the multi-span repre-
sentation (per esempio., the Attention mechanism). Further-
more, as the Resolution task already receives a
numeric anchor, it is redundant to calculate a men-
tion score. In preliminary experiments we did try
to add an antecedent score, with no resulting im-
provement. Our major adaptations to the Lee et al.
(2017) modello, described subsequently, are the re-
moval of the redundant components and the addi-
tion of an embedding matrix for representing the
Implicit classes.
6.1 Architecture
Given an anchor, our model assigns a score to
each possible anchor–head pair and picks the one
with the highest score. The head can be either a
token from the text (for the Reference case) O
one-of-six category labels (for the Implicit case).
We represent the anchor, each of the text tokens
and each category label as vectors.
Each of the implicit classes c1, . . . , c6 is repre-
sented as an embedding vector ci, which is ran-
domly initialized and trained with the system.
To represent the sentence tokens (ti), we first
represent each token as a concatenation of the
token embedding and the last state of a character
long short-term memory (LSTM) (Hochreiter and
Schmidhuber, 1997):
xi = [NO; LST M (eic1:ct)]
where ei is the ith token embedding and eicj
È
the jth character of the ith token. These repre-
sentations are then fed into a text-level biLSTM
resulting in the contextualized token representa-
tions ti:
ti = BILST M (x1:N, io)
Finalmente, the anchor, which may span several
gettoni, is represented as the average over its con-
textualized tokens.
a =
1
j − i + 1
j(cid:2)
k=i
tk
527
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
score
We predict
S(H, UN)
for
pair, Dove
every
UN
h ∈
head-anchor
possible
{c1, . . . , c6, t1, . . . , tn} and hi
the corre-
sponding vector. The pair is represented as a
concatenation of the head, the anchor and their
element-wise multiplication, and scored with a
multi-layer perceptron:
È
S(H, UN) = M LP ([H; UN; H (cid:6) UN])
We normalize all of the scores using softmax,
and train to minimize the cross-entropy loss.
Pre-trained LM To take advantage of the recent
success in pre-trained language models (Peters
et al., 2018; Devlin et al., 2018) we also make
use of ELMo contextualized embeddings instead
of the embedding matrix and the character LSTM
concatentation.
6.2 Training Details
The character embedding size is 30 and their
LSTM dimension is 10. We use Google’s pre-
trained 300-dimension w2v embeddings (Mikolov
et al., 2013) and fix the embeddings so they don’t
change during training. The text-level LSTM di-
mension is 50. The Implicit embedding size is the
same as the BiLSTM output, 100 units. The MLP
has a single hidden layer of size 150 and uses tanh
as the non-linear function. We use dropout of 0.2
on all hidden layers, internal representation, E
tokens representation. We train using the Adam
optimizer (Kingma and Ba, 2015) and a learning
rate of 0.001 with early stopping, based on the
development set. We shuffle the training data be-
fore every epoch. The annotation allows more than
one referent answer per anchor; in such case, we
take the closest one to the anchor as the answer for
training, and allow either one when evaluating.
The experiments using ELMo replaced the pre-
trained word embeddings and character LSTM.
It uses the default parameters in the AllenNLP
framework (Gardner et al., 2017), con 0.5 dropout
on the network, without gradients update on the
contextualized representation.
6.3 Experiments and Results
Data Set Splits We split the data set into train/
development/test, containing 7,447, 1,000, E
1,000 examples, rispettivamente. There is no overlap
of movies/TV-shows between the different splits.
528
Model
Oracle (Reference)
+ Elmo
Oracle (Implicit)
+ Elmo
Model (full)
+ Elmo
Reference
70.4
81.2
–
–
61.4
73.0
Implicit
–
–
82.8
90.6
69.2
80.7
Tavolo 5: NFH Resolution accuracies for the
Reference and Implicit cases on the development
set. Oracle (Reference) and Oracle (Implicit)
assume an oracle for the implicit vs. reference
decisions. Model (full) is our final model.
Metrics We measure the model performance of
the NFH head detection using accuracy. For every
esempio, we measure whether the model success-
fully predicted the correct label or not. We report
two additional measurements: Binary classifica-
tion accuracy between the Reference and Implicit
cases and a multiclass classification accuracy score,
which measures the class-identification accuracy
while treating all REFERENCE selections as a single
decision, regardless of the chosen token.
Results We find that 91.8% of the Reference cases
are nouns. To provide a simple baseline for the
task, we report accuracies solely on the Reference
examples (ignoring the Implicit ones) when choos-
ing one of the surrounding nouns. Choosing the
first noun in the text, the last one or the closest
one to the anchor leads to scores of 19.1%, 20.3%,
E 39.2%.
We conduct two more experiments to test our
model on the different FH kinds: Reference and
Implicit. In these experiments we assume an oracle
that tells us the head type (Implicit or Reference)
and restricts the candidate set for the correct kind
during both training and testing. Tavolo 5 sum-
marizes the results for the oracle experiments as
well as for the full model.
The final models accuracies are summarized
in Table 6. The complete model trained on the
entire training data achieves 65.6% accuracy on
the development set and 60.8% accuracy on the
test set. The model with ELMo embeddings (Peters
et al., 2018) adds a significant boost in perfor-
mance and achieves 77.2% E 74.0% accuracy
on the development and test sets, rispettivamente.
The development-set binary separation with
ELMo embeddings is 86.1% accuracy and cate-
gorical separation is 81.9%. This substantially
outperforms all baselines, but still lags behind
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Model
Base
+ Elmo
Development
65.6
77.2
Test
60.8
74.0
Tavolo 6: NFH Resolution accuracies on the
development and test sets.
the oracle experiments
Implicit-only).
(Reference-only and
As the oracle experiments perform better on
the individual Reference and Implicit classes, we
experimented with adding an additional objective
to the model that tries to predict the oracle de-
cision (implicit vs. reference). This objective was
realized as an additional
loss term. Tuttavia,
this experiment did not yield any performance
improvement.
We also experimented with linear models, con
features based on previous work that dealt with
antecedent determination (Ng et al., 2005; Liu
et al., 2016) such as POS tags and dependency
labels of the candidate head, whether the head is
the closest noun to the anchor, and so forth. Noi
also added some specific features that dealt with
the Implicit category, for example binarization
of the anchor based on its magnitude (per esempio., < 1,
< 10, < 1600, < 2100), if there was another
currency mention in the text, and so on. None
of these attempts surpassed the 28% accuracy on
the development set. For more details on these
experiments, see Appendix A.
6.4 Analysis
The base model’s results are relatively low, but
gain a substantial improvement by adding contex-
tualized embeddings. We perform an error anal-
ysis on the ELMo version, which highlights the
challenges of the task.
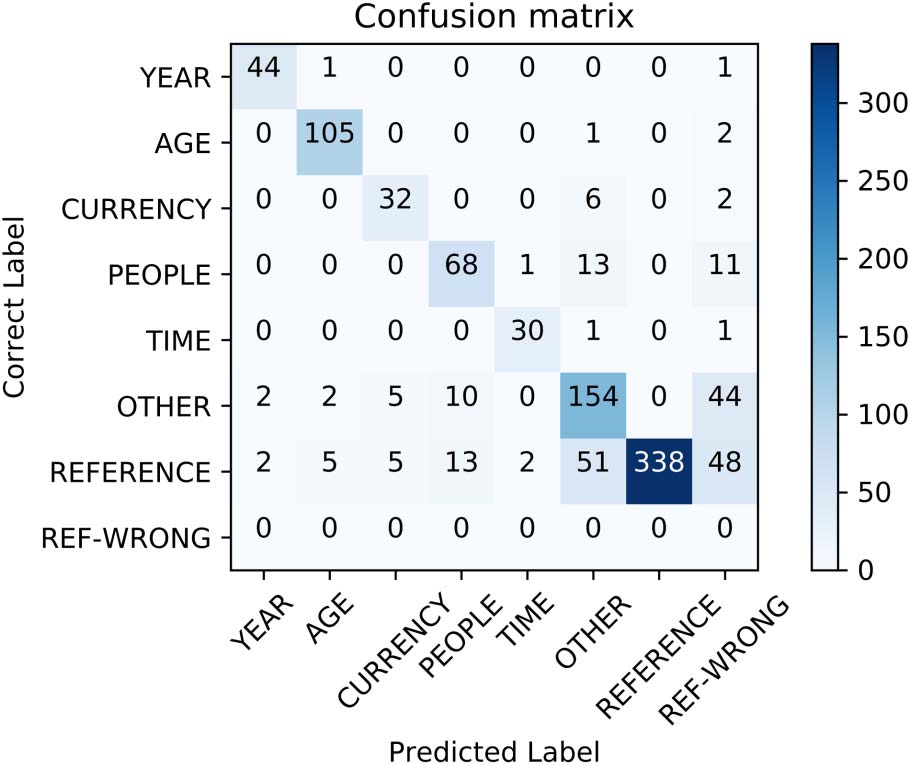
Figure 5 shows the confusion matrix of our
model and Table 7 lists some errors from the
development set.
Pattern-Resolvable Error Cases The first three
examples in Table 7 demonstrate error cases that
can be solved based on text-internal cues and
‘‘complex-pattern-matching’’ techniques. These
can likely be improved with a larger training set
or improved neural models.
The errors in rows 1 and 2 might have caused
by a multi-sentence patterns. A possible reason for
the errors is the lack of that pattern in the training
data. Another explanation could be a magnitude
Figure 5: Confusion matrix of the model. Each row/
column corresponds to a gold/predicted label re-
spectively. The last one (REF-WRONG), is used for
indicating an erroneous choice of a Reference head.
bias, where in row 1, One in the beginning of a
sentence usually refer to PEOPLE, whereas in row
2, Five is more likely to refer to an AGE.
In row 3, the model has to consider several
cues from the text, such as the phrase ‘‘a hundred
dollars’’ which contains the actual head and is of
a similar magnitude to the anchor. In addition, the
phrase: ‘‘it was more around’’ gives a strong hint
on a previous reference.
Inference/Common Sense Errors Another cate-
gory of errors includes those that are less likely
to be resolved with pattern-based techniques and
more data. These require common sense and/or
more sophisticated inferences to get right, and
will likely require a more sophisticated family of
models to solve.
In row 4, one refers to dad, but the model chose
sisters. These are the only nouns in this example,
and, with the lack of any obvious pattern, a model
needs to understand the semantics of the text to
identify the missing head correctly.
Row 5 also requires understanding the seman-
tics of the text, and some understanding of its dis-
course dynamic; where a conversation between the
two speakers takes place, with a reply of Krank to
L’oncle Irvin, that the model missed.
In Row 6, the model has difficulty collecting
the cues in the text that refer to an unmentioned
person, and therefore the answer is PEOPLE, but the
model predicts OTHER.
Finally, in Row 7 we observe an interesting
case of overfitting, which is likely to originate
529
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
t
l
a
c
_
a
_
0
0
2
8
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Text
Dreadwing: This will be my gift to the Dragon Flyz, my farewell gift .
One that will keep giving and giving and giving.
David Rossi: How long?
Harrison Scott: A year . Maybe five. It’s hard to keep track without a watch.
Henry Fitzroy: a hundred dollars, that’s all it takes for you to risk your life ?
Vicki Nelson: Actually, it was more around 98...
1
2
3
4
Evelyn Pons: He might be my legal dad , too!
Paula Novoa Pazos: No, because we’re not sisters , but you can look for another one.
Evelyn Pons: How did you look for one?
L’oncle Irvin: A soul .
Krank: Because you believe you have one? You don’t even have a body .
6 Jenny: Head in the clouds, that one. I don’t know why you’re so sweet on him.
5
7
Officer Mike Laskey: I can’t do that.
Joss Carter: Do you really wanna test me? ’Cause I’ve got a shiny new 1911 [...]
Predicted Truth
PEOPLE
gift
AGE
YEAR
OTHER
dollar
sisters
dad
body
soul
OTHER
PEOPLE
YEAR
OTHER
Table 7: Erroneous example predictions from the development data. Each row represents an example
from the data. The redder the words, the higher their scores. The two last columns contain the model
prediction and the gold label. Uppercase means the label is from the IMPLICIT classes, otherwise it is a
REFERENCE in lowercase.
from the word-character encoding. As the anchor
- 1991 is a four-digit number, which are usually
used to describe YEARs, its representation receives
a strong signal for this label, even though the few
words which precede it (a shiny new) are not likely
to describe a YEAR label.
7 Related Work
The FH problem has not been directly studied
in the NLP literature. However, several works
have dealt with overlapping components of this
problem.
Sense Anaphora The first, and most related, is the
line of work by Gardiner (2003), Ng et al. (2005),
and Recasens et al. (2016), which dealt with
sense anaphoric pronouns (‘‘Am I a suspect? -
you act like one’’, cf. Example (4)). Sense ana-
phora, sometimes also referred to as identity
of sense anaphora, are expressions that inherit
the sense from their antecedent but do not denote
the same referent (as opposed to coreference). The
sense anaphora phenomena also cover numerals,
and significantly overlap with many of our NFH
cases. However, they do not cover the Implicit
NFH cases, and also do not cover cases where the
target is part of a co-referring expression (‘‘I met
Alice and Bob. The two seem to get along well.’’).
In terms of computational modeling, the sense
anaphora task is traditionally split into two sub-
tasks: (i) identifying anaphoric targets and dis-
ambiguating their sense; and (ii) resolving the
to an antecedent. Gardiner (2003) and
target
Ng et al. (2005) perform both tasks, but restrict
themselves to one anaphora cases and their noun-
phrase antecedents. Recasens et al. (2016), on the
other hand, addressed a wider variety of sense
anaphors (e.g., one, all, another, few, most—a
total of 15 different senses, including numerals).
Recasens et al. (2016) annotated a corpus of a
third of the English OntoNotes (Weischedel et al.,
2011) with sense anaphoric pronouns and their
antecedents. Based on this data set, they introduce
a system for distinguishing anaphoric from non-
anaphoric usages. However, they do not attempt
to resolve any target to its antecedent. The non-
anaphoric examples in their work combines both
our Implicit class, as well as other non-anaphoric
examples indistinguishably, and therefore are not
relevant for our work.
In the current work, we restrict ourselves to
numbers and so cover only part of the sense-
anaphora cases handled in Recasens et al. (2016).
However, in the categories we do cover, we do
not limit ourselves to anaphoric cases (e.g., Ex-
amples (3), (4)) but include also non-anaphoric
cases that occur in FH constructions (e.g., Ex-
amples (1), (2)) and are interesting on their own
right. Furthermore, our models not only identify
the anaphoric cases but also attempt to resolve
them to their antecedent.
530
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
t
l
a
c
_
a
_
0
0
2
8
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Zero Reference
In zero reference, the argument
of a predicate is missing, but it can be easily
understood from context (Hangyo et al., 2013).
For example, in the sentence: ‘‘There are two
,
roads to eternity, a straight and narrow
’’ have a zero-
and a broad and crooked
anaphoric relationship to ‘‘two roads to eternity’’
(Iida et al., 2006). This phenomenon is usually
discussed as the context of zero pronouns, where
a pronoun is what is missing. It occurs mainly
in pro-drop languages such as Japanese, Chinese,
and Italian, but has also been observed in English,
mainly in conversational interactions (Oh, 2005).
Some, but not all, zero-anaphora cases result
in FH or NFH instances. Similarly to FH, the
omitted element can appear in the text, similar
to our Reference definition (zero endophora), or
outside of it, similar to our Implicit definition
(zero exophora). Identification and resolution of
this has attracted considerable interest mainly in
Japanese (Nomoto and Nitta, 1993; Hangyo et al.,
2013; Iida et al., 2016) and Chinese (Chen and
Ng, 2016; Yin et al., 2018a,b), but also in other
languages (Ferr´andez and Peral, 2000; Yeh and
Chen, 2001; Han, 2004; Kong and Zhou, 2010;
Mih˘ail˘a et al., 2010; Kope´c, 2014). However,
most of these works considered only the zero
endophora phenomenon in their studies, and even
those who did consider zero exophora (Hangyo
et al., 2013), only considered the author/reader
mentions, for example, ‘‘liking pasta (φ) eats (φ)
every day’’ (translated from Japanese). In this
study, we consider a wider set of possibilities.
Furthermore, to the best of our knowledge, we are
the first to tackle (a subset-of) zero anaphora in
English.
Coreference The coreference task is to find
within a document (or multiple documents) all
the corefering spans that form cluster(s) of the
same mention (which are the anaphoric cases
as described above). The FHs resolution task,
apart from the non-anaphoric cases, is to find
the correct anaphora reference of the target span.
The span identification component of our task
overlaps with the coreference one (see Ng [2010]
for a thorough summary on the NP coreference
resolution and Sukthanker et al. [2018] for a com-
parison between coreference and anaphora). Al-
the key
though the span search resemblance,
conceptual distinctions is that FHs allow the ana-
phoric span to be non co-referring.
Recent work on coreference resolution (Lee
et al., 2017) propose an end-to-end neural archi-
tecture that results in a state-of-the-art perfor-
mance. The work of Peters et al. (2018), Lee et al.
(2018), and Zhang et al. (2018) further improve
on their the scores with pre-training, refining span
representation and using biaffine attention model
for mention detection and clustering. Although
these models cannot be applied to the NFH task
directly, we propose a solution based on the model
of Lee et al. (2017), which we adapt to incorporate
the implicit cases.
Ellipsis The most studied type of ellipsis is the
Verb Phrase Ellipsis (VPE). Although the follow-
ing refers to this line of studies, the task and
resemblance to the NFH task hold up to the
other types of ellipsis as well (gapping [Lakoff
and Ross, 1970], sluicing [John, 1969], nominal
ellipsis [Lobeck, 1995], etc.). VPE is the anaphoric
process where a verbal constituent is partially or
totally unexpressed but can be resolved through
an antecedent from context (Liu et al., 2016). For
example, in the sentence: ‘‘His wife also works for
the paper, as did his father’’, the verb did is used
to represent the verb phrase works for the paper.
The VPE resolution task is to detect the target
word which creates the ellipsis and the anaphoric
verb phrase which it depicts. Recent work (Liu
et al., 2016; Kenyon-Dean et al., 2016) tackles
this problem by dividing it into two main parts:
Target detection and antecedent identification.
Semantic Graph Representations Several se-
mantic graph representation cover some of the
cases we consider. Abstract Meaning Represen-
tation is a graph-based semantic representation
for language (Pareja-Lora et al., 2013). It covers a
wide range of concepts and relations. Five of those
concepts: Year, age, monetary-quantity, time, and
person correlate to our implicit classes: YEAR,
AGE, CURRENCY, TIME, and PEOPLE, respectively.
The UCCA semantic representation (Abend
and Rappoport, 2013) explicitly marks missing
information, including the REFERENCE NFH cases,
but not the IMPLICIT ones.
8 Conclusions
Empty elements are pervasive in text, yet do not
receive much research attention. In this work,
we tackle a common phenomenon that did not
receive previous treatment. We introduce the FH
531
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
t
l
a
c
_
a
_
0
0
2
8
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
identification and resolution tasks and focus
on a common and important FH subtype: The
NFH. We demonstrate that the NFH is a com-
mon phenomenon, covering over 40% of the num-
ber appearances in a large dialog-based corpus
and a substantial amount in other corpora as well
(> 20%). We create data sets for the NFH iden-
tification and resolution tasks. We provide an
accurate method for identifying the NFH con-
structions and a neural baseline for the resolution
task. The resolution task proves challenging,
requiring further research. We make the code
and data sets available to facilitate such research
(github.com/yanaiela/num fh).
Ringraziamenti
We would like to thank Reut Tsarfaty and the
Bar-Ilan University NLP lab for the fruitful con-
versation and helpful comments. The work was
supported by the Israeli Science Foundation (grant
1555/15) and the German Research Foundation
via the German-Israeli Project Cooperation (DIP,
grant DA 1600/1-1).
Riferimenti
conference on empirical methods in natural lan-
elaborazione del calibro (EMNLP), pages 740–750.
Ido Dagan, Dan Roth, Mark Sammons, E
Fabio Massimo Zanzotto. 2013. Recognizing
textual entailment: Models and applications.
Synthesis Lectures on Human Language Tech-
nologies, 6(4):1–220.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, E
Kristina Toutanova. 2018. Bert: Pre-training
of deep bidirectional
transformers for lan-
guage understanding. arXiv preprint arXiv:
1810.04805.
Antonio Ferr´andez and Jes´us Peral. 2000. UN
computational approach to zero-pronouns in
Spanish. In Proceedings of the 38th Annual
Meeting on Association for Computational
Linguistica, pages 166–172.
Joseph L. Fleiss. 1971. Measuring nominal scale
agreement among many raters. Psicologico
Bulletin, 76(5):378.
Mary Gardiner. 2003. Identifying and resolving
thesis,
oneanaphora. Unpublished Honours
Macquarie University, novembre.
Omri Abend and Ari Rappoport. 2013. Universal
conceptual cognitive annotation (UCCA). In
Proceedings of the 51st Annual Meeting of
the Association for Computational Linguistics
(Volume 1: Documenti lunghi), pages 228–238.
Sofia.
Matt Gardner,
Joel Grus, Marco Neumann,
Oyvind Tafjord, Pradeep Dasigi, Nelson F.
Liu, Matteo Peters, Michael Schmitz, E
Luke S. Zettlemoyer. 2017. Allennlp: A deep
semantic natural language processing platform.
arXiv preprint arXiv:1803.07640.
Mauro Cettolo, Christian Girardi, and Marcello
Federico. 2012, May. Wit3: Web inventory of
transcribed and translated talks. Negli Atti
of the 16th Conference of the European Asso-
ciation for Machine Translation (EAMT),
pages 261–268. Trento.
Chen Chen and Vincent Ng. 2016. Chinese
zero pronoun resolution with deep neural
networks. In Proceedings of the 54th Annual
Riunione dell'Associazione per il Computazionale
Linguistica (Volume 1: Documenti lunghi), volume 1,
pages 778–788.
Matthew Gerber and Joyce Y. Chai. 2012. Se-
mantic role labeling of implicit arguments for
nominal predicates. Linguistica computazionale,
38(4):755–798.
Jiatao Gu, Zhengdong Lu, Hang Li, and Victor
O. K. Li. 2016. Incorporating copying mech-
anism in sequence-to-sequence learning. arXiv
preprint arXiv:1603.06393.
Na-Rae Han. 2004. Korean null pronouns: Clas-
sification and annotation. Negli Atti del
2004 ACL Workshop on Discourse Annotation,
pages 33–40.
Danqi Chen and Christopher Manning. 2014. UN
fast and accurate dependency parser using neu-
IL 2014
ral networks.
Negli Atti di
Masatsugu Hangyo, Daisuke Kawahara, E
Sadao Kurohashi. 2013. Japanese zero ref-
erence resolution considering exophora and
532
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
author/reader mentions. Negli Atti del
2013 Conference on Empirical Methods in
Elaborazione del linguaggio naturale, pages 924–934.
Sepp Hochreiter e Jürgen Schmidhuber. 1997.
Memoria a lungo termine. Calcolo neurale,
9(8):1735–1780.
Matthew Honnibal and Mark Johnson. 2015. An
improved non-monotonic transition system for
dependency parsing. Negli Atti di
IL
2015 Conference on Empirical Methods in Nat-
elaborazione del linguaggio urale, pages 1373–1378,
Lisbon.
Rodney Huddleston and Geoffrey K. Pullum.
2002. The Cambridge Grammar of English.
Language. Cambridge: Cambridge University
Press, pages 1–23.
Ryu Iida, Kentaro Inui, and Yuji Matsumoto.
2006. Exploiting syntactic patterns as clues in
zero-anaphora resolution. Negli Atti di
the 21st International Conference on Com-
putational Linguistics and 44th Annual Meet-
the Association for Computational
ing of
Linguistica, pages 625–632.
Ryu Iida, Kentaro Torisawa, Jong-Hoon Oh,
Canasai Kruengkrai, and Julien Kloetzer.
2016. Intra-sentential subject zero anaphora
resolution using multi-column convolutional
neural network. Negli Atti del 2016
Conference on Empirical Methods in Natural
Language Processing, pages 1244–1254.
Ross John. 1969. Guess who. Negli Atti del
5th Chicago Linguistic Society, pages 252–286.
Kian Kenyon-Dean, Jackie Chi Kit Cheung,
and Doina Precup. 2016. Verb phrase ellipsis
resolution using discriminative and margin-
infused algorithms. In Proceedings of EMNLP,
pages 1734–1743.
Mateusz Kope´c. 2014. Zero subject detection for
Polish. In Proceedings of the 14th Conference
of the European Chapter of the Association
for Computational Linguistics, volume 2: Corto
Carte, pages 221–225.
George Lakoff and John Robert Ross. 1970.
Gapping and the order of constituents. Progress
in Linguistics: A Collection of Papers, 43:249.
Kenton Lee, Luheng He, Mike Lewis, E
Luke Zettlemoyer. 2017. End-to-end neural
coreference resolution. arXiv preprint arXiv:
1707.07045.
Kenton Lee, Luheng He, and Luke S. Zettlemoyer.
2018. Higher-order coreference resolution with
coarse-to-fine inference. Negli Atti del
2018 Annual Conference of the North American
Capitolo dell'Associazione per il calcolo
Linguistica.
Iddo Lev, Bill MacCartney, Christopher D
Equipaggio, and Roger Levy. 2004. Solving logic
puzzles: From robust processing to precise
semantics. In Proceedings of the 2nd Workshop
on Text Meaning and Interpretation, pagine
9–16.
Zhengzhong Liu, Edgar Gonz`alez Pellicer, E
Daniel Gillick. 2016. Exploring the steps of verb
phrase ellipsis. In CORBON@ HLT-NAACL,
pages 32–40.
Anne C. Lobeck. 1995. Ellipsis: Functional
Heads, Licensing, and Identification, Oxford
University Press on Demand.
Mitchell P. Marcus, Mary Ann Marcinkiewicz,
and Beatrice Santorini. 1993. Building a large
annotated corpus of English: The Penn Treebank.
Linguistica computazionale, 19(2):313–330.
Diederik P. Kingma and Lei Ba. 2015. J.
Adam: A method for stochastic optimization.
In International Conference on Learning
Representations.
Stephen Merity, Caiming Xiong,
James
Bradbury, and Richard Socher. 2016. Pointer
sentinel mixture models. arXiv preprint arXiv:
1609.07843.
Fang Kong and Guodong Zhou. 2010. A tree
kernel-based unified framework for Chinese
zero anaphora resolution. Negli Atti di
IL 2010 Conference on Empirical Methods in
Elaborazione del linguaggio naturale, pages 882–891.
Claudiu Mih˘ail˘a, Iustina Ilisei, and Diana Inkpen.
2010. To be or not to be a zero pronoun: UN
machine learning approach for romanian. Multi-
linguality and Interoperability in Language Pro-
cessing with Emphasis on Romanian, 303–316.
533
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Tomás Mikolov,
Ilya Sutskever, Kai Chen,
Greg S. Corrado, and Jeff Dean. 2013. Dis-
tributed representations of words and phrases
and their compositionality. In Advances in
Neural Information Processing Systems, pagine
3111–3119.
Tatjana Moor, Michael Roth, and Anette Frank.
2013. Predicate-specific annotations for implicit
role binding: Corpus annotation, data analysis
and evaluation experiments. Negli Atti di
the 10th International Conference on Com-
putational Semantics (IWCS), pages 369–375,
Potsdam.
Hwee Tou Ng, Yu Zhou, Robert Dale, and Mary
Gardiner. 2005. A machine learning approach to
identification and resolution of one-anaphora.
In International Joint Conference on Artificial
Intelligenza, volume 19, page 1105.
Vincent Ng. 2010. Supervised noun phrase co-
reference research: The first fifteen years. In
Proceedings of the 48th Annual Meeting of
the Association for Computational Linguistics,
pages 1396–1411.
Tadashi Nomoto and Yoshihiko Nitta. 1993.
Resolving zero anaphora in japanese. Nel professionista-
ceedings of the Sixth Conference on European
Capitolo dell'Associazione per il calcolo
Linguistica, pages 315–321.
Sun-Young Oh. 2005. English zero anaphora as an
interactional resource. Research on Language
and Social Interaction, 38(3):267–302.
Antonio Pareja-Lora, Maria Liakata, and Stefanie
Dipper. 2013. Proceedings of the 7th linguistic
annotation workshop and interoperability with
discourse. In Proceedings of the 7th Linguistic
Annotation Workshop and Interoperability with
Discourse.
Fabian Pedregosa, Ga¨el Varoquaux, Alexandre
Gramfort, Vincent Michel, Bertrand Thirion,
Olivier Grisel, Mathieu Blondel,Peter Prettenhofer,
Ron Weiss, and Vincent Dubourg. 2011.
Scikit-learn: Machine learning in python.
Journal of Machine Learning Research,
12(Oct):2825–2830.
Matthew E. Peters, Marco Neumann, Mohit Iyyer,
Matt Gardner, Cristoforo Clark, Kenton
Lee, and Luke S. Zettlemoyer. 2018. Deep
contextualized word representations. Nel professionista-
ceedings of the 2018 Annual Conference of the
North American Chapter of the Association for
Linguistica computazionale.
Marta Recasens, Zhichao Hu,
and Olivia
Rhinehart. 2016. Sense anaphoric pronouns:
Am i one? In CORBON@ HLT-NAACL, pagine
1–6.
Subhro Roy and Dan Roth. 2015. Solving general
Negli Atti
arithmetic word problems.
on Empirical
2015 Conferenza
Di
Metodi nell'elaborazione del linguaggio naturale,
pages 1743–1752.
IL
Subhro Roy, Tim Vieira, and Dan Roth.
2015. Reasoning about quantities in natural
lingua. Transactions of the Association for
Linguistica computazionale, 3:1–13.
Georgios P. Spithourakis and Sebastian Riedel.
2018. Numeracy for language models: Eval-
uating and improving their ability to predict
numbers. arXiv preprint arXiv:1805.08154.
Rhea Sukthanker, Soujanya Poria, Erik Cambria,
and Ramkumar Thirunavukarasu. 2018. Ana-
phora and coreference resolution: A review.
arXiv preprint arXiv:1805.11824.
Andrew Trask, Felix Hill, Scott Reed, Jack
Rae, Chris Dyer, and Phil Blunsom. 2018.
Neural arithmetic logic units. arXiv preprint
arXiv:1808.00508.
Ralph Weischedel, Sameer Pradhan, Lance
Ramshaw, Martha Palmer, Nianwen Xue,
Mitchell Marcus, Ann Taylor, Craig Greenberg,
Eduard Hovy, and Robert Belvin. 2011. Onto-
notes release 4.0. LDC2011T03, Philadelphia,
PAPÀ: Linguistic Data Consortium.
Ching-Long Yeh and Yi-Jun Chen. 2001. An
empirical study of zero anaphora resolution
in chinese based on centering model. Nel professionista-
ceedings of Research on Computational Lin-
guistics Conference XIV, pages 237–251.
Qingyu Yin, Yu Zhang, Wei-Nan Zhang,
Ting Liu, and William Yang Wang. 2018UN.
Deep reinforcement learning for Chinese zero
IL
pronoun resolution.
56esima Assemblea Annuale dell'Associazione per
Negli Atti di
534
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
T
l
UN
C
_
UN
_
0
0
2
8
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Linguistica computazionale (Volume 1: Lungo
Carte), pages 569–578.
Qingyu Yin, Yu Zhang, Weinan Zhang, Ting
Liu, and William Yang Wang. 2018B. Zero
pronoun resolution with attention-based neural
rete. Negli Atti di
the 27th Inter-
national Conference on Computational Lin-
guistics, pages 13–23.
Rui Zhang, Cicero Nogueira dos Santos,
Michihiro Yasunaga, Bing Xiang,
E
Dragomir Radev. 2018. Neural coreference
resolution with deep biaffine attention by joint
mention detection and mention clustering. arXiv
preprint arXiv:1805.04893.
A Details of Linear Baseline
Implementation
Type
Labels
Structure
Match
Other
Feature Description
Anchor & head lemma
2 sized window lemmas
2 sized window POS tags
Dependency edge of target
Head POS tag
Head lemma
Left most child lemma of anchor head
Children of syntactic head
Question mark before or after the anchor
Sentence length bin (< 5 < 10 <)
Span length bin (1, 2 or more)
Hyphen in anchor span
Slash in anchor span
Apostrophe before or after the span
Apostrophe + ’s’ after span
Anchor is ending the sentence
Whether the text contains a currency expression
Whether the text contains a time expression
Entity exists in the sentence before the target
Target size bin (< 1 < 10 < 100 < 1600 < 2100 <)
The number shape (digit or written text)
Table 8: Features used for linear classifier.
This section lists the features used for the linear
baseline mentioned in Section 6.3. The features
are presented in Table 8. We used four type
of features: (1) Label features, making use of
parsing labels of dependency and POS-taggers, as
well as simple lexical features of the anchor’s
window. (2) Structure features,
incorporating
structural
information from the sentence and
the anchor’s spans. (3) Match features test for
specific patterns in the text, and (4) Other,
not-categorized features.
We used the features described above to train
a linear support vector machine classifier on the
same splits.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
8
0
1
9
2
3
2
1
9
/
/
t
l
a
c
_
a
_
0
0
2
8
0
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
535