Transactions of the Association for Computational Linguistics, 1 (2013) 279–290. Action Editor: Lillian Lee.
Submitted 11/2012; Revised 1/2013; Published 7/2013. c
(cid:13)
2013 Association for Computational Linguistics.
Good,Great,Excellent:GlobalInferenceofSemanticIntensitiesGerarddeMeloICSI,Berkeleydemelo@icsi.berkeley.eduMohitBansalCSDivision,UCBerkeleymbansal@cs.berkeley.eduAbstractAdjectiveslikegood,great,andexcellentaresimilarinmeaning,butdifferinintensity.In-tensityorderinformationisveryusefulforlanguagelearnersaswellasinseveralNLPtasks,butismissinginmostlexicalresources(dictionaries,WordNet,andthesauri).Inthispaper,wepresentaprimarilyunsupervisedapproachthatusessemanticsfromWeb-scaledata(e.g.,phraseslikegoodbutnotexcel-lent)torankwordsbyassigningthemposi-tionsonacontinuousscale.WerelyonMixedIntegerLinearProgrammingtojointlydeter-minetheranks,suchthatindividualdecisionsbenefitfromglobalinformation.Whenrank-ingEnglishadjectives,ourglobalalgorithmachievessubstantialimprovementsoverpre-viousworkonbothpairwiseandrankcorre-lationmetrics(specifically,70%pairwiseac-curacyascomparedtoonly56%bypreviouswork).De plus,ourapproachcanincorpo-rateexternalsynonymyinformation(increas-ingitspairwiseaccuracyto78%)andextendseasilytonewlanguages.Wealsomakeourcodeanddatafreelyavailable.11IntroductionCurrentlexicalresourcessuchasdictionariesandthesauridonotprovideinformationaboutthein-tensityorderofwords.Forexample,bothWordNet(Miller,1995)andRoget’s21stCenturyThesaurus(thesaurus.com)presentacceptable,great,andsu-perbassynonymsoftheadjectivegood.However,anativespeakerknowsthatthesewordsrepresentvaryingintensityandcaninfactgenerallyberankedbyintensityasacceptable
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
2
2
7
1
5
6
6
6
7
1
/
/
t
je
un
c
_
un
_
0
0
2
2
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
283
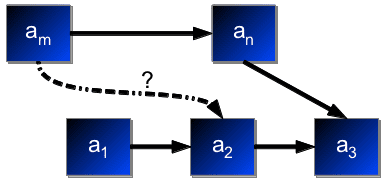
Figure2:EquivalenceInformation:Knowingthatam,a2aresynonymsgivestheMILPanindicationofwheretoplaceanonthescalewithrespecttoa1,a2,a3oflocalordivide-and-conquerapproaches,whereadjectivesarescoredwithrespecttoselectedpivotwords,andhencemanyadjectivesthatlackpairwiseevidencewiththepivotsarenotproperlyclassified,althoughtheymayhaveorderevidencewithsomethirdadjectivethatcouldhelpestablishtheranking.Optionalsynonymyinformationcanfurtherhelp,asshowninFigure2.Moreover,ourMILPalsogiveshigherweighttopairswithhigherscores,whichisusefulwhenbreakingglobalconstraintcyclesasinthesimpleexampleinFigure1.Ifweneedtobreakacon-straintviolatingtriangleorcycle,wewouldhavetomakearbitrarychoicesifwewererankingbasedonsgn(score(un,b))alone.Instead,wecanchooseabetterrankingbasedonthemagnitudeofthepair-wisescores.Astrongerscorebetweenanadjectivepairdoesn’tnecessarilymeanthattheyshouldbefurtherapartintheranking.ItmeansthatthesetwowordsareattestedtogetherontheWebwithrespecttotheintensitypatternsmorethanwithothercandi-datewords.Therefore,wetrytorespecttheorderofsuchwordpairsmoreinthefinalrankingwhenwearebreakingconstraint-violatingcycles.3RelatedWorkHatzivassiloglouandMcKeown(1993)presentedthefirststeptowardsautomaticidentificationofad-jectivescales,thoroughlydiscussingthebackgroundofadjectivesemanticsandameansofdiscoveringclustersofadjectivesthatbelongonthesamescale,thusprovidingonewayofcreatingtheinputforourrankingalgorithm.InkpenandHirst(2006)studynear-synonymsandnuancesofmeaningdifferentiation(suchasstylistic,attitudinal,etc.).Theyattempttoautomaticallyac-quireaknowledgebaseofnear-synonymdifferencesviaanunsuperviseddecision-listalgorithm.How-ever,theirmethoddependsonaspecialdictionaryofsynonymdifferencestolearntheextractionpat-terns,whileweuseonlyarawWeb-scalecorpus.Mohammadetal.(2013)proposedamethodofidentifyingwhethertwoadjectivesareantonymous.Thisproblemisrelatedbutdistinct,becausethede-greeofantonymydoesnotnecessarilydeterminetheirpositiononanintensityscale.Antonyms(e.g.,little,big)arenotnecessarilyontheextremeendsofscales.SheinmanandTokunaga(2009)andSheinmanetal.(2012)presentthemostcloselyrelatedpreviousworkonadjectiveintensities.Theycollectlexico-semanticpatternsviabootstrappingfromseedadjec-tivepairstoobtainpairwiseintensities,albeitusingsearchengine‘hits’,whichareunstableandprob-lematic(Kilgarriff,2007).Whiletheirapproachisprimarilyevaluatedintermsofalocalpairwiseclassificationtask,theyalsosuggestthepossibil-ityoforderingadjectivesonascaleusingapivot-basedpartitioningapproach.Althoughintuitiveintheory,theextractedpairwisescoresarefrequentlytoosparseforthistowork.Thus,manyadjec-tiveshavenoscorewithaparticularheadword.Inourexperiments,wereimplementedthisapproachandshowthatourMILPmethodimprovesoveritbyallowingindividualpairwisedecisionstobenefitmorefromglobalinformation.SchulamandFell-baum(2010)applytheapproachofSheinmanandTokunaga(2009)toGermanadjectives.Ourmethodextendseasilytovariousforeignlanguagesasde-scribedinSection5.Anotherrelatedtaskistheextractionoflexico-syntacticandlexico-semanticintensity-orderpat-ternsfromlargetextcorpora(Hearst,1992;ChklovskiandPantel,2004;TandonanddeMelo,2010).SheinmanandTokunaga(2009)followsDavidovandRappoport(2008)toautomaticallybootstrapadjectivescalingpatternsusingseedad-jectivesandWebhits.Thesemethodsthuscanbeusedtoprovidetheinputpatternsforouralgorithm.VerbOceanbyChklovskiandPantel(2004)ex-tractsvariousfine-grainedsemanticrelations(in-cludingthestronger-thanrelation)betweenpairsofverbs,usinglexico-syntacticpatternsovertheWeb.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
2
2
7
1
5
6
6
6
7
1
/
/
t
je
un
c
_
un
_
0
0
2
2
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
284
OurapproachofjointlyrankingasetofwordsusingpairwiseevidenceisalsoapplicabletotheVerbO-ceanpairs,andshouldhelpaddresssimilarsparsityissuesoflocalpairwisedecisions.Suchscaleswillagainbequiteusefulforlanguagelearnersandlan-guageunderstandingtools.deMarneffeetal.(2010)inferyes-or-noanswerstoquestionswithresponsesinvolvingscalaradjec-tivesinadialoguecorpus.Theycorrelateadjectiveswithratingsinamoviereviewcorpustofindthatgoodappearsinlower-ratedreviewsthanexcellent.Finally,therehasbeenalotofworkonmeasuringthegeneralsentimentpolarityofwords(Hatzivas-siloglouandMcKeown,1997;HatzivassiloglouandWiebe,2000;TurneyandLittman,2003;LiuandSeneff,2009;Taboadaetal.,2011;YessenalinaandCardie,2011;PangandLee,2008).Ourworkin-steadaimsatproducingalarge,unrestrictednumberofindividualintensityscalesfordifferentqualitiesandhencecanhelpinfine-grainedsentimentanaly-siswithrespecttoveryparticularcontentaspects.4Experiments4.1DataInputClustersInordertoobtaininputclustersforevaluation,westartedoutwiththesatelliteclusteror‘dumbbell’structureofadjectivesinWordNet3.0,whichconsistsoftwodirectantonymsasthepolesandanumberofothersatelliteadjectivesthatarese-manticallysimilartoeachofthepoles(GrossandMiller,1990).Foreachantonymypair,wedeter-minedanextendeddumbbellsetbylookingupsyn-onymsandwordsinrelated(satelliteadjectiveand‘see-also’)synonymsets.Wecutsuchanextendeddumbbellintotwoantonymoushalvesandtreatedeachofthesehalvesasapotentialinputadjectivecluster.MostoftheseWordNetclustersarenoisyforthepurposeofourtask,i.e.theycontainadjectivesthatappearunrelatableonasinglescaleduetopolysemyandsemanticdrift,e.g.violentwithrespecttosuper-naturalandaffected.MotivatedbySheinmanandTokunaga(2009),wesplitsuchhard-to-relatead-jectivesintosmallerscale-specificsubgroupsusingthecorpusevidence4.Forthis,weconsideranundi-4NotethatwedonotusetheWordNetdatasetofSheinmanandTokunaga(2009)forevaluation,asitdoesnotprovidefull438 115 60 35 19 12 14 5 4 3 0 100 200 300 400 500 2 3 4 5 6 7 8 9 10-14 15-17 # of chains Length of chain Figure3:Thehistogramofclustersizesafterpartitioning.41 27 12 3 3 2 0 10 20 30 40 50 3 4 5 6 7 8 # of chains Length of chain Figure4:Thehistogramofclustersizesinthetestset.rectededgebetweeneachpairofadjectivesthathasanon-zerointensityscore(basedontheWeb-scalescoringproceduredescribedinSection2.1.3).Theresultinggraphisthenpartitionedintoconnectedcomponentssuchthatanyadjectivesinasubgraphareatleastindirectlyconnectedviasomepathandthusmuchmorelikelytobelongtothesameinten-sityscale.Whilethisdoesbreakuppartitionswhen-everthereisnocorpusevidenceconnectingthem,orderingtheadjectiveswithineachsuchpartitionre-mainsachallengingtask.ThisisbecausetheWebevidencewillstillnotnecessarilydirectlyrelatealladjectives(inapartition)toeachother.Addition-ally,theWebevidencemaystillindicatethewrongdirection.Figure3showsthesizedistributionoftheresultingpartitions.PatternsToconstructourintensitypatternset,westartedwithacoupleofcommonrankableadjectiveseedpairssuchas(good,great)et(hot,boiling)andusedtheWeb-scalen-gramscorpus(BrantsandFranz,2006)tocollectthefewmostfrequentpat-ternsbetweenandaroundtheseseed-pairs(inbothdirections).Amongthese,wemanuallychoseascales.Instead,theirannotatorsonlymadepairwisecompar-isonswithselectwords,usinga5-wayclassificationscheme(neutral,mild,verymild,intense,veryintense).
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
2
2
7
1
5
6
6
6
7
1
/
/
t
je
un
c
_
un
_
0
0
2
2
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
285
smallsetofintuitivepatternsthatarelinguisticallyusefulfororderingadjectives,severalofwhichhadnotbeendiscoveredinpreviouswork.TheseareshowninTable1.Notethatweonlycollectedpat-ternsthatwerenotambiguousinthetwoorders,forexamplethepattern’?,pas?’isambiguousbe-causeitcanbeusedasboth’good,notgreat’and’great,notgood’.Alternatively,onecaneasilyalsousefully-automaticbootstrappingtechniquesbasedonseedwordpairs(Hearst,1992;ChklovskiandPantel,2004;YangandSu,2007;Turney,2008;DavidovandRappoport,2008).Cependant,oursemi-automaticapproachisasimpleandfastprocessthatextractsasmallsetofhigh-qualityandverygen-eraladjective-scalingpatterns.Thisprocesscanquicklyberepeatedfromscratchinanyotherlan-guage.Moreover,asdescribedinSection5.1,theEnglishpatternscanalsobeprojectedautomaticallytopatternsinotherlanguages.DevelopmentandTestSetsSection2.1describesthemethodforcollectingtheintensityscoresforad-jectivepairs,usingWeb-scalen-grams(BrantsandFranz,2006).WereliedonasmalldevelopmentsettotesttheMILPstructureandthepairwisescoresetup.Forthis,wemanuallychose5representativeadjectiveclustersfromthefullsetofclusters.Thefinaltestset,distinctfromthisdevelopmentset,consistsof569wordpairsin88clusters,eachannotatedbytwonativespeakersofEnglish.Boththegoldtestdata(andourcode)arefreelyavail-able.5Toarriveatthisdata,werandomlydrew30clusterseachforclustersizes3,4,and5+fromthehistogramofpartitionedadjectiveclustersinFig-ure3.Whilelabelingacluster,annotatorscouldex-cludewordsthattheydeemedunsuitabletofitonasinglesharedintensityscalewiththerestofthecluster.Fortunately,thepartitioningdescribedear-lierhadalreadyseparatedmostsuchcasesintodis-tinctclusters.Theannotatorsorderedtheremainingwordsonascale.Wordsthatseemedindistinguish-ableinstrengthcouldsharepositionsintheiranno-tation.Asourgoalistocomparescaleformationalgo-rithms,wedidnotincludetrivialclustersofsize2.Onsuchtrivialclusters,theWebevidencealonede-terminestheoutputandhenceallalgorithms,includ-5http://demelo.org/gdm/intensity/ingthebaseline,obtainthesamepairwiseaccuracy(definedbelow)of93.3%onaseparatesetof30ran-domclustersofsize2.Figure4showsthedistributionofclustersizesinourmaingoldset.Theinter-annotatoragreementintermsofCohen’sκ(Cohen,1960)onthepairwiseclassificationtaskwith3labels(weaker,stronger,orequal/unknown)was0.64.Intermsofpairwiseaccuracy,theagreementwas78.0%.4.2MetricsInordertothoroughlyevaluatetheperformanceofouradjectiveorderingprocedure,werelyonbothpairwiseandranking-correlationevaluationmetrics.ConsiderasetofinputwordsA={a1,a2,…,un}andtworankingsforthisset–agold-standardrank-ingrG(UN)andapredictedrankingrP(UN).4.2.1PairwiseAccuracyForapairofwordsai,aj,wemayconsidertheclassificationtaskofchoosingoneofthreelabels(<,>,=?)forthecaseofaibeingweaker,stronger,andequal(orunknown)inintensity,respectivement,com-paredtoa2:L(a1,a2)=
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
2
2
7
1
5
6
6
6
7
1
/
/
t
je
un
c
_
un
_
0
0
2
2
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
290
ReferencesMohitBansalandDanKlein.2011.Web-scalefeaturesforfull-scaleparsing.InProceedingsofACL2011.ThorstenBrantsandAlexFranz.2006.TheGoogleWeb1T5-gramcorpusversion1.1.LDC2006T13.ThorstenBrantsandAlexFranz.2009.Web1T5-gram,10Europeanlanguages,version1.LDC2009T25.TimothyChklovskiandPatrickPantel.2004.VerbO-cean:Miningthewebforfine-grainedsemanticverbrelations.InProceedingsofEMNLP2004.JacobCohen.1960.Acoefficientofagreementfornom-inalscales.EducationalandPsychologicalMeasure-ment,20(1):37–46.DmitryDavidovandAriRappoport.2008.Unsuper-viseddiscoveryofgenericrelationshipsusingpatternclustersanditsevaluationbyautomaticallygeneratedsatanalogyquestions.InProceedingsofACL2008.Marie-CatherinedeMarneffe,ChristopherD.Manning,andChristopherPotts.2010.Wasitgood?itwasprovocative.learningthemeaningofscalaradjectives.InProceedingsofACL2010.GerarddeMeloandGerhardWeikum.2009.Towardsauniversalwordnetbylearningfromcombinedevi-dence.InProceedingsofCIKM2009.ZhichengDou,RuihuaSong,XiaojieYuan,andJi-RongWen.2008.Areclick-throughdataadequateforlearn-ingwebsearchrankings?InProc.ofCIKM2008.DerekGrossandKatherineJ.Miller.1990.AdjectivesinWordNet.InternationalJournalofLexicography,3(4):265–277.VasileiosHatzivassiloglouandKathleenR.McKeown.1993.Towardstheautomaticidentificationofadjecti-valscales:Clusteringadjectivesaccordingtomeaning.InProceedingsofACL1993.VasileiosHatzivassiloglouandKathleenR.McKeown.1997.Predictingthesemanticorientationofadjec-tives.InProceedingsofACL1997.VasileiosHatzivassiloglouandJanyceM.Wiebe.2000.Effectsofadjectiveorientationandgradabilityonsen-tencesubjectivity.InProceedingsofCOLING2000.MartiHearst.1992.Automaticacquisitionofhyponymsfromlargetextcorpora.InProceedingsofCOLING1992.DianaInkpenandGraemeHirst.2006.Buildingandusingalexicalknowledgebaseofnear-synonymdif-ferences.ComputationalLinguistics,32(2):223–262.MauriceG.Kendall.1938.Anewmeasureofrankcor-relation.Biometrika,30(1/2):81–93.AdamKilgarriff.2007.Googleologyisbadscience.ComputationalLinguistics,33(1).WilliamH.Kruskal.1958.Ordinalmeasuresofassocia-tion.JournaloftheAmericanStatisticalAssociation,53(284):814–861.JingjingLiuandStephanieSeneff.2009.Reviewsenti-mentscoringviaaparse-and-paraphraseparadigm.InProceedingsofEMNLP2009.GeorgeA.Miller.1995.WordNet:Alexicaldatabaseforenglish.CommunicationsoftheACM,38(11):39–41.SaidM.Mohammad,BonnieJ.Dorr,GraemeHirst,andPeterD.Turney.2013.Computinglexicalcontrast.ComputationalLinguistics.BoPangandLillianLee.2008.Opinionminingandsentimentanalysis.FoundationsandTrendsinInfor-mationRetrieval,2(1-2):1–135,January.PeterF.SchulamandChristianeFellbaum.2010.Au-tomaticallydeterminingthesemanticgradationofger-manadjectives.InProceedingsofKONVENS2010.VeraSheinmanandTakenobuTokunaga.2009.AdjS-cales:Visualizingdifferencesbetweenadjectivesforlanguagelearners.IEICETransactionsonInformationandSystems,92(8):1542–1550.VeraSheinman,TakenobuTokunaga,I.Julien,P.Schu-lam,andC.Fellbaum.2012.RefiningWordNetadjec-tivedumbbellsusingintensityrelations.InProceed-ingsofGlobalWordNetConference2012.RionSnow,DanielJurafsky,andAndrewY.Ng.2006.Semantictaxonomyinductionfromheterogenousevi-dence.InProceedingsofCOLING/ACL2006.CharlesSpearman.1904.Theproofandmeasurementofassociationbetweentwothings.TheAmericanjournalofpsychology,15(1):72–101.FabianM.Suchanek,MauroSozio,andGerhardWeikum.2009.SOFIE:aself-organizingframeworkforinformationextraction.InProceedingsofWWW2009.MaiteTaboada,JulianBrooke,MilanTofiloskiy,andKimberlyVollz.2011.Lexicon-basedmethodsforsentimentanalysis.ComputationalLinguistics.NiketTandonandGerarddeMelo.2010.Informationextractionfromweb-scalen-gramdata.InProceed-ingsoftheSIGIR2010WebN-gramWorkshop.PeterD.TurneyandMichaelL.Littman.2003.Mea-suringpraiseandcriticism:Inferenceofsemanticorientationfromassociation.ACMTrans.Inf.Syst.,21(4):315–346,October.PeterD.Turney.2008.Auniformapproachtoanalogies,synonyms,antonyms,andassociations.InProceed-ingsofCOLING2008.XiaofengYangandJianSu.2007.Coreferenceresolu-tionusingsemanticrelatednessinformationfromauto-maticallydiscoveredpatterns.InProceedingsofACL2007.AinurYessenalinaandClaireCardie.2011.Composi-tionalmatrix-spacemodelsforsentimentanalysis.InProceedingsofEMNLP2011.