PERSPECTIVE
Feeding the machine: Challenges to reproducible
predictive modeling in resting-state connectomics
Andrew Cwiek1,2
, Sarah M. Rajtmajer3,4
, Bradley Wyble1
, Vasant Honavar3,5
,
Emily Grossner1,2, and Frank G. Hillary1,2
1Département de psychologie, Université d'État de Pennsylvanie, Parc universitaire, Pennsylvanie, Etats-Unis
2Social Life and Engineering Sciences Imaging Center, Université d'État de Pennsylvanie, Parc universitaire, Pennsylvanie, Etats-Unis
3College of Information Sciences and Technology, Université d'État de Pennsylvanie, Parc universitaire, Pennsylvanie, Etats-Unis
4Rock Ethics Institute, Université d'État de Pennsylvanie, Parc universitaire, Pennsylvanie, Etats-Unis
5Institute for Computational and Data Sciences, Université d'État de Pennsylvanie, Parc universitaire, Pennsylvanie, Etats-Unis
un accès ouvert
journal
Mots clés: Machine learning, Classifiers, Predictive modeling, Brain networks, Clinique
neuroscience
ABSTRAIT
In this critical review, we examine the application of predictive models, Par exemple,
classifiers, trained using machine learning (ML) to assist in interpretation of functional
neuroimaging data. Our primary goal is to summarize how ML is being applied and critically
assess common practices. Our review covers 250 studies published using ML and resting-state
functional MRI (IRMf) to infer various dimensions of the human functional connectome.
Results for holdout (“lockbox”) performance was, on average, ~13% less accurate than
performance measured through cross-validation alone, highlighting the importance of lockbox
data, which was included in only 16% of the studies. There was also a concerning lack of
transparency across the key steps in training and evaluating predictive models. The summary
of this literature underscores the importance of the use of a lockbox and highlights several
methodological pitfalls that can be addressed by the imaging community. We argue that,
ideally, studies are motivated both by the reproducibility and generalizability of findings as
well as the potential clinical significance of the insights. We offer recommendations for
principled integration of machine learning into the clinical neurosciences with the goal of
advancing imaging biomarkers of brain disorders, understanding causative determinants for
health risks, and parsing heterogeneous patient outcomes.
BACKGROUND
In settings where large amounts of well-characterized training data are available, modern
machine learning (ML) methods offer some of the most powerful approaches to discovering
regularities and extracting useful knowledge from data (Bishop, 2006; Goodfellow et al.,
2016; Hastie et al., 2009; Mitchell, 1997). Of particular interest are algorithms that, given a
data set of labeled samples, learn a predictive model, Par exemple, a classifier, for labeling
novel samples drawn from the same distribution as the training data. Programs for training
such classifiers typically optimize a desired objective function on a given set of training sam-
ples. Advances in ML have revolutionized the design of systems for natural language process-
ing (Manning et al., 2014; Mikolov et al., 2013; Turian et al., 2010), computer vision (Bradski
& Kaehler, 2008; Deng et al., 2009; Forsyth & Ponce, 2002), network analysis (Hamilton et al.,
Citation: Cwiek, UN., Rajtmajer, S. M.,
Wyble, B., Honavar, V., Grossner, E.,
& Hillary, F. G. (2022). Feeding the
machine: Challenges to reproducible
predictive modeling in resting-state
connectomics. Neurosciences en réseau,
6(1), 29–48. https://doi.org/10.1162/netn
_a_00212
EST CE QUE JE:
https://doi.org/10.1162/netn_a_00212
Informations complémentaires:
https://doi.org/10.1162/netn_a_00212
Reçu: 12 Février 2021
Accepté: 8 Octobre 2021
Intérêts concurrents: Les auteurs ont
a déclaré qu'aucun intérêt concurrent
exister.
Auteur correspondant:
Frank G. Hillary
fhillary@psu.edu
Éditeur de manipulation:
Olaf Sporns
droits d'auteur: © 2021
Massachusetts Institute of Technology
Publié sous Creative Commons
Attribution 4.0 International
(CC PAR 4.0) Licence
La presse du MIT
je
D
o
w
n
o
À
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
/
t
e
d
u
n
e
n
À
r
t
je
c
e
–
p
d
je
F
/
/
/
/
/
6
1
2
9
1
9
8
4
2
2
9
n
e
n
_
À
_
0
0
2
1
2
p
d
.
t
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Predictive modeling and network neuroscience
Classifier:
An algorithm designed to classify two
or more groups using a given set of
variables.
Training:
A generally iterative process wherein
an algorithm is refined to better
classify a subject into their correct
group by tuning the parameters for
selection of important variables.
Features:
The variables input into the algorithm
for use in classification.
Overfitting:
When the algorithm is too closely
attuned to the data it was trained on,
to the detriment of the algorithm’s
generalizability to new samples.
Dimensionality:
The number of features given to the
algorithme.
Cross-validation:
A process to limit overfitting through
repeated splitting of the data into
training and testing sets to prevent
overfitting.
2017), and bioinformatics (Baldi et al., 2001; Larrañaga et al., 2006; Min et al., 2017). A num-
ber of publicly available ML libraries (par exemple., Scikit-learn, TensorFlow) can now be deployed,
permitting “off-the-shelf” application of these analyses for a number of data types including
behavioral, genetic, and imaging data (Abadi et al., 2016; Abraham et al., 2014).
In one sense, predictive models trained using ML are like traditional statistical models, pour
exemple, regression: there are covariates, an outcome, and a statistical function linking the
covariates to the outcome. But where ML algorithms add value is in handling enormous num-
bers of features or predictors, heterogeneous data types (par exemple., images, text, genomic sequences,
molecular structures, réseaux, and longitudinal behavioral observations), and combining
them in complex, nonlinear ways to make accurate individualized prediction, c'est, a clinical
diagnosis. This review examines the use of predictive models in ML and resting-state connec-
tomics with focus on several particularly important issues, including “overfitting” and its
related consequences, sample size and implications for modeling clinical heterogeneity,
and methodological transparency.
Prediction Modeling in the Neurosciences
There has been growing use of ML to determine if brain network metrics can serve as classi-
fiers of brain disorders with several high-profile reviews recently published (Bassett et al.,
2020; Braun et al., 2018; Parkes et al., 2020; Vu et al., 2018). Many of the canonical networks
identified in rsfMRI studies (par exemple., default mode network) have been of critical focus in studies of
large-scale network plasticity in a range of brain disorders including schizophrenia (de Filippis
et coll., 2019; Lefort-Besnard et al., 2018; Progar & Peut, 1988; Steardo et al., 2020), autism (L.
Chen et al., 2020; Glerean et al., 2016; Hegarty et al., 2017), Alzheimer’s disease and related
dementias (Langella et al., 2021; Pellegrini et al., 2018; Salvatore et al., 2015), and brain injury
(Bonnelle et al., 2012; Caeyenberghs et al., 2017; Gilbert et al., 2018; Roy et al., 2017).
While the high dimensionality of functional imaging data—relationships between hundreds
or thousands of time series observations—may push the limits of traditional modeling, ML
approaches can capitalize on the complexity of multimodal datasets (Baltrušaitis et al.,
2019; Gao et al., 2020; Guo et al., 2019) and provide opportunity to examine interactions
among variables otherwise impossible to test. Donc, there is evident potential for the
application of ML to incorporate a wide array of data structures into prediction modeling
including behavioral, brain imaging, physiological measurements, and genetic markers.
Growing Pains in ML and Resting-State Connectomics
Perhaps the most common methodological concern in applied ML is overfitting, or training an
algorithm to predict with very high accuracy features within a single dataset at the expense of
predicting a phenomenon more generally (Dietterich, 1995; Ng, 1997; Roelofs et al., 2019;
Srivastava et al., 2014). Overfitting has profound implications for reproducibility, portability,
and generalizability of findings. Surtout, the difficulty of preventing overfitting is underap-
preciated, and even typical remedies, such as cross-validation, can allow for analysis hyper-
parameters to become tuned, or “overhyped,” to a specific set of data (Hosseini et al., 2020;
Poldrack et al., 2020). These concerns underscore the need for greater transparency in model
selection, enforcement of model parsimony, and rigorous testing and validation of trained models
on independent validation data, with attention to class imbalance in the data, relative costs of
false positives versus false negatives, and the tradeoffs between them (Varoquaux et al., 2017).
Related to overfitting are concerns about the size or heterogeneity in the training and test
samples (Poldrack et al., 2020). When a sample is overly restrictive along dimensions that
Neurosciences en réseau
30
je
D
o
w
n
o
À
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
t
/
e
d
u
n
e
n
À
r
t
je
c
e
–
p
d
je
F
/
/
/
/
/
6
1
2
9
1
9
8
4
2
2
9
n
e
n
_
À
_
0
0
2
1
2
p
d
t
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Predictive modeling and network neuroscience
Lockbox:
A set of data intentionally set aside
before training the algorithm and
used exactly once after training to
test the generalizability of the result.
influence outcome in neurological disorders (par exemple., severity of disease, age of onset), it may
reduce the study reproducibility and the ability to predict the phenomenon as it naturally
occurs (Caruana et al., 2000; Hawkins, 2004; Schaffer, 1993; Srivastava et al., 2014). As an
exemple, an investigator may have access to a large database of cases of individuals diagnosed
with a neurological or psychiatric disorder that can be used for training and test datasets. Même
with conservative training and only single exposure to the testing dataset (the gold standard),
the result may not generalize if the sample is restricted in its range of characteristics with
respect to demography, symptom severity, or disease/injury chronicity.
Goals of this Review
There is significant and justified enthusiasm for using ML approaches to advance our under-
standing of brain disorders. With the ever-increasing application of ML in the study of resting-
state connectomics, the importance of the implementation of and adherence to best practices
is further underscored. Given this backdrop, we review 250 papers using ML for diagnosis or
symptom profiling of brain disorders using resting-state fMRI methods, coding information
regarding the methods used with particular focus on how algorithmic “success” was deter-
mined, the use of a lockbox dataset (c'est à dire., a data set that can be accessed only once at the
end of the analysis, also called a holdout set, a test set, or an external set), transparency in
the approach, sample size and heterogeneity, and the types of conclusions drawn. We aim
to provide a summary of the state-of-the-art in ML applications to one area of clinical neuro-
science with the goal of identifying best practices and opportunities for methodological
improvement. While we focus on resting-state fMRI connectomics here, the issues addressed
likely have relevance for a wider range of ML applications in the neurosciences.
Method: Literature Review
We conducted a literature search using the following search terms in the PubMed database:
(ML OR classifier OR supervised learn OR unsupervised learn OR SVM) AND (brain) AND
(network OR graph OR connectivity) AND resting AND (imaging) AND (neurological OR
clinical OR brain injury OR multiple sclerosis OR epilepsy OR stroke OR CVA OR aneurysm
OR Parkinson’s OR MCI or Alzheimer’s OR dementia OR HIV OR SCI OR spinal cord OR
autism OR ADHD OR intellectual disability OR Down syndrome OR Tourette) AND
“humans”[MeSH Terms].
We did not bound the date range for our search, but we excluded non-English papers,
review papers, and animal studies. We also excluded papers that were based on simulations
or other nonhuman data. Our initial search returned 471 papers that were reviewed for inclu-
sion. Two reviewers independently screened all of the papers returned from the above search
at the title and abstract level for exclusionary criteria.
By examining each paper title and abstract, papers were excluded based on the following
catégories: (1) examined structural brain imaging only (n = 98; 21%); (2) did not examine a
clinical phenomenon (n = 59; 13%); (3) focused on automated tissue segmentation or lesion
identification (n = 48, 10%); (4) was focused on algorithm or method development without
clinical diagnostics (n = 41, 9%); (5) used other imaging approaches such as EEG/MEG (n =
33, 7%); (6) did not implement formal network analysis (n = 27, 6%); (7) was not an empirical
étude, including reviews and perspectives (n = 25, 5%); (8) did not use machine learning
(broadly defined) or classification (n = 13, 3%); ou (9) another reason consistent with the exclu-
sionary criteria (n = 9, 2%). This resulted in exclusion of 353 papers, and for the remaining 118
papers (25%) the full paper was included in the final analysis. For the full-text review, deux
Neurosciences en réseau
31
je
D
o
w
n
o
À
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
t
/
/
e
d
u
n
e
n
À
r
t
je
c
e
–
p
d
je
F
/
/
/
/
/
6
1
2
9
1
9
8
4
2
2
9
n
e
n
_
À
_
0
0
2
1
2
p
d
t
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Predictive modeling and network neuroscience
reviewers were assigned to each specific section based on their respective specialties and
completed a full analysis on multiple papers to identify any potential inconsistencies between
the reviewers. Following this brief training for inter-rater consistency, the reviewers completed
a full analysis of the papers independently.
Based on feedback during the review process, we broadened our review to include terms
sensitive to papers using deep learning approaches. A second identical keyword search to the
above was conducted, while inserting the following terms to capture ML and deep learning
approaches:
“(deep learn* OR deep belief network OR multilayer perceptron OR autoencoder OR
convolution neural network OR artificial neural network OR generative adversarial net-
work OR machine learning OR ML OR classifier OR supervised learn OR unsupervised
learn OR SVM) AND …”).
The second search (Avril 2021) revealed 625 papers and based on abstract review (or full
manuscript review if necessary), 405 papers were excluded based on the following categories
and several for multiple reasons: (1) did not use machine learning (broadly defined) or classi-
fication (179, 28.6%); (2) did not examine a clinical phenomenon (n = 90, 14.5%); (3) did not
implement formal network analysis (n = 29, 4.6%); (4) used other imaging approaches such as
EEG/MEG/PET (n = 28, 4.4%); (5) reviewed already existing literature, no new analysis (n = 24,
3.8%); (6) fMRI data were not included for prediction modeling (n = 22, 3.5%); (6) analyse
included structural neuroimaging only (n = 12, 1.9%); (7) prospective study or proposal (n = 6,
.009%); (8) study not available in English (n = 3, .004%); (9) animal studies (n = 2, .003%); et
(10) other reasons consistent with the exclusionary criteria (par exemple., pilot studies, lesion segmen-
tation studies, n = 11, .018%). This resulted in retention of 220 papers from our second search
(n = 625). After eliminating redundancies with the outcome of the initial search (n = 471, n =
118 included), the final review included 250 unique papers for analysis. A flowchart for the
literature review is provided in Figure 1.
Data Coding
To understand the methodological factors shaping machine learning use, the type of classifica-
tion algorithm utilized, subject population count, and the use of permutation testing with blind
analyse, as defined by Hosseini et al. (2020), were collected. En plus, key information per-
taining to the description of features input into the algorithm, the classifier design, and the per-
formance reporting metrics chosen to measure chosen ML technique’s findings were collected.
In addition to the year of publication, specific demographic factors of the participants used in
each paper were recorded. These factors include age, years of education, handedness, age of
diagnosis (where applicable), and socioeconomic status. Features used to train the algorithm
were recorded including the use of network metrics, behavioral data, injury or disease charac-
teristics, genetic information, blood biomarker information, medical history, et démographique
factors. For network metrics specifically, information regarding the node definition and count,
edge definition, and whole-brain versus subnetwork analysis were additionally recorded.
Elements shaping the result reporting of the classifier, including the metrics chosen by the
article, the type of cross-validation technique, ablation reporting, and use of a lockbox (c'est à dire., À
strictly observed separation between data used to train/optimize the analysis parameters and
data used to assess generalizability; see Hosseini et al., 2020) were a primary focus of this
revoir. Because classifier accuracy was a focus for our review, this was coded for all papers,
and in the case of multiple analyses, the test with the highest performance at the most stringent
Permutation testing:
A method for testing the final feature
set against chance performance
through repeated randomization of
class labels (c'est à dire., patient vs. healthy
control) and comparison of the
distributed accuracy to the observed
performance.
Neurosciences en réseau
32
je
D
o
w
n
o
À
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
t
/
e
d
u
n
e
n
À
r
t
je
c
e
–
p
d
je
F
/
/
/
/
/
6
1
2
9
1
9
8
4
2
2
9
n
e
n
_
À
_
0
0
2
1
2
p
d
.
t
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Predictive modeling and network neuroscience
je
D
o
w
n
o
À
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
t
/
/
e
d
u
n
e
n
À
r
t
je
c
e
–
p
d
je
F
/
/
/
/
/
6
1
2
9
1
9
8
4
2
2
9
n
e
n
_
À
_
0
0
2
1
2
p
d
.
t
Chiffre 1. PRISMA flowchart of literature review. *An initial PubMed search was conducted, following valuable feedback, an updated search
was conducted including articles up to the year 2021, and which included terms to broaden the search to include deep learning algorithms.
For details, please see section Method: Literature Review. **Initial Review did not delineate removal at particular step; updated review
includes a step-by-step workflow. ***220 from updated search + 30 nonduplicates from initial search. Modification of flowchart provided
by Page et al. (2021).
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
validation stage (cross-validation or lockbox) was selected for analysis. In cases where papers
did not report total accuracy, but did report sensitivity and specificity, we calculated an accu-
racy value based on sensitivity, specificity, and sample size (see Supporting Information For-
mula: Formula S1).
The presence of a lockbox was determined through keyword search of the full text for terms
such as “holdout,” “external,” “test set,” “testing,” “withheld,” or “validation-set,” followed by
a critical reading of the methodology. To qualify as a lockbox, the article had to (1) set aside a
subset of data for the purpose of testing the algorithm performance following training, (2) faire
explicit that no part of the data in the lockbox was included at any point during algorithm
development, et (3) not report multiple training/testing phases to arrive at the final lockbox
performance. From the 250 papers, 44 (16.8%) included a test dataset, and of those, 32
included both lockbox and cross-validation performance reports.
Neurosciences en réseau
33
Predictive modeling and network neuroscience
Ablation analysis:
A measure of the contribution of
particular variables through manual
removal or addition of specific
features during training.
Interpreting Model Performance
Investigators have several tools at their disposal to better understand the impact of individual
features on the final performance of the algorithm. While there are myriad ways in which spe-
cific tools can be implemented, we searched for and coded the four most common methods
observed in this literature set listed here in order of commonality: (1) feature importance, (2)
permutation testing, (3) ablation analysis, et (4) consensus analysis.
Feature importance, or the discriminative power of an individual feature as assigned by the
trained algorithm, is an inherent element of many machine learning methodologies wherein
features are ranked by their relative impact on the decision boundaries set by the algorithm. Un
article was coded as including feature importance if it included a report of some or all top-
ranking features with some quantitative analysis of their relative contribution, tel que (but not
limited to) Gini index, Kendall’s tau values, or the correlation coefficient r.
Permutation tests use thousands of randomized shufflings to simulate the distribution of pos-
sible outcomes that a given comparison could have revealed if the independent variable was
meaningless with respect to the analysis (c'est à dire., the null hypothesis distribution). This technique
can then measure the likelihood of an observed analysis outcome with an observed set of data or
analysis outcome. Papers that run such analyses and report the likelihood of chance performance,
generally in the form of p values, were coded as reporting this valuable analytical technique.
An ablation analysis examines the performance of the algorithm when portions of the algo-
rithm are removed in order to either improve performance (c'est à dire., during training) or to determine
which portions of the algorithm or dataset contribute to the algorithm’s accuracy. This is sim-
ilar to feature selection in the context of neuroscience (Guyon & Elisseeff, 2003). For a paper to
demonstrate an ablation report per our coding scheme, it must show the changes to perfor-
mance in training, whether as a function of feature reduction or of iteration count.
Consensus analysis is another common technique for analyzing relative importance of fea-
tures by way of the ratio of times a feature is selected across the number of training/validation
folds. Articles providing either a raw count or some other form of occurrence frequency for key
features were coded as demonstrating a basic consensus analysis.
RÉSULTATS
Representation of Clinical Disorders in Review
The final review included 250 studies largely composed of case-control designs focused on
prediction modeling of diagnostic accuracy. The studies ranged from traditional neurological
diagnoses (Alzheimer’s disease, brain injury) to psychiatric disease (depression, anxiety), à
neurodevelopmental diseases (schizophrenia, autism spectrum). A summary of the distinct
clinical disorders represented in the review is provided in Supporting Information Table S1.
The largest representation of studies examined Alzheimer’s disease or related dementias (n =
66, 26.4%), depression/anxiety (n = 40, 16.0%), schizophrenia spectrum disorder (n = 34,
13.6%), Autism spectrum disorder (n = 33, 13.2%), and brain injury (n = 15, 6.0%).
For training, sample sizes ranged from 17 à 1,305 subjects for total samples and 8 à 653
for group-level data (case-control designs). For test datasets, the sample sizes for the total pop-
ulation ranged from 8 à 477 subjects and group-level data ranged from 1 à 185. See Table 1
for breakdown of training and test dataset sample sizes based on population and subgroup.
These sample sizes are consistent with those observed elsewhere (Poldrack et al., 2020),
and we anticipate that the large majority of studies present in this review were underpowered
Neurosciences en réseau
34
je
D
o
w
n
o
À
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
/
t
e
d
u
n
e
n
À
r
t
je
c
e
–
p
d
je
F
/
/
/
/
/
6
1
2
9
1
9
8
4
2
2
9
n
e
n
_
À
_
0
0
2
1
2
p
d
t
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Predictive modeling and network neuroscience
Tableau 1.
Sample sizes for population and subgroups in training and test datasets
Sample
Range
Mean
Median
Training set (n = 250)
Total
17–1305
Subgroup
8–653
126.7
77
50.0
29
Test set (n = 44)
Total
8–477
96.6
39
Subgroup
1–185
38.1
20
Studies with n ≤ 50
Studies with n ≤ 30
Studies with n ≤ 20
80 (32.0%)
192 (76.8%)
23 (52.3%)
35 (79.6%)
24 (9.6%)
136 (54.4%)
14 (31.8%)
28 (63.6)
3 (1.2%)
82 (32.8%)
8 (18.2%)
22 (50.0%)
for reliable prediction modeling, resulting in low confidence in the portability of the reported
algorithm and reproducibility of the finding in other samples.
Network Characteristics
Consistent with the inclusionary criteria, 100% of the studies used at least one network metric
as input during classifier identification. Tableau 2 provides descriptive data for the types of
network studies included and the characteristics of the networks analyzed. A majority of
the studies used whole-brain network information as features (73%). Similar to other exami-
nations of the use of network neuroscience to examine clinical disorders, there was a wide
range of brain parcellation values, resulting in graphs of widely varying sizes and complexities
(Hallquist & Hillary, 2018).
Sample Characteristics
Sample characteristics including demographics and common clinical indicators were exam-
ined. While age of the sample was commonly reported, only 25.6% of studies included a mea-
sure of time since diagnosis, fewer still reported age of diagnosis (10.8%), and few included
demographic factors such as race (5.6%). Several studies lacked a “healthy control” group. Dans
these cases, the studies either compared the same sample at two timepoints (1) or classified
Tableau 2. Network data: Characteristics of functional brain imaging network analysis including in prediction modeling
Network Nodes (parcellation)
n = 221*
Range
<10 to 67,955
Median
90
Mean (SD)
483.9 (6,654.5)
Edge Definition n = 247*
67.9%
3.2%
Correlation
(e.g., Pearson’s r)
Partial
correlation
Multiple
6.1%
Mode
90
Causal
modeling
3.6%
Other
18.3%
Whole brain
Modules>100%,
including studies with more than one classification approach.
Neurosciences en réseau
36
Predictive modeling and network neuroscience
Tableau 4.
Validation measures
Validation procedures
Oui
94.1%
20.3%
70.8%
Non
4.2%
79.7%
12.5%
Unclear
1.7%
0.0%
16.7%
Cross-validation
Lockbox
If lockbox, compared
once (n = 24)
classification outputs. Enfin, 20.8% of studies utilized some other form of metric performance
reporting, such as F1 scores; all such measures fitting the “other” category were utilized in less
que 5% of papers.
Validation Approaches
Most studies utilized some form of cross-validation, including leave-one-out cross-validation
(LOOCV ) (58.8%), k-fold (35.6%), nested approaches (11.2%), and multiple approaches
(9.2%). Of note, 12 (4.8%) of the studies did not report any cross-validation use. In these cases,
the authors either provided no alternative validation method (n = 8) or used a lockbox but no
cross-validation (n = 4). The key diagnostic for overfitting, use of a lockbox, was only utilized
dans 16.8% of studies (Tableau 4). Of the studies using a lockbox, 81% (34/44) made clear that
iterative training never permitted access to the test (lockbox) data, et 73.8% (31/44) reported
accuracy results for both the training and lockbox data.
Interpreting Model Performance
Feature importance measures were the most common metric included, with nearly half of all
studies including some level of quantitative analysis (47.2%). The other three common tech-
niques for model interpretation were observed at a rate ranging between 1-in-3 to 1-in-5
papers. Permutation testing was included in 34.0% of all studies. Ablation reports were
included in 27.7%, and consensus analyses were utilized in 20.0% of all studies (voir
Tableau 5). It was rare for examiners to include some form of all four approaches described here
(2.8%), but about one-third of papers integrated two to three techniques (35.2%), more than a
third integrated at least one method (38.4%), and finally one-fifth of papers did not conduct an
analysis of feature importance (22.8%).
Tableau 5.
Common techniques for enhancing model interpretation
Model interpretation techniques
Feature importance
Permutation testing
Ablation analysis
Consensus features
Oui
47.2%
34.0%
27.7%
20.0%
Note: >100% due to multiple approaches used in some studies.
Non
52.8%
66.0%
72.3%
80.0%
37
Neurosciences en réseau
je
D
o
w
n
o
À
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
t
/
/
e
d
u
n
e
n
À
r
t
je
c
e
–
p
d
je
F
/
/
/
/
/
6
1
2
9
1
9
8
4
2
2
9
n
e
n
_
À
_
0
0
2
1
2
p
d
.
t
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Predictive modeling and network neuroscience
je
D
o
w
n
o
À
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
t
/
/
e
d
u
n
e
n
À
r
t
je
c
e
–
p
d
je
F
/
/
/
/
/
6
1
2
9
1
9
8
4
2
2
9
n
e
n
_
À
_
0
0
2
1
2
p
d
.
t
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
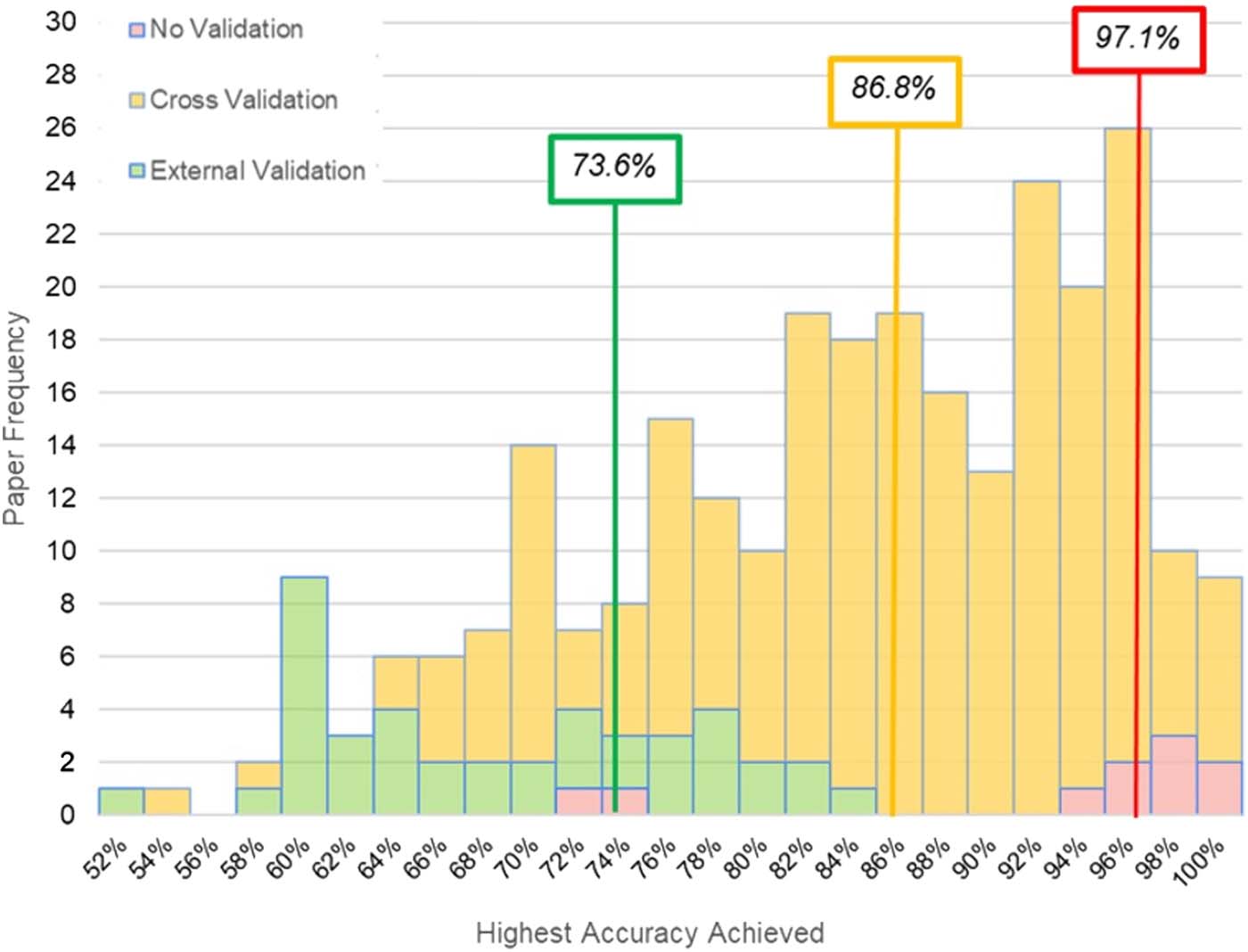
Chiffre 2. A histogram of accuracy scores for n = 250 studies reviewed reveals distinct distributions
and median scores (organized in text boxes by color) for classification accuracy based on results
using no validation, cross-validation, and external validation (c'est à dire., lockbox).
Classifier Performance
Measuring ML performance with no form of cross-validation or lockbox validation produced a
median accuracy of 97.1%. ML application using a cross-validation produced a median clas-
sification accuracy of 86.8%. When classification was performed on lockbox data, the median
classification accuracy dropped to 73.9%. The distribution for accuracy values across these
distinct cross-validation approaches is reported in Figure 2.
DISCUSSION
While our review confirms the exciting promise of ML approaches in the network neurosciences
to advance overall understanding of brain disorders, there also appears to be room for method-
ological growth. We first make several observations regarding clinical sampling and how net-
work neuroscience has been implemented in this literature as inputs for predictive modeling. Nous
then focus the remainder of the discussion on critical issues that, if addressed, can bring greater
precision to the use of ML in the neurosciences and ideally accelerate our understanding of the
pathophysiology of brain disorders. In the following we highlight several issues in order to foster
discussion in the literature: (1) need for uniformity in the creation of neural networks for predic-
tion, (2) issues of sample size and heterogeneity, (3) need for greater transparency of methods
and reporting standards, (4) the focus on classification accuracy at the expense of other informa-
tion, et (5) explainability and feature importance. We outline these concerns and link them to
eight decision points in the typical ML processing stream outlined in Figure 3, which serves as a
roadmap for key considerations and reporting opportunities at each step of the training process
with the goal of improving the interpretability, reproducibility, and clinical utility.
Neurosciences en réseau
38
Predictive modeling and network neuroscience
je
D
o
w
n
o
À
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
/
t
/
e
d
u
n
e
n
À
r
t
je
c
e
–
p
d
je
F
/
/
/
/
/
6
1
2
9
1
9
8
4
2
2
9
n
e
n
_
À
_
0
0
2
1
2
p
d
t
.
F
b
oui
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
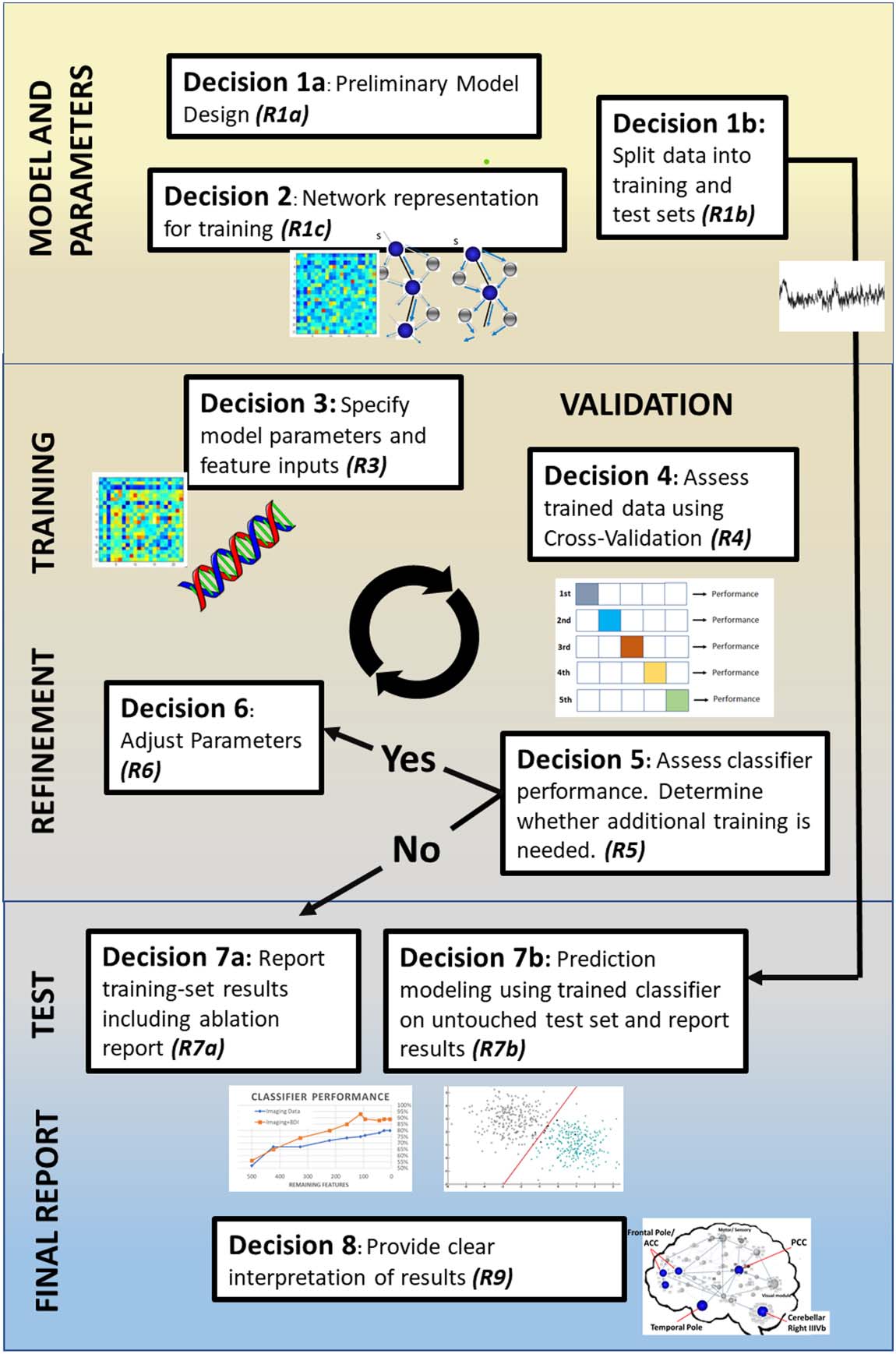
Illustration of distinct decision points in the typical ML pipeline in the papers included in
Chiffre 3.
this review. We identify eight distinct decision points where there are opportunities to report (R.)
information to maximize transparency. R1a: Justify classifier model choice from previous literature,
limitations of data, and clinical goals of study. R1b: Explain how data were split between training
and test sets (c'est à dire., lockbox), including sample sizes and any matching of demographics or disease
variables. R2: Make clear decisions about how the network was created, including edge definition
and brain parcellation. R3: Make explicit the specifics of the model (par exemple., parameter settings, kernel
les fonctions). Make clear which features (par exemple., network metrics, clinical variables) are included in the
model. R4: Report cross-validation method selection and implementation; justify use in context of
sample size and potential risk of performance overestimation. R5: Explain the conditions necessary
to terminate algorithm training, such as target performance or minimal feature count. R6: Make
explicit the hyperparameter settings and any manual tuning of parameters between training itera-
tion. R7a: Report training set results, including model performance, feature weights, and feature
counts across training iterations. R7b: Explicitly state that preprocessing is unchanged from the final
algorithm derived from training and that during training there was no access to the lockbox; provide
the final averaged cross-validation performance and feature importance for the test set. R8: Provide
clear interpretation and explainability for the model by highlighting any key findings in context of
potential clinical utility (c'est à dire., relevant regions of interest’s connectivity patterns).
Feature weight:
The discriminative ability of a given
feature as measured and quantified
through various methodologies.
Neurosciences en réseau
39
Predictive modeling and network neuroscience
Sample Sizes and Clinical Heterogeneity
Roughly one-third of the studies sampled in this review had no more than 50 subjects in their
total sample size for use of training and internal validation of their results. En outre, half of
all lockbox sets examined had subgroup sample sizes of 20 ou moins. Ainsi, roughly half of the
studies reviewed were likely underpowered to capture the stage, severity, and symptom con-
stellation evident in heterogeneous neurological and neuropsychiatric disorders. De plus,
small samples likely contributed to the use of LOOCV (58.8%) instead of k-fold (35.6%),
which may be more representative of the dataset (Poldrack et al., 2020).
Clinical characteristics of the participants (representativeness) that comprise a sample may
be just as vital as the sample size. Most neurological disorders maintain heterogeneous pre-
sentations. Par exemple, over a quarter of the studies focused on either schizophrenia or
autism, both understood as existing on a “spectrum” of symptoms, which speaks to the wide
range in clinical presentations (Hiremath et al., 2021; Kraguljac et al., 2021). Traumatic brain
injury, as another example (6% of the studies here), varies in symptomatology, mechanism and
location of injury, and severity and factors such as age at the time of injury and time postinjury.
All of these independent factors may have profound consequences for neural systems and
patient functioning (LaPlaca et al., 2020). To this point, few studies provided critical details
regarding their samples to help address representativeness including education (35.6%), temps
since diagnosis (25.6%), age at diagnosis (10.8%), and race (5.6%) (see Supporting Information
Table S2). The lack of clinical/demographic detail is of critical concern because even perfect
prediction modeling by a classifier will leave open the question as to how the results will gen-
eralize to other samples and undermines relevance for understanding clinical pathology.
Modern data-sharing resources provide one opportunity to facilitate generalizable results by
permitting clinical feature-dependent subgrouping. ENIGMA (Thompson et al., 2014, 2020),
ADNI (Jack et al., 2008), ADHD200 (Di Martino et al., 2014), and OpenNeuro (Markiewicz
et coll., 2021) are all leading examples of data-sharing consortia that increase diversity of data
collection sites, boost samples sizes, and enable representation clinical subgroups with respect
to pathology chronicity and severity. While data sharing between sites poses challenges with
respect to data harmonization (Radua et al., 2020), these factors (site/method) can be considered
as features in prediction modeling.
Brain Networks as Classifiers of Disease
In network neuroscience, one of the biggest challenges is determining what the network
should look like, including the number of nodes and how to define the links between them.
This problem is no less evident in prediction modeling, where the machine is constrained by
the complexity (or simplicity) of the representative neural network used for training. There has
been much recent work and emerging consensus regarding best practices for fMRI data pre-
traitement (Esteban et al., 2019; Nichols et al., 2017; Zuo et al., 2019) and guidance for how
networks might be reliably constructed and compared (Hallquist & Hillary, 2018; van den
Heuvel et al., 2017; van Wijk et al., 2010). Even so, there remains a wide range of applications
of network approaches and flexibility in workflows (c'est à dire., investigator degrees of freedom;
Gelman & Loken, 2014), which was evident in the current sampling of the literature. Just as
one example, and consistent with the review by Hallquist and Hillary (2018), there was an
enormous range in brain parcellation approaches with the number of nodes ranging from
<10 to over 67k (see Table 2). The number of nodes in any network is a fundamental deter-
minant for the downstream characteristics such as path length, local clustering,
degree, and even strength (Bullmore & Bassett, 2011; Bullmore Sporns, 2009;
Network Neuroscience
40
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
>