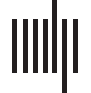ARTICLE DE RECHERCHE
Granularity of algorithmically constructed
publication-level classifications of research
publications: Identification of specialties
Peter Sjögårde1,2
and Per Ahlgren3,4
1University Library, Karolinska Institutet, Stockholm, Sweden
2Health Informatics Centre, Department of Learning, Informatics, Management and Ethics, Karolinska Institutet, Stockholm, Sweden
3Department of Statistics, Uppsala University, Uppsala, Sweden
4KTH Library, KTH Royal Institute of Technology, Stockholm, Sweden
Mots clés: algorithmic classification, article-level classification, classification system, granularity
level, specialty
ABSTRAIT
In this work, we build on and use the outcome of an earlier study on topic identification in
an algorithmically constructed publication-level classification (ACPLC), and address the issue
of how to algorithmically obtain a classification of topics (containing articles), where the
classes of the classification correspond to specialties. The methodology we propose, which is
similar to that used in the earlier study, uses journals and their articles to construct a baseline
classification. The underlying assumption of our approach is that journals of a particular size
and focus have a scope that corresponds to specialties. By measuring the similarity between (1)
the baseline classification and (2) multiple classifications obtained by topic clustering and
using different values of a resolution parameter, we have identified a best performing ACPLC.
In two case studies, we could identify the subject foci of the specialties involved, et le
subject foci of specialties were relatively easy to distinguish. Plus loin, the class size variation
regarding the best performing ACPLC is moderate, and only a small proportion of the articles
belong to very small classes. For these reasons, we conclude that the proposed methodology is
suitable for determining the specialty granularity level of an ACPLC.
1.
INTRODUCTION
In a recent article we proposed a methodology for identification of research topics in an algo-
rithmically constructed publication-level classification of research publications (ACPLC;
Sjögårde & Ahlgren, 2018). We used a large dataset of more than 30 million publications
in Web of Science to create an ACPLC, at the granularity level of topics. We consider topics
as problem areas addressed by researchers, representing “an underlying semantic theme” (Yan
et coll., 2012), and we see topics as the lowest level of aggregation to be considered for clas-
sification of subject areas (Besselaar & Heimeriks, 2006). Cependant, more levels of different
granularity are needed for an ACPLC to be used to answer a broader range of questions. Dans
the present study, we use a similar methodology to create a classification whose granularity
corresponds to research specialties. In the remainder of this paper, we use the term “specialty”
instead of “research specialty.” In short, a specialty is a “network of researchers who tend to
study the same research topics” (Morris & Van der Veer Martens, 2008). Cependant, the spe-
cialty notion is further discussed below. In this paper we identify the publications belonging to
specialties by grouping the topics obtained in the previous study.
un accès ouvert
journal
Citation: Sjögårde, P., & Ahlgren, P..
(2020). Granularity of algorithmically
constructed publication-level
classifications of research
publications: Identification of
specialties. Quantitative Science
Études, 1(1), 207–238.
https://doi.org/10.1162/qss_a_00004
EST CE QUE JE:
https://doi.org/10.1162/qss_a_00004
Reçu: 15 Janvier 2019
Accepté: 27 Juillet 2019
Auteur correspondant:
Peter Sjögårde
peter.sjogarde@ki.se
Éditeur de manipulation:
Vincent Larivière
droits d'auteur: © 2019 Peter Sjögårde and
Per Ahlgren. Published under a
Creative Commons Attribution 4.0
International (CC PAR 4.0) Licence.
La presse du MIT
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
The identification of specialties is part of a broader aim to develop a standard approach to
create a large and global hierarchical ACPLC of research publications in terms of geographical
uptake, coverage of subject areas, and citation databases, such as Web of Science or Scopus.
An ACPLC can be used for a great variety of analytical purposes and is especially useful for
recurrent analytical activities.
A classification system that groups publications into classes whose sizes correspond to spe-
cialties can be used to study the publication output of different actors within a specialty; le
collaboration between actors, dynamics, emergence and decline of specialties; and the rela-
tion between specialties. De plus, a hierarchical classification, including both classes corre-
sponding to topics and classes corresponding to specialties, makes it possible to identify topics
within a specialty and, Par exemple, a shifting focus of a specialty. We therefore suggest that
the level of specialties, together with the level of topics, should be included in a standard
ACPLC, and that such an ACPLC should be hierarchical.
The purpose of this paper is to find a theoretically grounded, practically applicable, et
useful granularity level of an ACPLC with respect to specialties. To determine the granularity
of specialties, a baseline classification is constructed. A set of journals is identified and used to
create a baseline classification. ACPLCs with different granularities, constructed by the use of
different values of a resolution parameter, are then compared to the baseline classification.
The classification that best fits the baseline classification is proposed to be used for biblio-
metric analyses of specialties. In contrast to earlier work, our aim is to create a classification
of publications that can be used to identify all specialties represented in Web of Science from
1980 onwards.
The remainder of this paper is structured as follows. Dans la section suivante, a short summary of
our previous article on topic identification is given. The framework of the study is outlined in
Section 3 and the specialty notion is discussed in Section 4. Data and methods are presented
in Section 5, and Section 6 gives the results. Conclusions are given in Section 7.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
2. SUMMARY OF THE SJÖGÅRDE-AHLGREN STUDY ON IDENTIFICATION OF TOPICS
To give the reader some background to the present study, in this section we summarize the
earlier study on topic identification (Sjögårde & Ahlgren, 2018). In that study, we discussed
how the resolution parameter given to the software Modularity Optimizer can be calibrated to
obtain publication classes corresponding to the size of topics.
A set of about 31 million articles and reviews from Bibmet, KTH Royal Institute of
Technology’s bibliometric database, which contains Web of Science data, was used for the
étude. The study involved a methodology consisting of four steps. In the first step, we con-
structed a baseline classification (BCPt) corresponding to topics, where BCPt contains synthesis
articles, operationalized as articles with at least 100 références. Each such article constitutes a
class, and its list of cited references points to the reference articles of the class (c'est à dire., to the
members of the class). The underlying assumption of this approach is that synthesis publica-
tions in general address a topic.
In the second step of the methodology, several ACPLCs of different granularity with respect
to the topic level were created by setting the resolution parameter of Modularity Optimizer to
different values. Normalized direct citation values between the articles in the dataset were
used, as proposed by Waltman and van Eck (2012). For the third step, classifications derived
from the ACPLCs were obtained, where each derived classification constitutes a classification
of the union of the classes of the baseline classification, BCPt. Ainsi, the latter classification and
Études scientifiques quantitatives
208
Granularity of classifications of research publications
a given derived one have exactly the same underlying reference articles. In the fourth and final
step of the methodology, the similarity between BCPt and each of the derived classifications
from the third step was quantified. For this purpose, the Adjusted Rand Index (ARI; Hubert &
Arabie, 1985) was used. We denoted the ACPLC such that its corresponding derived classifi-
cation exhibited the largest ARI similarity with BCPt by ACPLCt.
With respect to the results of the study, the class size variation regarding ACPLCt turned out
to be moderate, and only a small proportion of the articles belong to very small classes.
De plus, the outcomes of two case studies showed that the topics of the cases were closely
associated with different classes of ACPLCt, and that these classes tend to treat only one topic.
We concluded that the proposed methodology is suitable to determine the topic granularity
level of an ACPLC and that the ACPLC identified by this methodology is useful for bibliometric
analyses.
In the present study, we use a similar methodology to identify specialties. Le 230,559 clas-
ses obtained in the previous study, of which 136,939 have a size of at least 50 articles, sont
clustered into specialties. A baseline classification is constructed that corresponds to special-
liens, and a set of journals is used to create the baseline classification.
We need to point out that there is a substantial overlap between our earlier paper (Sjögårde
& Ahlgren, 2018) and the present one. The reason for this is that the four-step methodology
used in the earlier study, and briefly described above, is also used in the study underlying the
present paper.
3. FRAMEWORK
As in the previous study, we use a network-based approach to obtain a classification of research
publications (Fortunato, 2010). We use the Modularity Optimizer1 software, created by
Waltman and van Eck (2013), and the methodology put forward in Waltman and van Eck
(2012). This framework has also been used by others (Klavans & Boyack, 2017un, b). The alter-
native modularity function is used (Traag et al., 2011), together with the SLM algorithm for mod-
ularity optimization. We acknowledge that a new algorithm for modularity optimization has
been proposed (Traag et al., 2019). Cependant, to be consistent with the previous study, we use
the SLM algorithm in this study. We choose direct citation to express publication-publication
relations, rather than bibliographic coupling (Kessler, 1965), cocitations (par exemple., Marshakova-
Shaikevich, 1973; Petit, 1974), textual similarity (par exemple., Ahlgren & Colliander, 2009; Boyack
et coll., 2011), or combined approaches (par exemple., Colliander, 2015; Glänzel & Thijs, 2017). Direct
citation is more efficient as it gives rise to fewer relations than the mentioned approaches, et
there is empirical support that direct citations perform well in comparison with bibliographic
coupling and cocitations when it comes to larger data sets (Boyack, 2017).
In Sjögårde and Ahlgren (2018), a network model with two levels of hierarchy, topics and
specialties, was presented. This model comprises a logical classification: Each publication is
classified into exactly one class at each level of hierarchy.2 Moreover, all publications in a
class, at a level below the top level, are classified into exactly one and the same parent class.
It follows that each topic in the model belongs to exactly one specialty. Dans cette étude, dans lequel
we continue to use logical classifications, we obtain such a relation by clustering topics into
1 http://www.ludowaltman.nl/slm/.
2 A logical classification of a set of objects, Ô, is a set C of nonempty subsets of O such that (un) the union of the
sets in C is equal to O, et (b) the sets in C are pairwise disjoint. Ainsi, each object in O is classified into
exactly one set in C.
Études scientifiques quantitatives
209
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
specialties, rather than using the alternative approach to cluster publications directly into spe-
cialties. Logical classifications have some shortcomings: Topics can be addressed by several
specialties (Yan et al., 2012) ou, at a higher level of aggregation, disciplines (Wen et al., 2017),
phenomena not expressed by logical classifications. Cependant, the relation between a topic
and other specialties than the parent specialty, as well as relations between topics, can still
be expressed and analyzed by use of the relational strengths associated with the edges in
the model.
For further discussion on the general classification framework and for an explication of a
model that expresses the relations between classes at different hierarchical levels in the model,
we refer the reader to Sjögårde and Ahlgren (2018).
4. SPECIALTIES
Specialties have been studied since the 1960s in the field of sociology. In this literature, spe-
cialties are considered as smaller intellectual units within research disciplines (Chubin, 1976).
The researchers within the same specialty communicate with each other. They possess similar
competences and can engage in the same, or similar, research problems (Hagstrom, 1970).
The notion of specialties is closely related to the notion of invisible colleges (Crane, 1972;
Prix, 1965). Cependant, as pointed out by Morris and van der Veer Martens (2008), invisible
colleges “presuppose that the researchers are in frequent informal contact with one another,»
which is not the case for specialties.
We use the definition of a specialty that has been given by Morris and van der Veer Martens
(2008). They define a specialty as “a self-organized network of researchers who tend to study
the same research topics, attend the same conferences, read and cite each other’s research
papers and publish in the same journals.” Further, and in concurrence with others, we con-
sider specialties to be the largest homogeneous units of science “in that each specialty has its
own set of problems, a core of researchers, shared knowledge, a vocabulary, and literature”
(Scharnhorst et al., 2012) and that they “play an important role in the creation and validation
of new knowledge” (Colliander, 2014).
As early as 1974, Small and Griffith argued that publications can be clustered and that the
obtained clusters may represent specialties (Petit & Griffith, 1974). The single-linkage method
was used by Small and Griffith to cluster 1,832 publications, which today would be consid-
ered a very small number of publications. They used their results to identify specialties. Since
the 1970s, the technological advancements and the emergence of the Internet have changed
the preconditions for research communication. There has also been a growth in research ac-
tivity and production of research publications.
More lately, specialties have been identified and analyzed by the use of different clustering
techniques (Lucio-Arias & Leydesdorff, 2009; Morris & van der Veer Martens, 2008;
Scharnhorst et al., 2012). Different points of departure and different operationalizations of
the specialty notion have captured different aspects of specialties. Par exemple, clustering of
publications based on citation relations and clustering of researchers based on coauthorship
may result in different pictures of a specialty. The former approach identifies a set of publica-
tions and the latter a group of researchers belonging to a specialty. We attempt to capture the
publications belonging to each specialty, rather than the researchers belonging to the specialty.
A researcher can be part of several specialties, a property that cannot be expressed by the
coauthorship approach. For this reason, we consider this approach less suitable for the
identification of publications belonging to a specialty. We believe that it is preferable to base
classifications constructed for the purpose of bibliometric analyses of specialties on the network
Études scientifiques quantitatives
210
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
of publications, rather than on the network of researchers. Our approach makes it possible to
identify the researchers within a specialty without forcing every researcher into exactly one spe-
cialty. It also makes it possible to analyze the contribution of one researcher to multiple
specialties.
Kuhn (1996) estimates the number of core researchers in a specialty to be around 100.
Based on Lotka’s law (1926), Morris (2005) estimates the total number of researchers within
a specialty to be around 1,000, and the number of publications produced by a specialty to be
entre 100 et 5,000. Boyack et al. (2014) regard specialties to be “ranging from roughly a
hundred to a thousand articles per year.” We acknowledge that the size of specialties in terms
of publications may vary over time. Because the output of research publications has been
growing the last decades, it is likely that the total size of specialties, in terms of number of
publications, has been growing. Aussi, the yearly publication production of active specialties
is likely to be on average larger today than 10 ou 20 years ago. The size of specialties is an
empirical question that we intend to shed light on in the present study.
5. DATA AND METHODS
As in Sjögårde and Ahlgren (2018), KTH Royal Institute of Technology’s bibliometric database
Bibmet was used for the study. Bibmet contains Web of Science publications from the publi-
cation year 1980 onwards. In the present study, we use the same set of publications as in the
earlier study. We denote this set, in agreement with the earlier study, by P. P consists of
30,669,365 publications of the two document types: “Article” and “Review.” In the remainder
of this paper, we use the term “article” to refer to both articles and reviews.
5.1. Design of the Study
We attempt to find a granularity of an ACPLC, where the ACPLC is based on the articles in P,
that corresponds to specialties. In order to identify the granularity of specialties, a baseline
classification of publications (BCP) is created. The BCP is a set of journals, considered as clas-
ses, and each member of a class in BCP is a publication appearing in the class (c'est à dire., appearing
in the journal).
The BCP is compared to several ACPLCs with different granularities, where each such
ACPLC is obtained by clustering the classes of ACPLCt (see Section 2), which is thereby uti-
lized in the present study. An appropriate granularity is detected and an ACPLC is chosen, le
classes of which correspond to specialties. The methodology, which has four steps and a high
degree of similarity with the methodology proposed in Sjögårde and Ahlgren (2018), is de-
scribed in detail in steps I to IV below and schematically illustrated in Figure 1.
je. Creation of baseline classes
We construct a baseline classification to correspond to specialties, which we denote by BCPs.
For the creation of BCPs, a subset of journals covered by Web of Science is used. Each journal
constitutes a class, and the publications appearing in the journal are the members of the class.
The reason for using journals to obtain BCPs is that researchers within a specialty publish in
and read the same journals. The new possibilities to search, retrieve and read research articles
have changed the role of journals, but nevertheless many journals are still focused on specific
areas of expertise and the researchers within those areas. Such journals aim to publish articles
that are relevant to its audience. Par exemple, we consider bibliometrics as a specialty within
the discipline of library and information science, and the scope of the Journal of Informetrics as
Études scientifiques quantitatives
211
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 1.
Illustration of the design of the study.
roughly targeting the specialty of bibliometrics. In resemblance with Bradford’s law (1948),
researchers within a specialty need to go to several journals to find all the relevant articles
within their specialty. The boundaries of a specialty are vague and fading rather than sharp.
If we consider a journal, the scope of which roughly covers a specialty, a core set of the ar-
ticles in such journal is likely to be of high relevance to the core audience of the journal. Le
researchers that belong to this core audience can be considered as the backbone of the spe-
cialty. The rest of the articles in the journal have a fading relevance to this specialty. Some of
these articles will be of higher relevance to other specialties.
When creating BCPs, we attempt to delimit the set of journals to such journals that, regard-
ing their size and scope, can be considered as proxies for specialties. As BCPs is to be used as a
baseline to estimate the granularity of an ACPLC regarding specialties, the following three re-
quirements should be addressed:
UN.
B.
C.
To be able to compare the classifications, the union of the classes in BCPs must be a
subset of the union of the classes (c'est à dire., the topics) in ACPLCt.
Ideally, each class (journal) in BCPs should address exactly one specialty.
Ideally, each pair of distinct classes (journaux) should address different specialties.
Now, to satisfy point A, we kept, for a given journal, only articles (c'est à dire., publications that are
of the document types “Article” or “Review”) that are present in ACPLCt (c'est à dire., having a clas-
sification at the topic level).
To deal with point B, we first delimited the publication period to five years, namely 2008–
2012. By this operation, which resulted in 6,140,762 publications in 13,070 journaux, the risk
of including journals that, par exemple, have shifted subject focus over time is lowered. En addition-
dition to dealing with point B, the choice of publications from publication years that have both
incoming and outgoing citations can be assumed to have a stabilizing effect when these arti-
cles are being clustered, compared to more recent publications.
Études scientifiques quantitatives
212
Granularity of classifications of research publications
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
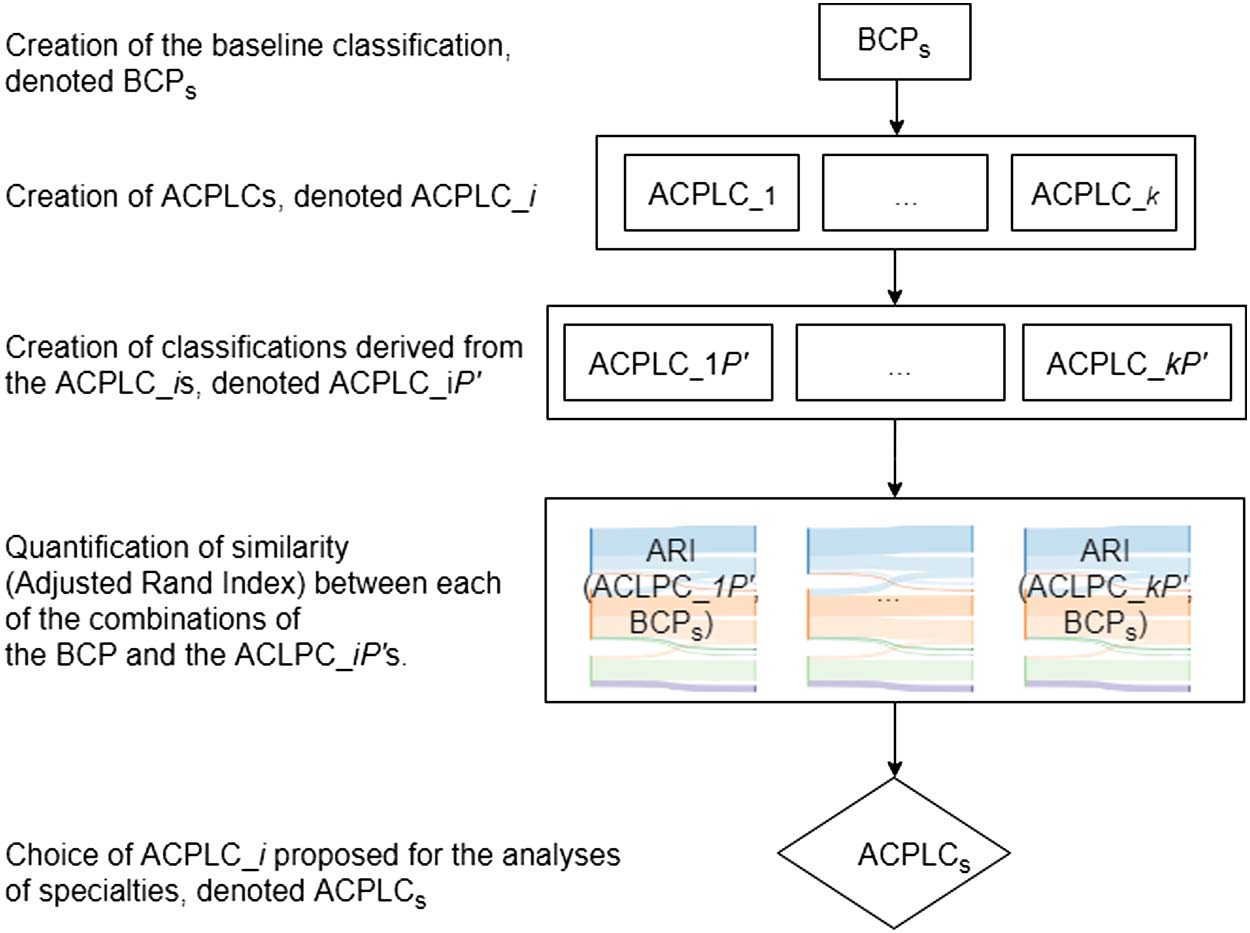
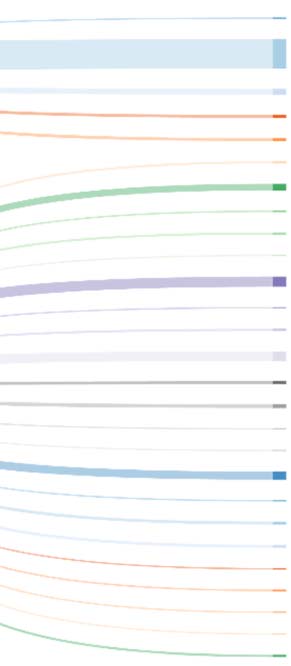
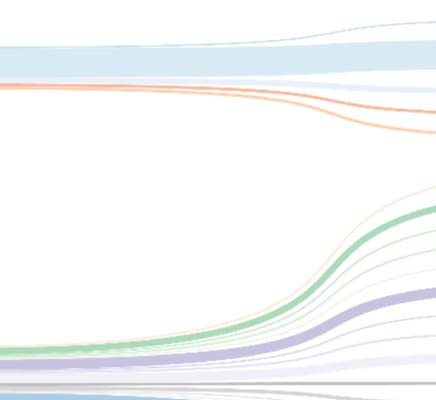
Chiffre 2. Number of journals per journal size for journals with 1 à 2,000 articles in 2008–2012.
We then removed all journals belonging to the Web of Science subject category
“Multidisciplinary Sciences,” because a journal in this category is clearly not focused on a
single specialty. After this, 13,023 journals remained. Suivant, we considered the distribution
of journals by size. Chiffre 2 shows the distribution limited to journals with less than or equal
à 2,000 articles. A typical journal, with respect to size and modal interval as a measure of
central tendency, published 90–100 articles from 2008 à 2012. By including journals be-
tween the 10th and 75th percentiles of the journal size distribution displayed in Figure 2, jour-
nals with 47–478 articles were included. With this journal size limitation, the risk to include
journals addressing multiple specialties (or journals with a narrower scope than a specialty) est
reduced. The limitation reduced the number of journals to 8,485.
Enfin, in order to further reduce the risk of including journals addressing multiple special-
liens, we took journal self-citations into account. The idea is that a one-specialty journal can be
assumed to cite itself to a larger extent compared to a journal that covers two or more special-
liens, other things held constant. In the light of this, we required, for a journal to be included in
BCPs, that the self-citation ratio (dans %) should be at least 10.3 The journal set was reduced to
1,540 journals by this procedure. Some test runs with different values of the threshold were
3 The self-citation ratio (s) for a journal j is given by:
sj ¼ cs
ra
(1)
where cs is the number of self-citations in j, and ra the total number of active references in j. References are
considered as active if they point to publications covered by the data source (Waltman et al., 2013). UN
reference is considered as a self-citation if the referencing publication and the referenced publication belong
to the same journal.
Études scientifiques quantitatives
213
Granularity of classifications of research publications
conducted. These runs showed that lower values of the threshold reduced the maximum ARI
valeur (cf. step IV below), which indicates that lowering the threshold value results in broader,
less focused journals. The threshold was set to include as many journals as possible and to
keep the ARI value reasonably high.
Some of the measures taken to satisfy point B are also relevant for satisfying point C (lequel
states that each pair of distinct classes should address different specialties), such as the limi-
tation to the publication years 2008–2012. With the aim to further raise the possibilities of
satisfying point C, we applied bibliographic coupling between journals. If two journals had
an overlap of 8% or more regarding their active cited references, they were considered as
specialty overlapping.4 This threshold was chosen after browsing the list of journal pairs sorted
in descending order based on number of shared cited references. Based on journal titles, it is
obvious that some journal pairs have an overlapping subject focus: Par exemple, the two jour-
nals Higher Education and Studies in Higher Education (19% citation overlap). A threshold for
the cited references overlap was chosen to include such apparent cases. En outre, test runs
were conducted with different threshold values. Higher values resulted in lower maximum ARI
valeurs. For this reason, we tried to keep the threshold value as low as possible (without con-
sidering journals with nonoverlapping subject focus as specialty overlapping).
We grouped journals so that all journals that were directly or indirectly connected, by a
cited reference overlap of 8% ou plus, were assigned the same group. Par exemple, if journal
j1 has a cited reference overlap of ≥ 8% with journal j2, and j2 has a cited reference overlap of
≥ 8% with j3, then j1, j2, and j3 are assigned to the same group. Note that j1 and j3 are assigned
to the same group even if they do not have an active reference article overlap of ≥ 8%. Chaque
obtained group of journals was considered as addressing the same specialty. One of the jour-
nals was then randomly selected from each group. After the execution of this procedure, 967
journals remained. This number is the number of journals (classes) in BCPs. We denote the
union of the classes in BCPs as P
.
0
II. Creation of ACPLCs of different granularity with respect to the specialty level
In order to obtain ACPLCs of different granularity, the first step was to measure the relatedness
between the classes (topics) of ACPLCt. We measured the relatedness as the average normal-
ized direct citation value between the articles belonging to the two classes: If class C contains
m articles and class C
n, the sum of the m × n normalized direct citation values between
0
articles in C and articles in C
was divided by m × n. In the second step, the generated class
relatedness values were iteratively given as input to Modularity Optimizer to cluster the classes
0
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
4 The overlap (oui) between two journals ( j1 and j2) is given by:
(cid:3)
(cid:1)
y ¼
1
2
m
A1
þ m
A2
(2)
where m is the number of shared cited references (c'est à dire., cited references occurring in both j1 and j2), A1 the
number of cited references in j1, and A2 the number of cited references in j2. The reference list of a journal
was obtained by concatenating the reference lists of the articles (published year 2010) in the journal. If a
reference article has been cited by more than one article in a journal, then this reference is counted multiple
times for that journal. Par exemple, if journal j1 has four references to article a and journal j2 has two ref-
erences to article a, then journals j1 and j2 have two shared cited references with respect to article a. Note
that we give the overlap measure threshold as a percentage in the running text.
Études scientifiques quantitatives
214
Granularity of classifications of research publications
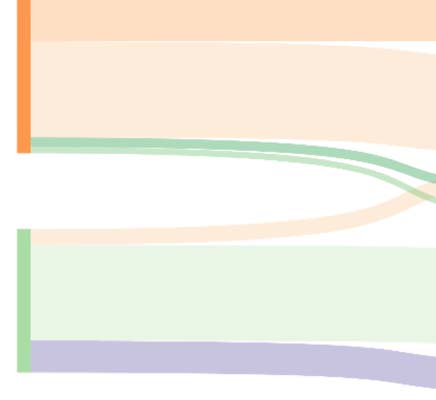
Chiffre 3. Two alluvial diagrams (A and B) illustrating the relation between two classifications. A shows two classifications with a high level of
similarité. B shows two classifications with a low level of similarity.
of ACPLCt, where the resolution parameter was set to different values in the iterations.5 By this,
ACPLCs were created for comparison of similarity with BCPs. We denote the ACPLCs by
ACPLC_1, …, ACPLC_k, where k is the number of created ACPLCs.
III. Creation of classifications derived from the ACPLCs
For each ACPLC_i (1 ≤ i ≤ k), a classification was derived from ACPLC_i in the following way:
(un)
(b)
Each class C in ACPLC_i such that C did not contain any articles in P
was removed
from ACPLC_i. Let ACPLC_i1 be the subset of ACPLC_i that resulted from the removal.
For each class C in ACPLC_i1, all articles in C that did not belong to P
were removed
from C. Let ACPLC_iP
be the set that resulted from these removal operations.
0
0
0
Clairement, the set ACPLC_iP
0
constitutes a classification of P
0
the baseline classification BCPs). Ainsi, ACPLC_iP
articles. We denote the k derived classifications as ACPLC_1P
fications then correspond to the classifications ACPLC_1, …, ACPLC_k.
0
0
(c'est à dire., of the union of the classes of
and BCPs have exactly the same underlying
, …, ACPLC_kP
. These classi-
0
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
IV. Quantification of the similarity between BCPs and the ACPLC_iP
0
s
We attempt to optimize the granularity of an ACPLC_iP
so that it exhibits as high a similarity as
possible with BCPs. Chiffre 3 illustrates the relation between two classifications as an alluvial
0
5 Our approach differs slightly from the approach used by Waltman and van Eck (2012). The latter approach
only uses average normalized direct citation values to reassign publications (at a given hierarchical level of
the classification) that belong to clusters with an insufficient number of publications. Ainsi, the preliminary
assignment of publications to clusters, which precedes the reassignment in question, is executed without the
use of average normalized direct citation values. The reason for our deviation from the Waltman–van Eck
approach is that Modularity Optimizer does not directly support their approach.
Études scientifiques quantitatives
215
Granularity of classifications of research publications
diagram. Example A shows two classifications A1 and A2 with a high similarity. Example B
shows two classifications where one of the classifications is more coarsely grained (B1) que
the other classification (B2). The similarity between A1 and A2 is higher than the similarity be-
tween B1 and B2. If we consider B1 as a baseline classification, then the granularity of B2
would be too finely grained.
0
As in our topic identification study, we used the ARI (Hubert & Arabie, 1985) to quantify the
similarity between BCPs and an ACPLC_iP
. The ARI ranges from 0 à 1. It is advantageous
over the original Rand Index proposed by Rand (1971), because it adjusts for chance. Le
ARI compares two classifications by considering pairs of items in one of the classifications
and whether or not each pair is grouped into the same class in the other classification.
Note that an ARI value of 1 between BCPt and an ACPLC_iP
corresponds to a situation in
which these two classifications are identical. For further information on ARI, we refer the reader
to Sjögårde and Ahlgren (2018).
0
0
To find the ACPLC_iP
with the highest ARI similarity with BCPs, we tested the similarity
after each run of Modularity Optimizer. A first run was made with a resolution parameter value
of 5E-7. This value was chosen based on previous experience and some testing. We then in-
creased the parameter value by 5E-7. This increase resulted in a higher ARI similarity, and we
therefore increased the resolution further by 5E-7 for the third run, from 1E-6 to 1.5E-6. Nous
continued by increasing the resolution by 5E-7 in total four more times, and thus seven runs
were done. The fifth run, with a resolution parameter value of 2.5E-6, gave rise to the highest
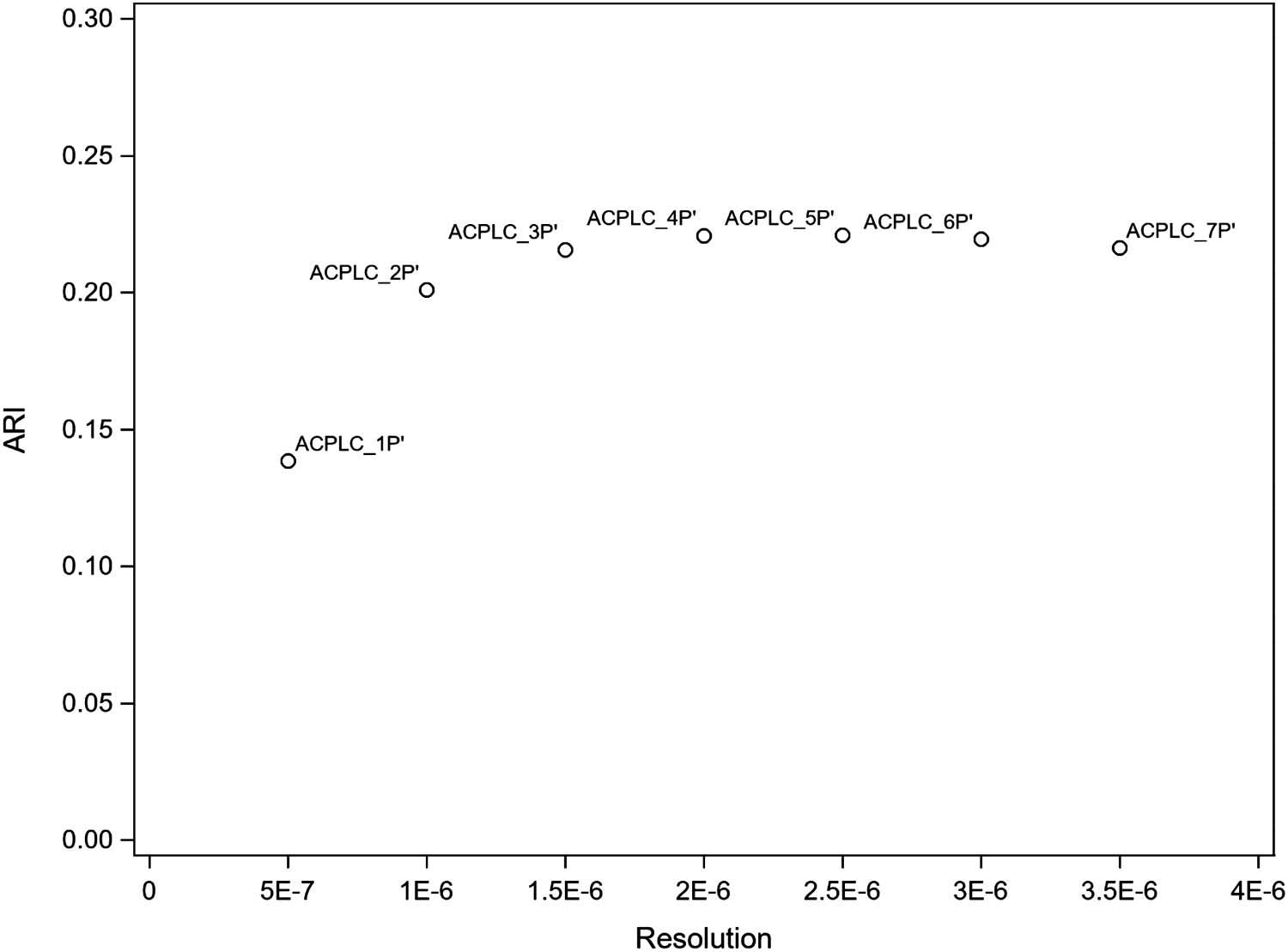
ARI similarity (see Table 2 and Figure 4, Section 6).
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
0
Chiffre 4. ARI values between ACPLC_iP
0
resolution parameter used to obtain the corresponding ACPLC_is. The order of ACPLC_iP
s corresponds to their order in Table 2.
s and BCPs. The vertical axis shows the ARI value and the horizontal axis shows the value of the
Études scientifiques quantitatives
216
Granularity of classifications of research publications
In total BCPs consists of 967 baseline classes. A given ACLPC_iP
consists of 202,647 arti-
clés, which is about 3.3% of the articles from the years 2008–2012 in the corresponding
0
ACPLC_i. The ACPLC_i such that ACLPC_iP
exhibits the largest ARI similarity with BCPs is
proposed to be used for the analyses of specialties. We denote this ACPLC_i by ACPLCs.
0
6. RESULTS AND DISCUSSION
Dans cette section, we first deal with the selection and properties of ACPLCs. Alors, as in the
earlier study on topic identification (Sjögårde & Ahlgren, 2018), we consider two cases. Nous
examine the specialties of articles belonging to (1) the Web of Science subject category
“Information science & Library Science," et (2) the Web of Science subject category
“Medical Informatics.”
6.1. Selection and Properties of ACPLCs
Chiffre 4 shows a scatterplot of the relation between the resolution value (horizontal axis) used
0
to obtain ACPLC_is and the ARI value (vertical axis), obtained by comparing the ACPLC_iP
s
0
with BCPs. ACPLC_5P
corresponds to ACPLC_5, lequel
we consider to be the most proper ACPLC_i with respect to granularity of specialties. In the
remainder of this paper, we denote ACPLC_5 as ACPLCs. Cependant, we acknowledge that
ACPLC_4P
have ARI values that are only slightly lower/higher than the value
0
of ACPLC_5P
0
perform almost as well as ACPLC_5P
0
has the highest ARI value. ACPLC_5P
0
. Ainsi, ACPLC_4P
0
and ACPLC_6P
and ACPLC_6P
.
0
0
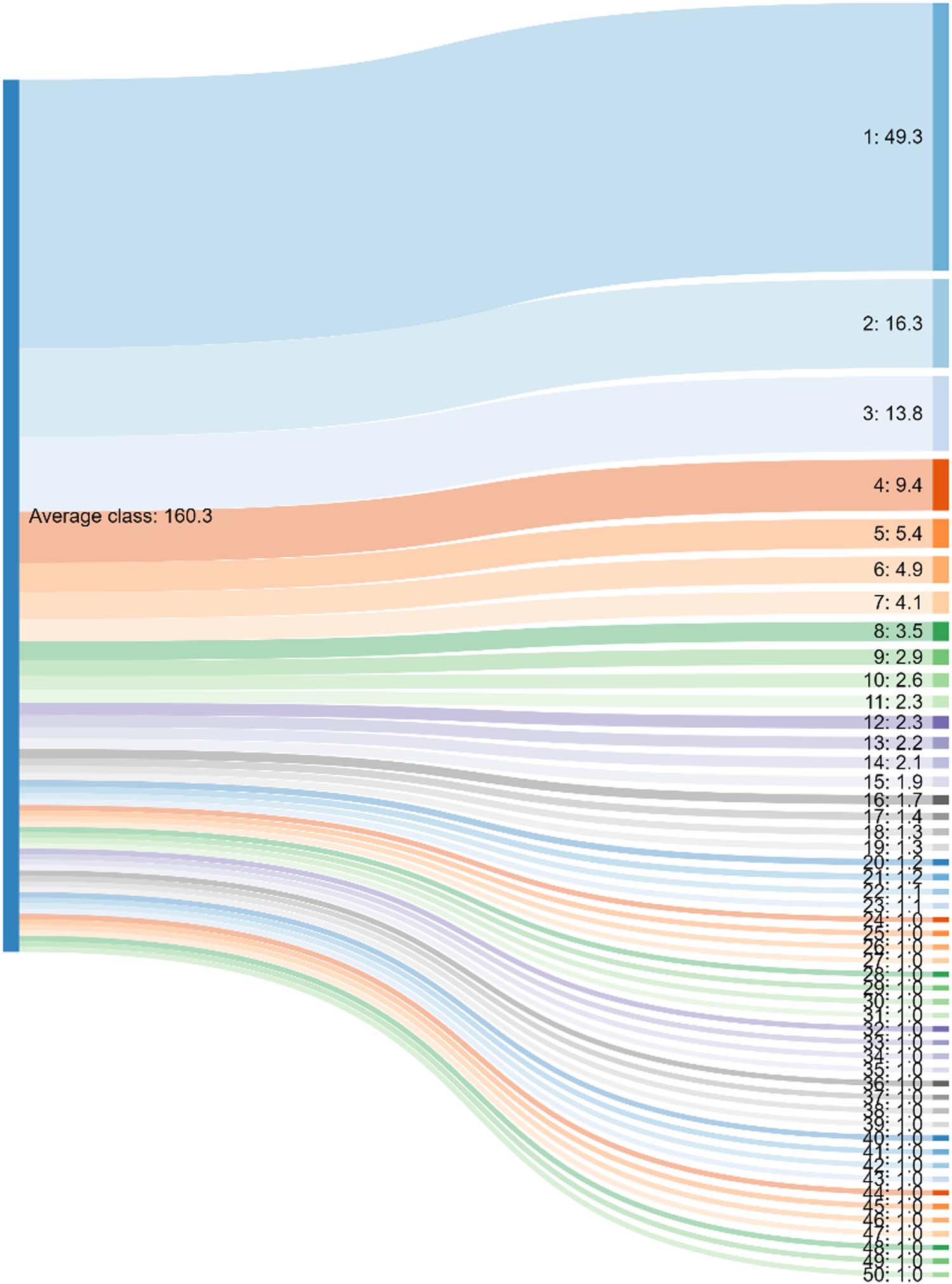
To get a picture of how well ACPLCs matches BCPs, we calculated the distribution of arti-
cles in an average class in BCPs into classes (journaux) in ACPLCs. This was done by first cal-
culating the average number of classes in ACPLCs into which the articles in a class in BCPs are
distributed, an average that is equal to 50 (after rounding to the nearest integer). We then se-
lected all 12 classes in BCPs that were distributed into exactly 50 classes. Let the set of these
classes be Psc. The average number of articles in a Psc class is 160.3. For each of the Psc classes,
we calculated the number of its articles in each of the 50 ACPLCs classes and sorted the re-
sulting table in descending order. The ACPLCs class with the highest number of articles (c'est à dire., le
class corresponding to the first row in the table) was assigned rank 1, the second largest class
(c'est à dire., the class corresponding to the second row in the table) was assigned rank 2, etc.. Dans ce
chemin, 12 ranked tables were obtained. Enfin, averages of the number of articles by rank
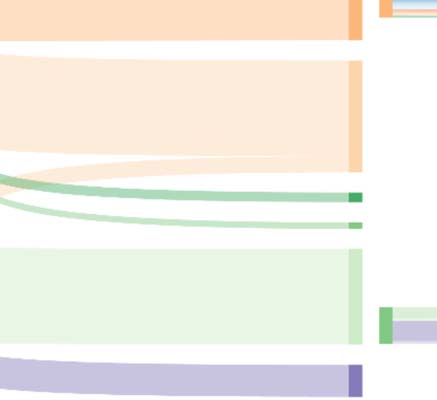
number, 1,…, 50, were calculated across all the 12 tables. Chiffre 5 shows the resulting
average distribution of articles in Psc (À gauche) into the 50 ACPLCs classes (À droite).
Ranks and average number of articles across the Psc classes are shown for ACPLCs.
Given that we consider the classes in ACPLCs as specialties, the distribution of journal ar-
ticles in a typical BCPs class follows a skewed distribution of specialties. About 41% of the
articles in an average BCPs class are distributed into the two most frequent specialties, et
34 specialties (classes 17 à 50) are represented by a single article (after rounding to nearest
integer). Ainsi, a high share of the articles of the average BCPs class is concentrated to a few
of the ACPLCs classes. We therefore consider the match between ACPLCs and BCPs as good.
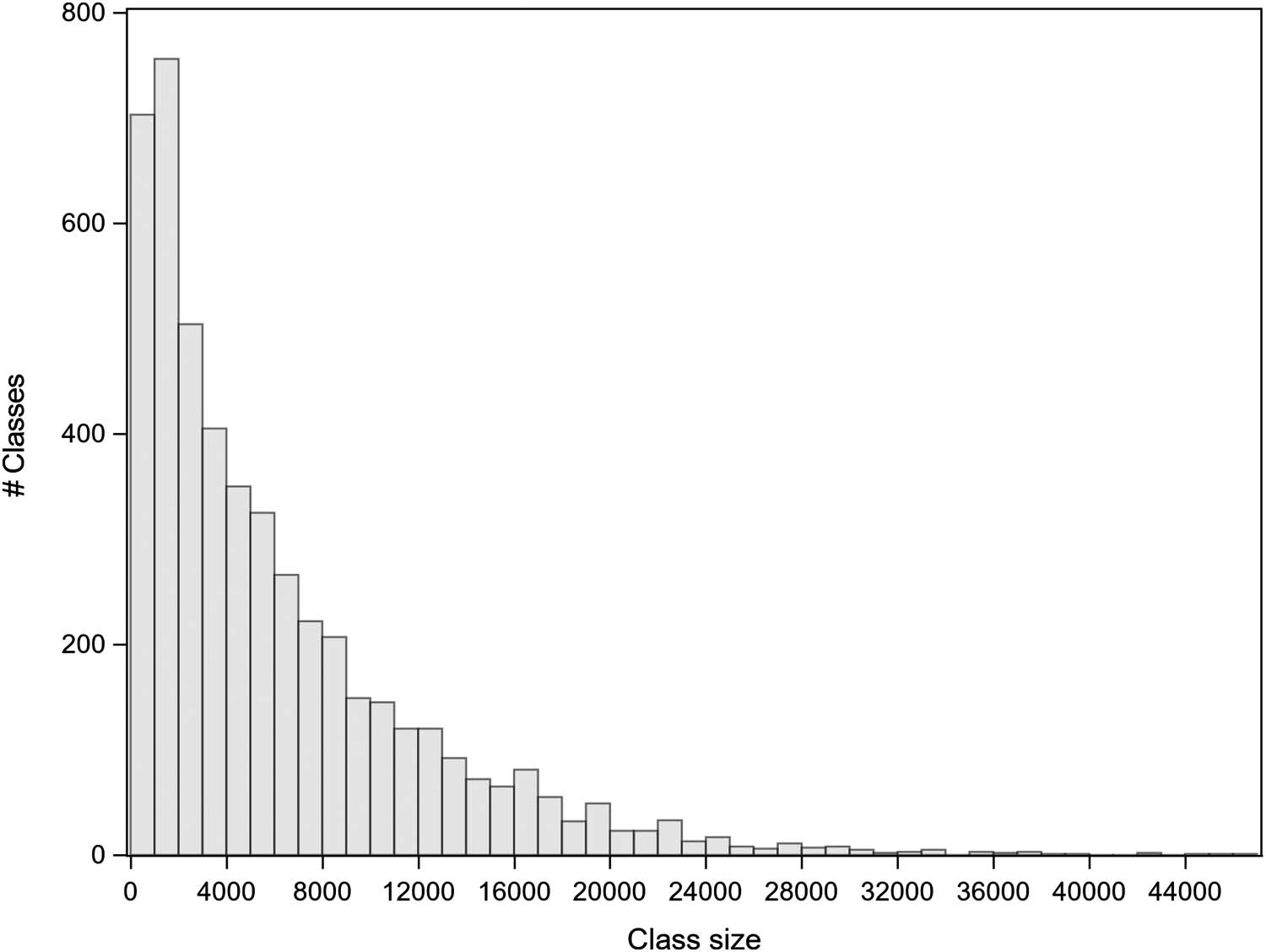
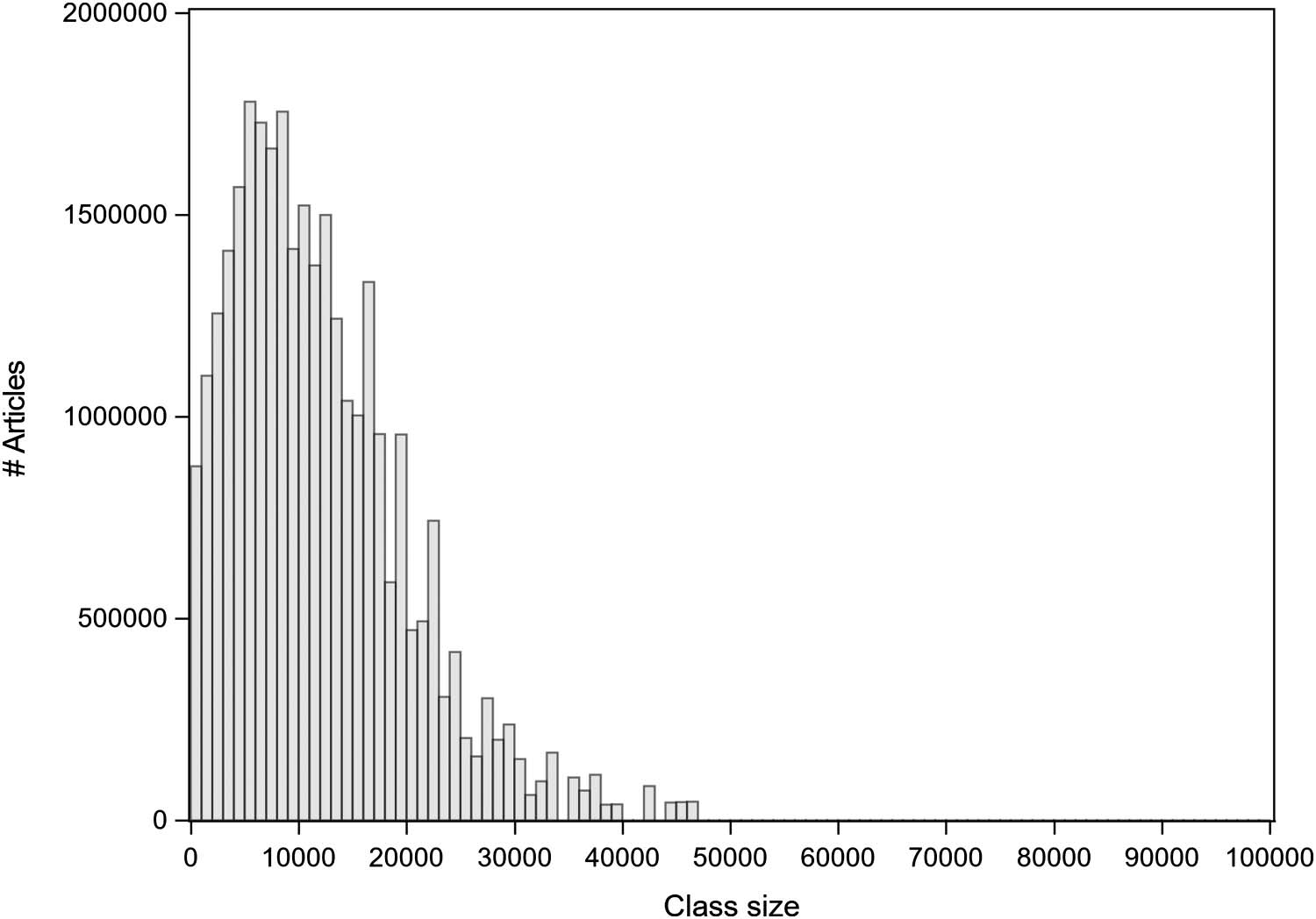
ACPLCs consists of 61,805 classes, ranging from 1 à 46,078 articles. Most of the classes are
small in size; cependant, these classes contain a small share of the total number of articles in
ACPLCs. Par exemple, classes with fewer than 500 articles contain about 1.2% of the articles in
ACPLCs. Chiffre 6 shows a histogram of the distribution of classes by class size (in terms of
number of articles). In order to include classes of a substantial size in the figure, classes with
fewer than 500 articles have been excluded from the figure.
Études scientifiques quantitatives
217
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 5. Alluvial diagram for an average class. The diagram shows the distribution of journal articles in BCPs into ACPLCs.6
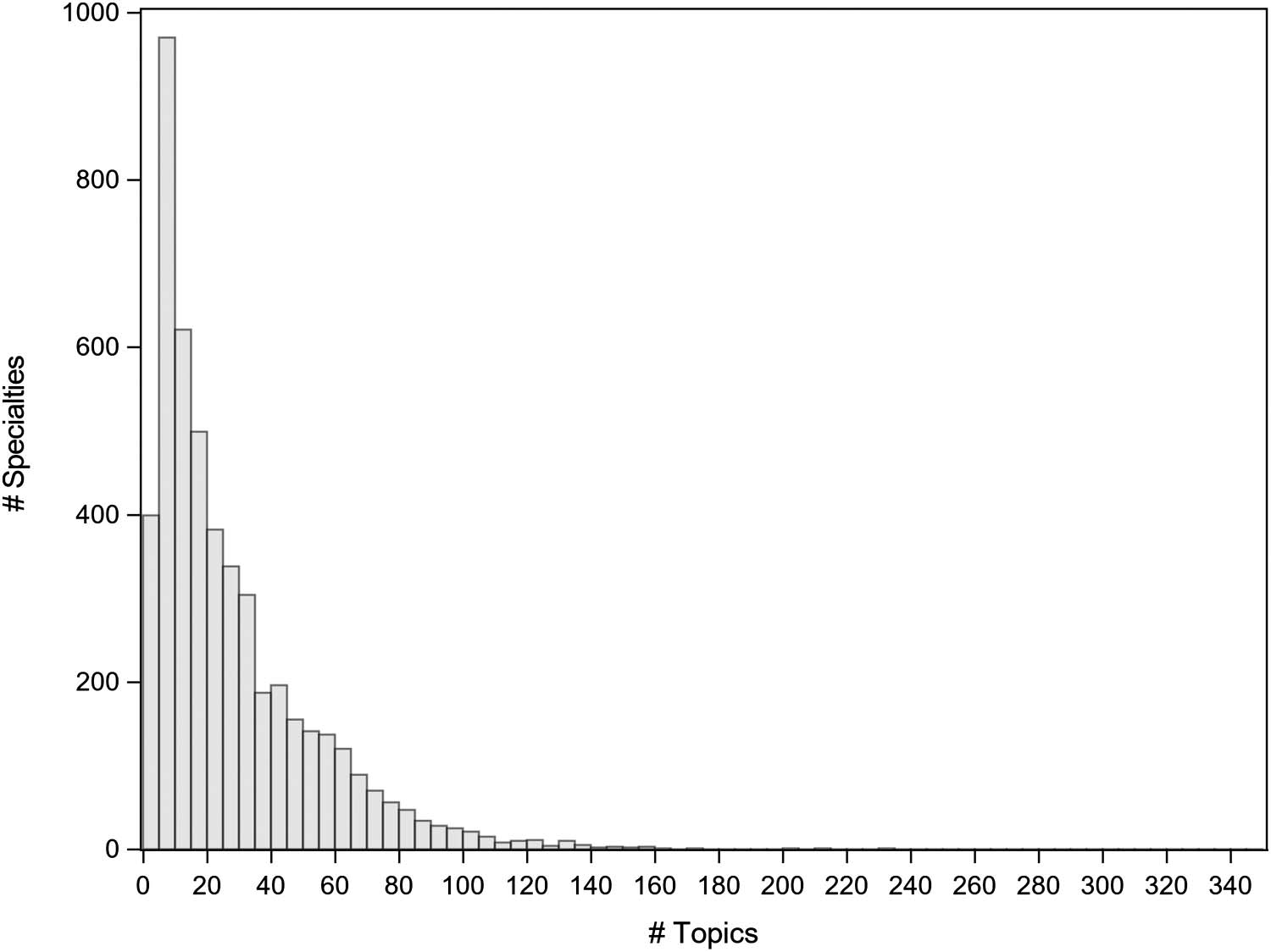
Most specialties of substantial size (minimum of 500 articles) have 5 (10th percentile) à 62
(90th percentile) subordinated topics of substantial size (a minimum of 50 articles), with a
mode of 6, a median of 19 and a mean of about 28 (Chiffre 7 and Table 1).
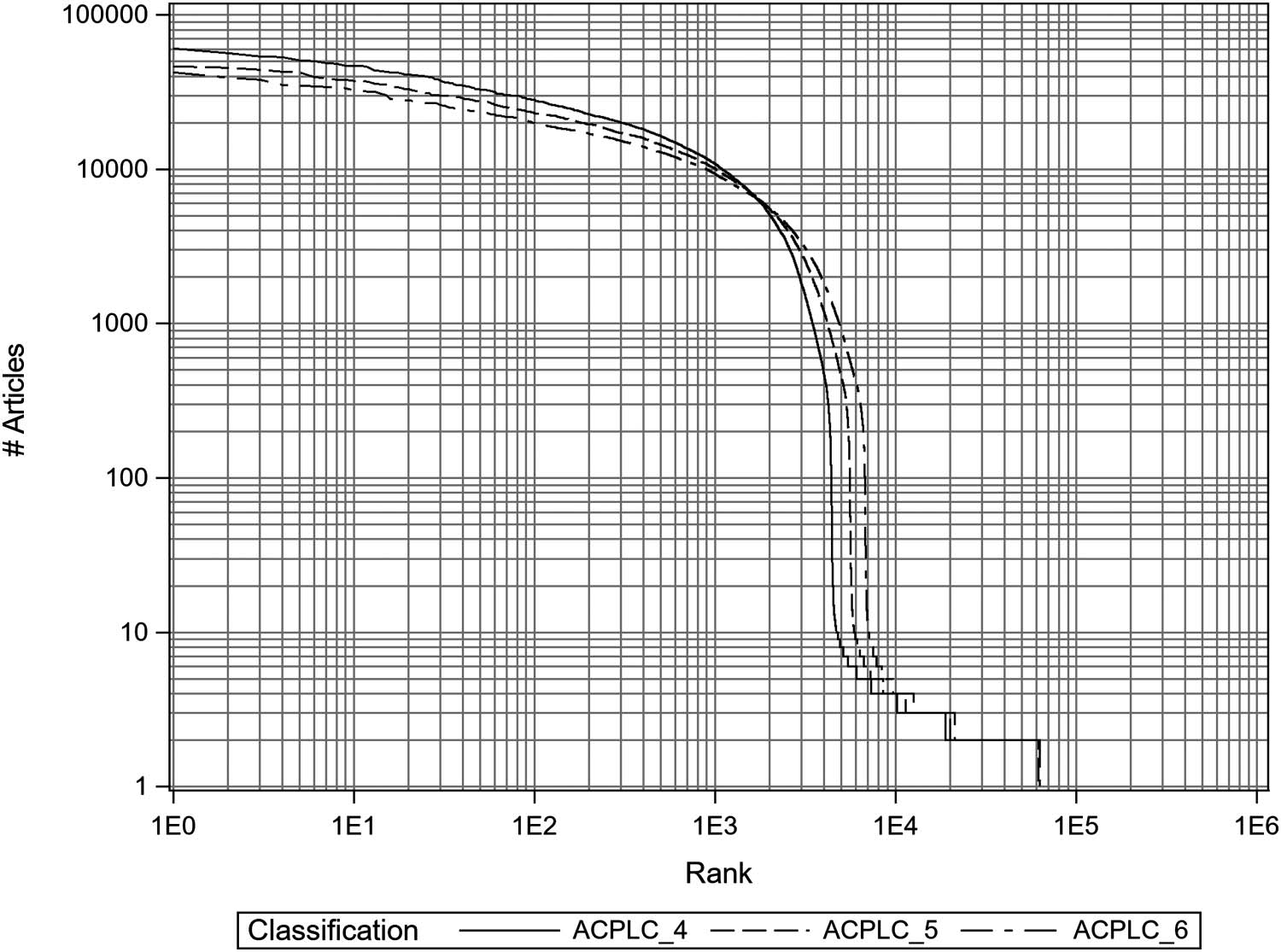
In Figure 8, class sizes are plotted by rank order for ACPLCs (= ACPLC_5), as well as for
ACPLC_4 and ACPLC_6. A log-10 scale is used on both the vertical axis (showing class sizes
by number of articles) and the horizontal axis (showing ranks). In this figure, all classes are
6 http://sankeymatic.com/ has been used for the illustration.
Études scientifiques quantitatives
218
Granularity of classifications of research publications
Chiffre 6. Histogram of number of classes by class size for ACPLCs. Classes with fewer than 500 articles disregarded.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 7. Histogram of number of specialties by number of subordinated topics for ACPLCs. Specialties with fewer than 500 articles and
topics with fewer than 50 articles disregarded.
Études scientifiques quantitatives
219
Granularity of classifications of research publications
Tableau 1. Distribution statistics of number of topics per specialty for ACPLCs. Specialties with fewer than 500 articles and topics with fewer than
50 articles disregarded
Mean # topics per specialty
27.6
Median # topics per specialty
19
Mode # topics per specialty
6
P10
5
P90
62
shown, including small size classes. About 4,200 classes contain at least 1,000 articles, à propos
1,000 classes contain at least 10,000 articles and about 30 classes contain at least 30,000
articles. In agreement with our study on topics, the size of classes is dropping rather slowly,
regardless of classification. The increasing granularity—from ACPLC_4 via ACPLCs to
ACPLC_6—is reflected by, Par exemple, corresponding, decreasing intercepts.
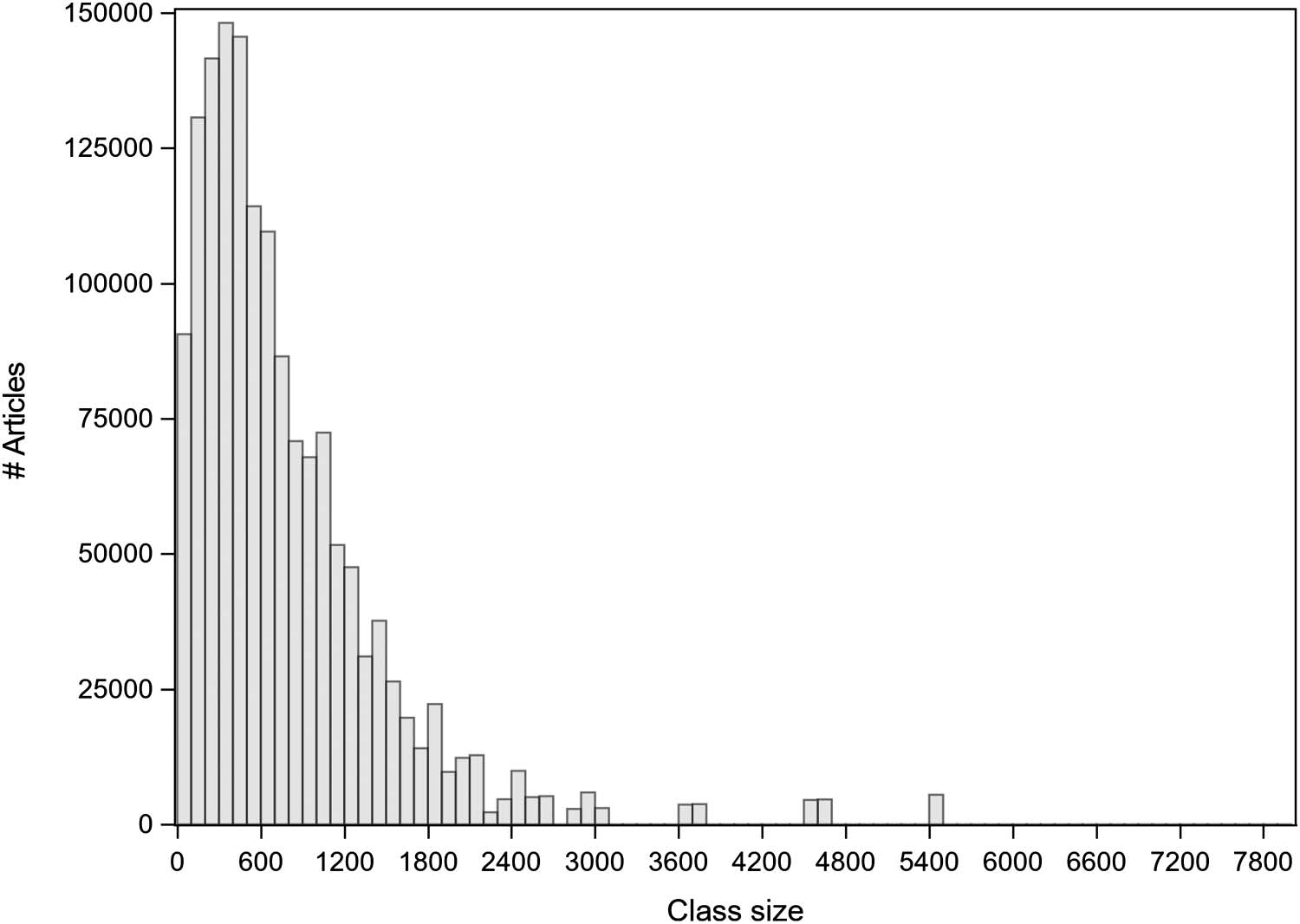
Chiffre 9 expresses the number of articles in P (vertical axis) that is associated with different
class sizes (horizontal axis). For a randomly selected article a, it is most probable that the size
of the specialty class in ACPLCs to which a belongs is 6,000–7,000 articles (cf. the highest bar
of the histogram in Figure 9). Eighty percent of the articles belong to classes consisting of 2,899
(10th percentile) à 22,819 (90th percentile) articles (Tableau 2). The median value of ACPLCs is
10,499 and the mean 12,016. This distribution is not as skewed as the corresponding topic
distribution (Sjögårde & Ahlgren, 2018, Chiffre 8).
The number of articles contributing to a specialty in 2015 (the most recent complete year at
the time for data extraction) is between 148 et 1,597, given that we only take the mid-80% of
the distribution into account (Tableau 3 and Figure 10). The median class size is 593. The mean
number of articles per specialty class is growing approximately linearly across the 10-year
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 8. Distribution of number of articles by class size for three classifications. The classes in ACPLC_3, ACPLC_4 = ACPLCs, and ACPLC_5
are ordered descending by size with respect to the horizontal axis. Log-10 scale used for both axes.
Études scientifiques quantitatives
220
Granularity of classifications of research publications
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 9. Histogram of number of articles by class size for ACPLCs.
period (Tableau 3). This can be expected, considering the linear growth of research publications
in Web of Science.
As mentioned in the introduction, Morris (2005) estimates the size of specialties to be be-
tween 100 et 5,000 articles (but not mentioning any time period), and Boyack et al. (2014)
estimate the yearly article output of a specialty to be somewhere between 100 et 1,000 ar-
ticles. The results of the present study cannot be easily compared to these figures. Le
0
0
Tableau 2. For each ACPLC_iP
, the ARI value between ACPLC_iP
are shown, as well as number of classes with at least 500 articles and class size distribution measures for ACPLC_i
and BCPs, and the value of the resolution parameter used to obtain ACPLC_i
Denotation
0
ACPLC_1P
0
ACPLC_2P
0
ACPLC_3P
0
ACPLC_4P
0
ACPLC_5P
0
ACPLC_6P
0
ACPLC_7P
Resolution
0.0000005
ARI
valeur
0.1385
# classes with
# articles ≥ 500
881
0.0000010
0.2010
0.0000015
0.2157
0.0000020
0.2208
0.0000025
0.2209
0.0000030
0.2195
0.0000035
0.2163
1,888
2,953
3,969
4,897
5,770
6,604
Études scientifiques quantitatives
Weighted class size distribution measures regarding
ACPLC_i (i = 1, …, 7): mean, median, 10th and
90th percentiles (denoted P10 and P90)
Median
# articles per class
57,984
P10
19,552
Mean
# articles per class
66,750
P90
121,981
31,123
20,426
15,228
12,016
9,936
8,564
27,377
17,960
13,145
10,499
8,589
7,429
8,866
59,985
5,260
39,326
3,765
29,509
2,899
22,819
2,342
18,655
1,900
16,351
221
Granularity of classifications of research publications
Tableau 3. For a 10-year period (at the time for data extraction), the table shows class size distribution measures for ACPLCs
Weighted distribution measures regarding ACPLCs: mean, median,
10th and 90th percentiles (denoted P10 and P90)
Publication year
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
# Articles
989,420
1,040,026
1,115,118
1,166,665
1,210,495
1,290,309
1,358,175
1,435,835
1,478,273
1,524,010
Mean # articles per class
438
Median # articles per class
366
461
497
525
555
603
647
705
749
789
384
415
437
454
484
516
551
572
593
P10
98
102
111
114
118
126
132
140
144
148
P90
869
918
974
1,028
1,109
1,216
1,302
1,434
1,513
1,597
estimations of Morris and Boyack et al. are rough. Morris does not mention any time period.
Plus loin, the work by Morris is rather old and the size of specialties may have increased in terms
of publication output. Tableau 3 shows that the number of articles in Web of Science has been
growing by more than 50% entre 2006 et 2015. Dans 2015, the size of specialties ranges
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 10. Histogram of number of articles by class size for the publication year 2015 and for ACPLCs.
Études scientifiques quantitatives
222
Granularity of classifications of research publications
from about 150 articles (10th percentile) à 1,600 (90th percentile) articles. Ainsi, the size of
specialties in 2015 is about 50% larger than the size estimated by Boyack et al. We regard this
difference as rather small, taking into account that Boyack et al. define the next larger level
(disciplines) to range from tens to hundreds of thousands of articles per year, several orders of
magnitude larger than our estimation of the size of specialties.
In agreement with Morris and Boyack et al., we find it reasonable not to consider publication
classes under some threshold to be regarded as specialties. One solution to the problem of small
class sizes is to reassign such classes (classes below a threshold) based on their relations with
larger classes (classes above or equal to the same threshold) as proposed by Waltman and van
Eck (2012). Cependant, how to set the threshold is a question that we do not address in this paper.
6.2. The Case of Information Science & Library Science
To explore how articles within the discipline of library and information science (LIS) are distrib-
uted into classes in ACPLCs, we retrieved all articles in P that belong to a journal classified into the
Web of Science subject category “Information Science & Library Science” and published in the
period 2011–2015. In total, 16,278 articles were retrieved. Let Plis be this set of articles.
For each class in ACPLCs, labels were automatically created based on author keywords.
Chi-square was used to quantify the relevance of author keywords in each class, and for each
class, three author keywords with highest rank were concatenated to a label (for more detail
see Sjögårde & Ahlgren, 2018). To distinguish the scope of each specialty, we used these la-
bels and the labels of the topics in each class. Recall that ACPLCs is obtained by clustering the
topics of ACPLCt, the best performing ACPLC with respect to topic identification (Sjögårde &
Ahlgren, 2018).
Tableau 4 shows the total number of articles in the 10 most frequent specialties and the number,
and the share, of articles in a specialty that belong to Plis. The top 10 specialties cover about 48%
of the articles in Plis. Some of the top 10 specialties are highly concentrated within the analyzed
Web of Science subject category (par exemple., “INFORMATION LITERACY//PUBLIC LIBRARIES//
ACADEMIC LIBRARIES,» 79%), whereas other specialties have a low share of its total number
of articles in this category (par exemple., “INNOVATION//PATENTS//OPEN INNOVATION,» 7%).
The highest ranked specialty, “BIBLIOMETRICS//CITATION ANALYSIS//IMPACT FACTOR,»
focuses on bibliometric indicators, mapping and evaluation of research, and the analysis of schol-
arly communication. We acknowledge that a majority of the largest topics in this specialty are the
same topics that were observed in the case study of Journal of Informetrics in the previous topics
étude (Sjögårde & Ahlgren, 2018, and Appendix 1 in this paper). The second-ranked specialty,
“INFORMATION LITERACY//PUBLIC LIBRARIES//ACADEMIC LIBRARIES,” focuses on library
science. This category includes topics such as information literacy, knowledge organization, dans-
formation practices and reference services. The specialty “INTERLENDING//DOCUMENT
DELIVERY//ACADEMIC LIBRARIES” includes topics specifically related to academic libraries,
such as electronic media, open access, interlending, library circulation systems and data repos-
itories. The scopes of specialties 4, 6, 7, 8 et 10 are captured rather well by their labels, et
these specialties are all clearly related to LIS. These five specialties include information retrieval,
knowledge management, library and information aspects of health service and occupation as
well as of innovation and patents. The specialty “ENTERPRISE RESOURCE PLANNING//
ENTERPRISE RESOURCE PLANNING ERP//END USER COMPUTING” includes some topics re-
lated to LIS (par exemple., IT business value, IT outsourcing, Information system planning, and Information
infrastructure). The LIS relevance of “UNIVERSAL SERVICE//TELECOMMUNICATIONS//ACCESS
PRICING” (rank 9) is within topics such as Internet access and Digital divide.
Études scientifiques quantitatives
223
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
Tableau 4. Distribution of articles in the Web of Science subject category “Information Science & Library Science” into specialties, 2011–2015
Rank
1
Specialty
BIBLIOMETRICS//CITATION ANALYSIS//IMPACT FACTOR
# articles
in Plis
1,867
Total # articles
in specialty
4,486
Share of specialty
in Plis
42%
2
3
4
5
6
7
8
9
INFORMATION LITERACY//PUBLIC
LIBRARIES//ACADEMIC LIBRARIES
INTERLENDING//DOCUMENT
DELIVERY//ACADEMIC LIBRARIES
RECOMMENDER SYSTEMS//COLLABORATIVE
FILTERING//INFORMATION RETRIEVAL
ELECTRONIC HEALTH RECORDS//ELECTRONIC
MEDICAL RECORD//MEDICAL INFORMATICS
ENTERPRISE RESOURCE PLANNING//ENTERPRISE
RESOURCE PLANNING ERP//END USER COMPUTING
KNOWLEDGE MANAGEMENT//KNOWLEDGE
SHARING//OPEN SOURCE SOFTWARE
INNOVATION//PATENTS//OPEN INNOVATION
UNIVERSAL SERVICE//TELECOMMUNICATIONS//
ACCESS PRICING
10
HEALTH LITERACY//INTERNET//MHEALTH
1,635
1,243
564
494
484
457
366
326
314
2,068
1,759
4,965
3,724
1,481
1,439
5,519
1,219
4,394
79%
71%
11%
13%
33%
32%
7%
27%
7%
Appendix 1 lists the 10 topics with most publications in Plis for the top 10 ranked specialties
with regard to Plis.
6.3. The Case of Medical Informatics (MI)
In analogy with the case of LIS, we retrieved all articles in P that belong to a Web of Science
subject category, in this case “Medical Informatics,” and published in the period 2011–2015,
to explore how articles within this discipline are distributed into classes in ACPLCs. In total,
12,516 articles were retrieved. Let Pmi be this set of articles.
Tableau 5 shows the top 10 specialties in Pmi, ranked by frequency. Only one specialty is
highly concentrated into the “Medical Informatics” category, namely “ELECTRONIC
HEALTH RECORDS//ELECTRONIC MEDICAL RECORD//MEDICAL INFORMATICS” (lequel
is also present in the LIS case). For the rest of the top 10 specialties, 14% or less of the articles
in the specialty belong to Pmi. This might suggest that MI is more interdisciplinary than LIS. Il
can also be the case that MI articles are published in broader journals, which are not classified
into the “Medical Informatics” Web of Science subject category.
The largest specialty in the “Medical Informatics” category focuses on clinical decision sup-
port systems, clinical research informatics and electronic health records. The second-ranked
specialty within the category, “HEALTH LITERACY//INTERNET//MHEALTH,” addresses topics
within mobile health such as personal health records, online health information, and online
support groups. The specialty “HEALTH TECHNOLOGY ASSESSMENT//EQ 5D//PRIORITY
SETTING” focuses on health technology assessment and cost effectiveness.
Études scientifiques quantitatives
224
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
Tableau 5. Distribution of articles in the Web of Science subject category “Medical Informatics” into specialties, 2011–2015
Rank
1
Specialty
ELECTRONIC HEALTH RECORDS//ELECTRONIC MEDICAL
RECORD//MEDICAL INFORMATICS
2
3
4
5
6
7
8
9
HEALTH LITERACY//INTERNET//MHEALTH
HEALTH TECHNOLOGY ASSESSMENT//EQ 5D//
PRIORITY SETTING
ADAPTIVE DESIGN//INTERIM ANALYSIS//DOSE FINDING
MISSING DATA//MULTIPLE IMPUTATION//
GENERALIZED ESTIMATING EQUATIONS
COMPETING RISKS//INTERVAL CENSORING//
COUNTING PROCESS
EVIDENCE-BASED MEDICINE//PUBLICATION BIAS//ABSTRACT
PATIENT SAFETY//MEDICATION ERRORS//MEDICAL ERRORS
TELEMEDICINE//TELEHEALTH//TELEPATHOLOGY
10
CAUSAL INFERENCE//PROPENSITY SCORE//
PRINCIPAL STRATIFICATION
# articles
in Pmi
1,548
Total # articles
in specialty
3,724
Share of
specialty in Pmi
42%
628
316
297
288
286
206
192
186
141
4,394
3,142
2,094
2,530
2,278
3,646
3,983
2,482
1,545
14%
10%
14%
11%
13%
6%
5%
7%
9%
The remaining seven top 10 ranked specialties have the following foci: (4) clinical trial de-
signes; (5) mathematical and statistical models and methods within the medical sciences; (6) pre-
diction and risk models; (7) evidence-based medicine, medical epistemology, meta-analysis
méthodes, and literature searching; (8) Patient safety (includes incident and error reporting); (9)
telehealth (can be seen as a predecessor to mobile health); et (10) gene ontologies.
Appendix 2 lists the 10 topics with most publications in Pmi for the top 10 ranked specialties
with regard to Pmi.
7. CONCLUSIONS
In this study we have discussed how the resolution parameter given to the Modularity Optimizer
software can be calibrated to cluster topics, obtained in a previous study on topic identification
(Sjögårde & Ahlgren, 2018), so that the obtained publication classes correspond to the size of
specialties. A set of journals has been used as baseline for the calibration. Journals were selected
based on their size and self-citation rate. The underlying assumption of our approach is that
journals of a particular size and focus have a scope that corresponds to specialties. By measur-
ing the similarity between (1) the baseline classification and (2) multiple classifications obtained
by using different values of the resolution parameter, we have identified a classification, lequel
we denote as ACPLCs, whose granularity corresponds to specialties.
Some criteria for the evaluation of ACPLCt, the best performing ACPLC with respect to topic
identification, are the same for the evaluation of ACPLCs. The differences in class sizes should
not be too large and “the number of very small clusters should be minimized as much as pos-
sible” (Šubelj et al., 2016). In ACPLCs, 80% of the articles belong to classes consisting of
2,899–22,819 articles. Plus loin, 80% of the articles belong to classes with a yearly publication
Études scientifiques quantitatives
225
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
rate of 98–869 articles in publication year 2006, increasing to 148–1,597 in the publication
année 2015. Only 1.2% of the articles in ACPLCs belong to classes with a total number of articles
less than 500. As in the previous study, the distribution follows a typical scientometric distribu-
tion, and we therefore consider the results, regarding class sizes, as satisfying.
In the present study, we have not implemented a reclassification of small classes. Cependant,
in accordance with the previous study, we consider reclassification of small classes to be de-
sirable for practical reasons. De plus, we think that content labeling of classes is a topic for
future work.
Another criterion stated by Šubelj et al. (2016) is that classes should make intuitive sense. Dans
addition, we stress that the focus of a specialty should be possible to identify and that two
specialties should have subject foci that can be distinguished. Two case studies, dans lequel
we have identified specialties within the disciplines of LIS and MI, have been performed to
evaluate these criteria. We could identify the subject foci of the specialties in these case studies,
and the subject foci of the specialties have been relatively easy to distinguish. Ainsi, the two
criteria are (environ) satisfied in our case. Plus loin, several of the specialties identified
in the LIS case have been identified by others (Bauer et al., 2016; Blessinger & Frasier, n.d.;
Figuerola et al., 2017; Janssens et al., 2006) and the same holds for several of the specialties
identified in the MI case (Kim & Delen, 2018; Schuemie et al., 2009; Wang et al., 2017).
Cependant, more case studies are needed to verify the soundness of the methodology used.
The aforementioned feature of the classification approach used in this study, logical clas-
sification, which assigns each topic to exactly one speciality, has some limitations. It is clear
that topics can be addressed by several specialties (or at higher level disciplines). Par exemple,
Appendix 1 et 2 show that the topic with the label “NATURAL LANGUAGE PROCESSING//
MEDICAL LANGUAGE PROCESSING//CLINICAL TEXT” is addressed by both the LIS and MI
disciplines. This topic is forced into exactly one specialty, “ELECTRONIC HEALTH
RECORDS//ELECTRONIC MEDICAL RECORD//MEDICAL INFORMATICS.” Thus, relations be-
tween this topic and, Par exemple, specialties within the LIS discipline are not expressed by
ACPLCs. Cependant, relations between a specialty and topics within other specialties can still be
analyzed using, par exemple, citation relations. Nevertheless, a logical classification to some
extent oversimplifies the complex structure of topic representation in research publications.
We acknowledge that direct citations perform less well than bibliographic coupling in a
recent study (Waltman et al., 2019). Cependant, a relatively low number of articles was used
in the study, à propos 700,000 in comparison with the over 31 million articles used in this study.
De plus, a relatively short publication window (2007–2016), in comparison with the present
étude (1980–2016), was used. Fait intéressant, the study shows that an extended direct citation
approche, in which direct citation relations within an extended set of publications are taken
into account, performs better than an ordinary direct citation approach. Which publication-
publication similarity measure to be used for the creation of an ACPLC still needs to be further
investigated, cependant.
0
We recognize that there is only a small difference in performance, regarding the ARI values,
0
.7 Donc, we can only determine the
between ACPLC_4P
granularity of specialties roughly. This is, cependant, not surprising, given the complex, overlap-
ping nature of research subject areas. Nevertheless, this study sets a benchmark of the size of
specialties and outlines a methodology for the calibration of ACPLCs.
and ACPLC_6P
, ACPLC_5P
0
7 ACPLC_4P
0
had the highest ARI value in an earlier version of the manuscript. In that version, BCPs was
delimited to publications from 2010.
Études scientifiques quantitatives
226
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
The combined outcome of our previous study on the classification of topics, and the present
study on the classification of specialties, is a two-level hierarchical classification. We believe
that such a classification comprises a valuable part of a research information system and pro-
pose that such a classification can be used for bibliometric analyses of topics and specialties.
REMERCIEMENTS
We would like to thank two anonymous reviewers for their relevant and constructive comments
on an earlier version of this paper.
CONTRIBUTIONS DES AUTEURS
Peter Sjögårde: Conceptualisation; methodology; software; formal analysis; writing—original
brouillon; writing—review & édition; visualization. Per Ahlgren: Conceptualisation; methodology;
formal analysis; writing—original draft; writing—review & édition.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
COMPETING INTERESTS
The authors have no competing interests.
INFORMATIONS SUR LE FINANCEMENT
No funding has been received.
DATA AVAILABILITY
The data analyzed in this manuscript is subject to copyright (by Clarivate Analytics®,
Philadelphia, Pennsylvania, Etats-Unis) and cannot be made available.
RÉFÉRENCES
Ahlgren, P., & Colliander, C. (2009). Document–document
similarity approaches and science mapping: Experimental
comparison of five approaches. Journal of Informetrics, 3(1),
49–63. https://doi.org/10.1016/j.joi.2008.11.003
Bauer, J., Leydesdorff, L., & Bornmann, L. (2016). Highly cited
papers in Library and Information Science (LIS): Authors,
institutions, and network structures. Journal of the Association for
Information Science and Technology, 67(12), 3095–3100.
https://doi.org/10.1002/asi.23568
Besselaar, P.. van den, & Heimeriks, G. (2006). Mapping research
topics using word-reference co-occurrences: A method and an
exploratory case study. Scientometrics, 68(3), 377–393. https://
doi.org/10.1007/s11192-006-0118-9
Blessinger, K., & Frasier, M.. (n.d.). Analysis of a Decade in Library
Literature: 1994–2004 | Blessinger | Collège & Research Libraries.
https://doi.org/10.5860/crl.68.2.155
Boyack, K. W. (2017). Investigating the effect of global data on
topic detection. Scientometrics, 111(2), 999–1015. https://est ce que je.
org/10.1007/s11192-017-2297-y
Boyack, K. W., Klavans, R., Petit, H., & Ungar, L. (2014).
Characterizing the emergence of two nanotechnology
topics using a contemporaneous global micro-model of
science. Journal of Engineering and Technology Management,
32, 147–159. https://doi.org/10.1016/j.jengtecman.
2013.07.001
Boyack, K. W., Newman, D., Duhon, R.. J., Klavans, R., Patek, M.,
Biberstine, J.. R.. et autres. (2011). Clustering More than Two Million
Biomedical Publications: Comparing the Accuracies of Nine
Text-Based Similarity Approaches. PLoS ONE, 6(3), e18029.
https://doi.org/10.1371/journal.pone.0018029
Bradford, S. C. (1948). Documentation. Londres: Lockwood.
Chubin, D. E. (1976). State of the field: The conceptualization of
scientific specialties. Sociological Quarterly, 17(4), 448–476.
https://doi.org/10.1111/j.1533-8525.1976.tb01715.x
Colliander, C. (2015). A novel approach to citation normalization:
A similarity-based method for creating reference sets. Journal de
the Association for Information Science and Technology, 66(3),
489–500. https://doi.org/10.1002/asi.23193
Études scientifiques quantitatives
227
Granularity of classifications of research publications
Colliander, Cristian. (2014). Science mapping and research
evaluation: A novel methodology for creating normalized citation
indicators and estimating their stability (Doctoral thesis).
Extrait de http://www.diva-portal.org/smash/record.jsf?
pid=diva2:752675
Crane, D. (1972). Invisible Colleges: Diffusion of Knowledge in
Scientific Communities. Chicago: University Of Chicago Press.
Figuerola, C. G., García Marco, F. J., & Pinto, M.. (2017). Cartographie
the evolution of library and information science (1978–2014)
using topic modeling on LISA. Scientometrics, 112(3),
1507–1535. https://doi.org/10.1007/s11192-017-2432-9
Fortunato, S. (2010). Community detection in graphs. Physics
Reports, 486(3–5), 75–174. https://doi.org/10.1016/j.physrep.
2009.11.002
Glänzel, W., & Thijs, B. (2017). Using hybrid methods and “core
documents” for the representation of clusters and topics: Le
astronomy dataset. Scientometrics, 111(2), 1071–1087. https://
doi.org/10.1007/s11192-017-2301-6
Hagstrom, W. (1970). Factors related to the use of different modes
of publishing research in four scientific fields. In E. C. Nelson &
K. D. Pollock (Éd.), Communication Among Scientists and
Engineers (pp. 85–124). Lexington, MA: Heath Lexington Books.
Hubert, L., & Arabie, P.. (1985). Comparing partitions. Journal de
Classification, 2(1), 193–218. https://doi.org/10.1007/BF01908075
Janssens, F., Leta, J., Glänzel, W., & De Moor, B. (2006). Towards
mapping library and information science. Information Processing
& Management, 42(6), 1614–1642. https://est ce que je.org/10.1016/
j.ipm.2006.03.025
Kessler, M.. M.. (1965). Comparison of the results of bibliographic
coupling and analytic subject indexing. American Documentation,
16(3), 223–233. https://doi.org/10.1002/asi.5090160309
Kim, Y.-M., & Delen, D. (2018). Medical informatics research trend
analyse: A text mining approach. Health Informatics Journal,
24(4), 432–452. https://doi.org/10.1177/1460458216678443
Klavans, R., & Boyack, K. W. (2017un). Research portfolio analysis
and topic prominence. Journal of Informetrics, 11(4), 1158–1174.
https://doi.org/10.1016/j.joi.2017.10.002
Klavans, R., & Boyack, K. W. (2017b). Which Type of Citation
Analysis Generates the Most Accurate Taxonomy of Scientific
and Technical Knowledge? Journal of the Association for
Information Science and Technology, 68(4), 984–998.
https://doi.org/10.1002/asi.23734
Kuhn, T. S. (1996). The Structure of Scientific Revolutions
(3rd edition). Chicago, IL: University of Chicago Press.
Lotka, UN. (1926). The frequency distribution of scientific productivity.
Journal of the Washington Academy of Science, 16, 317–323.
Lucio-Arias, D., & Leydesdorff, L. (2009). An indicator of research
front activity: Measuring intellectual organization as uncertainty
reduction in document sets. Journal of the American Society for
Information Science and Technology, 60(12), 2488–2498.
https://doi.org/10.1002/asi.21199
Marshakova-Shaikevich, je. (1973). System of document
connections based on references. Nauchno-Tekhnicheskaya
Informatsiya Seriya 2-Informatsionnye Protsessy, (6), 3–8.
Morris, S. UN. (2005). Manifestation of emerging specialties in
journal literature: A growth model of papers, références,
exemplars, bibliographic coupling, cocitation, and clustering
coefficient distribution. Journal of the American Society for
Information Science and Technology, 56(12), 1250–1273.
https://doi.org/10.1002/asi.20208
Morris, S. UN., & Van der Veer Martens, B. (2008). Mapping research
specialties. Annual Review of Information Science and
Technologie, 42(1), 213–295. https://doi.org/10.1002/
aris.2008.1440420113
Prix, D. J.. de S. (1965). Little Science, Big Science. New York:
Columbia University Press.
Rand, W. M.. (1971). Objective Criteria for the Evaluation of
Clustering Methods. Journal of the American Statistical
Association, 66(336), 846–850. https://doi.org/10.2307/2284239
Scharnhorst, UN., Börner, K., & Besselaar, P.. (2012). Models of
Science Dynamics. Springer: Berlin, Heidelberg.
Schuemie, M.. J., Talmon, J.. L., Moorman, P.. W., & Kors, J.. UN.
(2009). Mapping the domain of medical informatics. Methods of
Information in Medicine, 48(1), 76–83.
Sjögårde, P., & Ahlgren, P.. (2018). Granularity of algorithmically
constructed publication-level classifications of research
publications: Identification of topics. Journal of Informetrics,
12(1), 133–152. https://doi.org/10.1016/j.joi.2017.12.006
Petit, H. (1973). Co-citation in the scientific literature: A new
measure of the relationship between two documents. Journal de
the American Society for Information Science, 24(4), 265–269.
https://doi.org/10.1002/asi.4630240406
Petit, H., & Griffith, B. C. (1974). The structure of scientific
literatures I: Identifying and graphing specialties. Science Studies,
4(1), 17–40.
Šubelj, L., Van Eck, N. J., & Waltman, L. (2016). Clustering scientific
publications based on citation relations: A systematic
comparison of different methods. PLoS ONE, 11(4), e0154404.
https://doi.org/10.1371/journal.pone.0154404
Traag, V. UN., Waltman, L., & Eck, N. J.. van. (2019). From Louvain
to Leiden: Guaranteeing well-connected communities. Scientific
Reports, 9(1), 5233. https://doi.org/10.1038/s41598-019-
41695-z
Traag, V., Dooren, P., & van Nesterov, Oui. (2011). Narrow scope for
resolution-limit-free community detection. Physical Review E,
84(1), 016114. https://doi.org/10.1103/PhysRevE.84.016114
Waltman, L., & Van Eck, N. J.. (2012). A new methodology for
constructing a publication-level classification system of science.
Journal of the American Society for Information Science and
Technologie, 63(12), 2378–2392. https://doi.org/10.1002/asi.22748
Waltman, L., & Van Eck, N. J.. (2013). A smart local moving
algorithm for large-scale modularity-based community detection.
The European Physical Journal B, 86(11), 471. https://est ce que je.org/
10.1140/epjb/e2013-40829-0
Waltman, L., Van Eck, N. J., van Leeuwen, T. N., & Viser, M.. S.
(2013). Some modifications to the SNIP journal impact indicator.
Journal of Informetrics, 7(2), 272–285. https://est ce que je.org/10.1016/
j.joi.2012.11.011
Waltman, L., Boyack, K. W., Colavizza, G., & Van Eck, N. J.. (2019).
A Principled Methodology for Comparing Relatedness Measures
for Clustering Publications. Retrieved from ArXiv:1901.06815
[Cs], http://arxiv.org/abs/1901.06815.
Wang, L., Topaz, M., Plasek, J.. M., & Zhou, L. (2017). Content and
trends in medical informatics publications over the past two
decades. Studies in Health Technology and Informatics, 245,
968–972.
Wen, B., Horlings, E., van der Zouwen, M., & van den Besselaar, P..
(2017). Mapping science through bibliometric triangulation: Un
experimental approach applied to water research. Journal of the
Association for Information Science and Technology, 68(3),
724–738. https://doi.org/10.1002/asi.23696
Yan, E., Ding, Y., & Jacob, E. K. (2012). Overlaying communities
and topics: An analysis on publication networks. Scientometrics,
90(2), 499–513. https://doi.org/10.1007/s11192-011-0531-6
Études scientifiques quantitatives
228
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
APPENDIX
Appendix 1. Topics per Specialty – LIS
SPECIALTY
TOPIC
BIBLIOMETRICS//CITATION ANALYSIS//IMPACT FACTOR
FIELD NORMALIZATION//SOURCE NORMALIZATION//
RESEARCH EVALUATION
H INDEX//HIRSCH INDEX//G INDEX
RESEARCH COLLABORATION//SCIENTIFIC COLLABORATION//
CO AUTHORSHIP
AUTHOR CO CITATION ANALYSIS//BIBLIOGRAPHIC COUPLING//
CO CITATION ANALYSIS
GOOGLE SCHOLAR//SCOPUS//WEB OF SCIENCE
ALTMETRICS//MENDELEY//RESEARCHGATE
OVERLAY MAP//SCIENCE OVERLAY MAPS//JOURNAL CLASSIFICATION
CO AUTHORSHIP NETWORKS//SCIENTIFIC COLLABORATION//
CO AUTHOR NETWORKS
BOOK CITATION INDEX//SOCIAL SCIENCES AND HUMANITIES//
BOOK PUBLISHERS
WEBOMETRICS//WEB VISIBILITY//WEB LINKS
INFORMATION LITERACY//PUBLIC LIBRARIES//ACADEMIC LIBRARIES
INFORMATION LITERACY//INFORMATION LITERACY INSTRUCTION//
LIBRARY INSTRUCTION
LIBRARY 20//LIBRARIAN 2//ACADEMIC LIBRARIES
KNOWLEDGE ORGANIZATION//FACETED CLASSIFICATIONS//
INDEXING LANGUAGE
INTERACTIVE INFORMATION RETRIEVAL//END USER SEARCHING//
INFORMATION NEEDS AND USES
INFORMATION PRACTICES//AIDS TALK//BARRIERS TO INFORMATION
SEEKING
INFORMATION SCIENCE//DIKW HIERARCHY//PROPERTIES OF
DOCUMENTARY PRACTICE
PUBLIC LIBRARIES//CHILDRENS INTERNET PROTECTION ACT//
RURAL LIBRARIES
REFERENCE SERVICES//DIGITAL REFERENCE//REFERENCE DESK
HOPE OLSON//BISAC//KNOWLEDGE ORGANIZATION
ACADEMIC LIBRARY USE//ACADEMIC AND RESEARCH LIBRARIES//
ACADEMIC ASSIGNMENTS
# articles
in Plis
# articles
in topic
Share of topic
in Plis
193
190
125
83
79
75
75
70
65
60
194
104
93
92
85
81
62
61
57
48
258
317
184
142
121
113
148
136
93
80
212
110
106
128
99
99
68
66
66
51
75%
60%
68%
58%
65%
66%
51%
51%
70%
75%
92%
95%
88%
72%
86%
82%
91%
92%
86%
94%
Études scientifiques quantitatives
229
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
Appendix 1. (a continué )
SPECIALTY
TOPIC
INTERLENDING//DOCUMENT DELIVERY//ACADEMIC LIBRARIES
ELECTRONIC BOOKS//E BOOKS//E TEXTBOOK
OPEN ACCESS//OPEN ACCESS JOURNALS//GOLD OPEN ACCESS
DOCUMENT DELIVERY//INTERLENDING//INTERLIBRARY LOAN
ELECTRONIC JOURNALS//ELECTRONIC PERIODICALS//E JOURNALS
KOHA//INTEGRATED LIBRARY SYSTEMS//WEB SCALE DISCOVERY
INSTITUTIONAL REPOSITORIES//ACADEMIC AUTHORS//
DIGITAL LIBRARY FRAMEWORK
RESEARCH DATA//DATA SHARING//DATA REPOSITORIES
INTERFACE CONSISTENCY//ADAPTIVE LIBRARY SERVICES//
ALEXANDRIA DIGITAL LIBRARY PROJECT
CITATION STUDY//COLLECTION ASSESSMENT//ACADEMIC MEDICAL
CENTER LIBRARY
FRBR//DESCRIPTIVE CATALOGUING//FUNCTIONAL REQUIREMENTS
FOR BIBLIOGRAPHIC RECORDS FRBR
RECOMMENDER SYSTEMS//COLLABORATIVE FILTERING//
INFORMATION RETRIEVAL
FOLKSONOMY//SOCIAL TAGGING//COLLABORATIVE TAGGING
SENTIMENT ANALYSIS//OPINION MINING//SENTIMENT CLASSIFICATION
RECOMMENDER SYSTEMS//COLLABORATIVE FILTERING//
RECOMMENDATION SYSTEM
RELEVANCE CRITERIA//RELEVANCE JUDGEMENT//TEST COLLECTIONS
SESSION IDENTIFICATION//QUERY LOG ANALYSIS//
QUERY RECOMMENDATION
COMMUNITY QUESTION ANSWERING//SOCIAL QA//
ANSWER RECOMMENDATION
COLLABORATIVE INFORMATION SEEKING//SEARCH HISTORIES//
SOCIAL SEARCH
EXPERT FINDING//EXPERT SEARCH//ENTITY RETRIEVAL
MULTI DOCUMENT SUMMARIZATION//TEXT SUMMARIZATION//
DOCUMENT SUMMARIZATION
STEMMING//CROSS LANGUAGE INFORMATION RETRIEVAL//
CHARACTER N GRAMS
# articles
in Plis
# articles
in topic
Share of topic
in Plis
134
123
121
79
72
63
53
36
31
29
57
35
30
25
24
23
22
20
16
11
172
218
122
85
78
69
147
46
38
35
159
371
576
49
86
54
40
87
146
40
78%
56%
99%
93%
92%
91%
36%
78%
82%
83%
36%
9%
5%
51%
28%
43%
55%
23%
11%
28%
Études scientifiques quantitatives
230
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
Appendix 1. (a continué )
SPECIALTY
TOPIC
ELECTRONIC HEALTH RECORDS//ELECTRONIC MEDICAL RECORD//
MEDICAL INFORMATICS
NATURAL LANGUAGE PROCESSING//MEDICAL LANGUAGE
PROCESSING//CLINICAL TEXT
HEALTH INFORMATION TECHNOLOGY//ELECTRONIC HEALTH
RECORDS//MEANINGFUL USE
ALERT FATIGUE//CLINICAL DECISION SUPPORT SYSTEMS//
CLINICAL DECISION SUPPORT
CDISC//ISO IEC 11179//CLINICAL RESEARCH INFORMATICS
PHEWAS//PHENOME WIDE ASSOCIATION STUDY//
CLINICAL PHENOTYPE MODELING
HEALTH INFORMATION EXCHANGE//HEALTH RECORD BANK//
REGIONAL HEALTH INFORMATION ORGANIZATIONS
CPOE//E PRESCRIBING//ELECTRONIC PRESCRIBING
OPENEHR//LOINC//CLINICAL ARCHETYPES
SNOMED CT//UMLS//ABSTRACTION NETWORK
COPY PASTE//CLINICAL DOCUMENTATION//COMPUTER BASED
DOCUMENTATION
ENTERPRISE RESOURCE PLANNING//ENTERPRISE RESOURCE PLANNING ERP//
END USER COMPUTING
IT BUSINESS VALUE//BUSINESS VALUE OF IT//IT INVESTMENT
STRATEGIC INFORMATION SYSTEMS PLANNING//CHIEF INFORMATION
OFFICER//IT GOVERNANCE
IS RESEARCH//REFERENCE DISCIPLINE//IS DISCIPLINE
ENTERPRISE RESOURCE PLANNING//ENTERPRISE RESOURCE PLANNING
ERP//ERP IMPLEMENTATION
TOE FRAMEWORK//E COMMERCE ADOPTION//TECHNOLOGY
ORGANIZATION ENVIRONMENT FRAMEWORK
REQUIREMENTS UNCERTAINTY//SYSTEM SUCCESS//
SOFTWARE PROJECT RISK
CAREER ANCHORS//IS PERSONNEL//IT WORKFORCE
DATA QUALITY//INFORMATION QUALITY MANAGEMENT//
INFORMATION QUALITY
USER SATISFACTION//INFORMATION SYSTEMS SUCCESS//IS SUCCESS
SUBJECTIVITY STUDY//ACTOR ENGAGEMENT//
AGILE ANALYTICS
# articles
in Plis
# articles
in topic
Share of topic
in Plis
92
46
43
37
34
32
31
21
13
10
92
70
65
41
38
23
23
15
15
12
278
392
216
167
160
154
218
111
108
59
184
124
83
196
136
81
49
68
81
73
33%
12%
20%
22%
21%
21%
14%
19%
12%
17%
50%
56%
78%
21%
28%
28%
47%
22%
19%
16%
Études scientifiques quantitatives
231
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
Appendix 1. (a continué )
SPECIALTY
TOPIC
KNOWLEDGE MANAGEMENT//KNOWLEDGE SHARING//
OPEN SOURCE SOFTWARE
KNOWLEDGE SHARING//KNOWLEDGE MANAGEMENT//
KNOWLEDGE SHARING BEHAVIOR
KNOWLEDGE MANAGEMENT//ENTERPRISE BENEFITS//
KNOWLEDGE CHAIN
OPEN SOURCE SOFTWARE//OPEN SOURCE//OPEN SOURCE
SOFTWARE OSS
WIKIPEDIA//COOPERATIVE KNOWLEDGE GENERATION//ENCYCLOPAEDIAS
PERSONAL INFORMATION MANAGEMENT//ADAPTIVE WINDOW
MANAGER//ADVANCED MANAGEMENT OF PERSONAL INFORMATION
COMMUNITIES OF PRACTICE//ORGANIZING PRACTICES//
COMMUNITY OF PRACTICE
INTELLECTUAL CAPITAL//INTANGIBLE ASSETS//INTELLECTUAL CAPITAL IC
ENTERPRISE EVOLUTION//KNOWLEDGE CREATION//
AUTOMOBILE PROJECT
EUROPEAN SMES//BARRIERS OF IMPLEMENTATION//
CASE STUDY IN SINGAPORE
BLACK HAT SEO//COMMUNICATIONS ACTIVITIES//
CONSUMER COMPARISON
INNOVATION//PATENTS//OPEN INNOVATION
PATENT ANALYSIS//PATENT MINING//TECHNOLOGY INTELLIGENCE
NON PATENT REFERENCES//NON PATENT CITATION//SCIENCE LINKAGE
PROBABILISTIC ENTROPY//UNIVERSITY INDUSTRY GOVERNMENT
RELATIONSHIP//TRIPLE HELIX
ACADEMIC ENTREPRENEURSHIP//ENTREPRENEURIAL UNIVERSITY//
UNIVERSITY SPIN OFFS
PATENT VALUE//PATENTS//PATENT SYSTEM
USER INNOVATION//LEAD USERS//INNOVATION CONTESTS
SOFTWARE ECOSYSTEMS//BUSINESS ECOSYSTEM//
MOBILE COMPUTING INDUSTRY
ABSORPTIVE CAPACITY//POTENTIAL ABSORPTIVE CAPACITY//
COMBINATIVE CAPABILITIES
NATIONAL ELIGIBILITY TEST//RD EFFICIENCY//
CHINAS HIGH TECH INNOVATIONS
INVENTIVE ACTIVITIES//ASSIGNEE//CO PATENT
# articles
in Plis
# articles
in topic
Share of topic
in Plis
151
58
53
22
22
19
19
16
13
11
41
34
32
27
27
19
16
13
10
9
328
101
230
76
48
82
96
43
35
28
179
57
52
421
202
226
81
102
47
17
46%
57%
23%
29%
46%
23%
20%
37%
37%
39%
23%
60%
62%
6%
13%
8%
20%
13%
21%
53%
Études scientifiques quantitatives
232
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
Appendix 1. (a continué )
SPECIALTY
TOPIC
UNIVERSAL SERVICE//TELECOMMUNICATIONS//ACCESS PRICING
DIGITAL DIVIDE//BROADBAND ADOPTION//BROADBAND
ACCESS REGULATION//ACCESS PRICING//NEXT GENERATION
ACCESS NETWORKS
TD SCDMA//FORMAL STANDARDS//WAPI
SPECTRUM AUCTIONS//DIGITAL DIVIDEND//SPECTRUM TRADING
FIXED MOBILE SUBSTITUTION//MOBILE TELECOMMUNICATIONS//
FIXED TO MOBILE SUBSTITUTION
BILL AND KEEP//TERMINATION RATES//ACCESS PRICING
UNIVERSAL SERVICE//E RATE//UNIVERSAL SERVICE FUND
NET NEUTRALITY//NETWORK NEUTRALITY//CONTENT PROVIDERS
PRICE CAPS//INCENTIVE REGULATION//PRICE CAP REGULATION
AUSTRALIAN EXPERIENCE//BARRIERS TO TRADE AND INVESTMENT//
CAUSAL CHAIN OF REFORM
HEALTH LITERACY//INTERNET//MHEALTH
HEALTH LITERACY//NEWEST VITAL SIGN//S TOFHLA
PERSONAL HEALTH RECORDS//PATIENT PORTAL//
PATIENT ACCESS TO RECORDS
HEALTH INFORMATION SEEKING//HEALTH INFORMATION
AVOIDANCE//INFORMATION SEEKING
ONLINE SUPPORT GROUPS//COMPREHENSIVE HEALTH
ENHANCEMENT SUPPORT SYSTEM CHESS//
INTERNET CANCER SUPPORT GROUPS
MHEALTH//MEDICATION REMINDERS//REAL TIME ADHERENCE
MONITORING
INTERNET//HEALTH INFORMATION//ONLINE HEALTH
INFORMATION
TEXT MESSAGING//TEXT MESSAGE//MHEALTH
DISCERN//INTERNET//QUALITY OF INFORMATION
INTERNET CHILD HEALTH INFORMATION//ASSESSMENT
OF ACUTE DISEASES//AUTISM CEREBRAL PALSY
READABILITY//PATIENT EDUCATION MATERIALS//
FLESCH KINCAID GRADE LEVEL
# articles
in Plis
# articles
in topic
Share of topic
in Plis
71
48
39
28
24
17
17
17
12
8
73
39
35
28
20
14
13
8
7
6
150
121
63
68
56
60
35
70
39
30
544
281
118
220
275
193
218
207
46
147
47%
40%
62%
41%
43%
28%
49%
24%
31%
27%
13%
14%
30%
13%
7%
7%
6%
4%
15%
4%
Études scientifiques quantitatives
233
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
Appendix 2. Topics per Specialty – MIS
SPECIALTY
TOPIC
ELECTRONIC HEALTH RECORDS//ELECTRONIC MEDICAL
RECORD//MEDICAL INFORMATICS
NATURAL LANGUAGE PROCESSING//MEDICAL LANGUAGE
PROCESSING//CLINICAL TEXT
HEALTH INFORMATION TECHNOLOGY//ELECTRONIC HEALTH
RECORDS//MEANINGFUL USE
CDISC//ISO IEC 11179//CLINICAL RESEARCH INFORMATICS
ALERT FATIGUE//CLINICAL DECISION SUPPORT SYSTEMS//
CLINICAL DECISION SUPPORT
NURSING INFORMATION SYSTEM//CLINICAL INFORMATION
SYSTEMS//DOCUMENTATION TIME
OPENEHR//LOINC//CLINICAL ARCHETYPES
HEALTH INFORMATION EXCHANGE//HEALTH RECORD BANK//
REGIONAL HEALTH INFORMATION ORGANIZATIONS
CPOE//E PRESCRIBING//ELECTRONIC PRESCRIBING
SNOMED CT//UMLS//ABSTRACTION NETWORK
PHEWAS//PHENOME WIDE ASSOCIATION STUDY//
CLINICAL PHENOTYPE MODELING
HEALTH LITERACY//INTERNET//MHEALTH
PERSONAL HEALTH RECORDS//PATIENT PORTAL//PATIENT ACCESS
TO RECORDS
INTERNET//HEALTH INFORMATION//ONLINE HEALTH INFORMATION
ONLINE SUPPORT GROUPS//COMPREHENSIVE HEALTH ENHANCEMENT
SUPPORT SYSTEM CHESS//INTERNET CANCER SUPPORT GROUPS
MEDICAL APP//APPS//SMARTPHONE
MHEALTH//MEDICATION REMINDERS//REAL TIME ADHERENCE
MONITORING
TWITTER MESSAGING//INFOVEILLANCE//INFODEMIOLOGY
E PROFESSIONALISM//SOCIAL MEDIA//TWITTER MESSAGING
TEXT MESSAGING//TEXT MESSAGE//MHEALTH
MOBILE APPS//APPS//MHEALTH
PHYSICIAN RATING WEBSITE//RATING SITES//QUALITY TRANSPARENCY
# articles
in Pmi
# articles
in topic
Share of topic
in Pmi
188
127
112
110
104
89
87
84
76
49
112
48
37
33
32
31
30
29
25
23
278
392
167
216
152
111
154
218
108
160
281
193
220
165
275
113
274
218
126
61
68%
32%
67%
51%
68%
80%
56%
39%
70%
31%
40%
25%
17%
20%
12%
27%
11%
13%
20%
38%
Études scientifiques quantitatives
234
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
Appendix 2. (a continué )
SPECIALTY
TOPIC
HEALTH TECHNOLOGY ASSESSMENT//EQ 5D//PRIORITY SETTING
HEALTH TECHNOLOGY ASSESSMENT//HOSPITAL BASED HTA//MINI HTA
EQ 5D//SF 6D//EQ 5D 5L
VALUE OF INFORMATION//OPTIMAL TRIAL DESIGN//
VALUE OF INFORMATION ANALYSIS
HEALTH TECHNOLOGY ASSESSMENT//INSTITUTE FOR QUALITY
AND EFFICIENCY IN HEALTH CARE//FOURTH HURDLE
DYNAMIC TRANSMISSION//HALF CYCLE CORRECTION//
COST EFFECTIVENESS MODELING
STRENGTH OF PREFERENCES//IN PERSON INTERVIEW//
MULTI CRITERIA DECISION ANALYSIS
COST EFFECTIVENESS RATIOS//NET HEALTH BENEFIT//
COST EFFECTIVENESS ACCEPTABILITY CURVES
COVERAGE WITH EVIDENCE DEVELOPMENT//
MEDICARE COVERAGE//RISK SHARING AGREEMENTS
HORIZON SCANNING SYSTEMS//HORIZON SCANNING//
EARLY AWARENESS AND ALERT SYSTEMS
COMPARATIVE EFFECTIVENESS RESEARCH//PATIENT CENTERED
OUTCOMES RESEARCH//ELECTRONIC CLINICAL DATA
ADAPTIVE DESIGN//INTERIM ANALYSIS//DOSE FINDING
ADAPTIVE DESIGN//GROUP SEQUENTIAL TEST//
GROUP SEQUENTIAL DESIGN
CONTINUAL REASSESSMENT METHOD//DOSE FINDING//
DOSE FINDING STUDIES
TWO STAGE DESIGN//PHASE II DESIGN//PHASE II CLINICAL TRIALS
FAMILYWISE ERROR RATE//GATEKEEPING PROCEDURE//MULTIPLE TESTS
SCORE INTERVAL//BINOMIAL PROPORTION//BINOMIAL DISTRIBUTION
NONINFERIORITY MARGIN//NON INFERIORITY//NON INFERIORITY
TRIAL
MONOTONE MISSING//DISCRETE TIME LONGITUDINAL DATA//
INDEPENDENT MISSING
MINIMUM EFFECTIVE DOSE//MCP MOD//WILLIAMS TEST
META ANALYTIC PREDICTIVE//EPSILON INFORMATION PRIOR//
COMPUTATIONALLY INTENSIVE METHODS
MULTIREGIONAL CLINICAL TRIAL//BRIDGING STUDY//
MULTIREGIONAL TRIAL
# articles
in Pmi
# articles
in topic
Share of topic
in Pmi
58
38
29
28
26
15
14
14
12
10
58
50
28
27
18
16
12
12
9
8
118
411
95
153
82
67
74
91
20
158
221
200
113
119
140
112
37
57
42
68
49%
9%
31%
18%
32%
22%
19%
15%
60%
6%
26%
25%
25%
23%
13%
14%
32%
21%
21%
12%
Études scientifiques quantitatives
235
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
Appendix 2. (a continué )
SPECIALTY
TOPIC
MISSING DATA//MULTIPLE IMPUTATION//GENERALIZED
ESTIMATING EQUATIONS
GENERALIZED ESTIMATING EQUATIONS//QUASI LEAST SQUARES//GEE
MULTIPLE IMPUTATION//MISSING DATA//PREDICTIVE MEAN MATCHING
JOINT MODEL//SHARED PARAMETER MODEL//DYNAMIC PREDICTIONS
CONCORDANCE CORRELATION COEFFICIENT//TOTAL DEVIATION
INDEX//COEFFICIENT OF INDIVIDUAL AGREEMENT
PATTERN MIXTURE MODEL//MISSING NOT AT RANDOM//MISSING DATA
ZERO INFLATION//ZERO INFLATED MODELS//OVERDISPERSION
CENSORED COVARIATE//CENSORED PREDICTOR//
TWO PART STATISTICS
REGRESSION CALIBRATION//MEASUREMENT ERROR//CORRECTED SCORE
INFORMATIVE CLUSTER SIZE//WITHIN CLUSTER RESAMPLING//
CLUSTERED OBSERVATIONS
DOUBLE ROBUSTNESS//AUGMENTED INVERSE PROBABILITY
WEIGHTING AIPW//MISSING AT RANDOM
COMPETING RISKS//INTERVAL CENSORING//COUNTING PROCESS
INTEGRATED DISCRIMINATION IMPROVEMENT//NET RECLASSIFICATION
IMPROVEMENT//DECISION ANALYTIC MEASURES
MULTISTATE MODEL//ILLNESS DEATH PROCESS//AALEN JOHANSEN
ESTIMATOR
COMPETING RISKS//CUMULATIVE INCIDENCE FUNCTION//
CAUSE SPECIFIC HAZARD
RECURRENT EVENTS//PANEL COUNT DATA//
INFORMATIVE OBSERVATION TIMES
EXPLAINED VARIATION//TIME DEPENDENT ROC//C INDEX
CURE RATE MODEL//CURE MODEL//LONG TERM SURVIVAL MODELS
SURROGATE ENDPOINT//PRENTICE CRITERION//
LIKELIHOOD REDUCTION FACTOR
INTERVAL CENSORING//CURRENT STATUS DATA//
INTERVAL CENSORED DATA
CASE COHORT DESIGN//CASE COHORT//CASE COHORT STUDY
FRAILTY MODEL//CORRELATED FAILURE TIMES//
CROSS RATIO FUNCTION
# articles
in Pmi
# articles
in topic
Share of topic
in Pmi
23
23
22
19
19
16
13
12
10
10
28
23
20
19
19
17
13
13
12
12
104
218
112
66
137
142
41
105
43
67
110
111
117
174
68
95
84
127
77
104
22%
11%
20%
29%
14%
11%
32%
11%
23%
15%
25%
21%
17%
11%
28%
18%
15%
10%
16%
12%
Études scientifiques quantitatives
236
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
Appendix 2. (a continué )
SPECIALTY
TOPIC
EVIDENCE-BASED MEDICINE//PUBLICATION BIAS//ABSTRACT
MULTIVARIATE META-ANALYSIS//DERSIMONIAN LAIRD
ESTIMATOR//MANDEL PAULE ALGORITHM
MEDICAL EPISTEMOLOGY//EVIDENCE-BASED MEDICINE//
EVIDENCE IN MEDICINE
MIXED TREATMENT COMPARISON//NETWORK META-ANALYSIS//
MULTIPLE TREATMENTS META-ANALYSIS
MEDLINE//EMBASE//LITERATURE SEARCHING
NUMBER NEEDED TO TREAT//ABSOLUTE RISK REDUCTION//
NUMBER NEEDED TO TREAT NNT
TRIAL REGISTRATION//CLINICALTRIALSGOV//PUBLICATION BIAS
PUBLICATION BIAS//FUNNEL PLOT//SMALL STUDY EFFECTS
JOURNAL CLUB//EVIDENCE-BASED MEDICINE EDUCATION//FRESNO TEST
AWARENESS SCORE//CHIROPRACTIC QUESTIONNAIRES//
COMMUNITY OF PRACTICE KNOWLEDGE NETWORKS
CONFLICT OF INTEREST//EDITORIAL ETHICS//CONFLICTS OF INTEREST
PATIENT SAFETY//MEDICATION ERRORS//MEDICAL ERRORS
MEDICATION ERRORS//SMART PUMPS//MEDICATION
ADMINISTRATION ERRORS
BAR CODE MEDICATION ADMINISTRATION//BAR CODED MEDICATION
ADMINISTRATION//SCANNING COMPLIANCE
SIGN OUT//HANDOFF//HANDOVER
VOCERA//HOSPITAL COMMUNICATION SYSTEMS//PAGERS
INTERRUPTION//DISTRACTIONS//TASK SEVERITY
MEDWISE//THREAT AND ERROR MANAGEMENT TEM//
USER CONFIGURABLE EHR
INCIDENT REPORTING//MEDICATION INCIDENTS//ERROR REPORTING
MEDICAL DEVICE DESIGN//INSTITUTIONAL DECISION
MAKING//USER COMPUTER
NON TECHNICAL SKILLS//TEAMWORK//TEAM TRAINING
TRIGGER TOOL//GLOBAL TRIGGER TOOL//PREVENTABLE HARM
# articles
in Pmi
# articles
in topic
Share of topic
in Pmi
40
32
26
11
9
7
6
6
6
6
25
24
19
19
13
11
8
8
7
6
150
77
198
112
52
250
64
155
45
189
281
82
334
66
162
32
155
34
317
182
27%
42%
13%
10%
17%
3%
9%
4%
13%
3%
9%
29%
6%
29%
8%
34%
5%
24%
2%
3%
Études scientifiques quantitatives
237
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Granularity of classifications of research publications
Appendix 2. (a continué )
SPECIALTY
TOPIC
TELEMEDICINE//TELEHEALTH//TELEPATHOLOGY
TELEHEALTH//TELECARE//TELEHEALTHCARE
TELEMONITORING//HOME TELEMONITORING//TETEMONITORING
ELDERCARE TECHNOLOGY//HOME BASED CLINICAL
ASSESSMENT//PASSIVE INFRARED PIR MOTION DETECTORS
TELE ECHOGRAPHY//TELESONOGRAPHY//TELE ULTRASOUND
MOBILE TELEMEDICINE//MOBILE CARE//TIME FREQUENCY ENERGY
DISTRIBUTIONS
CHRONIC DISEASE METHODS THERAPY//CRITICAL PATHWAYS
MESH//HEATH CARE PRACTICES
TELEREHABILITATION//TELEPRACTICE//REMOTE ASSESSMENT
TELE EEG//INITIATE BUILD OPERATE TRANSFER STRATEGY//
INTERNATIONAL VIRTUAL E HOSPITAL FOUNDATION
ISI WEB OF SCIENCE DATABASE//LISTENING STYLES//
NON ADHERENCE FACTORS
TELEDERMATOLOGY//MOBILE TELEDERMATOLOGY//
STORE AND FORWARD
CAUSAL INFERENCE//PROPENSITY SCORE//PRINCIPAL STRATIFICATION
PROPENSITY SCORE//OBSERVATIONAL STUDY//COVARIATE BALANCE
PRINCIPAL STRATIFICATION//NONCOMPLIANCE//CAUSAL INFERENCE
MARGINAL STRUCTURAL MODELS//TARGETED MAXIMUM LIKELIHOOD
ESTIMATION//CAUSAL INFERENCE
DYNAMIC TREATMENT REGIMES//ADAPTIVE TREATMENT
STRATEGIES//OPTIMAL TREATMENT REGIME
MENDELIAN RANDOMIZATION//MENDELIAN RANDOMISATION//
ALLELE SCORES
PROPENSITY SCORE CALIBRATION//PROBABILISTIC BIAS
ANALYSIS//NONDIFFERENTIAL
RANDOMIZATION INFERENCE//MATCHED SAMPLING//FINE BALANCE
INSTRUMENTAL VARIABLES//PHYSICIAN PRESCRIBING
PREFERENCE//PHYSICIANS PRESCRIBING PREFERENCE
MARGINAL TREATMENT EFFECT//CORRELATED RANDOM
COEFFICIENT MODEL//LOCAL INSTRUMENTAL VARIABLES
UNCONFOUNDEDNESS//PROPENSITY SCORE MATCHING//
SELECTION ON OBSERVABLES
# articles
in Pmi
# articles
in topic
Share of topic
in Pmi
32
27
19
10
7
7
6
5
5
4
34
32
29
19
11
4
4
4
1
1
188
155
90
48
34
24
90
69
24
135
229
159
221
127
121
50
56
64
51
204
17%
17%
21%
21%
21%
29%
7%
7%
21%
3%
15%
20%
13%
15%
9%
8%
7%
6%
2%
0%
Études scientifiques quantitatives
238
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
1
1
2
0
7
1
7
6
0
8
2
8
q
s
s
_
un
_
0
0
0
0
4
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3