Transactions of the Association for Computational Linguistics, vol. 3, pp. 299–313, 2015. Action Editor: Kristina Toutanova.
Submission batch: 1/2015; Revision batch 5/2015; Published 6/2015.
2015 Association for Computational Linguistics. Distributed under a CC-BY-NC-SA 4.0 Licence.
c
(cid:13)
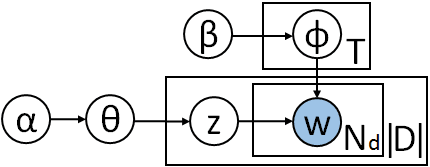
ImprovingTopicModelswithLatentFeatureWordRepresentationsDatQuocNguyen1,RichardBillingsley1,LanDu1andMarkJohnson1,21DepartmentofComputing,MacquarieUniversity,Sydney,Australia2SantaFeInstitute,SantaFe,NewMexico,USAdat.nguyen@students.mq.edu.au,{richard.billingsley,lan.du,mark.johnson}@mq.edu.auAbstractProbabilistictopicmodelsarewidelyusedtodiscoverlatenttopicsindocumentcollec-tions,whilelatentfeaturevectorrepresenta-tionsofwordshavebeenusedtoobtainhighperformanceinmanyNLPtasks.Inthispa-per,weextendtwodifferentDirichletmultino-mialtopicmodelsbyincorporatinglatentfea-turevectorrepresentationsofwordstrainedonverylargecorporatoimprovetheword-topicmappinglearntonasmallercorpus.Exper-imentalresultsshowthatbyusinginforma-tionfromtheexternalcorpora,ournewmod-elsproducesignificantimprovementsontopiccoherence,documentclusteringanddocumentclassificationtasks,especiallyondatasetswithfeworshortdocuments.1IntroductionTopicmodelingalgorithms,suchasLatentDirichletAllocation(Bleietal.,2003)andrelatedmethods(Blei,2012),areoftenusedtolearnasetoflatenttopicsforacorpus,andpredicttheprobabilitiesofeachwordineachdocumentbelongingtoeachtopic(Tehetal.,2006;Newmanetal.,2006;ToutanovaandJohnson,2008;Porteousetal.,2008;Johnson,2010;XieandXing,2013;Hingmireetal.,2013).Conventionaltopicmodelingalgorithmssuchastheseinferdocument-to-topicandtopic-to-worddis-tributionsfromtheco-occurrenceofwordswithindocuments.Butwhenthetrainingcorpusofdocu-mentsissmallorwhenthedocumentsareshort,theresultingdistributionsmightbebasedonlittleevi-dence.SahamiandHeilman(2006)andPhanetal.(2011)showthatithelpstoexploitexternalknowl-edgetoimprovethetopicrepresentations.SahamiandHeilman(2006)employedwebsearchresultstoimprovetheinformationinshorttexts.Phanetal.(2011)assumedthatthesmallcorpusisasampleoftopicsfromalargercorpuslikeWikipedia,andthenusethetopicsdiscoveredinthelargercorpustohelpshapethetopicrepresentationsinthesmallcorpus.However,ifthelargercorpushasmanyirrel-evanttopics,thiswill“useup”thetopicspaceofthemodel.Inaddition,Pettersonetal.(2010)proposedanextensionofLDAthatusesexternalinformationaboutwordsimilarity,suchasthesaurianddictio-naries,tosmooththetopic-to-worddistribution.Topicmodelshavealsobeenconstructedusingla-tentfeatures(SalakhutdinovandHinton,2009;Sri-vastavaetal.,2013;Caoetal.,2015).Latentfea-ture(LF)vectorshavebeenusedforawiderangeofNLPtasks(Glorotetal.,2011;Socheretal.,2013;Penningtonetal.,2014).Thecombinationofval-uespermittedbylatentfeaturesformsahighdimen-sionalspacewhichmakesitiswellsuitedtomodeltopicsofverylargecorpora.Ratherthanrelyingsolelyonamultinomialorla-tentfeaturemodel,asinSalakhutdinovandHinton(2009),Srivastavaetal.(2013)andCaoetal.(2015),weexplorehowtotakeadvantageofbothlatentfea-tureandmultinomialmodelsbyusingalatentfea-turerepresentationtrainedonalargeexternalcorpustosupplementamultinomialtopicmodelestimatedfromasmallercorpus.Ourmaincontributionisthatweproposetwonewlatentfeaturetopicmodelswhichintegratela-tentfeaturewordrepresentationsintotwoDirichlet
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
4
0
1
5
6
6
7
9
0
/
/
t
je
un
c
_
un
_
0
0
1
4
0
p
d
.
F
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
300
multinomialtopicmodels:aLatentDirichletAllo-cation(LDA)model(Bleietal.,2003)andaone-topic-per-documentDirichletMultinomialMixture(DMM)model(Nigametal.,2000).Specifically,wereplacethetopic-to-wordDirichletmultinomialcomponentwhichgeneratesthewordsfromtopicsineachDirichletmultinomialtopicmodelbyatwo-componentmixtureofaDirichletmultinomialcom-ponentandalatentfeaturecomponent.Inadditiontopresentingasamplingprocedureforthenewmodels,wealsocompareusingtwodif-ferentsetsofpre-trainedlatentfeaturewordvec-torswithourmodels.Weachievesignificantim-provementsontopiccoherenceevaluation,docu-mentclusteringanddocumentclassificationtasks,especiallyoncorporaofshortdocumentsandcor-porawithfewdocuments.2Background2.1LDAmodelTheLatentDirichletAllocation(LDA)topicmodel(Bleietal.,2003)representseachdocumentdasaprobabilitydistributionθdovertopics,whereeachtopiczismodeledbyaprobabilitydistributionφzoverwordsinafixedvocabularyW.AspresentedinFigure1,whereαandβarehyper-parametersandTisnumberoftopics,thegenerativeprocessforLDAisdescribedasfollows:θd∼Dir(un)zdi∼Cat(θd)φz∼Dir(β)wdi∼Cat(φzdi)whereDirandCatstandforaDirichletdistributionandacategoricaldistribution,andzdiisthetopicin-dicatorfortheithwordwdiindocumentd.Here,thetopic-to-wordDirichletmultinomialcomponentgeneratesthewordwdibydrawingitfromthecate-goricaldistributionCat(φzdi)fortopiczdi.(LDA)(DMM)Figure1:GraphicalmodelsofLDAandDMMWefollowtheGibbssamplingalgorithmfores-timatingLDAtopicmodelsasdescribedbyGriffithsandSteyvers(2004).Byintegratingoutθandφ,thealgorithmsamplesthetopiczdiforthecurrentithwordwdiindocumentdusingtheconditionaldistri-butionP(zdi|Z¬di),whereZ¬didenotesthetopicassignmentsofalltheotherwordsinthedocumentcollectionD,donc:P.(zdi=t|Z¬di)∝(Ntd¬i+α)Nt,wdi¬di+βNt¬di+Vβ(1)Notation:Nt,wdistherank-3tensorthatcountsthenumberoftimesthatwordwisgeneratedfromtopictindocumentdbytheDirichletmultinomialcomponent,whichinsection2.1belongstotheLDAmodel,whileinsection2.2belongstotheDMMmodel.Whenanindexisomitted,itindicatessum-mationoverthatindex(soNdisthenumberofwordsindocumentd).Wewritethesubscript¬dforthedocumentcol-lectionDwithdocumentdremoved,andthesub-script¬diforDwithjusttheithwordindocumentdremoved,whilethesubscriptd¬irepresentsdocu-mentdwithoutitsithword.Forexample,Nt¬diisthenumberofwordslabelledatopict,ignoringtheithwordofdocumentd.Visthesizeofthevocabulary,V=|W|.2.2DMMmodelforshorttextsApplyingtopicmodelsforshortorfewdocumentsfortextclusteringismorechallengingbecauseofdatasparsityandthelimitedcontextsinsuchtexts.Oneapproachistocombineshorttextsintolongpseudo-documentsbeforetrainingLDA(HongandDavison,2010;Wengetal.,2010;Mehrotraetal.,2013).Anotherapproachistoassumethatthereisonlyonetopicperdocument(Nigametal.,2000;Zhaoetal.,2011;YinandWang,2014).IntheDirichletMultinomialMixture(DMM)model(Nigametal.,2000),eachdocumentisas-sumedtoonlyhaveonetopic.Theprocessofgen-eratingadocumentdinthecollectionD,asshowninFigure1,istofirstselectatopicassignmentforthedocument,andthenthetopic-to-wordDirichletmultinomialcomponentgeneratesallthewordsinthedocumentfromthesameselectedtopic:θ∼Dir(un)zd∼Cat(je)φz∼Dir(β)wdi∼Cat(φzd)YinandWang(2014)introducedacollapsedGibbssamplingalgorithmfortheDMMmodelin
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
4
0
1
5
6
6
7
9
0
/
/
t
je
un
c
_
un
_
0
0
1
4
0
p
d
.
F
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
301
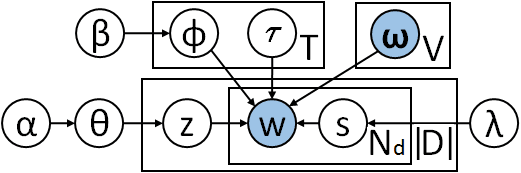
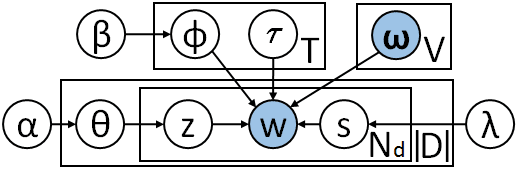
whichatopiczdissampledforthedocumentdus-ingtheconditionalprobabilityP(zd|Z¬d),whereZ¬ddenotesthetopicassignmentsofalltheotherdocuments,donc:P.(zd=t|Z¬d)∝(Mt¬d+α)Γ(Nt¬d+Vβ)Γ(Nt¬d+Nd+Vβ)Yw∈WΓ(Nt,w¬d+Nwd+β)Γ(Nt,w¬d+β)(2)Notation:Mt¬disthenumberofdocumentsas-signedtotopictexcludingthecurrentdocumentd;ΓistheGammafunction.2.3LatentfeaturevectormodelsTraditionalcount-basedmethods(Deerwesteretal.,1990;LundandBurgess,1996;BullinariaandLevy,2007)forlearningreal-valuedlatentfeature(LF)vectorsrelyonco-occurrencecounts.Recentap-proachesbasedondeepneuralnetworkslearnvec-torsbypredictingwordsgiventheirwindow-basedcontext(CollobertandWeston,2008;Mikolovetal.,2013;Penningtonetal.,2014;Liuetal.,2015).Mikolovetal.(2013)’smethodmaximizestheloglikelihoodofeachwordgivenitscontext.Pen-ningtonetal.(2014)usedback-propagationtomin-imizethesquarederrorofapredictionofthelog-frequencyofcontextwordswithinafixedwindowofeachword.Wordvectorscanbetraineddirectlyonanewcorpus.Inournewmodels,cependant,inordertoincorporatetherichinformationfromverylargedatasets,weutilizepre-trainedwordvectorsthatweretrainedonexternalbillion-wordcorpora.3NewlatentfeaturetopicmodelsInthissection,weproposetwonovelprobabilistictopicmodels,whichwecalltheLF-LDAandtheLF-DMM,thatcombinealatentfeaturemodelwithei-theranLDAorDMMmodel.WealsopresentGibbssamplingproceduresforournewmodels.(LF-LDA)(LF-DMM)Figure2:GraphicalmodelsofourcombinedmodelsIngeneral,LF-LDAandLF-DMMareformedbytakingtheoriginalDirichletmultinomialtopicmod-elsLDAandDMM,andreplacingtheirtopic-to-wordDirichletmultinomialcomponentthatgener-ateswordsfromtopicswithatwo-componentmix-tureofatopic-to-wordDirichletmultinomialcom-ponentandalatentfeaturecomponent.Informally,thenewmodelshavethestructureoftheoriginalDirichletmultinomialtopicmodels,asshowninFigure2,withtheadditionoftwomatricesτandωoflatentfeatureweights,whereτtandωwarethelatent-featurevectorsassociatedwithtopictandwordwrespectively.Ourlatentfeaturemodeldefinestheprobabilitythatitgeneratesawordgiventhetopicasthecate-goricaldistributionCatEwith:CatE(w|τtω>)=exp(τt·ωw)Pw0∈Wexp(τt·ωw0)(3)CatEisacategoricaldistributionwithlog-spaceparameters,i.e.CatE(w|u)∝exp(uw).Asτtandωware(row)vectorsoflatentfeatureweights,soτtω>isavectorof“scores”indexedbywords.ωisfixedbecauseweusepre-trainedwordvectors.Inthenexttwosections3.1and3.2,weexplainthegenerativeprocessesofournewmodelsLF-LDAandLF-DMM.WethenpresentourGibbssamplingproceduresforthemodelsLF-LDAandLF-DMMinthesections3.3and3.4,respectively,andexplainhowweestimateτinsection3.5.3.1GenerativeprocessfortheLF-LDAmodelTheLF-LDAmodelgeneratesadocumentasfol-lows:adistributionovertopicsθdisdrawnfordoc-umentd;thenforeachithwordwdi(insequen-tialorderthatwordsappearinthedocument),themodelchoosesatopicindicatorzdi,abinaryindi-catorvariablesdiissampledfromaBernoullidis-tributiontodeterminewhetherthewordwdiistobegeneratedbytheDirichletmultinomialorlatentfea-turecomponent,andfinallythewordisgeneratedfromthechosentopicbythedeterminedtopic-to-wordmodel.Thegenerativeprocessis:θd∼Dir(un)zdi∼Cat(θd)φz∼Dir(β)sdi∼Ber(λ)wdi∼(1−sdi)Cat(φzdi)+sdiCatE(τzdiω>)wherethehyper-parameterλistheprobabilityofawordbeinggeneratedbythelatentfeaturetopic-to-wordmodelandBer(λ)isaBernoullidistributionwithsuccessprobabilityλ.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
4
0
1
5
6
6
7
9
0
/
/
t
je
un
c
_
un
_
0
0
1
4
0
p
d
.
F
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
302
3.2GenerativeprocessfortheLF-DMMmodelOurLF-DMMmodelusestheDMMmodelassump-tionthatallthewordsinadocumentsharethesametopic.Thus,theprocessofgeneratingadocumentinadocumentcollectionwithourLF-DMMisasfol-lows:adistributionovertopicsθisdrawnforthedocumentcollection;thenthemodeldrawsatopicindicatorzdfortheentiredocumentd;foreveryithwordwdiinthedocumentd,abinaryindicatorvari-ablesdiissampledfromaBernoullidistributiontodeterminewhethertheDirichletmultinomialorla-tentfeaturecomponentwillbeusedtogeneratethewordwdi,andfinallythewordisgeneratedfromthesametopiczdbythedeterminedcomponent.Thegenerativeprocessissummarizedas:θ∼Dir(un)zd∼Cat(je)φz∼Dir(β)sdi∼Ber(λ)wdi∼(1−sdi)Cat(φzd)+sdiCatE(τzdω>)3.3InferenceinLF-LDAmodelFromthegenerativemodelofLF-LDAinFigure2,byintegratingoutθandφ,weusetheGibbssam-plingalgorithm(RobertandCasella,2004)toper-forminferencetocalculatetheconditionaltopicas-signmentprobabilitiesforeachword.TheoutlineoftheGibbssamplingalgorithmfortheLF-LDAmodelisdetailedinAlgorithm1.Algorithm1:AnapproximateGibbssamplingalgorithmfortheLF-LDAmodelInitializetheword-topicvariableszdiusingtheLDAsamplingalgorithmforiterationiter=1,2,…dofortopict=1,2,…,Tdoτt=argmaxτtP(τt|Z,S)fordocumentd=1,2,…,|D|doforwordindexi=1,2,…,NddosamplezdiandsdifromP(zdi=t,sdi|Z¬di,S¬di,τ,ω)Ici,Sdenotesthedistributionindicatorvari-ablesforthewholedocumentcollectionD.Insteadofsamplingτtfromtheposterior,weperformMAPestimationasdescribedinthesection3.5.Forsamplingthetopiczdiandthebinaryindicatorvariablesdioftheithwordwdiinthedocumentd,weintegrateoutsdiinordertosamplezdiandthensamplesdigivenzdi.Wesamplethetopiczdiusingtheconditionaldistributionasfollows:P.(zdi=t|Z¬di,τ,ω)∝(Ntd¬i+Ktd¬i+α) (1−λ)Nt,wdi¬di+βNt¬di+Vβ+λCatE(wdi|τtω>)!(4)Thenwesamplesdiconditionalonzdi=twith:P.(sdi=s|zdi=t)∝(1−λ)Nt,wdi¬di+βNt¬di+Vβfors=0λCatE(wdi|τtω>)fors=1(5)Notation:Duetothenewmodels’mixturearchi-tecture,weseparateoutthecountsforeachofthetwocomponentsofeachmodel.Wedefinetherank-3tensorKt,wdasthenumberoftimesawordwindocumentdisgeneratedfromtopictbythelatentfeaturecomponentofthegenerativeLF-LDAorLF-DMMmodel.WealsoextendtheearlierdefinitionofthetensorNt,wdasthenumberoftimesawordwindocumentdisgeneratedfromtopictbytheDirichletmulti-nomialcomponentofourcombinedmodels,whichinsection3.3referstotheLF-LDAmodel,whileinsection3.4referstotheLF-DMMmodel.ForbothtensorsKandN,omittinganindexreferstosum-mationoverthatindexandnegation¬indicatesex-clusionasbefore.SoNwd+Kwdisthetotalnumberoftimesthewordtypewappearsinthedocumentd.3.4InferenceinLF-DMMmodelFortheLF-DMMmodel,weintegrateoutθandφ,andthensamplethetopiczdandthedistributionselectionvariablessdfordocumentdusingGibbssamplingasoutlinedinAlgorithm2.Algorithm2:AnapproximateGibbssamplingalgorithmfortheLF-DMMmodelInitializetheword-topicvariableszdiusingtheDMMsamplingalgorithmforiterationiter=1,2,…dofortopict=1,2,…,Tdoτt=argmaxτtP(τt|Z,S)fordocumentd=1,2,…,|D|dosamplezdandsdfromP(zd=t,sd|Z¬d,S¬d,τ,ω)AsbeforeinAlgorithm1,wealsouseMAPes-timationofτasdetailedinsection3.5ratherthan
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
4
0
1
5
6
6
7
9
0
/
/
t
je
un
c
_
un
_
0
0
1
4
0
p
d
.
F
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
303
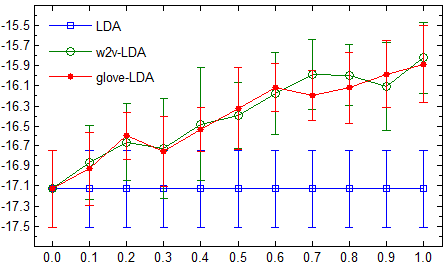
samplingfromtheposterior.Theconditionaldistri-butionoftopicvariableandselectionvariablesfordocumentdis:P.(zd=t,sd|Z¬d,S¬d,τ,ω)∝λKd(1−λ)Nd(Mt¬d+α)Γ(Nt¬d+Vβ)Γ(Nt¬d+Nd+Vβ)Yw∈WΓ(Nt,w¬d+Nwd+β)Γ(Nt,w¬d+β)Yw∈WCatE(w|τtω>)Kwd(6)UnfortunatelytheratiosofGammafunctionsmakesitdifficulttointegrateoutsdinthisdistribu-tionP.Aszdandsdarenotindependent,itiscom-putationallyexpensivetodirectlysamplefromthisdistribution,asthereare2(Nwd+Kwd)differentvaluesofsd.SoweapproximatePwithadistributionQthatfactorizesacrosswordsasfollows:Q(zd=t,sd|Z¬d,S¬d,τ,ω)∝λKd(1−λ)Nd(Mt¬d+α)(7)Yw∈W(cid:18)Nt,w¬d+βNt¬d+Vβ(cid:19)NwdYw∈WCatE(w|τtω>)KwdThissimplerdistributionQcanbeviewedasanapproximationtoPinwhichthetopic-word“counts”are“frozen”withinadocument.Thisap-proximationisreasonablyaccurateforshortdocu-ments.ThisdistributionQsimplifiesthecouplingbetweenzdandsd.ThisenablesustointegrateoutsdinQ.WefirstsamplethedocumenttopiczdfordocumentdusingQ(zd),marginalizingoversd:Q(zd=t|Z¬d,τ,ω)∝(Mt¬d+α)Yw∈W (1−λ)Nt,w¬d+βNt¬d+Vβ+λCatE(w|τtω>)!(Nwd+Kwd)(8)Thenwesamplethebinaryindicatorvariablesdiforeachithwordwdiindocumentdconditionalonzd=tfromthefollowingdistribution:Q(sdi=s|zd=t)∝((1−λ)Nt,wdi¬d+βNt¬d+Vβfors=0λCatE(wdi|τtω>)fors=1(9)3.5LearninglatentfeaturevectorsfortopicsToestimatethetopicvectorsaftereachGibbssam-plingiterationthroughthedata,weapplyregu-larizedmaximumlikelihoodestimation.ApplyingMAPestimationtolearnlog-linearmodelsfortopicmodelsisalsousedinSAGE(Eisensteinetal.,2011)andSPRITE(PaulandDredze,2015).How-ever,unlikeourmodels,thosemodelsdonotusela-tentfeaturewordvectorstocharacterizetopic-worddistributions.Thenegativeloglikelihoodofthecor-pusLunderourmodelfactorizestopic-wiseintofactorsLtforeachtopic.WithL2regularization1fortopict,theseare:Lt=−Xw∈WKt,w(cid:16)τt·ωw−log(cid:0)Xw0∈Wexp(τt·ωw0)(cid:1)(cid:17)+µkτtk22(10)TheMAPestimateoftopicvectorsτtisobtainedbyminimizingtheregularizednegativeloglikeli-hood.Thederivativewithrespecttothejthelementofthevectorfortopictis:∂Lt∂τt,j=−Xw∈WKt,w(cid:16)ωw,j−Xw0∈Wωw0,jCatE(w0|τtω>)(cid:17)+2µτt,j(11)WeusedL-BFGS2(LiuandNocedal,1989)tofindthetopicvectorτtthatminimizesLt.4ExperimentsToinvestigatetheperformanceofournewLF-LDAandLF-DMMmodels,wecomparedtheirperfor-manceagainstbaselineLDAandDMMmodelsontopiccoherence,documentclusteringanddocumentclassificationevaluations.Thetopiccoherenceeval-uationmeasuresthecoherenceoftopic-wordasso-ciations,i.e.itdirectlyevaluateshowcoherenttheassignmentofwordstotopicsis.Thedocumentclusteringanddocumentclassificationtasksevalu-atehowusefulthetopicsassignedtodocumentsareinclusteringandclassificationtasks.Becauseweexpectournewmodelstoperformcomparativelywellinsituationswherethereislit-tledataabouttopic-to-worddistributions,ourex-perimentsfocusoncorporawithfeworshortdoc-uments.Wealsoinvestigatedwhichvaluesofλper-formwell,andcomparedtheperformancewhenus-ingtwodifferentsetsofpre-trainedwordvectorsinthesenewmodels.4.1Experimentalsetup4.1.1DistributedwordrepresentationsWeexperimentedwithtwostate-of-the-artsetsofpre-trainedwordvectorshere.1TheL2regularizerconstantwassettoµ=0.01.2WeusedtheL-BFGSimplementationfromtheMallettoolkit(McCallum,2002).
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
4
0
1
5
6
6
7
9
0
/
/
t
je
un
c
_
un
_
0
0
1
4
0
p
d
.
F
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
304
Googlewordvectors3arepre-trained300-dimensionalvectorsfor3millionwordsandphrases.Thesevectorsweretrainedona100billionwordsubsetoftheGoogleNewscorpusbyusingtheGoogleWord2Vectoolkit(Mikolovetal.,2013).Stanfordvectors4arepre-trained300-dimensionalvectorsfor2millionwords.Thesevectorswerelearnedfrom42-billiontokensofCommonCrawlwebdatausingtheStanfordGloVetoolkit(Penning-tonetal.,2014).WerefertoourLF-LDAandLF-DMMmodelsus-ingGoogleandStanfordwordvectorsasw2v-LDA,glove-LDA,w2v-DMMandglove-DMM.4.1.2ExperimentaldatasetsWeconductedexperimentsonthe20-Newsgroupsdataset,theTagMyNewsnewsdatasetandtheSandersTwittercorpus.The20-Newsgroupsdataset5containsabout19,000newsgroupdocumentsevenlygroupedinto20differentcategories.TheTagMyNewsnewsdataset6(Vitaleetal.,2012)consistsofabout32,600EnglishRSSnewsitemsgroupedinto7categories,whereeachnewsdocumenthasanewstitleandashortdescription.Inourexperiments,wealsousedanewstitledatasetwhichconsistsofjustthenewstitlesfromtheTagMyNewsnewsdataset.Eachdatasetwasdown-cased,andweremovednon-alphabeticcharactersandstop-wordsfoundinthestop-wordlistintheMallettoolkit(McCallum,2002).Wealsoremovedwordsshorterthan3char-actersandwordsappearinglessthan10timesinthe20-Newsgroupscorpus,andunder5timesintheTagMyNewsnewsandnewstitlesdatasets.Inaddi-tion,wordsnotfoundinbothGoogleandStanfordvectorrepresentationswerealsoremoved.7Werefertothecleaned20-Newsgroups,TagMyNewsnews3Downloadat:https://code.google.com/p/word2vec/4Downloadat:http://www-nlp.stanford.edu/projects/glove/5Weusedthe“all-terms”versionofthe20-Newsgroupsdatasetavailableathttp://web.ist.utl.pt/acardoso/datasets/(Cardoso-Cachopo,2007).6TheTagMyNewsnewsdatasetisunbalanced,wherethelargestcategorycontains8,200newsitemswhilethesmall-estcategorycontainsabout1,800items.Downloadat:http://acube.di.unipi.it/tmn-dataset/71366,27and12wordswerecorrespondinglyremovedoutofthe20-Newsgroups,TagMyNewsnewsandnewstitledatasets.andnewstitledatasetsasN20,TMNandTMNti-tle,respectively.WealsoperformedexperimentsontwosubsetsoftheN20dataset.TheN20shortdatasetconsistsofalldocumentsfromtheN20datasetwithlessthan21words.TheN20smalldatasetcontains400doc-umentsconsistingof20randomlyselecteddocu-mentsfromeachgroupoftheN20dataset.Dataset#g#docs#w/dVN202018,820103.319,572N20short201,79413.66,377N20small2040088.08,157TMN732,59718.313,428TMNtitle732,5034.96,347Twitter42,5205.01,390Table1:Detailsofexperimentaldatasets.#g:numberofgroundtruthlabels;#docs:numberofdocuments;#w/d:theaveragenumberofwordsperdocument;V:thenum-berofwordtypesFinally,wealsoexperimentedonthepubliclyavailableSandersTwittercorpus.8Thiscorpuscon-sistsof5,512Tweetsgroupedintofourdifferenttop-ics(Apple,Google,Microsoft,andTwitter).DuetorestrictionsinTwitter’sTermsofService,theactualTweetsneedtobedownloadedusing5,512TweetIDs.Thereare850Tweetsnotavailabletodown-load.Afterremovingthenon-EnglishTweets,3,115Tweetsremain.Inadditiontoconvertingintolower-caseandremovingnon-alphabeticcharacters,wordswerenormalizedbyusingalexicalnormalizationdictionaryformicroblogs(Hanetal.,2012).Wethenremovedstop-words,wordsshorterthan3char-actersorappearinglessthan3timesinthecorpus.Thefourwordsapple,google,microsoftandtwit-terwereremovedasthesefourwordsoccurineveryTweetinthecorrespondingtopic.Moreover,wordsnotfoundinbothGoogleandStanfordvectorlistswerealsoremoved.9Inallourexperiments,afterre-movingwordsfromdocuments,anydocumentwithazerowordcountwasalsoremovedfromthecor-pus.FortheTwittercorpus,thisresultedinjust2,520remainingTweets.4.1.3GeneralsettingsThehyper-parameterβusedinbaselineLDAandDMMmodelswassetto0.01,asthisisacom-monsettingintheliterature(GriffithsandSteyvers,8Downloadat:http://www.sananalytics.com/lab/index.php9Thereare91removedwords.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
4
0
1
5
6
6
7
9
0
/
/
t
je
un
c
_
un
_
0
0
1
4
0
p
d
.
F
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
305
2004).Wesetthehyper-parameterα=0.1,asthiscanimproveperformancerelativetothestan-dardsettingα=50T,asnotedbyLuetal.(2011)andYinandWang(2014).Weraneachbaselinemodelfor2000iterationsandevaluatedthetopicsassignedtowordsinthelastsample.Forourmodels,weranthebaselinemodelsfor1500iterations,thenusedtheoutputsfromthelastsampletoinitializeourmodels,whichweranfor500furtheriterations.Wereportthemeanandstandarddeviationoftheresultsoftenrepetitionsofeachexperiment(sothestandarddeviationisapproximately3standarder-rors,ora99%confidenceinterval).4.2TopiccoherenceevaluationThissectionexaminesthequalityofthetopic-wordmappingsinducedbyourmodels.Inourmodels,topicsaredistributionsoverwords.Thetopiccoher-enceevaluationmeasurestowhatextentthehigh-probabilitywordsineachtopicaresemanticallyco-herent(Changetal.,2009;Stevensetal.,2012).4.2.1QuantitativeanalysisNewmanetal.(2010),Mimnoetal.(2011)andLauetal.(2014)describemethodsforautomaticallyevaluatingthesemanticcoherenceofsetsofwords.ThemethodpresentedinLauetal.(2014)usesthenormalizedpointwisemutualinformation(NPMI)scoreandhasastrongcorrelationwithhuman-judgedcoherence.AhigherNPMIscoreindicatesthatthetopicdistributionsaresemanticallymoreco-herent.Givenatopictrepresentedbyitstop-Ntopicwordsw1,w2,…,wN,theNPMIscorefortis:NPMI-Score(t)=X16i