Transactions of the Association for Computational Linguistics, vol. 4, pp. 215–229, 2016. Action Editor: Hwee Tou Ng.
Submission batch: 7/2015; Revision batch: 1/2016; 3/2016; Published 5/2016.
2016 Association for Computational Linguistics. Distributed under a CC-BY 4.0 Licence.
c
(cid:13)
J-NERD:JointNamedEntityRecognitionandDisambiguationwithRichLinguisticFeaturesDatBaNguyen1,MartinTheobald2,GerhardWeikum11MaxPlanckInstituteforInformatics2UniversityofUlm{datnb,weikum}@mpi-inf.mpg.demartin.theobald@uni-ulm.deAbstractMethodsforNamedEntityRecognitionandDisambiguation(NERD)performNERandNEDintwoseparatestages.Therefore,NEDmaybepenalizedwithrespecttoprecisionbyNERfalsepositives,andsuffersinrecallfromNERfalsenegatives.Conversely,NEDdoesnotfullyexploitinformationcomputedbyNERsuchastypesofmentions.ThispaperpresentsJ-NERD,anewapproachtoperformNERandNEDjointly,bymeansofaprob-abilisticgraphicalmodelthatcapturesmen-tionspans,mentiontypes,andthemappingofmentionstoentitiesinaknowledgebase.WepresentexperimentswithdifferentkindsoftextsfromtheCoNLL’03,ACE’05,andClueWeb’09-FACC1corpora.J-NERDcon-sistentlyoutperformsstate-of-the-artcompeti-torsinend-to-endNERDprecision,recall,andF1.1IntroductionMotivation:MethodsforNamedEntityRecogni-tionandDisambiguation,NERDforshort,typicallyproceedintwostages:•AttheNERstage,textspansofentitymentionsaredetectedandtaggedwithcoarse-grainedtypeslikePerson,Organization,Location,etc.ThisistypicallyperformedbyatrainedCondi-tionalRandomField(CRF)overwordsequences(e.g.,Finkeletal.(2005)).•AttheNEDstage,mentionsaremappedtoen-titiesinaknowledgebase(KB)basedoncon-textualsimilaritymeasuresandthesemanticco-herenceoftheselectedentities(e.g.,Cucerzan(2014);Hoffartetal.(2011);Ratinovetal.(2011)).Thistwo-stageapproachhaslimitations.First,NERmayproducefalsepositivesthatcanmisguideNED.Second,NERmaymissoutonsomeentitymentions,andNEDhasnochancetocompensateforthesefalsenegatives.Third,NEDisnotabletohelpNER,forexample,bydisambiguating“easy”mentions(e.g.,ofprominententitieswithmoreorlessuniquenames),andthenusingtheentitiesandknowledgeaboutthemasenrichedfeaturesforNER.Example:Considerthefollowingsentences:Davidplayedformanu,réel,andlagalaxy.Hiswifeposhperformedwiththespicegirls.ThisisdifficultforNERbecauseoftheabsenceofupper-casespelling,whichisnotuntypicalinso-cialmedia,forexample.MostNERmethodswillmissoutonmulti-wordmentionsorwordsthatarealsocommonnouns(“spice”)oradjectives(“posh”,“real”).Typiquement,NERwouldpassonlythemen-tions“David”,“manu”,and“la”totheNEDstage,whichthenispronetomanyerrorslikemappingthefirsttwomentionstoanyprominentpeoplewithfirstnamesDavidandManu,andmappingthethirdonetothecityofLosAngeles.WithNERandNEDper-formedjointly,thepossibledisambiguationof“lagalaxy”tothesoccerclubcanguideNERtotagtherightmentionswiththerighttypes(e.g.,recogniz-ingthat“manu”couldbeashortnameforasoccerteam),whichinturnhelpsNEDtomap“David”totherightentityDavidBeckham.Contribution:Thispaperpresentsanovelkindofprobabilisticgraphicalmodelforthejointrecogni-tionanddisambiguationofnamed-entitymentionsinnatural-languagetexts.Withthisintegratedap-proachtoNERD,weaimtoovercomethelimita-tionsofthetwo-stageNER/NEDmethodsdiscussedabove.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
216
Ourmethod,calledJ-NERD1,isbasedonasupervised,non-lineargraphicalmodelthatcom-binesmultipleper-sentencemodelsintoanentity-coherence-awareglobalmodel.Theglobalmodeldetectsmentionspans,tagsthemwithcoarse-grainedtypes,andmapsthemtoentitiesinasinglejoint-inferencestepbasedontheViterbialgorithm(forexactinference)orGibbssampling(forapprox-imateinference).TheJ-NERDmethodcomprisesthefollowingnovelcontributions:•atree-shapedmodelforeachsentence,whosestructureisderivedfromthedependencyparsetreeandthuscaptureslinguisticcontextinadeeperwaycomparedtopriorworkwithCRF’sforNERandNED;•richerlinguisticfeaturesnotconsideredinpriorwork,harnessingdependencyparsetreesandverbalpatternsthatindicatementiontypesaspartoftheirnsubjordobjarguments;•aninferencemethodthatmaintainstheuncer-taintyofbothmentioncandidates(i.e.,tokenspans)andentitycandidatesforcompetingmen-tioncandidates,andmakesjointdecisions,asopposedtofixingmentionsbeforereasoningontheirdisambiguation.Wepresentexperimentswiththreemajordatasets:theCoNLL’03collectionofnewswirearticles,theACE’05corpusofnewsandblogs,andtheClueWeb’09-FACC1corpusofwebpages.Base-linesthatwecompareJ-NERDwithincludeAIDA-light(Nguyenetal.,2014),Spotlight(Daiberetal.,2013),andTagMe(FerraginaandScaiella,2010),andtherecentjointNER/NEDmethodofDurrettandKlein(2014).J-NERDconsistentlyoutper-formsthesecompetitorsintermsofbothprecisionandrecall.2RelatedWorkNER:Detectingtheboundariesoftextspansthatde-notenamedentitieshasbeenmostlyaddressedbysupervisedCRF’soverwordsequences(McCallumandLi,2003;Finkeletal.,2005).TheworkofRati-novandRoth(2009)improvedthesetechniquesbyadditionalfeaturesfromcontextaggregationandex-ternallexicalsources(gazetteers,etc.).Passoset1TheJ-NERDsourceisavailableattheURLhttp://download.mpi-inf.mpg.de/d5/tk/jnerd-tacl.zip.al.(2014)harnessedskip-gramfeaturesandexter-naldictionariesforfurtherimprovement.Analter-nativelineofNERtechniquesisbasedondictionar-iesofname-entitypairs,includingnicknames,short-handnames,andparaphrases(e.g.,“thefirstmanonthemoon”).TheworkofFerraginaandScaiella(2010)andMendesetal.(2011)areexamplesofdictionary-basedNER.TheworkofSpitkovskyandChang(2012)isanexampleofalarge-scaledictio-narythatcanbeharnessedbysuchmethods.AnadditionaloutputoftheCRF’saretypetagsfortherecognizedwordspans,typicallylimitedtocoarse-grainedtypeslikePerson,Organization,andLocation(andalsoMiscellaneous).ThemostwidelyusedtoolofthiskindistheStanfordNERTagger(Finkeletal.,2005).ManyNEDtoolsusetheStan-fordNERTaggerintheirfirststageofdetectingmentions.MentionTyping:ThespecificNERtaskofinfer-ringsemantictypeshasbeenfurtherrefinedandex-tendedbyvariousworksonfine-grainedtyping(e.g.,politicians,musicians,singers,guitarists)forentitymentionsandgeneralnounphrases(FleischmanandHovy,2002;RahmanandNg,2010;LingandWeld,2012;Yosefetal.,2012;Nakasholeetal.,2013).Mostoftheseworksarebasedonsupervisedclassi-fication,usinglinguisticfeaturesfrommentionsandtheirsurroundingtext.OneexceptionistheworkofNakasholeetal.(2013)whichisbasedontextpatternsthatconnectentitiesofspecifictypes,ac-quiredbysequenceminingfromtheWikipediafull-textcorpus.Incontrasttoourwork,thosearesimplesurfacepatterns,andthetaskaddressedhereislim-itedtotypingnounphrasesthatlikelydenoteemerg-ingentitiesthatarenotyetregisteredinaKB.NED:MethodsandtoolsforNEDgobacktotheseminalworkofDilletal.(2003),BunescuandPasca(2006),Cucerzan(2007),andMilneandWit-ten(2008).Morerecentadvancesledtoopen-sourcetoolsliketheWikipediaMinerWikifier(MilneandWitten,2013),theIllinoisWikifier(Ratinovetal.,2011),Spotlight(Mendesetal.,2011),Semanticizer(Meijetal.,2012),TagMe(FerraginaandScaiella,2010;Cornoltietal.,2014),andAIDA(Hoffartetal.,2011)withitsimprovedvariantAIDA-light(Nguyenetal.,2014).Wechoosesome,namely,Spotlight,TagMeandAIDA-light,asbaselinesforourexperiments.Thesearethebest-performing,
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
217
publiclyavailablesystemsfornewsandwebtexts.Mostofthesemethodscombinecontextualsimilar-itymeasureswithsomeformofconsiderationforthecoherenceamongaselectedsetofcandidateen-titiesfordisambiguation.Thelatteraspectcanbecastintoavarietyofcomputationalmodels,likegraphalgorithms(Hoffartetal.,2011),integerlinearprogramming(Ratinovetal.,2011),orprobabilisticgraphicalmodels(Kulkarnietal.,2009).AllthesemethodsusetheStanfordNERTaggerordictionary-basedmatchingfortheirNERstages.Kulkarnietal.(2009)usesanILPorLPsolver(withrounding)fortheNEDinference,whichiscomputationallyexpen-sive.NotethatsomeoftheNEDtoolsaimtolinknotonlynamedentitiesbutalsogeneralconcepts(e.g.“worldpeace”)forwhichWikipediahasarticles.Inthispaper,wesolelyfocusonproperentities.JointNERD:Thereislittlepriorworkonperform-ingNERandNEDjointly.SilandYates(2013),andDurrettandKlein(2014)arethemostnotablemeth-ods.SilandYates(2013)firstcompilealiberalsetofmentionandentitycandidates,andthenperformjointrankingofthecandidates.DurrettandKlein(2014)presentaCRFmodelforcoreferenceres-olution,mentiontyping,andmentiondisambigua-tion.OurmodelisalsobasedonCRF’s,butdis-tinguishesitselffrompriorworkinthreeways:1)tree-shapedper-sentenceCRF’sderivedfromdepen-dencyparsetrees,asopposedtomerelyhavingcon-nectionsamongmentionsandentitycandidates;2)linguisticfeaturesaboutverbalphrasesfromdepen-dencyparsetrees;3)themaintainingofcandidatesforbothmentionsandentitiesandjointlyreason-ingontheiruncertainty.OurexperimentsincludecomparisonswiththemethodofDurrettandKlein(2014).Therearealsobenchmarkingeffortsonmeasuringtheperformanceforend-to-endNERD(Cornoltietal.,2013;Carmeletal.,2014;Usbecketal.,2015),asopposedtoassessingNERandNEDseparately.However,tothebestofourknowledge,noneoftheparticipantsinthesecompetitionsconsideredinte-gratingNERandNED.3J-NERDFactorGraphModel3.1OverviewTolabelasequenceofinputtokenshx1,…,xmiwithasequenceofoutputlabelshy1,…,ymi,con-sistingofNERtypesandNEDentities,wedeviseafamilyoflinear-chainandtree-shapedprobabilis-ticgraphicalmodels(Kolleretal.,2007).Weem-ploythesemodelstocompactlyencodeamulti-variateprobabilitydistributionoverrandomvari-ablesX∪Y,whereXdenotesthesetofinputtokensxiwemayobserve,andYdenotesthesetofoutputlabelsyiwemayassociatewiththesetokens.Bywritingx,wedenoteanassignmentoftokenstoX,whileydenotesanassignmentoflabelstoY.Inourrunningexample,“David”isthefirsttokenx1withthedesiredlabely1=PER:DavidBeckhamwherePERdenotestheNERtypePersonandDavidBeckhamistheen-tityofinterest.Consecutivetokenswithidenticalla-belsareconsideredtobeentitymentions.Forexam-ple,forx5=laandx6=galaxy,theoutputwouldideallybey5=ORG:LosAngelesGalaxyandy6=ORG:LosAngelesGalaxy,denotingthesoccerclub.Upfrontthesearemerelycandidatela-bels,though.Ourmethodmayalternativelyconsiderthelabelsy5=LOC:LosAngelesandy6=MISC:SamsungGalaxy.Thiswouldyieldin-correctoutputwithtwosingle-tokenmentionsandimproperentities.Thefeaturetemplatesf1–f17wedescribeindetailinSection4eachtakethepossibleassignmentsx,yoftokensandlabels,respectivement,asinputandgiveabinaryvalueorrealnumberasoutput.Binaryvaluesdenotethepresenceorabsenceofafeature(e.g.,aparticulartoken);real-valuedonestypicallydenotefrequenciesofobservedfeatures.Fortractability,probabilisticgraphicalmodelsaretypicallyconstrainedbymakingconditionalinde-pendenceassumptions,thusimposingstructureandlocalityonX∪Y.Inourmodels,wepostulatethatthefollowingconditionalindependenceassumptionshold:p(yi|X,oui)=p(yi|X,yprev(je))Thatis,thelabelyifortheithtokendirectlydependsonlyonthelabelyprev(je)ofsomeprevioustokenatpositionprev(je)andpotentiallyonallinputtokens.Thecasewhereprev(je)=i−1isthestandardset-tingforalinear-chainCRF,wherethelabelofato-kendependsonlyonthelabelofitsprecedingtoken.Wegeneralizethisapproachtoconsideringprev(je)tokensbasedontheedgesofadependencyparse
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
218
treeandprev(je)tokensderivedfromco-referencesinprecedingsentences.BytheHammersley-CliffordTheorem,suchagraphicalmodelcanbefactorizedintoaproductformwhereeachfactorcapturesasubsetA⊆X∪Yoftherandomvariables.Typically,eachfactorcon-sidersonlythoseXandYvariablesthatarecoupledbyaconditional(in-)dependenceassumptions,withoverlappingAsetsofdifferentfactors.Theprob-abilitydistributionencodedbythegraphicalmodelcanthenbeexpressedasfollows:p(X,oui)=1ZYAFA(xA,yA)Ici,FA(xA,yA)denotesthefactorsofthemodel,eachofwhichisofthefollowingform:FA(xA,yA)=exp(XkλkfA,k(xA,yA))ThenormalizationconstantZ=Px,yQAFA(xA,yA)ensuresthatthisdistri-butionsumsupto1,whileλkaretheparametersofthemodel,whichweaimtolearnfromvariousannotatedbackgroundcorpora.Ourinferenceobjectivethenistofindthemostprobablesequenceoflabelsy∗whengiventhetokensequencexasevidence:y∗=argmaxyp(oui|X)Thatis,inoursetting,wefixx=htok1,…,tokmitotheobservedtokensequence,whiley=hy1,…,ymirangesoverallpossiblesequencesofassociatedlabels.Inourapproach,whichwehencecoinedJ-NERD,eachyilabelrepresentsacombina-tionofNERtypeandNEDentity.State-of-the-artNERmethods,suchastheStan-fordNERTagger,employlinear-chainfactorgraph,knownasConditionalRandomFields(CRF’s)(Sut-tonandMcCallum,2012).Wealsodevisemoreso-phisticatedtree-shapedfactorgraphswhosestruc-tureisobtainedfromthedependencyparsetreesoftheinputsentences.Theseper-sentencemodelsareoptionallycombinedintoaglobalfactorgraphbyaddingalsocross-sentencedependencies(Finkeletal.,2005).Thesecross-sentencedependenciesareaddedwheneveroverlappingsetsofentitycan-didates(i.e.,potentialco-references)aredetectedamongtheinputsentences.Figure3givesanex-ampleofsuchaglobalgraphicalmodelfortwosen-tences.Thesearchspaceofcandidatelabelsforourmod-elsdependsonthecandidatesformentionspans(withthesameNERtype)andtheirNEDentities.Weusepruningheuristicstorestrictthisspace:can-didatespansformentionsarederivedfromdictio-naries,andweconsideronlythetop-20entitycan-didatesforeachcandidatemention.Foragivensen-tence,thistypicallyleadstoafewthousandcandi-datelabelsoverwhichtheCRFinferenceruns.Thecandidatesaredeterminedindependentlyforeachsentence.3.2FeaturesThesemodelsemployavarietyoffeaturetemplatesthatgeneratethefactorsofthejointprobabilitydis-tribution.SomeofthefeaturesarefairlystandardforNER/NED,whereasothersarenovel.•Standardfeaturesincludelexico-syntacticprop-ertiesoftokenslikePOStags,matchesindic-tionaries/gazetteers,andsimilaritymeasuresbe-tweentokenstringsandentitynames.Also,entity-entitycoherenceisanimportantfeatureforNED–notexactlyastandardfeature,butusedinsomepriorworks.•Featuresaboutthetopicaldomainofaninputtext(e.g.,politics,sports,football,etc.)areob-tainedbyaclassifierbasedon“easymentions”:thosementionsforwhichtheNEDdecisioncanbemadewithveryhighconfidencewithoutad-vancedfeatures.TheuseofdomainsforNEDwasintroducedbyNguyenetal.(2014).Ici,wefurtherextendthistechniquebyharnessingdomainfeaturesforjointinferenceonNERandNED.•Thethirdfeaturegroupcapturestypeddepen-denciesfromthesentenceparsing.Toourknowledge,thesehavenotbeenusedinpriorworkonNERandNED.TheNERtypesthatweconsiderarethestandardtypesPERforperson,LOCforlocationandORGfororganization.Allothertypesthat,forexample,theStanfordNERTaggerwouldmark,arecollapsedintoatypeMISCformiscellaneous.Theseincludelabelslikedateandmoney(whicharenotgenuineentitiesanyway)andalsoentitytypeslikeeventsand
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
219
creativeworkssuchasmovies,songs,etc.(whicharedisregardedbytheStanfordNERTagger).WeaddtwodedicatedtagsfortokenstoexpressthecasewhennomeaningfulNERtypeorNEDentitycanbeassigned.Fortokensthatshouldnotbelabeledasanamedentityatall(e.g.,“played”inourexam-ple),weusethetagOther.FortokenswithavalidNERtype,weaddthevirtualentityOut-of-KB(for“outofknowledgebase”)toitsentitycandi-dates,toprepareforthepossiblesituationwherethetoken(anditssurroundingtokens)actuallydenotesanemergingorlong-tailentitythatisnotcontainedintheknowledgebase.3.3Linear-ChainModelInthelocalmodels,J-NERDworksoneachsen-tenceS=htok1,…,tokmiseparately.Wecon-structalinear-chainCRF(seeFigure1)byintro-ducinganobservedvariablexiforeachtokentokithatrepresentsaproperword.Foreachxi,wead-ditionallyintroduceavariableyithatrepresentsthecombinedNERDlabel.AsinanyCRF,thexi,yiandyi,yi+1pairsareconnectedviafactorsF(X,oui),whoseweightsweobtainfromthefeaturefunctionsdescribedinSection4.y1y2y3y4y5y6x1x2x3x4x5x6DavidplayedmanureallagalaxyFigure1:Linear-chainmodel(CRF).3.4TreeModelThefactorgraphforthetree-shapedmodeliscon-structedinasimilarway.However,hereweaddafactorthatlinksapairoflabelsyi,yjiftheirrespec-tivetokenstoki,tokjareconnectedviaatypedde-pendencywhichweobtainfromtheStanfordparser.Figure2showsanexampleofsuchatreemodel.Thus,whilethelinear-chainmodeladdsfactorsbe-tweenlabelsofadjacenttokensonlybasedontheirpositionsinthesentence,thetreemodeladdsfac-torsbasedonthedependencyparsetreetoenhancethecoherenceoflabelsacrosstokens.3.5GlobalModelsForglobalmodels,weconsideranentireinputtextconsistingofmultiplesentencesS1,…,Sn=htok1,…,tokmi,foraugmentingeitheroneofthey1y2y3y4y5y6x1x2x3x4x5x6Davidplayedmanureallagalaxy[nsubj][pf][pf][pf][det]Figure2:Treemodel([pf]est[prepfor]).linear-chainmodelortree-shapedmodel.AsshowninFigure3,cross-sentenceedgesamongpairsoflabelsyi,yjareintroducedforcandidatesetsCi,Cjthatshareatleastonecandidateentity,suchas“David”and“DavidBeckham”.Additionally,weintroducefactorsforallpairsoftokensinadjacentmentionswithinthesamesentence,suchas“David”and“manu”.3.6Inference&LearningOurinferenceobjectiveistofindthemostprobablesequenceofNERDlabelsy∗=argmaxyp(oui|X)accordingtotheobjectivefunctionwedefinedinSection3.Insteadofconsideringtheactualdistri-butionp(X,oui)=1ZYAexp(XkλkfA,k(xA,yA))forthispurpose,weaimtomaximizeanequivalentobjectivefunctionasfollows.EachfactorAinourmodelcouplesalabelvariableytwithavariableyprev(t):eitheritsimmediatelyprecedingtokeninthesamesentence,oraparsing-dependency-linkedtokeninthesamesentence,oraco-reference-linkedtokeninadifferentsentence.Eachofthesefactorshasitsfeaturefunctions,andwecanregroupthesefeaturesonaper-tokenbasisgiventhelog-linearnatureoftheobjectivefunction.Thisleadstothefollowingoptimizationproblemwhichhasitsmax-imumforthesamelabelassignmentastheoriginalproblem:y∗=argmaxy1…ymexp(cid:18)mPt=1KPk=1λkfeaturek(yt,yprev(t),x1…xm)(cid:19)where•prev(t)istheindexoflabelyjonwhichytde-pends,•feature1..Karethefeaturefunctionsgeneratedfromtemplatesf1–f17ofSection4,
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
220
y1y2y3y4y5y6x1x2x3x4x5x6Davidplayedmanureallagalaxyy7y8y9y10y11x7x8x9x10x11DavidBeckhambornLondonEngland[nsubj][pf][pf][pf][det][nn][nn][nsubjpass][prepin]Figure3:Globalmodel,linkingtwotreemodels([pf]isshortfor[prepfor]).•andλkarethefeatureweights,i.e.,themodelparameterstobelearned.Theactualnumberofgeneratedfeatures,K,de-pendsonthetrainingcorpusandthechoiceofthegraphicalmodel.FortheCoNLL-YAGO2trainingset,thetreemodelshaveK=1,767parameters.Givenatrainedmodel,exactinferencewithrespecttotheaboveobjectivefunctioncanbeefficientlyperformedbyvariantsoftheViterbialgorithm(Sut-tonandMcCallum,2012)forthelocalmodels,bothinthelinear-chainandtree-shapedcases.Fortheglobalmodels,cependant,exactsolutionsarecompu-tationallyintractable.Therefore,weemployGibbssampling(Finkeletal.,2005)toapproximatetheso-lution.Asforthemodelparameters,J-NERDlearnsthefeatureweightsλkfromthetrainingdatabymax-imizingarespectiveconditionallikelihoodfunc-tion(SuttonandMcCallum,2012),usingavari-antoftheL-BFGSoptimizationalgorithm(LiuandNocedal,1989).Wedothisforeachlocalmodel(linear-chainandtreemodels),andapplythesamelearnedweightstothecorrespondingglobalmodels.OurimplementationusestheRISOtoolkit2forbe-liefnetworks.4FeatureTemplatesWedefinefeaturetemplatesfordetectingthecom-binedNER/NEDlabelsoftokenthatdenoteorarepartofanentitymention.Oncetheselabelsarede-termined,theactualboundariesofthementions,i.e.,theirtokenspans,aretriviallyderivedbycombiningadjacenttokenswiththesamelabel(anddisregard-ingalltokenswiththetagOther).LanguagePreprocessing.WeemploytheStan-2http://riso.sourceforge.net/fordCoreNLPtoolsuite3forprocessinginputdoc-uments.Thisincludestokenization,sentencedetec-tion,POStagging,lemmatization,anddependencyparsing.Alloftheseprovidefeaturesforourgraph-icalmodel.Inparticular,weharnessdependencytypesbetweennounphrases(deMarneffeetal.,2006),likensubj,dobj,prepin,prepfor,etc.Inthefollowing,weintroducethecompletesetoffeaturetemplatesf1throughf17usedbyourmethod.Templatesareinstantiatedbasedontheob-servedinputandthecandidatespaceofpossiblela-belsforthisinput,andguidedbydistantresourceslikeknowledgebasesanddictionaries.Templatesf1,f8–f13,f17generaterealnumbersasvaluesde-rivedfromfrequenciesintrainingdata;allothertemplatesgeneratebinaryvaluesdenotingpresenceorabsenceofcertainfeatures.Thegeneratedfeaturevaluesdependontheassignmentofinputtokenstovariablesxi∈X.Inaddition,ourgraphicalmodelsoftenconsideronlyaspecificsubsetofcandidatela-belsasassignmentstotheoutputvariablesyi∈Y.Therefore,weformulatethefeature-generationpro-cessasasetoffeaturefunctionsthatdependonboth(per-factorsubsetsof)XandY.Table1illustratesthefeaturegenerationbythesetofactivefeaturefunctionsforthetoken“manu”inourrunningexample,usingthreedifferentcandidatelabels.EntityRepositoryandName-EntityDictionary.Manyfeaturetemplatesharnessaknowledgebase,namely,YAGO2(Hoffartetal.,2013),asanen-tityrepositoryandasadictionaryofname-to-entitypairs(i.e.,aliasesandparaphrases).WeimporttheYAGO2meansandhasNamerelations,atotalofmorethan6Millionname-entitypairs(forca.3Milliondistinctentities).Wederiveadditional3http://stanfordnlp.github.io/CoreNLP/
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
221
Table1:Positivefeatures(valuesettotrueorrealnumber>0)forthetoken“manu”(x3)withcan-didatelabelsORG:ManchesterUnitedF.C.(y3),PER:ManuChao(y03)andOther(y003).ThedomainisFootballandthelinguisticpatternisprepfor[played,*].Featurey3y03y003f1:Token-TypePriorXXXf2:CurrentPOSXXXf3:In-DictionaryXXf4:Uppercasef5:SurroundingPOSXXXf6:SurroundingTokensXXXf7:SurroundingIn-DictionaryXXXf8:Token-EntityPriorXXf9:Token-Entityn-GramSimilarityXXf10:Token-EntityTokenContextsXXf11:Entity-EntityTokenCoherenceXXf12:Entity-DomainCoherenceXf13:Entity-EntityTypeCoherenceXXf14:Typed-DependencyXXf15:Typed-Dependency/POSXXf16:Typed-Dependency/In-DictionaryXf17:Token-EntityLinguisticContextsXNER-type-specificphrasedictionariesfromsupport-ingphrasesofGATE(Cunninghametal.,2011),e.g.,“Mr.”,“Mrs.”,“Dr.”,“President”,etc.forthetypePER;“city”,“river”,“park”,etc.forthetypeLOC;“company”,“institute”,“Inc.”,“Ltd.”,etc.forthetypeORG.PruningtheCandidateSpace.Toreducethedi-mensionalityofthegeneratedfeaturespaceandtomakethefactor-graphinferencetractable,weusepruningtechniquesbasedontheknowledgebaseandthedictionaries.Todetermineifatokencanbeamentionorpartofamention,wefirstperformexact-matchlookupsofallsub-sequencesagainstthename-entitydictionary.Asanoption(andbydefault),thiscanbelimitedtosub-sequencesthataretaggedasnounphrasesbytheStanfordparser.Forhigherrecall,wethenaddpartial-matchlookupswhenatokensub-sequencematchesonlysomebutnotalltokensofanentitynameinthedictionary.Forexample,forthesentence“Davidplayedformanu,realandlagalaxy”,weobtain“David”,“manu”,“real”,“lagalaxy”,“la”,and“galaxy”ascandidatementions.Foreachsuchcandidatemention,welookuptheknowledgebaseforentitiesandconsideronlythebestn(usingn=20inourexperiments)high-estrankedcandidateentities.Therankingisbasedonthestringsimilaritybetweenthementionandtheentityname,thepriorpopularityoftheentity,andthelocalcontextsimilarity(usingfeaturefunctionsf8,f9,f10describedinSubsection4.1).4.1StandardFeaturesForthefollowingdefinitionsofthefeaturetem-plates,letposidenotethePOStagoftoki,dicidenotetheNERtagfromthedictionarylookupoftoki,anddepidenotetheparsingdependencythatconnectstokiwithanothertoken.Further,wewritesuri=htoki−1,toki,toki+1itorefertothese-quenceoftokenssurroundingtoki.Asforthepos-siblelabels,wedenotebytypeiandentianNERtypeandcandidateentityforthecurrenttokentoki,respectively.Token-TypePrior.Featuref1(typei,toki)capturesapriorprobabilityfortokibeingofNERtypetypei.TheseprobabilitiesareestimatedfromanNER-annotatedtrainingcorpus.Inourexperiments,weusedtrainingsubsetsofdifferenttestcorporasuchasCoNLL.Forexample,wemaythusobtainaprioroff1(ORG,“Ltd.”)=0.8.CurrentPOS.Templatef2(typei,toki)generatesabinaryfeaturefunctioniftokentokioccursinthetrainingcorpuswithPOStagposiandNERlabeltypei.Forexample,f2(PER,“David”)=1ifthecurrenttoken“David”hasoccurredwithPOStagNNPandNERlabelPERinthetrainingcorpus.ForcombinationsoftokenswithPOStagsandNERtypesthatdonotoccurinthetrainingcorpus,noactualfeaturefunctionisgeneratedfromthetem-plate(i.e.,thevalueoffunctionwouldbe0).Fortherestofthissection,weassumethatallbinaryfeaturefunctionsaregeneratedfromtheirfeaturetemplatesinananalogousmanner.In-Dictionary.Templatef3(typei,toki)generatesabinaryfeaturefunctionifthecurrenttokentokioc-cursinthename-to-entitydictionaryforsomeentityofNERlabeltypei.Uppercase.Templatef4(typei,toki)generatesabinaryfeaturefunctionifthecurrenttokentokiap-pearsinupper-caseformandadditionallyhastheNERlabeltypeiinthetrainingcorpus.SurroundingPOS.Templatef5(typei,toki)gener-atesabinaryfeaturefunctionifthecurrenttoken
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
222
tokiandthePOSsequenceofitssurroundingtokenssuribothappearinthetrainingcorpus,wheretokialsohastheNERlabeltypei.SurroundingTokens.Templatef6(typei,toki)generatesabinaryfeaturefunctionifthecurrentto-kentokihasNERlabeltypei,giventhattokialsoappearswithsurroundingtokenssuriinthetrain-ingcorpus.Wheninstantiated,thistemplatecouldpossiblyleadtoahugenumberoffeaturefunctions.Fortractability,wethusignoresequencesthatoccuronlyonceinthetrainingcorpus.SurroundingIn-Dictionary.Templatef7(typei,toki)performsdictionarylookupsforsurroundingtokensinsuri.Similartof6,itgen-eratesabinaryfeaturefunctionifthecurrenttokentokiandthedictionarylookupsofitssurroundingtokenssuriappearinthetrainingcorpus,wheretokialsohasNERlabeltypei.Token-EntityPrior.Featuref8(enti,toki)capturesapriorprobabilityoftokihavingNEDlabelenti.Theseprobabilitiesarees-timatedfromco-occurrencefrequenciesofname-to-entitypairsinthebackgroundcor-pus,thusharnessinglink-anchortextsinWikipedia.Forexample,wemayhaveaprioroff8(DavidBeckham,“Beckham”)=0.7,asDavidismorepopular(aujourd'hui)thanhiswifeVictoria.Ontheotherhand,f8(DavidBeckham,“David”)maybelowerthanf8(DavidBowie,“David”),forexample,asthisstillactivepopstarismorefrequentlyandprominentlymentionedthantheretiredfootballplayer.Token-Entityn-GramSimilarity.Featuref9(enti,toki)measurestheJaccardsimilarityofcharacter-leveln-gramsofanameinthedictio-narythatincludestokiandistheprimary(i.e.,fullandmostfrequentlyused)nameofanen-tityentj.Forexample,forn=2thevalueoff9(DavidBeckham,“Becks”)is311.Inourexperiments,wesetn=3.Token-EntityTokenContexts.Featuref10(enti,toki)measurestheweightedoverlapsimilaritybetweenthetokencontexts(tok-cxt)oftokentokiandentityentj.Specifically,weuseaweightedgeneralizationofthestandardoverlapcoefficient,WO,betweentwosetsX,Yofweightedelements,Xk∈XandYk∈Y:WO(X,Oui)=Pkmin(Xk,Yk)min(PkXk,PkYk)Wesettheweightstobetf-idfscores,andhenceweobtain:f10(enti,toki)=WO(cid:16)tok-cxt(enti),tok-cxt(toki)(cid:17)Entity-EntityTokenCoherence.Featuref11(enti,entj)measuresthecoherencebetweenthetokencontextsoftwoentitycandidatesentiandentj:f11(enti,entj)=WO(cid:16)tok-cxt(enti),tok-cxt(entj)(cid:17)f11allowsustoestablishcross-dependenciesamonglabelsinourgraphicalmodel.Forex-ample,thetwoentitiesDavidBeckhamandManchesterUnitedarehighlycoherentastheysharemanytokensintheircontexts,suchas“cham-pions”,“league”,“premier”,“cup”,etc.Thus,theyshouldmappedjointly.4.2DomainFeaturesWeuseWordNetdomains,createdbyMiller(1995),MagniniandCavagli(2000),andBentivoglietal.(2004),toconstructataxonomyof46do-mains,includingPolitics,Économie,Sports,Science,Medicine,Biology,Art,Music,etc.Wecombinethedomainswithsemantictypes(classesofenti-ties)providedbyYAGO2,byassigningthemtotheirrespectivedomains.ThisisbasedonthemanualassignmentofWordNetsynsetstodomains,intro-ducedbyMagniniandCavagli(2000),andBen-tivoglietal.(2004),andextendstoadditionaltypesinYAGO2.Forexample,SingerisassignedtoMu-sic,andFootballPlayertoFootball,asub-domainofSports.ThesetypesincludethestandardNERtypesPerson(PER),Organization(ORG),Location(LOC),andMiscellaneous(MISC)whicharefurtherrefinedbytheYAGO2subclassOfhierarchy.Into-tal,the46domainsareenhancedwithca.350,000typesimportedfromYAGO2.J-NERDclassifiesinputtextsintodomainsbymeansof“easymentions”.Aneasymentionisamatchinthename-to-entitydictionaryforwhichthereexistatmostthreecandidateentities(Nguyenetal.,2014).Althoughthementionboundariesare
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
223
notexplicitlyprovidedasinput,J-NERDstillcanextracttheseeasymentionsfromtheentiretyofallmentioncandidates.Inthefollowing,letC∗bethesetofcandidateentitiesforthe“easy”mentionsintheinputdocu-ment.Foreachdomaind(seeSection3),wecom-putethecoherenceoftheeasymentionsM∗={m1,m2,…}:coh(M∗)=|C∗∩Cd||C∗|whereCdisthesetofallentitiesunderdomaind.Weclassifythedocumentintothedomainwiththehighestcoherencescore.Althoughthementionsandtheirentitiesmaybeinferredincorrectly,thedomainclassificationstilltendstoworkveryreliablyasitaggregatesoverall“easy”mentioncandidates.Thefollowingfeaturetemplatesexploitdomains.Entity-DomainCoherence.Templatef12(enti,toki)generatesabinaryfeaturefunctionthatcapturesthecoherencebetweenanentitycandidateentioftokentokiandthedomaindwhichtheinputtextisclassifiedinto.Thatis,f12(enti,toki)=1ifd∈dom(enti).Otherwise,thefeaturevalueis0.Entity-EntityTypeCoherence.Featuref13(enti,entj)computestherelatednessbe-tweentheWikipediacategoriesoftwocandidateentitiesenti∈Ciandentj∈Cj,whereCi,Cjdenotethetwosetsofcandidateentitiesassociatedwithtoki,tokj,respectivement:f13(enti,entj)=maxcu∈cat(enti)cv∈cat(entj)rel(cu,cv)wherethefunctionrel(cu,cv)computestherecip-rocallengthoftheshortestpathbetweencategoriescu,cvinthedomaintaxonomy(Nguyenetal.,2014).RecallthatourdomaintaxonomycontainsafewhundredthousandsofWikipediacategoriesin-tegratedintheYAGO2typehierarchy.4.3LinguisticFeaturesRecallthatweharvestdependency-parsingpatternsbyusingWikipediaasalargebackgroundcorpus.HereweharnessthatWikipediacontainsmanymen-tionswithexplicitlinkstoentitiesandthattheknowledgebaseprovidesuswiththeNERtypesfortheseentities.Typed-Dependency.Templatef14(typei,toki)generatesabinaryfeaturefunctioniftheback-groundcorpuscontainsthepatterndepi=deptype(arg1,arg2)wherethecurrenttokentokiiseitherarg1orarg2,andtokiislabeledwithNERlabeltypei.Typed-Dependency/POS.Templatef15(typei,toki)captureslinguisticpatternsthatcombineparsingdependencies(likeinf14)andPOStags(likeinf2)learnedfromanannotatedtrainingcorpus.ItgeneratesbinaryfeaturesifthecurrenttokentokiappearsinthedependencypatterndepiwithPOStagposiandthiscombinationalsooccursinthetrainingdataunderNERlabeltypei.Typed-Dependency/In-Dictionary.Templatef16(typei,toki)captureslinguisticpatternsthatcombineparsingdependencies(likeinf14)anddictionarylookups(likeinf3)learnedfromanannotatedtrainingcorpus.Itgeneratesabinaryfeaturefunctionifthecurrenttokentokiappearsinthedependencypatterndepiandhasanentrydiciinthename-to-entitydictionaryforsomeentitywithNERlabeltypei.Token-EntityLinguisticContexts.Featuref17(enti,toki)measurestheweightedoverlapbe-tweenthelinguisticcontexts(ling-cxt)oftokentokiandcandidateentityenti:f17(enti,toki)=WO(cid:16)ling-cxt(enti),ling-cxt(toki)(cid:17)5Experiments5.1DataCollectionsOurevaluationismainlybasedontheCoNLL-YAGO2corpusofnewswirearticles.Additionally,wereportonexperimentswithanextendedversionoftheACE-2005corpusandalargesampleoftheentity-annotatedClueWeb’09-FACC1Webcrawl.CoNLL-YAGO2isderivedfromtheCoNLL-YAGOcorpus(Hoffartetal.,2011)4byremovingtableswherementionsintablecellsdonothavelin-guisticcontext;atypicalexampleissportsresults.Theresultingcorpuscontains1,244documentswith20,924mentionsincluding4,774Out-of-KBen-tities.Ground-truthentitiesinYAGO2areprovidedbyHoffartetal.(2011).Foraconsistentground-4https://www.mpi-inf.mpg.de/yago-naga/yago/
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
224
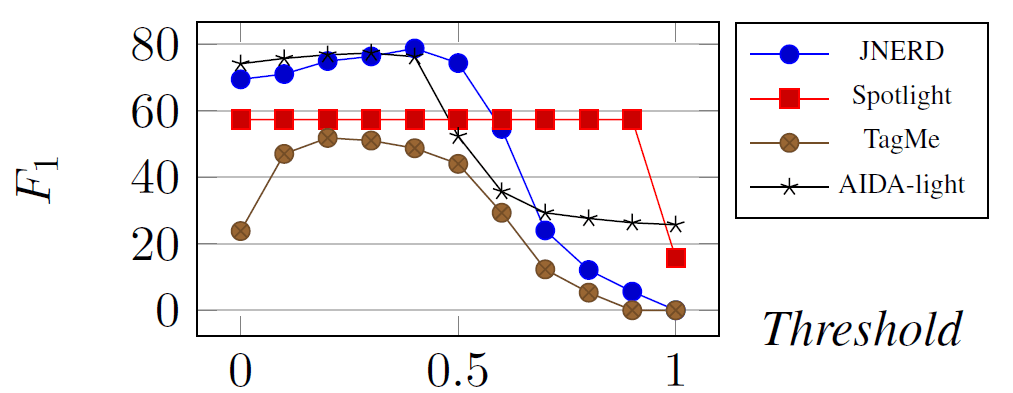
truthset,wederivedtheNERtypesfromtheNEDground-truthentities,fixingsomeerrorsintheorig-inalannotationsrelatedtometonymy(e.g.,label-ingthementionsin“IndiabeatsPakistan2:1”in-correctlyasLOC,whereastheentitiesarethesportsteamsoftypeORG).Thismakesthedatasetnotonlycleanerbutalsomoredemanding,asmetonymousmentionsareamongthemostdifficultcases.Forourevaluation,weusethe“testb”subsetofCoNLL-YAGO,which–aftertheremovaloftables–has231documentswith5,616mentionsincluding1,131Out-of-KBentities.Theother1,045doc-umentswithatotalof17,870mentions(including4,057Out-of-KBmentions)areusedfortraining.ACEisanextendedvariantoftheACE2005cor-pus5,withadditionalNEDlabelsbyBentivoglietal.(2010).Weconsideronlyproperentitiesandexcludementionsofgeneralconceptssuchas“rev-enue”,“worldeconomy”,“financialcrisis”,etc.,astheydonotcorrespondtoindividualentitiesinaknowledgebase.Thisreducesthenumberofmen-tions,butgivesthetaskacrispfocus.Wedisal-lowoverlappingmentionspansandconsideronlymaximum-lengthmentions,followingtherationaleoftheERDChallenge2014.Thetestsetcontains117documentswith2,958mentions.ClueWebcontainstworandomlysampledsubsetsoftheClueWeb’09-FACC16corpuswithFreebaseannotations:•ClueWeb:1,000documents(24,289mentions)eachwithatleast5entities.•ClueWeblong−tail:1,000documents(49,604mentions)eachwithatleast3long-tailentities.Weconsideranentitytobe“long-tail”ifithasatmost10incominglinksintheEnglishWikipedia.NotethattheseWebdocumentsareverydifferentinstylefromthenews-centricarticlesinCoNLLandACE.Alsonotethattheentitymarkupisautomat-icallygenerated,butwithemphasisonhighpreci-sion.Sothedatacapturesonlyasmallsubsetofthepotentialentitymentions,anditmaycontainasmallfractionoffalseentities.Inadditiontotheselargertestcorpora,weranexperimentswithseveralsmallerdatasetsusedinpriorwork:KORE(Hoffartetal.,2012),MSNBC5http://projects.ldc.upenn.edu/ace/6http://lemurproject.org/clueweb09/FACC1/(Cucerzan,2007),andasubsetofAQUAINT(MilneandWitten,2008).Eachofthesehasonlyafewhundredmentions,buttheyexhibitdifferentcharac-teristics.Thefindingsonthesedatasetsarefullyinlinewiththoseofourmainexperiments;hencenoexplicitresultsarepresentedhere.Inallofthesetestdatasets,theground-truthcon-sidersonlyindividualentitiesandexcludesgen-eralconcepts,suchas“climatechange”,“harmony”,“logic”,“algebra”,etc.TheseproperentitiesareidentifiedbytheintersectionofWikipediaarticlesandYAGO2entities.Thisway,wefocusonNERD.Systemsthataredesignedforthebroadertaskof“Wikification”arenotpenalizedbytheir(typicallylower)performanceoninputsotherthanproperen-titymentions.5.2MethodsunderComparisonWecompareJ-NERDinitsfourvariants(linearvs.treeandlocalvs.global)tovariousstate-of-the-artNER/NEDmethods.ForNER(i.e.,mentionboundariesandtypes)weusetherecentversion3.4.1oftheStanfordNERTagger7(Finkeletal.,2005)andtherecentversion2.8.4oftheIllinoisTagger8(RatinovandRoth,2009)asbaselines.ThesesystemshaveNERbench-markresultsonCoNLL’03thatareasgoodastheresultreportedinPassosetal.(2014).Weretrainedthismodelbyusingthesamecorpus-specifictrain-ingdatathatweuseforJ-NERD.ForNED,wecomparedJ-NERDagainstthefol-lowingmethodsforwhichweobtainedopen-sourcesoftwareorcouldcallaWebservice:•Berkeley-entity(DurrettandKlein,2014)usesajointmodelforcoreferenceresolution,NERandNEDwithlinkagetoWikipedia.•AIDA-light(Nguyenetal.,2014)isanopti-mizedvariantoftheAIDAsystem(Hoffartetal.,2011),basedonYAGO2.ItusestheStan-fordtoolforNER.•TagMe(FerraginaandScaiella,2010)isaWik-ifierthatmapsmentionstoentitiesorconceptsinWikipedia.ItusesaWikipedia-deriveddic-tionaryforNER.•Spotlight(Mendesetal.,2011)linksmentions7nlp.stanford.edu/software/CRF-NER.shtml8http://cogcomp.cs.illinois.edu/
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
225
toentitiesinDBpedia.ItusestheLingPipedictionary-basedchunkerforNER.SomesystemsuseconfidencethresholdstodecideonwhentomapamentiontoOut-of-KB.Foreachdataset,weusedwithhelddatatotunethesesystem-specificthresholds.Figure4illustratesthesensitiv-ityofthethresholdsfortheCoNLL-YAGO2dataset.Figure4:F1forvaryingconfidencethresholds.5.3EvaluationMeasuresWeevalutetheoutputqualityattheNERlevelaloneandfortheend-to-endNERDtask.WedonotevaluateNEDalone,asthiswouldrequiregivingaground-truthsetofmentionstothesystemstoruleoutthatNERerrorsaffectNED.MostcompetitorsdonothaveinterfacesforsuchacontrolledNED-onlyevaluation.Eachtestcollectionhasground-truthannotations(G)consistingoftextspansformentions,NERtypesofthementions,andmappingmentionstoentitiesintheKBortoOut-of-KB.RecallthattheOut-of-KBcasecapturesentitiesthatarenotintheKBatall.LetXbetheoutputofsystemX:detectedmentions,NERtypes,NEDmappings.FollowingtheERD2014Challenge(Carmeletal.,2014),wedefineprecisionandrecallofXforend-to-endNERDas:Prec(X)=|XagreeswithG|/|X|Rec(X)=|XagreeswithG|/|G|whereagreementmeansthatXandGoverlapinthetextspans(i.e.,haveatleastonetokenincommon)foramention,havethesameNERtype,andhavethesamemappingtoanentityorOut-of-KB.TheF1scoreofXistheharmonicmeanofprecisionandrecall.Forevaluatingthemention-boundarydetectionalone,weconsideronlytheoverlapoftextspans;forevaluatingNERcompletely,weconsiderbothmen-tionoverlapandagreementbasedontheassignedNERtypes.5.4ResultsforCoNLL-YAGO2OurfirstexperimentonCoNLL-YAGO2iscompar-ingthefourCRFvariantsofJ-NERDforthreetasks:mentionboundarydetection,NERtypingandend-to-endNERD.Then,thebestmodelofJ-NERDiscomparedagainstvariousbaselinesandapipelinedconfigurationofourmethod.Finally,wetestthein-fluenceofdifferentfeaturesgroups.5.4.1ExperimentsonCRFVariantsTable2comparesthedifferentCRFvariants.AllCRFshavethesamefeatures,butdifferintheirfac-tors.Therefore,somefeaturesarenoteffectiveforthelinearmodelandthetreemodel.Forthelin-earCRF,theparsing-basedlinguisticfeaturesandthecross-sentencefeaturesdonotcontribute;forthetreeCRF,thecross-sentencefeaturesarenoteffec-tive.Table2:ExperimentsonCoNLL-YAGO2.PerspectiveVariantsPrecRecF1MentionBoundaryDetectionJ-NERDlinear-local94.289.691.8J-NERDtree-local94.489.491.8J-NERDlinear-global95.190.392.6J-NERDtree-global95.890.693.1NERTypingJ-NERDlinear-local87.883.085.3J-NERDtree-local89.582.285.6J-NERDlinear-global88.683.485.9J-NERDtree-global90.483.886.9End-to-EndNERDJ-NERDlinear-local71.874.973.3J-NERDtree-local75.174.574.7J-NERDlinear-global77.674.876.1J-NERDtree-global81.975.878.7WeseethatallvariantsperformverywellonboundarydetectionandNERtyping,withsmalldifferencesonly.Forend-to-endNERD,cependant,J-NERDtree-globaloutperformsallothervariantsbyalargemargin.ThisresultsinachievingthebestF1scoreof78.7%,whichis2.6%higherthanJ-NERDlinear-global.Weperformedapairedt-testbe-tweenthesetwovariants,andobtainedap-valueof0.01.ThelocalvariantsofJ-NERDlosearound4%ofF1becausetheydonotcapturethecoherenceamongmentionsindifferentsentences.Intherestofourexperiments,wefocusonJ-NERDtree-globalandthetaskofend-to-endNERD.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
226
5.4.2ComparisonofJointvs.PipelinedModelsandBaselinesInthissubsection,wedemonstratethebenefitsofjointmodelsagainstpipelinedmodelsincludingstate-of-the-artbaselines.Inadditiontothecompeti-torsintroducedinSection5.2,weaddapipelinedconfigurationofJ-NERD,coinedP-NERD.Thatis,wefirstrunJ-NERDinNERmode(thusonlycon-sideringNERfeaturesf1..7andf14..16).ThebestsequenceofNERlabelsisthengiventoJ-NERDtoruninNEDmode(onlyconsideringNEDfeaturesf8..13andf17).Table3:Comparisonbetweenjointmodelsandpipelinedmodelsonend-to-endNERD.MethodPrecRecF1P-NERD80.175.177.5J-NERD81.975.878.7AIDA-light78.776.177.3TagMe64.643.251.8SpotLight71.147.957.3TheresultsareshowninTable3.J-NERDachievesthehighestprecisionof81.9%forend-to-endNERD,outperformingallcompetitorsbyasignificantmargin.ThisresultsinachievingthebestF1scoreof78.7%,whichis1.2%higherthanP-NERDand1.4%higherthanAIDA-light.NotethatNguyenetal.(2014)reportedhigherprecisionforAIDA-light,butthatexperimentdidnotconsiderOut-of-KBentitieswhichposeanextradifficultyinoursetting.Also,thetestcorpora–CoNLL-YAGO2vs.CoNLL-YAGO–arenotquitecompa-rable(seeabove).TagMeandSpotlightareclearlyinferioronthisdataset(morethan20%lowerinF1thanJ-NERD).Thesesystemsaremoregearedtowardsefficiencyandcopingwithpopularandthusfrequententities,whereastheCoNLL-YAGO2datasetcontainsverydifficulttestcases.ForthebestF1scoreofJ-NERD,weperformedapairedt-testagainsttheothermeth-ods’F1valuesandobtainedap-valueof0.075.WealsocomparedtheNERperformanceofJ-NERDagainstthestate-of-the-artmethodforNERalone,theStanfordNERTaggerversion3.4.1andtheIllinoisTagger2.8.4(Table4).Formentionboundarydetection,J-NERDachievedanF1scoreof93.1%versus93.4%byStanfordNER,93.3%byTable4:ExperimentsonNERagainststate-of-the-artNERsystems.PerspectiveVariantsPrecRecF1MentionBoundaryDetectionP-NERD95.690.592.9J-NERD95.890.693.1StanfordNER95.691.393.4IllinoisTagger95.591.293.3NERTypingP-NERD89.683.486.3J-NERD90.483.886.9StanfordNER89.384.586.8IllinoisTagger87.583.285.3IllinoisTagger,and92.9%byP-NERD.ForNERtyping,J-NERDachievedanF1scoreof86.9%ver-sus86.8%byStanfordNER,85.3%byIllinoisTag-ger,and86.3%byP-NERD.Sowecouldnotout-performthebestpriormethodforNERalone,butachievedverycompetitiveresults.Here,wedonotreallyleverageanyformofjointinference(combin-ingCRF’sacrosssentencesisusedinStanfordNER,aussi),butharnessrichfeaturesondomains,entitycandidates,andlinguisticdependencies.5.4.3InfluenceofFeaturesToanalyzetheinfluenceofthefeatures,weper-formedanadditionalablationstudyontheglobalJ-NERDtreemodel,whichisthebestvariantofJ-NERD,asfollows:•Standardfeaturesonlyincludefeaturesintro-ducedinSection4.1.•Standardanddomainfeaturesexcludethelin-guisticfeaturesf14,f15,f16,f17.•Standardandlinguisticfeaturesexcludesthedo-mainfeaturesf12andf13.•Allfeaturesisthefull-fledgedJ-NERDtree-globalmodel.Table5:FeatureInfluenceonCoNLL-YAGO2.PerspectiveSettingF1NERTypingStandardfeatures85.1Standardanddomainfeatures85.7Standardandlinguisticfeatures86.4Allfeatures86.9End-to-EndNERDStandardfeatures74.3Standardanddomainfeatures76.4Standardandlinguisticfeatures76.6Allfeatures78.7
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
227
Table5showstheresults,demonstratingthatlinguisticfeaturesarecrucialforbothNERandNERD.Forexample,inthesentence“Woolmerplayed19testsforEngland”,themention“Eng-land”referstoanorganization(theEnglishcricketteam),nottoalocation.Thedependency-typefea-tureprepfor[play,England]isadecisivecuetohandlesuchcasesproperly.DomainfeatureshelpinNEDtoeliminate,forexample,footballteamswhenthedomainiscricket.5.5End-to-EndNERDonACEForcomparisontotherecentlydevelopedBerkeley-entitysystem(DurrettandKlein,2014),theauthorsofthatsystemprovideduswithdetailedresultsfortheentity-annotatedACE’2005corpus,whichal-lowedustodiscountnon-entity(so-called“NOM-type”)mappings(seeSubsection5.1).Allothersys-tems,includingthebestJ-NERDmethod,wererunonthecorpusunderthesameconditions.Table6:NERDresultsonACE.MethodPrecRecF1P-NERD68.260.864.2J-NERD69.162.365.5Berkeley-entity65.661.863.7AIDA-light66.859.362.8TagMe60.643.550.7SpotLight68.729.641.4J-NERDoutperformsP-NERDandBerkeley-entity:F1scoresare1.3%and1.8%better,respec-tively,withat-testp-valueof0.05(Table6).Fol-lowingthesethreebest-performingsystems,AIDA-lightalsoachievesdecentresults.Theothersystemsshowsubstantiallyinferiorperformance.TheperformancegainsthatJ-NERDachievesoverBerkeley-entitycanbeattributedtotwofactors.First,therichlinguisticfeaturesofJ-NERDhelptocorrectlycopewithmoreofthedifficultcases,e.g.,whencommonnounsareactuallynamesofpeople.Second,thecoherencefeaturesofglobalJ-NERDhelptoproperlycoupledecisionsonrelatedentitymentions.5.6End-to-EndNERDonClueWebTheresultsforClueWebareshowninTable7.Again,J-NERDoutperformsallothersystemswithat-testp-valueof0.05.ThedifferencesbetweenJ-NERDandfastNEDsystemssuchasTagMeorSpotLightbecomesmallerasthenumberofprominententities(i.e.,prominentpeople,organiza-tionsandlocations)ishigheronClueWebthanonCoNLL-YAGO2.Table7:NERDresultsonClueWeb.DatasetMethodPrecRecF1ClueWebP-NERD80.967.173.3J-NERD81.567.573.8AIDA-light80.266.472.6TagMe78.460.568.3SpotLight79.757.166.5ClueWeblong−tailP-NERD81.264.471.8J-NERD81.465.172.3AIDA-light81.263.771.3TagMe78.458.366.9SpotLight81.256.366.56ConclusionsWehaveshownthatcouplingthetasksofNERandNEDinajointCRF-likemodelisbeneficial.OurJ-NERDmethodoutperformsstrongbaselinesonavarietyoftestdatasets.ThestrengthofJ-NERDcomesfromthreenovelassets.First,ourtree-shapedmodelscapturethestructureofdependencyparsetrees,andwecouplemultiplesuchtreemodelsacrosssentences.Second,weharnessnon-standardfeaturesaboutdomainsandnovelfeaturesbasedonlinguisticpatternsderivedfromparsing.Third,ourjointinferencemaintainsuncertaincandidatesforbothmentionsandentitiesandmakesdecisionsaslateaspossible.Inourfuturework,weplantoex-ploremoreusecasesforjointNERD,especiallyforcontentanalyticsovernewsstreamsandsocialme-dia.7AcknowledgmentsWewouldliketothankGregDurrettforhelpfuldis-cussionsaboutentitydisambiguationonACE.Wealsothanktheanonymousreviewers,andouractioneditorsLillianLeeandHweeTouNgfortheirverythoughtfulandhelpfulcomments.ReferencesLuisaBentivogli,PamelaForner,BernardoMagnini,andEmanuelePianta.2004.RevisingtheWordnetDo-mainsHierarchy:Semantics,CoverageandBalancing.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
228
InProceedingsoftheWorkshoponMultilingualLin-guisticRessources,MLR’04,pages101–108.ACL.LuisaBentivogli,PamelaForner,ClaudioGiuliano,AlessandroMarchetti,EmanuelePianta,andKaterynaTymoshenko.2010.ExtendingEnglishACE2005CorpusAnnotationwithGround-truthLinkstoWikipedia.InThePeople’sWebMeetsNLP:Collab-orativelyConstructedSemanticResources’10,pages19–27.COLING.RazvanBunescuandMariusPasca.2006.UsingEn-cyclopedicKnowledgeforNamedEntityDisambigua-tion.InEACL’06,pages9–16.ACL.DavidCarmel,Ming-WeiChang,EvgeniyGabrilovich,Bo-JunePaulHsu,andKuansanWang.2014.ERD’14:EntityRecognitionandDisambiguationChallenge.InSIGIR’14,page1292.ACM.MarcoCornolti,PaoloFerragina,andMassimilianoCia-ramita.2013.AFrameworkforBenchmarkingEntity-annotationSystems.InWWW’13,pages249–260.ACM.MarcoCornolti,PaoloFerragina,MassimilianoCia-ramita,HinrichSch¨utze,andStefanR¨ud.2014.TheSMAPHSystemforQueryEntityRecognitionandDisambiguation.InProceedingsoftheFirstInter-nationalWorkshoponEntityRecognitionandDisam-biguation,ERD’14,pages25–30.ACM.SilviuCucerzan.2007.Large-ScaleNamedEntityDis-ambiguationBasedonWikipediaData.InEMNLP-CONLL’07,pages708–716.ACL.SilviuCucerzan.2014.NameEntitiesMadeObvious:TheParticipationintheERD2014Evaluation.InPro-ceedingsoftheFirstInternationalWorkshoponEntityRecognitionandDisambiguation,ERD’14,pages95–100.ACM.HamishCunningham,DianaMaynard,KalinaBontcheva,ValentinTablan,NirajAswani,IanRoberts,GenevieveGorrell,AdamFunk,An-gusRoberts,DanicaDamljanovic,ThomasHeitz,MarkA.Greenwood,HoracioSaggion,JohannPetrak,YaoyongLi,andWimPeters.2011.TextProcessingwithGATE.UniversityofSheffield.JoachimDaiber,MaxJakob,ChrisHokamp,andPabloN.Mendes.2013.ImprovingEfficiencyandAccuracyinMultilingualEntityExtraction.InPro-ceedingsofthe9thInternationalConferenceonSe-manticSystems,I-SEMANTICS’13,pages121–124.ACM.Marie-CatherinedeMarneffe,BillMacCartney,andChristopherD.Manning.2006.Generatingtypedde-pendencyparsesfromphrasestructureparses.InPro-ceedingsoftheInternationalConferenceonLanguageResourcesandEvaluation,LREC’06,pages449–454.ELRA.StephenDill,NadavEiron,DavidGibson,DanielGruhl,R.Guha,AnantJhingran,TapasKanungo,SridharRa-jagopalan,AndrewTomkins,JohnA.Tomlin,andJa-sonY.Zien.2003.SemTagandSeeker:Bootstrap-pingtheSemanticWebviaAutomatedSemanticAn-notation.InWWW’03,pages178–186.ACM.GregDurrettandDanKlein.2014.AJointModelforEntityAnalysis:Coreference,Typing,andLinking.InTACL’14.ACL.PaoloFerraginaandUgoScaiella.2010.TAGME:On-the-flyAnnotationofShortTextFragments(byWikipediaEntities).InCIKM’10,pages1625–1628.ACM.JennyRoseFinkel,TrondGrenager,andChristopherManning.2005.IncorporatingNon-localInformationintoInformationExtractionSystemsbyGibbsSam-pling.InACL’05,pages363–370.ACL.MichaelFleischmanandEduardHovy.2002.FineGrainedClassificationofNamedEntities.InCOLING’02,pages1–7.ACL.JohannesHoffart,MohamedAmirYosef,IlariaBordino,HagenF¨urstenau,ManfredPinkal,MarcSpaniol,BilyanaTaneva,StefanThater,andGerhardWeikum.2011.RobustDisambiguationofNamedEntitiesinText.InEMNLP’11,pages782–792.ACL.JohannesHoffart,StephanSeufert,DatBaNguyen,Mar-tinTheobald,andGerhardWeikum.2012.KORE:KeyphraseOverlapRelatednessforEntityDisam-biguation.InCIKM’12,pages545–554.ACM.JohannesHoffart,FabianM.Suchanek,KlausBerberich,andGerhardWeikum.2013.YAGO2:ASpa-tiallyandTemporallyEnhancedKnowledgeBasefromWikipedia.ArtificialIntelligence,194:28–61.DaphneKoller,NirFriedman,LiseGetoor,andBenjaminTaskar.2007.GraphicalModelsinaNutshell.InAnIntroductiontoStatisticalRelationalLearning.MITPress.SayaliKulkarni,AmitSingh,GaneshRamakrishnan,andSoumenChakrabarti.2009.CollectiveAnnotationofWikipediaEntitiesinWebText.InKDD’09,pages457–466.ACM.XiaoLingandDanielS.Weld.2012.Fine-grainedEn-tityRecognition.InAAAI’12.AAAIPress.DongC.LiuandJorgeNocedal.1989.OntheLimitedMemoryBFGSMethodforLargeScaleOptimization.MathematicalProgramming,45(3):503–528.BernardoMagniniandGabrielaCavagli.2000.Integrat-ingSubjectFieldCodesintoWordnet.InProceed-ingsoftheInternationalConferenceonLanguageRe-sourcesandEvaluation,LREC’00,pages1413–1418.ELRA.AndrewMcCallumandWeiLi.2003.EarlyResultsforNamedEntityRecognitionwithConditionalRandom
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
229
Fields,FeatureInductionandWeb-enhancedLexi-cons.InHLT-NAACL’03,pages188–191.ACL.EdgarMeij,WouterWeerkamp,andMaartendeRijke.2012.AddingSemanticstoMicroblogPosts.InWSDM’12,pages563–572.ACM.PabloN.Mendes,MaxJakob,Andr´esGarc´ıa-Silva,andChristianBizer.2011.DbpediaSpotlight:SheddingLightontheWebofDocuments.InProceedingsofthe7thInternationalConferenceonSemanticSystems,I-SEMANTICS’11,pages1–8.ACM.GeorgeA.Miller.1995.WordNet:ALexicalDatabaseforEnglish.CommunicationsoftheACM,38(11):39–41.DavidMilneandIanH.Witten.2008.LearningtoLinkwithWikipedia.InCIKM’08,pages509–518.ACM.DavidMilneandIanH.Witten.2013.AnOpen-sourceToolkitforMiningWikipedia.ArtificialIntelligence,194:222–239.NdapandulaNakashole,TomaszTylenda,andGerhardWeikum.2013.Fine-grainedSemanticTypingofEmergingEntities.InACL’13,pages1488–1497.ACL.DatBaNguyen,JohannesHoffart,MartinTheobald,andGerhardWeikum.2014.AIDA-light:High-ThroughputNamed-EntityDisambiguation.InPro-ceedingsoftheWorkshoponLinkedDataontheWeb,LDOW’14.CEUR-WS.org.AlexandrePassos,VineetKumar,andAndrewMcCal-lum.2014.LexiconInfusedPhraseEmbeddingsforNamedEntityResolution.InCONLL’14,pages78–86.ACL.AltafRahmanandVincentNg.2010.InducingFine-grainedSemanticClassesviaHierarchicalandCollec-tiveClassification.InCOLING’10,pages931–939.ACL.LevRatinovandDanRoth.2009.DesignChallengesandMisconceptionsinNamedEntityRecognition.InCONLL’09,pages147–155.ACL.LevRatinov,DanRoth,DougDowney,andMikeAn-derson.2011.LocalandGlobalAlgorithmsforDis-ambiguationtoWikipedia.InHLT’11,pages1375–1384.ACL.AvirupSilandAlexanderYates.2013.Re-rankingforJointNamed-EntityRecognitionandLinking.InCIKM’13,pages2369–2374.ACM.ValentinI.SpitkovskyandAngelX.Chang.2012.ACross-LingualDictionaryforEnglishWikipediaCon-cepts.InProceedingsoftheInternationalConferenceonLanguageResourcesandEvaluation,LREC’12.ELRA.CharlesA.SuttonandAndrewMcCallum.2012.AnIntroductiontoConditionalRandomFields.Founda-tionsandTrendsinMachineLearning,4(4):267–373.RicardoUsbeck,MichaelR¨oder,Axel-CyrilleNgongaNgomo,CiroBaron,AndreasBoth,MartinBr¨ummer,DiegoCeccarelli,MarcoCornolti,DidierCherix,BerndEickmann,PaoloFerragina,ChristianeLemke,AndreaMoro,RobertoNavigli,FrancescoPiccinno,GiuseppeRizzo,HaraldSack,Ren´eSpeck,Rapha¨elTroncy,J¨orgWaitelonis,andLarsWesemann.2015.GERBIL–GeneralEntityAnnotationBenchmarkFramework.InWWW’15.ACM.MohamedAmirYosef,SandroBauer,JohannesHoffart,MarcSpaniol,andGerhardWeikum.2012.HYENA:HierarchicalTypeClassificationforEntityNames.InCOLING’12,pages1361–1370.ACL.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
0
9
4
1
5
6
7
3
7
8
/
/
t
je
un
c
_
un
_
0
0
0
9
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
230