Experts, Errors, and Context:
A Large-Scale Study of Human Evaluation for Machine Translation
Markus Freitag George Foster David Grangier
Viresh Ratnakar Qijun Tan Wolfgang Macherey
Google Research
{freitag, fosterg, grangier, vratnakar, qijuntan, wmach}@google.com
Abstrait
Human evaluation of modern high-quality
machine translation systems is a difficult prob-
lem, and there is increasing evidence that
inadequate evaluation procedures can lead to
erroneous conclusions. While there has been
considerable research on human evaluation,
the field still
lacks a commonly accepted
standard procedure. As a step toward this
goal, we propose an evaluation methodology
grounded in explicit error analysis, based on
the Multidimensional Quality Metrics (MQM)
framework. We carry out the largest MQM re-
search study to date, scoring the outputs of top
systems from the WMT 2020 shared task in
two language pairs using annotations provided
by professional translators with access to full
document context. We analyze the resulting
data extensively, finding among other results
a substantially different ranking of evaluated
systems from the one established by the WMT
crowd workers, exhibiting a clear preference
for human over machine output. Surprisingly,
we also find that automatic metrics based on
pre-trained embeddings can outperform hu-
man crowd workers. We make our corpus
publicly available for further research.
1
Introduction
Like many natural language generation tasks, ma-
chine translation (MT) is difficult to evaluate
because the set of correct answers for each in-
put is large and usually unknown. This limits the
accuracy of automatic metrics, and necessitates
costly human evaluation to provide a reliable gold
standard for measuring MT quality and progress.
Yet even human evaluation is problematic. Pour
instance, we often wish to decide which of two
translations is better, and by how much, but what
should this take into account? If one translation
sounds somewhat more natural than another, mais
contains a slight inaccuracy, what is the best way
to quantify this? To what extent will different
raters agree on their assessments?
The complexities of evaluating translations—
both machine and human—have been extensively
studied, and there are many recommended best
pratiques. Cependant, due to expedience, human
evaluation of MT is frequently carried out on
isolated sentences by inexperienced raters with
the aim of assigning a single score or ranking.
When MT quality is poor, this can provide a
useful signal; but as quality improves, there is
a risk that the signal will become lost in rater
noise or bias. Recent papers have argued that poor
human evaluation practices have led to mislead-
ing results, including erroneous claims that MT
has achieved human parity (Toral, 2020; L¨aubli
et coll., 2018).
Our key insight in this paper is that any scor-
ing or ranking of translations is implicitly based
on an identification of errors and other imperfec-
tion. Asking raters for a single score forces them
to synthesize this complex information, and can
lead to rushed judgments based on partial anal-
yses. En outre, the implicit weights assigned
by raters to different types of errors may not
match their importance in the current application.
An explicit error listing contains all necessary
information for judging translation quality, et
can thus be seen as a ‘‘platinum standard’’ for
other human evaluation methodologies. This in-
sight is not new: It is the conceptual basis for
the Multidimensional Quality Metrics (MQM)
framework developed in the EU QTLaunchPad
and QT21 projects (www.qt21.eu), which we
endorse and adopt for our experiments. MQM in-
volves explicit error annotation, deriving scores
from weights assigned to different errors, and re-
turning an error distribution as additional valuable
information.
MQM is a generic framework that provides
a hierarchy of translation errors that can be tai-
lored to specific applications. We identified a
hierarchy appropriate for broad-coverage MT,
and annotated outputs from 10 top-performing
1460
Transactions of the Association for Computational Linguistics, vol. 9, pp. 1460–1474, 2021. https://doi.org/10.1162/tacl a 00437
Action Editor: Alexandra Birch. Submission batch: 5/2021; Revision batch: 8/2021; Published 12/2021.
c(cid:2) 2021 Association for Computational Linguistics. Distributed under a CC-BY 4.0 Licence.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
‘‘systems’’ (including human references) for both
the English→German (EnDe) and Chinese→English
(ZhEn) language directions in the WMT 2020
news translation task (Barrault et al., 2020), en utilisant
professional translators with access to full docu-
ment context. For comparison purposes, we also
collected scalar ratings on a 7-point scale from
both professionals and crowd workers.
We analyze the resulting data along many
different dimensions: Comparing the system rank-
ings resulting from different rating methods,
including the original WMT scores; characterizing
the error patterns of modern neural MT systems,
including profiles of difficulty across documents,
and comparing them to human translation (HT);
measuring MQM inter-annotator agreement; et
re-evaluating the performance of automatic met-
rics submitted to the WMT 2020 metrics task. Notre
most striking finding is that MQM ratings sharply
revise the original WMT ranking of translations,
exhibiting a clear preference for HT over MT, et
promoting some low-ranked MT systems to much
higher positions. This in turn changes the conclu-
sions about the relative performance of different
automatic metrics; interestingly, we find that most
metrics correlate better with MQM rankings than
WMT human scores do. We hope these results
will underscore and help publicize the need for
more careful human evaluation, particularly in
shared tasks intended to assess MT or metric
performance. We release our corpus to encourage
further research. 1 We also release MQM Viewer,2
an interactive tool to analyze MQM data, compute
scores and their breakdowns as described in this
papier, and find slices of interesting examples. Notre
main contributions are:
• A proposal for a standard MQM scoring
scheme appropriate for broad-coverage MT.
• Release of a large-scale human evaluation
corpus for 2 méthodologies (MQM and
pSQM) with annotations for over 100k HT
and high-quality-MT segments in two lan-
guage pairs (EnDe and ZhEn) from WMT
2020. This is by far the largest study of human
evaluation results released to the public.
1https://github.com/google/wmt-mqm-human
-evaluation.
2https://github.com/google-research/google
-research/tree/master/mqm viewer.
• Re-evaluation of the performance of MT sys-
tems and automatic metrics on our corpus,
showing clear distinctions between HT and
MT based on MQM ratings, adding to the
evidence against claims of human parity.
• Showing that crowd-worker evaluations have
low correlation with MQM-based evalua-
tion, calling into question conclusions drawn
on the basis of such evaluations.
• Demonstration that automatic metrics based
on pre-trained embeddings can outperform
human crowd workers.
• Characterization of current error types in HT
and MT, identifying specific MT weaknesses.
2 Related Work
The ALPAC report (1966) defined an evaluation
methodology for MT based on ‘‘intelligibility’’
(comprehensibility) and ‘‘fidelity’’ (adequacy).
The ARPA MT Initiative (White et al., 1994)
defined an overall quality score based on ‘‘ade-
quacy’’, ‘‘fluency’’, and ‘‘comprehension’’. Le
first WMT evaluation campaign (Koehn and
Monz, 2006) used adequacy and fluency ratings
on a 5-point scale acquired from participants as
their main metric. Vilar et al. (2007) proposed
a ranking-based evaluation approach, which be-
came the official metric at WMT from 2008
jusqu'à 2016 (Callison-Burch et al., 2008). The rat-
ings were still acquired from the participants of
the evaluation campaign. Graham et al. (2013)
compared human assessor consistency levels for
judgments collected on a five-point interval-level
scale to those collected on a 1–100 continuous
scale, using machine translation fluency as a test
case. They claim that the use of a continuous scale
eliminates individual judge preferences, resulting
in higher levels of inter-annotator consistency.
Bojar et al. (2016) came to the conclusion that
fluency evaluation is highly correlated to ade-
quacy evaluation. As a consequence of the latter
two papers, continuous direct assessment focus-
ing on adequacy has been the official WMT met-
ric since 2017 (Bojar et al., 2017). Due to budget
constraints, WMT understandably conducts its hu-
man evaluation mostly with researchers and/or
crowd workers.
Avramidis et al. (2012) used professional trans-
lators to rate MT output on three different tasks:
1461
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
ranking, error classification, and post-editing.
Castilho et al. (2017) found that crowd workers
lack knowledge of translation and, compared w
professional translators, tend to be more accepting
de (subtle) translation errors. Graham et al. (2017)
showed that crowd-worker evaluation has to be
filtered to avoid contamination of results through
the inclusion of false assessments. The quality
of ratings acquired by either researchers or crowd
workers has further been questioned by Toral et al.
(2018) and L¨aubli et al. (2020). Mathur et al.
(2020) re-evaluated a subset of WMT submis-
sions with professional translators and showed
that the resulting rankings changed and were better
aligned with automatic scores. Fischer and L¨aubli
(2020) found that the number of segments with
wrong terminology, omissions, and typographi-
cal problems for MT output is similar to HT.
Fomicheva (2017) and Bentivogli et al. (2018)
raised the concern that reference-based human
evaluation might penalize correct translations that
diverge too much from the reference. The litera-
ture mostly agrees that source-based rather than
reference-based evaluation should be conducted
(L¨aubli et al., 2020). The impact of translationese
(Koppel and Ordan, 2011) on human evaluation
of MT has recently received attention (Toral et
al., 2018; Zhang and Toral, 2019; Freitag et al.,
2019; Graham et al., 2020). These papers show
that only natural source sentences should be used
for human evaluation.
As alternatives to adequacy and fluency,
Scarton and Specia (2016) presented reading
comprehension for MT quality evaluation.
(2018) proposed gap-filling,
Forcada et al.
where certain words are removed from reference
translations and readers are asked to fill the gaps
left using the machine-translated text as a hint.
Popovi´c (2020) proposed to ask annotators to just
label problematic parts of the translations instead
of assigning a score.
The Multidimensional Quality Metrics (MQM)
framework was developed in the EU QT-
LaunchPad and QT21 projects
(2012–2018)
(www.qt21.eu) to address the shortcomings of pre-
vious quality evaluation methods (Lommel et al.,
2014). MQM provides a generic methodology for
assessing translation quality that can be adapted to
a wide range of evaluation needs. Klubiˇcka et al.
(2018) designed an MQM-compliant error tax-
onomy for Slavic languages to run a case
study for 3 MT systems for English→Croatian.
Rei et al. (2020) used MQM labels to fine-tune
COMET for automatic evaluation. Thomson
and Reiter (2020) designed an error annotation
schema based on pre-defined error categories for
table-to-text tasks.
3 Human Evaluation Methodologies
We compared three human evaluation techniques:
the WMT 2020 baseline; ratings on a 7-point
Likert-type scale which we refer to as a Scalar
Quality Metric (SQM); and evaluations under the
MQM framework. We describe these method-
ologies in the following three sections, deferring
concrete experimental details about annotators and
data to the subsequent section.
3.1 WMT
As part of
the WMT evaluation campaign
(Barrault et al., 2020), WMT runs human evalua-
tion of the primary submissions for each language
pair. The organizers collect segment-level rat-
ings with document context (SR+DC) on a 0–100
scale using either source-based evaluation with a
mix of researchers/translators (for translations out
of English) or reference-based evaluation with
crowd workers (for translations into English).
En outre, WMT conducts rater quality con-
trols to remove ratings from raters that are not
trustworthy. En général, for each system, only
a subset of documents receive ratings, avec le
rated subset differing across systems. The orga-
nizers provide two different segment-level scores,
averaged across one or more raters: (un) the raw
score; et (b) a z-score which is standardized
for each annotator. Document- and system-level
scores are averages over segment-level scores.
For more details, we refer the reader to the WMT
findings papers.
3.2 SQM
Similar to the WMT setting, the Scalar Quality
Metric (SQM) evaluation collects segment-level
scalar ratings with document context. This evalu-
ation presents each source segment and translated
segment from a document in a table row, demander
the rater to pick a rating from 0 through 6. Le
rater can scroll up or down to see all the other
source/translation segments from the document.
Our SQM experiments used the 0–6 rating scale
described above, instead of the wider, continu
1462
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
You will be assessing translations at the segment level, where a segment may contain one or more
phrases. Each segment is aligned with a corresponding source segment, and both segments are
displayed within their respective documents. Annotate segments in natural order, as if you were
reading the document. You may return to revise previous segments.
Please identify all errors within each translated segment, up to a maximum of five. If there are more
than five errors, identify only the five most severe. If it is not possible to reliably identify distinct
errors because the translation is too badly garbled or is unrelated to the source, then mark a single
Non-translation error that spans the entire segment.
To identify an error, highlight the relevant span of text, and select a category/sub-category and
severity level from the available options. (The span of text may be in the source segment if the error
is a source error or an omission.) When identifying errors, please be as fine-grained as possible. Pour
example, if a sentence contains two words that are each mistranslated, two separate mistranslation
errors should be recorded. If a single stretch of text contains multiple errors, you only need to indicate
the one that is most severe. If all have the same severity, choose the first matching category listed in
the error typology (eg, Accuracy, then Fluency, then Terminology, etc.).
Please pay particular attention to document context when annotating. If a translation might be
questionable on its own but is fine in the context of the document, it should not be considered
erroneous; inversement, if a translation might be acceptable in some context, but not within the current
document, it should be marked as wrong.
There are two special error categories: Source error and Non-translation. Source errors should be
annotated separately, highlighting the relevant span in the source segment. They do not count against
the five-error limit for target errors, which should be handled in the usual way, whether or not they
resulted from a source error. There can be at most one Non-translation error per segment, and it
should span the entire segment. No other errors should be identified if Non-Translation is selected.
Tableau 1: MQM annotator guidelines.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
scale recommended by Graham et al. (2013), comme
this scale has been an established part of our ex-
isting MT evaluation ecosystem. It is possible that
system rankings may be slightly sensitive to this
nuance, but less so with raters who are translators
rather than crowd workers, we believe.
3.3 MQM
To adapt the generic MQM framework for our
contexte, we followed the official guidelines for
scientific research (MQM-usage-guidelines.pdf).
Our annotators were instructed to identify all
errors within each segment in a document, pay-
ing particular attention to document context;
see Table 1 for complete annotator guidelines.
Each error was highlighted in the text, and labeled
with an error category from Table 2, and a sever-
ville. To temper the effect of long segments, nous
imposed a maximum of five errors per segment,
instructing raters to choose the five most severe
errors for segments containing more errors. Seg-
ments that are too badly garbled to permit reliable
identification of individual errors are assigned a
special Non-translation error.
Error severities are assigned independent of
catégorie, and consist of Major, Minor, and Neu-
tral levels, corresponding, respectivement, to ac-
tual translation or grammatical errors, smaller
imperfections, and purely subjective opinions
about the translation. Many MQM schemes in-
clude an additional Critical severity which is
worse than Major, but we dropped this be-
cause its definition is often context-specific. Nous
the distinc-
felt
tion between Major and Critical was likely to
be highly subjective, while Major errors (true
that for broad coverage MT,
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
1463
Error Category
Accuracy
Fluency
Terminology
Style
Locale
convention
Other
Source error
Non-translation
Description
Translation includes information not present in the source.
Translation is missing content from the source.
Translation does not accurately represent the source.
Source text has been left untranslated.
Incorrect punctuation (for locale or style).
Incorrect spelling or capitalization.
Problems with grammar, other than orthography.
Wrong grammatical register (eg, inappropriately informal pronouns).
Internal inconsistency (not related to terminology).
Characters are garbled due to incorrect encoding.
Addition
Omission
Mistranslation
Untranslated text
Punctuation
Spelling
Grammar
Register
Inconsistency
Character encoding
Inappropriate for context Terminology is non-standard or does not fit context.
Inconsistent use
Awkward
Address format
Currency format
Date format
Name format
Telephone format
Time format
Terminology is used inconsistently.
Translation has stylistic problems.
Wrong format for addresses.
Wrong format for currency.
Wrong format for dates.
Wrong format for names.
Wrong format for telephone numbers.
Wrong format for time expressions.
Any other issues.
An error in the source.
Impossible to reliably characterize distinct errors.
Tableau 2: MQM hierarchy.
errors) would be easier to distinguish from Minor
ones (imperfections).
Since we are ultimately interested in scoring
segments, we require a weighting on error types.
We fixed the weight on Minor errors at 1, et
considered a range of Major weights from 1 à 10
(the Major weight suggested in the MQM stan-
dard). We also considered special weighting for
Minor Fluency/Punctuation errors. These occur
frequently and often involve non-linguistic phe-
nomena such as the spacing around punctuation
or the style of quotation marks. Par exemple, dans
German, the opening quotation mark is below
rather than above and some MT systems sys-
tematically use the wrong quotation marks. Since
such errors are easy to correct algorithmically and
do not affect the understanding of the sentence,
we wanted to ensure that their role would be to
distinguish among systems that are equivalent in
other respects. Major Fluency/Punctuation errors
that make a text ungrammatical or change its
meaning (par exemple., eliding the comma in Let’s eat,
grandma) are unaffected by this and have the
same weight as other Major errors. Enfin, à
ensure a well-defined maximum score, we set the
weight on the singleton Non-Translation category
to be the same as five Major errors (the maximum
number permitted).
Major Minor Flu/Punc Stab = pSQM
EnDe
ZhEn
5
5
5
10
10
10
5
5
5
10
10
10
1
1
1
1
1
1
1
1
1
1
1
1
1.0
0.5
0.1
1.0
0.5
0.1
1.0
0.5
0.1
1.0
0.5
0.1
36%
38%
39%
28%
43%
33%
19%
24%
28%
18%
19%
21%
Non
yes
yes
Non
Non
Non
yes
yes
yes
Non
Non
Non
Tableau 3: MQM ranking stability for different
weights.
For each weight combination subject to the
above constraints, we examined the stability of
system ranking using a resampling technique:
Draw 10k alternative test sets by sampling seg-
ments with replacement, and count the proportion
of resulting system rankings that match the rank-
ing obtained from the full original test set. Tableau 3
shows representative results. We found that a Ma-
jor, Minor, Fluency/Punctuation assignment of 5,
1, 0.1 gave the best combined stability across
1464
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Category
Weight
ratings / seg
rater pool
raters
Severity
Major
Non-translation
all others
Minor
Fluency/Punctuation
all others
Neutral
tous
25
5
0.1
1
0
Tableau 4: MQM error weighting.
both language pairs while additionally matching
the system-level SQM rankings from profes-
sional translators (= pSQM column in the table).
Tableau 4 summarizes this weighting scheme, dans
which segment-level scores can range from 0 (par-
fect) à 25 (worst). The final segment-level score
is an average over scores from all annotators.
3.4 Experimental Setup
We annotated the WMT 2020 English→German
and Chinese→English test sets, comprising 1418
segments (130 documents) et 2000 segments
(155 documents), respectivement. For each set we
chose 10 ‘‘systems’’ for annotation, y compris
the three reference translations available for
English→German and the two references avail-
able for Chinese→English. The MT outputs
included all top-performing systems according
to the WMT human evaluation, augmented with
systems we selected to increase diversity. Tableau 6
lists all evaluated systems.
Tableau 5 summarizes rating information for the
WMT evaluation and for our additional evalua-
tion: SQM with crowd workers (cSQM), SQM
with professional translators (pSQM), and MQM.
We used disjoint professional translator pools for
pSQM and MQM in order to avoid bias. All mem-
bers of our rater pools were native speakers of the
target language. Note that the average number of
ratings per segment is less than 1 for the WMT
evaluations because not all ratings surpassed the
quality control implemented by WMT. For cSQM,
we assess the quality of the raters based on a profi-
ciency test prior to launching a human evaluation.
This results in a rater pool similar in quality to
WMT, while ensuring three ratings for each doc-
ument. Fait intéressant, the expense for cSQM and
pSQM ratings were similar. MQM was 3 times
more expensive than both SQM evaluations.
WMT EnDe
WMT ZhEn
cSQM EnDe
cSQM ZhEn
pSQM
MQM
0.47
0.86
res./trans.
crowd
3
1
3
3
crowd
crowd
professional
professional
115
219
276
70
6
6
Tableau 5: Details of all human evaluations.
To ensure maximum diversity in ratings for
pSQM and MQM, we assigned documents in
round-robin fashion to all 20 different sets of 3
raters from these pools. We chose an assignment
order that roughly balanced the number of doc-
uments and segments per rater. Each rater was
assigned a subset of documents, and annotated
outputs from all 10 systems for those documents.
Both documents and systems were anonymized
and presented in a different random order to each
rater. The number of segments per rater ranged
from 6,830–7,220 for English→German and from
9,860–10,210 for Chinese→English.
4 Results
4.1 Overall System Rankings
For each human evaluation setup, we calculate a
system-level score by averaging the segment-level
scores for each system. Results are summarized in
Tableau 6. The system- and segment-level correla-
tions to our platinum MQM ratings are shown
in Figures 1 et 2 (English→German), et
Figures 3 et 4 (Chinese→English). Segment-
level correlations are calculated only for segments
that were evaluated by WMT. For both language
pairs, we observe similar patterns when looking
at the results of the different human evaluations,
and come to the following findings:
(je) Human Translations Are Underestimated by
Crowd Workers: Already in 2016, Hassan et al.
(2018) claimed human parity for news-translation
for Chinese→English. We confirm the findings
of Toral et al. (2018); L¨aubli et al. (2018) que
when human evaluation is conducted correctly,
professional translators can discriminate between
human and machine translations. All human
translations are ranked first by both the pSQM
and MQM evaluations for both language pairs.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
1465
(un) English→German
System
Human-B
Human-A
Human-P
Tohoku-AIP-NTT
OPPO
eTranslation
Tencent Translation
VolcTrans
Online-B
Online-A
5.16(1)
4.90(2)
4.32(3)
3.95(4)
3.79(5)
3.68(7)
3.77(6)
3.65(8)
3.60(9)
0.54(1)
0.64(2)
0.85(3)
1.14(4)
1.19(6)
1.16(5)
1.22(8)
1.23(9)
1.20(7)
0.22(1)
0.28(2)
0.57(3)
0.94(4)
1.07(5)
1.18(7)
1.15(6)
1.23(8)
1.34(9)
90.5(1)
85.7(4)
84.2(9)
88.6(2)
87.4(3)
82.5(10)
84.3(8)
84.6(6)
84.5(7)
85.3(5)
0.47(1)
0.58(2)
0.91(3)
1.40(4)
1.63(5)
1.78(7)
1.73(6)
1.80(8)
1.84(9)
2.23(10)
WMT↑ WMT RAW↑ cSQM↑ pSQM↑ MQM ↓ Major↓ Minor↓ Fluency↓ Accuracy↓
0.75(1)
0.569(1)
0.91(2)
0.446(4)
1.41(3)
0.299(10)
2.02(4)
0.468(3)
2.25(5)
0.495(2)
2.33(6)
0.312(9)
2.35(7)
0.386(6)
2.45(8)
0.326(7)
0.416(5)
2.48(9)
0.322(8)
0.28(1)
5.31(1)
0.33(2)
5.20(2)
0.50(3)
5.04(5)
0.61(5)
5.11(3)
0.62(6)
5.03(6)
0.56(4)
5.02(7)
0.63(7)
5.06(4)
0.64(8)
5.00(8)
4.95(9)
0.64(9)
4.85(10) 3.32(10) 2.99(10) 1.73(10) 1.32(10) 0.76(10)
(b) Chinese→English
0.74(1)
0.91(1)
3.43(1)
5.09(2)
0.82(10) 0.95(2)
3.62(2)
5.03(7)
1.31(7)
0.79(6)
5.03(3)
5.04(5)
1.24(5)
0.76(4)
5.13(4)
4.99(8)
1.23(4)
0.79(8)
5.19(5)
5.04(6)
1.23(3)
0.81(9)
5.20(6)
5.07(4)
1.27(6)
0.75(3)
5.34(7)
5.11(1)
1.38(8)
0.75(2)
5.41(8)
5.07(3)
1.43(9)
4.91(9)
0.77(5)
5.48(9)
1.51(10)
4.83(10) 3.89(10) 5.85(10) 5.08(10) 0.79(7)
2.52(1)
2.66(2)
3.71(3)
3.89(4)
3.96(5)
3.97(6)
4.07(9)
4.02(7)
4.05(8)
4.34(10)
2.71(1)
2.81(2)
4.26(3)
4.39(4)
4.43(6)
4.41(5)
4.61(7)
4.67(8)
4.73(9)
4.34(1)
4.29(2)
4.03(3)
4.02(4)
3.99(5)
3.99(5)
3.98(7)
3.97(8)
3.95(9)
Human-A
Human-B
VolcTrans
WeChat AI
Tencent Translation
OPPO
THUNLP
DeepMind
DiDi NLP
Online-B
–
−0.029(9)
0.102(1)
0.077(3)
0.063(4)
0.051(7)
0.028(8)
0.051(6)
0.089(2)
0.06(5)
–
74.8(9)
77.47(5)
77.35(6)
76.67(7)
77.51(4)
76.48(8)
77.96(1)
77.63(3)
77.77(2)
Tableau 6: Human evaluations for 10 submissions of the WMT20 evaluation campaign. Horizontal lines
separate clusters in which no system is significantly outperformed by another in MQM rating according
to the Wilcoxon rank-sum test used to assess system rankings in WMT20.
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
Chiffre 1: English→German: System correlation with
the platinum ratings acquired with MQM.
Chiffre 3: Chinese→English: System-level correlation
with the platinum ratings acquired with MQM.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 2: English→German: Segment-level correlation
with the platinum ratings acquired with MQM.
Chiffre 4: Chinese→English: Segment-level correlation
with the platinum ratings acquired with MQM.
1466
The gap between human translations and MT is
even more visible when looking at the MQM
ratings, which set the human translations first by
a statistically-significant margin, demonstrating
that the quality difference between MT and human
large.3 Another interesting
translation is still
observation is the ranking of Human-P for
English→German. Human-P is a reference trans-
lation generated using the paraphrasing method
de (Freitag et al., 2020) which asked linguists
to paraphrase existing reference translations as
much as possible while also suggesting using
sentence structures.
synonyms and different
Our results support the assumption that crowd
workers are biased to prefer literal, easy-to-rate
translations and rank Human-P low. Professional
translators on the other hand are able to see the
correctness of the paraphrased translations and
ranked them higher than any MT output. Similar
to the standard human translations,
the gap
between Human-P and the MT systems is larger
when looking at the MQM ratings. In MQM,
raters have to justify their ratings by labeling
the error spans which helps to avoid penalizing
non-literal translations.
(ii) WMT Has Low Correlation with MQM:
The human evaluation in WMT was conducted
by crowd workers (Chinese→English) or a mix of
researchers/translators (English→German) pendant
the WMT evaluation campaign. Plus loin, differ-
ent FROM all other evaluations in this paper,
WMT conducted a reference-based/monolingual
human evaluation for Chinese→English in which
the machine translation output was compared to
a human-generated reference. When comparing
the system ranks based on WMT for both lan-
guage pairs with the ones generated by MQM,
we can see low correlation for English→German
(voir la figure 1) and even negative correlation for
Chinese→English (voir la figure 3). We also see very
low segment-level correlation for both language
pairs (voir la figure 2 and Figure 4). Plus tard, we will
also show that the correlation of SOTA automatic
metrics are higher than the human ratings gener-
ated by WMT. The results question the reliability
of the human ratings acquired by WMT.
3En général, MQM ratings induce twice as many statis-
tically significant differences between systems as do WMT
ratings (Barrault et al., 2020), for both language pairs.
(iii) pSQM Has High System-Level Correla-
tion with MQM: The results for both language
pairs suggest
that pSQM and MQM are of
similar quality as their system rankings mostly
agree. Nevertheless, when zooming into the
segment-level correlations, we observe a much
lower correlation of ∼0.5 based on Kendall tau for
both language pairs. The difference in the two ap-
proaches is also visible in the absolute differences
of the individual systems. Par exemple, the sub-
missions of DiDi NLP and Tencent Translation
for Chinese→English are close for pSQM (only
0.04 absolute difference). MQM on the other
hand shows a larger difference of 0.19 points.
When the quality of two systems gets closer, un
more fine-grained evaluation schema like MQM
is needed. This is also important when doing sys-
tem development where the difference between
two variations for two systems can be minor.
Looking into the future when we get closer to
human translation quality, MQM will be needed
for reliable evaluation. On the other hand, pSQM
seems to be sufficient for an evaluation campaign
like WMT.
(iv) MQM Results Are Mainly Driven by Major
and Accuracy Errors:
In Table 6, we also show
the MQM error scores only based on Major/Minor
errors or only based on Fluency or Accuracy
errors. Fait intéressant, the MQM score based on
accuracy errors or based on Major errors gives
us almost the same rank as the full MQM score.
Later in the paper, we will see that the majority
of major errors are accuracy errors. This suggests
the quality of an MT system is still driven mostly
by accuracy errors as most fluency errors are
judged minor.
4.2 Error Category Distribution
MQM provides fine-grained error categories
grouped under 4 main categories (accuracy, flu-
ency, terminology, and style). The error distri-
bution for all 3 ratings for all 10 systems are
shown in Table 7. The error category Accuracy/
Mistranslation is responsible for the majority of
major errors for both language pairs. This suggests
that the main problem of MT is still mistransla-
tion of words or phrases. The absolute number
of errors is much higher for Chinese→English,
which demonstrates that this translation pair is
more challenging than English→German.
1467
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Error Categories
Errors Major Human
All MT
Tohoku
OPPO
eTrans
(%)
(%)
MQM MQM vs H. MQM vs H. MQM vs H. MQM vs H.
(un) English→German
Accuracy/Mistranslation
Style/Awkward
Fluency/Grammar
Accuracy/Omission
Accuracy/Addition
Terminology/Inappropriate
Fluency/Spelling
Accuracy/Untranslated tex
Fluency/Punctuation
Other
Fluency/Register
Terminology/Inconsistent
Non-translation
Fluency/Inconsistency
Fluency/Character enc.
All accuracy
All fluency
All except acc. & fluenc
33.2
14.6
10.7
3.6
1.8
8.3
2.3
3.1
20.3
0.5
0.6
0.3
0.2
0.1
0.1
41.7
34.2
24.2
All categories
100.0
Accuracy/Mistranslation
Accuracy/Omission
Fluency/Grammar
Locale/Name format
Terminology/Inappropriate
Style/Awkward
Accuracy/Addition
Fluency/Spelling
Fluency/Punctuation
Locale/Currency format
Fluency/Inconsistency
Fluency/Register
Locale/Address format
Non-translation
Terminology/Inconsistent
Other
All accuracy
All fluency
All except acc. & fluency
All categories
42.2
8.6
13.8
6.4
5.1
5.7
0.9
3.6
11.1
0.4
0.8
0.4
0.3
0.0
0.3
0.1
51.7
29.8
18.5
100.0
27.2
4.6
4.7
13.4
6.7
7.0
1.2
14.9
0.2
5.2
5.0
0.0
100.0
1.3
3.7
24.2
1.8
6.0
12.1
71.5
61.3
18.4
74.5
31.1
17.1
40.2
5.1
1.4
8.8
27.5
6.5
65.7
100.0
16.1
4.1
69.3
10.5
41.7
46.7
0.296
0.146
0.097
0.070
0.067
0.061
0.030
0.024
0.014
0.005
0.005
0.004
0.003
0.003
0.002
0.457
0.150
0.222
1.285
0.299
0.224
0.091
0.025
0.193
0.039
0.090
0.039
0.010
0.014
0.005
0.083
0.002
0.001
1.492
0.320
0.596
4.3
2.0
2.3
1.3
0.4
3.2
1.3
3.8
2.8
1.9
3.0
1.2
28.3
0.7
0.7
3.3
2.1
2.7
0.829
2.408
(b) Chinese→English
2.9
1.687
0.646
0.381
0.250
0.139
0.122
0.110
0.107
0.028
0.011
0.011
0.008
0.008
0.006
0.004
0.003
2.444
0.535
0.546
3.525
3.218
0.505
0.442
0.505
0.221
0.182
0.025
0.071
0.035
0.010
0.036
0.008
0.025
0.024
0.008
0.003
3.748
0.593
0.986
5.327
1.9
0.8
1.2
2.0
1.6
1.5
0.2
0.7
1.2
0.9
3.3
1.0
3.3
3.9
2.3
0.9
1.5
1.1
1.8
1.5
1.026
0.289
0.193
0.063
0.018
0.171
0.030
0.082
0.067
0.009
0.009
0.004
0.041
0.001
0.002
1.189
0.303
0.526
2.017
2.974
0.468
0.414
0.506
0.220
0.193
0.017
0.071
0.035
0.010
0.028
0.008
0.036
0.021
0.007
0.005
3.463
0.557
1.005
5.025
3.5
2.0
2.0
0.9
0.3
2.8
1.0
3.5
4.9
1.6
1.9
0.9
14.0
0.3
1.0
2.6
2.0
2.4
2.4
1.8
0.7
1.1
2.0
1.6
1.6
0.1
0.7
1.3
0.9
2.7
0.9
4.7
3.3
1.8
1.7
1.4
1.0
1.8
1.4
1.219
0.315
0.215
0.063
0.024
0.189
0.039
0.066
0.013
0.010
0.015
0.005
0.065
0.001
0.001
1.372
0.284
0.591
2.247
3.108
0.534
0.392
0.491
0.217
0.180
0.013
0.059
0.031
0.010
0.026
0.008
0.033
0.012
0.004
0.002
3.655
0.517
0.955
5.127
4.1
2.1
2.2
0.9
0.4
3.1
1.3
2.8
1.0
1.9
3.2
1.2
22.0
0.3
0.6
3.0
1.9
2.7
2.7
1.8
0.8
1.0
2.0
1.6
1.5
0.1
0.6
1.1
0.9
2.4
1.0
4.3
2.0
1.2
0.6
1.5
1.0
1.7
1.5
1.244
0.296
0.196
0.120
0.021
0.193
0.028
0.098
0.011
0.007
0.015
0.005
0.094
0.003
0.000
1.483
0.253
0.596
2.332
3.157
0.547
0.425
0.433
0.202
0.185
0.018
0.073
0.033
0.010
0.038
0.009
0.015
0.029
0.010
0.001
3.721
0.580
0.891
5.192
4.2
2.0
2.0
1.7
0.3
3.2
0.9
4.2
0.8
1.2
3.3
1.2
32.0
1.0
0.2
3.2
1.7
2.7
2.8
1.9
0.8
1.1
1.7
1.5
1.5
0.2
0.7
1.2
0.9
3.5
1.1
2.0
4.7
2.8
0.4
1.5
1.1
1.6
1.5
Tableau 7: Category breakdown of MQM scores for human translations (UN, B), machine translations (tous
systèmes), and some of the best systems. The ratio of system over human scores is in italics. Errors (%)
report the fraction of the total error counts in a category, Major (%) report the fraction of major error
for each category.
Tableau 7 decomposes system and human MQM
scores per category for English→German. Human
translations obtain lower error counts in all cat-
egories, except for additions. Human translators
might add tokens for fluency or better understand-
ing that are not solely supported by the aligned
source sentence, but accurate in the given con-
text. This observation needs further investigation
and couldy potentially be an argument for re-
laxing the source-target alignment during human
evaluation. Both systems and humans are mostly
penalized by accuracy/mistranslation errors, mais
systems record 4x more error points in these cat-
egories. De la même manière, sentences with more than 5
major errors (non-translation) are much more fre-
quent for systems (∼ 28× the human rate). Le
1468
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 5: EnDe: Document-level MQM scores.
Chiffre 6: ZhEn: Document-level MQM scores.
best systems are quite different across categories.
Tohoku is average in fluency but outstanding in
accuracy, eTranslation is excellent in fluency but
worse in accuracy, and OPPO ranks between the
two other systems in both aspects. Compared to
humans, the best systems are mostly penalized for
mistranslations and non-translation (badly garbled
phrases).
Tableau 7 shows that the Chinese→English trans-
lation task is more difficult than English→German
translation, with higher MQM error scores for hu-
man translations. Encore, humans are performing
better than systems across all categories except for
additions, omissions and spelling. Many spelling
mistakes relate to name formatting and capital-
ization, which is difficult for this language pair
(see name formatting errors). Mistranslation and
name formatting are the categories where the
systems are penalized the most compared to hu-
mans. When comparing systems, the differences
between the best systems is less pronounced than
for English→German, both in term of aggregate
score and per-category counts.
4.3 Document-error Distribution
We calculate document-level scores by averag-
ing the segment level scores of each document.
We show the average document scores of all
MT systems and all HTs for English→German in
Chiffre 5. The translation quality of humans is very
consistent over all documents and gets an MQM
score of around 1, which is equivalent to one mi-
nor error. This demonstrates that the translation
quality of humans is consistently independent of
the underlying source sentence. The distribution
of MQM errors for machine translations looks
much different. For some documents, MT gets
very close to human performance, while for other
documents the gap is clearly visible. Fait intéressant,
all MT systems have similar problems with the
same subset of documents, suggesting that the
quality of MT output depends on the actual in-
put sentence rather than solely on the underlying
MT system.
scores
The MQM document-level
pour
Chinese→English are shown in Figure 6. The dis-
tribution of MQM errors for the MT output looks
very similar to the ones for English→German.
There are documents that are more challenging
for some MT systems than others. Although
the document-level scores are mostly lower for
human translations, the distribution looks similar
to the ones from MT systems. We first suspected
that the reference translations were post-edited
from MT. This is not the case: These translations
originate from professional
translators without
access to post-editing but with access to CAT
tools (mem-source and translation memory).
Another possible explanation is the nature of
the source sentences. Most sentences come from
Chinese government news pages that have a
formal style that may be difficult
to render
in English.
4.4 Annotator Agreement and Reliability
Our annotations were performed by professional
raters with MQM training. All raters were given
roughly the same amount of work, with the same
number of segments from each system. This setup
should result in similar aggregated rater scores.
Tableau 8(un) reports the scores per rater ag-
the main error categories for
gregated over
English→German. All
raters provide scores
within ±20% around the mean, with rater 3 être-
ing the most severe rater and rater 1 the most
permissive. Looking at individual ratings, rater
2 rated fewer errors in accuracy categories but
used the Style/Awkward category more for errors
1469
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Categories
Rater 1
Rater 2
Rater 3
Rater 4
Rater 5
Rater 6
MQM vs avg. MQM vs avg. MQM vs avg. MQM vs avg. MQM vs avg. MQM vs avg.
(un) English→German
Accuracy
Fluency
Others
All
Accuracy
Fluency
Others
All
1.02
0.26
0.41
1.69
3.34
0.39
0.70
4.43
0.84
0.96
0.80
0.85
0.96
0.68
0.78
0.89
0.82
0.34
0.63
1.79
3.26
0.50
0.75
4.51
0.68
1.27
1.23
0.90
0.94
0.87
0.83
0.91
1.55
0.32
0.59
1.28
1.18
1.14
1.42
0.28
0.57
1.23
2.45
(b) Chinese→English
2.27
3.31
1.13
0.85
5.29
0.95
1.95
0.94
1.07
2.51
0.33
0.66
3.50
1.18
1.04
1.10
1.14
0.72
0.57
0.74
0.71
1.23
0.19
0.57
1.98
4.57
0.59
1.11
6.27
1.02
0.70
1.10
1.00
1.31
1.02
1.24
1.26
1.21
0.23
0.32
1.76
3.91
0.53
1.32
5.76
1.00
0.86
0.63
0.88
1.12
0.92
1.47
1.16
Tableau 8: MQM per rater and category. The ratio of a rater score over the average score is in italics.
Agreement
avg
Scoring type
min max
English→German MQM 0.584 0.536 0.663
Chinese→English MQM 0.412 0.356 0.488
English→German pSQM 0.304 0.221 0.447
Chinese→English pSQM 0.169 0.008 0.517
Tableau 9: Pairwise inter-rater agreement.
outside of fluency/accuracy. Inversement, rater 6
barely used this category. Differences in error
rates among raters are not severe but could be
reduced with corrections from annotation models
(Paun et al., 2018) especially when working with
larger annotator pools. The rater comparison on
Chinese→English in Table 8(b) reports a wider
range of scores than for English→German. All
raters provide scores within ±30% around the
mean. This difference might be due to the greater
difficulty of the translation task itself introducing
more ambiguity in the labeling. In the future, it
would be interesting to compare if translation be-
tween languages of different families suffer larger
annotator disagreement for MQM ratings.
In addition to characterizing individual rater
performances relative to the mean, we also directly
measured their pairwise agreement. It is not obvi-
ous how best to do this, since MQM annotations
are variable-length lists of two-dimensional items
(category and severity). Klubiˇcka et al. (2018)
use binary agreements over all possible categories
for each segment, but do not consider severity.
To reflect our weighting scheme and to enable
direct comparison to pSQM scores, we grouped
MQM scores from each rater into seven bins
with right boundaries 0, 5, 10, 15, 20, 24.99, 25,4
and measured agreement among the bins. Tableau 9
shows average, minimum, and maximum pairwise
rater agreements for MQM and pSQM ratings. Le
agreements for MQM are significantly better than
the corresponding agreements for pSQM, across
both language pairs. Basing scores on explicit
error annotations seems to provide a measurable
boost in rater reliability.
4.5 Impact on Automatic Evaluation
We compared the performance of automatic met-
rics submitted to the WMT20 Metrics Task when
gold scores came from the original WMT ratings
to the performance when gold scores were derived
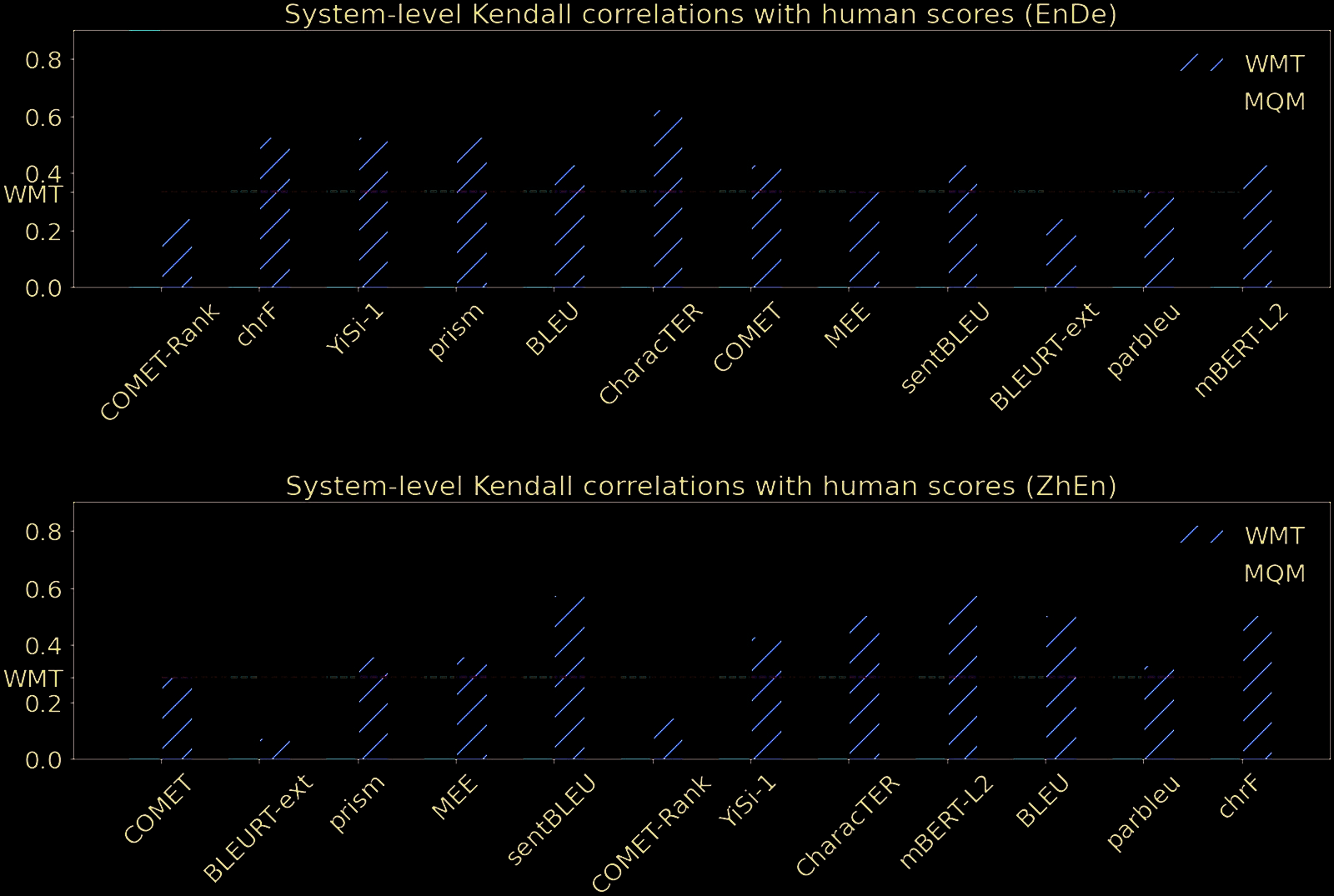
from our MQM ratings. Chiffre 7 shows Kendall’s
tau correlation for selected metrics at the system
level.5 As would be expected from the low correla-
tion between MQM and WMT scores, the ranking
of metrics changes completely under MQM. Dans
général, metrics that are not solely based on sur-
face characteristics do somewhat better, though
this pattern is not consistent (Par exemple, chrF
(Popovi´c, 2015) has a high correlation of 0.8
for EnDe). Metrics tend to correlate better with
MQM than they do with WMT, and almost all
4The pattern of document assignments to rater pairs
(though not the identities of raters) is the same for our MQM
and pSQM ratings, making agreement statistics comparable.
5The official WMT system-level results use Pearson cor-
relation, but since we are rating fewer systems (only 7 dans
the case of EnDe), Kendall is more meaningful; it also
corresponds more directly to the main use case of system
ranking.
1470
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Chiffre 7: System-level metric performance with MQM and WMT scoring for: (un) EnDe, top panel; et (b) ZhEn,
bottom panel. The horizontal blue line indicates the correlation between MQM and WMT human scores.
Average
EnDe
ZhEn
correlations
WMT MQM WMT MQM
Pearson, sys-level
Kendall, sys-level
Kendall, sys-level,
baselines only
Kendall, sys-level,
+human
Kendall, seg-level
Kendall, seg-level,
+human
0.539
0.23
0.436
0.27
0.467
0.20
0.387
0.26
0.170
0.00
0.159
0.00
0.883
0.02
0.637
0.10
0.676
0.06
0.123
0.68
0.228
0.00
0.161
0.00
0.318
0.41
0.309
0.42
0.514
0.10
0.426
0.20
0.159
0.00
0.157
0.00
0.551
0.21
0.443
0.23
0.343
0.34
0.159
0.64
0.298
0.00
0.276
0.00
Tableau 10: Average correlations for metrics at dif-
ferent granularities (using negative MQM scores
to obtain positive correlations). The baselines
only result averages over BLEU, sentBLEU,
TER, chrF, and chrF++; other results average
over all metrics available for the given condition.
The +human results include reference translations
among outputs to be scored. Numbers in italics are
average p-values from two-tailed tests, indicating
the probability that the observed correlation was
due to chance.
Tableau 10 shows average correlations with WMT
and MQM gold scores for different granularities.
At the system level, correlations are higher for
MQM than WMT, and for EnDe than ZhEn.
Correlations to MQM are quite good, though on
average they are statistically significant only for
EnDe. Fait intéressant, the average performance of
baseline metrics is similar to the global average
for all metrics in all conditions except for ZhEn
WMT, where it is substantially better. Adding
human translations to the outputs scored by the
metrics results in a large drop in performance,
especially for MQM, due to human outputs being
rated unambiguously higher than MT by MQM.
Segment-level correlations are generally much
lower than system-level, though they are sig-
nificant due to having greater support. MQM
correlations are again higher than WMT at this
granularity, and are higher for ZhEn than EnDe,
reversing the pattern from system-level results and
suggesting a potential for improved system-level
metric performance through better aggregation of
segment-level scores.
5 Conclusion
achieve better MQM correlation than WMT does
(horizontal dotted line).
We proposed a standard MQM scoring scheme
appropriate for broad-coverage, high-quality MT,
1471
translators
to acquire ratings by profes-
and used it
for Chinese→English and
sional
English→German data from the recent WMT
2020 evaluation campaign. These ratings served
as a platinum standard for various comparisons
to simpler evaluation methodologies, y compris
crowd worker evaluations. We release all data ac-
quired in our study to encourage further research
into both human and automatic evaluation.
Our study shows that crowd-worker human
evaluations (as conducted by WMT) have low
correlation with MQM scores, resulting in sub-
stantially different system-level rankings. Ce
finding casts doubt on previous conclusions made
on the basis of crowd-worker human evalua-
tion, especially for high-quality MT. We further
show that many automatic metrics, and in partic-
ular embedding-based ones, already outperform
crowd-worker human evaluation. Unlike ratings
acquired by crowd-worker and ratings acquired
by professional translators with simpler human
evaluation methodologies, MQM labels acquired
with professional translators show a large gap be-
tween the quality of human and machine generated
translations. This demonstrates that profession-
ally generated human translations still outperform
machine generated translations. En outre, nous
characterize the current error types in human
and machine translations, highlighting which error
types are responsible for the difference between
the two. We hope that researchers will use this as
motivation to establish more error-type specific
research directions.
Remerciements
We would like to thank Isaac Caswell for first
suggesting the use of MQM, Mengmeng Niu for
helping run and babysit the experiments, Rebecca
Knowles for help with WMT significance testing,
Yvette Graham for helping reproduce some of
the WMT experiments, and Macduff Hughes for
giving us the opportunity to do this study. Le
authors would also like to thank the anonymous
reviewers and the Action Editor of TACL for their
constructive reviews.
Les références
ALPAC. 1966. Language and Machines: Com-
puters in Translation and Linguistics; a Report,
volume 1416, National Academies.
Eleftherios Avramidis, Aljoscha Burchardt,
Christian Federmann, Maja Popovi´c, Cindy
Tscherwinka, and David Vilar. 2012. Involv-
ing Language Professionals in the Evaluation
of Machine Translation. In Proceedings of
the Eighth International Conference on Lan-
guage Resources and Evaluation (LREC’12),
pages 1127–1130, Istanbul, Turkey. européen
Language Resources Association (ELRA).
Lo¨ıc Barrault, Magdalena Biesialska, Ondˇrej Bojar,
Marta R. Costa-juss`a, Christian Federmann,
Yvette Graham, Roman Grundkiewicz, Barry
Haddow, Matthias Huck, Eric Joanis, Tom
Kocmi, Philipp Koehn, Chi-kiu Lo, Nikola
Ljubeˇsi´c, Christof Monz, Makoto Morishita,
Masaaki Nagata, Toshiaki Nakazawa, Santanu
Pal, Matt Post, and Marcos Zampieri. 2020.
Findings of
le 2020 Conference on Ma-
chine Translation (WMT20). In Proceedings
of the Fifth Conference on Machine Trans-
lation, pages 1–55, En ligne, Association for
Computational Linguistics.
Luisa Bentivogli, Mauro Cettolo, Marcello
Federico, and Christian Federmann. 2018.
Machine Translation Human Evaluation: An in-
vestigation of evaluation based on Post-Editing
and its relation with Direct Assessment. Dans
International Workshop on Spoken Language
Translation.
Ondrej Bojar, Rajen Chatterjee, Christian
Federmann, Yvette Graham, Barry Haddow,
Shujian Huang, Matthias Huck, Philipp Koehn,
Qun Liu, Varvara Logacheva, Christof Monz,
Matteo Negri, Matt Post, Raphael Rubino,
Lucia Specia, and Marco Turchi. 2017. Findings
of the 2017 Conference on Machine Translation
(WMT17). In Second Conference on Machine
Translation, pages 169–214. The Association
for Computational Linguistics.
Ondˇrej Bojar, Rajen Chatterjee, Christian Federmann,
Yvette Graham, Barry Haddow, Matthias
Huck, Antonio Jimeno Yepes, Philipp Koehn,
Varvara Logacheva, Christof Monz, Matteo
Negri, Aur´elie N´ev´eol, Mariana Neves, Martine
Popel, Matt Post, Raphael Rubino, Carolina
Scarton, Lucia Specia, Marco Turchi, Karin
Verspoor, and Marcos Zampieri. 2016. Find-
le 2016 Conference on Machine
ings of
1472
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Translation. In Proceedings of the First Con-
ference on Machine Translation: Volume 2,
Shared Task Papers, pages 131–198, Berlin,
Allemagne. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/W16-2301
Chris Callison-Burch, Philipp Koehn, Christof
Monz, Josh Schroeder, and Cameron Shaw
the Third
Fordyce. 2008. Proceedings of
Workshop on Statistical Machine Translation.
In Proceedings of
the Third Workshop on
Statistical Machine Translation.
Sheila Castilho, Joss Moorkens, Federico Gaspari,
Rico Sennrich, Vilelmini Sosoni, Panayota
Georgakopoulou, Pintu Lohar, Andy Way,
Antonio Valerio Miceli Barone, and Maria
Gialama. 2017. A Comparative Quality Evalu-
ation of PBSMT and NMT using Professional
Translators. AAMT.
Lukas Fischer and Samuel L¨aubli. 2020. What’s
the difference between professional human and
machine translation? A blind multi-language
study on domain-specific MT. In Proceedings
de
the Eu-
ropean Association for Machine Translation,
pages 215–224, online. European Association
for Machine Translation.
the 22nd Annual Conference of
Marina Fomicheva. 2017. The Role of Human
Reference Translation in Machine Translation
Evaluation. Ph.D. thesis, Universitat Pompeu
Fabra.
Mikel L. Forcada, Carolina Scarton, Lucia
Specia, Barry Haddow, and Alexandra Birch.
2018. Exploring gap filling as a cheaper alter-
native to reading comprehension questionnaires
when evaluating machine translation for gist-
ing. In Proceedings of the Third Conference
on Machine Translation: Research Papers,
pages 192–203.
Markus Freitag, Isaac Caswell, and Scott Roy.
2019. APE at scale and its implications on
MT evaluation biases. In Proceedings of the
Fourth Conference on Machine Translation,
pages 34–44, Florence, Italy. Association for
Computational Linguistics.
Markus Freitag, David Grangier, and Isaac
Caswell. 2020. BLEU might be guilty but ref-
erences are not innocent. In Proceedings of
le 2020 Conference on Empirical Methods
in Natural Language Processing (EMNLP),
pages 61–71.
Yvette Graham, Timothy Baldwin, Alistair
Moffat, and Justin Zobel. 2013. Continu-
ous measurement scales in human evaluation
In Proceedings of
of machine translation.
the 7th Linguistic Annotation Workshop and
Interoperability with Discourse, pages 33–41.
Yvette Graham, Timothy Baldwin, Alistair
Moffat, and Justin Zobel. 2017. Can ma-
chine translation systems be evaluated by the
crowd alone? Natural Language Engineering,
23(1):3–30.
Yvette Graham, Barry Haddow, and Philipp
Koehn. 2020. Translationese in machine trans-
lation evaluation. In Proceedings of the 2020
Conference on Empirical Methods in Natural
Language Processing (EMNLP), pages 72–81.
Hany Hassan, Anthony Aue, Chang Chen,
Vishal Chowdhary, Jonathan Clark, Christian
Federmann, Xuedong Huang, Marcin Junczys-
Dowmunt, William Lewis, Mu Li, Shujie Liu,
Tie-Yan Liu, Renqian Luo, Arul Menezes, Tao
Qin, Frank Seide, Xu Tan, Fei Tian, Lijun
Wu, Shuangzhi Wu, Yingce Xia, Dongdong
Zhang, Zhirui Zhang, and Ming Zhou. 2018.
Achieving Human Parity on Automatic Chinese
to English News Translation. arXiv preprint
arXiv:1803.05567.
Filip Klubiˇcka, Antonio Toral, and V´ıctor M.
S´anchez-Cartagena. 2018. Quantitative fine-
grained human evaluation of machine trans-
lation systems: A case study on english to
croatian. Machine Translation, 32(3):195–215.
Philipp Koehn and Christof Monz. 2006. Manual
and automatic evaluation of machine translation
In Proceed-
between european languages.
ings on the Workshop on Statistical Machine
Translation, pages 102–121.
Moshe Koppel and Noam Ordan. 2011. Trans-
lationese and its dialects. In Proceedings of
the 49th Annual Meeting of the Association for
Computational Linguistics: Human Language
Technologies – Volume 1, pages 1318–1326.
Samuel L¨aubli, Sheila Castilho, Graham Neubig,
Rico Sennrich, Qinlan Shen, and Antonio Toral.
1473
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
2020. A set of recommendations for assessing
human–machine parity in language transla-
tion. Journal of Artificial Intelligence Research,
67:653–672.
Samuel L¨aubli, Rico Sennrich, and Martin Volk.
2018. Has machine translation achieved human
parity? A case for document-level evaluation. Dans
Actes du 2018 Conference on Empir-
ical Methods in Natural Language Processing,
pages 4791–4796.
Arle Lommel, Hans Uszkoreit, and Aljoscha
Burchardt. 2014. Multidimensional quality
metrics (MQM): A framework for declar-
ing and describing translation quality metrics.
Tradum`atica, pages 455–463.
Nitika Mathur, Johnny Wei, Markus Freitag,
Qingsong Ma, and Ondˇrej Bojar. 2020. Re-
sults of the WMT20 metrics shared task. Dans
Proceedings of the Fifth Conference on Ma-
chine Translation, pages 688–725, En ligne.
Association for Computational Linguistics.
Silviu Paun, Bob Carpenter, Jon Chamberlain,
Dirk Hovy, Udo Kruschwitz, and Massimo
Poesio. 2018. Comparing Bayesian models of
annotation. Transactions of the Association for
Computational Linguistics, 6:571–585. https://
doi.org/10.1162/tacl a 00040
pour
Maja Popovi´c. 2015. chrF: Character n-gram
automatic MT evaluation.
F-score
In Proceedings of
the Tenth Workshop
on Statistical Machine Translation, pages
392–395, Lisbon, Portugal. Association for
Computational Linguistics. https://est ce que je
.org/10.18653/v1/W15-3049
Maja Popovi´c. 2020. Informative manual evalua-
tion of machine translation output. In Proceed-
ings of the 28th International Conference on
Computational Linguistics, pages 5059–5069.
pages 2685–2702, En ligne. Association for
Computational Linguistics.
Carolina Scarton and Lucia Specia. 2016.
A reading comprehension corpus for ma-
chine translation evaluation. In Proceedings of
the Tenth International Conference on Lan-
guage Resources and Evaluation (LREC’16),
pages 3652–3658.
Craig Thomson and Ehud Reiter. 2020. A gold
standard methodology for evaluating accu-
racy in data-to-text systems. In Proceedings of
the 13th International Conference on Natural
Language Generation, pages 158–168.
Antonio Toral. 2020. Reassessing claims of hu-
man parity and super-human performance in
machine translation at WMT 2019. En Pro-
ceedings of the 22nd Annual Conference of the
European Association for Machine Translation,
pages 185–194.
Antonio Toral, Sheila Castilho, Ke Hu, and Andy
Way. 2018. Attaining the unattainable? Re-
assessing claims of human parity in neural
machine translation. In Proceedings of the Third
Conference on Machine Translation: Research
Papers, pages 113–123, Belgium, Brussels.
Association for Computational Linguistics.
David Vilar, Gregor Leusch, Hermann Ney, et
Rafael E. Banchs. 2007. Human evaluation
of machine translation through binary system
comparisons. In Proceedings of
the Second
Workshop on Statistical Machine Translation,
pages 96–103.
John S. Blanc, Theresa A. O’onnell, and Francis
E. O’Mara. 1994. The ARPA MT evaluation
méthodologies: Evolution, lessons, and future
approaches. In Proceedings of the First Confer-
ence of the Association for Machine Translation
in the Americas.
Ricardo Rei, Craig Stewart, Ana C. Farinha, et
Alon Lavie. 2020. COMET: A neural frame-
work for MT evaluation. In Proceedings of
le 2020 Conference on Empirical Methods
in Natural Language Processing (EMNLP),
Mike Zhang and Antonio Toral. 2019. The effect
of translationese in machine translation test
sets. In Proceedings of the Fourth Conference
on Machine Translation (Volume 1: Research
Papers), pages 73–81.
1474
je
D
o
w
n
o
un
d
e
d
F
r
o
m
h
t
t
p
:
/
/
d
je
r
e
c
t
.
m
je
t
.
e
d
toi
/
t
un
c
je
/
je
un
r
t
je
c
e
–
p
d
F
/
d
o
je
/
.
1
0
1
1
6
2
/
t
je
un
c
_
un
_
0
0
4
3
7
1
9
7
9
2
6
1
/
/
t
je
un
c
_
un
_
0
0
4
3
7
p
d
.
F
b
oui
g
toi
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3