RESEARCH PAPER
Relational Topology-based Heterogeneous Network
Embedding for Predicting Drug-Target Interactions
Linlin Zhang1, Chunping Ouyang1,2†, Fuyu Hu1†, Yongbin Liu1,2, Zheng Gao3
1School of Computer, University of South China, Hengyang,Hunan, 421001, Chine
2Hunan Medical Big Data International Sci.&Technologie, Innovation Cooperation Base
3Department of Information and Library Science, Indiana University Bloomington Woodlawn Avenue, IN 47408, Bloomington, America
Mots clés: Link prediction; Heterogeneous information network; Drug-target interaction; Network embedding;
Feature representation
Citation: Zhang, L.L., Ouyang, C.P., Hu, F.Y., et coll.: Relational Topology-based Heterogeneous Network Embedding for Predicting
Drug-Target Interactions. Data Intelligence 5(2), 475-493 (2023). est ce que je: 10.1162/dint_a_00149
Reçu: Dec. 20, 2021; Revised: Apr. 15, 2022; Accepté: May 19, 2022
ABSTRAIT
Predicting interactions between drugs and target proteins has become an essential task in the drug
discovery process. Although the method of validation via wet-lab experiments has become available,
experimental methods for drug-target interaction (DTI) identification remain either time consuming or heavily
dependent on domain expertise. Donc, various computational models have been proposed to predict
possible interactions between drugs and target proteins. Cependant, most prediction methods do not consider
the topological structures characteristics of the relationship. In this paper, we propose a relational topology-
based heterogeneous network embedding method to predict drug-target interactions, abbreviated as RTHNE_
DTI. We first construct a heterogeneous information network based on the interaction between different
types of nodes, to enhance the ability of association discovery by fully considering the topology of the
réseau. Then drug and target protein nodes can be represented by the other types of nodes. According to
the different topological structure of the relationship between the nodes, we divide the relationship in the
heterogeneous network into two categories and model them separately. Extensive experiments on the real-
world drug datasets, RTHNE_DTI produces high efficiency and outperforms other state-of-the-art methods.
RTHNE_DTI can be further used to predict the interaction between unknown interaction drug-target pairs.
Corresponding author: Chunping Ouyang (E-mail: ouyangcp@126.com; ORCID: 0000-0002-2154-0079); Fuyu Hu
†
(E-mail: fyhu1124@163.com; ORCID: 0000-0002-1004-6913).
© 2022 Chinese Academy of Sciences. Published under a Creative Commons Attribution 4.0 International (CC BY 4.0)
Licence.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
.
t
/
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
1. INTRODUCTION
The prediction of drug-target interactions (DTIs) is the process of uncovering potential drug-target
interactions that are currently undiscovered through information on the structural characteristics of drugs
and targets, as well as known drug-target relationships and drug-drug relationships. Prediction of DTIs is
the key to developing new drugs. It plays an important role in the study of drug toxicity and side effects
and the treatment of diseases. Cependant, traditional methods based on large-scale biological experiments
usually take several years and are often very expensive [1]. Donc, the prediction of DTIs has received
great attention and computer-aided drug discovery has become a trend. In recent years, with the rapid
development of computer technology and the accumulation of large amounts of medical data, computational
solutions have shown feasible and reasonable in discovering new drug-target interactions (DTIs) in the age
of big data, methods such as machine learning and data mining have been widely used to solve various
complex problems in the field of biomedicine [2, 3, 4]. Actuellement, there are three types of prediction
approaches in computational-aided drug discovery, namely Attribute-based calculation methods [5], deep
learning-based [6, 7], and network-based [8, 9] méthodes.
In the past years, several approaches have focused on prediction methods based on similarity calculation
using the attributes of the drug and the target protein. The prediction method of similarity calculation usually
depends on the attributes of the drug and the target protein, tel que [5, 10]. Nevertheless, most of these
methods use the chemical structure and protein sequence of the drug. In public data sets, it is often difficult
to obtain the protein sequence and chemical information of many polymers. Deep learning has advanced
computational modeling of DTI by offering an increased feature extraction power in drug and protein data.
Such as [6, 7] are the prediction models of DTIs by deep learning. Cependant, these deep learning methods
do not consider the network topology information of drugs and target proteins, and the prediction results
are often unsatisfactory. In recent years, network-based approaches have demonstrated great advantages
compared to similarity-based methods. Especially heterogeneous network-based methods achieved good
results in DTI prediction by considering a wide variety of topological information and the complex
interaction relationship of heterogeneous data. Zeng et al. [9] constructed a heterogeneous network that
covers the network profile and attributes information between drugs, target proteins, and diseases. Un
arbitrary-order approximate embedded deep forest method is used to predict DTI. The relationship between
different nodes in a heterogeneous graph is different.
Dans ce document, we study the interaction relationship network between drugs and target proteins, et
classify all relationships in the heterogeneous network into two categories and model them separately
according to the characteristics of the topology of the relationships between nodes. This results in a topology-
based RTHNE_DTI heterogeneous network embedding method that can be used to predict unknown drug-
target protein interactions. Spécifiquement, our main contributions are as follows:
•
476
We proposed a heterogeneous network representation learning method named “RTHNE_DTI” to
predict DTI, it learns the distributed representation of nodes by embedding heterogeneous network
into low-dimensional spaces, which use the network topology information fully. On the other hand,
we apply the method of heterogeneous network representation learning to drug-target interaction
prediction, which achieves a more rapid and effective use of medical data, thereby significantly
improving prediction accuracy.
Data Intelligence
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
t
/
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
•
•
•
The traditional heterogeneous network representation learning method uses a uniform model to deal with
all relationships. Cependant, different node-node relationship represents different drug characteristics.
In hence, we divide the relationship in a heterogeneous network into two types: Affiliation relationship
and Peer relationship, and we design different models to represent them, which can better capture
the rich feature information between nodes.
En général, the prediction of drug-target interaction is carried out on the labeled network (Some drug
target relationship pairs with known interactions were added to the training set). Cependant, our model
can also achieve good prediction results on the unlabeled network. This solves the problem of
insufficient drug labeling data and low prediction accuracy.
We conduct different experiments using real drug data set and compare with other predictive models,
and the results show that RTHNE_DTI has the best predictive performance.
2. RELATED WORK
Computational methods in DTIs prediction have gained more attention because carrying out a biochemical
experiment on a large scale is costly and time-consuming. The early computational methods mainly focused
on similarity calculation between the attributes of the drug and the target protein. Then deep learning
methods for computational prediction of DTI have become more popular in recent years. The rapid
development of deep learning provides an effective way to predict DTI, especially for large-scale data
prediction tasks. Mayr et al. [11] compared several deep learning methods with other machine learning
and target prediction methods on large-scale drug discovery datasets and concluded that the deep learning
method has the best prediction performance. Lee et al. [12] predicted DTIs through convolutional neural
réseaux (CNNs) on original protein sequences. In a study called DeepDTA, Ozturk et al. [6] proposed a
deep-learning- based model to predict the binding affinity between drugs and targets, CNNs were mainly
used to model protein sequences and compound 1D representations. These methods are generally dependent
on drug and target attributes.
In recent years, heterogeneous network representation learning has become a hot topic of current
research and has good performance in link prediction [13]. Although heterogeneous network representation
learning methods have been widely used for link prediction in social networks with good results. La plupart
previous studies on networks have been based on homogeneous networks. Spécifiquement, the nodes in the
network are of the same type. With the development of network representation learning, in order to model
the heterogeneity of networks, some have tried heterogeneous network representation learning. Par exemple,
Shang et al. [14] proposed a framework, ESim, which uses random wandering based on matching paths to
generate sequences of nodes to optimize the similarity between multiple points. Fu et al. [15] proposed a
heterogeneous information network representation, HIN2vec, which differs from many previous works
based on skip gram language models in that the core of HIN2V ec is a neural network model that learns
the representation of nodes and relations (meta-paths) in the network. Han et al. [16] proposed an aspect-
level collaborative filtering model based on neural networks. In their model, they extract similarity matrices
of different aspect levels of nodes through different meta-paths and feed these matrices into a deep neural
network designed to learn aspect-level potential factors. These methods are commonly used in social
réseaux, scholar networks, etc..
Data Intelligence
477
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
t
/
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
Donc, prediction methods based on network topology are also widely used in DTI relationship
prediction. There are various networks in practice, such as social networks [17], citation networks [18], et
biological information networks [19]. And some interesting research works on network analysis have
attracted increasing attention. Particularly, link prediction is one of the hot spot tasks of network analysis.
Actuellement, most network-based DTI prediction is based on machine learning [8]. Wang et al. transformed
new DTI prediction problems into a two-layer graphical model named the restricted Boltzmann machine
(RBM). Wan et al. [20] developed a new nonlinear end-to-end learning model, called NeoDTI, lequel
integrates different heterogeneous information of drugs and targets, and learned the representation of drugs
and targets to predict DTIs. cependant, note that these approaches have the disadvantage of treating all node
relationships in the heterogeneous network equally and they may not work when chemical pathways and
protein interactions are unknown. Tableau 1 shows the categorization results.
Donc, we apply a heterogeneous network embedding method to predict DTIs, called RTHNE_DTI.
the biggest advantage of this method is that it can fully take into account the characteristics of different
node relationships in the network and is modeled for that feature.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
t
.
/
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Tableau 1. An overview and comparison of related reviews.
Attribute based calculation
méthodes
Network topology-based
méthodes
Deep learning-based
méthodes
Oui. Yamanishi [5]
X. Zheng [10]
H. Öztürk [6]
Y.-B. Wang [7]
UN. Mayr [11]
je. Lee [12]
X. Chen [8]
X. Zeng [9]
F. Wan [20]
√
√
√
√
√
√
3. PROBLEM DEFINITION
√
√
√
√
√
√
√
√
√
In this section, we introduce some basic definitions of heterogeneous network embedding to predict
DTIs.
Definition 1: Heterogeneous Network (HN).
A Heterogeneous Network is defined as a Graph G = (V, E, UN, Ø, oui), where V represents the set of nodes,
E ⊆ V × V represents the set of edges. Ø and y are the type mapping functions of nodes and edges,
respectivement, where Ø = V → N and y: E → R. Here N and R are the type sets of nodes and edges,
respectivement. A = N ∪ R, and while |N| + |R.| > 2, the network is called a heterogeneous network; otherwise
it is a homogeneous network.
478
Data Intelligence
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
Definition 2: Meta-path.
In a heterogeneous network, the meta-path P is a sequence of node types n1, n2, …, nm and edge types
r1, r2, …, rm−1, in the form of:
P.
r
1
r
m
−
1
= → …→
n
2
n
m
n
1
(1)
Definition 3: Heterogeneous Network Embedding.
Given a heterogeneous network G, the heterogeneous network embedding learns a low-dimensional
d for each vertex v ∈ V by a mapping function f: V → Rd, in which d << |V| is the dimension
vector Ev ∈ R
of the representation space.
4. THE PROPOSED APPROACH
4.1 Overall Framework
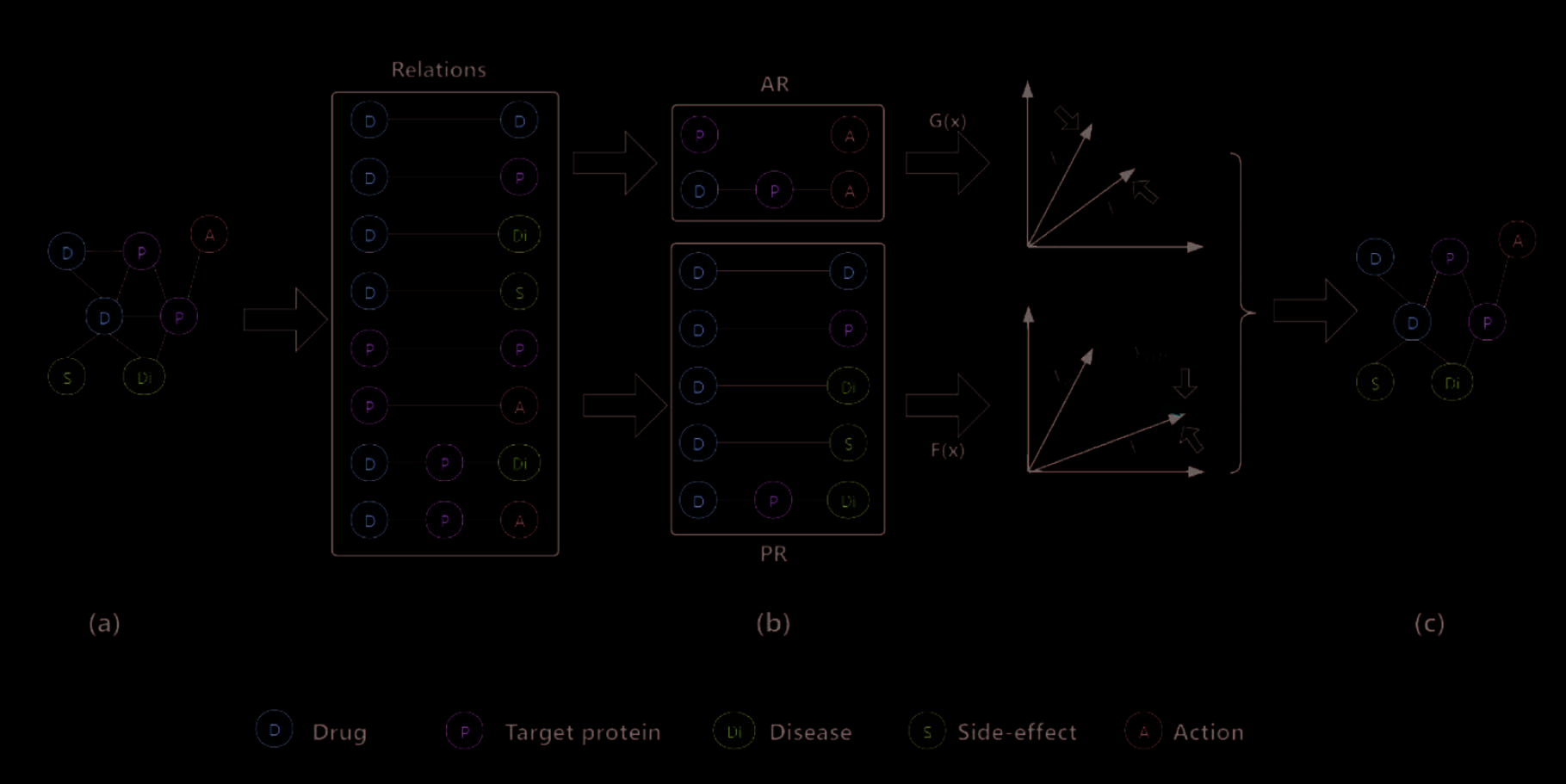
As shown in Figure 1, (a) is a heterogeneous network constructed by five types of nodes (drug, target
protein, disease, side-effect, action). In this network, there are not only simple relationships, such as D-D
but also compound relationships, such as D-P-Di. In (b), we divide all relationships into two categories
according to the relationship topology and model them separately. Finally, we apply the model to different
scenarios to verify the performance of our model.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
a
_
0
0
1
4
9
p
d
.
t
/
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 1. Structure of the RTHNE_DTI model. (a) A heterogeneous network of fi ve classes of nodes (drug, target
protein, disease, side effect and action) interacting with each other was constructed. (b) All relationships are
classifi ed into PR relationships and AR relationships. Then G(x) and F(x) are calculated respectively according to
the characteristics of the two relationships during the training process, and the training weights are updated
continuously update to obtain the node embedding results. (c) The embedding results are decoded to predict DTI.
Data Intelligence
479
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
4.2 Affiliation Relationship and Peer Relationship
In studying the data sets associated with the prediction of drug and target protein interactions, we found
that not all relationship pairs had an equal number of nodes of the two types of connections, and some
relationship pairs had a significantly different number of nodes of the two types of connections, as shown
in figure 2.
Our study of DrugBank found that the types of action of proteins are very few, only 47, but the variety
of proteins is wide. Hence, their relationship network looks like an action-centered network spreading
outward. As shown in Figure 2 (a). However, most of the relationships in the drug data set are like drugs
and proteins. The two types of nodes do not differ greatly in number, so they form a well-balanced network.
As shown in Figure 2 (b).
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
a
_
0
0
1
4
9
p
d
t
.
/
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 2. Different relationship topology. Node relationships in heterogeneous networks are classifi ed into two
categories based on the difference topology of nodes in the heterogeneous network. (a) Affi liation relationship with
unbalanced distribution of nodes in network relationships; (b) peer relationship with balanced distribution of nodes
in network relationships.
To fully use the topology characteristics of heterogeneous networks (HNs), we study the topological
features of different relationships in a heterogeneous network. In the network, the degree of a node can
well reflect the topological structure characteristics of the network [21]. In general, the degree of a node
refers to the number of edges associated with the node. In order to explore the difference between the
topological structures of different relationships in HN, we used the degree-based measure D(e) for
calculation:
( )
D e
=
480
max
(
dn dn
,
u
v
(
min
d d
,
n
u
)
)
n
v
(2)
Data Intelligence
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
vnd are the average
Where nu, nv represent the node type of nodes u, v in a relation tuple (u, v, e),
degrees for nu and nv, respectively. It is worth mentioning that D(e) ≥ 1. Here, a greater D(e) value indicates
that the topology of the two types of connected nodes is not identical, where one side is biased to the
other? That is, nodes with a high D(e) value show a stronger affiliation relationship (AR) between them,
and nodes connected by this relationship have more similar attributes [22]. However, for smaller D(e)
values, it shows that the topology of the two types of connected nodes is peer, which we named the peer
relationship (PR).
und and
In order to ensure the accuracy of the results, we compare these relationships from the perspective of
sparseness, annotated as S(e), so as to discover the differences in the network structure of different
relationships. We define S(e) as follows:
S e
( )
=
N
r
×
N
n
v
N
n
u
(3)
In the above formula, Nr is the number of edges in type r. In addition,
vnN are the number of
nodes of types nu and nv, respectively. It should be emphasized that in this way, these relationships can also
be consistently divided into two categories, PR and AR.
unN and
Table 2. Statistical analysis of dataset.
Nodes
Drug
Target
Disease
Side-effect
Action
Num of
Nodes
Relations
708
1512
5603
4192
47
D-D
D-P
P-P
D-Di
D-S
P-D
P-A
Num of
Relations
10036
1923
7360
199214
80164
1596745
2295
Avg.Du
Avg.Dv
D(e)
S(e)
Relationship
type
14.18
2.72
4.87
281.38
113.23
1056.05
1.52
14.18
1.27
4.87
35.55
19.12
284.98
48.83
1.00
2.14
1.00
7.91
5.92
3.71
32.17
0.02002
0.00180
0.00322
0.05022
0.02701
0.18848
0.03229
PR
PR
PR
PR
PR
PR
AR
We conducted a comprehensive analysis of the obtained data according to the above indicators, as
shown in Table 2.
4.3 Different models for PR and AR
To respect their different characteristics, we need to design different model treatments for them separately.
Here, for two nodes connected by a PR relationship, there is a strong interactive relationship, and their
topology structure is very similar. The nodes themselves contain rich structural information between two
nodes, so we model the PR as a transition between nodes in a low-dimensional vector space.
In addition, for relation type AR, Euclidean distance is used as the calculation to measure the proximity
of interacting nodes in low-dimensional space. It should be noted that the calculation methods we use for
the two relationships are very consistent mathematically [23]. We use the Euclidean distance method for
the AR mainly for the following reasons. First, the nodes connected by this relationship share the same
Data Intelligence
481
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
a
_
0
0
1
4
9
p
d
.
t
/
i
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
attributes [24], so the nodes connected by the AR can be directly approached in the vector space, which
is consistent with the Euclidean distance optimization [25]. Second, the purpose of the heterogeneous
network representation is to preserve the structural characteristics of the high-dimensional network. The
Euclidean method satisfies the condition of triangular inequality [26], which ensures that the first-order and
second-order similarities of the nodes remain unchanged.
Translation-based distance for peer relations. Through the study of Table 2, we found that in the
heterogeneous drug network constructed, most of the relationships are peer-to-peer. Specifically, a drug
acts on multiple diseases, and a disease can also be treated by multiple drugs. And the number of drug
nodes and disease nodes differs very little. Peer relationships show powerful interactions between nodes
with peer-to-peer structure. For the calculation of the score function of PR, we first give a PR-type relationship
tuple (a, r, b), where r ∈ RPR has a weight of wa,b. Then for the embedding of nodes a and b, we define
them as Pa and Pb respectively. In addition, we annotate the embedding of relation r as Qr. The final
definition is as follows:
(
f a b w P Q P
a b a
b
,
+
−
=
)
,
r
(4)
For the relationship tuples (a, r, b) ∈ TPR whose relationship is PR in the heterogeneous network, the
margin-based loss function [23] is defined as follows:
=
L
PR
∑ ∑ ∑
)
)
∈
∈
r PR a r b T
a r b
, ,
, ,
(
(
′
′
PR
∈
′
T
PR
max
⎡
⎣
0,
c
+
)
(
− ′
f a b f
,
(
),
a b
⎤
⎦
(5)
In the above formula, TPR represents the positive sample set in the PR triplet, and T’PR is the negative
sample set. c > 0 represents a margin hyperparameter.
Euclidean distance for affiliation relations. Only the target protein and its action type belong to the
AR relationship in the heterogeneous network we constructed. Spécifiquement, the types of protein nodes and
action nodes vary greatly in number. The nodes with this relationship can be directly approached in the
vector space, so we use Euclidean distance to calculate the proximity between two nodes. Given a set of
triples (m, je, n) with relationship type AR, where i ∈ Ri represents the action relationship between nodes m
and n. Its weight is defined as wm,n and the form is as follows:
m ng
(
,
)
=
w P
m n m
,
−
P.
n
2
2
(6)
Similar to the above formula, Pm and Pn are the embedding of nodes m and n, respectivement. g(m, n) est
to calculate the distance between m and n in a low-dimensional space. To ensure that the nodes connected
by the AR relationship are closer, we minimize g(m, n) as much as possible, therefore we define the margin-
based loss function as:
=
L
AR
∑ ∑
)
(
∈
∈
r AR m i n T m i n
∑
)
, ,
, ,
(
′
′
AR
∈
′
T
AR
maximum
⎡
⎣
0,
c
+
(
g m n
,
)
− ′
g
(
),
m n
⎤
⎦
(7)
As before, TAR and T’AR are the positive and negative examples in the AR relationship, respectivement.
482
Data Intelligence
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
/
.
t
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
4.4 Conjunctive Model
We have divided the node relationships of network into two categories based on the node distribution
differences in the heterogeneous networks. Ici, relations with unbalanced node distribution are Affiliation
Relations (AR) and relations with balanced node distribution are Peer Relations (PR). We first initialize all
the node embedding. Then for the node pairs of PR relations, we calculate the loss based on translation
model, and for the node pairs of AR relations, we calculate the loss based on Euclidean Distance. Enfin,
we fuse the two losses and continuously modify the embedding according to the final loss value. Spécifiquement,
we make the model more complete by fusing the loss of the two models to jointly update the weight of
node embedding. The pseudo code is shown in Algorithm 1.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
.
t
/
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
5. EXPERIMENTS AND ANALYSIS
5.1 Datasets and Experimental Setup
In this paper, the data set we used to construct the heterogeneous network includes the node type set
V = {drug, cible, diseases, side-effects, action}, the relationship type set R = {drug-drug, drug-target, drug-
diseases, drug-side-effects, target-target, target-diseases, target-action}. The data sources we used are as
follows:
DrugBank database is a unique bioinformatics and cheminformatics resource that combines detailed
drug data with comprehensive drug-target interaction, target-action information, and drug-drug interaction
information. We use the DrugBank version 3.0 and DrugBank version 5.1.6. [27].
Data Intelligence
483
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
HPDR (Human Protein Reference Database) contains manually curated scientific information
pertaining to the biology of most human proteins and the data of protein interactions extracted from the
HPRD database Release 9 [28].
CTD (Comparative Toxicogenomic Database) is a public website and research tool that provides four
types of core data: chemical-gene interactions, chemical-disease associations, gene-disease associations,
and chemical-phenotype associations. The drug-disease association and protein-disease association used
in this paper were extracted from CTD [29].
SIDER database contains information about marketed drugs and their adverse reaction records. Dans ce
papier, the drug-side-effects interactions were extracted from SIDER database Version 2 [30].
We obtained data from the above four sources, and after data preprocessing, we finally got 708 drugs,
1, 512 target proteins, 5603 diseases, 47 actions, et 4, 192 side effects. Some descriptive statistics of the
dataset are shown in Table 2.
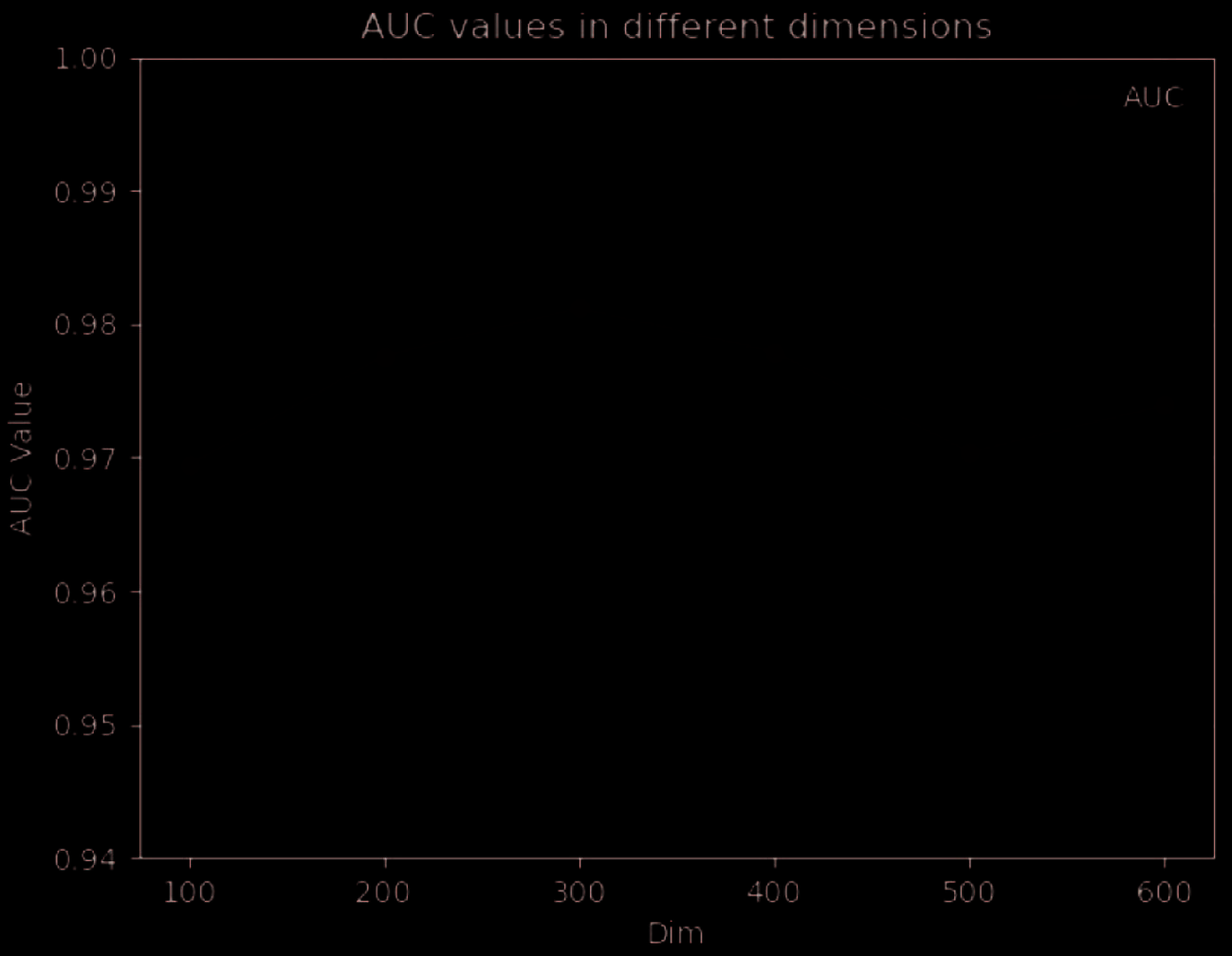
RTHNE_DTI has three parameters: embedding dimension d, the margin c, and a, we set c = 1, et
a = 0.01. To study the influence of different dimensions on our model, we explored parameter d. Comme indiqué
in figure 3, we can see that when the dimension is 300, the predicted AUC val ue is the highest. So we set
d=100 in the experiment.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
t
.
/
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 3. Parameter Analysis. Show the dimension value is when the best prediction result achieved.
484
Data Intelligence
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
In this paper, we conducted experiments under four tasks. In order to verify that dividing the relationship
into AR and PR can effectively improve the prediction performance, we conducted two experiments on
(1) the prediction performance of labeled networks based on PR relations only, et (2) the prediction
performance of labeled networks based on all relations. En particulier, it is not possible to predict DTI based
on AR only, because only the relationship between target and action is AR relationship. To verify the
performance of our model on unlabeled networks, we conducted a third experiment, (3) the prediction
performance of unlabeled networks based on all relations. To verify the robustness of our model, nous
performed a fourth experiment, (4) prediction performance based on the other datasets.
About evaluation metrics, we use AUC and AUPR to evaluate the performances of prediction.
5.2 Baseline Methods
DT-Hybrid [31] is a recommended method relying on network-based inference, which is based on
domain knowledge, including drug and target similarity.
BLMNI [32] improves the traditional BLM method and can be used to deal with the new drug and target
candidate problems, and it is called neighbor-based interaction-profile inferring.
HNM [33] combined with the drug target information, the intensity between the drug-disease pair is
calculated by the iterative algorithm on the heterogeneous graph.
MSCMF [10] uses multiple drug similarity matrices and multiple target similarity matrices to project
drugs and targets into a common low-dimensional feature space to predict DTI.
NetLapRLS [34] is a semi-supervised learning method—Laplacian regularized least square (LapRLS),
which use Laplacian Regular Least Squares (LapRLS) to simultaneously use a small amount of available
labeled data and a large amount of unlabeled data to obtain maximum generalization ability from the
chemical structure and genome sequence.
DTINet [35] is a network integration approach that integrates heterogeneous information of drug-target
heterogeneous networks.
RHINE [13] is a heterogeneous information network (HIN) embedding method which using the structural
characteristics of heterogeneous relations.
NeoDTI [20] integrates diverse information from heterogeneous networks and use graph neural network
to learn the representation of drugs and targets automatically.
EEG-DTI [36] propose an “end-to-end” learning framework based on heterogeneous graphical
convolutional networks to learn low-dimensional feature representations of drugs and targets.
Data Intelligence
485
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
t
/
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
5.3 Task 1: Predictive Performance of Labeled Network Based on PR Relationships Only
After analyzing the dataset, as shown in Table 2, we found that only the type of target-action relationship
is AR type, while most of the relationships in the drug-target heterogeneous network are PR type. And since
our task is to predict the interaction relationship between drug and target protein, here we temporarily
disregard the target-action relationship of AR type and only use the relationship of PR data, {drug-drug,
drug-target, drug-disease, drug-side effect, target-target, target-disease} and compare the performance of
our model with the other DTI prediction models.
During the experiment, we used 10% of the drug-target relationship and all other PR relationships as
the training set, and the remaining 90% of the drug-target relationships was held out as the test set.
According to the difference between positive and negative examples, we conducted two different
experiments, the first one in which the ratio between positive and negative samples was set to 1:10, le
other in which all unknown drug-target interacting pairs were considered as negative samples. Since the
EEG-DTI model must consider all negative sample relationship pairs, experiments with AUC (1:10) are not
supported.
The comparison results between our model and other models are shown in Table 3. The AUC scores
obtained by our model in two different scenario prediction experiments are 94.3% et 95.8%, lequel
exceeds the method NeoDTI by 3% et 2% respectivement. Compared to NeoDTI, the embedding dimension
of our method is 300, and NeoDTI is 1, 024.
What needs to be explained here is that in the NeoDTI experiment, in addition to the data mentioned
au-dessus de, the similarity information of the drug structure and the similarity information of the protein sequence
are also used. En outre, NeoDTI is very time consuming and its running time is about 100 times that
of our method.
Tableau 3. Performance evaluation of different models based on PR relations.
Method
AUC (1:10)
AUC (tous)
MSCMF*
DT-Hybrid*
BLMNI*
HNM*
NetLapRLS*
DTINet*
NeoDTI*
EEG-DTI*
RTHNE_DTI*
0.831
0.842
0.855
0.891
0.905
0.919
0.941
–
0.958
0.849
0.833
0.850
0.890
0.895
0.909
0.913
0.831
0.943
5.4 Task 2: Predictive Performance of Labeled Network Based on All Relationships
In this task, we consider the target-action AR-type relationship, modeled individually for the characteristics
of this relationship type, and incorporated it into the model of the PR-type relationship in task1. Nous
486
Data Intelligence
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
.
t
/
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
compare it with more advanced approaches. As before, we still use the 10% drug-target relationship and
all other relationships as the training set, and the remaining data is used as the test set. For a fair comparison,
we set the embedding dimension d = 100, because the two models run the most efficiently when the
dimensionality is low, and all unknown pairs were targeted as the negative samples for all methods in this
experiment. The results are shown in Table 4.
It can be seen from the results that our model is superior to the other two methods. Ici, the NeoDTI
method also utilizes the similarity information between the drug and the target protein, but the AUC value
of our model is still 9% higher than it. Compared with EEG-DTI, our model fully considers the difference
between AR relationship and PR relationship, and the AUC value is 11% higher than it. Compared with
the RHINE method, our method considers more heterogeneous relationships. In terms of AUPR metrics,
our model also far exceeds the RHINE model and is on par with the NeoDTI model. Ainsi, our results have
better performance in this task. En outre, in this experiment, the AUC value of our method is 96.93%,
which is about 3% higher than the result using only the PR relationship. It proves that the AR type relationship
is also very important to improve the prediction ability.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
t
/
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Tableau 4. Performance evaluation of different models based on all relations.
Method
NeoDTI*
EEG-DTI*
RHINE
RTHNE_DTI*
AUC
0.883
0.854
0.923
0.958
AUPR
0.288
0.600
0.145
0.264
5.5 Task3: Predictive Performance of Unlabeled Network Based on All Relationships
In the existing DTI prediction methods, the drug and target pairs with known relationships are added to
the training set to train the model. Cependant, we assume whether it is possible to not add the relationship
for prediction in the training set and only use others. In order to verify this conjecture, we conducted an
experiment on task 3.
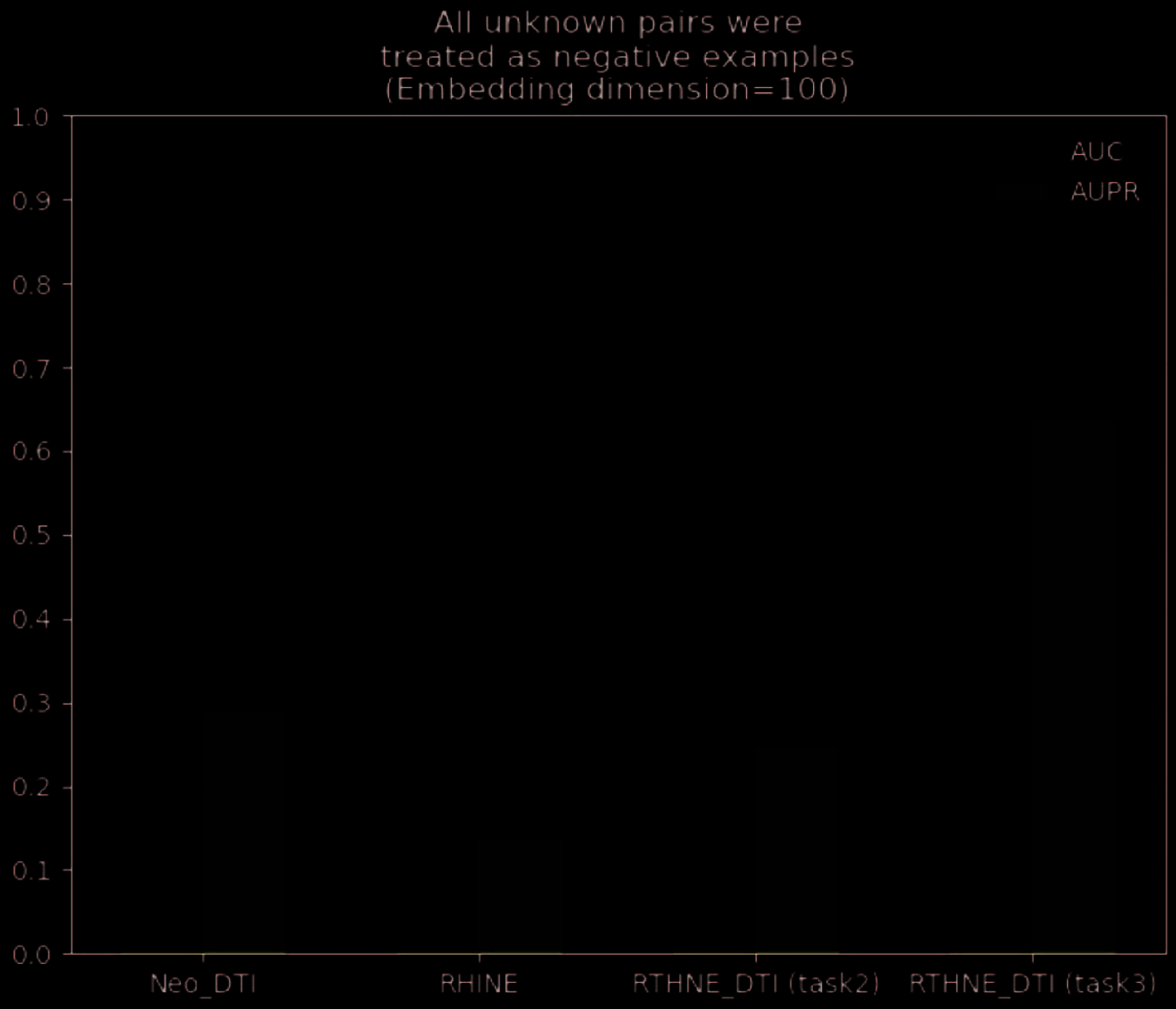
For task 3, We use all drug-target relationship pairs as test sets. The ratio of positive and negative samples
est 1:10. Through experiments, our model’s AUC and AUPR scores are 92.11% et 63.69%, respectivement.
Donc, we can use their external relationships to predict when we have no clue whether there is an
interaction between a drug and a target.
As shown in Figure 4, because we removed the target-drug interaction relationship in the task 3 experiment,
the AUC value of our model RTHNE_DTI in task 3 (without label) is lower than that in task 2 (with label),
but still much higher than the results of the NeoDTI model and RHINE model in task 2 (with label).
Data Intelligence
487
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
.
/
t
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 4. Performance evaluation of unlabeled network.
In addition, in terms of AUPR metrics, the results of our model RTHNE_DTI in task 3 (without labels)
are the best, much higher than the results of all models in task 2 (with labels).
5.6 Predictive performance based on other datasets
DBLP is an integrated database system of computer English literature with the author as the core of the
research results in the computer field. The details of the DBLP dataset are shown in Table 5.
Tableau 5. Statistical analysis of DBLP dataset.
Nodes
Term(T)
Paper(P.)
Author(UN)
Conference(C)
Num of
Nodes
8811
14376
14475
20
Relations
P-C
A-PC
P-P
D-Di
P-A
Num of
Relations
14376
24495
41794
88683
260605
Avg.tu
Avg.tv
D(e)
S(e)
Relation-
ship type
1.0
2.9
2.8
6.2
18.0
718.8
2089.7
2.9
10.7
29.6
718.8
720.6
1.0
1.7
1.6
0.05
0.08
0.0002
0.007
0.002
AR
AR
PR
PR
PR
From Table 5, we can see that the DBLP dataset contains more PR relations. We respectively predict the
two relationship pairs author-author (A-A) and author-conference (A-C) in this experiment. The result is
shown in Table 6.
488
Data Intelligence
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
Tableau 6. Performance evaluation of different datasets.
Dataset
DBLP(A-A)
DBLP(A-C)
Drug-target dataset (D-T)
AUC
0.924
0.906
0.969
The above experiments demonstrate that our method not only has good performance on drug networks,
but also can achieve good results on scholar networks, and AUC value of our model do not fluctuate much
on different datasets. It shows that our model has good robustness.
6. CONCLUSION AND FUTURE WORK
Accurately predicting the interaction between drugs and targets is important for drug research and
development. Dans ce document, we apply the method of heterogeneous network representation learning to
predict drug-target interactions. We build a heterogeneous network by the rich external relationships
between drugs and target proteins and learn about drug and protein representations through neighboring
nodes. We use data intelligence methods to divide the relationships into two categories: Affiliation relations
and Peer relations, based on the different topologies of the relationships in the heterogeneous network, et
model them separately. By doing this, our model can better capture the topological and semantic information
of drug network in the same time, thus taking shorter time and achieving better results. En outre, le
RTHNE_DTI model plays an important role in the real world. Par exemple, we used RTHNE_DTI to discover
a novel interaction between the drug Acemetacin and the target protein PTGS1, which has been proved to
be correct in Drugbank database. It has proven to provide a powerful and useful tool for the drug discovery
and drug repositioning process. In the future, we will consider the rich domain knowledge of drugs and
proteins based on heterogeneous networks to further enhance the predictive effect of RTHNE_DTI and
validate some of the predictions by wet lab experiments.
ACKNOWLEDGEMENTS
This research was funded by the National Natural Science Foundation of China, numéro de subvention 61402220,
the key program of Scientific Research Fund of Hunan Provincial Education Department, grant number
19A439, the Project supported by the Natural Science Foundation of Hunan Province, Chine, numéro de subvention
2020JJ4525 and grant number 2022JJ30495.
AUTHOR CONTRIBUTION STATEMENT
Ll. Z (zhanglinlin@stu.usc.edu.cn, ORCID: 0000-0002-5035-3571) was jointly responsible for the
investigation of the study, organization of data, conception, analyse, and validation of methods, preparation of
ressources, and preparation of the original manuscript. Cp. Ouyang (ouyangcp@126.com, ORCID: 0000-
0002-2154-0079) was jointly responsible for the investigation of the study, organization of the data, le
Data Intelligence
489
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
/
.
t
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
conceptualization of the methods, and review and editing of the manuscript, as well as supervision and
project management. Fy. H (fyhu1124@163.com, ORCID: 0000-0002-1004-6913) contributed to the
investigation of the study, the conceptualization of the methods, analyse, validation, and data curation.
Yb. L participated in the model optimization and experimental design and analyzed the results. Z.G
(gao27@indiana.edu) provided important feedback and edited the manuscript.
RÉFÉRENCES
[1] Kapetanovic, JE.: Computer-aided drug discovery and development (caddd): in silico-chemico-biological
approche. Chemico-Biological Interactions 171(2), 165–176 (2008)
[2] Pathak, J., Kiefer, R.C., Chute, C.G.: Mining drug-drug interaction patterns from linked data: A case study for
warfarin, clopidogrel, and simvastatin. Dans: 2013 IEEE International Conference on Bioinformatics and
Biomedicine, pp. 23–30 (2013)
[3] Ding, Y., Tang, J., Guo, F.: Identification of drug-target interactions via multiple information integration.
Information Sciences 418, 546–560 (2017)
[4] D’Souza, S., Prema, K., Balaji, S.: Machine learning models for drug–target interactions: current knowledge
and future directions. Drug Discovery Today 25(4),748–756 (2020)
[5] Yamanishi, Y., Araki, M., Gutteridge, UN., Honda, W., Kanehisa, M.: Prediction of drug–target interaction
net-works from the integration of chemical and genomic spaces. Bioinformatics 24(13), i232–i240, (2008)
[6] Öztürk, H., Özgür, UN., Ozkirimli, E.: Deepdta: deep drug–target binding affinity prediction. Bioinformatics
34(17), i821–i829 (2018)
[7] Wang, Y.-B., You, Z.-H., Lequel, S., Faire, H.-C., Chen, Z.-H., Zheng, K.: A deep learning-based method for
drug-target interaction prediction based on long short-term memory neural network. BMC Medical Informatics
and Decision Making 20(2), 1–9 (2020)
[8] Chen, X., Yan, C.C., Zhang, X., Zhang, X., Dai, F., Yin, J., Zhang, Y.: Drug–target interaction prediction:
databases, web servers and computational models. Briefings in Bioinformatics 17(4), 696–712 (2016)
[9] Zeng, X., Zhu, S., Hou, Y., Zhang, P., Li, L., Li, J., Huang, L.F., Lewis, S.J., Nussinov, R., Cheng F.: Réseau-
based prediction of drug–target interactions using an arbitrary-order proximity embedded deep forest.
Bioinformatics 36(9), 2805–2812 (2020)
[10] Zheng, X., Ding, H., Mamitsuka, H., Zhu, S.: Collaborative matrix factorization with multiple similarities for
predicting drug-target interactions. Dans: Proceedings of the 19th ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining, pp. 1025–1033 (2013)
[11] Mayr, UN., Klambauer, G., Unterthiner, T., Steijaert, M., Wegner, J.K., Ceulemans, H., Clevert, D.-A., Hochreiter,
S.: Large-scale comparison of machine learning methods for drug target prediction on chembl. Chemical
Science 9(24), 5441–5451(2018)
[12] Lee, JE., Keum, J., Nam, H.: Deepconv-dti: Prediction of drug-target interactions via deep learning with
convolution on protein sequences. Biologie computationnelle PLoS 15(6), e1007129, (2019)
[13] Lu, Y., Shi, C., Hu, L., Liu, Z.: Relation structure-aware heterogeneous information network embedding. Dans:
Proceedings of the AAAI Conference on Artificial Intelligence, pp. 4456–4463 (2019)
[14] Shang, J., Qu, M., Liu, J., Kaplan, L.M., Han, J., Peng, J.: Meta-path guided embedding for similarity search
in large-scale heterogeneous information networks (2016)
[15] Fu, T.-Y., Lee, W.-C., Lei, Z.: Hin2vec: Explore meta-paths in heterogeneous information networks for
representation learning. Dans: Actes du 2017 ACM on Conference on Information and Knowledge
Management, pp. 1797–1806 (2017)
490
Data Intelligence
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
.
/
t
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
[16] Han, X., Shi, C., Wang, S., Philip, S.Y., Song, L.: Aspect-level deep collaborative filtering via heterogeneous
information networks. In IJCAI, pp. 3393–3399 (2018)
[17] Muller, E., Peres, R.: The effect of social networks structure on innovation performance: A review and
directions for research. International Journal of Research in Marketing 36(1), 3–19 (2019)
[18] Bu, Y., Huang, Y., Lu, W.: Loops in publication citation networks. Journal of Information Science 46(6),
837–848 (2020)
[19] Jin, S., Zeng, X., Xia, F., Huang, W., Liu, X.: Application of deep learning methods in biological networks.
Briefings in Bioinformatics 22(2), 1902–1917 (2020)
[20] Wan, F., Hong, L., Xiao, UN., Jiang, T., Zeng, J.: Neodti: neural integration of neighbor information from a
heterogeneous network for discovering new drug–target interactions. Bioinformatics 35(1), 104–111 (2019)
[21] Wasserman, S., Faust, K., et coll.: Social network analysis: Methods and Applications 8, (1994)
[22] Faust, K.: Centrality in affiliation networks. Social Networks 19(2), 157–191 (1997)
[23] Bordes, UN., Usunier, N., Garcia-Duran, UN., Weston, J., Yakhnenko, O.: Translating embeddings for modeling
multi-relational data. In Advances in Neural Information Processing Systems, pp. 2787–2795 (2013)
[24] Lequel, J., Leskovec, J.: Community-affiliation graph model for overlapping network community detection.
Dans 2012 IEEE 12th International Conference on Data Mining, pp. 1170–1175 (2012)
[25] Danielsson, P.-E.: Euclidean distance mapping. Computer Graphics and Image Processing 14(3), 227–248
(1980)
[26] Hsieh, C.-K., Lequel, L., Cui, Y., Lin, T.-Y., Belongie, S., Estrin, D.: Collaborative metric learning. In Proceedings
of the 26th international conference on world wide web, pp. 193–201 (2017)
[27] Wishart, D.S., Feunang, Y.D., Guo, A.C., Lo, E.J., Marcu, UN., Grant, J.R., Sajed, T., Johnson, D., Li, C., Sayeeda,
Z.: Drugbank 5.0: a major update to the drugbank database for 2018. Nucleic Acids Research 46(D1),
D1074–D1082 (2018)
[28] Keshava Prasad, T., Goel, R., Kandasamy, K., Keerthikumar, S., Kumar, S., Mathivanan, S., Telikicherla, D.,
Raju, B.R., Shafreen, UN. Venugopal: Human protein reference database—2009 update. Nucleic Acids
Research 37(suppl 1), D767–D772 (2009)
[29] Davis, A.P., Murphy, C.G., Johnson, R., Lay, J.M., Lennon-Hopkins, K., Saraceni-Richards, C., Sciaky, D.,
King, B.L., Rosenstein, M.C., Wiegers T.C.: The comparative toxicogenomics database: update 2013.
Nucleicacids Research 41(D1), D1104–D1114 (2013)
[30] Kuhn, M., Campillos, M., Letunic, JE., Jensen, L.J., Bork, P.: A side effect resource to capture phenotypic effects
of drugs. Molecular Systems Biology 6(1), 343 (2010)
[31] Alaimo, S., Pulvirenti, UN., Giugno, R., Ferro, UN.: Drug–target interaction prediction through domain-tuned
network-based inference. Bioinformatics 29(16), 2004–2008 (2013)
[32] Mei, J.-P., Kwoh, C.-K., Lequel, P., Li, X.-L., Zheng, J.: Drug–target interaction prediction by learning from local
information and neighbors. Bioinformatics 29(2), 238–245 (2013)
[33] Wang, W., Lequel, S., Zhang, X., Li, J.: Drug repositioning by integrating target information through a
heterogeneous network model. Bioinformatics 30(20), 2923–2930 (2014)
[34] Xia, Z., Wu, L.-Y., Zhou, X., Wong, S.T.: Semi-supervised drug-protein interaction prediction from
heterogeneous biological spaces. In BMC Systems Biology, p. S6 (2010)
[35] Luo, Y., Zhao, X., Zhou, J., Lequel, J., Zhang, Y., Kuang, W., Peng, J., Chen, L., Zeng, J.: A network integration
approach for drug-target interaction prediction and computational drug repositioning from heterogeneous
information. Communications naturelles 8(1), 1–13 (2017)
[36] J.G., Peng, J., Wang, Y.: An end-to-end heterogeneous graph representation learning-based framework for
drug–target interaction prediction. Briefings in Bioinformatics 22(5), 1–9 (2021)
Data Intelligence
491
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
.
/
t
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
AUTHOR BIOGRAPHY
Linlin Zhang received her B.S. degree in Software Engineering from the
School of Computer Science, University of South China, Chine, dans 2020. Elle
is pursuing her M.S. degree with a specialization in software engineering
at the University of South China. Her research interests include network
representation learning and drug discovery.
ORCID: 0000-0002-5035-3571
Chunping Ouyang received a Ph.D. degree from the University of Science
& Technology Beijing, Chine, dans 2011. Depuis 2017 à 2018, she was a visiting
scholar at Indiana University Bloomington. She is a professor of computer
science at the University of South China and supervisor of postgraduate. Son
main research interests are semantic web technology, knowledge graphs,
natural language processing, and domain data analysis.
ORCID: 0000-0002-2154-0079
Fuyu Hu received her master’s degree in computer technology from the
School of Computer Science, South China University, Chine, dans 2021. Son
research interests include network representation learning and drug discovery.
She is working on a related project at the Bank of Communications in China.
ORCID: 0000-0002-1004-6913
492
Data Intelligence
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
/
t
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Relational Topology-based Heterogeneous Network Embedding for Predicting Drug-Target
Interactions
Yongbin Liu received a Ph.D. degree from the University of Science &
Technology Beijing, Chine, dans 2013. Depuis 2013 à 2015, he was a post-doc
research fellow at Tsinghua University. He is an associate professor at the
University of South China. His research interests include natural language
processing and knowledge engineering.
ORCID: 0000-0002-3369-3101
Zheng Gao is an Applied Scientist at Amazon Alexa AI. He received his
Ph.D. degree in Information Science and minor in Computer Science from
Indiana University Bloomington, advised by Prof. Xiaozhong Liu in 2020. Son
research interests are primarily in the area of Graph Mining and Natural
Language Processing (NLP). Particularly, he is applying deep learning
techniques on the interdisciplinary field therein them to solve Community
Detection, Information Retrieval and Recommendation related tasks. He is
currently working as an applied scientist at Amazon Alexa AI and build NLU
models to handle customer utterances.
ORCID: 0000-0001-7549-033X
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
d
n
/
je
t
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
5
2
4
7
5
2
0
8
9
7
7
2
d
n
_
un
_
0
0
1
4
9
p
d
.
t
/
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence
493