Deep Contextualized Self-training for Low Resource Dependency Parsing
Guy Rotman and Roi Reichart
Faculty of Industrial Engineering and Management, Technion, IIT
grotman@campus.technion.ac.il
roiri@ie.technion.ac.il
Astratto
Neural dependency parsing has proven very
effective, achieving state-of-the-art results
on numerous domains and languages.
Unfortunately, it requires large amounts of
labeled data, which is costly and laborious
to create. In this paper we propose a self-
training algorithm that alleviates this anno-
tation bottleneck by training a parser on
its own output. Our Deep Contextualized
Self-training (DCST) algorithm utilizes
representation models trained on sequence
labeling tasks that are derived from the
parser’s output when applied to unlabeled
dati, and integrates these models with
the base parser through a gating mech-
anism. We conduct experiments across
multiple languages, both in low resource
in-domain and in cross-domain setups, E
demonstrate that DCST substantially out-
performs traditional self-training as well as
recent semi-supervised training methods.1
1 introduzione
Deep neural networks (DNNs) have improved
the state-of-the-art in a variety of NLP tasks.
These include dependency parsing (Dozat and
Equipaggio, 2017), semantic parsing (Hershcovich
et al., 2017), named entity recognition (Yadav
and Bethard, 2018), part of speech (POS) tagging
(Plank and Agi´c, 2018), and machine translation
(Vaswani et al., 2017), among others.
Unfortunately, DNNs rely on in-domain labeled
training data, which is costly and laborious to
achieve. This annotation bottleneck limits the
applicability of NLP technology to a small number
of languages and domains. It is hence not a surprise
that substantial recent research efforts have been
1Our code is publicly available at https://github.
com/rotmanguy/DCST.
695
devoted to DNN training based on both labeled and
unlabeled data, which is typically widely available
(§ 2).
A prominent technique for training machine
learning models on labeled and unlabeled data
is self-training (Yarowsky, 1995; Abney, 2004).
In this technique, after the model is trained on a
labeled example set it is applied to another set
of unlabeled examples, and the automatically and
manually labeled sets are then combined in order
to re-train the model—a process that is sometimes
performed iteratively. Although self-training has
shown useful for a variety of NLP tasks, its success
for deep learning models has been quite limited
(§ 2).
Our goal is to develop a self-training algorithm
that can substantially enhance DNN models in
cases where labeled training data are scarce.
Particularly, we are focusing (§ 5) on the lightly
supervised setup where only a small in-domain
labeled dataset is available, and on the domain
adaptation setup where the labeled dataset may be
large but it comes from a different domain than
the one to which the model is meant to be applied.
Our focus task is dependency parsing, che è
essential for many NLP tasks (Levy and Goldberg,
2014; Angeli et al., 2015; Toutanova et al.,
2016; Hadiwinoto and Ng, 2017; Marcheggiani
et al., 2017), but where self-training has typically
failed (§ 2). Inoltre, neural dependency parsers
(Kiperwasser and Goldberg, 2016; Dozat and
Equipaggio, 2017) substantially outperform their
linear predecessors, which makes the develop-
ment of self-training methods that can enhance
these parsers in low-resource setups a crucial
challenge.
We present a novel self-training method, suit-
able for neural dependency parsing. Our algorithm
(§ 4) follows recent work that has demonstrated the
power of pre-training for improving DNN models
in NLP (Peters et al., 2018; Devlin et al., 2019)
Operazioni dell'Associazione per la Linguistica Computazionale, vol. 7, pag. 695–713, 2019. https://doi.org/10.1162/tacl a 00294
Redattore di azioni: Yue Zhang. Lotto di invio: 7/2019; Lotto di revisione: 9/2019; Pubblicato 12/2019.
C(cid:2) 2019 Associazione per la Linguistica Computazionale. Distribuito sotto CC-BY 4.0 licenza.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
T
l
UN
C
_
UN
_
0
0
2
9
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
Quello
and particularly for domain adaptation (Ziser and
Reichart, 2018). Tuttavia, whereas in previous
work a representation model, also known as a
contextualized embedding model, is trained on a
language modeling related task, our algorithm
is trained
utilizes a representation model
on sequence prediction tasks derived from the
parser’s output. Our representation model and
the base parser are integrated into a new model
through a gating mechanism, and the resulting
parser is then trained on the manually labeled data.
We experiment (§ 6,7) with a large variety of
lightly supervised and domain adaptation depen-
dency parsing setups. For the lightly supervised
case we consider 17 setups: 7 in different English
domains and 10 in other languages. For the domain
adaptation case we consider 16 setups: 6 in differ-
ent English domains and 10 In 5 other languages.
Our Deep Contextualized Self-training (DCST)
algorithm demonstrates substantial performance
gains over a variety of baselines, including tradi-
tional self-training and the recent cross-view train-
ing approach (CVT) (Clark et al., 2018) that was
designed for semi-supervised learning with DNNs.
2 Previous Work
Self-training in NLP Self-training has shown
useful for various NLP tasks, including word sense
disambiguation (Yarowsky, 1995; Mihalcea,
2004), bilingual lexicon induction (Artetxe et al.,
2018), neural machine translation (Imamura and
Sumita, 2018), semantic parsing (Goldwasser
et al., 2011), and sentiment analysis (He and
Zhou, 2011). For constituency parsing, self-
training has shown to improve linear parsers
both when considerable training data are available
(McClosky et al., 2006UN,B), and in the lightly
supervised and the cross-domain setups (Reichart
and Rappoport, 2007). Although several authors
failed to demonstrate the efficacy of self-training
for dependency parsing (per esempio., Rush et al., 2012),
recently it was found useful for neural dependency
parsing in fully supervised multilingual settings
(Rybak and Wr´oblewska, 2018).
The impact of self-training on DNNs is less
researched compared with the extensive investi-
gation with linear models. Recentemente, Ruder and
Plank (2018) evaluated the impact of self-training
and the closely related tri-training method (Zhou
and Li, 2005; Søgaard, 2010) on DNNs for
POS tagging and sentiment analysis. They found
self-training to be effective for the sentiment
compito di classificazione, but it failed to improve their
BiLSTM POS tagging architecture. Tri-training
has shown effective for both the classification and
the sequence tagging task, and in Vinyals et al.
(2015) it has shown useful for neural constituency
parsing. This is in-line with Steedman et al. (2003),
who demonstrated the effectiveness of the closely
related co-training method (Blum and Mitchell,
1998) for linear constituency parsers.
Lastly, Clark et al. (2018) presented the CVT
algorithm, a variant of self-training that uses
unsupervised representation learning. CVT differs
from classical self-training in the way it exploits
the unlabeled data: It
trains auxiliary models
on restricted views of the input to match the
predictions of the full model that observes the
whole input.
We propose a self-training algorithm based
on deep contextualized embeddings, dove il
embedding model is trained on sequence tagging
tasks that are derived from the parser’s output on
unlabeled data. In extensive lightly supervised
and cross-domain experiments with a neural
dependency parser, we show that our DCST
algorithm outperforms traditional self-training and
CVT.
Pre-training and Deep Contextualized Embed-
ding Our DCST algorithm is related to recent
work on DNN pre-training. In this line, a DNN
is first trained on large amounts of unlabeled data
and is then used as the word embedding layer of
a more complex model that is trained on labeled
data to perform an NLP task. Typically, only the
superiore, task-specific, layers of the final model are
trained on the labeled data, while the parameters
of the pre-trained embedding network are kept
fixed.
The most common pre-training task is language
modeling or a closely related variant (McCann
et al., 2017; Peters et al., 2018; Ziser and
Reichart, 2018; Devlin et al., 2019). The outputs
of the pre-trained DNN are often referred to as
contextualized word embeddings, as these DNNs
typically generate a vector embedding for each
input word, which takes its context into account.
Pre-training has led to performance gains in many
NLP tasks.
Recentemente, Che et al. (2018) incorporated ELMo
embeddings (Peters et al., 2018) into a neural
dependency parser and reported improvements
696
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
T
l
UN
C
_
UN
_
0
0
2
9
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
over a range of Universal Dependency (UD)
(McDonald et al., 2013; Niver et al., 2016, 2018)
languages in the fully supervised setup. In this
paper we focus on the lightly supervised and
domain adaptation setups, trying to compensate
for the lack of labeled data by exploiting auto-
matically labeled trees generated by the base
parser for unlabeled sentences.
Our main experiments (§7) are with models
that utilize non-contextualized word embeddings.
We believe this is a more practical setup when
considering multiple languages and domains.
Infatti, Che et al. (2018), who trained their
ELMo model on the unlabeled data of the CoNLL
2018 shared task, reported that “The training of
ELMo on one language takes roughly 3 days
on an NVIDIA P100 GPU.” Tuttavia, we also
demonstrate the power of our models when
ELMo embeddings are available (§8), in order
to establish the added impact of deep contextual-
ized self-training on top of contextualized word
embeddings.
Lightly Supervised Learning and Domain
Adaptation for Dependency Parsing Finally,
we briefly survey earlier attempts to learn parsers
in setups where labeled data from the domain to
which the parser is meant to be applied is scarce.
We exclude from this brief survey literature that
has already been mentioned above.
Some notable attempts are: exploiting short
dependencies in the parser’s output when applied
to large target domain unlabeled data (Chen et al.,
2008), adding inter-sentence consistency constra-
ints at test time (Rush et al., 2012), selecting effec-
tive training domains (Plank and Van Noord,
2011), exploiting parsers trained on different do-
mains through a mixture of experts (McClosky
et al., 2010), embedding features in a vector space
(Chen et al., 2014), and Bayesian averaging of a
range of parser parameters (Shareghi et al., 2019).
(2017) presented an
adversarial model for cross-domain dependency
parsing in which the encoders of the source and the
target domains are integrated through a gating
meccanismo. Their approach requires target do-
main labeled data for parser training and hence
it cannot be applied in the unsupervised domain
adaptation setup we explore (§ 5). We adopt their
gating mechanism to our model and extend it
to integrate more than two encoders into a final
modello.
Recentemente, Sato et al.
697
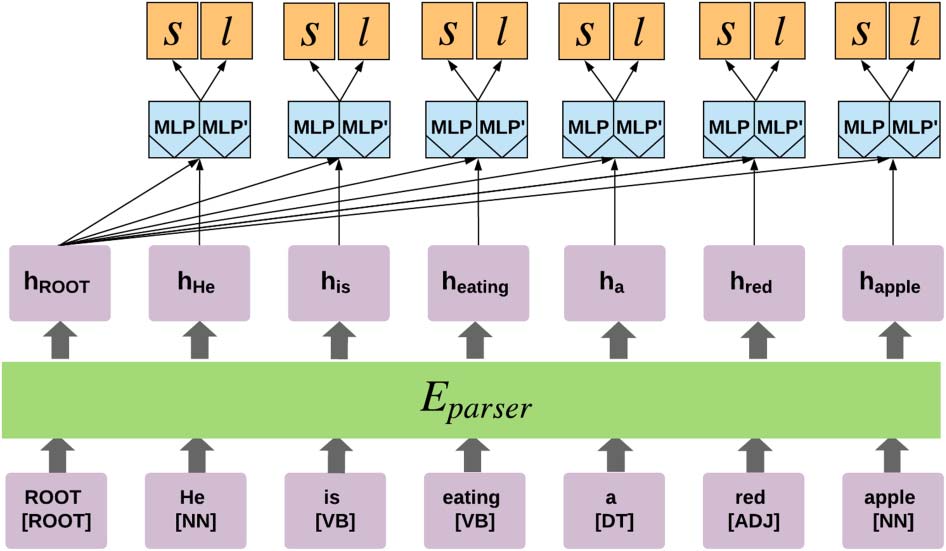
Figura 1: The BiAFFINE parser.
3 Background: The BiAFFINE Parser
The parser we utilize in our experiments is
the BiAFFINE parser (Dozat and Manning, 2017).
Because the structure of the parser affects our
DCST algorithm, we briefly describe it here.
A sketch of the parser architecture is provided
in Figure 1. The input to the parser is a sentence
(x1, x2, . . . , xm) of length m. An embedding
layer embeds the words into fixed-size vectors
(w1, w2, . . . , wm). Additionally, character-level
embeddings ck
retrieved from a CNN (Zhang
T
et al., 2015), and a POS embedding pt, are
concatenated to each word vector. At time t, IL
final input vector ft = [peso; ct; pt] is then fed into
a BiLSTM encoder Eparser that outputs a hidden
representation ht:
ht = Eparser(piedi).
(1)
Given the hidden representations of the i’th
word hi and the j’th word hj , the decoder outputs
a score si,j, indicating the model belief that the
latter should be the head of the former in the
dependency tree. More formally,
si,j = rT
i U rj + wT
j rj,
(2)
where ri = M LP (CIAO), and U and wj are learned
parameters (M LP is a multi-layered perceptron).
Allo stesso modo, a score li,j,k is calculated for the k’th
possible dependency label of the arc (io, j):
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
T
l
UN
C
_
UN
_
0
0
2
9
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
li,j,k = qT
i U
[qi; qj] + B
(cid:3)
k,
(3)
(cid:3)
(cid:3)T
kqj + w
k
(cid:3)(CIAO), and U
where qi = M LP
(cid:3)
k, and b
k
are learned parameters. During training the model
aims to maximize the probability of the gold tree:
k, w
(cid:3)
(cid:3)
M(cid:2)
i=1
P(yi|xi, θ) + P(sì(cid:3)
io
|xi, yi, θ),
(4)
Algorithm 1 Deep Contextualized Self-training (DCST)
Input: Labeled data L, Unlabeled data U
Algorithm:
1. Train the base parser on L (§ 3).
2. Parse the sentences of U with the base parser.
3. Transform the automatically parsed trees of U to one
or more word-level tagging schemes (§ 4.1).
4. Train (UN) contextualized embedding model(S) to predict
the word-level tagging(S) of U (§ 4.1).
5. Integrate the representation model(S) of step 4 with the
base parser, and train the resulting parser on L (§ 4.2).
where yi is the head of xi, sì(cid:3)
i is the label of the
arc (xi, yi), θ represents the model’s parameters,
), and p(sì(cid:3)
P(yi|xi, θ) ∝ exp(sxi,yi
|xi, yi, θ) ∝
io
). At test time, the parser runs the MST
esp(lxi,yi,sì(cid:3)
algorithm (Edmonds, 1967) on the arc scores in
order to generate a valid tree.
io
4 Deep Contextualized Self-training
In this section we present our DCST algorithm
for dependency parsing (Algorithm 1). As a semi-
supervised learning algorithm, DCST assumes a
labeled dataset L = {(xl
i=1, consisting of
sentences and their gold dependency trees, E
}|U|
an unlabeled dataset U = {xu
i=1, consisting of
io
sentences only.
)}|l|
io, yl
io
We start (Algorithm 1, step 1) by training the
base parser (the BiAFFINE parser in our case) on the
labeled dataset L. Once trained, the base parser can
output a dependency tree for each of the unlabeled
sentences in U (step 2). We then transform the
automatic dependency trees generated for U into
one or more word-level tagging schemes (step 3).
In § 4.1 we elaborate on this step. Then, we train
a BiLSTM sequence tagger to predict the word-
level tags of U (step 4). If the automatic parse
trees are transformed to more than one tagging
scheme, we train multiple BiLTMs—one for each
scheme. Finalmente, we construct a new parser by
integrating the base parser with the representation
BiLS™(S), and train the final parser on the
labeled dataset L (step 5). At this stage, the base
parser parameters are randomly initialized, while
the parameters of the representation BiLSTM(S)
are initialized to those learned in step 4.
We next discuss the three word-level tagging
schemes derived from the dependency trees (step
3), and then the gating mechanism utilized in order
to compose the hybrid parser (step 5).
698
4.1 Representation Learning (Steps 3 E 4)
In what follows we present the three word-level
tagging schemes we consider at step 3 of the DCST
algorithm. Transferring the parse trees into tagging
schemes is the key for populating information
from the original (base) parser on unlabeled data,
in a way that can later be re-encoded to the
parser through its word embedding layers. IL
key challenge we face when implementing this
idea is the transformation of dependency trees into
word level tags that preserve important aspects of
the information encoded in the trees.
the structural
We consider tagging schemes that maintain
various aspects of
informazione
encoded in the tree. Particularly, we start from
two tagging schemes that even if fully predicted
still leave ambiguity about the actual parse tree:
the number of direct dependants each word has
and the distance of each word from the root of the
tree. We then consider a tagging scheme, referred
to as the Relative POS-based scheme, from which
the dependency tree can be fully reconstructed.
While other tagging schemes can definitely be
proposed, we believe that the ones we consider
here span a range of possibilities that allows us to
explore the validity of our DCST framework.
More specifically,
the tagging schemes we
consider are defined as follows:
Number of Children Each word is tagged with
the number of its children in the dependency tree.
We consider only direct children, rather than other
descendants, which is equivalent to counting the
number of outgoing edges of the word in the tree.
Distance from the Root Each word is tagged
with its minimal distance from the root of the tree.
Per esempio, if the arc (ROOT , j) is included
in the tree, the distance of the j’th word from
the ROOT is 1. Likewise, if (ROOT , j) is not
included but (ROOT, io) E (io, j) are, then j’th
distance is 2.
Relative POS-based Encoding Each word is
tagged with its head word according to the relative
POS-based scheme (Spoustov´a and Spousta, 2010;
Strzyz et al., 2019) The head of a word is encoded
by a pair (P, e) ∈ P × [−m + 1, m − 1], Dove
P is the set of all possible parts of speech and m
is the sentence length. For a positive (negative)
number e and a POS p, the pair indicates that the
head of the represented word is the e’th word to its
right (left) with the POS tag p. To avoid sparsity
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
T
l
UN
C
_
UN
_
0
0
2
9
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
T
l
UN
C
_
UN
_
0
0
2
9
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
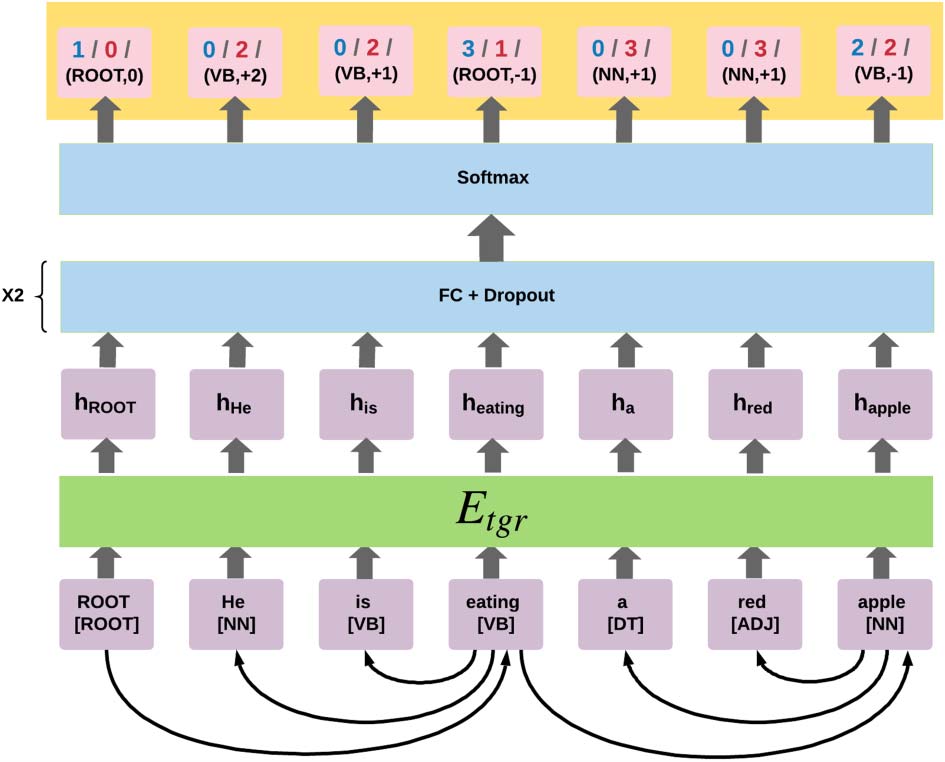
Figura 2: The sequence tagger applied to automatically
parsed sentences in U (Algorithm 1, step 4). The tagger
predicts for each word its label according to one of the
three tagging schemes: Number of Children (blue),
Distance from the Root (red), and Relative POS-based
Encoding (black). The curved arrows sketch the gold
dependency tree from which the word-level tags are
derived.
we coarsen the POS tags related to nouns, proper
names, verbs, adjectives, punctuation marks, E
brackets into one tag per category.
Although this word-level tagging scheme was
introduced as means of formulating dependency
parsing as a sequence tagging task, in practice
sequence models trained on this scheme are not
competitive with state-of-the-art parsers and often
generate invalid tree structures (Strzyz et al.,
2019). Here we investigate the power of this
scheme as part of a self-training algorithm.
The Sequence Tagger Our goal is to encode the
information in the automatically parsed trees into
a model that can be integrated with the parser at
later stages. This is why we choose to transform
the parse trees into word-level tagging schemes
that can be learned accurately and efficiently by
a sequence tagger. Note that efficiency plays a
key role in the lightly supervised and domain
adaptation setups we consider, as large amounts
of unlabeled data should compensate for the lack
of labeled training data from the target domain.
We hence choose a simple sequence tagging
architecture, depicted in Figure 2. The encoder
Etgr is a BiLSTM, similarly to Eparser of the
parser. The decoder is composed of two fully
connected layers with dropout (Srivastava et al.,
2014) and an exponential linear unit activation
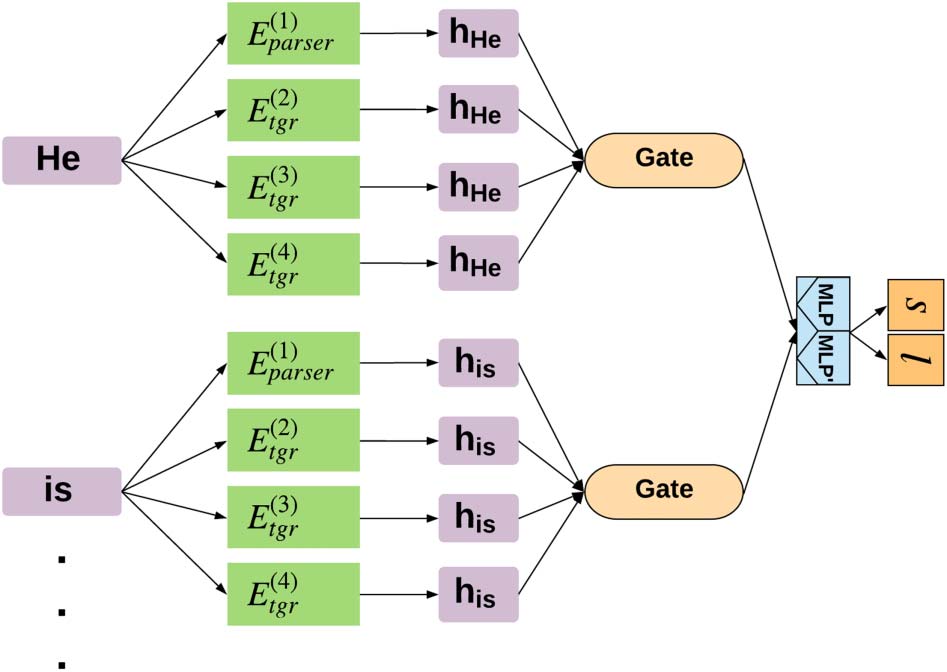
Figura 3: An illustration of the hybrid parser with three
auxiliary sequence taggers. An input word vector is
(1)
passed through the parser encoder (E
parser) and the
(4)
(2)
three pre-trained tagger encoders (E
tgr). IL
tgr
gating mechanism (Gate) computes a weighted average
of the hidden vectors. Finalmente, the output of the gating
mechanism is passed to the BiAFFINE decoder to predict
the arc and label scores for each word pair.
− E
function (Clevert et al., 2016), followed by a final
softmax layer that outputs the tag probabilities.
4.2 The Final Hybrid Parser (Step 5)
In step 5, the final step of Algorithm 1, we integrate
the BiLSTM of
the sequence tagger, Quale
encodes the information in the automatically
generated dependency trees, with the base parser.
Importantly, when doing so we initialize the
BiLSTM weights to those to which it converged
at step 4. The parameters of the base (BiAFFINE)
parser, in contrast, are randomly initialized. IL
resulting hybrid parser is then trained on the
labeled data in L. This way, the final model
integrates the information from both L and the
automatic tagging of U, generated in step 2 E 3.
We next describe how the encoders of the
sequence tagger and the BiAFFINE parser, Etgr
and Eparser, are integrated through a gating
meccanismo, similar to that of Sato et al. (2017).
The Gating Mechanism Given an input word
vector ft (§ 3), the gating mechanism learns to
scale between the BiLSTM encoder of the parser
to that of the sequence tagger (Figura 3):
at = σ(Wg[Eparser(piedi); Etgr(piedi)] + bg),
gt = at (cid:6) Eparser(piedi) + (1 − at) (cid:6) Etgr(piedi).
Dove (cid:6) is the element-wise product, σ is the
sigmoid function, and Wg and bg are the gating
699
mechanism parameters. The combined vector gt
is then fed to the parser’s decoder.
Extension to n ≥ 2 Sequence Taggers We can
naturally extend our hybrid parser to support n
auxiliary taggers (see again Figure 3). Given n
taggers trained on n different tagging schemes,
the gating mechanism is modified to be:
(io)
T
S
= W (io)
G
[E(1)
parser
(piedi); . . . ; E
(n+1)
tgr
(piedi)]
+ B(io)
(io)
G , UN
T
=
(cid:3)
(2)
(piedi); E
tgr
(io)
esp(S
)
T
n+1
j=1 exp(S
)
(j)
T
n+1(cid:2)
,
(io)
UN
T
(cid:6) E
(io)
tgr
(piedi).
(1)
gt = a
T
(cid:6) E(1)
parser
(piedi) +
i=2
This extension provides a richer representation
of the automatic tree structures, as every tagging
scheme captures a different aspect of the trees.
in most of our experiments, Quando
Infatti,
integrating the base parser with our three proposed
schemes, the resulting model was superior to
models that consider a single tagging scheme.
5 Evaluation Setups
This paper focuses on exploiting unlabeled data
in order to improve the accuracy of a supervised
parser. We expect this approach to be most useful
when the parser does not have sufficient labeled
data for training, or when the labeled training data
do not come from the same distribution as the test
dati. We hence focus on two setups:
io, yl
io
)}|l|
The Lightly Supervised In-domain Setup In
this setup we are given a small labeled dataset
L = {(xl
i=1 of sentences and their gold
dependency trees and a large unlabeled dataset
U = {(xu
i=1 of sentences coming from the
io
same domain, Dove |l| (cid:8) |U|. Our goal is to
parse sentences from the domain of L and U.
)}|U|
io, yl
io
)}|l|
)}|U|
The Unsupervised Domain Adaptation Setup
In this setup we are given a labeled source domain
dataset L = {(xl
i=1 of sentences and their
gold dependency trees, and an unlabeled dataset
U = {(xu
i=1 of sentences from a different
io
target domain. Unlike the lightly-supervised setup,
here L may be large enough to train a high-quality
parser as long as the training and test sets come
from the same domain. Tuttavia, our goal here is
to parse sentences from the target domain.
700
6 Experiments
We experiment with the task of dependency
parsing, in two setups: (UN) lightly supervised in-
domain and (B) unsupervised domain adaptation.
Data We consider two datasets: (UN) The English
OntoNotes 5.0 (Hovy et al., 2006) corpus.
This corpus consists of text from 7 domini:
broadcast conversation (bc: 11877 training, 2115
development, E 2209 test sentences), broadcast
news (bn: 10681, 1293, 1355), magazine (mz:
6771, 640, 778), news
(nw: 34967, 5894,
2325), bible (pt: 21518, 1778, 1867), telephone
conversation (tc: 12889, 1632, 1364), and Web
(wb: 15639, 2264, 1683).2 The corpus is annotated
with constituency parse trees and POS tags, COME
well as other labels that we do not use in
our experiments. The constituency trees were
converted to dependency trees using the Elitcloud
conversion tool.3 In the lightly supervised setup
we experiment with each domain separately.
We further utilize this corpus in our domain
(B) The UD dataset
adaptation experiments.
(McDonald et al., 2013; Nivre et al., 2016,
2018). This corpus contains more than 100
corpora of over 70 languages, annotated with dep-
endency trees and universal POS tags. For the
lightly supervised setup we chose 10 low-resource
languages that have no more than 10K training
sentences: Old Church Slavonic (cu), Danish
(da), Persian (fa), Indonesian (id), Latvian (lv),
Slovenian (sl), Swedish (sv), Turkish (tr), Urdu
(ur), and Vietnamese (vi), and performed mono-
lingual experiments with each.4 For the domain
adaptation setup we experiment with 5 languages,
considering two corpora from different domains
for each: Czech (cs fictree: fiction, cs pdt: news
and science), Galician (gl ctg: science and legal,
gl treegal: news), Italian (it isdt:
legal, news
and wiki, it postwita: social media), Romanian
(ro nonstandard: poetry and bible, ro rrt: news,
literature, science, legal and wiki), and Swedish
(sv lines:
literature and politics, sv talbanken:
news and textbooks).
Training Setups For the lightly supervised setup
we performed experiments with the 7 OntoNotes
2We removed wb test set sentences where all words are
POS tagged with ‘‘XX’’.
3https://github.com/elitcloud/elit-java.
4In case a language has multiple corpora, our training,
IL
sets are concatenations of
development and test
corresponding sets in these corpora.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
T
l
UN
C
_
UN
_
0
0
2
9
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
domains and the 10 UD corpora, for a total of
17 in-domain setups. For each setup we consider
three settings that differ from each other in the
size of the randomly selected labeled training and
development sets: 100, 500, O 1000.5 We use the
original test sets for evaluation, and the remaining
training and development sentences as unlabeled
dati.
For the English unsupervised domain adaptation
setup, we consider the news (nw) section of Onto-
Notes 5.0 as the source domain, and the remaining
sections as the target domains. The nw training
and development sets are used for the training
and development of the parser, and the unlabeled
versions of the target domain training and develop-
ment sets are used for training and development
of the representation model. The final model is
evaluated on the target domain test set.
Allo stesso modo, for unsupervised domain adaptation
with the UD languages, we consider within each
language one corpus as the source domain and the
other as the target domain, and apply the same
train/development/test splits as above. For each
language we run two experiments, differing in
which of the two corpora is considered the source
and which is considered the target.
For all domain adaptation experiments, Quando
training the final hybrid parser (Figura 3) we
sometimes found it useful to keep the parameters
of the BiLSTM tagger(S) fixed in order to avoid
an overfitting of the final parser to the source
domain. We treat the decision of whether or not
to keep the parameters of the tagger(S) fixed as a
hyper-parameter of the DCST models and tune it
on the development data.
We measure parsing accuracy with the standard
Unlabeled and Labeled Attachment Scores (UAS
and LAS), and measure statistical significance
with the t-test (following Dror et al., 2018).
consider
Models and Baselines We
four
variants of our DCST algorithm, differing on the
word tagging scheme on which the BiLSTM of
step 4 is trained (§ 4.1): DCST-NC: with the
Number of Children scheme, DCST-DR: con
the Distance from the Root scheme, DCST-RPE:
with the Relative POS-based Encoding scheme,
and DCST-ENS where the parser is integrated
with three BiLSTMs, one for each scheme (Dove
ENS stands for ensemble) (§ 4.2).
To put
the results of our DCST algorithm
in context, we compare its performance to the
following baselines. Base:
the BiAFFINE parser
(§ 3), trained on the labeled training data. Base-FS:
the BiAFFINE parser (§ 3), trained on all the labeled
data available in the full training set of the corpus.
In the domain adaptation setups Base-FS is trained
on the entire training set of the target domain.
This baseline can be thought of as an upper bound
on the results of a lightly-supervised learning
or domain-adaptation method. Base + Random
Gating (RG): a randomly initialized BiLSTM
is integrated to the BiAFFINE parser through the
gating mechanism, and the resulting model is
trained on the labeled training data. We compare
to this baseline in order to quantify the effect
of the added parameters of the BiLSTM and the
gating mechanism, when this mechanism does not
inject any information from unlabeled data. Self-
training: the traditional self-training procedure.
We first train the Base parser on the labeled
training data, then use the trained parser to parse
the unlabeled data, and finally re-train the Base
parser on both the manual and automatic trees.
We would also like to test the value of training a
representation model to predict the dependency
labeling schemes of § 4.1,
in comparison to
the now standard pre-training with a language
modeling objective. Hence, we experiment with a
variant of DCST where the BiLSTM of step 4 È
trained as a language model (DCST-LM). Finalmente,
we compare to the cross-view training algorithm
(CVT) (Clark et al., 2018), which was developed
for semi-supervised learning with DNNs.6
Hyper-parameters We use the BiAFFINE parser
implementation of Ma et al. (2018).7 We consider
the following hyper-parameters for the parser and
the sequence tagger: 100 epochs with an early
stopping criterion according to the development
set, the ADAM optimizer (Kingma and Ba, 2015),
a batch size of 16, a learning rate of 0.002, E
dropout probabilities of 0.33.
The 3-layer stacked BiLSTMs of the parser
and the
tagger generate hidden
representations of size 1024. The fully connected
layers of the tagger are of size 128 (first layer)
sequence
6https://github.com/tensorflow/models/
5In languages where the development set was smaller than
tree/master/research/cvt text.
1000 sentences we used the entire development set.
7https://github.com/XuezheMax/NeuroNLP2.
701
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
l
UN
C
_
UN
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
T
l
UN
C
_
UN
_
0
0
2
9
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
bc
bn
mz
nw
pt
tc
wb
Model
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
Base
Base+RG
DCST-LM
Self-Training
CVT
DCST-NC
DCST-DR
DCST-RPE
DCST-ENS
74.54
77.10
75.94
74.64
78.47
78.21
78.61
78.70
78.95
70.77
73.45
72.33
71.18
73.54
74.62
74.80
75.11
75.43
80.57
81.90
80.01
82.35
82.76
82.32
83.32
83.07
83.52
77.63
79.06
76.96
79.75
78.19
79.52
80.26
80.41
80.93
81.47
83.02
82.50
83.44
82.90
83.52
84.27
84.16
84.67
78.41
80.29
79.53
80.86
78.56
80.61
81.15
81.62
81.99
80.40
81.80
80.33
81.93
85.55
81.95
82.67
83.02
82.89
77.56
79.24
77.57
79.43
82.30
79.17
79.74
80.45
80.41
86.95
88.13
87.53
87.50
90.36
88.83
88.90
88.95
89.38
83.86
85.42
84.56
84.52
87.05
85.62
85.66
85.96
86.47
72.15
73.87
72.16
69.70
75.36
75.35
75.05
75.35
76.47
68.34
69.97
68.30
66.62
69.96
71.05
70.82
71.06
72.54
78.74
78.93
77.09
79.18
78.03
78.76
79.80
80.25
80.52
73.24
75.37
73.49
75.86
73.10
75.10
76.12
76.91
77.32
Base-FS
86.23
84.49
89.41
88.17
89.19
87.80
89.29
88.01
94.08
92.83
77.12
75.36
87.23
85.56
Tavolo 1: Lightly supervised OntoNotes results with 500 training sentences. Base-FS is an upper bound.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
T
UN
C
l
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
.
1
0
1
1
6
2
/
T
7
0
2
cu
da
fa
id
lv
sl
sv
tr
ur
vi
Model
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
Base
Base+RG
DCST-LM
Self-Training
CVT
DCST-NC
DCST-DR
DCST-RPE
DCST-ENS
75.87
77.98
77.67
75.19
61.57
78.85
79.31
80.57
80.55
67.25
69.01
68.90
68.07
45.60
69.75
70.20
71.83
71.79
78.13
80.21
80.23
79.76
72.77
81.23
81.30
81.48
82.07
74.16
76.11
76.06
75.92
66.93
76.70
76.81
77.45
78.04
82.54
84.74
83.92
85.04
81.08
85.94
86.20
86.82
87.02
78.59
80.83
79.89
81.05
74.32
81.85
82.14
82.69
83.13
72.57
73.18
72.61
74.07
72.51
74.18
74.56
74.56
74.47
57.25
57.56
57.36
58.73
54.94
58.63
58.92
59.19
59.13
72.81
74.51
73.89
74.79
68.90
76.19
76.99
77.45
77.63
65.66
67.60
66.59
68.22
57.36
68.73
69.24
70.38
70.36
76.00
78.18
76.90
77.71
67.89
79.26
80.34
80.45
80.68
69.28
71.27
70.12
71.33
59.79
72.72
73.35
74.13
74.32
78.58
79.90
78.73
79.72
77.08
81.05
81.40
81.95
82.40
72.78
73.70
72.51
74.12
69.60
75.09
75.41
75.98
76.61
56.07
58.42
57.33
57.34
53.17
58.17
58.30
59.49
59.60
39.37
40.32
39.27
40.06
32.95
39.95
40.25
41.45
41.72
84.49
86.18
85.78
85.63
81.49
86.17
86.19
86.86
86.96
78.10
79.65
79.27
79.51
72.72
79.91
79.68
80.92
80.85
67.18
68.75
69.11
68.24
60.84
69.93
69.46
70.23
70.37
62.51
64.64
65.09
63.96
50.98
65.91
65.65
66.26
66.88
Base-FS
86.13
81.46
85.55
82.93
91.06
88.12
77.42
62.31
85.02
81.59
86.04
82.22
85.18
81.36
62.21
46.23
89.84
85.12
73.26
69.69
Tavolo 2: Lightly supervised UD results with 500 training sentences. Base-FS is an upper bound.
l
UN
C
_
UN
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
T
l
UN
C
_
UN
_
0
0
2
9
4
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
E 64 (second layer). All other parser hyper-
parameters are identical to those of the original
implementation.
We utilize 300-dimensional pre-trained word
embeddings: Guanto (Pennington et al., 2014)8 for
English and FastText (Grave et al., 2018)9 for the
UD languages. Character and POS embeddings
are 100-dimensional and are initialized to random
normal vectors. CVT is run for 15K gradient
update steps.
7 Results
Tavolo 1 presents the lightly supervised OntoNotes
results when training with 500 labeled sentences,
and Table 2 presents the UD results in the same
setup. Tables 3 E 4 report domain adaptation
results for the 6 OntoNotes and 10 UD target do-
mains, rispettivamente. Underscored results are sig-
nificant compared to the highest scoring baseline,
based on t-test with p < 0.05.10
all
integrates
DCST with Syntactic Self-training DCST-
ENS, our model
three
that
syntactically self-trained BiLSTMs, is clearly the
best model. In the lightly supervised setup, it
performs best on 5 of 7 OntoNotes domains and
on 8 of 10 UD corpora (with the UAS measure).
In the cases where DCST-ENS is not the best
performing model, it is the second or third best
model. In the English and multilingual domain
adaptation setups, DCST-ENS is clearly the best
performing model, where in only 2 multilingual
target domains it is second.
Moreover, DCST-NC, DCST-DR, and DCST-
RPE, which consider only one syntactic scheme,
also excel in the lightly supervised setup. They
outperform all the baselines (models presented
above the top separating lines in the tables)
in the UD experiments, and DCST-RPE and
DCST-DR outperform all the baselines in 5 of
7 Ontonotes domains (with the LAS measure). In
the domain adaptation setup, however, they are on
par with the strongest baselines, which indicates
the importance of exploiting the information in all
three schemes in this setup (results are not shown
in Tables 3 and 4 in order to save space).
8http://nlp.stanford.edu/data/glove.
840B.300d.zip.
9https://fasttext.cc/docs/en/crawl-
vectors.html.
10For this comparison, Base-FS is not considered a
baseline, but an upper bound.
703
Note, that with few exceptions, DCST-NC is
the least effective method among the syntactically
self-trained DCST alternatives. This indicates
that encoding the number of children each word
has in the dependency tree is not a sufficiently
informative view of the tree.
Comparison to Baselines The CVT algorithm
performs quite well in the English OntoNotes
lightly supervised setup—it is the best performing
model on two domains (nw and pt) and the best
baseline for three other domains when considering
the UAS measure (bc, bn, and tc). However,
its performance substantially degrades in domain
adaptation. Particularly, in 5 out of 6 OntoNotes
setups and in 9 out of 10 UD setups it is the
worst performing model. Moreover, CVT is the
worst performing model in the lightly supervised
multilingual setup.
Overall,
this recently proposed model
that
demonstrated strong results across several NLP
tasks, does not rival our DCST models with
syntactic self-training in our experimental tasks.
Notice that Clark et al. (2018) did not experiment
in domain adaptation setups and did not consider
languages other than English. Our results suggest
that in these cases DCST with syntactic self-
training is a better alternative.
We next evaluate the impact of the different
components of our model. First, comparison with
DCST-LM—the version of our model where the
syntactically self-trained BiLSTM is replaced
with a BiLSTM trained on the same unlabeled
data but with a language modeling objective,
allows us to evaluate the importance of the
self-generated syntactic signal. The results are
conclusive: in all our four setups—English and
multilingual lightly supervised, and English and
multilingual domain adaptation—DCST-LM is
outperformed by DCST-ENS that considers all
three self-trained BiLSTMs. DCST-LM is also
consistently outperformed by DCST-RPE, DCST-
DR and DCST-NC that consider only one syntactic
annotation scheme, except from a few English
lightly supervised cases where it outperforms
DCST-NC by a very small margin. Syntactic
self-supervision hence provides better means of
exploiting the unlabeled data, compared with the
standard language modeling alternative.
Another question is whether the BiLSTM mod-
els should be trained at all. Indeed, in recent
papers untrained LSTMs with random weights
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
t
l
a
c
_
a
_
0
0
2
9
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
bc
bn
mz
pt
tc
wb
Model
LAS
LAS
LAS
LAS
LAS
LAS
Base
Base+RG
DCST-LM
Self-Training
CVT
81.60
82.51
82.48
80.61
74.81
85.17
85.36
85.77
84.52
84.90
85.48
85.77
86.28
85.38
84.49
87.70
88.34
89.28
87.69
85.71
75.46
75.68
75.72
73.62
72.10
83.85
84.34
84.34
82.82
82.31
DCST-ENS
85.96
88.02
88.55
91.62
79.97
87.38
Base-FS
84.49
88.17
87.80
92.83
75.36
85.56
Table 3: Unsupervised Domain adaptation OntoNotes results. Base-FS is an upper bound.
cs fictree
cs pdt
gl ctg
gl treegal
it isdt
it postwita
ro nonstandard
ro rrt
sv lines
sv talbanken
Model
Base
Base+RG
DCST-LM
Self-Training
CVT
DCST-ENS
Base-FS
LAS
69.92
73.12
73.59
69.50
59.77
75.28
84.46
LAS
LAS
81.83
80.86
83.33
81.53
81.53
59.05
58.97
59.41
59.67
51.12
86.50
59.75
83.70
84.44
LAS
60.31
60.52
60.54
61.41
50.31
60.98
78.09
LAS
67.82
67.54
67.52
68.02
58.60
69.13
90.02
LAS
80.72
80.36
80.95
82.01
70.07
83.06
81.22
LAS
65.03
65.93
65.19
66.47
50.82
67.65
81.71
LAS
LAS
62.75
61.50
62.46
63.84
45.15
77.08
77.58
77.40
77.60
45.25
63.46
77.86
84.99
82.43
LAS
77.93
78.04
77.62
77.64
62.87
78.97
86.67
Table 4: Unsupervised Domain adaptation UD results. Base-FS is an upper bound.
substantially
performance
enhanced model
(Zhang and Bowman, 2018; Tenney et al., 2019;
Wang et al., 2019; Wieting and Kiela, 2019).
the model
is identical
importantly,
in most experiments
Our results lead to two conclusions. Firstly,
to the
that
Base+RG,
syntactically trained DCST except that the BiAFFINE
parser is integrated with a randomly initialized
BiLSTM through our gating mechanism,
is
consistently outperformed by all our syntactically
self-trained DCST models, with very few
exceptions. Secondly, in line with the conclusions
of the aforementioned papers, Base+RG is one of
the strongest baselines in our experiments. Perhaps
most
this
model outperforms the Base parser—indicating
the positive impact of the randomly initialized
the
representation models. Moreover,
strongest baseline in 2 English domain adaptation
setups and in 5 of 10 languages in the lightly
supervised multilingual experiments (considering
the UAS measure), and is
the second-best
baseline in 5 out of 7 English lightly supervised
setups (again considering the UAS measure).
The growing evidence for the positive impact
of such randomly initialized models should
motivate further investigation of the mechanism
that underlies their success.
is
it
Finally, our results demonstrate the limited
traditional self-training: In English
power of
704
domain adaptation it harms or does not improve
the Base parser; in multilingual domain adaptation
it is the best model in 2 cases; and it is the best
baseline in 2 of the 7 English lightly supervised
setups and in 3 of the 10 multilingual lightly
supervised setups. This supports our motivation
to propose an improved self-training framework.
8 Ablation Analysis and Discussion
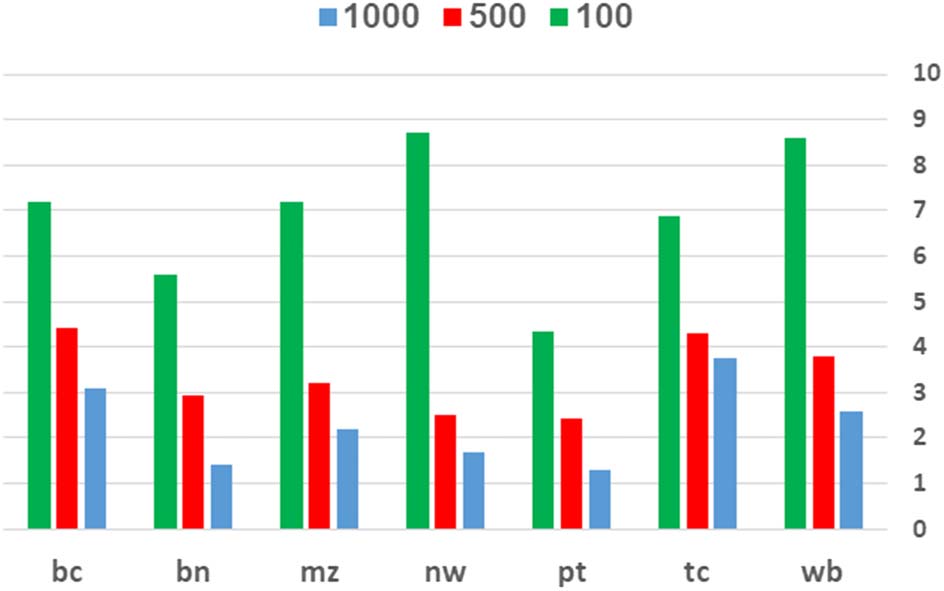
Impact of Training Set Size Figure 4 presents
the impact of the DCST-ENS method on the
BiAFFINE parser, in the 7 lightly supervised English
setups, as a function of the labeled training set
size of the parser. Clearly, the positive impact
is substantially stronger for smaller training sets.
Particularly, when the parser is trained with 100
sentences (the green bar) the improvement is
higher than 5 UAS points in 6 of 7 cases, among
which in 2 (nw and wb) it is higher than 8 UAS
points. For 500 training sentences the performance
gap drops to 2–4 UAS points, and for 1000 training
sentences it is 1–3 points.
This pattern is in line with previous literature
on the impact of training methods designed for the
lightly supervised setup, and particularly for self-
training when applied to constituency parsing
(Reichart and Rappoport, 2007). We note that
many studies failed to improve dependency
parsing with traditional self-training even for very
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
t
l
a
c
_
a
_
0
0
2
9
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Figure 4: UAS gap between DCST-ENS and the
Base parser, as a function of the training set size
(100/500/1000), across OntoNotes domains.
small training set sizes (Rush et al., 2012). We
also note that syntactically self-trained DCST
consistently improves the BiAFFINE parser in our
domain adaptation experiments, although the
entire training set of the news (nw) section of
OntoNotes is used for training.
Impact of Self-training Quality We next aim
to test the connection between the accuracy of
the self-trained sequence taggers and the quality
of the BiAFFINE parser when integrated with the
BiLSTM encoders of these taggers. Ideally, we
would expect that the higher the quality of the
BiLSTM, the more positive its impact on the
parser. This would indicate that the improvement
we see with the DCST models indeed results
from the information encoded in the self-trained
taggers.
To test this hypothesis, Figure 5 plots, for
each of the BiLSTM taggers considered in this
paper, the sentence-level accuracy scores of the
tagger when applied to the OntoNotes test sets
vs. the LAS scores of the BiAFFINE parser that was
integrated with the corresponding BiLSTM, when
that parser was applied to the same test sentences.
In such a plot, if the regression line that fits the
points has an R-squared (R2) value of 1, this
indicates a positive linear relation between the
self-trained tagger and the parser quality.
The resulting R2 values are well aligned
with the relative quality of the DCST models.
Particularly, DCST-LM, the least efficient method
where the tagger is trained as a language model
rather than on a syntactic signal, has an R2 of 0.03.
DCST-DR and DCST-NC, which are the next in
terms of parsing quality (Table 1), have R2 values
Figure 5: Auxiliary task accuracy scores of each
BiLSTM tagger vs. the LAS score of the BiAFFINE parser
when integrated with that BiLSTM. The BiLSTM
scores are computed on the test sets and reflect the
capability of the BiLSTM that was trained on unlabeled
data with syntactic signal extracted from the base
parser’s trees (or as a language model for DCST-LM)
to properly tag the test sentences. The points correspond
to sentence scores across all OntoNotes 5.0 test sets,
and the heat map presents the frequency of each point.
of 0.36 and 0.47, respectively, although DCST-DR
performs slightly better. Finally, DCST-RPE, the
best performing model among the four in all cases
but two, has an R2 value of 0.76. These results
provide a positive indication of the hypothesis
that the improved parsing quality is caused by the
representation model and is not a mere artifact.
Tagging Scheme Quality Analysis We next
aim to shed more light on the quality of the tagging
schemes with which we train our BiLSTM taggers.
We perform an error analysis on the parse trees
produced by the final hybrid parser (Figure 3),
when each of the schemes is used in the BiLSTM
tagger training step during the lightly supervised
setups. The metrics we compute correspond to the
three tagging schemes, and our goal is to examine
whether each of the self-trained representation
models (BiLSTMs) improves the capability of the
final parser to capture the information encoded in
its tagging scheme.
Particularly, we consider four metrics: Absolute
Difference of Number of Children (AD-NC):
The absolute difference between the number
of children a word has in the gold tree and
the corresponding number in the predicted tree;
Absolute Difference of Distance from the Root
(AD-DR): The absolute difference between the
705
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
t
l
a
c
_
a
_
0
0
2
9
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Model
AD-NC
AD-DR
AD-PDH
POS Head Error
Base
DCST-NC
DCST-DR
DCST-RPE
DCST-ENS
Base
DCST-NC
DCST-DR
DCST-RPE
DCST-ENS
0.305
0.274
0.264
0.263
0.257
0.366
0.327
0.322
0.316
0.312
OntoNotes
0.539
0.510
0.460
0.475
0.458
UD
0.600
0.551
0.538
0.534
0.524
1.371
1.196
1.099
1.128
1.121
1.377
1.168
1.135
1.137
1.128
0.162
0.146
0.141
0.137
0.135
0.163
0.148
0.146
0.141
0.139
Table 5: Tagging scheme error analysis.
Model
UAS
LAS
Base
54.86
DCST-LM 55.26
54.22
50.61
Self-Training
CVT
52.65
52.63
52.16
46.13
DCST-ENS
58.85
56.64
Table 6: Sentence length adaptation results.
distance of a word from the root in the gold tree
and the corresponding distance in the predicted
tree; Absolute Difference of Positional Distance
from the Head (AD-PDH): The absolute difference
between the positional distance of a word from
its head word according to the gold tree and the
corresponding number according to the predicted
tree (Kiperwasser and Ballesteros, 2018) (we
count the words that separate the head from the
modifier in the sentence, considering the distance
negative if the word is to the right of its head);
and POS Head Error: an indicator function which
returns 0 if the POS tag of the head word of a
given word according to the gold tree is identical
to the corresponding POS tag in the predicted tree,
and 1 otherwise.
For all the metrics we report the mean value
across all words in our test sets. The values of
AD-NC, AD-DR, and AD-PDH are hence in the
[0, M ] range, where M is the length of the longest
sentence in the corpus. The values of the POS
Head Error are in the [0, 1] range. For all metrics
lower values indicate that the relevant information
has been better captured by the final hybrid parser.
Table 5 presents a comparison between the Base
parser to our DCST algorithms. All in all, the
DCST models outperform the Base parser across
all comparisons, with DCST-ENS being the best
706
model in all 8 cases except from one. The analysis
indicates that in some cases a BiLSTM tagger
with a given tagging scheme directly improves
the capability of the final parser to capture the
corresponding information. For example, DCST-
DR, whose tagging scheme considers the distance
of each word from the root of the tree, performs
best (OntoNotes) or second best (UD) on the AD-
DR metric compared to all other models except for
the DCST-ENS model that contains the DCST-
DR model as a component. Likewise, DCST-RPE,
which encodes information about the POS tag of
the head word for every word in the sentence,
is the best performing model in terms of POS
Head Error. In contrast to the relative success of
DCST-RPE and DCST-DR in improving specific
capabilities of the parser, DCST-NC, our weakest
model across experimental setups,
is also the
weakest DCST model
in this error analysis,
even when considering the AD-NC metric that
measures success in predicting the number of
children a word has in the tree.
Sentence Length Adaptation We next aim to
test whether DCST can enhance a parser trained
on short sentences so that it can better parse long
sentences. Dependency parsers perform better on
short sentences, and we would expect self-training
to bring in high-quality syntactic information from
automatically parsed long sentences.
For this aim, we replicate the OntoNotes wb
in-domain experiment, except that we train the
parser on all training set sentences of up to 10
words, use the training set sentences with more
than 10 words as unlabeled data for sequence
tagger training (Algorithm 1, step 4), and test the
final parser on all test sentences with more than
10 words.
Table 6 shows that DCST-ENS improves the
Base parser in this setup by 3.99 UAS and LAS
points. DCST-LM achieves only a marginal UAS
improvement while CVT substantially harms the
parser. This result further supports the value of
our methods and encourages future research in
various under-resourced setups.
ELMo Embeddings Finally, we turn to invest-
igate the impact of deep contextualized word em-
beddings, such as ELMo (Peters et al., 2018), on
the base parser and on the DCST-ENS model.
To this end, we replace the Glove/FastText word
embeddings from our original experiments with
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
t
l
a
c
_
a
_
0
0
2
9
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
bc
bn
mz
nw
pt
tc
wb
Model
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
Base+ELMo
Base+ELMo+G
DCST-ENS+ELMo
77.96
74.47
80.00
73.97
70.91
75.94
83.12
80.42
85.02
80.18
77.45
81.98
84.62
81.15
86.24
81.37
78.41
82.54
83.09
80.91
84.56
80.35
78.24
81.91
88.82
87.73
90.27
85.55
84.92
86.86
73.84
70.19
77.68
69.23
66.78
72.72
79.67
76.02
82.00
75.77
72.68
77.93
Table 7: Lightly supervised OntoNotes results with ELMo embeddings.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
7
0
7
cu
da
fa
id
lv
sl
sv
tr
ur
vi
Model
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
UAS
LAS
Base+ELMo
Base+ELMo+G
DCST-ENS+ELMo
72.35
75.47
73.90
61.43
67.07
61.62
80.32
79.12
82.29
76.86
75.05
78.49
85.84
83.09
87.87
81.71
79.43
83.25
73.68
73.00
74.95
58.01
57.69
58.55
79.93
72.86
82.47
73.91
67.13
76.41
76.40
74.99
79.69
67.52
69.75
70.36
81.51
79.66
83.93
76.10
74.29
78.27
53.36
53.87
59.35
34.67
39.30
36.81
86.11
84.83
87.51
79.91
78.53
81.53
71.28
66.57
72.76
67.04
61.56
68.48
Table 8: Lightly supervised UD results with ELMo embeddings.
l
a
c
_
a
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
t
l
a
c
_
a
_
0
0
2
9
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
(cid:3)2
the multilingual ELMo word embeddings of Che
et al. (2018). We follow Che et al. (2018) and
define the ELMo word embedding for word i as:
wi = W ELM o · 1
, where W ELM o
3
is a trainable parameter and hELM o
is the hidden
representation for word i in the j’th BiLSTM
layer of the ELMo model, which remains fixed
throughout all experiments.
j=0 hELM o
i,j
i,j
We experiment with three models: Base +
ELMo: the BiAFFINE parser fed by the ELMo word
embeddings and trained on the labeled training
data; Base + ELMo + Gating (G): the BiAFFINE
parser fed by our original word embeddings, and
ELMo word embeddings are integrated through
our gating mechanism. Training is done on the
labeled training data only; and DCST-ENS +
ELMo: our ensemble parser where the BiLSTM
taggers and the Base parser are fed by the ELMo
word embeddings.
Tables 7 (OntoNotes) and 8 (UD) summarize
the results in the lightly supervised setups with 500
training sentences. As in previous experiments,
DCST-ENS+ELMo is the best performing model
in both setups. Although Base+ELMo+G is
superior in the cu and tr (LAS) setups, it is
inferior in all OntoNotes domains. Note also that
DCST-ENS+ELMo improves the UAS results of
DCST-ENS from Tables 1 and 2 on all OntoNotes
domains and on 7 out of 10 UD languages.
9 Conclusions
We proposed a new self-training framework
for dependency parsing. Our DCST approach is
based on the integration of (a) contextualized em-
bedding model(s) into a neural dependency parser,
where the embedding models are trained on
word tagging schemes extracted from the trees
generated by the base parser on unlabeled data.
lightly supervised and domain
In multilingual
adaptation experiments, our models consistently
outperform strong baselines and previous models.
In future work we intend to explore improved
word tagging schemes, sequence tagging archi-
tectures, and integration mechanisms. We shall also
consider cross-language learning where the lexical
gap between languages should be overcome.
Acknowledgments
We would like to thank the action editor and
the reviewers, as well as the members of the
their valuable
IE@Technion NLP group for
708
feedback and advice. This research was partially
funded by an ISF personal grant no. 1625/18.
References
Steven Abney. 2004. Understanding the Yarowsky
algorithm. Computational Linguistics, 30(3):
365–395.
Gabor Angeli, Melvin Jose Johnson Premkumar,
and Christopher D. Manning. 2015. Leveraging
linguistic structure for open domain information
extraction. In Proceedings of ACL.
Mikel Artetxe, Gorka Labaka, and Eneko Agirre.
2018. A robust
self-learning method for
fully unsupervised cross-lingual mappings of
the
word embeddings.
56th Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long
Papers), pages 789–798. Melbourne.
In Proceedings of
Avrim Blum and Tom Mitchell.
1998.
Combining labeled and unlabeled data with
co-training. In Proceedings of
the Eleventh
Annual Conference on Computational Learning
Theory, pages 92–100.
Wanxiang Che, Yijia Liu, Yuxuan Wang,
Bo Zheng, and Ting Liu. 2018. Towards
better ud parsing: Deep contextualized word em-
beddings, ensemble, and treebank concatena-
tion. In Proceedings of the CoNLL 2018 Shared
Task: Multilingual Parsing from Raw Text to
Universal Dependencies, pages 55–64.
Wenliang Chen, Youzheng Wu, and Hitoshi
Isahara. 2008. Learning reliable information for
dependency parsing adaptation. In Proceedings
of the 22nd International Conference on Com-
putational Linguistics-Volume 1, pages 113–120.
Wenliang Chen, Yue Zhang, and Min Zhang.
2014. Feature embedding for dependency
parsing. In Proceedings of COLING 2014,
the
on
Computational Linguistics: Technical Papers,
pages 816–826.
International Conference
25th
Kevin Clark, Minh-Thang Luong, Christopher
D. Manning, and Quoc V. Le. 2018. Semi-
supervised sequence modeling with cross-view
training. In Proceedings of the 2018 Conference
on Empirical Methods in Natural Language
Processing, pages 1914–1925.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
t
l
a
c
_
a
_
0
0
2
9
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Djork-Arn´e Clevert, Thomas Unterthiner, and
Sepp Hochreiter. 2016. Fast and accurate
deep network learning by exponential linear
units (ELUs). In 4th International Conference
on Learning Representations,
ICLR 2016,
San Juan, Puerto Rico, Conference Track
Proceedings.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Kristina Toutanova. 2019. BERT: Pre-training
of deep bidirectional transformers for language
understanding. In Proceedings of
the 2019
Conference of the North American Chapter of
the Association for Computational Linguistics:
Human Language Technologies, Volume 1
(Long and Short Papers), pages 4171–4186,
Minneapolis, MN.
Timothy Dozat and Christopher D. Manning. 2017.
Deep biaffine attention for neural dependency
parsing. In 5th International Conference on
Learning Representations, ICLR 2017, Toulon,
France, Conference Track Proceedings.
Rotem Dror, Gili Baumer, Segev Shlomov, and
Roi Reichart. 2018. The hitchhikers guide
to testing statistical significance in natural
language processing. In Proceedings of
the
56th Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long
Papers), pages 1383–1392, Melbourne.
Jack Edmonds. 1967. Optimum branchings.
Journal of Research of the National Bureau
of Standards B, 71(4):233–240.
Dan Goldwasser, Roi Reichart, James Clarke,
and Dan Roth. 2011. Confidence driven un-
supervised semantic parsing. In Proceedings of
the 49th Annual Meeting of the Association for
Computational Linguistics: Human Language
Technologies, pages 1486–1495.
Edouard Grave, Piotr Bojanowski, Prakhar Gupta,
Armand Joulin, and Tomas Mikolov. 2018.
Learning word vectors for 157 languages. In
Proceedings of the International Conference
on Language Resources and Evaluation (LREC
2018).
Christian Hadiwinoto and Hwee Tou Ng. 2017. A
dependency-based neural reordering model for
statistical machine translation. In Thirty-First
AAAI Conference on Artificial Intelligence.
Yulan He and Deyu Zhou. 2011. Self-training
from labeled features for sentiment analysis.
Information Processing & Management, 47(4):
606–616.
Daniel Hershcovich, Omri Abend, and Ari
Rappoport. 2017. A transition-based directed
acyclic graph parser for UCCA. In Proceedings
of the 55th Annual Meeting of the Association
for Computational Linguistics (Volume 1: Long
Papers), volume 1, pages 1127–1138.
Eduard Hovy, Mitchell Marcus, Martha Palmer,
Lance Ramshaw, and Ralph Weischedel. 2006.
Ontonotes: The 90% solution. In Proceedings of
the Human Language Technology Conference
the NAACL, Companion Volume: Short
of
Papers.
Kenji
Imamura and Eiichiro Sumita. 2018.
NICT self-training approach to neural machine
translation at NMT-2018. In Proceedings of the
2nd Workshop on Neural Machine Translation
and Generation, pages 110–115.
Diederik P. Kingma and Jimmy Ba. 2015. Adam:
A method for stochastic optimization.
In
Proceedings of ICLR.
Eliyahu Kiperwasser and Miguel Ballesteros.
2018. Scheduled multi-task learning: From
the
syntax to translation. Transactions of
Association for Computational Linguistics,
6:225–240.
Eliyahu Kiperwasser and Yoav Goldberg. 2016.
Simple and accurate dependency parsing
using bidirectional LSTM feature represen-
tations. Transactions of
the Association for
Computational Linguistics, 4:313–327.
Omer Levy and Yoav Goldberg. 2014. Dependency-
based word embeddings. In Proceedings of the
52nd Annual Meeting of the Association for
Computational Linguistics (Volume 2: Short
Papers), volume 2, pages 302–308.
Xuezhe Ma, Zecong Hu, Jingzhou Liu, Nanyun
Peng, Graham Neubig, and Eduard Hovy. 2018.
Stack-pointer networks for dependency parsing.
In Proceedings of the 56th Annual Meeting of
the Association for Computational Linguistics
(Volume 1: Long Papers), pages 1403–1414.
709
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
t
l
a
c
_
a
_
0
0
2
9
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Diego Marcheggiani, Anton Frolov, and Ivan Titov.
2017. A simple and accurate syntax-agnostic
neural model for dependency-based semantic
role labeling. In Proceedings of CoNLL.
Bryan McCann,
James Bradbury, Caiming
Xiong, and Richard Socher. 2017. Learned
in translation: Contextualized word vectors.
In Advances in Neural Information Processing
Systems, pages 6294–6305.
David McClosky, Eugene Charniak, and Mark
Johnson. 2006a. Effective self-training for
parsing. In Proceedings of the Main Conference
on Human Language Technology Conference of
the North American Chapter of the Association
of Computational Linguistics, pages 152–159.
David McClosky, Eugene Charniak, and Mark
Johnson. 2006b. Reranking and self-training for
parser adaptation. In Proceedings of the 21st
International Conference on Computational
Linguistics and the 44th annual meeting of
the Association for Computational Linguistics,
pages 337–344.
David McClosky, Eugene Charniak, and Mark
Johnson. 2010. Automatic domain adaptation
for parsing. In Human Language Technologies:
the North
The 2010 Annual Conference of
American Chapter of
the Association for
Computational Linguistics, pages 28–36.
Ryan McDonald,
Joakim Nivre, Yvonne
Quirmbach-Brundage, Yoav Goldberg, Dipanjan
Das, Kuzman Ganchev, Keith Hall, Slav Petrov,
Hao Zhang, Oscar T¨ackstr¨om, Claudia Bedini,
N´uria Bertomeu Castell´o, and Jungmee Lee.
2013. Universal dependency annotation for
multilingual parsing. In Proceedings of
the
51st Annual Meeting of the Association for
Computational Linguistics (Volume 2: Short
Papers), volume 2, pages 92–97.
Rada Mihalcea. 2004. Co-training and self-
training for word sense disambiguation. In
Proceedings of
the Eighth Conference on
Computational Natural Language Learning
(CoNLL-2004) at HLT-NAACL 2004.
Joakim Nivre, Mitchell Abrams,
ˇZeljko Agi´c,
Lars Ahrenberg, Lene Antonsen, Maria Jesus
Aranzabe, Gashaw Arutie, Masayuki Asahara,
Luma Ateyah, Mohammed Attia, Aitziber
Atutxa, Liesbeth Augustinus, Elena Badmaeva,
710
Miguel Ballesteros, Esha Banerjee, Sebastian
Bank, Verginica Barbu Mititelu, John Bauer,
Sandra Bellato, Kepa Bengoetxea, Riyaz
Ahmad Bhat, Erica Biagetti, Eckhard Bick,
Rogier Blokland, Victoria Bobicev, Carl
B¨orstell, Cristina Bosco, Gosse Bouma, Sam
Bowman, Adriane Boyd, Aljoscha Burchardt,
Marie Candito, Bernard Caron, Gauthier Caron,
G¨uls¸en Cebiro˘glu Eryi˘git, Giuseppe G. A.
Celano, Savas Cetin, Fabricio Chalub, Jinho
Choi, Yongseok Cho, Jayeol Chun, Silvie
Cinkov´a, Aur´elie Collomb, C¸ a˘grı C¸ ¨oltekin,
Miriam Connor, Marine Courtin, Elizabeth
Davidson, Marie-Catherine Marneffe, Valeria
Paiva, Arantza Ilarraza, Carly Dickerson,
Peter Dirix, Kaja Dobrovoljc, Timothy Dozat,
Kira Droganova, Puneet Dwivedi, Marhaba
Eli, Ali Elkahky, Binyam Ephrem, Tomaˇz
Erjavec, Aline Etienne, Rich´ard Farkas, Hector
Fernandez Alcalde, Jennifer Foster, Cl´audia
Freitas, Katar´ına Gajdoˇsov´a, Daniel Galbraith,
Marcos Garcia, Moa G¨ardenfors, Kim Gerdes,
Filip Ginter, Iakes Goenaga, Koldo Gojenola,
Memduh G¨okırmak, Yoav Goldberg, Xavier
G´omez Guinovart, Berta Gonz´ales Saavedra,
Matias Grioni, Normunds Gr¯uz¯ıtis, Bruno
Guillaume, C´eline Guillot-Barbance, Nizar
Habash, Jan Hajiˇc, Jan Hajiˇc Jr., Linh H`a
M˜y, Na-Rae Han, Kim Harris, Dag Haug,
Barbora Hladk´a, Jaroslava Hlav´aˇcov´a, Florinel
Hociung,
Jena Hwang,
Jel´ınek,
Radu Ion, Elena Irimia, Tom´aˇs
Anders Johannsen, Fredrik Jørgensen, H¨uner
Kas¸ıkara, Sylvain Kahane, Hiroshi Kanayama,
Jenna Kanerva, Tolga Kayadelen, V´aclava
Kettnerov´a, Jesse Kirchner, Natalia Kotsyba,
Simon Krek, Sookyoung Kwak, Veronika
Laippala, Lorenzo Lambertino, Tatiana Lando,
Septina Dian Larasati, Alexei Lavrentiev, John
%
%
ng LˆeHˆo`ng, Alessandro Lenci,
Lee, Phu
o
Saran Lertpradit, Herman Leung, Cheuk
Ying Li, Josie Li, Keying Li, Kyungtae
Lim, Nikola Ljubeˇsi´c, Olga Loginova,
Olga Lyashevskaya, Teresa Lynn, Vivien
Macketanz, Aibek Makazhanov, Michael
Mandl, Christopher Manning, Ruli Manurung,
C˘at˘alina M˘ar˘anduc, David Mareˇcek, Katrin
Marheinecke, Hector Martinez Alonso, Andr´e
Martins, Jan Maˇsek, Yuji Matsumoto, Ryan
Mcdonald, Gustavo Mendonc¸a, Niko Miekka,
Anna Missil¨a, C˘at˘alin Mititelu, Yusuke Miyao,
Simonetta Montemagni, Amir More, Laura
Petter Hohle,
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
t
l
a
c
_
a
_
0
0
2
9
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Moreno Romero, Shinsuke Mori, Bjartur
Mortensen, Bohdan Moskalevskyi, Kadri
Muischnek, Yugo Murawaki, Kaili M¨u¨urisep,
Pinkey Nainwani,
Juan Ignacio Navarro
Hor˜niacek, Anna Nedoluzhko, Gunta Neˇspore-
%
%
ng Nguyˆe˜n Thi, Huyˆe`n
B¯erzkalne, Lu
o
Nguyˆe˜n Thi Minh, Vitaly Nikolaev, Rattima
Nitisaroj, Hanna Nurmi, Stina Ojala, Ad´eday`o.
Ol´u`okun, Mai Omura, Petya Osenova, Robert
¨Ostling, Lilja Øvrelid, Niko Partanen, Elena
Pascual, Marco Passarotti, Agnieszka Patejuk,
Siyao Peng, Cenel-Augusto Perez, Guy
Perrier, Slav Petrov, Jussi Piitulainen, Emily
Pitler, Barbara Plank,Thierry Poibeau, Martin
Popel, Lauma Pretkalnin¸a, Sophie Pr´evost,
Prokopis Prokopidis, Adam Przepi´orkowski,
Tiina Puolakainen, Sampo Pyysalo, Andriela
R¨a¨abis, Alexandre Rademaker, Loganathan
Ramasamy, Taraka Rama, Carlos Ramisch,
Vinit Ravishankar, Livy Real, Siva Reddy,
Georg Rehm, Michael Rießler, Larissa
Rinaldi, Laura Rituma, Luisa Rocha, Mykhailo
Romanenko, Rudolf Rosa, Davide Rovati,
Shoval
Valentin Ros¸ca, Olga Rudina,
Samardˇzi´c,
Sadde,
Stephanie Samson, Manuela Sanguinetti,
Baiba Saul¯ıte, Yanin Sawanakunanon, Nathan
Schneider, Sebastian Schuster, Djam´e Seddah,
Wolfgang Seeker, Mojgan Seraji, Mo Shen,
Atsuko Shimada, Muh Shohibussirri, Dmitry
Sichinava, Natalia Silveira, Maria Simi, Radu
Simionescu, Katalin Simk´o, M´aria ˇSimkov´a,
Kiril Simov, Aaron Smith, Isabela Soares-
Bastos, Antonio Stella, Milan Straka, Jana
Strnadov´a, Alane Suhr, Umut Sulubacak, Zsolt
Sz´ant´o, Dima Taji, Yuta Takahashi, Takaaki
Tanaka,
Isabelle Tellier, Trond Trosterud,
Anna Trukhina, Reut Tsarfaty, Francis Tyers
Sumire Uematsu, Zdeˇnka Ureˇsov´a, Larraitz
Uria, Hans Uszkoreit, Sowmya Vajjala,
Daniel Niekerk, Gertjan Noord, Viktor Varga,
Veronika Vincze, Lars Wallin,
Jonathan
North Washington, Seyi Williams, Mats
Wir´en, Tsegay Woldemariam, Tak-Sum Wong,
Chunxiao Yan, Marat M. Yavrumyan, Zhuoran
Yu, Zdenˇek ˇZabokrtsk´y, Amir Zeldes, Daniel
Zeman, Manying Zhang, and Hanzhi Zhu. 2018.
Universal dependencies 2.2.
Saleh, Tanja
Shadi
Joakim Nivre, Marie-Catherine De Marneffe,
Filip Ginter, Yoav Goldberg,
Jan Hajic,
Christopher D. Manning, Ryan McDonald, Slav
711
Petrov, Sampo Pyysalo, Natalia Silveira, Reut
Tsarfaty, and Daniel Zeman. 2016. Universal
dependencies v1: A multilingual
treebank
collection. In LREC.
Jeffrey
Socher,
Pennington, Richard
and
Christopher D. Manning. 2014. GloVe: Global
vectors for word representation. In Proceedings
of the 2014 Conference on Empirical Methods
in Natural Language Processing (EMNLP),
pages 1532–1543.
Matthew Peters, Mark Neumann, Mohit
Iyyer, Matt Gardner, Christopher Clark,
Kenton Lee, and Luke Zettlemoyer. 2018.
Deep contextualized word representations. In
Proceedings of the 2018 Conference of the
North American Chapter of the Association for
Computational Linguistics: Human Language
Technologies, Volume 1 (Long Papers),
pages 2227–2237, New Orleans, LA.
Barbara Plank and ˇZeljko Agi´c. 2018. Distant
supervision from disparate sources for low-
resource part-of-speech tagging. In Proceedings
on Empirical
of
Methods in Natural Language Processing,
pages 614–620, Brussels.
2018 Conference
the
Barbara Plank and Gertjan Van Noord. 2011.
Effective measures of domain similarity for
parsing. In Proceedings of the 49th Annual
Meeting of the Association for Computational
Linguistics: Human Language Technologies-
Volume 1, pages 1566–1576.
Roi Reichart and Ari Rappoport. 2007. Self-
training for enhancement and domain adaptation
of statistical parsers trained on small datasets.
In Proceedings of the 45th Annual Meeting of
the Association of Computational Linguistics,
pages 616–623.
Sebastian Ruder and Barbara Plank. 2018. Strong
baselines for neural semi-supervised learning
In The 56th Annual
under domain shift.
Meeting of the Association for Computational
LinguisticsMeeting of
the Association for
Computational Linguistics.
Alexander M. Rush, Roi Reichart, Michael
Collins, and Amir Globerson. 2012. Improved
parsing and POS tagging using inter-sentence
In Proceedings of
consistency constraints.
the 2012 Joint Conference on Empirical
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
t
l
a
c
_
a
_
0
0
2
9
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Methods in Natural Language Processing and
Computational Natural Language Learning,
pages 1434–1444.
Piotr Rybak and Alina Wr´oblewska. 2018. Semi-
supervised neural system for tagging, parsing
and lematization. In Proceedings of the CoNLL
2018 Shared Task: Multilingual Parsing
from Raw Text
to Universal Dependencies,
pages 45–54.
Motoki Sato, Hitoshi Manabe, Hiroshi Noji, and
Yuji Matsumoto. 2017. Adversarial training for
cross-domain universal dependency parsing.
In Proceedings of the CoNLL 2017 Shared
Task: Multilingual Parsing from Raw Text to
Universal Dependencies, pages 71–79.
Ehsan Shareghi, Yingzhen Li, Yi Zhu, Roi
Reichart, and Anna Korhonen. 2019. Bayesian
learning for neural dependency parsing. In
Proceedings of the 2019 Conference of the
North American Chapter of the Association for
Computational Linguistics: Human Language
Technologies, Volume 1 (Long and Short
Papers), pages 3509–3519.
Anders Søgaard. 2010. Simple semi-supervised
In
part-of-speech
training
Proceedings of the ACL 2010 Conference Short
Papers, pages 205–208.
taggers.
of
Drahom´ıra Spoustov´a and Miroslav Spousta.
2010. Dependency parsing as a sequence
labeling task. Prague Bulletin of Mathematical
Linguistics, 94:7–14.
Nitish
Srivastava, Geoffrey Hinton, Alex
Krizhevsky,
and Ruslan
Ilya Sutskever,
Salakhutdinov. 2014. Dropout: A simple way
to prevent neural networks from overfitting.
Journal of Machine Learning Research,
15(1):1929–1958.
Mark
Steedman, Miles Osborne, Anoop
Sarkar, Stephen Clark, Rebecca Hwa, Julia
Hockenmaier, Paul Ruhlen, Steven Baker, and
Jeremiah Crim. 2003. Bootstrapping statistical
parsers from small datasets. In Proceedings of
the Tenth Conference on European Chapter of
the Association for Computational Linguistics-
Volume 1, pages 331–338.
Michalina Strzyz, David Vilares, and Carlos
G´omez-Rodrıguez. 2019. Viable dependency
712
parsing as sequence labeling. In Proceedings of
NAACL-HLT, pages 717–723.
Ian Tenney, Patrick Xia, Berlin Chen, Alex Wang,
Adam Poliak, R. Thomas McCoy, Najoung
Kim, Benjamin Van Durme, Samuel R.
Bowman, Dipanjan Das, and Ellie Pavlick.
2019. What do you learn from context? Probing
for sentence structure in contextualized word
representations. In Proceedings of ICLR.
Kristina Toutanova, Xi Victoria Lin, Wen-
tau Yih, Hoifung Poon, and Chris Quirk.
2016. Compositional learning of embeddings
relation paths in knowledge base and
for
the 54th Annual
text.
Meeting of the Association for Computational
Linguistics (Volume 1: Long Papers), volume 1,
pages 1434–1444.
In Proceedings of
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N. Gomez,
L´ ukasz Kaiser, and Illia Polosukhin. 2017.
In Advances
Attention is all you need.
in Neural Information Processing Systems,
pages 5998–6008.
Oriol Vinyals, L´ ukasz Kaiser, Terry Koo, Slav
Petrov, Ilya Sutskever, and Geoffrey Hinton.
2015. Grammar as a foreign language. In
Advances in Neural Information Processing
Systems, pages 2773–2781.
Alex Wang, Jan Hula, Patrick Xia, Raghavendra
Pappagari, R. Thomas McCoy, Roma Patel,
Najoung Kim, Ian Tenney, Yinghui Huang,
Katherin Yu, Shuning Jin, Berlin Chen,
Benjamin Van Durme, Edouard Grave, Ellie
Pavlick, and Samuel R. Bowman. 2019.
Can you tell me how to get past sesame
beyond
street? Sentence-level pretraining
the
language modeling.
57th Conference of
the Association for
Computational Linguistics, pages 4465–4476.
In Proceedings of
John Wieting and Douwe Kiela. 2019. No train-
ing required: Exploring random encoders for
sentence classification. In Proceedings of ICLR.
Vikas Yadav and Steven Bethard. 2018. A survey
on recent advances in named entity recognition
from deep learning models. In Proceedings
of
the 27th International Conference on
Computational Linguistics, pages 2145–2158.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
t
l
a
c
_
a
_
0
0
2
9
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
David Yarowsky. 1995. Unsupervised word sense
disambiguation rivaling supervised methods. In
33rd Annual Meeting of the Association for
Computational Linguistics.
Kelly W. Zhang and Samuel R. Bowman.
2018. Language modeling teaches you more
than translation does: Lessons learned through
auxiliary syntactic task analysis. In Proceedings
of the 2018 EMNLP Workshop BlackboxNLP:
Analyzing and Interpreting Neural Networks
for NLP, pages 359–361, Brussels.
Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015.
Character-level convolutional networks for text
classification. In Advances in Neural Infor-
mation Processing Systems, pages 649–657.
Zhi-Hua Zhou and Ming Li. 2005. Tri-training:
Exploiting unlabeled data using three classi-
fiers. IEEE Transactions on Knowledge & Data
Engineering, (11):1529–1541.
Yftah Ziser and Roi Reichart. 2018. Pivot
based language modeling for improved neural
domain adaptation. In Proceedings of the 2018
Conference of the North American Chapter
of
the Association for Computational Lin-
guistics: Human Language Technologies,
Volume 1 (Long Papers), pages 1241–1251,
New Orleans, LA.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
9
4
1
9
2
3
6
0
2
/
/
t
l
a
c
_
a
_
0
0
2
9
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
713