Transactions of the Association for Computational Linguistics, vol. 3, pp. 197–210, 2015. Action Editor: Sharon Goldwater.
Submission batch: 12/2014; Revision batch 3/2015; Published 4/2015.
2015 Association for Computational Linguistics. Distributed under a CC-BY-NC-SA 4.0 Licence.
c
(cid:13)
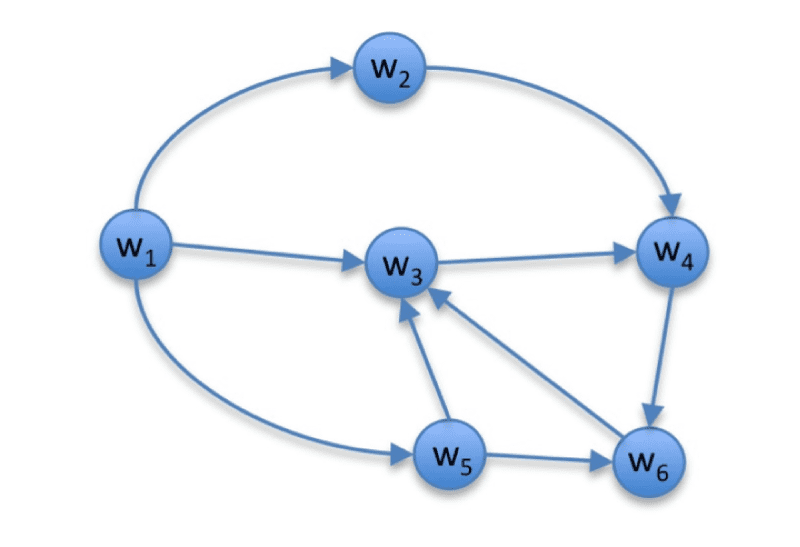
Higher-orderLexicalSemanticModelsforNon-factoidAnswerRerankingDanielFried1,PeterJansen1,GustaveHahn-Powell1,MihaiSurdeanu1,andPeterClark21UniversityofArizona,Tucson,AZ,USA2AllenInstituteforArtificialIntelligence,Seattle,WA,Etats-Unis{dfried,pajansen,hahnpowell,msurdeanu}@email.arizona.edupeterc@allenai.orgAbstractLexicalsemanticmodelsproviderobustperformanceforquestionanswering,mais,ingeneral,canonlycapitalizeondirectev-idenceseenduringtraining.Forexample,monolingualalignmentmodelsacquiretermalignmentprobabilitiesfromsemi-structureddatasuchasquestion-answerpairs;neuralnetworklanguagemodelslearntermembeddingsfromunstructuredtext.Allthisknowledgeisthenusedtoestimatethesemanticsimilaritybetweenquestionandanswercandidates.Wein-troduceahigher-orderformalismthatal-lowsalltheselexicalsemanticmodelstochaindirectevidencetoconstructindirectassociationsbetweenquestionandanswertexts,bycastingthetaskasthetraversalofgraphsthatencodedirecttermassocia-tions.Usingacorpusof10,000questionsfromYahoo!Answers,weexperimentallydemonstratethathigher-ordermethodsarebroadlyapplicabletoalignmentandlan-guagemodels,acrossbothwordandsyn-tacticrepresentations.Weshowthatanimportantcriterionforsuccessiscontrol-lingforthesemanticdriftthataccumu-latesduringgraphtraversal.Allinall,theproposedhigher-orderapproachimprovesfiveoutofthesixlexicalsemanticmod-elsinvestigated,withrelativegainsofupto+13%overtheirfirst-ordervariants.1IntroductionOpen-domainquestionanswering(QA),whichfindsshorttextualanswerstonaturallanguagequestions,isoftenviewedasthesuccessortokey-wordsearch(Etzioni,2011)andoneofthemostdifficultandwidelyapplicableend-userapplica-tionsofnaturallanguageprocessing(NLP).Fromsyntacticparsing,discourseprocessing,andlex-icalsemantics,QAnecessitatesaleveloffunc-tionalityacrossavarietyoftopicsthatmakeitanatural,yetchallenging,provinggroundformanyaspectsofNLP.Here,weaddressapartic-ularlychallengingQAsubtask:open-domainnon-factoidQA,wherequeriestaketheformofcom-plexquestions(e.g.,mannerorHowquestions),andanswersrangefromsinglesentencestoen-tireparagraphs.Becausethistaskissocomplexandlargeinscope,currentstate-of-the-artopen-domainsystemsperformatonlyabout30%P@1,oransweringroughlyoneoutofthreequestionscorrectly(Jansenetal.,2014).Inthispaperwefocusonanswerranking(AR),akeycomponentofnon-factoidQAthatfocusesonorderingcandidateanswersbasedonthelike-lihoodthattheycapturetheinformationneededtoansweraquestion.Unlikekeywordsearch,Berger(2000)observedthatlexicalmatchingmethodsaregenerallyinsufficientforQA,wherequestionsandanswersoftenhavelittletonolexicaloverlap(asinthecaseofWhereshouldwegoforbreakfast?andZoe’sDinerhasgreatpancakes).Previousworkhasshownthatlexicalsemantics(LS)mod-elsarewellsuitedtobridgingthis“lexicalchasm”,andatleasttwoflavorsoflexicalsemanticshavebeensuccessfullyappliedtoQA.ThefirsttreatsQAasamonolingualalignmentproblem,learningassociationsbetweenwords(orotherstructures)thatappearinquestion-answerpairs(Surdeanuetal.,2011;Yaoetal.,2013).Thesecondcomputesthesemanticsimilaritybetweenquestionandan-swerusinglanguagemodelsacquiredfromrele-vanttexts(Yihetal.,2013;Jansenetal.,2014).Herewearguethatwhilethesemodelsbegintobridgethe“lexicalchasm”,manystillsufferfromsparsityandonlycapitalizeondirectevi-dence.Returningtoourexamplequestion,ifwealsotrainontheQApairWhatgoeswellwithpan-cakes?andhashbrownsandtoast,wecanusethe
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
je
un
c
_
un
_
0
0
1
3
3
p
d
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
198
Figure1:Ahypotheticalgraphderivedfromalexicalse-manticalignmentmodel.indirectassociationbetweenbreakfast–pancakesandpancakes–hashbrownstolocateadditionalanswersforwheretovisitforbreakfast,includingRegee’shasthebesthashbrownsintown.WecanrepresentLSmodelsasagraph,asinFigure1.Foraword-basedalignmentmodel,thegraphnodesrepresentindividualwords,andthe(directed)edgescapturethelikelihoodofawordwaappearinginagoldanswergivenwordwqinthequestion.Groundingthisinourexample,w1mayrepresentbreakfast,w2pancakes,andw4hashbrowns.Foralanguagemodel,theedgescap-turethesimilarityofcontextsbetweenthewordsinthenodes.Forbothalignmentandlanguagemodelgraphs,weobservethatsemanticassocia-tionbetweentwowords(orstructures)storedinthenodescanbedeterminedbyinvestigatingthedifferentpathsthatconnectthesetwonodes,evenwhentheyarenotdirectlyconnected.Wecallthisclassofmodelshigher-orderlexicalmodels,incontrasttothefirst-orderlexicalmod-elsintroducedinpreviouswork,whichrelyonlyondirectevidencetoestimateassociationstrength.Forexample,allalignmentmodelsinpreviousworkcanestimateP(wq|wa),i.e.,theprobabil-ityofgeneratingthequestionwordwqifthean-swercontainsthewordwa,onlyifthispairhasbeenseenatleastonceintraining.Ontheotherhand,ourapproachcanestimateP(wq|wa)fromindirectevidence,e.g.,fromchainingtwodistinctquestion/answerpairsthatcontainthewords(wq,wi)et(wi,wa),respectively.Thecontributionsofthisworkare:1.Thisisthefirstworktoourknowledgethatproposeshigher-orderLSmodelsforQA.Weshowthatanimportantcriterionforsuccessiscontrollingforthesemanticdriftthatac-cumulatesinthegraphtraversalpaths,whichplaguestraditionalrandomwalkalgorithms.Forexample,weempiricallydemonstratethatpathsuptoalengthofthreearegener-allybeneficial,butlongerpathshurtordonotimproveperformance.2.WeshowthatavarietyofLSmodelsandrepresentations,includingalignmentandlan-guagemodels,overbothwordsandsyntac-ticstructures,canbeadaptedtotheproposedhigher-orderformalism.Inthislatterrespectweintroduceanovelsyntax-basedvariantoftheneuralnetworklanguagemodel(NNLM)ofMikolovetal.(2013)thatmodelssyntac-ticdependenciesratherthanwords,whichal-lowsittocaptureknowledgethatiscomple-mentarytothatofword-basedNNLMs.3.ThetrainingprocessforalignmentmodelsrequiresalargecorpusofQApairs.Duetotheseresourcerequirements,weevaluateourhigher-orderLSmodelsonacommu-nityquestionanswering(CQA)task(Wangetal.,2009;Jansenetal.,2014)acrossthousandsofhowquestions,andshowthatmosthigher-ordermodelsperformsignifi-cantlybetterthantheirfirst-ordervariants.4.Wedemonstratethatlanguagemodelsandalignmentmodelscapturecomplementaryin-formation,andcanbecombinedtoimprovetheperformanceoftheCQAsystemforman-nerquestions.2RelatedWorkWefocusonstatisticalLSmethodsforopen-domainQA,inparticularCQAtasks,suchastheonesdrivenbyYahoo!Answersdatasets(Wangetal.,2009;Jansenetal.,2014).Bergeretal.(2000)werethefirsttoproposeastatisticalLSmodelto“bridgethelexicalchasm”betweenquestionsandanswersforaQAtask.Buildingoffthiswork,anumberofLSmodelsus-ingeitherwordsorothersyntacticandsemanticstructureshavebeenproposedforQA(EchihabiandMarcu,2003;SoricutandBrill,2006;Rie-zleretal.,2007;Surdeanuetal.,2011;Yaoetal.,2013;Jansenetal.,2014),orrelatedtasks,suchassemantictextualsimilarity(Sultanetal.,2014).Cependant,allofthesemodelsfallintotheclassoffirst-ordermodels.Toourknowledge,thisworkisthefirsttoinvestigatehigher-orderLSmodelsforQA,whichcantakeadvantageofindirectev-idence,i.e.,the“neighborsofneighbors”intheassociationgraph.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
je
un
c
_
un
_
0
0
1
3
3
p
d
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
199
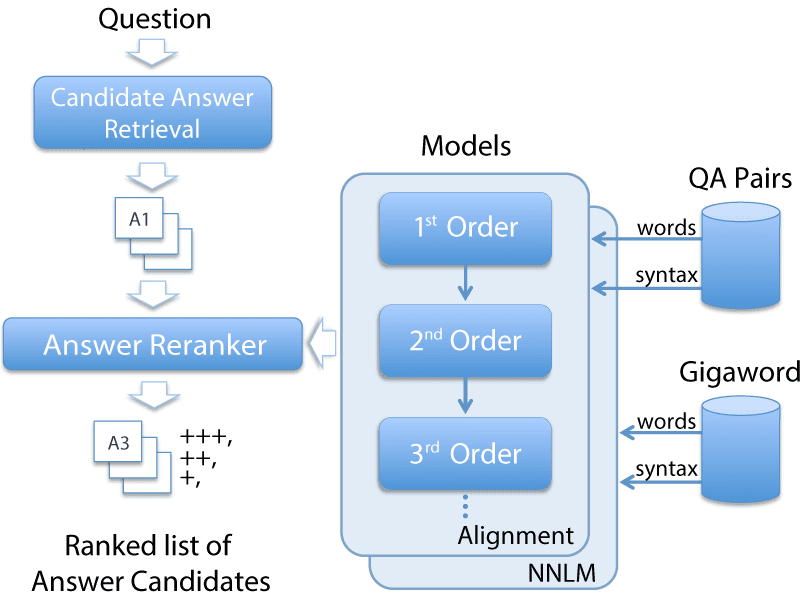
Second-orderlexicalmodelshaverecentlybeenbroughttobearonavarietyofotherNLPtasks.Zapirainetal.(2013)useasecond-ordermodelbasedondistributionalsimilarity(Lin,1998)toimproveaselectionalpreferencemodel,andLeeetal.(2012)useasimilarapproachforcoreferenceresolution.Ourworkexpandsontheseideaswithmodelsofarbitraryorder,anapproachtocontrolsemanticdrift,andanapplicationtoQA.Thisworkfallsunderthelargerumbrellaofalgorithmsforgraph-basedinference,whichhavebeensuccessfullyappliedtootherNLPandinformationretrievalproblems,suchasrela-tionextraction(ChakrabartiandAgarwal,2006;Chakrabarti,2007;LaoandCohen,2010),in-ferenceoverknowledgebases(Laoetal.,2011),namedisambiguation(Minkovetal.,2006),andsearch(Bhalotiaetal.,2002;Tongetal.,2006).Whilemanyoftheseapproachesuserandomwalkalgorithms,inpilotexperimentsweobservedthatrandomwalks,suchasPageRank(PR)(Pageetal.,1999),tendtoaccumulatesemanticdriftfromtheoriginatingnodebecausetheyconsiderallpossi-blepathsinthegraph.Thissemanticdriftreducesthequalityofthehigher-orderassociations,whichimpactsQAperformance.Hereweimplementaconservativegraphtraversalalgorithm,similarinspirittothe“cautiousbootstrapping”algorithmofYarowsky(WhitneyandSarkar,2012;Yarowsky,1995).Byconstrainingthetraversalpaths,oural-gorithmrunstwoordersofmagnitudefasterthanPR,whilecontrollingforsemanticdrift.3ApproachThearchitectureofourproposedQAframeworkisillustratedinFigure2.Hereweevaluatebothfirst-orderandhigher-orderLSmodelsinthecontextofcommunityquestionanswering(CQA),usingalargedatasetofQApairsfromYahoo!Answers1.WeuseastandardCQAevaluationtask(Jansenetal.,2014),whereonemustrankasetofuser-generatedanswerstoagivenquestion,suchthatthecommunity-selectedbestanswerappearsinthetopposition.Morespecifically,foragivenquestion,thecandidateretrieval(CR)componentfetchesallitscommunity-generatedanswersfromtheanswercollection,andgiveseachanswercan-didateaninitialrankingusingshallowinforma-1http://answers.yahoo.comFigure2:ArchitectureofthererankingframeworkforQA,showingarerankingcomponentthatincorporatestwoclassesoflexicalsemanticmodels(alignmentandneuralnetworklanguagemodels),implementedovertworepresentationsofcontent(wordsandsyntax).tionretrievalscoring.2Theseanswercandidatesarethenpassedontotheanswerrerankingcom-ponent,thefocusofthiswork.Theanswerreranking(AR)componentana-lyzestheanswercandidatesusingmoreexpensivetechniquestoextractfirst-orderandhigher-orderLSfeatures,andthesefeaturesarethenusedinconcertwithalearningframeworktorerankthecandidatesandelevatecorrectanswerstohigherpositions.Forthelearningframework,weuseSVMrank,avariantofSupportVectorMachinesforstructuredoutputadaptedtorankingprob-lems.3Inadditiontothesefeatures,eachrerankeralsoincludesasinglefeaturecontainingthescoreofeachcandidate,ascomputedbytheabovecan-didateretrievalcomponent.44First-OrderLexicalModelsWenextintroduceaseriesoffirst-orderLSmod-els,whichserveasthefoundationforthehigher-ordermodelsdiscussedinthenextsection.4.1NeuralNetworkLanguageModelsInspiredbypreviouswork(Yihetal.,2013;Jansenetal.,2014),weadapttheword2vecNNLMof2WeusedthesamescoringasJansenetal.(2014):co-sinesimilaritybetweenthequestionandcandidateanswer’slemmavectorrepresentations,withlemmasweightedusingtf.idf(Ch.6,(Manningetal.,2008)).3http://www.cs.cornell.edu/people/tj/svm_light/svm_rank.html4Includingthesescoresasfeaturesinthererankermodelisacommonstrategythatensuresthatthererankertakesad-vantageoftheanalysisalreadyperformedbytheCRmodel.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
je
un
c
_
un
_
0
0
1
3
3
p
d
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
200
Mikolovetal.(2013)tothisQAtask.Inparticu-lar,weusetheirskip-grammodelwithhierarchi-calsampling.Thismodelpredictsthecontextofawordgiventheworditself,andthroughthispro-cessembedswordsintoalatentconceptualspacewithafixednumberofdimensions.Consequently,relatedwordstendtohavevectorrepresentationsthatareclosetoeachotherinthisspace.Thistypeofpredictivealgorithmhasbeenfoundtoperformconsiderablybetterthancount-basedapproachestodistributionalsimilarityonavarietyofseman-tictasks(Baronietal.,2014).WederivefourLSmeasuresfromthesevec-tors,whicharethenareincludedasfeaturesinthereranker.Thefirstisameasureoftheover-allsimilarityofthequestionandanswercandi-date,whichiscomputedasthecosinesimilaritybetweentwocompositevectors.Thesecompositevectorsareassembledbysummingthevectorsforindividualquestion(oranswercandidate)mots,andre-normalizingthiscompositevectortounitlength.5Inadditiontothisoverallsimilarityscore,wecomputethepairwisesimilaritiesbetweeneachwordinthequestionandanswercandidates,andincludeasfeaturestheaverage,minimum,andmaximumpairwisesimilarities.4.2AlignmentModelsBergeretal.(2000)showedthatlearningquestion-to-answertransformationsusingastatisticalma-chinetranslation(SMT)modelbeginsto“bridgethelexicalchasm”betweenquestionsandan-swers.Webuilduponthisobservation,usingtheIBMModel1(Brownetal.,1993)variantofSur-deanuetal.(2011)todeterminetheprobabilitythataquestionQisatranslationofananswerA,P.(Q|UN):P.(Q|UN)=Yq∈QP(q|UN)(1)P.(q|UN)=(1−λ)Pml(q|UN)+λPml(q|C)(2)Pml(q|UN)=Xa∈A(T(q|un)Pml(un|UN))(3)wheretheprobabilitythatthequestiontermqisgeneratedfromanswerA,P.(q|UN),issmoothedusingthepriorprobabilitythatthetermqisgen-eratedfromtheentirecollectionofanswersC,Pml(q|C).Pml(q|UN)iscomputedasthesumof5Wealsotriedthemultiplicativestrategyforword-vectorcombinationofLevyandGoldberg(2014b),butitdidnotimproveourresults.theprobabilitiesthatthequestiontermqisatrans-lationofanyanswerterma,T(q|un),weightedbytheprobabilitythataisgeneratedfromA.ThetranslationtableforT(q|un)iscomputedus-ingGIZA++(OchandNey,2003).SimilartoSurdeanuetal.(2011)nous:(un)setPml(q|C)toasmallvalueforout-of-vocabularywords;(b)modifytheT(.|.)distributionstoguar-anteethattheprobabilityoftranslatingawordtoitself,i.e.,T(w|w),ishighest(MurdockandCroft,2005);et(c)tunethesmoothingparameterλonadevelopmentcorpus.QAsystemsgenerallyusetheabovemodeltodeterminetheglobalalignmentprobabilitybe-tweenagivenquestionandanswercandidate,P.(Q|UN).Anovelcontributionofourworkisthatwealsousethealignmentmodel’sproba-bilitydistributions(fromasourcewordtodes-tinationwords)asdistributedrepresentationsforsourcewords,basedontheobservationthatwordswithsimilaralignmentdistributionsarelikelytohaveasimilarmeaning.Formally,wedenotethealignmentvectorrepresentationfortheithwordinthevocabularyasw(je),anddefinethejthen-tryinthevectorasw(je)j=T(wordj|wordi),whereT(.|.)isthetranslationprobabilitydistri-butionfromEq.3.Thatis,thejthentryofthevectorforwordiistheconditionalprobabilityofseeingwordjinaquestion,giventhatwordiwasseeninacorrespondinganswer.Thevectorforeachwordthenrepresentsadiscrete(conditional)probabilitydistribution.Tocomparetwowords,weusethesquarerootoftheJensen-Shannondi-vergence(JSD)betweentheirconditionaldistri-butions.6Letm(je,j)betheelement-wiseaver-ageofthevectorsw(je)andw(j),thatis(w(je)+w(j))/2,andletK(w,v)betheKullback-Leiblerdivergencebetweendistributions(representedasvectors)wandv:K(w,v)=|V|Xi=0wilnwivi(4)où|V|isthevocabularysize(andthedimen-sionalityofw).ThenthedistancebetweenwordsiandjisJ(w(je),w(j))=rK(w(je),m(je,j))+K(w(j),m(je,j))2(5)6WeusethesquarerootoftheJensen-Shannondiver-gence,derivedfromKullback-Leiblerdivergence,sinceitisadistancemetric(inparticularitisfiniteandsymmetric).
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
je
un
c
_
un
_
0
0
1
3
3
p
d
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
201
WederivefouradditionalLSfeaturesfromthesealignmentvectorrepresentations,whichpar-allelthefeaturesderivedfromtheNNLMvec-torrepresentations(§4.1).ThefirstistheJSDbetweenthecompositealignmentvectorsforthequestionandtheanswercandidate,wherethecompositeisconstructedbysummingthevec-torsforindividualquestion(oranswercandidate)mots,anddividingbythenumberofvectorssummed.Wealsogeneratefeaturesfromtheav-erage,minimum,andmaximumpairwiseJSDbetweenwordsinthequestionandwordsintheanswercandidate.Inpractice,wehavefoundthattheadditionofthesefourfeaturesconsiderablyimprovestheperformanceofallalignmentmod-elsinvestigatedfortheQAtask.4.3ModelingSyntacticStructuresSurdeanuetal.(2011)demonstratedthatalign-mentmodelscanreadilycapitalizeonrepresen-tationsotherthanwords,includingrepresenta-tionsofsyntax.Hereweexpandontheirworkandexplorethreesyntacticvariationsofthealign-mentandNNLMmodels.ForthesemodelswemakeuseofcollapsedsyntacticdependencieswithprocessedCCcomplements(deMarneffeetal.,2006),extractedfromtheAnnotatedEnglishGi-gaword(Napolesetal.,2012).Thefirstmodelisastraightforwardadaptationofthealignmentmodelin§4.2,wheretherepre-sentationsofquestionsandanswersarechangedfrombagsofwordsto“bagsofsyntacticdepen-dencies”(Surdeanuetal.,2011).Thatis,thetermstobealigned(qandainEq.1to3)becomehhead,label,dependentidependencies,suchasheat,dobj,pancakesi,ratherthanwords.Themotivationbehindthischangeisthatitallowsthemodeltoalignsimplepropositionsratherthanwords,whichareamoreaccuraterepresentationoftheinformationencodedinthequestion.Whiletuningonthedevelopmentsetofquestionswefoundthatunlabeleddependencies,whichignorethemiddletermintheabovetuples,performedbetterthanlabeleddependencies,possiblyduetothesparsityofthelabeleddependencies.Assuch,allourdependencyalignmentmodelsuseunla-beleddependencies.Thesecondmodeladaptstheideaofworkingwithbagsofsyntacticdependencies,insteadofbagsofwords,toNNLMs,andbuildsanLMoverdependenciesratherthanwords.However,be-causetheNNLMembeddingsaregeneratedfromcontext,wemustfindaconsistentorderingofde-pendenciesthatmaintainscontextualinformation.Hereweorderdependenciesusingadepth-first,left-to-righttraversalofthedependencygraphoriginatingatthepredicateorrootnode.7Fig-ure3showsanexampleofsuchatraversal,whichresultsinthefollowingordering(usingunlabeleddependencies):(6)betimetimethetimesamebecountrycountrynobeshouldbebusinessbusinessthebusinessconcealingconcealinghistoryhistoryitsFigure3:DFSL→Rorderingofwordpairsstartingfromthesententialroot.ThesentenceistakenfromLTWENG20081201.0002oftheEnglishGigaword.Themodelusesthedefaultword2vecimple-mentationtocomputethetermembeddings.Toourknowledge,thissyntax-drivenextensionofNNLMsisnovel.DuringtuningwecomparedthelabeledandunlabeleddependencyrepresentationsagainstanNNLMmodelusingtraditionalbigrams(wherewordsarepairedbasedontheirlinearorder,i.e.,withoutanysyntacticmotivation).Encore,wefoundthatunlabeleddependenciesoutperformedsurfacebigramsandlabeleddependencies.Lastly,wealsoevaluatetherecentNNLMmodelproposedbyLevyandGoldberg(2014un),whomodifiedtheword2vecembeddingproce-duretoincludecontextderivedfromdependen-cies,arguingthatthisembeddingmodelencodesfunctionalsimilaritybetterthanMikolovetal.’sunigramsurfacestructuremodel.ItisimportanttonotethatwhileinoursyntacticNNLMmodeltheLMtermsare(lexicalizedunlabeled)syntacticdependencytuples,inLevyandGoldberg’smodeltheLMtermsarestillwords,butthecontextisdrivenbysyntaxinsteadofsurfacestructure.5Higher-orderlexicalmodelsThefirst-ordermodelswehavejustdescribedmakeuseofthedirectevidenceseenintrainingdatatocreateassociationsbetweenwords(orde-pendencies).Unfortunatelythistrainingdataisoftenquitesparse,andwhileitmaybepossi-bletoexhaustivelycreatetrainingdatawithbroad7Otherorderingschemesweretestedduringdevelopment,butDFSprovedtobethemoststableacrosssentences.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
je
un
c
_
un
_
0
0
1
3
3
p
d
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
202
coverageforartificiallynarrowdomainssuchasthingstoeatforbreakfast,thisquicklybecomesintractableforlargerdomains.Tomitigatethissparsity,hereweproposeamethodthatidentifiesassociationsthatwerenotexplicitlyseenduringtraining.Returningtoourexamplein§1,hadanalignmentmodellearnedtheassociationsbreak-fast–pancakesandpancakes–hashbrowns,themodelshouldbeabletomakeuseoftheindi-rectassociationbetweenbreakfast–hashbrownstofurther“bridgethelexicalchasm”,andiden-tifyanswercandidatescontainingthewordhash-brownstothequestionWhereisagoodplacetoeatbreakfast?Atfirstglance,algorithmssuchasPageR-ank(Pageetal.,1999)appeartoofferanattractiveandintuitivemethodtodeterminetheassociationbetweenarbitrarynodesinaweightedgraphbymodelingarandomwalktoconvergence(fromanygivenstartingnode).AsweshowinSection6,wehavefoundthatthesemethodsquicklyaccumulatesemanticdrift(McIntosh,2010),because:(un)theyruntoconvergence,i.e.,theytraversepathsofar-bitrarylength,et(b)theyexploretheentireasso-ciationspaceencodedintheneighborhoodgraph,bothofwhichintroduceconsiderablenoise.Forexample,bychainingevensmallnumbersofdi-rectassociations,suchasbreakfast–pancakes,pancakes–hashbrowns,hashbrowns–potato,andpotato–field,amodelthatdoesnotcontrolforse-manticdriftmaybetemptedtoanswerquestionsaboutbreakfastvenueswithanswersthatdiscusswheatfieldsorsoccerfields.Thus,keepingtheseindirectassociationsshortandon-contextiscriti-calforQA.Basedontheaboveobservations,hereweout-lineageneralmethodforcreatinghigher-orderlexicalsemanticmodelsthatincorporatesimplemeasurestocontrolforsemanticdrift,anddemon-stratehowtoapplyittobothalignmentgraphrep-resentationsandthedistributedvectorspacerepre-sentationsofaNNLM.Ourmethodreliesontwogeneralpropertiesofthefirst-orderLSmodels:(un)allmodelsincludeadistributedrepresentationforeachterm8thatisencodedasavector(e.g.,forNNLMsthisisaterm’sembeddinginvectorspace,andforalignmentmodelsthisisavectorofalignmentprobabilitiesfromagivenanswertermtoallpossiblequestionterms),et(b)modelsde-8Henceforthweuse“term”toindicateeitherawordoradependencyinalexicalsemanticsmodel.fineapairwisefunctionthatassignsalexicalsim-ilarityscorebetweenpairsofdirectlyconnectedterms(e.g.,forNNLMsthisisthecosinesimilar-ityofthecorrespondingtermembeddings,andforalignmentmodelsthisisgivendirectlybyT(q|un),fromEquation3).Intuitively,weincorporateindirectevidenceinourmodelsbyaveragingthedistributedrepresen-tationofatermtwiththedistributedrepresenta-tionsofitsneighbors,i.e.,thosetermswithhigh-estlexicalsimilaritytot.Tocontrolforseman-ticdriftweconsider:(un)onlythekmostsimilarneighborstothecurrentterm,et(b)shortpathsintheassociationgraph,e.g.,neighborsofneigh-borsbutnofurther.Forexample,forasecond-ordermodel,weconstructthisnewvectorrepre-sentationforeachnodeinthegraphbyaveragingthevectorofthenodeitselfandthevectorsofitskclosestneighbors(weightedbyeachpair’ssimilar-ity),sothatthevectorrepresentationofbreakfastbecomesaweightedsumofbreakfast,morning,nourriture,cereal,andsoforth.Byusingonlytheclos-estneighbors,weexcludelowassociatesofbreak-fast,suchasspoonorvacation,whichareonlymarginallyrelatedandthereforelikelytogeneratesemanticdrift.Formally,letwbethevectorrepresentation(ei-therfromanNNLMoralignmentmodel)ofagiventerm.Weconstructahigher-orderrepresen-tationˆwbylinearlyinterpolatingwwithitstopassociates,thosevectorswithhighestvalueofapairwisescoringfunctions:ˆw(je)=Xj∈Nk(w(je))s(w(je),w(j))w(j)(7)wheresisthefunctionthatmeasuresthelexi-calsimilaritybetweenterms,anddependsontherepresentationsused(salignorscos,seebelow).Nk(w(je)),theneighborhoodofthevectorw(je),denotestheindicesofthektermvectorswithhighestvaluesofs(w(je),·),andkisahyperpa-rameterthatcontrolshowmanyvectorsareinter-polated.Theresultingvectorsarerenormalized,asdiscussedlater.9Itisimportanttonotethatthisprocessofcreatinghigher-ordervectorscanbetrivially9Nk(w)includesw,becauseinallLSmodelsproposedhere,eachtermhasmaximalsimilaritywithitself.Thenor-malizationappliedaftercombiningallvectorshastheeffectofmodulatingthecontributionofthevectorwinthehigherorderrepresentationˆw,basedonhowsimilartheothervec-torsinNk(w)aretow.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
je
un
c
_
un
_
0
0
1
3
3
p
d
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
203
iteratedarbitrarily,constructingasecond-ordermodelfromafirst-ordermodel,thenathird-ordermodelfromasecond,etc.Intuitively,thismodelspathsofincreasinglengthintheassociationgraphoverterms.WenowdescribetheconcreteimplementationsoftheprocedureinthealignmentandtheNNLMsettings.Higher-orderAlignment:Inthealignmentset-ting,wherethevectorw(je)fortermicontainstheprobabilitiesthatthesource(answer)termiisalignedwiththedestination(question)termj,weusesalign(w(je),w(j))=T(termj|termi)(8)whereTisthetranslationprobabilityfromEqua-tion(3).WenormalizetheˆwvectorsofEqua-tion(7)usingtheL1norm,sothateachcontin-uestorepresentaprobabilitydistribution.In-tuitively,thesecond-orderalignmentdistributionˆw(je)forsourcetermiisalinearcombinationoftermi’smostprobabledestinationterms’distri-butions,weightedbythedestinationprobabilitiesfromw(je).Thehigher-ordermodelsgreatlyreducethesparsityofthefirst-orderalignmentgraph.Inafirst-orderwordalignmentmodel(i.e.,usingonlydirectevidence)trainedonapproximately70,000question/answerpairs(see§6.1),sourcewordsalignwithanaverageof31destinationwordswithnon-zeroprobability,outofa103,797wordvocabulary.Thesecond-ordermodelaligns1,535destinationwordstoeachsourcewordonaverage;thethird-ordermodel,8,287;andthefourth-ordermodel,15,736.Intheresultssection,weobservethatthissparsityreductionisonlyhelpfuluptoacertainpoint;havingtoomanyassociatesforeachwordreducesperformanceontheQAtask.Higher-orderNNLM:IntheNNLMsetting,weusethecosinesimilarityofvectorsasinterpolationweightsandtochoosethenearestneighbors:scos(w(je),w(j))=w(je)·w(j)||w(je)||||w(j)||(9)Wefoundthatapplyingthesoftmaxfunctiontoeachterm’svectorofk-highestscossimilarities,toensureallinterpolationweightsarepositiveandhaveaconsistentrangeacrossterms,improvedperformance.Assuch,allhigher-orderNNLMmodelsusethissoftmaxnormalization.Theresultinginterpolationcanbeconceptual-izedinseveralways.Viewingcosinesimilarityasarepresentationofentailment(Beltagyetal.,2013),thehigher-orderNNLMmodelreflectsmultiple-hopinferenceontopofthecorrespond-ingassociationgraph,similartothehigher-orderalignmentmodel.Theinterpolationcouldalsobeviewedassmoothingtermrepresentationsinvectorspace,averagingeachterm’svectorwithitsnearestneighborsaccordingtotheircosinesimilarity.Higher-orderHybridModel:Wealsoimple-mentahybridmodel,whichinterpolatesthealign-mentdistributionvectors,butusingthepairwisecosinesimilaritiesfromtheNNLMsetting:ˆwA(je)=Xj∈Nk(wN(je))scos(wN(je),wN(j))wA(j)wherewN(je)andwA(je)arerespectivelytheNNLMvectorandalignmentvectorrepresenta-tionsfortermi,andscosiscosinesimilarity.Inaddition,weexperimentedwiththeoppositehy-bridmodel:interpolatingtheNNLMvectorsus-ingalignmentassociateprobabilitiesasweights,butfoundthatitdidnotperformaswellasusingNNLMsimilaritiestointerpolatealignmentvec-tors.Ourconjectureisthatthehigherordertech-niquecanbeviewedasamethodofreducingspar-sity(eitherinthevectorsorinthecontextusedtocreatethem),andsincetheNNLMvectorstrainedonwords(asopposedtodependencies)arelesssparse,theybenefitlessfromthistechnique.6Experiments6.1DataTotesttheutilityofourapproach,weexperi-mentedwiththeQAscenariointroducedin§3usingthesubsetofYahoo!AnswersCorpusin-troducedbyJansenetal.(2014)10.Yahoo!An-swers11isanopendomaincommunity-generatedQAsite,withquestionsandanswersthatspanfor-malandprecisetoinformalandambiguouslan-guage.Thiscorpuscontains10,000QApairsfromacorpusofhowquestions.Eachquestioncontainsatleastfourcommunity-generatedanswers,oneofwhichwasvotedasthetopanswer.Thenumberofanswerstoeachquestionrangedfrom4toover50,10http://nlp.sista.arizona.edu/releases/acl201411http://answers.yahoo.com
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
je
un
c
_
un
_
0
0
1
3
3
p
d
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
204
withtheaverage9.50%ofQApairswereusedfortraining,25%fordevelopment,and25%fortest.Thefollowingadditionalresourceswereused:NNLMCorpus:Wegeneratedvectorrepresen-tationsforwordsusingtheword2vecmodelofMikolovetal.(2013),usingtheskip-gramarchitecturewithhierarchicalsampling.Vec-torsaretrainedusingtheentireGigawordcor-pusofapproximately4Gwords.12Weused200-dimensionalvectors(Jansenetal.,2014).AlignmentCorpus:WeuseaseparatepartitionofQApairstotrainanalignmentmodelbetweenquestionsandtopanswers.Thiscorpusof67,972QApairsdoesnotoverlapwiththecollectionof10,000pairsusedforthetraining,development,andtestingpartitions,butwaschosenaccordingtothesamecriteria.ThealignmentmodelwastrainedusingGIZA++overfiveiterationsofIBMModel1.6.2TuningThefollowinghyperparametersweretunedinde-pendentlytomaximizeP@1onthedevelopmentpartitionoftheYahoo!Answersdataset:NumberofVectorsInterpolated:Weinvesti-gatedtheeffectsofvaryingkinEq.7,i.e.,thenumberofmost-similarneighborvectorsinterpo-latedwhenconstructingahigher-ordermodel.Weexperimentedwithvaluesofkrangingfrom1to100andfoundthatthevaluedoesnotsubstantiallyaffectresultsacrossthesecond-orderwordalign-mentmodels.Sincevectorsusedinthehigher-orderinterpolationareweightedbytheirsimilar-itytoavectorw,thisislikelyduetoaswiftde-creaseinvaluesofthepairwisesimilarityfunction,s(w,·),beyondthevectorsclosesttow.Wechosetousek=20becauseitcomesfromastablermaximum,anditissufficientlysmalltomakecon-structionofhigher-ordermodelsfeasibleintermsoftimeandmemoryusage.BaseRepresentationType:WecomparedtheeffectsofusingeitherwordsorlemmasasthebaselexicalunitfortheLSmodels,andfoundthatwordsachievedhigherP@1scoresinboththealignmentandNNLMmodelsonthedevelop-mentdataset.Assuch,allresultsreportedhereusewordsforthesyntax-independentmodels,andtu-plesofwordsforthesyntax-drivenmodels.ContentFiltering:Weinvestigatedusingpart-of-speech(POS)tagstofilterthecontentconsid-12LDCcatalognumberLDC2012T21eredbythelexicalsimilaritymodels,byexcludingcertainnon-informativeclassesofwordssuchasdeterminers.UsingPOStagsgeneratedbyStan-ford’sCoreNLP(Manningetal.,2014),wefil-teredcontenttoonlyincludenouns,adjectives,verbs,andadverbsfortheword-basedmodels,andtupleswherebothwordshaveoneofthesefourPOStagsforthesyntax-basedmodels.WefoundthatthisincreasedP@1scoresforallword-basedalignmentandNNLMmodels(includingtheLevy-Goldberg(L-G)model13),butdidnotimproveperformanceformodelsthatuseddepen-dencyrepresentations.14ResultsreportedintheremainderofthispaperusethisPOSfilteringforallword-basedalignmentandNNLMmodels(in-cludingL-G’s)aswellasthedependencyalign-mentmodel,butnotforourdependencyNNLMmodel.156.3BaselinesWecompareagainstfivebaselinemodels:Random:selectsananswerrandomly;CR:usestherankingprovidedbyourshallowan-swerCandidateRetrieval(CR)component;Jansenetal.(2014):thebest-performinglexi-calsemanticmodelreportedinJansenetal.(2014)(row6intheirTable1).16PRU:PageRank(Pageetal.,1999)withuni-formteleportationprobabilities,constructedoverthewordalignmentgraph.LetAbetherow-stochastictransitionmatrixofthisgraph,wheretheithrowofAisthevectorw(je)(see§4.2).Fol-lowingthePRalgorithm,weaddsmall“teleporta-tion”probabilitiesfromateleportationmatrixT17tothealignmentmatrix,producingaPageRank13WemodifiedtheL-Galgorithmtoignoreanydependen-ciesnotmatchingthisfilteringcriterionwhenbuildingthecontextforaword.14Wehypothesizethatourfilteringcriterionfordependen-cies,whichrequiresbothheadandmodifierstohaveoneofthefourPOStags,wastooaggressive.Wewillexploreotherfilteringcriteriainfuturework.15Althoughfiltereddependenciesyieldedslightlylowerre-sultsinourtuningexperiments,weusetheminthedepen-dencyalignmentexperimentsbecausetheunfilteredthird-orderdependencyalignmentmodelwastoolargetofitintomemory.16Wedonotreporttheperformanceoftheirdiscourse-basedmodels,becausethesemodelsuseadditionalresourcesmakingthemincompatiblewiththeworkshownhere.17WeconstructtheteleportationmatrixTbysettingeachrowofTtobeauniformprobabilitydistribution,i.e.,eachentryinarowofTis1/|V|,où|V|isthevocabularysize.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
je
un
c
_
un
_
0
0
1
3
3
p
d
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
205
matrixP=α∗A+(1- un)∗T.Followingpre-viouswork(Pageetal.,1999),weusedα=0.15.Then,wecomputethematrixproductsP2,P3,…,usingrowsintheseproductsasvectorrepresenta-tionsforterms.Thus,theithrowofPkgivestheconditionalprobabilitiesofarrivingateachterminthegraphafterktransitionsbeginningattermi.PRP:PersonalizedPageRank(AgirreandSoroa,2009).ThismethodfollowsthesamealgorithmasPRU,butusesNNLMsimilaritiesoftermstode-finenon-uniformteleportationprobabilities(fol-lowingtheintuitionthatteleportationlikelihoodshouldbecorrelatedwithsemanticsimilarityofterms).Inparticular,weobtaintheithrowofTbycomputingthepairwisecosinesimilaritiesoftermi’sNNLMvectorwitheveryotherterm’svector,andtakingthesoftmaxofthesesimilaritiestoproduceaprobabilitydistribution,v(je).Toac-countformissingterms(duetothedifferenceinthealignmentandNNLMcorpora)wesmoothallteleportationprobabilitiesbyaddingasmallvalue,(cid:15),toeachentryofv(je).Therenormalizedv(je)thenbecomestheithrowofT.6.4ResultsAnalysisofhigher-ordermodelsTable1showstheperformanceoffirst-orderandhigher-orderalignmentandNNLMmodelsacrossrepresentationtype.Rowsinthetablearelabeledwiththeordersoftherepresentationsused.Win-dicatesamodelwherethebaseunitsarewords,whileDindicatesamodelwherethebaseunitsaredependencies;Adenotesanalignmentmodel,whileNdenotesanNNLMmodel.Distinctfea-turesaregeneratedforeachorderrepresentation(§§4.1,4.2,5)andusedintheSVMmodel.Forexample,WN(1-3)usesfeaturesconstructedfromthe1st,2nd,and3rdorderrepresentationsoftheword-basedNNLM.Combiningmultipleordersintoasinglefeaturespaceisimportant,aseachor-dercapturesdifferentinformation.Forexample,thetopfiveclosestassociatesforthetermdogun-derWN(1)sont:puppy,cat,dogs,dachshund,andpooch,whereasthetopassociatesunderWN(2)sont:mixedbreed,hound,puppy,rottweiler,andgroomer.Aggregatingfeaturesfromallordersintoasinglerankingmodelguaranteesthatallthisinformationisjointlymodeled.Weusethestandardimplementationsforpre-cisionat1(P@1)andmeanreciprocalrank(MRR)(Manningetal.,2008).Severaltrendsareapparentinthetable:(je)Allfirst-orderlexicalmodelsoutperformtherandomandCRbaselines,aswellasthesystemofJansenetal.Thelatterresultisexplainedbythenovelfeaturesproposedin§4.1and§4.2.Wedetailthecontributionofthesefeaturesintheab-lationexperimentsummarizedlaterinTable4.(ii)Moreimportantly,bothP@1andMRRgener-allyincreaseasweincorporatehigher-orderver-sionsofeachlexicalmodel.OutofthesixLSmodelsinvestigated,fiveimproveundertheircor-respondinghigher-orderconfigurations.Thisgainismostpronouncedforthedependencyalign-ment(DA)model,whoseP@1increasesfrom25.9%forthefirst-ordermodelto29.4%foramodelthatincorporatesfirst,second,andthird-orderfeatures.Ingeneral,theperformancein-creaseinhigher-ordermodelsislargerforsparserfirst-ordermodels,wherethehigher-ordermod-elsfillintheknowledgegapsoftheircorrespond-ingfirst-ordervariants.Thissparsityisgener-atedbymultiplecauses:(un)alignmentmodelsaresparserthanNNLMsbecausetheyweretrainedonlessdata(approximately67Kquestion-answerpairsvs.theentireGigaword);(b)modelsthatusesyntacticdependenciesasthebaselexicalunitsaresparserthanmodelsthatusewords.Weconjec-turethatthisiswhyweseethebiggestimprove-mentfromhigherorderforDA(whichcombinesbothsourcesofsparsity),andwedonotseeanimprovementfortheword-basedNNLM(WN).Thishypothesisissupportedbytheanalysisofthecorrespondingassociationgraphs:intheWAmodel,countingthenumberofwordscompris-ingthetop99%oftheprobabilitymassdistribu-tionforeachwordshowssparserepresentationswith10.1most-similarwordsonaverage;intheWNmodel,thesamestatisticshowsdensedis-tributedrepresentationswiththetop99%ofmassdistributedacross1.2millionmost-similarwordsperword(ou,about99%ofthevocabulary).(iii)Thehigher-ordermodelsperformwelluptoanorderof3or4,butnotfurther.Forexam-ple,theperformanceofthewordalignmentmodel(WA)decreasesatorder4(row7);similarly,theperformanceofthewordNNLM(WN)decreasesatorder5(row12).Thissupportsourinitialob-servationthatlongpathsintheassociationgraphaccumulatenoise,whichleadstosemanticdrift.(iv)TheLevy-GoldbergNNLM(DNL-G)isthebestfirst-ordermodel,whereasourdependency-
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
je
un
c
_
un
_
0
0
1
3
3
p
d
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
206
P@1MRR#ModelP@1Impr.MRRImpr.Baselines1Random14.2926.122CR19.57–43.15–3Jansenetal.(2014)26.57–49.31–WordAlignment(WA)4CR+WA(1)27.33+40%49.20+14%5CR+WA(1-2)29.01*+48%50.87*+18%6CR+WA(1-3)30.49*+56%51.92*+20%7CR+WA(1-4)29.65*+52%51.38*+19%WordNNLM(WN)8CR+WN(1)30.69+57%52.02+21%9CR+WN(1-2)29.57+51%51.29+19%10CR+WN(1-3)30.21+54%51.75+20%11CR+WN(1-4)30.41+55%51.91+20%12CR+WN(1-5)30.05+54%51.87+20%DependencyAlignment(DA)13CR+DA(1)25.89+32%48.24+12%14CR+DA(1-2)28.81*+47%50.50*+17%15CR+DA(1-3)29.41*+50%51.14*+19%OurDependencyNNLM(DNO)16CR+DNO(1)30.85+58%51.93+20%17CR+DNO(1-2)31.69*+62%52.35*+21%18CR+DNO(1-3)31.89*+63%52.43*+22%Levy-GoldbergDependencyNNLM(DNL-G)19CR+DNL-G(1)31.25+60%52.60+22%20CR+DNL-G(1-2)31.57+61%52.76+22%21CR+DNL-G(1-3)31.69+62%52.73+22%HybridModel:WordAlignmentwithNNLMSimilarity(WAN)22CR+WAN(1-2)29.37+50%51.05+18%23CR+WAN(1-3)30.45*+56%51.84*+20%PageRankModel:UniformTeleportation(PRU)24CR+PRU(1)27.29+39%49.21+14%25CR+PRU(1-2)30.33*+55%51.74*+20%26CR+PRU(1-3)30.17*+54%51.87*+20%PageRankModel:PersonalizedTeleportation(PRP)27CR+PRP(1)27.09+38%49.10+14%28CR+PRP(1-2)31.01*+58%52.25*+21%29CR+PRP(1-3)29.89*+53%51.70*+20%Table1:OverallresultsontheYahoo!Answersdatasetusingfirst-orderrepresentations(1)andfirst-orderincombinationwithhigher-orderrepresentations(1-n).Boldfontindicatesthebestscoreinagivencolumnforeachmodelgroup.Anasteriskindicatesthatascoreissignificantlybetter(p<0.05)thanthefirst-orderversionofthatmodel.Allsignificancetestswereimplementedusingone-tailednon-parametricbootstrapresamplingusing10,000iterations.modelcreationtimematrixsizeWA(1)–75MBWA(2)33seconds1.8GBWA(3)4.5minutes9.7GBWA(4)8.6minutes19GBPR(1)–41GBPR(2)45.6hours41GBPR(3)45.6hours41GBTable2:Runtimeandmemoryrequirementsforcreationofmatrices,fortheoriginalPageRankandourcautiousrandomwalkalgorithms.Creationofbothhigher-orderWAandPRmodelsistriviallyparallelizable,andwereportruntimesona2.7GHzprocessorwithparallelexecutionon10cores.basedNNLM(DNO)isthebesthigher-ordermodel.ThisisanencouragingresultforDNO,consideringitssimplicity.Ingeneral,NNLMsperformbetterthanalignmentmodelsforanswerreranking,whichisnotsurprisingconsideringthedifferenceinsizeofthetrainingdatasets.Toourknowledge,thisisthefirsttimethistypeofanaly-sishasbeenperformedforQA.(v)BothPRU(1-2)andPRP(1-2)performbetterthantheirfirst-ordervariantsandbetterthanour
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
l
a
c
_
a
_
0
0
1
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
207
P@1MRR#Model/FeaturesP@1Impr.MRRImpr.Baselines1Random14.2926.122CR19.57–43.15–3Jansenetal.(2014)26.57–49.31–Words4CR+WA(1)+WN(1)30.85+58%52.245CR+WA(1-2)+WN(1-2)31.85*+63%52.86*+23%6CR+WA(1-3)+WN(1-3)32.09*+64%52.97*+23%7CR+WA(1-4)+WN(1-4)31.69+62%52.75+22%Dependencies8CR+DA(1)+DNO(1)+DNL-G(1)31.49+61%52.93+23%9CR+DA(1-2)+DNO(1-2)+DNL-G(1-2)32.85*+68%53.73*+25%10CR+DA(1-3)+DNO(1-3)+DNL-G(1-3)32.77*+67%53.71*+24%WordsandDependencies11CR+WA(1)+WN(1)+DA(1)+DNO(1)+DNL-G(1)31.85+63%53.03+23%12CR+WA(1-2)+WN(1-2)+DA(1-2)+DNO(1-2)+DNL-G(1-2)32.89†+68%53.69†+24%13CR+WA(1-3)+WN(1-3)+DA(1-3)+DNO(1-3)+DNL-G(1-3)33.01†+69%53.96†+25%Table3:PerformanceontheYahoo!Answersdatasetforword,dependency,andmodelsthatcombinethewordandde-pendencyrepresentations.Boldfontindicatesthebestscoreinagivencolumnforeachmodelgroup.Anasteriskindicatesthatascoreissignificantlybetter(p<0.05)thanthefirst-orderversionofthatmodelgroup(1),and†indicatesthatascoreapproachessignificance(p<0.10).P@1MRRModelP@1DeltaMRRDeltaCR+WA(1)allfeatures27.33–49.20–−P(Q|A)25.69-6%48.35-2%−maxJSD27.330%49.100%−minJSD23.57-14%46.64-5%−compositeJSD27.17-1%49.020%−averageJSD25.41-7%47.70-3%CR+WN(1)allfeatures30.69–52.02–−maxcosinesim.29.65-3%51.49-1%−mincosinesim.29.69-3%51.43-1%−compositecosinesim.27.01-12%49.13-6%−averagecosinesim.26.49-14%49.04-6%Table4:Ablationexperimentsforfirst-orderwordmodels.Eachrowremovesasinglefeaturefromthecorrespondingcompletemodel(“allfeatures”).word-basedsecond-ordermodels(WAandWN).Asexpected,thepersonalizedPRalgorithmper-formsbetterthanPRU.However,theirperfor-mancedropsforthethird-ordermodels(rows26and29),whereasourmodelscontinuetoimproveintheirthird-orderconfiguration.Allourthird-ordermodelsperformbetterthanallthird-orderPRmodels.Thisiscausedbyour“cautious”traversalstrategythatconsidersonlytheclosestneighborsduringrandomwalks,whichcontrolsforsemanticdriftbetterthanthePRmethods.Fur-thermore,theresourcesrequiredforPRarecon-siderablylargerthantheonesneededtoimple-mentourmethods.Table2summarizesthere-quirementsofthePRalgorithmcomparedtoourclosestmethod(WA).Asthetableshows,PRhasaruntimethatistwoordersofmagnitudelargerthanWA’s,andrequiresfourtimesasmuchmem-orytostorethegeneratedhigher-ordermatrices.CombiningNNLMsandalignmentmodelsWeexplorecombinationsofNNLMsandalign-mentmodelsinTable3,whichlistsresultswhenhigher-orderNNLMsandalignmentmodelsarecombinedforagivenrepresentationtype.Eachlineinthetablecorrespondstoasinglean-swerrerankingmodel,whichincorporatesfeaturesfrommultipleLSmodels.Theseexperimentsre-inforceourpreviousobservations:higher-ordermodelsperformbetterthantheirfirst-ordervari-antsregardlessofrepresentationtype,butperfor-manceincreasesonlyforrelativelyloworders,e.g.,3ordersforwordsandwordscombinedwithdependencies,or2ordersfordependencies.Importantly,thetableshowsthatthecombina-tionofNNLMsandalignmentmodelsacrossrep-resentationtypesisbeneficial.Forexample,thebestfirst-ordercombinedmodel(row11inTa-ble3)performssimilarlytothebesthigher-orderindividualLSmodel(row18inTable1).Thebestcombinedhigher-ordermodel(row13inTa-ble3)hasaP@1scoreof33.01,approximately1.2%higherthanthebestindividualLSmodel(row18inTable1).Toourknowledge,thisisthe
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
l
a
c
_
a
_
0
0
1
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
208
highestperformancereportedonthisYahoo!An-swerscorpus,surpassingthebestmodelofJansenet.al(2014),whichincorporatesbothshallowanddeepdiscourseinformation,andachieves32.9P@1.FeatureablationexperimentsAlthoughthemainfocusofthisworkisonhigher-orderLSmodels,Table1showsthatevenourfirst-ordermodelsperformbetterthanthepreviousstateoftheart.ThisiscausedbythenovelfeaturesproposedoveralignmentmodelsandNNLMs.Tounderstandthecontributionofeachofthesefea-tures,weperformedanablationexperiment,sum-marizedinTable4,fortwomodels:onealignmentmodel(WA),andoneNNLM(WN).Thisanalysisindicatesthatmanyofthefeaturesproposedareimportant.Forexample,twoofthenovelJSDfea-turesforWAhaveahighercontributiontoover-allQAperformancethanthealignmentprobability(P.(Q|UN))proposedinpreviouswork(Surdeanuetal.,2011).ForWN,thetwonewfeaturespro-posedhere(maximumandminimumcosinesim-ilaritybetweenembeddingvectors)alsohaveapositivecontributiontooverallperformance,butlessthantheothertwofeaturesproposedinprevi-ouswork(Yihetal.,2013;Jansenetal.,2014).6.5DiscussionOneimportantobservationyieldedbytheprevi-ousempiricalanalysisisthathigher-ordermodelsperformwellforsparsefirst-ordervariants(e.g.,DA),butnotforfirst-ordermodelsthatrelyonalreadydenseassociationgraphs(e.g.,WN).Wesuspectthatindenselypopulatedgraphs,model-ingcontextbecomescriticalforsuccessfulhigher-ordermodels.Returningtoourexamplefrom§1,adenselypopulatedgraphmayalreadyhavetheassociationsbreakfast–pancakesandpancakes–hashbrownsthatallowittoidentifyrestaurantswithfavorablebreakfastfoods.Exploringhigher-orderassociationsinthissituationisonlyben-eficialifcontextiscarefullymaintained,other-wiseananswerrerankingsystemmayerroneouslyselectanswercandidateswithdifferentcontextsduetoaccumulatedsemanticdrift(e.g.,answersthatdiscussfilms,usingassociationsfromtextsreviewingBreakfastatTiffany’s).Incorporatingword-sensedisambiguationortopicmodelingintoalignmentorNNLMmodelsmaybegintoaddressthesecontextualissuesbypreferentiallyassociat-ingtermswithinagiventopic(suchasrestau-rantsorfilms),ultimatelyreducingsemanticdrift,andextendingthesehigher-ordermethodsbeyondafewhopsinthegraph.Ouranalysissuggeststhattheextrasparsitythatcontextually-dependentrepresentationsintroducemaymakethosemodelsevenmoreamenabletothehigher-ordermethodsdiscussedhere.Moregenerally,webelievethatgraph-basedin-ferenceprovidesarobustbutapproximatemiddle-groundtoinferenceforQA.Whereinferenceus-ingfirst-orderlogicoffersprovably-correctan-swersbutisrelativelybrittle(seeCh.1inMac-Cartney(2009)),LSmethodsofferrobustness,buthavelackedexplanatorypowerandtheabilitytoconnectknowledgeintoshortinferencechains.Herewehavedemonstratedthathigher-ordermethodscapitalizeonindirectevidencegatheredbyconnectingmultipledirectassociations,andindoingsosignificantlyincreaseperformanceoverLSapproachesthatusedirectevidencealone.Byincorporatingcontextualinformationandmakinguseoftheshortinferencechainsgeneratedbytraversingthesegraphicalmodels,wehypothe-sizethatgraph-basedsystemswillsoonbeabletoconstructsimplejustificationsfortheiranswerse-lection(e.g.,pancakesareabreakfastfood,andhashbrownsgowellwithpancakes).WehopeitwillsoonbepossibletofillthisgapininferencemethodsforQAwithhigher-orderLSmodelsforrobustbutapproximateinference.7ConclusionsWeintroduceahigher-orderformalismthatal-lowslexicalsemanticmodelstocapitalizeonbothdirectandindirectevidence.Wedemon-stratethatmanylexicalsemanticmodels,includ-ingmonolingualalignmentandneuralnetworklanguagemodels,workingoversurfaceorsyntac-ticrepresentations,canbetriviallyadaptedtothishigher-orderformalism.Usingacorpusofthou-sandsofnon-factoidhowquestions,weexperi-mentallydemonstratethathigher-ordermethodsperformbetterthantheirfirst-ordervariantsformostlexicalsemanticmodelsinvestigated,withstatistically-significantrelativegainsofupto13%overthecorrespondingfirstordermodels.AcknowledgementsWethanktheAllenInstituteforArtificialIntelli-genceforfundingthiswork.Wewouldalsoliketothankthethreeanonymousreviewersfortheirhelpfulcommentsandsuggestions.
l
D
o
w
n
o
un
d
e
d
f
r
o
m
H
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
l
a
c
_
a
_
0
0
1
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
209
ReferencesEnekoAgirreandAitorSoroa.2009.PersonalizingPageRankforwordsensedisambiguation.InPro-ceedingsofthe12thConferenceoftheEuropeanChapteroftheAssociationforComputationalLin-guistics.MarcoBaroni,GeorgianaDinu,andGerm´anKruszewski.2014.Don’tcount,predict!Asystematiccomparisonofcontext-countingvs.context-predictingsemanticvectors.InProceedingsofthe52ndAnnualMeetingoftheAssociationforComputationalLinguistics.IslamBeltagy,CuongChau,GemmaBoleda,DanGar-rette,KatrinErk,andRaymondMooney.2013.MontaguemeetsMarkov:Deepsemanticswithprobabilisticlogicalform.InProceedingsoftheSecondJointConferenceonLexicalandComputa-tionalSemantics.AdamBerger,RichCaruana,DavidCohn,DayneFrey-tag,andVibhuMittal.2000.Bridgingthelexicalchasm:Statisticalapproachestoanswerfinding.InProceedingsofthe23rdAnnualInternationalACMSIGIRConferenceonResearch&DevelopmentonInformationRetrieval.GauravBhalotia,ArvindHulgeri,CharutaNakhe,SoumenChakrabarti,andShashankSudarshan.2002.KeywordsearchingandbrowsingindatabasesusingBANKS.InProceedingsof18thInternationalConferenceonDataEngineering(ICDE).PeterF.Brown,StephenA.DellaPietra,VincentJ.DellaPietra,andRobertL.Mercer.1993.Themathematicsofstatisticalmachinetranslation:Parameterestimation.ComputationalLinguistics,19(2):263–311.SoumenChakrabartiandAlekhAgarwal.2006.Learningparametersinentityrelationshipgraphsfromrankingpreferences.InProceedingsof10thEuropeanConferenceonPrincipleandPracticeofKnowledgeDiscoveryinDatabases(PKDD).SoumenChakrabarti.2007.DynamicpersonalizedPageRankinentity-relationgraphs.InProceedingsofthe16thInternationalWorldWideWebConfer-ence(WWW).Marie-CatherinedeMarneffe,BillMacCartney,andChristopherD.Manning.2006.Generatingtypeddependencyparsesfromphrasestructureparses.InProceedingsoftheInternationalConferenceonLanguageResourcesandEvaluation(LREC).AbdessamadEchihabiandDanielMarcu.2003.Anoisy-channelapproachtoquestionanswering.InProceedingsofthe41stAnnualMeetingoftheAsso-ciationforComputationalLinguistics(ACL).OrenEtzioni.2011.Searchneedsashake-up.Nature,476(7358):25–26.PeterJansen,MihaiSurdeanu,andPeterClark.2014.Discoursecomplementslexicalsemanticsfornon-factoidanswerreranking.InProceedingsofthe52ndAnnualMeetingoftheAssociationforCom-putationalLinguistics(ACL).NiLaoandWilliamW.Cohen.2010.Relationalre-trievalusingacombinationofpath-constrainedran-domwalks.MachineLearning,81(1):53–67.NiLao,TomMitchell,andWilliamW.Cohen.2011.Randomwalkinferenceandlearninginalargescaleknowledgebase.InProceedingsoftheConferenceonEmpiricalMethodsinNaturalLanguagePro-cessing(EMNLP).HeeyoungLee,MartaRecasens,AngelChang,Mi-haiSurdeanu,andDanJurafsky.2012.Jointen-tityandeventcoreferenceresolutionacrossdocu-ments.InProceedingsoftheJointConferenceonEmpiricalMethodsinNaturalLanguageProcess-ingandComputationalNaturalLanguageLearning(EMNLP-CoNLL).OmerLevyandYoavGoldberg.2014a.Dependency-basedwordembeddings.InProceedingsofthe52ndAnnualMeetingoftheAssociationforComputa-tionalLinguistics(ACL).OmerLevyandYoavGoldberg.2014b.Linguisticreg-ularitiesinsparseandexplicitwordrepresentations.InProceedingsoftheConferenceonComputationalNaturalLanguageLearning(CoNLL).DekangLin.1998.Automaticretrievalandclusteringofsimilarwords.InProceedingsofthe36thAnnualMeetingoftheAssociationforComputationalLin-guisticsandthe17thInternationalConferenceonComputationalLinguistics(COLING-ACL-1998).BillMacCartney.2009.NaturalLanguageInference.Ph.D.thesis,StanfordUniversity.ChristopherD.Manning,PrabhakarRaghavan,andHinrichSch¨utze.2008.IntroductiontoInformationRetrieval.CambridgeUniversityPress.ChristopherD.Manning,MihaiSurdeanu,JohnBauer,JennyFinkel,StevenJ.Bethard,andDavidMc-Closky.2014.TheStanfordCoreNLPnaturallan-guageprocessingtoolkit.InProceedingsofthe52ndAnnualMeetingoftheAssociationforCom-putationalLinguistics(ACL).TaraMcIntosh.2010.ReducingSemanticDriftinBiomedicalLexiconBootstrapping.Ph.D.thesis,UniversityofSydney.TomasMikolov,KaiChen,GregCorrado,andJeffreyDean.2013.Efficientestimationofwordrepre-sentationsinvectorspace.InProceedingsoftheInternationalConferenceonLearningRepresenta-tions(ICLR).EinatMinkov,WilliamW.Cohen,andAndrewY.Ng.2006.Contextualsearchandnamedisambiguationinemailusinggraphs.InProceedingsofSIGIR.
l
D
o
w
n
o
un
d
e
d
f
r
o
m
H
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
3
1
5
6
6
7
3
0
/
/
t
l
a
c
_
a
_
0
0
1
3
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
210
VanessaMurdockandW.BruceCroft.2005.Atrans-lationmodelforsentenceretrieval.InProceedingsoftheConferenceonHumanLanguageTechnologyandEmpiricalMethodsinNaturalLanguagePro-cessing,pages684–691.CourtneyNapoles,MatthewGormley,andBenjaminVanDurme.2012.AnnotatedGigaword.InPro-ceedingsoftheJointWorkshoponAutomaticKnowl-edgeBaseConstructionandWeb-scaleKnowledgeExtraction,pages95–100.AssociationforCompu-tationalLinguistics.FranzJosefOchandHermannNey.2003.Asys-tematiccomparisonofvariousstatisticalalignmentmodels.ComputationalLinguistics,29(1):19–51.LawrencePage,SergeyBrin,RajeevMotwani,andTerryWinograd.1999.ThePageRankcitationranking:Bringingordertotheweb.TechnicalRe-port1999-66,StanfordInfoLab,November.StefanRiezler,AlexanderVasserman,IoannisTsochantaridis,VibhuMittal,andYiLiu.2007.Statisticalmachinetranslationforqueryexpansioninanswerretrieval.InProceedingsofthe45thAn-nualMeetingoftheAssociationforComputationalLinguistics(ACL).RaduSoricutandEricBrill.2006.Automaticquestionansweringusingtheweb:Beyondthefactoid.Jour-nalofInformationRetrieval-SpecialIssueonWebInformationRetrieval,9(2):191–206.Md.ArafatSultan,StevenBethard,andTamaraSum-ner.2014.Backtobasicsformonolingualalign-ment:Exploitingwordsimilarityandcontextualev-idence.TransactionsoftheAssociationforCompu-tationalLinguistics,2:219–230.MihaiSurdeanu,MassimilianoCiaramita,andHugoZaragoza.2011.Learningtorankanswerstonon-factoidquestionsfromwebcollections.Computa-tionalLinguistics,37(2):351–383.HanghangTong,ChristosFaloutsos,andJia-YuPan.2006.Fastrandomwalkwithrestartanditsapplica-tions.InProceedingsofthe6thInternationalCon-ferenceonDataMining(ICDM).Xin-JingWang,XudongTu,DanFeng,andLeiZhang.2009.Rankingcommunityanswersbymodelingquestion-answerrelationshipsviaanalogicalreason-ing.InProceedingsoftheAnnualACMSIGIRCon-ference.MaxWhitneyandAnoopSarkar.2012.Bootstrap-pingviagraphpropagation.InProceedingsofthe50thAnnualMeetingoftheAssociationforCompu-tationalLinguistics.XuchenYao,BenjaminVanDurme,ChrisCallison-Burch,andPeterClark.2013.Semi-Markovphrase-basedmonolingualalignment.InProceed-ingsoftheConferenceonEmpiricalMethodsinNat-uralLanguageProcessing(EMNLP).DavidYarowsky.1995.Unsupervisedwordsensedis-ambiguationrivalingsupervisedmethods.InPro-ceedingsofthe33rdAnnualMeetingoftheAssocia-tionforComputationalLinguistics(ACL).Wen-tauYih,Ming-WeiChang,ChristopherMeek,andAndrzejPastusiak.2013.Questionansweringusingenhancedlexicalsemanticmodels.InProceedingsofthe51stAnnualMeetingoftheAssociationforComputationalLinguistics(ACL).BenatZapirain,EnekoAgirre,LluisMarquez,andMi-haiSurdeanu.2013.Selectionalpreferencesforse-manticroleclassification.ComputationalLinguis-tics,39(3).