VILA: Improving Structured Content Extraction from Scientific PDFs
Using Visual Layout Groups
Zejiang Shen1 Kyle Lo1 Lucy Lu Wang1 Bailey Kuehl1
Daniel S. Weld1,2 Doug Downey1,3
1Allen Institute for AI, USA 2University of Washington, USA 3Northwestern University, Etats-Unis
{shannons,kylel,lucyw,baileyk,danw,dougd}@allenai.org
Abstrait
Accurately extracting structured content from
PDFs is a critical first step for NLP over
scientific papers. Recent work has improved
extraction accuracy by incorporating elemen-
tary layout information, Par exemple, chaque
token’s 2D position on the page, into language
model pretraining. We introduce new methods
that explicitly model VIsual LAyout (VILA)
groupes, c'est, text lines or text blocks, à
further improve performance. In our I-VILA
approche, we show that simply inserting spe-
cial tokens denoting layout group boundaries
into model inputs can lead to a 1.9% Macro
F1 improvement in token classification. In the
H-VILA approach, we show that hierarchical
encoding of layout-groups can result in up to
47% inference time reduction with less than
0.8% Macro F1 loss. Unlike prior layout-aware
approaches, our methods do not require expen-
sive additional pretraining, only fine-tuning,
which we show can reduce training cost by
up to 95%. Experiments are conducted on
a newly curated evaluation suite, S2-VLUE,
that unifies existing automatically labeled
datasets and includes a new dataset of man-
ual annotations covering diverse papers from
19 scientific disciplines. Pre-trained weights,
benchmark datasets, and source code are avail-
able at https://github.com/allenai
/VILA.
1
Introduction
Scientific papers are usually distributed in Portable
Document Format (PDF) without extensive se-
mantic markup. Extracting structured document
representations from these PDF files—i.e., identi-
fying title and author blocks, figures, références,
and so on—is a critical first step for downstream
NLP tasks (Beltagy et al., 2019; Wang et al., 2020)
and is important for improving PDF accessibility
(Wang et al., 2021).
376
Recent work demonstrates that document lay-
out information can be used to enhance content
extraction via large-scale,
layout-aware pre-
entraînement (Xu et al., 2020, 2021; Li et al.,
2021). Cependant, these methods only consider
individual tokens’ 2D positions and do not ex-
plicitly model high-level layout structures like
the grouping of text into lines and blocks (voir
limiting accuracy.
Chiffre 1 for an example),
Plus loin, existing methods come with enormous
computational costs: They rely on further pre-
training an existing pretrained model like BERT
(Devlin et al., 2019) on layout-enriched in-
put, and achieving the best performance from
the models requires more than a thousand (Xu
et coll., 2020) to several thousand (Xu et al., 2021)
GPU-hours. This means that swapping in a new
pretrained text model or experimenting with new
layout-aware architectures can be prohibitively
expensive, incompatible with the goals of green
AI (Schwartz et al., 2020).
In this paper, we explore how to improve
the accuracy and efficiency of structured con-
tent extraction from scientific documents by
using VIsual LAyout (VILA) groupes. Following
Zhong et al. (2019) and Tkaczyk et al. (2015),
our methods use the idea that a document page
can be segmented into visual groups of tokens
(either lines or blocks), and that the tokens within
each group generally have the same semantic
catégorie, which we refer to as the group unifor-
mity assumption (voir la figure 1(b)). Given text
lines or blocks generated by rule-based PDF
parsers (Tkaczyk et al., 2015) or vision models
(Zhong et al., 2019), we design two different meth-
ods to incorporate the VILA groups and the as-
sumption into modeling: The I-VILA model adds
layout indicator tokens to textual inputs to improve
the accuracy of existing BERT-based language
models, while the H-VILA model uses VILA
Transactions of the Association for Computational Linguistics, vol. 10, pp. 376–392, 2022. https://doi.org/10.1162/tacl a 00466
Action Editor: Kristina Toutanova. Submission batch: 8/2021; Revision batch: 11/2021; Published 4/2022.
c(cid:2) 2022 Association for Computational Linguistics. Distributed under a CC-BY 4.0 Licence.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
The H-VILA model performs group-level
predictions and can reduce model inference
time by 47% with less than 0.8% loss in
Macro F1.
3. We construct a unified benchmark suite
S2-VLUE, which enhances existing datasets
with VILA structures, and introduce a novel
dataset S2-VL that addresses gaps in existing
ressources. S2-VL contains hand-annotated
gold labels for 15 token categories on papers
spanning 19 disciplines.
The benchmark datasets, modeling code, and trained
weights are available at https://github
.com/allenai/VILA.
2 Related Work
2.1 Structured Content Extraction for
Scientific Documents
Prior work on structured content extraction for
scientific documents usually relies on textual or
visual features. Text-based methods like Scien-
ceParse (Ammar et al., 2018), GROBID (GRO,
2008–2021), or Corpus Conversion Service (Staar
et coll., 2018) combine PDF-to-text parsing engines
like CERMINE (Tkaczyk et al., 2015) or pdfalto,1
which output a sequence of tokens extracted
from a PDF, with machine learning models like
RNN (Hochreiter and Schmidhuber, 1997), CRF
(Lafferty et al., 2001), or Random Forest (Breiman
2001) trained to classify the token categories of
the sequence. Though these models are practical
and fairly efficient, they fall short in prediction
accuracy or generalize poorly to out-of-domain
documents. Vision-based Approaches (Zhong
et coll., 2019; He et al., 2017; Siegel et al., 2018),
on the other hand, treat the parsing task as an
image object detection problem: Given document
images, the models predict rectangular bound-
ing boxes, segmenting the page into individual
components of different categories. These models
excel at capturing complex visual layout structures
like figures or tables, but because they operate only
on visual signals without textual information, ils
cannot accurately predict fine-grained semantic
categories like title, author, or abstract, lequel
are of central importance for parsing scientific
documents.
1https://github.com/kermitt2/pdfalto (last ac-
cessed Jan. 1, 2022).
Chiffre 1: (un) Real-world scientific documents often
have intricate layout structures, so analyzing only flat-
tened raw text forfeits valuable information, yielding
sub-optimal results. (b) The complex structures can be
broken down into groups (text blocks or lines) that are
composed of tokens with the same semantic category.
structures to define a hierarchical model that mod-
els pages as collections of groups rather than of
individual tokens, increasing inference efficiency.
Previous datasets for evaluating PDF content
extraction rely on machine-generated labels of
imperfect quality, and comprise papers from a
limited range of scientific disciplines. To bet-
ter evaluate our proposed methods, we design a
new benchmark suite, Semantic Scholar Visual
Layout-enhanced Scientific Text Understanding
Evaluation (S2-VLUE). The benchmark extends
two existing resources (Tkaczyk et al., 2015;
Li et al., 2020) and introduces a newly curated
dataset, S2-VL, which contains high-quality hu-
man annotations for papers across 19 disciplines.
Our contributions are as follows:
1. We introduce a new strategy for PDF con-
tent extraction that uses VILA structures to
inject layout information into language mod-
le, and show that this improves accuracy
without the expensive pretraining required by
existing methods, and generalizes to different
language models.
2. We design two models that incorporate VILA
features differently. The I-VILA model in-
jects layout indicator tokens into the input
texts and improves prediction accuracy (en haut
à +1.9% Macro F1) and consistency com-
pared with the previous layout-augmented
language model LayoutLM (Xu et al., 2020).
377
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
2.2 Layout-aware Language Models
Recent methods on layout-aware language models
improve prediction accuracy by jointly modeling
documents’ textual and visual signals. LayoutLM
(Xu et al., 2020) learns a set of novel positional
embeddings that can encode tokens’ 2D spatial
location on the page and improves accuracy on
scientific document parsing (Li et al., 2020). More
recent work (Xu et al., 2021; Li et al., 2021) aims
to encode the document in a multimodal fashion
by modeling text and images together. Cependant,
these existing joint-approach models require ex-
pensive pretraining, and may be less efficient as a
consequence of their joint inputs (Xu et al., 2021),
making them less suitable for deployment at scale.
In this work, we aim to incorporate document lay-
out features in the form of visual layout groupings,
in novel ways that improve or match performance
without the need for expensive pretraining. Notre
work is well-aligned with recent efforts for in-
corporating structural information into language
models (Lee et al., 2020; Bai et al., 2021; Lequel
et coll., 2020; Zhang et al., 2019).
2.3 Training and Evaluation Datasets
The available training and evaluation datasets
for scientific content extraction models are auto-
matically generated from author-provided source
data—for example, GROTOAP2 (Tkaczyk et al.,
2014) and PubLayNet (Zhong et al., 2019) are con-
structed from PubMed Central XML and DocBank
(Li et al., 2020) from arXiv LaTeX source. De-
spite their large sample sizes, these datasets have
limited layout variation, leading to poor gener-
alization to papers from other disciplines with
distinct layouts. Aussi, due to the heuristic nature in
which the data are automatically labeled, they con-
tain systematic classification errors that can affect
downstream modeling performance. We elabo-
rate on the limitations of GROTOAP2 (Tkaczyk
et coll., 2014) and DocBank (Li et al., 2020) dans
Section 4. PubLayNet (Zhong et al., 2019) pro-
vides high-quality text block annotations on 330k
document pages, but its annotations only cover
five distinct categories. Livathinos et al. (2021)
and Staar et al. (2018) curated a multi-disciplinary,
manually annotated dataset of 2,940 paper pages,
but only make available the processed page fea-
tures without the raw text or source PDFs needed
for experiments with layout-aware methods. Nous
introduce a new evaluation dataset, S2-VL, à
address limitations in these existing datasets.
3 Methods
3.1 Problem Formulation
Following prior work (Tkaczyk et al., 2015; Li
et coll., 2020), our task is to map each token ti
in an input sequence T = (t1, . . . , tn) to its se-
mantic category ci (title, body text, reference,
etc.). Input tokens are extracted via PDF-to-text
tools, which output both the word ti and its
2D position on the page, a rectangular bound-
ing box ai = (x0, y0, x1, y1) denoting the left,
top, droite, and bottom coordinate of the word.
The order of tokens in sequence T may not re-
flect the actual reading order of the text due to
errors in PDF-to-text conversion (par exemple., in the orig-
inal DocBank dataset [Li et al., 2020]), lequel
poses an additional challenge to language models
pre-trained on regular texts.
Besides the token sequence T , additional vi-
sual structures G can also be retrieved from the
source document. Scientific papers are organized
into groups of tokens (lines or blocks), lequel
consist of consecutive pieces of text that can
be segmented from other pieces based on spa-
tial gaps. The group information can be extracted
via visual layout detection models (Zhong et al.,
2019; He et al., 2017) or rule-based PDF parsing
(Tkaczyk et al., 2015).
Officiellement, given an input page, the group de-
tector identifies a series of m rectangular boxes
for each group bj ∈ B = {b1, . . . , bm} dans le
input document page, where bj = (x0, y0, x1, y1)
denotes the box coordinates. Page tokens are allo-
cated to the visual groups gj = (bj, T (j)), où
T (j) = {ti | ai (cid:4) bj, ti ∈ T } contains all tokens
in the j-th group, and ai (cid:4) bj denotes that the cen-
ter point of token ti’s bounding box ai is strictly
within the group box bi. When two group regions
overlap and share common tokens, the system as-
signs the common tokens to the earlier group by
the estimated reading order from the PDF parser.
We refer to text block groups of a page as G(B) et
text line groups as G(L). In our case, we define text
lines as consecutive tokens appearing at the nearly
same vertical position.2 Text blocks are sets of
adjacent text lines with gaps smaller than a certain
threshold, and ideally the same semantic category.
C'est, even two close lines of different semantic
2Or horizontal position, when the text is written vertically.
378
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
of modeling, rather than only providing positional
information at the initial embedding layers as in
LayoutLM (Xu et al., 2020). We empirically show
that BERT-based models can learn to leverage
such special tokens to improve both the accuracy
and the consistency of category predictions, même
without an additional loss penalizing inconsistent
intra-group predictions.
1
1
In practice, given G, we linearize tokens T (j)
from each group and flatten them into a 1D
séquence. To avoid capturing confounding in-
formation in existing pretraining tasks, we insert
a new token previously unseen by the model,
[BLK], in-between text from different groups
T (j). The resulting input sequence is of the
, . . . , T (j)
nj , [BLK], T (j+1)
formulaire [[CLS], T (1)
, . . . ,
T (m)
nm , [SEP]], where T (j)
and nj indicate the i-th
je
token and the total number of tokens respectively
in the j-th group, et [CLS] et [SEP] are the
special tokens used by the BERT model and are
inserted to preserve a similar input structure.3 The
BERT-based models are fine-tuned on the token
classification objective with a cross entropy loss.
When I-VILA uses a visual pretrained language
model as input, such as LayoutLM (Xu et al.,
2020), the positional embeddings for the newly
injected [BLK] tokens are generated from the
corresponding group’s bounding box bj.
3.3 H-VILA: Visual Layout-guided
Hierarchical Model
The uniformity of group token categories also
suggests the possibility of building a group-level
classifier. Inspired by recent advances in model-
ing long documents, hierarchical structures (Lequel
et coll., 2020; Zhang et al., 2019) provide an ideal
architecture for the end task while optimizing for
computational cost. Illustrated in Figure 3, notre
hierarchical approach uses two transformer-based
models, one to encode each group in terms of its
words, and another modeling the whole document
in terms of the groups. We provide the details
below.
The Group Encoder is a lg-layer transformer
that converts each group gi into a hidden vec-
tor hi. Following the typical transformer model
setting (Vaswani et al., 2017), the model takes a
sequence of tokens T (j) within a group as input,
3Le [CLS] et [SEP] tokens are only inserted at the
beginning or end of each input sequence, and they do not
represent the sentence boundaries in this case.
379
Chiffre 2: Comparing inserting indicator tokens [BLK]
based on VILA groups and sentence boundaries. Dans-
dicators representing VILA groups (par exemple., text blocks
in the left figure) are usually consistent with the to-
ken category changes (illustrated by the background
color in (un)), while sentence boundary indicators fail
to provide helpful hints (both ‘‘false positives’’ and
‘‘false negatives’’ occur frequently in (b)). Best viewed
in color.
categories should be allocated to separate blocks,
and in our models we use a block detector trained
toward this objective. In practice, block or line
detectors may generate incorrect predictions.
In the following sections, we describe our two
models, I-VILA and H-VILA. The models take
a BERT-based pretrained language model as a
foundation, which may or may not
itself be
layout-aware (we experiment with DistilBERT,
BERT, RoBERTa, and LayoutLM in our experi-
ments). Our models then augment the base model
to incorporate group structures, as detailed below.
3.2 I-VILA: Injecting Visual
Layout Indicators
According to the group uniformity assumption,
token categories are homogeneous within a group,
and categorical changes should happen at group
boundaries. This suggests that layout information
should be incorporated in a way that informs
token category consistency intra-group and signals
possible token category changes inter-group.
Our first method supplies VILA structures by
inserting a special layout indicator token at each
group boundary in the input text, and models this
with a pretrained language model (which may or
may not be position-aware). We refer to this as
the I-VILA method. As shown in Figure 2(un),
the inserted tokens partition the text into seg-
ments that provide helpful structure to the model,
hinting at possible category changes. In I-VILA,
the special tokens are seen at all layers of the
model, providing VILA signals at different stages
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 3: Illustration of the H-VILA model. Texts from each visual layout group are encoded separatedly using
the group encoder, and the generated representation are subsequently modeled by a page encoder. The semantic
category are predicted at the group-level, which significantly improves efficiency.
je
(cid:2)
into a dense vector e(j)
and maps each token T (j)
je
of dimension d. Subsequently, a group vector ag-
gregation function f : Rnj ×d → Rd is applied that
(cid:3)
1 , . . . , e(j)
e(j)
projects the token representations
nj
to a single vector ˜hj that represents the group’s
textual information. A group’s 2D spatial infor-
mation is incorporated in the form of positional
embeddings, and the final group representation hj
can be calculated as:
hj = ˜hj + p(bj).
(1)
where p is the 2D positional embedding similar to
the one used in LayoutLM:
p(b) = Ex(x0) + Ex(x1) + Ew(x1 − x0)
+ Ey(y0) + Ey(y1) + Eh(y1 − y0),
(2)
where Ex, Ex, Ew, Eh are the embedding matri-
ces for x, y coordinates and width and height. Dans
pratique, we find that injecting positional infor-
mation using the bounding box of the first token
within the group leads to better results, and we
choose group vector aggregation function f to be
the average over all tokens representations.
The Page Encoder is another stacked trans-
former model of lp layers that operates on the
group representation hj generated by the group
encoder. It generates a final group representation
sj for downstream classification. A MLP-based
linear classifier is attached thereafter, and is
trained to generate the group-level category prob-
ability pjc.
Different from previous work (Yang et al.,
the choice of lg and lp to
2020), we restrict
{1, 12} such that we can load pre-trained weights
380
from BERT base models. Donc, no addi-
tional pretraining is required, and the H-VILA
model can be fine-tuned directly for the down-
stream classification task. Spécifiquement, we set
lg = 1 and initialize the group encoder from the
first-layer transformer weights of BERT. The page
encoder is configured as either a one-layer trans-
former or a 12-layer transformer that resembles
a full LayoutLM model. Weights are initialized
from the first-layer or full 12 layers of the Lay-
outLM model, which is trained to model texts in
conjunction with their positions.
Group Token Truncation As suggested in
Yang et al.’s (2020) travail, when an input docu-
ment of length N is evenly split into segments of
Ls, the memory footprint of the hierarchical model
is O(lgN Ls + lp( N
)2), and for long documents
Ls
with N (cid:6) Ls, it approximates as O(N 2/L2
s).
Cependant, in our case, it is infeasible to adopt the
Greedy Sentence Filling technique (Yang et al.,
2020) as it mingles signals from different groups
and obfuscates group structures. It is also less
desirable to simply use the maximum token count
per group max1≤j≤m nj to batch the contents
due to the high variance of group token length
(see Table 1). Plutôt, we choose a group token
truncation count ˜n empirically based on statistics
of the group token length distribution such that
N ≈ ˜nm, and use the first ˜n to aggregate the
group hidden vector hj for all groups (we pad the
sequence to ˜n when it is shorter).
4 Benchmark Suite
To systematically evaluate the proposed meth-
ods, we develop the the Semantic Scholar Visual
Train / Dev / Test Pages
Annotation Method
Scientific Discipline
Visual Layout Group
Number of Categories
Average Token Count2
1203 (591)
Average Text Line Count
90 (51)
Average Text Block Count 12 (16)
GROTOAP2
DocBank
S2-VL
83k / 18k / 18k 398k / 50k / 50k
Automatic
Life Science
PDF parsing
22
Automatic
Math / Physics / CS 19 Disciplines
Vision model
12
1.3k1
Human Annotation
Gold Label / Detection methods
15
838 (503)
60 (34)
15 (8)
790 (453)
64 (54)
22 (36)
1 This is the total number of pages in the S2-VL dataset; we use 5-fold cross-validation for training and testing.
2 We report the average token, text line, and text block count per page, with standard deviations in parentheses.
Tableau 1: Details for the three datasets in the S2-VLUE benchmark.
Layout-enhanced Scientific Text Understanding
Evaluation (S2-VLUE) benchmark suite. S2-
VLUE consists of three datasets—two previ-
ously released resources that we augment with
VILA information, and a new hand-curated dataset
S2-VL.
Key statistics for S2-VLUE are provided in
Tableau 1. Notably, the three constituent datasets
differ with respect to their: 1) annotation method,
2) VILA generation method, et 3) paper domain
coverage. We provide details below.
GROTOAP2 The GROTOAP2 dataset (Tkaczyk
et coll., 2014) is automatically annotated. Its text
block and line groupings come from the CER-
MINE PDF parsing tool (Tkaczyk et al., 2015);
text block category labels are then obtained by
pairing block texts with structured data from doc-
ument source files obtained from PubMed Central.
A small subset of data is inspected by experts, et
a set of post-processing heuristics is developed to
further improve annotation quality. Because to-
ken categories are annotated by group, the dataset
achieves perfect accordance between token labels
and VILA structures. Cependant, the method of
rule-based PDF parsing employed by the authors
introduces labeling inaccuracies due to imperfect
VILA detection: the authors find that block-level
annotation accuracy achieves only 92 Macro F1
in a small gold evaluation set. En plus, tous
samples are extracted from the PMC Open Access
Subset4 that includes only life sciences publica-
tion; these papers have less representation of
classification types like ‘‘equation’’, which are
common in other scientific disciplines.
4https://www.ncbi.nlm.nih.gov/pmc/tools/open
ftlist/ (last accessed Jan. 1, 2022).
DocBank The DocBank dataset (Li et al., 2020)
is fully machine-labeled without any postprocess-
ing heuristics or human assessment. The authors
first identify token categories by automatically
parsing the source TEX files available from arXiv.
Text block annotations are then generated by
grouping together tokens of the same category
using connected component analysis. Cependant,
only a specific set of token tags is extracted from
the main TEX file for each paper, leading to in-
accurate and incomplete token labels, especially
for papers employing LaTeX macro commands,5
Et ainsi, incorrect visual groupings. Ainsi, nous
develop a Mask R-CNN-based vision layout de-
tection model based on a collection of existing
ressources (Zhong et al., 2019; MFD, 2021; Il
et coll., 2017; Shen et al., 2021) to fix these inaccu-
racies and generate trustworthy VILA annotations
at both the text block and line level.6 As a result,
this dataset can be used to evaluate VILA models
under a different setting, since the VILA structures
are generated independently from the token anno-
tations. Because the papers in DocBank are from
arXiv, cependant, they primarily represent domains
like Computer Science, Physics, and Mathematics,
limiting the amount of layout variation.
5Par exemple, in DocBank, ‘‘Figure 1’’ in a figure cap-
tion block is usually labeled as ‘‘paragraph’’ rather than
‘‘caption’’. DocBank labels all tokens that are not explicitly
contained in the set of processed LaTeX tags as ‘‘paragraph.’’
6The original generation method for DocBank requires
rendering LaTeX source, which results in layouts different
from the publicly available versions of these documents on
arXiv. Cependant, because the authors of the dataset only
provide document page images, rather than the rendered
PDF, we can only use image-based approaches for layout
detection. We refer readers to the appendix for details.
381
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
S2-VL We introduce a new dataset to address
the three major drawbacks in existing work: 1)
annotation quality, 2) VILA fidelity, et 3) do-
main coverage. S2-VL is manually labeled by
graduate students who frequently read scien-
tific papers. Using the PAWLS annotation tool
(Neumann et al., 2021), annotators draw rectan-
gular text blocks directly on each PDF page, et
specify the block-level semantic categories from
15 possible candidates.7 Tokens within a group
can therefore inherit the category from the parent
text block. Inter-annotator agreement, in terms of
token-level accuracy measured on a 12-paper sub-
ensemble, is high at 0.95. The ground-truth VILA labels
in S2-VL can be used to fine-tune visual layout de-
tection models, and paper PDFs are also included,
making PDF-based structure parsing feasible; ce
enables VILA annotations to be created by dif-
ferent means, which is helpful for benchmarking
new VILA-based models. De plus, S2-VL cur-
rently contains 1337 pages of 87 papers from 19
different disciplines, y compris, Par exemple, Phi-
losophy and Sociology, which are not present in
previous data sets.
Dans l'ensemble, the datasets in S2-VLUE cover a wide
range of academic disciplines with different lay-
outs. The VILA structures in the three component
datasets are curated differently, which helps to
evaluate the generality of VILA-based methods.
5 Experimental Setup
5.1 Implementation Details
Our models are implemented using PyTorch
(Paszke et al., 2019) and the transformers library
(Wolf et al., 2020). A series of baseline and VILA
models are fine-tuned on 4-GPU RTX8000 or
A100 machines. The AdamW optimizer (Kingma
and Ba, 2015; Loshchilov and Hutter, 2019)
is adopted with a 5 × 10−5 learning rate and
(β1, β2) = (0.9, 0.999). The learning rate is lin-
early warmed up over 5% steps then linearly
decayed. For all datasets (GROTOAP2, DocBank,
S2-VL), unless otherwise specified, we select the
best fine-tuning batch size (40, 40, et 12) et
7Of our defined categories, 12 are common fields and
taken directly from other similar datasets (par exemple., title, abstract).
We add three categories: equation, header, and footer, lequel
commonly occur in scientific papers and are included in
full text mining resources like S2ORC (Lo et al., 2020) et
CORD-19 (Wang et al., 2020).
training epochs (24, 6,8 et 10) for all models. Comme
for S2-VL, given its smaller size, we use 5-fold
cross validation and report averaged scores, et
utiliser 2 × 10−5 learning rate with 20 epochs. Nous
split S2-VL based on papers rather than pages
to avoid exposing paper templates of test sam-
ples in the training data. Mixed precision training
(Micikevicius et al., 2018) is used to speed up the
training process.
Pour
I-VILA models, we fine-tune several
BERT-variants with VILA-enhanced text inputs,
and the models are initialized from pre-trained
weights available in the transformers library. Le
H-VILA models are initialized as mentioned in
Section 3.3, et, by default, positional information
is injected for each group.
5.2 Competing Methods
We consider three approaches that compete with
the proposed methods from different perspectives:
is the main baseline method.
1. Baselines The LayoutLM (Xu et al., 2020)
model
Il
to our
is the closest model counterpart
VILA-augmented models as it also injects
layout
information and achieves previous
SOTA performance on the Scientific PDF
parsing task (Li et al., 2020).
2. Sentence Breaks For I-VILA models, être-
sides using VILA-based indicators, we also
compare with indicators generated from sen-
tence breaks detected by PySBD (Sadvilkar
and Neumann, 2020). Chiffre 2(un) shows
the inserted sentence-break indica-
que
tors may have both ‘‘false-positive’’ or
‘‘false-negative’’ hints for token semantic
category changes, making it less helpful for
the end task.
3. Simple Group Classifier For hierarchical
models, we consider another baseline ap-
proach, where the group texts are separately
fed into a LayoutLM-based group classi-
fier. It doesn’t require complicated model
conception, and uses a full LayoutLM to model
each group’s text, as opposed to the lg = 1
layer used in the H-VILA models. Cependant,
8We try to keep gradient update steps the same for
the GROTOAP2 and the DocBank dataset. As DocBank
contains 4× examples, the number of DocBank models’
training epochs is reduced by 75%.
382
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
GROTOAP2
Macro F1 (cid:2) H(G) (cid:3)
DocBank
Macro F1 (cid:2) H(G) (cid:3)
S2-VL1
Macro F1 (cid:2) H(G) (cid:3)
LayoutLMBASE (Xu et al., 2020)
LayoutLMBASE + Sentence Breaks
LayoutLMBASE + I-VILA(Text Line)
LayoutLMBASE + I-VILA(Text Block)
92.34
91.83
92.37
93.38
0.78
0.78
0.73
0.53
91.06
91.44
92.79
92.00
2.64
2.62
2.17
2.10
82.69(6.04)
82.81(5.21)
83.77(5.75)2
83.44(6.48)
4.19(0.25)
4.21(0.55)
3.28(0.35)
2.83(0.34)
1 For S2-VL, we show averaged scores with standard deviation in parentheses across the 5-fold cross validation subsets.
2 In this table, we report S2-VL results using VILA structures detected by visual layout models. When the ground-truth
VILA structures are available, both I-VILA and H-VILA models can achieve better accuracy, shown in Table 6.
Tableau 2: Performance of baseline and I-VILA models on the scientific document extraction task. I-VILA provides
consistent accuracy improvements over the baseline LayoutLM model on all three benchmark datasets.
this method cannot account for inter-group
interactions, and is far less efficient.9
inconsistency for G is the arithmetic mean of all
individual groups gi:
5.3 Metrics
Prediction Accuracy The token label distri-
bution is heavily skewed towards categories
le
corresponding to paper body texts (par exemple.,
‘‘BODY CONTENT’’ category in GROTOAP2
ou
the ‘‘paragraph’’ category in S2-VL and
DocBank). Donc, we choose to use Macro
F1 as our primary evaluation metric for prediction
accuracy.
Group Category Inconsistency To better char-
acterize how different models behave with respect
to group structure, we also report a diagnostic
metric that calculates the uniformity of the token
categories within a group. Hypothetically, tokens
T (j) in the j-th group gj share the same category c,
and naturally the group inherits the semantic label
c. We use the group token category entropy to
measure the inconsistency of a model’s predicted
token categories within the same group:
H(G) =
1
m
m(cid:4)
je
H(gi).
(4)
H(G) acts as an auxiliary metric for evaluating
prediction quality with respect to the provided
VILA structures. In the remainder of this paper,
we report the inconsistency metric for text blocks
G(B) by default, and scale the values by a factor
de 100.
Measuring Efficiency We report the inference
time per sample as a measure of model efficiency.
We select 1,000 pages from the GROTOAP2 test
ensemble, and report the average model runtime for 3
runs on this subset. All models are tested on an
isolated machine with a single V100 GPU. Nous
report the time incurred for text classification;
time costs associated with PDF-to-text conversion
or VILA structure detection are not included (ces
are treated as pre-processing steps, which can be
cached and re-used when processing documents
with different content extractors).
H(g) = −
(cid:4)
c
pc log pc,
(3)
6 Results
where pc denotes the probability of a token in
group g being classified as category c. Quand
all tokens in a group have the same category,
the group token category inconsistency is zero.
H(g) reaches the maximum when pc is a uniform
distribution across all possible categories. Le
9Despite the group texts being relatively short, this method
causes extra computational overhead as the full LayoutLM
model needs to be run m times for all groups in a page.
The simple group classifier models are only trained for 5,
2, et 5 epochs for GROTOAP2, DocBank, and S2-VL for
tractability.
6.1 I-VILA Achieves Better Accuracy
inserting layout
Tableau 2 shows that I-VILA models lead to con-
sistent accuracy improvements without further
pretraining. Compared to the baseline LayoutLM
model,
indicators results in
+1.13%, +1.90%, et +1.29% Macro F1 im-
provements across the three benchmark datasets.
I-VILA models also achieve better token pre-
diction consistency;
the corresponding group
category inconsistency is reduced by 32.1%,
21.7%, et 21.7% compared to baseline. More-
over, VILA information is also more helpful
383
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
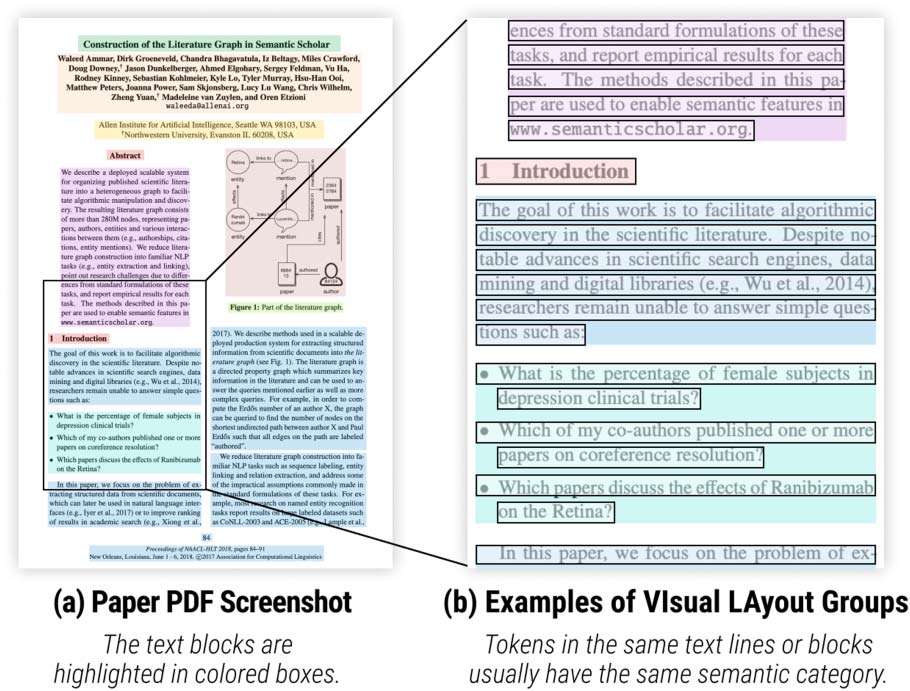
Chiffre 4: Model predictions for the 10th page of our paper draft. We present the token category and text block
bounding boxes (highlighted in red rectangles) based on the (un) ground-truth annotations and model predictions
from both I-VILA and H-VILA models (the three results happen to be identical) et (b) model predictions from
the LayoutLM model. When VILA is injected, the model achieves more consistent predictions for the example,
as indicated by arrows (1) et (2) in the figure. Best viewed in color.
GROTOAP2
DocBank
S2-VL
Macro F1 (cid:2) H(G) (cid:3)
Macro F1 (cid:2) H(G) (cid:3)
Macro F1 (cid:2) H(G) (cid:3)
Inference Time (ms)
LayoutLMBASE
Simple Group Classifier
H-VILA(Text Line)
H-VILA(Text Block)
92.34
92.65
91.65
92.37
0.78
0.00
0.32
0.00
91.06
87.01
91.27
87.78
2.64
0.00
1.07
0.00
82.69(6.04)
–1
83.69(2.92)
82.09(5.89)
4.19(0.25)
–
1.70(0.68)
0.36(0.12)
52.56(0.25)
82.57(0.30)
28.07(0.37)2
16.37(0.15)
1 The simple group classifier fails to converge for one run. We do not report the results for fair comparison.
2 When reporting efficiency in other parts of the paper, we use this result because of its optimal combination of accuracy and efficiency.
Tableau 3: Content extraction performance for H-VILA. The H-VILA models significantly reduce the inference
time cost compared to LayoutLM, while achieving comparable accuracy on the three benchmark datasets.
than language structures: I-VILA models based
on text blocks and lines all outperform the sen-
tence boundary-based method by a similar margin.
Chiffre 4 shows an example of the VILA model
prédictions.
6.2 H-VILA is More Efficient
Tableau 3 summarizes the efficiency improvements
of the H-VILA models with lg = 1 and lp = 12.
As block-level models perform predictions di-
rectly at the text block level, the group category
inconsistency is naturally zero. Compared to Lay-
outLM, H-VILA models with text lines brings
un 46.59% reduction in inference time, without
heavily penalizing the final prediction accuracies
(−0.75%, +0.23%, +1.21% Macro F1). When text
blocks are used, H-VILA models are even more
efficient (68.85% et 80.17% inference time re-
duction compared to the LayoutLM and simple
group classifier baseline), and they also achieve
similar or better accuracy compared to the simple
group classifier (−0.30%, +0.88% Macro F1 for
GROTOAP2 and DocBank).
Cependant, in H-VILA models, the inductive
bias from the group uniformity assumption also
has a drawback: Models are often less accurate
than their I-VILA counterparts, and performing
block level classification may sometimes lead to
worse results (−3.60% and −0.73% Macro F1
in the DocBank and S2-VL datasets compared to
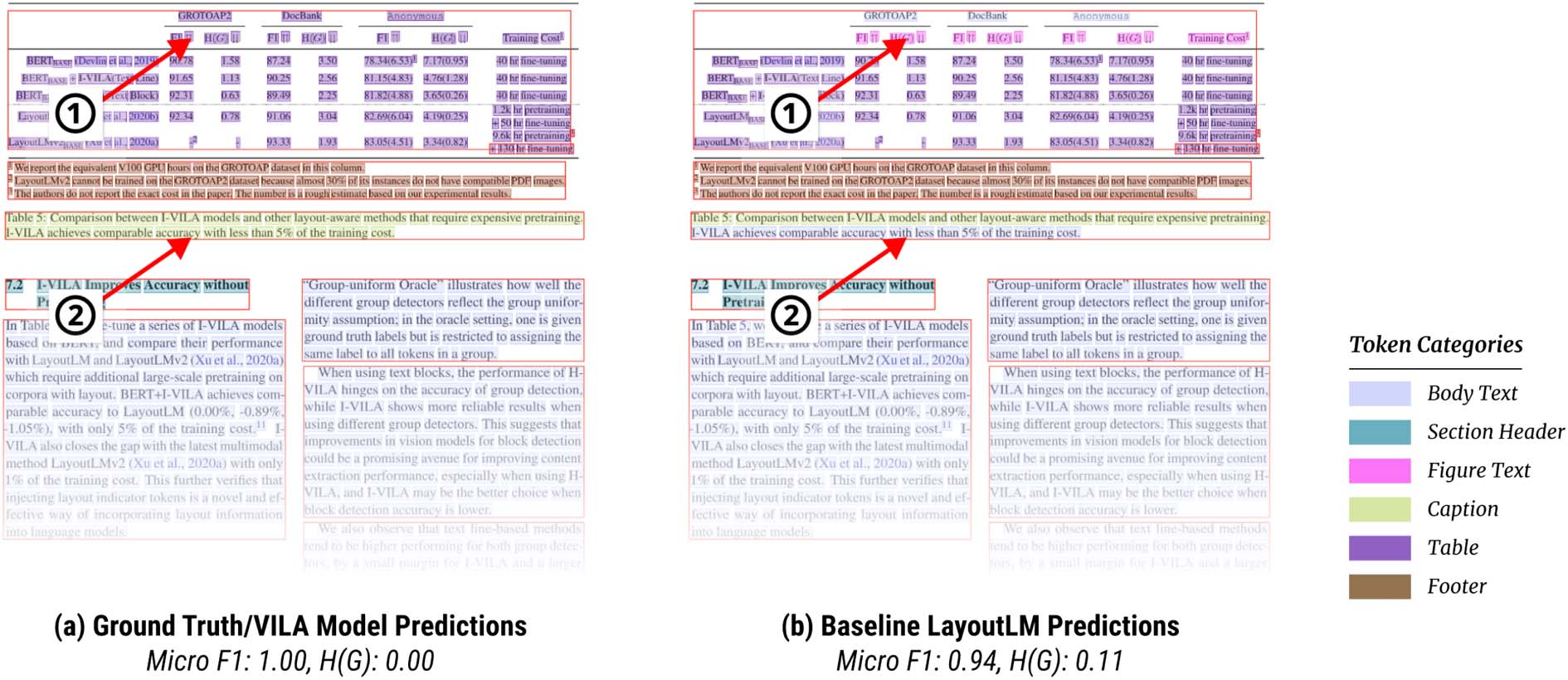
LayoutLM). De plus, shown in Figure 5, quand
the injected layout group is incorrect, the H-VILA
method lacks the flexibility to assign different
token categories within a group, leading to lower
384
Base Model Baseline Text Line G(L) Text Block G(B)
DistilBERT
BERT
RoBERTa
LayoutLM
90.52
90.78
91.64
92.34
91.14
91.65
92.04
92.37
92.12
92.31
92.52
93.38
Tableau 4: Content extraction performance (Macro
F1 on the GROTOAP2 dataset) for I-VILA using
different BERT model variants. I-VILA can be
applied to both standard BERT-based models and
layout-aware ones, and consistently improves the
classification accuracy.
tokens is a novel and effective way of incorpo-
rating layout information into language models.
8 VILA in Practice: The Impact of
Layout Group Detectors
Applying VILA methods in practice requires run-
ning a group layout detector as a critical first step.
Dans cette section, we analyze how the accuracy of
different block and line group detectors affects the
accuracy of H-VILA and I-VILA models.
The results are shown in Table 6. We report
on the S2-VL dataset using two automated group
detectors: the CERMINE PDF parser (Tkaczyk
et coll., 2015) and the Mask R-CNN vision model
trained on the PubLayNet dataset (Zhong et al.,
2019). We also report on using ground truth blocks
as an upper bound. The ‘‘Group-uniform Oracle’’
illustrates how well the different group detectors
reflect the group uniformity assumption; dans le
oracle setting, one is given ground truth labels
but is restricted to assigning the same label to all
tokens in a group.
When using text blocks, the performance of
H-VILA hinges on the accuracy of group detec-
tion, while I-VILA shows more reliable results
when using different group detectors. This sug-
gests that improvements in vision models for block
detection could be a promising avenue for improv-
ing content extraction performance, especially
when using H-VILA, and I-VILA may be the bet-
ter choice when block detection accuracy is lower.
We also observe that text line-based methods
tend to be higher performing for both group de-
tectors, by a small margin for I-VILA and a larger
one for H-VILA. The group detectors in our ex-
periments are trained on data from PubLayNet,
and applied to a different dataset, S2-VL. Ce
385
Chiffre 5: Illustration of models trained and evaluated
with incorrect text block detections (only the top half
of the page is shown). The blocks are created by vision
prédictions, which fails to capture the correct caption
text structure (arrow 1). Because the I-VILA model can
generate different token predictions within a group, it
maintains high accuracy, whereas H-VILA assigns the
same category for all tokens in the incorrect block,
leading to lower accuracy.
accuracy. Additional analysis of the impact of the
layout group predictions is detailed in Section 8.
7 Ablation Studies
7.1 I-VILA is Effective Across
BERT Variants
To test the applicability of the VILA methods,
we adapt I-VILA to different BERT variants and
train them on the GROTOAP2 dataset. Shown in
Tableau 4, I-VILA leads to consistent improvements
on DistilBERT (Sanh et al., 2019), BERT, et
RoBERTa (Liu et al., 2019),10 leading to up to
+1.77%, +1.69%, et 0.96% Macro F1 compared
to non-VILA counterparts.
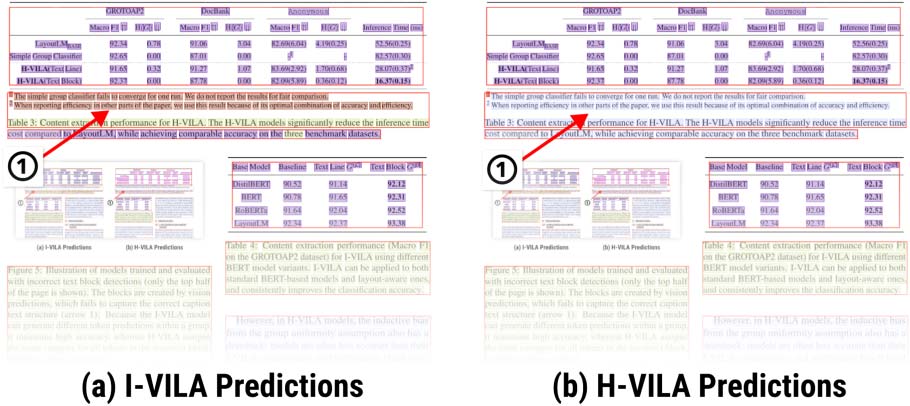
7.2 I-VILA Improves Accuracy
without Pretraining
In Table 5, we fine-tune a series of I-VILA models
based on BERT, and compare their performance
with LayoutLM and LayoutLMv2 (Xu et al.,
2021) which require additional large-scale pre-
training on corpora with layout. BERT+I-VILA
achieves comparable accuracy to LayoutLM
(0.00%, −0.89%, −1.05%), with only 5% de
the training cost.11 I-VILA also closes the gap
with the latest multimodal method LayoutLMv2
(Xu et al., 2021) with only 1% of the training cost.
This further verifies that injecting layout indicator
10Positional embeddings are not used in these models.
11Ça prend 10.5 hours to finish fine-tuning I-VILA on the
GROTOAP2 dataset using a 4 RTX 8000 machine, equivalent
to around 60 V100 GPU hours, environ 5% of the 1280
hours of the pretraining time for LayoutLM.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
GROTOAP2
F1 (cid:2) H(G) (cid:3) F1 (cid:2) H(G) (cid:3)
DocBank
S2-VL
F1 (cid:2)
H(G) (cid:3)
Training Cost1
90.78
BERTBASE (Devlin et al., 2019)
BERTBASE + I-VILA(Text Line)
91.65
BERTBASE + I-VILA(Text Block) 92.31
92.34
LayoutLMBASE (Xu et al., 2020)
1.58
1.13
0.63
0.78
87.24
90.25
89.49
91.06
3.50
2.56
2.25
2.64
78.34(6.53)1 7.17(0.95)
4.76(1.28)
81.15(4.83)
3.65(0.26)
81.82(4.88)
82.69(6.04)
4.19(0.25)
LayoutLMv2BASE (Xu et al., 2021)
–2
–
93.33
1.93
83.05(4.51)
3.34(0.82)
40 hr fine-tuning
40 hr fine-tuning
40 hr fine-tuning
1.2k hr pretraining
+ 50 hr fine-tuning
9.6k hr pretraining3
+ 130 hr fine-tuning
1 We report the equivalent V100 GPU hours on the GROTOAP dataset in this column.
2 LayoutLMv2 cannot be trained on the GROTOAP2 dataset because almost 30% of its instances do not have compatible
PDF images.
3 The authors do not report the exact cost in the paper. The number is a rough estimate based on our experimental results.
Tableau 5: Comparison between I-VILA models and other layout-aware methods that require expensive pretraining.
I-VILA achieves comparable accuracy with less than 5% of the training cost.
Group-uniform Oracle
I-VILA
H-VILA
Experiment
Group Source Max Macro F1
H(G)
Macro F1
H(G)
Macro F1
H(G)
Varying GB
Varying GL
Ground-Truth
Vision Model
PDF Parsing
Vision Model
PDF Parsing
100.00(0.00)
99.31(0.23)
96.91(1.09)
99.57(0.13)
99.70(0.12)
0.00(0.00)
1.09(0.30)
2.06(0.86)
0.42(0.18)1
0.38(0.26)
86.50(4.52)
83.44(6.48)
83.95(4.45)
83.77(5.75)
82.97(5.56)
1.86(0.29)
2.83(0.34)
3.93(0.93)
1.20(0.16)
1.28(0.13)
85.91(3.13)
82.09(5.89)
78.69(4.90)
83.69(2.92)
82.61(4.10)
0.35(0.19)
0.36(0.12)
0.02(0.01)
0.20(0.12)
0.00(0.00)
1 For text line detector experiments, we report H(G) based on text lines rather than blocks.
Tableau 6: VILA model performance when using different layout group detectors for text blocks G(B) and lines G(L)
on the S2-VL dataset.
domain transfer affects block detectors more than
line detectors, because the two datasets define
blocks differently. This setting is realistic because
ground truth blocks from the target dataset may
not always be available for training (même quand
labeled tokens are). Training a group detector on
S2-VL is likely to improve performance.
9 Conclusion
In this paper, we introduce two new ways to
integrate Visual Layout (VILA) structures into
the NLP pipeline for structured content extrac-
tion from scientific paper PDFs. We show that
inserting special indicator tokens based on VILA
(I-VILA) can lead to robust improvements in to-
ken classification accuracy (up to +1.9% Macro
F1) and consistency (up to −32% group category
inconsistency). En outre, we design a hierarchi-
cal transformer model based on VILA (H-VILA),
which can reduce inference time by 46% with less
que 0.8% Macro F1 reduction compared to previ-
ous SOTA methods. These VILA-based methods
can be easily incorporated into different BERT
variants with only fine-tuning, achieving compa-
rable performance against existing work with only
5% of the training cost. We ablate the influence of
different visual layout detectors on VILA-based
models, and provide suggestions for practical use.
We release a benchmark suite, along with a newly
curated dataset S2-VL, to systematically evaluate
the proposed methods.
Our study is well-aligned with the recent explo-
ration of injecting structures into language models,
and provides new perspectives on how to incorpo-
rate documents’ visual structures. The approach
shows how explicitly modeling task structure can
help achieve ‘‘green AI’’ goals, dramatically re-
ducing computation and energy costs without
significant loss in accuracy. While we evaluate on
scientific documents, related visual group struc-
tures also exist in other kinds of documents, et
adapting our techniques to those domains could
offer improvements in corporate reports, historical
archives, or legal documents, and this is an item
of future work.
386
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Remerciements
We thank the anonymous reviewers and TACL ed-
itors for their comments and feedback on our draft,
and we thank Ruochen Zhang, Mark Neumann,
Rodney Kinney, Dirk Groeneveld, and Mike
Cafarella for the helpful discussion and sugges-
tion. This project is supported in part by NSF
grant OIA-2033558, NSF RAPID award 2040196,
ONR grant N00014-21-1-2707, and the University
of Washington WRF/Cable Professorship.
Les références
2008–2021. Grobid. https://github.com
/kermitt2/grobid. Accessed: 2021-04-30.
2021. ICDAR2021 competition on mathematical
formula detection. http://transcriptorium
.eu/htrcontest/MathsICDAR2021/.
Accessed: 2021-04-30.
Waleed Ammar, Dirk Groeneveld, Chandra
Bhagavatula,
Iz Beltagy, Miles Crawford,
Doug Downey, Jason Dunkelberger, Ahmed
Elgohary, Sergey Feldman, Vu Ha, Rodney
Kinney, Sebastian Kohlmeier, Kyle Lo, Tyler
Murray, Hsu-Han Ooi, Matthew Peters, Joanna
Power, Sam Skjonsberg, Lucy Wang, Chris
Wilhelm, Zheng Yuan, Madeleine van Zuylen,
and Oren Etzioni. 2018. Construction of the
literature graph in semantic scholar. En Pro-
le
ceedings of
North American Chapter of
the Associa-
tion for Computational Linguistics: Human
Language Technologies, Volume 3 (Industry
Papers),
–
Louisiana. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/N18-3011
le 2018 Conference of
84–91, La Nouvelle Orléans
pages
He Bai, Peng Shi, Jimmy Lin, Yuqing Xie, Luchen
Tan, Kun Xiong, Wen Gao, and Ming Li.
2021. Segatron: Segment-aware transformer for
language modeling and understanding. En Pro-
ceedings of the AAAI Conference on Artificial
Intelligence, volume 35, pages 12526–12534.
Iz Beltagy, Kyle Lo, and Arman Cohan. 2019.
SciBERT: A pretrained language model for
scientific text. In Proceedings of
le 2019
Conference on Empirical Methods in Natural
Language Processing and the 9th International
Joint Conference on Natural Language Pro-
cessation (EMNLP-IJCNLP), pages 3615–3620,
387
Hong Kong, Chine. Association for Computa-
tional Linguistics. https://est ce que je.org/10
.18653/v1/D19-1371
Leo Breiman. 2001. Random forests. Machine
Apprentissage, 45(1):5–32. https://doi.org
/10.1023/UN:1010933404324
Jacob Devlin, Ming-Wei Chang, Kenton Lee, et
Kristina Toutanova. 2019. BERT: Pre-training
of deep bidirectional transformers for language
understanding. In Proceedings of
le 2019
Conference of the North American Chapter
of the Association for Computational Linguis-
tics: Human Language Technologies, Volume
1 (Long and Short Papers), pages 4171–4186,
Minneapolis, Minnesota. Association for Com-
putational Linguistics.
Kaiming He, Georgia Gkioxari, Piotr Doll´ar, et
Ross Girshick. 2017. Mask R-CNN. En Pro-
ceedings of the IEEE international conference
on computer vision, pages 2961–2969.
Sepp Hochreiter and J¨urgen Schmidhuber. 1997.
Long short-term memory. Neural Computa-
tion, 9(8):1735–1780. https://doi.org
/10.1162/neco.1997.9.8.1735
Diederik P. Kingma and Jimmy Ba. 2015. Adam:
A method for stochastic optimization. In 3rd
International Conference on Learning Repre-
sentations, ICLR 2015, San Diego, Californie, Etats-Unis,
May 7-9, 2015, Conference Track Proceedings.
John D. Lafferty, Andrew McCallum, et
Fernando C. N. Pereira. 2001. Conditional ran-
dom fields: Probabilistic models for segmenting
and labeling sequence data. In Proceedings
of the Eighteenth International Conference on
Machine Learning (ICML 2001), Williams Col-
lege, Williamstown, MA, Etats-Unis, Juin 28 – July
1, 2001, pages 282–289. Morgan Kaufmann.
Haejun Lee, Drew A. Hudson, Kangwook Lee,
and Christopher D. Manning. 2020. SLM:
Learning a discourse language representation
with sentence unshuffling. In Proceedings of
le 2020 Conference on Empirical Methods
in Natural Language Processing (EMNLP),
pages 1551–1562, En ligne. Association for
Computational Linguistics.
Minghao Li, Yiheng Xu, Lei Cui, Shaohan
Huang, Furu Wei, Zhoujun Li, and Ming
Zhou. 2020. DocBank: A benchmark dataset
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
layout analysis. In Proceed-
for document
the 28th International Conference
ings of
on Computational Linguistics, COLING 2020,
Barcelona, Espagne (En ligne), December 8–13,
2020, pages 949–960. International Committee
on Computational Linguistics.
Peizhao Li, Jiuxiang Gu, Jason Kuen, Vlad I.
Morariu, Handong Zhao, Rajiv Jain, Varun
Manjunatha, and Hongfu Liu. 2021. Self-
Doc: Self-supervised document representation
learning. In Proceedings of
the IEEE/CVF
Conference on Computer Vision and Pattern
Recognition, pages 5652–5660.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei
Du, Mandar Joshi, Danqi Chen, Omer Levy,
Mike Lewis, Luke Zettlemoyer, and Veselin
Stoyanov. 2019. RoBERTa: A robustly op-
timized BERT pretraining approach. CoRR,
cs.CL/1907.11692v1.
Nikolaos Livathinos, Cesar Berrospi, Maksym
Lysak, Viktor Kuropiatnyk, Ahmed Nassar,
Andre Carvalho, Michele Dolfi, Christoph
Auer, Kasper Dinkla, and Peter W. J.. Staar.
2021. Robust PDF document conversion us-
ing recurrent neural networks. In Thirty-Fifth
AAAI Conference on Artificial Intelligence,
AAAI 2021, Thirty-Third Conference on In-
novative Applications of Artificial Intelligence,
IAAI 2021, The Eleventh Symposium on Ed-
ucational Advances in Artificial Intelligence,
EAAI 2021, Virtual Event, Février 2-9, 2021,
pages 15137–15145. AAAI Press.
Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney
Kinney, and Daniel Weld. 2020. S2ORC:
The semantic scholar open research corpus.
In Proceedings of the 58th Annual Meeting
of the Association for Computational Linguis-
tics, pages 4969–4983, En ligne. Association for
Computational Linguistics.
Ilya Loshchilov and Frank Hutter. 2019. De-
coupled weight decay regularization. In 7th
International Conference on Learning Repre-
sentations, ICLR 2019, La Nouvelle Orléans, LA, Etats-Unis,
May 6–9, 2019. OpenReview.net.
Paulius Micikevicius, Sharan Narang,
Jonah
Alben, Gregory F. Diamos, Erich Elsen, David
Garc´ıa, Boris Ginsburg, Michael Houston,
Oleksii Kuchaiev, Ganesh Venkatesh, et
Hao Wu. 2018. Mixed precision training.
In 6th International Conference on Learning
Representations, ICLR 2018, Vancouver, BC,
Canada, Avril 30 – May 3, 2018, Conference
Track Proceedings. OpenReview.net.
Mark Neumann, Zejiang Shen,
and Sam
Skjonsberg. 2021. PAWLS: PDF annotation
with labels and structure. In Proceedings of
the 59th Annual Meeting of the Association
for Computational Linguistics and the 11th
International Joint Conference on Natural
Language Processing: System Demonstrations,
pages 258–264, En ligne. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/2021.acl-demo.31
Adam Paszke, Sam Gross, Francisco Massa,
Adam Lerer,
James Bradbury, Gregory
Chanan, Trevor Killeen, Zeming Lin, Natalia
Gimelshein, Luca Antiga, Alban Desmaison,
Andreas Kopf, Edward Yang, Zachary
DeVito, Martin Raison, Alykhan Tejani, Sasank
Chilamkurthy, Benoit Steiner, Lu Fang, Junjie
Bai, and Soumith Chintala. 2019. PyTorch:
An imperative style, high-performance deep
learning library. In Advances in Neural Infor-
mation Processing Systems, volume 32. Curran
Associates, Inc.
Shaoqing Ren, Kaiming He, Ross Girshick,
and Jian Sun. 2015. Faster R-CNN: Towards
real-time object detection with region proposal
réseaux. Advances in Neural
Information
Processing Systems, 28:91–99.
Nipun Sadvilkar and Mark Neumann. 2020.
PySBD: Pragmatic sentence boundary disam-
biguation. In Proceedings of Second Workshop
for NLP Open Source Software (NLP-OSS),
pages 110–114, En ligne. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/2020.nlposs-1.15
Victor Sanh, Lysandre Debut, Julien Chaumond,
and Thomas Wolf. 2019. Distilbert, a distilled
version of BERT: Smaller, faster, cheaper and
lighter. CoRR, cs.CL/1910.01108v4.
Roy Schwartz, Jesse Dodge, Noah A. Forgeron, et
Oren Etzioni. 2020. Green AI. Communications
of the ACM, 63(12):54–63. https://est ce que je
.org/10.1145/3381831
Zejiang Shen, Ruochen Zhang, Melissa Dell,
Benjamin Charles Germain Lee, Jacob Carlson,
and Weining Li. 2021. LayoutParser: UN
for deep learning based
unified toolkit
388
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
image
analyse.
In Document
document
Analysis and Recognition – ICDAR 2021,
pages 131–146, Cham. Springer International
Édition. https://doi.org/10.1007
/978-3-030-86549-8_9
Noah Siegel, Nicholas Lourie, Russell Power,
and Waleed Ammar. 2018. Extracting sci-
entific figures with distantly supervised neu-
the 18th
ral networks.
ACM/IEEE on joint conference on digital
libraries, pages 223–232. https://est ce que je
.org/10.1145/3197026.3197040
In Proceedings of
Peter W. J.. Staar, Michele Dolfi, Christoph
Auer, and Costas Bekas. 2018. Corpus con-
version service: A machine learning platform
to ingest documents at scale. In Proceed-
ings of the 24th ACM SIGKDD International
Conference on Knowledge Discovery & Données
Mining, pages 774–782. https://doi.org
/10.1145/3219819.3219834
Dominika Tkaczyk, Pawel Szostek, and Lukasz
Bolikowski. 2014. GROTOAP2 — the method-
large ground truth
ology of
dataset of scientific articles. D-Lib Mag-
Asie, 20(11/12). https://est ce que je.org/10
.1045/november14-tkaczyk
creating a
Dominika Tkaczyk, Paweł Szostek, Mateusz
Fedoryszak, Piotr Jan Dendek, and Łukasz
Bolikowski. 2015. CERMINE: Automatic ex-
traction of structured metadata from scientific
International Journal on Docu-
literature.
ment Analysis and Recognition (IJDAR),
https://est ce que je.org/10
18(4):317–335.
.1007/s10032-015-0249-8
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N. Gomez,
Łukasz Kaiser, and Illia Polosukhin. 2017. À-
tention is all you need. In Advances in Neural
Information Processing Systems, volume 30.
Curran Associates, Inc.
Lucy Lu Wang, Isabel Cachola, Jonathan Bragg,
Evie Yu-Yen Cheng, Chelsea Haupt, Matt
Latzke, Bailey Kuehl, Madeleine van Zuylen,
Linda Wagner, and Daniel S. Weld. 2021.
Improving the accessibility of scientific doc-
uments: Current state, user needs, and a system
solution to enhance scientific PDF accessi-
bility for blind and low vision users. CoRR,
cs.DL/2105.00076v1.
389
Lucy Lu Wang, Kyle Lo, Yoganand Chan-
drasekhar, Russell Reas, Jiangjiang Yang,
Darrin Eide, Kathryn Funk, Rodney Kinney,
Ziyang Liu, William Merrill, Paul Mooney,
Dewey A. Murdick, Devvret Rishi, Jerry
Sheehan, Zhihong Shen, Brandon Stilson, Alex
D. Wade, Kuansan Wang, Chris Wilhelm,
Boya Xie, Douglas Raymond, Daniel S. Weld,
Oren Etzioni, and Sebastian Kohlmeier. 2020.
CORD-19: The covid-19 open research dataset.
CoRR, cs.DL/2004.10706v4.
Thomas Wolf, Lysandre Debut, Victor Sanh,
Julien Chaumond, Clement Delangue, Antoine
Moi, Pierric Cistac, Tim Rault, Remi Louf,
Morgan Funtowicz, Joe Davison, Sam Shleifer,
Patrick von Platen, Clara Ma, Yacine Jernite,
Julien Plu, Canwen Xu, Teven Le Scao,
Sylvain Gugger, Mariama Drame, Quentin
Lhoest, and Alexander Rush. 2020. Transform-
ers: State-of-the-art natural language process-
ing. In Proceedings of the 2020 Conference
on Empirical Methods
in Natural Lan-
guage Processing: System Demonstrations,
pages 38–45, En ligne. Association for Compu-
tational Linguistics. https://est ce que je.org/10
.18653/v1/2020.emnlp-demos.6
Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang,
Furu Wei, and Ming Zhou. 2020. Layoutlm:
Pre-training of text and layout for document
image understanding. In KDD ’20: The 26th
ACM SIGKDD Conference on Knowledge Dis-
covery and Data Mining, Virtual Event, Californie,
Etats-Unis, August 23–27, 2020, pages 1192–1200.
ACM.
Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui,
Furu Wei, Guoxin Wang, Yijuan Lu, Dinei A.
F. Florˆencio, Cha Zhang, Wanxiang Che, Min
Zhang, and Lidong Zhou. 2021. LayoutLMv2:
Multi-modal pre-training for visually-rich doc-
ument understanding. In Proceedings of the
59th Annual Meeting of the Association for
Computational Linguistics and the 11th Inter-
national Joint Conference on Natural Language
Processing, ACL/IJCNLP 2021, (Volume 1:
Long Papers), Virtual Event, August 1–6, 2021,
pages 2579–2591. Association for Computa-
tional Linguistics.
Liu Yang, Mingyang Zhang, Cheng Li,
Michael Bendersky, and Marc Najork. 2020.
Au-delà 512 tokens: Siamese multi-depth
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
transformer-based hierarchical encoder
pour
long-form document matching. In Proceed-
ings of the 29th ACM International Conference
on Information & Knowledge Management,
pages 1725–1734. https://est ce que je.org/10
.1145/3340531.3411908
Xingxing Zhang, Furu Wei, and Ming Zhou.
2019. HIBERT: Document level pre-training
of hierarchical bidirectional transformers for
document summarization. In Proceedings of
the 57th Annual Meeting of the Association for
Computational Linguistics, pages 5059–5069,
Italy. Association for Computa-
Florence,
tional Linguistics. https://est ce que je.org/10
.18653/v1/P19-1499
Xu Zhong, Jianbin Tang, and Antonio Jimeno
Yepes. 2019. PubLayNet: Largest dataset ever
for document layout analysis. Dans 2019 Inter-
national Conference on Document Analysis
and Recognition (ICDAR), pages 1015–1022.
IEEE. https://doi.org/10.1109/ICDAR
.2019.00166
A Model Performance Breakdown
In Tables 7, 8, et 9, we present model accuracies
on GROTOAP2, DocBank, and S2-VL of each
category for the results reported in the main paper.
B Improvements of the DocBank Dataset
We implement several fixes for the public version
of the DocBank dataset to improve its accuracy
and create faithful VILA structures.
B.1 Dataset Artifacts
As the DocBank dataset is automatically generated
via parsing LaTeX source from arXiv, it will
inevitably include noise. De plus, the authors
only release the document screenshots and token
information parsed using PDFMiner12 instead of
the source PDF files, which causes additional
issues when using the dataset. We identify some
major error categories during the course of our
project, detailed as follows:
fonts,13 which are often used for rendering spe-
cial symbols in PDFs. Par exemple, the software
may incorrectly parse 25◦C as 25(cid:176)
C. Including such (cid:*) tokens in the in-
put text is not reasonable, because they break
the natural flow of the text and most pre-trained
language model tokenizers cannot appropriately
encode such tokens.
text
it will
label all
Erroneous Label Generation Token labels in
DocBank are extracted by parsing latex com-
mands. Par exemple,
dans
the command \abstract{*} as ‘‘abstract’’.
Though theoretically this approach may work well
for ‘‘standard’’ documents, we find the resulting
label quality is far from ideal when processing
real-world documents at scale. One major issue is
that it cannot appropriately handle user-created
macros, which are often used for compiling
complex math equations. It leads to very low
(label) accuracy in the ‘‘equation’’ category in the
dataset—in fact, we manually inspected 10 pages,
and found 60% of the math equation tokens are
wrongly labeled as other classes. Cette approche
also fails to appropriately label some document
texts that are passively generated with the La-
TeX commands, Par exemple, the ‘‘Figure *’’
produced by the \caption command is treated
as ‘‘paragraph’’.
Lack of VILA Structures As the DocBank
dataset generating method solely operates on the
document TeX sources, it does not include visual
layout information. The missing VILA structures
leads to low label accuracy for layout-sensitive
categories like figure and tables—for example,
when a figure contains selectable text (c'est à dire., it is
not stored in a format like PNG or JPG, mais
instead contains text tokens returned by the PDF
parser), the method cannot recognize such tokens
and thus it assigns incorrect labels (other than
‘‘figure’’). Though the authors tried to create
layout group structures by applying connected
component analysis method to PDF tokens,14 nous
observed different types of errors in the generated
groupes, Par exemple, mis-identifying paragraph
breaks (combining multiple paragraph blocks into
Incorrect PDF Parsing The PDFMiner soft-
ware does not work perfectly when parsing CID
12https://github.com/euske/pdfminer (last
accessed Jan. 1, 2022).
13https://en.wikipedia.org/wiki/Post
Script fonts (last accessed Jan. 1, 2022).
14The algorithm iteratively selects and groups adjacent
tokens with the same category, and ultimately produces a list
of token collections that approximate the layout groups.
390
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Abstrait
Acknowledgment
Affiliation
Author
BERTBASE
BERTBASE + I-VILA(Text Line)
BERTBASE + I-VILA(Text Block)
LayoutLMBASE
LayoutLMBASE + Sentence Breaks
LayoutLMBASE + I-VILA(Text Line)
LayoutLMBASE + I-VILA(Text Block)
Simple Group Classifier
H-VILA(Text Line)
H-VILA(Text Block)
97.42
97.65
97.67
98.05
97.92
97.99
98.12
96.10
98.47
98.01
95.83
95.89
96.46
96.29
96.32
96.41
96.81
95.53
95.88
96.45
96.12
96.61
96.80
96.64
96.68
96.72
96.93
97.10
96.21
96.14
96.91
97.17
97.23
97.49
96.74
97.29
96.96
97.48
97.46
97.38
# Tokens in Class
395788
88531
90775
26742
Author
Title
96.09
96.48
97.73
96.51
95.42
95.98
97.52
97.94
95.26
96.31
7083
Bib
Info
95.00
95.78
96.29
96.74
96.77
96.66
96.87
96.68
96.68
96.33
Body
Content
Conflict
Statement
98.80
98.93
98.99
99.06
99.11
99.11
99.14
98.94
99.16
99.08
88.66
88.28
91.88
91.16
90.42
90.75
91.43
93.25
89.67
91.67
223739
7567934
22289
contd.
droits d'auteur
Correspondence
Editor
Équation
Chiffre
Glossaire
Mots clés
BERTBASE
BERTBASE + I-VILA(Text Line)
BERTBASE + I-VILA(Text Block)
LayoutLMBASE
LayoutLMBASE + Sentence Breaks
LayoutLMBASE + I-VILA(Text Line)
LayoutLMBASE + I-VILA(Text Block)
Simple Group Classifier
H-VILA(Text Line)
H-VILA(Text Block)
# Tokens in Class
contd.
BERTBASE
BERTBASE + I-VILA(Text Line)
BERTBASE + I-VILA(Text Block)
LayoutLMBASE
LayoutLMBASE + Sentence Breaks
LayoutLMBASE + I-VILA(Text Line)
LayoutLMBASE + I-VILA(Text Block)
Simple Group Classifier
H-VILA(Text Line)
H-VILA(Text Block)
# Tokens in Class
97.34
97.38
97.85
97.63
97.62
97.47
97.66
97.56
97.78
97.98
57419
Page
Nombre
98.32
98.82
98.92
98.94
98.90
99.05
99.05
99.02
98.96
99.16
46884
89.66
89.57
91.29
89.99
90.07
90.97
91.04
92.11
89.96
90.37
26653
Dates
94.56
94.60
94.99
94.80
94.73
95.20
95.13
95.47
94.98
94.92
23702
Les références
Tableau
99.60
99.60
99.64
99.62
99.61
99.63
99.65
99.61
99.63
99.68
94.11
94.53
94.31
95.30
95.63
95.61
95.73
93.94
96.02
95.00
99.71
99.93
99.95
99.90
99.95
99.93
100.00
100.00
99.91
100.00
2937
Title
97.60
97.77
98.19
97.91
98.13
97.80
98.39
98.18
97.76
98.36
2340796
558103
22110
17.60
25.00
29.46
30.78
20.73
26.42
39.28
33.17
15.60
30.64
761
Type
87.62
93.70
93.09
91.24
91.68
94.59
95.17
94.91
93.61
95.07
4543
94.05
94.84
95.52
95.52
95.83
95.67
95.74
95.77
95.63
95.86
581554
80.18
81.35
80.45
83.83
84.99
84.16
87.00
80.35
84.01
78.29
2807
93.42
94.34
95.40
94.95
93.88
94.82
96.23
95.64
93.69
96.15
7012
Unknown
Macro F1
88.60
88.14
88.81
89.19
89.14
89.86
90.47
89.60
90.00
89.23
54639
90.78
91.65
92.31
92.34
91.83
92.37
93.38
92.65
91.65
92.37
–
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Tableau 7: Prediction F1 breakdown for all models on the GROTOAP2 dataset.
Abstract Author Caption Date
Chiffre
Footer
List
Paragraph Reference
Section
Tableau
Title Macro F1
BERTBASE
BERTBASE + I-VILA(Text Line)
BERTBASE + I-VILA(Text Block)
LayoutLMBASE
LayoutLMBASE + Sentence Breaks
LayoutLMBASE + I-VILA(Text Line)
LayoutLMBASE + I-VILA(Text Block)
LayoutLMv2BASE
Simple Group Classifier
H-VILA(Text Line)
H-VILA(Text Block)
97.82
97.99
98.15
98.63
98.48
98.57
98.68
98.68
93.85
98.68
98.57
89.96
90.67
90.66
92.25
92.70
92.64
92.31
93.04
84.68
90.95
86.81
93.91
95.74
96.56
96.88
96.93
97.35
97.44
97.49
96.55
95.46
95.76
87.33
88.12
87.83
87.13
88.06
87.87
87.69
89.55
71.04
80.99
70.33
71.97
88.85
79.49
76.56
77.65
90.78
83.41
85.60
80.63
88.79
80.29
84.76
88.29
88.40
94.26
94.35
94.37
94.03
95.30
91.58
93.84
91.23
75.99
80.20
80.72
89.67
90.46
90.77
90.56
93.63
83.84
90.77
79.82
96.84
97.85
97.51
97.72
97.81
98.44
98.13
98.46
97.53
98.36
97.53
92.05
92.68
92.62
93.16
92.61
92.87
93.27
94.30
92.54
93.81
92.97
92.81
94.91
94.86
96.31
96.58
96.60
96.44
96.48
85.33
95.27
86.70
74.19
77.39
76.91
77.38
78.84
80.43
79.51
84.41
73.85
78.46
79.84
89.31
90.34
90.22
92.80
92.81
92.78
92.48
93.10
92.65
89.81
93.52
87.24
90.25
89.49
91.06
91.44
92.79
92.00
93.34
87.01
91.27
87.78
# Tokens in Class
461898
81061
858862
3275
932150
158176
684786
20630188
1813594
154062
235801
26355
–
Tableau 8: Prediction F1 breakdown for all models on the DocBank dataset.
un) or overlapping layout groups (caused by
incorrect token labels), and chose not to use them.
B.2 Fixes and Enhancement
Based on the aforementioned issues, we imple-
ment the following fixes and enhance the DocBank
dataset with VILA structures.
Remove Incorrect PDF Tokens Provided that
there are no simple ways to recover the incorrect
(cid:*) tokens generated by PDFMiner, nous
simply remove them from the input text.
Generate VILA Structures We use pre-trained
Faster-RCNN models (Ren et al., 2015) from the
LayoutParser (Shen et al., 2021) tool to iden-
tify both the text lines and blocks based on the
page images. Spécifiquement, for text blocks, we use
the PubLayNet/mask rcnn R 50 FPN 3x/
model to detect the body content regions (inclure-
ing title, paragraph, chiffre, table, and list) et le
MFD/faster rcnn R 50 FPN 3x/ model to
detect the display math equation regions. We also
fine-tune a Fast RCNN model on the GROTOAP2
dataset (which has text line annotation), and use
391
Abstrait
Author
Bibliography
Caption
Équation
Chiffre
Footer
Footnote
BERTBASE
BERTBASE + I-VILA(Text Line)
BERTBASE + I-VILA(Text Block)
LayoutLMBASE
LayoutLMBASE + Sentence Breaks
LayoutLMBASE + I-VILA(Text Line)
LayoutLMBASE + I-VILA(Text Block)
LayoutLMv2BASE
H-VILA(Text Line)
H-VILA(Text Block)
# Tokens in Class
91.67(5.51)
89.38(6.50)
90.45(3.61)
91.87(4.89)
92.01(4.79)
91.77(5.85)
92.91(4.02)
91.09(6.46)
93.90(5.16)
93.40(6.14)
71.38(18.79)
65.93(15.48)
64.97(16.11)
69.39(11.30)
69.22(11.02)
69.81(7.86)
70.42(13.38)
63.42(17.55)
70.86(9.78)
67.03(19.43)
97.90(1.59)
97.92(1.56)
97.21(1.27)
98.08(1.13)
98.57(1.24)
98.09(1.64)
98.19(1.57)
97.74(2.00)
97.71(1.26)
96.11(3.38)
94.64(1.38)
96.66(1.39)
96.82(0.94)
92.98(7.35)
95.74(1.36)
94.06(2.91)
97.19(1.16)
96.73(1.39)
92.86(3.89)
92.76(6.47)
76.23(4.36)
83.22(5.87)
83.56(5.59)
77.49(7.13)
77.94(9.68)
84.48(7.00)
83.76(6.61)
77.18(13.70)
60.14(24.13)
72.11(13.35)
70.57(11.56)
74.46(18.48)
67.80(25.61)
71.57(21.49)
68.38(26.11)
83.71(11.53)
61.99(17.04)
57.75(22.46)
59.79(23.18)
67.42(18.90)
69.67(20.06)
67.23(23.01)
68.03(19.11)
64.37(22.24)
62.91(7.23)
72.78(12.45)
80.17(10.48)
77.22(17.59)
78.57(16.45)
77.10(15.64)
76.77(17.64)
70.20(12.43)
81.38(7.79)
86.87(8.64)
77.86(10.65)
79.64(11.21)
65.95(23.44)
63.72(22.01)
81.76(15.03)
83.66(9.88)
2854(432)
543(118)
15681(3704)
4046(2119)
2552(1872)
1402(1316)
480(205)
2468(1254)
contd.
Header
Mots clés
List
Paragraph
Section
Tableau
Title
Macro F1
BERTBASE
BERTBASE + I-VILA(Text Line)
BERTBASE + I-VILA(Text Block)
LayoutLMBASE
LayoutLMBASE + Sentence Breaks
LayoutLMBASE + I-VILA(Text Line)
LayoutLMBASE + I-VILA(Text Block)
LayoutLMv2BASE
H-VILA(Text Line)
H-VILA(Text Block)
# Tokens in Class
76.47(8.51)
81.53(7.94)
83.99(8.74)
88.21(5.81)
88.08(5.71)
87.14(6.49)
88.39(6.20)
86.95(6.84)
87.89(6.45)
86.49(6.08)
90.16(6.44)
87.06(5.57)
87.86(7.51)
88.14(5.94)
88.80(3.23)
86.66(6.24)
90.92(3.97)
89.71(7.95)
51.00(16.90)
58.64(8.10)
62.01(13.25)
58.21(15.15)
60.61(11.80)
65.82(10.92)
59.06(17.99)
68.36(10.05)
86.34(5.02)
76.97(18.82)
65.76(10.26)
55.82(16.99)
96.07(1.37)
96.67(1.13)
96.65(1.21)
96.88(0.87)
97.01(0.85)
97.17(1.26)
97.17(1.14)
96.65(0.71)
96.90(0.75)
96.43(1.40)
79.72(3.46)
87.21(3.25)
86.71(3.23)
88.14(2.73)
88.05(2.79)
89.79(2.48)
88.67(3.57)
89.48(4.13)
85.45(2.02)
86.72(4.55)
79.93(16.26)
85.58(15.67)
80.44(16.35)
82.02(15.58)
81.59(16.22)
86.00(12.33)
81.84(15.77)
81.69(15.05)
85.19(7.55)
81.38(14.94)
84.81(8.52)
84.80(5.84)
86.14(5.23)
89.90(8.17)
88.52(5.92)
89.89(7.47)
89.95(6.32)
88.46(6.00)
85.62(6.00)
84.39(9.10)
78.34(6.53)
81.15(4.83)
81.82(4.88)
82.69(6.04)
82.81(5.21)
83.77(5.75)
83.44(6.48)
83.05(4.51)
83.69(2.92)
82.09(5.89)
1122(463)
130(27)
2274(593)
95732(8226)
882(113)
3887(2041)
240(26)
–
Tableau 9: Prediction F1 breakdown for all models on the S2-VL dataset. Similar to the results in the
main paper, we show averaged scores with standard deviation in parentheses across the 5-fold cross
validation subsets.
it to detect the text lines. All other regions (ou
texts that are not covered by the detected blocks
or lines) are created by the connected component
analysis method.
Correct Label Errors Given the VILA structures,
we can easily correct some previously mentioned
errors like incorrect labels for ‘‘Figure *’’ by
applying majority voting for token labels in a text
block. Cependant, for the ‘‘equation’’ category,
given the low accuracy of the original DocBank
labels, neither majority voting nor other automatic
methods can easily recover the correct token cate-
gories. Ainsi, we choose to discard this category
in the modeling phase, namely, converting all
existing ‘‘equation’’ labels to the background
category ‘‘paragraph’’.
We update our methods for several rounds to
coordinate the fixes and enhancements, and ulti-
mately we can reduce more than 90% of the label
errors for figure and table captions. By using the
accurate pre-trained layout detection models, le
generated VILA structures are more than 95%
accurate.15
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
6
6
2
0
0
6
9
9
3
/
/
t
je
un
c
_
un
_
0
0
4
6
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
15We randomly sample 30 pages from both the training
and test dataset, and annotate the number of the incorrect
text blocks for each page. A text block is considered as
incorrect when it wrongly merges multiple regions (par exemple., deux
paragraphs or one paragraph and the adjacent section header)
or splits regions (par exemple., generating multiple blocks for one
paragraph). We report the average of page block accuracy.
392