A Scalable Peer-to-Peer
System for Music
Information Retrieval
George Tzanetakis,* Jun Gao,†
and Peter Steenkiste†‡
*Computer Science Department, Faculty
of Engineering
University of Victoria
PO BOX 3055 STNCSC
Victoria, British Columbia V8W3P6 Canada
gtzan@cs.uvic.ca
†Computer Science Department
‡Department of Electrical and Computer
Engineering
Carnegie Mellon University
5000 Forbes Avenue
Pittsburgh, Pennsylvania 15213 USA
{jungao,prs}@cs.cmu.edu
Currently, a large percentage of Internet traffic con-
sists of music files, typically stored in MP3 com-
pressed audio format, shared and exchanged over
peer-to-peer (P2P) networks. Searching for music is
performed by specifying keywords and naı¨ve string-
matching techniques. In the past years, the emerg-
ing research area of music information retrieval
(MIR) has produced a variety of new ways of look-
ing at the problem of music searching. Such MIR
techniques can significantly enhance the ways
users search for music over P2P networks. For that
to happen, there are two main challenges that need
to be addressed: scalability to large collections and
number of peers; and a richer set of search seman-
tics that can support MIR, especially when the re-
trieval is content-based. In questo articolo, we describe
a scalable P2P system that uses rendezvous points
(RPs) for music metadata registration and query
resolution. The system supports attribute-value
search semantics as well as content-based retrieval.
The performance of the system has been evaluated
in large-scale usage scenarios using ‘‘real,’’ auto-
matically calculated musical content descriptors.
One could argue that both the ideas of MIR and
P2P became familiar to the general public with
Napster (www.napster.com). Although crude both
in terms of search capabilities and P2P perfor-
mance, Napster provided for the first time an ex-
ample of sharing vast amounts of musical data over
large ad-hoc networks. Despite this early connec-
tion between MIR and P2P, there has not been
much progress in combining these two areas. Al-
though better P2P paradigms have been proposed,
searching for music is currently still performed us-
Computer Music Journal, 28:2, pag. 24–33, Estate 2004
(cid:1) 2004 Istituto di Tecnologia del Massachussetts.
ing traditional keyword-based text searching. Al-
though a variety of novel ways of searching and
retrieving music, especially in audio format, Avere
been proposed, they have not found their way into
P2P networks and remain largely academic exer-
cises.
There are many advantages to P2P networks,
such as distributed computing and storage power,
fault-tolerance, and reliability. Owing to copyright
restrictions, Tuttavia, major recording labels have
been reluctant to follow this paradigm, ma il
emergence of audio fingerprinting technology
(Haitsma and Kalker 2002) is likely going to change
this attitude. Although the intellectual property
issues behind P2P networks are complicated, we
believe that the use of techniques such as finger-
printing will allow digital music distribution while
protecting copyrights. Although the main focus of
the system is the use of P2P networks in MIR, IL
proposed architecture can be adapted for the re-
quirements of fingerprinting. One of the greatest
potential benefits of P2P networks is the ability to
harness the collaborative efforts of users to provide
semantic, subjective, and community-based tags to
describe musical content. We believe this aspect of
P2P networks provides a unique opportunity for
changing the way music is produced and distrib-
uted.
Centralized P2P networks such as Napster are
not robust and may be vulnerable to Denial-of-
Service attacks, because the central server forms
the system’s single point of failure. Such a system
does not scale well as registration and query load
increase. Distributed P2P systems, such as Gnu-
tella (www.gnutella.org) and KaZaA (www.kazaa
.com), are more robust, but because peers do not
24
Computer Music Journal
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
C
o
M
j
/
l
UN
R
T
io
C
e
–
P
D
F
/
/
/
/
/
2
8
2
2
4
1
8
5
4
0
8
5
0
1
4
8
9
2
6
0
4
3
2
3
1
1
2
2
2
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
explicitly register their shared files, a query may
have to be broadcast throughout the network to get
resolved. The potentially large number of messages
involved limits the system’s scalability and perfor-
mance. Distributed Hash Table (DHT)-based sys-
tems, such as those described in Stoica et al. (2001)
and Rowstron and Druschel (2001), achieve good
scalability by deploying a structured overlay P2P
network that supports efficient content location.
Tuttavia, the basic set of applications built on top
of DHT only supports exact file name lookup and
does not allow the rich search semantics desired
for MIR.
In questo articolo, we describe a robust, scalable P2P
system that provides flexible search semantics
based on attribute-value (AV) pairs and supports au-
tomatic extraction of musical features and content-
based similarity retrieval. The system is shown to
perform well under realistic loads consisting of fea-
tures automatically extracted from a large database
of audio recordings. The main contributions of this
article are a general content-discovery mechanism
that supports exact and similarity search based on
AV pairs and its evaluation using a specific set of
audio features computed on actual audio record-
ing. We believe that the proposed system provides
the necessary flexibility and performance for effec-
tive use of MIR for searching in peer-to-peer net-
works.
Related Work
The main focus of this article is the retrieval of
music in audio format over P2P networks. Much
recent exciting work in MIR is relevant to the de-
sign of our system, and we review some representa-
tive publications. Although this article mainly
describes similarity retrieval, the underlying frame-
work of features and calculating distances forms
the basis of a variety of audio-analysis algorithms
such as musical genre classification (Tzanetakis
and Cook 2002; Aucouturier and Pachet 2003), beat
detection and analysis (Foote and Cooper 2002),
similarity retrieval (Logan and Salomon 2001; Au-
couturier and Pachet 2002; Yang 2002), audio fin-
gerprinting (Haitsma and Kalker 2002), E
clustering and visualization (Rauber et al. 2002). In
addition to features computed from the automatic
analysis of audio content, features computed based
on text analysis of critics’ reviews as well as P2P
usage patterns have been shown to be effective for
classification (Whitman and Smaragdis 2002).
These articles are representative of each category.
A general overview of the current status in MIR
and an extensive bibliography can be found in Fu-
trelle and Downie (2002); another good overview of
the current state of the art and challenges in MIR is
found in Pachet (2003).
DHT-based systems such as those described in
Stoica et al. (2001) and Rowstron and Druschel
(2001) solve some of the scalability problems of the
well-known broadcast-based systems such as Gnu-
tella and KaZaA. The content discovery system
(CDS) proposed in this article is built on top of
such a DHT-based system. The idea of using MIR
over P2P was proposed in Wang et al. (2002); how-
ever, the proposed system’s architecture suffers
from scalability problems, and only the retrieval of
symbolic data is examined. The potential of inte-
grating MIR and the evolving semantic web was
explored in Baumann and Kluter (2002). More re-
cently, content-based retrieval over a P2P network
using the JXTA programming framework was pre-
sented in Baumann (2003). The proposed system is
mainly concerned with integrating feature repre-
sentations into the P2P system rather than using
the structure of the network to support exact and
similarity search. An initial description of the sys-
tem presented in this article can be found in Gao et
al. (2003). The main differences of this article from
previous work is the scalable and efficient support
of both exact and similarity searching based on
RPs, as well as the performance evaluation of using
audio features computed from actual audio record-
ings rather than synthetic data.
System Overview
Following recent work in P2P networks, our sys-
tem decouples the process of locating content from
the process of downloading it. Each node in the
network not only stores music files for sharing but
Tzanetakis, Gao, and Steenkiste
25
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
C
o
M
j
/
l
UN
R
T
io
C
e
–
P
D
F
/
/
/
/
/
2
8
2
2
4
1
8
5
4
0
8
5
0
1
4
8
9
2
6
0
4
3
2
3
1
1
2
2
2
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
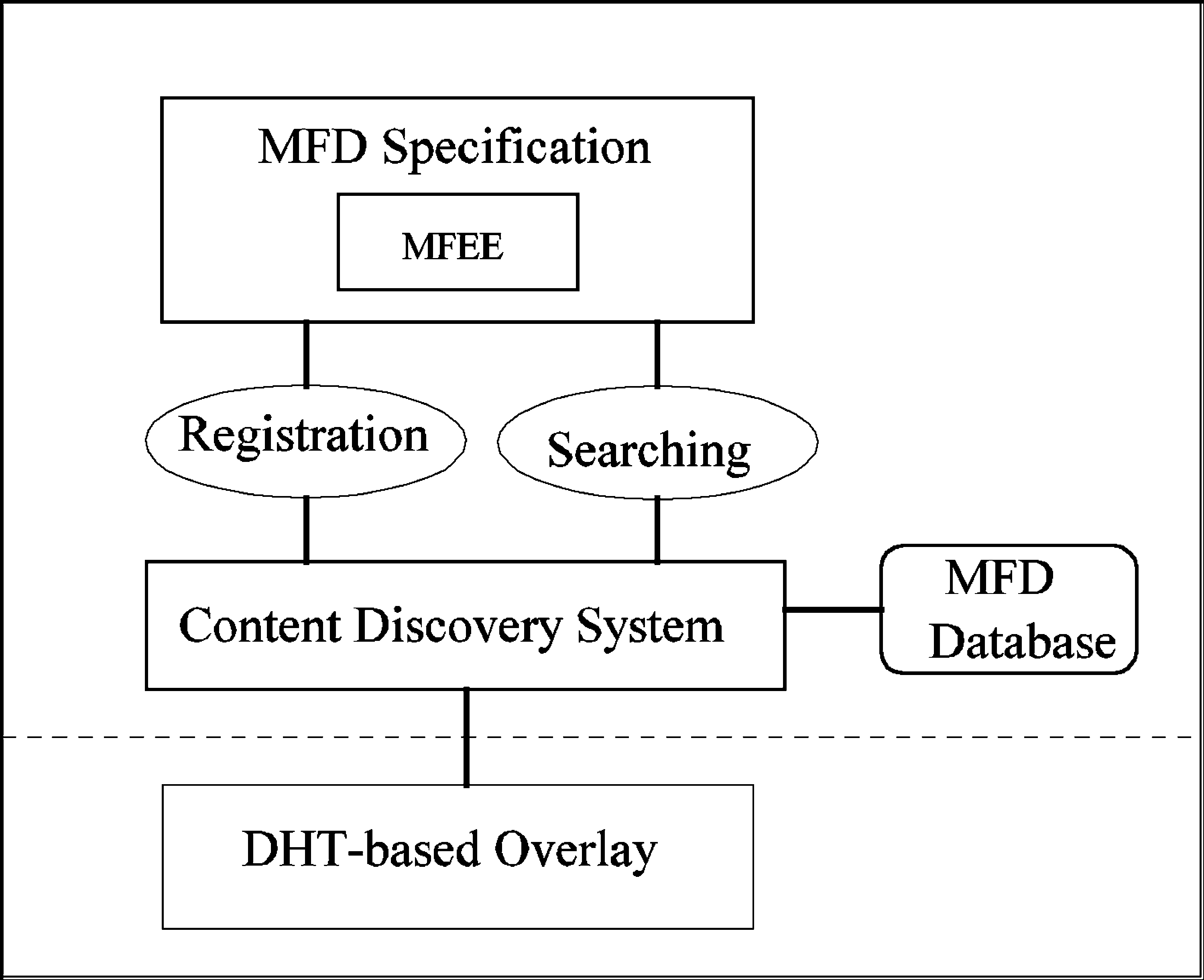
Figura 1. Software architec-
ture of a peer node (DHT
(cid:2) distributed hash table,
MFD (cid:2) music file descrip-
zione, MFEE (cid:2) Music Fea-
ture Extraction Engine).
also stores information about the location of other
music files in the network. Therefore, when the
user submits a search to the P2P system, the sys-
tem returns a set of peers from which the music
files that satisfy the search criteria can then be
downloaded. Each file in the system is described by
a music file description (MFD) which is essentially
a set of AV pairs. Per esempio, a possible MFD
might be the following: {artist (cid:2) U2, album (cid:2)
Rattle and Hum, song (cid:2) Desire, . . ., specCentroid
(cid:2) 0.65, mfcc2 (cid:2) 0.85, . . .}. Notice that the de-
scription contains both attributes that can be man-
ually specified by the user, such as artist or album,
as well as automatically extracted features for de-
scribing musical content (such as the Spectral Cen-
troid). The Music Feature Extraction Engine
(MFEE) calculates these features from the audio
files. These automatically extracted features, in ad-
dition to being used for content-based similarity
search, can also be used for various other types of
audio analysis, such as musical genre classification.
Two operations are supported by the system, E
both take MFDs as arguments. In registration, UN
new music file is made available for sharing, E
its associated MFD is registered to the P2P system.
During searching, the user query is converted into
an appropriate MFD that is then used to locate the
nodes that contain files that match the search cri-
teria. Once the nodes are located, they are con-
tacted directly to start the actual downloading of
the file. The main concern in the design of our sys-
tem is the efficient content discovery rather than
the actual downloading mechanism.
Figura 1 shows the software architecture on each
peer node. The MFD of either registration or search
query is passed to the content discovery system
(CDS), which runs on top of a DHT-based P2P sys-
tem, such as Chord (Stoica et al. 2001). In a DHT,
each peer is responsible for a region, represented
with a node ID, in a contiguous m-bit virtual ad-
dress space. A data item, such as a file name, is as-
sociated with some value in this address space, per esempio.,
by applying a uniform hash function to the data
item, and stored on the peer whose region covers
the value. Therefore, a DHT implements just one
operation, lookup(key), which yields the network
location of the node currently responsible for a
given key.
To implement a DHT, a lookup algorithm must
address the following issues: mapping keys in a
load-balanced way, forwarding a lookup for a key to
an appropriate node, and building routing tables
adaptively as nodes enter and exit the system. Cor-
respondingly, by applying the same computation to
the data item, a peer can locate it from the same
peer who stores it. A good introduction to looking
up data in P2P systems is found in Balakrishnan et
al. (2003). We present the algorithm used by the
CDS to distribute MFDs to peers in the Scalable
Content Discovery Section. The underlying mecha-
nism of DHT ensures routing and message forward-
ing efficiency in such a system: in Chord, a peer
only needs to keep information about O(log N)
neighboring peers, and the number of overlay hops
between two peers is O(log N), where N is the total
number of peers in the system. Each peer main-
tains a local MFD database to store the MFDs it is
assigned by the CDS. Upon the arrival of a query,
each peer examines its local MFD database and re-
turns the set of MFDs that match the query to the
query initiator. Subsequently, the query initiator
can download the actual music file from the peer
that owns the music.
Music Feature Extraction
The MFEE component takes as input an audio file
in either pulse-code modulation (PCM) format or a
26
Computer Music Journal
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
C
o
M
j
/
l
UN
R
T
io
C
e
–
P
D
F
/
/
/
/
/
2
8
2
2
4
1
8
5
4
0
8
5
0
1
4
8
9
2
6
0
4
3
2
3
1
1
2
2
2
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
compressed format (such as MP3) and produces a
feature vector, also known as the content-based
vector, of AV pairs that characterizes the particular
musical content of the file. In our system, noi usiamo
the feature set proposed in Tzanetakis and Cook
(2002) for the purpose of musical genre classifica-
zione. This feature vector statistically captures as-
pects of instrumentation and sound texture (what
instruments are playing and their density distribu-
tion over time), rhythm (fast-slow, strong-weak),
and pitch content (harmony). It has been shown to
be an effective representation for the purposes of
classification and retrieval of music. Features based
on the Short Time Fourier Transform as well as
Mel-Frequency Cepstral Coefficients are used to
represent sound texture, and features based on
Beat and Pitch Histograms are used to represent
rhythm and pitch content. More specifically, IL
means and variances of the Spectral Centroid, Rol-
loff, Flux, and Zero Crossings, as well as the first
five Mel-Frequency Cepstral Coefficients (MFCC)
over a 1-sec texture window using a 20-msec analy-
sis window are calculated to represent Spectral
Texture. For the Beat Histogram calculation, a Dis-
crete Wavelet Transform filterbank is applied, E
autocorrelation-based envelope periodicity detec-
tion is performed. For the Pitch Histogram calcula-
zione, the multiple pitch detection algorithm
described in Tolonen and Karjalainen (2000) È
used. The different types of information repre-
sented by the feature vector, combined with the
query flexibility of the system, support a rich vari-
ety of possible query specifications. Per esempio, UN
user can search only on the basis of rhythmic con-
tent while ignoring other aspects of music similar-
ity or combine metadata and content-based
similarity search.
We use standard linear quantization and normali-
zation to transform the dynamic ranges of the con-
tinuous features into discrete values necessary for
searching based on AV pairs. Linear quantization
was chosen so that the statistics of the distribution
of the features do not change. In our system, each
feature is quantized to 100 (cid:3) 1 discrete values. Ex-
periments comparing automatic classification of
the original continuous features and the quantized
features showed no significant differences in the re-
sults. Using the features and dataset (ten genres)
described in Tzanetakis and Cook (2002) and a
Gaussian classifier, we obtained 57.5 percent classi-
fication accuracy using the unquantized features
E 58 percent accuracy using the quantized ver-
sion.
(cid:2) v1,. . ., an
The results of the MFEE component, together
with manually annotated metadata such as artist
and album name, are combined to form the MFD,
which is a collection of AV pairs. Per esempio,
(cid:2) vn} consists of n AV pairs,
MFD1:{a1
where ai, io (cid:2) 1 . . .N, can be either a manually an-
notated attribute or a content-based feature attri-
bute. For specifying queries, MFDs are similarly
formed to represent the search criteria. In particu-
lar, the MFEE is used to generate a query MFD
when the user provides a sample piece of music.
Any subset of the MFD can be used for query speci-
fication, and using named AV pairs in MFDs allows
more possibilities than traditional keyword-based
searching. Some examples of possible queries of in-
creasing complexity are the following:
• Search for {artist (cid:2) U2}
• Search for {artist (cid:2) U2, year (cid:2) 1985, tempo (cid:2)
80 beats-per-minute (BPM) – 100 BPM}
• Search for {10 most similar to x.mp3 (content-
based similarity search)}
• Search for {10 most similar to x.mp3, artist (cid:2)
U2}
These are only symbolic pseudo-representations
of the queries. In an actual implementation, a vari-
ety of user interfaces for query specification would
be provided by the system (some interesting possi-
bilities are described in Tzanetakis et al. 2002). For
queries with content-based parts such as the last
two examples, the audio file x.mp3 is first con-
verted using the MFEE to numerical features that
describe musical content that are subsequently
used for similarity search. This mechanism allows
any audio file to be used in the system, even if it
does not have any metadata information associated
with it (Per esempio, a file recorded off a radio
broadcast).
Scalable Content Discovery
Unlike centralized systems in which files are regis-
tered at a single place, or broadcast-based systems
Tzanetakis, Gao, and Steenkiste
27
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
C
o
M
j
/
l
UN
R
T
io
C
e
–
P
D
F
/
/
/
/
/
2
8
2
2
4
1
8
5
4
0
8
5
0
1
4
8
9
2
6
0
4
3
2
3
1
1
2
2
2
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
Figura 2. Illustration
example of the Content
Discovery System.
X
sì
1
2
3
4
5
1
2
3
4
5
UN
e
F
q2
B
C
D
Some Nodes:
N[y=2] : {UN,e}
N[x=3] : {B,C,D}
N[y=3] : {B}
Registered MFDs:
a = (1,2)
b = (3,3)
c = (3,4)
d = (3,5)
e = (2,2)
f = (4,1)
Some Queries:
q0 : {y=2}
q1 : {x=3, y=3}
q2 : {x=4, y=3}
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
C
o
M
j
/
l
UN
R
T
io
C
e
–
P
D
F
/
/
/
/
/
2
8
2
2
4
1
8
5
4
0
8
5
0
1
4
8
9
2
6
0
4
3
2
3
1
1
2
2
2
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
the rich set of possible query semantics we desire
for MIR.
MFD Searching
(cid:2) H(ai
(cid:2) v1, . . ., am
We classify searches conducted by a user into two
categorie: exact searches and similarity searches.
In an exact search, the user is looking for MFDs
that match all the AV pairs specified in the query
simultaneously, and any extra AV pairs that may
be in the MFDs but not in the query are ignored.
(cid:2) vm}. Essere-
Suppose the query is Q:{a1
cause the MFDs that match Q are registered at RP
(cid:2) vi), IL
peers N1 through Nm, where Ni
CDS can send a single query message to any of
these peers to have the query fully resolved. For ef-
ficient resolution, the CDS chooses the peer that
has the smallest MFD database. Once a query is re-
ceived, the peer conducts a pair-wise comparison
between the query and all the entries in its data-
base to find the matching MFDs. An example
might be {artist (cid:2) U2, year (cid:2) 1985, tempo (cid:2) 100
BPM}, which means the matched MFD must have
the above three AV pairs in their description. Most
likely, the node that contains the locations of all
U2 songs will have the smallest local MFD data-
base, so it will be contacted and locally searched
for MFDs with the correct year and tempo.
where a query may potentially be sent to all peers
in the system, CDS uses a scalable approach based
on RPs for registration and query resolution. Essen-
tially, the P2P network is structured to efficiently
represent the space of AV pairs for the tasks of
searching and retrieving music.
MFD Registration
To register an MFD, the CDS applies a uniform
hash function such as SHA-1 to each AV pair in the
(cid:2) vi)→ Ni, Dove
MFD to obtain n node IDs: H(ai
Ni is the ID of a peer in the system. The MFD is
then sent to each of these peers, and this set of
peers is known as the RP set for this MFD. Upon
receiving an MFD, the peer inserts it into its data-
base. Hence, each peer is responsible for the AV
pairs that are mapped onto it. Per esempio, node N1
(cid:2) v1}. Figura
will receive all MFDs that contain {a1
2 shows a made-up small-scale example of how the
system works. The MFD is two-dimensional, con
the horizontal coordinate corresponding to the first
attribute and the vertical coordinate corresponding
to the second attribute. (This is only done for pur-
poses of illustration. The actual system can handle
multidimensional data as well.) One can visually
observe the distribution of the MFD (UN,B,C,D,e,F) E
how they are assigned to nodes such as N[X (cid:2) 3].
In two dimensions, each node is responsible for a
row or a column of the AV grid. Obviously, this re-
sults in significant overlap between the entries of
the local databases on each node, which enhances
the robustness of the system. Even in this con-
trived example, it can be seen that the load on each
node depends on the distribution of specific AV
pairs such as x (cid:2) 3. This issue is addressed by the
load-balancing scheme described later.
Because the number of AV pairs in an MFD is
typically small (per esempio., less than 50), the size of the
RP set for an MFD is small and registrations can be
done efficiently. Different MFDs will have different
corresponding RP sets, which naturally separates
the system’s registration load. An important point
is that registering each AV pair of an MFD individ-
ually allows the MFD to be searched using any
subset of its AV pairs, which is important to allow
28
Computer Music Journal
To further illustrate this process, in Figure 2, IL
query q0:{sì (cid:2) 2} will go to the corresponding node
N[sì (cid:2) 2] and directly return the correct answer {UN,
e}. The query q1: {X (cid:2) 3, sì (cid:2) 3} will check the data-
base size of nodes N[X (cid:2) 3] and N[sì (cid:2) 3], select the
smallest N[sì (cid:2) 3] , and then return the correct an-
swer {B}. Note that the answer is the location of the
music file that can then be subsequently down-
loaded.
In a similarity search, the user is trying to find
(cid:2) v1, . . ., f2
(cid:2) v2} and wants to find ten
(cid:2) v1} and send the query to the peer N
music files that have a similar feature vector to
what is specified in the query. Suppose the user has
a clip unknown.mp3 with an extracted feature vec-
tor {f1
songs that are most similar to the clip. Using the
same technique as above, the CDS may select a
pair, per esempio., {f1
(cid:2) v1)). This peer, instead of conducting a
((cid:2) H(f1
pair-wise equality test, computes the ‘‘distance’’
between the query vector and each MFD in its da-
tabase. Our current system uses Manhattan dis-
tance, defined as d(F, f’) (cid:2) |v1 – v1’| (cid:5) . . . (cid:5) |vm
(cid:6)
vm’|, where all the vi and vi’ represent the values of
vectors f and f’, rispettivamente. More sophisticated
ways of computing distance, such as ‘‘cosine dis-
tance,’’ may also be used. The distances are then
ranked, and the ten top MFDs that have the small-
est distance are returned to the user.
Tuttavia, sending the query to peer N alone will
fail to discover the MFDs that slightly differ from
the query in f1 but are similar or identical regarding
other features, because those MFDs are not regis-
tered with N. This is undesirable especially when
peer N does not have enough matches. In questo caso,
our system uses a limited expanding ring search to
gather more results: in addition to N, the query is
sent either by N or the query initiator to peers that
correspond to values that are near v1, per esempio., f1
(cid:7) 1, f1
(cid:7) 2, eccetera. Accordingly, these peers will
carry out the distance computation and return any
risultati. Figura 2 shows schematically this expand-
ing ring search for query q2:{X (cid:2) 3, sì (cid:2) 4} as two
concentric circles.
(cid:2) v1
(cid:2) v1
Ovviamente, it is also possible to combine exact
AV search and content-based similarity search.
This last point is important and directly influenced
the design of our system. Although it is possible to
use more elaborate data structures for multidimen-
sional nearest neighbor search (the similarity
search) such as KD-trees (Bentley 1975) and try to
distribute them over the P2P network, these struc-
tures do not directly support searching for arbitrary
subsets of AV pairs as our system does. Supporting
such searches is important for MIR, because we
would like to combine both metadata and content-
based retrieval in the same query. Finalmente, range
queries such as {tempo (cid:2) 80–120 BPM} are re-
solved by issuing multiple queries corresponding to
the values within the range. We are experimenting
with a more efficient multi-resolution approach to
range searching where not only values but also
ranges of values are assigned to nodes. That way,
the number of nodes that must be visited to resolve
a range query is reduced to O(logL), where L is the
length of the range. This method is described in
more detail in Gao and Steenkiste (2003).
Load Balancing
By using RPs, network-wide message flooding is
avoided at both registration and query times. How-
ever, in practice, some AV pairs may be much
more common or popular in MFDs than others. It
has been observed that the popularity of keywords
in Gnutella follows a Zipf-like distribution (Sripan-
idkulchai 2001). Such a distribution will cause a
few peers to be overloaded by registrations or
queries and thus create bottlenecks, while the ma-
jority of peers in the system stay underutilized. Fig-
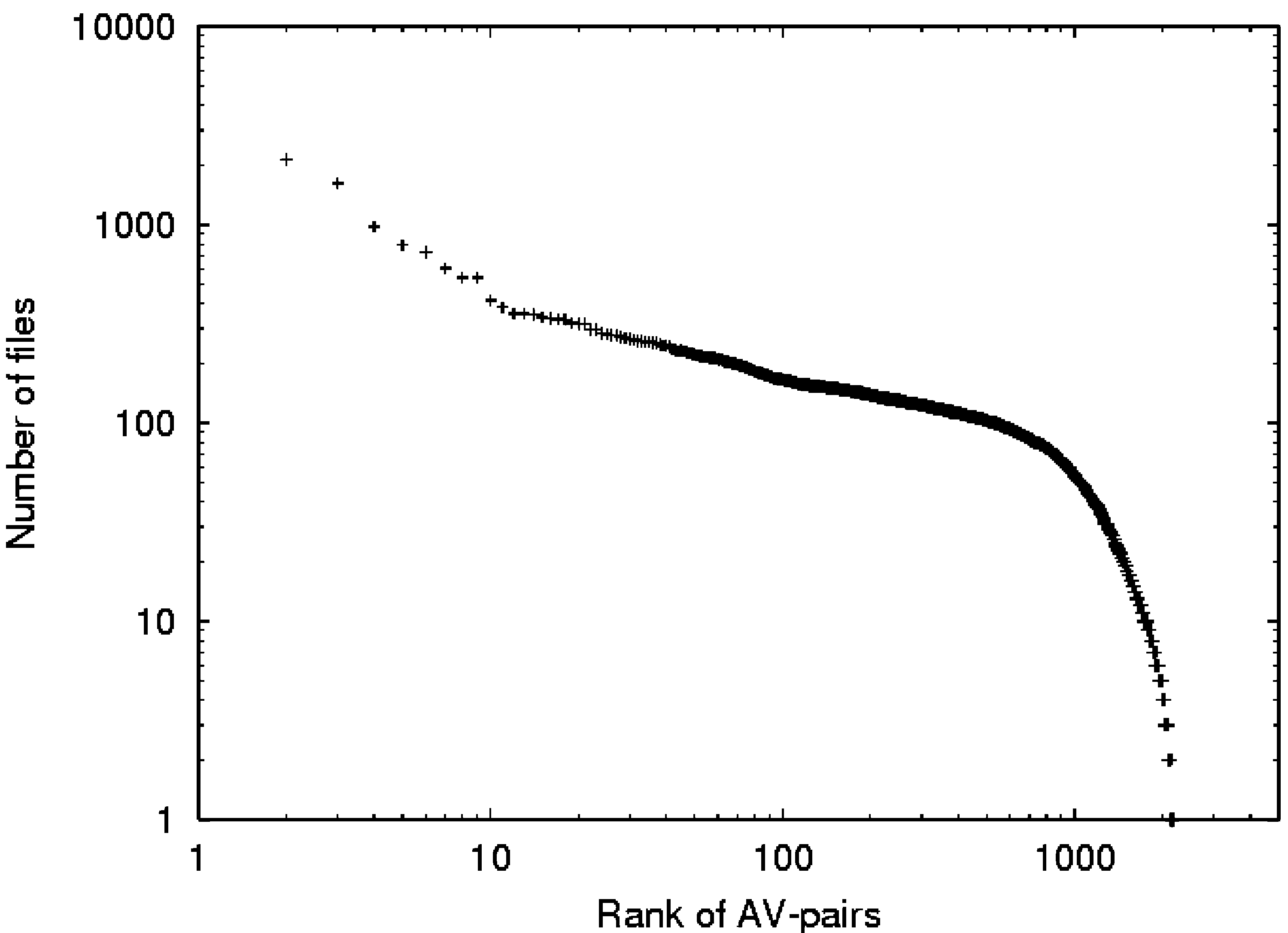
ure 3 shows a distribution of AV pairs computed
from automatically extracted musical content fea-
tures described in more detail in the System Evalu-
ation section. To improve the system’s throughput
under skewed load, the CDS deploys a distributed
dynamic load-balancing mechanism described in
Gao and Steenkiste (2004), where multiple peers
are used as RP points to share the heavy load in-
curred by popular AV pairs.
When a node corresponding to a data item (per esempio.,
an AV pair) becomes overloaded by registration or
queries, it recruits more nodes to share the load in-
stead of rejecting the registrations or queries. When
an AV pair appears in many MFDs, instead of send-
Tzanetakis, Gao, and Steenkiste
29
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
C
o
M
j
/
l
UN
R
T
io
C
e
–
P
D
F
/
/
/
/
/
2
8
2
2
4
1
8
5
4
0
8
5
0
1
4
8
9
2
6
0
4
3
2
3
1
1
2
2
2
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
Figura 3. Popularity distri-
bution of feature attrib-
utes.
Figura 4. Load-balancing
matrix.
Head node
0,0
Partitions
1,1
2,1
1,2
2,2
P,1
P,2
S
UN
C
io
l
P
e
R
1,R
2,R
P,R
ing all the MFDs to one peer, the system partitions
them among multiple peers. Allo stesso modo, if there are
a large number of queries for the same AV pair, IL
system allows the original peer who is responsible
for this pair to replicate its database at other peers.
Come esempio concreto, some particular AV pair
ad esempio {tempo (cid:2) 100 BPM} might be very com-
mon. Partitioning the set of songs that have that
particular AV pair among multiple RP points bal-
ances the registration load. Another type of load
that is possibly independent of the registration load
is the popularity of queries. Per esempio, a new re-
lease {artist(cid:2) Madonna, year (cid:2) 2003} will initially
only be registered with a few RPs, although many
queries will be requesting it. Replicating their in-
formation will balance the query load. The parti-
tions and replicas corresponding to one AV pair are
organized into a logical matrix, the load-balancing
matrix (LBM). Each column of the matrix holds a
partition of the MFDs that contain this AV pair
(which helps spread registration load) and nodes in
different rows within a column are replicas of each
other (which helps spread query load). An LBM
starts with one node and expands and shrinks de-
pending on the registration and query load. IL
number of partitions is proportional to the registra-
tion load, and the number of replicas is propor-
tional to the query load corresponding to this data
item.
Figura 4 shows the layout of the matrix for a data
item. Each node in the matrix has a column and
row index (P, R), and node IDs are determined by ap-
plying the hash function H to the data item (an AV
pair in this case) and the column and row indices
together: Ni(P, R) (cid:2) H(dati, P, R). To register a data
item, the registering node selects a random parti-
tion from the matrix and registers with each node
in that partition. To retrieve all possible matches, UN
query must be sent to all existing partitions in the
matrix; Tuttavia, only one node is selected from
each partition owing to replicas. An important
property of the LBM is that both the registration
load and query load are spread evenly within the
matrix.
As an optimization, each matrix may use a head
node, with ID (cid:2) Ni(0, 0) ((cid:2) H(dati, 0, 0)) to store
its current size and coordinate the matrix’s expan-
sion and shrinking. In Gao and Steenkiste (2004),
fault-tolerant mechanisms for restoring the size in-
formation when the head node fails are discussed.
An end point can retrieve the size of the matrix
from the head node. To ensure that the head node
will not become a performance bottleneck, end-
points can also obtain the size efficiently by con-
ducting binary probing along the two dimensions,
caching the size for future use. To summarize,
LBMs help eliminate ‘‘hot spots’’ in the system un-
der skewed load, and the system can maintain high
30
Computer Music Journal
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
C
o
M
j
/
l
UN
R
T
io
C
e
–
P
D
F
/
/
/
/
/
2
8
2
2
4
1
8
5
4
0
8
5
0
1
4
8
9
2
6
0
4
3
2
3
1
1
2
2
2
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
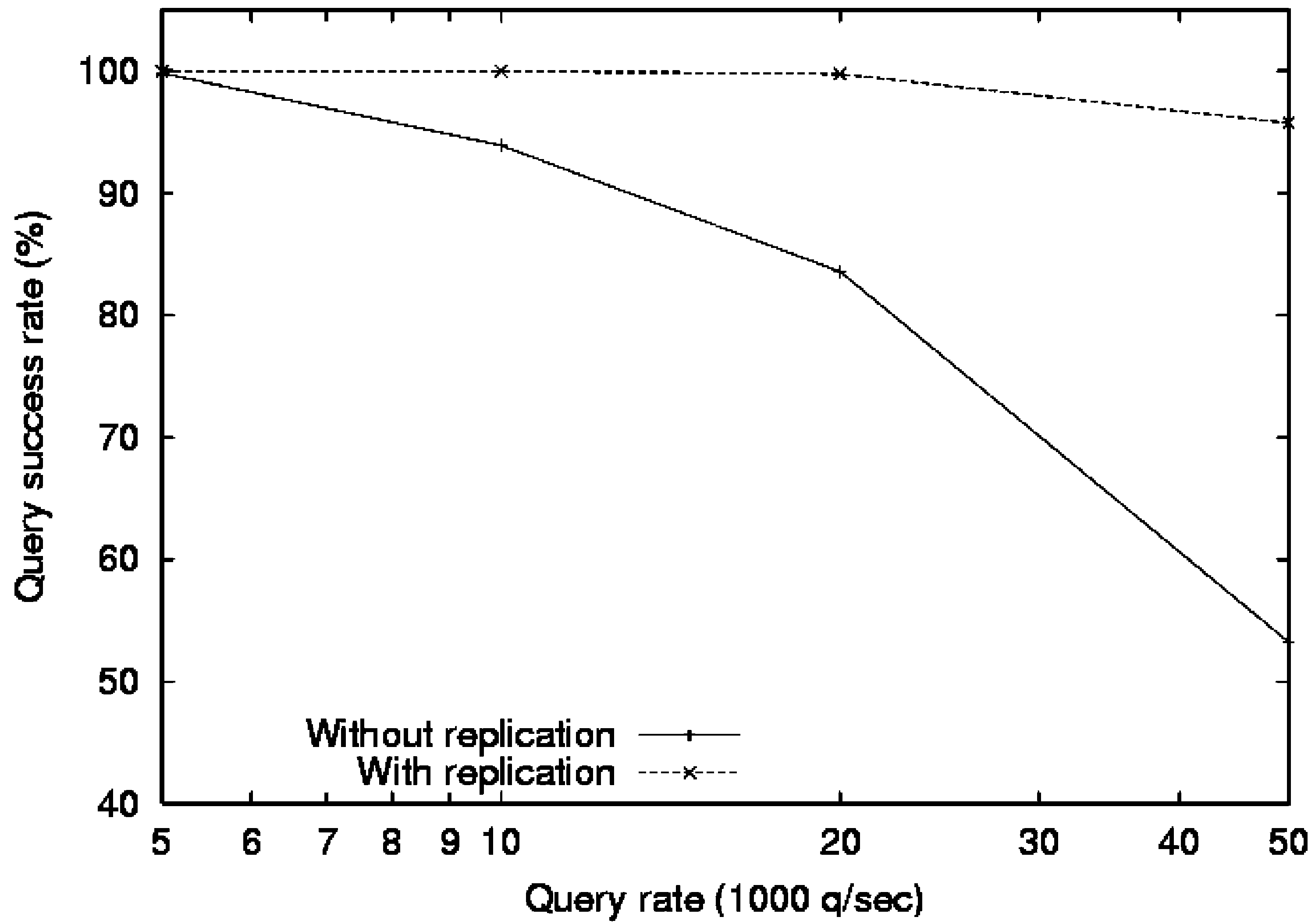
Figura 5. Query success
rate comparison.
throughput in processing registrations and queries
(Gao and Steenkiste in press).
System Evaluation
The MFEE is built using Marsyas (Tzanetakis and
Cook 2000), a free software framework for audio
analysis, and we evaluate our system using an
event-driven simulator (Gao and Steenkiste 2004).
For our experiments, we set up a P2P network that
ha 10,000 peers, and each peer is configured with
DSL-class link bandwidth (approximately 500
Kbps). As MFDs, 30 music content-based features
are used as attributes. They were automatically ex-
tracted from 5,000 MP3 files representing a variety
of genres and styles. Figura 3 shows the log-log plot
of the AV pair distribution in these files. There are
2,178 distinct AV pairs, and the distribution is
highly skewed: the most common AV pair (ranked
1) appears in 53 percent of the MFDs, E 41 AV
pairs only appear in 1 MFD.
For registration workload, we generated 100,000
MFDs by replicating each of the 5,000 files 20
times and assigning them to random peers. Each
peer registers the files it is assigned with the sys-
tem. Owing to the skewed feature distribution, reg-
istrations of common AV pairs result in multiple
partitions. For query load, 100,000 queries were
generated following a query-popularity Zipf distri-
bution independent from the AV pair distribution
shown in Figure 3. Each query corresponds to the
features of one particular music file. This is done in
order to emulate the behavior of a user who sub-
mits a music clip and looks for similar music. IL
most popular MFD occurs in over 10 percent of the
queries, and the majority of the MFDs only occur
in a few queries. A query’s initiator is randomly
picked from all peers, and for simplicity, only exact
matches are returned. A peer rejects a query and
generates a failure when the peer’s link utilization
has reached 100 percent owing to simultaneous
queries.
Figura 5 compares the query success rate as a
function of query arrival rate (Poisson arrival) A
the system under two scenarios. In the first sce-
nario, when reaching link capacity, a peer simply
rejects new queries that arrive at it without repli-
cating its content at other peers. Because for each
query the CDS has 30 candidate AV pairs, query
load can spread evenly among peers, even without
replication. Therefore, the system achieves a high
success rate under high load: Per esempio, the suc-
cess rate is 94 percent for a query rate of 10,000
queries per sec (q/sec). Tuttavia, as load increases
ulteriore, peers corresponding to popular queries will
become saturated, and the success rate drops
quickly. In the second scenario, by using the dy-
namic replication mechanism, peers who observe
high load will replicate their databases at other
peers to dissipate concentrated query load. As a re-
sult, we observe that with replication, the system
can sustain a much higher query rate while keeping
the success rate above 95 per cento.
Conclusions
In questo articolo, we described a scalable and load-
balanced P2P system that supports a rich set of
music search methods. In particular, our automatic
music feature extraction technique enables sophis-
ticated music content-based searches such as
content-based similarity retrieval. The RP-based
registration and query specification scheme ensures
system scalability by avoiding network-wide mes-
sage flooding encountered in current P2P systems.
Tzanetakis, Gao, and Steenkiste
31
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
C
o
M
j
/
l
UN
R
T
io
C
e
–
P
D
F
/
/
/
/
/
2
8
2
2
4
1
8
5
4
0
8
5
0
1
4
8
9
2
6
0
4
3
2
3
1
1
2
2
2
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
We evaluated the system using a realistic registra-
tion load obtained from a large set of music files.
Our dynamic load-balancing mechanism allows the
system to maintain high throughput under skewed
Zipf query load. It is our hope that the design of
our system will inspire additional research in the
interesting area of bringing state of the art MIR al-
gorithms to the increasingly popular P2P networks.
Another important aspect of the proposed system is
that new attributes can be incorporated into the
system with minimal effort.
We are currently refining the design of our sys-
tem to handle similarity searches more efficiently
and plan to further evaluate our system with traces
acquired from real users. Further experiments are
necessary for a more detailed evaluation of system
performance. Inoltre, user studies need to be
conducted to explore how users interact with the
system and their typical queries. Duplicate copies
of the same audio content can be detected by
adapting an audio-fingerprinting technique to work
with our P2P system.
Ringraziamenti
We gratefully acknowledge the support of the Na-
tional Science Foundation under grant ISS-008594.
This research was also sponsored in part by the De-
fense Advanced Research Project Agency and moni-
tored by ARFL/IFGA, Rome, New York 13441-4505
USA, under contract F30602-99-1-0518. Additional
support was provided by Intel.
Riferimenti
Aucouturier, J.J., and F. Pachet. 2002. ‘‘Music Similarity
Measures: What’s the Use?’’ Proceedings of the Inter-
national Conference in Music Information Retrieval.
Paris: IRCAM, pag. 157–163.
Aucouturier, J.J., and F. Pachet. 2003. ‘‘Representing Mu-
sical Genre: A State of the Art.’’ Journal of New Music
Research 32(1):83–93.
Balakrishnan, H., et al. 2003. ‘‘Looking Up Data in P2P
Systems.’’ Communications of the ACM 46(2):43–48.
Baumann, S. 2003. ‘‘Music Similarity Analysis in P2P En-
vironment.’’ In Proceedings of the 4th European Work-
shop on Image Analysis for Multimedia Interactive
Services. London: Word Scientific, pag. 314–319.
Baumann, S., e A. Kluter. 2002. ‘‘Super-Convenience
for Non-Musicians: Querying MP3 and the Semantic
Web.’’ Proceedings of the International Conference on
Music Information Retrieval. Paris: IRCAM, pag. 297–
298.
Bentley, J. 1975. ‘‘Multidimensional Binary Search Trees
Used for Associative Searching.’’ Communications of
the ACM 18(9):509–517.
Foote, J., and M. Cooper. 2002. ‘‘Audio Retrieval by
Rhythmic Similarity.’’ Proceedings of the Interna-
tional Conference on Music Information Retrieval.
Paris: IRCAM, pag. 265–266.
Futrelle, J., and J. S. Downie. 2002. ‘‘Interdisciplinary
Communities and Research Issues in Music Informa-
tion Retrieval.’’ Proceedings of the Third International
Conference on Music Information Retrieval. Paris:
IRCAM, pag. 215–221.
Gao, J., and P. Steenkiste. 2004. ‘‘Design and Evaluation
of a Distributed Scalable Content Discovery System.’’
IEEE Journal on Selected Areas in Communications
22(1):54–66.
Gao, J., and P. Steenkiste. 2003. ‘‘An Efficient Scheme
Supporting Range Queries in DHT-based Systems.’’
Carnegie Mellon University Technical Report
CMU-CS-03-215.
Gao, J., G. Tzanetakis, and P. Steenkiste. 2003.
‘‘Content-based Retrieval of Music in Scalable Peer-to-
Peer Networks.’’ Proceedings of the International
Conference on Multimedia and Expo. Piscataway,
New Jersey: Institute of Electrical and Electronics En-
gineers, pag. 309–312.
Haitsma J., and T. Kalker. 2002. ‘‘A Highly Robust Audio
Fingerprinting System.’’ Proceedings of the Third In-
ternational Conference on Music Information Re-
trieval. Paris: IRCAM, pag. 107–115.
Logan, B., e A. Salomon. 2001. ‘‘A Music Similarity
Function based on Signal Analysis.’’ Proceedings of the
International Conference on Multimedia and Expo.
Piscataway, New Jersey: Institute of Electrical and
Electronics Engineers, n.p.
Pachet, F. 2003 ‘‘Content Management for Electronic
Music Distribution.’’ Communications of the Associa-
tion for Computing Machinery 46(4):71–75.
Rauber, A., E. Pampalk, and D. Merkl. 2002 ‘‘Using Psy-
choacoustic Models and Self-organizing Maps to Cre-
ate a Hierarchical Structure of Music by Sound
Similarity.’’ Proceedings of the Third International
Conference on Music Information Retrieval. Paris:
IRCAM, pag. 71–80.
32
Computer Music Journal
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
C
o
M
j
/
l
UN
R
T
io
C
e
–
P
D
F
/
/
/
/
/
2
8
2
2
4
1
8
5
4
0
8
5
0
1
4
8
9
2
6
0
4
3
2
3
1
1
2
2
2
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
Rowstron, A., and P. Druschel. 2001. ‘‘Pastry: Scalable
Distributed Object Location and Routing for Large-
Scale Peer-to-Peer Systems.’’ Lecture Notes in Com-
puter Science 2218:329–350.
Sripanidkulchai, K. 2001. ‘‘The Popularity of Gnutella
Queries and its Implications on Scalability.’’ Available
online at www.cs.cmu.edu/(cid:1)kunwadee/research/p2p/
gnutella.html. Accessed 11 Febbraio 2004.
Stoica, I., et al. 2001. ‘‘Chord: A Scalable Peer-to-Peer
Lookup Service for Internet Applications.’’ Proceedings
SIGCOMM. New York: Association for Computing
Machinery, pag. 149–160.
Tolonen, T., and M. Karjalainen. 2000. ‘‘A Computation-
ally Efficient Multipitch Analysis Model.’’ IEEE Trans-
actions on Speech and Audio Processing 8(6):708–716.
Tzanetakis, G., and P. Cook. 2002. ‘‘Musical Genre Clas-
sification of Audio Signals.’’ IEEE Transactions on
Speech and Audio Processing 10(5):293–302.
Tzanetakis, G., UN. Ermolinskyi, and P. Cook. 2002. ‘‘Be-
yond the Query-by-Example Paradigm: New Query In-
terfaces for Music Information Retrieval.’’ Proceedings
del 2002 International Computer Music Confer-
ence. San Francisco: International Computer Music
Association, pag. 177–183.
Wang, C., J. Li, and S. Shi. 2002. ‘‘A Kind of Content-
Cased Music Information Retrieval Method in a Peer-
to-Peer Environment.’’ Proceedings of the Third
International Conference in Music Information Re-
trieval. Paris: IRCAM, pag. 178–186.
Whitman, B. and P. Smaragdis. 2002. ‘‘Combining Musi-
cal and Cultural Features for Intelligent Style Detec-
tion.’’ Proceedings of the Third International
Conference on Music Information Retrieval. Paris:
IRCAM, pag. 47–52.
Yang, C. 2002. ‘‘The MACSIS Acoustic Indexing Frame-
work for Music Retrieval: An Experimental Study.’’
Proceedings of the Third International Conference
on Music Information Retrieval. Paris: IRCAM,
pag. 52–62.
l
D
o
w
N
o
UN
D
e
D
F
R
o
M
H
T
T
P
:
/
/
D
io
R
e
C
T
.
M
io
T
.
e
D
tu
/
C
o
M
j
/
l
UN
R
T
io
C
e
–
P
D
F
/
/
/
/
/
2
8
2
2
4
1
8
5
4
0
8
5
0
1
4
8
9
2
6
0
4
3
2
3
1
1
2
2
2
0
P
D
.
F
B
sì
G
tu
e
S
T
T
o
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
Tzanetakis, Gao, and Steenkiste
33