REPORT
SAYCam: A Large, Longitudinal Audiovisual
Dataset Recorded From the Infant’s Perspective
Jessica Sullivan1, Michelle Mei1, Andrew Perfors2, Erica Wojcik1, and Michael C. Frank3
a n o p e n a c c e s s
j o u r n a l
Keywords: headcam, first-person video, child development
1Skidmore College
2University of Melbourne
3Stanford University
ABSTRACT
We introduce a new resource: the SAYCam corpus. Infants aged 6–32 months wore a
head-mounted camera for approximately 2 hr per week, over the course of approximately
two-and-a-half years. The result is a large, naturalistic, longitudinal dataset of infant- E
child-perspective videos. Over 200,000 words of naturalistic speech have already been
transcribed. Allo stesso modo, the dataset is searchable using a number of criteria (per esempio., age of
participant, location, setting, objects present). The resulting dataset will be of broad use to
psychologists, linguists, and computer scientists.
INTRODUCTION
From the roots of children’s language learning to their experiences with objects and faces, nat-
uralistic data about children’s home environment provides an important constraint on theories
of development (Fausey et al., 2016; MacWhinney, 2000; Oller et al., 2010). By analyzing the
information available to children, researchers can make arguments about the nature of chil-
dren’s innate endowment and their learning mechanisms (Brown, 1973; Rozin, 2001). Further,
children’s learning environments are an important source of individual variation between chil-
dren (Fernald et al., 2012; Hart & Risley, 1992; Sperry et al., 2019); hence, characterizing these
environments is an important step in developing interventions to enhance or alter children’s
learning outcomes.
When datasets—for example, the transcripts stored in the Child Language Data Exchange
System (MacWhinney, 2000)—are shared openly, they form a resource for the validation of
theories and the exploration of new questions (Sanchez et al., 2019). Further, while tabular and
transcript data were initially the most prevalent formats for data sharing, advances in storage
and computation have made it increasingly easy to share video data and associated metadata.
For developmentalists, one major advance is the use of Databrary, a system for sharing devel-
opmental video data that allows fine-grained access control and storage of tabular metadata
(Gilmore & Adolph, 2017). The advent of this system allows for easy sharing of video related
to children’s visual experience. Such videos are an important resource for understanding chil-
dren’s perceptual, conceptual, linguistico, and social development. Because of their richness,
such videos can be reused across many studies, making the creation of open video datasets a
high-value enterprise.
Citation: Sullivan, J., Mei, M.,
Perfors, A., Wojcik, E., & Frank, M. C.
(2021). SAYCam: A Large, Longitudinal
Audiovisual Dataset Recorded From
the Infant’s Perspective. Open Mind:
Discoveries in Cognitive Science,
5, 20–29. https://doi.org/10.1162
/opmi_a_00039
DOI:
https://doi.org/10.1162/opmi_a_00039
Supplemental Materials:
https://nyu.databrary.org/volume/564
Received: 19 Luglio 2020
Accepted: 11 Febbraio 2021
Competing Interests: The authors
declare no conflict of interest.
Corresponding Author:
Jessica Sullivan
jsulliv1@skidmore.edu
Copyright: © 2021
Istituto di Tecnologia del Massachussetts
Pubblicato sotto Creative Commons
Attribuzione 4.0 Internazionale
(CC BY 4.0) licenza
The MIT Press
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
/
e
D
tu
o
P
M
io
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
/
.
/
1
0
1
1
6
2
o
P
M
_
UN
_
0
0
0
3
9
1
9
1
9
8
3
6
o
P
M
_
UN
_
0
0
0
3
9
P
D
.
/
io
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
SAYCam Dataset
Sullivan et al.
One especially promising method for characterizing children’s visual experience is the
head-mounted camera (Aslin, 2012; Franchak et al., 2011), a lightweight camera or eye-tracker
that is worn by the child, often mounted on a hat or harness system. A “headcam” allows access
to information from the perspective of the child–albeit with some differences in view angle,
resolution, and orienting latency (Pusiol et al., 2014; Smith et al., 2015). Headcam data have
been used in recent years to understand a variety of questions about children’s visual input,
including the prevalence of social signals (Fausey et al., 2016), how children’s bodies and
hands shape their attention (Bambach et al., 2016), how children interact with adults (Yu &
Smith, 2013), which objects are in their visual field (Cicchino et al., 2011), and how their
motor development shapes their visual input (Kretch et al., 2014; Sanchez et al., 2019). These
datasets also let researchers access some of the “source data” for children’s generalizations
about object identity or early word learning (Clerkin et al., 2017). Data from headcams are
also an important dataset for studies of unsupervised learning in computer vision (Bambach
et al., 2016). Yet there are relatively few headcam datasets available publicly for reuse, E
those that are almost exclusively report cross-sectional, in-lab data (Franchak et al., 2018;
Sanchez et al., 2018), or sample from one developmental time point (Bergelson, 2017).
The current project attempts to fill this gap by describing a new, openly accessible dataset
of more than 415 hours of naturalistic, longitudinal recordings from three children. The SAY-
Cam corpus contains longitudinal videos of approximately two hr per week for three children
spanning from approximately six months to two and a half years of age. The data include un-
structured interactions in a variety of contexts, both indoor and outdoor, as well as a variety of
individuals and animals. The data also include structured annotations of context together with
full transcripts for a subsample (described below), and are accompanied by monthly parent
reports on vocabulary and developmental status. Together, these data present the densest look
into the visual experience of individual children currently available.
METHOD
Participants
Three families participated in recording head-camera footage (Vedi la tabella 1). Two families lived
in the United States during recording, while one family lived in Australia. All three families
spoke English exclusively. In all three families, the mother was a psychologist. All three children
had no siblings during the recording window. This research was approved by the institutional
review boards at Stanford University and Skidmore College. All individuals whose faces appear
in the dataset provided verbal assent, E, when possible, written consent. All videos have been
screened for ethical content.
Sam is the child of the family who lived in Australia. He wore the headcam from
6 months to 30 months of age. The family owned two cats and lived in a semirural neigh-
borhood approximately 20 miles from the capital city of Adelaide. Sam was diagnosed with
Tavolo 1. Participant information
Participant
Sam (S)
Alice (UN)
Asa (Y)
Location
Age at first recording (months) Age at last recording (months)
Adelaide, Australia
San Diego, California, USA and
Saratoga Springs, New York, USA
Saratoga Springs, New York, USA
6 M.
8 M.
7 M.
30 M.
31 M.
24 M.
OPEN MIND: Discoveries in Cognitive Science
21
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
/
e
D
tu
o
P
M
io
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
.
/
/
1
0
1
1
6
2
o
P
M
_
UN
_
0
0
0
3
9
1
9
1
9
8
3
6
o
P
M
_
UN
_
0
0
0
3
9
P
D
.
/
io
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
SAYCam Dataset
Sullivan et al.
autism spectrum disorder at age 3; as of this writing (at age 7), Sam is fully mainstreamed, ha
friends, and does not require any special support.
Alice is the child of a family who lived in the United States. She wore the headcam from
8 months to 31 months of age. The family also owned two cats throughout the recording period.
For the first half of the recordings, the family lived on a rural farm and kept other animals on or
near their property, including chickens; the family frequently visited a major city (San Diego).
For the second half of the recordings, the family lived in the suburbs in New York State.
Asa is the child of a family who lived in the United States. He wore the headcam from
7 months to 24 months of age. Data collection for this child terminated prematurely due to
the onset of the COVID-19 pandemic and the birth of a younger sibling. The family owns no
pets, and lives in the suburbs in New York State.
Materials
Parents completed the MacArthur-Bates Communicative Development Inventories (MCDI) In-
ventory each month (Fenson et al., 2007), as well as the Ages and Stages Questionnaire (Squires
et al., 1997) during the time periods required by the instrument. These materials are included
in the corpus, and can be used to identify the age at which each participant acquired particular
parole, particular motor capacities, and particular social and cognitive capacities. These data
may be useful for characterizing the children (per esempio., for their representativeness), but also for
identifying particular videos (described below) recorded immediately before or after particu-
lar developmental milestones (per esempio., for finding videos from before a child learned a particular
word, or became able to stand independently).
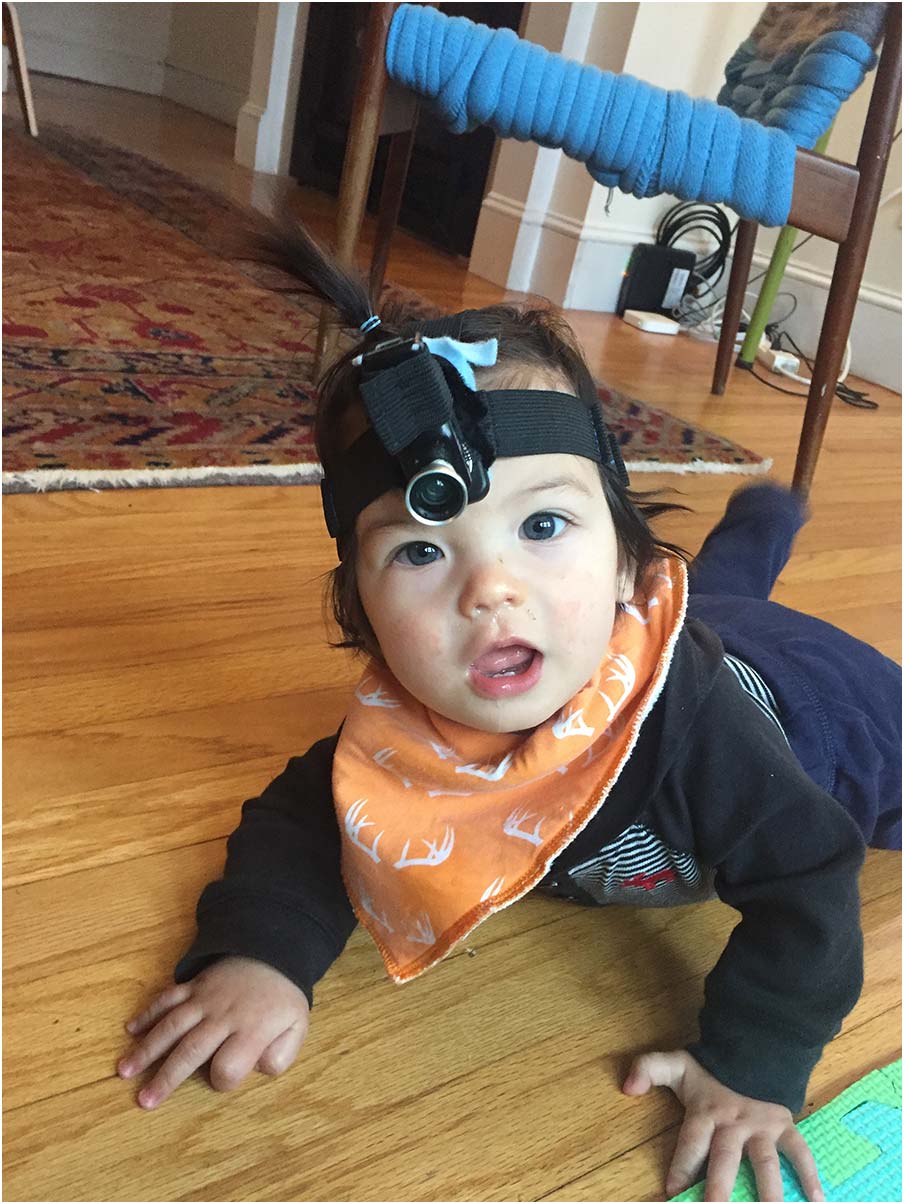
Videos were recorded using a Veho head-mounted camera on a custom mounting head-
band (Figura 1). Each Veho MUVI Pro micro DV camcorder camera was equipped with a
magnetic mount that allowed the attachment of a wide-angle fisheye lens to broaden the MUVI
Pro’s native 47- by 36-degree viewing angle to 109 by 70 degrees. We selected the Veho MUVI
camera after testing several headcams in-lab, and determining it provided the biggest vertical
visual angle and had physical dimensions that allowed for comfortable mounting near the
center of the forehead (giving a perspective that would be most similar to the child’s; see Long
et al., 2020, for a comparison of headcams). According to the specs provided at purchase, IL
camera captures video at a resolution of 480 P, and at up to 30 frames per s, although in prac-
tice, the frame rate sometimes dipped to approximately 20 frames per s. Audio quality from
the cameras was highly variable, and in some cases, the camera’s default audio recordings are
low quality.
On occasions where a child persistently refused to wear the headcam, the camera was
used as a normal camera (cioè., placed nearby and carried to new locations if necessary).
A spreadsheet detailing which videos are third person accompanies our data on Databrary
(https://nyu.databrary.org/volume/564/slot/47832/edit?asset=273993).
PROCEDURE
Videos were recorded naturalistically, in and around the homes, cars, neighborhoods, E
workplaces where the child spent time. The intention was to record videos twice per week;
once at a fixed time and once at a randomly chosen time. Given the practical constraints of
a multiyear project like this one, at times there were deviations from the planned procedure.
Per esempio, in the Alice dataset, there were some weeks where both recording times were
OPEN MIND: Discoveries in Cognitive Science
22
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
/
e
D
tu
o
P
M
io
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
/
.
/
1
0
1
1
6
2
o
P
M
_
UN
_
0
0
0
3
9
1
9
1
9
8
3
6
o
P
M
_
UN
_
0
0
0
3
9
P
D
.
/
io
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
SAYCam Dataset
Sullivan et al.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
/
e
D
tu
o
P
M
io
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
/
/
.
1
0
1
1
6
2
o
P
M
_
UN
_
0
0
0
3
9
1
9
1
9
8
3
6
o
P
M
_
UN
_
0
0
0
3
9
P
D
.
/
io
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Figura 1. Participant (7 months old) wearing Veho camera with fish eye lens.
determined pseudo-randomly because the fixed recording time was not feasible. Allo stesso modo, In
the Sam dataset, scheduling constraints occasionally meant that there was less variation in
the timing of recordings than one might otherwise expect. In the Asa dataset, the pseudo-
random time often occurred at a fixed time due to feasibility issues (per esempio., attendance at day
care), and occasional weeks were skipped due to travel or other logistical barriers; additionally,
most recordings for the Asa dataset are sampled from between 7 a.m. E 10 a.m. Technical
issues, such as memory card or camera failure, although infrequent, resulted in some skipped
recording sessions.
When recording, we obtained written consent or verbal assent (in accordance with in-
stitutional review board) for participants whose face and voice were featured in the videos.
Videos for which we were unable to secure assent/consent for people who were potentially
identifiable are omitted from the dataset.
Each recording session lasted until the battery on the Veho camera failed, or once
90 min had elapsed. In most cases, this resulted in recording sessions that lasted approxi-
mately 60 A 80 min. Each recording session typically resulted in multiple video files, con un
maximum single-file duration of 30 min.
Coding
One goal of our coding efforts was to tag each video with its contents, so that researchers
could search for content relevant to their research interests. To do this, videos were skimmed at
OPEN MIND: Discoveries in Cognitive Science
23
SAYCam Dataset
Sullivan et al.
an effective 10x-speed playback, and visually assessed for
locations and location
i cambiamenti. Coding occurred by playing each video in VLC (VideoLAN Client), and coding us-
ing custom spreadsheets with macros. Coders were highly trained and deeply familiar with
the dataset.
The following pieces of information were coded for each video. Primo, the coder briefly
described the contents of the video (per esempio., “Picked grass to play with during walk”; “On floor
looking at mirror with mom”; “watching parents in kitchen”). The coder also recorded the lo-
catione (per esempio., hallway, bedroom, kitchen, outdoors, car, …), the activity or activities (per esempio., being
held, walking, cooking, drinking, eating, listening to music, …), the individual(S) present (per esempio.,
child, dad, mom, grandparent, animal, …), the body parts visible (per esempio., arms/hands, legs/feet,
head/face), and the most salient objects (per esempio., flora, drink, tool, food, bed, book, …). See Table 2
for a full list of coding classifications. Criteria for each coding decision are outlined in our Read
Me document on Databrary (https://nyu.databrary.org/volume/564/slot/47832/-?asset=254904).
The coder also noted any potential ethical concerns for further screening, and any additional
notes.
Every time there was a significant change in location or in activity, we coded each com-
ponent of the video anew. Per esempio, if the child moved from the bedroom to the bathroom,
we coded all elements of the video (per esempio., objects, activity, body parts, individuals) once for the
bedroom and once for the bathroom.
The intention for coding videos was to allow other researchers to identify videos of in-
terest, not for analysis of the codes themselves. While such an analysis may be both possible
and extremely interesting in the future, we encourage caution at this point for several reasons.
Primo, relative frequencies of activities will not be accurately computed until the entire dataset is
coded. Secondo, while our coding scheme remained stable throughout the majority of coding,
there are a few items (per esempio., the location “Laundry Room,” the item “cream,” the activity “pat-
ting”) that were added to our coding scheme after coding began. Their dates of addition are
described in the Read Me file. Finalmente, some objects, activities, or locations may appear briefly
in particular videos, but not be tagged (per esempio., if the child is in the bedroom, throws a ball, E
briefly looks into the hallway to see if the ball landed there, only “location: bedroom” may be
tagged). The decision for whether or not to tag a particular entity within the video was subjec-
tive, and was guided by the intention of coding the videos in a way that would be helpful for
future researchers to identify videos that would be useful for their particular research projects.
Per esempio, in the current dataset, the tag “Object: Clothing” labels 114 videos (cioè., IL
videos where clothing was a salient feature of the child’s experience), and researchers who are
interested in children’s interactions with clothing will find at least one salient child–clothing
interaction in each of those videos. Tuttavia, the absence of the “Object: Clothing” tag for the
remaining videos certainly does not imply that everyone was naked.
Researchers interested in contributing to the ongoing coding effort should contact the
corresponding author.
Transcription
One goal of this project was to transcribe all of the utterances in each video. Videos were
assigned to college students and transcribed. Interested readers can contribute to the ongoing
transcription effort by contacting the corresponding author; our original training materials are
provided here: https://nyu.databrary.org/volume/564/slot/47832/-?asset=254904. Transcribers
noted the timestamp for the onset of each utterance, the contents of the utterance itself, IL
OPEN MIND: Discoveries in Cognitive Science
24
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
/
e
D
tu
o
P
M
io
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
/
.
/
1
0
1
1
6
2
o
P
M
_
UN
_
0
0
0
3
9
1
9
1
9
8
3
6
o
P
M
_
UN
_
0
0
0
3
9
P
D
/
.
io
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Tavolo 2.
Locations, Activities, Living Things, and Objects that are searchable in our corpus
Activity
Living Things
Objects
Body Parts
SAYCam Dataset
Sullivan et al.
Locations
Bathroom
Bedroom
California Room
Car
Closet
Deck/Porch
Garage
Hallway
Kitchen
Laundry Room
Living Room
Off Property
Office
Being Held
Cleaning
Cooking
Coversing
Crawling
Crying
Drawing
Drinking
Eating
Examining
Exploring
Gardening
Getting Changed/Dressed
Outside On Property
Getting Parental Attention
Piano Room
Imitating
Many Locations
Listening to Music
Stairway
Lying Down
Nursing
Overhearing Speech
Painting
Playing Music
Preparing for Outing
Reading
Running
Sitting
Standing
Taking a Walk
Tidying
Walking
Watching
Bird(S)
Appliance
Cat (with specific cat)
Dad
Dog
Fish
Grandma
Grandpa
Horse
Mom
Other Adult
Other Child
Participant
Bag
Bed
Book
Building
Car
Chair
Clothing
Computer
Container
Cream
Crib
Diapers/Wipes/Potty
Doll/Stuffed Toy
Door
Drawing
Drawing/Writing Implements
Drink
Flora
Food
Improvised Toy
Laundry Machine
Linen/Cloths
Mirror
Musical Instrument
Outdoors
Phone
Picture
Play Equipment
Puzzle
Tavolo
Tool
Toy
Wagon
Window
Present/Absent
Head/Face
Corpo
Arms/Hands
Legs/Feet
Other
Phone*
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
/
e
D
tu
o
P
M
io
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
/
.
/
1
0
1
1
6
2
o
P
M
_
UN
_
0
0
0
3
9
1
9
1
9
8
3
6
o
P
M
_
UN
_
0
0
0
3
9
P
D
/
.
io
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Note. In some cases, individuals were present in the dataset via phone and therefore were not embodied; for those cases, we
indicated the individual’s presence via “Phone” in the “Body Parts” section.
OPEN MIND: Discoveries in Cognitive Science
25
SAYCam Dataset
Sullivan et al.
speaker, any notable, significant, or contextually important actions, and any objects that were
relevant, visually salient, or interacted with. Transcribers were instructed to record any utter-
ances they heard verbatim. A new entry was created every time there was a change in speaker,
there was a meaningful pause
in conversation, O
there was a meaningful
between speaking. Each entry begins by recording the time in the video that the utterance in
question begins.
shift
RESULTS
There are over 1,800 videos with more than 460 unique recording sessions, yielding well over
500 hr of footage. Currently, Sopra 235,800 words have been transcribed, representing 16.5%
of the present dataset; 28.3% of the videos have been coded for location, activity, living things,
body parts, and objects and are now searchable.
Researchers can access our dataset, which contains AVI and MP4 videos, PDFs, and Excel
sheets representing our data at the Supplementary Materials online, and can search for rele-
vant videos here: https://skidmoreheadcam.shinyapps.io/SAYcam-TagSearch/. Per esempio, UN
researcher interested in studying the auditory input surrounding infant nursing could visit our
search tool, and search for segments containing nursing. At present, this would yield 53 videos;
the output table automatically includes a link to the relevant video, and a link to a Google Sheet
containing any available transcriptions. The researcher could then choose to analyze those 53
videos, or to further restrict their search (per esempio., by age, other individuals present, other activities
surrounding the event). Or, let’s say a researcher was interested in a child’s exposure to cats
prior to acquiring the word “cat.” The researcher would then access the child’s MCDI vocabu-
lary measures on Databrary in order to identify the month at which the child acquired the word
“cat.” They could then use our search tool to search for videos from that child from before the
child learned the word, and access those videos via the provided Databrary link.
Individuals can apply to access the data using Databrary’s (https://nyu.databrary.org/)
standard application process. Researchers will need to demonstrate that they are authorized
investigators from their institution, that they completed ethics training, and that their institution
has an institutional review board.
DISCUSSION
Beginning with early diary studies and continuing with video recordings of parents–child in-
teraction, naturalistic corpora have helped researchers both ensure the ecological validity of
theories of learning and development and generate new research questions (per esempio., Brown, 1973;
MacWhinney, 2000). The current dataset is a novel contribution to naturalistic developmental
corpora in several ways. Primo, the use of head-mounted cameras constrains the video record-
ings to the child’s point of view, allowing researchers to not simply observe the visual stimuli
surrounding a child, but also access the visual stimuli that is actually available to a child (Vedere
Yurovsky et al., 2013, for an example of how this first-person perspective can lead to novel in-
sights into learning mechanisms). Secondo, the biweekly recording schedule led to the creation
of a dataset with finer grained sampling than in most other longitudinal corpora (see Adolph
& Robinson, 2011, for a discussion of the importance of sampling rate). Third, the two-year
span of recordings is longer than most longitudinal datasets, allowing for researchers to track
development in a way that is not possible for shorter projects. Lastly, the open sharing of the
data on Databrary gives researchers (and their students) the rare opportunity to freely and easily
access the entire corpus.
OPEN MIND: Discoveries in Cognitive Science
26
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
/
e
D
tu
o
P
M
io
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
/
/
.
1
0
1
1
6
2
o
P
M
_
UN
_
0
0
0
3
9
1
9
1
9
8
3
6
o
P
M
_
UN
_
0
0
0
3
9
P
D
.
/
io
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
SAYCam Dataset
Sullivan et al.
We anticipate our data will be a valuable tool for researchers in developmental science,
and in particular to those interested in categorization and language learning. One of the most
important questions in language acquisition is how children connect words with their mean-
ing. This is a difficult problem for the language learner, because for any amount of evidence
about the use of a word, there is an infinite range of meanings that are consistent with that
evidence (Quine, 1960). Viewed as a categorization problem, the challenge posed to children
is to identify the extension of categories in the world and, simultaneously, to infer which labels
map onto those categories. Per esempio, a child must both determine that the word “cat” refers
to this particular cat and also that more generally it refers to a concept that includes other cats,
but not dogs or horses. This process may depend critically on the distribution of the objects
and entities in the child’s environment, the use of object labels in the child’s environment, E
the distributional relationship of the overlap between objects and labels—the present dataset
uniquely allows us to track children’s naturalistic audio and visual input, and to relate it to the
trajectory of their word learning.
Inoltre, this dataset will be of use for those interested in quantifying children’s early
naturalistic environments. Previous work (Yoshida & Smith, 2008) has shown that headcam
data is a viable proxy for infants’ eye movements, and that headcam footage is valuable for
exploring the composition of a child’s visual field (Aslin, 2009). We have previously used
headcam data to investigate how changing motor abilities affect children’s experience (Frank
et al., 2013), while others have used headcams to show the changing composition of children’s
visual input in early development (Fausey et al., 2016). Our longitudinal, naturalistic, first-
person dataset will allow researchers to ask and answer questions about the statistic of dyadic
interactions across time: our archive provides researchers with access to data on joint attention,
infant gaze, parental dyadic engagement, attachment, in addition to the basic statistics of the
infant’s perceptual experience. Infatti, early work using our data already suggests interesting
insights can be extracted by considering how social information is modulated by different
activity contexts (Long et al., 2020).
Finalmente, the density of our dataset is extremely important for the use of new neural network
algorithms, which tend to be “data hungry.” Already, researchers have explored what learning
progress is possible when new unsupervised visual learning algorithms are applied to our
dataset (Orhan et al., 2020; Zhuang et al., 2020). Infatti, as Orhan et al.
(2020) note, even
though our dataset is quite large by conventional standards, a child’s visual experience from
birth to age two and a half would in fact be two orders of magnitude larger still, and the machine
learning literature suggests that such an increase in data would be likely to lead to higher
performance and new innovations. Così, from a broader perspective, we hope our dataset is
part of the “virtuous cycle” of greater data access leading to algorithmic innovation—in turn
leading to new datasets being created.
ACKNOWLEDGMENTS
Our grateful acknowledgment goes to the students who coded and transcribed these data,
and to the individuals who were filmed in the recording sessions. Special thanks to Julia
Iannucci for work managing elements of this dataset.
FUNDING INFORMATION
JS, National
ID: R03 #HD09147.
Institutes of Health (h t t p : / / d x . d o i . o r g / 1 0 . 1 3 0 3 9 /100000002), Award
OPEN MIND: Discoveries in Cognitive Science
27
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
/
e
D
tu
o
P
M
io
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
/
/
.
1
0
1
1
6
2
o
P
M
_
UN
_
0
0
0
3
9
1
9
1
9
8
3
6
o
P
M
_
UN
_
0
0
0
3
9
P
D
/
.
io
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
SAYCam Dataset
Sullivan et al.
AUTHOR CONTRIBUTIONS
JS: Conceptualization: Supporting; Methodology: Equal; Data Collection: Equal; Funding: Lead;
Supervision: Lead; Writing – Original Draft: Equal; Writing – Review & Editing: Lead. MM:
Analysis and Coding: Lead; Data Collection: Supporting; Supervision: Supporting; Writing –
Original Draft: Equal; Writing – Review & Editing: Equal. AP: Conceptualization: Equal; Data
Collection: Equal; Methodology: Equal; Supervision: Supporting; Writing – Original Draft: Equal;
Writing – Review & Editing: Supporting. EW: Conceptualization: Supporting; Data Collection:
Equal; Methodology: Supporting; Supervision: Supporting; Visualization: Supporting; Writing –
Original Draft: Equal; Writing – Review & Editing: Supporting. MCF: Conceptualization: Equal;
Data Collection: Supporting; Funding: Supporting; Methodology: Equal; Supervision: Supporto-
ing; Writing – Original Draft: Equal; Writing – Review & Editing: Supporting.
REFERENCES
Adolph, K. E., & Robinson, S. R.
(2011). Sampling development.
Journal of Cognition and Development, 12(4), 411–423. DOI:
https://doi.org/10.1080/15248372.2011.608190, PMID: 22140355,
PMCID: PMC3226816
Aslin, R. (2009). How infants view natural scenes gathered from a
head-mounted camera. Optometry and Vision Science, 86(6),
561–565. DOI: https://doi.org/10.1097/OPX.0b013e3181a76e96,
PMID: 19417702, PMCID: PMC2748119
Aslin, R. (2012). Infant eyes: A window on cognitive development.
Infancy, 17(1), 126–140. DOI: https://doi.org/10.1111/j.1532
-7078.2011.00097.X, PMID: 22267956, PMCID: PMC3259733
Bambach, S., Smith, L., Crandall, D., & Yu, C. (2016). Objects in the
center: How the infant’s body constrains infant scenes. Proceed-
ings of the Joint IEEE International Conference on Development
and Learning and Epigenetic Robotics (pag. 132–137).
IEEE.
https://ieeexplore.ieee.org/document/7846804, DOI: https://doi
.org/10.1109/DEVLRN.2016.7846804
Bergelson, E.
(2017). SEEDLingS 6 Month. Databrary. Retrieved
ottobre 8, 2020 from http://doi.org/10.17910/B7.330
Cicchino, J., Aslin, R., & Rakison, D.
Brown, R. (1973). A first language: The early stages. Harvard Univer-
sity Press. DOI: https://doi.org/10.4159/harvard.9780674732469
(2011). Correspondence
between what infants see and know about causal and self-
propelled motion. Cognition, 118(2), 171–192. DOI: https://
doi.org/10.1016/j.cognition.2010.11.005, PMID: 21122832,
PMCID: PMC3038602
Clerkin, E. M., Hart, E., Rehg,
J. M., Yu, C., & Smith, l. B.
(2017). Real-world visual statistics and infants’ first-learned ob-
ject names. Philosophical Transactions of the Royal Society B:
Biological Sciences, 372(1711), Article 20160055. DOI: https://
doi.org/10.1098/rstb.2016.0055, PMID: 27872373, PMCID:
PMC5124080
Fausey, C., Jayaraman, S., & Smith, l. (2016). From faces to hands:
Changing visual input in the first two years. Cognition, 152(2),
101–107. DOI: https://doi.org/10.1016/j.cognition.2016.03.005,
PMID: 27043744, PMCID: PMC4856551
Fenson, L., Marchman, V. A., Thal, D. J., Dale, P. S., Reznick, J. S.,
(2007). MacArthur-Bates Communicative Develop-
& Bates, E.
ment Inventories: User’s guide and technical manual (2nd ed.).
Brookes Publishing. DOI: https://doi.org/10.1037/t11538-000
Fernald, A., Marchman, V., & Weisleder, UN.
(2012). SES differ-
ences in language processing skill and vocabulary are evident
at 18 months. Developmental Science, 16(2), 234–248. DOI:
https://doi.org/10.1111/desc.12019, PMID: 23432833, PMCID:
PMC3582035
Franchak, J., Kretch, K., & Adolph, K.
(2018). See and be seen:
free play.
Infant-caregiver social
Developmental Science, 21(4), Article e12626. DOI: https://
doi.org/10.1111/desc.12626,
PMCID:
PMC5920801
looking during locomotor
29071760,
PMID:
Franchak, J., Kretch, K., Soska, K., & Adolph, K.
(2011). Head-
mounted eye-tracking: A new method to describe infant looking.
Child Development, 82(6), 1738–1750. DOI: https://doi.org/10
.1111/j.1467-8624.2011.01670.x, PMID: 22023310, PMCID:
PMC3218200
Frank, M. C., Simmons, K., Yurovsky, D., & Pusiol, G. (2013).
Developmental and postural changes in children’s visual access
to faces. In M. Knauff (Ed.), Proceedings of the 35th Annual Con-
ference of the Cognitive Science Society (pag. 454–459). Cog-
nitive Science Society. http://langcog.stanford.edu/papers/FSYP
-cogsci2013.pdf
Gilmore, R., & Adolph, K.
(2017). Video can make behavioural
science more reproducible. Nature Human Behavior, 1(7), 1–2.
DOI: https://doi.org/10.1038/s41562-017-0128, PMID: 30775454,
PMCID: PMC6373476
Hart, B., & Risley, T.
(1992). American parenting of language-
learning children: Persisting differences in family-child interac-
tions observed in natural home environments. Developmental
Psychology, 28(6), 1096–1105. DOI: https://doi.org/10.1037
/0012-1649.28.6.1096
Kretch, K., Franchak, J., & Adolph, K. (2014). Crawling and walk-
ing infants see the world differently. Child Development, 85(4),
1503–1518. DOI: https://doi.org/10.1111/cdev.12206, PMID:
24341362, PMCID: PMC4059790
OPEN MIND: Discoveries in Cognitive Science
28
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
/
e
D
tu
o
P
M
io
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
/
/
.
1
0
1
1
6
2
o
P
M
_
UN
_
0
0
0
3
9
1
9
1
9
8
3
6
o
P
M
_
UN
_
0
0
0
3
9
P
D
.
/
io
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
SAYCam Dataset
Sullivan et al.
Lungo, B., Kachergis, G., Agrawal, K., & Frank, M. C. (2020). Detect-
ing social
information in a dense dataset of infants’ natural
visual experience. PsyArXiv. https://psyarxiv.com/z7tdg/. DOI:
https://doi.org/10.31234/osf.io/z7tdg
MacWhinney, B.
(2000). The CHILDES project: Tools for analyz-
ing talk. Transcription format and programs (Vol. 1). Psychology
Press.
Oller, D., Niyogi, P., Gray, S., Richards, J., Gilkerson, J., Xu, D.,
Yapanel, U., & Warren, S. F. (2010). Automated vocal analysis
of naturalistic recordings from children with autism, lingua
delay, and typical development. Proceedings of the National
Academy of Science, 107(30), 13354–13359. DOI: https://doi
.org/10.1073/pnas.1003882107, PMID: 20643944, PMCID:
PMC2922144
Orhan, UN. E., Gupta, V. V., & Lake, B. M.
(2020). Self-supervised
learning through the eyes of a child. ArXiv. https://arxiv.org/abs
/2007.16189
Pusiol, G., Soriano, L., Fei-Fei, L., & Frank, M.
(2014). Discov-
ering the signatures of joint attention in child-caregiver interac-
zione. Proceedings of the Annual Meeting of the Cognitive Science
Società, 36, 2805–2810.
Quine, W. V. (1960). Word and object. CON Premere.
Rozin, P. (2001). Social psychology and science: Some lessons from
Solomon Asch. Personality and Social Psychology Review, 5(1),
2–14. DOI: https://doi.org/10.1207/S15327957PSPR0501_1
Sanchez, A., Lungo, B., Kraus, UN. M., & Frank, M. C. (2018). Postural
developments modulate children’s visual access to social infor-
In Proceedings of the 40th Annual Conference of the
mazione.
Cognitive Science Society (pag. 2412–2417). Cognitive Science
Società.
http://langcog.stanford.edu/papers_new/sanchez-long
-2018-cogsci.pdf. DOI: https://doi.org/10.31234/osf.io/th92b
Sanchez, A., Meylan, S., Braginsky, M., MacDonald, K., Yurovsky,
D., & Frank, M. (2019). CHILDES-db: A flexible and reproducible
interface to the child language data exchange system. Behavior
Research Methods, 51(4), 1928–1941. DOI: https://doi.org/10
.3758/s13428-018-1176-7, PMID: 30623390
Smith, L., Yu, C., Yoshida, H., & Fausey, C.
(2015). Contributions
of head-mounted cameras to studying the visual environments
of infants and young children. Journal of Cognition and Develop-
ment, 16(3), 407–419. DOI: https://doi.org/10.1080/15248372
.2014.933430, PMID: 26257584, PMCID: PMC4527180
Sperry, D. E., Sperry, l. L., & Mugnaio, P. J. (2019). Reexamining the
verbal environments of children from different socioeconomic
backgrounds. Child Development, 90(4), 1303–1318. DOI:
https://doi.org/10.1111/cdev.13072, PMID: 29707767
Squires, J., Bricker, D., & Potter, l.
(1997). Revision of a parent-
completed developmental screening tool: Ages and stages ques-
tionnaires. Journal of Pediatric Psychology, 22(3), 313–328. DOI:
https://doi.org/10.1093/jpepsy/22.3.313, PMID: 9212550
Yoshida, H., & Smith, l.
(2008). What’s in view for toddlers? Us-
Infancy, 13(3),
ing a head camera to study visual experience.
229–248. DOI: https://doi.org/10.1080/15250000802004437,
PMID: 20585411, PMCID: PMC2888512
Yu, C., & Smith, l. (2013). Joint attention without gaze following:
Human infants and their parents coordinate visual attention
to objects through eye-hand coordination. PLoS ONE, 8, Article
79659. DOI: https://doi.org/10.1371/journal.pone.0079659,
PMID: 24236151, PMCID: PMC3827436
Yurovsky, D., Smith, l. B., & Yu, C. (2013). Statistical word learning
at scale: The baby’s view is better. Developmental Science,
16(6), 959–966. DOI: https://doi.org/10.1111/desc.12036,
PMID: 24118720, PMCID: PMC4443688
Zhuang, C., Yan, S., Nayebi, A., Schrimpf, M., Frank, M. C.,
(2020). Unsupervised neu-
DiCarlo, J. J., & Yamins, D. l. K.
ral network models of the ventral visual system. BioRxiv. DOI:
https://doi.org/10.1101/2020.06.16.155556
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
/
e
D
tu
o
P
M
io
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
/
.
/
1
0
1
1
6
2
o
P
M
_
UN
_
0
0
0
3
9
1
9
1
9
8
3
6
o
P
M
_
UN
_
0
0
0
3
9
P
D
.
/
io
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
OPEN MIND: Discoveries in Cognitive Science
29