Robust Dialogue State Tracking with Weak Supervision and Sparse Data
Michael Heck, Nurul Lubis, Carel van Niekerk,
Shutong Feng, Christian Geishauser, Hsien-Chin Lin, Milica Gaˇsi´c
Heinrich Heine University D¨usseldorf, Allemagne
{heckmi,lubis,niekerk,fengs,geishaus,linh,gasic}@hhu.de
Abstrait
Generalizing dialogue state tracking (DST) à
new data is especially challenging due to the
strong reliance on abundant and fine-grained
supervision during training. Sample sparsity,
distributional shift, and the occurrence of new
concepts and topics frequently lead to severe
performance degradation during inference. Dans
this paper we propose a training strategy to
build extractive DST models without the need
for fine-grained manual span labels. Deux
novel input-level dropout methods mitigate
the negative impact of sample sparsity. Nous
propose a new model architecture with a uni-
fied encoder that supports value as well as
slot independence by leveraging the attention
mechanism. We combine the strengths of tri-
ple copy strategy DST and value matching to
benefit from complementary predictions with-
out violating the principle of ontology inde-
pendence. Our experiments demonstrate that
an extractive DST model can be trained with-
out manual span labels. Our architecture and
training strategies improve robustness towards
sample sparsity, new concepts, and topics,
leading to state-of-the-art performance on a
range of benchmarks. We further highlight
our model’s ability to effectively learn from
non-dialogue data.
1
Introduction
Generalization and robustness are among the key
requirements for naturalistic conversational abil-
ities of task-oriented dialogue systems (Edlund
et coll., 2008). In a dialogue system, dialogue state
tracking (DST) solves the task of extracting mean-
ing and intent from the user input, and keeps track
of the user’s goal over the continuation of a con-
versation as part of a dialogue state (DS) (Jeune
et coll., 2010). A recommendation and booking sys-
tem for places, par exemple, needs to gather user
preferences in terms of budget, location, and so
forth. Concepts like these are assembled in an
ontology on levels of domain (par exemple., restaurant
or hotel), slot (par exemple., price or location), and value
(par exemple., ‘‘expensive’’ or ‘‘south’’). Accurate DST is
vital to a robust dialogue system, as the system’s
future actions depend on the conversation’s cur-
rent estimated state. Cependant, generalizing DST
to new data and domains is especially challeng-
ing. The reason is the strong reliance on super-
vised training.
Virtually all top-performing DST methods ei-
ther entirely or partially extract values directly
from context (Ni et al., 2021). Cependant, train-
ing these models robustly is a demanding task.
Extractive methods usually rely on fine-grained
labels on word level indicating the precise loca-
tions of value mentions. Given the richness of
human language and the ability to express the
same canonical value in many different ways,
producing such labels is challenging and very
costly, and it is no surprise that datasets of such
kind are rare (Zhang et al., 2020b; Deriu et al.,
2021). Reliance on detailed labels has another
downside; datasets are usually severely limited in
size. This in turn leads to the problem of sample
sparsity, which increases the risk for models to
over-fit to the training data, par exemple, by mem-
orizing values in their respective contexts. Sur-
fitting prevents a state tracker to generalize to
new contexts and values, which is likely to break
a dialogue system entirely (Qian et al., 2021).
Recently, domain-independent architectures have
been encouraged to develop systems that may be
built once and then applied to new scenarios
with no or little additional training (Rastogi et al.,
2020un,b). Cependant, training such flexible mod-
els robustly remains a challenge, and the ever-
growing need for more training samples spurs
creativity to leverage non-dialogue data (Heck
et coll., 2020un; Namazifar et al., 2021).
We propose novel strategies for extractive
DST that address the following four issues of
robustness and generalization. (1) We solve the
1175
Transactions of the Association for Computational Linguistics, vol. 10, pp. 1175–1192, 2022. https://doi.org/10.1162/tacl a 00513
Action Editor: Claire Gardent. Submission batch: 3/2022; Revision batch: 6/2022; Published 11/2022.
c(cid:2) 2022 Association for Computational Linguistics. Distributed under a CC-BY 4.0 Licence.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
problem of requiring fine-grained span labels
with a self-supervised training scheme. Specifi-
cally, we learn from random self-labeled samples
how to locate occurrences of arbitrary values.
All that is needed for training a full DST model
is the dialogue state ground truth, which is un-
doubtedly much easier to obtain than fine-grained
span labels. (2) We handle the sample sparsity
problem by introducing two new forms of input-
level dropout into training. Our proposed drop-
out methods are easy to apply and provide a more
economical alternative to data augmentation to
prevent memorization and over-fitting to certain
conversation styles or dialogue patterns. (3) Nous
add a value matching mechanism on top of ex-
traction to enhance robustness towards previously
unseen concepts. Our value matching is entirely
optional and may be utilized if a set of candidate
values is known during inference, par exemple,
from a schema or API. (4) We propose a new ar-
chitecture that is entirely domain-agnostic to fa-
cilitate transfer to unseen slots and domains. Pour
que, our model relies on the attention mecha-
nism and conditioning on natural language slot
descriptions. The established slot-independence
enables zero-shot transfer. We will demonstrate
that we can actively teach to track new domains
by learning from non-dialogue data. This is non-
trivial as the model must learn to interpret dia-
logue data from exposure to unstructured data.
2 Related Work
Traditional DS trackers perform prediction over a
fixed ontology (Mrkˇsi´c et al., 2017; Liu and Lane,
2017; Zhong et al., 2018) and therefore have var-
ious limitations in more complex scenarios (Ren
et coll., 2018; Nouri and Hosseini-Asl, 2018). Le
idea of fixed ontologies is not sustainable for
real world applications, as new concepts become
impossible to capture during test time. De plus,
the demand for finely labeled data quickly grows
with the ontology size, causing scalability issues.
Recent approaches to DST extract values di-
rectly from the dialogue context via span predic-
tion (Xu and Hu, 2018; Gao et al., 2019; Chao
and Lane, 2019), removing the need for fixed
value candidate lists. An alternative to this mech-
anism is value generation via soft-gated pointer-
generator copying (Wu et al., 2019; Kumar
et coll., 2020; Kim et al., 2020). Extractive meth-
ods have limitations as well, since many values
may be expressed variably or implicitly. Contex-
tual models such as BERT (Devlin et al., 2019)
support generalization over value variations to
some extent (Lee et al., 2019; Chao and Lane,
2019; Gao et al., 2019), and hybrid approaches
try to mitigate the issue by resorting to picklists
(Zhang et al., 2020un).
TripPy (Heck et al., 2020b) jointly addresses
the issues of coreference, implicit choice, et
value independence with a triple copy strategy.
Ici, a Transformer-based (Vaswani et al., 2017)
encoder projects each dialogue turn into a seman-
tic embedding space. Domain-slot specific slot
gates then decide whether or not a slot-value is
present in the current turn in order to update the
dialogue state. In case of presence, the slot gates
also decide which of the following three copy
mechanisms to use for extraction. (1) Span predic-
tion extracts a value directly from input. For that,
domain-slot specific span prediction heads pre-
dict per token whether it is the beginning or end
of a slot-value. (2) Informed value prediction cop-
ies a value from the list of values that the system
informed about. This solves the implicit choice
issue, where the user might positively but implic-
itly refer to information that the system provided.
(3) Coreference prediction identifies cases where
the user refers to a value that has already been
assigned to a slot earlier and should now also be
assigned to another slot in question. TripPy shows
good robustness towards new data from known
domains since it does not rely on a priori knowl-
edge of value candidates. Cependant, it does not
support transfer to new topics, since the archi-
tecture is ontology specific. Transfer to new do-
mains or slots is therefore impossible without
re-building the model. TripPy also ignores po-
tentially available knowledge about value candi-
dates, since its copy mechanisms operate solely
on the input. Dernièrement, training requires fine-grained
span labels, complicating the transfer to new
datasets.
While contemporary approaches to DST le-
verage parameter sharing and transfer learning
(Rastogi et al., 2020un; Lin et al., 2021), the need
for finely labeled training data is still high. Sam-
ple sparsity often causes model biases in the form
of memorization or other types of over-fitting.
Strategies to appease the hunger of larger models
are the exploitation of out-of-domain dialogue
data for transfer effects (Wu et al., 2020) and data
augmentation (Campagna et al., 2020; Yu et al.,
1176
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
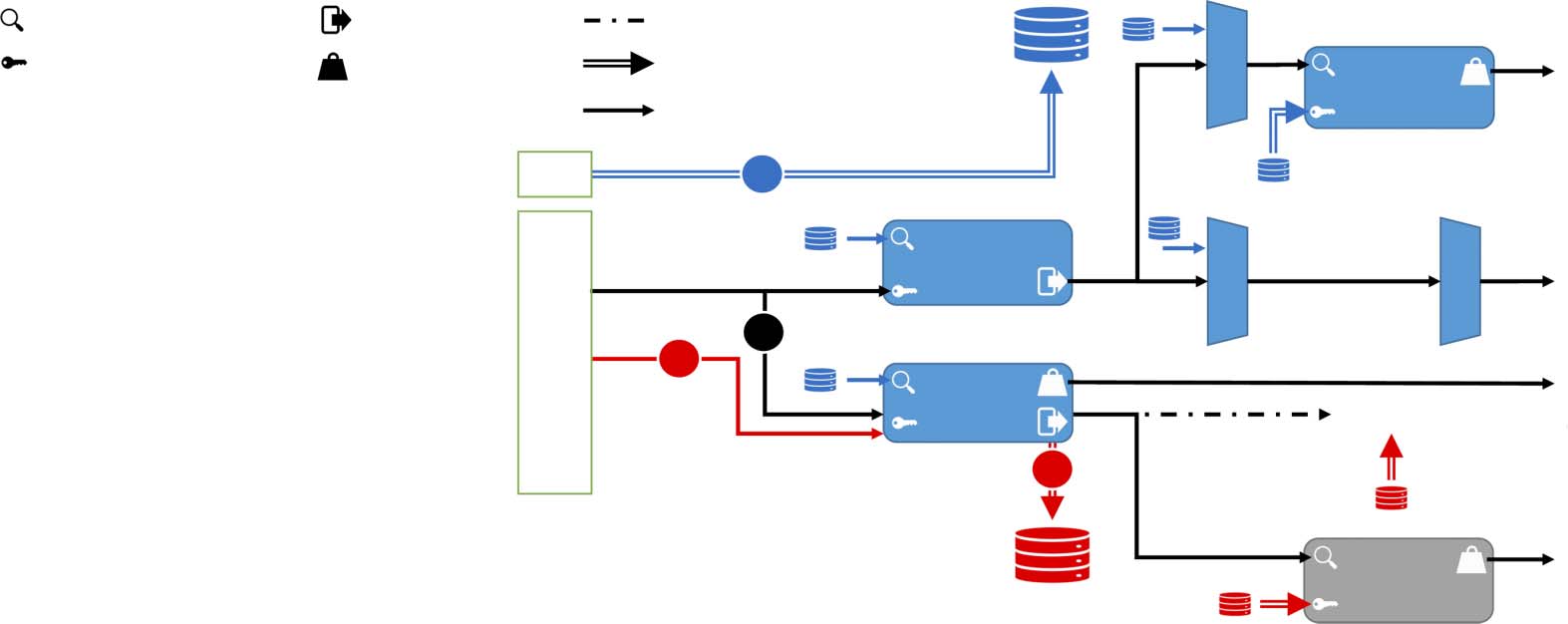
Chiffre 1: Proposed model architecture. TripPy-R takes the turn and dialogue history as input and outputs a DS.
All inputs are encoded separately with the same fine-tuned encoder. For inference, slot and value representations
are encoded once and then stored in databases for retrieval.
2020; Li et al., 2020; Dai et al., 2021). Cependant,
out-of-domain dialogue data is limited in quantity
aussi. Data augmentation still requires high
level knowledge about dialogue structures and
an adequate data generation strategy. Finalement,
more data also means longer training. We are
aware of only one recent work that attempts DST
with weak supervision. Liang et al. (2021) prendre
a few-shot learning approach using only a subset
of fully labeled training samples—typically from
the end of conversations—to train a soft-gated
pointer-generator network. In contrast, with our
approach to spanless training, we reduce the level
of granularity needed for labels to train extractive
models. Note that these strategies are orthogonal.
3 TripPy-R: Robust Triple Copy DST
Let {(U1, M1), . . . , (UT , MT )} be the sequence
of turns that form a dialogue. Ut and Mt are the
token sequences of the user utterance and preced-
ing system utterance at turn t. The task of DST is
(1) to determine for every turn whether any of the
domain-slot pairs in S = {S1, . . . , SN } is present,
(2) to predict the values for each Sn, et (3) à
track the dialogue state DSt. Our starting point
is triple copy strategy DST (Heck et al., 2020b),
because it has already been designed for robust-
ness towards unseen values. Cependant, we propose
a new architecture with considerable differences
to the baseline regarding its design, entraînement, et
inference to overcome the drawbacks of previ-
ous approaches as laid out in Section 2. We call
our proposed framework TripPy-R (pronounced
‘‘trippier’’), Robust triple copy strategy DST1.
Chiffre 1 is a depiction of our proposed model.
3.1 Model Layout
Joint Components We design our model to be
entirely domain-agnostic, adopting the idea of
conditioning the model with natural language de-
scriptions of concepts (Bapna et al., 2017; Rastogi
et coll., 2020b). For that, we use data-independent
prediction heads that can be conditioned with slot
descriptions to solve the tasks required for DST.
This is different to related work such as in Heck
et autres. (2020b), which uses data-dependent predic-
tion heads whose number depends on the ontology
size. In contrast, prediction heads in TripPy-R are
realized via the attention mechanism (Bahdanau
et coll., 2015). Spécifiquement, we use scaled dot-
product attention, implemented as multi-head at-
tention according to and defined by Vaswani et al.
(2017). We utilize this mechanism to query the in-
put for the presence of information. Among other
things, we deploy attention to predict whether or
not a slot-value is present in the input, or to conduct
sequence tagging—rather than span prediction—
by assigning importance weights to input tokens.
Unified Context/Concept Encoder Different
from other domain-agnostic architectures (Lee
et coll., 2019; Ma et al., 2019), we rely on a sin-
gle encoder that is shared among encoding tasks.
This unified encoder is used to produce repre-
sentations for dialogue turns and natural language
1https://gitlab.cs.uni-duesseldorf.de/general
/dsml/trippy-r-public.
1177
slot and value descriptions. The encoder function
is Enc(X) = [hCLS, h1, . . . , h|X|], where X is a
sequence of input tokens. hCLS can be interpreted
as a representation of the entire input sequence.
The vectors h1 to h|X| are contextual representa-
tions for the sequence of input tokens. We define
EncP(X) = [hCLS] and EncS(X) = [h1, . . . , h|X|]
as the pooled encoding and sequence encoding
of X, respectivement.
Dialogue turns and natural language slot and
value descriptions are encoded as
Rt = EncS(xCLS ⊕ Ut ⊕ xSEP ⊕ Mt⊕
xSEP ⊕ Ht ⊕ xSEP),
rSi = EncP(xCLS ⊕ Si ⊕ ”.” ⊕ Sdesc
⊕ xSEP),
RVSi ,j = EncS(xCLS ⊕ Si ⊕ ”is” ⊕ VSi,j ⊕ xSEP),
je
where Ht = {(Ut−1, Mt−1), . . . , (U1, M1)} is the
history of the dialogue up to turn t. The special
token xCLS initiates every input sequence, et
xSEP is a separator token to provide structure to
multi-sequence inputs. Sdesc
is the slot descrip-
je
tion of slot Si and VSi,j is a candidate value j for
slot Si.
Conditioned Slot Gate The slot gate outputs
a probability distribution over the output classes
C = {none, dontcare, span, inf orm, ref er,
true, f alse}. Our slot gate can be conditioned to
perform a prediction for one particular slot, allow-
ing our architecture to be ontology independent.
The slot attention layer attends to token represen-
tations of a dialogue turn given the representation
of a particular slot Si as query, c'est,
[go, gw] = MHAg(rSi, Rt, Rt),
(1)
where MHA(·)(Q, K, V , ˆk) is a multi-head at-
tention layer that expects a query matrix Q, un
key matrix K, a value matrix V and an optional
masking parameter ˆk. go is the layer-normalized
(Ba et al., 2016) attention output and gw are the
attention weights. For classification, the attention
output is piped into a feed-forward network (FFN)
conditioned with Si,
gs = softmax(L3(G2(rSi
⊕ G1(go)))) ∈ R7,
where L(·)(X) = W (·) · x + b(·) is a linear layer,
and G(·)(X) = GeLU(L(·)(X)) (Hendrycks and
Gimpel, 2016).
Sequence Tagging In order to keep the value
extraction directly from the input ontology-
independent as well, our model re-purposes at-
tention to perform sequence tagging. If the slot
gate predicts span, the sequence attention layer
attends to token representations of the current
dialogue turn given rSi as query, analogous to
Eq. (1):
[qo, qw] = MHAq(rSi, Rt, Rt, ˆrt).
(2)
Ici, ˆrt is an input mask that only allows attend-
ing to representations of user utterances.
In contrast to other work that leverages attention
for DST (Lee et al., 2019; Wu et al., 2019), nous
explicitly teach the model where to put the atten-
tion. This way, the predicted attention weights
qw become the sequence tagging predictions.
Tokens that belong to a value are assigned a
weight of 1, all other tokens are weighted 0. Since
(cid:5)1 = 1, we scale the target label sequences
(cid:5)qw
during training. During inference, we normalize
qw, namely,
ˆqw = [ˆq1, . . . , ˆq|X|], with ˆqj =
qw,j − 1
|X|
max∀q∈qw q
, (3)
so that we can infer sequence tags according to
an ‘‘IO’’ tagging scheme (Ramshaw and Marcus,
1995). All ˆqj > 0 are assigned the ‘‘I’’ tag, tous
others the ‘‘O’’ tag. The advantage of sequence
tagging over span prediction is that training can be
performed using labels for multiple occurrences
of the same slot-value in the input (par exemple
in the current turn and the dialogue history), et
that multiple regions of interest can be predicted.
To extract a value from the context, we pick the
sequence with the highest average token weight
according to ˆqw among all sequences of tokens
that were assigned the ‘‘I’’ tag and denote this
value prediction as Val(ˆqw).
Informed Value Prediction We adopt
dans-
formed value prediction from TripPy. Ontology
independence is established via our conditioned
slot gate. The inform memory It = {I 1
}
tracks slot-values that were informed by the sys-
tem in the current dialogue turn t. If the user
positively refers to an informed value, and if the
user does not express the value such that sequence
tagging can be used (c'est à dire., the slot gate predicts
inf orm), then the value ought to be copied from
It to DSt.
t , . . . , je
|S|
t
1178
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
We know from works on cognition that ‘‘all
collective actions are built on common ground and
its accumulation’’ (Clark and Brennan, 1991). Dans
autres mots, it must be established in a conversa-
tion what has been understood by all participants.
The process of forming mutual understanding is
known as grounding. Informed value prediction
in TripPy-R serves as a grounding component.
As long as the information shared by the system
has not yet been grounded (c'est à dire., confirmed by the
user), it is not added to the DS. This is in line
with information state and dialogue management
theories such as devised by Larsson and Traum
(2000), which view grounding as essential to the
theory of information states and therefore DST.
Coreference Prediction Although TripPy sup-
ports coreference resolution, this mechanism is
limited to an a priori known set of slots. We use
attention to establish slot independence for coref-
erence resolution to overcome this limitation. If
the slot gate predicts ref er for a slot Si, namely,
that it refers to a value that has previously been
assigned to another slot, then the refer attention
needs to predict the identity of said slot Sj, c'est,
[f o, f w] = MHAf(G5(rSi
⊕ G4(go)), RS, RS),
where the slot attention output go is first piped
through an FFN. RS = [rS1, . . . , rS|S|] ∈ Rd×|S|
is the matrix of stacked slot representations and
f w is the set of weights assigned to all candidate
slots for Sj. The slot with the highest assigned
weight is then our referred slot Sj. To resolve a
coreference, Si is updated with the value of Sj.
During inference, RS can be modified as desired
to accommodate new slots.
Value Matching In contrast to picklist based
methods such as that of Zhang et al. (2020un),
TripPy-R performs value matching as an optional
step. We first create slot-value representations for
all value candidates VSi,j of slot Si, et apprendre
matching of dialogue context qo to the list of
candidate values via value attention:
[rVSi,j , vw] = MHAq(rSi, RVSi,j , RVSi,j ),
[mo, mw] = MHAm(qo, RVSi
, RVSi
).
(4)
|.
|] ∈ Rd×|VSi
= [rVSi,1, . . . , rVSi,|VSi
where RVSi
mw should place a weight close to 1 on the cor-
rect value and weights close to 0 on all the oth-
ers. Dot-product attention as used in our model is
defined as softmax(Q · K(cid:7)) · V . Computing the
dot product between input and candidate value
representations is proportional to computing their
cosine similarities, which is cos(je) = q·k
(cid:5)q(cid:5)·(cid:5)k(cid:5)
∀q ∈ Q, k ∈ K. Donc, optimizing the model
to put maximum weight on the correct value and
to minimize the weights on all other candidates
forces representations of the input and of values
occurring in that input to be closer in their com-
mon space, and vice versa.
3.2 Training and Inference
Each training step requires the dialogue turn and
all slot and value descriptions to be encoded. Notre
unified encoder re-encodes all slot descriptions at
each step. Because the number of values might be
in the range of thousands, we encode them once
for each epoch. The encoder is fine-tuned towards
encoding all three input types. We optimize our
model given the joint loss for each turn,
L = λg · Lg + λq · Lq + λf · Lf + λm · Lm, (5)
),
/(cid:5)lq
Si
Lg = Σi(cid:4)(gs, Lg
Si
Lq = Σi(cid:4)(qw, lq
Si
Lf = Σi(cid:4)(f w, lf
Si),
Lm = Σi(cid:4)(mw, lm
Si),
(cid:5)1),
Lg
Si
lq
Si
lf
Si
lm
Si
∈ C,
∈ {0, 1}|X|,
∈ {0, 1}|S|,
∈ {0, 1}|VSi
|.
Si and lm
Ici, (cid:4)(·, ·) is the loss between a prediction and
a ground truth. Lg, Lq, Lf and Lm are the joint
losses of the slot gate, sequence tagger, corefer-
ence prediction and value matching. C'est (cid:5) · (cid:5)1 = 1
for lf
Si, c'est, labels for coreference pre-
diction and value matching are 1-hot vectors.
Back-propagating Lm also affects the sequence
tagger. We scale lq
since sequence tagging may
Si
have to label more than one token as being part
of a value.
During inference, the model can draw from
the rich output of the model, namely, slot gate
prédictions, coreference prediction, sequence tag-
ging and value matching to adequately update the
dialogue state. Slot and value descriptions are en-
coded only once with the fine-tuned encoder, alors
stored in databases, as illustrated in Figure 1 dans
steps 1(cid:2) et 2(cid:2). Pre-encoded slots condition the
attention and FFN layers, and pre-encoded values
are used for value matching. Note that it is straight-
forward to update these databases on-the-fly for a
1179
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
running system, thus easily expanding its capaci-
liens. Step 3(cid:2) is the processing of dialogue turns to
perform dialogue state update prediction.
3.3 Dialogue State Update
At turn t, the slot gate predicts for each slot
Si how it should be updated. none means that
no update is needed. dontcare denotes that any
value is acceptable to the user. span indicates that
a value is extractable from any of the the user
utterances {Ut, . . . , U1}. inf orm denotes that the
user refers to a value uttered by the system in
Mt. ref er indicates that the user refers to a value
that is already present in DSt in a different slot.
Classes true and f alse are used by slots that take
binary values.
If candidate values are known at inference,
TripPy-R can utilize value matching to benefit
from supporting predictions for the span case.
Because sequence tagging and value matching
predictions would compete over the slot update,
we use confidence scores to make an informed
décision. Given the current input, and candidate
values for a slot, we can use the attention weights
mw of the value attention as individual scores
for each value. We can also use the L2-norm
−
between input and values, namely, eSi,j = (cid:5)qo
(cid:5)2, and eSi = [eSi,1, . . . , eSi,|VSi
|] is the
rVSi,j
score set. Alors
Conf(C) = 1 −
(cid:2)(cid:2)(cid:3)
min∀c∈C c
(cid:4)
− min∀c∈C c
(cid:4)
,
/|C|
c∈C c
is applied to mw and eSi (interpreting them as
multisets rather than vectors) to compute two
confidence scores Conf(mw) and Conf(eSi) pour
the most likely value candidate. This type of con-
fidence captures the notion of difference between
the best score and the mean of all other scores, dans-
tuitively expressing model certainty. Val(mw) =
argmax(mw) and Val(eSi) = argmax(eSi) sont
the most likely candidates according to value at-
tention and L2-norm. For any slot that was pre-
dicted as span, the final prediction is
⎧
⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
S∗
i =
Val(mw), si
Si is categorical2∧
Conf(mw) > τ
Val(eSi), else if Conf(eSi) > τ
Val(ˆqw), else,
2For the distinction of categorical and non-categorical
slots, see Rastogi et al. (2020b) and Zang et al. (2020).
Chiffre 2: The proto-DST model for value tagging.
where τ ∈ [0, 1] is a threshold parameter that con-
trols the level of the model’s confidence needed
to still consider its value matching predictions.
4 Levels of Robustness in DST
We propose the following methods to improve
robustness in DST on multiple levels.
4.1 Robustness to Spanless Labels
Our framework introduces a novel training scheme
to learn from data without span labels, là-
fore lowering the demand for fine-grained labels.
that uses parts
We teach a proto-DST model
of TripPy-R’s architecture to tag random token
sub-sequences that occur in the textual input. Nous
use this model to locate value occurrences in each
turn t of a dialogue as listed in the labels for DSt.
The proto-DST model consists of the unified
encoder and the sequence attention of TripPy-R,
as depicted in Figure 2. Let Dt = (Ut, Mt) être
the input to the model, which is encoded as R(cid:10)
t =
EncS(xCLS ⊕ xNONE ⊕ xSEP ⊕ Ut ⊕ xSEP ⊕ Mt ⊕
xSEP). Let Y ∈ Dt be a sub-sequence of tokens
that was randomly picked from the input, encoded
as rY = EncP(xCLS ⊕ Y ⊕ xSEP). In Figure 2,
this corresponds to input types 1(cid:2) et 3(cid:2). Le
sequence tagger is then described as
[q(cid:10)
o, q(cid:10)
w] = MHAq(rY , R.(cid:10)
t, R.(cid:10)
t),
analogous to Eq. (2). For training, we minimize
Lq = (cid:4)(q(cid:10)
w, lq
Oui /(cid:5)lq
Oui
(cid:5)1),
lq
Oui
∈ {0, 1}|X|,
analogous to Eq. (5). At each training step, un
random negative sample ¯Y (cid:11)∈ Dt rather than a
positive sample is picked for training with proba-
bility pneg. For the Y ∈ Dt, the label lq
Y marks the
positions of all tokens of Y in Dt. For the ¯Y (cid:11)∈ Dt,
the label lq
¯Y puts a weight of 1 onto special to-
ken xNONE and 0 everywhere else. The desired
1180
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Training
Y ∈ Dt
¯Y (cid:11)∈ Dt
Tagging
rest.-price=expensive
rest.-area=centre
PMUL1188 xCLS xNONE xSEP
0
labels
0
labels
0
0
0
1
je
0
0
need a
1
0
1
0
train
1
0
to leave
0
0
0
0
0
0
0
0
from Cambridge after 15:30 xSEP
PMUL2340 xCLS xNONE xSEP Hi,
0
prediction
0
prediction
.25
0
0
0
0
0
je
0
0
am looking for
0
0
0
0
0
0
un
0
0
upscale restaurant
.87
0
0
0
0
0
dans
0
0
0
0
le
0
0
0
0
centre xSEP
0
.99
0
0
Tableau 1: Top: Training samples for the proto-DST. Y = {‘‘need’’, ‘‘a’’, ‘‘train’’} is a randomly picked
sub-sequence in Dt. The model needs to tag all tokens belonging to Y . For any random sequence
¯Y (cid:11)∈ Dt, all probability mass should be assigned to xNONE. Bottom: Example of tagging the training
data with a proto-DST given only spanless labels. The model needs to tag all tokens belonging to the
respective values. Note how the proto-DST successfully tagged the word ‘upscale’ as an occurrence of
the canonical value restaurant-price=expensive.
behavior of this model is therefore to distribute
the maximum amount of the probability mass
uniformly among all tokens that belong to the
randomly picked sequence. In case a queried se-
quence is absent from the input, all probability
mass should be assigned to xNONE. Tableau 1 lists
positive and negative training examples.
In order to tag value occurrences in dialogue
turns for training with spanless labels, we predict
for each value in DSt its position in Dt, given the
proto-DST. Let si
t be the value label for slot Si in
= EncP(xCLS ⊕
turn t, which is encoded as rsi
si
t
⊕ xSEP). Value tagging is performed as
t
[q(cid:10)
o, q(cid:10)
w] = MHAq(rsi
t
, R.(cid:10)
t, R.(cid:10)
t, ˆrt), ∀si
t
∈ DSt,
which corresponds to input types 2(cid:2) et 3(cid:2) dans
Chiffre 2. q(cid:10)
w is normalized according to Eq. (3).
Tableau 1 shows examples of value tagging with the
proto-DST. A set of tag weights ˆq(cid:10)
w is accepted
if more than half the probability mass is assigned
to word tokens rather than xNONE. We use a
morphological closing operation (Serra, 1982) à
smooth the tags, c'est,
ˆq(cid:10)
w
• ω = δ>ν(ˆq(cid:10)
w
⊕ ω) (cid:12) ω,
(6)
where ⊕ and (cid:12) are the dilation and erosion oper-
ators, δ is an indicator function, ˆq(cid:10)
w is interpreted
as an array, ω = [1, 1, 1] is a kernel, and ν is a
threshold parameter that allows filtering of tags
based on their predicted weights.
Contextual representations enable our value
tagger to also identify positions of value variants,
c'est à dire., different expressions of the same value (voir
Tableau 1 for an example). We tag turns without
their history. To generate labels for the history
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
portion, we simply concatenate the tags of the
preceding turns with the tags of the current turn.
4.2 Robustness to Sample Sparsity
We propose new forms of input-level dropout to
increase variance in training samples while pre-
venting an increase in data and training time.
Token Noising Targeted feature dropout (Xu
and Sarikaya, 2014) has already been used suc-
cessfully in the form of slot value dropout (SVD)
to stabilize DST model training (Chao and Lane,
2019; Heck et al., 2020b). During training, SVD
replaces tokens of extractable values in their con-
text by a special token xUNK with a certain prob-
ability. The representation of xUNK amalgamates
the contextual representations of all tokens that
are not in the encoder’s vocabulary Venc and there-
fore carries little semantic meaning.
Instead of randomly replacing target tokens with
xUNK, we use random tokens from a frequency-
sorted Venc. Spécifiquement, a target token is re-
placed with probability ptn by a token xk ∈ Venc,
where k is drawn from a uniform distribution
U(1, K). Since the least frequent tokens in Venc
tend to be nonsensical, we use a cut-off K (cid:13)
|Venc| for k. The idea behind this token noising
is to avoid a train-test discrepancy. With SVD,
xUNK is occasionally presented as target during
entraînement, but the model will always encounter valid
tokens during inference. With token noising, ce
mismatch does not occur. Plus loin, token noising
increases the variety of observed training samples,
while SVD potentially produces duplicate inputs
by masking with a placeholder.
History Dropout We propose history dropout
as another measure to prevent over-fitting due to
1181
sample sparsity. With probability phd, we discard
parts of the turn history Ht during training. Le
cut-off is sampled from U(1, t − 1). Utilizing
dialogue history is essential for competitive DST
(Heck et al., 2020b). Cependant, models might learn
correlations from sparse samples that do not hold
true on new data. The idea of history dropout is
to prevent the model from over-relying on the
history so as to not be thrown off by previously
unencountered conversational styles or contents.
4.3 Robustness to Unseen Values
Robustness to unseen values is the result of
multiple design choices. The applied triple copy
strategy as proposed by Heck et al. (2020b) fa-
cilitates value independence. Our proposed token
noising and history dropout prevent memorization
of reoccurring patterns. TripPy-R’s value match-
ing provides an alternative prediction for the DS
update, in case candidate values are available
during inference. Our model is equipped with the
partial masking functionality (Heck et al., 2020b).
Masking may be applied to informed values in
the system utterances Mt, . . . , M1 using xUNK,
which forces the model to focus on the system
utterances’ context information rather than spe-
cific mentions of values.
4.4 Robustness to Unseen Slots and Domains
Domain transfer has the highest demand for
generalizability and robustness. A transfer of the
strong triple copy strategy DST baseline to new
topics post facto is not possible due to ontology
dependence of slot gates, span prediction heads,
inform memory, and classification heads for co-
reference resolution. The latter two mechanisms
in particular contribute to robustness of DST to-
wards unseen values within known domains (Heck
et coll., 2020b). Cependant, the proposed TripPy-R
architecture is absolutely vital to establish robust-
ness of triple copy strategy DST to unseen slots
across new domains. TripPy-R is designed to be
entirely domain-agnostic by using a model archi-
tecture whose parts can be conditioned on natural
language descriptions of concepts.
5 Experimental Setup
5.1 Datasets
We use MultiWOZ 2.1 (Eric et al., 2020), WOZ
2.0 (Wen et al., 2017), sim-M, and sim-R (Shah
et coll., 2018) for robustness tests. MultiWOZ 2.1
is a standard benchmark for multi-domain dia-
logue modeling that contains 10000+ dialogues
covering 5 domains (train, restaurant, hotel, taxi,
attraction) et 30 unique domain-slot pairs. Le
other datasets are significantly smaller, making
sample sparsity an issue. We test TripPy-R’s value
independence on two specialized MultiWOZ test
sets, OOOHeck (Heck et al., 2020b) and OOOQian
(Qian et al., 2021), which replace many values
with out-of-ontology (OOO) valeurs. In addition to
MultiWOZ version 2.1, we test TripPy-R on 2.0,
2.2, 2.3, et 2.4 (Budzianowski et al., 2018; Zang
et coll., 2020; Han et al., 2021; Ye et al., 2021un).
5.2 Evaluation
We use joint goal accuracy (JGA) as the primary
metric to compare between models. The JGA
given a test set is the ratio of dialogue turns for
which all slots were filled with the correct value
(including none). For domain-transfer tests, nous
report per-domain JGA, and for OOO prediction
experiments, we also report per-slot accuracy.
We repeat each experiment 10 times for small
datasets, and three times for MultiWOZ and report
averaged numbers and maximum performance.
For evaluation, we follow Heck et al. (2020b).
5.3 Training
2
2
, 1−λg
We initialize our unified encoder with RoBERTa-
base (Liu et al., 2019). The input sequence length
est 180 after WordPiece tokenization (Wu et al.,
2016). The loss weights are (λg, λq, λf , λm) =
(0.8, 1−λg
, 0.1). (cid:4)g, (cid:4)f are cross entropy loss,
et (cid:4)q, (cid:4)m are mean squared error loss. We use
the Adam optimizer (Kingma and Ba, 2015) et
back-propagate through the entire network in-
cluding the encoder. We also back-propagate the
error for slot encodings, since we re-encode them
at every step. The learning rate is 5e-5 after a
warmup portion of 10% (5% for MultiWOZ), alors
decays linearly. The maximum number of epochs
est 20 for MultiWOZ, 50 for WOZ 2.0, et 100
for sim-M/R. We use early stopping with patience
(20% of max. epoch), based on the development
set JGA. The batch size is 16 (32 for MultiWOZ).
During training, the encoder output dropout rate is
30%, and ptn = phd = 30% (10% for MultiWOZ).
The weight decay rate is 0.01. For token noising,
we set K = 0.2 · |Venc|. We weight (cid:4)g for none
cases with 0.1. For value matching we tune τ in
decrements of 0.1 on the development sets.
1182
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Models
TripPy (baseline)
TripPy-R w/o value matching
TripPy-R
w/o History dropout
w/o Token noising
w/o Joint components
TripPy-R w/ spanless training
w/o value matching
w/ variants
sim-M
sim-R
WOZ 2.0
average
88.7±2.7
95.1±0.9
95.6±1.0
95.4±0.5
88.6±3.6
87.2±3.9
95.2±0.8
92.0±1.4
/
best
94.0
96.1
96.8
96.1
94.4
92.6
96.0
93.6
/
average
90.4±1.0
92.0±0.9
92.3±2.7
93.2±0.9
92.7±1.2
90.8±0.9
92.0±1.5
91.6±1.3
/
best
91.5
93.8
96.2
94.7
94.9
91.9
94.0
94.5
/
average
92.3±0.6
91.3±1.2
91.5±0.6
91.6±1.0
91.3±0.7
91.7±0.6
91.1±0.8
89.0±0.7
/
best
93.1
92.2
92.6
93.0
92.5
92.8
92.4
90.0
/
54.3
56.3
MultiWOZ 2.1
average
best
55.3±0.9
54.2±0.2
56.0±0.3
55.5±0.6
54.8±0.4
54.9±0.3
55.1±0.5
51.4±0.4
55.2±0.1
56.4
56.2
55.3
55.3
55.7
51.9
55.3
Tableau 2: DST results in JGA (± denotes standard deviation). w/o value matching refers to training and
inference.
For spanless training, the maximum length of
random token sequences for the proto-DST model
training is 4. The maximum number of epochs is
50 for the WOZ datasets and 100 for sim-M/R.
The negative sampling probability is pneg = 10%.
6 Experimental Results
Chiffre 3: Tagging performance of the proto-DST model
depending on the weight threshold ν.
6.1 Learning from Spanless Labels
The quality of the proto-DST for value tagging
determines whether or not training without ex-
plicit span labels leads to useful DST models. Nous
evaluate the tagging performance on the exam-
ple of MultiWOZ 2.1 by calculating the ratio of
turns for which all tokens are assigned the cor-
rect ‘‘IO’’ tag. Chiffre 3 plots the joint tagging
accuracy across slots, dependent on the weight
threshold in Eq. (6). It can be seen that an optimal
threshold is ν = 0.3. We found this to be true
across all datasets. We also found that the mor-
phological closing operation generally improves
tagging accuracy. Typical errors that are corrected
by this post-processing are gaps caused by oc-
casionally failing to tag special characters within
valeurs, Par exemple, ‘‘:’’ in times with hh:mm
format, and imprecisions caused by insecurities of
the model when tagging long and complex values
such as movie names. Average tagging accuracy
across slots is 99.8%. This is particularly notewor-
thy since values in MultiWOZ can be expressed
with a wide variety (par exemple., ‘‘expensive’’ might be
expressed as ‘‘upscale’’, ‘‘fancy’’, et ainsi de suite).
We attribute the high tagging accuracy to the ex-
pressiveness of the encoder-generated semantic
contextual representations.
Tableau 2 lists the JGA of TripPy-R when trained
without manual span labels. For the small datasets
we did not use xNONE and negative sampling, comme
it did not make a significant difference. We see
that performance is on par with models that were
trained with full supervision. If value matching on
top of sequence tagging is not used, performance
is slightly below its supervised counterparts. Nous
observed that value matching compensates for
minor errors caused by the sequence tagger that
was trained on automatic labels.3
Impact of Tagging Variants While our proto-
DST model already achieves very high accuracy
on all slots including the ones that expect values
with many variants, we tested whether explicit
tagging of variants may further improve perfor-
mance. Par exemple, if a turn contains the (canoni-
cal) value ‘‘expensive’’ for slot hotel-pricerange,
but expressed as ‘‘upscale’’, we would explicitly
tag such variants. While this strategy further im-
proved the joint tagging accuracy from 94.4%
à 96.1% (Chiffre 3), we did not see a rise in
DST performance (Tableau 2). Autrement dit, le
3Note that training with value matching also affects the
training of the sequence tagger, be it with or without using
span labels.
1183
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
contextual encoder is powerful enough to en-
dow the proto-DST model with the ability to tag
variants of values, based on semantic similarity,
which renders any extra supervision for this task
unnecessary.
6.2 Handling Sample Sparsity
Impact of Token Noising We experienced that
traditional SVD leads to performance gains on
sim-M, but not on any of the other tested datasets,
confirming Heck et al. (2020b). In contrast, token
noising improved the JGA for sim-M/R consid-
erably. Note that in Table 2, the TripPy baseline
for sim-M already uses SVD. On MultiWOZ 2.1,
we observed minor improvements. As with SVD,
WOZ 2.0 remained unaffected. The ontology for
WOZ 2.0 is rather limited and remains the same
for training and testing. This is not the case for
the other datasets, where values occur during test-
ing that were never seen during training. By all
appearances, presenting the model with a more di-
verse set of dropped-out training examples helps
generalization more than using a single place-
holder token. This seems especially true when
there are only few value candidates per slot, et
few training samples to learn from. A particularly
exemplaric case is found in the sim-M dataset.
Without token noising, trained models regularly
end up interpreting the value ‘‘last christmas’’ as
movie-date rather than movie-name, based on its
semantic similarity to dates. Token noising, on the
other hand, forces the model to put more empha-
sis on context rather than token identities, lequel
effectively removes the occurrence of this error.
Impact of History Dropout Table 2 shows that
history dropout does not adversely affect DST
performance. This is noteworthy because utilizing
the full dialogue history is the standard in contem-
porary works due to its importance for adequate
tracking. History dropout effectively reduces the
amount of training data by omitting parts of the
model input. En même temps, training sam-
ples are diversified, preventing the model from
memorizing patterns in the dialogue history and
promoting generalization. Chiffre 4 shows the se-
vere effects of over-fitting to the dialogue history
on small datasets, when not using history dropout.
Ici, models were only provided the current turn
as input, without historical context. Models with
history dropout fare considerably better, show-
ing that they do not over-rely on the historical
Chiffre 4: Performance loss due to mismatched train-
ing and testing conditions. Ici, history is provided
during training, but not during testing. sim-M/R and
WOZ 2.0 show clear signs of over-fitting without
history dropout.
Models
TripPy
Qian et al. (2021)
TripPy-R
TripPy-R + masking
OOOHeck
40.1±1.9
/
42.2±0.8
43.0±1.5
OOOQian
29.2±1.9
27.0±2.0
29.7±0.7
36.0±1.6
Tableau 3: Performance in JGA on artificial out-of-
ontology test sets (± denotes standard deviation).
information. Models without history dropout do
not only perform much worse, their performance
is also extremely unstable. On sim-R, the span
from least to highest relative performance drop is
0% à 39.4%. The results on MultiWOZ point to
the importance of the historical information for
proper tracking on more challenging scenarios.
Ici, performance drops equally in the absence of
dialogue history, whether or not history dropout
was used.
6.3 Handling Unseen Values
We probed value independence on two OOO test
sets for MultiWOZ. OOOHeck replaces most val-
ues by fictional but still meaningful values that
are not in the original ontology. Replacements are
consistent, c'est, the same value is always re-
placed by the same fictional stand-in. The overall
OOO rate is 84%. OOOQian replaces only values
of slots that expect names (c'est à dire., nom, departure,
and destination) with values from a different on-
tology. Replacements are not consistent across
dialogues, and such that names are shared across
all slots, Par exemple, street names may become
hotel names, restaurants may become train stops
and so on—that is, the distinction between con-
cepts is lost.
Tableau 3 lists the results. The performance loss
is more graceful on OOOHeck, and we see that
1184
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Models
Domains
hotel
repos. attr.
train taxi
avg.
19.5 16.4 22.8 22.9 59.2 28.2
TRADE (2019; 2020)
MA-DST (2020)
16.3 13.6 22.5 22.8 59.3 26.9
SUMBT (2019; 2020) 19.8 16.5 22.6 22.5 59.5 28.2
Li et al. (2021)∗
18.5 21.1 23.7 24.3 59.1 29.3
TripPy-R
Li et al. (2021)∗∗
18.3 15.3 27.1 23.7 61.5 29.2
24.4 26.2 31.3 29.1 59.6 34.1
Tableau 4: Best zero-shot DST results for various
models on MultiWOZ 2.1 in JGA. ∗ Li et al. (2021)
presents considerably higher numbers for models
with data augmentation. We compare against a
model without data augmentation. ∗∗ is a model
with three times as many parameters as ours.
TripPy-R has an advantage over TripPy. The per-
formance drop is more severe on OOOQian, avec
comparable JGA to the baseline of Qian et al.
(2021), which is a generative model. The authors
of that work attribute the performance degradation
to hallucinations caused by memorization effects.
For our extractive model the main reason is found
in the slot gate. The relative slot gate performance
drop for the train domain-slots is 23.3%, alors que
for other domain-slots it is 6.4%. We believe
the reason is that most of the arbitrary substi-
tutes carry no characteristics of train stops, mais
of other domains instead. This is less of a prob-
lem for the taxi domain for instance, since taxi
stops are of a variety of location types. The issue
of value-to-domain mismatch can be mitigated
somewhat with informed value masking in system
utterances (Section 4.3). While this does not par-
ticularly affect our model on the regular test set
or on the more domain-consistent OOOHeck, nous
can see much better generalization on OOOQian.
6.4 Handling Unseen Slots and Domains
Tableau 2 shows that moving from slot specific
to slot independent components only marginally
affects DST performance, while enabling tracking
of dialogues with unseen domains and slots.
Zero-shot Performance We conducted zero-
shot experiments on MultiWOZ 2.1 by excluding
all dialogues of a domain d from training and
then evaluating the model on dialogues of d. Dans
Tableau 4, we compare TripPy-R to recent models
that support slot independence. Even though we
did not specifically optimize TripPy-R for zero-
Chiffre 5: Performance of TripPy-R after training with
non-dialogue style data from a held-out domain.
shot abilities, our model shows a level of robust-
ness that is competitive with other contemporary
méthodes.
Impact of Non-dialogue Data Besides zero-
shot abilities, we were curious, is it feasible to
improve dialogue state tracking by learning the re-
quired mechanics purely from non-dialogue data?
This is a non-trivial task, as the model needs to
generalize knowledge learned from unstructured
data to dialogue, c'est, sequences of alternating
system and user utterances. We conducted this
experiment by converting MultiWOZ dialogues
of a held-out domain d into non-dialogue format
for training. For d, the model only sees isolated
sentences or sentence pairs without any structure
of a dialogue. Par conséquent, there is no ‘‘turn’’
history from which the model could learn. Le
assumption is that one would have some way to
label sequences of interest in non-dialogue sen-
tences, for instance with a semantic parser. Comme
this is a feasibility study, we resort to the slot lab-
els in DSt, which simulates having labels of very
high accuracy. We tested three different data for-
mats, (1) Review style: Only system utterances
with statements are used to learn from; (2) FAQ
style: A training example is formed by a user
question and the following system answer. Note
that this is contrary to what TripPy-R naturally
expects, which is a querying system and a re-
sponding user; et (3) FAQ+ style: Combines
review and FAQ style examples and adds user
questions again as separate examples.
Chiffre 5 shows that we observed considerable
improvements across all held-out domains when
using non-dialogue data to learn from. Apprentissage
from additional data, even if unstructured, is par-
ticularly beneficial for unique slots, such as the
restaurant-food slot which the model can not learn
about from any other domain in MultiWOZ (comme
1185
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
dialogue corpora. While profiting from more data
in general, its heterogeneity in particular did not
affect DST performance. Yu et al. (2020), Li et al.
(2020), and Dai et al. (2021) currently share the
top of the leaderboard for 2.1, all of which pro-
pose TripPy-style models that leverage data aug-
mentation. The main reason for performance
improvements lies in the larger amount of data
and in diversifying samples. TripPy-R does not
rely on more data, but diversifies training samples
with token noising and history dropout. On ver-
sion 2.2, the method of Tian et al. (2021) performs
best with a two-pass generative approach that uti-
lizes an error recovery mechanism. This mech-
anism can correct generation errors such as
caused by hallucination, which is a phenomenon
that does not occur with TripPy-R. Cependant, their
error recovery also has the potential to avoid prop-
agation of errors made early in the dialogue, lequel
is demonstrated by a heightened performance.
Cho et al. (2021) report numbers for the method
of Mehri et al. (2020) on version 2.3, which is
another TripPy-style model using an encoder that
was pre-trained on millions of conversations, thus
greatly benefiting from specialized knowledge.
For version 2.4, the current SOTA with the prop-
erties as stated above is presented by Ye et al.
(2021b) and reported in Ye et al. (2021un), lequel
is now surpassed by TripPy-R. The major differ-
ence to our model is the use of slot self-attention,
which allows their model to learn correlations
between slot occurrences. While TripPy-R does
not model slot correlations directly, it does how-
ever explicitly learn to resolve coreferences.
6.6 Implications of the Results
The zero-shot capabilities of our proposed
TripPy-R model open the door to many new ap-
plications. Cependant, it should be noted that its
performance on an unseen arbitrary domain and
on unseen arbitrary slots will likely degrade. Dans
such cases it would be more appropriate to per-
form adaptation, which the TripPy-R framework
facilitates. This means that one would transfer
the model as presented in Sections 4.3 et 4.4
and continue fine-tuning with limited—and poten-
tially unstructured (see Section 6.4)—data from
the new domain. Néanmoins, in applications such
as e-commerce (Zhang et al., 2018) or customer
support (Garc´ıa-Sardi˜na et al., 2018), whenever
new slots or even domains are introduced, ils
Chiffre 6: Comparison of TripPy-R and SOTA open
vocabulary DST models. ∗ denotes TripPy-style models.
is reflected in a poor zero-shot performance as
well). We also found that learning benefits from
the combination of different formats. The height-
ened performance given the FAQ+ style data is
not an effect of more data, but of its presenta-
tion, since we mainly re-use inputs with different
formats. This observation is reminiscent of find-
ings in psychology. Horst et al. (2011) showed
that children benefited from being read the same
story repeatedly. En outre, Johns et al. (2016)
showed that contextual diversity positively affects
word learning in adults. Note that this kind of
learning is in contrast to few-shot learning and
leveraging artificial dialogue data, which either
require fine-grained manual labels or high-level
knowledge of how dialogues are structured. Même
though the data we used is far-removed from what
a dialogue state tracker expects, TripPy-R still
manages to learn how to appropriately track these
new domains.
6.5 Performance Comparison
We evaluated on five versions of MultiWOZ
to place TripPy-R among contemporary work.
Versions 2.1 et 2.2 mainly propose general cor-
rections to the labels of MultiWOZ 2.0. Version
2.3 unifies annotations between dialogue acts and
dialogue states. In contrast, version 2.4 removes
all values that were mentioned by the system from
the dialogue state, unless they are proper names.
Chiffre 6 plots the results. The performance of
TripPy-R is considerably better on versions 2.3
et 2.4. This can be attributed to a more accurate
prediction of the inf orm cases due to better test
ground truths.
For fairness, we restricted our comparison to
models that have the same general abilities, que
est, they ought to be open-vocabulary and with-
out data-specific architectures. The SOTA on 2.0
(Su et al., 2022) proposes a unified generative
dialogue model to solve multiple tasks including
DST and benefits from pre-training on various
1186
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
are to a great extent related to ones that a de-
ployed system is familiar with. We believe that
the zero-shot performance presented in Table 4
is highly indicative of this set-up, as MultiWOZ
domains are different, yet to some extent related.
Plus loin, the TripPy-R model facilitates future
applications in complex domains such as health-
care. One of the biggest obstacles to harnessing
large amounts of natural language data in health-
care is the required labeling effort. This is par-
ticularly the case for applications in psychology,
as can be seen from the recent work of Rojas-
Barahona et al. (2018), where only 5K out of
1M interactions where labeled with spans for so
called thinking-errors by physiologists. A frame-
work like TripPy-R can completely bypass this
step by utilizing its proto-DST, as presented in
Section 4.1, eliminating the overbearing label-
ing effort.
7 Conclusion
In this work we present methods to facilitate
robust extractive dialogue state tracking with
weak supervision and sparse data. Our proposed
architecture—TripPy-R—utilizes a unified en-
coder, the attention mechanism, and conditioning
on natural language descriptions of concepts to
facilitate parameter sharing and zero-shot trans-
fer. We leverage similarity based value matching
as an optional step after value extraction, without
violating the principle of ontology independence.
We demonstrated the feasibility of training
without manual span labels using a self-trained
proto-DST model. Learning from spanless labels
enables us to leverage data with weaker supervi-
sion. We showed that token noising and history
dropout mitigate issues of pattern memorization
and train-test discrepancies. We achieved com-
petitive zero-shot performance and demonstrated
in a feasibility study that TripPy-R can learn to
track new domains by learning from non-dialogue
data. We achieve either competitive or state-of-
the-art performance on all tested benchmarks.
For future work we continue to investigate learn-
ing from non-dialogue data, potentially in a con-
tinuous fashion over the lifetime of a dialogue
système.
Remerciements
N. Lubis, C. van Niekerk, et S. Feng are sup-
ported by funding provided by the Alexander
von Humboldt Foundation in the framework of
the Sofja Kovalevskaja Award endowed by the
Federal Ministry of Education and Research,
while C. Geishauser and H.-C. Lin are sup-
ported by funds from the European Research
Council (ERC) provided under the Horizon 2020
research and innovation programme (grant agree-
ment no. STG2018804636). Computing resources
were provided by Google Cloud and HHU ZIM.
Les références
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey
E. Hinton. 2016. Layer normalization. CoRR,
abs/1607.06450v1.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua
Bengio. 2015. Neural machine translation by
jointly learning to align and translate. En Pro-
ceedings of the 3rd International Conference
on Learning Representations, San Diego, Californie,
Etats-Unis.
Ankur Bapna, Gokhan T¨ur, Dilek Hakkani-
T¨ur, and Larry Heck. 2017. Towards zero-
shot
frame semantic parsing for domain
scaling. In Proceedings of Interspeech 2017,
pages 2476–2480. https://est ce que je.org/10
.21437/Interspeech.2017-518
Paweł Budzianowski, Tsung-Hsien Wen, Bo-
Hsiang Tseng, I˜nigo Casanueva, Stefan Ultes,
Osman Ramadan, and Milica Gaˇsi´c. 2018.
MultiWOZ – A large-scale multi-domain Wizard-
of-Oz dataset for task-oriented dialogue mod-
elling. In Proceedings of the 2018 Conference
on Empirical Methods in Natural Language
Processing, pages 5016–5026, Brussels, Belgium.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/D18-1547
Giovanni Campagna, Agata Foryciarz, Mehrad
Moradshahi, and Monica Lam. 2020. Zero-
shot transfer learning with synthesized data
for multi-domain dialogue state tracking. Dans
Proceedings of the 58th Annual Meeting of
the Association for Computational Linguistics,
pages 122–132, En ligne. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/2020.acl-main.12
We thank the anonymous reviewers and the ac-
tion editors for their valuable feedback. M.. Heck,
Guan-Lin Chao and Ian Lane. 2019. BERT-DST:
Scalable end-to-end dialogue state tracking
1187
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
with bidirectional encoder representations from
transformer. In Proceedings of Interspeech
2019, pages 1468–1472. https://doi.org
/10.21437/Interspeech.2019-1355
Hyundong
Cho,
Chinnadhurai
Sankar,
Christopher Lin, Kaushik Ram Sadagopan,
Shahin Shayandeh, Asli Celikyilmaz, Jonathan
May, and Ahmad Beirami. 2021. CheckDST:
Measuring real-world generalization of dia-
logue state tracking performance. CoRR, abs/
2112.08321v1.
Herbert H. Clark and Susan E. Brennan. 1991.
Grounding in communication. In Lauren B.
Resnick, John M. Levine, and Stephanie D.
Teasley, editors, Perspectives on Socially
Shared Cognition, pages 127–149. Américain
Psychological Association, Washington, Etats-Unis.
https://doi.org/10.1037/10096-006
Yinpei Dai, Hangyu Li, Yongbin Li,
Jian
Sun, Fei Huang, Luo Si, and Xiaodan Zhu.
2021. Preview, attend and review: Schema-
aware curriculum learning for multi-domain
dialogue state tracking. In Proceedings of the
59th Annual Meeting of the Association for
Computational Linguistics and the 11th In-
ternational Joint Conference on Natural Lan-
guage Processing (Volume 2: Short Papers),
pages 879–885, En ligne. Association for Com-
putational Linguistics.
Jan Deriu, Alvaro Rodrigo, Arantxa Otegi,
Guillermo Echegoyen, Sophie Rosset, Eneko
Agirre, and Mark Cieliebak. 2021. Survey
on evaluation methods for dialogue systems.
Artificial Intelligence Review, 54(1):755–810.
https://doi.org/10.1007/s10462-020
-09866-X, PubMed: 33505103
Jacob Devlin, Ming-Wei Chang, Kenton Lee, et
Kristina Toutanova. 2019. BERT: Pre-training
of deep bidirectional transformers for language
le 2019
understanding. In Proceedings of
Conference of the North American Chapter
of the Association for Computational Linguis-
tics: Human Language Technologies, Volume 1
(Long and Short Papers), pages 4171–4186,
Minneapolis, Minnesota. Association for Com-
putational Linguistics.
Jens Edlund, Joakim Gustafson, Mattias Heldner,
and Anna Hjalmarsson. 2008. Towards human-
like spoken dialogue systems. Speech Com-
munication, 50(8–9):630–645. https://est ce que je
.org/10.1016/j.specom.2008.04.002
Mihail Eric, Rahul Goel, Shachi Paul, Abhishek
Sethi, Sanchit Agarwal, Shuyang Gao, Adarsh
Kumar, Anuj Goyal, Peter Ku, and Dilek
Hakkani-T¨ur. 2020. MultiWOZ 2.1: A consoli-
dated multi-domain dialogue dataset with state
corrections and state tracking baselines. Dans
Proceedings of the 12th Language Resources
and Evaluation Conference, pages 422–428,
Marseille, France. European Language Re-
sources Association.
Shuyang Gao, Abhishek Sethi, Sanchit Agarwal,
Tagyoung Chung, and Dilek Hakkani-T¨ur.
2019. Dialog state tracking: A neural read-
ing comprehension approach. In Proceedings
de
the Special
Interest Group on Discourse and Dialogue,
pages 264–273, Stockholm, Sweden. Associa-
tion for Computational Linguistics.
the 20th Annual Meeting of
Laura Garc´ıa-Sardi˜na, Manex Serras,
et
Arantza del Pozo. 2018. ES-Port: A sponta-
neous spoken human-human technical support
corpus for dialogue research in Spanish. Dans
Proceedings of the 11th International Confer-
ence on Language Resources and Evaluation,
pages 781–785, Miyazaki, Japan. européen
Language Resources Association.
Ting Han, Ximing Liu, Ryuichi Takanabu, Yixin
Lian, Chongxuan Huang, Dazhen Wan, Wei
Peng, and Minlie Huang. 2021. MultiWOZ 2.3:
A multi-domain task-oriented dialogue data-
set enhanced with annotation corrections and
co-reference annotation. In CCF International
Conference on Natural Language Processing
and Chinese Computing, pages 206–218.
Springer. https://doi.org/10.1007/978
-3-030-88483-3 16
Michael Heck, Christian Geishauser, Hsien-chin
Lin, Nurul Lubis, Marco Moresi, Carel van
Niekerk, and Milica Gaˇsi´c. 2020un. Out-of-
task training for dialog state tracking mod-
le. In Proceedings of the 28th International
Conference on Computational Linguistics,
pages 6767–6774, Barcelona, Espagne (En ligne).
International Committee on Computational
Linguistics. https://doi.org/10.18653
/v1/2020.coling-main.596
Michael Heck, Carel van Niekerk, Nurul Lubis,
Christian Geishauser, Hsien-Chin Lin, Marco
1188
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Moresi, and Milica Gaˇsi´c. 2020b. TripPy: UN
triple copy strategy for value independent neu-
ral dialog state tracking. In Proceedings of
the 21st Annual Meeting of the Special In-
terest Group on Discourse and Dialogue,
pages 35–44, 1st virtual meeting. Association
for Computational Linguistics.
Dan Hendrycks
and Kevin Gimpel. 2016.
Gaussian error linear units (GELUs). CoRR,
abs/1606.08415v4.
Jessica S. Horst, Kelly L. Parsons, and Natasha
M.. Bryan. 2011. Get the story straight: Contex-
tual repetition promotes word learning from
storybooks. Frontiers in Psychology, 2:17.
https://doi.org/10.3389/fpsyg.2011
.00017, PubMed: 21713179
Brendan T. Johns, Melody Dye, and Michael N.
Jones. 2016. The influence of contextual di-
versity on word learning. Psychonomic Bul-
letin & Review, 23(4):1214–1220. https://
doi.org/10.3758/s13423-015-0980-7,
PubMed: 26597891
Sungdong Kim, Sohee Yang, Gyuwan Kim, et
Sang-Woo Lee. 2020. Efficient dialogue state
tracking by selectively overwriting memory.
In Proceedings of the 58th Annual Meeting
of the Association for Computational Linguis-
tics, pages 567–582, En ligne. Association for
Computational Linguistics.
Diederik P. Kingma and Jimmy Ba. 2015. Adam:
A method for stochastic optimization. En Pro-
ceedings of the 3rd International Conference
on Learning Representations. San Diego, Californie,
Etats-Unis.
Adarsh Kumar, Peter Ku, Anuj Kumar Goyal,
Angeliki Metallinou, and Dilek Hakkani-T¨ur.
2020. MA-DST: Multi-attention based scal-
In Proceedings
able dialog state tracking.
de
the 34th AAAI Conference on Artificial
Intelligence, volume 34, pages 8107–8114.
https://doi.org/10.1609/aaai.v34i05
.6322
Staffan Larsson and David R. Traum. 2000.
Information state
and dialogue manage-
in the TRINDI dialogue move en-
ment
gine toolkit. Natural Language Engineering,
6(3–4):323–340. https://est ce que je.org/10.1017
/S1351324900002539
Hwaran Lee, Jinsik Lee, and Tae-Yoon Kim.
2019. SUMBT: Slot-utterance matching for
universal and scalable belief tracking. En Pro-
ceedings of the 57th Annual Meeting of the
Association for Computational Linguistics,
pages 5478–5483, Florence, Italy. Association
for Computational Linguistics.
Shiyang Li, Semih Yavuz, Kazuma Hashimoto,
Jia Li, Tong Niu, Nazneen Rajani, Xifeng
Yan, Yingbo Zhou, and Caiming Xiong. 2020.
CoCo: Controllable counterfactuals for evalu-
ating dialogue state trackers. In International
Conference on Learning Representations.
Shuyang Li, Jin Cao, Mukund Sridhar, Henghui
Zhu, Shang-Wen Li, Wael Hamza, and Julian
McAuley. 2021. Zero-shot generalization in
dialog state tracking through generative ques-
tion answering. In Proceedings of the 16th
Conference of the European Chapter of the
Association for Computational Linguistics:
Main Volume, pages 1063–1074, En ligne. Asso-
ciation for Computational Linguistics.
Shuailong Liang, Lahari Poddar, and Gyuri
Szarvas. 2021. Attention guided dialogue state
tracking with sparse supervision. CoRR, abs/
2101.11958v1.
Zhaojiang Lin, Bing Liu, Andrea Madotto,
Seungwhan Moon, Zhenpeng Zhou, Paul
Crook, Zhiguang Wang, Zhou Yu, Eunjoon
Cho, Rajen Subba, and Pascale Fung. 2021.
Zero-shot dialogue state tracking via cross-
task transfer. In Proceedings of the 2021 Con-
ference on Empirical Methods in Natural
Language Processing, pages 7890–7900, Sur-
line and Punta Cana, Dominican Republic.
Association for Computational Linguistics.
Bing Liu and Ian Lane. 2017. An end-to-end
trainable neural network model with belief
tracking for task-oriented dialog. In Proceed-
ings of Interspeech 2017, pages 2506–2510.
https://doi.org/10.21437/Interspeech
.2017-1326
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei
Du, Mandar Joshi, Danqi Chen, Omer Levy,
Mike Lewis, Luke Zettlemoyer, and Veselin
Stoyanov. 2019. RoBERTa: A robustly op-
timized BERT pretraining approach. CoRR,
abs/1907.11692v1.
Yue Ma, Zengfeng Zeng, Dawei Zhu, Xuan Li,
Yiying Yang, Xiaoyuan Yao, Kaijie Zhou, et
Jianping Shen. 2019. An end-to-end dialogue
1189
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
state tracking system with machine reading
comprehension and wide & deep classification.
CoRR, abs/1912.09297v2.
Shikib Mehri, Mihail Eric, and Dilek Hakkani-
T¨ur. 2020. DialoGLUE: A natural language
understanding benchmark for
task-oriented
dialogue. CoRR, abs/2009.13570v1.
Nikola Mrkˇsi´c, Diarmuid ´O. S´eaghdha, Tsung-
Hsien Wen, Blaise Thomson, and Steve Young.
2017. Neural belief tracker: Data-driven dia-
logue state tracking. In Proceedings of the 55th
Annual Meeting of the Association for Com-
putational Linguistics (Volume 1: Long Pa-
pers), pages 1777–1788, Vancouver, Canada.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/P17
-1163
Mahdi Namazifar, Alexandros
Papangelis,
Gokhan T¨ur, and Dilek Hakkani-T¨ur. 2021.
Language model is all you need: Natural lan-
guage understanding as question answering.
In Proceedings of
le 2021 IEEE Interna-
tional Conference on Acoustics, Speech and
Signal Processing, pages 7803–7807. IEEE.
https://doi.org/10.1109/ICASSP39728
.2021.9413810
Jinjie Ni, Tom Young, Vlad Pandelea, Fuzhao
Xue, Vinay Adiga, and Erik Cambria. 2021.
Recent advances in deep learning based di-
alogue systems: A systematic survey. CoRR,
abs/2105.04387v4.
Elnaz Nouri and Ehsan Hosseini-Asl. 2018.
Toward scalable neural dialogue state tracking
model. In Proceedings of the 2nd Conversa-
tional AI workshop at the 32nd Conference
on Neural Information Processing Systems.
Montr´eal, Canada.
Kun Qian, Ahmad Beirami, Zhouhan Lin,
Ankita De, Alborz Geramifard, Zhou Yu, et
Chinnadhurai Sankar. 2021. Annotation incon-
sistency and entity bias in MultiWOZ. En Pro-
ceedings of the 22nd Annual Meeting of the
Special Interest Group on Discourse and Dia-
journal, pages 326–337, Singapore and Online.
Association for Computational Linguistics.
Lance Ramshaw and Mitch Marcus. 1995. Texte
chunking using transformation-based learning.
In Proceedings of the 3rd Workshop on Very
Large Corpora, pages 82–94.
Abhinav Rastogi, Xiaoxue Zang, Srinivas
Sunkara, Raghav Gupta, and Pranav Khaitan.
2020un. Schema-guided dialogue state tracking
task at DSTC8. CoRR, abs/2002.01359v1.
Abhinav Rastogi, Xiaoxue Zang, Srinivas
Sunkara, Raghav Gupta, and Pranav Khaitan.
2020b. Towards scalable multi-domain con-
versational agents: The schema-guided dia-
the 34th
logue dataset. In Proceedings of
AAAI Conference on Artificial Intelligence,
volume 34, pages 8689–8696. https://est ce que je
.org/10.1609/aaai.v34i05.6394
Liliang Ren, Kaige Xie, Lu Chen, and Kai Yu.
2018. Towards universal dialogue state track-
ing. In Proceedings of the 2018 Conference on
Empirical Methods in Natural Language Pro-
cessation, pages 2780–2786, Brussels, Belgium.
Association for Computational Linguistics.
Lina M. Rojas-Barahona, Bo-Hsiang Tseng,
Yinpei Dai, Clare Mansfield, Osman Ramadan,
Stefan Ultes, Michael Crawford, and Milica
Gaˇsi´c. 2018. Deep learning for language un-
derstanding of mental health concepts derived
from cognitive behavioural therapy. En Pro-
ceedings of the 9th International Workshop on
Health Text Mining and Information Analysis,
pages 44–54, Brussels, Belgium. Association
for Computational Linguistics. https://est ce que je
.org/10.18653/v1/W18-5606
Jean Serra. 1982. Image Analysis and Mathe-
matical Morphology. Academic Press, Inc.
Pararth Shah, Dilek Hakkani-T¨ur, G¨okhan T¨ur,
Abhinav Rastogi, Ankur Bapna, Neha Nayak,
and Larry P. Heck. 2018. Building a conversa-
tional agent overnight with dialogue self-play.
CoRR, abs/1801.04871v1.
Yixuan Su, Lei Shu, Elman Mansimov, Arshit
Gupta, Deng Cai, Yi-An Lai, and Yi Zhang.
2022. Multi-task pre-training for plug-and-
play task-oriented dialogue system. En Pro-
ceedings of the 60th Annual Meeting of the
Association for Computational Linguistics
(Volume 1: Long Papers), pages 4661–4676,
Dublin, Ireland. Association for Computational
Linguistics.
Xin Tian, Liankai Huang, Yingzhan Lin, Siqi
Bao, Huang He, Yunyi Yang, Hua Wu,
1190
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Fan Wang, and Shuqi Sun. 2021. Amendable
generation for dialogue state tracking. En Pro-
ceedings of
the 3rd Workshop on Natural
Language Processing for Conversational AI,
pages 80–92, En ligne. Association for Compu-
tational Linguistics. https://est ce que je.org/10
.18653/v1/2021.nlp4convai-1.8
Kurian, Nishant Patil, Wei Wang, Cliff Young,
Jason Smith, Jason Riesa, Alex Rudnick, Oriol
Vinyals, Greg Corrado, Macduff Hughes, et
Jeffrey Dean. 2016. Google’s neural machine
translation system: Bridging the gap between
human and machine translation. CoRR, abs/
1609.08144v2.
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N.
Gomez, Łukasz Kaiser, and Illia Polosukhin.
2017. Attention is all you need. In Advances
in Neural Information Processing Systems,
volume 30, pages 5998–6008. Curran Asso-
ciates, Inc.
Tsung-Hsien Wen, David Vandyke, Nikola
Mrkˇsi´c, Milica Gaˇsi´c, Lina M. Rojas-Barahona,
Pei-Hao Su, Stefan Ultes, and Steve Young.
2017. A network-based end-to-end trainable
task-oriented dialogue system. In Proceed-
ings of the 15th Conference of the European
Chapter of
the Association for Computa-
tional Linguistics: Volume 1, Long Papers,
pages 438–449, Valencia, Espagne. Association
for Computational Linguistics.
Chien-Sheng Wu, Steven C. H. Hoi, Richard
Socher, and Caiming Xiong. 2020. TOD-BERT:
Pre-trained natural language understanding for
task-oriented dialogue. In Proceedings of the
2020 Conference on Empirical Methods in
Natural Language Processing, pages 917–929,
En ligne. Association for Computational Lin-
guistics.
Chien-Sheng Wu, Andrea Madotto, Ehsan
Hosseini-Asl, Caiming Xiong, Richard Socher,
and Pascale Fung. 2019. Transferable multi-
domain state generator for task-oriented di-
alogue systems. In Proceedings of the 57th
Annual Meeting of the Association for Compu-
tational Linguistics, pages 808–819, Florence,
Italy. Association for Computational Lin-
guistics.
Yonghui Wu, Mike Schuster, Zhifeng Chen,
Quoc V. Le, Mohammad Norouzi, Wolfgang
Macherey, Maxim Krikun, Yuan Cao, Qin
Gao, Klaus Macherey, Jeff Klingner, Apurva
Shah, Melvin Johnson, Xiaobing Liu, Łukasz
kaiser, Stephan Gouws, Yoshikiyo Kato, Taku
Kudo, Hideto Kazawa, Keith Stevens, George
Puyang Xu and Qi Hu. 2018. An end-to-end
approach for handling unknown slot values
in dialogue state tracking. In Proceedings of
the 56th Annual Meeting of the Association
for Computational Linguistics (Volume 1:
Long Papers), pages 1448–1457, Melbourne,
Australia. Association
for Computational
Linguistics.
Puyang Xu and Ruhi Sarikaya. 2014. Targeted
feature dropout for robust slot filling in nat-
ural language understanding. In Fifteenth An-
nual Conference of the International Speech
Communication Association, pages 258–262.
Fanghua Ye, Jarana Manotumruksa, and Emine
Yilmaz. 2021un. MultiWOZ 2.4: A multi-
domain task-oriented dialogue dataset with es-
sential annotation corrections to improve state
tracking evaluation. CoRR, abs/2104.00773v1.
Fanghua Ye, Jarana Manotumruksa, Qiang Zhang,
Shenghui Li, and Emine Yilmaz. 2021b.
Slot self-attentive dialogue state tracking. Dans
the Web Conference 2021,
Proceedings of
pages 1598–1608.
Steve Young, Milica Gaˇsi´c, Simon Keizer,
Franc¸ois Mairesse, Jost Schatzmann, Blaise
Thomson, and Kai Yu. 2010. The hidden
information state model: A practical frame-
work for POMDP-based spoken dialogue
management. Computer Speech & Language,
24(2):150–174. https://est ce que je.org/10.1016
/j.csl.2009.04.001
Tao Yu, Rui Zhang, Alex Polozov, Christophe
Meek, and Ahmed Hassan Awadallah. 2020.
SCoRe: Pre-training for context representa-
tion in conversational semantic parsing. Dans
International Conference on Learning Repre-
sentations.
Xiaoxue Zang, Abhinav Rastogi, Srinivas
Sunkara, Raghav Gupta, Jianguo Zhang, et
Jindong Chen. 2020. MultiWOZ 2.2: A di-
alogue dataset with additional annotation
1191
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
corrections and state tracking baselines. Dans
Proceedings of the 2nd Workshop on Natural
Language Processing for Conversational AI,
pages 109–117, En ligne. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/2020.nlp4convai-1.13
Jianguo Zhang, Kazuma Hashimoto, Chien-Sheng
Wu, Yao Wang, Philip Yu, Richard Socher,
and Caiming Xiong. 2020un. Find or classify?
Dual strategy for slot-value predictions on
multi-domain dialog state tracking. In Proceed-
ings of the 9th Joint Conference on Lexical
and Computational Semantics, pages 154–167,
Barcelona, Espagne (En ligne). Association for
Computational Linguistics.
Zheng Zhang, Ryuichi Takanobu, Qi Zhu,
MinLie Huang, and XiaoYan Zhu. 2020b.
Recent advances and challenges
in task-
oriented dialog systems. Science China Tech-
nological Sciences, 63:2011–2027. https://
doi.org/10.1007/s11431-020-1692-3
Zhuosheng Zhang, Jiangtong Li, Pengfei Zhu,
Hai Zhao, and Gongshen Liu. 2018. Model-
ing multi-turn conversation with deep utter-
ance aggregation. In Proceedings of the 27th
International Conference on Computational
Linguistics, pages 3740–3752, Santa Fe, Nouveau
Mexico, Etats-Unis. Association for Computational
Linguistics.
Victor Zhong, Caiming Xiong, and Richard
Socher. 2018. Global-locally self-attentive en-
coder for dialogue state tracking. En Pro-
ceedings of the 56th Annual Meeting of the
Association for Computational Linguistics
(Volume 1: Long Papers), pages 1458–1467,
Melbourne, Australia. Association for Compu-
tational Linguistics. https://est ce que je.org/10
.18653/v1/P18-1135
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
1
3
2
0
5
7
2
1
8
/
/
t
je
un
c
_
un
_
0
0
5
1
3
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
1192