OPAL: Ontology-Aware Pretrained Language Model for End-to-End
Task-Oriented Dialogue
Zhi Chen1, Yuncong Liu1, Lu Chen1∗, Su Zhu2, Mengyue Wu1, Kai Yu1∗
1X-LANCE Lab, Department of Computer Science and Engineering
MoE Key Lab of Artificial Intelligence, AI Institute, Shanghai Jiao Tong University
State Key Lab of Media Convergence Production Technology and Systems, Beijing, Chine
2AISpeech Co., Ltd., Suzhou, Chine
{zhenchi713, chenlusz, kai.yu}@sjtu.edu.cn
Abstrait
This paper presents an ontology-aware pre-
trained language model (OPAL) for end-to-end
task-oriented dialogue (TOD). Unlike chit-chat
dialogue models, task-oriented dialogue mod-
els fulfill at least two task-specific modules:
Dialogue state tracker (DST) and response
generator (RG). The dialogue state consists
of the domain-slot-value triples, which are
regarded as the user’s constraints to search
the domain-related databases. The large-scale
task-oriented dialogue data with the annotated
structured dialogue state usually are inacces-
sible. It prevents the development of the pre-
trained language model for the task-oriented
dialogue. We propose a simple yet effective
pretraining method to alleviate this problem,
which consists of two pretraining phases. Le
first phase is to pretrain on large-scale con-
textual text data, where the structured informa-
tion of the text is extracted by the information
extracting tool. To bridge the gap between
the pretraining method and downstream tasks,
we design two pretraining tasks: ontology-
like triple recovery and next-text generation,
which simulates the DST and RG, respectivement.
The second phase is to fine-tune the pretrained
model on the TOD data. The experimental re-
sults show that our proposed method achieves
an exciting boost and obtains competitive
performance even without any TOD data on
CamRest676 and MultiWOZ benchmarks.
1
Introduction
A task-oriented dialogue (TOD) system aims to
assist users in accomplishing a specific task by
interacting with natural language, Par exemple,
reserving a hotel or booking flight tickets. With the
popularity of the industrial dialogue system, le
∗The corresponding authors are Lu Chen and Kai Yu.
68
task-oriented dialogue system attracts extensive
attention in research.
The existing task-oriented dialogue system can
be classified into two categories: pipeline format
and end-to-end format. The pipeline TOD system
(Ultes et al., 2017; Weisz et al., 2018) is composed
of four modules: natural language understanding
(NLU) (Quirk et al., 2015), dialogue state track-
ing (DST) (Xu et al., 2020; Chen et al., 2020c),
dialogue policy (DP) (Chen et al., 2018, 2019,
2020b), and natural language generation (NLG)
(Wen et al., 2015; Li et al., 2016; Zhao et al.,
2017). Since each module of the system is trained
separately and executes sequentially, it faces two
serious issues: error accumulation and high anno-
tation cost. Ainsi, the end-to-end dialogue system
(Lee et al., 2019b; Zhao et al., 2019) gradually
becomes the research focus, which formulates the
task-oriented dialogue as a sequence-to-sequence
task. The dialogue state, database (DB) state, et
the corresponding system response are directly
concatenated together and flattened as a token se-
quence. The DB state is the status of the domain-
related database searched with the dialogue state,
as shown in Figure 1.
Thanks to the success of pretraining language
models (Kenton and Toutanova, 2019; Raffel
et coll., 2020), effective application has shed light
on open-domain (chit-chat) dialogues (Bao et al.,
2020; Adiwardana et al., 2020). Nevertheless, uti-
lizing such pretrained language models on TOD
systems remains challenging due to the limited
TOD data with annotated dialogue state. Unlike
the open-domain dialogue, TOD is restricted by
a dialogue ontology, which defines the dialogue
domains, the slots and their candidate values.
The TOD system needs to predict the dialogue
state and feedback the DB content to accomplish a
task. The dialogue state is structured information
Transactions of the Association for Computational Linguistics, vol. 11, pp. 68–84, 2023. https://doi.org/10.1162/tacl a 00534
Action Editor: Michel Galley. Submission batch: 12/2021; Revision batch: 5/2022; Published 1/2023.
c(cid:3) 2023 Association for Computational Linguistics. Distributed under a CC-BY 4.0 Licence.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
je
un
c
_
un
_
0
0
5
3
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
From the high-level perspective, we can abstract
the end-to-end TOD task into two sub-tasks:
ontology-like triple recovery and next-text gen-
eration, which corresponds to dialogue state
tracking task and response generating task. Le
ontology-like triple recovery in the TOD means
to predict the corresponding value given the do-
main and the slot. The next-text generation is easy
to design for the contextual text, which directly
fulfills with masking the last sentence. The chal-
lenge is how to design the ontology-like triple
recovery task, which needs to obtain the struc-
tured information from the contextual text. Dans
this paper, we utilize the external OpenIE tools
(Angeli et al., 2015; Kolluru et al., 2020)2 to ex-
tract the relation triples (subject-relation-object)
from the contextual text as the structured infor-
mation. In most cases, the domain-slot-value tri-
ple can be regarded as relation triple, Par exemple,
train-arrive-12:30. The relation triples extracted
from the contextual text can be regarded as the
ontology-like triples. We design self-supervised
ontology-like triple recovery task and next-text
generation task to pretrain the model.
The main contributions of
this paper are
summarized below:
• We leverage the external tool OpenIE to gen-
erate large amounts of TOD-like data, lequel
is important for the development of pretrained
language models in the TOD community.
• To the best of our knowledge, this is the
first work to design self-supervised tasks
for end-to-end TOD tasks. It bridges the gap
between pretrained language models and
end-to-end TOD models.
• The experimental
results show that our
proposed pretrained model OPAL can get
competitive performance even without any
annotated TOD data in the pretraining
processus.
• Further fine-tuned on the annotated TOD
data, our proposed method obtains excit-
ing performance gain on CamRest676 and
MultiWOZ datasets.
2 End-to-End Task-Oriented Dialogue
As previously introduced,
the pipeline dia-
logue system consists of four modules. The NLU
Chiffre 1: A task-oriented dialogue example. The di-
alogue model needs to infer the dialogue state based
on the dialogue history and ontology schema. The DB
state is searched by the generated dialogue state. Le
last step is to generate system response.
extracted from the dialogue context, which is a
set of domain-slot-value triples.
Recently, some works (Hosseini-Asl et al.,
2020; Lin et al., 2020) try to directly leverage the
pretrained language models, par exemple., GPT-2 (Radford
et coll., 2019) and BART (Lewis et al., 2020), dans
the end-to-end TOD system. Such models (Mehri
et coll., 2019) are pretrained on the large-scale
contextual text with the general self-supervised
method, par exemple., language modeling and language
denoising. Cependant, in the task-oriented dialogue
task, the dialogue state is structured information
rather than a contextual text. The inconsistency
between the pretrained and downstream tasks
will impact the performance of the PLMs on
the TOD benchmarks. To alleviate this problem,
SOLOIST (Peng et al., 2020un) fine-tunes the pre-
trained GPT-2 with the existing annotated TOD
data and then transfers it to the other task-oriented
dialogue generation tasks. De la même manière, NCM (Liu
et coll., 2021) first warm-ups the Transformer-
based model with large-scale Reddit1 (V¨olske
et coll., 2017) data and then fine-tunes the model
on the TOD data. Cependant, the existing TOD
data is too limited to pretrain a large-scale lan-
guage model.
To alleviate the problems above and advance
pretrained language model research, especially
its application on TOD, we propose an Ontology-
(OPAL).
aware PretrAined Language model
1http://files.pushshift.io/reddit/.
2https://github.com/dair-iitd/openie6.
69
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
je
un
c
_
un
_
0
0
5
3
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
module is to recognize the user’s intents and
the corresponding slot values. The DST module
combines the previous state and the results of the
NLU to update the current dialogue state. Le
DP module chooses the discrete dialogue acts
according to the dialogue state and the database
state to respond to the user. The NLG module gen-
erates the natural language based on the chosen
dialogue acts. There are at least four kinds of an-
notation in such systems: the user’s intent, the slot
valeur, the dialogue state, and the dialogue act.
The heavy annotation labor enormously increases
the cost of building a pipeline system. Its poor
scalability further influences the pipeline dialogue
system development.
Compared with the pipeline system, this pa-
per’s end-to-end task-oriented dialogue system
only requires the annotated dialogue state. Le
end-to-end TOD system is fed with the dialogue
context c and generates the dialogue state b and
delexicalized response r, where the database (DB)
state d is retrieved from the results searched
with b. The delexicalized response means that
the specific slot values are replaced with the cor-
responding slot placeholders. The lexicalized re-
sponse is recovered from the delexicalized one
with the generated dialogue state and DB state.
The training sample at each dialogue turn of the
end-to-end TOD model is defined as:
x = (c, b, d, r).
(1)
For the task-oriented dialogue, the dialogue con-
text not only consists of the dialogue history h
but also includes the dialogue ontology schema s,
which is usually ignored by the existing end-to-end
models. The ontology can be seen as prior knowl-
edge designed by the dialogue expert, lequel
defines the dialogue domain, slots, and candidate
valeurs. The end-to-end TOD model needs to fulfill
two sub-tasks: Dialogue state tracking (DST) et
response generation (RG). Officiellement, the learning
goal of the TOD model is to maximize the joint
probability pθ(X), which can be factorized in an
auto-regressive manner as:
pθ(X) = p(c, b, d, r),
= p(h, s, b, d, r),
= p(r|b, d, h, s)
(cid:5)
(cid:3)(cid:4)
RG
(cid:2)
p(b|h, s)
(cid:5)
(cid:3)(cid:4)
(cid:2)
DST
(2)
(3)
(4)
p(h, s),
70
where the factorization from (3) à (4) is based
on the fact that the database-lookup operation is
a deterministic process. The p(h, s) is the prior
probability of the paired dialogue and ontology
(as the input of the model), which depends on the
distribution of the (pre-)training data and is inde-
pendent on the model. The dialogue state tracker
intrinsically extracts the ontology-related con-
straints demanded by the user, where the ontology
schema is given in advance.
3 Ontology-Aware Pretraining Method
The existing task-oriented dialogue data with the
given ontology is limited to pretrain the language
model. To increase the scale of the pretraining
data, we divide the pretraining process into two
phases. The first phase pretrains the model on the
large-scale contextual text. The triples of the text
are extracted by the latest neural-based Open-
IE6 (Kolluru et al., 2020). There is still a glaring
discrepancy between the contextual text and the
dialogue. Par exemple, the dialogue always con-
tains co-reference and information ellipsis (Iyyer
et coll., 2017). We pretrain the model on the smaller
TOD data at the second phase to further decrease
the gap between the pretrained model and the
downstream tasks. The two phases are comple-
mentary to each other introduced as below:
Phase-1: Pretrained on Contextual Text
Dans
traditional dialogue pretrained models (Zhang
et coll., 2020c), the crawled Reddit data is popular
to be used as pretrained corpus. Cependant, Reddit
data contain lots of the co-reference and infor-
mation ellipsis, which seriously impact the perfor-
mance of the external information extraction tool.
Different from the dialogue data, the co-reference
and information ellipsis are infrequent in the con-
textual text of the Wikipedia.3 More details are
shown in Section 5.1 to validate the effects of pre-
trained corpora. We use the neural-based Open-
IE6 to extract the ontology-like knowledge of
contextual text automatically. We directly simu-
late the extracted subject-relation-object triples as
the domain-slot-value triples. As shown in Figure 2,
the object values in the extracted ontology are
masked during the pretraining process. One of
our designed pretraining tasks is to recover the
3https://dumps.wikimedia.org/enwiki/latest
/enwiki-latest-pages-articles.xml.bz2.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
je
un
c
_
un
_
0
0
5
3
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
je
un
c
_
un
_
0
0
5
3
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 2: The ontology-aware pretraining method contains two masking strategies: object-value mask and
next-text mask. The corresponding self-supervised learning methods are ontology-like triple recovery and
next-text generation. The ontology-like triples of the contextual text are extracted by the external tool OpenIE at
the pretraining phase-1 and matched with the given whole ontology at phase-2.
ontology-like triples (named ontology-like triple
recovery [OR]), which is similar to the DST task.
To increase the inference ability of the pretrained
model, we mask the next text (one or two sen-
tences, which are randomly chosen) and push the
model to infer the next text (named next-text
generation [NTG]), which is similar to the RG
task. Ainsi, the pretraining sample is composed of
four elements: masked ontology-like triples ˆs, le
masked document context ˆh, ontology-like triples
ˆb, and the next text ˆr. Similar to Equation 4, le
goal of the pretaining model is to maximize the
joint probability:
p(ˆh, ˆs, ˆb, ˆr) = p(ˆr|ˆb, ˆh, ˆs)
(cid:5)
(cid:2)
(cid:3)(cid:4)
NTG
p(ˆh, ˆs).
p(ˆb|ˆh, ˆs)
(cid:5)
(cid:3)(cid:4)
(cid:2)
OR
(5)
To obtain the qualified triples of a sentence using
OpenIE6, we remove all the stopwords in the
triples and filter the triples in which one of the
triple components is a blank space. It is also
the main reason that we do not choose the Reddit
at this pretraining phase. There are many pro-
nouns in the text, with which is hard to extract
qualified triples. This pretraining phase vastly in-
creases the scale of the pretraining data. Il y a
four steps to filter the triples of the sentence:
• Remove all
the stopwords in the triples
and filter the triples in which one of triple
component is a blank space.
71
• Remove the triples in which one of the triple
components contains more than 4 words.
• For the triples that have the same subject-
relation pair, randomly select one of the
triples and remove the others.
• Randomly select two triples from the rest of
triples, if their length is larger than two. Ce
is to extract no more than two triples in a
sentence.
Phase-2: Pretrained on TOD Data To further
decrease the gap between the pretrained language
model and the end-to-end model, we leverage the
smaller task-oriented data in the pretraining pro-
cess. Instead of extracting the ontology-like triples
with OpenIE6, the TOD ontology is designed by
the dialogue experts. We directly use the text
matching method to extract the domain-slot-value
triples from the dialogue context with the given
ontology. Note that the extracted triples with text
matching operation are not the dialogue state. Dans
this pretraining phase, the system-mentioned on-
tology triples also have to be recovered, which is
consistent with the previous pretraining process.
Autrement dit, different from SOLOIST (Peng
et coll., 2020un) and NCM (Liu et al., 2021), nous
do not need to use the annotated dialogue state
and only utilize the given dialogue ontology to
match the ontology-related triples. This attri-
bute increases the generalization of the proposed
Dataset
#Dialogue #Domain #Slot X-Domain Usage
Schema
TaskMaster
MultiWOZ
WOZ
CamRest676
22,825
17,304
10,438
1,200
676
17
7
7
1
1
123
281
46
4
4
(cid:2)
(cid:3)
(cid:2)
(cid:3)
(cid:3)
P.
P.
F
F
F
Tableau 1: The five task-oriented dialogue datasets
used in this paper. The X-domain (cross-domain)
means that a dialogue can contain different di-
alogue domains. The usages of
the datasets
are grouped into Pretraining (named as P) et
Fine-tuning (named as F), which means that the
corresponding dataset is used in the pretraining
phase and the fine-tuning phase.
of the pretraining process and the rests are the
downstream benchmarks. The WOZ (Mrkˇsi´c et al.,
2017) and the CamRest676 (Wen et al., 2016) sont
the single-domain task-oriented dialogue corpora,
which are the well-studied DST benchmark and
end-to-end TOD benchmark, respectivement. Multi-
WOZ is a kind of multi-domain dialogue corpus,
which is challenging due to its multi-domain set-
ting and diverse language styles. There are two
versions of the MultiWOZ dataset used in the
experiments: MultiWOZ2.0 (Budzianowski et al.,
2018) and MultiWOZ2.1 (Eric et al., 2019), où
MultiWOZ2.1 fixes most of DST annotation er-
rors in MultiWOZ2.0. To fairly compare to the
other baselines, we run the end-to-end TOD tasks
on the MultiWOZ2.0 and run the DST tasks on
the MultiWOZ2.0 and MultiWOZ2.1.
4.2 Metrics
For the dialogue state tracking task, we use the
joint goal accuracy (JGA) to evaluate the mod-
le. Only if all the predicted slot values at each
turn are exactly matched with the golden, does
it confirm the successful prediction of the DST
model. For the end-to-end TOD task, there are
three reported scores: Inform, Success, et
BLEU. Inform measures whether the system re-
sponse has provided the right entity. Success re-
ports whether the system response has provided
the requested slots. BLEU evaluates the
tous
naturalness of the generated system response.
Following Budzianowski et al. (2018), the com-
bined score (Combined) is also reported using
Combined = (Inform + Success) × 0.5 + BLEU.
Chiffre 3: A toy example to show the differences be-
tween the pretraining data and the fine-tuning data.
ontology-aware pretraining methods, where the
ontology is much easier to be obtained than the
dialogue state annotation. We share a toy example
to distinguish the usage of the pretraining TOD
data and the fine-tuning data of the end-to-end
TOD task in Figure 3. During the pretraining
processus, the ontology is extracted from the con-
text, which is just a part of the given ontology. Le
ontology recovery is to recover all the ontology-
related triples, Par exemple, the triple res-food-
Chinese is not
in the dialogue state. During
fine-tuning process, there is an extra database
searching step.
4 Experiments
We evaluate our proposed pretrained model
OPAL on dialogue state tracking tasks and end-
to-end TOD tasks. To further validate the effec-
tiveness of the proposed OPAL, we conduct the
ablation study to analyze the effects of the differ-
ent pretraining ingredients. Last but not least, nous
design the resource-limited experiments to figure
out the sample efficiency of the proposed OPAL
on the end-to-end TOD task and show some cases
to study the strength of the proposed OPAL.
4.1 Corpora
At phase-1 of the proposed OPAL, we use the
Wikipedia corpus to pretrain the model. Il y a
72.24 million samples collected from Wikipedia.
We have used five task-oriented dialogue datasets
in the experiments, shown in Table 1, where the
Schema (Rastogi et al., 2020) and the TaskMaster
(Byrne et al., 2019) are leveraged in the phase-2
72
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
je
un
c
_
un
_
0
0
5
3
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
4.3 Experimental Setup
We implement the proposed OPAL with Hug-
gingFace’s Transformers (Wolf et al., 2020) et
BART, which is a pretrained denoising autoen-
coder. To validate the generalization of the pro-
posed pretraining method, we set the base version
and large version (BARTL) of the BART as the
backbone of the proposed OPAL, named OPAL
and OPALL, respectivement. The learning rates of
the pretraining and fine-tuning are both 1e-5. Le
optimizer is AdamW. At phase-1 of the pretrain-
ing process, the total training steps is 280,000
and the batch size is 256. It is pretrained on four
P100 GPUs (16G memory for each). This pre-
training process costs 260 hours (one epoch on
Wikipedia). Similar to NCM (Liu et al., 2021),
we pretrain 100,000 steps at the phase-2. At the
fine-tuning process of the downstream tasks, le
batch size is 32. We conduct significant tests
(paired t-test) (Koehn, 2004) with five different
seeds on the end-to-end TOD task, where the final
results are trained with the default seed 42.
4.4 Baselines
We compare the proposed OPAL with the strong
baselines, which hold the state-of-the-art (SOTA)
performance on the DST and end-to-end TOD.
The DST models can be divided into two
catégories: classification method and generation
method. The classification methods rely on the
optional slot values of the ontology and select the
value from it. Their scalability is a severe problem
for the practical dialogue system. The genera-
tion methods directly extract the values from the
dialogue context, which are comparable to the
proposed OPAL.
For the end-to-end TOD tasks, the existing
end-to-end TOD systems can be grouped into
modular systems and sequential systems. Le
modular systems use multiple decoders to gener-
ate the downstream outputs independently and are
trained in an end-to-end manner. The sequential
systems formulate the end-to-end TOD as a single
sequence prediction problem. Sequicity (Lei et al.,
2018) proposes a two-stage CopyNet method to
generate the dialogue state and the system re-
sponse. HRED-TS (Peng et al., 2019) proposes
a teacher-student framework with a hierarchi-
cal recurrent encoder-decoder backbone. DAMD
(Zhang et al., 2020b) designs a domain-aware
multi-decoder network with the multi-action data
augmentation method. DSTC8 Winner Ham
et coll., 2020 and SimpleTOD (Hosseini-Asl et al.,
2020) successfully leverage the pretrained lan-
guage model GPT-2 for the end-to-end TOD
modeling in the unified way. Inspired by Simple-
TOD, SOLOIST (Peng et al., 2020un) fine-tunes
GPT-2 with out-of-domain TOD data and obtains
excellent transferability. MinTL-BART (Lin et al.,
2020) and UBAR (Yang et al., 2021) improve the
end-to-end TOD system by changing the input
content without extra assumptions. HTER (Santra
et coll., 2021) improves the end-to-end TOD sys-
tem by a hierarchical dialogue modeling mech-
anism. NCM (Liu et al., 2021) improves the
decoder with the noisy channel model and pro-
poses a two-stage pretrianing method to warm up
the Transformer-based model, where the model
first pretrains on the Reddit corpus and then on
the task-oriented dialogues. NCM is the clos-
est method to our proposed method. We mainly
compare our proposed method with this method.
4.5 Results on End-to-End TOD
We first fine-tune our pretrained models OPAL
and OPALL on two well-studied end-to-end
TOD datasets: MultiWOZ2.0 and CamRest676,
as shown in Table 2 and Table 3. We compare
our models with strong baselines in the end-to-
end dialogue learning setting.
To validate the generalization of our pro-
posed ontology-aware pretraining method, we set
the base-version and large-version BART as the
backbones of the pretraining models. Compared
with the performance fine-tuned on the origi-
nal BARTs, the proposed OPAL and OPALL
achieve 7.32 et 10.94 overall performance gains
on the MultiWOZ2.0 dataset and absolute 7.04
point gains on the CamRest676 dataset. SOLOIST
(Peng et al., 2020un) and NCM (Liu et al., 2021)
are the two closest methods to OPAL, lequel
both leverage the out-of-domain TOD in pre-
training the Transformer-based models. Different
from our methods, these two approaches rely on
DST annotation. Our proposed models can still
obtain the best task completion (Inform and Suc-
cess) and have lower BLEU scores than NCM
barely. Compared with overall baselines, notre
proposed models reach the new SOTA overall
performance (Combined) on both two datasets.
The large-version model OPALL outperforms the
base-version OPAL with a 2.53 performance gain
on the combined score. To fairly compare to
73
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
je
un
c
_
un
_
0
0
5
3
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Model
Model Size Dialogue Act
Inform Success BLEU Combined
Sequicity (Lei et al., 2018)
HRED-TS (Peng et al., 2019)
DSTC8 Winner (Ham et al., 2020)
DAMD (Zhang et al., 2020b)
SimpleTOD (Hosseini-Asl et al., 2020)
SOLOIST (Peng et al., 2020un)
MinTL-BART (Lin et al., 2020)
UBAR (Yang et al., 2021)
NCMB (Liu et al., 2021)
NCML (Liu et al., 2021)
HTER (Santra et al., 2021)
BART
OPAL
BARTL
OPALL
–
–
124M.
–
117M.
117M.
406M.
82M.
116M.
292M.
–
139M.
139M.
406M.
406M.
(cid:3)
(cid:2)
(cid:2)
(cid:2)
(cid:2)
(cid:3)
(cid:3)
(cid:3)
(cid:2)
(cid:2)
(cid:2)
(cid:3)
(cid:3)
(cid:3)
(cid:3)
66.40
70.00
73.00
76.40
84.40
85.50
84.88
88.20
85.90
86.90
91.72
87.50
89.40
86.20
88.00
45.30
58.00
62.40
60.40
70.10
72.90
74.91
79.50
74.80
76.20
75.80
72.20
81.10
70.30
82.80
15.54
17.50
16.00
16.60
15.01
16.54
17.89
16.43
19.76
20.58
19.05
16.67
18.60
17.01
20.80
71.39
81.50
83.50
85.00
92.26
95.74
97.78
100.28
100.11
102.13
102.81
96.53
103.85
95.26
106.20
Tableau 2: End-to-end response generation results on MultiWOZ2.0. (cid:2)et (cid:3)denote whether the dialogue
act annotation is used in the training process. We list all the model sizes of the Transformer-based
end-to-end TOD models. Notice that we directly use the UBAR result provided by Liu et al. According
the released code of the UBAR, they have not used the standard evaluation metric, which is unfair to
compare to other methods. We also run their code with released model checkpoint, whose combined
score is even worse than the result provided by Liu et al. Results are significant (p < 0.01) comparing
the OPAL model and BART model as the initialized TOD model.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
Model
Inform Success BLEU Combined
Sequicity
SOLOIST
NCMB
NCML
BART
OPAL
92.30
94.70
94.30
95.40
96.31
96.32
85.03
87.10
85.20
85.30
79.41
89.86
21.40
25.50
25.98
26.89
24.74
26.56
110.20
116.40
115.73
117.24
112.61
119.65
Table 3: End-to-end response generation results
on CamRest676.
other baselines, we only report the base-version
OPAL’s performance in the next experiments.
Compared with NCMB, our proposed OPAL
has higher task-completion (revealed by Inform +
Success) × 0.5) performance. However, BLEU
score of OPAL is lower than BLEU of NCMB.
Figure 4 shows the correlation between BLEU
score and task-complation ability. The fine-tuned
model
tried to balance between BLEU score
and task-completion ability. With the progress of
training process, the BLEU score is descending
and the task-completion ability is enhanced. The
main reason is that there are different expres-
l
a
c
_
a
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
l
a
c
_
a
_
0
0
5
3
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 4: The correlation between BLEU score
and task-completion ability at first 20 fine-tuning
epochs. They are the average evaluation results on
MultiWOZ2.0 with different five seeds.
sions on the same system intention, which is
the typical one-to-many mapping problem (Zhao
and Eskenazi, 2018) in the dialogue generation.
The final fine-tuned model has stronger task-
completion ability but sacrifices the dialogue di-
versity. In the evaluation, we choose the model
with the highest combination score.
74
Model
JGA
MultiWOZ
2.1
2.0
Model
FJST (Eric et al., 2017)
HyST (Goel et al., 2019)
SUMBT (Lee et al., 2019a)
TOD-BERT (Wu et al., 2020)
DST-Picklist (Zhang et al., 2020a)
SST (Chen et al., 2020a)
TripPy (Heck et al., 2020)
FPDSC (Zhou et al., 2021)
TRADE (Wu et al., 2019)
COMER (Ren et al., 2019)
NADST (Le et al., 2020)
DSTQA (Zhou and Small, 2019)
SOM-DST (Kim et al., 2020)
MinTL-BART (Lin et al., 2020)
SimpleTOD (Hosseini-Asl et al., 2020)
UBAR (Yang et al., 2021)
SOLOIST (Peng et al., 2020a)
OPAL
40.20
44.24
46.65
–
–
51.17
–
53.17
48.62
48.79
50.52
51.44
51.38
52.10
–
52.59
53.20
54.10
38.00
–
–
48.00
53.30
55.23
55.29
59.07
45.60
–
49.04
51.17
52.57
53.62
55.72
56.20
56.85
57.05
Table 4: Dialogue state tracking results on Mul-
tiWOZ2.0 and MultiWOZ2.1. The upper part is
for classification-based models and the lower part
belongs to generation-based models.
4.6 Results on DST
The
and
classification-based DST models
generation-based DST models are shown in the
upper part and lower part of the Table 4 and
Table 5, respectively. Table 4 reports the DST
results on the MultiWOZ2.0 and MultiWOZ2.1
datasets. Our proposed OPAL can obtain the
highest JGA among all
the generation-based
baselines on both datasets. Compared with the
classification-based SOTA model FPDSC (Zhou
et al., 2021), OPAL can even achieve 0.93%
JGA improvement on the MultiWOZ2.0 dataset.
Table 5 shows the DST results on WOZ, which is
a single-domain dataset and has only 4 slots. The
computational complexity of the classification-
based models is proportional to the number of
the candidate slot values. The classification-based
models have the advantage of predicting slot
values from valid candidates on the simpler
dialogue domain. It is the main reason that the
classification-based models are more popular on
the single-domain WOZ dataset. Compared with
the well-designed classification-based model BERT-
DST (Lai et al., 2020), OPAL has a 0.7% JGA
gain. OPAL gets 6.7% higher JGA over the
novel generation-based model TRADE (Wu et al.,
2019). Notice that we do not compare the pro-
NBT (Mrkˇsi´c et al., 2017)
GLAD (Zhong et al., 2018)
GCE (Nouri and Hosseini-Asl, 2018)
G-SAT (Balaraman and Magnini, 2019)
StateNet (Ren et al., 2018)
BERT-DST (Lai et al., 2020)
TRADE (Wu et al., 2019)†
OPAL
JGA
WOZ
84.4
88.1
88.5
88.7
88.9
90.5
84.5
91.2
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
l
a
c
_
a
_
0
0
5
3
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Table 5: Dialogue state tracking results on
the single-domain WOZ. The upper part
is
classification-based models and the lower part
belongs to generation-based model. † represents
that the result is produced by us from the re-
leased code.
posed model with variants (Yu et al., 2020; Li
et al., 2020; Dai et al., 2021) of the data aug-
mentation methods based on TripPy (Heck
et al., 2020). In this paper, we pay more attention
on the end-to-end task-oriented dialogue genera-
tion task. Our model is completely compatible
with these data augmentation methods. In the
future, we will try these augmentation methods
on our model.
5 Analysis
The analysis experiments evaluate the proposed
OPAL on the end-to-end TOD tasks to answer
three main questions: Q1: What role do the dif-
ferent pretraining corpora (Wikipedia and out-
of-domain TOD) play? Q2: What is the main
factor that affects the pretrained model? Q3:
Does OPAL have a higher sample efficiency than
the original BART in the limited-resource setting?
5.1 Ablation Study
Table 6 reports the ablation study of the pro-
posed OPAL, which has two pretraining phases.
The phase-1 of OPAL pretrains on the contextual
texts and phase-2 pretrains on the task-oriented
dialogues with the ontology-aware pretraining
method. To evaluate the effects of these two
corpora, we separately pretrain the backbones
(BART) only on the pretraining data contextual
texts or task-oriented dialogues, where the pre-
trained models are named as WIKI and TOD,
75
MultiWOZ2.0
Inform Success BLEU Combined
89.40
103.85
18.60
81.10
Model
88.40
89.00
86.90
OPAL
Effect of Pretrained Corpora
WIKI
TOD
REDD
Effect of Pretrained Tasks
w/o NTG
w/o OR
Effect of IE Tools
OpenIE-Stanford
BART
87.00
85.20
88.40
87.50
79.50
78.20
77.10
80.80
79.50
79.20
72.20
18.28
17.55
16.93
16.88
17.52
17.34
16.67
102.23
101.15
98.93
100.79
99.88
101.14
96.52
Table 6: Ablation study on MultiWOZ2.0. There
are three types of ablation study. The first is to
analyze the effects of the pretrained data. The
second is to validate the effects of the designed
pretrained tasks. The last is to figure out the ef-
fects of IE tools. Results are significant (p < 0.01)
comparing the OPAL model and BART model
as the initialized TOD model.
respectively. The pretrained models WIKI and
TOD still outperform the original BART by a
large margin. It indicates the efficiency of the
proposed ontology-aware pretraining method. Es-
pecially, the pretrained model WIKI that does not
see any TOD data at the pretraining phase can re-
sult in competitive performance with the NCML.
Compared with NCMB with a similar parameter
scale to our model, WIKI has apparent advantages
on both end-to-end TOD datasets. The WIKI has
the better performance with TOD. We know that
WIKI suffers from the unseen TOD data and
TOD suffers from the scale of the pretraining data.
Our proposed OPAL adopts a two-stage pretrain-
ing method to solve the above problem, a classic
example of ‘‘one plus one greater than two’’. The
two-stage pretrained model OPAL outperforms
the separated one with a 1.65 and 2.70 upper
combined score on MultiWOZ2.0. This indicates
that the ontology-aware contextual text corpus and
ontology-aware TOD data are complementary.
To further compare Wikipedia to the Reddit
corpus, we also use the same scale of Reddit data
to conduct the Phase-1 pretraining, named REDD.
WIKI is ahead of REDD in all the automatic
metrics (BLEU and task-completion). To deeply
analyze the effect factor, we calculate the occu-
pation rate of the extracted triples that contained
the pronouns as subject or object. As shown in
Figure 5, 31.0% of triples in Reddit data con-
tain pronouns. The highest frequency of pronouns
76
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
l
a
c
_
a
_
0
0
5
3
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 5: The occupation rate of the extracted triples
that contained pronouns as subject or object in the
Reddit corpus with OpenIE6.
is ‘‘i’’, which occupies 31%. Only 0.7% triples
contain pronouns in Wikipedia. In the TOD, the
domains and slot values in the dialogue states
are specific entities, which are not pronouns. The
meaningless pronouns increase the gap between
the pretraining model and the TOD model. The
co-reference and information ellipsis in Reddit
seriously hurt the performance of the external in-
formation extraction tool. It is the main reason that
we choose Wikipedia as the pretraining corpus.
We also evaluate the effects of the pretrained
tasks: ontology-like triple recovery (OR) and
next-text generation (NTG). We directly remove
the extracted triples in the input in ‘‘w/o OR’’
study. The ‘‘w/o NTG’’ means that the model only
needs to recover the masked triples. The results
show that the OR task and NTG task benefit the
task completion and the contextual consistency,
respectively. In the complex dialogue domain,
the single-task pretrained methods cannot achieve
comparable performance with OPAL. It indicates
that the two designed tasks are both significant
to reduce the gap between pretrained model and
TOD model.
We further validate the effects of different
OpenIE tools. In our main experiments, we use
the latest neural-based IE tool OpenIE6. There is
also a very popular rule-based IE tool OpenIE-
Stanford. Compared with OpenIE-Stanford, neural-
based OpenIE6 achieves promising performance
improvement on well-studied IE benchmarks
(Kolluru et al., 2020). As shown in Table 6,
WIKI with OpenIE6 is also better than OpenIE-
Stanford tool in all the metrics. However, the
improvement of neural-based OpenIE6 is lim-
ited, which indicates that the proposed pretraining
method is not sensitive about IE accuracy.
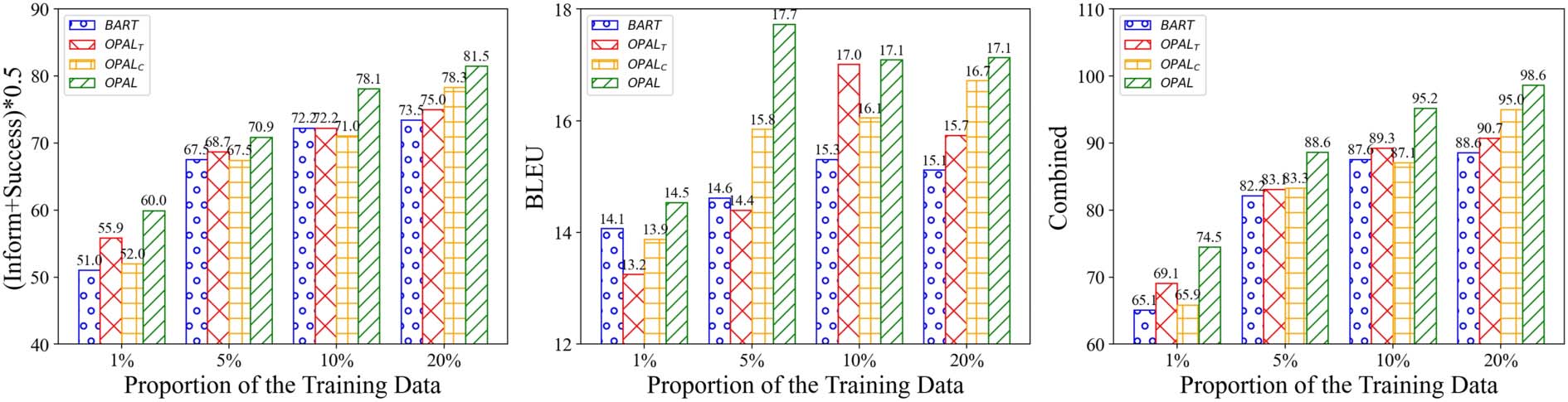
Figure 6: Resource-limited response generation results on MultiWOZ2.0. 1% (80 dialogues), 5% (400 dialogues),
10% (800 dialogues), and 20% (1600 dialogues) of training data are used to train each model.
5.2 Sample Efficiency
Under the different resource-limited settings, the
proposed OPAL can get all
the best perfor-
mance in terms of task completion (Inform and
Success), response naturalness (BLEU), and over-
all performance among the baselines, as shown
in Figure 6. It indicates the sample efficiency of
the proposed ontology-aware pretraining method.
When the training data is extremely limited (only
80 dialogues), TOD can improve overall per-
formance by a large margin (absolute 3.2 point
improvement)
than WIKI. This improvement
comes from the task completion ability, which
indicates the TOD data can increase the gener-
alization of the pretrained model for end-to-end
TOD tasks. With the training data increase, WIKI
pretrained on the large-scale context text data has
the larger performance gain than TOD. When
the number of the training data reaches 1600 di-
alogues, WIKI obtains absolute 4.8 point gains
over TOD. It indicates that the scale of the pre-
training data influences the growth potential of
the pretrained model. On the other hand, TOD
outperforms over the WIKI in three of four data
limitation cases on task-completion ability. How-
ever, WIKI achieves better performance on fluent
statement (revealed by BLEU). It indicates that
WIKI benefits the task-completion ability and
TOD facilitates fluency and context consistency.
5.3 Case Study
Our proposed pretrained model OPAL has im-
proved the performance on task completion and
contextual consistency over the original BART.
As shown in Figure 7, we can see that the dia-
logue model fine-tuned from BART misses re-
sponding a request (address) to the user. Instead,
our proposed OPAL accurately provides all the
requested information to the user. As shown in
Figure 7: Third dialogue turn in the dialogue session
SNG02115 from MultiWOZ2.0 development set. The
oracle response is represented as GT Response. BART
and OPAL means that the responses are generated by
the corresponding models.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
l
a
c
_
a
_
0
0
5
3
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 8: The first two dialogue turns in the dialogue
session SNG921 from the MultiWOZ2.0 development
set. The oracle response is represented as GT Re-
sponse. BART and OPAL means that the responses are
generated by the corresponding models.
Figure 8, at the first turn, we can see that our
proposed OPAL can provide the more similar re-
sponse as the oracle than BART. It indicates that
OPAL has the better performance on the response
77
prediction. At the second turn, the dialogue sys-
tem needs to provide the correct entity to the
user. The original BART model chooses to miss
it. Our proposed OPAL recommends an entity
to the user in time. Compared with the original
BART, the proposed OPAL has a obvious ad-
vantage in modeling the task-oriented dialogue,
which not only generates the precise response
but also completes the dialogue task successfully.
This performance improvement comes from the
two-stage ontology-aware pretraining method on
the large-scale contextual
text with the hand-
crafted ontology-like triples and the small task-
oriented dialogue data with given ontology.
6 Related Work
End-to-End TOD Systems Early studies for
end-to-end task-oriented dialogue systems either
design a neural network-based model or propose a
reinforcement learning method to use the reward
signal to update the whole system. In these sys-
tems, the modules in the pipeline TOD system still
exist and need their separated annotation. These
systems usually can get promising performance
on one specific task but have poor transferability.
With the emergence of the multi-domain TOD
benchmark, like MultiWOZ, the generative DST
method has replaced the classification method as
the mainstream over recent years due to its better
generalization ability. It encourages formulating
the end-to-end TOD as a text-to-text task. Lei
et al. (2018) propose a two-stage CopyNet to gen-
erate the dialogue state and response jointly with
a single seq2seq architecture. Zhang et al. (2020b)
design a data augmentation method to increase
the response diversity. The dialogue state, dia-
logue act, and the response are generated with
a shared encoder and the different decoders.
Note that our proposed model does not use the
annotated dialogue acts. Recently, some work
(Hosseini-Asl et al., 2020; Peng et al., 2020a;
Lin et al., 2020; Yang et al., 2021) directly
leverages the pretrained language models (like
GPT-2 and BART) as the end-to-end TOD model
in a unified way. Liu et al. (2021) propose
a Transformer-based noisy channel method to
model
the response prior and use the Reddit
data and TOD data to warm up the TOD model.
Most recently, Su et al. (2021) formulate all the
end-to-end TOD tasks as the unified generation
tasks, which learns in a multitask learning man-
ner. He et al. (2021) propose a semi-supervised
method to explicitly learn dialogue policy from
limited labeled dialogues. Our proposed pre-
trained method is compatible with these end-to-
end TOD training strategies.
Self-supervised Learning for Dialogue System
Recent advances in supervised learning have wit-
nessed the success of the pretrained language
models (PLMs) on language understanding and
generation tasks. Since the large-scale comment
data in Reddit can be regarded as a kind of chit-chat
dialogue, the self-supervised methods have been
used in the chit-chat systems first. DialoGPT
(Zhang et al., 2020c) adapts the pretrained GPT-2
in the large-scale dialogue data. PLATO (Bao
et al., 2020) proposes a discrete latent variable
pretraining method to solve the one-to-many prob-
lem of the dialogue system. Meena (Adiwardana
et al., 2020) pretrains a large-scale model with the
dialogue data and demonstrates its conversation
ability. SC-GPT (Peng et al., 2020b) uses a pre-
trained language model to convert a dialog act to
a natural language response. For the task-oriented
dialogue, the large-scale domain-specific dialogue
data is inaccessible. The TOD models (Jiang
et al., 2020; Wu et al., 2020; Yu et al., 2020)
are usually pretrained on the chit-chat dialogues
(Reddit) first and then fine-tuned on the smaller
released or synthetic TOD data. Different from
the above PLMs, we pretrain the TOD model
directly with the large-scale contextual text. We
extract relation triples of the contextual text as
the grounded ontology-like knowledge and de-
sign adaptive self-supervised learning tasks for
the end-to-end TOD.
Knowledge-grounded PLMs Recently, there is
an important branch of PLM to study how to
integrate the knowledge into the PLM. ERNIE
(Zhang et al., 2019) utilizes the external knowl-
edge graph to recognize the type of the mentioned
entity. There is a entity type embedding layer
as one of input representation. To enhance the
knowledge-related representation, they improve
the mask mechanism by masking a whole entity
directly. Similarly, Rosset et al. (2020) proposes
an knowledge-aware language model (KALM),
which is decoder-only Transformer-based archi-
like GPT. KALM proposes an entity
tecture,
tokenizer to directly segment popular entities as a
single token. Some fields, like medicine, include
78
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
l
a
c
_
a
_
0
0
5
3
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
considerable proprietary information, and it is
to integrate the proprietary knowledge
crucial
into the pretrained model. SMedBERT (Zhang
et al., 2021) incorporates deep structured seman-
tics knowledge from neighbors of linked-entity.
In this paper, we aim to utilize the external tool
OpenIE6 to produce lots of TOD-like data to
bridge the gap between pretrained task and end-
to-end TOD system. The proposed ontology-like
triple recovery task only masks the object val-
ues in the extracted triples, rather than randomly
masking mentioned entities.
7 Conclusion and Future Work
In this paper, we propose an ontology-aware
pretraining method for modeling the end-to-end
task-oriented dialogue. The scale of the exist-
ing task-oriented dialogue data is far from the
need for the pretrained model. Thus, we lever-
age the external tool OpenIE6 in extracting the
ontology-like knowledge of the large-scale con-
textual
texts. To bridge the gap between the
pretrained and end-to-end TOD models, we de-
sign two adaptive self-supervised learning tasks:
ontology-like triple recovery and next-text gener-
ation. The pretraining process is divided into two
phases, where phase-1 pretrains on the large-scale
ontology-aware contextual texts and phase-2 pre-
trains on the ontology-aware TOD data. Our
proposed OPAL achieves excellent performance
on the end-to-end TOD tasks and dialogue state
tracking tasks. In the future, we will evaluate the
effect of the different ontology-building methods.
Acknowledgments
their
We would like to thank the TACL team and
four anonymous reviewers for
insight-
ful comments. This work has been supported
by China NSFC Projects
(No.62120106006,
No.62106142, and No.92048205), Shanghai Mu-
nicipal Science and Technology Major Project
(2021SHZDZX0102), and CCF-Tencent Open
Fund and Startup Fund for Youngman Research
at SJTU (SFYR at SJTU).
Towards a human-like open-domain chatbot.
arXiv preprint arXiv:2001.09977.
Gabor Angeli, Melvin Jose Johnson Premkumar,
and Christopher D. Manning. 2015. Lever-
aging linguistic structure for open domain
In Proceedings of
information extraction.
the 53rd Annual Meeting of
the Associa-
tion for Computational Linguistics and the
7th International Joint Conference on Natural
Language Processing (Volume 1: Long Pa-
pers), pages 344–354. https://doi.org
/10.3115/v1/P15-1034
Vevake Balaraman and Bernardo Magnini.
2019. Scalable neural dialogue state tracking.
In 2019 IEEE Automatic Speech Recogni-
tion and Understanding Workshop (ASRU),
pages 830–837. IEEE.
Siqi Bao, Huang He, Fan Wang, Hua Wu, and
Haifeng Wang. 2020. PLATO: Pre-trained dia-
logue generation model with discrete latent
variable. In Proceedings of the 58th Annual
Meeting of the Association for Computational
Linguistics, pages 85–96. https://doi.org
/10.18653/v1/2020.acl-main.9
Paweł
Budzianowski,
Tsung-Hsien Wen,
I˜nigo Casanueva, Ultes
Bo-Hsiang Tseng,
Stefan, Ramadan Osman, and Milica Gaˇsi´c.
2018. MultiWOZ - a large-scale multi-domain
Wizard-of-Oz dataset for task-oriented dia-
logue modelling. In Proceedings of the 2018
Conference on Empirical Methods in Natural
Language Processing (EMNLP).
Bill
Byrne,
Karthik
Krishnamoorthi,
Chinnadhurai Sankar, Arvind Neelakantan,
Ben Goodrich, Daniel Duckworth, Semih
Yavuz, Amit Dubey, Kyu-Young Kim, and
Andy Cedilnik. 2019. Taskmaster-1: Toward
a realistic and diverse dialog dataset. In Pro-
ceedings of the 2019 Conference on Empirical
Methods in Natural Language Processing and
the 9th International Joint Conference on Nat-
ural Language Processing (EMNLP-IJCNLP),
pages 4516–4525. https://doi.org/10
.18653/v1/D19-1459
References
Daniel Adiwardana, Minh-Thang Luong, David
Jamie Hall, Noah Fiedel, Romal
R. So,
Thoppilan, Zi Yang, Apoorv Kulshreshtha,
Gaurav Nemade, Yifeng Lu, et al. 2020.
Lu Chen, Cheng Chang, Zhi Chen, Bowen Tan,
Milica Gaˇsi´c, and Kai Yu. 2018. Policy adap-
tation for deep reinforcement learning-based
dialogue management. In 2018 IEEE Interna-
tional Conference on Acoustics, Speech and
79
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
l
a
c
_
a
_
0
0
5
3
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Signal Processing (ICASSP), pages 6074–6078.
IEEE.
Lu Chen, Zhi Chen, Bowen Tan, Sishan
Long, Milica Gaˇsi´c, and Kai Yu. 2019.
AgentGraph: Toward universal dialogue man-
agement with structured deep reinforcement
IEEE/ACM Transactions on Au-
learning.
dio,
and Language Processing,
27(9):1378–1391. https://doi.org/10
.1109/TASLP.2019.2919872
Speech,
Lu Chen, Boer Lv, Chi Wang, Su Zhu, Bowen
Tan, and Kai Yu. 2020a. Schema-guided
multi-domain dialogue state tracking with graph
attention neural networks. In Proceedings of
the AAAI Conference on Artificial Intelligence,
volume 34, pages 7521–7528.
Zhi Chen, Lu Chen, Xiaoyuan Liu, and Kai
Yu. 2020b. Distributed structured actor-critic
learning for universal dia-
reinforcement
logue management. IEEE/ACM Transactions
on Audio, Speech, and Language Processing,
28:2400–2411. https://doi.org/10.1109
/TASLP.2020.3013392
Zhi Chen, Lu Chen, Zihan Xu, Yanbin Zhao, Su
Zhu, and Kai Yu. 2020c. Credit: Coarse-to-
fine sequence generation for dialogue state
tracking. arXiv preprint arXiv:2009.10435.
Yinpei Dai, Hangyu Li, Yongbin Li, Jian Sun,
Fei Huang, Luo Si, and Xiaodan Zhu. 2021.
Preview, attend and review: Schema-aware cur-
riculum learning for multi-domain dialog state
tracking. arXiv preprint arXiv:2106.00291.
Mihail Eric, Rahul Goel, Shachi Paul, Abhishek
Sethi, Sanchit Agarwal, Shuyag Gao, and Dilek
Hakkani-Tur. 2019. MultiWOZ 2.1: Multi-
domain dialogue state corrections and state
tracking baselines. arXiv preprint arXiv:1907
.01669.
Mihail Eric, Lakshmi Krishnan, Francois
Charette, and Christopher D. Manning. 2017.
Key-value retrieval networks for task-oriented
dialogue. In Proceedings of the 18th Annual
SIGdial Meeting on Discourse and Dialogue,
pages 37–49.
Rahul Goel, Shachi Paul, and Dilek Hakkanitur.
2019. Hyst: A hybrid approach for flexible and
accurate dialogue state tracking. arXiv preprint
arXiv:1907.00883. https://doi.org/10
.21437/Interspeech.2019-1863
Donghoon Ham, Jeong-Gwan Lee, Youngsoo
Jang, and Kee-Eung Kim. 2020. End-to-end
neural pipeline for goal-oriented dialogue sys-
tems using GPT-2. In Proceedings of
the
58th Annual Meeting of the Association for
Computational Linguistics, pages 583–592.
Wanwei He, Yinpei Dai, Yinhe Zheng, Yuchuan
Wu, Zheng Cao, Dermot Liu, Peng Jiang,
Min Yang, Fei Huang, Luo Si, Jian Sun, and
Yongbin Li. 2021. GALAXY: A generative
pretrained model for task-oriented dialog with
semi-supervised learning and explicit policy
injection. arXiv preprint arXiv:2111.14592.
Michael Heck, Carel van Niekerk, Nurul Lubis,
Christian Geishauser, Hsien-Chin Lin, Marco
Moresi, and Milica Gasic. 2020. TripPy: A
Triple copy strategy for value independent
neural dialog state tracking. In Proceedings
the Special
of
Interest Group on Discourse and Dialogue,
pages 35–44.
the 21th Annual Meeting of
Ehsan Hosseini-Asl, Bryan McCann, Chien-
Sheng Wu, Semih Yavuz, and Richard Socher.
2020. A simple language model for
task-
oriented dialogue. arXiv preprint arXiv:2005
.00796.
Mohit
In Proceedings of
Iyyer, Wen-tau Yih, and Ming-Wei
Chang. 2017. Search-based neural structured
sequential question answer-
learning for
the 55th Annual
ing.
Meeting of
the Association for Computa-
tional Linguistics (Volume 1: Long Papers),
pages 1821–1831. https://doi.org/10
.18653/v1/P17-1167
Zi-Hang Jiang, Weihao Yu, Daquan Zhou,
Yunpeng Chen, Jiashi Feng, and Shuicheng
Yan. 2020. ConvBERT: Improving BERT with
span-based dynamic convolution. Advances in
Neural Information Processing Systems, 33.
Jacob Devlin Ming-Wei Chang Kenton and Lee
Kristina Toutanova. 2019. BERT: Pretraining
of deep bidirectional transformers for language
understanding. In Proceedings of NAACL-HLT,
pages 4171–4186.
Sungdong Kim, Sohee Yang, Gyuwan Kim, and
Sang-Woo Lee. 2020. Efficient dialogue state
tracking by selectively overwriting memory.
In Proceedings of the 58th Annual Meeting of
80
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
l
a
c
_
a
_
0
0
5
3
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
the Association for Computational Linguistics,
pages 567–582.
Philipp Koehn. 2004. Statistical significance
tests for machine translation evaluation. In
Proceedings of the 2004 Conference on Empir-
ical Methods in Natural Language Processing,
pages 388–395, Barcelona, Spain. Association
for Computational Linguistics.
Keshav Kolluru, Vaibhav Adlakha, Samarth
Aggarwal, Soumen Chakrabarti. 2020. Open-
IE6: Iterative grid labeling and coordination
analysis for open information extraction. In
Proceedings of the 2020 Conference on Empir-
ical Methods in Natural Language Processing
(EMNLP), pages 3748–3761. https://doi
.org/10.18653/v1/2020.emnlp-main.306
Tuan Manh Lai, Quan Hung Tran, Trung Bui,
and Daisuke Kihara. 2020. A simple but
effective BERT model for dialog state track-
ing on resource-limited systems. In ICASSP
2020-2020 IEEE International Conference
on Acoustics, Speech and Signal Processing
(ICASSP), pages 8034–8038. IEEE.
Hung Le, Richard Socher, and Steven C. H. Hoi.
2020. Non-autoregressive dialog state track-
ing. In International Conference on Learning
Representations.
Hwaran Lee, Jinsik Lee, and Tae-Yoon Kim.
2019a. SUMBT: Slot-utterance matching for
universal and scalable belief tracking. In Pro-
ceedings of
the 57th Annual Meeting of
the Association for Computational Linguistics,
pages 5478–5483.
Sungjin Lee, Qi Zhu, Ryuichi Takanobu, Zheng
Zhang, Yaoqin Zhang, Xiang Li, Jinchao Li,
Baolin Peng, Xiujun Li, Minlie Huang, and
Jianfeng Gao. 2019b. ConvLab: Multi-domain
end-to-end dialog system platform. In Pro-
ceedings of the 57th Annual Meeting of the
Association for Computational Linguistics:
System Demonstrations, pages 64–69.
Wenqiang Lei, Xisen Jin, Min-Yen Kan,
Zhaochun Ren, Xiangnan He, and Dawei
Yin. 2018. Sequicity: Simplifying task-oriented
dialogue systems with single sequence-to-
sequence architectures. In Proceedings of the
56th Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long
Papers), pages 1437–1447.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer
Levy, Veselin Stoyanov, and Luke Zettlemoyer.
2020. BART: Denoising sequence-to-sequence
pretraining for natural
language generation,
translation, and comprehension. In Proceed-
ings of
the
Association for Computational Linguistics,
pages 7871–7880. https://doi.org/10
.18653/v1/2020.acl-main.703
the 58th Annual Meeting of
Jiwei Li, Will Monroe, Alan Ritter, Dan
Jurafsky, Michel Galley, and Jianfeng Gao.
learning for dia-
2016. Deep reinforcement
logue generation. In Proceedings of the 2016
Conference on Empirical Methods in Natural
Language Processing, pages 1192–1202.
Shiyang Li, Semih Yavuz, Kazuma Hashimoto,
Jia Li, Tong Niu, Nazneen Rajani, Xifeng
Yan, Yingbo Zhou, and Caiming Xiong. 2020.
CoCo: Controllable counterfactuals for evalu-
ating dialogue state trackers. In International
Conference on Learning Representations.
Zhaojiang
Lin, Andrea Madotto, Genta
Indra Winata,
and Pascale Fung. 2020.
MinTl: Minimalist transfer learning for task-
oriented dialogue systems. In Proceedings of
the 2020 Conference on Empirical Methods
in Natural Language Processing (EMNLP),
pages 3391–3405.
Qi Liu, Lei Yu, Laura Rimell, and Phil Blunsom.
2021. Pretraining the noisy channel model for
task-oriented dialogue. arXiv preprint arXiv:
2103.10518. https://doi.org/10.1162
/tacl a 00390
Shikib Mehri,
Razumovskaia,
Evgeniia
Tiancheng Zhao, and Maxine Eskenazi. 2019.
Pretraining methods for dialog context rep-
resentation learning. In Proceedings of
the
57th Annual Meeting of the Association for
Computational Linguistics, pages 3836–3845.
Nikola Mrkˇsi´c, Diarmuid ´O S´eaghdha, Tsung-
Hsien Wen, Blaise Thomson, and Steve Young.
2017. Neural belief tracker: Data-driven dia-
logue state tracking. In Proceedings of the 55th
Annual Meeting of the Association for Compu-
tational Linguistics (Volume 1: Long Papers),
pages 1777–1788. https://doi.org/10
.18653/v1/P17-1163
81
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
l
a
c
_
a
_
0
0
5
3
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Elnaz Nouri and Ehsan Hosseini-Asl. 2018.
Toward scalable neural dialogue state track-
ing. In NeurIPS 2018, 2nd Conversational
AI workshop.
Baolin Peng, Chunyuan Li, Jinchao Li, Shahin
Shayandeh, Lars Liden, and Jianfeng Gao.
2020a. SOLOIST: Few-shot task-oriented di-
alog with a single pre-trained auto-regressive
model. arXiv e-prints, arXiv–2005.
Baolin Peng, Chenguang Zhu, Chunyuan Li,
Xiujun Li, Jinchao Li, Michael Zeng, and
Jianfeng Gao. 2020b. Few-shot natural lan-
guage generation for task-oriented dialog. In
Proceedings of the 2020 Conference on Empir-
ical Methods in Natural Language Processing:
Findings, pages 172–182. https://doi.org
/10.18653/v1/2020.findings-emnlp.17
Shuke Peng, Xinjing Huang, Zehao Lin,
Feng Ji, Haiqing Chen, and Yin Zhang.
2019. Teacher-student framework enhanced
arXiv
multi-domain
preprint arXiv:1908.07137.
generation.
dialogue
Chris Quirk, Raymond Mooney, and Michel
Galley. 2015. Language to code: Learning se-
mantic parsers for if-this-then-that recipes. In
Proceedings of the 53rd Annual Meeting of
the Association for Computational Linguistics
and the 7th International Joint Conference
on Natural Language Processing (Volume 1:
Long Papers), pages 878–888. https://doi
.org/10.3115/v1/P15-1085
Alec Radford, Jeff Wu, Rewon Child, David
Luan, Dario Amodei, and Ilya Sutskever. 2019.
Language models are unsupervised multitask
learners. OpenAI blog, 1(8):9.
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, Michael
Matena, Yanqi Zhou, Wei Li, and Peter J. Liu.
2020. Exploring the limits of transfer learning
with a unified text-to-text transformer. Journal
of Machine Learning Research, 21(140):1–67.
Abhinav Rastogi, Xiaoxue Zang, Srinivas
Sunkara, Raghav Gupta, and Pranav Khaitan.
2020. Towards scalable multi-domain conver-
sational agents: The schema-guided dialogue
dataset. In Proceedings of
the AAAI Con-
ference on Artificial Intelligence, volume 34,
pages 8689–8696. https://doi.org/10
.1609/aaai.v34i05.6394
82
Liliang Ren, Jianmo Ni, and Julian McAuley.
2019. Scalable and accurate dialogue state
tracking via hierarchical sequence generation.
the 2019 Conference on
In Proceedings of
Empirical Methods
in Natural Language
Processing and the 9th International Joint
Conference on Natural Language Processing
(EMNLP-IJCNLP), pages 1876–1885.
Liliang Ren, Kaige Xie, Lu Chen, and Kai Yu.
2018. Towards universal dialogue state track-
ing. In Proceedings of the 2018 Conference
on Empirical Methods in Natural Language
Processing, pages 2780–2786.
Corby Rosset, Chenyan Xiong, Minh Phan, Xia
Song, Paul Bennett, and Saurabh Tiwary. 2020.
Knowledge-aware language model pretraining.
arXiv preprint arXiv:2007.00655.
Bishal Santra, Potnuru Anusha, and Pawan
Goyal. 2021. Hierarchical transformer for task
oriented dialog systems. In Proceedings of
the 2021 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
pages 5649–5658. https://doi.org/10
.18653/v1/2021.naacl-main.449
Yixuan Su, Lei Shu, Elman Mansimov, Arshit
Gupta, Deng Cai, Yi-An Lai, and Yi Zhang.
2021. Multi-task pre-training for plug-and-
play task-oriented dialogue system. arXiv pre-
print arXiv:2109.14739.
Stefan Ultes, Lina M. Rojas Barahona, Pei-Hao
Su, David Vandyke, Dongho Kim,
Inigo
Casanueva, Paweł Budzianowski, Nikola
Mrkˇsi´c, Tsung-Hsien Wen, Milica Gasic, and
Steve Young. 2017. Pydial: A multi-domain
statistical dialogue system toolkit. In Proceed-
ings of ACL 2017, System Demonstrations,
pages 73–78. https://doi.org/10.18653
/v1/P17-4013
Michael V¨olske, Martin Potthast, Shahbaz Syed,
and Benno Stein. 2017. Tl; dr: Mining Reddit
to learn automatic summarization. In Proceed-
ings of the Workshop on New Frontiers in
Summarization, pages 59–63. https://doi
.org/10.18653/v1/W17-4508
Gell´ert Weisz, Paweł Budzianowski, Pei-Hao Su,
and Milica Gaˇsi´c. 2018. Sample efficient deep
reinforcement learning for dialogue systems
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
l
a
c
_
a
_
0
0
5
3
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
with large action spaces. IEEE/ACM Transac-
tions on Audio, Speech, and Language Process-
ing, 26(11):2083–2097. https://doi.org
/10.1109/TASLP.2018.2851664
Tsung-Hsien Wen, Milica Gasic, Nikola Mrkˇsi´c,
Lina M. Rojas Barahona, Pei-Hao Su, Stefan
Ultes, David Vandyke, and Steve Young.
2016. Conditional generation and snapshot
learning in neural dialogue systems. In Pro-
ceedings of the 2016 Conference on Empirical
Methods in Natural Language Processing,
pages 2153–2162.
Tsung-Hsien Wen, Milica Gasic, Nikola Mrkˇsi´c,
Pei-Hao Su, David Vandyke, and Steve Young.
2015. Semantically conditioned LSTM-based
natural language generation for spoken dia-
logue systems. In Proceedings of
the 2015
Conference on Empirical Methods in Natural
Language Processing, pages 1711–1721.
Thomas Wolf, Lysandre Debut, Victor Sanh,
Julien Chaumond, Clement Delangue, Anthony
Moi, Pierric Cistac, Tim Rault, R´emi Louf,
Morgan Funtowicz, Joe Davison, Sam Shleifer,
Patrick von Platen, Clara Ma, Yacine Jernite,
Julien Plu, Canwen Xu, Teven Le Scao,
Sylvain Gugger, Mariama Drame, Quentin
Lhoest,
and Alexander M. Rush. 2020.
Transformers: State-of-the-art natural language
processing. In Proceedings of the 2020 Con-
ference on Empirical Methods in Natural
Language Processing: System Demonstrations,
pages 38–45, Online. Association for Compu-
tational Linguistics. https://doi.org/10
.18653/v1/2020.emnlp-demos.6
Chien-Sheng Wu, Steven CH Hoi, Richard
Socher, and Caiming Xiong. 2020. TOD-
BERT: Pretrained natural language understand-
ing for task-oriented dialogue. In Proceedings
of the 2020 Conference on Empirical Meth-
ods in Natural Language Processing (EMNLP),
pages 917–929.
Chien-Sheng Wu, Andrea Madotto, Ehsan
Hosseini-Asl, Caiming Xiong, Richard Socher,
and Pascale Fung. 2019. Transferable multi-
domain state generator for task-oriented di-
alogue systems. In Proceedings of the 57th
Annual Meeting of the Association for Compu-
tational Linguistics, pages 808–819.
Zihan Xu, Zhi Chen, Lu Chen, Su Zhu, and
Kai Yu. 2020. Memory attention neural net-
work for multi-domain dialogue state tracking.
In CCF International Conference on Natural
Language Processing and Chinese Computing,
pages 41–52. Springer.
Yunyi Yang, Yunhao Li, and Xiaojun Quan.
2021. UBAR: Towards fully end-to-end task-
oriented dialog system with GPT-2. In Pro-
ceedings of the AAAI Conference on Artificial
Intelligence, volume 35, pages 14230–14238.
https://doi.org/10.1609/aaai.v35i16
.17674
Tao Yu, Rui Zhang, Alex Polozov, Christopher
Meek, and Ahmed Hassan Awadallah. 2020.
SCoRe: Pre-training for context representa-
tion in conversational semantic parsing. In
International Conference on Learning Repre-
sentations.
Jianguo Zhang, Kazuma Hashimoto, Chien-
Sheng Wu, Yao Wang, S Yu Philip, Richard
Socher, and Caiming Xiong. 2020a. Find or
classify? Dual strategy for slot-value predic-
tions on multi-domain dialog state tracking.
In Proceedings of
the Ninth Joint Confer-
ence on Lexical and Computational Semantics,
pages 154–167.
Taolin Zhang, Zerui Cai, Chengyu Wang,
Minghui Qiu, Bite Yang, and Xiaofeng He.
2021. SMedBERT: A knowledge-enhanced pre-
trained language model with structured seman-
tics for medical text mining. In Proceedings
of the 59th Annual Meeting of the Associa-
tion for Computational Linguistics and the 11th
International Joint Conference on Natural Lan-
guage Processing (Volume 1: Long Papers),
pages 5882–5893. https://doi.org/10
.18653/v1/2021.acl-long.457
Yichi Zhang, Zhijian Ou, and Zhou Yu. 2020b.
Task-oriented dialog systems that consider
multiple appropriate responses under the same
context. In Proceedings of
the AAAI Con-
ference on Artificial Intelligence, volume 34,
pages 9604–9611.
Yizhe Zhang, Siqi Sun, Michel Galley, Yen-
Chun Chen, Chris Brockett, Xiang Gao,
Jianfeng Gao, Jingjing Liu, and William B.
Dolan. 2020c. DIALOGPT: Large-scale gener-
ative pre-training for conversational response
83
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
l
a
c
_
a
_
0
0
5
3
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
generation. In Proceedings of the 58th An-
nual Meeting of the Association for Compu-
tational Linguistics: System Demonstrations,
270–278. https://doi.org/10
pages
.18653/v1/2020.acl-demos.30
Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin
Jiang, Maosong Sun, and Qun Liu. 2019.
ERNIE: Enhanced language representation with
the
informative entities. In Proceedings of
57th Annual Meeting of the Association for
Computational Linguistics, pages 1441–1451.
https://doi.org/10.18653/v1/P19
-1139
Tiancheng Zhao and Maxine Eskenazi. 2018.
Zero-shot dialog generation with cross-domain
the 19th
latent actions. In Proceedings of
Annual SIGdial Meeting on Discourse and
Dialogue, pages 1–10.
Tiancheng Zhao, Kaige Xie,
and Maxine
Eskenazi. 2019. Rethinking action spaces for
reinforcement
learning in end-to-end dialog
agents with latent variable models. In Pro-
ceedings of the 2019 Conference of the North
American Chapter of the Association for Com-
putational Linguistics: Human Language Tech-
nologies, Volume 1 (Long and Short Papers),
pages 1208–1218.
Tiancheng Zhao, Ran Zhao, and Maxine Eskenazi.
2017. Learning discourse-level diversity for
neural dialog models using conditional vari-
ational autoencoders. In Proceedings of the
55th Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long
Papers), pages 654–664.
Victor Zhong, Caiming Xiong, and Richard
Socher. 2018. Global-locally self-attentive
encoder for dialogue state tracking. In ACL.
https://doi.org/10.18653/v1/P18
-1135
Jingyao Zhou, Haipang Wu, Zehao Lin, Guodun
Li, and Yin Zhang. 2021. Dialogue state track-
ing with multi-level fusion of predicted dia-
logue states and conversations. In Proceedings
of the 22nd Annual Meeting of the Special
Interest Group on Discourse and Dialogue,
pages 228–238.
Li Zhou and Kevin Small. 2019. Multi-domain
dialogue state tracking as dynamic knowledge
graph enhanced question answering. arXiv
preprint arXiv:1911.06192.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
3
4
2
0
6
7
8
7
9
/
/
t
l
a
c
_
a
_
0
0
5
3
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
84