Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
Citation:
Sawicki, Jan; Ganzha, Maria; Paprzycki, Marcin. The state of the art of Natural Language Processing – a systematic
automated review of NLP literature using NLP techniques. Data Intelligence. DOI: 10.1162/dint_a_00213
The state of the art of Natural Language Processing – a
systematic automated review of NLP literature using NLP
techniques
Jan Sawicki†, Maria Ganzha† , Marcin Paprzycki†
Astratto
Nowadays, natural language processing (PNL) is one of the most popular areas of, broadly un-
derstood, artificial intelligence. Therefore, every day, new research contributions are posted, for
instance, to the arXiv repository. Hence, it is rather difficult to capture the current “state of the
field” and thus, to enter it. This brought the idea of applying state-of-the-art NLP techniques
to analyse the NLP-focused literature. Di conseguenza, (1) meta-level knowledge, concerning the
current state of NLP has been captured, E (2) a guide to use of basic NLP tools is provided.
It should be noted that all the tools and the dataset described in this contribution are publicly
available. Inoltre, the originality of this review lies in its full automation. This allows easy
reproducibility and continuation and updating of this research in the future as new researches
emerge in the field of NLP.
Keywords: natural language processing, text processing, literature survey, keyword search,
keyphrase search, text embeddings, text summarizations
1. introduzione
Natural language processing (PNL) is rapidly growing in popularity in a variety of domains,
from closely related, like semantics [1, 3] and linguistics [2, 4] (e.g. inflection [176], phonetics
and onomastics [175], automatic text correction [177]), named entity recognition [179, 178] A
distant ones, like biobliometry [6], cybersecurity [7], quantum mechanics [8, 9], gender stud-
ies [10, 5], chimica [11] or orthodontia [12]. Questo, among others, brings an opportunity, for
early-stage researchers, to enter the area. Since NLP can be applied to many domains and lan-
guages, and involves use of many techniques and approaches, it is important to realize where to
start.
This contribution attempts at addressing this issue, by applying NLP techniques to analysis
of NLP-focused literature. Di conseguenza, with a fully automated, systematic, visualization-driven
literature analysis, a guide to the state-of-the-art of natural language processing is presented.
In this way, two goals are achieved. (1) Providing introduction to NLP for scientists entering
the field, E (2) supporting possible knowledge update for experienced researchers. The main
research questions (RQs) considered in this work are:
†Corresponding author; Warsaw University of Technology; email:
jan.sawicki2.dokt@pw.edu.pl; ORCID: 0000-
0002-8930-7564)
†Warsaw University of Technology; email: maria.ganzha@pw.edu.pl; ORCID: 0000-0001-7714-4844) †Polish
Academy of Sciences; email: paprzyck@ibspan.waw.pl; ORCID: 0000-0002-8069-2152)
© 2023 Chinese Academy of Sciences. Published under a Creative Commons Attribution 4.0 Internazionale (CC BY
4.0) licenza.
Preprint submitted to Data Intelligence
Febbraio 27, 2023
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
D
N
/
io
T
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
.
/
T
/
1
0
1
1
6
2
D
N
_
UN
_
0
0
2
1
3
2
0
7
3
5
4
5
D
N
_
UN
_
0
0
2
1
3
P
D
.
/
T
io
F
B
sì
G
tu
e
S
T
T
o
N
0
9
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
RQ1: What datasets are considered to be most useful?
RQ2: Which languages, other than English, appear in NLP research?
RQ3: What are the most popular fields and topics in current NLP research?
RQ4: What particular tasks and problems are most often studied?
RQ5: Is the field “homogenous”, or are there easily identifiable “subgroups”?
RQ6: How difficult is it to comprehend the NLP literature?
Taking into account that the proposed approach is, itself, anchored in NLP, this work is also
an illustration of how selected standard NLP techniques can be used in practice, and which of
them should be used for which purpose. Tuttavia, it should be made clear that considerations
presented in what follows should be treated as “illustrative examples”, not “strict guidelines”.
Inoltre, it should be stressed that none of the applied techniques has been optimized to the
task (e.g. no hyperparameter tuning has been applied). This is a deliberate choice, as the goal is
to provide an overview and “general ideas”, rather than overwhelm the reader with technical de-
tails of individual NLP approaches. For technical details, concerning optimization of mentioned
approcci, reader should consult referenced literature.
The whole analysis has been performed in Python – a programming language which is ubiq-
uitous in data science research and projects for years [17, 16, 21, 18, 20, 19]. Python was also
chosen for the following reasons:
• It provides a heterogeneous environment
• It allows use of Jupyter Notebooks1, which allow quick and easy prototyping, testing and
code sharing
• There exists an abundance of data science libraries2, which allow everything from acquir-
ing the dataset, to visualizing the result
• It offers readability and speed in development [171]
Presented analysis follows the order of research questions. To make the text more readable,
readers are introduced to pertinent NLP methods in the context of answering individual questions.
2. Data and preprocessing
At the beginning of NLP research, there is always data. This section introduces the dataset
consisting of research papers used in this work, and describes how it was preprocessed.
1https://jupyter.org
2https://pypi.org
2
Data Intelligence
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
D
N
/
io
T
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
.
/
/
T
1
0
1
1
6
2
D
N
_
UN
_
0
0
2
1
3
2
0
7
3
5
4
5
D
N
_
UN
_
0
0
2
1
3
P
D
.
/
T
io
F
B
sì
G
tu
e
S
T
T
o
N
0
9
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
2.1. Data used in the research
To adequately represent the domain, and to apply NLP techniques, it is necessary to select an
abundant, and well-documented, repository of related texts (stored in a digital format). Inoltre,
to automatize the conducted analysis, and to allow easy reproduction, it is crucial to choose
a set of papers, which can be easily accessed, e.g. a database with a functional Application
Programming Interface (API). Finalmente, for obvious reasons, open access datasets are the natural
targets for NLP-oriented work.
In the context of this work, while there are multiple repositories, which contain NLP-related
literature, the best choice turned out to be arXiv (for the papers themselves, and for the metadata
it provided), combined with the Semantic Scholar (for the “citation network” and other important
metadati; see Section 3.3.1).
Note that other datasets have been considered, but were not selected. Reasons for this deci-
sion have been summarized in Table 1.
Tavolo 1: Consideration regarding databases not used in the analysis
Database
Google Scholar
PubMed
ResearchGate
Scopus
JSTOR
Microsoft Academic
The reason for in applicability in this research task
Google Scholar does not contain actual data (testo, PDF,
eccetera.)
of any work – there are only links to other
databases. Inoltre, performed tests determined that the
API (Python “scholarly” library) works well with small
queries, but fetching information about thousands of pa-
pers results in download rate limits, and temporary IP
address blocking. Finalmente, Google Scholar is criticized,
among others, for excessive secrecy [14], biased search
algorithms [13], and incorrect citation counts [15].
PubMed is mainly focused on medical and biological pa-
pers. Therefore, the number of works related to NLP is
somewhat limited, and difficult to identify using straight-
forward approaches.
There are two main problems with ResearchGate, as seen
from the perspective of this work: lack of easy-accessible
API and restrictions on some articles’ availability (large
number of papers has to be requested from authors – and
such requests may not be fulfilled, or wait time may be
excessive).
The Scopus API is not fully open-access, and has restric-
tions on the number of requests that can be issues within
a specific time.
Even though the JSTOR website 3 declares that API ex-
ist, the link does not provide any information about it
(404 not found).
The Microsoft Academic API is very well documented,
but it does not provide true open access (requires a sub-
scription key). Inoltre, it does not contain the actual
text of works; mostly metadata.
Data Intelligence
3
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
D
N
/
io
T
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
T
/
/
.
1
0
1
1
6
2
D
N
_
UN
_
0
0
2
1
3
2
0
7
3
5
4
5
D
N
_
UN
_
0
0
2
1
3
P
D
.
T
/
io
F
B
sì
G
tu
e
S
T
T
o
N
0
9
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
2.1.1. Dataset downloading and filtering
The papers were fetched from arXiv on 26 agosto 2021. The resulting dataset includes all ar-
ticles, which have been extracted as a result of issuing the query “natural language processing”4.
Di conseguenza, 4712 articles were retrieved. Two articles were discarded because their PDFs were
too complicated for the tools that were used for the text extraction (1710.10229v1 – problems
with chart on page 15; 1803.07136v1 – problems with chart on page 6; Vedere, also, section 2.2).
Even though the query was not bounded by the “time when the article was uploaded to arXiv”
parameter, it turned out that a solid majority of the articles had submission dates from the last
decade. Specifically, the distribution was as follows:
• 192 records uploaded before 2010-01-01
• 243 records from between (including) 2010-01-01 E 2014-12-31
• 697 records from between (including) 2015-01-01 E 2017-12-31
• 3580 records uploaded after 2018-01-01
On the basis of this distribution, it was decided that there is no reason to impose time con-
straints, because the “old” works should not be able to “overshadow” the “newest” literature.
Inoltre, it was decided that it is worth keeping all available publications, as they might result
in additional findings (per esempio., as what concerns the most original work, described in Section 3.7.4).
Finalmente, all articles not written in English were discarded, reducing the total count to 4576
texts. This decision, while somewhat controversial, was made to be able to understand the results
(by the authors of this contribution) and to avoid complex issues related to text translation. How-
ever, it is easy to observe that the number of texts not written in English (and stored in arXiv) era
relatively small (< 5%). Nevertheless, this leaves open a question: what is the relationship be-
tween NLP-related work that is written in English and that written in other languages. However,
addressing this topic is out of scope of this contribution.
2.2. Text preprocessing
Obviously, the key information about a research contribution is contained in its text. There-
fore, subsequent analysis applied NLP techniques to texts of downloaded papers. To do this, the
following preprocessing has been applied. The PDFs have been converted to plain text, using
pdfminer.six (a Python library5). Here, notice that there are several other libraries that can also
be used to convert PDF to text. Specifically, the following libraries have been tried: pdfminer6,
pdftotree7, BeautifulSoup8. On the basis of performed tests, pdfminer.six was selected, because
it provided the simplest API, produced results, which did not have to be further converted (as
opposite to, e.g., BeautifulSoup), and performed the fastest conversion.
4Specifically,
the query had the form http://export.arxiv.org/api/query?search\_query=all:\%
22natural\%20language\%20processing\%22&start=0\&max\_results=10000. Since such query may take
long time to load; to reduce time, one can change the value of the max results parameter to a smaller number, e.g.
5
5https://pdfminersix.readthedocs.io/en
6https://github.com/euske/pdfminer
7https://github.com/HazyResearch/pdftotree
8https://www.crummy.com/software/BeautifulSoup
4
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
.
t
/
/
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
3
2
0
7
3
5
4
5
d
n
_
a
_
0
0
2
1
3
p
d
.
/
t
i
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
Use of different text analysis methods may require different preprocessing. Some methods,
like keyphrase search, work best when the text is “thoroughly cleaned”; i.e. almost reduced to a
“bag of words” [167]. This means that, for instance, words are lemmatized, there is no punctua-
tion, etc. However, some more recent techniques (like text embeddings [168]) can (and should)
be trained on a “dirty” text, like Wikipedia [169] dumps9 or Common Crawl10. Hence, it is nec-
essary to distinguish between (at least) two levels of text cleaning: (A) “delicately cleaned” text
(in what follows, called “Stage 1” cleaning), where only parts insignificant to the NLP analysis
are removed, and (B) a “very strictly cleaned” text (called “Stage 2” cleaning). Specifically,
”Stage 1” cleaning includes removal of:
• charts and diagrams improperly converted to text,
• arXiv “watermarks”,
• references section (which were not needed, since metadata from Semantic Scholar was
used),
• links, formulas, misconverted characters (e.g. “ff”).
Stage 2 cleaning is applied to the results of Stage 1 cleaning, and consists of the following
operations:
• All punctuation, numbers and other non-letter characters were removed, leaving only let-
ters.
• Adposition, adverb, conjunction, coordinating conjunction, determiner, interjection, nu-
meral, particle, pronoun, punctuation, subordinating conjunction, symbol, end of line,
space were removed. Parts of speech left after filtering were: verbs, nouns, auxiliaries
and “other”. The “other” category is usually tagged for meaningless text, e.g. “asdfgh”.
However, these were not deleted in case the algorithm detected something that was, in fact,
important, e.g. domain-specific shortcuts and abbreviations like CNN, RNN, etc.
• Words have been lemmatized.
Note that while individual NLP techniques may require more specific data cleaning, the two
(Stage 1 and Stage 2) workflows are generic enough to be successfully applied in the majority of
typical NLP applications.
3. Performed experiments, applied methods and analysis of results
This section traverses research questions RQ1 to RQ6 and summarizes the findings for each
one of them. Furthermore, it introduces specific NLP methods used to address each question.
Interested readers are invited to study referenced literature to find additional details.
3.1. RQ1: finding most popular datasets used in NLP
As noted, a fundamental aspect for all data science projects is the data. Hence, this section
summarizes the most popular (open) datasets that are used in NLP research. Here, the informa-
tion about these datasets (names of datasets) was extracted from the analyzed texts, using Named
Entity Recognition and Keyphrase search. Let us briefly summarize these two methods.
9https://dumps.wikimedia.org
10https://commoncrawl.org
Data Intelligence
5
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
.
t
/
/
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
3
2
0
7
3
5
4
5
d
n
_
a
_
0
0
2
1
3
p
d
t
/
.
i
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
3.1.1. Named Entity Recognition – NER
Named Entity Recognition (NER) can be seen as finding an answer to “the problem of lo-
cating and categorizing important nouns, and proper nouns, in a text” [180]. Here, automatic
methods should facilitate extraction of, among others, named topics, issues, problems, and other
“things” mentioned in texts (e.g. in articles). Hence, the spaCy [100] NER model “en-core-web-
lg”11 has been used to extract named entities. These entities have been linked by co-occurrence,
and visualized as networks (further described in section 3.4).
SpaCy has been chosen over other models (e.g.
transformers [101] pipeline12), because it
was simpler to use, and performed faster.
3.1.2. Keyphrase search
Another simple and effective way of extracting information from text, is keyword and/or
keyphrase search [181, 166]. This technique can be used not only in the preliminary exploratory
data analysis (EDA), but also to extract actual and useful findings. Furthermore, keyphrase
search is also complementary to, and extends, results of Named Entity Recognition (NER) (Sec-
tion 3.1.1).
To apply keyphrase search, first, texts were cleaned with Stage 2 cleaning (see Section 2.2).
Second, they were converted to phrases (n-grams) of lengths 1-4. Next, two exhaustive lists were
created, based on all phrases (n-grams): (a) allowed phrases (609 terms), and (b) banned phrases
(1235 terms). The allowed phrases contained word and phrases, which were meaningful for natu-
ral language processing or were specific enough to be considered separate, e.g. TF-IDF, accuracy,
annotation, NER, taxonomy. The list of banned phrases contains words and phrases, which on
their own carried no significant meaning for this research, e.g. bad, big, bit, long, power, index,
default. The banned phrases also contained some incoherent phrases, which slipped through the
previous cleaning phases. These lists were used to filter the phrases found in the texts. Obtained
results were converted to networks of phrase co-occurrence, to visualize phrase importance, and
relations between phrases.
3.1.3. Approaches to finding names of most popular NLP datasets
Keyword search was used to extract names of NLP datasets used in collected papers. To prop-
erly factor out dataset names and omit noise words, two approaches were applied: unsupervised
and list-based.
Unsupervised approach included extracting words (proper nouns detected with Python spaCy13
library) in the near neighborhood (max 3 words before or after) of words “data”, “dataset” and
similar.
In list-based approaches, the algorithm looked for particular dataset names that were identi-
fied in the three big aggregated lists of NLP datasets141516.
11https://github.com/explosion/spacy-models/releases/tag/en\_core\_web\_lg-3.2.0
12https://huggingface.co/transformers/main\_classes/pipelines.html\
#tokenclassificationpipeline
13https://spacy.io
14https://metatext.io/datasets
15https://github.com/niderhoff/nlp-datasets
16https://github.com/karthikncode/nlp-datasets
6
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
/
/
t
.
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
3
2
0
7
3
5
4
5
d
n
_
a
_
0
0
2
1
3
p
d
/
.
t
i
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
3.1.4. Findings related to RQ1; what are the most popular NLP datasets
This section presents the findings, which answer RQ1, i.e. which datasets are most often
used in NLP research. To best show datasets that are popular, and outline which are used to-
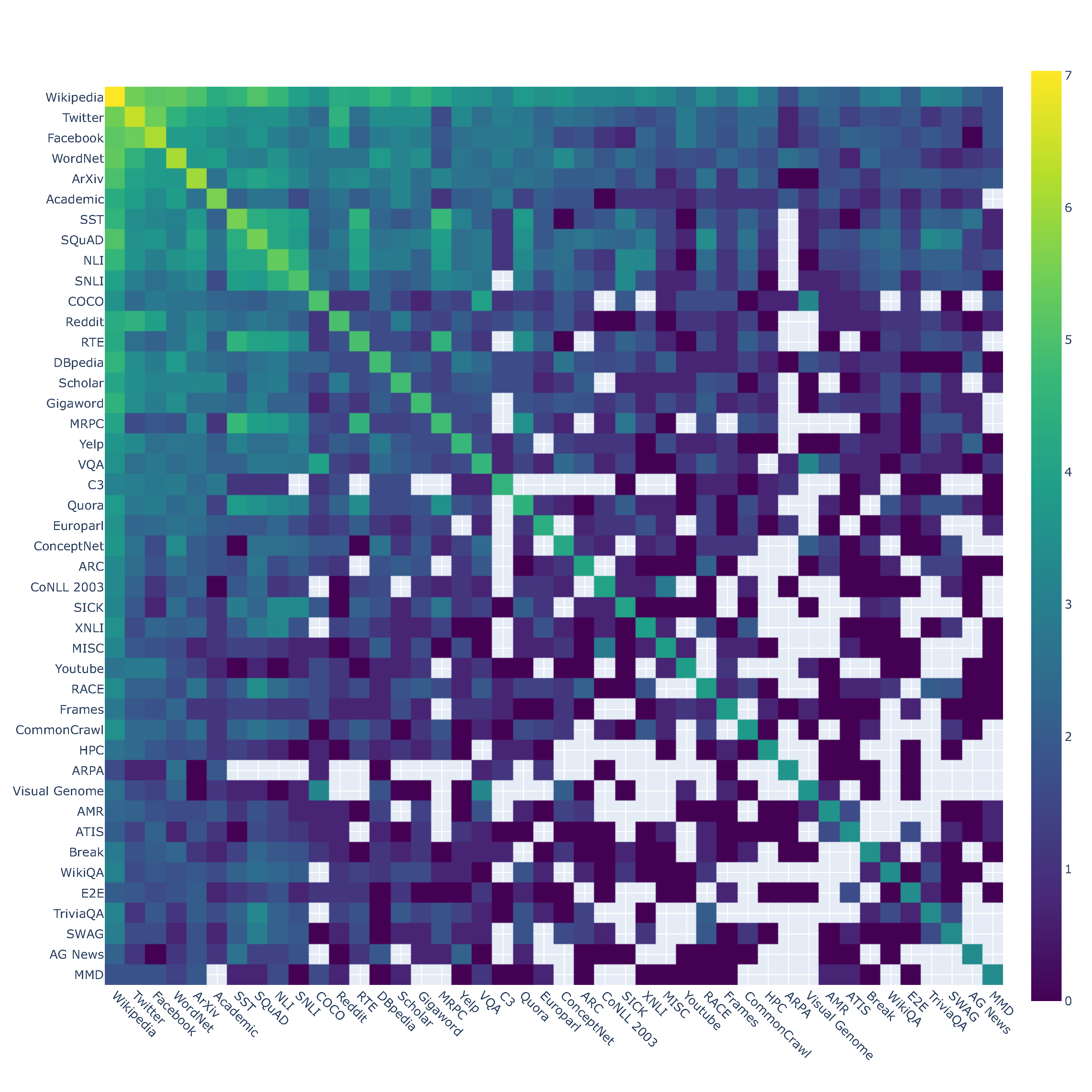
gether, a heatmap has been created. It is presented in Figure 1. In general, a heatmap allows
getting not only a general ranking of features (looking only at the diagonal), but also provides
the information of correlation of features, or lack thereof.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
t
/
/
.
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
3
2
0
7
3
5
4
5
d
n
_
a
_
0
0
2
1
3
p
d
.
t
/
i
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Figure 1: Heatmap of top 10 percentile of NLP datasets co-usage (logarithmic scale).
It can be easily seen that the most popular dataset, used in NLP, is Wikipedia. Among the
top 4 most popular datasets, one can find also: Twitter, Facebook, and WordNet. There is a high
correlation between use of datasets, which were extracted from Twitter and Facebook, which are
very frequently used together. This is both intuitive and observable in articles dedicated to social
network analysis [114], social text sentiment analysis[118], social media mining [116] and other
Data Intelligence
7
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
social science related texts [117]. Manual checking determined also that Twitter is extremely
popular in sentiment analysis and other emotion-related explorations [115].
3.2. Findings related to RQ2: what languages are studied in NLP research
The second research question concerned languages that were analyzed in reported research
(not the language the paper was written in). This information was mined using the same two
methods, i.e. keyphrase search and NER. The results were represented in two ways. The basic
method was a co-occurrence heatmap presented in Figure 2.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
/
t
.
/
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
3
2
0
7
3
5
4
5
d
n
_
a
_
0
0
2
1
3
p
d
/
.
t
i
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Figure 2: Heatmap of language co-occurrence in articles.
For clarity, the following is the ranking of top 20 most popular languages, by number of
papers in which they have been considered:
1. English: 2215
8
Data Intelligence
(QJOLVK&KLQHVH*HUPDQ)UHQFK6SDQLVK$UDELF-DSDQHVH,WDOLDQ5XVVLDQ&]HFK’XWFK/DWLQ+LQGL3RUWXJXHVH7XUNLVK*UHHN.RUHDQ)LQQLVK6ZHGLVK3ROLVK’DQLVK9LHWQDPHVH3HUVLDQ%HQJDOL7KDL+XQJDULDQ5RPDQLDQ+HEUHZ,ULVK8UGX7DPLO1RUZHJLDQ%DVTXH&URDWLDQ,QGRQHVLDQ,QGRQHVLDQ&URDWLDQ%DVTXH1RUZHJLDQ7DPLO8UGX,ULVK+HEUHZ5RPDQLDQ+XQJDULDQ7KDL%HQJDOL3HUVLDQ9LHWQDPHVH’DQLVK3ROLVK6ZHGLVK)LQQLVK.RUHDQ*UHHN7XUNLVK3RUWXJXHVH+LQGL/DWLQ’XWFK&]HFK5XVVLDQ,WDOLDQ-DSDQHVH$UDELF6SDQLVK)UHQFK*HUPDQ&KLQHVH(QJOLVK(cid:21)(cid:22)(cid:23)(cid:24)(cid:25)(cid:26)+HDWPDS(cid:3)RI(cid:3)ODQJXDJHV(cid:3)(cid:3)(cid:3)(cid:3)(cid:3)(cid:3)WRS(cid:3)(cid:20)(cid:17)(cid:19)(cid:3)SHUFHQWLOH(cid:3)(cid:3)(cid:3)(cid:3)(cid:3)(cid:3)(cid:3)ORJDULWKPLF(cid:3)VFDOH(cid:3)
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
2. Chinese: 809
3. German: 682
4. French: 533
5. Spanish: 416
6. Arabic: 306
7. Japanese: 299
8. Italian: 257
9. Russian: 239
10. Czech: 221
11. Dutch: 209
12. Latin: 171
13. Hindi: 166
14. Portuguese: 154
15. Turkish: 144
16. Greek: 133
17. Korean: 130
18. Finnish: 125
19. Swedish: 125
20. Polish: 98
As it is visible in Figure 2, the most popular language is English, but it may be caused by
the bias of analyzing only English-language-written papers. Next, there is no particular posi-
tive, or negative, correlation between languages. However, there are slight negative correlations
between languages Basque and Bengali, Irish and Thai, and Thai and Urdu, which means that
these languages are very rarely researched together. There are two observations regarding these
languages. (1) All of them are niche and do not have a big speaking population. (2) All pairs
have very distant geographical origins, so there may be a low demand for their co-studying.
3.3. Findings related to RQ3: what are the popular fields, and topics, of research
Let us now discuss the finding related to the most popular fields and topics of reported re-
search. In order to ascertain them, in addition to keyphrase search and NER, metadata mining
and text summarization have been applied. Let us now introduce these methods in some detail.
3.3.1. Metadata mining
In addition to the information available within the text of a publication, further information
can be found in its metadata. For instance, the date of publishing, overall categorization, hierar-
chical topic assignment and more, as discussed in the next paragraphs.
Therefore, metadata has been fetched both from the original source (arXiv API) and from
the Semantic Scholar17. As a result, for each retrieved paper, the following information became
available for further analysis:
• data: title, abstract and PDF,
• metadata: authors, arXiv category and publishing date,
17https://www.semanticscholar.org
Data Intelligence
9
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
.
/
/
t
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
3
2
0
7
3
5
4
5
d
n
_
a
_
0
0
2
1
3
p
d
.
t
/
i
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
• citations/references,
• topics.
Note that the Semantic Scholar topics are different from the arXiv categories. The arXiv
categories follow a set taxonomy18, which is used by the person who uploads the text. On the
other hand, the Semantic Scholar “uses machine language techniques to analyze publications and
extract topic keywords that balance diversity, relevance, and coverage relative to our corpus.”19.
The metadata from both sources was complete for all articles (there were no missing fields
for any of the papers). Obviously, one cannot guarantee that the information itself was correct.
This had to be (and was) assumed, to use this data in further analysis.
3.3.2. Matching literature to research topics
In literature review, one may analyze all available information. However, it is much faster
to initially check if a particular paper’s topic is related to ones planned/ongoing research. Both
Semantic Scholar and arXiv provide this information in the metadata. Semantic Scholar provides
“topics”, while arXiv provides “categories”.
Figure 3 shows (1) what topics are the most popular (see the first column from the left), and
(2) the correlation of topics. The measure used in the heatmap (correlation matrix) is the count
of articles tagged with topics (logarithmic scale has been used).
Obviously, the most popular field of research is “Natural Language Processing”. It is also
worth mentioning that Artificial intelligence, Machine Learning and Deep Learning also score
high in the article count. This is intuitive, as current applications of NLP are pursued using
approaches from, broadly understood, artificial intelligence.
Moreover, the correlation, and high score, between “Deep Learning” and “Artificial Neural
Networks” mirrors the influence of BERT and similar models. On the other hand, there are topics,
which very rarely coincide. These are, for instance, Parsing and Computer Vision, Convolutional
Neural Networks and Machine Translation, Speech Recognition and Sentiment analysis.
There is also one topic worth pointing out to: Baseline (configuration management). Accord-
ing to the Semantic Scholar, it is defined as “an agreed description of the attributes of a product,
at a point in time, which serves as a basis for defining change”20. This topic does not suit the
NLP particularly, as it is too vague, and it could have been incorrectly assigned by the machine
learning algorithm on the backend of Semantic Scholar.
Yet another interesting aspect is the evolution of topics in time, which gives a wider perspec-
tive of what topics are on the rise in, or fall from, popularity. Figures 4 show the most popular
categories in time. The category cs.CL (“Computation and Language”) is a dominating in all pe-
riods because it is the main subcategory of NLP. However, multiple interesting observation can
be made. First, categories that are particularly popular nowadays are: cs.LG (Machine Learn-
ing), cs.AI (Artificial Intelligence), cs.CV (Computer Vision and Pattern Recognition). Second,
there are categories, which experience a drop in interest. These are: stat.ML (Machine Learning)
and cs.NE (Neural and Evolutionary Computing).
Moving to “categories” from arXiv, it is important to elaborate the difference between them
and “topics”. As mentioned, arXiv follows a taxonomy with two levels: primary category (al-
ways a single one) and secondary categories (may be many).
18https://arxiv.org/category_taxonomy
19https://www.semanticscholar.org/faq\#extract-key-phrases
20https://www.semanticscholar.org/topic/Baseline-(configuration-management)/3403
10
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
/
.
t
/
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
3
2
0
7
3
5
4
5
d
n
_
a
_
0
0
2
1
3
p
d
.
/
t
i
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
t
/
/
.
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
3
2
0
7
3
5
4
5
d
n
_
a
_
0
0
2
1
3
p
d
.
t
/
i
Figure 3: Correlation matrix between top 0.5 percentile of topics (logarithmic scale)
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence
11
1DWXUDO(cid:3)ODQJXDJH(cid:3)SURFHVVLQJ%DVHOLQH(cid:3)(cid:11)FRQILJXUDWLRQ(cid:3)PDQDJHPHQW(cid:12)0DFKLQH(cid:3)OHDUQLQJ:RUG(cid:3)HPEHGGLQJ’HHS(cid:3)OHDUQLQJ%HQFKPDUN(cid:3)(cid:11)FRPSXWLQJ(cid:12)3DUVLQJ0DFKLQH(cid:3)WUDQVODWLRQ&RPSXWDWLRQ([SHULPHQW7H[W(cid:3)FRUSXV$UWLILFLDO(cid:3)QHXUDO(cid:3)QHWZRUN$OJRULWKP&RPSXWHU(cid:3)YLVLRQ5HFXUUHQW(cid:3)QHXUDO(cid:3)QHWZRUN&RQYROXWLRQDO(cid:3)QHXUDO(cid:3)QHWZRUN,QIRUPDWLRQ(cid:3)UHWULHYDO4XHVWLRQ(cid:3)DQVZHULQJ6HQWLPHQW(cid:3)DQDO\VLV/RQJ(cid:3)VKRUW(cid:16)WHUP(cid:3)PHPRU\6SHHFK(cid:3)UHFRJQLWLRQ/DQJXDJH(cid:3)PRGHO/DQJXDJH(cid:3)PRGHO6SHHFK(cid:3)UHFRJQLWLRQ/RQJ(cid:3)VKRUW(cid:16)WHUP(cid:3)PHPRU\6HQWLPHQW(cid:3)DQDO\VLV4XHVWLRQ(cid:3)DQVZHULQJ,QIRUPDWLRQ(cid:3)UHWULHYDO&RQYROXWLRQDO(cid:3)QHXUDO(cid:3)QHWZRUN5HFXUUHQW(cid:3)QHXUDO(cid:3)QHWZRUN&RPSXWHU(cid:3)YLVLRQ$OJRULWKP$UWLILFLDO(cid:3)QHXUDO(cid:3)QHWZRUN7H[W(cid:3)FRUSXV([SHULPHQW&RPSXWDWLRQ0DFKLQH(cid:3)WUDQVODWLRQ3DUVLQJ%HQFKPDUN(cid:3)(cid:11)FRPSXWLQJ(cid:12)’HHS(cid:3)OHDUQLQJ:RUG(cid:3)HPEHGGLQJ0DFKLQH(cid:3)OHDUQLQJ%DVHOLQH(cid:3)(cid:11)FRQILJXUDWLRQ(cid:3)PDQDJHPHQW(cid:12)1DWXUDO(cid:3)ODQJXDJH(cid:3)SURFHVVLQJ(cid:21)(cid:22)(cid:23)(cid:24)(cid:25)(cid:26)+HDWPDS(cid:3)RI(cid:3)WRSLFV
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
Figure 4: Most popular categories in time (top 96 percentile for each time period)
To best show this relation, as well as categories’ popularity, a treemap chart has been created,
which is most suitable for “nested” category visualization. It is shown in Figure 5.
Similarly to the Semantic Scholar “topics”, the largest primary category is cs.CL (Compu-
tation and Language), which is a counterpart to the NLP topic from the arXiv nomenclature.
Its top secondary categories are cs.LG/stat.ML (both categories of Machine Learning) and cs.AI
(Artificial Intelligence). This is, again, consistent with previous findings and shows how these
domains overlap each other. It is also worth noting the presence of cs.CV (Computer Vision and
Pattern Recognition), which, although to a lesser degree, is also important in the NLP literature.
Manual verification shows that, in this context, computer vision refers mostly to image descrip-
tion with text [95], visual question answering [96], using transformer neural networks for image
recognition [97, 98], and other image pattern recognition, vaguely related to NLP.
Similarly, as for topics, a trend analysis has been performed for categories. It is presented
in Figure 6. The most popular topic over time is NLP, followed by Artificial neural network,
Experiment, Deep learning, and Machine learning. Here, no particular evolution is noticeable,
except for rise in interests in the Language model topic.
3.3.3. Citations
Another interesting metainformation, is the citation count [84, 85]. Hence, this statistic was
used to determine key works, which were then used to establish key research topic in NLP (ad-
dressing also RQ1-3).
It is well known that, in most cases, the distribution of node degree in a citation network
is exponential [94]. Specifically, there are many works with 0-1 citations, and very few with
more than 10 citations. In this context, the citations network of top 10% of most highly cited
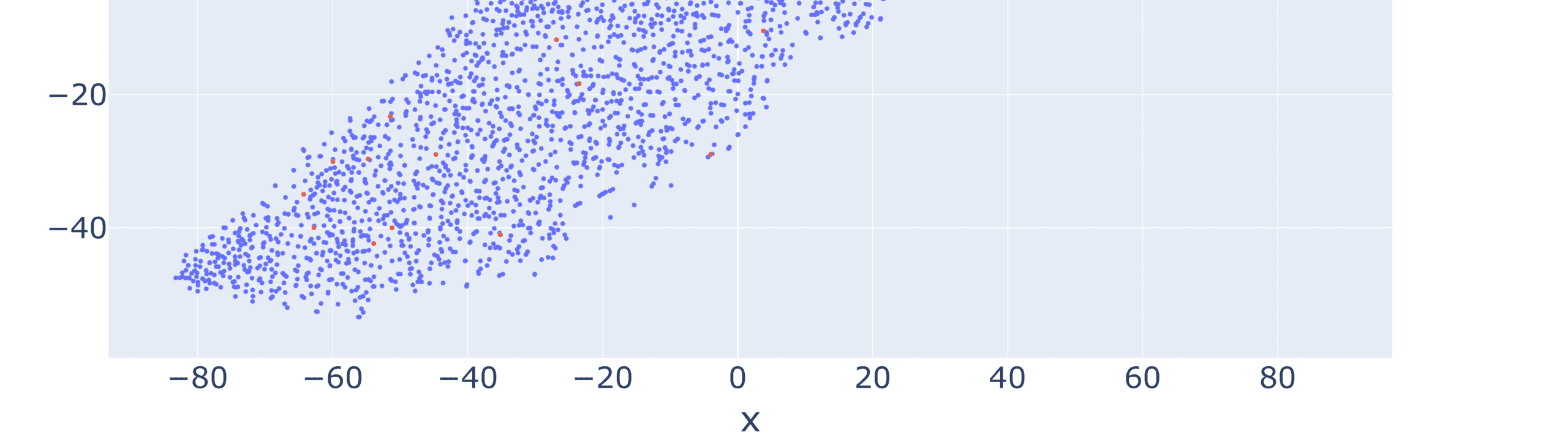
papers is depicted in Figure 7. The most cited papers are 1810.04805v2 [31] (5760 citations),
1603.04467v2 [86] (2653 citations) and 1606.05250v3 [87] (1789 citations). The first one is the
introduction of the BERT model. Here, it is easy to notice that this papers absolutely dominates
the network in terms of the degree. It is the networks focal point. This means that the whole
domain not only revolves around one particular topic, but also around a single paper.
The second paper concerns TensorFlow, the state-of-the-art library for neural networks con-
struction and management. The third introduces “Squad” – a text dataset with over 100,000
questions, used for machine learning. It is important to note that these are the top 3 papers when
12
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
i
/
t
.
/
1
0
1
1
6
2
d
n
_
a
_
0
0
2
1
3
2
0
7
3
5
4
5
d
n
_
a
_
0
0
2
1
3
p
d
.
/
t
i
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
FV(cid:17)&/,(cid:17)(cid:21)(cid:17)(cid:26)FV(cid:17)$,FV(cid:17)/*FV(cid:17),5FV(cid:17)’/FV(cid:17)+&(cid:19)(cid:24)(cid:20)(cid:19)(cid:20)(cid:24)(cid:21)(cid:19)(cid:21)(cid:24)FV(cid:17)&/FV(cid:17),5FV(cid:17)$,FV(cid:17)+&FV(cid:17)/*+(cid:17)(cid:22)(cid:17)(cid:20)+(cid:17)(cid:22)(cid:17)(cid:20)(cid:30)(cid:3)+(cid:17)(cid:22)(cid:17)(cid:22)(cid:30)(cid:3)+(cid:17)(cid:22)(cid:17)(cid:23)(cid:30)(cid:3)+(cid:17)(cid:22)(cid:17)(cid:25),(cid:17)(cid:21)(cid:17)(cid:26)FV(cid:17)1(FV(cid:17)6((cid:19)(cid:24)(cid:20)(cid:19)(cid:20)(cid:24)(cid:21)(cid:19)(cid:21)(cid:24)FV(cid:17)&/FV(cid:17),5FV(cid:17)/*FV(cid:17)$,VWDW(cid:17)0/,(cid:17)(cid:21)(cid:17)(cid:26)FV(cid:17)6,FV(cid:17)&9FV(cid:17)6((cid:19)(cid:21)(cid:19)(cid:23)(cid:19)(cid:25)(cid:19)(cid:27)(cid:19)(cid:20)(cid:19)(cid:19)(cid:20)(cid:21)(cid:19)(cid:20)(cid:23)(cid:19)FV(cid:17)&/FV(cid:17)/*VWDW(cid:17)0/FV(cid:17)$,FV(cid:17),5FV(cid:17)&9FV(cid:17)1(FV(cid:17)6,FV(cid:17)&
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
• In Arabic and Italian, Japanese, Polish, Estonian, Swedish and Finish, there is a visible
trend of interest in named entity recognition.
• Dependency parsing is more pronounced in research on languages such as German, French,
Czech, Japanese, Spanish, Slovene, Swahili and Russian.
• In Basque, Ukrainian, Bulgarian the domain does not have particular homogeneous sub-
domain distribution. The problems of interests are: co-reference resolution, dependency
parsing, dialogue-focused research, language modeling, machine translation, multitask
apprendimento, named entity recognition, natural language inference, part-of-speech tagging,
question answering.
• In Bengali, a special area of interest is part-of-speech tagging.
• Research focused on Catalan have a particular interests in dialogue-related texts.
• Research regarding Indonesian have a very high percent of sentiment analysis research.
Even higher than most popular topic of machine translation.
• Studies on Norwegian language are strongly focused on sentiment analysis, which peeks
over the most common domain of most of the languages – machine translation.
• Research focusing on Russian puts a special effort in analyzing dialogues and dependency
parsing.
There are only minimal difference between datasets used for English and Chinese, and other
languages. The key ones are:
• Facebook is present as one of the main sources in many languages, being particularly
popular data source for: Bengali, and Spanish
• Twitter is a key data source in research on languages: Arabic, Dutch, French, German,
Hindi, Italian, Korean, Spanish, Tamil
• WordNet is very often used in research involving: Moldovan and Romanian
• Tibetan language research nearly never uses Twitter as the dataset.
3.6. Findings concerning RQ4: most popular specific tasks and problems
At the heart of the research is yet another key aspect – the specific problem that is being
tackled, or the task, which is being solved. This may seem similar to the domain, or to the
general direction of the research. Tuttavia, some general problems contain specific problems
(e.g. machine translation and English-Chinese machine translation, or named entity recognition
and named entity linking). D'altra parte, some specific problems have more complicated
relation, e.g. machine translation, which in NLP can be solved using neural networks, but neural
networks are also an independent domain on their own, which is also a superdomain (or a sub-
domain) Di, for instance, image recognition. These complicated relations point to the need for a
standardized NLP taxonomy. Questo, Tuttavia, is also out of scope of this contribution.
Let us come back to the methods of analyzing specific results. To extract most popular spe-
cific tasks and particular problems, methods described above, such as NER, keyphrase search,
26
Data Intelligence
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
D
N
/
io
T
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
.
T
/
/
1
0
1
1
6
2
D
N
_
UN
_
0
0
2
1
3
2
0
7
3
5
4
5
D
N
_
UN
_
0
0
2
1
3
P
D
.
/
T
io
F
B
sì
G
tu
e
S
T
T
o
N
0
9
S
e
P
e
M
B
e
R
2
0
2
3
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
D
N
/
io
T
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
/
/
.
T
1
0
1
1
6
2
D
N
_
UN
_
0
0
2
1
3
2
0
7
3
5
4
5
D
N
_
UN
_
0
0
2
1
3
P
D
.
T
/
io
F
B
sì
G
tu
e
S
T
T
o
N
0
9
S
e
P
e
M
B
e
R
2
0
2
3
Figura 12: Datasets and NLP problems for chosen languages.
Data Intelligence
27
(cid:19)(cid:24)(cid:19)(cid:19)(cid:20)(cid:19)(cid:19)(cid:19)(cid:20)(cid:24)(cid:19)(cid:19)DXWRPDWLF(cid:3)VSHHFK(cid:3)UHFRJQLWLRQFFJFKXQNLQJFRPPRQ(cid:3)VHQVHFRQVWLWXHQF\(cid:3)SDUVLQJFRUHIHUHQFH(cid:3)UHVROXWLRQGHSHQGHQF\(cid:3)SDUVLQJGLDORJXHGRPDLQ(cid:3)DGDSWDWLRQHQWLW\(cid:3)OLQNLQJJUDPPDWLFDO(cid:3)HUURU(cid:3)FRUUHFWLRQLQIRUPDWLRQ(cid:3)H[WUDFWLRQODQJXDJH(cid:3)PRGHOLQJOH[LFDO(cid:3)QRUPDOL]DWLRQPDFKLQH(cid:3)WUDQVODWLRQPLVVLQJ(cid:3)HOHPHQWVPXOWL(cid:16)WDVN(cid:3)OHDUQLQJQDPHG(cid:3)HQWLW\(cid:3)UHFRJQLWLRQQDWXUDO(cid:3)ODQJXDJH(cid:3)LQIHUHQFHSDUDSKUDVH(cid:3)JHQHUDWLRQSDUW(cid:16)RI(cid:16)VSHHFK(cid:3)WDJJLQJTXHVWLRQ(cid:3)DQVZHULQJUHODWLRQ(cid:3)SUHGLFWLRQUHODWLRQVKLS(cid:3)H[WUDFWLRQVHPDQWLF(cid:3)SDUVLQJVHPDQWLF(cid:3)UROH(cid:3)ODEHOLQJVHPDQWLF(cid:3)WH[WXDO(cid:3)VLPLODULW\VHQWLPHQW(cid:3)DQDO\VLVVKDOORZ(cid:3)V\QWD[VLPSOLILFDWLRQVWDQFH(cid:3)GHWHFWLRQVXPPDUL]DWLRQWD[RQRP\(cid:3)OHDUQLQJWHPSRUDO(cid:3)SURFHVVLQJWH[W(cid:3)FODVVLILFDWLRQZRUG(cid:3)VHJPHQWDWLRQZRUG(cid:3)VHQVH(cid:3)GLVDPELJXDWLRQGDWD(cid:16)WR(cid:16)WH[W(cid:3)JHQHUDWLRQ(cid:19)(cid:24)(cid:19)(cid:19)(cid:20)(cid:19)(cid:19)(cid:19)(cid:20)(cid:24)(cid:19)(cid:19)DXWRPDWLF(cid:3)VSHHFK(cid:3)UHFRJQLWLRQFFJFKXQNLQJFRPPRQ(cid:3)VHQVHFRQVWLWXHQF\(cid:3)SDUVLQJFRUHIHUHQFH(cid:3)UHVROXWLRQGHSHQGHQF\(cid:3)SDUVLQJGLDORJXHGRPDLQ(cid:3)DGDSWDWLRQHQWLW\(cid:3)OLQNLQJJUDPPDWLFDO(cid:3)HUURU(cid:3)FRUUHFWLRQLQIRUPDWLRQ(cid:3)H[WUDFWLRQODQJXDJH(cid:3)PRGHOLQJOH[LFDO(cid:3)QRUPDOL]DWLRQPDFKLQH(cid:3)WUDQVODWLRQPLVVLQJ(cid:3)HOHPHQWVPXOWL(cid:16)WDVN(cid:3)OHDUQLQJQDPHG(cid:3)HQWLW\(cid:3)UHFRJQLWLRQQDWXUDO(cid:3)ODQJXDJH(cid:3)LQIHUHQFHSDUDSKUDVH(cid:3)JHQHUDWLRQSDUW(cid:16)RI(cid:16)VSHHFK(cid:3)WDJJLQJTXHVWLRQ(cid:3)DQVZHULQJUHODWLRQ(cid:3)SUHGLFWLRQUHODWLRQVKLS(cid:3)H[WUDFWLRQVHPDQWLF(cid:3)SDUVLQJVHPDQWLF(cid:3)UROH(cid:3)ODEHOLQJVHPDQWLF(cid:3)WH[WXDO(cid:3)VLPLODULW\VHQWLPHQW(cid:3)DQDO\VLVVKDOORZ(cid:3)V\QWD[VLPSOLILFDWLRQVWDQFH(cid:3)GHWHFWLRQVXPPDUL]DWLRQWD[RQRP\(cid:3)OHDUQLQJWHPSRUDO(cid:3)SURFHVVLQJWH[W(cid:3)FODVVLILFDWLRQZRUG(cid:3)VHJPHQWDWLRQZRUG(cid:3)VHQVH(cid:3)GLVDPELJXDWLRQGDWD(cid:16)WR(cid:16)WH[W(cid:3)JHQHUDWLRQGDWDVHW2WKHU$FDGHPLF$U;LY&2&2)DFHERRN1/,61/,64X$’6677ZLWWHU:LNLSHGLD:RUG1HWFRXQWFRXQWSUREOHPSUREOHPODQJXDJH *HUPDQODQJXDJH 6SDQLVKODQJXDJH $UDELFODQJXDJH )UHQFK
Data Intelligence Just Accepted MS.
https://doi.org/10.1162/dint_a_00213
The state of the art of Natural Language Processing
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
D
N
/
io
T
/
l
UN
R
T
io
C
e
–
P
D
F
/
D
o
io
/
io
T
.
/
/
1
0
1
1
6
2
D
N
_
UN
_
0
0
2
1
3
2
0
7
3
5
4
5
D
N
_
UN
_
0
0
2
1
3
P
D
.
/
T
io
F
B
sì
G
tu
e
S
T
T
o
N
0
9
S
e
P
e
M
B
e
R
2
0
2
3
Figura 13: Datasets and NLP problems for chosen languages.
28
Data Intelligence
(cid:19)(cid:20)(cid:19)(cid:19)(cid:21)(cid:19)(cid:19)(cid:22)(cid:19)(cid:19)(cid:23)(cid:19)(cid:19)(cid:24)(cid:19)(cid:19)(cid:25)(cid:19)(cid:19)DXWRPDWLF(cid:3)VSHHFK(cid:3)UHFRJQLWLRQFFJFKXQNLQJFRPPRQ(cid:3)VHQVHFRQVWLWXHQF\(cid:3)SDUVLQJFRUHIHUHQFH(cid:3)UHVROXWLRQGHSHQGHQF\(cid:3)SDUVLQJGLDORJXHGRPDLQ(cid:3)DGDSWDWLRQHQWLW\(cid:3)OLQNLQJJUDPPDWLFDO(cid:3)HUURU(cid:3)FRUUHFWLRQLQIRUPDWLRQ(cid:3)H[WUDFWLRQODQJXDJH(cid:3)PRGHOLQJPDFKLQH(cid:3)WUDQVODWLRQPXOWL(cid:16)WDVN(cid:3)OHDUQLQJQDPHG(cid:3)HQWLW\(cid:3)UHFRJQLWLRQQDWXUDO(cid:3)ODQJXDJH(cid:3)LQIHUHQFHSDUDSKUDVH(cid:3)JHQHUDWLRQSDUW(cid:16)RI(cid:16)VSHHFK(cid:3)WDJJLQJTXHVWLRQ(cid:3)DQVZHULQJUHODWLRQVKLS(cid:3)H[WUDFWLRQVHPDQWLF(cid:3)SDUVLQJVHPDQWLF(cid:3)UROH(cid:3)ODEHOLQJVHPDQWLF(cid:3)WH[WXDO(cid:3)VLPLODULW\VHQWLPHQW(cid:3)DQDO\VLVVKDOORZ(cid:3)V\QWD[VLPSOLILFDWLRQVWDQFH(cid:3)GHWHFWLRQVXPPDUL]DWLRQWH[W(cid:3)FODVVLILFDWLRQZRUG(cid:3)VHJPHQWDWLRQZRUG(cid:3)VHQVH(cid:3)GLVDPELJXDWLRQGDWD(cid:16)WR(cid:16)WH[W(cid:3)JHQHUDWLRQPLVVLQJ(cid:3)HOHPHQWVUHODWLRQ(cid:3)SUHGLFWLRQWD[RQRP\(cid:3)OHDUQLQJWHPSRUDO(cid:3)SURFHVVLQJOH[LFDO(cid:3)QRUPDOL]DWLRQ(cid:19)(cid:20)(cid:19)(cid:19)(cid:21)(cid:19)(cid:19)(cid:22)(cid:19)(cid:19)(cid:23)(cid:19)(cid:19)(cid:24)(cid:19)(cid:19)(cid:25)(cid:19)(cid:19)DXWRPDWLF(cid:3)VSHHFK(cid:3)UHFRJQLWLRQFFJFKXQNLQJFRPPRQ(cid:3)VHQVHFRQVWLWXHQF\(cid:3)SDUVLQJFRUHIHUHQFH(cid:3)UHVROXWLRQGHSHQGHQF\(cid:3)SDUVLQJGLDORJXHGRPDLQ(cid:3)DGDSWDWLRQHQWLW\(cid:3)OLQNLQJJUDPPDWLFDO(cid:3)HUURU(cid:3)FRUUHFWLRQLQIRUPDWLRQ(cid:3)H[WUDFWLRQODQJXDJH(cid:3)PRGHOLQJPDFKLQH(cid:3)WUDQVODWLRQPXOWL(cid:16)WDVN(cid:3)OHDUQLQJQDPHG(cid:3)HQWLW\(cid:3)UHFRJQLWLRQQDWXUDO(cid:3)ODQJXDJH(cid:3)LQIHUHQFHSDUDSKUDVH(cid:3)JHQHUDWLRQSDUW(cid:16)RI(cid:16)VSHHFK(cid:3)WDJJLQJTXHVWLRQ(cid:3)DQVZHULQJUHODWLRQVKLS(cid:3)H[WUDFWLRQVHPDQWLF(cid:3)SDUVLQJVHPDQWLF(cid:3)UROH(cid:3)ODEHOLQJVHPDQWLF(cid:3)WH[WXDO(cid:3)VLPLODULW\VHQWLPHQW(cid:3)DQDO\VLVVKDOORZ(cid:3)V\QWD[VLPSOLILFDWLRQVWDQFH(cid:3)GHWHFWLRQVXPPDUL]DWLRQWH[W(cid:3)FODVVLILFDWLRQZRUG(cid:3)VHJPHQWDWLRQZRUG(cid:3)VHQVH(cid:3)GLVDPELJXDWLRQGDWD(cid:16)WR(cid:16)WH[W(cid:3)JHQHUDWLRQPLVVLQJ(cid:3)HOHPHQWVUHODWLRQ(cid:3)SUHGLFWLRQWD[RQRP\(cid:3)OHDUQLQJWHPSRUDO(cid:3)SURFHVVLQJOH[LFDO(cid:3)QRUPDOL]DWLRQGDWDVHW2WKHU$FDGHPLF$U;LY&2&2)DFHERRN1/,61/,64X$’6677ZLWWHU:LNLSHGLD:RUG1HWFRXQWFRXQWSUREOHPSUREOHPODQJXDJH .RUHDQODQJXDJH 5RPDQLDQODQJXDJH +LQGLODQJXDJH ,WDOLDQ Data Intelligence Just Accepted MS. https://doi.org/10.1162/dint_a_00213 The state of the art of Natural Language Processing metadata mining, text summarization, and network visualization were used. Before presenting specific results, an important aspect of keyphrase search needs to be mentioned. An unsupervised search for particular specific topics of research cannot be reasonably performed. All approaches of unsupervised keyphrase search that have been tried (in an exploratory fashion) produced thou- sands of potential results. Therefore, supervised keyphrase search has been applied. Therefore, the NLP problems were determined based on an exhaustive (multilingual) list, aggregating most popular NLP tasks27. The list has been extracted from the website and pruned of any additional markdown28, to obtain a clean text format. Prossimo, all keywords and keyphrases from the text of each paper has been compared with the NLP tasks list. Finalmente, each paper has been assigned a list of problems found in its text. Figura 14 shows the popularity (by count) of problems addressed in NLP literature. Again, there is a dominating problem – machine translation. This is very intuitive, if one takes into account the recent studies [119, 121, 122, 123, 124] showing that lack of high fidelity machine translation remains the key barrier for world-wide communication. This problem seems very persistent, because it was indicated also in older research (e.g. in text from 1968 [120]). Here, it is important to recall that this contribution is likely to be biased towards translation involving English language, because it only analyzed English-written literature. The remaining top 3 most popular problems are question answering [126] and sentiment In both these domains, there are already state-of-the-art models ready to be analysis [129]. used29. What is interesting, for both question answering and sentiment analysis, most of the models are based either on BERT or its variation, DistilBERT [125]. 3.7. RQ5: seeking outliers in the NLP domain Some scientific research areas are homogeneous, and all publication revolve around similar topic (group of topics). D'altra parte, some can be very diverse, with individual papers touching very different subfields. Finalmente, there are also domains where, from a more or less homogeneous set, a separate, distinguishable, subset can be pointed to. To verify the structure of the field of NLP, two methods have been used. One is, previously introduced, metadata mining. The second one was text embedding and cauterization. Let us briefly introduce the second one. 3.7.1. Text embeddings One of ubiquitous methods in text processing are word, sentence and document embeddings. Text embeddings, which ”convert texts to numbers”, have been used to determine key differ- ences/similarities between analyzed texts. Embeddings can be divided into: contextualized and context-less [33]. Scientific papers often use words, which strongly depend on the context The prime example is the word “BERT” [31], which on the one hand is a character from a TV show, but in the NLP world it is a name of one of the state-of-the-art embedding models. In this context, envision application of BERT, the NLP method, to analysis of dialogues in children TV, where one of the dialogues would in- clude BERT, the character. Similar situation concerns words like network (either neural network, graph network, social network, or computer network), “spark” [32] (either a small fiery particle, 27https://github.com/sebastianruder/NLP-progress 28https://www.markdownguide.org 29https://huggingface.co/models?language=en&pipeline_tag=question-answering Data Intelligence 29 l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . e d u d n / i t / l a r t i c e – p d f / d o i / io / . / T 1 0 1 1 6 2 d n _ a _ 0 0 2 1 3 2 0 7 3 5 4 5 d n _ a _ 0 0 2 1 3 p d t / . i f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 Data Intelligence Just Accepted MS. https://doi.org/10.1162/dint_a_00213 The state of the art of Natural Language Processing l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . e d u d n / i t / l a r t i c e – p d f / d o i / io . T / / 1 0 1 1 6 2 d n _ a _ 0 0 2 1 3 2 0 7 3 5 4 5 d n _ a _ 0 0 2 1 3 p d t . / i f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 Figura 14: Histogram of problems tackled in NLP literature. 30 Data Intelligence (cid:19)(cid:21)(cid:19)(cid:19)(cid:23)(cid:19)(cid:19)(cid:25)(cid:19)(cid:19)(cid:27)(cid:19)(cid:19)(cid:20)(cid:19)(cid:19)(cid:19)(cid:20)(cid:21)(cid:19)(cid:19)(cid:20)(cid:23)(cid:19)(cid:19)(cid:20)(cid:25)(cid:19)(cid:19)LQWHQW(cid:3)GHWHFWLRQ(cid:3)DQG(cid:3)VORW(cid:3)ILOOLQJPLVVLQJ(cid:3)HOHPHQWVVKDOORZ(cid:3)V\QWD[WD[RQRP\(cid:3)OHDUQLQJWHPSRUDO(cid:3)SURFHVVLQJOH[LFDO(cid:3)QRUPDOL]DWLRQGDWD(cid:16)WR(cid:16)WH[W(cid:3)JHQHUDWLRQUHODWLRQVKLS(cid:3)H[WUDFWLRQJUDPPDWLFDO(cid:3)HUURU(cid:3)FRUUHFWLRQVWDQFH(cid:3)GHWHFWLRQUHODWLRQ(cid:3)SUHGLFWLRQSDUDSKUDVH(cid:3)JHQHUDWLRQVLPSOLILFDWLRQFFJFRQVWLWXHQF\(cid:3)SDUVLQJVHPDQWLF(cid:3)WH[WXDO(cid:3)VLPLODULW\FRPPRQ(cid:3)VHQVHDXWRPDWLF(cid:3)VSHHFK(cid:3)UHFRJQLWLRQZRUG(cid:3)VHJPHQWDWLRQHQWLW\(cid:3)OLQNLQJVHPDQWLF(cid:3)UROH(cid:3)ODEHOLQJWH[W(cid:3)FODVVLILFDWLRQFRUHIHUHQFH(cid:3)UHVROXWLRQZRUG(cid:3)VHQVH(cid:3)GLVDPELJXDWLRQFKXQNLQJVHPDQWLF(cid:3)SDUVLQJGRPDLQ(cid:3)DGDSWDWLRQGHSHQGHQF\(cid:3)SDUVLQJSDUW(cid:16)RI(cid:16)VSHHFK(cid:3)WDJJLQJPXOWL(cid:16)WDVN(cid:3)OHDUQLQJQDWXUDO(cid:3)ODQJXDJH(cid:3)LQIHUHQFHLQIRUPDWLRQ(cid:3)H[WUDFWLRQGLDORJXHQDPHG(cid:3)HQWLW\(cid:3)UHFRJQLWLRQVXPPDUL]DWLRQODQJXDJH(cid:3)PRGHOLQJVHQWLPHQW(cid:3)DQDO\VLVTXHVWLRQ(cid:3)DQVZHULQJPDFKLQH(cid:3)WUDQVODWLRQ&RXQW3UREOHP Data Intelligence Just Accepted MS. https://doi.org/10.1162/dint_a_00213 The state of the art of Natural Language Processing or the name of a popular Big Data library), lemma (either a proven proposition in logic, or a morphological form of a word), eccetera. Hence, in this study, using contextualized text embeddings is more appropriate. This being the case, very popular static text embeddings like Glove [35] and Word2Vec [36, 37] have not been used. There are many libraries and models available for contextualized text embedding, per esempio.: trans- formers [101], flair [34], gensim [159] and models: BERT [31] (and its variations like Roberta [39], DistilBERT [125]), GPT-2 [38], T5 [40], ELMo [99] and others. Tuttavia, most of them require specific and high-end hardware to operate reasonably fast (i.e. GPU acceleration [29]). Here, the decision was to proceed with FastText [30]. FastText is designed to produce time efficient results, which can be recreated on standard hardware. Inoltre, it is designed for “text representations and text classifiers”30, which is exactly what is needed in this work. 3.7.2. Embedding and clustering It is important to highlight that since FastText, like most embeddings, has been trained on a pretty noisy data [30], the input text of articles was preprocessed only with Stage 1 cleaning (see Section 2.2). Prossimo, a grid search [53] was performed, to tune hyperparameters. While, as noted earlier, hyperparameter tuning has not been applied, use of grid search, reported here, illustrates that there exist ready-to-use libraries that can be applied when hyperparameter tuning is required. Overall, the best embeddings were produced by a model with the following hyperparameters31: • dimension: 20 • minimum subword size: 3 • maximum subword size: 6 • number of epochs: 5 • learning rate: 0.00005 Finalmente, the FastText model was further trained in an unsupervised mode (which is standard in majority of cases for general language modelling), on texts of papers, to better fit the representa- zione. After embeddings have been calculated, their vector representations have been clustered. Since there was no response variable, an unsupervised classifier was applied. Again (as in Sec- zione 3.7.1), the main goal was simplicity and time efficiency. Out of all tested algorithms (K-means [45], OPTICS [46, 47], DBSCAN [48, 49], HDB- SCAN [51] and Birch [52]), the best time efficiency, combined with relative simplicity of use, was achieved with K-means (Vedere, also [42, 41]). Inoltre, in found research, K-means cluster- ing showed best results, when applied to FastText embeddings (Vedere, [170]). The evaluation of clustering has been performed using three clustering metrics: Silhouette score [54], Davies-Bouldin score [55], Cali´nski-Harabasz Score [56]. These metrics were chosen because they allow evaluation of unsupervised clustering. To visualize the results on a 2D plane, the multidimensional FastText vectors were converted with t-distributed stochastic neighbor em- bedding (T-SNE) method [44, 43]. T-SNE has been suggested by text embedding visualizations reported in earlier work [173, 172]. 30https://fasttext.cc 31https://fasttext.cc/docs/en/options.html Data Intelligence 31 l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . e d u d n / i t / l a r t i c e – p d f / d o i / io . / / T 1 0 1 1 6 2 d n _ a _ 0 0 2 1 3 2 0 7 3 5 4 5 d n _ a _ 0 0 2 1 3 p d t . / i f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 Data Intelligence Just Accepted MS. https://doi.org/10.1162/dint_a_00213 The state of the art of Natural Language Processing l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . e d u d n / i t / l a r t i c e – p d f / d o i / io . / / T 1 0 1 1 6 2 d n _ a _ 0 0 2 1 3 2 0 7 3 5 4 5 d n _ a _ 0 0 2 1 3 p d . / t i f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 Figura 15: “The blade of NLP”. A visualization of all paper text embeddings grouped in clusters (dimensionality reduced with T-SNE). 3.7.3. RQ5: outliers found in the NLP research Visualizations of embeddings are shown in Figure 15. Note that Figure 15 is mainly aesthetic, as actual relations are rarely visible, when dimension reduction is applied. The number of clusters has been evaluated according to 3 clustering metrics (Silhouette score [54], Davies-Bouldin score [55], Cali´nski-Harabasz Score [56]) and the best clustering score has been achieved for 2 clusters. Hence, further analysis considers separation of the embeddings into 2 clusters. To further explore why these particular embeddings appear in the same group, various tests were performed. Primo, wordclouds of texts (titles and paper texts) in the clusters have been built. The texts for wordclouds were processed with Stage 2 cleaning. Title wordclouds are shown in Figure 16, while text wordclouds are shown in Figure 17. Further, citation count comparison (Figures 18 E 19) and authors were checked for text in both clusters. Last, the differences in topics from Semantic Scholar (Figures 20 E 21) and categories from arXiv (Figures 22 E 23) have been checked. Based on the content of Figures 16, 17, 18, 19, 20, 21, 22, 23 and the author per cluster distribution analysis the following conclusions have been drawn: • There is one specific outlier, this is the cluster of work related to texts embeddings. • Content of texts shows strong topical shift towards deep neural networks. • Categories and topics of clusters are not particularly far away from each other, because their distribution is similar. There is a higher representation of computer vision and infor- mation retrieval area in the smaller cluster (cluster 0). • There are no distinguishable authors who are responsible for texts in both clusters. 32 Data Intelligence Data Intelligence Just Accepted MS. https://doi.org/10.1162/dint_a_00213 The state of the art of Natural Language Processing l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . Figura 16: Wordcloud of titles of papers in cluster 0 (left) E 1 (right) T / l a r t i c e – p d f / d o i / e d u d n / i i / / T . 1 0 1 1 6 2 d n _ a _ 0 0 2 1 3 2 0 7 3 5 4 5 d n _ a _ 0 0 2 1 3 p d / T . i f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 Figura 17: Wordcloud of texts of papers in cluster 0 (left) E 1 (right) Data Intelligence 33 learninglanguageneuralnetworksdeeptextmodelssurveyknowledgebasednaturalrecurrentprocessinganalysismachineembeddingspretrainedtopicarabicrepresentationtaskcoderepresentationsdocumentretrievalvectorrankingspecifictextualvisualgenerativedocumentsimagegraphbasesapproachapplicationstransformerwomenisispropagandatopicsemotionscomparisonmainstreamreligiousgroupautomaticdialectidentificationsystemswrittentextscontinuouslocationgeolocationlexicaldialectologymixturedensitybinarizersemevalparsingdependencyironydetectionembeddedcollaborativefilteringcoldstartpredictionexploringnaturalnessbuggydeviationboundnoncausaldistributedcompositionalsemanticslegaltransformersbertspeechtaggingmixedindiansocialmediaiconworldpositioncomposetreestructureslookimaginematchimprovingcrossmodalthemeweightedkeywordsphrasebenchmarklargehealthcaremimicdatasetsunpairedcaptioningpivotingtransferlabelingdomainbaseukhousecommonsspeechesnavigatingfastscalabledecodinginterpretingembeddingpedagogicaloverviewtsrnnsteganalysissentimentclassificationdiscoverynovelcoronaviruscovidonlinediscussionsnlplstmnetworkconversationalsearchreportdagstuhlseminarselfsupervisedcontrastiveweakerrorstochasticgradientdescentoptimizationalgorithmscreationcurationcomprehensiveextractionapplicationcorpusnewsarticlesammubiomedicalammusprobabilisticmodellingmorphologicallyrichlanguagesfvqafactquestionansweringdetectingmaliciouspowershellcommandsitisynthesisdataaugmentationstateartgenerationcoretasksevaluationconvergenceratetrainingmultitaskargumentationminingmetrictransformslanguagelearningneuralnaturalbasedtextprocessingdeepmodelswordnetworksanalysismodeldataclassificationembeddingsnetworkattentionmachinenlpknowledgebertsemanticsurveydetectiontransformerapproachrecognitionextractiongraphinformationgenerationentitysentimentrepresentationrepresentationsspeechquestionembeddingpredictionsequencetranslationefficientstudypretraineddomainsocialansweringmodelingadversarialunderstandingevaluationtasksystemcorpuscodeautomaticvisualsentencerecurrentselftrainingtransformersframeworknamedtransferconvolutionallargeimprovingimageminingsystemstaskslanguagesscalemultilingualclinicaldatasetmediaretrievalcasemedicallowchineselevelinferencecontextidentificationsimilarityunsupervisedmethodspretrainingparsingonlinereviewbiasnewsawaresupervisedtextualmethodapplicationsrelationhumannewautomatedfeaturesdocumentresourcearabiccovidsearchtimemultimodaltwitterintelligenceevaluatinglstmbiomedicaltechniquesmemorysummarizationstructureddisambiguationdependencyperformanceshotrelationstextsselectionmultitaskresearchenglishjointrobustcontextualwebfinespacetaggingstructurepredictingopenartificialhierarchicalvectorfeaturelinguisticsensehealthsegmentationapplicationstategenderdetectingarchitecturemultiplegeneratingreasoningcaptioningmatchingsimplemorphologicalendlatentresolutionaicrosslingualemotiondynamicwordscontextualizedexploringquantumfasthybridrealcompressionempiricaldialoguelegalshortaugmentationdatasetsalgorithmssourcecontrastivelabelingtemporalreadingcomprehensioninterprequestionscorporaenhancedgraphslongdevelopmentlexicaladaptivemodelnetworkimportneuralcodeoutputdatumsetlemmawordprintfollowuselearnfunctionimagearabicfeaturelayertrainingtimelearningvalueletdialectlanguagenptextresultaddtrainnumberrandomtopicbasepdproofinputdeepneuronshapekerasmethodsystemtaskpythonprobabilityepochvectorworkmeanweightdenseclassificationnewexampledatasetsuphi(cid:128)providedatatypescorepredkrdshowmachinecorpuslevelmatrixdefcaseprocesspresentsamplesatisfyinformationalgorithmtheoremdifferentapplycreatecolumntechniquegenerateapplicationdefinepredictionxiexpmsarowstepreturninequalityprogramformatneedlogprovewriteerrortensorflownumpytermiianalysiscontainvariablegxgradientstategiveitemenvironmentcomputerapproachlargehightestassumenoteidentificationbindholdregressioncidcidincludeallowresearchdocumentactivationperformrangeratedftagrankdropcorollaryobservenaturalclassagentfindspacermproblemsiembedsearchsentenceintroductionlistconsiderdropoutrandomnessprocessingaccuracygooddemonstratesimilarmaxfileimghidestudysequenceobtainfixtransferrepresentationcombinedummypointexistmainpathcommonequationlstmfoldparameterdtlenknowcompleteimplyincomeorderlabelfieldrunpredictcharacterconvolutionalmpgdi(cid:128)simplerepresentmodelwordlanguagetaskbaseresultsetdatumdatasetmethodusesentencecidtextfeaturenetworklearntrainingdifferentinformationperformanceworkexamplesystemapproachrepresentationtrainnumberlayerinputvectorshowproposetimeneuralfollowattentiontestscorelearninglabelgivelargealgorithmembeddingclassificationfunctionvaluesemanticgenerateembedimagequestiontermhighdocumentproblemprovidesequenceprocesscaseanalysisentitystatecontextsamplenaturallevelexperimentoutputcorpusdomaintypebertincludestudynlpfinduserknowledgepapersizeaccuracygraphcompareperformparametertokenpresentmachinerelationapplyresearchdeepconsiderdatagoodneworderrepresentevaluationcontainpredictionclassarchitectureanswermeanpairstepsimilardistributionstructurehumantargetweightobtaintransformersimilarityimprovesourcespacematrixqueryietechniqueachievemeasureevaluatespecificpredictdefineextractformapplicationprocessingdescribetopicprobabilityneedlstmlowsmallidentifybaselinecomputeaveragecodepretrainerequirelossreportrelatetranslationsearchnodewellpointsingleendmetricclassifierenglishnoterulewaysentimentlengthfocusintroduceinstanceerrorexistselectcorrespondpreviousencodermultipleincreasecategoryphraseconceptoriginaldesignavailabletagcnnframeworkspeechratepossibleobjectallowcreateimportantranktakegeneraldetectionaddsupport Data Intelligence Just Accepted MS. https://doi.org/10.1162/dint_a_00213 The state of the art of Natural Language Processing l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . e d u d n / i t / l a r t i c e – p d f / d o i / io / . / T 1 0 1 1 6 2 d n _ a _ 0 0 2 1 3 2 0 7 3 5 4 5 d n _ a _ 0 0 2 1 3 p d . / t i f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 Figura 18: Histogram of citation counts in cluster 1 (bigger cluster) – logarithmic scale • The distribution of citation counts is similar in both clusters. Inoltre, manual verification showed that deep neural networks is actually the biggest subdomain of NLP, and it touches upon issues, which do not appear in other works. These issues are strictly related to neural networks (e.g. attention mechanism, network architectures, transfer learning, eccetera.) They are universal, and their applications play an important role in NLP, but also in other domains (image processing[109], signal processing [110], anomaly detection [112], clinical medicine [113] and many others [111]). 3.7.4. “Most original papers” In addition to unsupervised clustering, an additional approach to outlier detection has been applied. Specifically, metadata representing citations/reference information was further ana- lyzed. On the one hand, of the “citation spectrum” are the most influential works (as shown in Section 3.3.3). On the other side, there are papers that either are new and have not been cited yet, or those that do not have high influence. Tuttavia, the true “original” works are papers which have many citations (they are in top 2 percentile), but very few references (bottom 2 percentile). Based on performed analysis, it was found that such papers are: • “Natural Language Processing (almost) from Scratch” [88] – a neural network approach to learning internal representations of text, based on unlabeled training data. A similar idea was used in future publications, particolarmente, the most cited paper about BERT model [31]. 34 Data Intelligence (cid:19)(cid:21)(cid:23)(cid:25)(cid:27)(cid:19)(cid:24)(cid:19)(cid:19)(cid:20)(cid:19)(cid:19)(cid:19)(cid:20)(cid:24)(cid:19)(cid:19)(cid:21)(cid:19)(cid:19)(cid:19)(cid:21)(cid:24)(cid:19)(cid:19)&LWDWLRQV(cid:3)FRXQWV(cid:3)(cid:11)FOXVWHU(cid:3)(cid:20)(cid:12)[VXP(cid:3)RI(cid:3)\ Data Intelligence Just Accepted MS. https://doi.org/10.1162/dint_a_00213 The state of the art of Natural Language Processing l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . e d u d n / i t / l a r t i c e – p d f / d o i / io . / T / 1 0 1 1 6 2 d n _ a _ 0 0 2 1 3 2 0 7 3 5 4 5 d n _ a _ 0 0 2 1 3 p d t / . i f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 Figura 19: Histogram of citation counts in cluster 0 (smaller cluster) – logarithmic scale • “Experimental Support for a Categorical Compositional Distributional Model of Mean- ing” [89] – a paper about “modelling compositional meaning for sentences using empirical distributional methods”. • “Gaussian error linear units (gelus)" [90] – paper introducing GELU, a new activation function in neural networks, which was extensively tested in future research [160]. Each of these papers introduced novel, very innovative ideas that inspired further research directions. They can be thus treated as belonging to a unique (separate) subset of contributions. 3.8. RQ6: Text comprehension Finally, an additional aspect of text belonging to the dataset was measured; text comprehensi- bility. This is a very complicated problem, which is still being explored. Taking into account that one of the considered audiences are researchers interested in starting work in NLP, text difficulty, using existing text complexity metrics, was evaluated. An important note is that these metrics are known for problems, ad esempio: not considering complicated mathematical formula; skipping charts, pictures and other visuals. Keeping this in mind, let us proceed further. 3.8.1. Text complexity The most common comprehensibility measures map text to school grade, in the American education system [28]. In this way, it is established what is the expected level of reader that should be able to understand the text. The used measures were: Data Intelligence 35 (cid:19)(cid:20)(cid:21)(cid:22)(cid:23)(cid:19)(cid:24)(cid:20)(cid:19)(cid:20)(cid:24)(cid:21)(cid:19)&LWDWLRQV(cid:3)FRXQWV(cid:3)(cid:11)FOXVWHU(cid:3)(cid:19)(cid:12)[VXP(cid:3)RI(cid:3)\ Data Intelligence Just Accepted MS. https://doi.org/10.1162/dint_a_00213 The state of the art of Natural Language Processing l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . e d u d n / i t / l a r t i c e – p d f / d o i / io / T / . 1 0 1 1 6 2 d n _ a _ 0 0 2 1 3 2 0 7 3 5 4 5 d n _ a _ 0 0 2 1 3 p d . T / i f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 Figura 20: Histogram of topics counts in cluster 1 (bigger cluster) • Flesch Reading Ease [23] • Flesch Kincaid Grade [23] • Gunning Fog [24] • Smog Index [25] • Automated Readability Index [23] • Coleman Liau Index [26] • Linsear Write Formula [27] All measures return results on equal scale (school grade). Inoltre, they were all con- sistent in terms of paper scores. To provide the least biased results, the numerical values (Sez- zione 3.8.2) have been averaged to achieve a single, straightforward, measure for text complexity. Here, it should be noted that this was done also because delving into discussion of ultimate valid- ity of individual comprehensibility measurements and pros/cons of each of them is out of scope of current contribution. Piuttosto, the combined measure was calculated to obtain a general idea as to the “readability” of the literature in question. The results can be averaged together between metrics, because all of they refer to the same scale (school grade). 36 Data Intelligence 1DWXUDO(cid:3)ODQJXDJH(cid:3)SURFHVVLQJ$UWLILFLDO(cid:3)QHXUDO(cid:3)QHWZRUN([SHULPHQW0DFKLQH(cid:3)OHDUQLQJ’HHS(cid:3)OHDUQLQJ$OJRULWKP7H[W(cid:3)FRUSXV&RPSXWHU(cid:3)YLVLRQ:RUG(cid:3)HPEHGGLQJ/DQJXDJH(cid:3)PRGHO(cid:19)(cid:24)(cid:19)(cid:19)(cid:20)(cid:19)(cid:19)(cid:19)(cid:20)(cid:24)(cid:19)(cid:19)(cid:21)(cid:19)(cid:19)(cid:19)(cid:21)(cid:24)(cid:19)(cid:19)7RSLFV(cid:3)FRXQWV(cid:3)(cid:11)FOXVWHU(cid:3)(cid:20)(cid:12)(cid:3)(cid:16)(cid:3)WRS(cid:3)(cid:20)(cid:19)[VXP(cid:3)RI(cid:3)\ Data Intelligence Just Accepted MS. https://doi.org/10.1162/dint_a_00213 The state of the art of Natural Language Processing l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . e d u d n / i t / l a r t i c e – p d f / d o i / io / . / T 1 0 1 1 6 2 d n _ a _ 0 0 2 1 3 2 0 7 3 5 4 5 d n _ a _ 0 0 2 1 3 p d t . / i f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 Figura 21: Histogram of topics counts in cluster 0 (smaller cluster) 3.8.2. RQ6: establishing complexity level of NLP literature Results of the text complexity (RQ6) are rather intuitive. Come mostrato in figura 24, the averaged score of 15 comprehensibility metrics suggests that the majority of papers, in the NLP domain, can be understood by a person after “15th grade”. This matches roughly a person who finished the “1st stage” of college education (engineering studies, bachelor degree, and similar). Obviously, this result shows that use of such metrics to “scientific texts” has limited applicability, as they are based mostly on syntactic features of the text, while the semantics makes some of them difficult to follow even for the specialists. Questo, particularly, applies to texts which contain mathematical equations, which are being removed during text preprocessing. 3.9. Summary of key results Let us now summarize the key finding, in the form of a question-answer for each of RQs that have been postulated in Section 1. RQ1: What datasets are considered to be most useful? The datasets used most commonly for NLP research are: Wikipedia, Twitter, Facebook, WordNet, arXiv, Academic, SST (The Stanford Sentiment Treebank), SQuAD (The Stan- ford Question Answering Dataset), NLI and SNLI (Stanford Natural Language Inference Corpus), COCO (Common Objects in Context), Reddit. RQ2: Which languages, other than English, appear as a topic of NLP research? Data Intelligence 37 1DWXUDO(cid:3)ODQJXDJH(cid:3)SURFHVVLQJ$UWLILFLDO(cid:3)QHXUDO(cid:3)QHWZRUN/DQJXDJH(cid:3)PRGHO([SHULPHQW’HHS(cid:3)OHDUQLQJ5HFXUUHQW(cid:3)QHXUDO(cid:3)QHWZRUN7H[W(cid:3)FRUSXV&RPSXWHU(cid:3)YLVLRQ$OJRULWKP0DFKLQH(cid:3)OHDUQLQJ(cid:19)(cid:20)(cid:19)(cid:21)(cid:19)(cid:22)(cid:19)7RSLFV(cid:3)FRXQWV(cid:3)(cid:11)FOXVWHU(cid:3)(cid:19)(cid:12)(cid:3)(cid:16)(cid:3)WRS(cid:3)(cid:20)(cid:19)[VXP(cid:3)RI(cid:3)\ Data Intelligence Just Accepted MS. https://doi.org/10.1162/dint_a_00213 The state of the art of Natural Language Processing l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . e d u d n / i t / l a r t i c e – p d f / d o i / i t / / . 1 0 1 1 6 2 d n _ a _ 0 0 2 1 3 2 0 7 3 5 4 5 d n _ a _ 0 0 2 1 3 p d . / t i f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 Figura 22: Histogram of categories counts in cluster 1 (bigger cluster) Languages analyzed most commonly in NLP research, apart from English and Chinese, are: German, French and Spanish. RQ3: What are the most popular fields and topics in current NLP research? The most popular fields studied in NLP literature are: Natural Language Processing/Lan- guage Computing, artificial intelligence, machine learning, neural networks and deep learn- ing and text embedding. RQ4: What particular tasks and problems are most often studied? Particular tasks and problems, which appear in the literature, are: text embedding with BERT and transformers, machine translation between English and other languages (es- pecially English-Chinese), sentiment analysis (most popular with Twitter and Wikipedia datasets), question answering models (with Wikipedia and SQuAD datasets), named entity recognition, and text summarization. RQ5: Is the field “homogenous”, or are there easily identifiable “subgroups”? According to the text embedding analysis, there is not enough evidence to find a strongly distinguishable clusters. Hence, there are no outstanding subgroups in the NLP literature. RQ6: How difficult is it to comprehend the NLP literature? According to averaged standard comprehensibility measures, scientific texts related to NLP can be digested by a 15th graders, which maps to the 3rd year of higher education (e.g. Università, Bachelor’s degree studies etc.) 38 Data Intelligence FV(cid:17)&/FV(cid:17)/*FV(cid:17)$,VWDW(cid:17)0/FV(cid:17),5FV(cid:17)&9FV(cid:17)&