Transactions of the Association for Computational Linguistics, 2 (2014) 105–118. Action Editor: Sharon Goldwater.
Submitted 11/2013; Revised 2/2014; Published 4/2014. c
(cid:13)
2014 Association for Computational Linguistics.
ParallelAlgorithmsforUnsupervisedTaggingSujithRaviGoogleMountainView,CA94043sravi@google.comSergeiVassilivitskiiGoogleMountainView,CA94043sergeiv@google.comVibhorRastogi∗TwitterSanFrancisco,CAvibhor.rastogi@gmail.comAbstractWeproposeanewmethodforunsupervisedtaggingthatfindsminimalmodelswhicharethenfurtherimprovedbyExpectationMax-imizationtraining.Incontrasttopreviousapproachesthatrelyonmanuallyspecifiedandmulti-stepheuristicsformodelminimiza-tion,ourapproachisasimplegreedyapprox-imationalgorithmDMLC(DISTRIBUTED-MINIMUM-LABEL-COVER)thatsolvesthisobjectiveinasinglestep.Weextendthemethodandshowhowtoef-ficientlyparallelizethealgorithmonmodernparallelcomputingplatformswhilepreservingapproximationguarantees.Thenewmethodeasilyscalestolargedataandgrammarsizes,overcomingthememorybottleneckinprevi-ousapproaches.Wedemonstratethepowerofthenewalgorithmbyevaluatingonvarioussequencelabelingtasks:Part-of-Speechtag-gingformultiplelanguages(includinglow-resourcelanguages),withcompleteandin-completedictionaries,andsupertagging,acomplexsequencelabelingtask,wherethegrammarsizealonecangrowtomillionsofentries.Ourresultsshowthatforallofthesesettings,ourmethodachievesstate-of-the-artscalableperformancethatyieldshighqualitytaggingoutputs.1IntroductionSupervisedsequencelabelingwithlargelabeledtrainingdatasetsisconsideredasolvedproblem.For∗∗TheresearchdescribedhereinwasconductedwhiletheauthorwasworkingatGoogle.instance,stateoftheartsystemsobtaintaggingac-curaciesover97%forpart-of-speech(POS)taggingontheEnglishPennTreebank.However,learningaccuratetaggerswithoutlabeleddataremainsachal-lenge.Theaccuraciesquicklydropwhenfacedwithdatafromadifferentdomain,langue,orwhenthereisverylittlelabeledinformationavailablefortraining(BankoandMoore,2004).Recently,therehasbeenanincreasingamountofresearchtacklingthisproblemusingunsuper-visedmethods.ApopularapproachistolearnfromPOS-tagdictionaries(Merialdo,1994),wherewearegivenarawwordsequenceandadictionaryoflegaltagsforeachwordtype.LearningfromPOS-tagdictionariesisstillchallenging.Completeword-tagdictionariesmaynotalwaysbeavailableforuseandineverysetting.Whentheyareavailable,thedictionariesareoftennoisy,resultinginhightag-gingambiguity.Furthermore,whenapplyingtag-gersinnewdomainsordifferentdatasets,wemayencounternewwordsthataremissingfromthedic-tionary.TherehavebeensomeeffortstolearnPOStaggersfromincompletedictionariesbyextendingthedictionarytoincludethesewordsusingsomeheuristics(ToutanovaandJohnson,2008)orusingothermethodssuchastype-supervision(GarretteandBaldridge,2012).Inthiswork,wetackletheproblemofunsuper-visedsequencelabelingusingtagdictionaries.ThefirstreportedworkonthisproblemwasonPOStag-gingfromMerialdo(1994).TheapproachinvolvedtrainingastandardHiddenMarkovModel(HMM)usingtheExpectationMaximization(EM)algo-rithm(Dempsteretal.,1977),thoughEMdoesnot
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
6
9
1
5
6
6
8
2
8
/
/
t
je
un
c
_
un
_
0
0
1
6
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
106
performwellonthistask(Johnson,2007).Morere-centmethodshaveyieldedbetterperformancethanEM(voir(RaviandKnight,2009)foranoverview).OneinterestinglineofresearchintroducedbyRaviandKnight(2009)explorestheideaofper-formingmodelminimizationfollowedbyEMtrain-ingtolearntaggers.TheirideaiscloselyrelatedtotheclassicMinimumDescriptionLengthprinci-pleformodelselection(Barronetal.,1998).Ils(1)formulateanobjectivefunctiontofindthesmall-estmodelthatexplainsthetext(modelminimizationstep),andthen,(2)fittheminimizedmodeltothedata(EMstep).ForPOStagging,thismethod(RaviandKnight,2009)yieldsthebestperformancetodate;91.6%taggingaccuracyonastandardtestdatasetfromtheEnglishPennTreebank.Theorig-inalworkfrom(RaviandKnight,2009)usesanin-tegerlinearprogramming(ILP)formulationtofindminimalmodels,anapproachwhichdoesnotscaletolargedatasets.Ravietal.(2010b)introducedatwo-stepgreedyapproximationtotheoriginalob-jectivefunction(calledtheMIN-GREEDYalgo-rithm)thatrunsmuchfasterwhilemaintainingthehightaggingperformance.GarretteandBaldridge(2012)showedhowtouseseveralheuristicstofur-therimprovethisalgorithm(forinstance,betterchoiceoftagbigramswhenbreakingties)andstackothertechniquesontop,suchascarefulinitializationofHMMemissionmodelswhichresultsinfurtherperformancegains.Theirmethodalsoworksun-derincompletedictionaryscenariosandcanbeap-pliedtocertainlow-resourcescenarios(GarretteandBaldridge,2013)bycombiningmodelminimizationwithsupervisedtraining.Inthiswork,weproposeanewscalablealgorithmforperformingmodelminimizationforthistask.Bymakinganassumptiononthestructureofthesolu-tion,weprovethatavariantofthegreedysetcoveralgorithmalwaysfindsanapproximatelyoptimalla-belset.Thisisincontrasttopreviousmethodsthatemployheuristicapproacheswithnoguaranteeonthequalityofthesolution.Inaddition,wedonothavetorelyonadhoctie-breakingproceduresorcarefulinitializationsforunknownwords.Finally,notonlyistheproposedmethodapproximatelyop-timal,itisalsoeasytodistribute,allowingittoeas-ilyscaletoverylargedatasets.Weshowempiricallythatourmethod,combinedwithanEMtrainingstepoutperformsexistingstateoftheartsystems.1.1OurContributions•Wepresentanewmethod,DISTRIBUTEDMINIMUMLABELCOVER,DMLC,formodelminimizationthatusesafast,greedyalgorithmwithformalapproximationguaranteestothequalityofthesolution.•Weshowhowtoefficientlyparallelizetheal-gorithmwhilepreservingapproximationguar-antees.Incontrast,existingminimizationap-proachescannotmatchthenewdistributedal-gorithmwhenscalingfromthousandstomil-lionsorevenbillionsoftokens.•Weshowthatourmethodeasilyscalestobothlargedataandgrammarsizes,anddoesnotre-quirethecorpusorlabelsettofitintomemory.Thisallowsustotacklecomplextaggingtasks,wherethetagsetconsistsofseveralthousandlabels,whichresultsinmorethanonemillionentriesinthegrammar.•Wedemonstratethepowerofthenewmethodbyevaluatingunderseveraldiffer-entscenarios—POStaggingformultiplelan-guages(includinglow-resourcelanguages),withcompleteandincompletedictionaries,aswellasacomplexsequencelabelingtaskofsu-pertagging.Ourresultsshowthatforallthesesettings,ourmethodachievesstate-of-the-artperformanceyieldinghighqualitytaggings.2RelatedWorkRecently,therehasbeenanincreasingamountofresearchtacklingthisproblemfrommultipledi-rections.SomeeffortshavefocusedoninducingPOStagclusterswithoutanytags(Christodoulopou-losetal.,2010;Reichartetal.,2010;Moonetal.,2010),butevaluatingsuchsystemsprovesdif-ficultsinceitisnotstraightforwardtomaptheclus-terlabelsontogoldstandardtags.Amorepop-ularapproachistolearnfromPOS-tagdictionar-ies(Merialdo,1994;RaviandKnight,2009),incom-pletedictionaries(HasanandNg,2009;GarretteandBaldridge,2012)andhuman-constructeddictionar-ies(Goldbergetal.,2008).
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
6
9
1
5
6
6
8
2
8
/
/
t
je
un
c
_
un
_
0
0
1
6
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
107
Anotherdirectionthathasbeenexploredinthepastincludesbootstrappingtaggersforanewlan-guagebasedoninformationacquiredfromotherlan-guages(DasandPetrov,2011)orlimitedannota-tionresources(GarretteandBaldridge,2013).Ad-ditionalworkfocusedonbuildingsupervisedtag-gersfornoisydomainssuchasTwitter(Gimpeletal.,2011).WhilemostoftherelevantworkinthisareacentersonPOStagging,therehasbeensomeworkdoneforbuildingtaggersformorecomplexsequencelabelingtaskssuchassupertagging(Ravietal.,2010a).OtherrelatedworkincludealternativemethodsforlearningsparsemodelsviapriorsinBayesianin-ference(GoldwaterandGriffiths,2007)andposte-riorregularization(Ganchevetal.,2010).Butthesemethodsonlyencouragesparsityanddonotexplic-itlyseektominimizethemodelsize,whichistheob-jectivefunctionusedinthiswork.Moreover,taggerslearnedusingmodelminimizationhavebeenshowntoproducestate-of-the-artresultsfortheproblemsdiscussedhere.3ModelFollowingRaviandKnight(2009),weformulatetheproblemasthatoflabelselectiononthesentencegraph.Formally,wearegivenasetofsequences,S={S1,S2,…,Sn}whereeachSiisasequenceofwords,Si=wi1,wi2,…,wi,|Si|.WitheachwordwijweassociateasetofpossibletagsTij.Wewilldenotebymthetotalnumberof(possiblydu-plicate)words(tokens)inthecorpus.Additionally,wedefinetwospecialwordsw0andw∞withspecialtagsstartandend,andconsiderthemodifiedsequencesS0i=w0,Si,w∞.Tosim-plifynotation,wewillrefertow∞=w|Si|+1.Thesequencelabelproblemasksustoselectavalidtagtij∈Tijforeachwordwijintheinputtominimizeaspecificobjectivefunction.Wewillrefertoatagpair(ti,j−1,tij)asalabel.Ouraimistominimizethenumberofdistinctlabelsusedtocoverthefullinput.Formally,givenase-quenceS0iandatagtijforeachwordwijinS0i,lettheinducedsetoflabelsforsequenceS0ibeLi=|S0i|[j=1{(ti,j−1,tij)}.Thetotalnumberofdistinctlabelsusedoverallse-quencesisthenφ=(cid:12)(cid:12)∪iLi|=(cid:12)(cid:12)[je|Si|+1[j=1{(ti,j−1,tij)}|.Notethattheorderofthetokensinthelabelmakesadifferenceas{(NN,VP)}et{(VP,NN)}aretwodistinctlabels.Nowwecandefinetheproblemformally,follow-ing(RaviandKnight,2009).Problem1(MinimumLabelCover).GivenasetSofsequencesofwords,whereeachwordwijhasasetofvalidtagsTij,theproblemistofindavalidtagassignmenttij∈Tijforeachwordthatminimizesthenumberofdistinctlabelsortagpairsoverallsequences,φ=(cid:12)(cid:12)SiS|Si|+1j=1{(ti,j−1,tij)}|.TheproblemiscloselyrelatedtotheclassicalSetCoverproblemandisalsoNP-complete.ToreduceSetCovertothelabelselectionproblem,mapeachelementioftheSetCoverinstancetoasinglewordsentenceSi=wi1,andletthevalidtagsTi1con-tainthenamesofthesetsthatcontainelementi.Considerasolutiontothelabelselectionproblem;everysentenceSiiscoveredbytwolabels(w0,ki)et(ki,w∞),forsomeki∈Ti1,whichcorrespondstoanelementibeingcoveredbysetkiintheSetCoverinstance.ThusanyvalidsolutiontothelabelselectionproblemleadstoafeasiblesolutiontotheSetCoverproblem({k1,k2,…})ofexactlyhalfthesize.Finally,wewilluse{{…}}notationtodenoteamultisetofelements,i.e.asetwhereanelementmayappearmultipletimes.4AlgorithmInthisSection,wedescribetheDISTRIBUTED-MINIMUM-LABEL-COVER,DMLC,algorithmforapproximatelysolvingtheminimumlabelcoverproblem.Wedescribethealgorithminacentral-izedsetting,anddeferthedistributedimplementa-tiontoSection5.Beforedescribingthealgorithm,webrieflyexplaintherelationshipoftheminimumlabelcoverproblemtosetcover.4.1ModificationofSetCoverAswepointedoutearlier,theminimumlabelcoverproblemisatleastashardastheSetCoverprob-
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
6
9
1
5
6
6
8
2
8
/
/
t
je
un
c
_
un
_
0
0
1
6
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
108
1:Input:AsetofsequencesSwitheachwordswijhavingpossibletagsTij.2:Output:Atagassignmenttij∈Tijforeachwordwijapproximatelyminimizinglabels.3:LetMbethemultisetofallpossiblelabelsgeneratedbychoosingeachpossibletagt∈Tij.M=[i|Si|+1[j=1[t0∈Ti,j−1t∈Tij{{(t0,t)}}(1)4:LetL=∅bethesetofselectedlabels.5:repeat6:Selectthemostfrequentlabelnotyetse-lected:(t0,t)=argmax(s0,s)/∈L|M∩(s0,s)|.7:Foreachbigram(wi,j−1,wij)wheret0∈Ti,j−1andt∈Tijtentativelyassignt0towi,j−1andttowij.Add(t0,t)toL.8:Ifawordgetstwoassignments,selectoneatrandomwithequalprobability.9:Ifabigram(wi,j−1,wij)isconsistentwithassignmentsin(t0,t),fixthetenta-tiveassignments,andsetTi,j−1={t0}andTij={t}.RecomputeM,themulti-setofpossiblelabels,withtheupdatedTi,j−1andTij.10:untiltherearenounassignedwordsAlgorithm1:MLCAlgorithm1:Input:AsetofsequencesSwitheachwordswijhavingpossibletagsTij.2:Output:Atagassignmenttij∈Tijforeachwordwijapproximatelyminimizinglabels.3:(GraphCreation)InitializeeachvertexvijwiththesetofpossibletagsTijanditsneighborsvi,j+1andvi,j−1.4:repeat5:(MessagePassing)Eachvertexvijsendsitspos-siblytagsTijtoitsforwardneighborvij+1.6:(CounterUpdate)EachvertexreceivesthethetagsTi,j−1andaddsallpossiblelabels{(s,s0)|s∈Ti,j−1,s0∈Tij}toaglobalcounter(M.).7:(MaxLabelSelection)EachvertexqueriestheglobalcounterMtofindthemaximumlabel(t,t0).8:(TentativeAssignment)Eachvertexvijselectsatagtentativelyasfollows:Ifoneofthetagst,t0isinthefeasiblesetTij,ittentativelyselectsthetag.9:(RandomAssignment)Ifbotharefeasibleitse-lectsoneatrandom.Thevertexcommunicatesitsassignmenttoitsneighbors.10:(ConfirmedAssignment)Eachvertexreceivesthetentativeassignmentfromitsneighbors.Iftogetherwithitsneighborsitcanmatchthese-lectedlabel,theassignmentisfinalized.IftheassignedtagisT,thenthevertexvijsetsthevalidtagsetTijto{t}.11:untilnounassignedverticesexist.Algorithm2:DMLCImplementationlem.Anadditionalchallengecomesfromthefactthatlabelsaretagsforapairofwords,andhencearerelated.Forexample,ifwelabelawordpair(wi,j−1,wij)comme(NN,VP),thenthelabelforthenextwordpair(wij,wi,j+1)hastobeoftheform(VP,*),i.e.,ithastostartwithVP.Previouswork(Ravietal.,2010a;Ravietal.,2010b)recognizedthischallengeandemployedtwophaseheuristicapproaches.Eschewingheuristics,wewillshowthatwithonenaturalassumption,evenwiththisextrasetofconstraints,thestandardgreedyalgorithmforthisproblemresultsinasolutionwithaprovableapproximationratioofO(logm).Inpractice,cependant,thealgorithmperformsfarbetterthantheworstcaseratio,andsimilartotheworkof(Gomesetal.,2006),wefindthatthegreedyapproachselectsacoverapproximately11%worsethantheoptimumsolution.4.2MLCAlgorithmWepresentinAlgorithm1ourMINIMUMLABELCOVERalgorithmtoapproximatelysolvethemini-mumlabelcoverproblem.Thealgorithmissimple,efficient,andeasytodistribute.Thealgorithmchooseslabelsoneatatime,select-ingalabelthatcoversasmanywordsaspossiblein
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
6
9
1
5
6
6
8
2
8
/
/
t
je
un
c
_
un
_
0
0
1
6
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
109
everyiteration.Forthis,itgeneratesandmaintainsamulti-setofallpossiblelabelsM(Step3).Themulti-setcontainsanoccurrenceofeachvalidlabel,forexample,ifwi,j−1hastwopossiblevalidtagsNNandVP,andwijhasonepossiblevalidtagVP,thenMwillcontaintwolabels,namely(NN,VP)et(VP,VP).SinceMisamulti-setitwillcontainduplicates,e.g.thelabel(NN,VP)willappearforeachadjacentpairofwordsthathaveNNandVPasvalidtags,respectively.Ineachiteration,thealgorithmpicksalabelwiththemostnumberofoccurrencesinMandaddsittothesetofchosenlabels(Step6).Intuitively,thisisagreedysteptoselectalabelthatcoversthemostnumberofwordpairs.Oncethealgorithmpicksalabel(t0,t),ittriestoassignasmanywordstotagstort0aspossible(Step7).Awordcanbeassignedt0ift0isavalidtagforit,andtavalidtagforthenextwordinsequence.Similarly,awordcanbeassignedt,iftisavalidtagforit,andt0avalidtagforthepreviousword.Somewordscangetbothassignments,inwhichcasewechooseonetentativelyatrandom(Step8).Ifaword’stentativerandomtag,sayt,isconsistentwiththechoicesofitsadjacentwords(sayt0fromthepreviousword),thenthetentativechoiceisfixedasapermanentone.Wheneveratagisselected,thesetofvalidtagsTijforthewordisreducedtoasin-gleton{t}.OncethesetofvalidtagsTijchanges,themulti-setMofallpossiblelabelsalsochanges,asseenfromEq1.Themulti-setisthenrecom-puted(Step9)andtheiterationsrepeateduntilallofwordshavebeentagged.Wecanshowthatunderanaturalassumptionthissimplealgorithmisapproximatelyoptimal.Assumption1(c-feasibility).Letc≥1beanynum-ber,andkbethesizeoftheoptimalsolutiontotheoriginalproblem.Ineachiteration,theMLCalgo-rithmfixesthetagsforsomewords.Wesaythatthealgorithmisc-feasible,ifaftereachiterationthereexistssomesolutiontotheremainingproblem,con-sistentwiththechosentags,withsizeatmostck.Theassumptionencodesthefactthatasinglebadgreedychoiceisnotgoingtodestroytheoverallstructureofthesolution,andanearlyoptimalso-lutionremains.Wenotethatthisassumptionofc-feasibilityisnotonlysufficient,aswewillformallyshow,butisalsonecessary.Indeed,withoutanyas-sumptions,oncethealgorithmfixesthetagforsomewords,anoptimallabelmaynolongerbeconsis-tentwiththechosentags,anditisnothardtofindcontrivedexampleswherethesizeoftheoptimalso-lutiondoublesaftereachiterationofMLC.SincetheunderlyingproblemisNP-complete,itiscomputationallyhardtogivedirectevidencever-ifyingtheassumptiononnaturallanguageinputs.However,onsmallexamplesweareabletoshowthatthegreedyalgorithmiswithinasmallconstantfactoroftheoptimum,specificallyitiswithin11%oftheoptimummodelsizeforthePOStaggingproblemusingthestandard24kdataset(RaviandKnight,2009).Combinedwiththefactthatthefinalmethodoutperformsstateoftheartapproaches,thisleadsustoconcludethatthestructuralassumptioniswelljustified.Lemma1.Undertheassumptionofc-feasibility,theMLCalgorithmachievesaO(clogm)approx-imationtotheminimumlabelcoverproblem,wherem=Pi|Si|isthetotalnumberoftokens.Proof.ToprovetheLemmawewilldefineanobjec-tivefunction¯φ,countingthenumberofunlabeledwordpairs,asafunctionofpossiblelabels,andshowthat¯φdecreasesbyafactorof(1−O(1/ck))ateveryiteration.Todefine¯φ,wefirstdefineφ,thenumberofla-beledwordpairs.Consideraparticularsetofla-bels,L={L1,L2,…,Lk}whereeachlabelisapair(ti,tj).Call{tij}avalidassignmentofto-kensifforeachwij,wehavetij∈Tij.ThenthescoreofLunderanassignmentt,whichwedenotebyφt,isthenumberofbigramlabelsthatappearinL.Formally,φt(L)=|∪i,j{{(ti,j−1,tij)∩L}}|.Enfin,wedefineφ(L)tobethebestsuchassign-ment,φ(L)=maxtφt(L),and¯φ(L)=m−φ(L)thenumberofuncoveredlabels.Considerthelabelselectedbythealgorithminev-erystep.Bythec-feasibilityassumption,thereex-istssomesolutionhavingcklabels.Thus,somela-belfromthatsolutioncoversatleasta1/ckfractionoftheremainingwords.Theselectedlabel(t,t0)maximizestheintersectionwiththeremainingfea-siblelabels.Theconflictresolutionstepensuresthatinexpectationtherealizedbenefitisatleastahalfofthemaximum,therebyreducing¯φbyatleasta
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
6
9
1
5
6
6
8
2
8
/
/
t
je
un
c
_
un
_
0
0
1
6
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
110
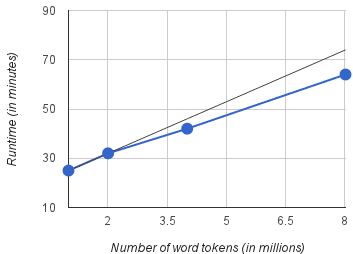
(1−1/2ck)fraction.Therefore,afterO(kclogm)operationsallofthelabelsarecovered.4.3FittingtheModelUsingEMOncethegreedyalgorithmterminatesandreturnsaminimizedgrammaroftagbigrams,wefollowtheapproachofRaviandKnight(2009)andfitthemin-imizedmodeltothedatausingthealternatingEMstrategy.Inthisstep,werunanalternatingoptimizationprocedureiterativelyinphases.Ineachphase,weinitialize(andpruneaway)parameterswithinthetwoHMMcomponents(transitionoremissionmodel)usingtheoutputfromthepreviousphase.Weinitializethisprocedurebyrestrictingthetran-sitionparameterstoonlythosetagbigramsselectedinthemodelminimizationstep.Wetrainincon-junctionwiththeoriginalemissionmodelusingEMalgorithmwhichprunesawaysomeoftheemissionparameters.Inthenextphase,wealternatetheini-tializationbychoosingtheprunedemissionmodelalongwiththeoriginaltransitionmodel(withfullsetoftagbigrams)andretrainusingEM.Thealter-natingEMiterationsareterminatedwhenthechangeinthesizeoftheobservedgrammar(i.e.,thenumberofuniquebigramsinthetaggingoutput)is≤5%.1Werefertoourentireapproachusinggreedymini-mizationfollowedbyEMtrainingasDMLC+EM.5DistributedImplementationTheDMLCalgorithmisdirectlysuitedtowardsparallelizationacrossmanymachines.WeturntoPregel(Malewiczetal.,2010),anditsopensourceversionGiraph(Apa,2013).Inthesesystemsthecomputationproceedsinrounds.Ineveryround,ev-erymachinedoessomelocalprocessingandthensendsarbitrarymessagestoothermachines.Se-mantically,wethinkofthecommunicationgraphasfixed,andineachroundeachvertexperformssomelocalcomputationandthensendsmessagestoitsneighbors.Thismodeofparallelprogrammingdi-rectstheprogrammersto“Thinklikeavertex.”ThespecificsystemslikePregelandGiraphbuildinfrastructurethatensuresthattheoverallsystem1FormoredetailsonthealternatingEMstrategyandhowinitializationwithminimizedmodelsimproveEMperformanceinalternatingiterations,referto(RaviandKnight,2009).isfaulttolerant,efficient,andfast.Inaddition,theyprovideimplementationofcommonlyuseddis-tributeddatastructures,suchas,forexampleglobalcounters.Theprogrammer’sjobissimplytospecifythecodethateachvertexwillrunateveryround.WeimplementedtheDMLCalgorithminPregel.TheimplementationisstraightforwardandgiveninAlgorithm2.Themulti-setMofAlgorithm1isrepresentedasaglobalcounterinAlgorithm2.Themessagepassing(Step3)andcounterupdate(Step4)stepsupdatethisglobalcounterandhenceper-formtheroleofStep3ofAlgorithm1.Step5se-lectsthelabelwithlargestcount,whichisequivalenttothegreedylabelpickingstep6ofAlgorithm1.Fi-nallysteps6,7,and8updatethetagassignmentofeachvertexperformingtherolesofsteps7,8,and9,respectively,ofAlgorithm1.5.1SpeedinguptheAlgorithmTheimplementationdescribedabovedirectlycopiesthesequentialalgorithm.Herewedescribeaddi-tionalstepswetooktofurtherimprovetheparallelrunningtimes.SingletonSets:Astheparallelalgorithmpro-ceeds,thesetoffeasiblesetsassociatedwithanodeslowlydecreases.Atsomepointthereisonlyonetagthatanodecantakeon,howeverthistagisrare,andsoittakesawhileforittobeselectedusingthegreedystrategy.Nevertheless,ifanodeandoneofitsneighborshaveonlyasingletagleft,thenitissafetoassigntheuniquelabel2.ModifyingtheGraph:Asisoftenthecase,thebottleneckinparallelcomputationsisthecommu-nication.Toreducetheamountofcommunicationwereducethegraphonthefly,removingnodesandedgesoncetheynolongerplayaroleinthecompu-tation.Thissimplemodificationdecreasesthecom-municationtimeinlaterroundsasthetotalsizeoftheproblemshrinks.6ExperimentsandResultsInthisSection,wedescribetheexperimentalsetupforvarioustasks,settingsandcompareempiricalperformanceofourmethodagainstseveralexisting2Wemustjudiciouslyinitializetheglobalcountertotakecareofthisassignment,butthisiseasilyaccomplished.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
6
9
1
5
6
6
8
2
8
/
/
t
je
un
c
_
un
_
0
0
1
6
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
111
baselines.Theperformanceresultsforallsystems(onalltasks)aremeasuredintermsoftaggingaccu-racy,i.e.%oftokensfromthetestcorpusthatwerelabeledcorrectlybythesystem.6.1Part-of-SpeechTaggingTask6.1.1TaggingUsingaCompleteDictionaryData:Weuseastandardtestset(consistingof24,115wordtokensfromthePennTreebank)forthePOStaggingtask.Thetagsetconsistsof45dis-tincttaglabelsandthedictionarycontains57,388word/tagpairsderivedfromtheentirePennTree-bank.Per-tokenambiguityforthetestdataisabout1.5tags/token.Inadditiontothestandard24kdataset,wealsotrainandtestonlargerdatasets—973ktokensfromthePennTreebank,3MtokensfromPTB+Europarl(Koehn,2005)data.Methods:WeevaluateandcompareperformanceforPOStaggingusingfourdifferentmethodsthatemploythemodelminimizationideacombinedwithEMtraining:•EM:TrainingabigramHMMmodelusingEMalgorithm(Merialdo,1994).•ILP+EM:Minimizinggrammarsizeusingintegerlinearprogramming,followedbyEMtraining(RaviandKnight,2009).•MIN-GREEDY+EM:Minimizinggrammarsizeusingthetwo-stepgreedymethod(Ravietal.,2010b).•DMLC+EM:Thiswork.Results:Table1showstheresultsforPOStag-gingonEnglishPennTreebankdata.Onthesmallertestdatasets,allofthemodelminimizationstrate-gies(methods2,3,4)tendtoperformequallywell,yieldingstate-of-the-artresultsandlargeimprove-mentoverstandardEM.Whentraining(andtesting)onlargercorporasizes,DMLCyieldsthebestre-portedperformanceonthistasktodate.Amajoradvantageofthenewmethodisthatitcaneasilyscaletolargecorporasizesandthedistributedna-tureofthealgorithmstillpermitsfast,efficientop-timizationoftheglobalobjectivefunction.So,un-liketheearliermethods(suchasMIN-GREEDY)itisfastenoughtorunonseveralmillionsoftokenstoyieldadditionalperformancegains(showninlastcolumn).Speedups:WealsoobserveasignificantspeedupwhenusingtheparallelizedversionoftheDMLCalgorithm.Performingmodelminimizationonthe24ktokensdatasettakes55secondsonasinglema-chine,whereasparallelizationpermitsmodelmini-mizationtobefeasibleevenonlargedatasets.Fig1showstherunningtimeforDMLCwhenrunonaclusterof100machines.Wevarytheinputdatasizefrom1Mwordtokenstoabout8Mwordtokens,whileholdingtheresourcesconstant.Boththealgo-rithmanditsdistributedimplementationinDMLCarelineartimeoperationsasevidentbytheplot.Infact,forcomparison,wealsoplotastraightlinepassingthroughthefirsttworuntimes.Thestraightlineessentiallyplotsruntimescorrespondingtoalinearspeedup.DMLCclearlyachievesbetterrun-timesshowingevenbetterthanlinearspeedup.Thereasonforthisisthatdistributedversionhasacon-stantoverheadforinitialization,independentofthedatasize.Whiletherunningtimeforrestoftheim-plementationislinearindatasize.Thus,asthedatasizebecomeslarger,theconstantoverheadbecomeslesssignificant,andthedistributedimplementationappearstocompleteslightlyfasterasdatasizein-creases.Figure1:Runtimevs.datasize(measuredin#ofwordtokens)on100machines.Forcomparison,wealsoplotastraightlinepassingthroughthefirsttworuntimes.Thestraightlineessentiallyplotsruntimescorrespondingtoalinearspeedup.DMLCclearlyachievesbetterruntimesshowingabetterthanlinearspeedup.6.1.2TaggingUsingIncompleteDictionariesWealsoevaluateourapproachforPOStaggingunderotherresource-constrainedscenarios.Obtain-
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
6
9
1
5
6
6
8
2
8
/
/
t
je
un
c
_
un
_
0
0
1
6
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
112
MethodTaggingaccuracy(%)te=24kte=973ktr=24ktr=973ktr=3.7M1.EM81.782.32.ILP+EM(RaviandKnight,2009)91.63.MIN-GREEDY+EM(Ravietal.,2010b)91.687.14.DMLC+EM(thiswork)91.487.587.8Table1:Resultsforunsupervisedpart-of-speechtaggingonEnglishPennTreebankdataset.Taggingaccuraciesfordifferentmethodsareshownonmultipledatasets.teshowsthesize(numberoftokens)inthetestdata,trrepresentsthesizeoftherawtextusedtoperformmodelminimization.ingacompletedictionaryisoftendifficult,espe-ciallyfornewdomains.Toverifytheutilityofourmethodwhentheinputdictionaryisincomplete,weevaluateagainststandarddatasetsusedinpreviouswork(GarretteandBaldridge,2012)andcompareagainstthepreviousbestreportedperformanceforthesametask.Inalltheexperiments(describedhereandinsubsequentsections),weusethefol-lowingterminology—rawdatareferstounlabeledtextusedbydifferentmethods(formodelminimiza-tionorotherunsupervisedtrainingproceduressuchasEM),dictionaryconsistsofword/tagentriesthatarelegal,andtestreferstodataoverwhichtaggingevaluationisperformed.EnglishData:ForEnglishPOStaggingwithin-completedictionary,weevaluateonthePennTree-bank(Marcusetal.,1993)data.Following(GarretteandBaldridge,2012),weextractedaword-tagdic-tionaryfromsections00-15(751,059tokens)con-sistingof39,087wordtypes,45,331word/tagen-tries,aper-typeambiguityof1.16yieldingaper-tokenambiguityof2.21ontherawcorpus(treatingunknownwordsashavingall45possibletags).Asintheirsetup,wethenusethefirst47,996tokensofsection16asrawdataandperformfinalevalua-tiononthesections22-24.WeusetherawcorpusalongwiththeunlabeledtestdatatoperformmodelminimizationandEMtraining.Unknownwordsareallowedtohaveallpossibletagsinboththesepro-cedures.ItalianData:Theminimizationstrategypre-sentedhereisageneral-purposemethodthatdoesnotrequireanyspecifictuningandworksforotherlanguagesaswell.Todemonstratethis,wealsoper-formevaluationonadifferentlanguage(Italian)us-ingtheTUTcorpus(Boscoetal.,2000).Follow-ing(GarretteandBaldridge,2012),weusethesamedatasplitsastheirsetting.Wetakethefirsthalfofeachofthefivesectionstobuildtheword-tagdic-tionary,thenextquarterasrawdataandthelastquarterastestdata.Thedictionarywasconstructedfrom41,000tokenscomprisedof7,814wordtypes,8,370word/tagpairs,per-typeambiguityof1.07andaper-tokenambiguityof1.41ontherawdata.Therawdataconsistedof18,574tokensandthetestcon-tained18,763tokens.Weusetheunlabeledcorpusfromtherawandtestdatatoperformmodelmini-mizationfollowedbyunsupervisedEMtraining.OtherLanguages:Inordertotesttheeffective-nessofourmethodinothernon-Englishsettings,wealsoreporttheperformanceofourmethodonsev-eralotherIndo-EuropeanlanguagesusingtreebankdatafromCoNLL-XandCoNLL-2007sharedtasksondependencyparsing(BuchholzandMarsi,2006;Nivreetal.,2007).Thecorpusstatisticsforthefivelanguages(Danish,Greek,Italian,PortugueseandSpanish)arelistedbelow.Foreachlanguage,weconstructadictionaryfromtherawtrainingdata.Theunlabeledcorpusfromtherawtrainingandtestdataisusedtoperformmodelminimizationfol-lowedbyunsupervisedEMtraining.Asbefore,un-knownwordsareallowedtohaveallpossibletags.WereportthefinaltaggingperformanceonthetestdataandcompareittobaselineEM.GarretteandBaldridge(2012)treatunknownwords(wordsthatappearintherawtextbutaremissingfromthedictionary)inaspecialmanneranduseseveralheuristicstoperformbetterinitializationforsuchwords(forexample,theprobabilitythatanunknownwordisassociatedwithaparticulartagis
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
6
9
1
5
6
6
8
2
8
/
/
t
je
un
c
_
un
_
0
0
1
6
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
113
conditionedontheopennessofthetag).Theyalsouseanauto-supervisiontechniquetosmoothcountslearntfromEMontonewwordsencountereddur-ingtesting.Incontrast,wedonotapplyanysuchtechniqueforunknownwordsandallowthemtobemappeduniformlytoallpossibletagsinthedictio-nary.Forthisparticularsetofexperiments,theonlydifferencefromtheGarretteandBaldridge(2012)setupisthatweincludeunlabeledtextfromthetestdata(butwithoutanydictionarytaglabelsorspecialheuristics)toourexistingwordtokensfromrawtextforperformingmodelminimization.Thisisastan-dardpracticeusedinunsupervisedtrainingscenar-ios(forexample,Bayesianinferencemethods)andingeneralforscalabletechniqueswherethegoalistoperforminferenceonthesamedataforwhichonewishestoproducesomestructuredprediction.LanguageTrainDictTest(tokens)(entries)(tokens)DANISH94386187975852GREEK65419128944804ITALIAN71199149345096PORTUGUESE206678300535867SPANISH89334171765694Results:Table2(column2)comparespreviouslyreportedresultsagainstourapproachforEnglish.Weobservethatourmethodobtainsahugeimprove-mentoverstandardEMandgetscomparableresultstothepreviousbestreportedscoresforthesametaskfrom(GarretteandBaldridge,2012).Itisencourag-ingtonotethatthenewsystemachievesthisper-formancewithoutusinganyofthecarefully-chosenheuristicsemployedbythepreviousmethod.How-ever,wedonotethatsomeofthesetechniquescanbeeasilycombinedwithourmethodtoproducefur-therimprovements.Table2(column3)alsoshowsresultsonItal-ianPOStagging.Weobservethatourmethodachievessignificantimprovementsintaggingaccu-racyoverallthebaselinesystemsincludingthepre-viousbestsystem(+2.9%).Thisdemonstratesthatthemethodgeneralizeswelltootherlanguagesandproducesconsistenttaggingimprovementsoverex-istingmethodsforthesametask.ResultsforPOStaggingonCoNLLdatainfivedifferentlanguagesaredisplayedinFigure2.Notethattheproportionofrawdataintestversustrain5060708090DANISHGREEKITALIANPORTUGUESESPANISH79.466.384.680.183.177.865.68278.581.3EMDMLC+EM(cid:6)(cid:7)(cid:9)(cid:9)(cid:10)(cid:11)(cid:9)(cid:1)(cid:5)(cid:8)(cid:8)(cid:13)(cid:12)(cid:7)(cid:8)(cid:14)(cid:1)(cid:3)(cid:2)(cid:4)Figure2:Part-of-SpeechtaggingaccuracyfordifferentlanguagesonCoNLLdatausingincompletedictionaries.(fromthestandardCoNLLsharedtasks)ismuchsmallercomparedtotheearlierexperimentalset-tings.Ingeneral,weobservethataddingmorerawdataforEMtrainingimprovesthetaggingquality(sametrendobservedearlierinTable1:column2versuscolumn3).Despitethis,DMLC+EMstillachievessignificantimprovementsoverthebaselineEMsystemonmultiplelanguages(asshowninFig-ure2).Anadditionaladvantageofthenewmethodisthatitcaneasilyscaletolargercorporaanditpro-ducesamuchmorecompactgrammarthatcanbeefficientlyincorporatedforEMtraining.6.1.3TaggingforLow-ResourceLanguagesLearningpart-of-speechtaggersforseverelylow-resourcelanguages(e.g.,Malagasy)isverychal-lenging.Inadditiontoscarce(token-supervised)labeledresources,thetagdictionariesavail-ablefortrainingtaggersaretinycomparedtootherlanguagessuchasEnglish.GarretteandBaldridge(2013)combinevarioussupervisedandsemi-supervisedlearningalgorithmsintoacommonPOStaggertrainingpipelinetoaddresssomeofthesechallenges.Theyalsoreporttaggingaccuracyimprovementsonlow-resourcelanguageswhenus-ingthecombinedsystemoveranysinglealgorithm.Theirsystemhasfourmainparts,inorder:(1)Tagdictionaryexpansionusinglabelpropagationalgo-rithm,(2)Weightedmodelminimization,(3)Ex-pectationmaximization(EM)trainingofHMMsus-ingauto-supervision,(4)MaxEntMarkovModel(MEMM)training.Theentireprocedureresultsinatrainedtaggermodelthatcanthenbeappliedtotaganyrawdata.3Step2inthisprocedureinvolves3Formoredetails,refer(GarretteandBaldridge,2013).
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
6
9
1
5
6
6
8
2
8
/
/
t
je
un
c
_
un
_
0
0
1
6
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
114
MethodTaggingaccuracy(%)English(PTB00-15)Italian(TUT)1.Random63.5362.812.EM69.2060.703.Type-supervision+HMMinitialization(GarretteandBaldridge,2012)88.5272.864.DMLC+EM(thiswork)88.1175.79Table2:Part-of-SpeechtaggingaccuracyusingPTBsections00-15andTUTtobuildthetagdictionary.Forcompar-ison,wealsoincludetheresultsforthepreviouslyreportedstate-of-the-artsystem(method3)forthesametask.MethodTaggingaccuracy(%)TotalKnownUnknownLow-resourcetaggingusing(GarretteandBaldridge,2013)80.7(70.2)87.6(90.3)66.1(45.1)Low-resourcetaggingusingDMLC+EM(thiswork)81.1(70.8)87.9(90.3)66.7(46.5)Table3:Part-of-Speechtaggingaccuracyforalow-resourcelanguage(Malagasy)onAll/Known/Unknowntokensinthetestdata.Taggingperformanceisshownformultipleexperimentsusingdifferent(incomplete)dictionarysizes:(un)petit,(b)tiny(showninparentheses).Thenewmethod(row2)significantlyoutperformstheexistingmethodwithp<0.01forsmalldictionaryandp<0.05fortinydictionary.aweightedversionofmodelminimizationwhichusesthemulti-stepgreedyapproachfromRavietal.(2010b)enhancedwithadditionalheuristicsthatusestagweightslearntvialabelpropagation(inStep1)withintheminimizationprocess.WereplacethemodelminimizationprocedureintheirStep2withourmethod(DMLC+EM)anddi-rectlycomparethisnewsystemwiththeirapproachintermsoftaggingaccuracy.Noteforallotherstepsinthepipelinewefollowthesameprocedure(andrunthesamecode)asGarretteandBaldridge(2013),includingthesamesmoothingprocedureforEMini-tializationinStep3.Data:WeusetheexactsamesetupasGarretteandBaldridge(2013)andrunexperimentsonMala-gasy,anAustronesianlanguagespokeninMadagas-car.Weusethepubliclyavailabledata4:100krawtokensfortraining,aword-tagdictionaryacquiredwith4hoursofhumanannotationeffort(usedfortype-supervision),andaheld-outtestdataset(5341tokens).Weprovidetheunlabeledcorpusfromtherawtrainingdataalongwiththeword-tagdictionaryasinputtomodelminimizationandevaluateonthetestcorpus.Werunmultipleexperimentsfordif-ferent(incomplete)dictionaryscenarios:(a)small=2773word/tagpairs,(b)tiny=329word/tagpairs.Results:Table3showsresultsonMalagasydatacomparingasystemthatemploys(unweighted)4github.com/dhgarrette/low-resource-pos-tagging-2013DMLCagainsttheexistingstate-of-the-artsystemthatincorporatesamulti-stepweightedmodelmin-imizationcombinedwithadditionalheuristics.Weobservethatswitchingtothenewmodelminimiza-tionprocedurealoneyieldssignificantimprovementintaggingaccuracyunderbothdictionaryscenarios.Itisencouragingthatabetterminimizationproce-durealsoleadstohighertaggingqualityontheun-knownwordtokens(column4inthetable),evenwhentheinputdictionaryistiny.6.2SupertaggingComparedtoPOStagging,amorechallengingtaskislearningsupertaggersforlexicalizedgrammarformalismssuchasCombinatoryCategorialGram-mar(CCG)(Steedman,2000).Forexample,CCG-bank(HockenmaierandSteedman,2007)contains1241distinctsupertags(lexicalcategories)andthemostambiguouswordhas126supertags.Thispro-videsamuchmorechallengingstartingpointforthesemi-supervisedmethodstypicallyappliedtothetask.Yet,thisisanimportanttasksincecre-atinggrammarsandresourcesforCCGparsersfornewdomainsandlanguagesishighlylabor-andknowledge-intensive.Asdescribedearlier,ourapproachscaleseasilytolargedatasetsaswellaslabelsizes.Toevaluateitonthesupertaggingtask,weusethesamedatasetfrom(Ravietal.,2010a)andcompareagainsttheirbase-linemethodthatusesanmodified(two-step)version l D o w n o a d e d f r o m h t t p : / / d i r e c t . m i t . e d u / t a c l / l a r t i c e - p d f / d o i / . 1 0 1 1 6 2 / t l a c _ a _ 0 0 1 6 9 1 5 6 6 8 2 8 / / t l a c _ a _ 0 0 1 6 9 p d . f b y g u e s t t o n 0 9 S e p e m b e r 2 0 2 3 115 MethodSupertaggingaccuracy(%)AmbiguousTotal1.EM38.745.62.ILP∗+EM(Ravietal.,2010a)52.157.33.DMLC+EM(thiswork)55.959.3Table4:Resultsforunsupervisedsupertaggingwithadictionary.Here,wereportthetotalaccuracyaswellasaccuracyonjusttheambiguoustokens(i.e.,tokenswhichhavemorethanonetaggingpossibility).∗Thebaselinemethod2requiresseveralpre-processingstepsinordertorunfeasiblyforthistask(describedinSection6.2).Incontrast,thenewapproach(DMLC)runsfastandalsopermitsefficientparallelization.oftheILPformulationformodelminimization.Data:WeusetheCCGbankdataforthisex-periment.Thisdatawascreatedbysemi-auto-maticallyconvertingthePennTreebanktoCCGderivations(HockenmaierandSteedman,2007).Weusethestandardsplitsofthedatausedinsemi-supervisedtaggingexperiments(BankoandMoore,2004)—sections0-18fortraining(i.e.,toconstructtheword-tagdictionary),andsections22-24fortest.Results:Table4comparestheresultsfortwobaselinesystems—standardEM(method1),andapreviouslyreportedsystemusingmodelminimiza-tion(method2)forthesametask.WeobservethatDMLCproducesbettertaggingsthaneitheroftheseandyieldssignificantimprovementinaccu-racy(+2%overall,+3.8%onambiguoustokens).NotethatitisnotfeasibletoruntheILP-basedbaseline(method2inthetable)directlysinceitisveryslowinpractice,soRavietal.(2010un)useasetofpre-processingstepstoprunetheoriginalgrammarsize(uniquetagpairs)from>1Mtosev-eralthousandentriesfollowedbyamodifiedtwo-stepILPminimizationstrategy.Thisisrequiredtopermittheirmodelminimizationsteptoberuninafeasiblemanner.Ontheotherhand,thenewap-proachDMLC(method3)scalesbetterevenwhenthedata/labelsizesarelarge,henceitcanberunwiththefulldatausingtheoriginalmodelminimizationformulation(ratherthanatwo-stepheuristic).Ravietal.(2010un)alsoreportfurtherimprove-mentsusinganalternativeapproachinvolvinganILP-basedweightedminimizationprocedure.InSection7webrieflydiscusshowtheDMLCmethodcanbeextendedtothissettingandcombinedwithothersimilarmethods.7DiscussionandConclusionWepresentafast,efficientmodelminimizationalgorithmforunsupervisedtaggingthatimprovesuponprevioustwo-stepheuristics.Weshowthatun-derafairlynaturalassumptionofc-feasibilitythesolutionobtainedbyourminimizationalgorithmisO(clogm)-approximatetotheoptimal.Althoughinthecaseoftwo-stepheuristics,thefirststepguar-anteesanO(logm)-approximation,thesecondstep,whichisrequiredtogetaconsistentsolution,canintroducemanyadditionallabelsresultinginaso-lutionarbitrarilyawayfromtheoptimal.Ouronestepapproachensuresconsistencyateachstepofthealgorithm,whilethec-feasibilityassumptionmeansthatthesolutiondoesnotdivergetoomuchfromtheoptimalineachiteration.Inadditiontoprovingapproximationguaranteesforthenewalgorithm,weshowthatitisparalleliz-able,allowingustoeasilyscaletolargerdatasetsthanpreviouslyexplored.Ourresultsshowthatthealgorithmachievesstate-of-the-artperformance,outperformingexistingmethodsonseveraldiffer-enttasks(bothPOStaggingandsupertagging)andworkswellevenwithincompletedictionariesandextremelylow-resourcelanguageslikeMalagasy.Forfuturework,itwouldbeinterestingtoapplyaweightedversionoftheDMLCalgorithmwherela-bels(i.e.,tagpairs)canhavedifferentweightdistri-butionsinsteadofuniformweights.Ouralgorithmcanbeextendedtoallowaninputweightdistribu-tiontobespecifiedforminimization.Inordertoinitializetheweightswecoulduseexistingstrate-giessuchasgrammar-informedinitialization(Ravietal.,2010a)oroutputdistributionslearntviaothermethodssuchaslabelpropagation(GarretteandBaldridge,2013).
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
6
9
1
5
6
6
8
2
8
/
/
t
je
un
c
_
un
_
0
0
1
6
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
116
References2013.Apachegiraph.http://giraph.apache.org/.MicheleBankoandRobertC.Moore.2004.Part-of-speechtaggingincontext.InProceedingsofCOLING,pages556–561.AndrewRBarron,JormaRissanen,andBinYu.1998.TheMinimumDescriptionLengthPrincipleinCod-ingandModeling.IEEETransactionsofInformationTheory,44(6):2743–2760.CristinaBosco,VincenzoLombardo,DanielaVassallo,andLeonardoLesmo.2000.BuildingaTreebankforItalian:adata-drivenannotationschema.InProceed-ingsoftheSecondInternationalConferenceonLan-guageResourcesandEvaluationLREC-2000,pages99–105.SabineBuchholzandErwinMarsi.2006.Conll-xsharedtaskonmultilingualdependencyparsing.InProceed-ingsofCoNLL,pages149–164.ChristosChristodoulopoulos,SharonGoldwater,andMarkSteedman.2010.TwodecadesofunsupervisedPOSinduction:Howfarhavewecome?InProceed-ingsoftheConferenceonEmpiricalMethodsinNatu-ralLanguageProcessing(EMNLP),pages575–584.DipanjanDasandSlavPetrov.2011.Unsupervisedpart-of-speechtaggingwithbilingualgraph-basedprojec-tions.InProceedingsofthe49thAnnualMeetingoftheAssociationforComputationalLinguistics:Hu-manLanguageTechnologies-Volume1,pages600–609.A.P.Dempster,N.M.Laird,andD.B.Rubin.1977.MaximumlikelihoodfromincompletedataviatheEMalgorithm.JournaloftheRoyalStatisticalSociety,Se-riesB,39(1):1–38.KuzmanGanchev,Jo˜aoGrac¸a,JenniferGillenwater,andBenTaskar.2010.Posteriorregularizationforstruc-turedlatentvariablemodels.JournalofMachineLearningResearch,11:2001–2049.DanGarretteandJasonBaldridge.2012.Type-supervisedHiddenMarkovModelsforpart-of-speechtaggingwithincompletetagdictionaries.InProceed-ingsoftheConferenceonEmpiricalMethodsinNat-uralLanguageProcessingandComputationalNatu-ralLanguageLearning(EMNLP-CoNLL),pages821–831.DanGarretteandJasonBaldridge.2013.Learningapart-of-speechtaggerfromtwohoursofannotation.InProceedingsoftheConferenceoftheNorthAmericanChapteroftheAssociationforComputationalLinguis-tics:HumanLanguageTechnologies,pages138–147.KevinGimpel,NathanSchneider,BrendanO’Connor,DipanjanDas,DanielMills,JacobEisenstein,MichaelHeilman,DaniYogatama,JeffreyFlanigan,andNoahA.Smith.2011.Part-of-speechtaggingforTwitter:annotation,features,andexperiments.InPro-ceedingsofthe49thAnnualMeetingoftheAssocia-tionforComputationalLinguistics:HumanLanguageTechnologies:shortpapers-Volume2,pages42–47.YoavGoldberg,MeniAdler,andMichaelElhadad.2008.EMcanfindprettygoodHMMPOS-taggers(whengivenagoodstart).InProceedingsofACL,pages746–754.SharonGoldwaterandThomasL.Griffiths.2007.AfullyBayesianapproachtounsupervisedpart-of-speechtagging.InACL.FernandoC.Gomes,CludioN.Meneses,PanosM.Pardalos,andGerardoValdisioR.Viana.2006.Ex-perimentalanalysisofapproximationalgorithmsforthevertexcoverandsetcoveringproblems.KaziSaidulHasanandVincentNg.2009.Weaklysuper-visedpart-of-speechtaggingformorphologically-rich,resource-scarcelanguages.InProceedingsofthe12thConferenceontheEuropeanChapteroftheAssocia-tionforComputationalLinguistics,pages363–371.JuliaHockenmaierandMarkSteedman.2007.CCG-bank:AcorpusofCCGderivationsanddependencystructuresextractedfromthePennTreebank.Compu-tationalLinguistics,33(3):355–396.MarkJohnson.2007.Whydoesn’tEMfindgoodHMMPOS-taggers?InProceedingsoftheJointConferenceonEmpiricalMethodsinNaturalLanguageProcess-ingandComputationalNaturalLanguageLearning(EMNLP-CoNLL),pages296–305.PhilippKoehn.2005.Europarl:AParallelCorpusforStatisticalMachineTranslation.InMachineTransla-tionSummitX,pages79–86.GrzegorzMalewicz,MatthewH.Austern,AartJ.CBik,JamesC.Dehnert,IlanHorn,NatyLeiser,andGrze-gorzCzajkowski.2010.Pregel:asystemforlarge-scalegraphprocessing.InProceedingsofthe2010ACMSIGMODInternationalConferenceonManage-mentofdata,pages135–146.MitchellP.Marcus,BeatriceSantorini,andMaryAnnMarcinkiewicz.1993.Buildingalargeannotatedcor-pusofEnglish:ThePennTreebank.ComputationalLinguistics,19(2):313–330.BernardMerialdo.1994.TaggingEnglishtextwithaprobabilisticmodel.ComputationalLinguistics,20(2):155–171.TaesunMoon,KatrinErk,andJasonBaldridge.2010.CrouchingDirichlet,HiddenMarkovModel:Unsu-pervisedPOStaggingwithcontextlocaltaggenera-tion.InProceedingsoftheConferenceonEmpiricalMethodsinNaturalLanguageProcessing,pages196–206.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
6
9
1
5
6
6
8
2
8
/
/
t
je
un
c
_
un
_
0
0
1
6
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
117
JoakimNivre,JohanHall,SandraK¨ubler,RyanMcDon-ald,JensNilsson,SebastianRiedel,andDenizYuret.2007.TheCoNLL2007sharedtaskondependencyparsing.InProceedingsoftheCoNLLSharedTaskSessionofEMNLP-CoNLL,pages915–932.SujithRaviandKevinKnight.2009.Minimizedmodelsforunsupervisedpart-of-speechtagging.InProceed-ingsoftheJointConferenceofthe47thAnnualMeet-ingoftheAssociationforComputationalLinguisticsandthe4thInternationalJointConferenceonNaturalLanguageProcessingoftheAsianFederationofNatu-ralLanguageProcessing(ACL-IJCNLP),pages504–512.SujithRavi,JasonBaldridge,andKevinKnight.2010a.Minimizedmodelsandgrammar-informedinitializa-tionforsupertaggingwithhighlyambiguouslexicons.InProceedingsofthe48thAnnualMeetingoftheAs-sociationforComputationalLinguistics(ACL),pages495–503.SujithRavi,AshishVaswani,KevinKnight,andDavidChiang.2010b.Fast,greedymodelminimizationforunsupervisedtagging.InProceedingsofthe23rdIn-ternationalConferenceonComputationalLinguistics(COLING),pages940–948.RoiReichart,RaananFattal,andAriRappoport.2010.ImprovedunsupervisedPOSinductionusingintrinsicclusteringqualityandaZipfianconstraint.InProceed-ingsoftheFourteenthConferenceonComputationalNaturalLanguageLearning,pages57–66.MarkSteedman.2000.TheSyntacticProcess.MITPress,Cambridge,MA,USA.KristinaToutanovaandMarkJohnson.2008.ABayesianLDA-basedmodelforsemi-supervisedpart-of-speechtagging.InAdvancesinNeuralInformationProcessingSystems(NIPS),pages1521–1528.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
1
6
9
1
5
6
6
8
2
8
/
/
t
je
un
c
_
un
_
0
0
1
6
9
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
118