Neural Modeling for Named Entities and Morphology (NEMO2)
Dan Bareket1,2 and Reut Tsarfaty1
1Bar Ilan University, Ramat-Gan, Israel
2Open Media and Information Lab (OMILab), The Open University of Israel, Israel
dbareket@gmail.com, reut.tsarfaty@biu.ac.il
Abstrait
Named Entity Recognition (NER) is a funda-
mental NLP task, commonly formulated as
classification over a sequence of tokens. Mor-
phologically rich languages (MRLs) pose a
challenge to this basic formulation, as the
boundaries of named entities do not neces-
sarily coincide with token boundaries, rather,
they respect morphological boundaries. To ad-
dress NER in MRLs we then need to answer
two fundamental questions, namely, what are
the basic units to be labeled, and how can these
units be detected and classified in realistic set-
tings (c'est à dire., where no gold morphology is avail-
capable). We empirically investigate these questions
on a novel NER benchmark, with parallel token-
level and morpheme-level NER annotations,
which we develop for Modern Hebrew, a mor-
phologically rich-and-ambiguous language. Notre
results show that explicitly modeling morphol-
ogical boundaries leads to improved NER per-
formance, and that a novel hybrid architecture,
in which NER precedes and prunes morpho-
logical decomposition, greatly outperforms the
standard pipeline, where morphological de-
composition strictly precedes NER, setting a
new performance bar for both Hebrew NER
and Hebrew morphological decomposition
tasks.
1
Introduction
Named Entity Recognition (NER) is a fundamental
task in the area of Information Extraction (IE),
in which mentions of Named Entities (NE) sont
extracted and classified in naturally occurring
texts. This task is most commonly formulated as a
sequence labeling task, where extraction takes the
form of assigning each input token with a label
that marks the boundaries of the NE (par exemple., B, je,
Ô), and classification takes the form of assigning
labels to indicate entity type (PER, ORG, LOC, etc.).
impression from
latest NER performance, brought about by neural
models on the main English NER benchmarks—
Despite a common initial
Morphologically
CoNLL 2003 (Tjong Kim Sang, 2003) and Onto-
Remarques (Weischedel et al., 2013)—the NER task
in real-world settings is far from solved. Spe-
cifically, NER performance is shown to greatly
diminish when moving to other domains (Luan
et coll., 2018; Song et al., 2018), when address-
ing the long tail of
rare, unseen, and new
user-generated entities (Derczynski et al., 2017),
and when handling languages with fundamentally
different structure than English. En particulier, là
is no readily available and empirically verified
neural modeling strategy for neural NER in those
languages with complex word-internal structure,
also known as morphologically rich languages.
rich
(MRL)
(Tsarfaty et al., 2010; Seddah et al., 2013; Tsarfaty
et coll., 2020) are languages in which substantial
information concerning the arrangement of words
into phrases and the relations between them is
expressed at the word level, rather than in a fixed
word-order or a rigid structure. The extended
amount of information expressed at word-level
and the morpho-phonological processes creating
these words result in high token-internal com-
plexity, which poses serious challenges to the ba-
sic formulation of NER as classification of raw,
space-delimited, tokens. Spécifiquement, while NER
in English is formulated as the sequence labeling
of space-delimited tokens, in MRLs a single to-
ken may include multiple meaning-bearing units,
henceforth morphemes, only some of which are
relevant for the entity mention at hand.
languages
In this paper we formulate two questions con-
cerning neural modeling strategies for NER in
MRLs, namely: (je) What should be the granularity
of the units to be labeled? Space-delimited tokens
or finer-grain morphological segments? et, (ii)
How can we effectively encode, and accurately de-
tect, the morphological segments that are relevant
to NER, and specifically in realistic settings, quand
gold morphological boundaries are not available?
To empirically investigate these questions we
develop a novel parallel benchmark, containing
909
Transactions of the Association for Computational Linguistics, vol. 9, pp. 909–928, 2021. https://doi.org/10.1162/tacl a 00404
Action Editor: Richard Sproat. Submission batch: 1/2021; Revision batch: 3/2021; Published 9/2021.
c(cid:2) 2021 Association for Computational Linguistics. Distributed under a CC-BY 4.0 Licence.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
parallel
token-level and morpheme-level NER
annotations for texts in Modern Hebrew—a mor-
phologically rich and morphologically ambiguous
langue, which is known to be notoriously hard
to parse (More et al., 2019; Tsarfaty et al., 2019).
Our results show that morpheme-based NER is
superior to token-based NER, which encourages
a segmentation-first pipeline. En même temps,
we demonstrate that token-based NER improves
morphological segmentation in realistic scenarios,
encouraging a NER-first pipeline. While these two
findings may appear contradictory, we aim here
to offer a resolution; a hybrid architecture where
the token-based NER predictions precede and
prune the space of morphological decomposition
options, while the actual morpheme-based NER
takes place only after the morphological decom-
position. We empirically show that the hybrid ar-
chitecture we propose outperforms all token-based
and morpheme-based model variants of Hebrew
NER on our benchmark, and it further outperforms
all previously reported results on Hebrew NER and
morphological decomposition. Our error analysis
further demonstrates that morpheme-based mod-
els better generalize, c'est, they contribute to
recognizing the long tail of entities unseen during
entraînement (out-of-vocabulary, OOV), in particular
those unseen entities that turn out to be composed
of previously seen morphemes.
The contribution of this paper is thus manifold.
D'abord, we define key architectural questions for
Neural NER modeling in MRLs and chart the
space of modeling options. Deuxième, we deliver
a new and novel parallel benchmark that allows
one to empirically compare and contrast the mor-
pheme vs. token modeling strategies. Troisième, nous
show consistent advantages for morpheme-based
NER, demonstrating the importance of morpho-
logically aware modeling. Next we present a
novel hybrid architecture which demonstrates
an even further improved performance on both
NER and morphological decomposition tasks.
Our results for Hebrew present a new bar on these
tasks, outperforming the reported state-of-the-art
results on various benchmarks.1
2 Research Questions: NER for MRLs
In MRLs, words are internally complex, and word
boundaries do not generally coincide with the
1Données & code: https://github.com/OnlpLab
/NEMO.
boundaries of more basic meaning-bearing units.
This fact has critical ramifications for sequence
labeling tasks in MRLs in general, and for NER
in MRLs in particular. Consider, par exemple, le
three-token Hebrew phrase in (1):2
(1) (cid:2)(cid:3)יסל דנליאתמ ונסט
tasnu
mithailand
flew.1PL from-Thailand to-China
‘we flew from Thailand to China’
lesin
It is clear that (cid:2)דנליאת/thailand (Thaïlande) et
(cid:2)(cid:3)יס/sin (Chine) are NEs, and in English, each NE
is its own token. In the Hebrew phrase though,
neither NE constitutes a single token. In either
case, the NE occupies only one of two morphemes
in the token, the other being a case-assigning
preposition. This simple example demonstrates an
extremely frequent phenomenon in MRLs such
as Hebrew, Arabic, or Turkish, that the adequate
boundaries for NEs do not coincide with token
boundaries, and tokens must be segmented in or-
der to obtain accurate NE boundaries.3
The segmentation of tokens and the identifica-
tion of adequate NE boundaries is, cependant, far
from trivial, due to complex morpho-phonological
and orthographic processes in some MRLs (Vania
et coll., 2018; Klein and Tsarfaty, 2020). This means
that the morphemes that compose NEs are not nec-
essarily transparent in the character sequence of
the raw tokens. Consider for example phrase (2):
(2) (cid:2)(cid:3)בלה תיבל (cid:16)ורמה
hamerotz
the-race
‘the race to the White House’
labayit
halavan
to-house.DEF the-white
Ici, the full form of the NE (cid:2)(cid:3)בלה תיבה / habayit
halavan (the White House), is not present in the
utterances, only the sub-string (cid:2)(cid:3)בלה תיב / bayit
halavan ((le) maison Blanche) is present in (2)—
due to phonetic and orthographic processes sup-
pressing the definite article (cid:2)ה/ha in certain envi-
ronments. In this and many other cases, it is not
only that NE boundaries do not coincide with
2Glossing conventions are in accord with the Leipzig
Glossing Rules (Comrie et al., 2008).
3We use the term morphological segmentation (or seg-
mentation) to refer to splitting raw tokens into morphological
segments, each carrying a single Part-Of-Speech tag. C'est,
we segment away prepositions, determiners, subordination
markers and multiple kinds of pronominal clitics, that attach
to their hosts via complex morpho-phonological processes.
this work, we use the terms morphological
Throughout
segment, morpheme, or segment interchangeably.
910
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
token boundaries, they do not coincide with char-
acters or sub-strings of the token either. This calls
for accessing the more basic meaning-bearing
units of the token, c'est, to decompose the to-
kens into morphemes.
Unfortunately though, the morphological de-
composition of surface tokens may be very
challenging due to extreme morphological ambi-
guity. The sequence of morphemes composing a
token is not always directly recoverable from its
character sequence, and is not known in advance.4
This means that for every raw space-delimited
token, there are many conceivable readings which
impose different segmentations, yielding different
sets of potential NE boundaries. Consider for
example the token (cid:2)ינבל (lbny) in different contexts:
a nutshell, is as follows: In order to detect accu-
rately NE boundaries, we need to segment the raw
token first, cependant, in order to segment tokens
correctly, we need to know the greater semantic
content, y compris, Par exemple, the participating
entities. How can we break out of this apparent
loop?
Enfin, MRLs are often characterized by
an extremely sparse lexicon, consisting of a
long-tail of OOV entities unseen during training
(Czarnowska et al., 2019). Even in cases where
all morphemes are present in the training data,
morphological compositions of seen morphemes
may yield tokens and entities which were unseen
during training. Take for example the utterance in
(4), which the reader may inspect as familiar:
(3) (un) (cid:2)ינבל הרשה
hasara
the-minister
‘Minister [Livni]P ER’
livni
[Livni]P ER
(b) (cid:2)(cid:16)נג ינבל
gantz
le-beny
Gantz]P ER
for-[Benny
‘for [Benny Gantz]P ER’
(c) (cid:2)רקיה ינבל
hayakar
li-bni
for-son.POSS.1SG the-dear
‘for my dear son’
(d) (cid:2)רמיח ינבל
livney
brick.CS
‘clay bricks’
kheymar
clay
Dans (3un) the token (cid:2)ינבל is completely consumed as
a labeled NE. Dans (3b) (cid:2)ינבל is only partly consumed
by an NE, et en (3c) et (3d) the token is entirely
out of an NE context. Dans (3c) the token is com-
posed of several morphemes, et en (3d) it con-
sists of a single morpheme. These are only some
of the possible decompositions of this surface
token, other alternatives may still be available. Comme
shown by Goldberg and Tsarfaty (2008), Vert
and Manning (2010), Seeker and C¸ etino˘glu
(2015), Habash and Rambow (2005), More et al.,
(2019), et d'autres, the correct morphological de-
composition becomes apparent only in the larger
(syntactic or semantic) contexte. The challenge, dans
4This ambiguity gets magnified by the fact that Semitic
languages that use abjads, like Hebrew and Arabic, lack
capitalization altogether and suppress all vowels (diacritics).
911
(4) (cid:2)דנליאתל (cid:3)יסמ ונסט
misin
tasnu
flew.1PL
from-China
’we flew from China to Thailand’
lethailand
to-Thailand
Exemple (4) is in fact example (1) with a switched
flight direction. This subtle change creates two
new surface tokens (cid:2)(cid:3)יסמ, (cid:2)דנליאתל which might
not have been seen during training, even if
example (1) had been observed. Morphological
compositions of an entity with prepositions,
conjunctions, definite markers, possessive clitics
and more, cause mentions of seen entities to have
unfamiliar surface forms, which often fail to be
accurately detected and analyzed.
Given the aforementioned complexities, in or-
der to solve NER for MRLs we ought to answer
the following fundamental modeling questions:
Q1. Units: What are the discrete units upon
which we need to set NE boundaries in MRLs? Are
they tokens? characters? morphemes? a represen-
tation containing multiple levels of granularity?
Q2. Architecture: When employing morphemes
in NER, the classical approach is ‘‘segmentation-
first’’. Cependant, segmentation errors are detri-
mental and downstream NER cannot recover
from them. How is it best to set up the pipeline so
that segmentation and NER could interact?
Q3. Generalization: How do the different mod-
eling choices affect NER generalization in MRLs?
How can we address the long tail of OOV NEs
in MRLs? Which modeling strategy best handles
pseudo-OOV entities that result from a previously
unseen composition of already seen morphemes?
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
3 Formalizing NER for MRLs
Nickname
Input
Lit
Output
To answer the aforementioned questions, we chart
and formalize the space of modeling options for
neural NER in MRLs. We cast NER as a sequence
labeling task and formalize it as f : X → Y,
where x ∈ X is a sequence x1, . . . , xn of n
discrete strings from some vocabulary xi ∈ Σ,
and y ∈ Y is a sequence y1, .., yn of the same
length, where yi ∈ Labels, and Labels is a finite
set of labels composed of the BIOSE tags (c'est à dire.,
BIOLU as described in Ratinov and Roth, 2009).
Every non-O label is also enriched with an entity
type label. Our list of types is presented in Table 2.
3.1 Token-Based or Morpheme-Based?
Our first modeling question concerns the discrete
units upon which to set the NE boundaries. That
est, what is the formal definition of the input
vocabulary Σ for the sequence labeling task?
The simplest scenario, adopted in most NER
études, assumes token-based input, where each
token admits a single label—hence token-single:
NERtoken-single : W → L
Ici, W = {w∗|w ∈ Σ} is the set of all possible
token sequences in the language and L = {l∗|l ∈
Labels} is the set of all possible label sequences
over the label set defined above. Each token gets
assigned a single label, so the input and output se-
quences are of the same length. The drawback of
this scenario is that since the input for token-single
incorporates no morphological boundaries, the ex-
act boundaries of the NEs remain underspecified.
This case is exemplified at the top row of Table 1.
There is another conceivable scenario, où
the input is again the sequence of space-delimited
tokens, and the output consists of complex la-
bels (henceforth multi-labels) reflecting, for each
token, the labels of its constituent morphemes;
henceforth, a token-multi scenario:
N ERtoken−multi : W → L∗
Ici, W = {w∗|w ∈ Σ} is the set of sequences of
tokens as in token-single. Each token is assigned a
multi-label, c'est, a sequence (l∗ ∈ L) which indi-
cates the labels of the token’s morphemes in order.
The output is a sequence of such multi-labels,
one multi-label per token. This variant incorpo-
token-single
token-multi
morpheme
(cid:2)(cid:3)ורמה
(cid:2)תיבל
(cid:2)(cid:12)בלה
(cid:2)(cid:3)ורמה
(cid:2)תיבל
(cid:2)(cid:12)בלה
(cid:2)ה
(cid:2)(cid:3)ורמ
(cid:2)ל
(cid:2)ה
(cid:2)תיב
(cid:2)ה
(cid:2)(cid:12)בל
the-race
to-house.DEF
the-white
the-race
to-house.DEF
the-white
le
course
à
le
maison
le
blanc
Ô
B ORG
E ORG
Ô + Ô
Ô + B ORG + I ORG
I ORG + E ORG
Ô
Ô
Ô
B ORG
I ORG
I ORG
E-ORG
Tableau 1: Input/output for token-single,
token-
multi, and morpheme models for example (2) dans
Section 2.
rates morphological information concerning the
number and order of labeled morphemes, but lacks
the precise morphological boundaries. This is il-
lustrated at the middle of Table 1. A downstream
application may require (possibly noisy) heuris-
tics to determine the precise NE boundaries of
each individual label in the multi-label for an
input token.
Another possible scenario is a morpheme-based
scénario, assigning a label l ∈ L for each segment:
N ERmorph : M → L
Ici, M = {m∗|m ∈ Morphemes} is the set of
sequences of morphological segments in the lan-
guage, and L = {l∗|l ∈ Labels} is the set of label
sequences as defined above. The upshot of this
scenario is that NE boundaries are precise. An ex-
ample is given in the bottom row of Table 1. Mais,
since each token may contain many meaningful
morphological segments, the length of the token
sequence is not the same as the length of morpho-
logical segments to be labeled, and the model as-
sumes prior morphological segmentation—which
in realistic scenarios is not necessarily available.
3.2 Realistic Morphological Decomposition
A major caveat with morpheme-based modeling
strategies is that they often assume an ideal scena-
rio of gold morphological decomposition of the
space-delimited tokens into morphological seg-
ments (cf. Nivre et al., 2007; Pradhan et al., 2012).
But in reality, gold morphological decomposition
is not known in advance, it has to be predicted au-
tomatically, and prediction errors may propagate
to contaminate the downstream task.
912
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Our second modeling question therefore con-
cerns the interaction between the morphological
decomposition and the NER tasks: How would it
be best to set up the pipeline so that the prediction
of the two tasks can interact?
To answer this, we define morphological de-
composition as consisting of
two subtasks:
morphological analysis (MA) and morphological
disambiguation (MARYLAND). We view sentence-based
MA as:
M A : W → P(M.)
Here W = {w∗|w ∈ Σ} is the set of possi-
ble token sequences as before, M = {m∗|m ∈
M orphemes} is the set of possible morpheme
sequences, and P(M.) is the set of subsets of M.
The role of M A is then to assign a token sequence
w ∈ W with all of its possible morphological
decomposition options. We represent this set of al-
ternatives in a dense structure that we call a lattice
(exemplified in Figure 1). MD is the task of pick-
ing the single correct morphological path M ∈ M
through the MA lattice of a given sentence:
M D : P.(M.) → M
Now, assume x ∈ W is a surface sentence in
the language, with its morphological decompo-
sition initially unknown and underspecified. In a
Standard pipeline, MA strictly precedes MD:
M DStandard : M = M D(M A(X))
The main problem here is that MD errors may
propagate to contaminate the NER output.
We propose a novel Hybrid alternative,
dans
which we inject a task-specific signal, in this case
NER,5 to constrain the search for M through the
lattice:
M DHybrid : M = M D(M A(X) (cid:2) NERtoken(X))
Ici, the restriction M A(X) (cid:2) N ER(X) indicates
pruning the lattice structure M A(X) to contain
only MD options that are compatible with the
token-based NER predictions, and only then
apply M D to the pruned lattice.
Both M DStandard and M DHybrid are disam-
biguation architectures that result in a morpheme
sequence M ∈ M. The latter benefits from
the NER signal, while the former doesn’t. Le
5We can do this for any sequence labeling task in MRLs.
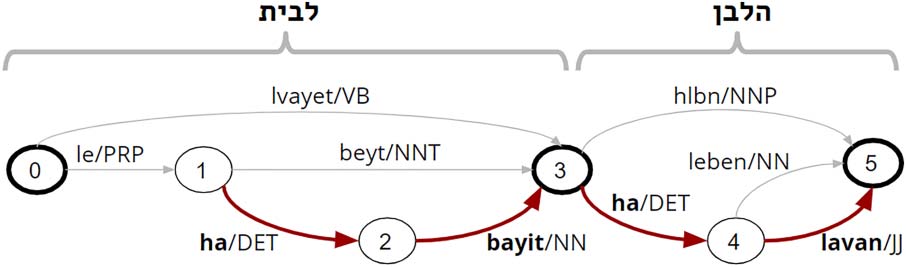
Chiffre 1: Lattice for a partial list of analyses of the
Hebrew tokens (cid:2)(cid:12)בלה תיבל corresponding to Table 1.
Bold nodes are token boundaries. Light nodes are
segment boundaries. Every path through the lattice
is a single morphological analysis. The bold path is a
single NE.
sequence M ∈ M can be used in one of two
ways. We can use M as input to a morpheme
model to output morpheme labels. Or, we can rely
on the output of the token-multi model and align
the token’s multi-label with the segments in M .
In what follows, we want to empirically assess
the effect of different modeling choices (token-
single, token-multi, morpheme) and disambigua-
tion architectures (Standard, Hybrid) on the
performance of NER in MRLs. To this end, nous
need a corpus that allows training and evalu-
ating NER at both token and morpheme-level
granularity.
4 The Data: A Novel NER Corpus
This work empirically investigates NER mod-
eling strategies in Hebrew, a Semitic language
known for its complex and highly ambiguous
morphology. Ben-Mordecai
the only
previous work on Hebrew NER to date, annotated
space-delimited tokens, basing their guidelines
on the CoNLL 2003 shared task (Chinchor et al.,
1999).
(2005),
Popular Arabic NER corpora also label space-
delimited tokens (ANERcorp [Benajiba et al.,
2007], AQMAR [Mohit et al., 2012], TWEETS
[Darwish, 2013]), with the exception of the Arabic
portion of OntoNotes (Weischedel et al., 2013)
and ACE (LDC, 2008) which annotate NER labels
on gold morphologically pre-segmented texts.
Cependant, these works do not provide a compre-
hensive analysis on the performance gaps between
morpheme-based and token-based scenarios.
In agglutinative languages as Turkish, token
segmentation is always performed before NER
(T¨ur et al., 2003; K¨uc¸ ¨uk and Can, 2019,
re-enforcing the need to contrast the token-based
913
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
first contribution is
scénario, widely adopted for Semitic languages,
with the morpheme-based scenarios in other
MRLs.
Notre
thus a parallel
corpus for Hebrew NER; one version consists
of gold-labeled tokens and the other consists of
gold-labeled morphemes, for the same text. Pour
ce, we performed gold NE annotation of the He-
brew Treebank (Sima’an et al., 2001), based on the
6,143 morpho-syntactically analyzed sentences of
the HAARETZ corpus, to create both token-level
and morpheme-level variants, as illustrated at the
topmost and lowest rows of Table 1, respectivement.
Annotation Scheme We started off with the
guidelines of Ben-Mordecai (2005), from which
we deviate in three main ways. D'abord, we label NE
boundaries and their types on sequences of mor-
phemes, in addition to the space-delimited token
annotations.6 Secondly, we use the finer-grained
entity categories list of ACE (LDC, 2008).7 Fi-
enfin, we allow nested entity mentions, as in Finkel
and Manning (2009) and Benikova et al. (2014).8
Annotation Cycle As Fort et al. (2009) put it,
examples and rules would never cover all possi-
ble cases because of the specificity of natural
language and the ambiguity of formulation. À
address this we employed the cyclic approach of
agile annotation as offered by Alex et al. (2010).
Every cycle consisted of: annotation, evaluation
and curation, clarification and refinements. Nous
used WebAnno (Yimam et al., 2013) as our
annotation interface.
The Initial Annotation Cycle was a two-stage
pilot with 12 participants, divided into 2 teams
de 6. The teams received the same guidelines,
with the exception of the specifications of entity
boundaries. One team was guided to annotate the
minimal string that designates the entity. The other
was guided to tag the maximal string which can
still be considered as the entity. Our agreement
analysis showed that the minimal guideline gen-
erally led to more consistent annotations. Based
on this result (as well as low-level refinements)
6A single NE is always continuous. Token-morpheme
discrepancies do not lead to discontinuous NEs.
7Entity categories are listed in Table 2. We dropped the
NORP category, since it introduced complexity concerning
the distinction between adjectives and group names. LAW did
not appear in our corpus.
8Nested labels are are not modeled in this paper, mais ils
are published with the corpus, to allow for further research.
Sentences
Tokens
Morphemes
All mentions
Type: Person (PER)
Type: Organization (ORG)
Type: Geo-Political (GPE)
Type: Location (LOC)
Type: Facility (FAC)
Type: Work-of-Art (WOA)
Type: Event (EVE)
Type: Product (DUC)
Type: Language (ANG)
train
dev
test
4,937
93,504
127,031
500
8,531
11,301
706
12,619
16,828
6,282
2,128
2,043
1,377
331
163
114
57
36
33
499
193
119
121
28
12
9
12
2
3
932
267
408
195
41
11
6
0
3
1
Tableau 2: Basic corpus statistics. Standard HTB
splits.
from the pilot, we devised the full version of the
guidelines.9
Annotation, Evaluation, and Curation: Every
annotation cycle was performed by two annotators
(UN, B) and an annotation manager/curator (C). Nous
annotated the full corpus in 7 cycles. We evaluated
the annotation in two ways, manual curation and
automatic evaluation. After each annotation step,
the curator manually reviewed every sentence in
which disagreements arose, as well as specific
points of difficulty pointed out by the annotators.
The inter-annotator agreement metric described
below was also used to quantitatively gauge the
progress and quality of the annotation.
Clarifications and Refinements: In the end of
each cycle we held a clarification talk between
UN, B, and C, in which issues that came up during
the cycle were discussed. Following that talk we
refined the guidelines and updated the annota-
tors, which went on to the next cycle. In the
end we performed a final curation run to make
sentences from earlier cycles comply with later
refinements.10
(IAA)
Inter-Annotator Agreement
IAA
is commonly measured using the κ-statistic.
Cependant, Pyysalo et al. (2007) show that it is not
suitable for evaluating inter-annotator agreement
in NER. Plutôt, an F1 metric on entity mentions
has in recent years been adopted for this purpose
(Zhang, 2013). This metric allows for computing
pair-wise IAA using standard F1 score by treating
9The complete annotation guide is publicly available at
https://github.com/OnlpLab/NEMO-Corpus.
10UN, B, and C annotations are published to enable research
on learning with disagreements (Plank et al., 2014).
914
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 2: The token-single and token-multi models. Le
input and output correspond to rows 1,2 in Table 1.
Triangles indicate string embeddings. Circles indicate
char-based encoding.
one annotator as gold and the other as the
prediction.
Notre
full corpus pair-wise F1
scores are:
IAA(UN,C)=96.
IAA(UN,B)=89,
Tableau 2 presents final corpus statistics.
IAA(B,C)=92,
Annotation Costs The annotation took on av-
erage about 35 seconds per sentence, and thus a
total of 60 hours for all sentences in the corpus
for each annotator. Six clarification talks were
held between the cycles, which lasted from thirty
minutes to an hour. Giving a total of about 130
work hours of expert annotators.11
5 Experimental Settings
Goal We set out to empirically evaluate the
representation alternatives for the input/output
sequences (token-single, token-multi, morpheme)
and the effect of different architectures (Standard,
Hybrid) on the performance of NER for Hebrew.
Modeling Variants All experiments use the
corpus we just described and employ a standard
Bi-LSTM-CRF architecture for implementing the
neural sequence labeling task (Huang et al., 2015).
Our basic architecture12 is composed of an em-
bedding layer for the input and a 2-layer Bi-LSTM
11The corpus is available at https://github.com
/OnlpLab/NEMO-Corpus.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 3: The morpheme model. The input and output
correspond to row 3 in Table 1. Triangles indicate string
embeddings. Circles indicate char-based encoding.
followed by a CRF inference layer—for which we
test three modeling variants.
Figures 2–3 present
the variants we em-
ploy. Chiffre 2 shows the token-based variants,
token-single and token-multi. The former outputs
a single BIOSE label per token, and the latter
outputs a multi-label per token—a concatenation
of BIOSE labels of the morphemes composing
the token. Chiffre 3 shows the morpheme-based
variant for the same input phrase. It has the same
basic architecture, but now the input consists of
morphological segments instead of tokens. Le
model outputs a single BIOSE label for each
morphological segment in the input.
In all modeling variants, the input may be en-
coded in two ways: (un) String-level embeddings
(token-based or morpheme-based) optionally ini-
tialized with pre-trained embeddings. (b) Char-
level embeddings, trained simultaneously with
the main task (cf. Ma and Hovy, 2016; Chiu and
Nichols, 2015; Lample et al., 2016). For char-
based encoding (of either tokens or morphemes)
we experiment with CharLSTM, CharCNN, ou
NoChar, c'est, no character embedding at all.
We pre-trained all token-based or morpheme-
based embeddings on the Hebrew Wikipedia
dump of Goldberg (2014). For morpheme-based
embeddings, we decompose the input using More
et autres. (2019), and use the morphological seg-
ments as the embedding units.13 We compare
13Embeddings and Wikipedia corpus also available in:
12Using the NCRF++ suite of Yang and Zhang (2018).
https://github.com/OnlpLab/NEMO.
915
Parameter
Value
Parameter
Optimizer
*Batch Size
LR decay
Epochs
Bi-LSTM layers
*Word Emb Dim
Word Hidden Dim
SGD *LR (token-single)
*LR (token-multi)
*LR (morpheme)
Dropout
*CharCNN window
Char Emb dim
*Char Hidden Dim
8
0.05
200
2
300
200
Value
0.01
0.005
0.01
0.5
7
30
70
Tableau 3: Summary of hyper-parameter tuning. Le
* indicates divergence from the NCRF++ proposed
setup and empirical findings (Yang and Zhang,
2018).
GloVe (Pennington et al., 2014) and fastText
(Bojanowski et al., 2017). We hypothesize that
since FastText uses sub-string information,
it
will be more useful for analyzing OOVs.
Hyper Parameters Following Reimers and
Gurevych (2017) and Yang et al. (2018), nous
performed hyper-parameter tuning for each of our
model variants. We performed hyper-parameter
tuning on the dev set in a number of rounds of ran-
dom search, independently on every input/output
and char-embedding architecture. Tableau 3 shows
our selected hyper-parameters.14 The Char CNN
window size is particularly interesting as it was
not treated as a hyper-parameter in Reimers and
Gurevych (2017), Yang et al. (2018). Cependant,
given the token-internal complexity in MRLs we
conjecture that the window size over characters
might make a crucial effect. In our experiments
we found that a larger window (7) increased the
performance. For MRLs, further research into
this hyper-parameter might be of interest.
Evaluation Standard NER studies typically in-
voke the CoNLL evaluation script that anchors
NEs in token positions (Tjong Kim Sang, 2003).
Cependant, it is inadequate for our purposes because
we want to compare entities across token-based
vs. morpheme-based settings. To this end, we use
a revised evaluation procedure, which anchors the
entity in its form rather than its index. Specifi-
cally, we report F1 scores on strict, exact-match
14A few interesting empirical observations diverging from
those of Reimers and Gurevych (2017) and Yang et al. (2018)
are worth mentioning. We found that a lower Learning Rate
than the one recommended by Yang et al. (2018) (0.015),
led to better results and less occurrences of divergence. Nous
further found that raising the number of Epochs from 100 à
200 did not result in over-fitting, and significantly improved
NER results. We used for evaluation the weights from the
best epoch.
of the surface forms of the entity mentions. That
est, the gold and predicted NE spans must exactly
match in their form, boundaries, and entity type.
In all experiments, we report both token-level
F-scores and morpheme-level F-scores, for all
models.
• Token-Level Evaluation. Pour
the sake
of backwards compatibility with previous
work on Hebrew NER, we first define
token-level evaluation. For token-single this
is a straightforward calculation of F1 against
gold spans. For token-multi and morpheme,
we need to map the predicted label sequence
of that token to a single label, and we do so
using linguistically informed rules we devise
(as elaborated in Appendix A).15
• Morpheme-Level Evaluation. Our ultimate
goal is to obtain precise boundaries of the
NEs. Ainsi, our main metric evaluates NEs
against the gold morphological boundaries.
For morpheme and token-single models, ce
is a straightforward F1 calculation against
gold spans. Note for token-single we are ex-
pected to pay a price for boundary mismatch.
For token-multi, we know the number and
order of labels, so we align the labels in the
multi-label of the token with the morphemes
in its morphological decomposition.16
For all experiments and metrics, we report mean
and confidence interval (0.95) over ten runs.
Input-Output Scenarios We experiment with
two kinds of input settings: token-based, where the
input consists of the sequence of space-delimited
tokens, and morpheme-based, where the input
consists of morphological segments. Pour
le
morpheme input, there are three input variants:
(je) Morph-gold: where the morphological se-
quence is produced by an expert (idealistic).
(ii) Morph-standard: where the morphologi-
cal sequence is produced by a standard
segmentation-first pipeline (realistic).
15In the morpheme case we might encounter ‘‘illegal’’
label sequences in case of a prediction error. We employ
similar linguistically informed heuristics to recover from that
(see Appendix A).
16In case of a misalignment (in the number of morphemes
and labels) we match the label-morpheme pairs from the final
one backwards, and pad unpaired morphemes with O labels.
916
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 4: Token-level evaluation on dev w/ gold
segmentation. CharCNN for morph, CharLSTM for
tok.
Chiffre 5: Morph-level evaluation on dev w/ gold
segmentation. CharCNN for morph, CharLSTM for
tok.
(iii) Morph-hybrid: where the morphological se-
quence is produced by the hybrid architecture
we propose (realistic).
In the token-multi case we can perform
morpheme-based evaluation by aligning individ-
ual labels in the multi-label with the morpheme
sequence of the respective token. Again we have
three options as to which morphemes to use:
(je) Tok-multi-gold: The multi-label is aligned
with morphemes produced by an expert
(idealistic).
(ii) Tok-multi-standard: The multi-label
est
aligned with morphemes produced by a
standard pipeline (realistic).
(iii) Tok-multi-hybrid: The multi-label is aligned
with morphemes produced by the hybrid
architecture we propose (realistic).
Pipeline Scenarios Assume an input sentence x.
In the Standard pipeline we use YAP,17 the cur-
rent state-of-the-art morpho-syntactic parser for
Hebrew (More et al., 2019), for the predicted
segmentation M = M D(M A(X)). In the Hybrid
pipeline, we use YAP to first generate complete
morphological lattices M A(X). Alors, to obtain
M A(X) (cid:2) N ER(X) we omit lattice paths where
the number of morphemes in the token decompo-
sition does not conform with the number of labels
in the multi-label of NERtoken-multi(X). Alors, nous
apply YAP to obtain M D(M A(X) (cid:2) N ER(X))
17For other languages this may be done using models for
canonical segmentation as in (Kann et al., 2016).
on the constrained lattice. In predicted morphol-
ogy scenarios (either Standard or Hybrid), we use
the same model weights as trained on the gold seg-
ments, but feed predicted morphemes as input.18
6 Results
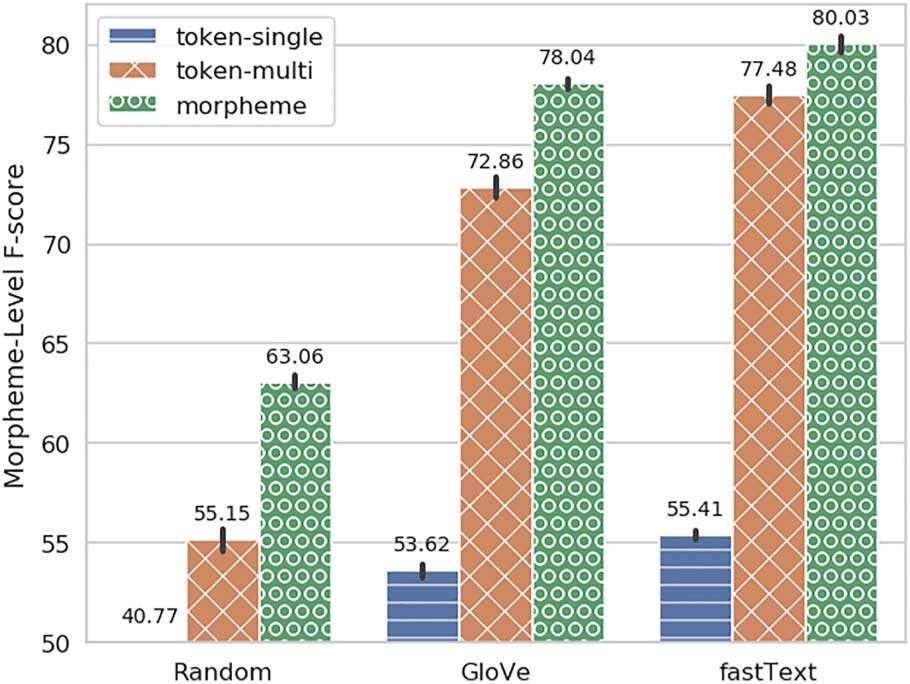
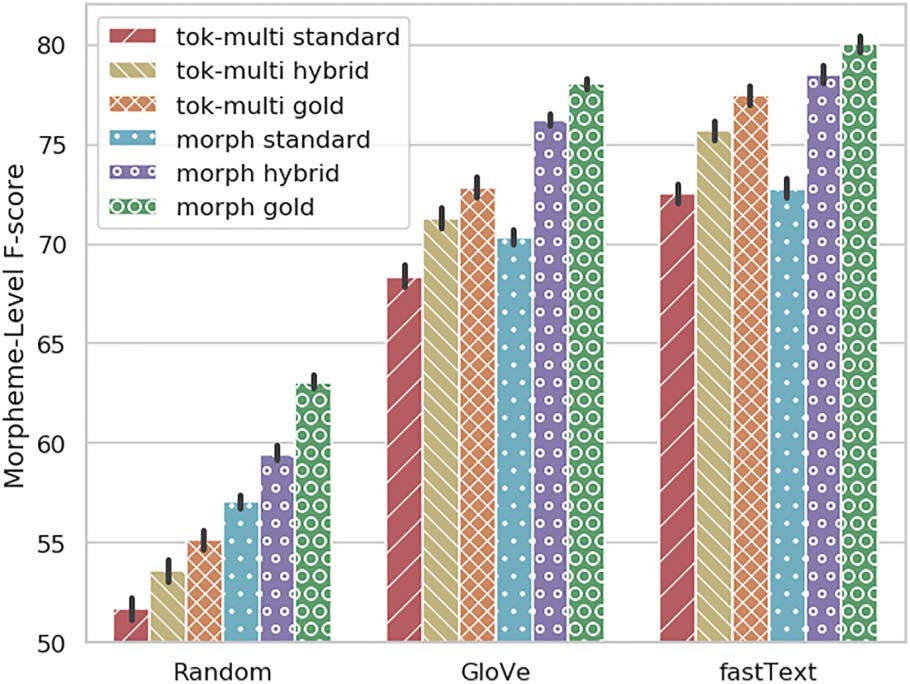
6.1 The Units: Tokens vs. Morphemes
Chiffre 4 shows the token-level evaluation for the
different model variants we defined. We see that
morpheme models perform significantly better
than the token-single and token-multi variants. Dans-
terestingly, explicit modeling of morphemes leads
to better NER performance even when evaluated
against token-level boundaries. As expected, le
performance gaps between variants are smaller
with fastText
than they are with embeddings
that are unaware of characters (GloVe) or with
no pre-training at all. We further pursue this in
Section 6.3.
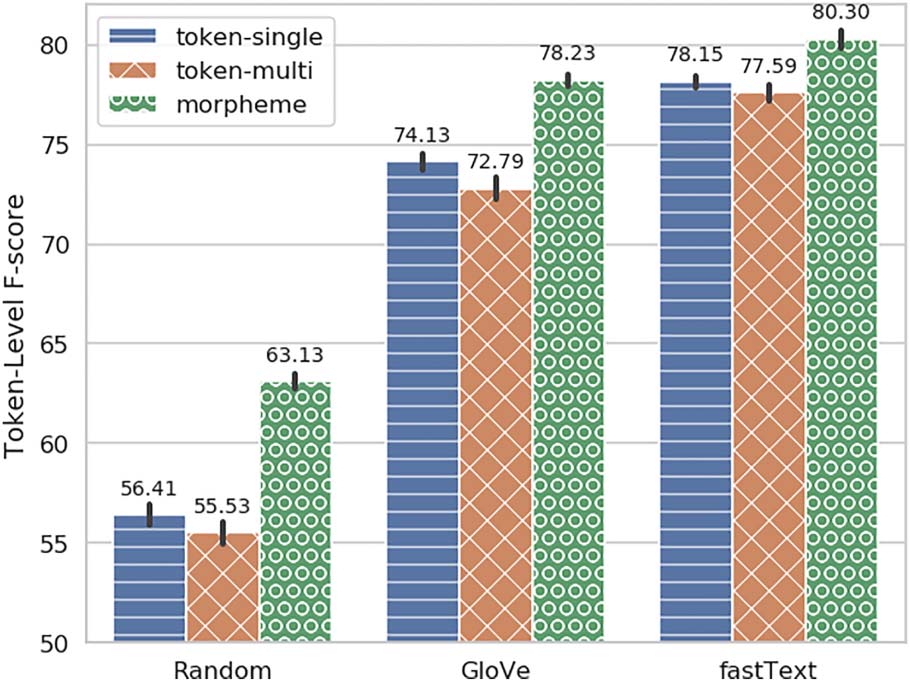
Chiffre 5 shows the morpheme-level evaluation
for the same model variants as in Figure 4. Le
most obvious trend here is the drop in the perfor-
mance of the token-single model. Ceci est attendu,
reflecting the inadequacy of token boundaries for
identifying accurate boundaries for NER. Inter-
estingly, morpheme and token-multi models keep
a similar level of performance as in token-level
evaluation, only slightly lower. Their perfor-
mance gap is also maintained, with morpheme
performing better than token-multi. An obvious
18We do not re-train the morpheme models with predicted
segmentation, which might achieve better performance (par exemple.,
jackknifing). We leave this for future work.
917
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 6: Token-level evaluation in realistic scenarios
on dev, comparing gold, standard, and hybrid mor-
phology. CharCNN for morph, CharLSTM for tok. Re-
sults for Gold, token-single and token-multi are taken
from Figure 4.
Chiffre 7: Morph-level evaluation in realistic scenarios
on dev, comparing gold, standard, and hybrid mor-
phology. CharCNN for morph, CharLSTM for tok. Re-
sults for Gold, token-single and token-multi are taken
from Figure 5.
caveat is that these results are obtained with gold
morphology. What happens in realistic scenarios?
6.2 L'architecture: Pipeline vs. Hybrid
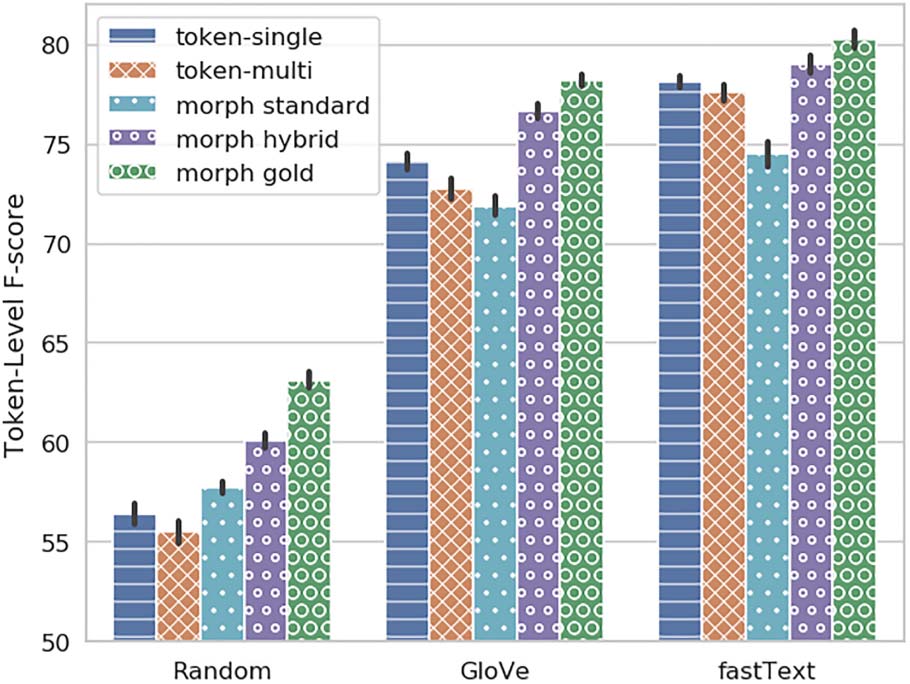
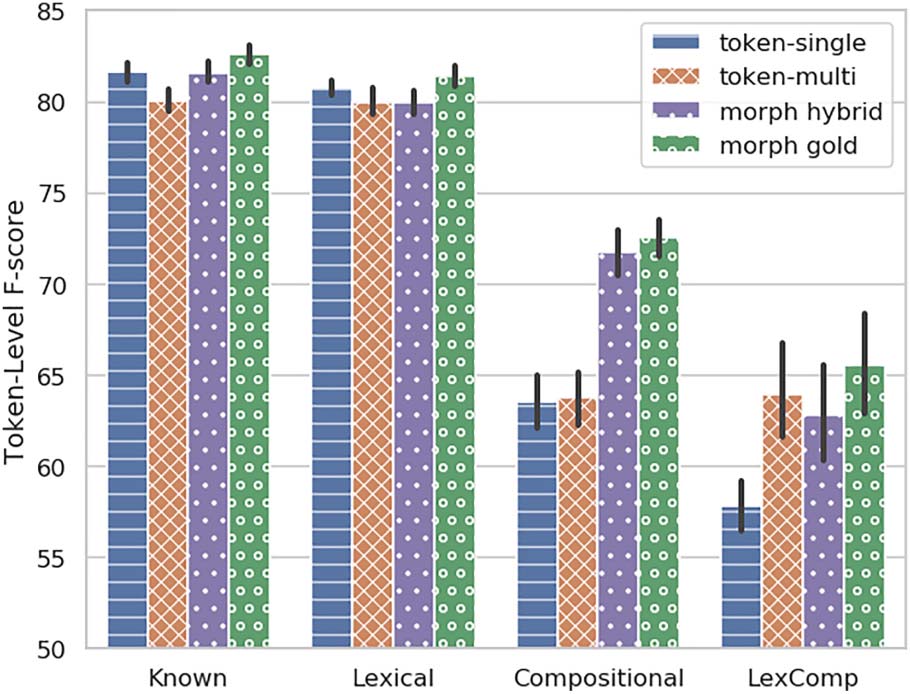
Chiffre 6 shows
the token-level evaluation
results in realistic scenarios. We first observe
a significant drop for morpheme models when
Standard predicted segmentation is introduced
instead of gold. This means that MD errors are
indeed detrimental for the downstream task, dans
a non-negligible rate. Deuxième, we observe that
much of this performance gap is recovered with
the Hybrid pipeline. It is noteworthy that while
morph hybrid lags behind morph gold, it is still
than token-based models,
consistently better
token-single and token-multi.
Chiffre 7 shows morpheme-level evaluation re-
sults for the same scenarios as in Table 6. All
trends from the token-level evaluation persist,
including a drop for all models with predicted seg-
mentation relative to gold, with the hybrid variant
recovering much of the gap. Again morph gold
outperforms token-multi, but morph hybrid shows
great advantages over all tok-multi variants. Ce
performance gap between morph (gold or hybrid)
and tok-multi indicates that explicit morphological
modeling is indeed crucial for accurate NER.
6.3 Morphologically Aware OOV Evaluation
As discussed in Section 2, morphological compo-
sition introduces an extremely sparse word-level
‘‘long-tail’’ in MRLs. In order to gauge this phe-
nomenon and its effects on NER performance,
we categorize unseen, out-of-training-vocabulary
(OOTV) mentions into 3 catégories:
• Lexical: Unknown mentions caused by an
unknown token which consists of a single
morpheme. This is a strictly lexical unknown
with no morphological composition (most
English unknowns are in this category).
• Compositional: Unknown mentions caused
by an unknown token which consists of mul-
tiple known morphemes. These are unknowns
introduced strictly by morphological compo-
sition, with no lexical unknowns.
• LexComp: Unknown mentions caused by an
unknown token consisting of multiple mor-
phemes, of which (at least) one morpheme
was not seen during training. Dans de tels cas,
both unknown morphological composition
and lexical unknowns are involved.
We group NEs based on these categories, et
evaluate each group separately. We consider men-
tions that do not fall into any category as Known.
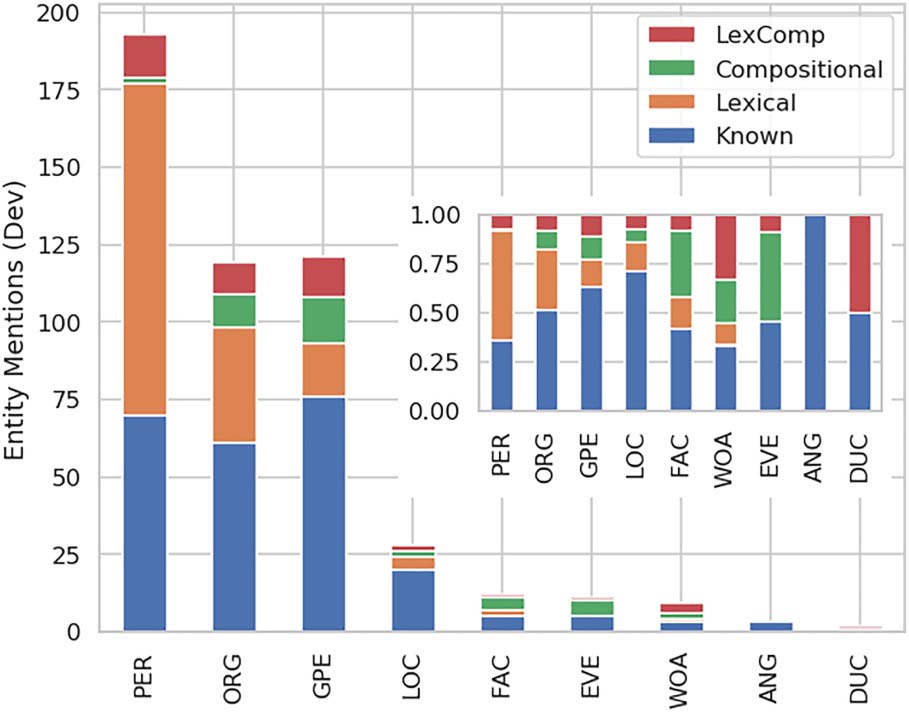
Chiffre 8 shows the distributions of entity men-
tions in the dev set by entity type and OOTV
catégorie. OOTV categories that involve compo-
sition (Comp and LexComp) are spread across all
categories but one, and in some they even make
up more than half of all mentions.
918
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 8: Entity mention counts and ratio by category
and OOTV category, for dev set.
Chiffre 9: Token-level evaluation on dev by OOTV
catégorie. Using fastText and CharLSTM.
Chiffre 9 shows token-level evaluation19 with
fastText embeddings, grouped by OOTV type. Nous
first observe that indeed unknown NEs that are due
to morphological composition (Comp and Lex-
Comp) proved the most challenging for all models.
We also find that in strictly Compositional OOTV
mentions, morpheme-based models exhibit their
most significant performance advantage, support-
ing the hypothesis that explicit morphology helps
to generalize. We finally observe that token-multi
models perform better than token-single mod-
els for these NEs (in contrast with the trend for
non-compositional NEs). This corroborates the
hypothesis that even partial modeling of morphol-
ogy (as in token-multi compared to token-single) est
better than none, leading to better generalization.
String-level vs. Character-level Embeddings
To further understand the generalization capacity
of different modeling alternatives in MRLs,
we probe into the interplay of string-based and
char-based embeddings in treating OOTV NEs.
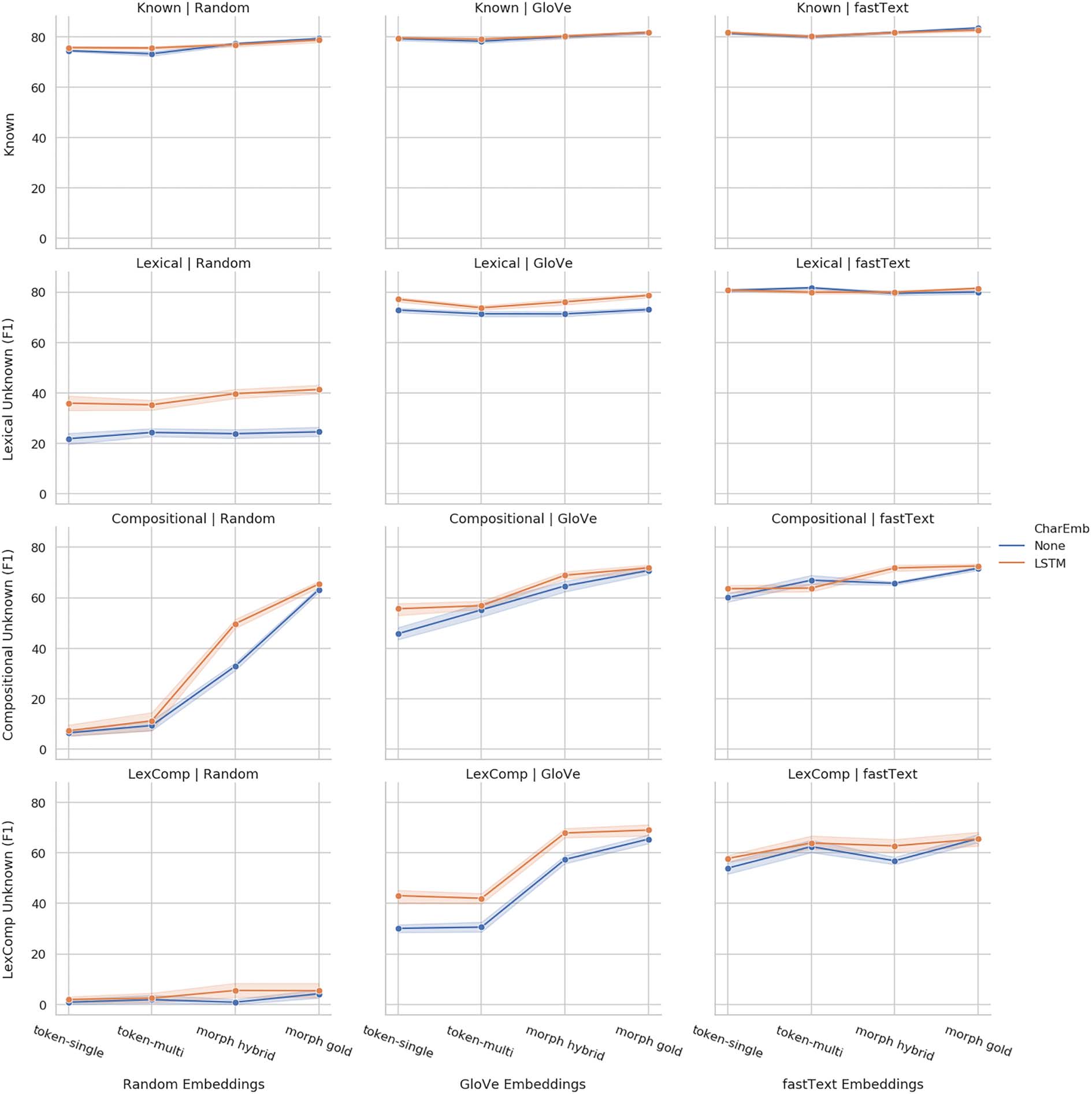
Chiffre 10 presents 12 plots, each of which
presents the level of performance (y-axes) for all
models (x-axes). Token-based models are on the
left of each x-axis, morpheme-based are on the
droite. We plot results with and without character
embeddings,20 in orange and blue, respectivement.
19This section focuses on token-level evaluation, which is
a permissive evaluation metric, allowing us to compare the
models on a more level playing field, where all models (dans-
cluding token-single) have an equal opportunity to perform.
20For brevity we only show char LSTM (vs. no char
there was no significant difference with
representation),
CNN.
The plots are organized in a large grid, avec le
type of NE on the y-axes (Known, Lex, Comp,
LexComp), and the type of pre-training on the
x-axes (No pre-training, GloVe, fastText).
At the top-most row, plotting the accuracy for
Known NEs, we see a high level of performance
for all pre-training methods, with not much
differences between the type of pre-training, avec
or without
the character embeddings. Mobile
further down to the row of Lexical unseen NEs,
char-based representations lead to significant
advantages when we assume no pre-training, mais
with GloVe pre-training the performance substan-
tially increases, and with fastText the differences
in performance with/without char-embeddings al-
most entirely diminish, indicating the char-based
embeddings are somewhat redundant in this case.
The two lower rows in the large grid show the
performance for Comp and LexComp unseen NEs,
which are ubiquitous in MRLs. For Compositional
NEs, pre-training closes only part of the gap be-
tween token-based and morpheme-based models.
Adding char-based representations indeed helps
the token-based models, but crucially does not
close the gap with the morpheme-based variants.
Enfin, for LexComp NEs at the lowest row,
we again see that adding GloVe pre-training and
char-based embeddings does not close the gap
with morpheme-based models, indicating that not
all morphological information is captured by these
vectors. For fastText with char-based embed-
dings the gap between token-multi and mor-
pheme greatly diminishes, but is still well above
token-single. This suggests biasing the model to
919
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 10: Token-level evaluation on dev for different OOTV types, char- and word-embeddings.
learn about morphology (either via multi-labels
or by incorporating morphological boundaries)
has advantages for analysing OOTV entities, être-
yond the contribution of char-based embeddings
alone.
All in all, the biggest advantage of morpheme-
based models over token-based models is their
ability to generalize from observed tokens to
composition-related OOTV (Comp/LexComp).
character-based embeddings do help
While
token-based models generalize,
the contribu-
tion of modeling morphology is indispensable,
above and beyond the contribution of char-based
embeddings.
6.4 Setting in the Greater Context
Test Set Results Table 4 confirms our best
results on the Test set.The trends are kept, though
results on Test are lower than on Dev. The morph
gold scenario still provides an upperbound of the
performance, but it is not realistic. For the realistic
scenarios, morph hybrid generally outperforms all
other alternatives. The only divergence is that in
token-level evaluation, token-multi performs on a
par with morph hybrid on the Test set.
Results on MD Tasks. While the Hybrid pipe-
line achieves superior performance on NER, it
also improves the state-of-the-art on other tasks
920
Model
Eval
Morph- morph gold
Level
dev
80.03 ± 0.4
78.51 ± 0.5
morph hybrid
72.79 ± 0.5
morph standard
token-multi hybrid 75.70 ± 0.5
test
79.10 ± 0.6
77.11 ± 0.7
69.52 ± 0.6
74.64 ± 0.3
Token- morph gold
Level
morph hybrid
morph standard
token-multi
token-single
79.28 ± 0.6
80.30 ± 0.5
77.64 ± 0.7
79.04 ± 0.5
73.53 ± 0.8
74.52 ± 0.7
77.59 ± 0.4
77.75 ± 0.3
78.15 ± 0.3 77.15 ± 0.6
Tableau 4: Test vs. dev: Results with fastText for
all Models. morph-gold presents
an ideal
upper-bound.
in the pipeline. Tableau 5 shows the Seg+POS re-
sults of our Hybrid pipeline scenario, compared
with the Standard pipeline which replicates the
pipeline of More et al. (2019). We use the me-
trics defined by More et al. (2019). We show sub-
stantial improvements for the Hybrid pipeline
over the results of More et al. (2019), and also
outperforming the Test results of Seker and
Tsarfaty (2020).
Comparison with Prior Art. Tableau 6 presents
our results on the Hebrew NER corpus of Ben-
Mordecai (2005) compared to their model, lequel
uses a hand-crafted feature-engineered MEMM
with regular-expression rule-based enhancements
and an entity lexicon. Like Ben-Mordecai (2005)
we performed three 75%-25% random train/test
splits, and used the same seven NE cate-
gories (PER,LOC,ORG,TIME,DATE,PERCENT,MONEY).
We trained a token-single model on the original
space-delimited tokens and a morpheme model on
automatically segmented morphemes we obtained
using our best segmentation model (Hybrid MD
on our trained token-multi model, as in Table 5).
Since their annotation includes only token-level
boundaries, all of the results we report conform
with token-level evaluation.
Tableau 6 presents the results of these exper-
iments. Both models significantly outperform
the previous state-of-the-art by Ben-Mordecai
(2005), setting a new performance bar on this
earlier benchmark. De plus, we again observe
an empirical advantage when explicitly modeling
morphemes, even with the automatic noisy seg-
mentation that is used for the morpheme-based
entraînement.
921
dev Standard (More et al., 2019)
Ptr-Network (Seker and Tsarfaty, 2020)
Hybrid (This work)
test Standard (More et al., 2019)
Ptr-Network (Seker and Tsarfaty, 2020)
Hybrid (This work)
Seg+POS
92.36
93.90
93.12
89.08
90.49
90.89
Tableau 5: Morphological segmentation & POS
scores.
Precision Recall F1
84.54
Ben-Mordecai (2005)
MEMM+HMM+REGEX
86.84
This work
±0.5
token-single+FT+CharLSTM
86.93
This work
morph-Hybrid+FT+CharLSTM ±0.6
74.31 79.10
84.71
82.6
±0.9 ±0.5
83.59 85.22
±0.8 ±0.5
Tableau 6: NER comparison with Ben-Mordecai
(2005).
7 Discussion: Joint Modeling
Alternatives and Future Work
study provides
The present
the motivation
and the necessary foundations for comparing
morpheme-based and token-based modeling for
NER. While our findings clearly demonstrate
the advantages of morpheme-based modeling for
NER in a morphologically rich language, it is
clear that our proposed Hybrid architecture is not
the only modeling alternative for linking NER
and morphology.
Par exemple, a previous study by G¨ung¨or et al.
(2018) addresses joint neural modeling of mor-
phological segmentation and NER labeling, pro-
posing a multi-task learning approach for joint
MD and NER in Turkish. They employ separate
Bi-LSTM networks for the MD and NER tasks,
with a shared loss to allow for joint learning. Their
results indicate improved NER performance, avec
no improvement in the MD results. Contrary to
our proposal, they view MD and NER as distinct
tasks, assuming a single NER label per token, et
not providing disambiguated morpheme-level
boundaries for the NER task. Plus généralement,
they test only token-based NER labeling and
do not attend to the question of input/output
granularity in their models.
A different approach for joint NER and mor-
phology is jointly predicting the segmentation and
labels for each token in the input stream. This is
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
the approach taken, par exemple, by the lattice-
based Pointer-Network of Seker and Tsarfaty
(2020). As shown in Table 5, their results for
morphological segmentation and POS tagging are
on a par with our reported results and, at least in
principle, it should be possible to extend the Seker
and Tsarfaty (2020) approach to yield also NER
prédictions.
Cependant, our preliminary experiments with a
lattice-based Pointer-network for token segmen-
tation and NER labeling shows that this is not a
straightforward task. Contrary to POS tags, lequel
are constrained by the MA, every NER label can
potentially go with any segment, and this leads
to a combinatorial explosion of the search space
represented by the lattice. Par conséquent, the NER pre-
dictions are brittle to learn, and the complexity of
the resulting model is computationally prohibitive.
A different approach to joint sequence segmen-
tation and labeling can be applying the neural
model directly on the character-sequence of the
input stream. Such an approach is for instance
the char-based labeling as segmentation setup
proposed by Shao et al. (2017). Shao et al. use a
character-based Bi-RNN-CRF to output a single
label-per-char which indicates both word bound-
et (using BIES sequence labels) and the POS
tags. This method is also used in their universal
segmentation paper, (Shao et al., 2018). Cependant,
as seen in the results of Shao et al. (2018),
char-based labeling for
segmenting Semitic
languages lags far behind all other languages,
precisely because morphological boundaries are
not explicit in the character sequences.
Additional proposals are those of Kong et al.
(2015); Kemos et al. (2019). D'abord, Kong et al.
(2015) proposed to solve, Par exemple, Chinese
segmentation and POS tagging using dynamic
programming with neural encoding, by using a
Bi-LSTM to encode the character input, and then
feeding it to a semi-Markov CRF to obtain prob-
abilities for the different segmentation options.
Kemos et al. (2019) propose an approach similar
to Kong et al. (2015) for joint segmentation
and tagging but add convolution layers on top
of the Bi-LSTM encodings to obtain segment
features hierarchically and then feed them to the
semi-Markov CRF.
Preliminary experiments we conducted confirm
that char-based joint segmentation and NER label-
ing for Hebrew, either using char-based labeling
or a seq2seq architecture, still lags behind our
reported results. We conjecture that this is due
to the complex morpho-phonological and ortho-
graphic processed in Semitic languages. Going
into char-based modeling nuances and offering a
sound joint solution for a language like Hebrew
is an important matter that merits its own in-
vestigation. Such work is feasible now given the
new corpus, cependant, it is out of the scope of the
current study.
All in all, the design of sophisticated joint
modeling strategies for morpheme-based NER
poses fascinating questions—for which our work
provides a solid foundation (data, protocols,
metrics, strong baselines). More work is needed
for investigating joint modeling of NER and
morphology, in the directions portrayed in this
section, yet it is beyond the scope of this paper,
and we leave this investigation for future work.
Enfin, while the joint approach is appealing,
we argue that the elegance of our Hybrid solution
is precisely in providing a clear and well-defined
interface between MD and NER through which
the two tasks can interact, while still keeping the
distinct models simple, robust, and efficiently
trainable. It also has the advantage of allowing
us to seamlessly integrate sequence labelling
with any lattice-based MA, in a plug-and-play
language-agnostic fashion, towards obtaining fur-
ther advantages on both of these tasks.
8 Conclusion
This work addresses the modeling challenges of
neural NER in MRLs. We deliver a parallel token-
vs-morpheme NER corpus for Modern Hebrew,
that allows one to assess NER modeling strate-
gies in morphologically rich-and-ambiguous en-
vironments. Our experiments show that while
NER benefits from morphological decomposition,
downstream results are sensitive to segmentation
errors. We thus propose a Hybrid architecture
in which NER precedes and prunes the mor-
phological decomposition. This approach greatly
outperforms a Standard
pipeline in realistic
(non-gold) scenarios. Our analysis further shows
that morpheme-based models better recognize
OOVs that result from morphological composi-
tion. All in all we deliver new state-of-the-art re-
sults for Hebrew NER and MD, along with a novel
benchmark, to encourage further investigation into
the interaction between NER and morphology.
922
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Remerciements
We are grateful to the BIU-NLP lab members as
well as 6 anonymous reviewers for their insightful
remarks. We further thank Daphna Amit and Zef
Segal for their meticulous annotation and profound
discussions. This research is funded by an ISF
Individual Grant (1739/26) and an ERC Starting
Grant (677352), for which we are grateful.
Les références
Bea Alex, Claire Grover, Rongzhou Shen, et
Mijail Kabadjov. 2010. Agile corpus annota-
tion in practice: An overview of manual and
automatic annotation of CVs. In Proceedings
of the Fourth Linguistic Annotation Workshop,
pages 29–37, Uppsala, Sweden. Association for
Computational Linguistics.
Naama Ben-Mordecai. 2005. Hebrew Named En-
tity Recognition. Master’s thesis, Department
of Computer Science, Ben-Gurion University.
https://doi.org/10.1007/978-3-540
-70939-8 13
Yassine Benajiba, Paolo Rosso, and Jos´e Miguel
Bened´ıRuiz. 2007. Anersys: An Arabic named
entity recognition system based on maximum
In Computational Linguistics and
entropy.
Intelligent Text Processing, pages 143–153,
Berlin, Heidelberg. Springer Berlin Heidelberg.
Darina Benikova, Chris Biemann, and Marc
Reznicek. 2014. NoSta-D named entity anno-
tation for German: Guidelines and dataset. Dans
Proceedings of the Ninth International Confer-
ence on Language Resources and Evaluation
(LREC-2014), pages 2524–2531, Reykjavik,
Iceland. European Languages Resources Asso-
ciation (ELRA).
Piotr Bojanowski, Edouard Grave, Armand
Joulin, and Tomas Mikolov. 2017. Enriching
word vectors with subword information. Trans-
actions of the Association for Computational
Linguistics, 5:135–146. https://doi.org
/10.1162/tacl a 00051
N. Chinchor, E. Brun, L. Ferro, and P. Robinson.
1999. Named entity recognition task definition.
The MITRE Corporation and SAIC.
Jason P. C. Chiu and Eric Nichols. 2015.
Named entity recognition with bidirectional
LSTM-CNNS. CoRR, abs/1511.08308.
Bernard Comrie, Martin Haspelmath,
et
Balthasar Bickel. 2008. The Leipzig glossing
rules: Conventions for interlinear morpheme-
by-morpheme glosses. Department of Linguis-
tics of the Max Planck Institute for Evolutionary
Anthropology & the Department of Linguistics
of the University of Leipzig.
Paula Czarnowska, Sebastian Ruder, Edouard
Grave, Ryan Cotterell, and Ann Copestake.
2019. Don’t forget the long tail! A comprehen-
sive analysis of morphological generalization
lexicon induction. In Proceed-
in bilingual
ings of the 2019 Conference on Empirical Meth-
ods in Natural Language Processing and the
9th International Joint Conference on Natu-
ral Language Processing (EMNLP-IJCNLP),
pages 974–983, Hong Kong, Chine. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/D19-1090
Kareem Darwish. 2013. Named entity recogni-
tion using cross-lingual resources: Arabic as
un exemple. In Proceedings of the 51st An-
nual Meeting of the Association for Computa-
tional Linguistics (Volume 1: Long Papers),
pages 1558–1567, Sofia, Bulgaria. Association
for Computational Linguistics.
Leon Derczynski, Eric Nichols, Marieke van
Erp, and Nut Limsopatham. 2017. Results
of the WNUT2017 shared task on novel and
emerging entity recognition. In Proceedings
of the 3rd Workshop on Noisy User-generated
Texte, pages 140–147, Copenhagen, Denmark.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/W17
-4418
Jenny Rose Finkel and Christopher D. Manning.
2009. Nested named entity recognition. Dans
Actes du 2009 Conference on Em-
pirical Methods in Natural Language Pro-
cessation: Volume 1 – Volume 1, EMNLP ’09,
pages 141–150, Stroudsburg, Pennsylvanie, Etats-Unis.
Association for Computational Linguistics.
https://doi.org/10.3115/1699510
.1699529
923
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Kar¨en Fort, Maud Ehrmann,
and Adeline
Nazarenko. 2009. Towards a methodology
for named entities annotation. In Proceedings
of the Third Linguistic Annotation Workshop
(LAW III), pages 142–145, Suntec, Singapore.
Association for Computational Linguistics.
https://doi.org/10.3115/1698381
.1698406
Yoav Goldberg. 2014. Hebrew Wikipedia depen-
dency parsed corpus, v.1.0.
Yoav Goldberg and Reut Tsarfaty. 2008. A sin-
gle generative model for joint morphological
segmentation and syntactic parsing. En Pro-
ceedings of ACL-08: HLT, pages 371–379,
Columbus, Ohio. Association for Computa-
tional Linguistics.
Spence Green and Christopher D. Manning. 2010.
Better Arabic parsing: Baselines, evaluations,
and analysis. In Proceedings of the 23rd In-
ternational Conference on Computational Lin-
guistics (Coling 2010), pages 394–402, Beijing,
Chine. Coling 2010 Organizing Committee.
Onur G¨ung¨or, Suzan ¨Usk¨udarli, and Tunga
G¨ung¨or. 2018. Improving named entity recog-
nition by jointly learning to disambiguate mor-
phological tags. CoRR, abs/1807.06683.
Nizar Habash and Owen Rambow. 2005. Arabic
tokenization, part-of-speech tagging and mor-
phological disambiguation in one fell swoop.
In Proceedings of the 43rd Annual Meeting of
the Association for Computational Linguistics
(ACL’05), pages 573–580, Ann-Arbor, Michi-
gan. Association for Computational Linguistics.
https://doi.org/10.3115/1219840
.1219911
Zhiheng Huang, Wei Xu, and Kai Yu. 2015.
Bidirectional LSTM-CRF models for sequence
tagging. CoRR, abs/1508.01991.
Katharina Kann, Ryan Cotterell, and Hinrich
Sch¨utze. 2016. Neural morphological analy-
sis: Encoding-decoding canonical segments. Dans
Actes du 2016 Conference on Em-
pirical Methods in Natural Language Process-
ing, pages 961–967, Austin, Texas. Association
for Computational Linguistics.
Apostolos Kemos, Heike Adel, and Hinrich
Sch¨utze. 2019. Neural semi-Markov conditional
pour
robust
character-based
random fields
In Proceedings of
part-of-speech tagging.
le 2019 Conference of the North American
Chapter of
the Association for Computa-
tional Linguistics: Human Language Tech-
nologies, Volume 1 (Long and Short Papers),
pages 2736–2743, Minneapolis, Minnesota.
Association for Computational Linguistics.
Stav Klein and Reut Tsarfaty. 2020. Getting the
##life out of living: How adequate are word-
pieces for modelling complex morphology? Dans
Proceedings of the 17th SIGMORPHON Work-
shop on Computational Research in Phonetics,
Phonology, and Morphology, pages 204–209,
En ligne. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2020.sigmorphon-1.24
Lingpeng Kong, Chris Dyer, and Noah A Smith.
2015. Segmental recurrent neural networks.
arXiv preprint arXiv:1511.06018.
Dilek K¨uc¸ ¨uk and Fazli Can. 2019. A tweet dataset
annotated for named entity recognition and
stance detection. CoRR, abs/1901.04787.
Guillaume Lample, Miguel Ballesteros, Sandeep
Subramanien, Kazuya Kawakami, and Chris
Dyer. 2016. Neural architectures for named
entity recognition. CoRR, abs/1603.01360.
LDC. 2008. ACE (automatic content extraction)
english annotation guidelines for entities ver-
sion 6.6.
Yi Luan, Luheng He, Mari Ostendorf, et
Hannaneh Hajishirzi. 2018. Multi-task identi-
fication of entities, relations, and coreference
for scientific knowledge graph construction.
le 2018 Conference on
In Proceedings of
Empirical Methods in Natural Language Pro-
cessation, pages 3219–3232, Brussels, Belgium.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/D18
-1360
Xuezhe Ma and Eduard H. Hovy. 2016. End-to-
labeling via bi-directional
end sequence
LSTM-CNNS-CRF. CoRR, abs/1603.01354.
Behrang Mohit, Nathan Schneider, Rishav
Bhowmick, Kemal Oflazer, and Noah A. Forgeron.
2012. Recall-oriented learning of named enti-
924
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
ties in Arabic Wikipedia. In Proceedings of the
13th Conference of the European Chapter of
the Association for Computational Linguistics,
pages 162–173, Avignon, France. Association
for Computational Linguistics.
Amir More, Amit Seker, Victoria Basmova, et
Reut Tsarfaty. 2019. Joint
transition-based
models for morpho-syntactic parsing: Parsing
strategies for MRLs and a case study from
modern Hebrew. Transactions of the Associa-
tion for Computational Linguistics, 7:33–48.
https://doi.org/10.1162/tacl a
00253
Joakim Nivre, Johan Hall, Sandra K¨ubler, Ryan
McDonald's, Jens Nilsson, Sebastian Riedel, et
Deniz Yuret. 2007. The CoNLL 2007 shared
task on dependency parsing. In Proceedings
de
le 2007 Joint Conference on Empiri-
cal Methods in Natural Language Processing
and Computational Natural Language Learn-
ing (EMNLP-CoNLL), pages 915–932, Prague,
Czech Republic. Association for Computational
Linguistics.
Jeffrey
Socher,
Pennington, Richard
et
Christopher Manning. 2014. GloVe: Global
vectors for word representation. In Proceed-
ings of
le 2014 Conference on Empirical
Methods in Natural Language Processing
(EMNLP), pages 532–1543, Doha, Qatar.
Association for Computational Linguistics.
https://doi.org/10.3115/v1/D14
-1162
Barbara Plank, Dirk Hovy, and Anders Søgaard.
2014. Learning part-of-speech taggers with
inter-annotator agreement loss. In Proceedings
of the 14th Conference of the European Chap-
ter of the Association for Computational Lin-
guistics, pages 742–751, Gothenburg, Sweden.
Association for Computational Linguistics.
h t t p s : / / d o i . o r g / 1 0 . 3 1 1 5 / v 1
/E14-1078
Sameer Pradhan, Alessandro Moschitti, Nianwen
Xue, Olga Uryupina, and Yuchen Zhang. 2012.
CoNLL-2012 shared task: Modeling multilin-
gual unrestricted coreference in OntoNotes. Dans
Joint Conference on EMNLP and CoNLL –
Shared Task, pages 1–40, Jeju Island, Korea.
Association for Computational Linguistics.
925
Sampo Pyysalo, Filip Ginter, Juho Heimonen,
Jari Bj¨orne, Jorma Boberg, Jouni J¨arvinen, et
Tapio Salakoski. 2007. Bioinfer: A corpus for
information extraction in the biomedical do-
main. BMC bioinformatics, 8(1):50. https://
doi.org/10.1186/1471-2105-8-50
Lev Ratinov and Dan Roth. 2009. Design chal-
lenges and misconceptions in named entity
reconnaissance. In Proceedings of the Thirteenth
Conference on Computational Natural Lan-
guage Learning (CoNLL-2009), pages 147–155,
Boulder, Colorado. Association for Computa-
tional Linguistics. https://est ce que je.org/10
.3115/1596374.1596399
Nils Reimers and Iryna Gurevych. 2017. Optimal
hyperparameters for deep LSTM-networks for
sequence labeling tasks. CoRR, abs/1707.
06799.
Djam´e Seddah, Reut Tsarfaty, Sandra K¨ubler,
Marie Candito, Jinho D. Choi, Rich´ard Farkas,
Jennifer Foster, Iakes Goenaga, Koldo Gojenola
Galletebeitia, Yoav Goldberg, Spence Green,
Nizar Habash, Marco Kuhlmann, Wolfgang
Maier, Joakim Nivre, Adam Przepi´orkowski,
Ryan Roth, Wolfgang Seeker, Yannick Versley,
Veronika Vincze, Marcin Woli´nski, Alina
Wr´oblewska, and Eric Villemonte de la
Clergerie. 2013. Overview of the SPMRL 2013
shared task: A cross-framework evaluation of
parsing morphologically rich languages. En Pro-
ceedings of the Fourth Workshop on Statistical
Parsing of Morphologically-Rich Languages,
pages 146–182, Seattle, Washington, Etats-Unis.
Association for Computational Linguistics.
Wolfgang Seeker and ¨Ozlem C¸ etino˘glu. 2015.
A graph-based lattice dependency parser for
joint morphological segmentation and syntac-
tic analysis. Transactions of the Association
for Computational Linguistics, 3:359–373.
https://doi.org/10.1162/tacl a
00144
Amit Seker and Reut Tsarfaty. 2020. A pointer
network architecture for joint morphological
segmentation and tagging. In Findings of the
Association for Computational Linguistics:
EMNLP 2020, pages 4368–4378, En ligne.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2020
.findings-emnlp.391
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Yan Shao, Christian Hardmeier, and Joakim
Nivre. 2018. Universal word segmentation:
Implementation and interpretation. Transac-
tions of
the Association for Computational
Linguistics, 6:421–435. https://doi.org
/10.1162/tacl a 00033
Yan Shao, Christian Hardmeier, J¨org Tiedemann,
and Joakim Nivre. 2017. Character-based joint
segmentation and POS tagging for Chinese us-
ing bidirectional RNN-CRF. In Proceedings of
the Eighth International Joint Conference on
Natural Language Processing (Volume 1: Long
Papers), pages 173–183, Taipei, Taiwan. Asian
Federation of Natural Language Processing.
Khalil Sima’an, Alon Itai, Yoad Winter, Alon
Altman, and Noa Nativ. 2001. Building a tree-
bank of modern Hebrew text. Traitement Auto-
matique des Langues, 42(2):347–380.
Hye-Jeong Song, Byeong-Cheol Jo, Chan-Young
Parc, Jong-Dae Kim, and Yu-Seop Kim. 2018.
Comparison of named entity recognition meth-
odologies in biomedical documents. Biomedi-
cal Engineering Online, 17(2):158. https://
doi.org/10.1186/s12938-018-0573-6
Erik F. Tjong Kim Sang. 2003. Introduction to the
conll-2003 shared task: Language-independent
named entity recognition. In Proceedings of
the Seventh Conference on Natural Language
Learning at HLT-NAACL 2003 – Volume 4,
CONLL ’03, pages 142–147, Stroudsburg, Pennsylvanie,
Etats-Unis. Association for Computational Linguis-
tics. https://doi.org/10.3115/1119176
.1119195
Reut Tsarfaty, Dan Bareket, Stav Klein, et
Amit Seker. 2020. From SPMRL to NMRL:
What did we learn (and unlearn) in a decade
of parsing morphologically-rich languages
(MRLs)? In Proceedings of the 58th Annual
Meeting of
the Association for Computa-
tional Linguistics, pages 7396–7408, En ligne.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2020
.acl-main.660
Reut Tsarfaty, Shoval Sadde, Stav Klein, et
Amit Seker. 2019. What’s wrong with Hebrew
NLP? And how to make it right. In Proceedings
of the 2019 Conference on Empirical Meth-
ods in Natural Language Processing and the
9th International Joint Conference on Natu-
ral Language Processing (EMNLP-IJCNLP):
System Demonstrations,
259–264,
Hong Kong, Chine. Association for Compu-
tational Linguistics. https://est ce que je.org/10
.18653/v1/D19-3044
pages
Reut Tsarfaty, Djam´e Seddah, Yoav Goldberg,
Sandra Kuebler, Yannick Versley, Marie
Candito, Jennifer Foster, Ines Rehbein, et
Lamia Tounsi. 2010. Statistical parsing of mor-
phologically rich languages (SPMRL) what,
how and whither. In Proceedings of the NAACL
HLT 2010 First Workshop on Statistical
Parsing of Morphologically-Rich Languages,
pages 1–12, Les anges, Californie, Etats-Unis. Asso-
ciation for Computational Linguistics.
G¨okhan T¨ur, Dilek Hakkani-t¨ur, and Kemal
Oflazer. 2003. A statistical information extrac-
tion system for turkish. Natural Language En-
gineering, 9(2):181–210. https://doi.org
/10.1017/S135132490200284X
Clara Vania, Andreas Grivas, and Adam Lopez.
2018. What do character-level models learn
about morphology? The case of dependency
parsing. In Proceedings of the 2018 Confer-
ence on Empirical Methods in Natural Lan-
guage Processing, pages 2573–2583, Brussels,
Belgium. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/D18-1278
Ralph Weischedel, Martha Palmer, Mitchell
Marcus, Eduard Hovy, Sameer Pradhan, Lance
Ramshaw, Nianwen Xue, Ann Taylor, Jeff
Kaufman, Michelle Franchini, Mohammed
El-Bachouti, Robert Belvin, and Ann Houston.
2013. Ontonotes release 5.0. Linguistic Data
Consortium, Philadelphia, Pennsylvanie.
Jie Yang, Shuailong Liang, and Yue Zhang.
2018. Design challenges and misconceptions
in neural sequence labeling. In Proceedings of
the 27th International Conference on Compu-
tational Linguistics (COLING). https://
doi.org/10.18653/v1/P18-4013
Jie Yang and Yue Zhang. 2018. NCRF++: Un
open-source neural sequence labeling toolkit.
In Proceedings of the 56th Annual Meeting of
the Association for Computational Linguistics.
Seid Muhie Yimam, Iryna Gurevych, Richard
Eckart de Castilho, and Chris Biemann. 2013.
926
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
WebAnno: A flexible, Web-based and visually
supported system for distributed annotations.
In Proceedings of the 51st Annual Meeting
of the Association for Computational Linguis-
tics: System Demonstrations, pages 1–6, Sofia,
Bulgaria. Association for Computational Lin-
guistics.
Ziqi Zhang. 2013. Named Entity Recognition:
Challenges in Document Annotation, Gazetteer
Construction and Disambiguation. Ph.D. thesis,
University of Sheffield.
A Alignment Heuristics
Aligning Multi-labels to Single Labels. In or-
der to evaluate morpheme-based labels (morph or
token-multi) in token-based settings, we intro-
duce a deterministic procedure to extend the
morphological labels to token boundaries. Spe-
cifically, we use regular expressions to map the
multiple sequence labels to a single label by
choosing the first non-O entity category (BIES) comme
the single category. In case the sequence of labels
is not valid (par exemple., B comes after E, or there is
an O between two I labels), we use a relaxed
mapping that does not take the order of the labels
into consideration: if there is an S or both B and
E in the sequence, return an S. Otherwise, if there
is an E, return an E; if there is a B, return a B; si
there is an I return an I (Chiffre 11).
Aligning Multi-labels to Morphemes. In order
to obtain morpheme boundary labels from token-
multi, we introduce a deterministic procedure to
align the token’s predicted multi-label with the list
of morphemes predicted for it by the MD. Specif-
ically, we align the multi-labels to morphemes in
the order that they are both provided. In case of a
mismatch between the number of labels and mor-
phemes predicted for the token, we match label-
morpheme pairs from the final one backwards. If
the number of morphemes exceeds the number of
labels, we pad unpaired morphemes with O labels.
If the number of labels exceeds the morphemes,
we drop unmatched labels (Chiffre 12).
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
927
Chiffre 12: Multi-label to morpheme alignment.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
4
1
9
6
2
4
7
2
/
/
t
je
un
c
_
un
_
0
0
4
0
4
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 11: Multi-label to single label alignment.
928