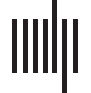ARTICLE DE RECHERCHE
Auditory Word Comprehension Is Less
Incremental in Isolated Words
Phoebe Gaston1,3*
, Christian Brodbeck2,3*
, Colin Phillips1
, and Ellen Lau1
1Department of Linguistics, University of Maryland, College Park, MARYLAND, Etats-Unis
2Institute for Systems Research, University of Maryland, College Park, MARYLAND, Etats-Unis
3Department of Psychological Sciences, University of Connecticut, Storrs, CT, Etats-Unis
*Denotes equal contribution.
Mots clés: auditory word recognition, cohort entropy, continuous speech, lexical access, lexical
traitement, magnetoencephalography, phoneme surprisal, temporal response function
ABSTRAIT
Partial speech input is often understood to trigger rapid and automatic activation of successively
higher-level representations of words, from sound to meaning. Here we show evidence from
magnetoencephalography that this type of incremental processing is limited when words are
heard in isolation as compared to continuous speech. This suggests a less unified and automatic
word recognition process than is often assumed. We present evidence from isolated words
that neural effects of phoneme probability, quantified by phoneme surprisal, are significantly
stronger than (statistically null) effects of phoneme-by-phoneme lexical uncertainty, quantified
by cohort entropy. In contrast, we find robust effects of both cohort entropy and phoneme
surprisal during perception of connected speech, with a significant interaction between the
contexts. This dissociation rules out models of word recognition in which phoneme surprisal and
cohort entropy are common indicators of a uniform process, even though these closely related
information-theoretic measures both arise from the probability distribution of wordforms
consistent with the input. We propose that phoneme surprisal effects reflect automatic access
of a lower level of representation of the auditory input (par exemple., wordforms) while the occurrence
of cohort entropy effects is task sensitive, driven by a competition process or a higher-level
representation that is engaged late (or not at all) during the processing of single words.
INTRODUCTION
Speech recognition necessarily involves the access of multiple levels of representation in
response to auditory input, from phonemes to wordforms to higher-level lexical-syntactic rep-
resentations that link wordforms to meaning. While much about this process remains to be
elucidated, research on spoken word recognition has reached broad consensus on several
points. The contributions of a vast behavioral literature (reviewed by, par exemple., Dahan & Magnuson,
2006; Magnuson, 2016; Magnuson et al., 2013; McQueen, 2007) indicate an incremental,
phoneme-by-phoneme process of winnowing down the phonological wordforms that are
consistent with the unfolding auditory input (par exemple., Allopenna et al., 1998; Grosjean, 1980;
Zwitserlood, 1989; and following). Conceptual information associated with those wordforms
can be incrementally activated (par exemple., Yee & Sedivy, 2006; Zwitserlood, 1989; and following),
and syntactic information is rapidly invoked (par exemple., Marslen-Wilson & Tyler, 1980; McAllister,
1988; and following). This process is highly sensitive to distributional statistics, captured by
word frequency (par exemple., Connine et al., 1990; Dahan et al., 2001).
un accès ouvert
journal
Citation: Gaston, P., Brodbeck, C.,
Phillips, C., & Lau, E. (2023). Auditory
word comprehension is less
incremental in isolated words.
Neurobiology of Language, 4(1),
29–52. https://est ce que je.org/10.1162
/nol_a_00084
EST CE QUE JE:
https://doi.org/10.1162/nol_a_00084
Reçu: 22 Septembre 2021
Accepté: 26 Septembre 2022
Intérêts concurrents: Les auteurs ont
a déclaré qu'aucun intérêt concurrent
exister.
Auteur correspondant:
Phoebe Gaston
phoebe.gaston@gmail.com
Éditeur de manipulation:
Steven Small
droits d'auteur: © 2022
Massachusetts Institute of Technology
Publié sous Creative Commons
Attribution 4.0 International
(CC PAR 4.0) Licence
La presse du MIT
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
n
o
/
je
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
un
_
0
0
0
8
4
p
d
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
The evidence leading to this consensus comes from a broad array of experimental
approaches that vary as to which aspects of word recognition they can most effectively probe.
These approaches use stimuli that vary from sublexical phoneme sequences to natural, con-
nected speech. Combining evidence from these different paradigms is usually guided by an
assumption that there is a uniform, automatic progression of processing triggered by speech
input, such that we can expect datapoints from different points in that progression to cohere.
Under this assumption, simpler or single-word paradigms will straightforwardly capture the
fundamental word recognition sequence in isolation, while presenting more complex input
allows us to investigate how contextual information influences, Par exemple, the speed of pro-
cessing or the set of lexical candidates under consideration.
In Figure 1, we sketch a representative sequence of processing proposed to occur in
response to each phoneme of speech input. TRACE (McClelland & Elman, 1986) is an example
of a model that is consistent with the illustrated principles. Each level of representation auto-
matically determines the most likely interpretation of the input through local competition and
broadcasts this interpretation through feed-forward and feed-back connections. An assumption
of automaticity implies that any speech input engages this processing hierarchy in the same
manière. The task context might change the information available at different levels, but not
the basic sequence of processing. Cependant, if that assumption of automaticity is incorrect, alors
the basic process of word recognition could deviate significantly according to the demands of
different comprehension scenarios. This deviation could occur because of variation in, pour
instance, the relevance of different types of information to different experimental tasks, the ease
of word segmentation, or the degree to which word-to-word dependencies occur in the input.
In this article we present neural evidence that word recognition in isolation may proceed in
a qualitatively different way than word recognition in continuous speech. Behavioral measures
or paradigms requiring an explicit response to each stimulus make comparison between iso-
lated words and continuous speech difficult, with single trials generally measuring the status of
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
n
o
/
je
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
un
_
0
0
0
8
4
p
d
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 1. Automatic sequence of processing assumed to occur in response to each phoneme of
speech input. Straight arrows indicate connections between levels of representation. Curved arrows
indicate a within-level competition/selection process.
Neurobiology of Language
30
Auditory word comprehension in isolated words
just a single item in the lexicon. Plutôt, we turn to a neural measure—multivariate temporal
response function (mTRF) analysis of magnetoencephalography (MEG) responses—that can be
applied in exactly the same way to single-word and continuous-speech listening, et ça
reflects distributional properties of the entire class of word candidates consistent with each
presented phoneme. We show that the effects of two measures that have both been understood
to reflect automatic wordform-level processing in fact dissociate robustly according to the
nature of the experiment. This dissociation implicates a break in the automaticity of the
sequence of activation and indicates a difference between the processing of words presented
in isolation and words presented in continuous speech. Our findings have implications for the
architecture of word recognition models as well as for experimental approaches to studying
speech perception.
Phoneme Surprisal and Cohort Entropy
The neural response to speech has been shown to be modulated by information-theoretic
properties of the set of wordforms that match the auditory input at any given phoneme
(Brodbeck et al., 2018, 2022b; Di Liberto et al., 2019; Donhauser & Baillet, 2020; Ettinger
et coll., 2014; Gagnepain et al., 2012; Gaston & Marantz, 2018; Gillis et al., 2021; Gwilliams
et coll., 2018, 2021; Gwilliams & Marantz, 2015; Kocagoncu et al., 2017). Two of these prop-
erties in particular—cohort entropy and phoneme surprisal—have emerged as promising
means of investigating the time course of auditory word recognition.
Phoneme surprisal at a given phoneme is a measure of how much information that pho-
neme provides for identifying the current word. It is defined as the conditional probability of
that phoneme given the preceding sequence of phonemes in the current word. Phoneme sur-
prisal at position i in a wordform is defined as −log2 p(ki | k1, … ki−1) where ki is the phoneme
at position i and i = 1 for the first phoneme in the wordform. Cohort entropy at that same
phoneme, in contrast, is a measure of how much uncertainty there is across word forms that
match the phoneme sequence up to the current phoneme. It is determined by the probability
distribution over wordforms that might complete that phoneme sequence. Cohort entropy at
position i in a wordform is defined as
XCi
−
w
ð
p wð
j k1; … ki
Þ (cid:2) log2 p wð
j k1; … kiÞÞ
where w is each wordform in the cohort Ci of wordforms consistent with the sequence of pho-
nemes k1, … ki. One of the critical differences between these formulations is that cohort
entropy is forward-looking in a way that phoneme surprisal is not. A cohort entropy effect
reflects expectations for potential wordform candidates that would be consistent with the cur-
rent input, while a phoneme surprisal effect may only reflect the degree to which previously
formed representations are updated based on the new input (see Pickering & Gambi, 2018, sur
entropy effects as strong evidence for prediction).
More neural activity is generally observed in response to higher surprisal, or lower proba-
bility, phonemes, consistent with many cognitive domains in which predictable or higher
probability stimuli elicit reduced neural responses (see Aitchison & Lengyel, 2017). Exactly
how cohort entropy should be expected to drive neural activity in this case is less clear, though
there is evidence for the relevance of the broader concept of entropy across a range of areas
within cognitive neuroscience (Bestmann et al., 2008; Crupi et al., 2018; Friston, 2005; Hale,
2016; Strange et al., 2005; Weissbart et al., 2020; Whiteley & Sahani, 2008; Willems et al.,
2016). A larger set of word candidates has a higher cohort entropy than a smaller set of
Neurobiology of Language
31
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
n
o
/
je
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
un
_
0
0
0
8
4
p
d
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
candidates, but the size of the candidate set is not the only determinant of uncertainty; a set of
candidates in which probability is equally distributed has a higher cohort entropy than a set
of candidates in which probability is concentrated on a single candidate. Greater uncertainty
among word candidates could be associated with more neural activity attributable either to
an intensified process of lexical competition (Gagnepain et al., 2012) or to increased atten-
tional gain on bottom-up input (Donhauser & Baillet, 2020), or it could be instead that lower
uncertainty is a precondition for other processes to be engaged (Ettinger et al., 2014).
Despite these differences, phoneme surprisal and cohort entropy are often investigated and
presented in tandem as interchangeable indicators of wordform-level processing. One likely
reason for this approach in the literature is that the conditional probabilities underlying both
measures are calculated from the same probability distributions of wordforms consistent with
the input. The two variables are also often correlated, and their effects in neural data frequently
co-occur. Enfin, in a hypothesized model of word recognition that includes automatic
engagement of successive representational levels regardless of task or context, phoneme sur-
prisal and cohort entropy effects are simply two different windows into the same automatic
flow of activation through the system.
Variation in Neural Effects of Cohort Entropy and Phoneme Surprisal
Despite frequently being treated interchangeably, a careful look at the prior literature reveals
considerable variation in whether and when phoneme surprisal and cohort entropy effects
manifest across experiments. This variation has not previously been examined systematically.
Ainsi, before we proceed to our own study, we review this literature and consider whether
there are properties of the stimulus or experimental context that can help explain when cohort
entropy and phoneme surprisal effects do or do not occur, and what this might mean for the
processes and levels of representation they describe. An account of this variability is important
for improving the utility of phoneme surprisal and cohort entropy as measures for investigating
speech perception and, specifically, the class of active items in competition for recognition at
any given point in a word. Cependant, understanding this variability also has the potential to
illuminate dissociable subprocesses in word recognition.
We begin by trying to characterize why cohort entropy and phoneme surprisal effects occur
at all in some experiments and not in others, though further efforts to understand variation in
the localization and time course of these effects will also be important. In Table 1, we sum-
marize existing electrophysiology (primarily MEG) studies that have tested for effects of cohort
entropy and phoneme surprisal on neural activity. Effects of both cohort entropy and phoneme
surprisal have been reported in behavioral measures of auditory word recognition (Baayen
et coll., 2007; Balling & Baayen, 2012; Bien et al., 2011; Kemps et al., 2005; Wurm et al.,
2006). Cependant, testing for such effects in behavioral data generally requires constructing a
cumulative measure of a phoneme-level variable across the course of the word or selecting the
variable’s value at just one phoneme position as the predictor. Therefore we restrict our focus
here to neural measures that have the temporal resolution to examine cohort entropy and pho-
neme surprisal effects on a phoneme-by-phoneme basis. We exclude two additional studies
(Di Liberto et al., 2019; Gwilliams et al., 2018), which did not report effects of cohort entropy
and phoneme surprisal separately, as well as a third study (Wang et al., 2021) in which results
are described as being inconsistent with a cohort entropy effect, even though cohort entropy
values are not used for comparison between critical conditions.
Tableau 1 demonstrates that phoneme surprisal and cohort entropy effects have very different
profiles across studies. Phoneme surprisal effects were reported in all studies that tested for
Neurobiology of Language
32
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
n
o
/
je
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
un
_
0
0
0
8
4
p
d
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Tableau 1.
Properties of the stimulus and experimental task for existing electrophysiology studies reporting phoneme surprisal or cohort entropy effects.
Phoneme
surprisal effect?
yes
Cohort entropy
effect?
Non
Stimulus
Experimental task
single words
pause detection
Étude
Gagnepain et al. (2012)
Ettinger et al. (2014)
Brennan et al. (2014)
Lewis and Poeppel (2014)
Gwilliams and Marantz (2015)
Kocagoncu et al. (2017)
Gaston and Marantz (2018)
Brodbeck et al. (2018)
Donhauser and Baillet (2020)
Gwilliams et al. (2021)
Gillis et al. (2021)
Brodbeck et al. (2022b)
yes
–
–
yes
–
yes
yes
yes
yes
yes
yes
yes^
Non
Non
–
yes^
yes*
yes
–
yes
yes
yes
Multimorphemic
words included?
Non
yes
Non
Non
yes
single words
lexical decision
single words
lexical decision
single words
lexical decision
single words
lexical decision
single words
nonword detection
not specified
three-word phrases
phrase acceptability
continuous speech
comprehension questions
continuous speech
comprehension questions
continuous speech
comprehension questions
continuous speech
comprehension questions
continuous speech
comprehension questions
yes
yes
yes
yes
yes
yes
Note. Dashes indicate studies that did not test for the specified effect. Superscripts indicate that a reported cohort entropy effect did not survive when phoneme surprisal was controlled for
(*), or that such a test was not performed (^).
UN
toi
d
je
t
o
r
oui
w
o
r
d
c
o
m
p
r
e
h
e
n
s
je
o
n
je
n
je
s
o
je
un
t
e
d
w
o
r
d
s
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
n
o
/
je
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
un
_
0
0
0
8
4
p
d
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
N
e
toi
r
o
b
o
o
g
oui
je
je
o
F
L
un
n
g
toi
un
g
e
3
3
Auditory word comprehension in isolated words
eux (Brodbeck et al., 2018, 2022b; Donhauser & Baillet, 2020; Ettinger et al., 2014;
Gagnepain et al., 2012; Gaston & Marantz, 2018; Gillis et al., 2021; Gwilliams et al.,
2021; Gwilliams & Marantz, 2015), and thus appear to be robust to variation in stimulus
and experimental task. Cohort entropy, in contrast, produces mixed results. Among studies that
presented single words and short phrases, three reported cohort entropy effects (Ettinger et al.,
2014; Gaston & Marantz, 2018; Kocagoncu et al., 2017) and three tested for but failed to find
eux (Brennan et al., 2014; Gagnepain et al., 2012; Lewis & Poeppel, 2014). The presence or
absence of multimorphemic words (words comprised of a root and at least one affix) dans le
study is potentially relevant, as the three studies that failed to find cohort entropy effects
included only monomorphemic words. Cependant, more important in our view is that the three
single-word studies that reported cohort entropy effects did not exclude the possibility that
these effects were due to the highly correlated phoneme surprisal measure. Gaston and
Marantz (2018) in fact found that their significant cohort entropy effect was no longer signif-
icant in a model that controlled for phoneme surprisal, and the other two studies (Ettinger
et coll., 2014; Kocagoncu et al., 2017) did not conduct such a test. In continuous speech, cohort
entropy effects were reported in all studies that tested for them (Brodbeck et al., 2018, 2022b;
Gillis et al., 2021; Gwilliams et al., 2021), with methods that controlled for effects of phoneme
surprisal. We conclude that, in the existing electrophysiology literature on speech recognition,
there is strong evidence for phoneme surprisal effects across the board, but for cohort entropy
effects only in continuous speech.
A true dissociation between cohort entropy and phoneme surprisal effects would indicate
not only that these measures index different levels of representation or processes, but also that
the activity that drives cohort entropy effects may be reduced or occur not at all during the
processing of single words, or at least not incrementally (c'est à dire., phoneme by phoneme). This is
not consistent with all processing steps being engaged in a fully automatic sequence during
speech recognition. Cependant, this interpretation of the prior literature is complicated by the
fact that many of these studies did not control for potential confounds, such as acoustic var-
iables and overlapping responses to different phonemes. Differences in statistical power or
analysis methods (which vary widely) may also have contributed to the apparent influence
of stimulus on cohort entropy effects.
The Current Study
Hypothesizing that cohort entropy and phoneme surprisal do, en effet, dissociate, et ça
cohort entropy effects do not occur for single words, we evaluated cohort entropy and pho-
neme surprisal effects on the neural response to speech in a simple single-word paradigm and
then directly compared these data to an existing continuous-speech data set (Brodbeck et al.,
2022b). Comparing single-word and continuous-speech data requires that the two types of
responses be evaluated with the same method. Analysis techniques traditionally applied to
single-word studies are not suitable for responses to continuous speech and generally fail to
account for acoustic and other confounding variables as well as the overlapping nature of
phoneme responses. Plutôt, we modeled source-localized MEG data with multivariate tem-
poral response functions (Chiffre 2), a method that deals with acoustic confounds and was orig-
inally developed for continuous speech. This allowed for novel comparison between single
words and continuous speech as well as a more accurate characterization of the single-word
response relative to previous analyses.
Participants heard a list of 1,000 monomorphemic words with an interstimulus interval of
267 ms and were asked to respond to randomly occurring semantic relatedness probes to
Neurobiology of Language
34
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
n
o
/
je
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
un
_
0
0
0
8
4
p
d
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
n
o
/
je
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
un
_
0
0
0
8
4
p
d
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
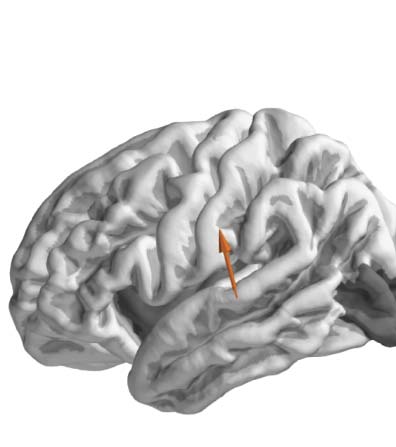
Chiffre 2. Multivariate temporal response function (mTRF) analysis of magnetoencephalography data. mTRF analysis models brain activity as
a continuous response to multiple concurrent predictor variables that describe the sequence of words. mTRF models were estimated separately
pour chaque sujet, and the resulting model fits were analyzed at the group level. (UN) For mTRF analysis, brain responses were analyzed as
continuous recordings, temporally aligned with the stimulus sequence of words, presented with a 267 ms interstimulus interval. Predictor
variables that quantify different properties of the stimuli were also continuous time series, aligned with the stimuli. Cohort entropy and pho-
neme surprisal were generated using impulses at phoneme onsets, scaled by the relevant quantity. Covariates included word and phoneme
onsets, an 8-band auditory envelope spectrogram (c'est à dire., eight predictors reflecting different frequency bands), and an 8-band auditory onset
spectrogram. (B) Neural activity was quantified as distributed minimum norm current estimates, c'est à dire., estimated currents at a grid of dipoles
covering the cortical surface. The analysis was restricted to the temporal, frontal, and parietal lobes (the dark shading indicates regions
excluded from the analysis). One dipole from one representative subject is used in this figure for illustration (brown arrow). (C) TRFs were
estimated using a coordinate descent algorithm to predict the neural signal from the predictor variables. Each predictor (UN), convolved with the
corresponding TRF (C), equals to a component of the predicted response (D). These response components are thus again aligned with the
stimulus, repeated at the top of (D). TRFs were estimated jointly, c'est à dire., each TRF, convolved with its corresponding predictor variable, predicted
a component of the neural activity, and the sum of these component responses is the predicted brain response (E). Model performance was
evaluated by the proportion of the variability in the measured response that was explained by the predicted response, using fivefold
cross-validation.
Neurobiology of Language
35
Auditory word comprehension in isolated words
ensure attention and motivate higher-level lexical processing (see Brodbeck et al., 2018, sur
the lack of lexical effects in unattended speech). Models were fit using fivefold cross-validation
in each subject separately. We evaluated the models by the proportion of variability they
explained in the source-localized MEG recordings, correcting for multiple comparisons using
threshold-free cluster enhancement (Forgeron & Nichols, 2009). Unless noted specifically, anal-
yses were performed on the surface of the temporal, frontal, and parietal lobes combined
(excluded areas are shaded in Figure 2B).
MATERIALS AND METHODS
Participants
We collected MEG data from 24 people. Sample size was chosen in accordance with the
previous studies cited in Table 1. All participants were right-handed, native speakers of
English, and seven were also native speakers of additional languages. None reported a his-
tory of neurological or linguistic impairment, brain injury, or hearing loss. All reported nor-
mal or corrected-to-normal vision. The procedure was approved by the Institutional Review
Board at the University of Maryland, College Park, and all participants provided written
informed consent. Participants were compensated with their choice of $15 or one course
credit per hour of participation. The full session (including another, unrelated study) lasted
2 hr.
One data set was excluded before data processing because of participant fatigue and an
earbud falling out during the experiment. After this exclusion, we computed accuracy on
the semantic relatedness task and excluded any participant with accuracy lower than a cutoff
one standard deviation below the mean. This excluded three of 23 participants and provides
assurance that the included participants were accessing lexical information above the word-
form level. After preprocessing, two additional data sets were excluded due to excessive
magnetic noise. Eighteen data sets are therefore included in our analysis. Raw data are avail-
able at doi:10.18112/openneuro.ds004276.v1.0.0.
Stimuli
Our stimuli were word recordings from the Massive Auditory Lexical Decision (MALD) data-
base (Tucker et al., 2019), which includes the timing of phoneme boundaries as determined by
a forced aligner. The set of 1,000 words we selected had no missing variables in the database
and were monomorphemic per MALD, the CELEX lexical database (Baayen et al., 1995), et
first author judgment. We excluded all items with the following labels in MALD: Preposition,
Interjection, Nom, Unclassified, Conjunction, Pronoun, Determiner, Letter, Not, Ex, Article,
À. We also removed items with the 10% lowest frequency values, and we excluded homo-
phones, inappropriate and particularly evocative words, and any item for which the pronun-
ciation in the recording was noticeably divergent from American English. The full lists of
stimuli and semantic relatedness probes (see below), as well as associated stimulus variables
from MALD, are available at osf.io/u56ea/.
Procedure
The study was always the second of two experiments in a session. Before the MEG recording,
we used a Polhemus 3SPACE FASTRAK (Polhemus, 2012) to digitize participant head shapes
as well as the positions of five affixed marker coils. These marker coils were used to record
head position relative to the MEG sensors before and after each study in the session. Nous
Neurobiology of Language
36
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
n
o
/
je
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
un
_
0
0
0
8
4
p
d
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
recorded continuous MEG data, inside a magnetically shielded room, with a 160-channel
axial gradiometer whole-head system (Kanazawa Institute of Technology, Kanazawa, Japan).
Our sampling rate was 1000 Hz, and we used an online 60 Hz notch filter and 200 Hz
low-pass filter.
Participants lay supine and looked at a screen overhead, while holding a button box in
each hand. They wore foam earbuds and volume was adjusted to their comfort level. Nous
instructed participants that they would hear a long series of random words and that they
should simply listen to the words while watching for probe words that would randomly appear
on the screen with a question mark. They were instructed to press a button (with left hand for
“No” and right hand for “Yes”) to indicate whether the word on the screen was related in any
way to the word they had heard just before it. Because probe words were unpredictable, good
performance on the task requires lexical-syntactic and conceptual information access to have
occurred for most stimuli.
We used Presentation (Neurobehavioral Systems, 2022) to present the experiment. Notre
parameter and scenario files are available on OSF (https://osf.io/u56ea/). Il y avait 1,000
auditory trials interspersed pseudorandomly with 97 semantic relatedness probe trials. Le
amount of time between trials was 267 ms. A visual fixation cross was on screen continuously
during auditory trials and during the intertrial interval. Each auditory trial simply consisted of
presentation of the auditory stimulus and lasted the length of the auditory stimulus. Visual
probe trials were pseudorandomly distributed with a maximum interlude of 20 trials between
probes. The probe (par exemple., “podium?») stayed on the screen until the participant pressed a button
to answer.
We selected this task so that it would apply equally well to all types of words and because
we did not want button presses to occur on critical trials (as would happen in, par exemple., lexical
décision). The probe trials for which we expected participants to answer “No” were selected
randomly from the list of eligible words that we did not end up using for auditory trials. Probe
trials for which we expected participants to answer “Yes” were synonyms taken from the
WordNet (https://wordnet.princeton.edu) page of the preceding auditory item and were also
monomorphemic so as not to be trivially distinguishable from “No” trials. There was no
overlap between probe words and words used in auditory trials. Which auditory trials would
be followed with a probe were randomly selected. “Yes” and “No” probes were equally
distributed.
The experiment lasted roughly 17 min. There was no built-in break, but participants were
instructed that if they wished to take a break, they should simply delay their button press on a
probe trial.
Data Preprocessing
We processed the data using mne-python Version 0.22 (Gramfort et al., 2013, 2014) et
Eelbrain Version 0.34 (Brodbeck et al., 2019). Code for processing and analysis can be
accessed via https://osf.io/u56ea/.
During file conversion with mne-python’s kit2fiff GUI, we excluded any faulty marker mea-
surements. We co-registered each digitized head shape with the Freesurfer (Fischl, 2012)
“fsaverage” brain, using mne-python’s co-registration GUI. We first used rotation and transla-
tion to align the digitized head shape and average MRI by the three fiducial points. We then
used rotation, translation, and three-axis scaling to minimize the distance between digitized
head shape and average MRI points using the iterative closest point (ICP) algorithme.
Neurobiology of Language
37
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
n
o
/
je
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
un
_
0
0
0
8
4
p
d
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
Convergence was always achieved within 40 iterations. For one participant, outlying points on
the digitized head shape were removed between fitting to the fiducials and applying ICP.
Flat channels were automatically removed, and we used temporal signal space separation
(Taulu & Simola, 2006) for removal of extraneous artifacts, with a buffer duration of 10 s. Nous
then band-pass filtered the recordings between 1 et 40 Hz (mne-python default settings) et
used independent components analysis (ICA), with the extended infomax method, for removal
of ocular, cardiac, and other extraneous artifacts. Components were selected manually based
on their topography and time course. After removing artifactual ICA components, we further
low-pass filtered the data at 20 Hz, cropped it from 1 s before the first word to 2 s after the last
word, and down-sampled it to 100 Hz.
To compute a noise covariance matrix, we used 2 min of empty room data recorded before
or after each session. We defined the source space on the white matter surface with a fourfold
icosahedral subdivision, avec 2,562 sources per hemisphere. Orientation of the source dipoles
was fixed perpendicular to the white matter surface. Continuous data were source localized
with the regularized minimum norm estimator (λ = 1/6). The use of signed current estimates
ensures that the expected (mean) value of the noise is 0, making this method suitable for
single-trial source localization.
Analysis
Behavioral data
Mean accuracy was computed after the exclusion of one participant a priori. The mean num-
ber of correct probe responses was 73.6 (out of 97) with a standard deviation of 18.4. Le
number of correct probe responses was lower than one standard deviation below the mean
for three participants, so they were excluded from further analysis. One participant answered
13 de 97 probes correctly. We kept this participant in the data set because this was so far below
chance that the only plausible explanation seemed to be that they had reversed which hand
they were supposed to use to make “yes” and “no” responses.
Predictors for neural data
For each acoustic or linguistic variable of interest used as a predictor of the neural response
(see list below), a time series was created indicating the value of the predictor at each time
point in the experiment. Our study did not actually present a single continuous stimulus
(rather, we presented individual words with short intervening pauses), but a single time series
reflecting predictor values (or pauses) throughout the entire experiment could still be created
(see Figure 2A). Probe trials were modeled simply as silence. The timing of phoneme onsets
was taken from the forced aligner information made available with the MALD recordings.
For acoustic predictors (envelope and onset spectrogram), the value of the predictor could
vary continuously at each time point of the stimulus. Linguistic predictors consist of impulses
at phoneme onsets only and thus have a value of zero at all other points in the stimulus. De la
lexical predictors, phoneme onset and word onset each consist of binary impulses, alors que
entropy and phoneme surprisal consist of impulses that are scaled continuously according
to the entropy or surprisal value of that phoneme.
Acoustic envelope spectrogram. A gammatone spectrogram (Heeris, 2013) was computed for
each stimulus waveform with 256 channels regularly spaced in equivalent rectangular band-
width space between 20 et 5000 Hz. These spectrograms were resampled to 100 Hz to
match the MEG data and binned into eight equally spaced frequency bands.
Neurobiology of Language
38
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
n
o
/
je
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
un
_
0
0
0
8
4
p
d
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
Acoustic onset spectrograms. The high-resolution gammatone spectrograms were processed
with an algorithm for acoustic edge extraction (Brodbeck et al., 2020; Fishbach et al.,
2001). The onset spectrograms were also resampled to 100 Hz and binned into eight bands.
Word onsets. Word onsets were represented as a single, equally valued impulse at the onset of
every word, as determined from the forced alignments. These were included to control for
responses that uniformly occur time-locked to speech onset for all words.
Phoneme onsets. Phoneme onsets (excluding phonemes that were also word onsets) were rep-
resented as equally valued impulses on a single predictor time series that included all remain-
ing phoneme positions. These were included to control for responses that occur time-locked
from phoneme onset but do not scale with surprisal and entropy.
Phoneme surprisal and cohort entropy. These variables were calculated based on an implemen-
tation of the cohort model of word perception (Marslen-Wilson, 1987), as in Brodbeck et al.
(2018). Initially, a dictionary was created combining frequency information from SUBTLEX
(Brysbaert & Nouveau, 2009) with pronunciations (phoneme sequences) from the CMU Pronounc-
ing Dictionary (Weide, 1994), adding any pronunciations for stimuli that were missing from the
CMU dictionary. This dictionary was then used to compute the set of words compatible with
the input so far for each word at each phoneme position. These cohorts, together with the
SUBTLEX frequencies, were used to compute a probability distribution over possible words
for each phoneme position. The cohort entropy predictor contained an impulse at each pho-
neme onset, scaled by the entropy of that cohort. The phoneme surprisal predictor contained
an impulse at each phoneme onset scaled by the surprisal of that phoneme, based on the pos-
terior probability of that phoneme given the preceding phoneme’s cohort.
mTRF analysis
An mTRF maps a set of predictor variables to a single outcome time series. Ici, independent
mTRFs were estimated for each subject and for each virtual current source of source-localized
MEG data (voir la figure 2). The neural response at time t, represented as yt, is predicted jointly
from N predictor time series, represented as xi,t, convolved with a corresponding mTRF, rep-
resented as hi,τ, with weights for all N predictors at a range of delays T:
^y t
¼
XN
XT
je
τ
Salut;τ (cid:3) xi;t−τ
mTRFs were generated from a basis of 50 ms wide Hamming windows centered at Tbasis =
[−100, …, 1000) ms. All responses and predictors were standardized by centering and divid-
ing by the mean absolute value.
For a given set of predictors, the predictive power was estimated through fivefold cross-
validation. For this, the continuous data and corresponding predictors were split into five con-
tiguous partitions of equal length. The neural responses of each partition were predicted with
an mTRF trained on the remaining four partitions to minimize ‘1 error. Within each set of four
training partitions, each partition in turn served as validation data once. Thus four mTRFs were
estimated based on coordinate descent, with early stopping based on the validation data
(David et al., 2007). The validation data were used to selectively stop training predictors when
they caused an increase in error in the validation set. Those four mTRFs were then averaged to
predict the responses to the unseen (fifth) test segment.
Neurobiology of Language
39
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
n
o
/
je
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
un
_
0
0
0
8
4
p
d
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
For evaluating the predictive power of phoneme surprisal and cohort entropy, we com-
pared the predictive power of the full model with that of a model that was identical except
for not including the predictor under investigation. Together with the cross-validation, ce
assures a conservative estimate of the unique predictive power of the predictor under inves-
tigation, while controlling for the predictive power of all the other variables. The anatomical
maps of explanatory power of the two models were smoothed (Gaussian kernel, SD = 5 mm)
and compared using a mass-univariate related measures t test based on threshold-free cluster
enhancement (TFCE; Forgeron & Nichols, 2009), with a null distribution based on 10,000 random
permutations of condition (model) labels.
For analysis of the individual predictor TRFs, the five estimates of the TRFs from the five dif-
ferent test partitions were averaged in each subject. To visualize the TRF current over time, le
TRF was restricted to the anatomical region of interest (ROI) defined as the area in which the
surprisal predictor significantly improved predictions (p ≤ 0.05 corrected with TFCE). To visu-
alize TRF amplitudes, the absolute values of the TRFs were averaged across the anatomical ROI
(see Figure 5A in Results section). To visualize the anatomical distribution, the absolute values of
the TRF were averaged across a given time window and subjects, and the resulting images were
smoothed with a Gaussian kernel (SD = 5 mm; see Figure 5B). To visualize current direction, le
TRFs were further analyzed using principal component analysis (see Figure 5C and D). Within
the same area, defined based on significance of the surprisal predictor, and separately for each
hemisphere and each participant, principal component analysis was applied to the surprisal TRF,
such that the TRF was decomposed into different time courses, each with a specific anatomical
distribution. To visualize the dominant trend in the TRFs, the first principal component was ana-
lyzed, c'est à dire., a single spatial topography and corresponding time course for each participant.
The advantage of this approach over the amplitude analysis is that the signed current direc-
tion can be visualized. Because the sign of a principal component is arbitrary, the components
were aligned across subjects such that the average current vector was pointing upward. Pour
components whose average current vector pointed downward, both component and time
course were multiplied by −1.
The TRF time course was then evaluated in each hemisphere using a mass-univariate one-
sample t test with TFCE, with the null hypothesis that the average current direction is random
(c'est à dire., not different from 0). The null distribution was based on the maximum statistic in 10,000
random permutations of the signs. To test for hemispheric differences, a mass-univariate
repeated measures t test with the same parameters was used.
Status of the first phoneme
Two previous studies did not find evidence for surprisal and entropy effects related to the first
phoneme of each word (Brodbeck et al., 2018; Gaston & Marantz, 2018). Cependant, depuis
neither study actually showed a significant difference between surprisal or entropy effects at
first vs. subsequent phonemes, we here performed a preliminary analysis to determine whether
surprisal and entropy at word-initial phonemes should be modeled separately from at subse-
quent phonemes. To this end, we compared the model treating all phonemes uniformly (comme
depicted in Figure 2) to a model in which surprisal and entropy at the first phoneme were
modeled as separate predictors from surprisal and entropy at noninitial phonemes. The more
complex model, in which they were modeled separately, was not significantly better (p =
0.341, multiple comparison correction in bilateral temporal lobe only). We therefore pro-
ceeded with the simpler model in which surprisal and entropy at initial phonemes are not
modeled separately (as shown in Figure 2).
Neurobiology of Language
40
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
n
o
/
je
/
je
un
r
t
je
c
e
–
p
d
F
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
un
_
0
0
0
8
4
p
d
.
je
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
Overall model performance
We assessed the overall performance of the full model in held-out data by averaging relevant
performance metrics across subjects, and then reporting the maximum across the brain. Le
full model explained 2.9% of the variability of the source-localized MEG responses at the best
current dipole. A more common metric is the correlation between the predicted and the actual
MEG signal, which reached r = 0.25, in line with previous studies.
Comparison with connected speech
For this comparison, data from 12 participants listening to 47 min of a nonfiction audiobook
were used (for more details see Brodbeck et al., 2022b; data available via Brodbeck et al.,
2022un). The two data sets had one participant in common. Data were acquired on the same
MEG equipment and processed and analyzed with analogous procedures, with one exception:
For estimation of the mTRF models, data were split into four partitions instead of five. This was
done to speed up computations (requiring training of fewer models) and because the longer
recording resulted in more training data per participant. Audiobook stimuli were labeled using
the Montreal Forced Aligner (McAuliffe et al., 2017), and predictor variables were generated
as for the single-word data.
The audiobook data set included more data per participant, raising the concern that larger
effect sizes would be expected just because of the larger amount of data. In total, a participant
in the single-word experiment heard 1,000 words with a total of 4,889 phonemes, whereas the
connected speech stimuli contained 27,810 phonemes. To address this, we repeated the com-
parison between experiments with a subset of the continuous-speech data. A similar number
of phonemes could be achieved by combining segments 5 et 6 of the audiobook stimulus
(4,964 phonemes). Fivefold cross-validation was used for this analysis just as for the single-
word experiment.
RÉSULTATS
To ensure that responses reflect attentive lexical processing, we applied behavioral exclusion
criteria (see Materials and Methods, though note that statistical outcomes do not change when
behavioral exclusions are not applied). Subjects included in the analyses presented here
responded accurately to at least 69% of relatedness probes (group mean 82.9%).
To test whether phoneme surprisal and cohort entropy improve the estimated neural
response in a single-word design, we fitted three separate TRF models: the full model depicted
in Figure 2, un (otherwise identical) model missing the surprisal predictor, and an (otherwise
identical) model missing the entropy predictor. To control for responses associated with differ-
ent aspects of speech processing, all models included an acoustic envelope spectrogram, un
acoustic onset spectrogram, and word and phoneme onsets. We found that the full model was
significantly better than the model without phoneme surprisal (p < 0.001), indicating that pho-
neme surprisal explains a component of the brain responses that none of the other included
variables could explain. However, comparison with the model lacking cohort entropy led to
no significant difference (p = 0.260, see Figure 3A and B). The difference between the two
variables was reliable: The model improvement due to surprisal (i.e., the explanatory power
of surprisal) was significantly larger than that due to entropy (p = 0.007).
This finding contrasts with previously reported results in connected speech (see Table 1). To
address this apparent difference, we compared our single-word data to an existing continuous-
speech data set (Brodbeck et al., 2022b) that consisted of recordings from 12 participants
listening to 47 min of an audiobook and had been acquired with the same MEG scanner.
Neurobiology of Language
41
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
a
_
0
0
0
8
4
p
d
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
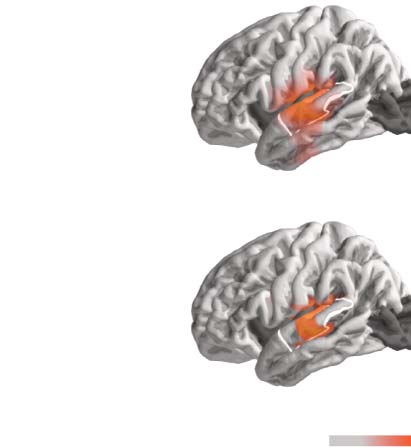
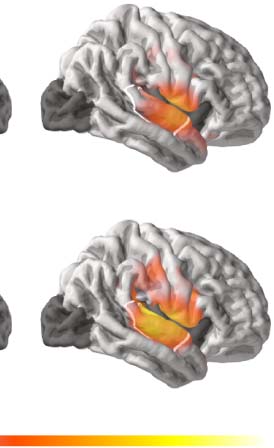
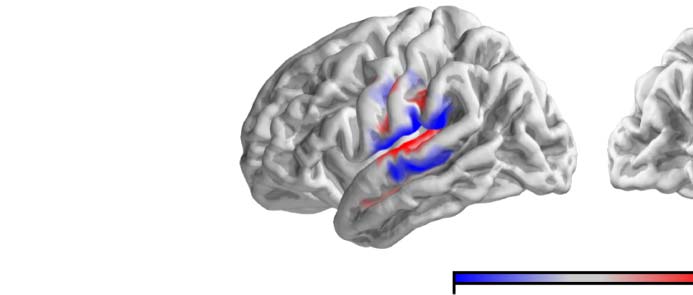
Figure 3. Model evaluation and comparison to continuous speech. The anatomical plots (A, D) show regions where the given predictor
significantly improved the model fit (p < 0.05, corrected). The white outline indicates an anatomical region of interest (ROI) defined as the
posterior two thirds of the superior temporal gyrus. The swarm plots (B, C) show average proportion of variability in that ROI that is uniquely
explained by entropy or surprisal, respectively. Each dot represents one participant. The black dot represents a single participant that took part
in both experiments. While surprisal improves the model fit in both experiments in almost all participants, entropy does so only in the
continuous-speech data. Explained variability (explanatory power) is expressed as percentage of the maximum variability explained by the
full model in the single-word data.
The correlation between the surprisal and entropy values over all phonemes was similar in the
two data sets (single words: r = 0.39; continuous speech: r = 0.41). Using closely matched
analysis methods, we found that, for the continuous-speech data (see Figure 3C and D),
phoneme surprisal significantly improved the model (p < 0.001) and cohort entropy did as
well (p < 0.001). In the whole brain analysis, the explanatory power of phoneme surprisal
and cohort entropy did not differ significantly (p = 0.720).
To confirm that this difference between experiments was statistically meaningful, we com-
pared the two data sets directly. We extracted the mean of the model fit metric in an anatom-
ically defined ROI, including the posterior two thirds of the superior temporal gyrus of each
hemisphere. This value did not differ between the left and right hemisphere ROIs in any of
the four categories (surprisal/entropy, single words/continuous speech; all t ≤ 1.74, p ≥
0.110), so we averaged the values for the two hemispheres. The conclusion that there is a dif-
ference between experiments would follow from an interaction between cohort measure (sur-
prisal vs. entropy) and experiment (single words vs. continuous speech). However, due to the
different effect sizes between experiments, the additive model underlying ANOVA may not be
appropriate. Instead, we calculated the ratio between the predictive power of entropy and
surprisal for each participant, and then across participants compared this ratio between contin-
uous speech and single words. This ratio was significantly higher for continuous speech than for
single words (continuous speech M = 0.68, SD = 0.45; single words M = 0.10, SD = 0.59; t28 =
2.80, p = 0.009). Based on this difference in ratio, we reject the null hypothesis that surprisal
and entropy make equal relative contributions to the explanatory power of the models in the
two experiments. Consistent with this conclusion, effect sizes for predictive power in the ROI
were large for surprisal in both paradigms (single words: d = 1.62; connected speech: d = 2.14)
but for entropy only in connected speech (d = 1.72) and not in single words (d = 0.39).
To test that this effect was not due to the unequal amounts of data in the two experiments,
we performed a follow-up analysis with a subset of the continuous-speech data. Stimulus seg-
ments 5 and 6 of the continuous-speech experiment together contained 4,964 phonemes,
comparable to the 4,889 phonemes in the single-word experiment. Figure 4 shows the
Neurobiology of Language
42
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
a
_
0
0
0
8
4
p
d
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
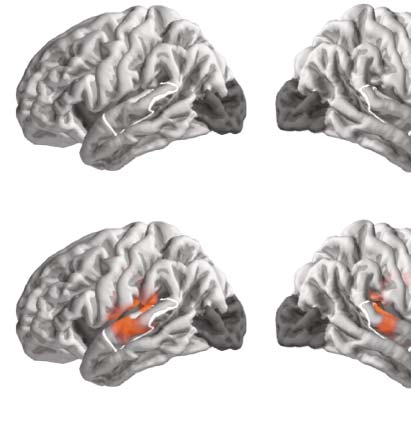
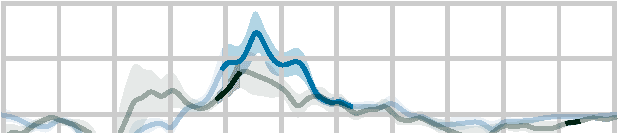
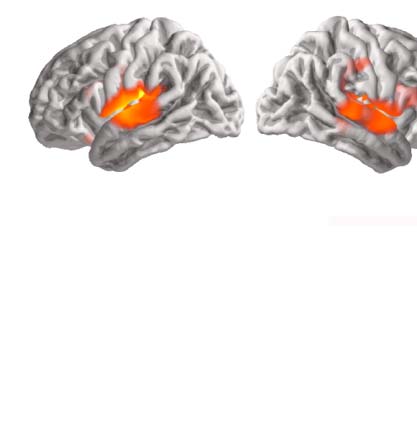
Figure 4. Comparison between single words and continuous speech when number of phonemes is
matched. Matching the number of phonemes between experiments leads to more comparable effect
sizes, but does not change the primary conclusions. Details are the same as in Figure 3B and C but
using only a subset of the data from the continuous-speech experiment, so that the number of pho-
nemes heard by each participant is matched between the two experiments.
comparison between experiments when number of phonemes was matched. As expected, this
reduction in the amount of data led to a reduction in effect sizes for continuous speech
(surprisal: d = 1.45; entropy: d = 1.36), but it did not change the main result: The ratio between
entropy and surprisal was still higher in the continuous-speech data than in single words
(continuous speech: M = 1.01, SD = 0.73; vs. single words: t28 = 3.67, p = 0.001).
A further concern is that isolated monosyllabic words may be too short to engage higher-
level processes. If it is only multisyllabic words that engage processes giving rise to cohort
entropy effects, then this could lead to an imbalance between entropy and surprisal effect size
in the whole single-word data set. To address this, we re-analyzed the single-word data with
separate entropy and surprisal predictors for mono- and multisyllabic words (the stimuli con-
tained 453 mono- and 547 multisyllabic words). The overall predictive power was reduced as
expected due to the reduced amount of training data, especially for monosyllabic words
(which contain fewer phonemes). However, the overall pattern remained the same, with
higher predictive power for surprisal than entropy (average in the ROI, monosyllabic: t28 =
2.42, p = 0.027; multisyllabic: t28 = 5.06, p < 0.001).
Finally, we examined the nature of the estimated response functions for phoneme surprisal
in the single-word data set (Figure 5). The analysis of the TRFs was restricted to a mirror-
symmetric anatomical region, based on the area in which surprisal significantly improved
the model fit in at least one hemisphere. The overall TRF amplitude exhibited two broad peaks,
centered on approximately 100 and 350 ms latency (Figure 5A). The anatomical distribution of
estimated currents in both peaks is consistent with primary sources in the bilateral superior
temporal gyrus (Figure 5B). In order to visualize the direction of the source currents, we
extracted the first principal component of the TRF for each participant and each hemisphere
(Figure 5C and D). Figure 5D shows the average anatomical distribution of the first principal
component across subjects. The result in both hemispheres is consistent with a current dipole
in auditory cortex, whose average direction is indicated by the arrows in Figure 5D. The cor-
responding time course, visualized in Figure 5C, indicates that the early peak had an upward
Neurobiology of Language
43
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
a
_
0
0
0
8
4
p
d
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
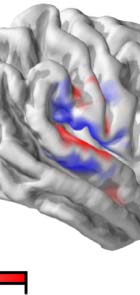
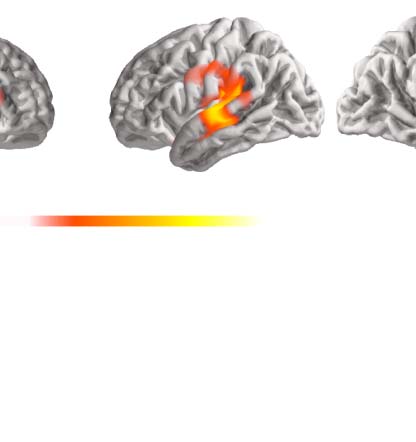
Figure 5. Temporal response function (TRF) to phoneme surprisal in isolated words. (A) Response amplitude, plotted separately for each
hemisphere, summed across all sources in a symmetric region of interest (ROI) defined from significant model improvement due to surprisal
in at least one hemisphere. Responses are shown at the normalized scale used for model fitting and with arbitrary units. TRFs exhibit two broad
peaks in time. The two black horizontal bars indicate time windows for anatomical plots in panel B. Shaded bands indicate the within-subject
standard error of the mean. (B) Average response amplitude during two peaks in the TRF, suggesting primary sources in the superior temporal
gyrus of both hemispheres. Unlike the other plots in this figure, plots in this panel are not constrained to the ROI. (C) To visualize current
direction over time, the TRF from each subject was decomposed using principal component analysis, separately for the left and the right
hemisphere. The plot shows the average time course of the first principal component across subjects. Opaque line segments indicate time
ranges in which the respective TRF is significantly different from zero. (D) Average anatomical distribution of the first principal component. The
color indicates current on the cortical surface, directed into or out of the brain. The average current direction for each hemisphere, indicated
by the arrows, is consistent with auditory cortex activity.
current direction, while the second peak was dominated by downward current. This time
course was further analyzed with mass-univariate t tests, correcting for the time range from
0 to 1,000 ms. Even though activity in the early peak did not reach significance in the right
hemisphere, the difference between hemispheres was not significant (p = 0.063, at 70 ms).
DISCUSSION
This study examined cohort entropy and phoneme surprisal effects in a single-word paradigm
using an mTRF analysis, modeling both acoustic and linguistic predictors of neural activity. We
found that phoneme surprisal is a significant predictor of neural activity during speech recog-
nition, as have many previous studies (Brodbeck et al., 2018, 2022b; Donhauser & Baillet,
2020; Ettinger et al., 2014; Gagnepain et al., 2012; Gaston & Marantz, 2018; Gillis et al.,
2021; Gwilliams et al., 2021; Gwilliams & Marantz, 2015). The spatial distribution of the effect
along the superior temporal gyrus is also consistent with previous work. The TRF for phoneme
surprisal in our study appears to peak twice, in line with Gwilliams and Marantz (2015),
Gaston and Marantz (2018), and Brodbeck et al. (2022b).
In contrast to the robust effect of phoneme surprisal, we did not observe a significant effect
of cohort entropy. In a direct comparison to our single-word data set, we analyzed an existing
continuous-speech data set (Brodbeck et al., 2022b) in the same manner, and found effects of
both phoneme surprisal and cohort entropy. The ratio of the predictive power between entropy
and surprisal differed significantly between the two experiments. The direct comparison of
these two data sets substantiates our generalization about the existing literature, that cohort
Neurobiology of Language
44
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
a
_
0
0
0
8
4
p
d
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
entropy effects are weak or nonexistent in studies that use single words or short phrases, while
they are robust in studies that use continuous, naturalistic speech as stimuli.
How could this dissociation between phoneme surprisal and cohort entropy occur? As
reviewed in the Introduction, it is frequently assumed that speech input triggers a relatively
automatic and uniform process including incremental activation of phoneme, wordform,
lexical-syntactic, and conceptual units. However, if the same neural process is engaged for
word recognition in single words and in continuous speech, then the neural response should
also reflect the same lexical properties. This would predict cohort entropy effects for any task
involving word recognition. If anything, prevailing assumptions might lead one to expect that
lexical uncertainty would be lower when additional context is available (potentially minimiz-
ing cohort entropy effects in continuous speech). Importantly, however, cohort entropy
depends not only on the number of lexical candidates but the distribution of probability
among them, and so should not be systematically impacted in this way even when context
is accounted for. To make sense of the dissociation that we observed, with stronger cohort
entropy effects in continuous speech, in the following sections we hypothesize that (1) brain
responses related to phoneme surprisal and cohort entropy arise from different levels of
representation or different subprocesses, and (2) their dissociation implies a break in the
automatic sequence of processing involved in word recognition.
Non-automaticity in the Lexical Access Sequence
The pattern of dissociation that we observed could have several different explanations, con-
tingent on the precise neural processes indexed by cohort entropy and phoneme surprisal. In
Figure 6A, we reproduce our illustration from Figure 1 of a fully automatic processing
sequence in response to each phoneme of speech input. In Figure 6B–D, we illustrate
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
a
_
0
0
0
8
4
p
d
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Fully automatic vs. alternative processing sequences in response to each phoneme of speech input. (A) Fully automatic processing
Figure 6.
sequence in which both phoneme surprisal and cohort entropy effects arise. (B–D) Proposed partial processing sequences in which phoneme
surprisal but not cohort entropy effects occur. Red diamonds indicate processes or levels of representation that might be delayed or suspended
from incremental (phoneme-locked) processing during recognition of single words. As in Figure 1, straight arrows indicate connections
between levels of representation. Curved arrows indicate a within-level competition/selection process.
Neurobiology of Language
45
Auditory word comprehension in isolated words
alternatives to this sequence that might better represent what occurs incrementally in single-
word paradigms that do not elicit cohort entropy effects. It is possible that the decoupled
processes do not occur at all in single-word processing; alternatively, they could be engaged
sporadically, engaged much later (beyond the 1,000 ms window captured by the TRF), or
engaged in a less strictly incremental, time-locked manner rather than on a phoneme-by-
phoneme basis.
One possible explanation for the dissociation is based on the reasoning that cohort entropy
is specifically a measure of the amount of lexical competition occurring (Gagnepain et al.,
2012). We can imagine a scenario in which initial activation of multiple lexical candidates
is automatic, but the competitive process of winnowing out the weaker candidates is applied
only when rapid selection of a single best candidate is particularly helpful or necessary for the
task at hand. Accordingly, phoneme surprisal effects might require only activation of, for exam-
ple, the wordform level of representation, rather than the competition process that occurs
within that level (a scenario illustrated by Figure 6B, in which within-level competition pro-
cesses are not occurring above the phoneme level). In contrast, cohort entropy effects would
reflect the competitive selection process that allows a single best candidate to be identified as
early as possible, and this process might be engaged only when faced with the time pressure of
processing connected speech.
Another possibility is that phoneme surprisal and cohort entropy effects reflect different
levels of representation that are not all automatically accessed to the same degree. Access
to “lower” levels of representation, such as phoneme or wordform representations, might be
more automatic, whereas access to “higher” levels of representation, such as lexical-syntactic
or conceptual units, might be more dependent on context and task demands. For instance,
surprisal effects might require only wordform-level activation, while cohort entropy effects
might require lexical-syntactic activation or higher. Similarly, phoneme surprisal effects could
implicate up to lexical-syntactic activation while cohort entropy effects require conceptual
activation or higher. These two possibilities are illustrated in Figure 6C and Figure 6D, respec-
tively. Consistent with such an explanation, semantic priming from partial wordforms seems to
be more reliable in connected speech (Zwitserlood, 1989) than in a single-word lexical-
decision paradigm, where form-based priming predominates (Gaskell & Marslen-Wilson,
2002). Even within a single-word paradigm, Bentin et al. (1993) argue that the extent to which
a task requires semantic processing can influence the degree of semantic priming that occurs,
as indexed by the N400 response.
Though less likely, we can acknowledge two alternative explanations in which phoneme
surprisal effects do not reflect the activation of wordform representations while cohort entropy
effects do. We consider these explanations less likely because they would imply an absence of
incremental wordform-level processing in the single-word tasks, despite behavioral evidence
to the contrary. One possibility is that apparent phoneme surprisal effects arise due to prelex-
ical phonotactic processing, involving representations sensitive to the probability of phoneme
sequences in the language independent of wordform representations. The second possibility
arises from the proposal of Norris and McQueen (2008) that “off-line” perceptual learning
could lead to wordform frequency effects on phoneme probability without concurrent word-
form activation causing online top-down effects. In either of these scenarios, a phoneme
surprisal effect does not necessarily imply wordform activation; cohort entropy could reflect
anything at the wordform level or above.
It also remains possible that correlations between neural activity and cohort entropy are not
driven by lexical competition or uncertainty per se but by a secondary process that is sensitive
Neurobiology of Language
46
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
a
_
0
0
0
8
4
p
d
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
to lexical competition or uncertainty. If that process is engaged only by continuous speech,
cohort entropy effects would also appear to be modulated, despite lexical processing in either
case. A clear contender for such a secondary process emerges from outside the domain of
language. Neural effects of entropy have been hypothesized to reflect heightened sensitivity,
via increased post-synaptic gain, to bottom-up sensory inputs in high-uncertainty contexts
(Donhauser & Baillet, 2020; Feldman & Friston, 2010; Friston, 2005; Strange et al., 2005).
To maintain this hypothesis while integrating our findings, it must be admitted that this top-
down modulation is not obligatory: The effect of surprisal in our study provides evidence that
linguistic representations above the phoneme were engaged, and yet we did not see the effect
of entropy associated with the hypothesized sensitization to the bottom-up input. Our results
do not directly speak to whether the entropy effects arise due to sensitization to the input, or
due to neural activity at a different level of processing. However, in either case, the results
suggest that there is a neural process that leads to this modulation of brain activity in contin-
uous speech, but not in single words.
Single Words vs. Continuous Speech
What are the differences between single-word paradigms and continuous speech that would
make any of the distinctions described in the previous section possible? First, the reliable pres-
ence of pauses between words in single-word studies may constitute a key change in task
demands, by leaving sufficient time for full lexical access to occur after wordform offset and
before the next wordform begins and thus reducing the necessity for incremental processing.
Early competitive selection might be unnecessary, and/or access to higher-level syntactic and
conceptual units could be deferred until the pause makes the auditory wordform uniquely iden-
tifiable. Among the single-word studies we have reviewed, the pause detection (Gagnepain
et al., 2012) and nonword detection (Kocagoncu et al., 2017) tasks incorporate lengthy inter-
stimulus intervals averaging 2,000 ms, and the lexical decision studies (Brennan et al., 2014;
Ettinger et al., 2014; Gwilliams & Marantz, 2015; Lewis & Poeppel, 2014) wait for a participant
response after each word. Our study used a shorter but still considerable interstimulus interval
of 267 ms with only occasional semantic relatedness probes and also did not find a cohort
entropy effect.
Second, the syntactic and semantic structure in continuous speech provides another moti-
vation for incremental processing: Rapid access to lexical and conceptual content for the
current word provides information that might aid recognition of the subsequent word. This
rationale for rapid processing is absent in single-word paradigms that lack structure. Even
beyond not requiring speed in lexical or conceptual access, the tasks employed in single-word
paradigms may in some cases not require lexical or conceptual access at all. For instance, our
task involved semantic relatedness judgments with written probes. It is conceivable that this
task might be solved successfully by temporarily “buffering” the input from each word as a
form-based representation, and only accessing conceptual representations if a probe occurs,
rather than accessing lexical and conceptual representations for every stimulus. By contrast,
the speed of continuous speech, its many between-word dependencies, and the imperative to
build sentence-level and message-level interpretations could be what drive competition or
incremental higher-level activation (and therefore cohort entropy effects) in naturalistic
paradigms.
We might expect that cohort entropy effects could be observed for single words if a task
were designed such that earlier identification of the word is encouraged and incremental
higher-level activation becomes more advantageous, whether via the elimination of pauses
Neurobiology of Language
47
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
a
_
0
0
0
8
4
p
d
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
or by the addition of some higher-level structure. Likewise, pauses could be added to contin-
uous speech. The three-word phrases used by Gaston and Marantz (2018; e.g., “to chew
gum,” “the shredder broke”) are an interesting test of these hypotheses, as they lack within-
phrase pauses and have syntactic and semantic structure. Nevertheless, Gaston and Marantz
did not find cohort entropy effects when their cohort entropy variables were evaluated in the
same model as phoneme surprisal. This suggests that only longer sequences of continuous
speech elicit cohort entropy effects, and therefore that a buffering process may play a medi-
ating role here. Speech rate (almost certainly higher in studies using continuous speech) may
also be relevant.
Another line of investigation for understanding what drives neural cohort entropy effects
might involve the contrast between monomorphemic and multimorphemic words. The two
types of stimuli can be closely matched in length (itself another factor to consider), but only
multimorphemic words can be viewed as structured sequences of units of meaning of the kind
that might encourage more incremental processing. The inclusion of multimorphemic words
in a single-word study could thus motivate earlier selection and higher-level activation so that
initial morphemes can be recognized in time to begin processing any potential subsequent
morphemes. In Table 1 we noted that all single-word studies that do not include multimorphe-
mic words also do not report cohort entropy effects (Brennan et al., 2014; Gagnepain et al.,
2012; Lewis & Poeppel, 2014). This is true of our study as well. Among the single-word studies
that do report cohort entropy effects, albeit without controlling for phoneme surprisal, Ettinger
et al. (2014) include multimorphemic words and Kocagoncu et al. (2017) do not indicate
whether multimorphemic words are included in their stimuli or not. This factor deserves
further investigation.
For any potentially relevant stimulus properties that might distinguish isolated words and
continuous speech and that can be conceptualized as continuous variables, attempting to
demonstrate co-variation between this stimulus property and the size of the entropy effect
within a data set would be a particularly effective means of narrowing the current hypothesis
space.
Implications
If auditory word recognition in most single-word studies proceeds in the manner we have pro-
posed, with candidate selection or higher-than-wordform-level processing delayed or sus-
pended entirely, there are two major implications. The first is that the cascading, incremental
lexical access process is not automatic but rather is motivated by time pressure and modulable
with the extent of that time pressure. The second is that auditory word recognition in many
single-word studies may differ fundamentally from the process most researchers assume they
are studying (that is, speech recognition in natural contexts). This would invite re-interpretation
of existing neural and behavioral data and would motivate increased use of more naturalistic
designs in future work or identification of changes to single-word paradigms that would drive
cohort entropy effects so that these paradigms can be used with greater confidence that they
are representative of the processing of natural, connected speech. We note that some of the
strongest behavioral evidence for incremental lexical processing comes from eye tracking in
the visual world paradigm, as this method provides a continuous measure of lexical activation
over the course of speech input. Most visual world studies, however, present target lexical
stimuli within sentences, and even with single-word stimuli the task (find a visual referent)
may encourage rapid incremental access. Reconciliation between apparent cohort activation
effects in the visual world paradigm and neural cohort entropy effects is likely to be a
Neurobiology of Language
48
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
a
_
0
0
0
8
4
p
d
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
productive step forward, integrating paradigms that investigate the status of individual items in
order to make inferences about the set of lexical candidates and paradigms that investigate
properties of the set itself.
Conclusion
Our goal in this study was to evaluate whether auditory word recognition should be assumed
to proceed in the same way for isolated single words and natural connected speech. We also
intended to establish a better understanding of what drives phoneme surprisal and cohort
entropy effects during speech recognition, while modeling the stimulus as thoroughly as cur-
rent methods allow. We directly compared single-word and continuous-speech data from
MEG and demonstrated that the paradigms differ in a way that is consistent with patterns in
the existing literature, where phoneme surprisal effects are robust and cohort entropy effects
occur sporadically. We found that the ratio between the predictive power of cohort entropy
and phoneme surprisal is significantly higher (closer to one) for continuous speech as com-
pared to single words; indeed, we do not observe a cohort entropy effect for single words
at all. We proposed that this is because phoneme surprisal effects arise from the activation
of a lower-level (e.g., wordform) representation of the speech input while cohort entropy
effects arise from a competition process or activation of a higher-level (e.g., lexical-syntactic)
representation whose engagement is delayed or does not occur in single-word paradigms. This
dissociation suggests (1) that the full sequence of steps involved in auditory word recognition
does not proceed automatically and (2) that the extent to which higher levels of representation
and/or lexical competition processes are engaged depends on the nature of the stimulus or
experimental task. Finally, this study has also helped validate multivariate temporal response
function analysis as a promising method for future work in single-word paradigms.
ACKNOWLEDGMENTS
We thank Daphne Amir, Fen Ingram, and Stephanie Pomrenke for assistance with stimulus
selection, and Aura Cruz Heredia for assistance with some of the data collection. We also
thank two anonymous reviewers for their helpful feedback. Finally, the two first authors thank
Silas for napping enough to allow this paper to be revised.
FUNDING INFORMATION
Ellen Lau, National Science Foundation (https://dx.doi.org/10.13039/100000001), Award ID:
BCS-1749407. Colin Phillips, National Science Foundation (https://dx.doi.org/10.13039
/100000001), Award ID: DGE-1449815. Phoebe Gaston, National
Institutes of Health
(https://dx.doi.org/10.13039/100000002), Award ID: T32-DC017703. Christian Brodbeck,
National Science Foundation (https://dx.doi.org/10.13039/100000001), Award ID:
BCS-1754284.
AUTHOR CONTRIBUTIONS
Phoebe Gaston: Conceptualization; Data curation; Formal analysis; Investigation; Methodol-
ogy; Project administration; Writing—original draft; Writing—review & editing. Christian
Brodbeck: Conceptualization; Data curation; Formal analysis; Methodology; Software; Valida-
tion; Visualization; Writing—review & editing. Colin Phillips: Conceptualization; Funding
acquisition; Supervision; Writing—review & editing. Ellen Lau: Conceptualization; Funding
acquisition; Supervision; Writing—review & editing. Phoebe Gaston and Christian Brodbeck
are co–first authors.
Neurobiology of Language
49
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
a
_
0
0
0
8
4
p
d
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
DATA AVAILABILITY STATEMENT
Raw data are available at https://doi.org/10.18112/openneuro.ds004276.v1.0.0. Stimulus and
presentation information as well as analysis code can be accessed via https://osf.io/u56ea.
REFERENCES
Aitchison, L., & Lengyel, M. (2017). With or without you: Predictive
coding and Bayesian inference in the brain. Current Opinion in
Neurobiology, 46, 219–227. https://doi.org/10.1016/j.conb.2017
.08.010, PubMed: 28942084
Allopenna, P. D., Magnuson, J. S., & Tanenhaus, M. K. (1998).
Tracking the time course of spoken word recognition using eye
movements: Evidence for continuous mapping models. Journal of
Memory and Language, 38(4), 419–439. https://doi.org/10.1006
/jmla.1997.2558
Baayen, H., Piepenbrock, R., & Gulikers, L. (1995). CELEX2
LDC96L14 [Data set]. Linguistic Data Consortium. https://
catalog.ldc.upenn.edu/LDC96L14
Baayen, H., Wurm, L. H., & Aycock, J. (2007). Lexical dynamics for
low-frequency complex words: A regression study across tasks
and modalities. The Mental Lexicon, 2(3), 419–463. https://doi
.org/10.1075/ml.2.3.06baa
Balling, L. W., & Baayen, H. (2012). Probability and surprisal in
auditory comprehension of morphologically complex words.
Cognition, 125(1), 80–106. https://doi.org/10.1016/j.cognition
.2012.06.003, PubMed: 22841290
Bentin, S., Kutas, M., & Hillyard, S. A. (1993). Electrophysiological
evidence for task effects on semantic priming in auditory word
processing. Psychophysiology, 30(2), 161–169. https://doi.org
/10.1111/j.1469-8986.1993.tb01729.x, PubMed: 8434079
Bestmann, S., Harrison, L. M., Blankenburg, F., Mars, R. B.,
Haggard, P., Friston, K. J., & Rothwell, J. C. (2008). Influence of
uncertainty and surprise on human corticospinal excitability dur-
ing preparation for action. Current Biology, 18(10), 775–780.
https://doi.org/10.1016/j.cub.2008.04.051, PubMed: 18485711
Bien, H., Baayen, R. H., & Levelt, W. J. M. (2011). Frequency effects
in the production of Dutch deverbal adjectives and inflected
verbs. Language and Cognitive Processes, 26(4–6), 683–715.
https://doi.org/10.1080/01690965.2010.511475
Brennan, J., Lignos, C., Embick, D., & Roberts, T. P. L. (2014).
Spectro-temporal correlates of lexical access during auditory
lexical decision. Brain and Language, 133, 39–46. https://doi
.org/10.1016/j.bandl.2014.03.006, PubMed: 24769280
Brodbeck, C., Bhattasali, S., Cruz Heredia, A. A. L., Resnik, P.,
Simon, J. Z., & Lau, E. (2022a). Data from: Parallel processing
in speech perception with local and global representations of
linguistic context ( Version 5) [Data set]. Dryad. https://doi.org
/10.5061/DRYAD.NVX0K6DV0
Brodbeck, C., Bhattasali, S., Cruz Heredia, A. A. L., Resnik, P.,
Simon, J. Z., & Lau, E. (2022b). Parallel processing in speech
perception with local and global representations of linguistic
context. ELife, 11, Article e72056. https://doi.org/10.7554/eLife
.72056, PubMed: 35060904
Brodbeck, C., Das, P., Brooks, T., & Reddigari, S. (2019). Eelbrain
0.31 ( Version 0.31) [Software]. Zenodo. https://doi.org/10.5281
/zenodo.3564850
Brodbeck, C., Hong, L. E., & Simon, J. Z. (2018). Rapid transforma-
tion from auditory to linguistic representations of continuous
speech. Current Biology, 28(24), 3976–3983. https://doi.org/10
.1016/j.cub.2018.10.042, PubMed: 30503620
Brodbeck, C., Jiao, A., Hong, L. E., & Simon, J. Z. (2020). Neural
speech restoration at the cocktail party: Auditory cortex recovers
masked speech of both attended and ignored speakers. PLOS
Biology, 18(10), Article e3000883. https://doi.org/10.1371
/journal.pbio.3000883, PubMed: 33091003
Brysbaert, M., & New, B. (2009). Moving beyond Kučera and
Francis: A critical evaluation of current word frequency norms
and the introduction of a new and improved word frequency
measure for American English. Behavior Research Methods,
41(4), 977–990. https://doi.org/10.3758/ BRM.41.4.977,
PubMed: 19897807
Connine, C. M., Mullennix, J., Shernoff, E., & Yelen, J. (1990). Word
familiarity and frequency in visual and auditory word recogni-
tion. Journal of Experimental Psychology: Learning, Memory,
and Cognition, 16(6), 1084–1096. https://doi.org/10.1037/0278
-7393.16.6.1084, PubMed: 2148581
Crupi, V., Nelson, J. D., Meder, B., Cevolani, G., & Tentori, K.
(2018). Generalized information theory meets human cognition:
Introducing a unified framework to model uncertainty and infor-
mation search. Cognitive Science, 42(5), 1410–1456. https://doi
.org/10.1111/cogs.12613, PubMed: 29911318
Dahan, D., & Magnuson, J. S. (2006). Spoken word recognition. In
M. J. Traxler & M. A. Gernsbacher (Eds.), Handbook of psycho-
linguistics (2nd ed., pp. 249–283). Elsevier. https://doi.org/10
.1016/B978-012369374-7/50009-2
Dahan, D., Magnuson, J. S., & Tanenhaus, M. K. (2001). Time
course of frequency effects in spoken-word recognition:
Evidence from eye movements. Cognitive Psychology, 42(4),
317–367. https://doi.org/10.1006/cogp.2001.0750, PubMed:
11368527
David, S. V., Mesgarani, N., & Shamma, S. A. (2007). Estimating
sparse spectro-temporal receptive fields with natural stimuli. Net-
work: Computation in Neural Systems, 18(3), 191–212. https://
doi.org/10.1080/09548980701609235, PubMed: 17852750
Di Liberto, G. M., Wong, D., Melnik, G. A., & de Cheveigné, A.
(2019). Low-frequency cortical responses to natural speech
reflect probabilistic phonotactics. NeuroImage, 196, 237–247.
https://doi.org/10.1016/j.neuroimage.2019.04.037, PubMed:
30991126
Donhauser, P. W., & Baillet, S. (2020). Two distinct neural
timescales for predictive speech processing. Neuron, 105(2),
385–393. https://doi.org/10.1016/j.neuron.2019.10.019,
PubMed: 31806493
Ettinger, A., Linzen, T., & Marantz, A. (2014). The role of mor-
phology in phoneme prediction: Evidence from MEG. Brain
and Language, 129, 14–23. https://doi.org/10.1016/j.bandl
.2013.11.004, PubMed: 24486600
Feldman, H., & Friston, K. J. (2010). Attention, uncertainty, and
free-energy. Frontiers in Human Neuroscience, 4, 215. https://
doi.org/10.3389/fnhum.2010.00215, PubMed: 21160551
Fischl, B. (2012). FreeSurfer. NeuroImage, 62(2), 774–781. https://
doi.org/10.1016/j.neuroimage.2012.01.021, PubMed:
22248573
Fishbach, A., Nelken, I., & Yeshurun, Y. (2001). Auditory edge
detection: A neural model for physiological and psychoacous-
tical responses to amplitude transients. Journal of Neurophysi-
ology, 85(6), 2303–2323. https://doi.org/10.1152/jn.2001.85.6
.2303, PubMed: 11387378
Neurobiology of Language
50
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
a
_
0
0
0
8
4
p
d
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
Friston, K. (2005). A theory of cortical responses. Philosophical
Transactions of the Royal Society B: Biological Sciences,
360(1456), 815–836. https://doi.org/10.1098/rstb.2005.1622,
PubMed: 15937014
Gagnepain, P., Henson, R. N., & Davis, M. H. (2012). Temporal
predictive codes for spoken words in auditory cortex. Current
Biology, 22(7), 615–621. https://doi.org/10.1016/j.cub.2012.02
.015, PubMed: 22425155
Gaskell, M. G., & Marslen-Wilson, W. D. (2002). Representation
and competition in the perception of spoken words. Cognitive
Psychology, 45(2), 220–266. https://doi.org/10.1016/S0010
-0285(02)00003-8, PubMed: 12528902
Gaston, P., & Marantz, A. (2018). The time course of contextual
cohort effects in auditory processing of category-ambiguous
words: MEG evidence for a single “clash” as noun or verb.
Language, Cognition, and Neuroscience, 33(4), 402–423.
https://doi.org/10.1080/23273798.2017.1395466
Gillis, M., Vanthornhout, J., Simon, J. Z., Francart, T., & Brodbeck,
C. (2021). Neural markers of speech comprehension: Measuring
EEG tracking of linguistic speech representations, controlling
the speech acoustics. Journal of Neuroscience, 41(50),
10316–10329. https://doi.org/10.1523/ JNEUROSCI.0812-21
.2021, PubMed: 34732519
Gramfort, A., Luessi, M., Larson, E., Engemann, D. A., Strohmeier,
D., Brodbeck, C., Goj, R., Jas, M., Brooks, T., Parkkonen, L., &
Hämäläinen, M. (2013). MEG and EEG data analysis with
MNE-Python. Frontiers in Neuroscience, 7, 267. https://doi.org
/10.3389/fnins.2013.00267, PubMed: 24431986
Gramfort, A., Luessi, M., Larson, E., Engemann, D. A., Strohmeier,
D., Brodbeck, C., Parkkonen, L., & Hämäläinen, M. S. (2014).
MNE software for processing MEG and EEG data. NeuroImage,
86, 446–460. https://doi.org/10.1016/j.neuroimage.2013.10
.027, PubMed: 24161808
Grosjean, F. (1980). Spoken word recognition processes and the
gating paradigm. Perception & Psychophysics, 28(4), 267–283.
https://doi.org/10.3758/BF03204386, PubMed: 7465310
Gwilliams, L., King, J.-R., Marantz, A., & Poeppel, D. (2021).
Neural dynamics of phoneme sequences: Position-invariant
code for content and order. bioRxiv. https://doi.org/10.1101
/2020.04.04.025684
Gwilliams, L., & Marantz, A. (2015). Non-linear processing of a
linear speech stream: The influence of morphological structure
on the recognition of spoken Arabic words. Brain and Language,
147, 1–13. https://doi.org/10.1016/j.bandl.2015.04.006,
PubMed: 25997171
Gwilliams, L., Poeppel, D., Marantz, A., & Linzen, T. (2018). Pho-
nological (un)certainty weights lexical activation. In Proceedings
of the 8th Workshop on Cognitive Modeling and Computational
Linguistics (CMCL 2018) (pp. 29–34). Association for Computa-
tional Linguistics. https://doi.org/10.18653/v1/ W18-0104
Hale, J. (2016). Information-theoretical complexity metrics. Lan-
guage and Linguistics Compass, 10(9), 397–412. https://doi.org
/10.1111/lnc3.12196
Heeris, J. (2013). Gammatone Filterbank Toolkit. https://github
.com/detly/gammatone
Kemps, R. J. J. K., Wurm, L. H., Ernestus, M., Schreuder, R., &
Baayen, H. (2005). Prosodic cues for morphological complexity
in Dutch and English. Language and Cognitive Processes, 20(1–2),
43–73. https://doi.org/10.1080/01690960444000223
Kocagoncu, E., Clarke, A., Devereux, B. J., & Tyler, L. K. (2017).
Decoding the cortical dynamics of sound-meaning mapping.
Journal of Neuroscience, 37(5), 1312–1319. https://doi.org/10
.1523/JNEUROSCI.2858-16.2016, PubMed: 28028201
Lewis, G., & Poeppel, D. (2014). The role of visual representations
during the lexical access of spoken words. Brain and Language,
134, 1–10. https://doi.org/10.1016/j.bandl.2014.03.008,
PubMed: 24814579
Magnuson, J. S. (2016). Mapping spoken words to meaning. In
M. G. Gaskell & J. Mirkovic (Eds.), Speech perception and spoken
word recognition (pp. 76–96). Routledge.
Magnuson, J. S., Mirman, D., & Myers, E. (2013). Spoken word
recognition. In D. Reisberg (Ed.), Oxford handbook of cognitive
psychology (pp. 412–441). Oxford University Press. https://doi
.org/10.1093/oxfordhb/9780195376746.013.0027
Marslen-Wilson, W. D. (1987). Functional parallelism in spoken
word-recognition. Cognition, 25(1–2), 71–102. https://doi.org
/10.1016/0010-0277(87)90005-9, PubMed: 3581730
Marslen-Wilson, W. D., & Tyler, L. K. (1980). The temporal structure
of spoken language understanding. Cognition, 8(1), 1–71. https://
doi.org/10.1016/0010-0277(80)90015-3, PubMed: 7363578
McAllister, J. M. (1988). The use of context in auditory word recog-
nition. Perception & Psychophysics, 44(1), 94–97. https://doi.org
/10.3758/BF03207482, PubMed: 3405735
McAuliffe, M., Socolof, M., Mihuc, S., Wagner, M., & Sonderegger,
M. (2017). Montreal Forced Aligner: Trainable text-speech align-
ment using Kaldi. In Proceedings of the 18th Conference of the
International Speech Communication Association (INTERSPEECH
2017). International Speech Communication Association. https://
doi.org/10.21437/Interspeech.2017-1386
McClelland, J. L., & Elman, J. L. (1986). The TRACE model of
speech perception. Cognitive Psychology, 18(1), 1–86. https://
doi.org/10.1016/0010-0285(86)90015-0, PubMed: 3753912
McQueen, J. M. (2007). Eight questions about spoken word recog-
nition. In M. G. Gaskell (Ed.), The Oxford handbook of psycho-
linguistics (pp. 37–54). Oxford University Press. https://doi.org/10
.1093/oxfordhb/9780198568971.013.0003
Neurobehavioral Systems. (2022). Presentation [Software]. https://
www.neurobs.com/
Norris, D., & McQueen, J. M. (2008). Shortlist B: A Bayesian model
of continuous speech recognition. Psychological Review, 115(2),
357–395. https://doi.org/10.1037/0033-295X.115.2.357,
PubMed: 18426294
Pickering, M. J., & Gambi, C. (2018). Predicting while compre-
hending language: A theory and review. Psychological Bulletin,
144(10), 1002–1044. https://doi.org/10.1037/ bul0000158,
PubMed: 29952584
Polhemus. (2012). 3SPACE FASTRACK user manual. https://all
-guidesbox.com/manual/1645779/polhemus-3space-fastrak
-operation-user-s-manual-124.html
Smith, S. M., & Nichols, T. E. (2009). Threshold-free cluster
enhancement: Addressing problems of smoothing, threshold
dependence and localisation in cluster inference. NeuroImage,
44(1), 83–98. https://doi.org/10.1016/j.neuroimage.2008.03
.061, PubMed: 18501637
Strange, B. A., Duggins, A., Penny, W., Dolan, R. J., & Friston, K. J.
(2005). Information theory, novelty and hippocampal responses:
Unpredicted or unpredictable? Neural Networks, 18(3),
225–230. https://doi.org/10.1016/j.neunet.2004.12.004,
PubMed: 15896570
Taulu, S., & Simola, J. (2006). Spatiotemporal signal space separa-
tion method for rejecting nearby interference in MEG measure-
ments. Physics in Medicine and Biology, 51(7), 1759–1768.
https://doi.org/10.1088/0031-9155/51/7/008, PubMed:
16552102
Tucker, B. V., Brenner, D., Danielson, D. K., Kelley, M. C., Nenadić,
F., & Sims, M. (2019). The Massive Auditory Lexical Decision
Neurobiology of Language
51
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
a
_
0
0
0
8
4
p
d
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Auditory word comprehension in isolated words
(MALD) database. Behavior Research Methods, 51(3), 1187–1204.
https://doi.org/10.3758/s13428-018-1056-1, PubMed: 29916041
Wang, Y. C., Sohoglu, E., Gilbert, R. A., Henson, R. N., & Davis,
M. H. (2021). Predictive neural computations support spoken
word recognition: Evidence from MEG and competitor priming.
Journal of Neuroscience, 41(32), 6919–6932. https://doi.org/10
.1523/JNEUROSCI.1685-20.2021, PubMed: 34210777
Weide, R. (1994). CMU pronouncing dictionary [Open source app].
Carnegie Mellon University. https://www.speech.cs.cmu.edu/cgi
-bin/cmudict
Weissbart, H., Kandylaki, K. D., & Reichenbach, T. (2020). Cortical
tracking of surprisal during continuous speech comprehension.
Journal of Cognitive Neuroscience, 32(1), 155–166. https://doi
.org/10.1162/jocn_a_01467, PubMed: 31479349
Whiteley, L., & Sahani, M. (2008). Implicit knowledge of visual
uncertainty guides decisions with asymmetric outcomes. Journal
of Vision, 8(3), 2. https://doi.org/10.1167/8.3.2, PubMed:
18484808
Willems, R. M., Frank, S. L., Nijhof, A. D., Hagoort, P., & van den
Bosch, A. (2016). Prediction during natural language compre-
hension. Cerebral Cortex, 26(6), 2506–2516. https://doi.org/10
.1093/cercor/bhv075, PubMed: 25903464
Wurm, L. H., Ernestus, M. T. C., Schreuder, R., & Baayen, H.
(2006). Dynamics of the auditory comprehension of prefixed
words: Cohort entropies and Conditional Root Uniqueness
Points. The Mental Lexicon, 1(1), 125–146. https://doi.org/10
.1075/ml.1.1.08wur
Yee, E., & Sedivy, J. C. (2006). Eye movements to pictures reveal
transient semantic activation during spoken word recognition.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 32(1), 1–14. https://doi.org/10.1037/0278-7393.32.1.1,
PubMed: 16478336
Zwitserlood, P. (1989). The locus of the effects of sentential-
semantic context in spoken-word processing. Cognition, 32(1),
25–64. https://doi.org/10.1016/0010-0277(89)90013-9,
PubMed: 2752705
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
n
o
/
l
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
/
4
1
2
9
2
0
6
7
0
9
6
n
o
_
a
_
0
0
0
8
4
p
d
.
l
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Neurobiology of Language
52