Neural Event Semantics for Grounded Language Understanding
Shyamal Buch
Li Fei-Fei
Noah D. Homme bon
{shyamal,feifeili}@cs.stanford.edu
ngoodman@stanford.edu
Université de Stanford, États-Unis
Abstrait
We present a new conjunctivist framework,
neural event semantics (NES), for composi-
tional grounded language understanding. Notre
approach treats all words as classifiers that
compose to form a sentence meaning by mul-
tiplying output scores. These classifiers apply
to spatial regions (events) and NES derives
its semantic structure from language by rout-
ing events to different classifier argument
inputs via soft attention. NES is trainable
end-to-end by gradient descent with min-
imal supervision. We evaluate our method
on compositional grounded language tasks in
controlled synthetic and real-world settings.
NES offers stronger generalization capability
than standard function-based compositional
frameworks, while improving accuracy over
state-of-the-art neural methods on real-world
language tasks.
1
Introduction
le
semantics
compositional
de
Capturing
dans
grounded language is a long-standing goal
natural language processing. Composition yields
systematicity, and is thus essential to developing
systems that can generalize broadly in real-world
settings. Recent progress with neural module net-
travaux (Andreas et al., 2016b; Hu et al., 2017) et
related models (Johnson et al., 2017b; Yi et al.,
2018; Bahdanau et al., 2019un) have moved neural
network methods closer to this goal.
These works are largely based on the idea,
functionism (Montague, 1970), that semantic com-
position is function composition. In Figure 1(un),
function predicates compose by nesting: Predi-
cates like ‘‘red’’ and ‘‘circle’’ operate on sets
of elements, progressively filtering them at each
Project Website:
https://neural-event-semantics.github.io/.
875
step (circle(red(X))). The final relational
predicate above is thus several steps removed
from the original inputs x,oui. De la même manière, in mod-
ule networks, atomic module blocks compose
by sequentially passing outputs of intermediate
blocks to later modules. The diverse composition
ruleset needed to coordinate function inputs and
outputs leads to complexity in this paradigm,
which has practical implications for its fundamen-
tal learnability. En effet, neural module network
instantiations of this framework often depend on
low-level ground truth module layout programs
(Johnson et al., 2017b) or large amounts of training
data to sustain end-to-end reinforcement learning
méthodes (Yi et al., 2018; Mao et al., 2019).
While functionism is the dominant paradigm in
linguistic semantics, there is an intriguing alterna-
tive: event semantics (Davidson, 1967). Conjunc-
tivism (Pietroski, 2005) is a particularly powerful
version of event semantics, wherein the only com-
position operator is conjunction—structure arises
by routing event variables to the function pred-
icates. We illustrate this key difference between
paradigms in Figure 1: in a conjunctivist set-
ting (Chiffre 1(b)), even the relational above has
events e1, e2 directly routed as input, plutôt que
taking inputs that are output results of a sequence
of filter operations. Overall meaning is still
preserved, since e1 concurrently routes to (red,
circle) and e2 to (vert, square). All mod-
ule outputs directly contribute to the final truth
value without intermediate steps. Altogether, ce
shift from deriving compositional structure by
functional module layout to conjunctive events
routing offers a path to improved learnability; nous
explore the implications of this line of thinking in
the context of compositional neural models.
We propose neural event semantics (NES), un
new conjunctivist framework for compositional
grounded language understanding. Our work
addresses the drawbacks of modern neural mod-
ule approaches by re-examining the underlying
Transactions of the Association for Computational Linguistics, vol. 9, pp. 875–890, 2021. https://doi.org/10.1162/tacl a 00402
Action Editor: Luke Zettlemoyer. Submission batch: 3/2021; Revision batch: 4/2021; Published 8/2021.
c(cid:2) 2021 Association for Computational Linguistics. Distributed under a CC-BY 4.0 Licence.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
je
un
c
_
un
_
0
0
4
0
2
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
We evaluate our NES framework on a series
of grounded language tasks aimed at assessing
its generalizability. We verify the merits of our
conjunctivist design in a controlled comparison
with functionist methods on the
synthetic
ShapeWorld benchmark (Kuhnle and Copestake,
2017). We show NES exhibits stronger systematic
generalization over prior
techniques, without
requiring any low-level supervision. Plus loin, nous
verify the flexibility of the framework in real-
world language settings, offering significant gains
(+4 à 6 points) in the state-of-the-art accuracy for
language and zero-shot generalization tasks on
the CiC reference game benchmark (Achlioptas
et coll., 2019).
2 Background and Related Work
The reliance of
Compositional Neural Networks. The advent
of neural module networks (NMN) (Andreas
et coll., 2016un,b; Hu et al., 2017) and related
techniques (Johnson et al., 2017b; Yi et al., 2018;
Bahdanau et al., 2019un) has proven to be a driving
force in compositional language understanding.
These techniques share a key principle: Petit,
reusable neural network modules stack together as
functional building blocks in an overall executable
neural program. A parsing system determines
the programmatic layout, wiring the outputs of
intermediate blocks to the inputs of other blocks.
these techniques on pre-
specified module libraries, ground truth super-
vision on functional module layouts, and/or
sample-inefficient reinforcement learning meth-
ods (Williams, 1992) has motivated subsequent
work to eschew explicit semantics for recurrent
attentional computation techniques (Hudson and
Manning, 2018; Perez et al., 2018; Hu et al.,
2018; Hudson and Manning, 2019). This class of
more implicit semantics methods offers the ben-
efits of end-to-end differentiability of traditional
non-compositional neural networks (Lake et al.,
2017), making them better suited for real-world
settings. As a trade-off, cependant, these methods
exhibit less systematic generalization than their
more explicit counterparts (Marois et al., 2018;
Jayram et al., 2019; Bahdanau et al., 2019b).
Recent work has also suggested that the modular
network approach leads to limitations of system-
atic generalization: Functional module layout can
lead to entangled concept understanding (Bahdanau
et coll., 2019un; Subramanian et al., 2020). While
Chiffre 1: (un) Prior neural network methods for com-
positional semantics, such as neural module networks,
derive compositional structure through nested appli-
cation of function modules. This paradigm, rooted
in functionism, is powerful but retains drawbacks to
learnability due to its complexity. (b) We propose
neural event semantics (NES), a new framework based
on conjunctivism, where all words are classifiers and
output scores compose by simple multiplication. Nous
call the input spatial regions to these classifiers events:
NES derives semantic structure from language by
learning how to route event inputs of classifiers for
different words in a context-sensitive manner. Par
relaxing this routing operation with soft attention, NES
enables end-to-end differentiable learning without low-
level supervision for compositional grounded language
understanding.
semantics framework, shifting from functionism
to conjunctivism. The focus of NES revolves
around event variables, abstractions of entities
dans le monde (par exemple., in images, we can think of
events as spatial regions). We treat all words
as event classifiers: For each word, a single
score indicates the presence of a concept on a
specific input (par exemple., red, above in Figure 1(b)).
We compose output scores from classifiers by
multiplication, generalizing logical conjunction.
The structural heart of NES is the intermedi-
ate soft (attentional) event routing stage, lequel
ensures that these otherwise independent word-
level modules receive contextually consistent
event inputs. In this way, the simple product of all
classifier scores accurately represents the intended
compositional structure of the full sentence. Notre
NES framework is end-to-end differentiable, capable
to learn from high-level supervision by gradient
descent while providing interpretability at the level
of individual words.
876
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
je
un
c
_
un
_
0
0
4
0
2
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
these works go on to propose mitigating measures,
such as module-level pretraining, we consider an
orthogonal approach:
re-visiting the underly-
ing semantics foundation. This enables us to
address the challenges jointly: Our NES frame-
work retains the end-to-end learnability of implicit
méthodes, while improving upon the systematic
generalizability of explicit ones.
language input
Grounded Compositional Semantics. Our work
is also closely related to the broader, pre-neural
network body of prior work which developed mod-
els for compositional semantics in grounded lan-
guage settings (Matuszek et al., 2012; Krishnamurthy
and Kollar 2013; 2014). These methods all share
the two-stage approach of semantic parsing and
evaluation, and combine functionist and con-
junctivist elements. The parsing stage typically
leverages a (functionist) combinatory categorial
grammar (CCG) parser (Zettlemoyer and Collins,
to a dis-
2005) to map input
crete (conjunctive) logical form bound by an
existential closure. The evaluation stage passes
visual segments as input to these predicates to
obtain a final score representing its truth con-
dition. In our work, we aim to generalize these
frameworks to a modular neural network set-
ting, embracing conjunctivist design across all
stages to improve end-to-end learnability. Notre
proposed soft event routing mechanism relaxes
prior discrete constraints and offers an alternative
to probablistic program (Krishnamurthy et al.,
2016) formulations. Ensemble, NES is able to
learn how to predict the (soft) conjunctive neural
logical forms while jointly learning the under-
lying semantics of each concept (without pre-
specification) end-to-end from denotation alone.
Grounded Language Understanding. The space
of grounded language understanding methods and
tasks is large, encompassing tasks in image-
caption agreement (Kuhnle and Copestake, 2017;
Suhr et al., 2019), reference grounding (Monroe
et coll., 2017; Achlioptas et al., 2019), instruction
following (Ruis et al., 2020; Vogel and Jurafsky,
2010; Chaplot et al., 2018), captioning (Chen
et coll., 2015), and question answering (Antol et al.,
2015; Johnson et al., 2017un; Hudson and Manning,
2019), entre autres. Souvent, the ability to operate
with only high-level labels is critical (Karpathy
and Fei-Fei, 2015). Consistent with recent work
(Bahdanau et al., 2019un), we center our analysis
on foundational tasks of caption agreement and
reference grounding, on both synthetic and real-
world language data, with the understanding that
core insights can translate to related tasks.
3 Technical Approach
3.1 Prelude: Classical Conjunctivism to NES
To explain our proposed differentiable neural
approche, we first revisit classical logic in our
current context. In conjunctivist event semantics
(Pietroski, 2005), we work with the space of exis-
tentially quantified conjunctions of predicates.
For illustration, consider the partial logical form:
∃e1, e2 ∈ V. [[circle(e1) ∧ on(e1, e2)]]
(1)
where ei are event variables and V is the domain
of candidate event values. To evaluate this expres-
sion, we need an interpretation of the variables:
an assignment of event values in V to each event
variable ei. We then route these events to the argu-
ments of predicates based on the logical form. Le
logical form gives the abstract template for which
events route to which inputs and, most crucially,
which arguments are shared across predicates (e1
routes to ‘‘circle’’ and the first argument of ‘‘on’’).
We make this routing explicit by a routing tensor
Awri ∈ {0, 1}: For each argument slot (r) of each
predicate (w, for word), Awr∗ ∈ {0, 1}n is a one-
hot vector indicating which of the n event variables
ei ∈ e belongs in this argument slot. We can thus
rewrite the matrix expression in Equation (1) comme:
[[circle(A11∗e, A12∗e) ∧ on(A21∗e, A22∗e)]] (2)
Without loss of generality,1 we upgrade each
predicate to take a fixed m arguments; ici
m = 2. Équation (2) makes it clear that the routing
tensor A is the key syntactical element specifying
the structure of the logical form in Equation (1).
Having routed events ei to predicate arguments
via A, we can evaluate the predicates (‘‘circle’’,
‘‘on’’). These predicates are Boolean functions,
assigned by a lookup table (lexicon). We compose
the outputs of these Boolean functions by con-
junction to get the truth-value of the entire matrix.
This describes how we evaluate the matrix expres-
sion in Equation (1) for a specific assignment of
ei in V . We arrive at the final interpretation of
1We add a background event variable e∅, backed by a null
representation; A can route e∅ to extra slots. In Equation (2),
routed events to ‘‘circle’’ are A11∗e = e1 and A12∗e = e∅.
877
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
je
un
c
_
un
_
0
0
4
0
2
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
je
un
c
_
un
_
0
0
4
0
2
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 2: We propose neural event semantics (NES), an end-to-end differentiable framework based on
conjunctivist event semantics (Sec 3.1). NES parses input text to a neural logical form F , which can score a given
set of input events. In NES, all words are event classifiers (Section 3.3) whose scores compose by multiplication
(Section 3.4). The structural heart of NES is a differentiable event argument routing operation (Section 3.2),
ensuring arguments to each event classifier are contextually correct. NES semantically grounds F to an input
world W by existential event variable intepretation (Section 3.5), finding a satisfying assignment (if one exists)
of events e from values V .
Équation (1) by existential quantification: recherche-
ing over the possible assignments to see if there
exists one that makes the matrix true.
We emphasize that the logical form is fully
determined by the routing tensor A and the lex-
icon mapping each word/predicate to a Boolean
fonction. Evaluation is specified by conjunctive
composition and finding a satisfying variable
interpretation. Our strategy to develop a learn-
able framework is to soften each of the key
components: argument routing (Section 3.2),
predicate evaluation (Section 3.3), conjunctive
composition (Section 3.4), and existential event
interpretation (Section 3.5).
Overview. We propose a neural event semantics
(NES) framework, illustrated in Figure 2, lequel
relaxes this classical logic into a differentiable
computation that can be learned end-to-end. NES
takes a text statement T and constructs a neural
logical form F . This form is specified by a now
real-valued routing tensor Awri ∈ [0, 1] and a
lexicon associating event classifiers Mw to each
word w. NES specifies composition via the prod-
uct of classifier prediction scores, as a relaxation
of conjunction. Enfin, evaluation is completed
by existentially interpreting event variables ei into
878
a domain of event values V (grounded representa-
tions extracted from a visual world W ) by a max
operator.
3.2 Differentiable Event Argument Routing
Our first key operation in NES is to predict
the argument routing tensor A from the input
langue. Critique, we relax A from its
original discrete formulation in Section 3.1 à
a continuous-valued one Awri ∈ [0, 1], où
Awr∗ ∈ [0, 1]n is normalized by softmax over the
index for the n events ei. This softened routing
can be seen as a form of attention, determining
which argument slot r for a word w will attend to
which event variables ei (voir la figure 3). We predict
these attentions directly from the input tokenized
text sequence T = [t1, . . . , tl], of length l. Pour
each token word tw, we pass a word embedding
qw as input to a bidirectional LSTM (Graves and
Schmidhuber, 2005) that serves as the sequence
encoder and outputs forward/backward hidden
states (h→
∈ Rdh) capturing the bidirectional
context surrounding tw. Passing the concatenated
states through a linear layer, we obtain a final
hidden state:
w , h←
w
hw = W ([h→
w , h←
w ]) + b ∈ Rdh
(3)
3.2, Chiffre
3). Denoting
(Section
events
ei ∈ Rde, e∅ as a null background event, et
e = [e1 · · · en−1 | e∅] ∈ Rn×de, we can formalize
the routed inputs as Awr∗e ∈ Rde. The concate-
nation of these routed inputs over all m argument
slots is input to Mw.
Chiffre 3: Words as Classifiers of Routed Events.
All words w correspond to modules Mw of a single
type signature. Predicted argument routing attention
A routes input events e from the overall
logical
form F to the specific arguments in the event
classifier Mw (per Equation (5)), ensuring contextual
consistency between event classifiers for different
words. qw, a decontextualized word embedding,
indicates to Mw its lexical concept. Mw shown
here with maximum arity m = 2 slots and n = 3
events (including the ungrounded background event
e∅); since ‘‘circle’’ only binds to one argument e1,
is bound to e∅. See Section 3.2
the second slot
et 3.3.
From hw, a multilayer perceptron (MLPROUTE)
network outputs for each argument slot r:
Awr∗ = softmax(MLPROUTE(hw))
(4)
Over the full input sequence of length l, we obtain
the full argument routing tensor A ∈ [0, 1]l×m×n,
with m argument slots per word and n events.
Note that the prediction of A from input text T
plays the role of capturing syntax for NES, en utilisant
the language to derive coordination of argument
routings across different words.2
A key design aspect of the routing operation:
Because A can route an ungrounded background
event e∅ to (extra) argument slots, NES can
implicitly learn the arity of each word. Plus loin,
the attention formulation enables partial routing
of such background events; we observe later in
Section 4.1.4 that this is critical to enabling the
more complex coordination necessary to handle
negation.
3.3 Words as Event Classifiers
In NES, all words are event classifiers: Words
are associated with modules Mw that output a
real-valued score sw of how true a lexical con-
cept is for a given set of (routed) event inputs
While in principle the modules can be com-
pletely separate for each word in the lexicon,
we choose to share the weights of the different
classifiers Mw: This improves memory efficiency
for large vocabularies and is helpful in real-world
language generalization settings. Ainsi, we can
realize modules Mw by an MLP network that
receives the word embedding qw as further input
(voir la figure 3), computing its output sw as:
sw = σ(MLPMw ([Aw1∗e, . . . , Awm∗e; qw]))
(5)
where σ denotes the sigmoid function that
normalizes the output score sw ∈ [0, 1].3
3.4 Conjunctive Composition in NES
Per Section 3.1, the matrix of a classical conjunc-
tive logical form (for a given interpretation of
variables) is evaluated by composing Boolean
predicate outputs by conjunction. For the neu-
logical form F in NES, we consider the
ral
real-valued generalization of conjunction: Nous
compose the l word-level scores sw from the
classifiers Mw (Équation (5)) by multiplication
(cid:2)
w sw). For numerical stability, we calculate
(
the combined log score in log space:
log sF =
1
je
(cid:3)
w
log sw
(6)
where the length normalization is optional but
helps with training on variable length sequences.
3.5 Existential Event Variable Interpretation
In previous Section 3.2-3.4, we’ve described how
NES translates input language to a neural log-
ical form F , and how such a logical form can
operate for a specific intepretation (binding) de
events to candidate values V . Now, we describe
the final existential variable interpretation step,
which relaxes the existential quantification of
classical logic (Équation (1)) into a max operation
2We emphasize that this is a language-only operation:
Coordination here is not conditional on the later ground-
ing step to specific event values V in the visual world
(Section 3.5).
3qw is a decontextualized embedding that only represents
the standalone lexical concept, not the recurrent embedding
hw. Consistent with Subramanian et al. (2020), we find this
improves systematic generalization in NES and baselines.
879
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
je
un
c
_
un
_
0
0
4
0
2
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
over possible event interpretations of a specific
input domain V .
Candidate Event Values V . We decompose our
input world W into a set of candidate event
proposals, with corresponding representation val-
ues V . In our experiments, we process input
visual scenes W with a pre-trained convolutional
visual encoder φ (Simonyan and Zisserman, 2015;
He et al., 2016) to provide a set of up to k candidate
event value representations V = {v1, . . . , vk},
with v ∈ Rde. These candidate values capture the
information corresponding to the localized image
segment surrounding that specific event; we base
our approach on recent findings of object-centric
representations for compositional modular net-
work approaches (Yi et al., 2018). To capture
spatial information, we augment each representa-
tion with the spatial coordinates of the center of
its bounding box; this enables NES and our rele-
vant baseline methods (par exemple., NMN) to assess the
semantics of spatial relationships (par exemple., ‘‘below’’)
while operating directly on event values.
Assignment and Final Scoring. Given the
domain V of candidate event values, an interpre-
tation is thus an assignment of each of the n − 1
grounded event variables (we don’t include e∅) à
a unique value in V : We denote this assignment
operation as e ← V . We translate the existential
closure (∃e1, e2 in Figure 2) as an operation that
determines the best scoring assignment of event
candidate values to event variables. Expanded,
the final grounded score s∗
sF is:
F = max
e←V
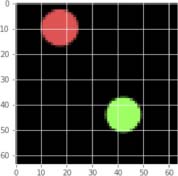
Chiffre 4: Qualitative Results (Scoring). Exemple
end-to-end NES results on ShapeWorld. We show
an input world with two event candidates (for clar-
ville) with representations v1, v2 for the red and green
circles, respectivement. We visualize the possible event
assignments (e1, e2) ∈ {(v1, v2), (v2, v1)} and the clas-
sifier scores sw ∈ [0, 1] for each assignment, y compris
stop words. We find NES provides correct and con-
sistent predictions across assignments and concepts,
without any explicit logical form-level supervision.
See Section 4.1.4.
We apply a straightforward binary cross entropy
the level of text statements and their
loss at
truth labels to the final output score s∗
F , without
needing any low-level ground truth supervision
of the neural logical form. Dans l'ensemble, our full NES
framework offers advantages from both traditional
neural module network methods and end-to-end
differentiable implicit semantics techniques.
The max operation in Equation (7) is a technical
challenge for the end-to-end training. To improve
gradient flow, we propose to use a tunable approxi-
mation fmax, which approaches the max as β → ∞
and is always upper-bounded by it:
s∗
F = max
e←V
1
je
w
(cid:3)
log Mw(Aw1∗e, . . . , Awm∗e; qw)
fmax(s; β) =
(cid:4)
q (sq)β+1
(cid:4)
q (sq)β
≤ max(s)
(8)
(7)
Chiffre 4 visualizes output score tables (inclure-
ing sw, sF , s∗
F ) with k = 2 candidate event values
and n = 3 events including background e∅. Nous
highlight that Figure 4 shows how each individual
module provides consistent outputs depending
on the specific event interpretation e ← V (par exemple.,
‘‘below’’ is only true if (e1, e2) bind to (v2, v1),
pas (v1, v2)). The final score s∗
F reflects the sF of
that correct assignment, since it is the max score.
3.6 Training: Learning from Denotation
We train our overall system end-to-end with gra-
dient descent with a dataset of (statement T , monde
scene W , true/false denotation label Y ) triplets.
880
In context, s is a vector of all the scores sF
(Équation (6)) corresponding to the assignments
e ← V , and the output of Equation (8) is a
bounded approximation of s∗
F in Equation (7).
See Appendix A for correctness and details.4 Dur-
ing test-time inference, we still use the original
max operation shown in Equation (7).
4Bound follows from H¨older’s inequality. Équation 8 est
important since standard alternatives (par exemple., log-sum-exp) do
not have this upper-bound, and the possibility of multiple
valid assignments e ← V renders softmax inappropriate.
Since fmax converges quickly to the max operation as β
increases, we can use numerically stable values β ≤ 4 pendant
entraînement.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
je
un
c
_
un
_
0
0
4
0
2
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
4 Experiments
4.1 Experiments: Synthetic Language
We design the first series of experiments to
highlight key compositional and generalization
properties of NES in a controlled, synthetic setting.
4.1.1 Dataset and Tasks
ShapeWorld. Our synthetic tasks and datasets
are based on the ShapeWorld benchmark suite
(Kuhnle and Copestake, 2017), ce qui était
designed specifically for evaluation of compo-
sitional models for grounded semantics. Ici,
events are based on simple objects: shapes with
different color attributes and spatial relation-
ships. Images are generated by sampling events
from task-specific distributions with visual noise
(par exemple., hue, size variance), and are placed without
hard grid constraints. For each image, multiple
true/false language statements are generated with
a templated grammar (Copestake et al., 2016).
Negative statements are generated close to the
distribution of positive statements to ensure dif-
ficulty: Models must understand all aspects of
the statement correctly to output a truth condition
label. We visualize an example in the qualitative
résultats (Chiffre 4).
Task A: Standard Generalization. This gener-
alization task evaluates compositional models on
the standard setting where train and evaluation
splits are based on the same underlying input event
distribution. This task is similar to the original
SHAPES dataset (Andreas et al., 2016b), without
shape positions locked to a 3 × 3 spatial grid.
Task B: Compositional Generalization. Le
compositional generalization task examines the
systematic generalization of models to an unseen
event distribution. During test time, every instance
has at least one event sampled from a held-out
distribution. Par exemple, while red triangles and
blue squares may be present at train time, blue
triangles and red squares are only present during
test time. Critique, any language associated with
these unseen events is always false during training
since these events are never actually present. Ainsi,
models that overfit on complete phrases during
training will not generalize well at test time.
Task Variant: Negation. For both tasks, nous
include a variation with negation to ensure NES
can model non-intersective modifiers, which are
prevalent in real-world grounded language. Dans
these variants,
true and false statements that
include attribute-level negation (par exemple., phrases like
‘‘not red’’) are also generated for each image.
4.1.2 Baseline and Model Details
Baselines. Across our synthetic experiments, nous
compare NES against baselines in 3 catégories:
• Black-box neural networks. These base-
line neural network models combine CNN,
LSTM, and attention components (Johnson
et coll., 2017un) and represent standard end-
to-end black-box techniques for language +
vision tasks.
• Functionist approaches. For our functionist
baselines, we consider the prevailing para-
meterizations of the neural module networks
(NMN) framework (Andreas et al., 2016b).
For the modules, we leverage the base generic
module design introduced in the E2ENMN
framework (Hu et al., 2017; Bahdanau
et coll., 2019un). Because our experiments are
event-centric, the inputs and implementation
of the framework are consistent with prior
travail (Yi et al., 2018; Mao et al., 2019;
Subramanian et al., 2020). Ainsi, each module
takes as input a set of localized event values
(originally from the image), an attention over
these values (from a preceding module step),
and a decontextualized word embedding.
The module then applies the attention and
processes the input, before outputting an
updated attention to be used in dependent
downstream module steps. For end-to-end
(E2E) experiments, ground truth programs
are used to pre-train the parsing module
layout generator, which is the structural heart
of NMN. This parser is implemented using
a sequence-to-sequence Bi-LSTM (Hu et al.,
2017; Johnson et al., 2017b). We emphasize
que, in our experiments, we ensure consistent
hidden state sizes for both the modules and
the sequence encoder for NMN and NES,
as well as consistent event-centric visual +
decontextualized word embedding input.
• Implicit semantics methods. This class
of models leverages recursive computation
units with attention over visual and textual
to provide better compositionality
input
than traditional end-to-end black-box neural
méthodes de réseau. We examine the MAC
881
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
je
un
c
_
un
_
0
0
4
0
2
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
model (Hudson and Manning, 2018, 2019)
as a representative baseline, following recent
prior work (Bahdanau et al., 2019un). Similar
to our NMN baseline, we report results with
an event-centric version of the MAC model,
following Mao et al. (2019), such that MAC
is able to attend over a discrete set of localized
event values. Ainsi, we can enable fair and
consistent comparison of MAC, NMN, et
other baselines with NES.
Implementation Details. Models and baselines
are implemented in PyTorch (Paszke et al.,
2019). Localized event candidate values V are
extracted by a pre-processing step. Our encoder
φ is a ResNet-101 network (He et al., 2016),
and localized event feature representations are
based on conv4 features per prior work (Johnson
et coll., 2017un; Hudson and Manning, 2018) avec
pixel grid coordinates (per Section 3.5) to capture
the necessary spatial and visual information for
the downstream semantics. Following standard
work in object detection (He et al., 2017), nous
use pooling to ensure all localized event values
have the same dimension. Word embeddings
are 300-dim GloVe.6B embeddings (Pennington
et coll., 2014). All
inputs are
consistent across all models for fair comparison.
As noted previously, model sizes are also kept
consistent across models where applicable. Please
refer to the supplement for implementation and
additional details.5
text and visual
4.1.3 Validating Conjunctivism
Overview. Our first experiments are centered
around validating a fundamental design principle
underlying our NES framework:
that concept
meaning can be effectively represented by
conjunction of event classifiers. Both NMN and
NES leverage syntax to guide their composi-
tional structure: functional module layout (NMN)
and event routing (NES), respectively.6 Here, nous
isolate the impact of the design philosophy on
the quality of the learned semantics by providing
5Available at https://neural-event-semantics
.github.io/.
6We note that while we focus on the functionist
realizations of NMNs prevalent in prior work, we recognize
that the broader family of modular network approaches can in-
clude conjunctivist elements as well. A key intention of these
experiments is to illustrate the value of our conjunctivist
design as a compelling direction for future modular network
conception.
882
Chiffre 5: Validating Conjunctivism. Ici, we provide
ground truth (GT) logical forms for both functionist
(NMN) and conjunctivist (NES) approaches. Con-
trolling other factors, we observe that our conjunc-
tivist NES framework provides better systematic
generalization (Task B) than a functionist one. Voir
Section 4.1.3.
ground truth (GT) ‘‘syntax’’ (layout or routing) à
each framework, assessing performance on Tasks
A and B.
Systematic Generalization. Chiffre 5 shows the
results for both NMN-GT and NES-GT. Both
frameworks perform equally well on the standard
generalization task (Task A), showing that the
NES conjunctivist design preserves the efficacy
of the functionist paradigm. In Task B however,
while both frameworks perform reasonably well,
NES exhibits stronger systematic generalization
capability than the NMN model when evaluated
on an unseen event distribution. These quantitative
results suggest
that NES enables a stronger
decoupling of individual concepts, yielding higher
accuracy when they are composed for unseen
events.
To explore concept disentanglement further,
we analyze the color sensitivity of color words
in Figure 6. For this analysis, we take the trained
models from Task B and examine the normalized
response score of different modules (par exemple., red)
to a continuous spectrum of color input. Nous
sample the input shapes for each color classifier
from the unseen event distribution. Our analysis
suggests that NES offers stronger disentangle-
ment of attribute concepts: color words respond to
separated and appropriate spectral regions,
dans
contrast to NMN.7
7This finding, with respect to NMN, is analogous and
consistent with concurrent prior work (Subramanian et al.,
2020).
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
je
un
c
_
un
_
0
0
4
0
2
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
In Figure 8, we visualize the event routing
predictions from an example NES model trained
end-to-end. Consistent with our observation in
Chiffre 4, we see that the model can learn approx-
imate routings and implicit arity of the different
event classifiers. Though event routings are mod-
eled as soft attention and classifier output scores
are continuous, both have approached nearly dis-
crete outputs by the end of learning, capturing the
underlying logical structure of the domain.8
Negation. Enfin, we demonstrate that NES is
capable of handling non-intersective modifiers by
examining its ability to model property negation.
In contrast with functionist models, conjunctivist
event semantics must handle negation through
modification of the input event to the given pred-
icate (Pietroski, 2005). In Figure 9, we show the
results from these experiments. D'abord, we observe
that NES can maintain the same level of general-
ization accuracy in variants of Task A and B that
contain negation. Visualizing an example model,
we see that NES learns to coordinate negation
through its event routing stage: the presence of
‘‘not’’ in the textual input can lead NES to predict
a soft routing Aw1∗ that attends to a combination
of both e1 and the ungrounded background e∅ for
the first argument of ‘‘red’’ (denoted as e(cid:12)
1 dans le
example). Now, when this specific ‘‘red’’ attribute
classifier processes its updated event arguments,
its classification behavior is reversed: a high score
when the attribute is not present in the original e1.
We compare with an ablation variant of NES
that removes this routing flexibility: for attribute
classifiers Mw, we restrict their routing attention
Aw∗∗ to only consider the n−1 grounded events in
the first argument slot (removing e∅ from consider-
ation) and fix the second slot a2 to the background
e∅. Because individual event classifier mod-
ules only take decontextualized word embedd-
ings, the event routing mechanism is the only way
for context information to influence the classifica-
tion. Ainsi, this ablation directly reflects the impact
of the flexible event routing mechanism and its
usage of the ungrounded background event to
8Without low-level supervision to break symmetry, it
is possible for separate end-to-end training runs to learn
different but equivalent routing schemes (and matching event
classifiers): Par exemple, NES can learn event classifiers
M where argument slot 2 is consistently its primary slot
(instead of slot 1). In such a case, we can use the jointly
learned (consistently inverted) event routings to remap for
visualization.
Chiffre 6: Validating Conjunctivism: Attribute
Response. Response graphs for color attributes on
ShapeWorld data in Task B. Our conjunctivist NES
framework offers stronger disentangled understanding
of each word as a concept classifier, compared to the
prior functionist NMN framework. See Section 4.1.3.
4.1.4 End-to-End Experiments
Overview. Having validated that conjunctivist
composition can support strong performance with
known event routings, our second set of synthetic
experiments are designed to assess the full end-
to-end learning capability of the NES framework,
including the critical event routing stage. Dans ce
setting, we offer no ground truth logical form input
or supervision to the NES model, and evaluate per-
formance on all tasks. We do necessary program
layout pre-training for the E2E-Func (NMN) base-
line prior to end-to-end REINFORCE training.
Generalization. In Figure 7, we show that our
initial findings in Section 4.1.3 hold in the more
general end-to-end setting, across the broader set
of model classes. While compositional methods
consistently outperform the noncompositional
baselines, there is a clear differentiation between
MAC and NES/E2E-Func on Task B (systematic
novel-event generalization). This suggests that
MAC relies too strongly on correlative associa-
tions of text phrases for unseen events, overfitting
at training.
In Figure 4, we visualize a table of NES
score predictions on a specific input V , using a
two-event setting for visual clarity. An input state-
ment is considered true if there is an assignment
(grounding to V ) of the events with a high overall
score. Across different event assignments e ← V ,
NES provides consistent and correct score out-
puts. Because NES considers each word as its own
event classifier (with appropriate routing), it pro-
vides interpretable indicators for which attributes
are specifically not present for each assignment.
883
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
je
un
c
_
un
_
0
0
4
0
2
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 7: End-to-End Methods. Generalization performance of end-to-end-methods on ShapeWorld tasks. Nous
observe that our conjunctivist NES framework offers stronger generalization performance on both standard (Task
UN) and systematic (Task B) compositional task settings. See Section 4.1.4 for additional details and analysis.
Chiffre 8: Learned Event Routing. We visualize the
predicted soft event routings of a sentence from
Chiffre 4. (je) shows how ‘‘a’’ and ‘‘triangle’’ are
effectively arity-1 functions, with the same event e1
routed to their first argument, and e∅ to the second. (iii)
shows the same, with e2. (ii) shows an arity-2 routing for
relational predicates, et (iv) shows how punctuation
can be given an arity-0 routing. See Section 4.1.4.
handle more complex language settings. We find
that while the ablation maintains performance
on the standard tasks, its accuracy significantly
decreases in this setting where some input state-
ments have negation. Dans l'ensemble, we observe that the
rich, augmented event space and flexible event
routing stage enable our conjunctivist framework
to learn how to model non-intersective modifiers, un
crucial step for real-world language (Section 4.2).
4.2 Experiments: Real-World Language
Having validated the efficacy of NES in a con-
trolled synthetic setting, we now explore NES in
a grounded reference game task to demonstrate
its broader applicability. Because the overall
end-to-end NES framework requires no low-level
supervision during training, it mirrors the broader
Chiffre 9: Negation with NES. (un) We visualize
one way in which NES can handle coordination for
non-intersective modifiers (par exemple., attribute negation) par
leveraging the background event e∅. NES soft routing
leads to a modified event argument input e(cid:12)
1 attending
over e1 and e∅, enabling the red classifier to output
the opposite prediction (now, output score = 1.0 si
original e1 is not red). (b) NES performance on
Task A and B negation variants remains consistent.
Ablation (Section 4.1.4) highlights the impact of the
event routing mechanism.
applicability of
(MAC)
to less
langue.
semantics methods
implicit
structuré, human-generated
Chairs-in-Context (CiC). The Chairs-in-Context
(CiC) dataset (Achlioptas et al., 2019) contains
chairs and other objects from the ShapeNet
dataset, paired with human-generated language
collected in the context of a reference game. Chaque
CiC input consists of a set of 3 chairs represent-
ing a contrastive communication context, with a
884
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
je
un
c
_
un
_
0
0
4
0
2
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
human utterance (up to 33 tokens) intended to
identify one of the chairs. In total, there are over
75k triplets with an 80-10-10 split for train-val-
test. CiC also contains a zero-shot evaluation set
with triplets of unseen object classes (par exemple., tables).
CiC is challenging due to its relatively long-tail
language diversity and varied visual inputs.
Task A: Language Generalization. Our first CiC
benchmark task is language generalization, où
a model must ground the specific chair from the
input set given a referring utterance. The dataset
split ensures no overlap in speaker-listener pairs
between training and evaluation, so models must
generalize to new communication contexts.
Task B: Zero-Shot Generalization. Our second
CiC benchmark task is zero-shot generalization,
which examines the ability for the model
à
generalize from understanding attribute concepts
learned in a chairs context to contexts with unseen
object classes like tables and lamps. The overall
task setting is the same as before, but during
evaluation the triplets are composed of objects
from a particular unseen class. For consistency
with prior work, all models here are evaluated
on an image-only setting (c'est à dire., no 3D point-cloud
representation). We provide a breakdown of the
results on the full zero-shot transfer set by class.
Models and Implementation. Our main base-
line is the recent ShapeGlot (SG) architecture
(Achlioptas et al., 2019). The SG baseline lever-
ages recurrent, convolutional, and attention com-
ponents in an end-to-end architecture to achieve
state-of-the-art performance on the language and
zero-shot generalization datasets. We also con-
sider a conjunctive baseline with event classifiers
without the soft event routing stage, reminiscent of
a product-of-experts (PoE) classification setting.
This baseline serves to illustrate the impact of
the flexible routing stage on compositionality, et
in particular handling of non-intersective modi-
fiers. We additionally report two compositional
baselines from Section 4.1.2, MAC and NMN, fol-
lowing the protocols outlined by our previous end-
to-end synthetic experiments 4.1.4. Because CiC
contains unstructured human-generated text and it
is difficult to train NMN end-to-end from denota-
tion alone, we initialize the sequence-to-sequence
program generator in the NMN baseline by pre-
training on auxiliary parse information for 1,000
examples (Suhr et al., 2019; Yi et al., 2018); tous
Method
Majority
*SG-NoAttn
*SG-Attn
LSTM-Attn
PoE
NMN
MAC
NES
NES
NES
NES+
Input
Listener Acc.
N/A
VGG16-SN
VGG16-SN
VGG16-SN
VGG16-SN
VGG16-SN
VGG16-SN
VGG16
VGG16-SN
Res101
Res101
0.333
0.812 ± 0.008
0.817 ± 0.008
0.731 ± 0.012
0.752 ± 0.009
0.763 ± 0.023
0.818 ± 0.013
0.842 ± 0.005
0.856 ± 0.005
0.853 ± 0.011
0.870 ± 0.009
Tableau 1: CiC-Language Generalization. NES on
real-world language from the Chairs-in-Context
(CiC) dataset. *SG architectures from Achlioptas
et autres. (2019) are the previously reported state-
of-the-art method. NES+ grounds sub-events on
the feature grid input. -SN indicates ShapeNet
pre-trained features.
other baselines do not have any additional supervi-
sion data. Enfin, we also consider a denser input
event space for NES corresponding to sub-regions
in the image input. Ici, sub-events are addition-
ally sampled from the (unannotated) final conv4
feature grid of the encoder network; we denote
this as NES+ in our experiments. We adopt con-
sistent experimental settings from Achlioptas et al.
(2019), treating each chair as an event candidate
espace, with predictions normalized by 3-way soft-
max over possible target images. All model sizes
are kept comparable in number of parameters for
fair comparison. We leverage the same pre-trained
VGG16 features (Simonyan and Zisserman, 2015;
Chang et al., 2015) and GloVe (Wiki.6B) embed-
dings (Pennington et al., 2014). For completeness,
we report results with VGG16 and ResNet-101
without ShapeNet pre-training for both tasks.
Analysis. We report our results in Table 1 et
Tableau 2 against
the prior state-of-the-art SG
architecture (Achlioptas et al., 2019). The MAC
baseline provides comparable performance to the
prior state-of-the-art. The NMN baseline has rea-
sonable accuracy, albeit lower than the MAC and
SG baselines. This is likely due to the ambiguity
in longer token sequences (up to 33 tokens),
which can contain filler words and occasional
disfluencies that hurt the efficacy of the sequence-
to-sequence program generator. Néanmoins,
NMN outperforms the PoE baseline, which serves
885
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
je
un
c
_
un
_
0
0
4
0
2
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
je
un
c
_
un
_
0
0
4
0
2
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 10: CiC Qualitative Results. We visualize results on the (un) CiC evaluation set and (b) zero-shot evaluation
ensemble. Chair and bed triplets (c∗, b∗) are shown with NES output scores. Tables show relative classifier scores that are
normalized per word, for visualization purpose only (par exemple., if a word has classifier scores of 1.0 across events, alors
we show them as 0.333). NES grounds real-world reference language and provides meaningful interpretability
on how individual classifiers contribute to the final score. (c) Event classifiers can be used standalone for
retrieval, showing lexical consistency between antonyms; (d) shows Pearson correlations (p-value < 1e − 13).
See Section 4.2.
Model
Major.
*SG
PoE
NMN
MAC
NES
w/VGG16
w/Res101
Zero-Shot Classes
Lamp
0.333
0.501
0.422
0.462
0.533
Bed
0.333
0.564
0.466
0.492
0.531
Table
0.333
0.637
0.587
0.572
0.632
Sofa
0.333
0.536
0.483
0.532
0.551
All
0.333
0.560
0.490
0.515
0.567
in both the main (chairs) and unseen zero-shot set-
tings. We also show how learned event classifiers
are lexically consistent by performing standalone
retrieval of antonym pairs. We observe that high-
ranked retrievals for a word classifier correlate
with low-ranked retrievals of its antonym.
0.544
0.573
0.578
0.589
0.693
0.715
0.588
0.610
0.601
0.622
4.3 Overall Discussion
Table 2: CiC-Zero Shot Generalization. Zero-
shot generalization to unseen objects on the
Chairs-in-Context (CiC) dataset. Results suggest
NES can learn words as event classifiers in a
general, object-agnostic manner. *SG model from
(Achlioptas et al., 2019).
as a simplistic conjunctive modular baseline
without the NES event routing framework.
We observe that our model
improves over
the prior state-of-the-art work on this dataset by
a large margin on the original neural listener
task. Further, NES significantly improves zero-
shot generalization performance, indicating that
it has learned event classifiers for attributes (e.g.,
‘‘messy’’, ‘‘tall’’) that can generalize to entirely
unseen input event distributions. We visualize
qualitative results in Figure 10: NES can provide
interpretable event classifier outputs at the word
level without any additional low-level supervision,
We provide additional discussion of the overall
NES framework, considering its broader implica-
tions, limitations, and avenues for further work.
Broader Generality. In the above sections, we
have described our key results of NES on the
ShapeWorld and CiC benchmarks. However,
modular neural network approaches like NMN
are intuitively suited to settings where the visual
and language environments are particularly regu-
lar, context-free, and unambiguous. In its current
formulation, NES is similarly suited to such struc-
tured settings: effective generalization to highly
irregular and context-sensitive vision and lan-
guage settings in images and videos (Zhou et al.,
2019), remains outside the current scope of the pre-
sented paper. Nonetheless, we believe that careful
consideration of some of the key elements in the
NES framework, such as the proposed soft event
routing system with ungrounded events used for
coordinating richer meaning, can offer a promising
route towards improving the state-of-the-art.
886
Computational Complexity. Through its exis-
tential quantification operating over events, the
complexity of event assignment (Equation (7))
during inference scales by O(kn−1), where k is
the number of visual event candidates V and
n − 1 the number of events e in the logical form
F (excluding e∅). This was not an issue in the
domains examined here, but may become one
in complex vision-language domains. Exploring
potential relationships with concurrent techniques
(Bogin et al., 2020) that increase computational
complexity but also improve systematicity may
prove insightful here as well.
5 Conclusion
In this work, we introduced neural event seman-
tics (NES) for compositional grounded language
framework’s conjunctivist
understanding. Our
design offers a compelling alternative to designs
rooted primarily in function-based semantics: By
deriving structure from events and their (soft)
routings, NES operates with a simpler composition
ruleset (conjunction) and effectively learns seman-
tic concepts without any low-level ground truth
supervision. Controlled synthetic experiments
(ShapeWorld) show the generalization benefits of
our framework, and we demonstrate broader appli-
cability of NES on real-world language data (CiC)
by significantly improving language and zero-shot
generalization over prior state-of-the-art. Ulti-
mately, our work shows that deep consideration of
the mechanisms for compositional neural methods
may yield techniques better suited for differen-
tiable neural modeling, maintaining core expres-
sivity for grounded language understanding tasks.
Acknowledgments
We sincerely thank Alex Tamkin, Jesse Mu, Mike
Wu, Panos Achlioptas, Robert Hawkins, Boris
Perkhounkov, Fereshte Khani, Robin Jia, Elisa
Kreiss, Jim Fan, Juan Carlos Niebles, Thomas
Icard, and Paul Pietroski for helpful discussions
and support. We are grateful
to our action
editor, Luke Zettlemoyer, and our anonymous
reviewers for their insightful and constructive
feedback during the review process. S. Buch is
supported by an NDSEG Fellowship. This work
was supported in part by the Office of Naval
Research grant ONR MURI N00014-16-1-2007
and by a NSF Expeditions Grant, Award Number
(FAIN) 1918771. This article reflects the authors’
opinions and conclusions, and not any other entity.
References
Panos Achlioptas, Judy Fan, Robert Hawkins,
Noah Goodman, and Leonidas J. Guibas.
2019. ShapeGlot: Learning language for shape
the IEEE
differentiation. In Proceedings of
International Conference on Computer Vision,
pages 8938–8947. https://doi.org/10
.1109/ICCV.2019.00903
Jacob Andreas, Marcus Rohrbach, Trevor
Darrell, and Dan Klein. 2016a. Learning
to compose neural networks for question
answering. NAACL. https://doi.org
/10.18653/v1/N16-1181
Jacob Andreas, Marcus Rohrbach, Trevor Darrell,
and Dan Klein. 2016b. Neural module net-
works. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recog-
nition, pages 39–48. https://doi.org
/10.1109/CVPR.2016.12
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu,
Margaret Mitchell, Dhruv Batra, C. Lawrence
Zitnick, and Devi Parikh. 2015. VQA: Visual
question answering. In Proceedings of the IEEE
International Conference on Computer Vision.
https://doi.org/10.1109/ICCV.2015
.279
Dzmitry Bahdanau, Shikhar Murty, Michael
Noukhovitch, Thien Huu Nguyen, Harm de
Vries, and Aaron Courville. 2019a. Systematic
generalization: What is required and can it be
learned? ICLR.
Dzmitry Bahdanau, Harm de Vries, Timothy J.
O’Donnell, Shikhar Murty, Philippe Beaudoin,
Yoshua Bengio, and Aaron Courville. 2019b.
CLOSURE: Assessing systematic general-
ization of CLEVR models. arXiv preprint
arXiv:1912.05783.
Ben Bogin, Sanjay Subramanian, Matt Gardner,
and Jonathan Berant. 2020. Latent compo-
sitional
representations improve systematic
generalization in grounded question answering.
arXiv preprint arXiv:2007.00266. https://
doi.org/10.1162/tacl a 00361
887
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
l
a
c
_
a
_
0
0
4
0
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Angel X. Chang, Thomas Funkhouser, Leonidas
Guibas, Pat Hanrahan, Qixing Huang, Zimo
Li, Silvio Savarese, Manolis Savva, Shuran
Song, Hao Su, et al. 2015. ShapeNet: An
information-rich 3D model repository. arXiv
preprint arXiv:1512.03012.
Devendra Singh Chaplot, Kanthashree Mysore
Sathyendra, Rama Kumar Pasumarthi, Dheeraj
Rajagopal, and Ruslan Salakhutdinov. 2018.
Gated-attention architectures for task-oriented
language grounding. In Thirty-Second AAAI
Conference on Artificial Intelligence.
Xinlei Chen, Hao
Fang, Tsung-Yi Lin,
Ramakrishna Vedantam, Saurabh Gupta, Piotr
Doll´ar, and C. Lawrence Zitnick. 2015.
Microsoft COCO captions: Data collection
and evaluation server. arXiv preprint arXiv:
1504.00325.
Ann Copestake, Guy Emerson, Michael Wayne
Goodman, Matic Horvat, Alexander Kuhnle,
and Ewa Muszy´nska. 2016. Resources for
building applications with dependency mini-
mal recursion semantics. In Proceedings of
the Tenth International Conference on Lan-
guage Resources and Evaluation (LREC’16),
pages 1240–1247.
Donald Davidson. 1967. The logical form of
action sentences. In The Logic of Decision and
Action, pages 81–120. Pittsburgh: University of
Pittsburgh Press.
Alex Graves and J¨urgen Schmidhuber. 2005.
Framewise phoneme classification with bidi-
rectional LSTM and other neural network
architectures. Neural Networks,
18(5–6):
602–610. https://doi.org/10.1016/j
.neunet.2005.06.042,
Pubmed:
16112549
Kaiming He, Georgia Gkioxari, Piotr Doll´ar,
and Ross Girshick. 2017. Mask R-CNN.
In Proceedings of the IEEE International Con-
ference on Computer Vision, pages 2961–2969.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and
Jian Sun. 2016. Deep residual
learning for
image recognition. In Proceedings of the IEEE
Conference on Computer Vision and Pattern
Recognition, pages 770–778.
Ronghang Hu, Jacob Andreas, Trevor Darrell,
and Kate Saenko. 2018. Explainable neural
computation via stack neural module networks.
In Proceedings of the European Conference on
Computer Vision (ECCV), pages 53–69.
Ronghang Hu, Jacob Andreas, Marcus Rohrbach,
Trevor Darrell, and Kate Saenko. 2017.
to
Learning
reason: End-to-end module
for visual question answering.
networks
In Proceedings of
the IEEE International
Conference on Computer Vision.
Drew A. Hudson and Christopher D. Manning.
2018. Compositional attention networks for
machine reasoning. In International Conference
on Learning Representations (ICLR).
Drew A. Hudson and Christopher D. Manning.
2019. GQA: A new dataset for real-world visual
reasoning and compositional question answer-
ing. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recogni-
tion, pages 6700–6709. https://doi.org
/10.1109/CVPR.2019.00686
T. S. Jayram, Vincent Marois, Tomasz Kornuta,
Vincent Albouy, Emre Sevgen, and Ahmet S.
learning in visual
Ozcan. 2019. Transfer
reasoning. arXiv preprint
and relational
arXiv:1911.11938.
Justin Johnson, Bharath Hariharan, Laurens
van der Maaten, Li Fei-Fei, C. Lawrence
Zitnick, and Ross Girshick. 2017a. CLEVR:
A diagnostic dataset for compositional
lan-
guage and elementary visual reasoning. In
Proceedings of
the IEEE Conference on
Computer Vision and Pattern Recognition,
IEEE. https://doi
pages 1988–1997.
.org/10.1109/CVPR.2017.215
Justin Johnson, Bharath Hariharan, Laurens
van der Maaten, Judy Hoffman, Li Fei-
Fei, C. Lawrence Zitnick, and Ross B.
Girshick. 2017b. Inferring and executing pro-
grams for visual reasoning. In Proceedings of
the IEEE International Conference on Com-
puter Vision, pages 3008–3017. https://
doi.org/10.1109/ICCV.2017.325
Andrej Karpathy and Li Fei-Fei. 2015. Deep
visual-semantic
for generating
alignments
image descriptions. In Proceedings of the IEEE
888
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
l
a
c
_
a
_
0
0
4
0
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Conference on Computer Vision and Pattern
Recognition, pages 3128–3137. https://
doi.org/10.1109/CVPR.2015.7298932
A joint model of language and perception
for grounded attribute learning. International
Conference on Machine Learning.
Jayant Krishnamurthy and Thomas Kollar. 2013.
Jointly learning to parse and perceive: Con-
necting natural language to the physical world.
Transactions of the Association for Compu-
tational Linguistics, 1:193–206. https://
doi.org/10.1162/tacl a 00220
Jayant Krishnamurthy, Oyvind Tafjord, and
Aniruddha Kembhavi. 2016. Semantic pars-
ing to probabilistic programs for situated
question answering. In Proceedings of
the
2016 Conference on Empirical Methods in
Natural Language Processing, pages 160–170,
Austin, Texas. Association for Computational
Linguistics. https://doi.org/10.18653
/v1/D16-1016
Alexander Kuhnle and Ann A. Copestake. 2017.
ShapeWorld - A new test methodology for
language understanding. CoRR,
multimodal
abs/1704.04517.
Brenden M. Lake, Tomer D. Ullman, Joshua B.
Tenenbaum, and Samuel J. Gershman. 2017.
learn and think
that
Building machines
like people. Behavioral and Brain Sci-
ences, 40. https://doi.org/10.1017
/S0140525X16001837, Pubmed: 27881212
Will Monroe, Robert XD Hawkins, Noah D.
Goodman, and Christopher Potts. 2017. Col-
ors in Context: A pragmatic neural model
for grounded language understanding. Trans-
actions of the Association for Computational
Linguistics, 5:325–338. https://doi.org
/10.1162/tacl a 00064
Richard Montague. 1970. Universal grammar.
https://doi
Theoria,
.org/10.1111/j.1755-2567.1970
.tb00434.x
36(3):373–398.
Adam Paszke, Sam Gross, Francisco Massa,
Adam Lerer,
James Bradbury, Gregory
Chanan, Trevor Killeen, Zeming Lin, Natalia
Gimelshein, Luca Antiga, Alban Desmaison,
Andreas Kopf, Edward Yang, Zachary DeVito,
Martin Raison, Alykhan Tejani, Sasank
Chilamkurthy, Benoit Steiner, Lu Fang, Junjie
Bai, and Soumith Chintala. 2019. PyTorch:
An imperative style, high-performance deep
learning library. In H. Wallach, H. Larochelle,
A. Beygelzimer, F. d’ Alch´e-Buc, E. Fox,
in
and R. Garnett,
Neural Information Processing Systems 32,
pages 8024–8035. Curran Associates, Inc.
editors, Advances
Mateusz Malinowski and Mario Fritz. 2014. A
multi-world approach to question answering
about real-world scenes based on uncertain
information
input. Advances
processing systems, 27:1682–1690.
neural
in
Jeffrey
Socher,
Pennington, Richard
and
Christopher D. Manning. 2014. GloVe: Global
vectors for word representation. In Empiri-
cal Methods in Natural Language Process-
ing (EMNLP), pages 1532–1543. https://
doi.org/10.3115/v1/D14-1162
Jiayuan Mao, Chuang Gan, Pushmeet Kohli,
and Jiajun Wu.
Joshua B. Tenenbaum,
2019. The neuro-symbolic concept
learner:
Interpreting scenes, words, and sentences
In International
supervision.
from natural
Conference on Learning Representations.
Vincent Marois, T. S. Jayram, Vincent Albouy,
Tomasz Kornuta, Younes Bouhadjar, and
Ahmet S. Ozcan. 2018. On transfer learning
using a MAC model variant. arXiv preprint
arXiv:1811.06529.
Cynthia Matuszek, Nicholas FitzGerald, Luke
Zettlemoyer, Liefeng Bo, and Dieter Fox. 2012.
Ethan Perez, Florian Strub, Harm De Vries,
Vincent Dumoulin, and Aaron Courville.
2018. FiLM: Visual reasoning with a general
In Thirty-Second AAAI
conditioning layer.
Conference on Artificial Intelligence.
Paul M. Pietroski. 2005. Events and Semantic
Architecture. Oxford University Press.
Laura Ruis, Jacob Andreas, Marco Baroni, Diane
Bouchacourt, and Brenden M. Lake. 2020.
A benchmark for systematic generalization in
grounded language understanding. Advances in
Neural Information Processing Systems.
889
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
l
a
c
_
a
_
0
0
4
0
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Karen Simonyan and Andrew Zisserman. 2015.
Very deep convolutional networks for large-
In International
scale image recognition.
Conference on Learning Representations.
interpretations
Sanjay Subramanian, Ben Bogin, Nitish Gupta,
Tomer Wolfson, Sameer Singh,
Jonathan
Berant, and Matt Gardner. 2020. Obtaining
faithful
from compositional
the
neural networks.
58th Annual Meeting of the Association for
Computational Linguistics, pages 5594–5608.
https://doi.org/10.18653/v1/2020
.acl-main.495
In Proceedings of
Alane Suhr, Stephanie Zhou, Ally Zhang, Iris
Zhang, Huajun Bai, and Yoav Artzi. 2019. A
Corpus for reasoning about natural language
grounded in photographs. In Proceedings of
the 57th Annual Meeting of the Association for
Computational Linguistics, pages 6418–6428.
https://doi.org/10.18653/v1/P19
-1644
Adam Vogel and Dan Jurafsky. 2010. Learning
In Pro-
to follow navigational directions.
ceedings of the 48th Annual Meeting of the
Association for Computational Linguistics,
pages 806–814.
Ronald J. Williams. 1992. Simple statistical
gradient-following algorithms for connection-
ist reinforcement learning. Machine learning,
https://doi.org/10
8(3–4):229–256.
.1007/BF00992696
Kexin Yi, Jiajun Wu, Chuang Gan, Antonio
Torralba,
Josh
Pushmeet Kohli,
Tenenbaum. 2018. Neural-symbolic VQA: Dis-
entangling reasoning from vision and language
understanding. In Advances in Neural Infor-
mation Processing Systems, pages 1039–1050.
and
Luke S. Zettlemoyer and Michael Collins. 2005.
Learning to map sentences to logical form:
Structured classification with probabilistic
categorial grammars. UAI ’05, Proceedings of
the 21st Conference in Uncertainty in Artificial
Intelligence.
Luowei Zhou, Yannis Kalantidis, Xinlei Chen,
Jason J. Corso, and Marcus Rohrbach. 2019.
Grounded video description. In Proceedings
of the IEEE Conference on Computer Vision
and Pattern Recognition, pages 6578–6587.
https://doi.org/10.1109/CVPR
.2019.00674
A Appendix: Equation 8
We describe a formula for an approximation of the
max function (L∞-norm), used during training to
improve end-to-end gradient flow (Section 3.6).
Let s ∈ Rn ≥ 0 be a vector of non-negative
scores. We consider fmax : Rn → R (Equation (8)
in Section 3.6):
fmax(s; β) =
(cid:4)
i (si)β+1
(cid:4)
i (si)β
where β ≥ 0 is a hyperparameter. As β → ∞,
fmax(s; β) → s∗, where s∗ = max(s) = L∞(s).
We can show this by dividing the numerator and
denominator by (s∗)β+1 and taking the limit:
lim
β→∞
fmax(s) = lim
β→∞
(cid:5) (cid:4)
i (si)β+1 / (s∗)β+1
(cid:4)
i (si)β / (s∗)β+1
(cid:6)
(9)
Now all terms where |si| < s∗ tend to 0, leaving
us just the maximum terms in the numerator and
denominator where |si| = s∗. Thus, Equation (9)
reduces to 1
1/s∗ = s∗ , as desired.
Further, |fmax(s)| has the essential property of
always being upper-bounded by s∗. We show this
by H¨older’s inequality. Let xi = si, yi = (si)β,
and let p → ∞ and q → 1 (satisfying conditions
1/p + 1/q = 1 and p, q ∈ (1, ∞)). Then,
(cid:3)
|xiyi| ≤
(cid:4)
(cid:7)
i
(cid:4)
i
|xiyi|
(cid:8) 1
q
|yi|q
≤
(cid:5)
(cid:3)
(cid:5)
i
(cid:3)
i
|xi|p
|xi|p
(cid:5)
(cid:6) 1
p
(cid:3)
(cid:6) 1
q
|yi|q
i
(cid:6) 1
p
i
|fmax(s)| ≤ L∞(s) = s∗
Thus, with non-negative scores si ≥ 0, we have
fmax(s) = max(s) and fmax(s) ≤ max(s).
lim
β→∞
890
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
0
2
1
9
5
7
7
1
8
/
/
t
l
a
c
_
a
_
0
0
4
0
2
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3