Structured Self-Supervised Pretraining for Commonsense Knowledge
Graph Completion
Jiayuan Huang•∗, Yangkai Du•∗, Shuting Tao•∗, Kun Xu(cid:3), Pengtao Xie(cid:2)†
•Zhejiang University, Chine, (cid:3)Tencent AI Lab, Etats-Unis, (cid:2)UC San Diego, Etats-Unis
p1xie@eng.ucsd.edu
Abstrait
To develop commonsense-grounded NLP ap-
plications, a comprehensive and accurate com-
monsense knowledge graph (CKG) is needed.
It is time-consuming to manually construct
CKGs and many research efforts have been de-
voted to the automatic construction of CKGs.
Previous approaches focus on generating con-
cepts that have direct and obvious relationships
with existing concepts and lack an capability
to generate unobvious concepts. In this work,
we aim to bridge this gap. We propose a gen-
eral graph-to-paths pretraining framework that
leverages high-order structures in CKGs to
capture high-order relationships between con-
cepts. We instantiate this general framework
to four special cases: long path, path-to-path,
router, and graph-node-path. Experiments on
two datasets demonstrate the effectiveness of
our methods. The code will be released via the
public GitHub repository.
1
Introduction
Commonsense knowledge has been widely used
to boost many NLP applications, such as dialog
generation (Zhou et al., 2018), question answering
(Talmor et al., 2018), story generation (Guan et al.,
2020), and so forth. To ground an application with
commonsense, one needs to access a common-
sense knowledge graph (CKG) where nodes repre-
sent concepts such as ‘‘maintain muscle strength’’,
‘‘exercise regularly’’, and edges represent the re-
lationships between concepts such as ‘‘maintain
muscle strength’’ has a prerequisite of ‘‘exercise
regularly’’.
Commonsense knowledge involves almost all
concepts in a human’s daily life. These concepts
have very rich and diverse relationships. As a
result, it is extremely challenging, if not impossi-
ble, for humans to list all commonsense concepts
and relationships exhaustively. To address this is-
∗Equal contribution.
†Corresponding author.
sue, many efforts (Malaviya et al., 2020; Bosselut
et coll., 2019) have been devoted to automatically
constructing CKGs. A commonly used approach
est: Given a head concept and a relation, train
a generative model to generate the tail concept.
Typiquement, the generative model consists of an
encoder that encodes the concatenation of head
concept and relation, and a decoder that takes the
embedding generated by the encoder as input and
decodes a tail concept. While simple, these ap-
proaches treat a CKG as a collection of individual
concept-relation-concept triples without consid-
ering the rich structures in a CKG. Par conséquent,
although existing methods can generate new con-
cepts that have direct and obvious relationships
with existing concepts in a CKG, they are lack-
ing in generating concepts that are indirectly and
unobviously related to existing concepts.
This problem can be potentially addressed by
exploiting the rich structures in a CKG to perform
high-order reasoning that helps to generate un-
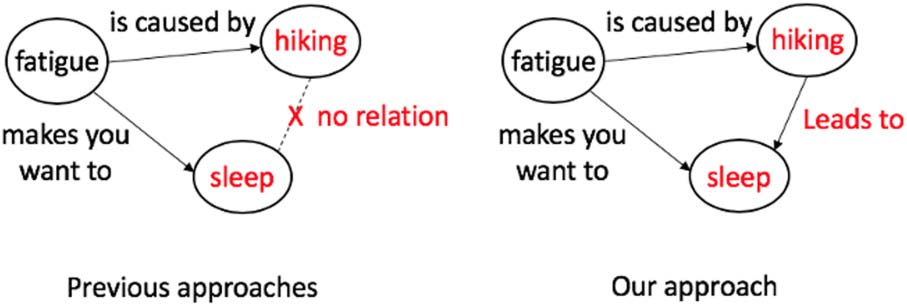
obvious concepts. Chiffre 1 shows an example.
Previous approaches are able to generate obvious
concepts/relations such as generating ‘‘hiking’’
given ‘‘fatigue’’ and ‘‘is caused by’’ and generat-
ing ‘‘sleep’’ given ‘‘fatigue’’ and ‘‘makes people
want to’’. Cependant, since the relationship between
‘‘hiking’’ and ‘‘sleep’’ is not obvious, previous
approaches are unlikely to generate a tail concept
of ‘‘sleep’’ given a head concept ‘‘hiking’’ and a
relation ‘‘leads to’’. One potential solution to ad-
dress this problem is leveraging high-order struc-
ture: Because fatigue is caused by hiking and
fatigue makes people want to sleep, there should
be a ‘‘leads to’’ relationship from hiking to sleep.
To this end, we propose to leverage the rich
structure in a CKG to pretrain encoder-decoder
models for generating more accurate and diverse
commonsense knowledge. We propose a general
graph-to-paths structured pretraining framework.
To construct a pretraining example, we randomly
sample a sub-graph from a CKG and use it as input.
1268
Transactions of the Association for Computational Linguistics, vol. 9, pp. 1268–1284, 2021. https://doi.org/10.1162/tacl a 00426
Action Editor: Minlie Huang. Submission batch: 4/2021; Revision batch: 7/2021; Published 11/2021.
c(cid:4) 2021 Association for Computational Linguistics. Distributed under a CC-BY 4.0 Licence.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
• To capture long-range relationships between
concepts and to be able to generate novel
concepts that do not have direct relation-
ships with existing concepts, we instantiate
the graph-to-paths framework to a long-path
pretraining method.
• We instantiate the graph-to-paths framework
to a path-to-path pretraining method, to en-
hance the reasoning ability of commonsense
generation models: Given a path between two
concepts, predict another path between these
two concepts.
• We instantiate the graph-to-paths framework
to a router pretraining approach, to enhance
the ability of commonsense generation mod-
els in understanding concepts: Given the
inbound relations and inbound concepts of
a router concept, predict outbound relations
of the router concept.
• We instantiate the graph-to-paths framework
to a graph-node-path pretraining approach to
address the limitations of router pretraining:
Given a local graph involving a concept c, dans
graph-node-path pretraining, a path starting
from c is predicted.
• We demonstrate the effectiveness of our
methods in experiments conducted on two
datasets.
2 Related Works
2.1 Commonsense Knowledge Generation
Several works have been proposed for automatic
construction of knowledge bases. Li et al. (2016)
designed an LSTM-based model
to determine
whether a relationship holds between two entities.
Saito et al. (2018) proposed to jointly perform
knowledge completion and generation. Bosselut
et autres. (2019) developed transformer-based language
models to generate knowledge tuples. Feldman
et autres. (2019) developed a method to judge the
validity of a head-relation-tail knowledge tuple
using a pre-trained bidirectional language model.
Malaviya et al. (2019) proposed to leverage local
graph structure and pre-trained language models
to generate a tail entity given a head entity and a
Chiffre 1: Illustration of leveraging high-order structure
to generate unobvious concepts. Because the relation-
ship between ‘‘hiking’’ and ‘‘sleep’’ is not obvious,
previous approaches are unlikely to generate a tail con-
cept of ‘‘sleep’’ given a head concept ‘‘hiking’’ and
a relation ‘‘leads to’’. Our method addresses this pro-
blem by leveraging high-order structure: Because fa-
tigue is caused by hiking and fatigue makes people
want to sleep, there should be a ‘‘leads to’’ relationship
from hiking to sleep.
Then we randomly sample one or more paths from
the CKG and use them as outputs. Part of the nodes
in output paths are overlapped with those in the
input sub-graph. We pretrain an encoder and a
decoder by mapping input sub-graphs to output
paths. Spécifiquement, an input sub-graph is fed into
the encoder, which yields an encoding. Then the
encoding is fed into the decoder which generates
output paths.
We instantiate the general graph-to-paths frame-
work to four concrete cases, each capturing a spe-
cial type of structured information. Spécifiquement,
we consider four types of structures: (1) concepts
have long-range relations; (2) multiple paths ex-
ist between a pair of source and target concept;
(3) each concept has multiple inbound relations
and outbound relations with other concepts; et
(4) each concept is involved in a local graph and
initiates a path. To capture these structures, we in-
stantiate the general graph-to-paths framework to
four specific pretraining methods: (1) pretraining
on individual paths; (2) path-to-path pretraining;
(3) router pretraining; et (4) graph-node-path
pretraining. We conduct extensive experiments
on two datasets, where the results demonstrate the
effectiveness of our pretraining methods.
The major contributions of this paper include:
• We propose a graph-to-paths general frame-
work which leverages the rich structures in
a commonsense knowledge graph to pretrain
commonsense generation models for gener-
ating commonsense knowledge that is more
accurate and diverse.
1269
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
relation. In these works, entities and relations are
generated individually without considering their
correlations. Par conséquent, these methods cannot
generate unobvious entities/relations that require
high-order reasoning.
2.2 Graph Representation Learning
Classic approaches for graph representation learn-
ing can be categorized as: (1) embedding meth-
ods: Par exemple, DeepWalk (Perozzi et al., 2014)
leveraged truncated random walk to learn node
embeddings, LINE (Tang et al., 2015) used edge
sampling to learn node embeddings in large-scale
graphs, HARP (Chen et al., 2017) utilized hierar-
chical representation learning to capture global
(2) matrix-factorization-
structures in graphs;
based methods: Par exemple, NetMF (Qiu et al.,
2018) discovered a theoretical connection be-
tween DeepWalk’s implicit matrix and graph
Laplacians and proposed an embedding approach
based on this connection, HOPE (Ou et al., 2016)
proposed an asymmetric transitivity preserving
graph representation learning method for directed
graphs.
Recently, graph neural networks (GNNs) have
achieved remarkable performance for graph mod-
eling. GNN-based approaches can be classi-
fied into two categories: Spectral approaches and
message-passing approaches. The spectral ap-
proaches generally use graph spectral theory to
design parameterized filters. Based on Fourier
transform on graphs, Bruna et al. (2013) defined
convolution operations for graphs. To reduce the
heavy computational cost of graph convolution,
Defferrard et al. (2016) utilized fast localized
spectral
filtering. Graph convolution network
(GCN) (Kipf and Welling, 2016) truncated the
Chebyshev polynomial to the first-order approx-
imation of the localized spectral filters. Le
message-passing approaches basically aggregate
the neighbors’ information through convolution
opérations. GAT (Veliˇckovi´c et al., 2017) lev-
eraged attention mechanisms to aggregate the
neighbours’ information with different weights.
GraphSAGE (Hamilton et al., 2017) generalized
representation learning to unseen nodes using
neighbours’ information. Graph pooling methods
such as DiffPool (Ying et al., 2018) and HGP-SL
(Zhang et al., 2019) were developed to aggre-
gate node-level representations into graph-level
representations.
2.3 Knowledge Graph Embedding
Knowledge graph embedding methods aim to
learn continuous vector-based representations of
nodes and edges in a knowledge graph. TransE
(Bordes et al., 2013) learns node and edge repre-
sentations by encouraging the summation of the
embeddings of a head entity and a relation to be
close to the embedding of a tail entity. TransH
(Wang et al., 2014) models a relation as a trans-
lation operation on a hyperplane. Given an entity-
relation-entity triple (h, r, t), TransH projects the
embeddings of h and t onto the hyperplane of
r and encourages the projections to be close to
the translation vector. TransG (Xiao et al., 2015)
uses Bayesian nonparametric models to generate
multiple representations of the same relation to
account for the fact that one relation type can
have multiple semantics. To address the problem
that the degree of nodes is typically distributed
in a power-law fashion, TranSparse (Ji et al.,
2016) proposes to determine the sparsity level of
the transfer matrix for a relation according to its
number of connected nodes.
2.4 Language Representation Learning
Recently, pretraining on large-scale text corpus
for language representation learning has achieved
substantial success. The GPT model (Radford
et coll., 2018) is a language model based on Trans-
former (Vaswani et al., 2017). Unlike Trans-
former, which defines a conditional probability
on an output sequence given an input sequence,
GPT defines a marginal probability on a single
séquence. GPT-2 (Radford et al., 2019) is an ex-
tension of GPT, which modifies GPT by moving
layer normalization to the input of each sub-block
and adding an additional layer normalization after
the final self-attention block. Byte pair encoding
(BPE) (Sennrich et al., 2015) is used to represent
the input sequence of tokens. BERT (Devlin et al.,
2018) aims to learn a Transformer encoder for
representing texts. To train the encoder, BERT
masks some percentage of input tokens at ran-
dom, and then predicts those masked tokens by
feeding hidden vectors (produced by the encoder)
corresponding to masked tokens into an output
softmax over word vocabulary.
Auto-Regressive Transformers (BART) (Lewis
et coll., 2019) pretrains a Transformer encoder and
a Transformer decoder jointly. To pretrain BART
weights, input texts are corrupted randomly, tel
1270
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
as token masking, token deletion, text infilling,
then a network is learned to reconstruct
etc.,
original texts. ALBERT (Lan et al., 2019) uses
parameter-reduction methods to reduce the mem-
ory consumption and increase the training speed
of BERT. It also introduces a self-supervised loss
which models inter-sentence coherence. RoBERTa
(Liu et al., 2019) is a replication study of BERT
pretraining. It shows that the performance of BERT
can be significantly improved by carefully tuning
the training process, tel que (1) training the model
longer, with bigger batches, over more data; (2)
removing the next sentence prediction objective;
et (3) training on longer sequences, etc..
3 Methods
Dans cette section, we first propose a general graph-to-
paths pretraining framework, then instantiate this
general framework to four specific cases. Given
a commonsense knowledge graph, we automati-
cally construct a pretraining dataset that captures
high-order structured information of common-
sense knowledge. Each pretraining example con-
sists of an input sub-graph and one or more paths.
The input sub-graph can have arbitrary graph
structures. An output path is a special type of sub-
graph whose structure is required to be a directed
chain, c'est, each node (except the first and last
un) has one inbound edge and one outbound
bord. The input sub-graph and output paths are re-
quired to have some overlapping nodes so that the
input and output are related. Given these training
examples, we pretrain an encoder and a decoder
by mapping input sub-graphs to output paths.
Spécifiquement, given an input sub-graph, we use the
encoder to encode it; then the encoding is fed into
the decoder to generate output paths. Afterwards,
the pretrained encoder and decoder are finetuned
for commonsense knowledge generation. For the
outputs, we choose to use paths instead of arbi-
trarily structured sub-graphs because decoding a
path is much easier than decoding a graph and can
be readily done by many models such as GPT2,
BART, etc.. Suivant, we discuss how to capture some
specific types of structures by instantiating the
general graph-to-paths pretraining framework to
specific cases.
3.1 Case 1: Long-Path Pretraining
In a CKG, there are many paths, each containing
an alternating sequence of concepts and relations.
These paths capture long-range relationships be-
tween concepts. Par exemple, from the following
chemin: hiking – [requires] – boots – [can be] – very
heavy, we can infer that hiking may be a heavy-
duty exercise since hiking requires boots and
boots can be very heavy. Such a relationship is
not obvious and is difficult to capture by previous
approaches. To capture these long-range relation-
ships, we instantiate the general graph-to-paths
framework to a long-path pretraining method,
which performs pretraining on long paths, comme
shown in Figure 2a. Consider a path e1, r1, e2, r2,
e3 · · · ri, ei+1 · · · , where e and r represent con-
cepts and relations respectively, and ei, ri, ei+1
form a knowledge triple where ei and ei+1 is the
head and tail concept respectively and ri depicts
the relationship between these two concepts. Nous
concatenate concepts and relations in this path
to form a sentence where concepts and relations
are separated with a special token [SEP]. These
special tokens are used to determine the bound-
aries of generated concepts and relations. Alors
on top of these sentences, we pretrain a BART
(Lewis et al., 2019) model: Each sentence is cor-
rupted by token masking, token infilling, et
token corruption; then the corrupted sentence is
fed into the BART model as input to decode the
original sentence. The special tokens do not partic-
ipate in sentence corruption. Compared with the
graph-to-paths general framework, in long-path
pretraining, we omit input graphs and only retain
output paths. The output paths are used to train an
encoder and a decoder simultaneously, which is
different from graph-to-paths where output paths
are used to train a decoder only.
3.2 Case 2: Path-to-Path Pretraining
Given a source concept s and a target concept t,
there may be several long paths connecting these
two concepts. Each path reflects a relationship be-
tween the two concepts. Since these relationships
are about the same source and target concept,
they are related in semantics. We are interested
in asking: Given one long-range relationship be-
tween two concepts, can the model predict other
long-range relationships between these two con-
cepts? If so, the model is considered to have strong
reasoning ability on commonsense knowledge.
This motivates us to instantiate the graph-to-paths
framework to a path-to-path pretraining method
(as shown in Figure 2b) which takes one path
1271
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 2: (un) Pretraining on individual paths. We randomly sample long paths from the graph. For each path, le
strings of concepts and relations along the path are concatenated into a long string. Pretraining is performed on
the long strings. (b) Path-to-path pretraining. Given a randomly sampled source node (par exemple., 1) and a randomly
sampled target node (par exemple., 7), we randomly sample two paths connecting these two nodes. Pretraining is performed
by taking the concatenated string of one path as input and predicting the concatenated string of the other path. (c)
Router pretraining. Given a randomly sampled node (par exemple., 5), we perform pretraining by taking some randomly
sampled inbound nodes of this node as inputs and predicting some randomly sampled outbound nodes of this
node. (d) Graph-node-path pretraining. Given a node (par exemple., 5), we randomly sample a subgraph containing this
node and a path starting from this node. Pretraining is performed by taking the graph as input and predicting the
chemin. We show a pretraining example for each method.
between two concepts as input and generates an-
other path between them. For both the input and
output path, we transform them into sentences
as described in Section 3.1. We feed the input
sentence into a BART encoder which produces en-
codings, and then feed the encodings into a BART
decoder to generate the output sentence. Com-
pared with the general graph-to-paths framework,
in path-to-path pretraining, the input sub-graph
has a special structure, which is a path.
3.3 Case 3: Router Pretraining
In a CKG, each concept c is connected with
multiple other concepts. Some of the edges are
connected to c. We refer to the relationships rep-
resented by these edges as inbound relations and
refer to the concepts connected to c via inbound
edges as inbound concepts. Some edges are from
c to other concepts. We refer to these concepts
as outbound concepts and the corresponding re-
lations as outbound relations. A commonsense
generation model is considered to have strong
ability in understanding the concept c if the model
can generate the outbound relationships of c with
other concepts given the inbound relations and
inbound concepts of c. Based on this idea, we in-
stantiate the graph-to-paths general framework to
a router pretraining method, as shown in Figure 2c.
For each inbound concept cin and the associated
inbound relation rin, we concatenate the phrases
in cin, rin, and c together to form a sentence. Alors
we use the BART encoder to encode this sentence
and obtain an embedding ein. We average the ein
corresponding to all inbound concepts and rela-
tions and get ¯ein. Then for each outbound concept
cout and its corresponding outbound relation rout,
we concatenate the phrases in c, rout, and cout
into a sentence and decode this sentence from
¯ein using the BART decoder. Compared with the
general graph-to-paths framework, in router pre-
entraînement, input graphs have the following special
structure: there exists a single target node c; tous
other nodes are connected to the target node but
do not have connections among themselves; le
target node has inbound edges only. Il y a
multiple output paths, each starting with c and
having a length of one.
3.4 Case 4: Graph-Node-Path Pretraining
In router pretraining, the inbound concepts are
considered to be independent, which are actually
pas. Because these concepts have inbound rela-
tionships with the same concept, they are semanti-
cally related and have direct relationships among
themselves as well. The relationships among
inbound concepts provide valuable information
for better understanding these concepts. On the
other hand, router pretraining generates outbound
1272
knowledge triples instead of long paths, lequel
therefore cannot capture long-range relationships
between concepts.
To bridge these two gaps, we instantiate the
graph-to-paths framework to a graph-node-path
pretraining method which generates a path start-
ing from a concept, given a local graph containing
this concept. At each concept c, we sample a
local graph G containing c and a path p start-
ing with c. The local graph is sampled using
breadth-first-search, with c as the origin. The tar-
get path is sampled by depth-first-search with c
as the origin as well. During sampling, we ensure
that other than c, no node appears in the graph
and the path simultaneously. We feed G into a
graph neural network (Schlichtkrull et al., 2018)
to learn node embeddings. Given a node n in G,
let {(h, r, n)} denote all knowledge triples where
n is the tail concept. We concatenate h and r
and use a BART encoder or GPT/GPT2 to encode
this concatenation. Let a denote the average of all
such embeddings. A hidden representation of n is
calculated as:
z = σ(U a + W e)
(1)
where e is the BART/GPT/GPT2 encoding of the
text in n, U and W are weight matrices, and σ de-
notes element-wise nonlinear activation. The node
embeddings are averaged to form an embedding
of the graph G. Then the graph embedding is fed
into a BART decoder or a GPT/GPT2 decoder to
generate the path.
3.5 Comparison of Four Pretraining
Methods
Dans cette section, we make a comparison of the four
pretraining methods. Long-path pretraining is the
simplest one among the four. It is very easy to con-
struct a number of pretraining examples (paths)
for long-path pretraining. And the pretraining
method is very simple, which is the same as pre-
training on regular texts. Path-to-path pretraining
requires path pairs sharing the same source node
and target node, which are not as available as indi-
vidual paths used in long-path pretraining. Path-to-
path pretraining and long-path pretraining both
aim to capture long-range relationships between
concepts, but using different ways: Path-to-path
pretraining predicts another long-range relation
between two concepts given one long-range rela-
tion between these two concepts; long-path pre-
training performs language modeling on long
paths to capture long-term semantics. These two
pretraining methods are both based on paths,
where each intermediate node has only one in-
bound edge and one outbound edge. Router pre-
training generalizes this by allowing each node
to have multiple inbound edges and multiple out-
bound edges, to capture the multi-faceted relation-
ships of each node with other nodes. But router
pretraining performs encoding/decoding locally
at each node, without accounting for long-range
relationships. Graph-node-path pretraining gener-
alizes router pretraining by allowing a long path
to be decoded and allowing inbound nodes to
have mutual connections. Similar to path-to-path
pretraining, the pretraining examples in router pre-
training and graph-node-path pretraining may not
be abundantly available.
Long-path and path-to-path pretraining capture
long-range semantic dependency between con-
cepts. Models pretrained using these two methods
are good for commonsense-grounded text genera-
tion tasks, such as dialog generation (Zhou et al.,
2018), story generation (Guan et al., 2020), et
so on, which require long-term reasoning among
entities. Router pretraining captures multifaceted
relationships between nodes, which is good for
reasoning tasks such as question-answering on
knowledge graphs (Lukovnikov et al., 2017).
Graph-to-path pretraining integrates the merits
of router pretraining and long-path pretraining,
which is good for tasks involving both long-range
and multi-faceted reasoning, such as text genera-
tion from knowledge graphs (Koncel-Kedziorski
et coll., 2019).
3.6 Multi-objective Pretraining
In previous subsections, we have discussed several
special cases of graph-to-paths pretraining. These
special cases capture different types of structures
in a commonsense knowledge graph. In order to
simultaneously capture all these different types of
structures in a single encoder-decoder model, nous
can train this model by minimizing the combi-
nations of objectives of long-path, path-to-path,
router, and graph-node-path pretraining meth-
ods. Spécifiquement, we aim to solve the following
problem:
minE,D Llp(E, D) + λ1Lp2p(E, D)
+ λ2Lr(E, D) + λ3Lgnp(E, D)
(2)
1273
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
where Llp(·), Lp2p(·), Lr(·), and Lgnp(·) are the
loss functions of long-path, path-to-path, router,
and graph-node-path pretraining respectively. λ1,
λ2, λ3 are tradeoff parameters. E is an encoder
and D is a decoder. E and D are shared in these
four loss functions. We set E to be a BART en-
coder and D to be a BART decoder.
3.7 Commonsense Generation
Given the models pretrained on high-order struc-
photos, we continue to finetune them on low-order
knowledge triples. Given a head concept and a
relation, we train the model to generate a tail
concept. To finetune an encoder and a decoder pre-
trained by the four structured pretraining methods,
we concatenate the head concept and the relation,
then feed the concatenation into the encoder. En-
codings of the concatenation are subsequently
fed into the decoder to generate the tail concept.
For all four pretraining methods, the encoder can
be a BART encoder and the decoder can be a
BART decoder. En outre, for graph-node-path
pretraining, the encoder can be a GPT/GPT2 and
the decoder can be a GPT/GPT2 as well. In our
current experiment setting, following (Bosselut
et coll., 2019), we generate one tail concept. Notre
method can be extended to generate multiple tail
concepts by using probabilistic decoding or beam
recherche.
3.8 Multi-task Learning
In the methods developed in previous sections,
pretraining and finetuning are performed sepa-
rately. An alternative way is to perform them
jointly in a multi-task learning framework which
simultaneously trains an encoder and a decoder
on automatically-constructed (graph, paths) pairs
used for structured pretraining and (concept,
relation, concept) triples used for training com-
monsense generation models. Let Lsp and Lcg
denote loss functions of the structured pretraining
task and commonsense generation task respec-
tivement. Joint training amounts to solving the fol-
lowing problem:
Lcg + λLsp,
(3)
where λ is a tradeoff parameter.
4 Experiments
Dans cette section, we present experimental results.
4.1 Datasets
In our experiments, two datasets were used: Con-
ceptNet (Speer and Havasi, 2013) and ATOMIC
(Sap et al., 2019). The ConceptNet dataset (Li
et coll., 2016) contains 34 different types of rela-
tions and 100K knowledge triples, which covers a
wide range of commonsense knowledge obtained
from the Open Mind Common Sense (OMCS)
entries in ConceptNet 5 (Speer et al., 2016). Le
triples of ConceptNet are in the sro format (par exemple.,
keyboard, Partof, Computer). The most confident
1200 triples are used for testing. The validation
set and training set contain 1200 and 100K triples
respectivement. The ATOMIC dataset (Sap et al.,
2019) contains 877K social commonsense knowl-
edge triples around specific event prompts (par exemple.,
‘‘X goes to the store’’). The commonsense in
ATOMIC is distilled in nine dimensions, covering
the event’s causes, its effects on the agent, et
its effect on other direct or implied participants.
ATOMIC events are treated as phrase subjects.
The dimension is treated as phrase relation. Le
causes/effects are treated as phrase objects. Le
data split follows that in Sap et al. (2019), où
the number of training, development, and test
triples is 710K, 80K, and 87K, respectivement.
For long-path pretraining on ConceptNet, nous
randomly sample 100K paths for training and
5K paths for validation. The validation set was
used for hyperparameter tuning. For long-path pre-
training on ATOMIC, we randomly sample 11K
paths for training and 1K paths for validation. Pour
path-to-path pretraining on ConceptNet, we ran-
domly sample 100K path pairs that share the same
source and target concept for training and 5K path
pairs for validation. On ATOMIC, we could not
find enough path pairs due to the special property
of ATOMIC. For router pretraining on Concept-
Net, we sample router concepts that have 2, 5,
et 10 inbound relations, where the number of
training instances is 37K, 125K, and 54K, respecter-
tivement; the number of development instances is 2K,
6K, and 3K, respectivement. On ATOMIC, we could
not find enough router concepts due to the spe-
cial property of ATOMIC. For graph-node-path
pretraining on ConceptNet, we randomly sample
2.9K graph-path pairs for training and 1K pairs
for validation. For graph-node-path pretraining on
ATOMIC, we randomly sample 16K graph-path
pairs for training and 1K pairs for validation. Le
statistics of all datasets are summarized in Table 1.
1274
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Dataset
Train
Dev
Test
ConceptNet
ATOMIC
Long-path (C)
Long-path (UN)
Path-to-path (C)
Router-2 (C)
Router-5 (C)
Router-10 (C)
Graph-node-path (C)
Graph-node-path (UN)
100K
710K
100K
11K
100K
54K
54K
54K
2.9K
16K
2.4K
1.2K
80K 87K
5K
1K
5K
3K
3K
3K
1K
1K
–
–
–
–
–
–
–
–
Tableau 1: Dataset statistics: number of instances
in the train, development (dev), and test set. (C)
denotes ConceptNet and (UN) denotes ATOMIC.
Long-path (C) denotes the number of long paths
randomly sampled from the ConceptNet dataset.
Similar meanings hold for other notations with
such a format. Router-2 denotes that the number
of inbound nodes and outbound nodes are both 2.
4.2 Experimental Settings
Hyperparameters For the encoder and decoder
in all four pretraining methods, we experimented
the BART encoder and BART decoder. En addition-
dition, for graph-node-path pretraining, we also
experimented GPT or GPT2 as encoder and de-
coder. In BART-based experiments, following the
hyperparameter settings in BART, the number of
layers in the encoder and decoder was set to 12,
the size of hidden state was set to 1024, et
the number of attention heads was set to 12. Pour
BART-based methods, the input embeddings are
the same as those in BART. The dimension is
1024. For GPT and GPT-2 based methods, le
input embeddings include byte pair encodings of
tokens and position embeddings, the same as those
in GPT and GPT-2. The embedding dimension in
GPT and GPT2-small is 768; the embedding di-
mension in GPT-medium is 1024. Model weights
were initialized using the pretrained model in
Lewis et al. (2019) on general-domain corpora.
The learning rate was set to 1e − 5 and batch size
was set to 16. During the finetuning process of
the pretrained models, the learning rate was set to
1e − 5 and the batch size was set to 64 for Con-
ceptNet; the learning rate was set to 5e − 5 et le
batch was set to 64 for ATOMIC. We used Adam
(Kingma and Ba, 2014) for optimization where
the learning rate was decayed linearly and 1% de
training steps were used for warm-up. For GPT-2
based experiments in graph-node-path pretrain-
ing, following (Radford et al., 2019) settings, nous
used two models. The small model has 12 layers
with 768-dimensional hidden states. The medium
model has 16 layers with 1024-dimensional hid-
den states. Weights of both models were initialized
with the pretrained models in (Radford et al., 2019)
on general-domain corpora. For both the pretrain-
ing and finetuning process on ConceptNet, le
learning rate and batch size were set to 1e − 5 et
32 for the small model and 1e − 5 et 16 for the
medium model. For ATOMIC, the learning rate
was set to 1.5e − 5 with batch size as 32. For both
models and both datasets, the learning rate was
decayed linearly and 1% of training steps were
used for warm-up. In multi-objective pretraining,
we set the tradeoff parameters λ1, λ2, λ3, à 1. Dans
multi-task learning, we set the tradeoff parameter
λ to 0.2.
Baselines We compare our methods with:
• COMET (Bosselut et al., 2019) directly per-
forms training on triples without structured
pretraining as our methods do. Given a head
concept and a relation, their concatenation
is fed into a GPT model to generate the tail
concept.
• Context Prediction (Hu et al., 2019) uses
subgraphs to predict their surrounding graph
structures. The encoder and decoder are
based on BART.
• Attribute Masking (Hu et al., 2019) masks
edge attributes (relations) and lets GNNs
predict those attributes based on neighboring
structure. The encoder and decoder are based
on BART.
• CKBG (Saito et al., 2018) trains a bi-
directional LSTM network by generating tail
concept given head concept and relation, et
generating head concept given tail concept
and relation.
• LSTM (Hochreiter and Schmidhuber, 1997)
is trained by generating tail concept given
head concept and relation.
• 9ENC9DEC (Sap et al., 2019) trains 9
seq2seq models for 9 knowledge dimensions
1275
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
in Atomic using GRU network. Each model
for a given type is trained by generating the
target phrase given head event phrase.
• Event2(IN)VOLUN (Sap et al., 2019)
groups knowledge dimensions depending on
whether they denote voluntary. ‘‘Voluntary’’
decoders shares one encoder and another
five ‘‘involuntary’’ decoders share another
encoder.
• Event2PERSONX/Y (Sap et al., 2019)
groups knowledge dimensions depending on
whether they are agents of the event.
• NearestNeighbor (Sap et al., 2019) dans-
code the event phrase and relation to a
low-dimensional embedding, then find the
nearest neighbor in vector space to generate
the target phrase.
Evaluation Metrics We perform both human
evaluation and automatic evaluation to measure
whether the generated concepts are correct and
comprehensive. In human evaluation, we ran-
domly sample 1200 (head concept h, relation
r) pairs from the test set. For each pair, we apply
each method to generate a tail concept t. Three un-
dergraduate students independently judge whether
the generated tail concept has the relation r with
the head concept. The rating is binary: 1 denotes
t has relation r with h. The final evaluation score
is the average of ratings given by all students on
all pairs. For automatic evaluation, we use the
following metrics.
• AVG Score. Given a head concept s and
a relation r, a tail concept o is generated.
The newly formed triple (s, r, o) is fed into a
pretrained binary classifier – Bilinear AVG
model (Li et al., 2016), which judges whether
the relationship between s and o is correct.
AVG score measures the percentage of newly
formed triples that are correct. The higher,
the better.
• Perplexity measures the language quality of
generated concepts. The lower, the better.
• BLEU-2 (Papineni et al., 2002) mea-
sures 2-gram overlap between generated
concepts and groundtruth concepts. Higher
is better.
• N/Tsro. If a newly formed triple (s, r, o) does
not exist in the training set, it is considered
as a novel triple. N/Tsro is the proportion of
newly formed triples that are novel. Higher
is better.
• N/To. Given a newly generated tail concept,
if it does not exist in the training set, it is con-
sidered as a novel concept. N/To represents
the proportion of newly generated concepts
that are novel. The higher, the better.
Among these metrics, human scores, AVG score,
perplexity, and BLEU-2 measure the correctness
of generated concepts, which are analogous to
‘‘precision’’. N/Tsro and N/To measure com-
prehensiveness of generated concepts, which are
analogous to ‘‘recall’’. Note that all these auto-
matic evaluation metrics have caveats and should
be used with caution. Par exemple, perplex-
ity measures the language quality of generated
concepts; cependant, good language quality does
not necessarily imply semantic correctness. AVG
score is calculated using an external bi-linear clas-
sifier. Due to the limitation of this classifier, it
may result in false positives and false negatives.
Human scores are relatively more reliable than
these automated scores. Cependant, human scores
can only reflect precision, not recall. Because the
number of generated concepts is very large, it
is highly difficult to measure comprehensiveness
(recall) of these generated concepts manually.
4.3 Human Evaluation Results
Tableau 2 shows the human evaluation results
(mean±standard deviation) on ConceptNet. Mean
and standard deviation are calculated on the indi-
vidual results of the three annotators. For mean, le
higher, the better. The Kappa coefficient of three
annotators is 0.74, which indicates a strong level
of agreement among them. In router, the num-
ber of inbound nodes is set to 10. For methods
marked with ‘‘Pretrain’’, structured pretraining
and the finetuning of commonsense generation
models are performed separately. For methods
marked with ‘‘Joint’’, structured training and
commonsense generation are performed jointly
in the multi-task learning framework described
1276
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Method
BART
Long-path (BART, Pretrain)
Long-path (BART, Joint)
Path-to-path (BART, Pretrain)
Path-to-path (BART, Joint)
Router (BART, Pretrain)
Router (BART, Joint)
Graph-node-path (BART, Pretrain)
Graph-node-path (BART, Joint)
Multi-objective (BART, Pretrain)
Multi-objective (BART, Joint)
COMET (GPT)
Graph-node-path (GPT, Pretrain)
Graph-node-path (GPT, Joint)
Human Score (%)
91.40±0.27
93.49±0.19
94.02±0.11
93.82±0.25
94.26±0.17
93.15±0.31
94.01±0.29
93.71±0.14
93.99±0.10
94.75±0.16
94.92±0.09
92.18±0.34
93.77±0.16
94.15±0.20
Tableau 2: Human evaluation results (average rat-
ing ± standard deviation) on ConceptNet. Nous
randomly sample 1200 (head concept h, rela-
tion r) pairs from the test set. For each pair,
we apply each method to generate a tail concept
t. Three undergraduate students independently
judge whether the generated tail concept has the
relation r with the head concept. The rating is bi-
nary: 1 denotes t has relation r with h. The final
evaluation score is the average of ratings given
by all students on all pairs. Long-path (BART,
Pretrain) denotes that a BART model is pretrained
using long-path; pretraining and finetuning are
separated.
that pretraining
and finetuning are performed jointly. ‘‘Multi-
objective’’ denotes that the pretraining objectives
in long-path, path-to-path, and router are added
ensemble. In router, 10 inbound nodes are used.
‘‘Joint’’ denotes
in Eq. (3). From this table, we make the follow-
ing observations.
D'abord, long-path pretraining on individual paths
outperforms BART (which does not have struc-
tured pretraining). This is because long-path
pretraining can help to capture the long-range
semantic relationships between concepts, lequel
helps to generate diverse and novel tail concepts
that do not have obvious and indirect relationships
with the head concepts. In contrast, BART trains
the generation model solely based on concepts
that have direct relationships and hence lacks the
capability to capture the indirect and long-range
relationships between concepts.
Deuxième, path-to-path pretraining works better
than BART. In path-to-path pretraining, given
one long-range relation between two concepts, le
model
is encouraged to predict another rela-
tionship between these two concepts. This is a
challenging task involving semantic reasoning.
By training the model to perform such reasoning,
the model is able to better understand concepts
and relations and hence yields better performance
in generating commonsense knowledge.
Troisième, router pretraining outperforms BART.
In router pretraining, the model is encouraged to
generate outbound relations of a concept c given
the inbound concepts and relations of c. This is
another challenging task requiring thorough un-
derstanding of c. By training the model to perform
this task, the model gains better ability to cap-
ture the complicated semantics of concepts and
consequently can better generate new concepts.
Fourth, graph-node-path (BART, Pretrain) par-
forms better than BART; graph-node-path (GPT,
Pretrain) outperforms COMET (GPT). These re-
sults demonstrate the effectiveness of graph-node-
path pretraining. Graph-node-path pretraining
takes the direct relationships between inbound
concepts into account and generates long paths.
This enables the model to better understand in-
bound concepts and capture long-range relations
between concepts. Par conséquent, the model pre-
trained by graph-node-path pretraining works bet-
ter than BART and COMET (GPT), which does
not have structured pretraining.
Fifth, multi-objective pretraining based on
BART works better than individual pretraining
methods including long-path, path-to-path, router,
and graph-node-path which are based on BART as
well. This is because in multi-objective pretrain-
ing, the loss functions of long-path, path-to-path,
router, and graph-node-path are combined, lequel
can capture multiple types of structured informa-
tion simultaneously. In contrast, in each individual
pretraining methods, only one type of structured
information is captured.
joint
training which simultaneously
performs structured training and commonsense
knowledge generation performs better than sepa-
rating pretraining and finetuning. This is evidenced
by the results that long-path (joint) performs better
than long-path (pretrain); path-to-path (joint) par-
forms better than path-to-path (pretrain); router
(joint) performs better than router (pretrain); graph-
node-path (joint) performs better than graph-
node-path (pretrain); and multi-objective (joint)
performs better than multi-objective (pretrain).
The reason is that, in pretrain, pretraining and
Sixth,
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
1277
Method
Perplexity↓
AVG score↑
N/Tsro ↑
N/To ↑
BART
Context Prediction (BART) (Hu et al., 2019)
Attribute Masking (BART) (Hu et al., 2019)
Long-path (BART, Pretrain)
Long-path (BART, Joint)
Path-to-path (BART, Pretrain)
Path-to-path (BART, Joint)
Router (BART, 2 inbound nodes, Pretrain)
Router (BART, 5 inbound nodes, Pretrain)
Router (BART, 10 inbound nodes, Pretrain)
Router (BART, 10 inbound nodes, Joint)
Graph-node-path (BART, Pretrain)
Graph-node-path (BART, Joint)
Multi-objective (BART, Pretrain)
Multi-objective (BART, Joint)
COMET (GPT) (Bosselut et al., 2019)
Graph-node-path (GPT, Pretrain)
Graph-node-path (GPT, Joint)
Graph-node-path (GPT2-small, Pretrain)
Graph-node-path (GPT2-small, Joint)
Graph-node-path (GPT2-medium, Pretrain)
Graph-node-path (GPT2-medium, Joint)
LSTM (Hochreiter and Schmidhuber, 1997)
CKBG (Saito et al., 2018)
4.18
4.11
4.16
4.07
4.05
4.08
4.08
5.13
5.28
4.72
4.25
4.41
4.39
4.21
4.17
4.32
4.44
4.37
4.87
4.82
4.48
4.51
–
–
93.50
92.75
94.01
93.33
93.29
93.58
93.50
81.50
88.75
90.08
93.42
94.70
95.33
95.58
94.33
95.25
95.42
95.50
90.67
94.00
93.41
93.59
60.83
57.17
56.25
55.47
54.18
62.58
63.81
59.38
62.50
44.33
46.25
49.42
66.50
68.25
71.62
62.93
64.04
59.25
71.75
69.83
74.50
79.75
64.33
66.01
86.25
86.25
5.00
5.89
5.14
4.83
4.85
5.02
4.08
8.25
8.42
9.25
8.75
5.16
5.22
4.57
6.90
3.75
4.83
4.16
8.58
7.67
6.08
5.94
7.83
8.67
Tableau 3: Automatic evaluation results on ConceptNet. Four automatic evaluation metrics are used,
including perplexity, AVG score, N/Tsro, and N/To. For perplexity, the lower, the better. For other
metrics, the higher, the better. The notations of methods are similar to those in Table 2.
Method
Perplexity↓
BLEU-2↑
N/Tsro ↑
N/To ↑
9ENC9DEC (Sap et al., 2019)
NearestNeighbor (Sap et al., 2019)
Event2(IN)VOLUN (Sap et al., 2019)
Event2PERSONX/Y (Sap et al., 2019)
BART
Long-path (BART)
COMET (GPT)
Graph-node-path (GPT)
–
–
–
–
10.49
9.82
11.14
11.02
10.01
6.61
9.67
9.24
19.81
21.28
22.86
22.41
100.0
–
100.0
100.0
100.0
100.0
100.0
100.0
8.61
–
9.52
8.22
11.79
13.19
9.71
9.83
Tableau 4: Automatic evaluation results on ATOMIC. The notations are similar to those in Table 3. Given
a head concept and a relation, different methods generate a tail concept. The tail concept is evaluated
by judging whether it is plausible.
finetuning are separated; during finetuning, le
pretrained encoder and decoder are learned by
minimizing the commonsense generation loss
solely; if training dataset used for finetuning is
petit,
the finetuned model may be overfitted
to the small-sized finetuning dataset and is un-
able to generalize. In joint training, the structured
pretraining loss serves as a regularizer. Le Pre-
training loss encourages the encoder and decoder
to perform two tasks well instead of focusing on
the commonsense generation task. Par conséquent, le
risk of overfitting can be reduced.
1278
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Head concept + Relation
Method
Tail concept
Plausible
keyboard + Partof
something that is very good
+ HasProperty
doll + IsA
wing + used for
bathe + Causes
pianist + CapableOf
cloth + AtLocation
perl + IsA
computer + CapableOf
BART
Long-path (BART)
Router (BART)
COMET (GPT)
Graph-node-path (GPT)
BART
Long-path (BART)
Router (BART)
COMET
Graph-node-path (GPT)
BART
Long-path (BART)
Router (BART)
COMET
Graph-node-path (GPT)
BART
Long-path (BART)
Router (BART)
COMET (GPT)
Graph-node-path (GPT)
BART
Long-path (BART)
Router (BART)
COMET (GPT)
Graph-node-path (GPT)
BART
Long-path (BART)
Router (BART)
COMET
Graph-node-path (GPT)
BART
Long-path (BART)
Router (BART)
COMET
Graph-node-path (GPT)
BART
Long-path (BART)
Router (BART)
COMET
Graph-node-path (GPT)
BART
Long-path (BART)
Router (BART)
COMET
Graph-node-path (GPT)
mouse
computer
computer
mouse
computer
bad
good
good
bad
very rare
toy
not real person
thing you play with
hobby
child toy
fly
fly
fly
lift
fly
clean
get clean
become clean
nudity
clean clothe
poetry
play piano
play piano very well
play violin
play piano
store
cloth store
closet
trunk
cloth closet
mouse
program language
program language
computer
program language
do well
be use
be turn off
do anything
perform task
Non
yes
yes
Non
yes
Non
yes
yes
Non
yes
yes
yes
yes
Non
yes
yes
yes
yes
Non
yes
yes
yes
yes
yes
yes
Non
yes
yes
Non
yes
yes
yes
yes
Non
yes
Non
yes
yes
Non
yes
Non
yes
yes
Non
yes
Tableau 5: Examples of generating tail concepts on ConceptNet. For router, the number of inbound nodes
est 10. For long-path, router, and graph-node-path, they are all pretraining methods.
1279
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Method
Perplexity↓
Entity score↑
Seq2Seq (Sutskever et al., 2014)
MemNet (Ghazvininejad et al., 2018)
CopyNet (Zhu et al., 2017)
CCM (Zhou et al., 2018)
BART
Long-path (BART, Pretrain)
Path-to-path (BART, Pretrain)
Router (BART, Pretrain)
Graph-node-path (BART, Pretrain)
Multi-objective (BART, Pretrain)
COMET (GPT)
Graph-node-path (GPT, Pretrain)
47.02
46.85
40.27
39.18
37.59
36.41
36.55
36.72
36.48
36.42
37.31
36.96
0.72
0.76
0.96
1.18
0.75
1.26
1.31
1.35
1.30
1.33
0.72
0.97
Tableau 6: Results on test set of Reddit single-round dialog dataset. For perplexity, le
lower, the better; for entity score, the higher, the better.
4.4 Automatic Evaluation Results
Tableau 3 shows automatic evaluation results on
the ConceptNet dataset. From this table, we make
the following observations. D'abord, in general, par-
forming structured training and commonsense
generation jointly achieves better performance
than conducting them sequentially (c'est à dire., pretrain-
ing first, then finetuning). Par exemple, long-path
(joint) achieves better perplexity, N/Tsro, et
N/To than long-path (pretrain); router (10 dans-
bound nodes, joint) achieves better perplexity,
AVG score, and N/Tsro than router (10 inbound
nodes, pretrain); graph-node-path (GPT2-small,
joint) achieves better perplexity, AVG score, et
N/Tsro than graph-node-path (GPT2-small, pre-
train); and multi-objective (joint) achieves better
perplexity, N/Tsro, and N/To than multi-objective
(pretrain). This further demonstrates the effective-
ness of joint training which uses structured training
loss to regularize the commonsense generation
model.
Deuxième, path-to-path pretraining achieves bet-
ter perplexity, AVG score, N/Tsro, and N/To than
BART, which shows that by capturing long-range
relationships between concepts via path-to-path
pretraining, better commonsense knowledge can
be generated. Troisième, in general, if a method has
better perplexity and AVG score, it has worse
N/Tsro and N/To. This is because perplexity and
AVG score are analogous to precision, and N/Tsro
and N/To are analogous to recall. Precision and
recall are two conflicting goals. To achieve higher
recall, more diverse concepts need to be generated,
which introduces more noise that degrades preci-
sion; vice versa. Our long-path and path-to-path
methods achieve better ‘‘precision’’ than BART.
Our graph-node-path (BART) and multi-objective
methods achieve better ‘‘recall’’ than BART. Notre
graph-node-path (GPT) methods achieve better
‘‘recall’’ than COMET (GPT). Fourth, overall,
our pretraining methods work better than context
prediction (Hu et al., 2019) and attribute masking
(Hu et al., 2019). The reason is that these two
baseline methods focus on learning short-term
and local representations by defining objectives
based on short-term and local structures while our
methods learn long-range relationships.
Tableau 4 shows the automatic evaluation results
on the ATOMIC dataset. Compared with BART,
long-path (BART) achieves better perplexity,
BLEU-2, and N/To. Compared with COMET
(GPT), graph-node-path (GPT) achieves better
perplexity and N/To, and worse BLEU-2.
4.5 Qualitative Evaluation Results
Tableau 5 shows some examples of generating tail
concepts given head concepts and relations using
the models trained on ConceptNet. From this ta-
ble, we make the following observations. D'abord, le
tail concepts generated by our methods are more
accurate than BART and COMET. Par exemple,
given ‘‘perl’’ and ‘‘IsA’’, BART generates mouse
and COMET generates ‘‘computer’’, which are
not correct, while the tail concepts generated by
our methods are all correct. Deuxième, our methods
can generate unobvious concepts while BART
1280
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
and COMET lack such a capability. Par exemple,
given ‘‘doll’’ and ‘‘IsA’’, our proposed long-path
pretraining method generates a tail concept of
‘‘not real person’’. In ConceptNet, ‘‘doll’’ and
‘‘not real person’’ do not have a direct relation-
ship. By pretraining on long paths, our method
is able to capture the long-range semantic depen-
dency between concepts and generates unobvious
tail concepts. In contrast, the correct tail concepts
generated by COMET and BART are mostly ob-
vious and have direct relationships with head
concepts.
4.6 Experiments on
Commonsense-Grounded Dialog
Generation
Dans cette section, we apply our models pre-
trained on commonsense knowledge graphs
for commonsense-grounded dialog generation
(Young et al., 2018; Zhou et al., 2018). We use
the 10M Reddit single-round dialog dataset (Zhou
et coll., 2018), which contains about 3.4M training
conversational pairs, 10K validation pairs, et
20K test pairs. Each pair consists of an input
conversation history and an output response. Le
vocabulary size is set to 30K. Given a conversa-
tion history, it is fed into a BART or GPT model
pretrained by our methods on ConceptNet, et
the model decodes a response. Hyperparameters
mostly follow those in Section 4.2. Perplexity and
entity score (Zhou et al., 2018) are used as eval-
uation metrics. Entity score measures the average
number of entities that per response has.
Tableau 6 shows the results on the test set of Red-
dit single-round dialog dataset. From this table,
we make the following observations. D'abord, notre
methods including long-path, path-to-path, router,
graph-node-path, and multi-objective work better
than BART. Our graph-node-path method outper-
forms GPT. The reason is that our methods can
capture long-range relationships among concepts
and multi-faceted semantics of concepts. Deuxième,
BART and GPT perform better than Seq2Seq,
MemNet, CopyNet, and CCM in terms of per-
plexity. This is probably because BART and GPT
are pretrained on large-scale text corpora.
5 Conclusions and Future Work
In this paper, we study the automatic construction
of commonsense knowledge graphs (CKGs), pour
the sake of facilitating commonsense-grounded
NLP applications. To address the limitation of
previous approaches which cannot generate unob-
vious concepts, we leverage the rich structure
in CKGs to pretrain commonsense generation
models. We propose a general graph-to-paths pre-
training framework which pretrains an encoder
and a decoder by mapping input sub-graphs to
output paths. We instantiate this general frame-
work to four special cases, for capturing four
types of structures: (1) individual long paths; (2)
pairs of paths that share the same source and
target concept; (3) multi-connectivity of each con-
cept with other concepts; et (4) local graphs
at each concept. The corresponding four cases
sont: (1) pretraining on individual
long paths;
(2) path-to-path pretraining; (3) router pretrain-
ing; et (4) graph-node-path pretraining. On two
datasets, we perform both human evaluation and
automatic evaluation. The results demonstrate the
effectiveness of our methods.
For future work, we will develop a graph-to-
graph model which takes an existing common-
sense subgraph as input and generates a larger
graph containing novel concepts and relations.
When generating the target graph, concepts and
relations are generated simultaneously. In addi-
tion, we will incorporate external unstructured
texts which contain implicit commonsense knowl-
edge to generate CKGs.
Acknowledgment
This work was supported by gift funds from
Tencent AI Lab and Amazon AWS.
Les références
Antoine Bordes, Nicolas Usunier, Alberto
Garcia-Duran,
Jason Weston, and Oksana
Yakhnenko. 2013. Translating embeddings for
modeling multi-relational data. In Advances
in Neural Information Processing Systems,
pages 2787–2795.
Antoine Bosselut, Hannah Rashkin, Maarten
Sap, Chaitanya Malaviya, Asli Celikyilmaz,
and Yejin Choi. 2019. Comet: Commonsense
transformers for automatic knowledge graph
construction. In Proceedings of the 57th Annual
Meeting of the Association for Computational
Linguistics, pages 4762–4779.
1281
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Joan Bruna, Wojciech Zaremba, Arthur Szlam,
and Yann LeCun. 2013. Spectral networks and
locally connected networks on graphs. arXiv
preprint arXiv:1312.6203.
Haochen Chen, Bryan Perozzi, Yifan Hu, et
Steven Skiena. 2017. Harp: Hierarchical repre-
sentation learning for networks. arXiv preprint
arXiv:1706.07845.
Micha¨el Defferrard, Xavier Bresson, and Pierre
Vandergheynst. 2016. Convolutional neural
networks on graphs with fast localized spectral
filtering. In Advances in Neural Information
Processing Systems, pages 3844–3852.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, et
Kristina Toutanova. 2018. BERT: Pre-training
of deep bidirectional
transformers for lan-
guage understanding. arXiv preprint arXiv:
1810.04805.
Joshua Feldman, Joe Davison, and Alexander M.
Rush. 2019. Commonsense knowledge min-
ing from pretrained models. In Proceedings
of the 2019 Conference on Empirical Meth-
ods in Natural Language Processing and the
9th International Joint Conference on Natural
Language Processing (EMNLP-IJCNLP).
Marjan Ghazvininejad, Chris Brockett, Ming-Wei
Chang, Bill Dolan, Jianfeng Gao, Wen-tau
Yih, and Michel Galley. 2018. A knowledge-
grounded neural conversation model. En Pro-
ceedings of the AAAI Conference on Artificial
Intelligence, volume 32.
Jian Guan, Fei Huang, Zhihao Zhao, Xiaoyan
Zhu, and Minlie Huang. 2020. A knowledge-
enhanced pretraining model for commonsense
story generation. Transactions of the Associa-
tion for Computational Linguistics, 8:93–108.
Will Hamilton, Zhitao Ying, and Jure Leskovec.
2017. Inductive representation learning on large
graphs. In Advances in Neural Information Pro-
cessing Systems, pages 1024–1034.
Sepp Hochreiter and J¨urgen Schmidhuber. 1997.
Long short-term memory. Neural Computation,
9(8):1735–1780.
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka
Zitnik, Percy Liang, Vijay Pande, and Jure
Leskovec. 2019. Strategies for pre-training
graph neural networks. arXiv preprint arXiv:
1905.12265.
Guoliang Ji, Kang Liu, Shizhu He, and Jun Zhao.
2016. Knowledge graph completion with adap-
tive sparse transfer matrix. In AAAI, volume 16,
pages 985–991.
Diederik P. Kingma and Jimmy Ba. 2014. Adam:
A method for stochastic optimization. arXiv
preprint arXiv:1412.6980.
Thomas N. Kipf and Max Welling. 2016. Semi-
supervised classification with graph convolu-
tional networks. arXiv preprint arXiv:1609.
02907.
Rik Koncel-Kedziorski, Dhanush Bekal, Yi Luan,
Mirella Lapata, and Hannaneh Hajishirzi.
2019. Text generation from knowledge graphs
with graph transformers. arXiv preprint
arXiv:1904.02342.
Zhenzhong Lan, Mingda Chen, Sebastian
Homme bon, Kevin Gimpel, Piyush Sharma, et
Radu Soricut. 2019. ALBERT: A lite BERT for
self-supervised learning of language represen-
tations. arXiv preprint arXiv:1909.11942.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer
Levy, Ves Stoyanov, and Luke Zettlemoyer.
2019. BART: Denoising sequence-to-sequence
pre-training for natural language generation,
translation, and comprehension. arXiv preprint
arXiv:1910.13461.
Xiang Li, Aynaz Taheri, Lifu Tu, and Kevin
Gimpel. 2016. Commonsense knowledge base
achèvement. In Proceedings of the 54th Annual
the Association for Computa-
Meeting of
tional Linguistics (Volume 1: Long Papers),
pages 1445–1455.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei
Du, Mandar Joshi, Danqi Chen, Omer Levy,
Mike Lewis, Luke Zettlemoyer, and Veselin
Stoyanov. 2019. RoBERTa: A robustly opti-
mized bert pretraining approach. arXiv preprint
arXiv:1907.11692.
Denis Lukovnikov, Asja Fischer, Jens Lehmann,
and S¨oren Auer. 2017. Neural network-based
question answering over knowledge graphs on
word and character level. In Proceedings of
1282
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
the 26th international conference on World
Wide Web, pages 1211–1220.
Chaitanya Malaviya, Chandra Bhagavatula,
Antoine Bosselut, and Yejin Choi. 2019. Ex-
ploiting structural and semantic context for
commonsense knowledge base completion.
Computing Research Repository, arXiv:1910.
02915.
Chaitanya Malaviya, Chandra Bhagavatula,
Antoine Bosselut, and Yejin Choi. 2020. Com-
monsense knowledge base completion with
structural and semantic context. Procédure
de
the 34th AAAI Conference on Artificial
Intelligence.
Mingdong Ou, Peng Cui, Jian Pei, Ziwei Zhang,
and Wenwu Zhu. 2016. Asymmetric transitiv-
ity preserving graph embedding. In Proceed-
ings of the 22nd ACM SIGKDD international
conference on Knowledge discovery and data
mining, pages 1105–1114.
Kishore Papineni, Salim Roukos, Todd Ward,
and Wei-Jing Zhu. 2002. BLEU: a method for
automatic evaluation of machine translation.
In Proceedings of the 40th Annual Meeting of
the Association for Computational Linguistics,
pages 311–318.
Bryan Perozzi, Rami Al-Rfou, and Steven
Skiena. 2014. Deepwalk: Online learning of
social representations. In Proceedings of the
20th ACM SIGKDD International Conference
on Knowledge Discovery and Data Mining,
pages 701–710.
Jiezhong Qiu, Yuxiao Dong, Hao Ma, Jian Li,
Kuansan Wang, and Jie Tang. 2018. Réseau
embedding as matrix factorization: Unifying
line, pte, and node2vec. En Pro-
deepwalk,
ceedings of the Eleventh ACM International
Conference on Web Search and Data Mining,
pages 459–467.
Alec Radford, Karthik Narasimhan, Tim Sali-
mans, and Ilya Sutskever. 2018. Improving lan-
guage understanding by generative pre-training.
OpenAI blog.
Itsumi Saito, Kyosuke Nishida, Hisako Asano, et
Junji Tomita. 2018. Commonsense knowledge
base completion and generation. In Proceed-
ings of the 22nd Conference on Computational
Natural Language Learning, pages 141–150.
Maarten Sap, Ronan Le Bras, Emily Allaway,
Chandra Bhagavatula, Nicholas Lourie, Hannah
Rashkin, Brendan Roof, Noah A. Forgeron, et
Yejin Choi. 2019. Atomic: An atlas of ma-
chine commonsense for
if-then reasoning.
33:3027–3035.
Michael Schlichtkrull, Thomas N. Kipf, Pierre
Bloem, Rianne Van Den Berg, Ivan Titov, et
Max Welling. 2018. Modeling relational data
with graph convolutional networks. In Euro-
pean Semantic Web Conference, pages 593–607.
Springer.
Rico Sennrich, Barry Haddow, and Alexandra
Birch. 2015. Neural machine translation of
rare words with subword units. arXiv preprint
arXiv:1508.07909.
Robert Speer and Catherine Havasi. 2013.
Conceptnet 5: A large semantic network for re-
lational knowledge. In The People’s Web Meets
NLP, pages 161–176.
Robyn Speer, Joshua Chin, and Catherine Havasi.
2016. Conceptnet 5.5: An open multilingual
graph of general knowledge. arXiv preprint
arXiv:1612.03975.
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le.
2014. Sequence to sequence learning with
neural networks. In Advances in Neural Infor-
mation Processing Systems, pages 3104–3112.
Alon Talmor, Jonathan Herzig, Nicholas Lourie,
and Jonathan Berant. 2018. CommonsenseQA:
A question answering challenge targeting com-
monsense knowledge. arXiv preprint arXiv:
1811.00937.
Jian Tang, Meng Qu, Mingzhe Wang, Ming
Zhang, Jun Yan, and Qiaozhu Mei. 2015. Doubler:
Large-scale information network embedding.
In Proceedings of the 24th International Con-
ference on World Wide Web, pages 1067–1077.
Alec Radford, Jeffrey Wu, Rewon Child, David
Luan, Dario Amodei, and Ilya Sutskever. 2019.
Language models are unsupervised multitask
learners. OpenAI blog.
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N. Gomez,
Łukasz Kaiser, and Illia Polosukhin. 2017.
In Advances
Attention is all you need.
1283
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
in Neural Information Processing Systems,
pages 5998–6008.
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa
Casanova, Adriana Romero, Pietro Lio, et
Yoshua Bengio. 2017. Graph attention net-
travaux. arXiv preprint arXiv:1710.10903.
Zhen Wang, Jianwen Zhang, Jianlin Feng, et
Zheng Chen. 2014. Knowledge graph embed-
ding by translating on hyperplanes. In AAAI,
volume 14, pages 1112–1119. Citeseer.
Han Xiao, Minlie Huang, Yu Hao, and Xiaoyan
Zhu. 2015. Transg: A generative mixture model
for knowledge graph embedding. arXiv preprint
arXiv:1509.05488.
Zhitao Ying, Jiaxuan You, Christopher Morris,
Xiang Ren, Will Hamilton, and Jure Leskovec.
2018. Hierarchical graph representation learn-
ing with differentiable pooling. In Advances
in Neural Information Processing Systems,
pages 4800–4810.
Tom Young, Erik Cambria, Iti Chaturvedi, Hao
Zhou, Subham Biswas, and Minlie Huang.
2018. Augmenting end-to-end dialogue systems
with commonsense knowledge. In Thirty-Second
AAAI Conference on Artificial Intelligence.
Zhen Zhang, Jiajun Bu, Martin Ester, Jianfeng
Zhang, Chengwei Yao, Zhi Yu, and Can Wang.
2019. Hierarchical graph pooling with structure
learning. arXiv preprint arXiv:1911.05954.
Hao Zhou, Tom Young, Minlie Huang, Haizhou
Zhao, Jingfang Xu, and Xiaoyan Zhu. 2018.
Commonsense knowledge aware conversation
generation with graph attention. In Interna-
tional Joint Conferences on Artificial Intelli-
gence Organization (IJCAI), pages 4623–4629.
Wenya Zhu, Kaixiang Mo, Yu Zhang, Zhangbin
Zhu, Xuezheng Peng, and Qiang Yang. 2017.
Flexible end-to-end dialogue system for knowl-
edge grounded conversation. arXiv preprint
arXiv:1709.04264.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
2
6
1
9
7
4
7
5
9
/
/
t
je
un
c
_
un
_
0
0
4
2
6
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
1284