FAITHDIAL: A Faithful Benchmark for Information-Seeking Dialogue
Nouha Dziri† ♦ § Ehsan Kamalloo†
Mo Yu¶∗ Edoardo M. Ponti♣
Sivan Milton‡ Osmar Zaiane† §
Siva Reddy♦ ‡
‡McGill University, Canada
†University of Alberta, Canada
♦Mila – Quebec AI Institute, Canada
¶WeChat AI, Tencent, USA ♣University of Edinburgh, Reino Unido
§Alberta Machine Intelligence Institute (Amii), Canada
dziri@cs.ualberta.ca
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
yo
a
C
_
a
_
0
0
5
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Abstracto
The goal of information-seeking dialogue is
to respond to seeker queries with natural
language utterances that are grounded on
knowledge sources. Sin embargo, dialogue sys-
tems often produce unsupported utterances, a
phenomenon known as hallucination. To mit-
igate this behavior, we adopt a data-centric
solution and create FAITHDIAL, a new bench-
mark for hallucination-free dialogues, por
editing hallucinated responses in the Wizard
of Wikipedia (WOW) benchmark. We observe
that FAITHDIAL is more faithful than WoW
while also maintaining engaging conversa-
ciones. We show that FAITHDIAL can serve as
training signal for: i) a hallucination critic,
which discriminates whether an utterance is
faithful or not, and boosts the performance
por 12.8 F1 score on the BEGIN benchmark
compared to existing datasets for dialogue
coherencia; ii) high-quality dialogue genera-
ción. We benchmark a series of state-of-the-art
models and propose an auxiliary contrastive
objective that achieves the highest level of
faithfulness and abstractiveness based on sev-
eral automated metrics. Más, we find
that the benefits of FAITHDIAL generalize to
zero-shot transfer on other datasets, como
CMU-Dog and TopicalChat. Finalmente, humano
evaluation reveals that responses generated by
models trained on FAITHDIAL are perceived as
more interpretable, cooperative, and engaging.
1
Introducción
Despite the recent success of knowledge-grounded
neural conversational models (Thoppilan et al.,
2022; Prabhumoye et al., 2021; Zhao et al., 2020,
inter alia) in generating fluent responses, ellos
also generate unverifiable or factually incorrect
statements, a phenomenon known as hallucination
(Rashkin et al., 2021b; Dziri et al., 2021; Shuster
∗Work done while at IBM Research.
et al., 2021). Ensuring that models are trustworthy
is key to deploying them safely in real-world
applications, especially in high-stakes domains.
De hecho, they can unintentionally inflict harm on
members of the society with unfounded statements
or can be exploited by malicious groups to spread
large-scale disinformation.
Recientemente, Dziri et al. (2022a) investigated the
underlying roots of this phenomenon and found
eso
the gold-standard conversational datasets
(Dinan et al., 2019; Gopalakrishnan et al., 2019;
Zhou y cols., 2018)—upon which the models are
commonly fine-tuned—are rife with hallucina-
ciones, in more than 60% of the turns. An example
of hallucination in Wizard of Wikipedia (WoW;
Dinan et al. 2019) is shown in the red box of
Cifra 1. In WoW, an information SEEKER aims to
learn about a topic and a human WIZARD harnesses
conocimiento (typically a sentence) de Wikipedia
to answer. This behavior, where the human WIZ-
ARD ignores the knowledge snippet and assumes a
fictitious persona, can later reverberate in the dia-
logue system trained on this kind of data. En cambio,
the ideal WIZARD response, highlighted in green,
should acknowledge the bot’s nature, and when-
ever the knowledge is not sufficient or relevant,
it should acknowledge its ignorance of the topic.
Desafortunadamente, modeling solutions alone cannot
remedy the hallucination problem. By mimicking
the distributional properties of the data, modelos
are bound to ‘‘parrot’’ the hallucinated signals
en el momento de la prueba (Bender et al., 2021). What is more,
Dziri et al. (2022a) observe that GPT2 not only
replicates, but even amplifies hallucination around
20% when trained on WOW. This finding also
extends to models that are designed explicitly
to be knowledge-grounded (Prabhumoye et al.,
2021; Rashkin et al., 2021b). Filtering noisy or
high-error data (Zhang and Hashimoto, 2021) es
also prone to failure as it may either break the
1473
Transacciones de la Asociación de Lingüística Computacional, volumen. 10, páginas. 1473–1490, 2022. https://doi.org/10.1162/tacl a 00529
Editor de acciones: Wenjie Li. Lote de envío: 6/2022; Lote de revisión: 8/2022; Publicado 12/2022.
C(cid:4) 2022 Asociación de Lingüística Computacional. Distribuido bajo CC-BY 4.0 licencia.
enhancing other dialogue aspects like coopera-
tiveness, creativity, and engagement. These bene-
fits also generalize to other knowledge-grounded
datasets like CMU-DoG (Zhou y cols., 2018) y
TopicalChat (Gopalakrishnan et al., 2019) en un
zero-shot transfer setting.
FAITHDIAL also provides supervision for hallu-
cination critics, which discriminate whether an
utterance is faithful or not. We source positive
examples from FAITHDIAL and negative examples
from WOW. Compared to other dialogue infer-
ence datasets (Welleck et al., 2019a; Nie et al.,
2021), the classifiers trained on this data (cual
we call FAITHCRITIC) transfer better to general
NLU tasks like MNLI (Williams et al., 2018) y
achieve state-of-the-art on BEGIN (Dziri et al.,
2022b), a dialogue-specific knowledge grounding
benchmark in a zero-shot setting.
De este modo, FAITHDIAL holds promise to encourage
faithfulness in information-seeking dialogue and
make virtual assistants both more trustworthy. Nosotros
release data and code for future research.2
2 FAITHDIAL: Dataset Design
Given the motivations adduced above, the pri-
mary goal of this work is to create a resource for
faithful knowledge-grounded dialogue that allows
for both training high-quality models and measur-
ing the degree of hallucination of their responses.
We define the notion of faithfulness formally as
follows:
Definición 2.1 (Faithfulness). Given an utterance
y, a dialogue history H = (u1, . . . , un−1), y
knowledge K = (k1, . . . , kj) at turn n, we say that
un is faithful with respect to K iff the following
condition holds:
• ∃ Γn such that Γn (cid:3) y, dónde (cid:3) denotes
semantic consequence and Γn is a non-empty
subset of Kn. En otras palabras, there is no
interpretation I such that all members of Γn
are true and un is false.
Por eso, an utterance can optionally be grounded
on multiple facts but not none.
In what follows, we present the design of our
task as well as our annotation pipeline to curate
2https://mcgill-nlp.github.io/FaithDial/.
Cifra 1: A representative FAITHDIAL annotation: Sub-
jective and hallucinated (rojo) information present in
the wizard’s utterance of WoW data are edited into
utterances faithful to the given knowledge (verde). En
FAITHDIAL, the wizard assumes the persona of a bot.
cohesion of discourse or it may require excluding
entire dialogues.
En este trabajo, we adopt instead a data-centric
solution to address hallucinations and cre-
ate FAITHDIAL, a new benchmark for faithful1
knowledge-grounded dialogue. Específicamente, nosotros
ask annotators to amend hallucinated utterances
in WOW by making them faithful to the corre-
sponding knowledge snippets from Wikipedia and
acknowledging ignorance when necessary. Este
approach is vastly more scalable than creating
FAITHDIAL from scratch while retaining the co-
hesiveness of conversations. Además, it allows
us to shed light on hallucinations by contrasting
corresponding WIZARD’s responses in WOW and
FAITHDIAL.
Como resultado, FAITHDIAL contains around 50K
turns across 5.5K conversations. Extensive human
validation reveals that 94.4% of the utterances
in FAITHDIAL are faithful (es decir., without hallu-
cinations), compared to only 20.9% in WOW.
Además, we benchmark several state-of-the-art
modelos (Radford et al., 2019; Roller et al., 2021;
Rafael y col., 2020; Rashkin et al., 2021b) on dia-
logue generation. If trained on FAITHDIAL, we find
that they are significantly more faithful while also
1Faithfulness is sometimes referred to as attribution
(Dziri et al., 2022b; Rashkin et al., 2021a) or fidelity (Sipos
et al., 2012).
1474
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
yo
a
C
_
a
_
0
0
5
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
FAITHDIAL. In our dialogue setting, we simulate
interactions between two speakers: an information
SEEKER and a bot WIZARD.
Definición 2.2 (INFORMATION SEEKER: A Human).
The information SEEKER, a human, aims at learning
about a specific topic in a conversational manner.
They can express subjective information, bring up
a new set of facts independent from the source K,
and even open up new sub-topics.
From the perspective of Definition 2.2, utter-
ances pronounced by the SEEKER have a large
degree of freedom. Por ejemplo, the human can
chat about personal life and can ask a diverse set
of questions. Por otro lado, the WIZARD is
more restricted on what they can communicate.
Definición 2.3 (WIZARD: A Bot). The Wizard,
a bot, aims at conversing in a knowledgeable
manner about the SEEKER’s unique interests, re-
sorting exclusively to the available knowledge
k. They can reply to a direct question or pro-
vide information about the general topic of the
conversation.3
From Definition 2.3, it follows that there are
three key rules the bot must abide by: Primero, él
should be truthful by providing information that
is attributable to the source K. Segundo, it should
provide information conversationally, eso es, usar
naturalistic phrasing of K, support follow-up dis-
cussion with questions, and prompt the user’s
opinions. Tercero, it should acknowledge its igno-
rance of the answer in those cases where K does
not include it while still moving the conversation
forward using K.
2.1 Data Selection
Rather than creating a novel benchmark from
scratch, sin embargo, we opt for fixing problematic
utterances (which are the majority) in existing
dialogue benchmarks (Dziri et al., 2022a). El
reason is three-fold: 1) while mostly hallucinated,
existing datasets still contain useful faithful in-
formación; 2) as correction is faster than creation
from scratch, this enables us to annotate exam-
ples on a larger scale; 3) two versions of the
same dialogue turn, either hallucinated or faithful,
can provide signal for (contrastive) learning and
3To encourage naturalness in the response, annotators
were also asked to express empathy such as ‘‘I’m sorry about
…''. in case the SEEKER expresses a very unfortunate event.
Dataset Generic
Hallucination
Full Partial Faith. Uncoop.
Entailment
WoW
CMU
Topical
5.3
13.2
12.7
19.7
61.4
46.8
42.3
5.1
17.1
24.1
16.2
22.9
8.5
4.1
0.5
Mesa 1: The breakdown of responses from WOW,
CMU-DoG and TopicalChat according to BEGIN
taxonomy (Dziri et al., 2022b). ‘‘Faith.’’ refers
to faithful responses and ‘‘Uncoop.’’ refers to
faithful but uncooperative responses given the
conversation history.
evidence for a linguistic analysis. En particular, nosotros
focus on WOW as our benchmark backbone.
Initial pilot study revealed that WOW dialogues
are more suitable for editing compared to other
prominent knowledge-grounded dialogue bench-
marks: TopicalChat (Gopalakrishnan et al., 2019)
and CMU-DoG (Zhou y cols., 2018). De hecho, accord-
ing to Dziri et al. (2022a), as shown in Table 1,
WOW is relatively less hallucinated compared
with CMU-DoG and TopicalChat. Además, full
hallucinations—responses that contain no faith-
ful content and that therefore need to be entirely
thrown out— are highly prevalent in the latter
two (61.4% in CMU-DoG and 46.8% in Top-
icalChat and only 19.7% in WOW). Además,
knowledge snippets in WOW tend to be shorter,
which is preferable as longer knowledge is cor-
related with increased hallucination due to the
constrained cognitive capacity for text navigation
and comprehension in humans (De Jong, 2010;
DeStefano and LeFevre, 2007).
Our first step consists in filtering out WOW
conversations where ground-truth knowledge K
was not given, and annotators relied on per-
sonal knowledge instead. Entonces, we focus on
SEEKER-initiated conversations and sample 44%
from the train set (4094 conversaciones), 100%
from the validation set (764 conversaciones), y
100% from the test set (791 conversaciones).4
2.2 Crowd-sourced Annotations
Following the guidelines for ethical crowdsourc-
ing outlined in Sheehan (2018), we hire Amazon
4We use the original WOW splits. Please note that only
the training set in FAITHDIAL is smaller than the WOW training
set because of limited budget. The main goal of this paper is
to provide a high-quality faithful dialogue benchmark rather
than providing a large-scale dataset for training.
1475
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
yo
a
C
_
a
_
0
0
5
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Mechanical Turk (AMT) workers to edit utter-
ances in WOW dialogues that were found to exhibit
unfaithful responses.5 First, workers were shown
dialogues from WOW and asked to determine
whether the WIZARD utterances are faithful to the
source knowledge. To guide them in this decision,
they were additionally requested to identify the
speech acts (VRM taxonomy; Stiles 1992) semejante
as disclosure, edification, pregunta, acknowledg-
mento, etcétera; and the response attribution
classes (BEGIN taxonomy; Dziri et al. 2022b)
such as hallucination and entailment for each of
the WIZARD’s utterances according to Dziri et al.’s
(2022a) schema.
2.2.1 Editing the Wizard’s Utterances
Workers were instructed to edit the WIZARD’s utter-
ances in the following cases, depending on their
faithfulness.
Hallucination. They should remove information
eso
is unsupported by the given knowledge
snippet K, and replace it with information that
is supported. To ensure that the responses are
creative, we disallowed workers from copying
segments from K. They were instead instructed to
paraphrase the source knowledge as much as pos-
sible without changing its meaning (Ladhak et al.,
2022; Lux et al., 2020; Goyal and Durrett, 2021).
If the inquiry of the SEEKER cannot be satisfied by
the knowledge K, the WIZARD should acknowledge
their ignorance and carry on the conversation by
presenting the given knowledge in an engaging
manner. In the example shown in Table 3, el nuevo
WIZARD confirms that it cannot surf and instead
enriches the conversation by talking about surfing
as opposed to the original WIZARD who hallucinates
personal information.
Generic utterances such as ‘‘That’s nice’’ should
be avoided solely on their own. Workers are in-
structed to enrich these responses with content
that is grounded on the knowledge.
Uncooperativeness If the response was deter-
mined to be faithful but uncooperative with respect
5To ensure clarity in the task definition, we provided
turkers with detailed examples for our terminology. Más-
encima, we performed several staging rounds over the course of
several months. See the full set of instructions in Appendix
§A, the pay structure in Appendix §B, and details about our
quality control in Sec. 3.1 and Sec. 3.2.
Dataset
Turns
Conversations
Avg. Tokens for WIZARD
Avg. Tokens for SEEKER
Avg. Tokens for KNOWLEDGE
Turns per Conversation
Tren
36809
4094
20.29
17.25
27.10
9
Valid
6851
764
21.76
16.65
27.17
9
Prueba
7101
791
20.86
16.49
27.42
9
Mesa 2: Dataset statistics of FAITHDIAL.
to the user’s requests, workers are required to
make it coherent with the dialogue history while
keeping it faithful.
2.2.2 Editing the Seeker’s Utterances
Although the SEEKER has no restrictions on their
utterances, it is inevitable that the conversation
may drift away—because of the edits on the
WIZARD’s response—making the existing SEEKER’s
next utterance in WOW incoherent with the new
contexto. In these cases, they perform edits on the
SEEKER’s next utterance to make it coherent. Estafa-
sider Table 3 where workers had to edit the WOW
SEEKER’s utterance as it was not coherent anymore
with the freshly edited WIZARD’s response.
3 Dataset Quality
3.1 Crowdworker Quality Control
To be eligible for the task, workers have to be
located in the United States or Canada and have
to answer successfully 20 questions as part of
a qualification test. Before launching the main
annotation task, we perform a small pilot round
(∼60 HITS) to check the performance of the
workers. If we observe any errors, we email the
concerned workers and provide them with exam-
ples on how to fix their mistakes in future HITS.
Workers are also encouraged to reach out to us
in case they find annotating a particular example
ambiguous. At the end of the pilot round, nosotros
revoke access for workers who provide poor qual-
ity annotations. After several staging rounds, nosotros
launch the main annotation stage. To ensure the
quality does not drop, a linguistics major stu-
dent evaluates the performance of workers daily
(10 HITS on average per worker) and rejects
poor quality work. Repeated mistakes result in the
worker being blocked from the task entirely. En
total, we ended up recruiting 10 well-trained work-
ers. We also perform automatic quality control
checks to enforce that workers avoid copying
segments from the source knowledge.
1476
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
yo
a
C
_
a
_
0
0
5
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
WoW
FAITHDIAL
Seeker: I would love to learn to surf but I’m terrified of
sharks! Do you surf?
Knowledge: Surfing is a surface water sport in which the wave rider, referred to as a surfer, rides on the forward or deep
face of a moving wave, which is usually carrying the surfer towards the shore.
Seeker: I would love to learn to surf but I’m terrified of
sharks! Do you surf?
Wizard: I absolutely love to surf, just riding on the
forward face of a moving wave is so exhilarating.
Are there a lot of sharks near you? (BEGIN: Partial
hallucination, VRM: disclosure)
Seeker: I have no idea how many sharks are in the Gulf
of Mexico but there out there! lol Where do like to surf?
(incoherent with the freshly edited Wizard response)
Wizard: Desafortunadamente, it’s impossible for me to surf.
Remember, I’m just your virtual bot! Sorry to hear you’re
terrified from sharks. Sin embargo, did you know that a surfer
is someone who can ride on either the forward or deep face
of a wave which typically sends her/him close to the shore?
Seeker: Yeah, what scares me is the sharks, is there any
non-ocean waves out there?
Knowledge: Waves suitable for surfing are primarily found in the ocean, but can also be found in lakes or in rivers in the
form of a standing wave or tidal bore.
Wizard: There’s a little hidden cove near me that has
great waves, although waves suitable for surfing are
primarily found in the Pacific ocean. Have you ever
watched people surf? (BEGIN: hallucination, VRM:
disclosure & edification)
Wizard: For sure there is. An alternative to ocean waves
could be lakes and rivers which have a phenomenon called
standing waves. Have you ever watched people surf?
Mesa 3: A dialogue example showing the process of editing WOW utterances to convert them to
FAITHDIAL utterances. Text highlighted in red indicates hallucinated content. Text in violet indicates the
BEGIN labels and the speech act VRM labels as identified by annotators.
3.2 Human validation
To evaluate the quality of FAITHDIAL, we run
two final rounds of annotations. En primer lugar, we ask
3 new workers to edit the same 500 respuestas.
Since there is no straightforward way to mea-
sure inter-annotator agreement on edits, following
Dziri et al. (2022a), we measure the inter-annotator
agreement on the identified response attribution
classes (BEGIN) and the speech acts (VRM). Nosotros
report an inter-annotator agreement of 0.75 y
0.61 Fleiss’ κ, respectivamente, which shows sub-
stantial agreement according to Landis and Koch
(1977). This is an indicator of overall annota-
tion quality: If the worker can reliably identify
speech acts, they generally also produce reason-
able edits. En segundo lugar, we assign three new workers
to judge the faithfulness of the same 500 edited
respuestas (we use majority vote). Assuming the
pre-existing labels to be correct, the F1 score of
the majority-vote annotations for both taxonomies
are similarly high: 90% for BEGIN and 81% para
VRM. In total, we found that FAITHDIAL contains
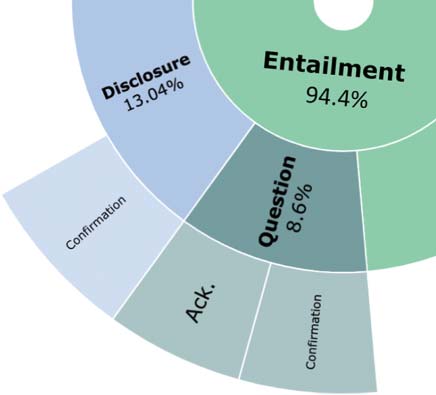
94.4% faithful responses and 5.6% hallucinated
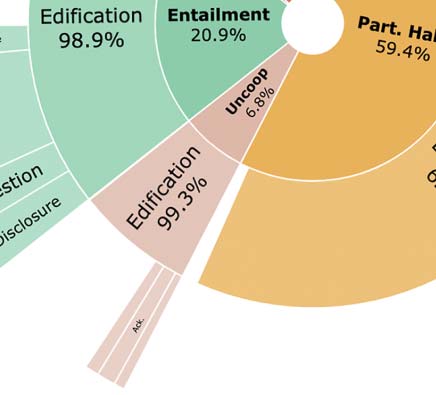
respuestas, as shown in Figure 2(a) (inner circle),
and this shows the high quality of FAITHDIAL.
4 Dataset Analysis
4.1 Estadísticas de conjuntos de datos
En general, FAITHDIAL contains a total of 5,649 di-
alogues consisting of 50,761 utterances. Mesa 2
reports statistics for each dataset split. To curate
FAITHDIAL, workers edited 84.7% of the WIZARD
respuestas (21,447 utterances) y 28.1% del
SEEKER responses (7,172 utterances). En particular,
3.8 WIZARD turns per conversation were modified
on average, as opposed to only 1.2 SEEKER turns.
The low percentage of the SEEKER edits shows
that our method does not disrupt the cohesive-
ness of the conversations.
4.2 Linguistic Phenomena
4.2.1 Faithfulness
Based on our human validation round of 500
examples, FAITHDIAL contains 94.4% faithful re-
sponses and 5.6% hallucinated responses. Sobre el
other hand, our large-scale audit of the entirety
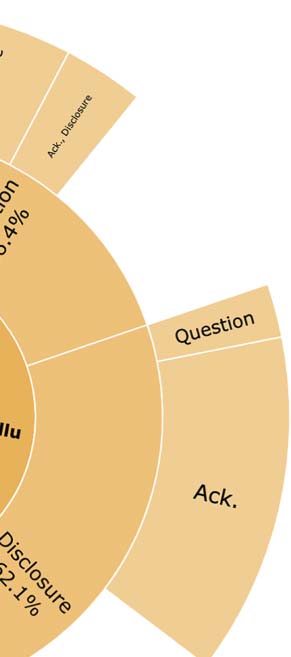
of WOW reveals that it is interspersed with hal-
lucination (71.4%), with only a few faithful turns
(20.9%), as shown in Figure 2(b) (inner circle).
This finding is consistent with the analysis of Dziri
et al. (2022a) on a smaller sample. In our work,
1477
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
yo
a
C
_
a
_
0
0
5
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
yo
a
C
_
a
_
0
0
5
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
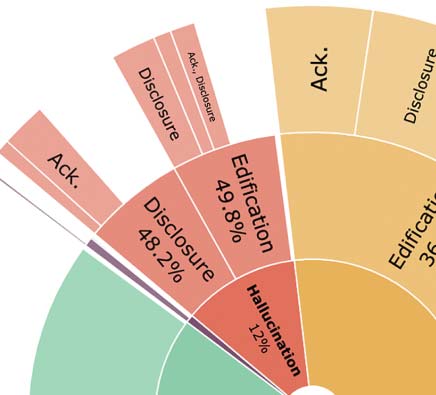
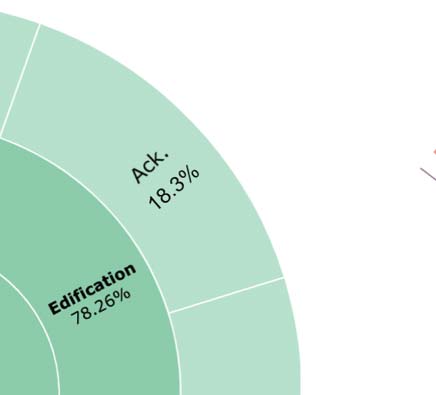
Cifra 2: Coarse-grained (BEGIN) and fine-grained speech act (VRM) distributions used by wizards in FAITHDIAL
and WOW. The inner most circle shows the breakdown of coarse-grained types: Hallucination (rojo), Entailment
(verde), Partial Hallucination (yellow), Generic (purple), and Uncooperative (pink). The outer circles show the
fine-grained types of each coarse-grained type.
FAITHDIAL cleanses dialogues from hallucination
almost entirely.
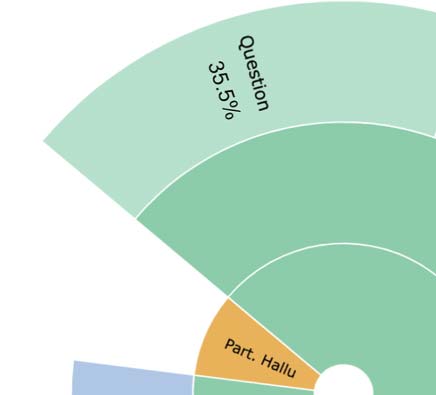
We also report the speech acts used to en-
sure faithfulness in FAITHDIAL in the outer circle
En figura 2. We observe that WIZARD resorts to
a diverse set of speech acts to convey faithful
information in a conversational style (see the En-
tailment pie): 78.26% of the responses contain
objective content (Edification) that is interleaved
with dialogue acts such as acknowledging receipt
of previous utterance (18.3%), asking follow-up
preguntas (35.5%), and sparking follow-on dis-
cussions by expressing opinions still attributable
to the knowledge source (36.2%). Además, el
WIZARD used some of these very techniques, semejante
as Disclosure (13.04%) and Questions (8.6%), en
isolation. Por otro lado, faithfulness strate-
gies (see Entailment) in WOW are mostly limited
to edification (98.9%), curbing the naturalness of
respuestas.
4.2.2 Abstractiveness
After establishing the faithfulness of FAITHDIAL,
we investigate whether it stems from an increased
level of extractiveness or abstractiveness with
respect to the knowledge source. Extractive re-
sponses reuse the same phrases as the knowledge
source, while abstractive responses express the
same meaning with different means. Although ex-
tractive responses are an easy shortcut to achieving
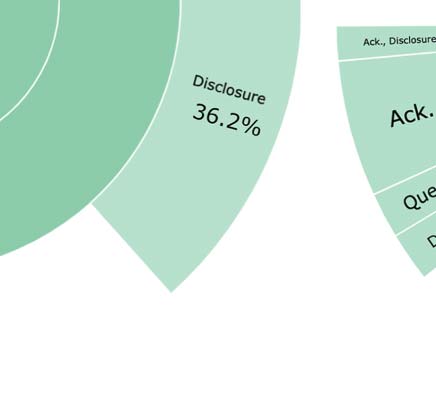
Cifra 3: Density and coverage in WOW (Dinan et al.,
2019) (izquierda) vs. FAITHDIAL (bien). Responses in FAITH-
DIAL tend to be abstractive to a large degree compared
to WOW.
more faithfulness, it comes at the cost of creativ-
idad. Idealmente, we want responses that are faithful as
well as creative, meaning responses that are not
just a copy paste of the knowledge but rather a cre-
ative use of it. To measure creativity, we borrow
two metrics from Grusky et al. (2018) designed to
quantify the extractive and abstractive nature of
summaries: Density and Coverage. Density repre-
sents the average length of the text spans copied
from the knowledge that are contained in the re-
respuesta. Coverage instead measures the percentage
of words existing in a response that are also found
in the source knowledge. Cifra 3 illustrates the
density and coverage distributions in FAITHDIAL
(bien) vs. WOW (izquierda). We observe that while the
coverage (x-axis) is similar in both FAITHDIAL and
1478
WOW, the density (y-axis) is always low in FAITH-
DIAL but often high in WOW. This indicates that
responses in FAITHDIAL tend to be abstractive to a
large degree.
Based on this, we also study which specific
abstractive strategies WIZARD adopts to present
knowledge from K without repeating long frag-
mentos. The strategies we discovered fall into five
broad categories: inference of new knowledge
from K, rewording, reshaping the syntactic struc-
tura, abridging long expressions, and introduc-
ing connectives.
4.2.3 Fallback Responses in FAITHDIAL
We further probe the WIZARD responses with re-
spect
to their ability to handle unanswerable
preguntas. We randomly sample 45 dialogues
containing 400 responses and ask a linguist to
annotate them. En general, Encontramos eso 48% del
conversations contain unanswerable utterances:
De término medio, 33% of the WIZARD responses within
the same conversation were edited to provide fall-
back responses. Out of those fallback responses,
30% were triggered by personal questions, 50%
by objective questions about the topic, y 20%
by opinions. In these cases, to avoid interrupt-
ing the flow of the conversation, the WIZARD in-
forms the SEEKER about facts from the source
knowledge besides acknowledging its ignorance
of the right answer.
5 experimentos
The purpose of FAITHDIAL is two-fold: primero, el
collected labels can serve as training data for
a critic to determine whether a given response
is faithful or hallucinated. The second goal is
providing high-quality data to generate faith-
ful responses in information-seeking dialogue.
Given knowledge Kn and the conversation his-
tory H = (u1, . . . , un−1), the task is to generate a
response un faithful to Kn. We benchmark a se-
ries of state-of-the-art dialogue models (Radford
et al., 2019; Roller et al., 2021; Rafael y col., 2020;
Rashkin et al., 2021b) on FAITHDIAL. Nosotros también
evaluate them on WOW and in a zero-shot transfer
setup on CMU-DoG, and TopicalChat). We im-
plement all the baselines using the Huggingface
Transformers library (Wolf et al., 2020).
Trained on
DECODE
DNLI
MNLI
FAITHCRITIC
MNLI
62.5†
52.4†
93.1
74.7†
Tested on
BEGIN
58.8†
59.8†
61.1†
71.6†
FAITHCRITIC
38.5†
30.9†
81.6†
86.5
Mesa 4: Transfer results (exactitud) of the hal-
lucination critics trained and tested on different
conjuntos de datos. † indicates zero-shot transfer results and
bolded numbers denote best performance.
5.1 Task I: Hallucination Critic
We frame the problem of identifying hallucination
as a binary classification task where the goal is
to predict whether an utterance is faithful or not,
given the source knowledge. This characteriza-
tion of the problem is reminiscent of previous
trabajar (Dziri et al., 2019; Welleck et al., 2019b;
Nie et al., 2021) on detecting contradiction within
a conversation.
For this purpose, we curate a dataset, FAITH-
CRITIC, derived from human annotations in FAITH-
DIAL. Específicamente, we take 14k WIZARD utterances
from WOW labeled as hallucination (Sección 2)
as negative examples. The WIZARD responses from
WOW labeled as entailment along with newly
edited WIZARD utterances (20k in total) count as
positive examples. En general, FAITHCRITIC consists
of 34k examples for training. We compare the
performance of models trained on FAITHCRITIC
against models trained on two dialogue infer-
ence datasets—DNLI (Welleck et al., 2019b) y
DECODE (Nie et al., 2021)—and on a well-known
natural language inference (NLI) conjunto de datos, MNLI
(Williams et al., 2018). For all datasets, we choose
RoBERTaLarge (Liu et al., 2019) as a pre-trained
modelo. We measure the transfer performance of
different critics on MNLI, BEGIN, and FAITH-
CRITIC in zero-shot settings wherever possible.
The results are presented in Table 4. En el
zero-shot setting, the critic trained on FAITHCRITIC
substantially outperforms the baselines on MNLI
and BEGIN by a large margin, Indicando que
FAITHDIAL allows transfer to both a generic lan-
guage understanding task as well as dialogue-
specific knowledge grounding benchmark. On
the other hand,
the transfer performance of
DECODE and DNLI are poor on both generic
and dialogue-specific classification tasks. Sur-
prisingly, MNLI transfers well to FAITHCRITIC.
1479
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
yo
a
C
_
a
_
0
0
5
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
5.2 Task II: Dialogue Generation
5.2.2 Automatic Evaluation
5.2.1 Métodos
For the task of dialogue generation, we consider
a series of state-of-the-art models ranging from
general-purpose LMs—such as GPT2 (Radford
et al., 2019), DIALOGPT (Zhang et al., 2020b),
and T5 (Rafael y col., 2020)—to models that are
specifically designed to provide better grounding,
such as DoHA (Prabhumoye et al., 2021), or to
alleviate hallucination, such as CTRL (Celos
et al., 2021b). DoHA augments BART (Luis
et al., 2020) with a two-view attention mech-
anism that separately handles the knowledge
document and the dialogue history during gen-
eration. CTRL equips LMs with control tokens
(
y
learned at training time. en el momento de la prueba, these steer
a model towards generating utterances faithful
to a source of knowledge. Finalmente, we adopt a
training strategy, called loss truncation (Kang and
Hashimoto, 2020) to cope with the presence of
hallucination in WOW, by adaptively eliminating
examples with a high training loss.
In addition to existing models, we also consider
an auxiliary objective to attenuate hallucination
durante el entrenamiento (Cao and Wang, 2021; Tang et al.,
2022). En particular, we adopt InfoNCE (van den
Oord et al., 2018), a contrastive learning loss,
to endow models with the capability of distin-
guishing faithful responses x+ from hallucinated
ones x−. Given an embedding of the context
C, which includes both conversation history and
conocimiento:
LInfoNCE = − log
(cid:2)
exp.(C(cid:7)x+)
X(cid:8) exp.(C(cid:7)X(cid:8))
(1)
To generate up to k = 8 negative candidates x−,
we follow a perturb-and-generate strategy for each
utterance in the training data. Más precisamente, nosotros
manipulate the gold knowledge snippets to alter
their meaning and feed them along with the his-
tory to an auto-regressive model fine-tuned on
WOW. We use two perturbation techniques pro-
posed by Dziri et al. (2022b): verb substitution
and entity substitution. Además, utterances
labeled as hallucination by human annotators in
WOW are also included in the negative samples.
We rely on several metrics that provide a
multi-faceted measure of performance. A first
group measures the degree of hallucination of
generated responses. The Critic model trained on
FAITHCRITIC (Sección 5.1) returns the percentage of
utterances identified as unfaithful. Q2 (Honovich
et al., 2021) measures faithfulness via question
answering. It takes a candidate response as in-
put and then generates corresponding questions.
Entonces, it identifies possible spans in the knowledge
source and the candidate response to justify the
question–answer pairs (Durmus et al., 2020; Wang
et al., 2020). Finalmente, it compares the candidate
answers with the gold answers, in terms of either
token-level F1 score or a NLI-inspired similarity
score based on a RoBERTa model. BERTScore
(Zhang et al., 2020a) rates the semantic similarity
between the generated response r and the knowl-
edge K based on the cosine of their sentence
embeddings. F1 measures instead the token-level
lexical overlap between u and K. Finalmente, as a
second set of metrics, we report BLEU (Papineni
et al., 2002) and ROUGE (lin, 2004), which re-
flect instead the n-gram overlap between u and
the gold (faithful) response g.
WoW vs FAITHDIAL.
In order to evaluate the
ability of FAITHDIAL to reduce hallucination in
generated responses, Mesa 5 illustrates three ex-
training data.
perimental setups with different
WOW corresponds to the first block and FAITH-
DIAL to the second block. The third block reflects
a hybrid setup where a model is fine-tuned sequen-
tially on WOW as an intermediate task and then
on FAITHDIAL. We evaluate all on the FAITHDIAL
test set.
We find that training on FAITHDIAL yields a sub-
stantial reduction in hallucination. Por ejemplo,
T5 trained on FAITHDIAL decreases hallucination
por 42.2% according to the Critic and increases
the faithfulness score (Q2-NLI) por 4.3% com-
pared to T5 trained on WOW.6 This corroborates
the prominence of data quality compared to the
data quantity (FAITHDIAL is one third the size of
WOW). When initializing the models trained on
FAITHDIAL with the noisy checkpoint from WOW
(third block), we observe a performance boost in
all models across all metrics, except a marginal
6The relatively high score of T5-WOW on Q2-NLI may be
due to this metric not being robust to partial hallucinations.
1480
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
yo
a
C
_
a
_
0
0
5
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Modelos
Critic ↓
GPT2
DIALOGPT
DOHA
T5
T5-CTRL
T5-LOSSTRUNCATION
GPT2
DIALOGPT
DOHA
T5
T5-CTRL
T5-LOSSTRUNCATION
T5-INFONCE
GPT2
DIALOGPT
DoHA
T5
T5-CTRL
T5-LOSSTRUNCATION
T5-InfoNCE
W.
oh
W.
yo
a
i
D
h
t
i
a
F
)
W.
oh
W.
+
(
yo
a
i
D
h
t
i
a
F
60.1
59.4
53.2
46.5
45.2
41.4
5.8
5.6
4.9
4.3
5.7
4.0
1.4
7.2
8.2
1.6
2.0
4.5
4.0
1.4
Q2 ↑
NLI
51.4
52.5
70.1
75.2
76.2
79.4
69.8
66.2
78.3
79.5
81.5
80.2
80.9
73.4
65.6
77.4
80.1
83.5
79.1
79.8
F1
42.2
41.4
63.3
67.7
70.3
71.2
58.4
56.5
69.1
70.4
72.4
71.9
70.8
62.3
54.5
66.7
70.2
73.4
70.2
69.8
BERTScore↑
(tu, k)
F1↑
(tu, k)
BLEU↑
(tu, gramo)
ROUGE↑
(tu, gramo)
0.29
0.34
0.32
0.41
0.45
0.43
0.36
0.36
0.39
0.41
0.46
0.42
0.39
0.39
0.42
0.40
0.41
0.50
0.41
0.40
47.7
53.5
56.1
61.7
65.2
65.0
50.4
52.3
58.3
59.2
62.2
59.1
55.8
54.2
48.6
55.8
57.5
64.6
58.9
57.1
7.3
8.3
9.4
9.5
9.9
9.8
9.5
9.6
9.9
10.3
10.4
10.2
10.9
10.0
8.9
11.4
11.5
10.9
10.4
11.5
18.3
29.5
32.3
32.9
33.1
33.4
33.4
33.1
31.8
33.9
33.9
33.9
35.8
34.2
32.3
36.5
37.2
35.6
33.9
36.5
Mesa 5: Model performance on the test split of FAITHDIAL. Bolded results indicate best performance.
Metrics measure either the degree of hallucination of generated responses u with respect to knowledge
K or their overlap with gold faithful responses g. Gray blocks correspond to models that are specifically
designed to alleviate hallucinations. Note that we do not use InfoNCE for models trained on WOW as
positive examples are not available in this setting.
drop in Critic for GPT2 and DIALOGPT. Este
shows that models can extract some useful con-
versational skills from WOW despite its noisy
naturaleza.
Modelos. Primero, we observe that T5 consistently
performs favorably in reducing hallucination in all
setups and across all metrics, compared to the rest
of the vanilla baselines: GPT2, DIALOGPT, y
DOHA. Además, we compare models that are
designed specifically to alleviate hallucination.
Results are reported in the gray blocks of Table 5.
We choose the best vanilla model T5 as the back-
bone for CTRL, INFONCE, and LOSSTRUNCATION.
By virtue of these methods, faithfulness increases
even further, which demonstrates their effective-
ness. Sample responses from different models are
presented in Table 6.
Abstractiveness. We find that while FAITHDIAL,
especially in the hybrid setup, increases the se-
mantic similarity between generated responses
and knowledge (BERTScore) por 7% compared to
WOW, the word overlap (F1) between them is al-
most unaffected. This indicates that WOW induces
extractiveness over abstractiveness in models,
which is not desirable. This is especially true
for T5-CTRL variants, as their training objective
encourages word overlap. En cambio, we observe
that T5-INFONCE achieves both faithfulness and
abstractiveness as it yields the lowest scores
for hallucination (1.4 Critic) and extractiveness
(55.8 F1).
5.2.3 Human Evaluation
In addition to the automated metrics, nosotros llevamos a cabo
human evaluation to assess the presence of hallu-
cination in models trained on FAITHDIAL, también
as other aspects in generated dialogues such as co-
operativeness, engagingness, and abstractiveness.
Following Rashkin et al. (2021a), our evaluation
consists of a two-stage annotation process. Primero,
the annotators are asked to determine whether
responses are stand-alone (es decir., their meaning is
interpretable even without access to the source
conocimiento). If not, they are deemed to be too
vague or ill-formed to judge their faithfulness.
Segundo, if the response is interpretable, the an-
notators are requested to evaluate whether the
response is grounded on the source knowledge. Si
the response was deemed not faithful, we further
1481
yo
D
oh
w
norte
oh
a
d
mi
d
F
r
oh
metro
h
t
t
pag
:
/
/
d
i
r
mi
C
t
.
metro
i
t
.
mi
d
tu
/
t
a
C
yo
/
yo
a
r
t
i
C
mi
–
pag
d
F
/
d
oh
i
/
.
1
0
1
1
6
2
/
t
yo
a
C
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
yo
a
C
_
a
_
0
0
5
2
9
pag
d
.
F
b
y
gramo
tu
mi
s
t
t
oh
norte
0
9
S
mi
pag
mi
metro
b
mi
r
2
0
2
3
Context
Responses
Knowledge: A paramedic is a healthcare professional,
predominantly in the pre-hospital and out-of-hospital
ambiente, and working mainly as part of emergency
medical services (EMS), such as on an ambulance.
Historia: Do you like medical science or have you
considered being a paramedic?
Knowledge: In the Middle Ages and Renaissance,
green was the color commonly associated with
comerciantes, bankers and the gentry, while red was
reserved for the nobility.
Historia:
Sí, that is camouflage. It is the color most closely
associated with spring, naturaleza, salud, youth, hope,
and envy. I love green. It is so versatile.
T5-LOSSTRUNCATION-WOW: I’m a nurse and I know a lot about
EMS. I’m in the hospital and it can be tiring. (Hallucination)
T5-INFONCE-FAITHDIAL: I am a bot so I can’t be a paramedic.
Sin embargo, I know that a paramedic is a healthcare profes-
sional, providing medical care principally in the pre-hospital
and out-of-hospital environment like an ambulance. (Faithful)
T5-CTRL-WOW: Green is so nice to have. It brings joy and
excitement. It is so well known for being associated with
comerciantes, banks, and the gentry. (Partial Hallucination)
T5-CTRL-FAITHDIAL: Oh, Frío! Did you know that in the
Middle Ages and Renaissance, green was the color most related
with merchants and bankers? (Faithful)
Mesa 6: Sample responses from different models. Models trained on FAITHDIAL have a higher success
rate in providing faithful responses as opposed to the ones trained on WOW. Text highlighted in red
indicates hallucination.
Modelos
Interpretable
Hallucination
W.
oh
W.
T5
T5-CTRL
T5-LOSSTRUNCATION
l T5
a
i
D
h
t
i
a
F
T5-WOW
T5-CTRL
T5-LOSSTRUNCATION
T5-INFONCE
93.2%
95.2%
94.3%
94.4%
95.2%
96.7%
94.2%
97.2%
55.8%∗∗
44.2%∗
42.5%∗∗
23.2%∗
20.9%∗
20.8%∗
24.2%∗
19.9%
Faithfulness
Abst.
1.95∗
0.92∗
1.87∗
2.43∗
2.44
1.42∗
2.42∗
2.92
Coop.
2.97∗
1.97∗
2.87∗
3.63
3.59
2.55∗
3.59
3.79
Enga.
1.72∗
1.33∗
1.83∗
2.33
2.37
2.10∗
2.03∗
2.60
Generic
2.2%
0.9%
1.2%
1.4%
1.0%
1.0%
0.9%
0.9%
Mesa 7: Human evaluation on 1600 generated FAITHDIAL responses (200 × 8) from different models
on the test data. ∗ and ∗∗ indicates that the results are significantly different from the best result in
that column (bolded) with p-value < 0.05, < 0.01 respectively. ‘Coop.’, ‘Abst.’, and ‘Enga.’ means
cooperativeness, abstractiveness, and engagingness, respectively.
ask the annotators to mark it as hallucination
or generic.
On the other hand, if the response was deemed
faithful, workers are asked to score three qual-
ities: Cooperativeness means that the response
is coherent with the previous turn and does not
try to mislead the interlocutor or act unhelpfully.
Engagingness involves engaging the interlocu-
tor by prompting further replies and moving the
conversation forward.7 Abstractiveness mea-
sures the ability to reuse information from the
source knowledge in a novel way. To enable flex-
7A low score in cooperativeness is correlated with a low
score in engagingness, but the opposite is not necessarily
true.
ibility in rating, we ask annotators to rate each
quality on a Likert scale from 1 (low quality) to
4 (high quality).
Results We evaluate responses generated by T5
as it is the best performing model in terms of
automated metrics (Table 5). We provide hu-
man annotators with 200 responses, where each is
scored by 3 humans raters. Results are depicted in
Table 7. We measure the agreement for each of
the 7 qualities separately using Krippendorff’s α
and find that the agreement (0.92, 0.91, 0.88, 0.90,
0.89, 0.75, 0.85, respectively) is reliably high.
Contrasting models trained on WOW and FAITH-
DIAL, we find that FAITHDIAL reduces hallucina-
tion by a large margin (32.6%) while increasing
1482
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
l
a
c
_
a
_
0
0
5
2
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Models
Trained on
Tested on
Critic ↓
T5
T5
T5
TopicalChat
FAITHDIAL
CMU-DoG
FAITHDIAL
WOW
FAITHDIAL
TopicalChat
TopicalChat
CMU-DoG
CMU-DoG
WOW
WOW
95.0
59.3
95.5
21.8
57.9
7.7
Q2 ↑
F1
46.2
57.3
39.5
50.5
69.4
72.9
NLI
53.2
67.1
49.2
57.3
72.1
79.7
F1 ↑
(u, K)
6.6
12.5
1.9
17.1
59.6
57.4
Hallucination
71.4%∗
41.0%
68.4%∗
48.4%
48.0%
24.2%
Faithfulness
Abst.
2.01∗
3.44
2.51∗
3.23
1.90∗
2.67
Coop.
3.53
3.07∗
3.43
3.29∗
2.96∗
3.54
Enga.
2.56
2.20∗
1.57∗
2.14
1.39∗
2.78
Table 8: Transfer results of faithful response generation from FAITHDIAL to other dialogue datasets. The
most right block corresponds to human evaluation. ∗ indicates that the results are statistically significant
(p-value < 0.05) and bolded results denote best performance.
interpretability. Also, we observe that training
models on FAITHDIAL enhances the coopera-
tiveness, engagingness, and abstractiveness of
responses, as they tend to prompt further con-
versations, acknowledge previous utterances, and
abstract information from the source knowledge.
We see that CTRL benefits faithfulness but at
the expense of cooperativeness and abstractive-
ness of the responses. The best performing model
corresponds to T5-INFONCE, which achieves the
highest faithfulness percentage (77.4%) and the
highest dialogue quality scores.
Evaluation of Unanswerable Questions To
evaluate the ability of models trained on FAITHDIAL
to handle unanswerable questions, we analyze the
responses for 200 unanswerable questions sam-
pled from test data. Each response is manually
evaluated by 3 annotators whether the answer
is appropriate. Inter-annotator agreement based
on Krippendorff’s alpha is 0.9 which is sub-
stantially high. Results indicate that T5-INFONCE
substantially outperform
trained on FAITHDIAL
T5-LOSSTRUNCATION trained on WOW in answer-
ing properly unanswerable questions (83.2%
vs. 33.3%).
5.2.4 Transfer from FAITHDIAL to
Other Datasets
To further examine the usefulness of FAITHDIAL
in out-of-domain setting, we test the performance
of T5-FAITHDIAL on TopicalChat (Gopalakrishnan
et al., 2019), CMU-DoG (Zhou et al., 2018), and
WoW (Dinan et al., 2019). Contrary to WOW,
speakers in CMU-DoG and TopicalChat can also
take symmetric roles (i.e., both act as the wiz-
ard). Knowledge is provided from Wikipedia
movie articles in CMU-DoG and from diverse
sources—such as Wikipedia, Reddit, and news
articles—in TopicalChat. Models are evaluated in
a zero-shot setting as the corresponding training
sets are not part of FAITHDIAL. Results are de-
picted in Table 8. Since these testing benchmarks
are fraught with hallucinations (see Table 1), we
do not compare the quality of the response u
with respect to the gold response g. We report
both automatic metrics and human evaluation. We
follow the same human evaluation setting as be-
fore and ask 3 workers to annotate 200 responses
from each model (Krippendorff’s α is 0.82, 0.79,
0.85 on TopicalChat, CMU-DoG, and WOW re-
spectively). In this regard, the models trained on
FAITHDIAL are far more faithful than the models
trained on in-domain data despite the distribution
shift. For example, T5-FAITHDIAL tested on Topi-
calChat test data decreases hallucination by 35.7
points on Critic, by 13.9 points on Q2-NLI, and
by 30.4 points on human scores. Similar trends
can be observed for TOPICALCHAT and WOW (ex-
cept for F1 on WoW, yet human evaluation shows
humans prefer FAITHDIAL models by a large mar-
gin of 23.8). Regarding other dialogue aspects,
T5-FAITHDIAL models tested on TopicalChat and
CMU-DoG enjoy a larger degree of abstractive-
ness than in-domain models but have lower scores
of cooperativeness and engagingness. However,
all of these aspects are enhanced when tested
in-domain on WoW.
6 Related Work
Hallucination in Natural Language Gener-
ation. Hallucination in knowledge-grounded
neural language generation has recently received
increasing attention from the NLP community (Ji
et al., 2022). Tasks include data-to-text genera-
tion (Wiseman et al., 2017; Parikh et al., 2020),
machine translation (Raunak et al., 2021; Wang
1483
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
l
a
c
_
a
_
0
0
5
2
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
and Sennrich, 2020), summarization (Durmus
et al., 2020; Kang and Hashimoto, 2020), gen-
erative question answering (Li et al., 2021), and
dialogue generation (Dziri et al., 2021, 2022b;
Rashkin et al., 2021b).
These works focus on either devising au-
tomatic metrics to identify when hallucination
occurs (Wiseman et al., 2017) or finding possible
causes for this degenerate behaviour, including
out-of-domain generalization and noisy training
data points (Kang and Hashimoto, 2020; Raunak
et al., 2021) and exposure bias caused by MLE
training (Wang and Sennrich, 2020).
Hallucination in Dialogue Systems. Halluci-
nations in knowledge-grounded neural dialogue
research problem
generation is an emergent
(Roller et al., 2021; Mielke et al., 2022; Shuster
et al., 2021; Dziri et al., 2021; Rashkin et al.,
2021b). Existing work aims predominantly to
address hallucinations via engineering loss func-
tions or enforcing consistency constraints, for
instance by conditioning generation on control
tokens (Rashkin et al., 2021b), by learning a
token-level hallucination critic to flag problem-
atic entities and replace them (Dziri et al., 2021),
or by augmenting the dialogue system with a
module retrieving relevant knowledge (Shuster
et al., 2021).
Although promising,
these approaches are
prone to replicate—or even amplify—the noise
found in training data. Dziri et al. (2022a) demon-
strated that more than 60% of three popular
dialogue benchmarks are rife with hallucination,
which is picked up even by models designed
to increase faithfulness. To the best of our
knowledge, FAITHDIAL is the first dataset for
information-seeking dialogue that provides highly
faithful curated data.
Hallucination Evaluation. Recently introduced
benchmarks can serve as testbeds for knowledge
grounding in dialogue systems, such as BEGIN
(Dziri et al., 2022b), DialFact (Gupta et al., 2022),
Conv-FEVER (Santhanam et al., 2021), and At-
tributable to Identified Sources (AIS) framework
(Rashkin et al., 2021a). Meanwhile, a recent study
has reopened the question of the most reliable
metric for automatic evaluation of hallucination-
free models, with the Q2 metric (Honovich et al.,
2021) showing performance comparable to human
annotation. In this work, we further contrigute to
this problem by proposing a critic model—trained
on our collected FAITHCRITIC data—that achieves
high performance on the BEGIN benchmark.
7 Conclusions
We release FAITHDIAL, a new benchmark for
faithful information-seeking dialogue, where a
domain-expert bot answers queries based on
gold-standard knowledge in a conversational
manner. Examples are created by manually edit-
ing hallucinated and uncooperative responses in
Wizard of Wikipedia (WOW), which constitute
79.1% of the original dataset. Leveraging the
resulting high-quality data, we train both a hallu-
cination critic, which discriminates whether utter-
ances are faithful to the knowledge and achieves
a new state of the art on BEGIN, and several dia-
logue generation models. In particular, we propose
strategies to take advantage of both noisy and
cleaned data, such as intermediate fine-tuning on
WOW and an auxiliary contrastive objective. With
both automated metrics and human evaluation, we
verify that models trained on FAITHDIAL drastically
enhance faithfulness and abstractiveness, both in-
domain and during zero-shot transfer to other
datasets, such as TopicalChat and CMU-DoG.
Acknowledgments
We are grateful
to the anonymous reviewers
for helpful comments. We would like to thank
MTurk workers for contributing to the creation
of FAITHDIAL and for giving feedback on various
pilot rounds. SR acknowledges the support of
the the IBM-Mila grant, the NSERC Discovery
grant, and the Facebook CIFAR AI chair pro-
gram. OZ acknowledges the Alberta Machine
Intelligence Institute Fellow Program and the
Canadian Institute for Advanced Research AI
Chair Program.
A AMT Instructions
Here, we detail the instructions given to workers in
the annotation task. We follow instructions from
Dziri et al. (2022a) in determining BEGIN and
VRM categories. Additionally, according to the
identified categories, we ask workers to perform
1484
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
l
a
c
_
a
_
0
0
5
2
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
a particular edit. Below are the questions we
ask in every HIT:
1. Does the WIZARD’s response contain other
information that is NOT supported by K?
(e.g., facts, opinions, feelings) (Yes/No)
(a) If the response is hallucinated, what is
the type of the unsupported information?
(options: expressing a personal experi-
ence, expressing an opinion, expressing
feelings, expressing unsupported facts,
giving advice, acknowledging informa-
tion from the SEEKER)
(b) If the response is hallucinated, was the
unsupported information triggered by
a question/opinion from the SEEKER?
(Yes/No)
(c) Besides unsupported information, does
the WIZARD’s response contain thoughts/
opinions/feelings/facts
that are sup-
ported by K? (Yes/No)
(d) Modify the WIZARD’s sentence such that
the response:
i. uses only the facts from K to make
the response informative.
ii. is not a copy paste of K but a
paraphrase of it.
iii. is relevant to the previous utterance
and cooperative with the SEEKER.
(e) If
the response is not hallucinated,
does the WIZARD’s response express
personal thoughts/opinions/feelings that
are supported by K? (Yes/No)
(f) If
the response is not hallucinated,
does the WIZARD’s response contain
is
factual/objective information that
supported by K? (Yes/No)
2. If the answer is ‘‘No’’ to (e) and (f), the
response is flagged as generic. We ask the
annotators to modify the WIZARD’s sentence
such that the response is supported by K.
3. If
the response is faithful, workers are
asked the following question: Is the WIZARD’s
response cooperative with the SEEKER’s re-
ignore
sponse? i.e.
answering a question, or does not act in
any unhelpful way.
the WIZARD does not
(a) If yes, no modification is required for
the WIZARD’s response.
(b) If no, modify the bot sentence such that:
i. The response is relevant to the previ-
ous utterance and cooperative with
the SEEKER.
ii. The response is not a copy paste of
K but a paraphrase of it.
B Pay Structure
We pay crowdworkers a base pay of $1.70/HIT (USD). To retain excellent workers for all rounds, we give a bonus of $35–$40 per 100 HITs that are submitted successfully. The average amount of time spent per HIT is 6 min, that it, in one hour, workers are able to complete 10 HITS. This is equivalent to $17–$18 per hour.
References
Emily M. Bender, Timnit Gebru, Angelina
McMillan-Major, and Shmargaret Shmitchell.
2021. On the dangers of stochastic parrots:
Can language models be too big? In Pro-
ceedings of
the 2021 ACM Conference on
Fairness, Accountability, and Transparency,
610–623. https://doi.org/10
pages
.1145/3442188.3445922
Shuyang Cao and Lu Wang. 2021. CLIFF: Con-
trastive learning for improving faithfulness
and factuality in abstractive summarization.
In Proceedings of
the 2021 Conference on
Empirical Methods in Natural Language Pro-
cessing, pages 6633–6649, Online and Punta
Cana, Dominican Republic. Association for
Computational Linguistics.
Ton De Jong. 2010. Cognitive load theory, ed-
ucational research, and instructional design:
Some food for thought. Instructional Science,
38(2):105–134. https://doi.org/10.1007
/s11251-009-9110-0
Diana DeStefano and Jo-Anne LeFevre. 2007.
reading: A
load in hypertext
Cognitive
review. Computers
in Human Behavior,
23(3):1616–1641. https://doi.org/10
.1016/j.chb.2005.08.012
Emily Dinan, Stephen Roller, Kurt Shuster,
Angela Fan, Michael Auli, and Jason Weston.
1485
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
l
a
c
_
a
_
0
0
5
2
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
2019. Wizard of Wikipedia: Knowledge-
powered conversational agents. In 7th Interna-
tional Conference on Learning Representations,
ICLR 2019, New Orleans, LA, USA, May 6–9,
2019. OpenReview.net.
Esin Durmus, He He, and Mona Diab. 2020.
FEQA: A question answering evaluation frame-
work for faithfulness assessment in abstrac-
the
tive summarization. In Proceedings of
58th Annual Meeting of the Association for
Computational Linguistics, pages 5055–5070,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2020.acl-main.454
Nouha Dziri, Ehsan Kamalloo, Kory Mathewson,
and Osmar Zaiane. 2019. Evaluating coher-
ence in dialogue systems using entailment.
In Proceedings of
the 2019 Conference of
the North American Chapter of the Associ-
ation for Computational Linguistics: Human
Language Technologies, Volume 1 (Long and
Short Papers), pages 3806–3812, Minneapolis,
Minnesota. Association for Computational
Linguistics. https://doi.org/10.18653
/v1/N19-1381
Nouha Dziri, Andrea Madotto, Osmar Za¨ıane,
and Avishek Joey Bose. 2021. Neural path
hunter: Reducing hallucination in dialogue
In Proceed-
systems via path grounding.
ings of
the 2021 Conference on Empirical
Methods in Natural Language Processing,
pages 2197–2214, Online and Punta Cana,
Dominican Republic. Association for Compu-
tational Linguistics. https://doi.org/10
.18653/v1/2021.emnlp-main.168
the 2022 Conference of
Nouha Dziri, Sivan Milton, Mo Yu, Osmar
Zaiane, and Siva Reddy. 2022a. On the ori-
gin of hallucinations in conversational models:
Is it the datasets or the models? In Proceed-
the North
ings of
American Chapter of the Association for Com-
putational Linguistics: Human Language Tech-
nologies, pages 5271–5285, Seattle, United
States. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2022.naacl-main.387
Nouha Dziri, Hannah Rashkin, Tal Linzen, and
David Reitter. 2022b. Evaluating attribution
in dialogue aystems: The BEGIN benchmark.
Transactions of the Association for Compu-
tational Linguistics, 10:1066–1083. https://
doi.org/10.1162/tacl a 00506
Karthik Gopalakrishnan, Behnam Hedayatnia,
Qinlang Chen, Anna Gottardi, Sanjeev Kwatra,
Anu Venkatesh, Raefer Gabriel, and Dilek
Hakkani-T¨ur. 2019. Topical-Chat: Towards
knowledge-grounded open-domain conversa-
tions. In Proceedings of Interspeech 2019,
pages 1891–1895. https://doi.org/10
.21437/Interspeech.2019-3079
Tanya Goyal and Greg Durrett. 2021. Annotat-
ing and modeling fine-grained factuality in
the 2021
summarization. In Proceedings of
Conference of the North American Chapter
of
the Association for Computational Lin-
guistics: Human Language Technologies,
pages 1449–1462, Online. Association for
Computational Linguistics. https://doi
.org/10.18653/v1/2021.naacl-main
.114
Max Grusky, Mor Naaman, and Yoav Artzi.
2018. Newsroom: A dataset of 1.3 million
summaries with diverse extractive strategies.
the 2018 Conference of
In Proceedings of
the North American Chapter of the Associ-
ation for Computational Linguistics: Human
Language Technologies, Volume 1 (Long Pa-
pers), pages 708–719. https://doi.org
/10.18653/v1/N18-1065
Prakhar Gupta, Chien-Sheng Wu, Wenhao Liu,
and Caiming Xiong. 2022. DialFact: A bench-
mark for fact-checking in dialogue. In Pro-
ceedings of
the 60th Annual Meeting of
the Association for Computational Linguistics
(Volume 1: Long Papers), pages 3785–3801,
Dublin,
Ireland. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/2022.acl-long.263
Or Honovich, Leshem Choshen, Roee Aharoni,
Ella Neeman, Idan Szpektor, and Omri Abend.
2021. q2: Evaluating factual consistency in
knowledge-grounded dialogues via question
generation and question answering. In Pro-
ceedings of the 2021 Conference on Empirical
Methods in Natural Language Processing,
pages 7856–7870, Online and Punta Cana,
1486
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
l
a
c
_
a
_
0
0
5
2
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Dominican Republic. Association for Compu-
tational Linguistics. https://doi.org/10
.18653/v1/2021.emnlp-main.619
Language Processing (Volume 2: Short Pa-
pers), pages 942–947. https://doi.org
/10.18653/v1/2021.acl-short.118
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu,
Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang,
Andrea Madotto, and Pascale Fung. 2022.
Survey of hallucination in natural
language
generation. CoRR, abs/2202.03629.
Daniel Kang and Tatsunori B. Hashimoto. 2020.
language generation via
Improved natural
loss truncation. In Proceedings of
the 58th
Annual Meeting of the Association for Com-
putational Linguistics, pages 718–731, Online.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2020
.acl-main.66
Faisal Ladhak, Esin Durmus, He He, Claire
Cardie,
2022.
and Kathleen McKeown.
Faithful or extractive? On mitigating the
faithfulness-abstractiveness trade-off
in ab-
stractive summarization. In Proceedings of the
60th Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long
Papers), pages 1410–1421, Dublin, Ireland.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2022
.acl-long.100
J. Richard Landis and Gary G. Koch. 1977.
The measurement of observer agreement for
categorical data. biometrics, pages 159–174.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Abdelrahman Mohamed,
Ghazvininejad,
Omer Levy, Veselin Stoyanov, and Luke
Zettlemoyer. 2020. BART: Denoising sequence-
to-sequence pre-training for natural language
generation, translation, and comprehension. In
Proceedings of the 58th Annual Meeting of
the Association for Computational Linguistics,
pages 7871–7880, Online. Association for
Computational Linguistics. https://doi
.org/10.18653/v1/2020.acl-main.703
Chenliang Li, Bin Bi, Ming Yan, Wei Wang,
and Songfang Huang. 2021. Addressing se-
mantic drift in generative question answering
with auxiliary extraction. In Proceedings of
the 59th Annual Meeting of the Association
for Computational Linguistics and the 11th
International Joint Conference on Natural
Chin-Yew Lin. 2004. ROUGE: A package for
automatic evaluation of summaries. In Text
Summarization Branches Out, pages 74–81,
Barcelona, Spain. Association for Computa-
tional Linguistics.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei
Du, Mandar Joshi, Danqi Chen, Omer Levy,
Mike Lewis, Luke Zettlemoyer, and Veselin
Stoyanov. 2019. Roberta: A robustly opti-
mized BERT pretraining approach. CoRR,
abs/1907.11692.
Klaus-Michael Lux, Maya Sappelli, and Martha
Larson. 2020. Truth or error? Towards sys-
tematic analysis of factual errors in abstractive
summaries. In Proceedings of the First Work-
shop on Evaluation and Comparison of NLP
Systems, pages 1–10.
Sabrina J. Mielke, Arthur Szlam, Emily Dinan,
and Y-Lan Boureau. 2022. Reducing conversa-
tional agents’ overconfidence through linguis-
tic calibration. Transactions of the Association
for Computational Linguistics, 10:857–872.
Yixin Nie, Mary Williamson, Mohit Bansal,
Douwe Kiela, and Jason Weston. 2021.
I
like fish, especially dolphins: Addressing
contradictions in dialogue modeling. In Pro-
ceedings of the 59th Annual Meeting of the
Association for Computational Linguistics
and the 11th International Joint Conference
on Natural Language Processing (Volume 1:
Long Papers), pages 1699–1713, Online.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2021
.acl-long.134
A¨aron van den Oord, Yazhe Li, and Oriol
Vinyals. 2018. Representation learning with
contrastive predictive coding. CoRR, abs/1807
.03748.
Kishore Papineni, Salim Roukos, Todd Ward,
and Wei-Jing Zhu. 2002. BLEU: A method for
automatic evaluation of machine translation.
In Proceedings of the 40th Annual Meeting of
the Association for Computational Linguistics,
pages 311–318. Association for Computational
Linguistics. https://doi.org/10.3115
/1073083.1073135
1487
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
l
a
c
_
a
_
0
0
5
2
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Ankur
Parikh, Xuezhi Wang,
Sebastian
Gehrmann, Manaal Faruqui, Bhuwan Dhingra,
Diyi Yang, and Dipanjan Das. 2020. ToTTo:
A controlled table-to-text generation dataset.
In Proceedings of
the 2020 Conference on
Empirical Methods in Natural Language Pro-
cessing (EMNLP), pages 1173–1186, Online.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2020
.emnlp-main.89
Shrimai
Prabhumoye, Kazuma Hashimoto,
Yingbo Zhou, Alan W. Black, and Ruslan
Salakhutdinov. 2021. Focused attention im-
proves document-grounded generation. In Pro-
ceedings of the 2021 Conference of the North
American Chapter of
the Association for
Computational Linguistics: Human Language
Technologies,
4274–4287, Online.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2021
.naacl-main.338
pages
Alec Radford, Jeffrey Wu, Rewon Child, David
Luan, Dario Amodei, and Ilya Sutskever.
2019. Language models are unsupervised mul-
titask learners. OpenAI Blog, 1(8):9.
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, Michael
Matena, Yanqi Zhou, Wei Li, and Peter J. Liu.
2020. Exploring the limits of transfer learning
with a unified text-to-text transformer. Journal
of Machine Learning Research, 21:1–67.
Hannah Rashkin, Vitaly Nikolaev, Matthew
Lamm, Michael Collins, Dipanjan Das, Slav
Petrov, Gaurav Singh Tomar, Iulia Turc, and
David Reitter. 2021a. Measuring attribution
in natural language generation models. CoRR,
abs/2112.12870.
Hannah Rashkin, David Reitter, Gaurav Singh
Tomar, and Dipanjan Das. 2021b. Increasing
faithfulness in knowledge-grounded dialogue
with controllable features. In Proceedings of
the 59th Annual Meeting of the Association
for Computational Linguistics and the 11th
International Joint Conference on Natural Lan-
guage Processing (Volume 1: Long Papers),
pages 704–718, Online. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/2021.acl-long.58
Vikas Raunak, Arul Menezes, and Marcin
Junczys-Dowmunt. 2021. The curious case of
hallucinations in neural machine translation.
the 2021 Conference of
In Proceedings of
the North American Chapter of the Associ-
ation for Computational Linguistics: Human
Language Technologies, pages 1172–1183,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2021.naacl-main.92
Stephen Roller, Emily Dinan, Naman Goyal,
Da Ju, Mary Williamson, Yinhan Liu, Jing
Xu, Myle Ott, Eric Michael Smith, Y-Lan
Boureau, and Jason Weston. 2021. Recipes
In
for building an open-domain chatbot.
Proceedings of
the
the 16th Conference of
European Chapter of
the Association for
Computational Linguistics: Main Volume,
pages 300–325, Online. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/2021.eacl-main.24
Sashank
Santhanam, Behnam Hedayatnia,
Spandana Gella, Aishwarya Padmakumar,
Seokhwan Kim, Yang Liu, and Dilek Hakkani-
Tur. 2021. Rome was built in 1776: A case
study on factual correctness in knowledge-
grounded response generation. CoRR, abs/2110
.05456.
Kim Bartel Sheehan. 2018. Crowdsourcing
research: Data collection with Amazon’s Me-
chanical Turk. Communication Monographs,
85(1):140–156. https://doi.org/10.1080
/03637751.2017.1342043
Kurt Shuster, Spencer Poff, Moya Chen,
Douwe Kiela, and Jason Weston. 2021. Re-
trieval augmentation reduces hallucination in
conversation. In Findings of the Association
for Computational Linguistics: EMNLP 2021,
pages 3784–3803, Punta Cana, Dominican
Republic. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2021.findings-emnlp.320
Ruben
Sipos,
Pannaga
Shivaswamy,
and
Thorsten Joachims. 2012. Large-margin learn-
ing of submodular summarization models.
the 13th Conference of
In Proceedings of
the European Chapter of the Association for
Computational Linguistics, pages 224–233.
William B. Stiles. 1992. Describing Talk: A
Taxonomy of Verbal Response Modes. Sage
Publications.
1488
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
l
a
c
_
a
_
0
0
5
2
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
Xiangru Tang, Arjun Nair, Borui Wang, Bingyao
Wang, Jai Desai, Aaron Wade, Haoran Li, Asli
Celikyilmaz, Yashar Mehdad, and Dragomir
Radev. 2022. CONFIT: Toward faithful
dialogue summarization with linguistically-
informed contrastive fine-tuning. In Proceed-
ings of
the North
American Chapter of
the Association for
Computational Linguistics: Human Language
Technologies,
5657–5668, Seattle,
United States. Association for Computational
Linguistics. https://doi.org/10.18653/v1
/2022.naacl-main.415
the 2022 Conference of
pages
Romal Thoppilan, Daniel De Freitas, Jamie
Hall, Noam Shazeer, Apoorv Kulshreshtha,
Heng-Tze Cheng, Alicia Jin, Taylor Bos,
Leslie Baker, Yu Du, YaGuang Li, Hongrae
Lee, Huaixiu Steven Zheng, Amin Ghafouri,
Marcelo Menegali, Yanping Huang, Maxim
Krikun, Dmitry Lepikhin, James Qin, Dehao
Chen, Yuanzhong Xu, Zhifeng Chen, Adam
Roberts, Maarten Bosma, Yanqi Zhou, Chung-
Ching Chang, Igor Krivokon, Will Rusch,
Marc Pickett, Kathleen S. Meier-Hellstern,
Meredith Ringel Morris, Tulsee Doshi, Renelito
Delos Santos, Toju Duke, Johnny Soraker,
Ben Zevenbergen, Vinodkumar Prabhakaran,
Mark Diaz, Ben Hutchinson, Kristen Olson,
Alejandra Molina, Erin Hoffman-John, Josh
Lee, Lora Aroyo, Ravi Rajakumar, Alena
Butryna, Matthew Lamm, Viktoriya Kuzmina,
Joe Fenton, Aaron Cohen, Rachel Bernstein,
Ray Kurzweil, Blaise Aguera-Arcas, Claire
Cui, Marian Croak, Ed H. Chi, and Quoc
Le. 2022. Lamda: Language models for dialog
applications. CoRR, abs/2201.08239.
Alex Wang, Kyunghyun Cho, and Mike Lewis.
2020. Asking and answering questions to eval-
uate the factual consistency of summaries. In
Proceedings of the 58th Annual Meeting of
the Association for Computational Linguistics,
pages 5008–5020.
Chaojun Wang and Rico Sennrich. 2020. On ex-
posure bias, hallucination and domain shift in
neural machine translation. In Proceedings of
the 58th Annual Meeting of the Association for
Computational Linguistics, pages 3544–3552,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2020.acl-main.326
Sean Welleck, Jason Weston, Arthur Szlam,
and Kyunghyun Cho. 2019a. Dialogue natu-
ral language inference. In Proceedings of the
57th Annual Meeting of the Association for
Computational Linguistics, pages 3731–3741.
Sean Welleck, Jason Weston, Arthur Szlam,
and Kyunghyun Cho. 2019b. Dialogue natu-
ral language inference. In Proceedings of the
57th Annual Meeting of the Association for
Computational Linguistics, pages 3731–3741,
Florence,
Italy. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/P19-1363
Adina Williams, Nikita Nangia, and Samuel
Bowman. 2018. A broad-coverage challenge
corpus for sentence understanding through
inference. In Proceedings of the 2018 Con-
ference of
the North American Chapter of
the Association for Computational Linguis-
tics: Human Language Technologies, Volume 1
(Long Papers), pages 1112–1122, New Or-
leans, Louisiana. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/N18-1101
Sam Wiseman, Stuart Shieber, and Alexander
Rush. 2017. Challenges in data-to-document
the 2017
In Proceedings of
generation.
Conference on Empirical Methods in Natu-
ral Language Processing, pages 2253–2263,
Copenhagen, Denmark. Association for Com-
putational Linguistics. https://doi.org/10
.18653/v1/D17-1239
Thomas Wolf, Lysandre Debut, Victor Sanh,
Julien Chaumond, Clement Delangue, Anthony
Moi, Pierric Cistac, Tim Rault, Remi Louf,
Morgan Funtowicz, Joe Davison, Sam Shleifer,
Patrick von Platen, Clara Ma, Yacine Jernite,
Julien Plu, Canwen Xu, Teven Le Scao,
Sylvain Gugger, Mariama Drame, Quentin
Lhoest, and Alexander Rush. 2020. Transform-
ers: State-of-the-art natural language process-
ing. In Proceedings of the 2020 Conference
on Empirical Methods
in Natural Lan-
guage Processing: System Demonstrations,
pages 38–45, Online. Association for Compu-
tational Linguistics. https://doi.org/10
.18653/v1/2020.emnlp-demos.6
Tianyi Zhang and Tatsunori B. Hashimoto. 2021.
On the inductive bias of masked language
1489
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
l
a
c
_
a
_
0
0
5
2
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
modeling: From statistical to syntactic depen-
dencies. In Proceedings of the 2021 Conference
of the North American Chapter of the Associ-
ation for Computational Linguistics: Human
Language Technologies, pages 5131–5146,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2021.naacl-main.404
Tianyi Zhang, Varsha Kishore, Felix Wu,
Kilian Q. Weinberger,
and Yoav Artzi.
2020a. Bertscore: Evaluating text generation
with BERT. In 8th International Conference
on Learning Representations,
ICLR 2020,
Addis Ababa, Ethiopia, April 26–30, 2020.
OpenReview.net.
Yizhe Zhang, Siqi Sun, Michel Galley, Yen-
Chun Chen, Chris Brockett, Xiang Gao,
Jianfeng Gao, Jingjing Liu, and Bill Dolan.
2020b. DIALOGPT: Large-scale generative pre-
training for conversational response generation.
In Proceedings of the 58th Annual Meeting
of the Association for Computational Linguis-
tics: System Demonstrations, pages 270–278,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653/v1
/2020.acl-demos.30
Xueliang Zhao, Wei Wu, Can Xu, Chongyang
Tao, Dongyan Zhao, and Rui Yan. 2020.
Knowledge-grounded dialogue generation with
pre-trained language models. In Proceedings of
the 2020 Conference on Empirical Methods
in Natural Language Processing (EMNLP),
pages 3377–3390, Online. Association for
Computational Linguistics. https://doi.org
/10.18653/v1/2020.emnlp-main.272
Kangyan Zhou, Shrimai Prabhumoye, and Alan
for document
W. Black. 2018. A dataset
grounded conversations. In Proceedings of the
2018 Conference on Empirical Methods in
Natural Language Processing, pages 708–713,
Brussels, Belgium. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/D18-1076
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
5
2
9
2
0
6
5
9
5
6
/
/
t
l
a
c
_
a
_
0
0
5
2
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
9
S
e
p
e
m
b
e
r
2
0
2
3
1490