Morphology Matters: A Multilingual Language Modeling Analysis
Hyunji Hayley Park
University of Illinois
hpark129@illinois.edu
Katherine J. Zhang
Carnegie Mellon University
kjzhang@cmu.edu
Coleman Haley
Johns Hopkins University
chaley7@jhu.edu
Kenneth Steimel
Indiana University
ksteimel@iu.edu
Han Liu
University of Chicago∗
hanliu@uchicago.edu
Lane Schwartz
University of Illinois
lanes@illinois.edu
Astratto
Prior studies in multilingual language model-
ing (per esempio., Cotterell et al., 2018; Mielke et al.,
2019) disagree on whether or not inflectional
morphology makes languages harder to model.
We attempt to resolve the disagreement and
extend those studies. We compile a larger
corpus of 145 Bible translations in 92 lan-
guages and a larger number of typological
features.1 We fill in missing typological data
for several languages and consider corpus-
based measures of morphological complexity
in addition to expert-produced typological
caratteristiche. We find that several morphological
measures are significantly associated with
higher surprisal when LSTM models are
trained with BPE-segmented data. We also
investigate linguistically motivated subword
segmentation strategies like Morfessor and
Finite-State Transducers (FSTs) and find that
these segmentation strategies yield better
performance and reduce the impact of a lan-
guage’s morphology on language modeling.
1
introduzione
With most research in Natural Language Pro-
cessazione (PNL) directed at a small subset of the
world’s languages, whether the techniques devel-
oped are truly language-agnostic is often not
known. Because the vast majority of research fo-
cuses on English, with Chinese a distant second
(Mielke, 2016), neither of which is morphologi-
cally rich, the impact of morphology on NLP tasks
for various languages is not entirely understood.
Several studies have investigated this issue in
the context of language modeling by comparing a
∗Work done while at University of Colorado Boulder.
1https://github.com/hayleypark
/MorphologyMatters.
261
number of languages, but found conflicting results.
Gerz et al. (2018) and Cotterell et al. (2018)
find that morphological complexity is predictive
of language modeling difficulty, while Mielke
et al. (2019) conclude that simple statistics of a
text like the number of types explain differences
in modeling difficulty, rather than morphological
measures.
This paper revisits this issue by increasing the
number of languages considered and augmenting
the kind and number of morphological features
used. We train language models for 92 languages
IL
from a corpus of Bibles fully aligned at
verse level and measure language modeling
performance using surprisal (the negative log-
likelihood) per verse (see §4.5). We investigate
how this measure is correlated with 12 linguist-
generated morphological features and four corpus-
based measures of morphological complexity.
Additionally, we contend that the relation be-
tween segmentation method, morphology, E
language modeling performance needs further
investigation. Byte-Pair Encoding (BPE; Shibata
et al., 1999) is widely used in NLP tasks including
machine translation (Sennrich et al., 2016) COME
an unsupervised information-theoretic method for
segmenting text data into subword units. Variants
of BPE or closely related methods such as
WordPiece (Kudo, 2018) are frequently used by
state-of-the-art pretrained language models (Liu
et al., 2019; Radford et al., 2019; Devlin et al.,
2019; Yang et al., 2019). Tuttavia, BPE and other
segmentation methods may vary in how closely
they capture morphological segments for a given
lingua, which may affect language modeling
performance.
Therefore, this paper focuses on the following
two research questions:
1. Does a language’s morphology influence
language modeling difficulty?
Operazioni dell'Associazione per la Linguistica Computazionale, vol. 9, pag. 261–276, 2021. https://doi.org/10.1162/tacl a 00365
Redattore di azioni: Richard Sproat. Lotto di invio: 8/2020; Lotto di revisione: 11/2020; Pubblicato 3/2021.
C(cid:3) 2021 Associazione per la Linguistica Computazionale. Distribuito sotto CC-BY 4.0 licenza.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
T
l
UN
C
_
UN
_
0
0
3
6
5
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
2. If so, how do different segmentation methods
interact with morphology?
In order to answer the first question, we
train models using data sets segmented by
characters and BPE units. Our results show that
BPE language modeling surprisal is significantly
correlated with measures of morphological
typology and complexity. This suggests that BPE
segments are ineffective in mitigating the effect
of morphology in language modeling.
As for the second question, we consider more
linguistically motivated segmentation methods to
compare with BPE: Morfessor (Creutz and Lagus,
2007) and Finite-State Transducers (FSTs) (Vedere
§4.3). Our comparison of the models using the
different segmentation methods shows that Mor-
fessor reduces the impact of morphology for
more languages than BPE. FST-based segmen-
tation methods outperform the other segmentation
methods when available. These results suggest
that morphologically motivated segmentations
improve cross-linguistic language modeling.
2 Modeling Difficulty Across Languages
Studies have demonstrated that different
lan-
guages may be unequally difficult to model and
have tested the relations between such modeling
difficulty and morphological properties of lan-
guages, using different segmentation methods.
Vania and Lopez (2017) compared the effec-
tiveness of word representations based on different
segmentation methods in modeling 10 languages
with various morphological
typologies. They
trained word-level language models, but utilized
segmentation methods to create word embeddings
that included segment-level information. Compar-
ing character, BPE, and Morfessor segmentations,
they concluded that character-based representa-
tions were most effective across languages, con
BPE always outperforming Morfessor. Tuttavia,
models based on hand-crafted morphological
analyses outperformed all other segmentation
methods by a wide margin.
Gerz et al. (2018) trained n-gram and neural
language models over 50 languages and argued
that the type of morphological system is predictive
of model performance. Their results show that lan-
guages differ with regard to modeling difficulty.
They attributed the differences among languages
to four types of morphological systems: isolating,
fusional, introflexive, and agglutinative. While
they found a significant association between
the morphological type and modeling difficulty,
Type-Token Ratio (TTR) was the most predictive
of language modeling performance.
Cotterell et al. (2018) arrived at a similar con-
clusion modeling 21 languages using the Europarl
corpus (Koehn, 2005). When trained with n-gram
and character-based Long Short-Term Memory
(LSTM) models, the languages showed differ-
ent modeling difficulties, which were correlated
with a measure of morphology, Morphological
Counting Complexity (MCC) or the number of
inflectional categories (Sagot, 2013).
Tuttavia, Mielke et al. (2019) failed to repro-
duce the correlation with MCC when they in-
creased the scope to 69 languages, utilizing a Bible
corpus (Mayer and Cysouw, 2014). They also
reported no correlation with measures of morpho-
syntactic complexity such as head-POS entropy
(Dehouck and Denis, 2018) and other linguist-
generated features (Dryer and Haspelmath, 2013).
Piuttosto, they found that simpler statistics, namely,
the number of types and number of characters
per word, correlate with language model sur-
prisal using BPE and character segmentation,
rispettivamente.
3 Morphological Measures
Different measures of morphology are used to
represent a language’s morphology.
3.1 Linguist-generated Measures
The most
linguistically informed measures of
morphology involve expert descriptions of lan-
guages. The World Atlas of Language Structures
(WALS; Dryer and Haspelmath, 2013) has been
used frequently in the literature to provide typo-
logical information. WALS is a large database of
linguistic features gathered from descriptive mate-
rials, such as reference grammars. It contains 144
chapters in 11 areas including phonology, mor-
phology, and word order. Each chapter describes a
feature with categorical values and lists languages
that have each value. Tuttavia, not all languages
in the database have data for all the features, E
for some languages there is no data at all.
The studies reviewed in §2 all relied on this
expert-description approach to quantify morpho-
logical properties. Gerz et al. (2018) focused
on WALS descriptions of inflectional synthe-
sis of verbs, fusion, exponence, and flexivity,
262
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
T
l
UN
C
_
UN
_
0
0
3
6
5
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
while Mielke et al. (2019) looked at two WALS
caratteristiche, 26A ‘‘Prefixing vs. Suffixing in Inflec-
tional Morphology’’ and 81A ‘‘Order of Subject,
Object and Verb.’’ Cotterell et al. (2018) used
UniMorph (Kirov et al., 2018), instead of WALS,
to calculate MCC. Vania and Lopez (2017) did
not cite any databases but provided descriptions
of four morphological types (fusional, aggluti-
native, root-and-pattern, and reduplication) E
categorized 10 languages into these types.
A major issue with this approach to representing
morphology is that there is not enough expert
data available to enable comparisons across many
different languages. Infatti, Mielke et al. (2019)
chose their two WALS features because data for
these features existed for most of their languages.
Inoltre, Bentz et al. (2016) showed that their
WALS-based measure had lower correlations
with other measures of morphological complexity
due to this issue of missing data.
3.2 Corpus-based Measures
In contrasto, corpus-based measures of morphology
can be easily calculated on a given data set.
These measures include the number of types, TTR,
Moving-Average TTR (MATTR; Covington and
McFall, 2010), and Mean Length of Words
(MLW). The exact definition of the measures
may vary depending on studies, but we define
them as in Table 1, where a word token is a
string separated by spaces in the training set after
tokenization but before segmentation.
While some studies (per esempio., Mielke et al., 2019)
consider these measures as simple statistics of
a corpus, other studies have found that they can be
used as approximate measures of morphological
complexity. Kettunen (2014) showed that TTR,
MATTR, and MLW can capture the overall rank-
ing of morphological complexity generated by
information-theoretic and expert-generated mea-
sures of morphological complexity. Bentz et al.
(2016) compared different measures of mor-
phological complexity for 519 languages across
101 families and showed a strong correlation
between all measures, which were based on cor-
pus statistics,
informazione
linguistic expertise,
theory, and translation alignment. They argued
that corpus-based measures, including TTR, E
other measures of morphological complexity can
be used interchangeably. Inoltre, Gerz et al.
Measure
Types
TTR
MATTR
MLW
Definition
Number of unique word tokens
Number of unique word tokens divided by total
number of word tokens
Average TTR calculated over a moving window
Di 500 word tokens
Average number of characters per word token
Tavolo 1: Corpus-based measures of morphology
this study. These measures are
defined for
calculated on tokenized data sets before applying
any segmentation method.
(2018) showed that TTR is influenced by the mor-
phological typology of a language. According to
them, isolating languages tend to have small TTR
values and are often easier to model while the
opposite is true for agglutinative languages.
Given the previous
literature, we utilize
these corpus-based measures, as well as expert-
generated WALS features, as a proxy for mor-
phological differences among languages in our
study.
4 Methods
We design our experiments to test whether a lan-
guage’s morphology is correlated with language
model performance, depending on the segmenta-
tion method. We represent a language’s morpho-
logy using WALS features and corpus statistics.
We train language models for Bible translations
In 92 languages based on five different segmenta-
tion methods: character, BPE, Morfessor, and FST
with BPE or Morfessor back-off strategies (FST
+BPE & FST+Morfessor). We use surprisal per
verse (Mielke et al., 2019) as the evaluation
metric to compare language modeling perfor-
mance across different languages and different
segmentation methods. Additionally, we quan-
tify the difference in surprisal per verse between
segmentation methods to compare the relative
strength of each segmentation method with regard
to morphological complexity.
4.1 Data
Our data consist of 145 Bible translations in 92
languages covering 22 language families,2 fully
2For each language, we report the family assigned by
WALS (Dryer and Haspelmath, 2013): 6 Afro-Asiatic,
1 Algic, 1 Altaic, 2 Austro-Asiatic, 6 Austronesian, 1
Aymaran, 3 Dravidian, 4 Eskimo-Aleut, 1 Guaicuruan, 33
Indo-European, 1 Japanese, 1 Korean, 1 Mande, 6 Mayan,
263
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
T
l
UN
C
_
UN
_
0
0
3
6
5
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
aligned at the verse level. The majority of the
data came verse-aligned from Mielke et al. (2019)
(original data from Mayer and Cysouw, 2014).
We added more Bibles from another corpus
(Christodoulopoulos and Steedman, 2014) E
from online Bible resources (see Appendix A
for more information). We refer to each language
by ISO 639-3 code when applicable.
We followed Mielke et al.’s (2019) method to
split the data into training, development, and test
sets: The verse-aligned data were divided into
blocks of 30 verses, with the first five verses
being assigned to the development set, il prossimo
five to the test set and the rest to the training set.
The resulting training set had 16,926 verses while
development and test sets had 4,225 verses each.
It should be noted that both Mielke et al. (2019)
and Christodoulopoulos and Steedman (2014)
provided tokenized data. We tokenized the
newly added Bibles using Mielke and Eisner’s
(2019) tokenizer, following Mielke et al. (2019).
When both tokenized and untokenized versions
were available, we included the tokenized versions
only.
We chose to replace characters that only
occurred one time with a special UNK symbol.
Mielke et al. (2019) applied this procedure to
characters that appear less than 25 times in
the training set except for Chinese, where only
singleton characters were replaced. Because we
added several
languages where the original
strategy would have resulted in removing too
much data, we preprocessed singleton characters
across the board.
We also corrected several errors present in the
dati. Per esempio, the Bible translations in Shona
(sna) and Telugu (tel) were mis-coded as Shan
(shn) and Tecpatl`an Totonac (tcw), rispettivamente.
4.2 Morphological Measures Selected
in questo documento, we adopt
two approaches to
representing a language’s morphology. Primo, we
rely on expert descriptions of languages in WALS,
manually augmenting the database to rectify
the issue of missing data. Secondo, we utilize
corpus-based measures like TTR to represent the
morphological complexity of a given language.
WALS Features While some previous studies
(per esempio., Gerz et al., 2018; Vania and Lopez, 2017)
6 Niger-Congo, 4 Quechuan, 5 Sino-Tibetan, 1 Songhay, 1
Tai-Kadai, 2 Tupian, 2 Uralic, 2 Uto-Aztecan, 2 Creoles.
categorized relatively well-known languages into
a small number of morphological types, come
categorization is not always clear. Some other
studies (per esempio., Cotterell et al., 2018; Mielke et al.,
2019) selected a small number of available typo-
logical features to compare, but their conclusions
were at odds, possibly calling for exploration
of other measures. Therefore, we consider all
available morphological features described by
WALS to explore which features affect language
modeling and how. Instead of making theoretical
claims about morphological typology, we explore
which typological features make a language’s
morphology more complex for LSTM language
models.
To that end, we augmented the existing WALS
database by consulting reference grammars for
each language. Of the 92 languages in our corpus,
six were not in the WALS database.3 In addition,
many of the languages in the database had missing
data for some features. Per esempio, we had no
data for any of the morphological features of
Afrikaans (afr). We manually assigned missing
features where possible following the descriptions
in the relevant WALS chapters regarding the
procedures used to assign feature values to
languages.
IL
Of the almost 200 features in WALS,
editors of the database labeled 12 of them as
morphological features. Therefore, we considered
these 12 caratteristiche, listed in Table 2 and described
below,4 to test the hypothesis that morphological
complexity correlates with modeling difficulty.
Feature 20A describes how closely grammatical
markers (inflectional formatives) are phonologi-
cally connected to a host word or stem. IL
markers can be isolating, concatenative, or even
nonlinear (cioè., ablaut and tone).
Features 21A and 21B measure the exponence
of selected grammatical markers. Exponence
refers to the number of categories that a single
morpheme expresses. For 21A, the selected gram-
matical markers were case markers. For 21B, Essi
were tense-aspect-mood markers.
Feature 22A measures how many grammatical
categories may appear on verbs in a language.
These categories include tense-aspect-mood, ne-
gation, voice, and agreement.
3ikt, lat, nch, tbz, wbm, zom.
4See https://wals.info/chapter for more
details and examples of these features.
264
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
T
l
UN
C
_
UN
_
0
0
3
6
5
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
ID
20UN
21UN
21B
22UN
23UN
24UN
25UN
25B
26UN
27UN
28UN
29UN
Nome
Fusion of Selected Inflectional Formatives
Exponence of Selected Inflectional Formatives
Exponence of Tense-Aspect-Mood Inflection
Inflectional Synthesis of the Verb
Locus of Marking in the Clause
Locus of Marking in Possessive Noun Phrases
Locus of Marking: Whole-language Typology
Zero Marking of A and P Arguments
Prefixing vs. Suffixing in Inflectional Morphology
Reduplication
Case Syncretism
Syncretism in Verbal Person/Number Marking
Tavolo 2: IL 12 morphological features in WALS.
Features 23A through 25B describe the exis-
tence and locus of marking in different kinds of
frasi. A phrase may have marking on either
its head, its dependent(S), both, or neither. In full
clauses, the verb is the head, and the subject and
object arguments are dependents. In possessive
noun phrases, the possessed noun is the head
while the possessor is dependent.
Feature 26A measures the degree to which
languages use prefixes versus suffixes in their
inflectional morphology. Feature 27A describes
which languages use
reduplication produc-
tively and whether or not both full and partial
reduplication are used.
Both Features 28A and 29A measure syn-
cretism. Syncretism occurs when a single inflected
form corresponds to more than one function. 28UN
measures case syncretism specifically while 29A
measures syncretism in the subject agreement
marking of verbs.
Types, TTR, MATTR, and MLW We cal-
culated the number of types, TTR, MATTR, E
MLW using an adapted script from the Python
module LexicalRichness.5 We used a window size
Di 500 for MATTR, following previous studies
(per esempio., Kettunen, 2014). The definitions of the
measures are found in Table 1. All measures were
calculated based on the word tokens in the training
set before applying any segmentation method.
4.3 Segmentation Methods
We chose to train only open-vocabulary lan-
guage models for fair comparison. Word-level
models will predict UNK for out-of-vocabulary
word tokens and cannot be fairly compared with
character- and subword-level models as a result.
Specifically, we trained language models using
five segmentation methods: character, BPE, Mor-
fessor, FST+BPE, and FST+Morfessor. These
segmentation methods provide a way to segment
any given text into smaller pieces, some of which
approximate morphemes.
A morpheme is the smallest meaning-bearing
morphological unit while a morph is the surface
representation of one or more morphemes. Lin-
guistically motivated methods like Morfessor and
FSTs are designed with the goal of producing sub-
word segments that are closely aligned to the true
morphs constituting a word. While BPE was not
designed with morpheme segmentation in mind,
its resulting subwords are commonly believed to
align with morphs to some degree due to morph
subsequences being frequent in the data.
Segmenting words into morphs may reduce the
impact of rich morphology as highly inflected
words can be broken into smaller pieces that are
likely to contribute similar meanings across con-
texts in the corpus. Tavolo 3 provides examples of
the segmentation methods we used to train lan-
guage models. The original verse is provided for
reference only and was not used to train any
models.
Character We trained character-based lan-
guage models, following previous studies (Mielke
et al., 2019; Gerz et al., 2018; Cotterell et al.,
2018). Character language models are trained to
predict the next character given the preceding con-
testo, and the vocabulary includes an underscore
(cid:4) (cid:5) to denote word boundaries.
BPE We trained BPE-based language models,
following Mielke et al. (2019). Starting with
character segmentation, BPE operations combine
characters into larger chunks based on their
frequencies to create units somewhere between
characters and words with the number of merge
operations as the hyperparameter (Sennrich et al.,
2016). We used 0.4 × types as the number of
merges, as Mielke et al. (2019) reported that to be
most effective with their corpus.6 BPE language
models are trained to predict the next BPE unit.
The double at sign (cid:4)@@(cid:5) is used to indicate
segments that are not word-final.
6Additional static numbers of merge operations were also
5https://github.com/LSYS/LexicalRichness.
tested, with nearly identical results.
265
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
T
l
UN
C
_
UN
_
0
0
3
6
5
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Segmentation
Esempio
Yuhannanın kardes¸i Yakubu kılıc¸la ¨old¨urd¨u .
Tokenized
Y u h a n n a n ı n
Character
Yuhan@@ nanın kardes¸i Yakubu kılıc¸la ¨old¨urd¨u .
BPE
Yuhanna@@ nın kardes¸@@ i Yakub@@ u kılıc¸@@ la ¨old¨urd¨u .
Morfessor
Yuhan@@ nanın kardes¸@@ i Yakub@@ u kılıc¸@@ la ¨ol@@ d¨ur@@ d¨u .
FST+BPE
FST+Morfessor Yuhanna@@ nın kardes¸@@ i Yakub@@ u kılıc¸@@ la ¨ol@@ d¨ur@@ d¨u .
k a r d e s¸ i
Y a k u b u
k ı l ı c¸ l a
¨o l d ¨u r d ¨u .
Tavolo 3: Turkish examples for different segmentation methods. An English translation is ‘‘And he
killed James the brother of John with the sword’’ (Acts 12:2). FST does not produce analyses for
Yuhannanın (‘‘John’s’’), for which BPE or Morfessor back-off was used. The segmentation created
by human experts was the same as FST+Morfessor. (cid:4)@@(cid:5) denotes subword segmentation and (cid:4) (cid:5)
encodes space between word tokens for character segmentation.
Morfessor Morfessor (Creutz and Lagus, 2007)
is a word segmentation method explicitly designed
for morphological segmentation. The default im-
plementation utilizes a unigram language model
to find morph-like constructs. While like BPE
this approach is information-theoretic, it selects
segments top–down and includes a prior term for
the length of segments, regularizing segments to
be more plausible morphemes.
Using the default settings with Morfessor 2.0
(Virpioja et al., 2013), we trained Morfessor on
the training set and applied the segmentation to
all data sets. Just like BPE, the language models
are trained to predict the next morph unit.
FST Whereas segmentation based on BPE and
Morfessor may or may not resemble actual mor-
phemes, morpheme segmentation from FSTs
provides a knowledge-based method to segment
a text into morphemes. Finite-state morphologi-
cal analyzers are rule-based systems that take a
surface string as input and produce all possible
morphological analyses as output. To use FSTs for
segmentation, we changed existing morphological
analyzers into segmenters and developed a heuris-
tic to select one analysis for a given word token.
FSTs for Plains Cree (Arppe et al., 2014–2019),
German (Schmid et al., 2004), English (Axelson
et al., 2015), Finnish (Pirinen, 2015), Indonesian
(Larasati et al., 2011), Cuzco Quechua (Vilca
et al., 2012), and Turkish (C¸ ¨oltekin, 2014, 2010)
were used as morphological segmenters.
Most FSTs are designed to provide analyses for
surface forms, not morphological segmentations.
Fortunately, morpheme boundaries are frequently
part of FSTs due to their relevance for lexico-
phonological phenomena. By modifying the FST
before the cleanup rules that remove morpheme
boundaries can apply, we create a morphological
segmenter that takes in a surface form and re-
turns the surface form with morpheme boundary
markers. If the analyzer provides segmentations,
the transducer is used as-is.
Per esempio,
the Turkish FST produces a
morphological analysis for the surface form kılıc¸la
(‘‘with the sword’’) in the example in Table 3:
kılıc¸
stead of producing such an analysis for the given
word, the segmenter produces the segmented sur-
face form kılıc¸@@ la, which is used in the
FST segmentation methods.
Because a FST may return multiple analyses
or segmentations given a single word, a heuristic
method was used to determine which segmentation
to select. Generalmente, we chose the segmentation
with the fewest segments. Tuttavia, the English
segmenter based on Axelson et al. (2015) always
returns the input string itself as a possible segmen-
tation if covered by the analyzer. Per esempio,
walks would produce two segmentations in the
English segmenter: walks and walk@@ s. For
this segmenter, we selected the fewest number of
segments excluding the input string itself (per esempio.,
choosing walk@@ s over walks).
When a FST produces no analyses for a given
word, as in the case of Yuhannanın (John’s) In
Tavolo 3, we adopt the FST-augmented BPE seg-
mentation (FST+BPE) and FST-augmented Mor-
fessor segmentation (FST+Morfessor), dove noi
fall back to BPE or Morfessor segmentation when-
ever FST segmentation is unavailable. As shown
in the table, FST+BPE and FST+Morfessor
only differ in the segmentation of the unanalyzed
word. For this particular verse, the human segmen-
tation agrees with the FST+Morfessor segmen-
tazione. FST+BPE and FST+Morfessor models
are trained just like BPE or Morfessor models to
predict the next subword unit.
266
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
T
l
UN
C
_
UN
_
0
0
3
6
5
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
4.4 Modelli
5 Results
Following Mielke et al. (2019), we trained Long
Short-Term Memory (LSTM) models introduced
by Merity et al. (2018) for each of the seg-
mentation methods. Three LSTM models using
character, BPE, and Morfessor segmentation were
trained for all languages. For a select group of lan-
guages, we also trained models using FST+BPE
and FST+Morfessor units. The neural architec-
ture consisted of an initial embedding layer, mul-
tiple LSTM layers, and a linear decoder layer.
For our particular experiments, we adopted the
hyperparameters from Mielke et al. (2019) (Vedere
Merity et al., 2018, for their character PTB sett-
tings). The batch size used for character models
era 128 con 500 epochs of training. All other
models used a batch size of 40 and were trained
for 200 epochs.
4.5 Metrics
Surprisal per Verse One major evaluation
metric for
language models is the negative
log-likelihood on a test set. The negative log-
likelihood, or surprisal, is the amount of infor-
mation a language model needs to generate the
next unit. Following Mielke et al. (2019), we
define the surprisal at
the verse level, Dove
NLL (vij) = − log2 p(vij) with a verse vij (for
ith verse in language j). Because each verse is
intended to express the same meaning across lan-
guages, differences in per-verse surprisal across
languages primarily indicate differences in cross-
linguistic language model quality (piuttosto che
differences in meaning content).
For each language j, we average the negative
log-likelihood across the 4,225 verses in the test
(cid:2)
set, making Lj = 1
4225
4225
i=1 NLL (vij).
Surprisal Difference Additionally, we quantify
the difference between segmentation methods
in language modeling performance as shown in
Equazione 1. This quantity compares the relative
strength of one segmentation method to another.
ΔSj1,Sj2 =
Lj1 − Lj2
1
2 (Lj1 + Lj2)
(1)
Sj1 and Sj2 are two segmentation methods to
compare and Lj1 and Lj2 represent the surprisal
per verse for the language models based on the
two segmentation methods. If ΔSj1,Sj2 is positive,
Sj1 resulted in a higher surprisal than Sj2 and Sj2
was more effective in modeling a given language.
We now present results from our experiments.
We report the strong association between several
morphological features and surprisal per verse
for BPE language models, compared to language
models based on other segmentation methods.
Then, we show the trade offs between different
segmentation methods and how they interact with
morphological complexity. Our assumption is
Quello, if a segmentation method reduces the impact
of morphology, the surprisal values of language
models based on that segmentation will have
weaker correlations with measures of morphology.
5.1 Correlation Studies with Character and
BPE Models
We investigated correlations between surprisal per
verse and various measures of morphology (cioè.,
WALS features, number of types, TTR, MATTR,
MLW). Benjamini and Hochberg’s (1995) pro-
cedure was used to control the false discovery
rate, so only p ≤ 8
· 0.05 (≈ 0.027) is considered
15
significant.
WALS Features We tested for association
between surprisal and each selected WALS fea-
ture with the Kruskal–Wallis test, or one-way
ANOVA on ranks. This non-parametric test was
chosen because the distribution of surprisal values
did not meet the assumption of normality. UN
significant test result in this context means that
there are significant differences in the median
surprisal values between categories for a given
feature. In order for the test to be effective, only
feature values with a sample size ≥ 5 were tested.
For the character models, no features showed
significant association with surprisal. Tuttavia,
for the BPE models, half of the morphological
features had significant association with surprisal.
These features were 21A ‘‘Exponence of Selected
Inflectional Formatives,’’ 23A ‘‘Locus of Mark-
ing in the Clause,’’ 24A ‘‘Locus of Marking in
Possessive Noun Phrases,’’ 25A ‘‘Locus of Mark-
ing: Whole-language Typology,’’ 25B ‘‘Zero
Marking of A and P Arguments,’’ and 29A ‘‘Syn-
cretism in Verbal Person/Number Marking.’’
For the features shown to have an effect on
the BPE surprisal, we calculated the effect sizes
and performed post-hoc comparisons to determine
which categories were significantly different. In
this context, effect size (η2) indicates the propor-
tion of variance in surprisal per verse explained by
267
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
T
l
UN
C
_
UN
_
0
0
3
6
5
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Segmentation
BPE
Morfessor
ID
21UN
23UN
24UN
25UN
25B
29UN
21UN
23UN
26UN
29UN
p-value
1.3e-05
6.7e-06
2.2e-04
6.5e-05
0.014
2.0e-04
0.009
0.002
0.022
0.024
η2
0.28
0.28
0.228
0.253
0.06
0.198
0.109
0.135
0.064
0.072
Tavolo 4: p-values and effect sizes of WALS
features that showed significant effect on surprisal
per verse. Large effect sizes (≥ 0.14) are in bold.
each WALS feature, and η2 ≥ 0.14 is considered
a large effect (Tomczak and Tomczak, 2014).
The p-values and effect sizes are summarized in
Tavolo 4. The effect size was large for all of the
significant features except for 25B.
For Feature 21A, the median surprisal value for
languages with no case was significantly lower
than the median value for other types. Allo stesso modo,
for 23A, the median surprisal value for languages
with no marking was significantly lower than the
value for other types. In the cases of both 24A and
25UN, languages with double marking had higher
surprisal values than those with single or no mark-
ing. For 25B, languages with non-zero marking
had slightly higher surprisal values than those
with zero-marking. Lastly, for 29A, languages
without syncretism had higher surprisal values
than those with syncretism or with no marking.
Generalmente, less inflectional morphology was
associated with lower surprisal while more inflec-
tional morphology was associated with higher
surprisal.
Corpus-based Measures A similar
trend
emerged for corpus-based measures of mor-
phological complexity. The surprisal per verse
of BPE models was highly correlated with type
count, TTR, MATTR, and MLW. Yet with char-
acter models,
the strength of the correlation
was weak and often insignificant. These results
suggest that BPE segmentation was ineffective in
reducing the impact of morphological complexity.
Tavolo 5 summarizes the correlation coefficients
and corresponding p-values. For the character-
based models, only the number of types and
Segmentation
Measure
Character
BPE
Morfessor
Types
TTR
MATTR
MLW
Types
TTR
MATTR
MLW
Types
TTR
MATTR
MLW
Spearman’s ρ
0.19∗
0.15
0.17∗
0.06
0.80∗∗∗
0.76∗∗∗
0.68∗∗∗
0.61∗∗∗
0.50∗∗∗
0.44∗∗∗
0.39∗∗∗
0.30∗∗∗
Tavolo 5: Correlation between surprisal per verse
per segmentation method and morphological
complexity measures. ∗p < 0.027, ∗∗∗p < 0.0005.
MATTR showed a significant correlation in
Spearman’s rank-order correlation, and those
correlations were rather weak. In contrast, the
BPE models presented strong correlations with all
of the corpus-based measures at any reasonable
alpha value (p < 10−16). The number of types
showed the strongest correlation, followed by
TTR, MATTR, and MLW in that order.
5.2 Comparison with Morfessor and
Finite-State Transducer Models
We trained language models using three additional
segmentation methods: Morfessor, FST+BPE,
and FST+Morfessor. Because Morfessor is an
unsupervised method, we were able to utilize it
to segment all languages, but we were able to
generate FST segmentation for only a few lan-
guages. As such, we compare the character, BPE,
and Morfessor models for all languages before
looking into a subset of them where the FST
methods were available.
the majority of
Morfessor Models Morfessor
segmentation
performed better than both character and BPE
segmentation for
languages.
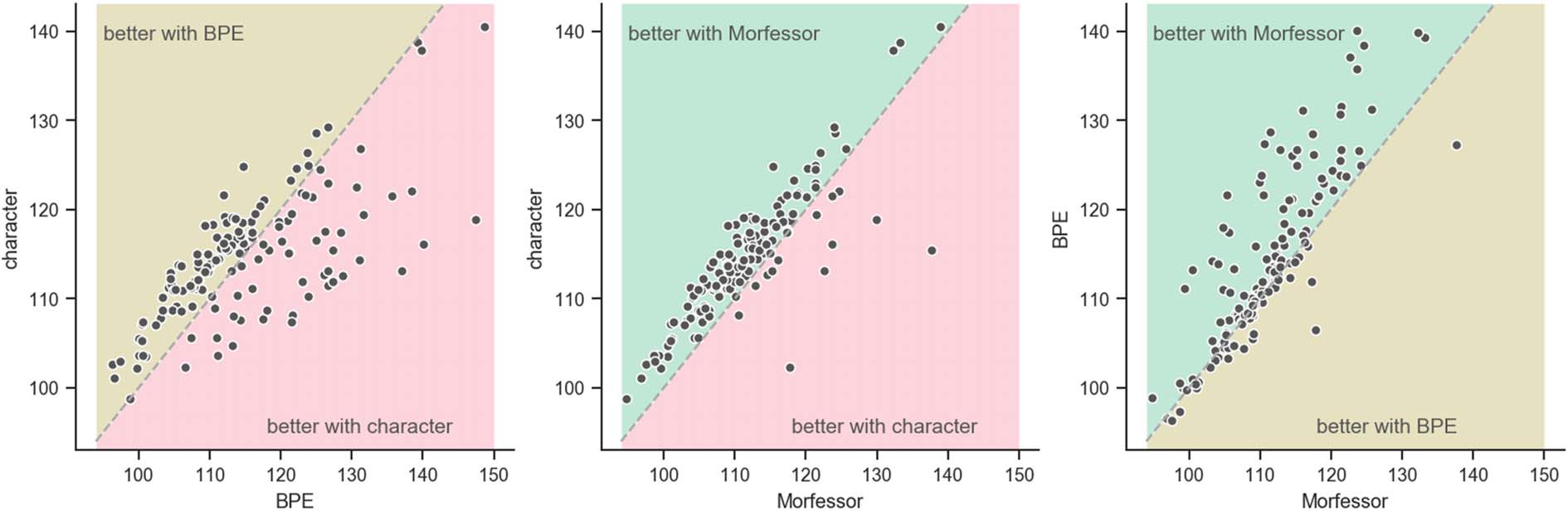
Figure 1 shows the pairwise comparisons of the
surprisal per verse values of a given language on
different segmentation strategies. As shown in the
plot on the left, the relative strength between BPE
and character segmentation methods is not clear.
BPE segmentation produced slightly better results
for 49 of the 92 languages, but character segmen-
tation produced much lower surprisal values for
268
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
t
l
a
c
_
a
_
0
0
3
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
t
l
a
c
_
a
_
0
0
3
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 1: Pairwise comparisons of surprisal per verse values for character, BPE, and Morfessor models. For the
majority of the languages, Morfessor segmentation resulted in lower surprisal per verse than character or BPE
segmentation.
the rest of the languages. In contrast, Morfessor
clearly outperformed character and BPE for most
of the languages, as shown in the plots in the
middle and on the right. Only 12 out of the 92
languages had higher surprisal values for Mor-
fessor segmentation than character, while a total
of 66 languages performed better with Morfessor
segmentation than with BPE.
In addition, Morfessor models’ surprisal per
verse showed weaker correlations with measures
of morphology. Only four WALS features showed
significant association with the Morfessor models:
21A ‘‘Exponence of Selected Inflectional Forma-
tives,’’ 23A ‘‘Locus of Marking in the Clause,’’
26A ‘‘Prefixing vs. Suffixing in Inflectional
Morphology,’’ and 29A ‘‘Syncretism in Verbal
Person/Number Marking.’’ The effect sizes were
also much smaller than those for the BPE models
as shown in Table 4.
Just as with the BPE models, the median sur-
prisal for languages with no marking was much
lower than the surprisal for other types for Fea-
tures 21A, 23A, and 29A. For 26A, there was only
a significant difference between weakly suffix-
ing languages and strongly prefixing languages,
with strongly prefixing languages having a lower
median surprisal per verse.
As shown in Table 5, corpus-based statistics still
showed significant correlations with the surprisal
per verse value of Morfessor models, but the
correlations were moderate compared to those of
the BPE models.
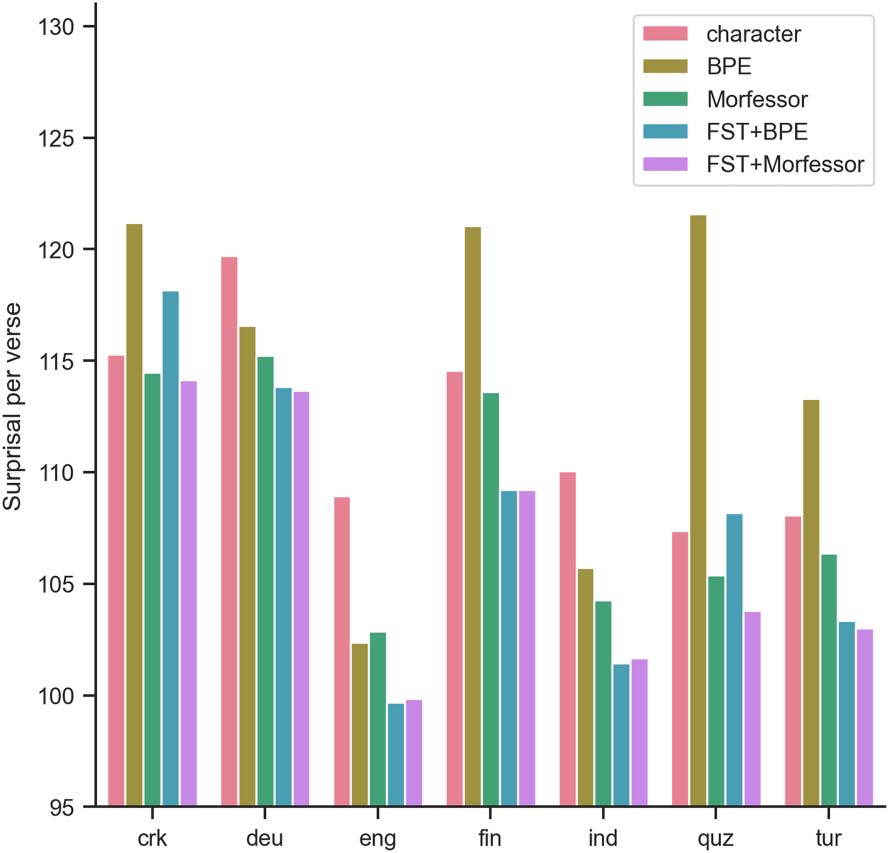
FST Models When available, a FST segmen-
tation method resulted in the best performance.
Figure 2: Surprisal per verse per segmentation method
including FST segmentation methods. FST+BPE or
FST+Morfessor models outperform all other models.
The graph in Figure 2 displays the surprisal of
FST+BPE and FST+Morfessor models in com-
parison to the segmentation methods discussed
above. For all seven languages, either FST+BPE
or FST+Morfessor segmentation (or both) shows
a clear decrease in the surprisal per verse com-
pared to the BPE and Morfessor segmentations.
5.3 Surprisal Difference and
Morphological Complexity
In order to look into the effect of morphological
complexity on the relative strength of a given
segmentation method, we conducted correlation
studies with the difference between the surprisal
269
Difference
Δ BPE, char
Δ Morfessor, char
Δ BPE, Morfessor
Measure
Types
TTR
MATTR
MLW
Types
TTR
MATTR
MLW
Types
TTR
MATTR
MLW
Spearman’s ρ
0.95∗∗∗
0.92∗∗∗
0.77∗∗∗
0.74∗∗∗
0.71∗∗∗
0.66∗∗∗
0.50∗∗∗
0.53∗∗∗
0.86∗∗∗
0.86∗∗∗
0.80∗∗∗
0.75∗∗∗
Table 6: Correlation between surprisal differences
and morphological complexity measures for
character, BPE, and Morfessor models. All
p-values < 10−11.
per verse for pairs of segmentation methods (the
Δ values as defined in §4.5). We considered only
the measures of morphological complexity that
were continuous variables (i.e., number of types,
TTR, MATTR, and MLW).
As shown in Table 6, all of the corpus-based
statistics were highly correlated to the Δ values.
The correlations range from moderate to high
using Spearman’s ρ (0.50 < ρ < 0.95). Even
though the strength of correlations varied slightly,
number of types, TTR, MATTR, and MLW all
showed a similar correlation with the difference
statistics. They all had a positive correlation with
Δ BPE, char. This indicates that the more morpho-
logically complex a language is, the better it
is modeled with character segmentation com-
pared to BPE segmentation. Similarly, there were
positive correlations between the morphological
measures and Δ Morfessor, char, suggesting that char-
acter segmentation works better than Morfessor
in modeling morphologically complex languages.
Δ BPE, Morfessor also had positive correlations with
complexity measures. This means that languages
with higher morphological complexity tend to
record lower surprisal values with Morfessor seg-
mentation than BPE. While BPE and Morfessor
models outperformed character models on aver-
age as shown in §5.2, the positive correlations
with Δ Morfessor, char and Δ BPE, char suggest that
character segmentation outperformed BPE and
Morfessor segmentation for languages with very
rich morphology.
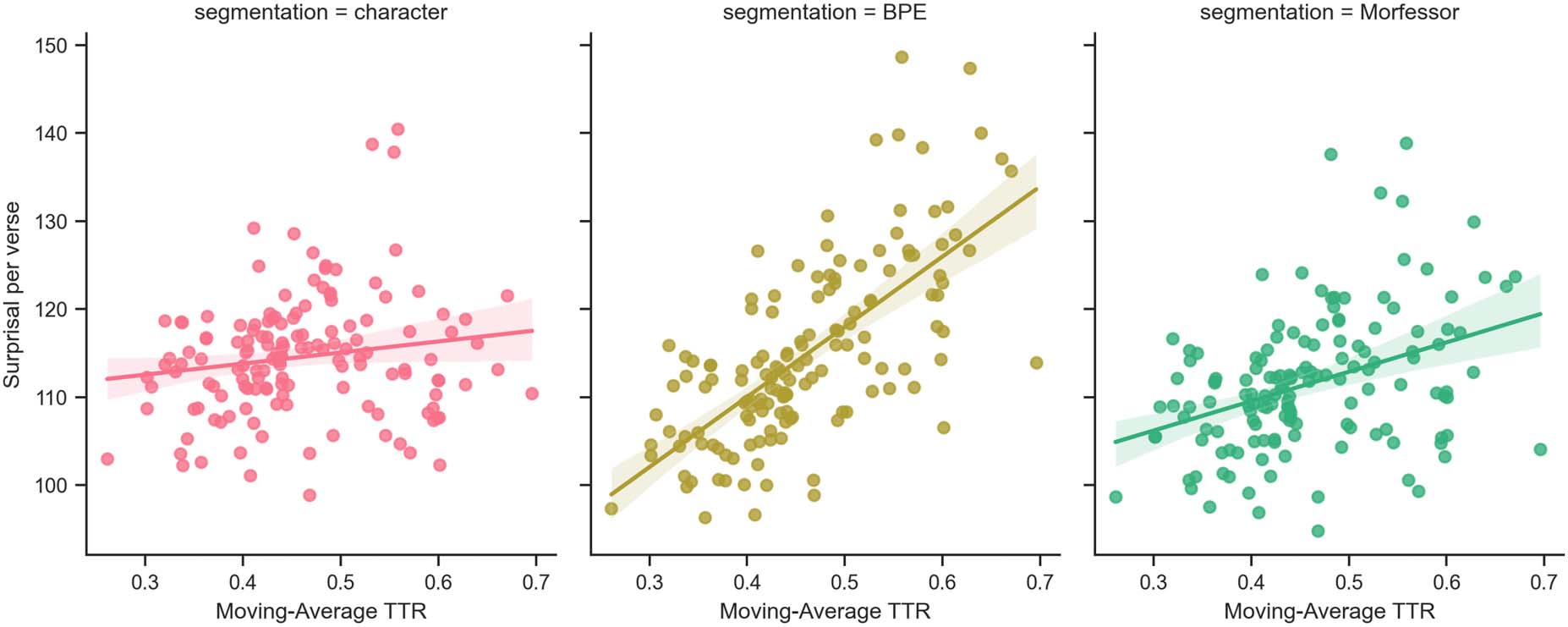
These results are supported by Figure 3, where
the surprisal per verse for different segmentation
models is plotted against MATTR.7 For languages
with lower MATTR, BPE and Morfessor perform
better than character segmentation. However, for
languages with higher MATTR, character and
Morfessor models outperform BPE.
6 Discussion
Our results show that BPE models’ surprisal
per verse is highly correlated with a language’s
morphology, represented by several WALS fea-
tures and corpus-based measures. Morfessor
shows weaker correlations with such measures
and records better performance for most of the
languages. FST-based models outperform others
when available. In this section, we discuss the
implications of these findings in the context of
previous work and future research.
6.1 Morphology and Surprisal
In accordance with the prior work discussed in
§2, we found differences in modeling difficulty
between languages. The correlation studies in §5
provide evidence that morphology is a substan-
tial contributing factor to these differences. Six
WALS (Dryer and Haspelmath, 2013) morphol-
ogy features showed association with the surprisal
per verse of BPE language models. Corpus-based
statistics like number of types and MATTR
showed strong correlations with BPE surprisal,
supporting the relationship between modeling
difficulty and morphological complexity.
Our conclusion that a language’s morphology
impacts language modeling difficulty agrees with
Cotterell et al. (2018) and Gerz et al. (2018), but
is at odds with Mielke et al. (2019). We included
languages known for their rich morphology, such
as Western Canadian Inuktitut (ikt) and Central
Alaskan Yup’ik (esu), which may have increased
the variation in morphological complexity in the
corpus. We also augmented the WALS data by
consulting reference grammars, so we were able
to consider 11 more morphological WALS fea-
tures than Mielke et al. (2019). We found that the
morphological feature Mielke et al. (2019) consid-
ered, 26A ‘‘Prefixing vs. Suffixing in Inflectional
7The same trend was captured when we plotted with the
other corpus-based measures.
270
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
t
l
a
c
_
a
_
0
0
3
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
t
l
a
c
_
a
_
0
0
3
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 3: Surprisal per verse plotted against MATTR for character, BPE, and Morfessor segmentation methods.
Lines indicate the regression estimate with 95% confidence intervals.
Morphology,’’
indeed showed no correlation
with BPE surprisal. However, our results show
that there are aspects of morphology that affect
surprisal that were not considered before.
Previous work, such as Gerz et al. (2018),
focused only on aspects of morphology that they
believed a priori would predict language model
performance. In contrast, our study tested all of the
morphological features listed in WALS and also
tested each of them individually. We found that
two of the four features in Gerz et al. (2018), 20A
‘‘Fusion of Selected Inflectional Formatives’’ and
22A ‘‘Inflectional Synthesis of the Verb,’’ showed
no association with language model performance.
Additionally, we found several features that af-
fected language modeling performance, specif-
ically locus of marking and syncretism, which
were not mentioned in the literature. These results
show that the features tied to morphological com-
plexity in previous work are not necessarily the
same features that affect language modeling.
In addition to differences in results, our inter-
pretation of corpus-based statistics like TTR also
diverges from previous work. While Mielke et al.
(2019) reported high correlations between lan-
guage model performance and such statistics,
they considered them only as simple statis-
results repli-
tics of
cate Mielke et al. (2019) in that
the number
of types was the most predictive of BPE lan-
guage model surprisal among all the variables
considered. However, we argue that corpus-based
statistics can be used as an approximate measure
of morphological complexity based on previous
In fact, our
the data.
studies. These corpus-based measures of morphol-
ogy are reported to capture the overall ranking
of morphological complexity (Kettunen, 2014;
Bentz et al., 2016) and can be interpreted in
relation to morphological typology (Gerz et al.,
2018). We also believe our results indicate that
TTR and the WALS features capture similar
information. For example, the positive correla-
tion of Δ BPE, Morfessor for corpus-based measures
corresponds to the smaller effect sizes of WALS
features found for Morfessor compared to BPE.
This indicates a lesser effect of rich morphology
on Morfessor models compared to BPE.
6.2 Segmentation Methods and Surprisal
While the primary goal of this work is to ana-
lyze the relation of a language’s morphology
to language modeling performance, we found
this to be entangled with the level and method
of segmentation. Our results show that
there
is significant variation in the effectiveness of
segmentation methods cross-linguistically, and
suggest challenges to the status quo methods of
subword segmentation in particular. While the
subword segmentation methods we used gener-
ally outperformed character-level segmentation,
the higher the TTR, the smaller the difference in
surprisal for both BPE and Morfessor, suggesting
that these methods are less effective at segment-
ing languages with highly complex morphology.
Of pre-existing methods, we found Morfessor to
have the lowest surprisal per verse for most of the
languages considered. Morfessor’s weaker corre-
lations with WALS features and other measures
271
like TTR suggest that its better performance may
be due to a better ability to model languages with
a wider range of morphological attributes. This
is in line with Bostrom and Durrett (2020), who
showed that Unigram LM (Kudo, 2018), a seg-
mentation algorithm similar to Morfessor, often
outperforms BPE and produces more morph-like
segmentation in the context of language model
pretraining in English and Japanese.
However, Morfessor was significantly outper-
formed by character segmentation for a small
subset of languages.8 Many of these languages
have been classified as polysynthetic, suggest-
ing that perhaps Morfessor
is ill-suited for
such languages (see Klavans, 2018; Tyers and
Mishchenkova, 2020; Mager et al., 2018, for dis-
cussions on challenges polysynthetic languages
pose for NLP tasks).
Additionally, for a typologically diverse sub-
set of languages for which we could obtain
FST morphological segmenters, we considered
novel segmentation methods: FST+BPE and
FST+Morfessor. We found this simple extension
of BPE and Morfessor with morphological infor-
mation achieved the lowest surprisal per verse
in all available languages. The overall success
of combining statistical segmentations with FSTs
further confirms the impact of morphology on
language modeling and yields significant promise
for the use of segmentation based on linguistic
morphological information.
7 Conclusion
A language’s morphology is
strongly asso-
for
ciated with language modeling surprisal
BPE-segmented language models. BPE model
surprisal is associated with 6 out of the 12 stud-
ied WALS morphology features, indicating that
there are aspects of some languages’ morphology
that BPE does not help mitigate. Strong correla-
tions with corpus-based measures of morphology
such as TTR further suggest that the more types
available in a language (often by means of rich
morphology), the harder it is to model based on
BPE units. Morfessor, which was designed with
morpheme induction in mind, performs better for
most languages and shows less association with
morphological features. When available, the lin-
guistically informed method of FST-augmented
8amh, arz, ayr, cmn, esu, heb, ike, ikt, kal, quh, tel, xho.
BPE outperformed Morfessor for cmn and heb.
BPE or Morfessor segmentation performs best,
indicating a further promise for using linguistic
knowledge to combat the effects of morphology
on language model surprisal.
These conclusions were only possible through
manual augmentation of typological databases and
expansion of studied languages. Future efforts
could adopt our approach for other areas of lan-
guage. Using linguistically informed resources
across many languages is an avenue for improving
neural models in NLP in both design and analysis.
Acknowledgments
This paper builds on our prior work for the
2019 Sixth Frederick Jelinek Memorial Summer
Workshop on Speech and Language Technology
(JSALT 2019) (Schwartz et al., 2020). We thank
the organizers of the workshop and the members
of our workshop team on Neural Polysynthetic
Language Modeling for inspiring us to pursue
this research direction. Our special
thanks to
Rebecca Knowles, Christo Kirov, Lori Levin,
Chi-kiu (Jackie) Lo, and TACL reviewers and
editors for their feedback on our manuscript. We
thank Ata Tuncer for his assistance with Turkish
segmentation. This work utilizes resources sup-
ported by the National Science Foundation’s
Major Research Instrumentation program, grant
#1725729, as well as the University of Illinois at
Urbana-Champaign.
References
Antti Arppe, Atticus Harrigan, Katherine
Schmirler, Lene Antonsen, Trond Trosterud,
Sjur Nørstebø Moshagen, Miikka Silfverberg,
Arok Wolvengrey, Conor Snoek,
Jordan
Lachler, Eddie Antonio Santos, Jean Okim¯asis,
and Dorothy Thunder. 2014–2019. Finite-
state transducer-based computational model of
Plains Cree morphology.
Eric Axelson, Sam Hardwick, Krister Lind´en,
Kimmo Koskenniemi, Flammie Pirinen, Mikka
Silfverberg, and Senka Drobac. 2015. Helsinki
finite-state technology resources.
Yoav Benjamini and Yosef Hochberg. 1995.
Controlling the false discovery rate: A practical
and powerful approach to multiple testing.
Journal of the Royal Statistical Society: Series B
272
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
t
l
a
c
_
a
_
0
0
3
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
(Methodological), 57(1):289–300. DOI: https://
doi.org/10.1111/j.2517-6161.1995
.tb02031.x
Christian Bentz, Tatyana Ruzsics, Alexander
Koplenig, and Tanja Samardˇzi´c. 2016. A com-
parison between morphological complexity mea-
sures: Typological data vs. language corpora. In
Proceedings of the Workshop on Computational
Linguistics for Linguistic Complexity (CL4LC),
pages 142–153, Osaka, Japan. The COLING
2016 Organizing Committee.
Kaj Bostrom and Greg Durrett. 2020. Byte pair
encoding is suboptimal for language model
pretraining. CoRR, cs.CL/2004.03720v1.
C¸ aˇgrı C¸ ¨oltekin. 2010. A freely available morpho-
logical analyzer for Turkish. In Proceedings of
the Seventh International Conference on Lan-
guage Resources and Evaluation (LREC’10).
Valletta, Malta. European Language Resources
Association (ELRA).
C¸ aˇgrı C¸ ¨oltekin. 2014. A set of open source tools
language processing. In
for Turkish natural
Proceedings of the Ninth International Con-
ference on Language Resources and Evalua-
tion (LREC’14), Reykjavik, Iceland. European
Language Resources Association (ELRA).
Christos Christodoulopoulos and Mark Steedman.
2014. A massively parallel corpus: The Bible
in 100 languages. Language Resources and
Evaluation, 49:1–21. DOI: https://doi
.org/10.1007/s10579-014-9287-y,
PMID: 26321896, PMCID: PMC4551210
the 2018 Conference of
Ryan Cotterell, Sabrina J. Mielke, Jason Eisner,
and Brian Roark. 2018. Are all
languages
equally hard to language-model? In Proceed-
the North
ings of
American Chapter of
the Association for
Computational Linguistics: Human Language
Technologies, Volume 2 (Short Papers),
pages 536–541, New Orleans, Louisiana.
Association for Computational Linguistics.
DOI: https://doi.org/10.18653/v1
/N18-2085
Mathias Creutz and Krista Lagus. 2007. Unsu-
pervised models for morpheme segmentation
and morphology learning. ACM Transac-
tions on Speech and Language Processing,
4(1):3:1–3:34. DOI: https://doi.org
/10.1145/1187415.1187418
Mathieu Dehouck and Pascal Denis. 2018. A
framework for understanding the role of mor-
phology in universal dependency parsing. In
Proceedings of the 2018 Conference on Empir-
ical Methods in Natural Language Processing,
pages 2864–2870, Brussels, Belgium. Asso-
ciation for Computational Linguistics. DOI:
https://doi.org/10.18653/v1/D18
-1312
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Kristina Toutanova. 2019. BERT: Pre-training
of deep bidirectional transformers for language
the 2019
understanding. In Proceedings of
Conference of the North American Chapter of
the Association for Computational Linguistics:
Human Language Technologies, Volume 1
(Long and Short Papers), pages 4171–4186,
Minneapolis, Minnesota. Association
for
Computational Linguistics.
Matthew S. Dryer and Martin Haspelmath,
editors. 2013. WALS Online. Max Planck Insti-
tute for Evolutionary Anthropology, Leipzig.
Daniela Gerz, Ivan Vuli´c, Edoardo Maria Ponti,
Roi Reichart, and Anna Korhonen. 2018. On the
relation between linguistic typology and (limi-
tations of) multilingual language modeling. In
Proceedings of the 2018 Conference on Empir-
ical Methods in Natural Language Processing,
pages 316–327, Brussels, Belgium. Associ-
ation for Computational Linguistics. DOI:
https://doi.org/10.18653/v1/D18
-1029
Kimmo Kettunen. 2014. Can type-token ratio
be used to show morphological complexity of
languages? Journal of Quantitative Linguistics,
21(3):223–245. DOI: https://doi.org
/10.1080/09296174.2014.911506
Michael A. Covington and Joe D. McFall. 2010.
Cutting the Gordian knot: The moving-average
type–token ratio (MATTR). Journal of Quanti-
tative Linguistics, 17(2):94–100. DOI: https://
doi.org/10.1080/09296171003643098
Christo Kirov, Ryan Cotterell,
John Sylak-
Glassman, G´eraldine Walther, Ekaterina
Vylomova, Patrick Xia, Manaal Faruqui,
Sebastian Mielke, Arya McCarthy, Sandra
K¨ubler, David Yarowsky, Jason Eisner, and
273
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
t
l
a
c
_
a
_
0
0
3
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Mans Hulden. 2018. UniMorph 2.0: Universal
morphology. In Proceedings of the Eleventh
International Conference on Language Re-
sources
(LREC 2018),
Miyazaki, Japan. European Language Re-
sources Association (ELRA).
and Evaluation
Judith L. Klavans. 2018. Computational chal-
lenges for polysynthetic languages. In Proceed-
ings of the Workshop on Computational Modeling
of Polysynthetic Languages, pages 1–11, Santa
Fe, New Mexico, USA. Association for Com-
putational Linguistics.
Philipp Koehn. 2005. Europarl: A parallel
corpus for statistical machine translation. In
Proceedings of the Tenth Machine Translation
Summit, pages 79–86. Phuket, Thailand.
AAMT.
Taku Kudo. 2018. Subword regularization:
Improving neural network translation models
with multiple subword candidates. In Pro-
ceedings of
the 56th Annual Meeting of
the Association for Computational Linguis-
tics (Volume 1: Long Papers), pages 66–75,
Melbourne, Australia. Association for Com-
putational Linguistics. DOI: https://doi
.org/10.18653/v1/P18-1007, PMID:
29382465
Septina Dian Larasati, Vladislav Kuboˇn, and
Daniel Zeman. 2011. Indonesian morphology
(MorphInd): Towards an indonesian
tool
corpus.
In Cerstin Mahlow and Michael
Piotrowski, editors, Systems and Frameworks
for Computational Morphology, Springer
Berlin Heidelberg,
Berlin, Heidelberg,
pages 119–129. DOI: https://doi.org
/10.1007/978-3-642-23138-4 8
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei
Du, Mandar Joshi, Danqi Chen, Omer Levy,
Mike Lewis, Luke Zettlemoyer, and Veselin
Stoyanov. 2019. RoBERTa: A robustly op-
timized BERT pretraining approach. CoRR,
cs.CL/1907.11692v1.
Manuel Mager, Elisabeth Mager, Alfonso
Medina-Urrea, Ivan Vladimir Meza Ruiz, and
Katharina Kann. 2018. Lost
in translation:
Analysis of information loss during machine
translation between polysynthetic and fusional
languages. In Proceedings of the Workshop
on Computational Modeling of Polysynthetic
Languages, pages 73–83, Santa Fe, New
Mexico, USA. Association for Computational
Linguistics.
Thomas Mayer and Michael Cysouw. 2014.
Creating a massively parallel Bible corpus.
In Proceedings of
the Ninth International
Conference on Language Resources and
Evaluation (LREC’14), pages 3158–3163,
Reykjavik, Iceland. European Language Re-
sources Association (ELRA).
Stephen Merity, Nitish Shirish Keskar, and
Richard Socher. 2018. An analysis of neural
language modeling at multiple scales. CoRR,
cs.CL/1803.08240v1.
Sabrina J. Mielke. 2016. Language diversity in
ACL 2004 - 2016.
Sabrina J. Mielke, Ryan Cotterell, Kyle Gorman,
Brian Roark, and Jason Eisner. 2019. What
kind of language is hard to language-model?
In Proceedings of the 57th Annual Meeting of
the Association for Computational Linguistics,
pages 4975–4989, Florence,
Italy. Associ-
ation for Computational Linguistics. DOI:
https://doi.org/10.18653/v1/P19
-1491
Sabrina J. Mielke and Jason Eisner. 2019.
Spell once, summon anywhere: A two-level
open-vocabulary language model. Proceedings
of the AAAI Conference on Artificial Intelli-
gence, 33:68436850. DOI: https://doi
.org/10.1609/aaai.v33i01.33016843
Tommi A. Pirinen. 2015. Omorfi — free and
open source morphological lexical database for
Finnish. In Proceedings of the 20th Nordic
Conference
of Computational Linguistics
(NODALIDA 2015), pages 313–315, Vilnius,
Lithuania. Link¨oping University Electronic
Press, Sweden.
Alec Radford, Jeff Wu, Rewon Child, David
Luan, Dario Amodei, and Ilya Sutskever. 2019.
Language models are unsupervised multitask
learners.
Benoˆıt Sagot. 2013. Comparing complexity
measures. In Computational Approaches to
Morphological Complexity, Paris, France.
Surrey Morphology Group.
274
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
t
l
a
c
_
a
_
0
0
3
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Helmut Schmid, Arne Fitschen, and Ulrich Heid.
2004. SMOR: A German computational mor-
phology covering derivation, composition and
inflection. In Proceedings of the Fourth Inter-
national Conference on Language Resources
and Evaluation (LREC’04), pages 1–263, Lis-
bon, Portugal. European Language Resources
Association (ELRA).
Lane Schwartz, Francis Tyers, Lori Levin,
Christo Kirov, Patrick Littell, Chi-kiu Lo,
Emily Prud’hommeaux, Hyunji Hayley Park,
Kenneth Steimel, Rebecca Knowles, Jeffrey
Micher, Lonny Strunk, Han Liu, Coleman
Haley, Katherine J. Zhang, Robbie Jimerson,
Vasilisa Andriyanets, Aldrian Obaja Muis,
Naoki Otani, Jong Hyuk Park, and Zhisong
Zhang. 2020. Neural polysynthetic language
modelling. CoRR, cs.CL/2005.05477v2.
Rico Sennrich, Barry Haddow, and Alexandra
Birch. 2016. Neural machine translation of rare
words with subword units. In Proceedings of
the 54th Annual Meeting of the Association
for Computational Linguistics (Volume 1: Long
Papers), pages 1715–1725, Berlin, Germany.
Association for Computational Linguistics.
DOI: https://doi.org/10.18653/v1
/P16-1162
Yusuke
Takuya Kida,
Shuichi
Shibata,
Fukamachi, Masayuki
Takeda, Ayumi
Shinohara, Takeshi Shinohara, and Setsuo
Arikawa. 1999. Byte pair encoding: A text
compression scheme that accelerates pattern
matching. Technical
report, Department of
Informatics, Kyushu University.
Maciej Tomczak and Ewa Tomczak. 2014. The
need to report effect size estimates revisited.
An overview of some recommended measures
of effect size. Trends in Sport Sciences,
1(21):19–25.
Francis Tyers and Karina Mishchenkova. 2020.
Dependency annotation of noun incorporation
in polysynthetic languages. In Proceedings
of
on Universal
Dependencies (UDW 2020), pages 195–204,
Barcelona, Spain (Online). Association for
Computational Linguistics.
the Fourth Workshop
Clara Vania and Adam Lopez. 2017. From cha-
racters to words to in between: Do we capture
morphology? In Proceedings of the 55th An-
nual Meeting of the Association for Computa-
tional Linguistics (Volume 1: Long Papers),
pages 2016–2027, Vancouver, Canada. Asso-
ciation for Computational Linguistics. DOI:
https://doi.org/10.18653/v1/P17
-1184
Hugo David Calderon Vilca, Flor Cagniy
C´ardenas Mari˜n´o, and Edwin Fredy Mamani
Calderon. 2012. Analizador morf´ologico de
la lengua Quechua basado en software libre
Helsinkifinite-statetransducer (HFST).
Sami Virpioja, Peter Smit, Stig-Arne Gr¨onroos,
and Mikko Kurimo. 2013. Morfessor 2.0:
Python implementation and extensions for
Morfessor baseline. Technical report, Aalto
University; Aalto-yliopisto.
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime G.
Carbonell, Ruslan Salakhutdinov, and Quoc V.
Le. 2019. XLNet: Generalized autoregressive
pretraining for
In
Hanna Wallach, Hugo Larochelle, Alina
Beygelzimer, Florence d’Alch´e Buc, Emily
Fox, and Roman Garnett, editors, Advances
in Neural Information Processing Systems 32,
pages 5753–5763. Curran Associates, Inc.
language understanding.
A Data
We began with the data used in Mielke et al.
(2019). This was originally a subset of a Bible
corpus (Mayer and Cysouw, 2014), which is
no longer publically available. We excluded
constructed languages (epo, tlh) from the data,
keeping a total of 104 verse-aligned Bibles
in 60 languages9 in 12 language families. To
increase the number of the languages and lan-
guage families represented, we added 41 Bibles
in 32 languages to the data. Thirteen Bible trans-
lations in 13 languages10 were sourced from
In
Christodoulopoulos and Steedman (2014).
9afr, aln, arb, arz, ayr, bba, ben, bqc, bul, cac, cak, ceb,
ces, cmn, cnh, cym, dan, deu, ell, eng, fin, fra, guj, gur, hat,
hrv, hun, ind, ita, kek, kjb, lat, lit, mah, mam, mri, mya, nld,
nor, plt, poh, por, qub, quh, quy, quz, ron, rus, som, tbz, tel,
tgl, tpi, tpm, ukr, vie, wal, wbm, xho, zom.
10als, amh, dje, heb, isl, jpn, kor, pck, slk, slv, spa,
swe, tha.
275
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
t
l
a
c
_
a
_
0
0
3
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
addition, we included 28 Bible translations in 21
languages scraped from various online sources.
Two of the Bibles scraped were in Spanish (spa)
and Telugu (tel), languages which were already
included in the Bible corpora (Mayer and Cysouw,
2014; Christodoulopoulos and Steedman, 2014).
These translations were included because the
new Spanish Bible was a parallel source of the
Paraguayan Guaran´ı (gug) translation, and the
Telugu Bible obtained from Mielke et al. (2019)
was originally mislabeled as Tecpatl´an Totonac
(tcw). The Central Alaskan Yup’ik (esu) Bible was
from https://bibles.org. 26 Bibles in 19
languages11 were from http://bible.com.
The Greenlandic (kal) Bible was obtained from
http://old.bibelselskabet.dk.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
5
1
9
2
4
1
5
8
/
/
t
l
a
c
_
a
_
0
0
3
6
5
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
11crk, gug, gui, hin, ike, ikt, kan, mal, mar, nch, nep, nhe,
pes, pol, sna, spa, tel, tob, tur.
276