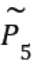On the Robustness of Dialogue History Representation in
Conversational Question Answering: A Comprehensive Study
and a New Prompt-based Method
Zorik GekhmanT∗ Nadav OvedT ∗ Orgad KellerG Idan SzpektorG Roi ReichartT
T Technion – Israel Institute of Technology, Israel GGoogle Research, Israel
{zorik@campus.|nadavo@campus.|roiri@}technion.ac.il
{orgad|szpektor}@google.com
Astratto
Most work on modeling the conversation his-
tory in Conversational Question Answering
(CQA) reports a single main result on a com-
mon CQA benchmark. While existing models
show impressive results on CQA leaderboards,
it remains unclear whether they are robust to
shifts in setting (sometimes to more realis-
tic ones), training data size (per esempio., from large
to small sets) and domain. In this work, we
design and conduct the first large-scale robust-
ness study of history modeling approaches for
CQA. We find that high benchmark scores
do not necessarily translate to strong robust-
ness, and that various methods can perform
extremely differently under different settings.
Equipped with the insights from our study, we
design a novel prompt-based history modeling
approach and demonstrate its strong robust-
ness across various settings. Our approach is
inspired by existing methods that highlight
historic answers in the passage. Tuttavia, In-
stead of highlighting by modifying the passage
token embeddings, we add textual prompts
directly in the passage text. Our approach
is simple, easy to plug into practically any
modello, and highly effective, thus we recom-
mend it as a starting point for future model
developers. We also hope that our study and
insights will raise awareness to the importance
of robustness-focused evaluation, in addition
to obtaining high leaderboard scores, leading
to better CQA systems.1
1
introduzione
Conversational Question Answering (CQA) In-
volves a dialogue between a user who asks
questions and an agent that answers them based
on a given document. CQA is an extension of the
∗Authors contributed equally to this work.
1Our code and data are available at: https://github
.com/zorikg/MarCQAp.
351
traditional single-turn QA task (Rajpurkar et al.,
2016), with the major difference being the pres-
ence of the conversation history, which requires
effective history modeling (Gupta et al., 2020).
Previous work demonstrated that the straightfor-
ward approach of concatenating the conversation
turns to the input is lacking (Qu et al., 2019UN),
leading to various proposals of architecture com-
ponents that explicitly model the conversation
history (Choi et al., 2018; Huang et al., 2019;
Yeh and Chen, 2019; Qu et al., 2019UN,B; Chen
et al., 2020; Kim et al., 2021). Tuttavia, there is
no single agreed-upon setting for evaluating the
effectiveness of such methods, with the majority
of prior work reporting a single main result on
a CQA benchmark, such as CoQA (Reddy et al.,
2019) or QuAC (Choi et al., 2018).
While recent CQA models show impressive re-
sults on these benchmarks, such a single-score
evaluation scheme overlooks aspects that can be
essential in real-world use-cases. Primo, QuAC and
CoQA contain large annotated training sets, Quale
makes it unclear whether existing methods can re-
main effective in small-data settings, dove il
annotation budget is limited. Inoltre, the eval-
uation is done in-domain, ignoring the model’s
robustness to domain shifts, with target domains
that may even be unknown at model training
time. Inoltre, the models are trained and
evaluated using a ‘‘clean’’ conversation history
between 2 humans, while in reality the history
can be ‘‘noisy’’ and less fluent, due to the in-
correct answers by the model (Li et al., 2022).
Finalmente, these benchmarks mix the impact of ad-
vances in pre-trained language models (LMs) con
conversation history modeling effectiveness.
In this work, we investigate the robustness
of history modeling approaches in CQA. We ask
whether high performance on existing benchmarks
also indicates strong robustness. To address this
Operazioni dell'Associazione per la Linguistica Computazionale, vol. 11, pag. 351–366, 2023. https://doi.org/10.1162/tacl a 00549
Redattore di azioni: Preslav I. Nakov. Lotto di invio: 7/2022; Lotto di revisione: 11/2022; Pubblicato 4/2023.
C(cid:3) 2023 Associazione per la Linguistica Computazionale. Distribuito sotto CC-BY 4.0 licenza.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
T
l
UN
C
_
UN
_
0
0
5
4
9
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Training In-Domain Evaluation
Out-Of-Domain Evaluation
Data source
Domain
83,568
# Esempi
# Conversations 11,567
QuAC QuAC QuAC-NH
7,354
1,000
10,515
1,204
CoQA
DoQA
children stories literature mid-high school news wikipedia cooking movies travel
1,884 1,713
400
1,797
400
1,626
100
1,425
100
1,653
100
1,630
100
1,649
100
400
Tavolo 1: Datasets statistics.
question, we carry out the first large-scale robust-
ness study using 6 common modeling approaches.
We design 5 robustness-focused evaluation set-
tings, which we curate based on 4 existing CQA
datasets. Our settings are designed to evaluate
efficiency in low-data scenarios, the ability to
scale in a high-resource setting, as well as robust-
ness to domain-shift and to noisy conversation
history. We then perform a comprehensive ro-
bustness study, where we evaluate the considered
methods in our settings.
We focus exclusively on history modeling, as it
is considered the most significant aspect of CQA
(Gupta et al., 2020), differentiating it from the
classic single-turn QA task. To better reflect the
contribution of the history modeling component,
we adapt the existing evaluation metric. Primo, A
avoid differences which stem from the use of dif-
ferent pre-trained LMs, we fix the underlying LM
for all the evaluated methods, re-implementing
all of them. Secondo, instead of focusing on final
scores on a benchmark, we focus on each model’s
improvement (Δ%) compared to a baseline QA
model that has no access to the conversation
history.
Our results show that history modeling meth-
ods perform very differently in different settings,
and that approaches that achieve high benchmark
scores are not necessarily robust under low-data
and domain-shift settings. Inoltre, we notice
that approaches that highlight historic answers
within the document by modifying the document
embeddings achieve the top benchmark scores,
but their performance is surprisingly lacking in
low-data and domain-shift settings. We hypothe-
size that history highlighting yields high-quality
representation, but since the existing highlighting
methods add dedicated embedding parameters,
specifically designed to highlight the document’s
gettoni, they are prone to over-fitting.
These findings motivate us to search for
an alternative history modeling approach with
improved robustness across different settings.
Following latest trends w.r.t. prompting in NLP
(Liu et al., 2021) we design MarCQAp, a novel
prompt-based approach for history modeling,
which adds textual prompts within the grounding
document in order to highlight previous answers
from the conversation history. While our approach
is inspired by the embedding-based highlighting
metodi, it is not only simpler, but it also shows
superior robustness compared to other evaluated
approcci. As MarCQAp is prompt-based, it can
be easily combined with any architecture, allow-
ing to fine-tune any model with a QA architecture
for the CQA task with minimal effort. Così, we
hope that it will be adopted by the community as
a useful starting point, owing to its simplicity, COME
well as high effectiveness and robustness. We also
hope that our study and insights will encourage
more robustness-focused evaluations, in addition
to obtaining high leaderboard scores, leading to
better CQA systems.
2 Preliminari
2.1 CQA Task Definition and Notations
Given a text passage P , the current question qk
and a conversation history Hk in a form of a
sequence of previous questions and answers Hk =
(q1, a1, . . . , qk−1, ak−1), a CQA model predicts the
answer ak based on P as a knowledge source. IL
answers can be either spans within the passage P
(extractive) or free-form text (abstractive).
2.2 CQA Datasets
Full datasets statistics are presented in Table 1.
QuAC (Choi et al., 2018) and CoQA (Reddy
et al., 2019) are the two leading CQA datasets,
with different properties. In QuAC, the questions
are more exploratory and open-ended with longer
answers that are more likely to be followed up.
This makes QuAC more challenging and realistic.
We follow the common practice in recent work
(Qu et al., 2019UN,B; Kim et al., 2021; Li et al.,
2022), focusing on QuAC as our main dataset,
using its training set for training and its vali-
dation set for in-domain evaluation (the test set
is hidden, reserved for a leaderboard challenge).
352
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
T
l
UN
C
_
UN
_
0
0
5
4
9
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
We use CoQA for additional pre-training or for
domain-shift evaluation.
DoQA (Campos et al., 2020) is another CQA
dataset with dialogues from the Stack Exchange
online forum. Due to its relatively small size, Esso
is typically used for testing transfer and zero-shot
apprendimento. We use it for domain-shift evaluation.
QuAC Noisy-History (QuAC-NH)
is based on
a datatset of human-machine conversations col-
lected by Li et al. (2022), using 100 passages
from the QuAC validation set. While Li et al. used
it for human evaluation, we use it for automatic
evaluation, leveraging the fact that the answers
are labeled for correctness, which allows us to use
the correct answers as labels.
k=1 = {(P, Hk, qk)}M
In existing CQA datasets, each conversa-
zione (q1, a1, .., qm, am) and the corresponding
passage P , are used to create m examples
k=1, where Hk =
{Ek}M
(q1, a1, . . . qk−1, ak−1). ak is then used as a la-
bel for Ek. Since QuAC-NH contains incorrect
if ak is incorrect we discard Ek to
answers,
avoid corrupting the evaluation set with incor-
rectly labeled examples. We also filtered out
invalid questions (Li et al., 2022) and answers
that did not appear in P .2
2.3 CQA Related Work
Conversation History Modeling is the major chal-
lenge in CQA (Gupta et al., 2020). Early work
used recurrent neural networks (RNNs) and vari-
ants of attention mechanisms (Reddy et al., 2019;
Choi et al., 2018; Zhu et al., 2018). Another
trend was to use flow-based approaches, Quale
generate a latent representation for the tokens in
Hk, using tokens from P (Huang et al., 2019;
Yeh and Chen, 2019; Chen et al., 2020). Modern
approcci, which are the focus of our work, lever-
age Transformer-based (Vaswani et al., 2017)
pre-trained language models.
The simplest approach to model the history with
pre-trained LMs is to concatenate Hk with qk and
P (Choi et al., 2018; Zhao et al., 2021). Alter-
native approaches rewrite qk based on Hk and
use the rewritten questions instead of Hk and qk
(Vakulenko et al., 2021), or as an additional train-
ing signal (Kim et al., 2021). Another fundamental
approach is to highlight historic answers within
2Even though Li et al. only used extractive models, UN
Pre-trained
LM Size
Base
Large
Base
Base
Base
Training
Evaluation
QuAC
CoQA + QuAC
QuAC smaller samples
QuAC
QuAC
QuAC
QuAC
QuAC
CoQA + DoQA
QuAC-NH
Standard
High-Resource
Low-Resource
Domain-Shift
Noisy-History
Tavolo 2: Summary of our proposed settings.
P by modifying the passage’s token embeddings
(Qu et al., 2019UN,B). Qu et al. also introduced
a component that performs dynamic history se-
lection after each turn is encoded. Yet, in our
corresponding baseline we utilize only the his-
toric answer highlighting mechanism, owing to its
simplicity and high effectiveness. A contempora-
neous work proposed a global history attention
component, designed to capture long-distance
dependencies between conversation turns (Qian
et al., 2022).3
3 History Modeling Study
In this work, we examine the effect of a model’s
history representation on its robustness. To this
end, we evaluate different approaches under sev-
eral settings that diverge from the standard
supervised benchmark (§3.1). This allows us to
examine whether the performance of some meth-
ods deteriorates more quickly than others in
different scenarios. To better isolate the gains
from history modeling, we measure performance
compared to a baseline QA model which has
no access to Hk (§3.2), and re-implement all
the considered methods using the same under-
lying pre-trained language model (LM) for text
representation (§3.3).
3.1 Robustness Study Settings
We next describe each comparative setting in our
study and the rationale behind it, as summarized
in Table 2. Tavolo 1 depicts the utilized datasets.
Standard. Defined by Choi et al. (2018), Questo
setting is followed by most studies. We use a
medium-sized pre-trained LM for each method,
commonly known as its base version,
Poi
fine-tune and evaluate the models on QuAC.
High-Resource. This setting examines the ex-
tent
to which methods can improve their
performance when given more resources. To this
small portion of the answers did not appear in the passage.
3Pubblicato 2 weeks before our submission.
353
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
T
l
UN
C
_
UN
_
0
0
5
4
9
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
end, we use a large pre-trained LM, perform ad-
ditional pre-training on CoQA (with the CQA
objective), and then fine-tune and evaluate on
QuAC.
Low-Resource.
In this setting, we examine the
resource efficiency of the history modeling ap-
proaches by reducing the size of the training set.
This setting is similar to the standard setting,
except that we fine-tune on smaller samples of
QuAC’s training set. For each evaluated method
we train 4 model variants: 20%, 10%, 5%, E 1%,
reflecting the percentage of training data retained.
Domain-Shift. This setting examines robust-
ness to domain shift. A tal fine, we use the
8 domains in the CoQA and DoQA datasets as
test sets from unseen target domains, evaluating
the models trained under the standard setting on
these test-sets.
Noisy-History. This setting examines robust-
ness to noisy conversation history, dove il
answers are sometimes incorrect and the conver-
sation flow is less fluent. A tal fine, we evaluate
the models trained under the standard setting on
the QuAC-NH dataset, consisting of conversations
between humans and other CQA models (§2.2).
We note that a full human-machine evaluation
requires a human in the loop. We choose to eval-
uate against other models predictions as a middle
ground. This allows us to test the models’ behav-
ior on noisy conversations with incorrect answers
and less fluent flow, but without a human in the
loop.
3.2 Evaluation Metric
The standard CQA evaluation metric is the average
word-level F1 score (Rajpurkar et al., 2016; Choi
et al., 2018; Reddy et al., 2019; Campos et al.,
2020).4 Since we focus on the impact of history
modeling, we propose to consider each model’s
improvement in F1 (Δ%) compared to a baseline
QA model that has no access to the dialogue
history.
3.3 Pre-trained LM
To control for differences which stem from the
use of different pre-trained LMs, we re-implement
all the considered methods using the Longformer
(Beltagy et al., 2020), a sparse-attention Trans-
former designed to process long input sequences.
4We follow the calculation presented in Choi et al. (2018).
It is therefore a good fit for handling the con-
versation history and the source passage as a
combined (long) input. Prior work usually utilized
dense-attention Transformers, whose input length
limitation forced them to truncate Hk and split
P into chunks, processing them separately and
combining the results (Choi et al., 2018; Qu et al.,
2019UN,B; Kim et al., 2021; Zhao et al., 2021). Questo
introduces additional complexity and diversity in
the implementation, while with the Longformer
we can keep implementation simple, as this model
can attend to the entire history and passage.
the state-of-the-art
We would also like to highlight RoR (Zhao
et al., 2021), which enhances a dense-attention
Transformer to better handle long sequences.
Notably,
result on QuAC
was reported using ELECTRA+RoR with simple
history concatenation (see CONCAT in §3.4). While
this suggests that ELECTRA+RoR can outper-
form the Longformer, since our primary focus
is on analyzing the robustness of different his-
tory modeling techniques rather than on long
sequence modeling, we opt for a general-purpose
commonly used LM for long sequences, Quale
exhibits competitive performance.
3.4 Evaluated Methods
In our study we choose to focus on modern history
modeling approaches that
leverage pre-trained
LMs. These models have demonstrated significant
progress in recent years (§2.3).
NO HISTORY A classic single-turn QA model
without access to Hk. We trained a Longformer
for QA (Beltagy et al., 2020), using qk and P as a
single packed input sequence (ignoring Hk). IL
model then extracts the answer span by predicting
its start and end positions within P .
In contrast to the rest of the evaluated methods,
we do not consider this method as a baseline for
history modeling, but rather as a reference for
calculating our Δ% metric. As discussed in §3.2,
we evaluate all history modeling methods for their
ability to improve over this model.
CONCAT Concatenating Hk to the input (cioè.,
to qk and P ), che è (arguably) the most
straightforward way to model the history (Choi
et al., 2018; Qu et al., 2019UN; Zhao et al.,
2021). Other than the change to the input, Questo
model architecture and training is identical to NO
HISTORY.
354
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
T
l
UN
C
_
UN
_
0
0
5
4
9
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
REWRITE This
approach was proposed in
Vakulenko et al. (2021). It consists of a pipeline
of two models, question rewriting (QR) E
question answering (QA). An external QR model
first generates a rewritten question ˜qk, based on
qk and Hk. ˜qk and P are then used as input to
a standard QA model, identical to NO HISTORY,
but trained with the rewritten questions. For the
external QR model we follow Lin et al. (2020),
Vakulenko et al. (2021), and Kim et al. (2021)
and fine-tune T5-base (Raffel et al., 2020) on the
CANARD dataset (Elgohary et al., 2019). We use
the same QR model across all the settings in our
study (§3.1), meaning that in the low-resource
setting we limit only the CQA data, which is used
to train the QA model.
REWRITEC Hypothesizing that there is useful in-
formation in Hk on top of the rewritten question
˜qk, we combine REWRITE and CONCAT, obtaining
a model which is similar to CONCAT, except that
it replaces qk with ˜qk.
ExCorDLF Our implementation of the ExCorD
approach, proposed in Kim et al. (2021). Invece
of rewriting the original question, qk, at inference
time (REWRITE), ExCorD uses the rewritten ques-
tion only at training time as a regularization signal
when encoding the original question.
HAELF Our implementation of the HAE ap-
proach proposed in Qu et al. (2019UN), Quale
highlights the conversation history within P . In-
stead of concatenating Hk to the input, HAE
highlights the historic answers {ai}k−1
i=1 within
P , by modifying the passage token embeddings.
HAE adds an additional dedicated embedding
layer with 2 learned embedding vectors, denoting
whether a token from P appears in any historic
answers or not.
PosHAELF Our implementation of the PosHAE
approach proposed in Qu et al. (2019B), which ex-
tends HAE by adding positional information. IL
embedding matrix is extended to contain a vector
per conversation turn, each vector representing the
turn that the corresponding token appeared in.
3.5 Implementation Details
We fine-tune all models on QuAC for 10 epochs,
employ an accumulated batch size of 640, a weight
decay of 0.01, and a learning rate of 3 · 10−5. Nel
high-resource setup, we also pre-train on CoQA
Original Work
CONCAT
Qu et al. (2019UN)
Original LM Original Result
BERT
62.0
Our Impl.
65.8
REWRITE
Vakulenko et al. (2021)
BERT
Not Reported
REWRITEC
ExCorD
N/A (this baseline was first proposed in this work)
Kim et al. (2021)
RoBERTa
HAE
Qu et al. (2019UN)
PosHAE
Qu et al. (2019B)
BERT
BERT
64.6
67.3
67.5
68.9
69.8
67.7
63.9
64.7
Tavolo 3: F1 scores comparison between original
implementations and ours (using Longformer as
the LM), for all methods described in §3.4, in the
standard setting.
for 5 epochs. We use a maximum output length
Di 64 gettoni. Following Beltagy et al. (2020), we
set Longformer’s global attention to all the tokens
of qk. We use the cross-entropy loss and AdamW
optimizer (Kingma and Ba, 2015; Loshchilov and
Hutter, 2019). Our implementation makes use
of the HuggingFace Transformers (Wolf et al.,
2020), and PyTorch-Lightning libraries.5
the base LM (used in all
settings
except high-resource) we found that a Long-
former that was further pre-trained on SQuADv2
(Rajpurkar et al., 2018),6 achieved consistently
better performance than the base Longformer.
Così, we adopted it as our base LM. For the large
LM (used in the high-resource setting) we used
Longformer-large.7
For
In §5, we introduce a novel method (MarCQAp)
and perform statistical significance tests (Dror
et al., 2018, 2020). Following Qu et al. (2019B),
we use the Student’s paired t-test with p < 0.05,
to compare MarCQAp to all other methods in each
setting.
In our re-implementation of the evaluated meth-
ods, we carefully followed their descriptions and
implementation details as published by the authors
in their corresponding papers and codebases. A
key difference in our implementation is the use
of a long sequence Transformer, which removes
the need to truncate Hk and split P into chunks
(§3.3). This simplifies our implementation and
avoids differences between methods.8 Table 3
compares between our results and those reported
in previous works. In almost all cases we achieved
5https://github.com/PyTorchLightning
/pytorch-lightning.
6https://huggingface.co/mrm8488
/longformer-base-4096-finetuned-squadv2.
7https://huggingface.co/allenai
/longformer-large-4096.
8The maximum length limit of Hk varies between dif-
ferent works, as well as how sub-document chunks are
handled.
355
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
t
l
a
c
_
a
_
0
0
5
4
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Setting
LM
Training set size
NO HISTORY
concat
REWRITE
REWRITEC
ExCorDLF
HAELF
PosHAELF
MarCQAp (§5)
Low-Resource
Longformer-base
Pre-trained SQuAD
8K (10%)
52.9
53.4 (+0.9%)
56.4 (+6.6%)
57.2 (+8.1%)
57.2 (+8.1%)
55.0 (+4.0%)
55.1 (+4.2%)
57.4 (+14.8%) 61.3 (+15.9%) 64.6 (+16.6%)
16K (20%)
55.4
57.8 (+4.3%)
59.2 (+6.9%)
60.6 (+9.4%)
60.3 (+8.8%)
59.8 (+7.9%)
60.9 (+9.9%)
4K (5%)
800 (1%)
50.0
45.0
51.2 (+2.4%)
43.9 (-2.4%)
54.0 (+8.0%)
46.5 (+3.3%)
54.4 (+8.8%)
42.3 (-6.0%)
53.0 (+6.0%)
46.0 (+2.2%)
44.5 (-1.1%)
50.8 (+1.6%)
40.5 (-10.0%) 51.0 (+2.0%)
48.2 (+7.1%)
High-Resource
Standard
Longformer-base
Longformer-large
Pre-trained SQuAD Pre-trained CoQA
Avg Δ%
–
+1.3%
+6.2%
+5.1%
+6.3%
+3.1%
+1.5%
+13.6%
80K (100%)
60.4
65.8 (+8.9%)
64.6 (+7.0%)
67.3 (+11.4%)
67.5 (+11.8%)
69.0 (+14.2%)
69.8 (+15.6%)
70.2 (+16.2%)
80K (100%)
65.6
72.3 (+10.2%)
69.0 (+5.2%)
72.5 (+10.5%)
73.8 (+12.3%)
73.2 (+11.4%)
74.2 (+12.9%)
74.7 (+13.7%)
Table 4: In-domain F1 and Δ% scores on the full QuAC validation set, for the standard, high-resource
and low-resource settings. We color coded the Δ% for positive and negative numbers.
a higher score (probably since Longformer out-
performs BERT), with the exception of ExCorD,
where we achieved a comparable score (proba-
bly since Longformer is actually initialized using
RoBERTa’s weights [Beltagy et al., 2020]).
4 Results and Analysis
We next discuss the takeaways from our study,
where we evaluated the considered methods across
the proposed settings. Table 4 presents the results
of the standard, high-resource, and low-resource
settings. Table 5 further presents the domain-shift
results. Finally, Table 6 depicts the results of the
noisy-history setting. Each method is compared
to NO HISTORY by calculating the Δ% (§3.2). The
tables also present the results of our method,
termed MarCQAp, which is discussed in §5.
We further analyze the effect of the conversa-
tion history length in Figure 1, evaluating models
from the standard setting with different limits on
the history length. For instance, when the limit is
2, we expose the model to up to the 2 most recent
turns, by truncating Hk.9
Key Findings A key goal of our study is to
examine the robustness of history modeling ap-
proaches to setting shifts. This research reveals
limitations of the single-score benchmark-based
evaluation adopted in previous works (§4.1), as
such scores are shown to be only weakly correlated
with low-resource and domain-shift robustness.
Furthermore, keeping in mind that history mod-
eling is a key aspect of CQA, our study also
demonstrates the importance of isolating the con-
tribution of the history modeling method from
9We exclude REWRITE, since it utilizes Hk only in the
form of the rewritten question. For REWRITEC , we truncate
the concatenated Hk for the CQA model, while the QR model
remains exposed to the entire history.
other model components (§4.2). Finally, we dis-
cover that while existing history highlighting
approaches yield high-quality input representa-
tions, their robustness is surprisingly poor. We
further analyze the history highlighting results
and provide possible explanations for this phe-
nomenon (§4.3). This finding is the key motivation
for our proposed method (§5).
4.1 High CQA Benchmark Scores do not
Indicate Good Robustness
First, we observe some expected general trends:
All methods improve on top of NO HISTORY, as
demonstrated by the positive Δ% in the standard
setting, showing that all the methods can leverage
information from Hk. All methods scale with more
training data and a larger model (high-resource),
and their performances drop significantly when
the training data size is reduced (low-resource)
or when they are presented with noisy history. A
performance drop is also observed when evaluat-
ing on domain-shift, as expected in the zero shot
setting.
However, not all methods scale equally well
and some deteriorate faster than others. This
phenomenon is illustrated in Table 7, where the
methods are ranked by their scores in each set-
ting. We observe high instability between settings.
For instance, PosHAELF is top performing in
3 settings but
in 2 others.
is second worst
REWRITE is second best in low-resource, but among
the last ones in other settings. So is the case
with CONCAT: Second best in domain-shift but
among the worst ones in others. In addition, while
all the methods improve when they are exposed
to longer histories (Figure 1), some saturate earlier
than others.
356
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
t
l
a
c
_
a
_
0
0
5
4
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Setting
Domain
NO HIST.
CONCAT
REWRITE
REWRITEC
ExCorDLF
HAELF
PosHAELF
MarCQAp (§5)
Domain-Shift
Children Sto.
Literature
CoQA
M/H Sch.
News
Wikipedia
Cooking
DoQA
Movies
Travel
54.8
42.6
50.3
50.1
58.2
46.9
45.0
44.0
62.2 (+13.5%)
48.0 (+12.7%)
55.3 (+9.9%)
54.9 (+9.6%)
59.9 (+2.9%)
54.8 (+16.8%)
52.0 (+15.6%)
48.4 (+10%)
60.1 (+9.7%)
47.7 (+12.0%)
55.0 (+9.3%)
54.8 (+9.4%)
60.9 (+4.6%)
44.6 (-4.9%)
43.2 (-4.0%)
40.9 (-7.0%)
62.7 (+14.4%)
49.0 (+15.0%)
56.7 (+12.7%)
55.2 (+10.2%)
59.4 (+2.1%)
52.0 (+10.9%)
49.1 (+9.1%)
46.4 (+5.5%)
62.7 (+14.4%)
51.5 (+20.9%)
58.2 (+15.7%)
57.0 (+13.8%)
63.6 (+9.3%)
53.7 (+14.5%)
51.1 (+13.6%)
48.6 (+10.5%)
61.8 (+12.8%)
50.5 (+18.5%)
56.6 (+12.5%)
55.4 (+10.6%)
60.9 (+4.6%)
45.0 (-4.1%)
45.1 (+0.2%)
45.1 (+2.5%)
56.6 (+3.3%)
66.7 (+21.7%)
47.4 (+11.3%)
56.4 (+32.4%)
55.4 (+10.1%)
61.8 (+22.9%)
52.7 (+5.2%)
60.8 (+21.4%)
61.7 (+6.0%)
67.5 (+16.0%)
45.6 (-2.8%)
45.8 (+1.8%)
53.3 (+13.6%)
51.8 (+15.1%)
44.7 (+1.6%)
50.1 (+13.9%)
Avg Δ%
–
+11.4%
+3.6%
+10.0%
+14.1%
+7.2%
+4.6%
+19.6%
Table 5: F1 and Δ% scores for the domain-shift setting. We color coded the Δ% for positive and
negative numbers.
Setting
NO HISTORY
CONCAT
REWRITE
REWRITEC
ExCorDLF
HAELF
PosHAELF
MarCQAp (§5)
Noisy-History
49.9
55.3 (+10.8%)
56.0 (+12.2%)
58.5 (+17.2%)
56.8 (+13.8%)
57.9 (+16.0%)
60.1 (+20.4%)
62.3 (+24.9%)
Table 6: F1 and Δ% scores for the noisy-history
setting.
We conclude that the winner does not take it
all: There are significant instabilities in meth-
ods’ performance across settings. This reveals
the limitations of the existing single-score bench-
mark evaluation practice, and calls for more
comprehensive robustness-focused evaluation.
4.2 The Contribution of the History
Modeling Method should be Isolated
In the high-resource setting, NO HISTORY reaches
65.6 F1, higher than many CQA results reported
in previous work (Choi et al., 2018; Qu et al.,
2019a,b; Huang et al., 2019). Since it is clearly
ignoring the history, this shows that significant
improvements can stem from simply using a better
LM. Thus comparing between history modeling
methods that use different LMs can be misleading.
This is further illustrated with HAELF ’s and
PosHAELF ’s results. The score that Kim et al.
reported for ExCorD is higher than Qu et al.
reported for HAE and PosHAE. While both au-
thors used a setting equivalent to our standard
setting, Kim et al. used RoBERTa while Qu
et al. used BERT, as their underlying LM. It is
therefore unclear whether ExCorD’s higher score
stems from better history representation or from
choosing to use RoBERTa. In our study, HAELF
Table 7: Per setting rankings of the methods evalu-
ated in our study (top is best), excluding MarCQAp.
C is CONCAT, R is REWRITE, RC is REWRITEC, Ex is
ExCorDLF , H is HAELF , and PH is PosHAELF .
and PosHAELF actually outperform ExCorDLF
in the standard setting. This suggests that these
methods can perform better than reported, and
demonstrates the importance of controlling for the
choice of LM when comparing between history
modeling methods.
(2019a)
As can be seen in Figure 1, CONCAT sat-
urates at 6 turns, which is interesting since
Qu et al.
reported saturation at 1
turn in a BERT-based equivalent. Furthermore,
Qu et al. observed a performance degradation
with more turns, while we observe stability. These
differences probably stem from the history trunca-
tion in BERT, due to the input length limitation of
dense attention Transformers. This demonstrates
the advantages of sparse attention Transformers
for history modeling evaluation, since the com-
parison against CONCAT can be more ‘‘fair’’. This
comparison is important, since the usefulness of
any method should be established by comparing it
to the straight-forward solution, which is CONCAT
in case of history modeling.
We would also like to highlight PosHAELF ’s
F1 scores in the noisy-history (60.1) and the
20% low-resource setting (60.9), both lower than
the 69.8 F1 in the standard setting. Do these
performance drops reflect
lower effectiveness
in modeling the conversation history? Here the
Δ% comes to the rescue. While the Δ% de-
creased between the standard and the 20% settings
357
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
t
l
a
c
_
a
_
0
0
5
4
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 1: F1 as a function of # history turns, for models
from the standard setup. The first occurrence of the
maximum F1 value (saturation point) is highlighted.
Figure 2: Δ% as a function of # training examples.
Results taken from the standard and low-resource
settings.
(15.6 → 9.9),
it actually increased in the
noisy-history setting (to 20.4). This indicates
that even though the F1 decreased, the ability
to leverage the history actually increased.
We conclude that our study results support the
design choices we made, in our effort to better iso-
late the contribution of the history representation.
We recommend future works to compare history
modeling methods using the same LM (prefer-
ably a long sequence LM), and to measure a Δ%
compared to a NO HISTORY baseline.
4.3 History Highlighting is Effective in
Resource-rich Setups, but is not Robust
The most interesting results are observed for the
history highlighting methods: HAE and PosHAE.
First, when implemented using the Longformer,
HAELF and PosHAELF perform better than re-
ported in previous work, with 68.9 and 69.8 F1
respectively, compared to 63.9 and 64.7 reported
by Qu et al. using BERT. The gap between HAELF
and PosHAELF demonstrates the effect of the po-
sitional information in PosHAELF . This effect is
further observed in Figure 1: HAELF saturates
earlier since it cannot distinguish between dif-
ferent conversation turns, which probably yields
conflicting information. PosHAELF saturates at
9 turns,
later than the rest of the methods,
which indicates that it can better leverage long
conversations.
PosHAELF outperforms all methods in the stan-
dard, high-resource, and noisy-history settings,10
demonstrating the high effectiveness of history
highlighting. However, it shows surprisingly poor
10We ignore MarCQAp’s results in this section.
performance in low-resource and domain-shift set-
tings, with extremely low average Δ% compared
to other methods. The impact of the training set
size is further illustrated in Figure 2. We plot the
Δ% as a function of the training set size, and
specifically highlight PosHAELF in bold red. Its
performance deteriorates significantly faster than
others when the training set size is reduced. In
the 1% setting it is actually the worst performing
method.
This poor robustness could be caused by the
additional parameters added in the embedding
layer of PosHAELF . Figure 2 demonstrates that
properly training these parameters, in order to
benefit from this method’s full potential, seems
to require large amounts of data. Furthermore,
the poor domain-shift performance indicates that,
even with enough training data, this embedding
layer seems to be prone to overfitting to the source
domain.
We conclude that history highlighting clearly
yields a very strong representation, but the addi-
tional parameters of the embedding layer seem to
require large amounts of data to train properly and
over-fit to the source domain. Is there a way to
highlight historic answers in the passage, without
adding dedicated embedding layers?
In §5 we present MarCQAp, a novel history
modeling approach that is inspired by PosHAE,
adopting the idea of history highlighting. How-
ever, instead of modifying the passage embedding,
we highlight historic answers by adding textual
prompts directly in the input text. By leveraging
prompts, we reduce model complexity and remove
the need for training dedicated parameters, hoping
to mitigate the robustness weaknesses of PosHAE.
358
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
t
l
a
c
_
a
_
0
0
5
4
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
5 MarCQAp
Motivated by our findings, we design MarCQAp,
a novel prompt-based history modeling approach
that highlights answers from previous conversa-
tion turns by inserting textual prompts in their
respective positions within P . By highlighting
with prompts instead of embedding vectors, we
hope to encode valuable dialogue information,
while reducing the learning complexity incurred
by the existing embedding-based methods. Thus,
we expect MarCQAp to perform well not only in
high-resource settings, but also in low-resource
and domain adaptation settings, in which prompt-
ing methods have shown to be particularly useful
(Brown et al., 2020; Le Scao and Rush, 2021;
Ben-David et al., 2022).
Prompting often refers to the practice of
adding phrases to the input,
in order to en-
courage pre-trained LMs to perform specific
tasks (Liu et al., 2021), yet it is also used as
a method for injecting task-specific guidance
during fine-tuning (Le Scao and Rush, 2021;
Ben-David et al., 2022). MarCQAp closely re-
sembles the prompting approach from Ben-David
et al. (2022) since our prompts are: (1) discrete
(i.e., the prompt is an actual text-string), (2) dy-
namic (i.e., example-based), and (3) added to the
input text and the model then makes predictions
conditioned on the modified input. Moreover, as
in Ben-David et al., in our method the underlying
LM is further trained on the downstream task with
prompts. However, in contrast to most prompting
approaches, which predefine the prompt’s loca-
tion in the input (Liu et al., 2021), our prompts are
inserted in different locations for each example. In
addition, while most textual prompting approaches
leverage prompts comprised of natural language,
our prompts contain non-verbal symbols (e.g.,
"<1>“, Guarda la figura 3 and §5.1), which were proven
useful for supervision of NLP tasks. For instance,
Aghajanyan et al. (2022) showed the usefulness
of structured pre-training by adding HTML sym-
bols to the input text. Finalmente, to the best of our
knowledge, this work is the first to propose a
prompting mechanism for the CQA task.
5.1 Method
MarCQAp utilizes a standard single-turn QA
model architecture and input, with the input com-
prising the current question qk and the passage P .
For each CQA example (P, Hk, qk), MarCQAp
Figura 3: The MarCQAp highlighting scheme: Answers
to previous questions are highlighted in the grounding
document, which is then provided as input to the model.
inserts a textual prompt within P , based on in-
formation extracted from the conversation history
Hk. In extractive QA, the answer ak is typically a
span within P . Given the input (P, Hk, qk), Mar-
CQAp transforms P into an answer-highlighted
passage (cid:2)Pk, by constructing a prompt pk and in-
serting it within P . pk is constructed by locating
the beginning and end positions of all historic
answers {ai}k−1
i=1 within P , and inserting a unique
textual marker for each answer in its respective
positions (see example in Figure 3). The input
( (cid:2)Pk, qk) is then passed to the QA model, instead
Di (P, qk).
In abstractive QA, a free form answer is gen-
erated based on an evidence span that is first
extracted from P . Hence, the final answer does
not necessarily appear in P . To support this set-
ting, MarCQAp highlights the historical evidence
spans (which appear in P ) instead of the generated
answers.
To encode positional dialogue information, IL
markers for aj ∈ {ai}k−1
i=1 include its turn index
number in reverse order, questo è, k − 1 − j. Questo
encodes relative historic positioning w.r.t. the cur-
rent question qk, allowing the model to distinguish
between the historic answers by their recency.
MarCQAp highlights only the historic answers,
since the corresponding questions do not appear
in P . While this might lead to information loss,
in §5.3 we implement MarCQAp’s variants that
add the historic questions to the input, and show
359
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
T
l
UN
C
_
UN
_
0
0
5
4
9
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
that the contribution of the historic questions to
the performance is minor.11
‘NO ANSWER’
A CQA dialogue may also contain unanswer-
able questions. Before inserting the prompts,
MarCQAp first appends a ‘NO ANSWER’ string
to P .12 Each historical
is then
highlighted with prompts, similarly to ordinary
historical answers. For example see a4 in Figure 3.
MarCQAp has several advantages over prior
approcci. Primo, since it is prompt-based, it does
not modify the model architecture, which makes
it easier to port across various models, alleviat-
ing the need for model-specific implementation
and training procedures. Additionally, it naturally
represents overlapping answers in P , which was
a limitation in prior work (Qu et al., 2019UN,B).
Overlapping answers contain tokens which relate
to multiple turns, yet the existing token-based em-
bedding methods encode the relation of a token
from P only to a single turn from Hk. Since
MarCQAp is span-based, it naturally represents
overlapping historic answers (per esempio., see a2 and a3
in Figure 3).
5.2 MarCQAp Evaluation
We evaluate MarCQAp in all our proposed
experimental settings (§3.1). As presented in
Tables 4, 5, E 6, it outperforms all other methods
in all settings. In the standard, high-resource,
and noisy-history settings,
its performance is
very close to PosHAELF ,13 indicating that our
prompt-based approach is an effective alterna-
tive implementation for the idea of highlighting
historical answers. Similarly to PosHAELF , Mar-
CQAp is able to handle long conversations and its
performance gains saturate at 9 turns (Figura 1).
Tuttavia, in contrast to PosHAELF , MarCQAp
performs especially well in the low-resource and
the domain-shift settings.
In the low-resource settings, MarCQAp out-
performs all methods by a large margin, con
an average Δ% of 13.6% compared to the best
baseline with 6.3%. The dramatic improvement
over PosHAELF ’s average Δ% (1.5% → 13.6%)
serves as a strong indication that our prompt-based
11Which is also in line with the findings in Qu et al.
(2019B).
Figura 4: An example of MarCQAp’s robustness in
the low-resource setting. Even though ExCorDLF ,
HAELF , and PosHAELF predict correct answers in the
standard setting, they fail on the same example when
the training data size is reduced to 10%. MarCQAp
predicts a correct answer in both settings.
approach is much more robust. This boost in ro-
bustness is best illustrated in Figure 2, Quale
presents the Δ% as a function of the training set
size, highlighting PosHAELF (red) and MarCQAp
(green) specifically. An example of MarCQAp’s
robustness in the low-resource setting is provided
in Figure 4.
In the domain-shift settings, MarCQAp is
the best performing method in 6 out of 8 do-
mains.14 On the remaining two domains (Cooking
& Movies), CONCAT is the best performing.15
Notably, MarCQAp’s average Δ% (19.6%) È
substantially higher compared to the next best
method (14.1%). These results serve as additional
strong evidence of MarCQAp’s robustness.
MarCQAp’s Performance Using Different
LMs
In addition to Longformer, we evaluated
MarCQAp using RoBERTa (Liu et al., 2019)
and BigBird (Zaheer et al., 2020) in the stan-
dard setting. The results are presented in Table 8.
MarCQAp shows a consistent positive effect
across different LMs, which further highlights
its effectiveness.
12Only if it is not already appended to P , in some datasets
14For the Travel domain MarCQAp’s improvement over
the passages are always suffixed with ‘NO ANSWER’.
ExCorDLF is not statistically significant.
13In the standard and high-resource MarCQAp’s improve-
15The differences between CONCAT and MarCQAp for both
ments over PosHAELF are not statistically significant.
domains are not statistically significant.
360
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
T
l
UN
C
_
UN
_
0
0
5
4
9
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Model
No History MarCQAp
Δ%
RoBERTa
BigBird
Longformerbase
Longformersquad
57.7
57.6
60.0
60.4
68.0
66.3
68.4
70.2
(+17.9%)
(+15.1%)
(+14.0%)
(+16.6%)
Tavolo 8: MarCQAp’s standard setting per-
formance across different Transformer-based
pre-trained LMs.
BiDAF++ w/ 2-Context (Choi et al., 2018)
HAE (Qu et al., 2019UN)
FlowQA (Huang et al., 2019)
GraphFlow (Chen et al., 2020)
HAM (Qu et al., 2019B)
FlowDelta (Yeh and Chen, 2019)
GHR (Qian et al., 2022)
RoR (Zhao et al., 2021)
MarCQAp (Ours)
60.1
62.4
64.1
64.9
65.4
65.5
73.7
74.9
74.0
We note that since RoBERTa is a dense-
attention Transformer with input length limita-
tion of 512 gettoni, longer passages are split into
chunks. This may lead to some chunks containing
part of the historic answers, and therefore partial
highlighting by MarCQAp. Our analysis showed
Quello 51% of all examples in QuAC were split
into several chunks, E 61% the resulted chunks
contained partial highlighting. MarCQAp’s strong
performance with RoBERTa suggests that it can
remain effective even with partial highlighting.
Official QuAC Leaderboard Results For com-
pleteness, we submitted our best performing
modello (from the high-resource setting) to the
official QuAC leaderboard,16 evaluating its per-
formance on the hidden test set. Tavolo 9 presents
the results.17 MarCQAp achieves a very competi-
tive score of 74.0 F1, very close to the published
state-of-the art (RoR by Zhao et al. [2021] con
74.9 F1), yet with a much simpler model.18
5.3 Prompt Design
Recall that MarCQAp inserts prompts at the begin-
ning and end positions for each historical answer
within P (Figura 3). The prompts are designed
with predefined marker symbols and include the
answer’s turn index (per esempio., “<1>“). This design
builds on 3 main assumptions: (1) textual prompts
can represent conversation history information,
(2) the positioning of the prompts within P facil-
itates highlighting of historical answers, E (3)
indexing the historical answers encodes valuable
informazione. We validate our design assumptions
by comparing MarCQAp against ablated variants
(Tavolo 10).
16https://quac.ai.
17The leaderboard contains additional results for mod-
els which (at the time of writing) include no descriptions
or published papers, rendering them unsuitable for fair
comparison.
18See §3.3 for a discussion of RoR.
Tavolo 9: Results from the official QuAC leader-
board, presenting F1 scores for the hidden test set,
for MarCQAp and other models with published
papers.
To validate assumption (1), we compare Mar-
CQAp to MARCQAPC, a variant which adds Hk
to the input, in addition to (cid:2)Pk and qk. MARC-
QAPC is exposed to information from Hk via two
fonti: The concatenated Hk and the MarCQAp
prompt within (cid:2)Pk. We observe a negligible ef-
fect,19 suggesting that MarCQAp indeed encodes
information from the conversation history, since
providing Hk does not add useful information on
top of (cid:2)Pk.
To validate assumptions (2) E (3), noi usiamo
two additional MarCQAp’s variants. Answer Pos
inserts a constant predefined symbol (“<>“), In
each answer’s beginning and end positions within
P (cioè., similar to MarCQAp, but without turn
indexing). Random Pos inserts the same number
of symbols but in random positions within P .
Answer Pos achieves a Δ% of 12.7%, while
Random Pos achieves 1.7%. This demonstrates
that the positioning of the prompts within P is cru-
cial, and that most of MarCQAp’s performance
gains stem from its prompts positioning w.r.t.
historical answers {ai}k−1
i=1 . When the prompts
are inserted at meaningful positions, the model
seems to learn to leverage these positions in
order to derive an effective history representa-
zione. Surprisingly, Random Pos leads to a minor
improvement of 1.7%.20 Finalmente, MarCQAp’s im-
provement over Answer Pos (a Δ% of 15.9%
compared to 12.7%), indicates that answer in-
dexing encodes valuable information, helping us
validate assumption (3).
Finalmente, since textual prompts allow for easy
informazione, we make
injection of additional
19The difference is not statistically significant.
20The difference is statistically significant, we did not
further investigate the reasons behind this particular result.
361
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
T
l
UN
C
_
UN
_
0
0
5
4
9
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
NO HISTORY
Random Pos
Answer Pos
Full Q
Word from Q
Word from Q + Index
MARCQAPC
MarCQAp
52.9
53.8 (+1.7%)
59.6 (+12.7%)
59.2 (+11.9%)
60.4 (+14.2%)
60.7 (+14.8%)
61.5 (+16.3%)
61.3 (+15.9%)
Tavolo 10: F1 and Δ% scores for MarCQAp’s
ablated variants,
IL
low-resource setting.
in the 10% setup of
several initial attempts in this direction, inject-
ing different types of information into our textual
prompts. In Word from Q, the marker contains
the first word from the historic answer’s corre-
sponding question, which is typically a wh-word
(per esempio., ‘‘
also add the historic answer’s turn index (per esempio.,
‘‘
historic question into the prompt. Word from Q
and Word from Q + Index achieved comparable
scores, lower than MarCQAp’s but higher than
Answer Pos’s.21 This suggests that adding se-
mantic information is useful (since Word from Q
outperformed Answer Pos), and that combining
such information with the positional information
is not trivial (since MarCQAp outperformed Word
from Q + Index). This points to the effects of the
prompt structure and the information included:
We see that ‘‘<1>’’ and ‘‘
form ‘‘<>’’, yet constructing a prompt by naively
combining these signals (‘‘
lead to complementary effect. Finalmente, Word from
Q outperformed Full Q. We hypothesize that
since the full question can be long, it might sub-
stantially interfere with the natural structure of
the passage text. This provides evidence that the
prompts should probably remain compact symbols
with small footprint within the passage. These ini-
tial results call for further exploration of optimal
prompt design in future work.
5.4 Case Study
Figura 5 presents an example of all evaluated
methods in action from the standard setting. IL
current question ‘‘Did he have any other crit-
ics?’’ has two correct answers: Alan Dershowitz
or Omer Bartov. We first note that all methods
21Both differences are statistically significant.
Figura 5: Our case study example, comparing answers
predicted by each evaluated method in the standard
setting. We provide a detailed analysis in §5.4.
predicted a name of a person, which indicates that
the main subject of the question was captured cor-
rectly. Yet, the methods differ in their prediction
of the specific person.
REWRITE and CONCAT predict a correct answer
(Alan Dershowitz), yet CONCAT predicts it based on
incorrect evidence. This may indicate that CONCAT
did not capture the context correctly (just the fact
that it needs to predict a person’s name), and was
lucky enough to guess the correct name.
È interessante notare, REWRITEC predicts Daniel Gold-
hagen, which is different
from the answers
predicted by CONCAT and REWRITE. This shows that
combining both methods can yield completely dif-
ferent results, and demonstrates an instance where
REWRITEC performs worse than REWRITE and CON-
CAT (for instance in the 1% low-resource setting).
This is also an example of a history modeling flaw,
since Daniel Goldhagen was already mentioned
as a critic in previous conversation turns.
This example also demonstrates how errors
can propagate through a pipeline-based system.
362
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
T
l
UN
C
_
UN
_
0
0
5
4
9
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
The gold rewritten question is ‘‘Did Norman
Finkelstein have any other critics aside from
Peter Novick and Daniel Goldhagen?’’,22 while
the question rewriting model generated ‘‘Besides
Peter Novick, did Norman Finkelstein have any
other critics?’’, omitting Daniel Goldhagen. Questo
makes it impossible for REWRITE to figure out
that Daniel Goldhagen was already mentioned,
making it a legitimate answer. This reveals that
REWRITE might have also gotten lucky and provides
a possible explanation for the incorrect answer
predicted by REWRITEC.
ExCorDLF , HAELF , and PosHAELF not only
predict a wrong answer, but also seem to fail
to resolve the conversational coreferences, since
the pronoun ‘‘he’’, in the current question ‘‘Did
he have any other critics?’’, refers to Norman
Finkelstein.
MarCQAp predicts a correct answer, Omer
Bartov. This demonstrates an instance where Mar-
CQAp succeeds while HAELF and PosHAELF
fail, even though they are all history-highlighting
metodi. È interessante notare, MarCQAp is the only
model that predicts Omer Bartov, a non-trivial
choice compared to Alan Dershowitz, since Omer
Bartov appears later in the passage, further away
from the historic answers.
6 Limitations
This work focuses on a single-document CQA
setting, which is in line with the majority of the
previous work on conversation history model-
ing in CQA (§2.3). Correspondingly, MarCQAp
was designed for single-document CQA. Apply-
ing MarCQAp in multi-document settings (Qu
et al., 2020; Anantha et al., 2021; Adlakha et al.,
2022) may result in partial history representation,
since the retrieved document may contain only
part of the historic answers, therefore MarCQAp
will only highlight the answers which appear in
the document.23
In §5.3 we showed initial evidence that Mar-
CQAp prompts can encode additional informa-
tion that can be useful for CQA. In this work we
focused on the core idea behind prompt-based an-
swer highlighting, as a proposed solution in light
of our results in §4. Yet, we did not conduct a com-
22As annotated in CANARD (Elgohary et al., 2019).
23We note that this limitation applies to all highlighting
approcci, including HAE and PosHAE (Qu et al., 2019UN,B).
prehensive exploration in search of the optimal
prompt design, and leave this for future work.
7 Conclusione
the first compre-
In this work, we carry out
hensive robustness study of history modeling
approaches for Conversational Question Answer-
ing (CQA), including sensitivity to model and
training data size, domain shift, and noisy history
input. We revealed limitations of the existing
benchmark-based evaluation, by demonstrating
that it cannot reflect the models’ robustness to
such changes in setting. Inoltre, we proposed
evaluation practices that better isolate the contri-
bution of the history modeling component, E
demonstrated their usefulness.
We also discovered that highlighting historic
answers via passage embedding is very effective
in standard setups, but it suffers from substantial
performance degradation in low data and domain
shift settings. Following this finding, we design
a novel prompt-based history highlighting ap-
proach. We show that highlighting with prompts,
rather than with embeddings, significantly im-
prove robustness, while maintaining overall high
performance.
Our approach can be a good starting point for
future work, due to its high effectiveness, robust-
ness, and portability. We also hope that the insights
from our study will encourage evaluations with
focusonrobustness,leading to better CQA systems.
Ringraziamenti
We would like to thank the action editor and
the reviewers, as well as the members of the
IE@Technion NLP group and Roee Aharoni for
their valuable feedback and advice. The Technion
team was supported by the Zuckerman Fund to the
Technion Artificial Intelligence Hub (Tech.AI).
This research was also supported in part by a
grant from Google.
Riferimenti
Vaibhav Adlakha, Shehzaad Dhuliawala, Kaheer
Suleman, Harm de Vries, and Siva Reddy.
2022. Topiocqa: Open-domain conversational
question answering with topic switching. Trans-
actions of the Association for Computational
https://doi
Linguistica,
.org/10.1162/tacl_a_00471
10:468–483.
363
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
T
l
UN
C
_
UN
_
0
0
5
4
9
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Armen Aghajanyan, Dmytro Okhonko, Mike
Lewis, Mandar Joshi, Hu Xu, Gargi Ghosh,
e Luke Zettlemoyer. 2022. HTLM: Hyper-
text pre-training and prompting of language
models. In International Conference on Learn-
ing Representations.
Raviteja Anantha, Svitlana Vakulenko, Zhucheng
Tu, Shayne Longpre, Stephen Pulman, E
Srinivas Chappidi. 2021. Open-domain ques-
tion answering goes conversational via ques-
tion rewriting. Negli Atti di
IL 2021
Conference of
the North American Chap-
the Association for Computational
ter of
Linguistica: Tecnologie del linguaggio umano,
NAACL-HLT 2021, Online, June 6–11, 2021,
pages 520–534. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/2021.naacl-main.44
Iz Beltagy, Matthew E. Peters, and Arman
Cohan. 2020. Longformer: The long-document
transformer. CoRR, abs/2004.05150.
Eyal Ben-David, Nadav Oved, and Roi Reichart.
2022. PADA: Example-based prompt learning
for on-the-fly adaptation to unseen domains.
Transactions of the Association for Computatio-
nal Linguistics, 10:414–433. https://doi
.org/10.1162/tacl_a_00468
Tom Brown, Benjamin Mann, Nick Ryder,
Melanie Subbiah, Jared D. Kaplan, Prafulla
Dhariwal, Arvind Neelakantan, Pranav Shyam,
Girish Sastry, Amanda Askell, Sandhini
Agarwal, Ariel Herbert-Voss, Gretchen
Krueger, Tom Henighan, Rewon Child, Aditya
Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens
Inverno, Chris Hesse, Mark Chen, Eric
Sigler, Mateusz Litwin, Scott Gray, Benjamin
Chess, Jack Clark, Christopher Berner, Sam
McCandlish, Alec Radford, Ilya Sutskever,
and Dario Amodei. 2020. Language models
are few-shot learners. In Advances in Neural
Information Processing Systems, volume 33,
pages 1877–1901. Curran Associates, Inc.
Jon Ander Campos, Arantxa Otegi, Aitor Soroa,
Jan Deriu, Mark Cieliebak, and Eneko Agirre.
2020. Doqa – accessing domain-specific faqs
via conversational QA. Negli Atti del
58esima Assemblea Annuale dell'Associazione per
Linguistica computazionale, ACL 2020, Online,
July 5–10, 2020, pages 7302–7314. Association
for Computational Linguistics.
Yu Chen, Lingfei Wu, and Mohammed J. Zaki.
2020. Graphflow: Exploiting conversation flow
with graph neural networks for conversational
machine comprehension. Negli Atti di
the Twenty-Ninth International Joint Confer-
ence on Artificial Intelligence, IJCAI 2020,
ijcai.org. https://doi
pages 1230–1236.
.org/10.24963/ijcai.2020/171
Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar,
Wen-tau Yih, Yejin Choi, Percy Liang, E
Luke Zettlemoyer. 2018. Quac: Question an-
swering in context. Negli Atti di
IL
2018 Conference on Empirical Methods in
Elaborazione del linguaggio naturale, Brussels, Bel-
gium, ottobre 31 – November 4, 2018,
pages 2174–2184. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/D18-1241
Rotem Dror, Gili Baumer, Segev Shlomov, E
Roi Reichart. 2018. The hitchhiker’s guide
to testing statistical significance in natural
language processing. Negli Atti di
IL
56esima Assemblea Annuale dell'Associazione per
Linguistica computazionale, ACL 2018, Mel-
bourne, Australia, July 15–20, 2018, Volume 1:
Documenti lunghi, pages 1383–1392. Associazione per
Linguistica computazionale. https://doi
.org/10.18653/v1/P18-1128
Rotem Dror, Lotem Peled-Cohen,
Segev
Shlomov, and Roi Reichart. 2020. Statisti-
cal Significance Testing for Natural Language
in lavorazione. Synthesis Lectures on Human
Language Technologies. Morgan & Claypool
Publishers. https://doi.org/10.1007
/978-3-031-02174-9
A
rewrite
Ahmed Elgohary, Denis Peskov, and Jordan L.
Boyd-Graber. 2019. Can you unpack that?
questions-in-context.
Apprendimento
IL 2019 Conference on
Negli Atti di
Empirical Methods
in Natural Language
Processing and the 9th International Joint
Conferenza sull'elaborazione del linguaggio naturale,
EMNLP-IJCNLP 2019, Hong Kong, China,
November 3–7, 2019, pages 5917–5923.
Associazione per la Linguistica Computazionale.
https://doi.org/10.18653/v1/D19
-1605
Somil Gupta, Bhanu Pratap Singh Rawat,
and Hong Yu. 2020. Conversational ma-
chine comprehension: A literature review. In
364
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
T
l
UN
C
_
UN
_
0
0
5
4
9
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Proceedings of the 28th International Confer-
ence on Computational Linguistics, COLING
2020, Barcelona, Spain (Online), Dicembre
8–13,
Interna-
tional Committee on Computational Linguis-
tic. https://doi.org/10.18653/v1
/2020.coling-main.247
2739–2753.
pagine
2020,
Hsin-Yuan Huang, Eunsol Choi, and Wen-tau
Yih. 2019. Flowqa: Grasping flow in history
for conversational machine comprehension. In
7th International Conference on Learning Rep-
resentations, ICLR 2019, New Orleans, LA,
USA, May 6–9, 2019. OpenReview.net.
Gangwoo Kim, Hyunjae Kim, Jungsoo Park, E
Jaewoo Kang. 2021. Learn to resolve conver-
sational dependency: A consistency training
framework for conversational question an-
swering. In Proceedings of the 59th Annual
Riunione dell'Associazione per il Computazionale
Linguistics and the 11th International Joint
Conference on Natural Language Process-
ing, ACL/IJCNLP 2021,
(Volume 1: Lungo
Carte), Virtual Event, August 1–6, 2021,
pages 6130–6141. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/2021.acl-long.478
Diederik P. Kingma and Jimmy Ba. 2015. Adam:
A method for stochastic optimization. In 3rd
International Conference on Learning Repre-
sentations, ICLR 2015, San Diego, CA, USA,
May 7–9, 2015, Conference Track Proceedings.
Teven Le Scao and Alexander Rush. 2021.
How many data points is a prompt worth?
IL 2021 Conference of
Negli Atti di
the North American Chapter of the Associ-
ation for Computational Linguistics: Umano
Language Technologies, pages 2627–2636,
Online. Association for Computational Linguis-
tic. https://doi.org/10.18653/v1
/2021.naacl-main.208
Huihan Li, Tianyu Gao, Manan Goenka, E
Danqi Chen. 2022. Ditch the gold stan-
dard: Re-evaluating conversational question
answering. In Proceedings of the 60th Annual
Riunione dell'Associazione per il Computazionale
Linguistica (Volume 1: Documenti lunghi), ACL
2022, Dublin,
Ireland, May 22–27, 2022,
pages 8074–8085. Associazione per il calcolo-
linguistica nazionale. https://doi.org/10
.18653/v1/2022.acl-long.555
365
Sheng-Chieh Lin, Jheng-Hong Yang, Rodrigo
Nogueira, Ming-Feng Tsai, Chuan-Ju Wang,
and Jimmy Lin. 2020. Conversational question
reformulation via sequence-to-sequence archi-
tectures and pretrained language models. CoRR,
abs/2004.01909.
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao
Jiang, Hiroaki Hayashi, and Graham Neubig.
2021. Pre-train, prompt, and predict: A system-
atic survey of prompting methods in natural
language processing. CoRR, abs/2107.13586.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei
Du, Mandar Joshi, Danqi Chen, Omer Levy,
Mike Lewis, Luke Zettlemoyer, and Veselin
Stoyanov. 2019. RoBERTa: A robustly op-
timized BERT pretraining approach. CoRR,
abs/1907.11692.
Ilya Loshchilov and Frank Hutter. 2019. De-
coupled weight decay regularization. In 7th
International Conference on Learning Repre-
sentations, ICLR 2019, New Orleans, LA, USA,
May 6–9, 2019. OpenReview.net.
Jin Qian, Bowei Zou, Mengxing Dong, Xiao
Li, AiTi Aw, and Yu Hong. 2022. Capturing
conversational interaction for question answer-
ing via global history reasoning. In Findings
Di
the Association for Computational Lin-
guistics: NAACL 2022, Seattle, WA, United
States, July 10–15, 2022, pages 2071–2078.
for Computational Linguis-
Association
tic. https://doi.org/10.18653/v1
/2022.findings-naacl.159
Chen Qu, Liu Yang, Cen-Chieh Chen, Minghui
Qiu, W. Bruce Croft, and Mohit Iyyer. 2020.
Open-retrieval conversational question answer-
ing. Proceedings of
the 43rd International
ACM SIGIR Conference on Research and
Development in Information Retrieval.
Chen Qu, Liu Yang, Minghui Qiu, W. Bruce Croft,
Yongfeng Zhang, and Mohit Iyyer. 2019UN.
BERT with history answer embedding for con-
versational question answering. Negli Atti
of the 42nd International ACM SIGIR Confe-
rence on Research and Development in Infor-
mation Retrieval, SIGIR 2019, Paris, France,
July 21–25, 2019, pages 1133–1136. ACM.
Chen Qu, Liu Yang, Minghui Qiu, Yongfeng
Zhang, Cen Chen, W. Bruce Croft, and Mohit
Iyyer. 2019B. Attentive history selection for
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
T
l
UN
C
_
UN
_
0
0
5
4
9
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
conversational question answering. In Procedi-
ings of the 28th ACM International Conference
on Information and Knowledge Management,
CIKM 2019, Beijing, China, November 3–7,
2019, pages 1391–1400. ACM.
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, Michael
Matena, Yanqi Zhou, Wei Li, and Peter J.
Liu. 2020. Exploring the limits of transfer
learning with a unified text-to-text
trans-
former. Journal of Machine Learning Research,
21:140:1–140:67.
Pranav Rajpurkar, Robin Jia, and Percy Liang.
2018. Know what you don’t know: Unanswer-
able questions for squad. Negli Atti di
the 56th Annual Meeting of the Association
for Computational Linguistics, ACL 2018, Mel-
bourne, Australia, July 15–20, 2018, Volume 2:
Short Papers, pages 784–789. Associazione per
Linguistica computazionale. https://doi
.org/10.18653/v1/P18-2124
Pranav Rajpurkar,
testo.
Negli Atti di
Jian Zhang, Konstantin
Lopyrev, and Percy Liang. 2016. Squad:
100, 000+ questions for machine compre-
IL
hension of
2016 Conference on Empirical Methods in
Elaborazione del linguaggio naturale, EMNLP 2016,
Austin, Texas, USA, November 1–4, 2016,
pagine
for
Linguistica computazionale. https://doi
.org/10.18653/v1/D16-1264
2383–2392. The Association
Siva Reddy, Danqi Chen, e Christopher D.
Equipaggio. 2019. Coqa: A conversational ques-
tion answering challenge. Transactions of
the Association for Computational Linguistics,
7:249–266. https://doi.org/10.1162
/tacl_a_00266
Svitlana Vakulenko, Shayne Longpre, Zhucheng
Tu, and Raviteja Anantha. 2021. Question
rewriting for conversational question answer-
ing. In WSDM ’21, The Fourteenth ACM
International Conference on Web Search and
Data Mining, Virtual Event, Israel, Marzo
8–12, 2021, pages 355–363. ACM.
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N. Gomez,
Lukasz Kaiser, and Illia Polosukhin. 2017. A-
tention is all you need. In Advances in Neural
Information Processing Systems 30: Annual
Conference on Neural Information Processing
366
Sistemi 2017, December 4–9, 2017, Lungo
Beach, CA, USA, pages 5998–6008.
Thomas Wolf, Lysandre Debut, Victor Sanh,
Julien Chaumond, Clement Delangue, Anthony
Moi, Pierric Cistac, Tim Rault, Remi Louf,
Morgan Funtowicz, Joe Davison, Sam Shleifer,
Patrick von Platen, Clara Ma, Yacine Jernite,
Julien Plu, Canwen Xu, Teven Le Scao,
Sylvain Gugger, Mariama Drame, Quentin
Lhoest, and Alexander Rush. 2020. Trans-
formers: State-of-the-art natural
lingua
processing. Negli Atti del 2020 Contro-
ference on Empirical Methods in Natural
Language Processing: System Demonstrations,
pages 38–45, Online. Association for Compu-
linguistica nazionale. https://doi.org/10
.18653/v1/2020.emnlp-demos.6
Yi-Ting Yeh and Yun-Nung Chen. 2019.
Flowdelta: Modeling flow information gain in
reasoning for conversational machine compre-
hension. In Proceedings of the 2nd Workshop
on Machine Reading for Question Answering,
MRQA@EMNLP 2019, Hong Kong, China,
novembre 4, 2019, pages 86–90. Association
for Computational Linguistics.
Manzil Zaheer, Guru Guruganesh, Kumar
Avinava Dubey, Joshua Ainslie, Chris Alberti,
Santiago Onta˜n´on, Philip Pham, Anirudh
Ravula, Qifan Wang, Li Yang, and Amr Ahmed.
2020. Big bird: Transformers for longer se-
quences. In Advances in Neural Information
Processing Systems 33: Annual Conference
on Neural
Information Processing Systems
2020, NeurIPS 2020, December 6–12, 2020,
virtual.
Jing Zhao, Junwei Bao, Yifan Wang, Yongwei
Zhou, Youzheng Wu, Xiaodong He, and Bowen
Zhou. 2021. Ror: Read-over-read for long
document machine reading comprehension.
In Findings of
the Association for Compu-
linguistica nazionale: EMNLP 2021, Virtual
Event
/ Punta Cana, Dominican Republic,
16–20 November, 2021, pages 1862–1872.
Association
for Computational Linguis-
tic. https://doi.org/10.18653/v1
/2021.findings-emnlp.160
Chenguang Zhu, Michael Zeng, and Xuedong
Huang. 2018. Sdnet: Contextualized attention-
based deep network for conversational question
answering. CoRR, abs/1812.03593.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
5
4
9
2
1
4
5
1
9
9
/
/
T
l
UN
C
_
UN
_
0
0
5
4
9
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3