Transactions of the Association for Computational Linguistics, vol. 3, pp. 183–196, 2015. Action Editor: Patrick Pantel.
Submission batch: 9/2014; Revision batch 1/2015; Revision batch 3/2015; Published 3/2015.
2015 Association for Computational Linguistics. Distributed under a CC-BY-NC-SA 4.0 Licence.
c
(cid:13)
FromVisualAttributestoAdjectivesthroughDecompositionalDistributionalSemanticsAngelikiLazaridouGeorgianaDinu∗AdamLiskaMarcoBaroniCenterforMind/BrainSciencesUniversityofTrento{angeliki.lazaridou|georgiana.dinu|adam.liska|marco.baroni}@unitn.itAbstractAsautomatedimageanalysisprogresses,thereisincreasinginterestinricherlinguistican-notationofpictures,withattributesofob-jects(e.g.,furry,brown…)attractingmostattention.Bybuildingontherecent“zero-shotlearning”approach,andpayingatten-tiontothelinguisticnatureofattributesasnounmodifiers,andspecificallyadjectives,weshowthatitispossibletotagimageswithattribute-denotingadjectivesevenwhennotrainingdatacontainingtherelevantan-notationareavailable.Ourapproachreliesontwokeyobservations.First,objectscanbeseenasbundlesofattributes,typicallyex-pressedasadjectivalmodifiers(adogissome-thingfurry,brown,etc.),andthusafunctiontrainedtomapvisualrepresentationsofob-jectstonominallabelscanimplicitlylearntomapattributestoadjectives.Second,ob-jectsandattributescometogetherinpictures(thesamethingisadoganditisbrown).Wecanthusachievebetterattribute(andob-ject)labelretrievalbytreatingimagesas“vi-sualphrases”,anddecomposingtheirlinguis-ticrepresentationintoanattribute-denotingadjectiveandanobject-denotingnoun.Ourapproachperformscomparablytoamethodexploitingmanualattributeannotation,itout-performsvariouscompetitivealternativesinbothattributeandobjectannotation,anditau-tomaticallyconstructsattribute-centricrepre-sentationsthatsignificantlyimproveperfor-manceinsupervisedobjectrecognition.∗Currentaffiliation:ThomasJ.WatsonResearchCenter,IBM,gdinu@us.ibm.com1IntroductionAsthequalityofimageanalysisalgorithmsim-proves,thereisincreasinginterestinannotatingim-ageswithlinguisticdescriptionsrangingfromsin-glewordsdescribingthedepictedobjectsandtheirproperties(Farhadietal.,2009;Lampertetal.,2009)toricherexpressionssuchasfull-fledgedim-agecaptions(Kulkarnietal.,2011;Mitchelletal.,2012).Thistrendhasgeneratedwideinterestinlin-guisticannotationsbeyondconcretenouns,withtheroleofadjectivesinimagedescriptionsreceiving,inparticular,muchattention.Adjectivesareofspecialinterestbecauseoftheircentralroleinso-calledattribute-centricimagerep-resentations.Thisframeworkviewsobjectsasbun-dlesofproperties,orattributes,commonlyex-pressedbyadjectives(e.g.,furry,brown),andusesthelatterasfeaturestolearnhigher-level,seman-ticallyricherrepresentationsofobjects(Farhadietal.,2009).1Attribute-basedmethodsachievebettergeneralizationofobjectclassifierswithlesstrain-ingdata(Lampertetal.,2009),whileatthesametimeproducingsemanticrepresentationsofvisualconceptsthatmoreaccuratelymodelhumanse-1Inthispaper,weassumethat,justlikenounsarethelin-guisticcounterpartofvisualobjects,visualattributesareex-pressedbyadjectives.Aninformalsurveyoftherelevantlitera-turesuggeststhat,whenattributeshavelinguisticlabels,theyareindeedmostlyexpressedbyadjectives.Therearesomeattributes,suchasparts,thataremorenaturallyexpressedbyprepositionalphrases(PPs:withatail).Fait intéressant,DinuandBaroni(2014)showedthatthedecompositionfunctionwewilladoptherecanderivebothadjective-nounandnoun-PPphrases,suggestingthatourapproachcouldbeseamlesslyextendedtovisualattributesexpressedbynoun-modifyingPPs.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
u
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
je
un
c
_
un
_
0
0
1
3
2
p
d
.
F
b
oui
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
184
manticintuition(Silbereretal.,2013).De plus,automatedattributeannotationcanfacilitatefiner-grainedimageretrieval(e.g.,searchingforarockybeachratherthanasandybeach)andprovidethebasisformoreaccurateimagesearch(forexampleincasesofvisualsensedisambiguation(Divvalaetal.,2014),whereauserdisambiguatestheirquerybysearchingforimagesofwoodencabinetasfurnitureandnotjustcabinet,whichcanalsomeancouncil).Classicattribute-centricimageanalysisrequires,cependant,extensivemanualandoftendomain-specificannotationofattributes(Vedaldietal.,2014),ou,atbest,complexunsupervisedimage-and-text-miningprocedurestolearnthem(Bergetal.,2010).Atthesametime,resourceswithhigh-qualityper-imageattributeannotationsarelimited;tothebestofourknowledge,coverageofallpub-liclyavailabledatasetscontainingnon-classspecificattributesdoesnotexceed100attributes,2ordersofmagnitudesmallerthantheequivalentobject-annotateddatasets(Dengetal.,2009).De plus,manyvisualattributescurrentlyavailable(e.g.,2D-boxy,furnitureleg),albeitvisuallymeaningful,donothavestraightforwardlinguisticequivalents,ren-deringtheminappropriateforapplicationsrequir-ingnaturallinguisticexpressions,suchasthesearchscenariosconsideredabove.Apromisingwaytolimitmanualattributeanno-tationeffortistoextendrecentlyproposedzero-shotlearningmethods,untilnowappliedtoobjectrecog-nition,tothetaskoflabelingimageswithattribute-denotingadjectives.Thezero-shotapproachreliesonthepossibilitytoextract,throughdistributionalmethods,semanticallyeffectivevector-basedwordrepresentationsfromtextcorpora,onalargescaleandwithoutsupervision(TurneyandPantel,2010).Inzero-shotlearning,trainingimageslabeledwithobjectnamesarealsorepresentedasvectors(offea-turesextractedwithstandardimage-analysistech-niques),whicharepairedwiththevectorsrepre-sentingthecorrespondingobjectnamesinlanguage-baseddistributionalsemanticspace.Givensuch2TheattributedatasetsweareawareofaretheonesofFarhadietal.(2010),FerrariandZisserman(2007)andRus-sakovskyandFei-Fei(2010),containingannotationsfor64,7and25attributes,respectivement.(ThiscountexcludestheSUNAttributesDatabase(Pattersonetal.,2014),whoseattributescharacterizescenesratherthanconcreteobjects.)−400−300−200−1000100200300−150−100−50050100150puppycutefurrycarmetallicplasticbirdfeatheredwild−150−100−50050100−250−200−150−100−50050100150200puppycutefurrycarmetallicplasticbirdfeatheredwildFigure1:t-SNE(VanderMaatenandHinton,2008)visu-alizationof3objectstogetherwiththe2nearestattributesinourvisualspace(gauche),andofthecorrespondingnounsandadjectivesinlinguisticspace(droite).pairedtrainingdata,variousalgorithms(Socheretal.,2013;Fromeetal.,2013;Lazaridouetal.,2014)canbeusedtoinduceacross-modalprojectionofimagesontolinguisticspace.Thisprojectionisthenappliedtomappreviouslyunseenobjectstothecor-respondinglinguisticlabels.Themethodtakesad-vantageofthesimilaritiesinthevectorspacetopolo-giesofthetwomodalities,allowinginformationpropagationfromthelimitednumberofobjectsseenintrainingtovirtuallyanyobjectwithavector-basedlinguisticrepresentation.Toadaptzero-shotlearningtoattributes,werelyontheirnatureas(salient)propertiesofobjects,andonhowthisisreflectedlinguisticallyinmodifierre-lationsbetweenadjectivesandnouns.Webuildontheobservationthatvisualandlinguisticattribute-adjectivevectorspacesexhibitsimilarstructures:Thecorrelationρbetweenthepairwisesimilari-tiesinvisualandlinguisticspaceofallattributes-adjectivesfromourexperimentsis0.14(significantatp<0.05).3Whilethecorrelationissmallerthanforobject-noundata(0.23),weconjectureitissufficientforzero-shotlearningofattributes.Wewillconfirmthisbytestingacross-modalprojectionfunctionfromattributes,suchascolorsandshapes,ontoadjectivesinlinguisticsemanticspace,trainedonpre-existingannotateddatasetscoveringlessthan100attributes(Experiment1).Weproceedtodevelopanapproachachievingequallygoodattribute-labelingperformancewithoutmanualattributeannotation.Inspiredbylinguisticandcognitivetheoriesthatcharacterizeobjectsasat-tributebundles(Murphy,2002),wehypothesizethatwhenwelearntoprojectimagesofobjectstothecorrespondingnounlabels,weimplicitlylearnto3Inthispaper,wereportsignificanceatα=0.05threshold.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
l
a
c
_
a
_
0
0
1
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
185
−800−600−400−2000200400600800−1000−800−600−400−2000200400600800only fruitsparkling winesmooth pastevibrant redmobile visitherbal liqueurrich chocolateclear honeyorange liqueurmixed fruitnew orangeorangeirish creamliqueurwhite rumFigure2:Imagestaggedwithorangeandliqueuraremappedinlinguisticspaceclosertothevectorofthephraseorangeliqueurthantotheorangeorliqueurvec-tors(t-SNEvisualization)(thefigurealsoshowsthenear-estneighboursofphrase,adjectiveandnouninlinguis-ticspace).Themappingistrainedusingsolelynoun-annotatedimages.associatethevisualproperties/attributesoftheob-jectstothecorrespondingadjectives.Asanexam-ple,Figure1(left)displaysthenearestattributesofcar,birdandpuppyinthevisualspaceand,inter-estingly,therelativedistancebetweenthenounde-notingobjectsandtheadjectivedenotingattributesisalsopreservedinthelinguisticspace(right).Wefurtherobservethat,asalsohighlightedbyrecentworkinobjectrecognition,anyobjectinanimageis,inasense,avisualphrase(SadeghiandFarhadi,2011;Divvalaetal.,2014),i.e.,theobjectanditsattributesaremutuallydependent.Forexam-ple,wecannotvisuallyisolatetheobjectdrumfromattributessuchaswoodenandround.Indeed,withinourdata,in80%ofthecasestheprojectedimageofanobjectisclosertothesemanticrepresentationofaphrasedescribingitthantoeithertheobjectorattributelabels.SeeFigure2foranexample.Motivatedbythisobservation,weturntorecentworkindistributionalsemanticsdefiningavectordecompositionframework(DinuandBaroni,2014)which,givenavectorencodingthemeaningofaphrase,aimsatdecouplingitsconstituents,produc-ingvectorsthatcanthenbematchedtoasequenceofwordsbestcapturingthesemanticsofthephrase.Weadoptthisframeworktodecomposeimagerep-resentationsprojectedontolinguisticspaceintoanadjective-nounphrase.Weshowthatthemethodyieldsresultscomparabletothoseobtainedwhenus-ingattribute-labeledtrainingdata,whileonlyrequir-ingobject-annotateddata.Interestingly,thisdecom-positionalapproachalsodoublestheperformanceofobject/nounannotationoverthestandardzero-shotapproach(Experiment2).Giventhepositiveresultsofourproposedmethod,weconcludewithanextrinsicevaluation(Experiment3);weshowthatattribute-centricrepresentationsofimagescre-atedwiththedecompositionalapproachboostper-formanceinanobjectclassificationtask,supportingclaimsaboutitspracticalutility.Inadditiontocontributionstoimageannotation,ourworksuggestsnewtestbedsfordistributionalsemanticrepresentationsofnounsandassociatedadjectives,andprovidesmorein-depthevidenceofthepotentialofthedecompositionalapproach.2Generalexperimentalsetup2.1Cross-ModalMappingOurapproachreliesoncross-modalmappingfromavisualsemanticspaceV,populatedwithvector-basedrepresentationsofimages,ontoalinguistic(distributionalsemantic)spaceWofwordvectors.Themappingisperformedbyfirstinducingafunctionfproj:Rd1→Rd2fromdatapoints(vi,wi),wherevi∈Rd1isavectorrepresentationofanimagetaggedwithanobjectoranattribute(suchasdogormetallic),andwi∈Rd2isthelinguisticvectorrepresentationofthecorrespondingword.Themappingfunctioncansubsequentlybeappliedtoanygivenimagevi∈Vtoobtainitsprojectionw0i∈Wontolinguisticspace:w0i=fproj(vi)Specifically,weconsidertwomappingmethods.IntheRIDGEregressionapproach,welearnalinearfunctionFproj∈Rd2×d1bysolvingtheTikhonov-Phillipsregularizationproblem,whichminimizesthefollowingobjective:||WTr−FprojVTr||22−||λFproj||22,whereWTrandVTrareobtainedbystackingthewordvectorswiandcorrespondingimagevectorsvi,fromthetrainingset.44Theparameterλisdeterminedthroughcross-validationonthetrainingdata.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
l
a
c
_
a
_
0
0
1
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
186
Second,motivatedbythesuccessofCanonicalCorrelationsAnalysis(CCA)(Hotelling,1936)inseveralvision-and-languagetasks,suchasimageandcaptionretrieval(Gongetal.,2014;Hardoonetal.,2004;Hodoshetal.,2013),weadaptnormalizedCanonicalCorrelationsAnalysis(NCCA)tooursetup.GiventwopairedobservationmatricesXandY,inourcaseWTrandVTr,CCAseekstwoprojectionmatricesAandBthatmaximizethecorrelationbetweenATXandBTY.ThiscanbesolvedefficientlybyapplyingSVDtoˆC1/2XXˆCXYˆC1/2YY=UΣVTwhereˆCstandsforthecovariancematrix.Finally,theprojectionmatricesaredefinedasA=ˆC1/2XXUandB=ˆC1/2YYV.Gongetal.(2014)proposeanor-malizedvariantofCCA,inwhichtheprojectionma-tricesarefurtherscaledbysomepowerλofthesin-gularvaluesΣreturnedbytheSVDsolution.Inourexperiments,wetunethechoiceofλonthetrainingdata.Trivially,ifλ=0,NCCAreducestoCCA.Notethatothermappingfunctionscouldalsobeused.Weleaveamoreextensiveexplorationofpos-siblealternativestofurtherresearch,sincethedetailsofhowthevision-to-textconversionisconductedarenotcrucialforthecurrentstudy.Asincreasinglymoreeffectivemappingmethodsaredeveloped,wecaneasilyplugthemintoourarchitecture.Throughtheselectedcross-modalmappingfunc-tion,anyimagecanbeprojectedontolinguisticspace,wheretheword(possiblyoftheappropriatepartofspeech)correspondingtothenearestvectorisreturnedasacandidatelabelfortheimage(fol-lowingstandardpracticeindistributionalsemantics,wemeasureproximitybythecosinemeasure).2.2DecompositionDinuandBaroni(2014)haverecentlyproposedageneraldecompositionframeworkthat,givenadis-tributionalvectorencodingaphrasemeaningandthesyntacticstructureofthatphrase,decomposesitintoasetofvectorsexpectedtoexpressthese-manticsofthewordsthatcomposedthephrase.Inoursetup,weareinterestedinadecompositionfunc-tionfDec:Rd2→R2d2which,givenavisualvec-torprojectedontothelinguisticspace,assumesitrepresentsthemeaningofanadjective-nounphrase,anddecomposesitintotwovectorscorrespondingtotheadjectiveandnounconstituents[wadj;wnoun]=fDec(wAN).WetakefDectobealinearfunctionand,followingDinuandBaroni(2014),weuseastrainingdatavectorsofadjective-nounbigramsdi-rectlyextractedfromthecorpustogetherwiththeconcatenationofthecorrespondingadjectiveandnounwordvectors.WeestimatefDecbysolvingaridgeregressionproblemminimizingthefollowingobjective:||[WTradj;WTrnoun]−FdecWTrAN||22−||λFdec||22whereWTradj,WTrnoun,WTrANarethematricesobtainedbystackingthetrainingdatavectors.Theλparam-eteristunedthroughgeneralizedcross-validation(Hastieetal.,2009).2.3RepresentationalSpacesLinguisticSpaceWeconstructdistributionalvec-torsfromtextthroughthemethodrecentlyproposedbyMikolovetal.(2013),towhichwefeedacor-pusof2.8billionwordsobtainedbyconcatenatingEnglishWikipedia,ukWaCandBNC.5Specifically,weusedtheCBOWalgorithm,whichinducesvec-torsbypredictingatargetwordgiventhewordssur-roundingit.Weconstructvectorsof300dimensionsconsideringacontextwindowof5wordstoeithersideofthetarget,settingthesub-samplingoptionto1e-05andthenegativesamplingparameterto5.6VisualSpacesFollowingstandardpractice,im-agesarerepresentedasbagsofvisualwords(BoVW)(SivicandZisserman,2003).7Locallow-levelimagefeaturesareclusteredintoasetofvisualwordsthatactashigher-leveldescriptors.Inourcase,weusePHOW-colorimagefeatures,avari-antofdenseSIFT(Boschetal.,2007),andavi-sualvocabularyof600words.Spatialinformationispreservedwithatwo-levelspatialpyramidrep-resentation(Lazebniketal.,2006),achievingafi-naldimensionalityof12,000.TheentirepipelineisimplementedusingtheVLFeatlibrary(VedaldiandFulkerson,2010),anditssetupisidenticaltothe5http://wacky.sslmit.unibo.it,http://www.natcorp.ox.ac.uk6TheparametersaretunedontheMENwordsimilaritydataset(Brunietal.,2014).7Infutureresearch,wemightobtainaperformanceboostsimplybyusingthemoreadvancedvisualfeaturesrecentlyin-troducedbyKrizhevskyetal.(2012).
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
l
a
c
_
a
_
0
0
1
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
187
CategoryAttributesColorblack,blue,brown,gray,green,orange,pink,red,violet,white,yellowPatternspotted,stripedShapelong,round,rectangular,squareTexturefurry,smooth,rough,shiny,metallic,vegetation,wooden,wetTable1:Listofattributesintheevaluationdataset.ImageAttributesObjectfurrycatwhitesmoothgreencocktailshinyTable2:Sampleannotationsfromtheevaluationdataset.toolkit’sbasicrecognitionsampleapplication.8WeapplyPositivePointwiseMutualInformation(Evert,2005)totheBoVWcounts,andreducetheresultingvectorsto300dimensionsusingSVD.2.4EvaluationDatasetForevaluationpurposes,weusethedatasetconsist-ingofimagesannotatedwithadjective-nounphrasesintroducedinRussakovskyandFei-Fei(2010),whichpertainsto384WordNet/ImageNetsynsetswith25imagespersynset.Theimagesweremanu-allyannotatedwith25attribute-denotingadjectivesrelatedtotexture,color,patternandshape,respect-ingtheconstraintsthatacolormustcoverasignifi-cantpartofthetargetobject,andallotherattributesmustpertaintotheobjectasawhole(asopposedtoparts).Table1liststhe25attributesandTable2illustratessampleannotations.9Inordertoincreaseannotationquality,weonlyconsiderattributeswithfullannotatorconsensus,foratotalof8,449annotatedimages,with2.7attributesper-imageonaverage.Furthermore,tomakethelin-guisticannotationmorenaturalandavoidsparsityproblems,werenamedexcessivelyspecificobjectswithanoundenotingamoregeneralcategory,fol-lowingrecentworkonentry-levelcategories(Or-8http://www.vlfeat.org/applications/apps.html9Althoughvegetationisanoun,wehavekeptitintheeval-uationset,treatingitasanadjective.TrainingEvaluation#im.#attr.#obj.#im.#attr.#obj.Exp.110,74997-leave-one-attribute-outExp.223,000-7508,44925203Table3:Summaryoftrainingandevaluationsets.donezetal.,2013);e.g.,colobusguerezawasre-labeledasmonkey.Thefinalevaluationdatasetcon-tains203distinctobjects.3Experiment1:Zero-shotattributelearningInSection1,weshowedthatthereisasignifi-cantcorrelationbetweenpairwisesimilaritiesofad-jectivesinalanguage-baseddistributionalseman-ticspaceandthoseofvisualfeaturevectorsex-tractedfromimageslabeledwiththecorrespondingattributes.Inthefirstexperiment,wetestwhetherthiscorrespondenceinattribute-adjectivesimilar-itystructureacrossmodalitiessufficestosuccess-fullyapplyzero-shotlabeling.Welearnacross-modalfunctionfromanannotateddatasetanduseittolabelimagesfromanevaluationdatasetwithattributesoutsidethetrainingset.WewillrefertothisapproachasDIRA,forDirectRetrievalusingAttributeannotation.Notethatthisisthefirsttimethatzero-shottechniquesareusedintheattributedomain.Inthepresentevaluation,wedistinguishDIRA-RIDGEandDIRA-NCCA,accordingtothecross-modalfunctionusedtoprojectfromimagestolinguisticrepresentations(seeSection2.1above).3.1Cross-modaltrainingandevaluationTogathersufficientdatatotrainacross-modalmappingfunctionforattributes/adjectives,wecom-binethepubliclyavailabledatasetsofFarhadietal.(2009)andFerrariandZisserman(2007)withat-tributesandassociatedimagesextractedfromMIR-FLICKR(HuiskesandLew,2008).10Theresultingdatasetcontains72distinctattributesand2,300im-ages.Eachimage-attributepairrepresentsatrainingdatapoint(v,wadj),wherevisthevectorrepresen-tationoftheimage,andwadjisthelinguisticvectoroftheattribute(correspondingtoanadjective).Noinformationaboutthedepictedobjectisneeded.10Wefilteredoutattributesnotexpressedbyadjectives,suchaswheelorleg.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
l
a
c
_
a
_
0
0
1
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
188
0.40.50.60.70.80.91Dirᴬ-RidgeDecDirᴬ-nCCARussakovsky and Fei-Fei (2010)AttributesRoc AreaFigure3:Performanceofzero-shotattributeclassification(asmeasuredbyAUC)comparedtothesupervisedmethodofRussakovskyandFei-Fei(2010),whereavailable.Thedark-redhorizontallinemarkschanceperformance.Tofurthermaximizetheamountoftrainingdatapoints,weconductaleave-one-attribute-outevalua-tion,inwhichthecross-modalmappingfunctionisrepeatedlylearnedonall72attributesfromthetrain-ingset,aswellasallbutoneattributefromtheeval-uationset(Section2.4),andtheassociatedimages.Thisresultsin72+(25−1)=96trainingattributesintotal.Onaverage,45imagesperattributeareused.Theperformanceismeasuredforthesingleattributethatwasexcludedfromtraining.Anumeri-calsummaryoftheexperimentsetupispresentedinthefirstrowofTable3.3.2ResultsanddiscussionRussakovskyandFei-Fei(2010)trainedseparateSVMclassifiersforeachattributeintheevaluationdatasetinacross-validationsetting.Thisfullysu-pervisedapproachcanbeseenasanambitiousup-perboundforzero-shotlearning,andwedirectlycompareourperformancetotheirsusingtheirfigureofmerit,namelyareaundertheROCcurve(AUC),whichiscommonlyusedforbinaryclassificationproblems.11AperfectclassifierachievesanAUCof1,whereasanAUCof0.5indicatesrandomguess-ing.ForpurposesofAUCcomputation,DIRAisconsideredtolabeltestimageswithagivenadjec-tiveifthelinguistic-spacedistancebetweentheirmappedrepresentationandtheadjectiveisbelowacertainthreshold.AUCmeasurestheaggregatedperformanceoverallthresholds.Togetasenseof11Table4reportshit@kresultsforDIRA,whichwillbedis-cussedbelowinthecontextofExperiment2.whatAUCcomparestointermsofprecisionandre-call,theAUCofDIRAforfurryis0.74,whiletheprecisionis71%andthecorrespondingrecall14%.Forthemoredifficultbluecase,AUCisat0.5,pre-cisionandrecallare2%and55%,respectively.TheAUCresultsarepresentedinFigure3(ig-noreredbarsfornow).Weobservefirstthat,ofthetwomappingfunctionsweconsidered,RIDGE(bluebars)clearlyoutperformsNCCA(yellowbars).Ac-cordingtoaseriesofpairedpermutationtests,RIDGEhasasignificantlylargerAUCin13/25cases,NCCAinonly2.Thisissomewhatsurpris-inggiventhebetterperformanceofNCCAintheexperimentsofGongetal.(2014).However,oursetupisquitedifferentfromtheirs:Theyperformallretrievaltasksbyprojectingtheinputvisualandlanguagedataontoacommonmultimodalspacedif-ferentfrombothinputspaces.NCCAisawell-suitedalgorithmforthis.Weaiminsteadatproduc-inglinguisticannotationsofimages,whichismoststraightforwardlyaccomplishedbyprojectingvisualrepresentationsontolinguisticspace.Regression-basedlearning(inourcase,viaRIDGE)isamorenaturalchoiceforthispurpose.Comingnowtoamoregeneralanalysisofthere-sults,asexpected,andanalogouslytothesupervisedsetting,DIRA-RIDGEperformancevariesacrossat-tributes.Someachieveperformanceclosetothesupervisedmodel(e.g.,rectangularorwooden)and,for18outof25,theperformanceiswellabovechance(bootstraptest).Theexceptionsare:blue,square,round,vegetation,smooth,spottedandstriped.Interestingly,forthelast4attributesin
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
l
a
c
_
a
_
0
0
1
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
189
thislist,RussakovskyandFei-Fei(2010)achievedtheirlowestperformance,attributingittothelower-qualityofthecorrespondingimageannotations.Furthermore,RussakovskyandFei-Fei(2010)ex-cluded5attributesduetoinsufficienttrainingdata.Ofthese,ourperformanceforblue,vegetationandsquareisnotparticularlyencouraging,butforvioletandpinkweachievemorethan0.7AUC,atthelevelofthesupervisedclassifiers,suggestingthatthepro-posedmethodcancomplementthelatterwhenan-notateddataarenotavailable.ForadifferentperspectiveontheperformanceofDIRA,wetookseveralobjectsandqueriedthemodelfortheirmostcommonattribute,basedontheaverageattributerankacrossallimagesoftheobjectinthedataset.Reassuringly,welearnthatsunflow-ersareonaverageyellow(meanrank2.3),fieldsaregreen(4.4),cabinetsarewooden(4)andvansmetal-lic(6.6)(strawberriesare,suspiciously,blue,2.7).Overall,thisexperimentshowsthat,justlikeob-jectclassification,attributeclassifiersbenefitfromknowledgetransferbetweenthevisualandlinguis-ticmodalities,andzero-shotlearningcanachievereasonableperformanceonattributesandthecorre-spondingadjectives.Thisconclusionisbasedontheassumptionthatper-imageannotationsofattributesareavailable;inthefollowingsection,weshowhowequalandevenbetterperformancecanbeattainedusingdatasetsannotatedwithobjectsonly,there-forewithoutanyhand-codedattributeinformation.4Experiment2:LearningattributesfromobjectsandvisualphrasesHavingshownthatreasonablyaccurateannotationsofunseenattributescanbeobtainedwithzero-shotlearningwhenasmallamountofmanualannota-tionisavailable,wenowproceedtotesttheintu-ition,preliminarilysupportedbythedatainFigure1,that,sinceobjectsarebundlesofattributes,at-tributesareimplicitlylearnedtogetherwithobjects.Wethustrytoinduceattribute-denotingadjectivela-belsbyexploitingonlywidely-availableobject-noundata.Atthesametime,buildingontheobserva-tionillustratedinFigure2thatpicturesofobjectsarepicturesofvisualphrases,weexperimentwithavectordecompositionmodelwhichtreatsimagesascompositeandderivesadjectiveandnounanno-tationsjointly.Wecompareitwithstandardzero-shotlearningusingdirectlabelretrievalaswellasagainstanumberofchallengingalternativesthatex-ploitgold-standardinformationaboutthedepictedobjects.ThesecondrowofTable3givesanumeri-calsummaryofthesetupforthisexperiment.4.1Cross-modaltrainingWenowassumeobjectannotationsonly,intheformoftrainingdata(v,wnoun),wherevisthevectorrepresentationofanimagetaggedwithanobjectandwnounisthelinguisticvectorofthecorrespondingnoun.Toensurehighimageabilityanddiversity,weuseastrainingobjectlabelsthoseappearingintheCIFAR-100dataset(Krizhevsky,2009),combinedwiththosepreviouslyusedintheworkofFarhadietal.(2009),aswellasthemostfrequentnounsinourcorpusthatalsoexistinImageNet,foratotalof750objects-nouns.Foreachobjectlabel,wein-cludeatmost50imagesfromthecorrespondingIm-ageNetsynset,resultingin≈23,000trainingdatapoints.Imagescontainingobjectsfromtheevalua-tiondatasetareexcluded,sothatbothadjectiveandnounretrievaladheretothezero-shotparadigm.4.2Object-agnosticmodelsDIROTheDirectRetrievalusingObjectannota-tionapproachprojectsanimageontothelinguisticspaceandretrievesthenearestadjectivesascandi-dateattributelabels.TheonlydifferencewithDIRA(moreprecisely,DIRA-RIDGE),thezero-shotap-proachwetestedabove,isthatthemappingfunctionhasbeentrainedonobject-noundataonly.DECTheDecompositionmethodusesthefDecfunctioninspiredbyDinuandBaroni(2014)(seeSection2.2),toassociatetheimagevectorprojectedontolinguisticspacetoanadjectiveandanoun.WetrainfDecwithabout≈50,000traininginstances,selectedbasedoncorpusfrequency.Thesedataarefurtherbalancedbynotallowingmorethan100trainingsamplesforanyadjectiveornouninordertopreventveryfrequentwordssuchasotherornewfromdominatingthetrainingdata.Noimagedataareused,andthereisnoneedformanualannota-tion,astheadjective-nountuplesareautomaticallyextractedfromthecorpus.Attesttime,givenanimagetobelabeled,
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
l
a
c
_
a
_
0
0
1
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
190
weprojectitsvisualrepresentationontothelin-guisticspaceanddecomposetheresultingvectorw0intotwocandidateadjectiveandnounvectors:[w0adj;w0noun]=fDec(w0).Wethensearchthelin-guisticspaceforadjectivesandnounswhosevectorsarenearesttow0adjandw0noun,respectively.4.3Object-informedmodelsAcross-modalfunctiontrainedexclusivelyonobject-noundatamightbeabletocaptureonlypro-totypicalcharacteristicsofanobject,asinducedfromtext,independentlyofwhethertheyarede-pictedinanimage.Althoughthegoldannotationofourdatasetshouldalreadypenalizethisimage-independentlabelingstrategy(seeSection2.4),wecontrolforthisbehaviourbycomparingagainstthreemodelsthathaveaccesstothegoldnounan-notationsoftheimageandfavoradjectivesthataretypicalmodifiersofthenouns.LMWebuildabigramLanguageModelbyusingtheBerkeleyLMtoolkit(PaulsandKlein,2012)12ontheone-trillion-tokenGoogleWeb1Tcorpus13andsmoothprobabilitieswiththe“Stupid”back-offtechnique(Brantsetal.,2007).Givenanimagewithobject-nounannotation,wescoreallattributes-adjectivesbasedonthelanguage-model-derivedconditionalprobabilityp(adjective|noun).Allimagesofthesameobjectproduceidenticalrankings.Asanexample,amongthetopattributesofcocktailwefindheady,creamyandfruity.VLMLMdoesnotexploitvisualinformationabouttheimagetobeannotated.AnaturalwaytoenhanceitistocombineitwithDIRO,ourcross-modalmappingadjectiveretrievalmethod.Inthevisually-enrichedLanguageModel,weinterpolate(usingequalweights)theranksproducedbythetwomodels.Intheresultingcombination,attributesthatarebothlinguisticallysensibleandlikelytobepresentinthegivenimageshouldberankedhigh-est.Weexpectthisapproachtobechallengingtobeat.MacKenzie(2014)recentlyintroducedasimi-larmodelinasupervisedsetting,whereitimprovedoverstandardattributeclassifiers.12https://code.google.com/p/berkeleylm/13https://catalog.ldc.upenn.edu/LDC2006T13LMSPVLMDIRODECDIRA@12051107@5571643123@10892994437@20181750195951@50333272438168@100565582678977Table4:Percentagehit@kattributeretrievalscores.SPTheSelectionalPreferencemodelrobustlycapturessemanticrestrictionsimposedbyanounontheadjectivesmodifyingit(Erketal.,2010).Con-cretely,foreachnoundenotingatargetobject,weidentifyasetofadjectivesADJnounthatco-occurwithitinamodifierrelationmorethat20times.Byaveragingthelinguisticvectorsoftheseadjec-tives,weobtainavectorwprototypicalnoun,whichshouldcapturethesemanticsoftheprototypicaladjectivesforthatnoun.Adjectivesthathavehighersimilar-itywiththisprototypevectorareexpectedtodenotetypicalattributesofthecorrespondingnounandwillberankedasmoreprobableattributes.SimilarlytoLM,allimagesofthesameobjectproduceidenticalrankings.Asanexample,amongthetopattributesofcocktailwefindfantastic,deliciousandperfect.4.4ResultsWeevaluatetheperformanceofthemodelsonattribute-denotingadjectiveretrieval,usingasearchspacecontainingthetop5,000mostfrequentad-jectivesinourcorpus.Tables4and5presenthit@kandrecall@kresults,respectively(k∈{1,5,10,20,50,100}).Hit@kmeasurestheper-centageofimagesforwhichatleastonegoldat-tributeexistsamongthetopkretrievedattributes.Recall@kmeasurestheproportionofgoldattributesretrievedamongthetopk,relativetothetotalnum-berofgoldattributesforeachimage.14Firstofall,weobservethatLMandSP–thetwomodelsthathaveaccesstogoldobject-nounannota-tionandareentirelylanguage-based–althoughwellabovetherandombaseline(k/5,000),achieveratherlowperformance.Thisconfirmsthattomodelourtestsetaccurately,itisnotsufficienttopredicttypi-calattributesofthedepictedobjects.14Duetotheleave-one-attribute-outapproachusedtotrainandtestDIRA(seeSection3),itisnotpossibletocomputerecallresultsforthismodel.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
l
a
c
_
a
_
0
0
1
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
191
LMSPVLMDIRODEC@110204@5237215@103515423@2091030935@502020492259@1003534614470Table5:Percentagerecall@kattributeretrievalscores.DIRODECDIRA@1120@53100@105141@209202@5020296@100334112Table6:Percentagehit@knounretrievalscores.TheDIROmethod,whichexploitsvisualin-formation,performsnumericallysimilarlytotheobject-informedmodelsLMandSP,withbetterhitandrecallathighranks.AlthoughworsethanDIRA,therelativelyhighperformanceofDIROisapromisingresult,suggestingobjectannotationsto-getherwithlinguisticknowledgeextractedinanun-supervisedmannerfromlargecorporacanreplace,tosomeextent,manualattributeannotations.How-ever,DIROdoesnotdirectlymodelanysemanticcompatibilityconstraintsbetweentheretrievedad-jectivesandtheobjectpresentintheimage(seeex-amplesbelow).Hence,theobject-informedmodelVLM,whichcombinesvisualinformationwitlin-guisticco-occurrencestatistics,doublestheperfor-manceofDIRO,LMandSP.OurDECmodel,whichtreatsimagesasvisualphrasesandjointlydecouplestheirsemantics,out-performsevenVLMbyalargemargin.Italsoout-performsDIRA,thestandardzero-shotlearningap-proachusingattribute-adjectiveannotateddata(seealsotheattribute-by-attributeAUCcomparisonbe-tweenDEC,DIRAandthefully-supervisedap-proachofRussakovskyandFei-FeiinFigure3).Interestingly,accountingforthephrasalnatureofvisualinformationleadstosubstantialperformanceimprovementinobjectrecognitionthroughzero-shotlearning(i.e.,taggingimageswiththedepictednouns)aswell.Table6providesthehit@kresultsobtainedwiththeDIROandDECmethodsforthenounretrievaltaskinasearchspaceof10,000mostImageModelTopitemTophit(Rank)A:white,brownN:dogDECA:whitewhite(1)N:dogdog(1)DIROA:animalwhite(27)N:goatdog(25)LMA:straybrown(74)VLMA:petbrown(17)A:shiny,roundN:syrupDECA:shinyshiny(1)N:flansyrup(170)DIROA:crunchyshiny(15)N:ramekinsyrup(113)LMA:chocolateshiny(84)VLMA:chocolateshiny(17)Table7:Imageswithgoldattribute-adjectiveandobject-nounlabels,andhighest-rankeditemsforeachmodel(Topitem),aswellashighest-rankedcorrectitemandrank(Tophit).Nounresultsfor(V)LMareomittedsincethesemodelshaveaccesstothegoldnounlabel.frequentnounsfromourcorpus.NotethatDIROrepresentsthelabelretrievaltechniquethathasbeenstandardlyusedinconjunctionwithzero-shotlearn-ingforobjects:Thecross-modalfunctionistrainedonimagesannotatedwithnounsthatdenotetheob-jectstheydepict,anditisthenusedfornounlabelretrievalofunseenobjectsthroughanearestneigh-borsearchofthemappedimagerepresentation(theDIRAcolumnshowsthatzero-shotnounretrievalusingthemappingfunctiontrainedonadjectivesworksverypoorly).DECdecomposesinsteadthemappedimagerepresentationintotwovectorsde-notingadjectiveandnounsemantics,respectively,andusesthelattertoperformthenearestneigh-borsearchforanounlabel.Althoughnotdirectlycomparable,theresultsofDECreportedhereareinthesamerangeofstate-of-the-artzero-shotlearningmodelsforobjectrecognition(Fromeetal.,2013).AnnotationexamplesTable7presentssomein-terestingpatternsweobservedintheresults.Thefirstexampleillustratesthecaseinwhichconductingadjectiveandnounretrievalindependentlyresultsinmixinginformation,whichdamagestheDIROap-proach:Adjectivalandnominalpropertiesarenotdecoupledproperly,sincetheanimalpropertyofthedepicteddogisreflectedinboththeanimaladjec-tiveandthegoatnoun.Atthesametime,thewhite-
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
l
a
c
_
a
_
0
0
1
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
192
nessoftheobject(anadjectivalproperty)influencesnounselection,sincegoatstendtobewhite.Instead,DECunpacksthevisualsemanticsinanaccurateandmeaningfulway,producingcorrectattributeandnounannotationsthatformacceptablephrases.LMandVLMarenegativelyaffectedbyco-occurrencestatisticsandguessstrayandpetasadjectives,bothtypicalbutgenericandabstractdogproperties.Inthenextexample,DIROpredictsareason-ablenounlabel(ramekin),focusingonthecontainerratherthantheliquiditcontains.Byignoringtherelationbetweentheadjectiveandthenoun,there-sultingadjectiveannotation(crunchy)issemanti-callyincompatiblewiththenounlabel,emphasizingtheinabilityofthismethodtoaccountforsemanticrelationsbetweenattributes-adjectivesandobject-nouns.DEC,ontheotherhand,mistakenlyanno-tatestheobjectasflaninsteadofsyrup.However,havingcapturedtherightgeneralcategoryoftheob-ject(“smoothgelatinousitemsthatreflectlight”),itranksasemanticallyappropriateandcorrectat-tribute(shiny)atthetop.Finally,LMandVLMchoosechocolate,anattributesemanticallyappro-priateforsyrupbutirrelevantforthetargetimage.SemanticplausibilityofphrasesTheexamplesabovesuggestthatonefundamentalwayinwhichDECimprovesoverDIROisbyproducingseman-ticallycoherentadjective-nouncombinations.Moresystematicevidenceforthisconjectureisprovidedbyafollow-upexperimentonthelinguisticqual-ityofthegeneratedphrases.Werandomlysampled2imagesforeachofthe203objectsinourdataset.Foreachimage,weletthetwomodelsgen-erate9descriptivephrasesbycombiningtheirre-spectivetop3adjectiveandnounpredictions.Fromtheresultinglistsof3,654phrases,wepickedthe200mostcommononesforeachmodel,withonly1/8ofthesecommonphrasesbeingsharedbyboth.Theselectedphraseswerepresented(inrandomor-derandconcealingtheirorigin)totwolinguistically-sophisticatedannotators,whowereaskedtoratetheirdegreeofsemanticplausibilityona1-3scale(theannotatorswerenotshownthecorrespondingimagesandhadtoevaluatephrasespurelyonlin-guistic/semanticgrounds).Sincethetwojudgeswerelargelyinagreement(ρ=0.63),weaveragedtheirratings.ThemeanaveragedplausibilityscoreDEC LMvLMDIRODIRA0.250.30.350.40.450.50.55SPFigure4:Distributionsof(per-image)concretenessscoresacrossdifferentmodels.Redlinemarksmedianvalues,boxedgescorrespondto1stand3rdquartiles,thewiskersextendtothemostextremedatapointsandout-liersareplottedindividually.forDIROphraseswas1.74(s.d.:0.76),forDECitwas2.48(s.d.:0.64),withthedifferencesignificantaccordingtoaMann-Whitneytest.Thetwoanno-tatorsagreedinassigningthelowestscore(“com-pletelyimplausible”)tomorethan1/3oftheDIROphrases(74/200;e.g.,tinnedtostada,animalbird,hollowhyrax),buttheyunanimouslyassignedthelowestscoretoonly7/200DECphrases(e.g.,cylin-dricalbed-sheet,sweetramekin,woodenmeat).Wethushavesolidquantitativesupportthatthesuperior-ityofDECispartiallyduetohowitlearnstojointlyaccountforadjectiveandnounsemantics,producingphrasesthatarelinguisticallymoremeaningful.AdjectiveconcretenessWecangainfurtherin-sightintothenatureoftheadjectiveschosenbythemodelsbyconsideringthefactthatphrasesthataremeanttodescribeanobjectinapictureshouldmostlycontainconcreteadjectives,andthusthede-greeofconcretenessoftheadjectivesproducedbyamodelisanindirectmeasureofitsquality.Follow-ingHillandKorhonen(2014),wedefinethecon-cretenessofanadjectiveastheaverageconcretenessscoreofthenounsitmodifiesinourtextcorpus.Nounconcretenessscoresaretaken,inturn,fromTurneyetal.(2011).Foreachtestimageandmodel,weobtainaconcretenessscorebyaveragingthecon-cretenessofthetop5adjectivesthatthemodelse-lectedfortheimage.Figure4reportsthedistribu-tionsoftheresultingscoresacrossmodels.Wecon-
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
l
a
c
_
a
_
0
0
1
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
193
firmthatthepurelylanguage-basedmodels(LM,SP)areproducinggenericabstractadjectivesthatarenotappropriatetodescribeimages(e.g.,crypto-graphickey,homemadebread,Greeksalad,beatenyolk).Theimage-informedVLMandDIROmodelsproduceconsiderablymoreconcreteadjectives.Notsurprisingly,DIRA,thatwasdirectlytrainedoncon-creteadjectives,producesthemostconcreteones.Importantly,DEC,despitebeingbasedonacross-modalfunctionthatwasnotexplicitlyexposedtoadjectives,producedadjectivesthatareapproachingtheconcretenesslevelofthoseofDIRA(bothdiffer-encesbetweenDECandDIRO,DECandDIRAaresignificantasbypairedMann-Whitneytests).5UsingDECforattribute-basedobjectclassificationAsdiscussedintheintroduction,attributescanef-fectivelybeusedforattribute-basedobjectclas-sification.Inthissection,weshowthatclas-sifierstrainedonattributerepresentationscreatedwithDEC–whichdoesnotrequireanyattribute-annotatedtrainingdatanortrainingabatteryofat-tributeclassifiers–outperform(andarecomplemen-taryto)standardBoVWfeatures.WeuseasubsetofthePascalVOC2008dataset.15Specifically,followingFarhadietal.(2009),weusetheoriginalVOCtrainingsetfortraining/validation,andtheVOCvalidationsetfortesting.One-vs-alllinear-SVMclassifiersaretrainedforallVOCob-jects,using3alternativeimagerepresentations.First,wetraindirectlyonBoVWfeatures(PHOW,seeSection2.3),asintheclassicobjectrecognitionpipeline.WecomparePHOWtoanattribute-centricapproachwithattributelabelsauto-maticallygeneratedbyDEC.AllVOCimagesareprojectedontothelinguisticspaceusingthecross-modalmappingfunctiontrainedwithobject-noundataonly(seeSection4.1),fromwhichwefurtherremovedallimagesdepictingaVOCobject.EachimageprojectionisthendecomposedthroughDECintotwovectorsrepresentingadjectiveandnounin-formation.Thefinalattribute-centricvectorrepre-sentinganimageiscreatedbyrecordingthecosinesimilaritiesoftheDEC-generatedadjectivevector15http://pascallin.ecs.soton.ac.uk/challenges/VOC/voc2008/ImageObjectPredictedAttributesaeroplanethick,wet,dry,cylindrical,motionless,translucentdogcuddly,wild,cute,furry,white,colouredTable8:TwoVOCimageswithsometopattributesas-signedbyDEC:theseattributes,togetherwiththeirco-sinesimilaritiestothemappedimagevectors,serveasattribute-centricrepresentations.withalltheadjectivesinourlinguisticspace.Infor-mally,thisrepresentationcanbethoughtofasavec-torofweightsdescribingtheappropriatenessofeachadjectiveasanannotationfortheimage.16Thisiscomparabletostandardattribute-basedclassification(Farhadietal.,2009),inwhichimagesarerepre-sentedasdistributionsoverattributesestimatedwithasetofadhocsupervisedattribute-specificclassi-fiers.Table8showexamplesoftopattributesauto-maticallyassignedbyDEC.Whilenotnearlyasac-curateasmanualannotation,manyattributesarerel-evanttotheobjects,bothasspecificallydepictedintheimage(theaeroplaneiswet),butalsomorepro-totypically(aeroplanesarecylindricalingeneral).Wealsoperformfeature-levelfusion(FUSED)byconcatenatingthePHOWandDECfeatures,andre-ducingtheresultingvectorto100dimensionswithSVD(Brunietal.,2014)(SVDdimensionalityde-terminedbycross-validationonthetrainingset).5.1ResultsThereisanimprovementoverPHOWvisualfeatureswhenusingDEC-basedattributevectors,withaccu-racyraisingfrom30.49%to32.76%.TheconfusionmatricesinFigure5showthatPHOWandDECdonotonlydifferinquantitativeperformance,butmakedifferentkindsoferrors,inpartpointingatthedif-ferentmodalitiesthetwomodelstapinto.PHOW,forexample,tendstoconfusecatswithsofas,prob-ablybecausetheformerareoftenpicturedlyingon16Giventhattheresultingrepresentationsareverydense,wesparsifythembysettingtozerosalladjectivedimensionswithcosinebelowtheglobalmeancosinevalue.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
l
a
c
_
a
_
0
0
1
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
194
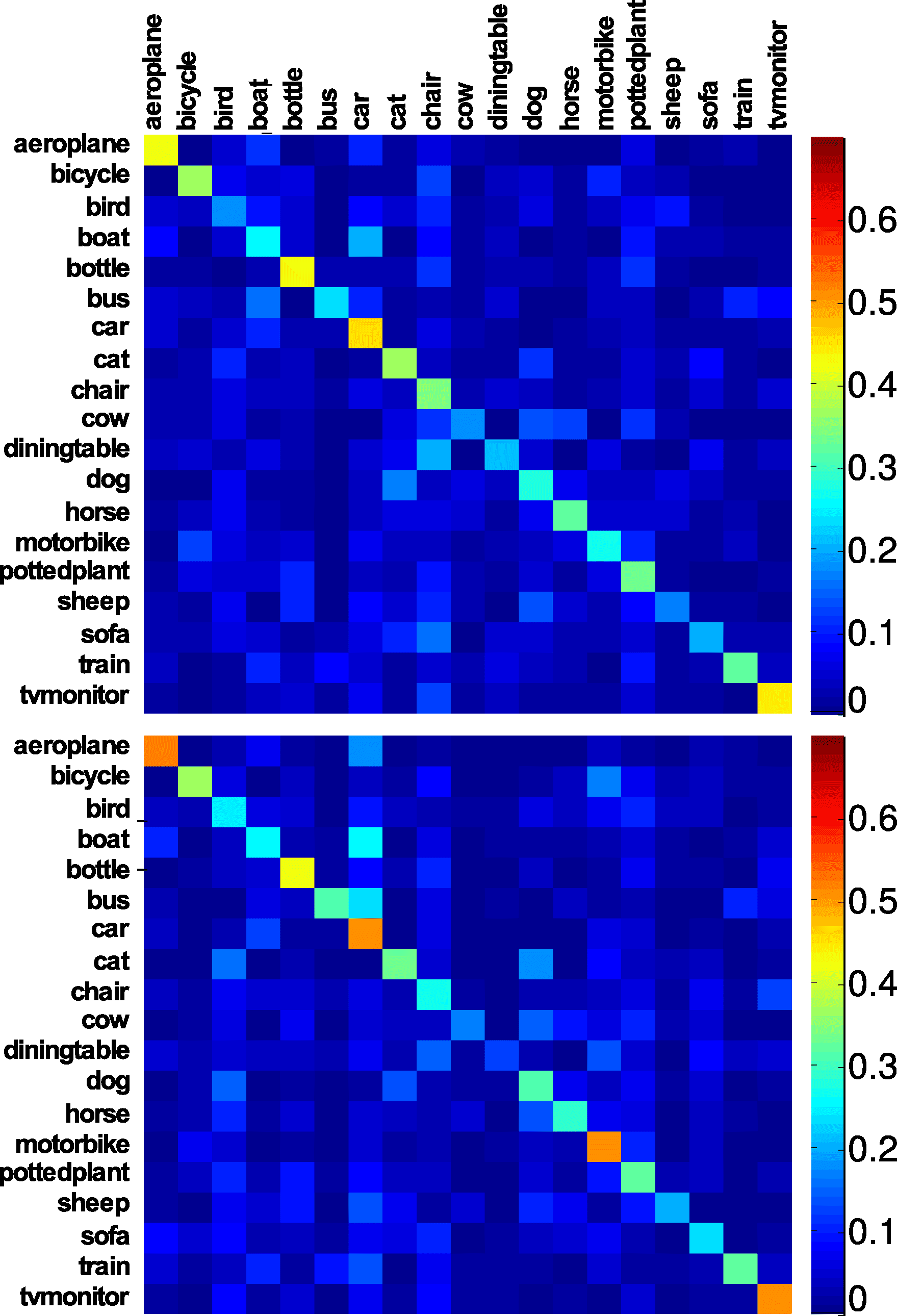
Figure5:ConfusionmatricesforPHOW(top)andDEC(bottom).Warmer-colorcellscorrespondtohigherpro-portionsofimageswithgoldrowlabeltaggedbyanalgo-rithmwiththecolumnlabel(e.g.,thefirstcellsshowthatDECtagsalargerproportionofaeroplanescorrectly).thelatter.DEC,ontheotherhand,tendstocon-fusechairswithTVmonitors,partiallymisguidedbythetaxonomicinformationencodedinlanguage(botharepiecesoffurniture).Indeed,thecombinedFUSEDapproachoutperformsbothrepresentationsbyalargemargin(35.81%),confirmingthatthelinguistically-enrichedinformationbroughtbyDECistoacertainextentcomplementarytothelower-levelvisualevidencedirectlyexploitedbyPHOW.Overall,theperformanceofoursystemisquiteclosetotheoneobtainedbyFarhadietal.(2009)withen-semblesofsupervisedattributeclassifierstrainedonmanuallyannotateddata(themostcomparableac-curacyfromtheirTable1isat34.3%).1717Farhadiandcolleaguesreducethebiasforthepeoplecat-egorybyreportingmeanper-classaccuracy;wedirectlyex-cludedpeoplefromourversionofthedataset.6ConclusionWeextendedzero-shotimagelabelingbeyondob-jects,showingthatitispossibletotagimageswithattribute-denotingadjectivesthatwerenotseendur-ingtraining.Forsomeattributes,performancewascomparabletothatofper-attributesupervisedclassi-fiers.Wefurthershowedthatattributesareimplicitlyinducedwhenlearningtomapvisualvectorsofob-jectstotheirlinguisticrealizationsasnouns,andthatimprovementsinbothattributeandnounretrievalareattainedbytreatingimagesasvisualphrases,whoselinguisticrepresentationsmustbedecom-posedintoacoherentwordsequence.Theresultingmodeloutperformedasetofstrongrivals.Whiletheperformanceofthezero-shotdecompositionalap-proachintheadjective-nounphraselabelingalonemightstillbelowforpracticalapplications,thismodelcanstillproduceattribute-basedrepresenta-tionsthatsignificantlyimproveperformanceinasupervisedobjectrecognitiontask,whencombinedwithstandardvisualfeatures.Bymappingattributesandobjectstophrasesinalinguisticspace,wearealsolikelytoproducemorenaturaldescriptionsthanthosecurrentlyusedincomputervision(fluffykittensratherthan2-boxytables).Infuturework,wewanttodelvemoreintothelinguisticandpragmaticnaturalnessofat-tributes:Canwepredictnotjustwhichattributesofadepictedobjectaretrue,butwhicharemoresalientandthusmorelikelytobementioned(redcarovermetalcar)?Canwepickthemostappro-priateadjectivetodenoteanattributegiventheob-jectinthepicture(moist,ratherthandamplips)?Weshouldalsoaddressattributedependencies:byignoringthem,wecurrentlygetundesiredresults,suchastheaeroplaneinTable8beingtaggedasbothwetanddry.Moreambitiously,inspiredbyKarpa-thyetal.(2014),weplantoassociateimagefrag-mentswithphrasesofarbitrarysyntacticstructures(e.g.,PPsforbackgrounds,aVPsformainevents),pavingthewaytofull-fledgedcaptiongeneration.AcknowledgmentsWethanktheTACLreviewersfortheirfeedback.WeweresupportedbyERC2011StartingIndepen-dentResearchGrantn.283554(COMPOSES).
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
l
a
c
_
a
_
0
0
1
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
195
ReferencesTamaraBerg,AlexanderBerg,andJonathanShih.2010.AutomaticattributediscoveryandcharacterizationfromnoisyWebdata.InProceedingsofECCV,pages663–676,Crete,Greece.AnnaBosch,AndrewZisserman,andXavierMunoz.2007.Imageclassificationusingrandomforestsandferns.InProceedingsofICCV,pages1–8,RiodeJaneiro,Brazil.ThorstenBrants,AshokPopat,PengXu,FranzOch,andJeffreyDean.2007.Largelanguagemodelsinma-chinetranslation.InProceedingsofEMNLP,pages858–867,Prague,CzechRepublic.EliaBruni,NamKhanhTran,andMarcoBaroni.2014.Multimodaldistributionalsemantics.JournalofArti-ficialIntelligenceResearch,49:1–47.JiaDeng,WeiDong,RichardSocher,Lia-JiLi,andLiFei-Fei.2009.Imagenet:Alarge-scalehierarchi-calimagedatabase.InProceedingsofCVPR,pages248–255,MiamiBeach,FL.GeorgianaDinuandMarcoBaroni.2014.Howtomakewordswithvectors:Phrasegenerationindistributionalsemantics.InProceedingsofACL,pages624–633,Baltimore,MD.SantoshDivvala,AliFarhadi,andCarlosGuestrin.2014.Learningeverythingaboutanything:Webly-supervisedvisualconceptlearning.InProceedingsofCVPR,Columbus,OH.KatrinErk,SebastianPad´o,andUlrikePad´o.2010.Aflexible,corpus-drivenmodelofregularandinverseselectionalpreferences.ComputationalLinguistics,36(4):723–763.StefanEvert.2005.TheStatisticsofWordCooccur-rences.Ph.Ddissertation,StuttgartUniversity.AliFarhadi,IanEndres,DerekHoiem,andDavidForsyth.2009.Describingobjectsbytheirattributes.InProceedingsofCVPR,pages1778–1785,MiamiBeach,FL.AliFarhadi,MohsenHejrati,MohammadA.Sadeghi,PeterYoung,CyrusRashtchian,JuliaHockenmaier,andDavidForsyth.2010.Everypicturetellsastory:Generatingsentencesfromimages.InProceedingsofECCV,Crete,Greece.VittorioFerrariandAndrewZisserman.2007.Learningvisualattributes.InProceedingsofNIPS,pages433–440,Vancouver,Canada.AndreaFrome,GregCorrado,JonShlens,SamyBen-gio,JeffDean,Marc’AurelioRanzato,andTomasMikolov.2013.DeViSE:Adeepvisual-semanticem-beddingmodel.InProceedingsofNIPS,pages2121–2129,LakeTahoe,NV.YunchaoGong,LiweiWang,MicahHodosh,JuliaHock-enmaier,andSvetlanaLazebnik.2014.Improvingimage-sentenceembeddingsusinglargeweaklyan-notatedphotocollections.InProceedingsofECCV,pages529–545,Zurich,Switzerland.DavidRHardoon,SandorSzedmak,andJohnShawe-Taylor.2004.Canonicalcorrelationanalysis:Anoverviewwithapplicationtolearningmethods.Neu-ralComputation,16(12):2639–2664.TrevorHastie,RobertTibshirani,andJeromeFriedman.2009.TheElementsofStatisticalLearning,2ndedi-tion.Springer,NewYork.FelixHillandAnnaKorhonen.2014.Concretenessandsubjectivityasdimensionsoflexicalmeaning.InPro-ceedingsofACL,pages725–731,Baltimore,Mary-land.MicahHodosh,PeterYoung,andJuliaHockenmaier.2013.Framingimagedescriptionasarankingtask:Data,modelsandevaluationmetrics.JournalofArti-ficialIntelligenceResearch,47:853–899.HaroldHotelling.1936.Relationsbetweentwosetsofvariates.Biometrika,28(3/4):321–377.MarkHuiskesandMichaelLew.2008.TheMIRFlickrretrievalevaluation.InProceedingsofMIR,pages39–43,NewYork,NY.AndrejKarpathy,ArmandJoulin,andLiFei-Fei.2014.Deepfragmentembeddingsforbidirectionalimagesentencemapping.InProceedingsofNIPS,pages1097–1105,Montreal,Canada.AlexKrizhevsky,IlyaSutskever,andGeoffreyHinton.2012.ImageNetclassificationwithdeepconvolutionalneuralnetworks.InProceedingsofNIPS,pages1097–1105,LakeTahoe,Nevada.AlexKrizhevsky.2009.Learningmultiplelayersoffea-turesfromtinyimages.Master’sthesis.GirishKulkarni,VisruthPremraj,SagnikDhar,SimingLi,YejinChoi,AlexanderBerg,andTamaraBerg.2011.Babytalk:Understandingandgeneratingsim-pleimagedescriptions.InProceedingsofCVPR,pages1601–1608,ColoradoSprings,CO.ChristophHLampert,HannesNickisch,andStefanHarmeling.2009.Learningtodetectunseenobjectclassesbybetween-classattributetransfer.InPro-ceedingsofCVPR,pages951–958,MiamiBeach,FL.AngelikiLazaridou,EliaBruni,andMarcoBaroni.2014.Isthisawampimuk?cross-modalmappingbetweendistributionalsemanticsandthevisualworld.InPro-ceedingsofACL,pages1403–1414,Baltimore,MD.SvetlanaLazebnik,CordeliaSchmid,andJeanPonce.2006.Beyondbagsoffeatures:Spatialpyramidmatchingforrecognizingnaturalscenecategories.InProceedingsofCVPR,pages2169–2178,Washington,DC.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
1
3
2
1
5
6
6
7
5
8
/
/
t
l
a
c
_
a
_
0
0
1
3
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
196
CalvinMacKenzie.2014.Integratingvisualandlinguis-ticinformationtodescribepropertiesofobjects.Un-dergraduateHonorsThesis,ComputerScienceDepart-ment,UniversityofTexasatAustin.TomasMikolov,KaiChen,GregCorrado,andJeffreyDean.2013.Efficientestimationofwordrepresenta-tionsinvectorspace.http://arxiv.org/abs/1301.3781/.MargaretMitchell,XufengHan,JesseDodge,AlyssaMensch,AmitGoyal,AlexBerg,KotaYamaguchi,TamaraBerg,KarlStratos,andHalDaum´eIII.2012.Midge:Generatingimagedescriptionsfromcomputervisiondetections.InProceedingsofEACL,pages747–756,Avignon,France.GregoryMurphy.2002.TheBigBookofConcepts.MITPress,Cambridge,MA.VicenteOrdonez,JiaDeng,YejinChoi,AlexanderBerg,andTamaraBerg.2013.Fromlargescaleimagecate-gorizationtoentry-levelcategories.InProceedingsofICCV,pages1–8,Sydney,Australia.GenevievePatterson,ChenXu,HangSu,andJamesHays.2014.TheSUNattributedatabase:Beyondcat-egoriesfordeepersceneunderstanding.InternationalJournalofComputerVision,108(1-2):59–81.AdamPaulsandDanKlein.2012.Large-scalesyntacticlanguagemodelingwithtreelets.InProceedingsofACL,pages959–968,JejuIsland,Korea.OlgaRussakovskyandLiFei-Fei.2010.Attributelearn-inginlarge-scaledatasets.InProceedingsofECCV,pages1–14.MohammadSadeghiandAliFarhadi.2011.Recognitionusingvisualphrases.InProceedingsofCVPR,pages1745–1752,ColoradoSprings,CO.CarinaSilberer,VittorioFerrari,andMirellaLapata.2013.Modelsofsemanticrepresentationwithvisualattributes.InProceedingsofACL,pages572–582,Sofia,Bulgaria.JosefSivicandAndrewZisserman.2003.VideoGoogle:Atextretrievalapproachtoobjectmatchinginvideos.InProceedingsofICCV,pages1470–1477,Nice,France.RichardSocher,MilindGanjoo,ChristopherManning,andAndrewNg.2013.Zero-shotlearningthroughcross-modaltransfer.InProceedingsofNIPS,pages935–943,LakeTahoe,NV.PeterTurneyandPatrickPantel.2010.Fromfrequencytomeaning:Vectorspacemodelsofsemantics.Jour-nalofArtificialIntelligenceResearch,37:141–188.PeterTurney,YairNeuman,DanAssaf,andYohaiCo-hen.2011.Literalandmetaphoricalsenseidentifi-cationthroughconcreteandabstractcontext.InPro-ceedingsofEMNLP,pages680–690,Edinburgh,UK.LaurensVanderMaatenandGeoffreyHinton.2008.Visualizingdatausingt-SNE.JournalofMachineLearningResearch,9(2579-2605).AndreaVedaldiandBrianFulkerson.2010.VLFeat–anopenandportablelibraryofcomputervisional-gorithms.InProceedingsofACMMultimedia,pages1469–1472,Firenze,Italy.AndreaVedaldi,SiddarthMahendran,StavrosTsogkas,SubhransuMaji,RossGirshick,JuhoKannala,EsaRahtu,IasonasKokkinos,MatthewBlaschko,DavidWeiss,BenTaskar,KarenSimonyan,NaomiSaphra,andSammyMohamed.2014.Understandingobjectsindetailwithfine-grainedattributes.InProceedingsofCVPR,Columbus,OH.