Transactions of the Association for Computational Linguistics, vol. 2, pp. 561–572, 2014. Action Editor: Ryan McDonald.
2014 Association for Computational Linguistics.
Submission batch: 10/2014; Revision batch 11/2014; Published 12/2014. c
(cid:13)
561
ExploringCompositionalArchitecturesandWordVectorRepresentationsforPrepositionalPhraseAttachmentYonatanBelinkov,TaoLei,ReginaBarzilayMassachusettsInstituteofTechnology{belinkov,taolei,regina}@csail.mit.eduAmirGlobersonTheHebrewUniversitygamir@cs.huji.ac.ilAbstractPrepositionalphrase(PP)attachmentdisam-biguationisaknownchallengeinsyntacticparsing.ThelexicalsparsityassociatedwithPPattachmentsmotivatesresearchinwordrepresentationsthatcancapturepertinentsyn-tacticandsemanticfeaturesoftheword.Onepromisingsolutionistousewordvectorsin-ducedfromlargeamountsofrawtext.How-ever,state-of-the-artsystemsthatemploysuchrepresentationsyieldmodestgainsinPPat-tachmentaccuracy.Inthispaper,weshowthatwordvectorrepre-sentationscanyieldsignificantPPattachmentperformancegains.Thisisachievedviaanon-lineararchitecturethatisdiscriminativelytrainedtomaximizePPattachmentaccuracy.Thearchitectureisinitializedwithwordvec-torstrainedfromunlabeleddata,andrelearnsthosetomaximizeattachmentaccuracy.Weobtainadditionalperformancegainswithal-ternativerepresentationssuchasdependency-basedwordvectors.WhentestedonbothEn-glishandArabicdatasets,ourmethodoutper-formsbothastrongSVMclassifierandstate-of-the-artparsers.Forinstance,weachieve82.6%PPattachmentaccuracyonArabic,whiletheTurboandCharniakself-trainedparsersobtain76.7%and80.8%respectively.11IntroductionTheproblemofprepositionalphrase(PP)attach-mentdisambiguationhasbeenunderinvestigation1Thecodeanddataforthisworkareavailableathttp://groups.csail.mit.edu/rbg/code/pp.SheatespaghettiwithbutterSheatespaghettiwithchopsticksFigure1:TwosentencesillustratingtheimportanceoflexicalizationinPPattachmentdecisions.Inthetopsentence,thePPwithbutterattachestothenounspaghetti.Inthebottomsentence,thePPwithchop-sticksattachestotheverbate.foralongtime.However,despiteatleasttwodecadesofresearch(BrillandResnik,1994;Rat-naparkhietal.,1994;CollinsandBrooks,1995),itremainsamajorsourceoferrorsforstate-of-the-artparsers.Forinstance,inacomparativeevaluationofparserperformanceontheWallStreetJournalcor-pus,Kummerfeldetal.(2012)reportthatPPattach-mentisthelargestsourceoferrorsacrossallparsers.Moreover,theextentofimprovementovertimehasbeenratherlimited,amountingtoabout32%errorreductionsincetheworkof(Collins,1997).PPattachmentsareinherentlylexicalizedandpart-of-speech(POS)tagsarenotsufficientfortheircorrectdisambiguation.Forexample,thetwosen-tencesinFigure1varybyasinglenoun—buttervschopsticks.However,thisworddeterminesthestructureofthewholePPattachment.Ifthecorre-
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
0
3
1
5
6
6
9
4
7
/
/
t
l
a
c
_
a
_
0
0
2
0
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
562
spondingwordisnotobservedinthetrainingdata,astandardlexicalizedparserdoesnothavesufficientinformationtodistinguishbetweenthesetwocases.Infact,72%ofhead-childpairs(e.g.spaghetti-butter)fromtheWallStreetJournaltestsetareun-seenintraining.Notsurprisingly,resolvingtheseambiguitiesischallengingforparsersthathavere-strictedaccesstowordsemantics.Theseconsiderationshavemotivatedrecentex-plorationsinusingdistributedwordrepresenta-tionsforsyntacticparsing(CirikandS¸ensoy,2013;Socheretal.,2013;Leietal.,2014).Low-dimensionalwordembeddingshelpunveilseman-ticsimilaritybetweenwords,therebyalleviatingthedatasparsityproblemassociatedwithPPat-tachment.Inthiscontext,largeamountsofrawdatausedtoconstructembeddingseffectivelyen-richlimitedsyntacticannotations.Whiletheseap-proachesshowinitialpromise,theystilllagbehindself-trainedparsers(McCloskyetal.,2006).Theseparsersalsoutilizerawdatabutinadifferentway:self-trainedparsersuseittogetadditional(noisy)annotations,withoutcomputingnewwordrepresen-tations.Theseresultssuggestthatembedding-basedrepresentationshavenotyetbeenutilizedtotheirfullpotential.Weshowthatembedding-basedrepresentationscanindeedsignificantlyimprovePPattachmentac-curacy.Weachievethisbyusingsuchrepresen-tationswithinacompositionalneuralnetworkar-chitecture.Therepresentationsareinitiallylearnedfromanunlabeledcorpus,butarethenfurtherdis-criminativelytrainedtomaximizePPattachmentaccuracy.Wealsoexplorealternativerepresenta-tionssuchasdependency-basedwordvectorsthataretrainedfromparsedtextsusingthesyntacticcon-textinadependencytree.WetestourapproachforPPattachmentdisam-biguationonEnglishandArabicdatasets,com-paringittofull-scaleparsersandasupportvec-tormachine(SVM)ranker.Ourmodeloutper-formsallbaselines,includingaself-trainedparser.ThedifferenceisparticularlyapparentonArabic.Forinstance,ourmodelachievesPPattachmentaccuracyof82.6%whiletheTurbo(Martinsetal.,2013),RBG(Leietal.,2014),andCharniakself-trained(McCloskyetal.,2006)parsersobtain76.7%,80.3%,and80.8%respectively.Ourresultsdemonstratethatrelearningtheembeddingscon-tributestothemodelperformance,acrossarangeofconfigurations.Wealsonoticethatrepresentationsbasedonsyntacticcontextaremorepowerfulthanthosebasedonlinearcontext.Thismayexplaintheimprovedperformanceofself-trainedparsersoverparsersthatrelyonlinearcontextembeddings.2RelatedWorkProblemformulationTypically,PPattachmentdisambiguationismodeledasabinaryclassificationdecisionbetweenaprecedingnounorverb(BrillandResnik,1994;Ratnaparkhietal.,1994;CollinsandBrooks,1995;OlteanuandMoldovan,2005;ˇSuster,2012).Inaddition,theproblemofPPat-tachmenthasalsobeenaddressedinthecontextoffullparsing(AttererandSch¨utze,2007;Agirreetal.,2008).Forinstance,Green(2009)engineeredstate-splitfeaturesfortheStanfordparsertoimproveAra-bicPPattachment.Inthiswork,wedoisolatePPattachmentsfromotherparsingdecisions.Atthesametime,wecon-sideramorerealisticscenariowheremultiplecan-didateheadsareallowed.Wealsocompareagainstfull-scaleparsersandshowthatourmodelpredic-tionsimproveastate-of-the-artdependencyparser.InformationsourcesLexicalsparsityassociatedwithdisambiguatingPPattachments(Figure1)hasspurredresearcherstoexploitawiderangeofinfor-mationsources.Ontheonehand,researchershaveexploredusingmanuallycraftedresources(StetinaandNagao,1997;Gamalloetal.,2003;OlteanuandMoldovan,2005;MedimiandBhattacharyya,2007).Forinstance,Agirreetal.(2008)demon-stratethatusingWordNetsemanticclassesbene-fitsPPattachmentperformance.Ontheotherhand,researchershavelookedintousingco-occurrencestatisticsfromrawtext(Volk,2002;OlteanuandMoldovan,2005;GalaandLafourcade,2007).Suchstatisticscanbetranslatedintowordvectorsfromwhichacosinesimilarityscoreiscalculated(ˇSuster,2012).Wealsorelyonwordvectors,butourmodelcapturesmorecomplexrelationsamongthem.AlgorithmicapproachOurworkismostsimilartorecursiveneuralnetworkparsers(Costaetal.,2003;Menchettietal.,2005;Socheretal.,2010).In
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
0
3
1
5
6
6
9
4
7
/
/
t
l
a
c
_
a
_
0
0
2
0
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
563
particular,Socheretal.(2013)obtaingoodparsingperformancebybuildingcompositionalrepresenta-tionsfromwordvectors.However,tocombatthecomputationalcomplexityofthefullparsingsce-nario,theyrelyonaprobabilisticcontext-freegram-martoprunesearchspace.Incontrast,focusingonPPattachmentallowsustoconsidervariousneu-ralnetworkarchitecturesthataremoreappropriateforthistask,includingternary,binary,anddistance-dependentcompositions.Furthermore,weinvesti-gatemodificationstotheoriginalwordvectorsinseveralimportantdirections:enrichingwordvectorswithsemanticandsyntacticknowledgeresources,relearningthembybackpropagatingerrorsfromsu-perviseddata,andusingdependency-basedvectors.Weshowthatsuchmodificationsleadtobetterwordvectorsandsignificantperformancegains.3ModelWebeginbyintroducingsomenotation.Allvectorsv∈Rnareassumedtobecolumnvectors.Wede-noteagivensentencebyxandthesetofprepositionsinxbyPR(x).Inotherwords,PR(x)isthesetofwordswhosePOStagsareprep.ThePPattachmentlabeloftheprepositionz∈PR(x)isdenotedbyy(z)∈x.Namely,y(z)=hindicatesthattheheadoftheprepositionzish.Ourclassificationapproachistoconstructascor-ingfunctions(x,z,h;θ)foraprepositionz∈PR(x)anditscandidateheadhinthesentencex.Wethenchoosetheheadbymaximizings(x,z,h;θ)overh.Thesetofpossiblecandidates{h}canbeofarbitrarysize,thusdepartingfromthebinaryclassi-ficationscenarioconsideredinmuchofthepreviouswork(Section2).Thesetofparametersisθ.3.1CompositionalframeworkOurapproachtoconstructingthescorefunctionisasfollows.First,weassumethatallwordsinthesentencearerepresentedasvectorsinRn.Next,wecomposevectorscorrespondingtotherelevantpreposition,itscandidatehead,andotherwordsinthesentencetoobtainanewvectorp∈Rn.Thefinalscoreisalinearfunctionofthisvector.Thebasiccompositionoperationisdefinedasasinglelayerinaneuralnetwork(Socheretal.,2010).Givenvectorsu,v∈Rn,representingtwowords,weformanewvectorviaafunction:g(W[u;v]+b)∈Rn(1)whereb∈Rnisavectorofbiasterms,[u;v]∈R2nisaconcatenationofuandvintoacolumnvector,W∈Rn×2nisacompositionmatrix,andgisanon-linearactivationfunction.2Givenacandidateheadhforprepositionz,weapplysuchcompositionstoasetofwords,resultinginavectorp.Thefinalscores(x,z,h;θ)isgivenbyw·p,wherew∈Rnisaweightvector.Theparameterstobelearnedareθ=(W,b,w).3.2CompositionarchitecturesTherearevariouspossiblewaystocomposeandob-tainthevectorp.Table1showsthreebasiccompo-sitionarchitecturesthatareusedinourmodel.Inallcases,elementsliketheheadofthePP,thepreposi-tion,andthefirstchildoftheprepositionarecom-posedusingEq.1toderiveaparentvectorthatisthenscoredbythescorevectorw.Thearchitec-turesdifferinthenumberofcompositionsandtheirtype.Forinstance,theHead-Childmodelusesonlytheheadandchildinasinglecomposition,ignoringthepreposition.TheHead-Prep-Child-Ternarycom-posesallthreeelementssimultenuously,reflectingternaryinteractions.TheHead-Prep-Childmodel,ontheotherhand,firstcomposestheprepositionandchildtoformaparentp1representingthePP,thencomposesp1withtheheadintoanotherparentp2(=p)thatisscoredbyw.Thistwo-stepprocessfa-cilitatescapturingdifferentsyntacticrelationswithdifferentcompositionmatrices.Weturntothisnext.GranularityThebasiccompositionarchitectures(Table1)assumeaglobalmatrixWforallcomposi-tionoperations.InthecaseoftheHead-Prep-Childmodel,wealsoconsideralocalvariantwithdiffer-entmatricesforthetwocompositions:Wbottomforcomposingtheprepositionzwithitschildcintoaparentp1representingthePP,andWtopforcom-posingtheheadhwithp1intoaparentp2.Thecompositionequationsarethen:p1=g(Wbottom[z;c]+bbottom)p2=g(Wtop[h;p1]+btop)2Weusetanhwhichperformedslightlybetterthansigmoidinpreliminaryexperiments.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
0
3
1
5
6
6
9
4
7
/
/
t
l
a
c
_
a
_
0
0
2
0
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
564
ModelEquationsStructureHead-Child(HC)p=g(W[h;c]+b)pchHead-Prep-Child(HPC)p1=g(W[z;c]+b)p2p1czhp2=g(W[h;p1]+b)Head-Prep-Child-Ternary(HPCT)p=g(WTern[h;z;c]+b)pczhTable1:Basiccompositionarchitectures.h,z,c∈Rnarevectorsforthehead,thepreposition,anditschildrespectively;p,p1,p2∈Rnareparentvectorscreatedduringcompositionoperations;W∈Rn×2n,WTern∈Rn×3narebinaryandternarycompositionmatricesrespectively;b∈Rnisabiasterm;andgisanon-linearfunction.Inthiscase,thesetofparametersisθ=(Wtop;btop;Wbottom;bbottom;w).WecallthisvarianttheHead-Prep-Child-Local(HPCL)model.Thecompositionarchitecturesdescribedthusfaronlyconsideredthecomposedwordsbutnottheirrelativepositioninthesentence.Suchpositionin-formationmaybeuseful,sincecandidatesclosertotheprepositionaretypicallymorelikelytoattach.Tomodelthisdifference,weintroducedistance-dependentparametersandmodifytheHead-Prep-Childmodel(Table1,middlerow)asfollows:foraheadhatdistancedfromthepreposition,welet:p2=g(Wd[h;p1]+bd)whereWd∈Rn×2nandbd∈Rnarethema-trixandbiasforcomposingwithheadsatdis-tancedfromthepreposition.p1isdefinedasinTable1.Thesetofparametersisthenθ=({Wd;bd}d;W;b;w).Toreducethenumberofparametersweuseonlyd=1,…,5,andclipdis-tancesgreaterthan5.WenamethismodelHead-Prep-Child-Dist(HPCD).ContextItmayalsobeusefultoexploitwordssur-roundingthecandidateheadsuchasthefollowingword.Thiscanbeintegratedinthecompositionar-chitecturesinthefollowingway:foreachcandidatehead,representedbyavectorh∈Rn,concatenateavectorrepresentingthewordfollowingthecan-didate.Ifsuchavectorisnotavailable,appendazerovector.Thisresultsinanewvectorh0∈R2nrepresentingthehead.Tocomposeitwithavectorp1∈RnrepresentingthePP,weuseacompositionmatrixofsizen×3n,similartotheternarycom-positiondescribedabove.WerefertothismodelasHead-Prep-Child-Next(HPCN).3.3TrainingFortraining,weadoptamax-marginframework.Givenatrainingcorpusofpairsofsentencesandattachments,{x(i),y(i)},weseektominimizethefollowingobjectivefunction:J(θ)=TXi=1Xz∈PR(x(i))maxhhs(x(i),z,h;θ)−s(x(i),z,y(i)(z);θ)+∆(h,y(i)(z))i(2)where∆isthezero-oneloss.ForoptimizationweuseminibatchAdaGrad(Duchietal.,2011).Notethattheobjectiveisnon-differentiablesoAdaGradisusedwiththesubgradi-entofJ(θ),calculatedwithbackpropagation.ForregularizationweuseDropout(Hintonetal.,2012),arecentmethodforpreventingco-adaptationoffeatures,whereinputunitstotheneuralnetwork
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
0
3
1
5
6
6
9
4
7
/
/
t
l
a
c
_
a
_
0
0
2
0
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
565
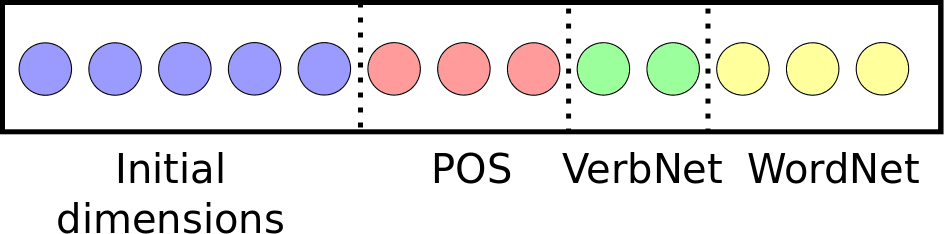
arerandomlydropped.Randomdroppingoccursin-dependentlyforeachtrainingexampleandhastheeffectofcreatingmultiplethinnednetworksthataretrainedwithsharedparameters.Inourimplementa-tionwedropoutinputunitsbeforeeachnon-linearlayer,includingtheinitialwordvectors.Wedonotdropoutunitsafterthefinalnon-linearlayer.NotethatDropoutisknowntobeespeciallyusefulwhencombinedwithAdaGrad(Wageretal.,2013).HyperparametersandinitializationWeusethefollowingdefaulthyperparameterswithoutfurthertuningunlessnotedotherwise:Dropoutparameterρ=0.5(Hintonetal.,2012),AdaGradinitiallearn-ingrateη=1.0(Dyer,n.d.),andminibatchsizeof500.Learnedparametersareinitializedsimi-larlytopreviouswork(BengioandGlorot,2010;Socheretal.,2013):compositionmatricesaresettoW=0.5[II]+(cid:15),where(cid:15)∼U(−1n,1n);biastermsbaresettozero;andtheweightvectorissettow∼U(−1√n,1√n).4WordvectorrepresentationsOurapproachassumesavectorrepresentationforeachword.Suchrepresentationshavegainedpopu-larityinrecentyears,duetotheabilitytotrainthemfromlargeunlabeleddatasets,andtheireaseofuseinawidevarietyoftasks(Turianetal.,2010).Therearevariousapproachestotrainingvectorrepresentations(CollobertandWeston,2008;Ben-gioetal.,2009).HerewechosetofocusontheSkip-grammethodrecentlyproposedbyMikolovetal.(2013a).TheSkip-grammodelmaximizestheaveragelog-probabilityofeverywordgeneratingitscontext,whichismodeledviaaneuralnetarchitec-ture,butwithoutthenon-linearity.Toimproveeffi-ciency,thisprobabilityisapproximatedbyahierar-chicalsoftmax(Mikolovetal.,2013b)withvocabu-larywordsrepresentedinabinaryHuffmantree.3Inthesimplestvariantofourmethod,wetraintheSkip-gramrepresentationonunlabeledtext,anduseitasafixedrepresentationwhentrainingthePPattachmentmodel(seeSection3.3).Belowwecon-siderseveralvariationsonthisapproach.3Preliminaryexperimentswithothermodelvariations(e.g.negativesampling)havenotledtonotableperformancegains.Figure2:Illustrationofanenrichedwordvector.Initialdimensionslearnedfromrawtextsareen-richedwithbinaryvectorsindicatingpart-of-speechtags,VerbNetframes,andWordNethypernyms.4.1RelearningwordvectorsTheSkip-gramwordvectorsareoriginallylearnedfromrawtext,withtheobjectiveofmaximizingthelikelihoodofco-occurringwords.HereourgoalistomaximizePPattachmentaccuracy,anditispossi-blethatadifferentrepresentationisoptimalforthistask.WemaythustakeadiscriminativeapproachandupdatethevectorstomaximizePPattachmentaccuracy.Technicallythisjustrequirestakingthesubgradientofourobjective(Eq.2)withrespecttothewordvectors,andupdatingthemaccordingly.Addingthewordvectorsasparameterssignifi-cantlyincreasesthenumberoffreeparametersinthemodel,andmayleadtooverfitting.Toreducethiseffect,weuseDropoutregularization(Section3.3).Wealsoemployasmallerinitiallearningrateforthewordvectorscomparedtoothermodelparameters.4Finally,notethatsincetheobjectiveisnon-convex,thevectorsobtainedafterthisprocedurewilltypicallydependontheinitialvalueused.Therelearningproceduremaythusbeviewedasfine-tuningthewordvectorstoimprovePPattachmentaccuracy.4.2EnrichingwordvectorsThewordvectorsweusearetrainedfromrawtext.However,itiseasytoenrichthemusingstructuredknowledgeresourcessuchasVerbNetorWordNet,aswellasmorpho-syntacticinformationavailableintreebanks.Ourapproachtoenrichingwordvectorsistoex-tendthemwithbinaryvectors.Forexample,givenavectorhforthecandidatehead,weaddbinary-valueddimensionsforitspart-of-speechandthatofthefollowingword.NextweaddabinarydimensionforVerbNetindicatingwhetherthecandidatehead4Wetunedη=[0.001,0.01,0.1,1]ontheEnglishdevsetandchosethebestvalue(η=0.001)forallotherexperiments.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
0
3
1
5
6
6
9
4
7
/
/
t
l
a
c
_
a
_
0
0
2
0
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
566
appearswiththeprepositioninaverbframe.Finally,foreachtophypernyminWordNet,weaddabinarydimensionindicatingwhetheritisahypernymofthecandidatehead,aimingforsemanticclusteringinformation.Notethatwedonotperformsensedis-ambiguationsothisinformationmaybenoisy.Figure2illustratestheresultingenrichedvector.Similardimensionsareappendedtovectorsrepre-sentingotherwordsparticipatinginthecomposi-tions.Ourexperimentsshowthatsuchanextensionsignificantlyimprovesperformance.4.3SyntacticwordvectorsInthestandardSkip-grammodelwordvectorsaretrainedfromrawtextusingthelinearcontextofneighboringwords.Wealsoconsideranalterna-tivemethodforcreatingwordvectorsbyusingthesyntacticcontextofwords.SuchsyntacticcontextisexpectedtoberelevantforresolvingPPattach-ments.Givenadependency-parsedtext,wefollowBansaletal.(2014)andcreateanewcorpusoftu-ples(l,g,p,c,l),foreverywordc,itsparentpwithdependencylabell,anditsgrandparentg.ThenwetrainanordinarySkip-grammodelonthiscorpus,butwithasmallwindowsizeof2.Notethatthelabellappearsonbothendssoitcontributestothecon-textofthewordaswellasitsgrandparent.Wefindthatsyntacticvectorsyieldsignificantperformancegainscomparedtostandardvectors.55Experimentalsetup5.1ExtractingPPattachmentsInstancesofPPattachmentdecisionsareextractedfromstandardtreebanks.WeusetheCATiBde-pendencytreebank(HabashandRoth,2009)forArabicandaconversionofthePenntreebank(PTB)todependencyformatforEnglish.6Standardtrain/dev/testsplitsareused:sections2-21/22/23ofthePTBforEnglish,andthesplitfromtheSPRMLshared-taskforArabic(Seddahetal.,2013).AsTa-ble2shows,thedatasetsofthetwolanguagesarefairlysimilarinsize,exceptforthemuchlargersetofprepositionsintheEnglishdata.ExtractinginstancesofPPattachmentsfromthetreebanksisdoneinthefollowingway.Foreach5WealsoexperimentedwithanothermethodforcreatingsyntacticvectorsbyLevyandGoldberg(2014)andobservedArabicEnglishTrainTestTrainTestTotal42,3873,91735,3591,951Candidates4.54.33.73.6VocabsizesAll8,2302,94411,4292,440Heads8,2252,93610,3952,133Preps13107246Children4,2221,4245,504983Table2:StatisticsofextractedPPattachments,showingtotalsizes,averagenumberofcandidateheads,andvocabularysizes.ArabicEnglishCorpusarTenTenWikipediaBLLIPTokens130M120M43MTypes43K218K317KTable3:StatisticsofArabicandEnglishcorporausedforcreatingwordvectors.preposition,welookforallpossiblecandidateheadsinafixedprecedingwindow.Typically,thesewillbenounsorverbs.Onlyprepositionswithanounchildareconsidered,leavingoutsomerareexcep-tions.Empirically,limitingcandidateheadstoap-pearcloseenoughbeforetheprepositionisnotanunrealisticassumption:wechoosea10-wordwin-dowandfindthatitcoversabout94/99%ofAra-bic/EnglishPPattachments.Unambiguousattach-mentswithasinglepossiblecandidatearediscarded.5.2CreatingwordvectorsTheinitialwordvectorsarecreatedfromrawtextsusingtheSkip-grammodelwithhierarchicalsoft-max,asdescribedinSection4.7WeuseaportionofWikipediaforEnglish8andthearTenTencorpusforArabic,containingwebtextscrawledin2012(Be-linkovetal.,2013;Artsetal.,2014).Table3similarperformancegains.6WeusedthePennconvertertool:http://nlp.cs.lth.se/software/treebank-converter.7Weusedtheword2vectool:https://code.google.com/p/word2vec,withdefaultsettings.Weexperimentedwithwordvectorsof25,50,100,and200dimensions,andfound100toworkbestinmostcases.8http://mattmahoney.net/dc/textdata.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
0
3
1
5
6
6
9
4
7
/
/
t
l
a
c
_
a
_
0
0
2
0
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
567
showsthecomparablesizesofthedatasets.TheArabiccorpushasbeentokenizedandlemmatizedwithMADA(HabashandRambow,2005;Habashetal.,2005),anecessaryprocedureinordertoseparatesomeprepositionsfromtheirchildwords.Inaddi-tion,lemmatizationreducesvocabularysizeandfa-cilitatessharinginformationbetweendifferentmor-phologicalvariantsthathavethesamemeaning.Forsyntacticwordvectors,weusetheEnglishvectorsin(Bansaletal.,2014),whichweretrainedfromaparsedBLLIPcorpus(minusPTB).ForAra-bic,wefirstconvertthemorphologically-processedarTenTencorpustoCoNLLformatwiththeSPMRLshared-taskscripts(Seddahetal.,2013).ThenweparsethecorpuswithabaselineMSTparser(Sec-tion5.3)andcreatesyntacticwordvectorsasde-scribedinSection4.3.TheArabicsyntacticvectorswillbemadeavailabletotheresearchcommunity.Forenrichingwordvectors,weusepart-of-speechinformation9fromthetreebanksaswellastheAra-bicandEnglishVerbNets(Kipperetal.,2008;Mousser,2010)andWordNets(Rodr´ıquezetal.,2008;PrincetonUniversity,2010).Intotal,theseresourcesaddtoeachwordvector46/67extendeddimensionsinArabic/English,representingsyntac-ticandsemanticinformationabouttheword.5.3BaselinesWecompareagainstfull-scaleparsers,anSVMranker,andasimplebutstrongbaselineofalwayschoosingtheclosestcandidatehead.ParsersWemostlycomparewithdependencyparsers,includingthestate-of-the-artTurbo(Mar-tinsetal.,2010;Martinsetal.,2013)andRBGparsers(Leietal.,2014),inadditiontoasecond-orderMSTparser(McDonaldetal.,2005)andtheMaltparser(Nivreetal.,2006).Wealsocomparewithtwoconstituencyparsers:anRNNparser(Socheretal.,2013),whichalsouseswordvectorsandaneuralnetworkapproach,andtheCharniakself-trainedrerankingparser(McCloskyetal.,2006).Wetrainallparsersonthetrain/devsetsandreporttheirPPattachmentaccuracyonthetestsets.10Fortheself-trainedparserwefollowedthe9WeusegoldPOStagsinallsystemsandexperiments.10TheonlyexceptionistheRNNparser,forwhichweusethebuilt-inEnglishmodelinStanfordparser’s(version3.4);SourceFeatureTemplateTreebankhw,pw,cw,hw-cw,ht,nt,hpdWordNethh,chVerbNethpvfWordVectorssim(hv,cv)BrownClustershc*,pc*,cc*,hc4,pc4,cc4,hc*-cc*,hc4-cc4Table4:FeaturetemplatesfortheSVMbaseline.Bi-lexicaltemplatesappearwitha“-”.Abbrevi-ations:hw/pw/cw=head/prep/childword,ht=headtag,nt=nextwordtag,hpd=head-prepdis-tance;hh/ch=head/childhypernym;hpvf=head-prepfoundinverbframe;hv/cv=head/childvec-tor;hc*/pc*/cc*=head/prep/childfullbitstring,hc4/pc4/cc4=head/prep/child4-bitprefix.procedurein(McCloskyetal.,2006)withthesameunsuperviseddatasetsthatareusedinourPPmodel.SVMWeconsideralearning-to-rankformulationforourproblem,whereeachexampleprovidesacor-rectcandidateheadandseveralincorrectcandidates.Weordertheseinasimplelistwherethecorrectcan-didatehasthehighestrankandallothercandidateshaveasinglelowerrank.WethenrankthesewithanSVMranker11andselectthetopcandidate.Thisformulationisnecessarybecausewedepartfromthebinaryclassificationscenariothatwasusedinprevi-ouswork(Section2).TheSVMrankerusesthefollowingfeatures:thecandidatehead,preposition,andchild;bi-lexicalconjunctionsofhead-child;part-of-speechtagsoftheheadandthefollowingword;andthecandi-datehead’sdistancefromthepreposition.WealsoaddtopWordNethypernymsforheadandchild,andanindicatorofwhethertheprepositionappearsinthehead’ssub-categorizationframeinVerbNet.Thisconfigurationparallelstheinformationusedinourmodelbutfailstoexploitrawdata.Therefore,weconsidertwomoretypesoffeatures.First,weusewordvectorsbycomputingcosinesimilaritybe-tweenvectorsofthecandidateheadandthechildforArabicwedotrainanewRNNmodel.11WeuseSVMRank:http://www.cs.cornell.edu/people/tj/svm_light/svm_rank.html.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
0
3
1
5
6
6
9
4
7
/
/
t
l
a
c
_
a
_
0
0
2
0
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
568
ofthepreposition.ThisfeaturewasfoundusefulinpreviousworkonPPattachment(ˇSuster,2012).Whilethislimitsthecontributionofthewordvec-torstothelearnedmodeltoonedimension,attemptstousemoredimensionsintheSVMwereunsuccess-ful.12Incontrast,thecompositionalmodelsbettercapturethefulldimensionalityofthewordvectors.AsecondtypeoffeaturesinducedfromrawdatathatweconsiderareBrownclusters,whichwerefoundtobeusefulindependencyparsing(Kooetal.,2008).Comparedtodistributedvectors,BrownclustersprovideamorediscreterepresentationthatiseasiertoincorporateintheSVM.Wecreateclus-tersfromourunsupervisedcorporausingtheLiang(2005)implementationofBrown’salgorithm,andaddfeaturesinthespiritof(Kooetal.,2008).Specifically,weaddfullandprefixedbitstringsforthehead,preposition,andchild,aswellasbi-lexicalversionsforhead-childpairs.13Table4showsasummaryoftheSVMfeatures.6ResultsTable5summarizestheresultsofourmodelandothersystems.OurbestresultsareobtainedwiththeHead-Prep-Child-Dist(HPCD)modelusingsyn-tacticvectors,enriching,andrelearning.Thefullmodeloutperformsbothfull-scaleparsersandaded-icatedSVMmodel.MoreadvancedparsersdodemonstratehigheraccuracyonthePPattachmenttask,butourmethodoutperformsthemaswell.Notethattheself-trainedrerankingparser(Charniak-RS)performsespeciallywellandquitebetterthantheRNNparser.Thistrendisconsistentwiththeresultsin(Kummerfeldetal.,2012;Socheretal.,2013).Ourcompositionalarchitectureiseffectiveinex-ploitingrawdata:usingonlystandardwordvec-torswithnoenriching,ourHPCD(basic)modelper-formscomparablytoanSVMwithaccesstoallen-richingfeatures.Onceweimprovetherepresenta-tion,weoutperformboththeSVMandfullparsers.Incomparison,thecontributionofrawdatatotheSVM,aseitherwordvectorsorBrownclusters,isratherlimited.12Forexample,wetriedaddingallwordvectordimensionsasfeatures,aswellaselement-wiseproductsofthevectorsrep-resentingtheheadandthechild.13Asin(Kooetal.,2008),welimitthenumberofuniquebitstringsto1,000sofullstringsarenotequivalenttowordforms.SystemArabicEnglishClosest62.781.7SVM77.086.0w/wordvectors77.585.9w/Brownclusters78.085.7w/Brownclusters+prefixes77.085.7Malt75.479.7MST76.786.8Turbo76.788.3RBG80.388.4RNN68.985.1Charniak-RS80.888.6HPCD(basic)77.185.4w/enriching80.487.7w/syntactic79.187.1w/relearning80.086.6HPCD(full)82.688.7RBG+HPCD(full)82.790.1Table5:PPattachmentaccuracyofourHPCDmodelcomparedtoothersystems.HPCD(full)usessyntacticvectorswithenrichingandrelearning.ThelastrowisamodifiedRBGparserwithafeatureforthePPpredictionsofourmodel.TherelativeperformanceisconsistentacrossbothEnglishandArabic.ThetablealsodemonstratesthattheArabicdatasetismorechallengingforallmod-els.Thiscanbeexplainedbyalargeraveragecandi-dateset(Table2),afreerwordorderthatmanifestsinlongerattachments(averageheadandPPdistanceis3.3inArabicvs1.5inEnglish),andthelexicalsparsityinducedbytherichermorphology.EffectonparsingToinvestigatehowourPPat-tachmentmodelcontributestothegeneralparsingtask,weincorporatedthepredictionsofourmodelinanexistingdependencyparser.WemodifiedtheRBGparser(Leietal.,2014)suchthatabinaryarcfeaturefiresforeveryPPattachmentpredictedbyourmodel.Forbothtestsets,wefindthatthepars-ingperformance,measuredastheunlabeledattach-mentscore(UAS),increasesbyaddingthepredic-tionsinthisway(Table6).ThemodifiedparseralsoachievesthebestPPattachmentnumbers(Table5).Interestingly,incorporatingthePPpredictionsinaparserleadstoagaininparsingperformancethat
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
0
3
1
5
6
6
9
4
7
/
/
t
l
a
c
_
a
_
0
0
2
0
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
569
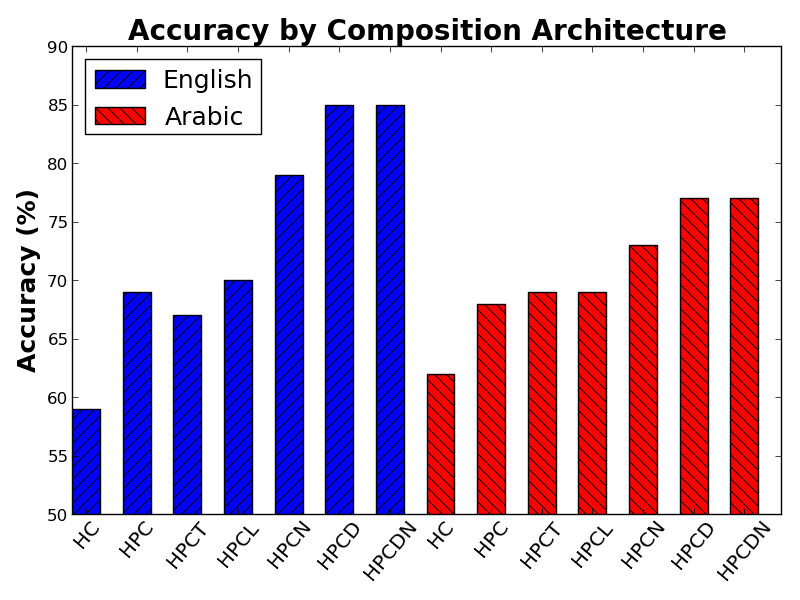
SystemArabicEnglishRBG87.7093.96RBG+predictedPP87.9594.05RBG+oraclePP89.0994.42Table6:Parsingperformance(UAS)oftheRBGparser,withpredictedandoraclePPs.isrelativelylargerthanthegaininPPaccuracy.Forexample,relativetoanoracleupperboundofforc-inggoldPParcsintheparseroutput(Table6),thereductioninEnglishparsingerrorsis20%,whereasthereductioninPPerrorsisonly15%.ThisaffirmstheimportanceofPPattachmentdisambiguationforpredictingotherattachmentsinthesentence.RRRdatasetMuchofthepreviousworkonPPattachmentfocusedonabinaryclassificationsce-nario(Section2)andhasbeenevaluatedontheRRRdataset(Ratnaparkhietal.,1994).Suchsystemscannotbeeasilyevaluatedinoursettingwhichal-lowsmultiplecandidateheads.Ontheotherhand,ourfullmodelexploitscontextualinformationthatisnotavailableintheRRRdataset.Nevertheless,usingasimplerversionofourmodelweobtainanaccuracyof85.6%ontheRRRtestset.14Thisiscomparabletomuchofthepreviouswork(OlteanuandMoldovan,2005),butstilllagsbehindthe88.1%ofStetinaandNagao(1997),whoalsousedWord-Netinformation.However,ouruseofWordNetisratherlimitedcomparedtotheirs,indicatingthatourenrichingmethodcanbeimprovedwithothertypesofinformation.6.1AlternativecompositionarchitecturesInthissectionweanalyzehowdifferentcompositionarchitectures(Section3.2)contributetotheoverallperformance.Toisolatethecontributionofthear-chitecture,wefocusonstandard(linear)wordvec-tors,withnorelearningorenriching.AsFigure3shows,simplermodelstendtoperformworsethanmorecomplexones.Thebestvariantsusediffer-entcompositionmatricesbasedonthedistanceofthecandidateheadfromthePP(HPCD,HPCDN).Whiletheresultsshownarefor100-dimensional14Hereweappliedbasicpreprocessingsimilarlyto(CollinsandBrooks,1995),converting4-digitnumberstoYEARandothernumberstoNUMBER;othertokenswerelower-cased.Figure3:PPattachmentaccuracyofdifferentarchi-tectures.(HC)usesonlythecandidateheadandthechildofthepreposition;(HPC*)modelsusehead,preposition,andchild,withthefollowingvariants:(HPCT)ternarycomposition;(HPCL)localmatri-cesfortopandbottomcompositions;(HPCN)con-textwords;(HPCD)distance-dependentmatrices;(HPCDN)combinesHPCD+HPCN.vectors,similartrendsareobservedwithlowerdi-mensions,althoughthegapsbetweensimpleandcomplexmodelsarethenmoresubstantial.WehavealsoexperimentedwithcompositionsthroughtheentirePPsubtree.However,thisresultedinaperformancedrop(toabout50%),implyingthataddingmorewordstothecompositerepresentationofthePPdoesnotleadtoadistinguishingrepresen-tationwithregardstothepossiblecandidateheads.6.2AlternativerepresentationsInthissection,weanalyzehowdifferentwordvectorrepresentations(Section4)contributetoourmodel.WefocusontheHPCDmodel,whichbuildsatwo-stepcompositestructurewithdistance-dependentcompositionmatrices.Wetakethebasicrepresen-tationtobestandard(linear)wordvectors,withoutenrichingorrelearning.Ineachparagraphbelow,weinvestigatehowadifferentaspectoftherepre-sentationaffectsPPattachmentperformance.RelearningwordvectorsIntraditionalarchitec-tures,theprocessofwordvectorinductionisinde-pendentofthewaythevectorisusedinthepars-ingalgorithm.Wehypothesizethatbyconnecting
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
0
3
1
5
6
6
9
4
7
/
/
t
l
a
c
_
a
_
0
0
2
0
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
570
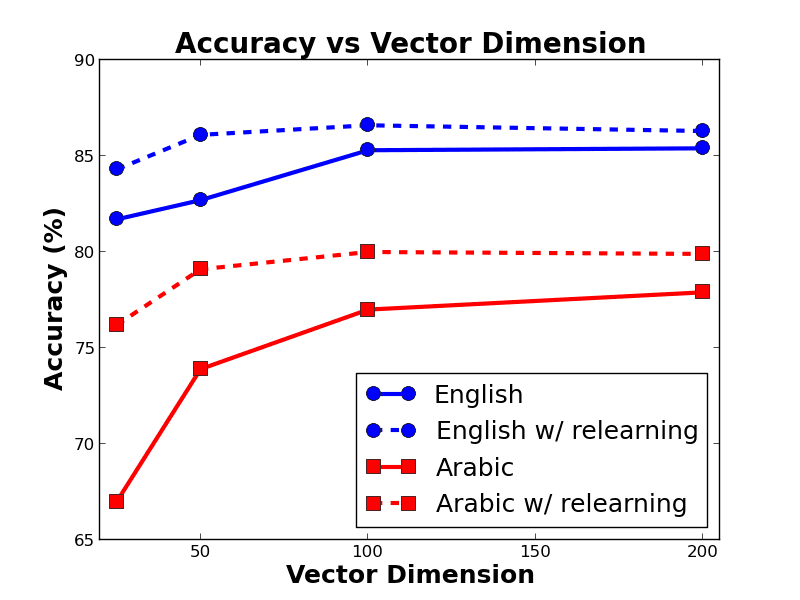
Figure4:Effectsofrelearningstandardwordvec-torsinEnglishandArabic.thesetwoprocessesandtailoringthewordvectorstothetaskathand,wecanfurtherimprovetheac-curacyofthePPattachments.WethusrelearnthewordvectorsduringtrainingasdescribedinSec-tion4.1.Indeed,asFigure4shows,doingsocon-sistentlyimprovesperformance,especiallywithlowdimensionalvectors.Interestingly,syntacticwordvectorsalsobenefitfromtheupdate(Table8).ThisindicatesthatthesupervisedPPattachmentsprovidecomplementarysignaltonoisydependenciesusedtoconstructsyntacticvectors.EnrichingwordvectorsAsubstantialbodyofworkhasdemonstratedthatmultiplefeaturescanhelpindisambiguatingPPattachments(Section2).Tothisend,weenrichwordvectorswithaddi-tionalknowledgeresources(Section4.2).AsTa-ble7shows,thisenrichmentyieldssizableperfor-mancegains.Mostofthegaincomesfrompart-of-speechinformation,whileWordNetandVerbNethaveasmallercontribution.Updatingthewordvec-torsduringtraininghasanadditionalpositiveeffect.Notethatevenwithnoenrichment,ourmodelperformscomparablytoanSVMwithaccesstoallenrichingfeatures(Table5).Whenenriched,ourmodeloutperformstheSVMbyamarginof2-3%.Withrelearning,thegapsareevenlarger.SyntacticwordvectorsWhilemostoftheworkinparsingreliesonlinearwordvectors(Socheretal.,2013;Leietal.,2014),weconsideranalter-nativevectorrepresentationthatcapturessyntacticRepresentationArabicEnglishw/oenriching77.185.4w/enriching+POS78.586.4+NextPOS79.787.5+WordNet+VerbNet80.487.7w/enriching+relearning81.788.1w/enriching+relearn.+syn.82.688.7Table7:PPattachmentaccuracywhenenrichingwordvectorswithpart-of-speechtagsofthecandi-datehead(POS)andthefollowingword(NextPOS),andwithWordNetandVerbNetfeatures.RepresentationArabicEnglishLinear77.185.4Syntactic79.187.1Syntacticw/relearning80.787.7Table8:PPattachmentaccuracyoflinear(standard)andsyntactic(dependency-based)wordvectors.context.AsdescribedinSection4.3,suchvectorsareinducedfromalargecorpusprocessedbyanau-tomaticdependencyparser.Whilethecorpusismostlikelyfraughtwithparsingmistakes,itstillcontainssufficientdependencyinformationforlearninghigh-qualitywordvectors.Table8confirmsourassump-tions:usingsyntactically-informedvectorsyieldssignificantperformancegains.7ConclusionThisworkexploreswordrepresentationsforPPat-tachmentdisambiguation,akeyprobleminsyntac-ticparsing.Weshowthatwordvectors,inducedfromlargevolumesofrawdata,yieldsignificantPPattachmentperformancegains.Thisisachievedviaanon-lineararchitecturethatisdiscriminativelytrainedtomaximizePPattachmentaccuracy.Wedemonstrateperformancegainsbyusingalternativerepresentationssuchassyntacticwordvectorsandbyenrichingvectorswithsemanticandsyntacticin-formation.Wealsofindthatthepredictionsofourmodelimprovetheparsingperformanceofastate-of-the-artdependencyparser.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
0
3
1
5
6
6
9
4
7
/
/
t
l
a
c
_
a
_
0
0
2
0
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
571
AcknowledgmentsThisresearchisdevelopedincollaborationwiththeArabicLanguageTechnologies(ALT)groupatQatarComputingResearchInstitute(QCRI)withintheIYASproject.Theauthorsacknowledgethesup-portoftheU.S.ArmyResearchOfficeundergrantnumberW911NF-10-1-0533,theDARPABOLTprogramandtheUS-IsraelBinationalScienceFoun-dation(BSF,GrantNo2012330).WethanktheMITNLPgroupandtheTACLreviewersfortheircomments,andDjam´eSeddahandMohitBansalforhelpingwithscriptsanddata.Anyopinions,find-ings,conclusions,orrecommendationsexpressedinthispaperarethoseoftheauthors,anddonotneces-sarilyreflecttheviewsofthefundingorganizations.ReferencesEnekoAgirre,TimothyBaldwin,andDavidMartinez.2008.ImprovingParsingandPPAttachmentPer-formancewithSenseInformation.InProceedingsofACL-HLT.TressyArts,YonatanBelinkov,NizarHabash,AdamKil-garriff,andVitSuchomel.2014.arTenTen:ArabicCorpusandWordSketches.JournalofKingSaudUni-versity-ComputerandInformationSciences.MichaelaAttererandHinrichSch¨utze.2007.Preposi-tionalPhraseAttachmentWithoutOracles.Computa-tionalLinguistics,33(4).MohitBansal,KevingGimpel,andKarenLivescu.2014.TailoringContinuousWordRepresentationsforDe-pendencyParsing.InProceedingsofACL.YonatanBelinkov,NizarHabash,AdamKilgarriff,NoamOrdan,RyanRoth,andV´ıtSuchomel.2013.arTen-Ten:anew,vastcorpusforArabic.InProceedingsofWACL.YoshuaBengioandXavierGlorot.2010.Understandingthedifficultyoftrainingdeepfeedforwardneuralnet-works.InProceedingsofAISTATS,volume9,May.YoshuaBengio,J´erˆomeLouradour,RonanCollobert,andJasonWeston.2009.Curriculumlearning.InPro-ceedingsofICML.EricBrillandPhilipResnik.1994.ARule-BasedApproachtoPrepositionalPhraseAttachmentDisam-biguation.InProceedingsofCOLING,volume2.VolkanCirikandH¨usn¨uS¸ensoy.2013.TheAI-KUSys-temattheSPMRL2013SharedTask:UnsupervisedFeaturesforDependencyParsing.InProceedingsofSPMRL.MichaelCollinsandJamesBrooks.1995.Prepo-sitionalPhraseAttachmentthroughaBacked-OffModel.CoRR.MichaelCollins.1997.ThreeGenerative,LexicalisedModelsforStatisticalParsing.InProceedingsofACL.RonanCollobertandJasonWeston.2008.AUnifiedArchitectureforNaturalLanguageProcessing:DeepNeuralNetworkswithMultitaskLearning.InPro-ceedingsofICML.FabrizioCosta,PaoloFrasconi,VincenzoLombardo,andGiovanniSoda.2003.TowardsIncrementalParsingofNaturalLanguageUsingRecursiveNeuralNetworks.AppliedIntelligence,19(1-2).JohnDuchi,EladHazan,andYoramSinger.2011.AdaptiveSubgradientMethodsforOnlineLearningandStochasticOptimization.JMLR,12.ChrisDyer.n.d.NotesonAdaGrad.Unpublishedmanuscript,availableathttp://www.ark.cs.cmu.edu/cdyer/adagrad.pdf.NuriaGalaandMathieuLafourcade.2007.PPattach-mentambiguityresolutionwithcorpus-basedpatterndistributionsandlexicalsignatures.ECTI-CITTrans-actionsonComputerandInformationTechnology,2.PabloGamallo,AlexandreAgustini,andGabrielP.Lopes.2003.AcquiringSemanticClassestoElabo-rateAttachmentHeuristics.InProgressinArtificialIntelligence,volume2902ofLNCS.SpringerBerlinHeidelberg.SpenceGreen.2009.ImprovingParsingPer-formanceforArabicPPAttachmentAmbi-guity.Unpublishedmanuscript,availableathttp://www-nlp.stanford.edu/courses/cs224n/2009/fp/30-tempremove.pdf.NizarHabashandOwenRambow.2005.ArabicTok-enization,Part-of-SpeechTaggingandMorphologicalDisambiguationinOneFellSwoop.InProceedingsofACL.NizarHabashandRyanRoth.2009.CATiB:TheColumbiaArabicTreebank.InProceedingsoftheACL-IJCNLP.NizarHabash,OwenRambow,andRyanRoth.2005.MADA+TOKAN:AToolkitforArabicTokenization,Diacritization,MorphologicalDisambiguation,POSTagging,StemmingandLemmatization.InProceed-ingsoftheSecondInternationalConferenceonArabicLanguageResourcesandTools.GeoffreyE.Hinton,NitishSrivastava,AlexKrizhevsky,IlyaSutskever,andRuslanSalakhutdinov.2012.Im-provingneuralnetworksbypreventingco-adaptationoffeaturedetectors.CoRR.KarinKipper,AnnaKorhonen,NevilleRyant,andMarthaPalmer.2008.Alarge-scaleclassificationofEnglishverbs.LanguageResourcesandEvaluation,42(1).
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
0
3
1
5
6
6
9
4
7
/
/
t
l
a
c
_
a
_
0
0
2
0
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
572
TerryKoo,XavierCarreras,andMichaelCollins.2008.SimpleSemi-supervisedDependencyParsing.InPro-ceedingsofACL-HLT.JonathanK.Kummerfeld,DavidHall,JamesR.Curran,andDanKlein.2012.ParserShowdownattheWallStreetCorral:AnEmpiricalInvestigationofErrorTypesinParserOutput.InProceedingsofEMNLP-CoNLL.TaoLei,YuXin,YuanZhang,ReginaBarzilay,andTommiJaakkola.2014.Low-RankTensorsforScor-ingDependencyStructures.InProceedingsofACL.OmerLevyandYoavGoldberg.2014.Dependency-BasedWordEmbeddings.InProceedingsofACL.PercyLiang.2005.Semi-SupervisedLearningforNatu-ralLanguage.Master’sthesis,MassachusettsInstituteofTechnology.AndreMartins,NoahSmith,EricXing,PedroAguiar,andMarioFigueiredo.2010.TurboParsers:Depen-dencyParsingbyApproximateVariationalInference.InProceedingsofEMNLP.AndreMartins,MiguelAlmeida,andNoahA.Smith.2013.TurningontheTurbo:FastThird-OrderNon-ProjectiveTurboParsers.InProceedingsofACL.DavidMcClosky,EugeneCharniak,andMarkJohnson.2006.EffectiveSelf-TrainingforParsing.InProceed-ingsofHLT-NAACL.RyanMcDonald,KobyCrammer,andFernandoPereira.2005.OnlineLarge-MarginTrainingofDependencyParsers.InProceedingsofACL.SrinivasMedimiandPushpakBhattacharyya.2007.AFlexibleUnsupervisedPP-attachmentMethodUsingSemanticInformation.InProceedingsofIJCAI.SauroMenchetti,FabrizioCosta,PaoloFrasconi,andMassimilianoPontil.2005.Widecoveragenaturallanguageprocessingusingkernelmethodsandneuralnetworksforstructureddata.PatternRecognitionLet-ters,26(12).TomasMikolov,KaiChen,GregCorrado,andJeffreyDean.2013a.EfficientEstimationofWordRepresen-tationsinVectorSpace.InProceedingsofWorkshopatICLR.TomasMikolov,IlyaSutskever,KaiChen,GregCorrado,andJeffreyDean.2013b.DistributedRepresentationsofWordsandPhrasesandtheirCompositionality.InProceedingsofNIPS.JaouadMousser.2010.ALargeCoverageVerbTaxon-omyforArabic.InProceedingsofLREC.J.Nivre,J.Hall,andJ.Nilsson.2006.MaltParser:AData-DrivenParser-GeneratorforDependencyPars-ing.InProceedingsofLREC.MarianOlteanuandDanMoldovan.2005.PP-attachmentDisambiguationusingLargeContext.InProceedingsofHLT-EMNLP.PrincetonUniversity.2010.WordNet.http://wordnet.princeton.edu.AdwaitRatnaparkhi,JeffReynar,andSalimRoukos.1994.AMaximumEntropyModelforPrepositionalPhraseAttachment.InProceedingsofHLT.HoracioRodr´ıquez,DavidFarwell,JaviFerreres,ManuelBertran,MusaAlkhalifa,andM.AntoniaMart´ı.2008.ArabicWordNet:Semi-automaticExtensionsusingBayesianInference.InProceedingsofLREC.Djam´eSeddah,ReutTsarfaty,SandraK¨ubler,MarieCan-dito,JinhoD.Choi,Rich´ardFarkas,JenniferFos-ter,etal.2013.OverviewoftheSPMRL2013SharedTask:ACross-FrameworkEvaluationofPars-ingMorphologicallyRichLanguages.InProceedingsofSPMRL.RichardSocher,ChristopherD.Manning,andAndrewY.Ng.2010.LearningContinuousPhraseRepresenta-tionsandSyntacticParsingwithRecursiveNeuralNet-works.InProceedingsofNIPSDeepLearningandUnsupervisedFeatureLearningWorkshop.RichardSocher,JohnBauer,ChristopherD.Manning,andNgAndrewY.2013.ParsingwithCompositionalVectorGrammars.InProceedingsofACL.JiriStetinaandMakotoNagao.1997.CorpusBasedPPAttachmentAmbiguityResolutionwithaSemanticDictionary.InFifthWorkshoponVeryLargeCorpora.SimonˇSuster.2012.ResolvingPP-attachmentambi-guityinFrenchwithdistributionalmethods.Mas-ter’sthesis,Universit´edeLorraine&RijksuniversiteitGroningen.JosephTurian,Lev-ArieRatinov,andYoshuaBengio.2010.WordRepresentations:ASimpleandGeneralMethodforSemi-SupervisedLearning.InProceed-ingsofACL.MartinVolk.2002.CombiningUnsupervisedandSuper-visedMethodsforPPAttachmentDisambiguation.InProceedingsofCOLING.StefanWager,SidaWang,andPercyLiang.2013.DropoutTrainingasAdaptiveRegularization.InPro-ceedingsofNIPS.