ARTICLE DE RECHERCHE
A framework for creating knowledge graphs of
scientific software metadata
Aidan Kelley1
and Daniel Garijo2
1Washington University in St. Louis, St. Louis, Etats-Unis
2Information Sciences Institute, University of Southern California, Les anges, Etats-Unis
Mots clés: FAIR, knowledge graphs, metadata, metadata extraction, scientific software
ABSTRAIT
An increasing number of researchers rely on computational methods to generate or
manipulate the results described in their scientific publications. Software created to this
end—scientific software—is key to understanding, reproduction, and reusing existing work in
many disciplines, ranging from Geosciences to Astronomy or Artificial Intelligence. Cependant,
scientific software is usually challenging to find, set up, and compare to similar software due to
its disconnected documentation (dispersed in manuals, readme files, websites, and code
comments) and the lack of structured metadata to describe it. Par conséquent, researchers have to
manually inspect existing tools to understand their differences and incorporate them into their
travail. This approach scales poorly with the number of publications and tools made available
every year. In this paper we address these issues by introducing a framework for automatically
extracting scientific software metadata from its documentation (in particular, their readme
files); a methodology for structuring the extracted metadata in a Knowledge Graph (KG) de
scientific software; and an exploitation framework for browsing and comparing the contents of
the generated KG. We demonstrate our approach by creating a KG with metadata from over
10,000 scientific software entries from public code repositories.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
1.
INTRODUCTION
Computational methods have become crucial for making scientific discoveries in areas rang-
ing from Astronomy (LIGO-VIRGO, n.d.) or High Energy Physics (Albrecht, Alves et al., 2019)
to Geosciences (USGS, n.d.) and Biology (Prlić & Lapp, 2012). Software developed for this
purpose is known as scientific software, and refers to the code, tools, frameworks, and scripts
created in the context of a research project to process, analyze or generate a result in an aca-
demic publication. Examples of scientific software involve novel algorithm implementations,
simulation models, data processing work flows, and data visualization scripts.
Scientific software is key for the reproducibility of scientific results as it helps others under-
stand how a data product has been created or modified as part of a computational experiment
or simulation and avoids replicating effort. Donc, scientific software should adapt the prin-
ciples for Finding, Accessing, Interoperating and Reusing scientific data (FAIR) (Wilkinson
et coll., 2016) to help scientists find, compare, understand, and reuse the software developed
by other researchers (Lamprecht, Garcia et al., 2020).
Heureusement, the scientific community, academic publishers, and public stakeholders have
started taking measures towards making scientific software a first-class citizen for academic
un accès ouvert
journal
Citation: Kelley, UN., & Garijo, D. (2021).
A framework for creating knowledge
graphs of scientific software metadata.
Études scientifiques quantitatives, 2(4),
1423–1446. https://doi.org/10.1162/qss
_a_00167
EST CE QUE JE:
https://doi.org/10.1162/qss_a_00167
Corresponding Authors:
Aidan Kelley
aidankelley@wustl.edu
Daniel Garijo
dgarijo@isi.edu
droits d'auteur: © 2021 Aidan Kelley and
Daniel Garijo. Published under a
Creative Commons Attribution 4.0
International (CC PAR 4.0) Licence.
La presse du MIT
A framework for creating knowledge graphs of scientific software metadata
recherche. Par exemple, initiatives such as the Software Carpentry events (Software Carpentry,
n.d.) or the Scientific Paper of the Future Initiative (n.d.) teach researchers about best practices
for software documentation and description; community groups such as FAIR4RS are actively
analyzing how to evolve the FAIR principles for Research Software (FAIR4RS, n.d.); institutions
such as the Software Sustainability Institute (n.d.), OpenAIRE (n.d.) and the Software Heritage (n.d.)
project help preserve and archive existing software; code repositories such as GitHub (n.d.)
provide the means to store and version code; software registries such as ASCL (Shamir, Wallin
et coll., 2013) encourage scientists to describe software metadata; and container repositories
such as DockerHub (n.d.) help capture the computational environment and dependencies
needed for software execution. Cependant, despite these efforts, two main challenges remain
for efficiently and effectively finding, reusing, comparing, and understanding scientific
software:
1. Software metadata is heterogeneous, disconnected, and defined at different levels of
detail. When researchers share their code, they usually include human-readable instruc-
tion (par exemple., in readme files) containing an explanation of its functionality, installations
instructions, and how to execute it. Cependant, researchers do not often follow common
guidelines when preparing these instructions, structuring information in different
sections and with usage assumptions that may require a close inspection for correct
interpretation. This heterogeneity makes reusing and understanding existing scientific
software a time-consuming manual process. En outre, support files (par exemple., sample input
files, extended documentation, Docker images, executable notebooks) are becoming
increasingly important to capture the context of scientific software, but they are often
disconnected from the main instructions, even when they are part of the same repository.
2. Finding and comparing scientific software is a manual process: According to Hucka and
Graham (2018), the means followed by researchers to find and compare software are by
doing a keyword search in code repositories; reading survey papers; or following recom-
mendations from a colleague. The scientific community has developed general-purpose
software metadata registries (CERN & OpenAIRE, 2013; FigShare, n.d.) to help reuse and
credit scientists; and in some scientific communities, software metadata repositories have
started collecting their own software descriptions to facilitate software comparison, credit
and use (Gil, Ratnakar, & Garijo, 2015; Shamir et al., 2013). Cependant, populating and
curating these resources with metadata is, overall, a manual process.
In this paper we address these issues by proposing the following contributions:
▪ A SOftware Metadata Extraction Framework (SOMEF) designed to automatically capture
23 common scientific software metadata categories and export them in a structured man-
ner (using JSON-LD (Champin, Longley, & Kellogg, 2020), RDF (Miller & Manola, 2004),
and JSON representations). SOMEF extends our previous work (Mao, Garijo, & Fakhraei,
2019) (which recognized four metadata categories with supervised classification and
seven metadata categories through the GitHub API) by expanding the training corpus
(depuis 75 à 89 entries); by applying a wider variety of supervised classification pipelines;
by introducing new techniques for detecting metadata categories (based on the structure
used in the different sections of a readme file and regular expressions); and by detecting
12 new metadata categories and auxiliary files (par exemple., notebooks, Dockerfiles) in a scientific
software repository.
▪ A methodology for extracting, enriching, and linking scientific software metadata using
SOMEF.
Études scientifiques quantitatives
1424
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
▪ A framework for browsing and comparing scientific software based on the results of the
previous methodology.
We use Knowledge Graphs (KGs) (Bonatti, Decker et al., 2019) to represent scientific soft-
ware metadata, as they have become the de facto method for representing, sharing, and using
knowledge in AI applications. In our KG, nodes represent software entries linked to their asso-
ciated metadata (creators, instructions, etc.) and their context (examples, notebooks, Docker
files, etc.) through different edges. We illustrate our methodology and framework by automat-
ically building a KG with over 10,000 scientific software entries from Zenodo.org (CERN &
OpenAIRE, 2013) and GitHub.
The remainder of the paper is structured as follows: We first describe our framework for
scientific software metadata extraction and how it structures metadata from readme files in
Section 2. Suivant, in Section 3, we describe our methodology for extracting, enriching, and link-
ing scientific software metadata in a KG, followed by our approach to exploit its contents by
browsing and comparing different entries. We then discuss the limitations of our work in
Section 4 and compare our approach against related efforts in the state of the art (Section 5)
before concluding the paper in Section 6.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
2. SOMEF: A SCIENTIFIC SOFTWARE METADATA EXTRACTION FRAMEWORK
An increasing number of researchers and developers follow best practices for software docu-
mentation (Guides, n.d.) and populate their repositories with readme files to ease the reusability
of their code. Readme files are usually markdown documents that provide basic descriptions of
the functionality of a software component, how to run it, and how to operate it. Donc, dans
our work, we target readme files as the main source from which to extract metadata. Dans ce
section we first introduce the metadata fields we focus on and our rationale for extracting them,
followed by the supervised and alternative methods we have developed to extract as many
metadata fields as possible. We end this section by describing the export formats we support,
extending existing software metadata representation vocabularies and community standards.
2.1. Common Scientific Software Metadata in Code Repositories
Despite existing guidelines (Guides, n.d.), readme files do not have a predefined structure, et
scientific software authors usually structure them in creative ways to communicate their soft-
ware instructions and setup. When we started our work, we had four main requirements for
metadata categories to extract:
▪ Description: To discover and understand the main purpose of a software component.
▪
▪ Execution instructions: Which indicate how a software component can be used and
Installation instructions: How to set up and use a software component.
comment.
▪ Citation: To attribute the right credit to authors.
These categories can be easily expanded to gather more details to help findability (par exemple.,
domain keywords), usability (par exemple., requirements, Licence), support (par exemple., how to contribute),
and understanding (par exemple., usage examples) of scientific software. En fait, related work has
already categorized software metadata by interviewing domain scientists (Gil et al., 2015)
and creating community surveys to identify ideal metadata that scientists would prefer to better
find, understand, and reuse scientific software (Hucka & Graham, 2018). Using these efforts as
Études scientifiques quantitatives
1425
A framework for creating knowledge graphs of scientific software metadata
a reference, we conducted an experiment to assess the common documentation practices
followed by scientific software authors for their software: We built a corpus of repositories from
different scientific disciplines, and we analyzed the structure of their readme files to find com-
mon metadata fields to extract.
The corpus consists of 89 Markdown readme files from GitHub repositories. GitHub is one
of the largest code repositories to date (Gousios, Vasilescu et al., 2014), with a wide diversity in
documentation maturity, software purpose, and programming languages. Our criteria for
selecting repositories included repositories with high-quality documentation; popular reposi-
tories (measured by the number of stars, releases, contributors, and dependent projects); et
repositories designed to support scientists in their research. Scientific software contributed the
most to the selection of repositories, although we included other tools typically used by sci-
entists to implement their applications (par exemple., Web development tools such as React). We also
used as reference the Awesome curated list of repositories for different scientific domains
(Awesome, n.d.), and popular tools using GeoJSON, Open Climate Science, etc., which pro-
vided links to relevant scientific projects. To be as diverse as possible, repositories covered a
wide variety of programming languages, ranging from C++ and Python to Cuda, with a pre-
dominance of Python and C (30% chaque).
To analyze the corpus, we manually inspected the headers of the sections of the readme
files included on each repository, grouping them together by category and counting the num-
ber of occurrences. Par conséquent, we grouped 898 section headers into 25 metadata categories
derived from related work. Headers that were unrelated to any identified metadata category
were dismissed. Chiffre 1 shows the results of the 15 most common categories we found. Comme
expected, installation, usage, and citation are among the most common categories, followed
by the software requirements needed to install a given software component, the license or
copyright restrictions, where to find more documentation, and how to contribute or how to
deal with software-related problems. Some of the categories have an overlap and in some cases
it becomes challenging to correctly identify a metadata field. Par exemple, the description of
repositories is often found in the Introduction/Overview, or in the Getting started
catégories. Example can include invocation commands, Support and FAQs often refer on
how to address problems with code, etc..
Chiffre 1. Distribution of the common header categories in our 89 readme files corpus.
Études scientifiques quantitatives
1426
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
Tableau 1. Number of ground truth excerpts and their mean length by metadata category
Category
Description
Installation
Invocation
Citation
# Excerpts
336
929
1,134
316
Mean length (words)
27.95 ± 28.46
9.24 ± 11.39
7.74 ± 9.88
8.20 ± 7.40
Using the results of our analysis, we expanded our initial software metadata list with the
metadata categories listed below. We excluded metadata categories that did not appear in at
least 10% of the corpus, (c'est à dire., at least nine times):
▪ Usage instructions, examples, and notes: Assumptions and considerations recorded by
the authors when executing a software component, or examples on how to use it.
▪ Documentation: Information on where to find additional documentation about a soft-
ware component (besides the readme file).
▪ Requirements: Prerequisites and dependencies needed to execute a software component.
▪ Support: Guidelines and links of where to obtain support for a software component.
▪ License: License and usage terms of a software component.
▪ Long name: A longer version of the name of a software component, as the repository
name is sometimes not enough for proper identification.
We decided not to include the categories related to Training and Output as they often
refer to domain-specific scientific software (in the context of Machine Learning projects). Nous
also considered the following categories, which are not present in Table 1 but are important
auxiliary files that may be needed to set up or understand scientific software:
▪ Digital Object Identifier (EST CE QUE JE): In some cases authors include a reference publication
and a DOI (par exemple., in Zenodo) for their code, which helps tracking snapshots of their work.
▪ Dockerfiles: Needed to create a computational environment for a scientific software
component. Some code repositories include more than one.
▪ Computational notebooks, which often showcase how to execute the target software,
how to prepare data for its usage, or how to operate with the produced results. More
recently, links to live environments such as Binder (n.d.) are starting to appear as part
of readme files as well, although they are not yet a common practice.
2.2. Supervised Methods for Software Metadata Classification
We extend our previous work (Mao et al., 2019) to train supervised binary classifiers to extract
descriptions, installation instructions, citations, and invocation excerpts from readme files. Le
rationale for developing supervised classifiers for these categories was to attempt to extract
them at a granular level, as their related excerpts can often be found scattered across different
sections in readme files (par exemple., invocation commands can sometimes be found in examples,
installation, or usage sections).
2.2.1. Training corpus
We trained our classifiers using the 89 readme files from our preliminary section analysis
(expanding the 75 readme files in the initial corpus from Mao et al. (2019)). All readmes
Études scientifiques quantitatives
1427
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
Tableau 2.
Best classification results for each metadata category
Classifier
Description
Installation
Invocation
Citation
Best pipeline
CountVectorizer + LogisticRegression
TFIDFVectorizer + StochasticGradientDescent
CountVectorizer + NaiveBayes
CountVectorizer + NaiveBayes
Precision
0.85
0.92
0.88
0.89
Recall
0.79
0.9
0.9
0.98
F-Measure
0.82
0.91
0.89
0.93
consist of plain text rendered Markdown (c'est à dire., without markup), divided in paragraph excerpts
(separated by newline delimiters). We built the ground truth by manually inspecting the read-
mes and annotating them with the right category by hand. Par conséquent, we ended up with the
paragraph excerpts shown in Table 1.
To balance each corpus, we sampled negative examples for each category to obtain a 50%
positive and 50% negative sample distribution. For each category, the negative class contained
random samples from the other three categories (12.5% from each), plus control sentences
from the Treebank corpus (Marcus, Kim et al., 1994) (up to 12.5%), to make the system more
robust (c'est à dire, to ensure that the classifiers do not devolve into a code vs. natural text classifier).
2.2.2. Classification results
We used the Scikit-learn framework (Pedregosa, Varoquaux et al., 2011) to train different
binary supervised classifiers. Because the corpora are based on text, we first transformed each
excerpt into a feature vector (using the CountVectorizerand TfidfVectorizer methods from Scikit
learn library). We then applied available binary classifiers (namely StochasticGradientDescent
with log as loss function, LogisticRegression, NaiveBayes, Perceptron, RandomForest, Ada-
Boost, XGB, DecisionTree and BernoulliBayes) and selected the pipelines with best results
in average. All results are cross-validated using stratified fivefold cross-validation. The best
results for each category can be seen in Table 2, and have an average above 0.85 precision.
We prioritized pipelines that maximized precision and F-Measure to favor the extraction of
correct results. That said, our approach works best with paragraphs containing multiple sen-
tences (short paragraphs with one sentence may miss some of the context needed for the cor-
rect classification). All model files from our experiments, as well as the rankings from each
vectorizer and classifier combination we tried, are available online with a Zenodo DOI
(Mao, vmdiwanji et al., 2020).
We also considered removing stop words and using stemming algorithms in our excerpt
feature extraction as they have proven to be useful in texts to prevent a feature matrix from
becoming too sparse. Cependant, the computer science domain includes very precise words
(par exemple., within invocation commands), and we did not see an improvement when incorporating
these methods in our analysis pipelines. Ainsi, we discarded stemming and stop word
removal from our final results.
2.3. Alternative Methods for Software Metadata Classification
While our supervised classification results show appropriate results for the Description, Instal-
lation, Invocation, and Citation categories, the remaining metadata categories do not appear in
a consistent manner in the selected repositories, and finding representative corpora for training
requires a significant effort. Donc, we explored three main alternative methods for recog-
nizing metadata categories, further described below.
Études scientifiques quantitatives
1428
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
2.3.1. Header analysis
Leveraging the results of our readme header analysis, we designed a method to annotate
readme sections based on their headers. The intuition is that if a section is named after one
of the main categories identified (par exemple., “Description” or “About”), then the body of that section
will contain the right metadata (par exemple., description) of the target software. Authors use very dif-
ferent names for their sections, but following our initial analysis we learned how different key-
words can be grouped together using synonyms. For each metadata category, we looked at the
most common keywords and retrieved their Wordnet sinsets (Miller, 1995), paying special care
to select those with the correct meaning (par exemple., “manual” may refer to something that requires
manual effort, or an installation manual). We then created a method to automatically tag each
header of a readme file with the closest category in meaning (if any), annotating the respective
section text as its value. To evaluate our results, we created a new corpus labeling each of the
898 headers present in the 89 readme files.
This approach is less granular than supervised classification (multiple paragraphs may be
annotated under a single category), and weak against typos in headers, but yields surprisingly
good results for some of the target metadata categories. Tableau 3 includes an overview of the F-
Measure results of the extracted headers for the repositories in our corpus. Metadata categories
such as License, Requirements, Invocation, and Documentation have very high F-Measure,
indicating an agreement from the community when describing them in software documenta-
tion. Citation and Installation have a high F-Measure, although not as good as the supervised
classification results. The Description and Usage categories behave slightly worse, which indi-
cates ambiguous usage by authors in their documentation (this is also the case of the Support
catégorie, which yields the worst results). Upon further inspection, we also discovered that a
small number of the errors are not caused by ambiguity problems, but rather by formatting
errors in the markdown files. Appendix B includes a full table with the precision and recall
metrics used to calculate the F-Measures of Table 3.
2.3.2. Regular expressions
Some metadata categories can be recognized using regular expressions in the readme files.
Some examples are when authors include citations following the BibTeX syntax (used to man-
age references in LaTeX) or when authors include badges that display as clickable icons, tel
as the ones for computational notebooks, Zenodo DOIs, package repositories, etc.. Chiffre 2
shows an example for the Pandas code repository, where many badges are displayed (inclure-
ing one to the Zenodo DOI). We currently support regular expressions for extracting BibTeX
citations as well as Zenodo DOIs and Binder executable notebooks (Binder, n.d.) from badges.
2.3.3.
File exploration
We downloaded a snapshot of the code of each analyzed repository and searched for the fol-
lowing files:
▪ License: The best practices for code repositories in GitHub include adding a license file
(LICENSE.md) stating which type of license is supported by the code.
▪ Dockerfile: Files that include a set of instructions to create a virtual environment using
Docker. These files are becoming popular to facilitate reproducibility, and they are easily
recognizable by their name (Dockerfile).
▪ Executable notebooks: We support the recognizing of Jupyter notebooks (with format .
ipynb), whichare usually added as part of Python projects to showcase the functionality
of the software component.
Études scientifiques quantitatives
1429
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
Summary of the different categories supported by SOMEF and their main extraction techniques. Supervised classification techniques
Tableau 3.
operate in a paragraph-based basis, while header analysis reports results by sections. Support for detecting a metadata field with regular
expressions, file exploration and GitHub API is indicated with an “X”
Category
Description
Installation
Invocation
Citation
Usage
Documentation
Requirements
Support
License
Nom
Long Name
EST CE QUE JE
Dockerfile
Notebooks
Owner
Mots clés
Source code
Releases
Changelog
Issue tracker
Programming languages
Download URL
Stars
Supervised classification
(F-Measure)
0.82
Header analysis
(F-Measure)
0.68
Regular expression
File exploration
GitHubAPI
X (short)
Extraction method
0.91
0.89
0.93
0.85
0.91
0.87
0.68
0.95
0.93
0.52
1
X (bibtex)
X
X
X
X
X
X
X (readme)
X
X
X
X
X
X
X
X
X
X
X
Chiffre 2. Badges displayed in the Pandas code repository.
Études scientifiques quantitatives
1430
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
Because multiple notebooks or Dockerfiles may exist in one software repository, we anno-
tate all of them when exploring a repository.
2.3.4. GitHub API
GitHub provides an API with basic repository metadata filled by the authors, and we exploit it
to obtain additional metadata. We extract the following categories:
▪ Name: Short name of the repository (typically the id of the target repository).
▪ Owner: Person or organization in charge of the repository.
▪ Keywords: Author-selected keywords to improve findability of their software.
▪ Source code: URL of the source code repository.
▪ Releases: Links to the different snapshot versions of the software component.
▪ Download URL: URL where to download the target software associated with a release
(typically the installer, package, or a tar ball to a stable version).
▪ Changelog: Description provided by authors for each release, typically listing the main
novelties and issues addressed for a given release.
Issue tracker: Link to the issue list of the target repository.
▪
▪ Programming languages: Main programming languages used in a repository. If auxiliary
files are included (par exemple., notebooks, setup scripts, etc.), this will return all the available
languages and their distribution.
▪ Stars: Number of stars assigned by users. Note that this feature is time-dependent, comme
users may star or un-star a repository.
While some of these metadata categories were not identified as critical by related work or
our main category analysis (par exemple., owner, stars), we consider them useful metadata that can help
in understanding how a software component has evolved or how it is supported by the com-
munity. Ainsi, they are included in the metadata extraction reports.
Tableau 3 shows a summary of all the metadata categories we support, along with the
methods that can be used to extract them. We note that some of the categories may be
extracted by more than one method or be tagged in more than one category (par exemple., require-
ments and installation instructions), leaving to users the choice of selecting the preferred one.
2.4. Exporting Scientific Software Metadata
To ease the reusability of our results, we support exporting our extracted metadata in three
main serializations with different levels of detail. As the supervised classification methods print
out a confidence in their classification, we have set up the ability to set a threshold (which by
default is 0.8) to filter out nonsignificant results. Results from header analysis, regular expres-
sions, and the GitHubAPI are assigned the highest confidence.
2.4.1. Codemeta export
Codemeta (Jones, Boettiger et al., 2017) is a JSON-LD (Champin et al., 2020) vocabulary
which extends the Schema.org (Guha, Brickley, & Macbeth, 2016) de facto standard to pro-
vide basic markup of scientific software metadata. Codemeta is lightweight and is gaining
popularity and support among code registries as it provides a cross-walk between different
vocabulary terms for scientific software metadata. Cependant, Codemeta does not support some
of the metadata terms we extract (par exemple., invocation command, notebooks, Dockerfiles), lequel
are thus not included in the export. The methods used for extracting each metadata category
(par exemple., classifiers, GitHubAPI) and their confidence are also not included.
Études scientifiques quantitatives
1431
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
2.4.2. RDF export
We have aligned all extracted metadata categories with the Software Description Ontology
(Garijo, Osorio et al., 2019), an ontology that extends Codemeta and Schema.org to represent
software metadata, and provides the ability to serialize the results in W3C Turtle format
(Carothers & Prud’hommeaux, 2014). Cependant, to avoid complicating the output, this export
does not serialize the method used on each extraction or its confidence.
2.4.3.
JSON export
We provide a JSON representation that indicates, for each extracted metadata category, le
technique used for its extraction and its confidence, in addition to the detected excerpt.
The JSON snippet below shows an example for the Description category of a Python library.
This way, the provenance associated with each extraction is recorded as part of the result.
“description”: [
{
“excerpt”: “KGTK is aPython library …”,
“confidence”: [0.8294290479925978],
“technique”: “Supervised classification”
}
]
3. TOWARDS KNOWLEDGE GRAPHS OF SCIENTIFIC SOFTWARE METADATA
In this section we describe how, using SOMEF, we create, populate and exploit KGs of scien-
tific software metadata.
3.1. Knowledge Graph Creation Methodology
Chiffre 3 shows the main steps of our methodology for enriching and linking scientific software
metadata by integrating a code repository and a software metadata registry. Arrows represent
the dataflow, while numbers represent step execution order. D'abord, we scrape a list of software
entries from a target software registry (par exemple., Zenodo). Alors, for each entry, we retrieve its ver-
sion data, extract all code repository links, if present, and download the full text of its readme
file. The readme file is parsed by SOMEF, and the results are combined and then aggregated
into a KG. Enfin, we enrich the resultant software entries by extracting keywords and gener-
ate a second KG which is combined with the first. An assumption of our methodology is the
existence of the link between the software metadata registry and the code repository where the
readme files reside.
3.2. Representing Scientific Software Metadata
Chiffre 4 shows a snapshot of the main classes and properties we used to represent software
metadata in our KG. We use a simple data model that reuses concepts from the Software
Études scientifiques quantitatives
1432
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
Chiffre 3.
Scientific software Knowledge Graph creation methodology.
Description Ontology (Garijo et al., 2019) to represent software, software versions, and their
authors, as indicated in the figure. We then used an N-ary relationship pattern (Rector & Noy,
2006) to qualify found keywords with additional metadata (par exemple., whether they are title key-
words or description keywords), which we use for search purposes.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
3.3. SOSEN: A Knowledge Graph of Scientific Software Metadata
To demonstrate our approach, we built SOSEN, a KG integrating Zenodo.org, an open source
metadata registry with thousands of scientific software descriptions, and GitHub as the main
code repository from which readme files are parsed. We use Zenodo because it specifically
stores scientific software and has a simple, open API; GitHubstores much of the code available
in Zenodo and has an open API as well. Other open repositories were considered but dis-
carded for this version of SOSEN due to their broad scope beyond scientific software (par exemple.,
Software Heritage, n.d.); or lack of explicit link to a code repository (par exemple., FigShare, n.d.).
Chiffre 5 shows a high-level overview of the architecture used to implement our methodol-
ogy. D'abord, we obtained a list of software entries from Zenodo, an open-access repository of
scientific documents. To obtain the software entries (called records ), we performed a blank
recherche, filtering by software. This returned a list of the 10,000 most recent records. The choice
de 10,000 is a limitation imposed by Zenodo, and pagination cannot be used to circumvent
this limit. To obtain a larger set of entries, we performed the same search again, with order
Chiffre 4. An overview of the data model used in the SOSEN KG.
Études scientifiques quantitatives
1433
A framework for creating knowledge graphs of scientific software metadata
Chiffre 5. Architecture for generating the SOSEN KG.
reversed, which yielded another 10,000 records. This meant that the 20,000 software entries
retrieved were almost half of the total software entries in Zenodo (at the time of writing), lequel
we considered sufficient for demonstrating our methodology.
We then enriched all software entries using SOMEF with the RDF export, enabling super-
vised classification, header analysis, regular expressions, file exploration and the GitHub API
for extracting software metadata categories. We filtered out entries that did not have an asso-
ciated GitHub link and used SOMEF with the latest commit of each repository. Par conséquent, nous
extracted metadata categories from 69% of the candidate software records (presque 13,800).
Suivant, we automatically extracted keywords from the description and title of each software
entry. This was achieved by splitting the title or description into words and removing stop
words. Enfin, we computed the properties needed to support the representation of TF-IDF
scores to retrieve entities efficiently.
As for the structure of the KG itself, we chose a permanent Uniform Resource Identifier
(URL) scheme, with the prefix https://w3id.org/okn/i. Instances of the Software class
have the same name as their corresponding GitHub repositories, which are unique. Tableau 4
displays examples of other entity URIs using an example from the SOSEN KG.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
3.4. SOSEN: Knowledge Graph Assessment
Chiffre 6 shows a subgraph of one of the entries of the SOSEN KG, highlighting how the infor-
mation is combined from Zenodo, SOMEF (retrieved from GitHubreadmes), and the keyword
enrichment analysis performed as part of our methodology.
Tableau 5 shows the total number of entities in the SOSEN KG, while Figure 7 shows statistics
on the completeness of the main software metadata categories. Metadata categories displayed
Tableau 4.
w3id.org/okn/i, and is common for all entities
Example URIs for different classes of entities in the graph. The _ prefix stands for https://
Entity
Logiciel
SoftwareSource
SoftwareVersion
Keyword
Example URI
_:Software/dgarijo/ Widoco
_:SoftwareSource/dgarijo/ Widoco
_:SoftwareVersion/dgarijo/ Widoco/v1.4.14
_:Keyword/ontology
QualifiedKeywordRelationship
_:Software/dgarijo/ Widoco/QualifiedKeyword/ontology
Études scientifiques quantitatives
1434
A framework for creating knowledge graphs of scientific software metadata
Chiffre 6. A subgraph of a software entry in the SOSEN KG, showing the different information sources.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
to the right of “license” in Figure 7 (with the exception of “doi”) come only from the GitHub
API, and therefore some entries are incomplete because the authors who created them did not
add enough information. Those categories to the left of “license” were extracted using classi-
fiers, regular expressions, header analysis, or the GitHub API (par exemple., documentation is comple-
mented by pointing to the source readme file, hence the high completion rate in the KG), et
are prompt to precision and recall errors. Some metadata categories, such as the detection of
auxiliary files (Docker, Notebooks) were not yet supported at the time of the creation of the
SOSEN KG and therefore are not included in the figure. Categories that are shared by all repos-
itories by default (c'est à dire., source code, issue tracker, programming language, owner) are not
included in the figure for simplicity.
Notably, less than a quarter of the software entities have user-defined keywords. This hin-
ders their findability, although a search based on the keywords in the titles of these repositories
would likely reach them (most software entities have titles).
Plus loin, we see that more than half of the entries have both a license and a version. Ce
statistic is important, as having a license is necessary to reuse the code, and a software entity
having multiple versions suggests that it has been maintained, which may be an indicator of its
qualité (almost half of the entries have multiple versions with independent releases of code).
Tableau 5.
The number of entities of a given class in the SOSEN KG
Entity class
Logiciel
SourceCode
SoftwareVersion
Keyword
Person
Total triples
Études scientifiques quantitatives
Count
13,763
13,763
50,795
88,304
11,858
3,927,004
1435
A framework for creating knowledge graphs of scientific software metadata
Chiffre 7. Coverage of the main properties used in the SOSEN KG. The total number of software
instances is included for reference.
We see that the categories detected without the GitHub API are relatively sparse. This may
be due to user omission (c'est à dire., authors not adding sufficient detail to their readme), SOMEF error
(c'est à dire., the classifiers missing a metadata category), or the property being mentioned in docu-
mentation external to the readme. A lack of these categories means that the user will, in many
cases, have to revert to manually browsing the code repository for relevant information.
Chiffre 8 shows the distribution of the top 15 programming languages in the SOSEN KG (dehors
de 267), with Python as the most commonly used. Note that a repository may contain files in
more than one programming language (par exemple., Python, Jupyter notebooks, and shell scripts to
help starting up the project), and hence the number of times programming languages appear
may be higher than the number of software instances in the KG.
All of these statistics were generated using SPARQL queries against the SOSEN KG, lequel
can be accessed under a Zenodo DOl (Kelley & Garijo, 2020).
Chiffre 8. Distribution of the top 15 programming languages in the SOSEN KG.
Études scientifiques quantitatives
1436
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
Chiffre 9. Snapshot of the Jupyter notebook we developed to search and compare software metadata entries in the SOSEN KG.
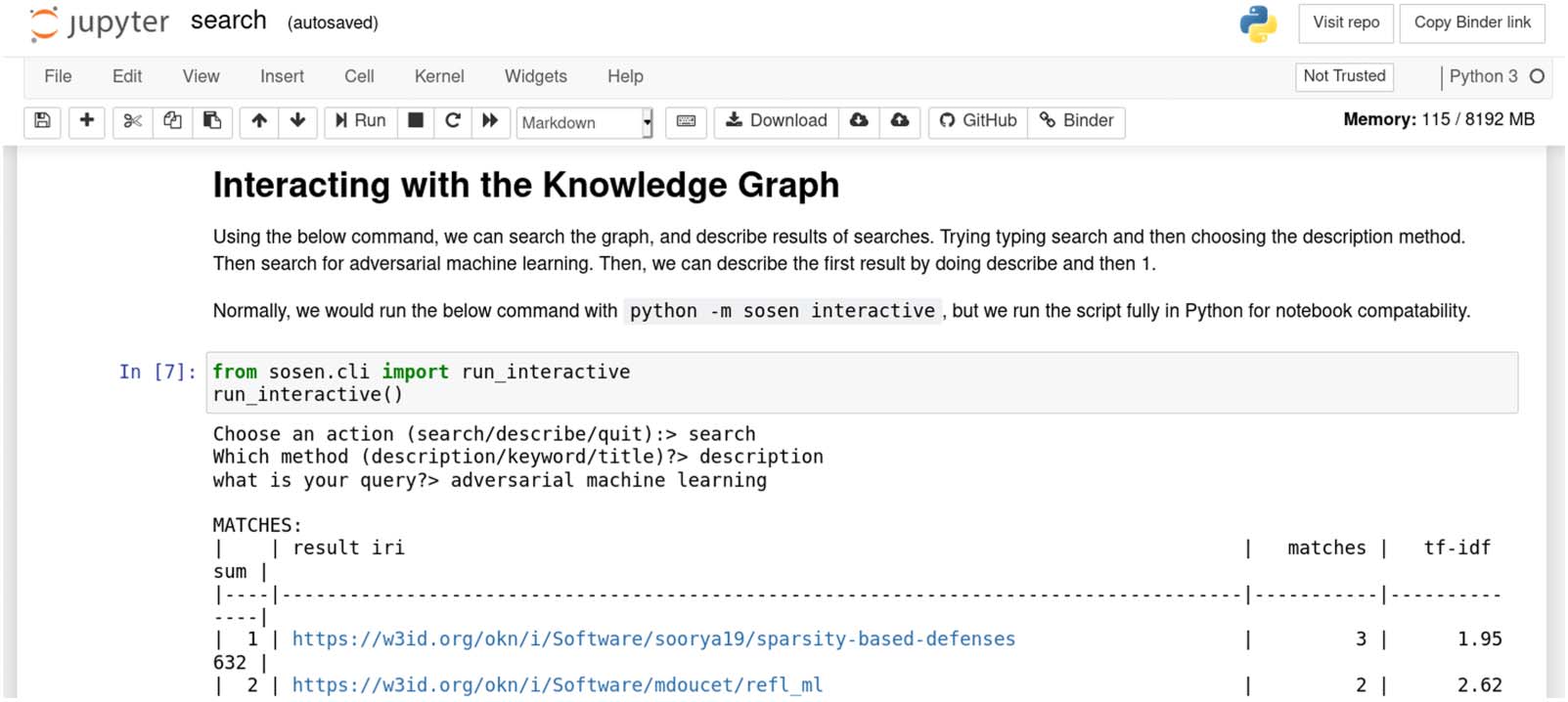
3.5. SOSEN CLI: A Framework for Using the SOSEN KG
We created a command line interface (CLI) Python framework (Kelley & Garijo, 2021) to ease
search and comparison of scientific software in the SOSEN KG. The framework can be used
through Jupyter Notebooks as shown in Figure 9. D'abord, we implemented a TF-IDF based key-
word search using SPARQL (see Appendix A). This functionality is exposed through the
search method of the SOSEN CLI. Users enter a query, which is broken into keywords, split-
ting at the space character. Alors, users can choose between three methods for keyword
recherche: user-defined, title, or description keywords. An example result for the search “knowl-
edge graph construction” is shown in Table 6.
We also implemented a method to describe and compare software. The search method
returns result URIs, which can be passed into the describe method to give a short summary
of the target software. If multiple URIs are passed to the describe method, they are compared
side by side. The results are sorted so that, for a given metadata category, values that are in
common show up first. An example can be seen in Table 7, where we describe the top two
results for the search “knowledge graph construction” from Table 6. We are able to compare
relevant information between the two software packages and see that both use similar lan-
guages and have open source licenses. The metadata shown for the side-by-side comparison
uses as reference some of the most demanded fields (Hucka & Graham, 2018) by scientists
when searching software. Cependant, the number of metadata categories has been reduced
on purpose to avoid overwhelming users.
Tableau 6.
method. The search has been limited to the first five results
The result of searching “knowledge graph construction” using the description keyword
1
2
3
4
5
Result URI
https://w3id.org/okn/i/Software/SDM-TIB/SDM-RDFizer
Matches
3
TF-IDF sum
2.29
https://w3id.org/okn/i/Software/usc-isi-i2/kgtk
https://w3id.org/okn/i/Software/SystemsGenetics/KINC
https://w3id.org/okn/i/Software/TBFY/knowledge-graph
https://w3id.org/okn/i/Software/pykeen/pykeen
2
2
2
2
3.38
2.81
1.69
1.45
1437
Études scientifiques quantitatives
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
Example subset of the comparison functionality. These are the top two results for the search “knowledge graph construction,” using
Tableau 7.
the description keywords method. By default, the SOSEN CLI will output the table to the terminal, but it can be configured to output LaTeX
markup (as shown in the example)
Nom
author
SDM-TIB
SDM-RDFizer
kgtk
usc-isi-i2
description
An Efficient RML-Compliant Engine for Knowledge Graph Construction
Knowledge Graph Toolkit
languages
Dockerfile
Python
” ”
” ”
” ”
Dockerfile
Python
Makefile
Shell
Licence
https://api.github.com/licenses/apache-2.0
https://api.github.com/licenses/mit
4. DISCUSSION
Our work aims to address important challenges for software findability, comparison, et
understanding that are performed mostly in a manual manner today. In this section we discuss
some of the assumptions and limitations of our approach, which may inform new research
challenges and lines of future work.
4.1. Software Metadata Availability
While readme files are highly informative for setting up and describing software, they may
contain typos, be incomplete, or be nonexistent. Using other sources for documentation, tel
as manuals, reports, and publications, may help retrieving additional insight into how to use a
particular scientific software component. Par exemple, publications may contain additional
insight on the assumptions and restrictions of a software component. Repositories sometimes
contain input and output samples that may help understand how to prepare and transform data
for a particular software component, or how to combine it with other software. In this work we
have started capturing auxiliary files of scientific software, but additional work is needed to
describe all these ad hoc resources in the right context.
During our analysis, we have prioritized extracting precise descriptions of software meta-
data fields by different methods (supervised classification, header analysis, regular expressions,
file exploration or the GitHub API). Some of these methods may extract the same fields, lead-
ing to similar, redundant statements. A postprocessing step would help curating redundancies
in the graph.
En même temps, the work proposed here may be used to inform users on how well their
repositories are described, enforcing better practices on software description for authors to
help dissemination and findability of their software.
4.2. Updating and Extending the SOSEN KG
SOSEN was designed with extensibility in mind. We believe that many of the design choices of
the project (such as using KGs) make SOSEN extensible, both for adding new data from exist-
ing sources and for incorporating new data sources, as we detail below.
We are continually evolving SOMEF, and as a result, the SOSEN KG may need to be
updated with new data from existing sources. We have a pipeline for recreating the KG,
Études scientifiques quantitatives
1438
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
and plan to update the SOSEN KG after each major SOMEF release. This is a process that
occurs in bulk, and it is not designed to be incremental at the moment.
Updating the SOSEN KG with data from other registries is relatively easy, but needs addi-
tional work to find the right correspondence between entries in different catalogs. This has
been left out of the scope of this publication. Donc, at the moment, our methodology
has an assumption of having an explicit link between the target metadata registry and the code
repository to integrate.
4.3. Finding Scientific Software
The SOSEN framework makes good first steps towards improving scientific software findability.
As shown in Figure 7, we are able to retrieve a significant number of keywords from the
descriptions extracted by SOMEF, integrating them together in an enriched KG. En outre,
we extract metadata categories that may inform the search (par exemple., enabling specifying a license,
programming language or software requirements). Current limitations of our approach include
that our search algorithm uses exact keyword matching, which behaves poorly to spelling
errors and ambiguities; and that the KG entities are not dereferenceable (c'est à dire., KG entities do
not resolve in a browser). Using scientific software text embeddings and fuzzy search (tel que
that supported by text search engines) are promising solutions to address the first limitation.
Using a LinkedData Frontend may address the second limitation.
The SOSEN KG is not large in size, and therefore many scientific software packages are
currently missing. Cependant, the scope of this work is to demonstrate our methodology with
a working KG of enriched entries from readme files.
4.4. Software Understanding and Comparison
Our work for automated metadata extraction and comparison extracts categories that are usu-
ally hard to find in other metadata registries without manual curation. The SOSEN CLI exposes
this information easily, without requiring users to be SPARQL experts to exploit the contents of
the SOSEN KG. The metadata fields exposed in the SOSEN CLI have not directly been vali-
dated with a user evaluation, but they are a subset of the metadata categories identified by
community surveys with more than 60 answers from scientists of different disciplines (Hucka
& Graham, 2018). En outre, two software packages can be put side by side, allowing users
to assess the limitations of each and make an informed decision. Further work is needed to
explore other meaningful ways to compare software, Par exemple, by exploring their code,
calculating analytics (par exemple., how well documented or maintained the code is), coverage of tests,
code comments, or exploring support files (notebooks, Dockerfiles, etc.).
5. RELATED WORK
5.1. Scientific Software Metadata Extraction from Text and Code
While an extensive amount of work exists to extract entities and events from text, few
approaches have paid attention to scientific software documentation. The Artificial Intelli-
gence Knowledge Graph (AIKG) (Dessì, Osborne et al., 2020) and the Open Research Knowl-
edge Graph (ORKG) (Jaradeh, Oelen et al., 2019) both leverage deep learning techniques to
extract mentions to methods and, in some cases, tools used in scientific publications. Comment-
jamais, their focus is on research papers, and hence they do not handle external code reposito-
ries or readme files, which are the focus of our work. The OpenAIRE Research Graph (Manghi,
2020) is an ongoing effort to create a KG of open science artefacts, including scientific
Études scientifiques quantitatives
1439
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
software. Cependant, OpenAIRE focuses on the integration of public repositories at scale (par exemple.,
by linking duplicate entities); while our approach extracts software-specific metadata.
Other areas of related work perform static code analysis (Ilyas & Elkhalifa, 2016) pour
different purposes, ranging from code quality to cybersecurity. Among these efforts, quelques
techniques can be used to extract metadata. Par exemple, libraries such as PyCG (Salis,
Sotiropoulos et al., 2021) or pydeps (n.d.) can be used to extract the requirements and depen-
dencies in a software project. These techniques are usually oriented towards a single program-
ming language, but may complement the metadata extraction categories we perform with
our work.
Other approaches mine code repositories and popular web forums such as Stack Overflow
to create KGs for question answering (Abdelaziz, Dolby et al., 2020), retrieve code similar to a
given function (Mover, Sankaranarayanan et al., 2018), autocomplete code snippets (Luan,
Lequel, et coll., 2019), or help finding software to perform a particular functionality described
in natural language (CodeSearchNet) (Husain, Wu et al., 2019). The scope of these approaches
is different from ours, which is focused on automatically describing and linking software meta-
data. Cependant, these initiatives define useful directions to expand and combine with our work
(par exemple., finding similar software).
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Perhaps the approach that most resembles our work (besides our initial work in Mao et al.
(2019), where we introduced an initial version of our framework) is AIMMX (Tsay, Braz et al.,
2020), a recent AI model metadata extractor from code repositories that captures their data
dependencies, machine learning framework (par exemple., TensorFlow), and references. AIMMX also
labels the main purpose of a machine learning code repository (medical domain, video learn-
ing, etc.). Plutôt, SOMEF extracts up to 23 metadata fields that range from software setup and
auxiliary files to how to obtain support from the community, and can be applied to any type of
scientific software.
5.2. Scientific Software Code Repositories and Metadata Registries
Code repositories such as GitHub (n.d.), GitLab (n.d.) and BitBucket (n.d.) are perhaps the most
widely used by the scientific community to store, test, integrate, and disseminate scientific
software code. Cependant, these repositories do not hold much machine-readable software
metadata besides license, programming language, creator, and keywords. De la même manière, quand
releasing code, scientists may use platforms such as FigShare (n.d.) and Zenodo (CERN &
OpenAIRE, 2013), as they provide DOIs stating how to cite particular code; code archival
services such as Software Heritage (n.d.) or package repositories such as Pypi (n.d.) and Maven
Central (Maven Central Repository Search, n.d.), which focus on disseminating an executable
version of the code. In all these cases, metadata is often optional, and must be added manually
by researchers.
Software metadata registries provide metadata descriptions of scientific software, comple-
menting code repositories, and are usually curated by hand by domain experts. Par exemple,
the Community Surface Dynamics Modeling System (CSDMS) (Peckham, Hutton, & Norris,
2013) contains hundreds of codes for models for Earth surface processes; the Astrophysics
Source Code Library (ASCL) contains unambiguous code descriptions in Astrophysics (Shamir
et coll., 2013); and OntoSoft (Gil et al., 2015), describes scientific software for Geosciences.
These registries usually contain high-quality software metadata entries, but curating them by
hand requires significant expertise. Our techniques may be used to automatically fill in entries,
easing the work from curators and users.
Études scientifiques quantitatives
1440
A framework for creating knowledge graphs of scientific software metadata
Enfin, Wikidata (Vrandečić & Krötzsch, 2014), a general-purpose KG which contains part
of the information in Wikipedia in machine-readable manner, also stores high-level software
metadata descriptions. Wikidata relies on manual curation as well, but has a strong, lively
community of contributors and editors, making it an ideal candidate to integrate with our work
and link to external entities (chercheurs, licenses, frameworks, etc.).
5.3. Scientific Software Metadata Comparison
Creating surveys to review existing work is a time-consuming task. For this reason, chercheurs
have started leveraging KGs to create comparisons of related work. Par exemple, the Open
Research Knowledge Graph (Jaradeh et al., 2019) uses the content extracted from scientific
publications to create interactive surveys to compare existing publications,but does not sup-
port scientific software.
Other platforms, such as OpenML (Vanschoren, van Rijn et al., 2013) and Papers with code
(n.d.) take a more practical approach, providing comparison benchmarks on how well differ-
ent machine learning methods perform for a particular task. This comparison excludes most
software metadata, but is very informative to showcase the efficiency of a given method for a
given task.
Enfin, software registries such as our previous work in OntoSoft (Gil et al., 2015) et
OKG-Soft (Garijo et al., 2019) provide the means to compare different scientific software
entries using a UI. In contrast, the presented work takes a lightweight approach which does
not require a UI to access and query the KG, making it easier to maintain (but becoming less
visually attractive for users).
6. CONCLUSIONS AND FUTURE WORK
Given the volume of publications made available every year, it is becoming increasingly
important to understand and reuse existing scientific software. Scientific software should
become a first-class citizen in scholarly research, and the scientific community is starting to
recognize its value (Forgeron, Katz, & Niemeyer, 2016). In this work we have introduced SOMEF,
a framework for automating scientific software metadata extraction that is capable of extract-
ing up to 23 software metadata categories; and a methodology to convert its results into
connected KGs of scientific software metadata. We have demonstrated our methodology by
building the SOSEN KG, a KG with over 10,000 enriched entries from Zenodo and GitHub;
and a framework to help the exploration and comparison of these entries. Both SOMEF and
SOSEN are actively maintained open source software, and available under an open license
(Kelley & Garijo, 2021; Mao et al., 2020).
Our work uncovers exciting lines of future work. D'abord, we are working towards addressing
the current limitations of our software metadata extraction framework (par exemple., by removing
redundant extractions, improving robustness to typos in headers, and augmenting the training
corpus). Deuxième, we are exploring new metadata categories to facilitate software reuse and
understanding, such as software package dependencies (different from the installation require-
ments); named entities that may be used to qualify relationships (par exemple., installation instructions
in Unix); and improving the capture of the functionality of a software component.
Troisième, we aim to improve the annotation of auxiliary files, not only recognizing them but
also qualifying their relationship with the software component being described. Par exemple,
identifying whether a notebook is an example, a preparation step, or needed for setting up a
software component; or extracting additional software details from the reference publication.
Études scientifiques quantitatives
1441
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
.
/
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
To package all these files together, we plan to leverage the RO-Crate specification (Sefton,
Ó Carragáin et al., 2021; Ó Carragáin, Goble et al., 2019), capturing the context in which all
these files are used together when incorporating them into the SOSEN KG.
Enfin, we plan to expand the SOSEN KG with additional data sources (par exemple., by including
all Zenodo software entries and FigShare software entries with readme files); and integrating
our KG with public KGs such as Wikidata (Vrandečić & Krötzsch, 2014), which have a strong
community of users that can help curate and refine the software metadata extraction errors. Dans
particular, Wikidata contains a vast collection of scholarly articles, which we plan to explore
to align to those entries in SOSEN KG with reference publications.
REMERCIEMENTS
We would like to thank Yolanda Gil, Allen Mao, Shobeir Fakhraei, HaripriyaDharmala,
Jiaying Wang, Rosna Thomas, Thomas Eblen, Vedant Diwanji and Joseph Lee for their
contributions.
CONTRIBUTIONS DES AUTEURS
Aidan Kelley: Enquête, Logiciel, Writing—original draft, Writing—review & édition.
Daniel Garijo: Enquête, Logiciel, Surveillance, Writing—original draft, Writing—review
& édition.
COMPETING INTERESTS
The authors have no competing interests.
INFORMATIONS SUR LE FINANCEMENT
This work was performed as part of the Research Experience for Undergraduates (REU) pro-
gram, supported by National Science Foundation (NSF) grant #1659886. This work was also
funded by the Defense Advanced Research Projects Agency with award W911NF-18-1-0027,
the National Science Foundation with award ICER-1440323 and the Madrid Government
(Comunidad de Madrid-Spain) under the Multiannual Agreement with Universidad Politécnica
de Madrid in the line Support for R&D projects for Beatriz Galindo researchers, in the context
of the V PRICIT (Regional Programme of Research and Technological Innovation).
DATA AVAILABILITY
Datasets related to this article can be found at https://doi.org/10.6084/m9.figshare.14916684.v1:
The SOSEN-KG (Turtle format), hosted at FigShare. https://doi.org/10.5281/zenodo.4574207:
SOMEF 0.4.0 software and training corpus, hosted at Zenodo. https://zenodo.org/record
/4574224: SOSEN-KG repository and examples, hosted at Zenodo.
RÉFÉRENCES
Abdelaziz, JE., Dolby, J., McCusker, J.. P., & Srinivas, K. (2020).
Graph4code: A machine interpretable knowledge graph for
code. arXiv preprint, arXiv:2002.09440.
Albrecht, J., Alves, UN. UN. Jr., Amadio, G., Andronico, G., Anh-Ky,
N., … Yazgan, E. (2019). A roadmap for HEP software and com-
puting R&D for the 2020s. Computing and Software for Big Sci-
ence, 3(1), 7. https://doi.org/10.1007/s41781-018-0018-8
Awesome. (n.d.). https://awesome.re/ (accessed February 25, 2021).
Binder. (n.d.). https://mybinder.org/ (accessed February 27, 2021).
BitBucket (n.d.). https:// bitbucket.org/ (accessed February 25,
2021).
Bonatti, P.. UN., Decker, S., Polleres, UN., & Presutti, V. (2019). Knowl-
edge graphs: New directions for knowledge representation on
the semantic web (Dagstuhl Seminar 18371). In Dagstuhl reports
(Vol. 8).
Carothers, G., & Prud’hommeaux, E. (2014). RDF 1.1 turtle ( W3C
Recommendation). W3C. https://www.w3.org/ TR/2014/ REC
-turtle-20140225/
Études scientifiques quantitatives
1442
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
CERN & OpenAIRE. (2013). Zenodo. CERN. Retrieved from https://
www.zenodo.org/. https://doi.org/10.25495/7gxk-rd71
Champin, P.-A., Longley, D., & Kellogg, G. (2020). JSON-ld 1.1
( W3C Recommendation). W3C. https://www.w3.org/ TR/2020
/REC-json-ld11-20200716/
Dessì, D., Osborne, F., Recupero, D. R., Buscaldi, D., Motta, E., &
Sack, H. (2020). AI-KG: An automatically generated knowledge
graph of artificial intelligence. In International Semantic Web
Conference (pp. 127–143). https://doi.org/10.1007/978-3-030
-62466-8_9
DockerHub. (n.d.). https://hub.docker.com/ (accessed February 25,
2021).
FAIR4RS. (n.d.). FAIR for research software. https://www.rd-alliance
.org/groups/fair-research-software-fair4rs-wg (accessed February
25, 2021).
FigShare. (n.d.). https://figshare.com/ (accessed February 27,
2021).
Garijo, D., Osorio, M., Khider, D., Ratnakar, V., & Gil, Oui. (2019).
OKG-Soft: An open knowledge graph with machine readable sci-
entific software metadata. 15th International Conference on
eScience (eScience) (pp. 349–358). IEEE. https://doi.org/10.1109
/eScience.2019.00046
Gil, Y., Ratnakar, V., & Garijo, D. (2015). Ontosoft: Capturing sci-
entific software metadata. Proceedings of the 8th International
Conference on Knowledge Capture (p. 32). https://est ce que je.org/10
.1145/2815833.2816955
GitHub. (n.d.). https://github.com/ (accessed February 25, 2021).
GitLab. (n.d.). https://gitlab.com/ (accessed February 25, 2021).
Gousios, G., Vasilescu, B., Serebrenik, UN., & Zaidman, UN. (2014).
Lean GHTorrent: GitHub data on demand. Actes du
11th Working Conference on Mining Software Repositories
(pp. 384–387). https://doi.org/10.1145/2597073.2597126
Guha, R.. V., Brickley, D., & Macbeth, S. (2016). Schema.org: Evo-
lution of structured data on the web. Communications of the
ACM, 59(2), 44–51. https://doi.org/10.1145/2844544
Guides, G. (n.d.). Documenting your project in GitHub. https://
guides.github.com/features/wikis/ (accessed February 27, 2021).
Hucka, M., & Graham, M.. J.. (2018). Software search is not a
science, even among scientists: A survey of how scientists and
engineers find software. Journal of Systems and Software, 141,
171–191. https://doi.org/10.1016/j.jss.2018.03.047
Husain, H., Wu, H.-H., Gazit, T., Allamanis, M., & Brockschmidt,
M.. (2019).Codesearchnet challenge: Evaluating the state of
semantic code search. arXiv preprint, arXiv:1909.09436.
Ilyas, B., & Elkhalifa, je. (2016). Static code analysis: A systematic
literature review and an industrial survey (Master’s thesis).
https://urn.kb.se/resolve?urn=urn%3Anbn%3Ase%3Abth-12871
Jaradeh, M.. Y., Oelen, UN., Farfar, K. E., Prinz, M., D’Souza, J., …
Auer, S. (2019). Open research knowledge graph: Next genera-
tion infrastructure for semantic scholarly knowledge. Procédure
of the 10th International Conference on Knowledge Capture
(pp. 243–246). https://doi.org/10.1145/3360901.3364435
Jones, M.. B., Boettiger, C., Mayes, UN. C., Forgeron, UN., Slaughter, P., …
Goble, C. (2017). CodeMeta: an exchange schema for software
metadata. KNB Data Repository. https://doi.org/10.5063
/SCHEMA/CODEMETA-2.0
Kelley, UN., & Garijo, D. (2020). SoSEN-KG: Knowledge graph dump
for SoSEN: Software Search Engine. Zenodo. https://est ce que je.org/10
.5281/ZENODO.3956451
Kelley, UN., & Garijo, D. (2021). SOSEN-CLI first release. Zenodo.
https://doi.org/10.5281/ZENODO.4574224
Lamprecht, A.-L., Garcia, L., Kuzak, M., Martinez, C., Arcila, R., …
Capella-Gutierrez, S. (2020). Towards FAIR principles for
research software. Data Science, 3(1), 37–59. https://est ce que je.org/10
.3233/DS-190026
LIGO-VIRGO. (n.d.). Software for gravitational wave data. https://
www.gw-openscience.org/software/ (accessed February 25,
2021).
Luan, S., Lequel, D., Barnaby, C., Sen, K., & Chandra, S. (2019).
Aroma: Code recommendation via structural code search. Pro-
ceedings of ACM Programming Languages, 3 (OOPSLA). https://
doi.org/10.1145/3360578
Manghi, P.. (2020).OpenAIRE research graph for research. Zenodo.
https://doi.org/10.5281/zenodo.3903646
Mao, UN., Garijo, D., & Fakhraei, S. (2019). SoMEF: A framework for
capturing scientific software metadata from its documentation.
IEEE International Conference on Big Data (pp. 3032–3037).
https://doi.org/10.1109/BigData47090.2019.9006447
Mao, UN., vmdiwanji, Garijo, D., Kelley, UN., Dharmala, H., …
jiaywan. (2020). KnowledgeCaptureAndDiscovery/somef:
SOMEF 0.4.0. Zenodo. https://doi.org/10.5281/zenodo.4574207
Marcus, M., Kim, G., Marcinkiewicz, M.. UN., MacIntyre, R., Bies,
UN., … Schasberger, B. (1994). The Penn treebank: Annotating
predicate argument structure. In HUMAN LANGUAGE TECH-
NOLOGY: Proceedings of a Workshop held at Plainsboro,
New Jersey, March 8–11, 1994. https://doi.org/10.3115
/1075812.1075835
Maven Central Repository Search. (n.d.). https://search.maven.org/
(accessed February 27, 2021).
Miller, E., & Manola, F. (2004). RDF primer ( W3C Recommenda-
tion). W3C. https://www.w3.org/ TR/2004/ REC-rdf-primer
-20040210/
Miller, G. UN. (1995).Wordnet: A lexical database for English. Com-
munications of the ACM, 38(11), 39–41. https://doi.org/10.1145
/219717.219748
Mover, S., Sankaranarayanan, S., Olsen, R.. B. P., & Chang, B.-Y. E.
(2018). Mining framework usage graphs from app corpora. 2018
IEEE 25th International Conference on Software Analysis, Evolu-
tion and Reengineering (pp. 277–289). https://doi.org/10.1109
/SANER.2018.8330216
Ó Carragáin, E., Goble, C., Sefton, P., & Soiland-Reyes, S. (2019). UN
lightweight approach to research object data packaging. Zenodo.
https://doi.org/10.5281/zenodo.3250687
OpenAIRE. (n.d.). https://www.openaire.eu/mission-and-vision
(accessed February 25, 2021).
Papers with code. (n.d.). https://paperswithcode.com/ (accessed
Février 27, 2021).
Peckham, S. D., Hutton, E. W., & Norris, B.
(2013). UN
component-based approach to integrated modeling in the geos-
ciences: The design of CSDMS. Computers & Geosciences, 53,
3–12. https://doi.org/10.1016/j.cageo.2012.04.002
Pedregosa, F., Varoquaux, G., Gramfort, UN., Michel, V., Thirion, B.,
… Duchesnay, É. (2011). Scikit-learn: Machine learning in
Python. Journal of Machine Learning Research, 12, 2825–2830.
Prlić, UN., & Lapp, H. (2012). The PLOS computational biology soft-
ware section. PLOS Computational Biology, 8(11), e1002799.
https://doi.org/10.1371/journal.pcbi.1002799
pydeps: Python module dependency visualization. (n.d.). https://
github.com/thebjorn/pydeps
Pypi: The python package index. (n.d.). https://pypi.org/ (accessed
Février 27, 2021).
Rector, UN., & Noy, N. (2006). Defining N-ary relations on the
semantic web ( W3C Note). W3C. https://www.w3.org/TR/2006
/NOTE-swbp-n-aryRelations-20060412/
Salis, V., Sotiropoulos, T., Louridas, P., Spinellis, D., & Mitropoulos,
D. (2021). PyCG: Practical call graph generation in Python. 2021
Études scientifiques quantitatives
1443
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
A framework for creating knowledge graphs of scientific software metadata
IEEE/ACM 43rd International Conference on Software Engineering
(ICSE) (pp. 1646–1657). https://doi.org/10.1109/ICSE43902.2021
.00146
Scientif ic Paper of
(n.d.). https://
scientificpaperofthefuture.org/spf.html (accessed February 25,
2021).
the Future Ini tiat ive.
Sefton, P., Ó Carragáin, E., Soiland-Reyes, S., Corcho, O., Garijo,
D., … Portier, M.. (2021). RO-Crate Metadata Specification 1.1
(Technologie. représentant). https://doi.org/10.5281/ZENODO.3406497
Shamir, L., Wallin, J.. F., Allen, UN., Berriman, B., Teuben, P., …
DuPrie, K. (2013). Practices in source code sharing in astrophys-
ics. Astronomy and Computing, 1, 54–58. https://est ce que je.org/10.1016
/j.ascom.2013.04.001
Forgeron, UN. M., Katz, D. S., & Niemeyer, K. E. (2016).Software cita-
tion principles. PeerJ Computer Science, 2, e86. https://doi.org
/10.7717/peerj-cs.86
Software Carpentry. (n.d.). https://software-carpentry.org/about
(accessed February 25, 2021).
Software Heritage. (n.d.). https://www.softwareheritage.org/
(accessed February 25, 2021).
Software Sustainability Institute. (n.d.). https://software.ac.uk/
(accessed February 25, 2021).
Tsay, J., Braz, UN., Hirzel, M., Shinnar, UN., & Mummert, T. (2020).
AIMMX: Artificial Intelligence Model Metadata Extractor. Pro-
ceedings of the 17th International Conference on Mining Soft-
ware Repositories (pp. 81–92). https://doi.org/10.1145/3379597
.3387448
USGS. (n.d.). US Geological Survey: Software for Water Resources
Applications. https://www.usgs.gov/mission-areas/water
-resources/software (accessed February 25, 2021).
Vanschoren, J., van Rijn, J.. N., Bischl, B., & Torgo, L. (2013). OpenML:
Networked science in machine learning. SIGKDD Explorations,
15(2), 49–60. https://doi.org/10.1145/2641190.2641198
Vrandečić, D., & Krötzsch, M.. (2014). Wikidata: A free collaborative
knowledge base. Communications of the ACM, 57(10), 78–85.
https://doi.org/10.1145/2629489
Wilkinson, M.. D., Dumontier, M., Aalbersberg, je. J., Appleton, G.,
Axton, M., … Mons, B. (2016). The FAIR Guiding Principles for
scientific data management and stewardship. Scientific Data, 3,
160018. https://doi.org/10.1038/sdata.2016.18, PubMed: 26978244
APPENDIX A: IMPLEMENTING TF-IDF SEARCH USING A SPARQL QUERY
Figure A1 shows the SPARQL query that would be generated if users searched for the key-
words “knowledge” and “graph”, using the description keyword method. To search for differ-
ent keywords, we would modify the newline-separated list of keywords in the query. To use a
different search method, the properties with the word “description” in them would be swapped
out for their equivalent property names for the user-defined or title keywords.
The query works by first getting the global document count. Alors, for each keyword in the
list, it attempts to link that keyword string to a Keyword entity in the graph. If no match for the
keyword is found in the graph, no document uses this keyword, and thus it is ignored. Addi-
tionally, the query retrieves the total number of documents that the keyword appears in. Ce,
together with the document count, is used to compute the inverse document frequency (IDF).
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
.
/
Suivant, we have the Keyword entities together with their respective IDFs. The query now
matches Keyword entities to Software entities that use this keyword in their description. Nous
do this by looking for a QualifiedKeyword object that points to both specified keyword and
software. The existence of the QualifiedKeyword object means that there is an edge from the
software to the keyword, because the QualifiedKeyword exists to describe that edge. Cependant,
this does not mean that the keyword exists in the description; it could be in the title or user-
defined list. Using the sosen:inDescriptionCount property, which tells us the number of
times this keyword appears in the description of the Software entity, we then additionally get
the sosen:descriptionKeywordCount property, which stores the total number of key-
words in the software description. With these two properties, we can compute the term fre-
quency (TF) of the keyword, which we multiply by its IDF to get the TF-IDF score.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
With the keywords that match and their TF-IDF scores, the query computes the total num-
ber of keywords that matched and the sum of the TF-IDF scores of all matching keywords. Le
results are then sorted in descending order primarily by the number of keyword matches, avec
the TF-IDF score sums as a secondary key, used to break ties.
The biggest benefit of writing a keyword search as a SPARQL query is that it may be com-
bined with other SPARQL queries. Par exemple, we can do a keyword search but add filters,
specifying that the software had to have a release in the last 6 mois, use Python as a lan-
guage, or have an open-source license.
Études scientifiques quantitatives
1444
A framework for creating knowledge graphs of scientific software metadata
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
Figure A1. A SPARQL query showing TF-IDF based keyword matching for the values knowledge
and graph.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Études scientifiques quantitatives
1445
A framework for creating knowledge graphs of scientific software metadata
APPENDIX B: HEADER ANALYSIS EVALUATION DETAILS
Table B1 provides additional information on the precision and recall results obtained in the
header analysis evaluation.
Table B1. Detailed header evaluation results
Category
Description
Installation
Invocation
Citation
Usage
Documentation
Requirements
Support
License
Total
20
Correct
13
82
21
36
75
18
31
9
30
72
20
33
55
18
29
6
30
Incorrect Missed
5
16
3
7
32
2
2
8
0
7
10
1
3
20
0
2
3
0
Precision
0.72
Recall
0.65
F-Measure
0.68
0.82
0.87
0.82
0.63
0.90
0.93
0.43
1.00
0.88
0.95
0.92
0.73
1.00
0.93
0.67
1.00
0.85
0.91
0.87
0.68
0.95
0.93
0.52
1.00
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
e
d
toi
q
s
s
/
un
r
t
je
c
e
–
p
d
je
F
/
/
/
/
2
4
1
4
2
3
2
0
0
7
8
4
4
q
s
s
_
un
_
0
0
1
6
7
p
d
/
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Études scientifiques quantitatives
1446