The FLORES-101 Evaluation Benchmark
for Low-Resource and Multilingual Machine Translation
Naman Goyal1, Cynthia Gao1, Vishrav Chaudhary1, Peng-Jen Chen1,
Guillaume Wenzek2, Da Ju1, Sanjana Krishnan1, Marc’Aurelio Ranzato1,
Francisco Guzm´an1, Angela Fan2,3
1Facebook AI Research, USA, 2Facebook AI Research, France, 3LORIA
flores@fb.com
Abstract
One of the biggest challenges hindering pro-
gress in low-resource and multilingual ma-
chine translation is the lack of good evaluation
benchmarks. Current evaluation benchmarks
either lack good coverage of low-resource lan-
guages, consider only restricted domains, or
are low quality because they are constructed
using semi-automatic procedures. In this work,
we introduce the FLORES-101 evaluation bench-
mark, consisting of 3001 sentences extracted
from English Wikipedia and covering a variety
of different topics and domains. These sen-
tences have been translated in 101 languages
by professional translators through a carefully
controlled process. The resulting dataset en-
ables better assessment of model quality on
the long tail of low-resource languages, in-
cluding the evaluation of many-to-many multi-
lingual translation systems, as all translations
are fully aligned. By publicly releasing such
a high-quality and high-coverage dataset, we
hope to foster progress in the machine trans-
lation community and beyond.
1
Introduction
Machine translation (MT) is one of the most
successful applications in natural language pro-
cessing, as exemplified by its numerous practical
applications and the number of contributions on
this topic at major machine learning and nat-
ural language processing venues. Despite recent
advances in translation quality for a handful of lan-
guage pairs and domains, MT systems still perform
poorly on low-resource languages, that is, lan-
guages without a lot of training data. In fact, many
low-resource languages are not even supported
by most popular translation engines. Yet, much
of the world’s population speak low-resource lan-
guages and would benefit from improvements in
translation quality on their native languages. As a
result, the field has been increasing focus towards
low-resource languages.
522
At present, there are very few benchmarks on
low-resource languages. These often have very
low coverage of low-resource languages (Riza
et al., 2016; Thu et al., 2016; Guzm´an et al.,
2019; Barrault et al., 2020a; Nekoto et al., 2020;
Ebrahimi et al., 2021; Kuwanto et al., 2021), lim-
iting our understanding of how well methods gen-
eralize and scale to a larger number of languages
with a diversity of linguistic features. There are
some benchmarks that have high coverage, but
these are often in specific domains, like COVID-
19 (Anastasopoulos et al., 2020) or religious
texts (Christodouloupoulos and Steedman, 2015;
Malaviya et al., 2017; Tiedemann, 2018; Agi´c and
Vuli´c, 2019); or have low quality because they are
built using automatic approaches (Zhang et al.,
2020; Schwenk et al., 2019, 2021). As a result, it
is difficult to draw firm conclusions about research
efforts on low-resource MT. In particular, there
are even fewer benchmarks that are suitable for
evaluation of many-to-many multilingual transla-
tion, as these require multi-lingual alignment (i.e.,
having the translation of the same sentence in
multiple languages), which hampers the progress
of the field despite all the recent excitement on
this research direction.
We present the FLORES-101 benchmark, con-
sisting of 3001 sentences sampled from various
topics in English Wikipedia and professionally
translated in 101 languages. With this dataset, we
make several contributions. First, we provide the
community with a high-quality benchmark that
has much larger breadth of topics and coverage
of low resource languages than any other existing
dataset (§4). Second, FLORES-101 is suitable for
many-to-many evaluation, meaning that it enables
seamless evaluation of 10,100 language pairs. This
enables the evaluation of popular multilingual MT
systems as well as the evaluation of regionally-
relevant
language pairs like Spanish-Aymara
and Vietnamese-Thai, for example. Third, we
Transactions of the Association for Computational Linguistics, vol. 10, pp. 522–538, 2022. https://doi.org/10.1162/tacl a 00474
Action Editor: Colin Cherry. Submission batch: 7/2021; Revision batch: 11/2021; Published 5/2022.
c(cid:2) 2022 Association for Computational Linguistics. Distributed under a CC-BY 4.0 license.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
thoroughly document the annotation process we
followed (§3), helping the community build in-
stitutional knowledge about how to construct MT
datasets. Fourth, we release not only sentences
with their translation but also rich meta-data that
enables other kinds of evaluations and tasks, such
as document level translation, multimodal trans-
lation, and text classification. Fifth, we propose
to use the BLEU metric based on sentence piece
tokenization (Kudo and Richardson, 2018) (§5) to
enable evaluation of all languages in the set in a
unified and extensible framework, while preserv-
ing the familiarity of BLEU. Finally, we publicly
release both data and baselines used in our ex-
periments (§6), to foster research in low-resource
machine translation and related areas.
2 Related Work
A major challenge in machine translation, partic-
ularly as the field shifts its focus to low-resource
languages, is the lack of availability of evalua-
tion benchmarks. Much recent work has focused
on the creation of training corpora (Auguste Tapo
et al., 2021; Ali et al., 2021; Adelani et al., 2021;
Gezmu et al., 2021; Nyoni and Bassett, 2021;
Chauhan et al., 2021) and development of models
(Koneru et al., 2021; Nagoudi et al., 2021; Aulamo
et al., 2021), but evaluation is critical to being able
to assess and improve translation quality.
Traditionally, the yearly Workshop on Machine
Translation (WMT) and its associated shared tasks
have provided standardized benchmarks and met-
rics to the community, fostering progress by pro-
viding means of fair comparison among various
approaches. Over recent years, the main trans-
lation task at WMT has challenged participants
with low-resource languages, but the evaluation
has been limited to a handful of languages—for
example, Latvian in 2017 (Bojar et al., 2017),
Kazakh in 2018 (Bojar et al., 2018), Gujarati
and Lithuanian in 2019 (Barrault et al., 2019),
and Inuktitut, Khmer, Pashto, and Tamil in 2020
(Barrault et al., 2020b). Moreover, these tasks
have considered translation to and from English
only, while the field has been recently focusing on
large-scale multilingual models (Johnson et al.,
2016; Aharoni et al., 2019; Freitag and Firat,
2020; Fan et al., 2020).
There are other datasets for evaluation pur-
poses, such as Flores v1.0 (Guzm´an et al., 2019),
LORELEI (Strassel and Tracey, 2016), ALT
(Thu et al., 2016; Riza et al., 2016; Ding et al.,
2016), and TICO-19 (Anastasopoulos et al., 2020),
as well as datasets for specific languages such as
Igbo (Ezeani et al., 2020) and Fon (Dossou and
Emezue, 2020). These are similar to FLORES-101
because they focus on low-resource languages.
However, the language coverage of these datasets
is much smaller. Among these, only TICO-19 is
suitable for multilingual machine translation, but
its content is centered around COVID-19, un-
like the much broader coverage of topics offered
by FLORES-101. The Tatoeba corpus (Tiedemann,
2020) covers a large number of languages and
translation directions, but the low volume of sen-
tences for many directions makes the evaluation
less reliable. Further, many of the Tatoeba cor-
pus sentences are very short and straightforward,
making the dataset not as generalizable to a more
diverse set of content.
3 Dataset Construction
We describe how FLORES-101 was constructed,
first noting where the sentences originated from
and subsequently describing the carefully de-
signed translation process.
3.1 Sourcing Sentences
Original Source. All source sentences were ex-
tracted from multiple Wikimedia sources, as this is
a repository of text that is public and freely avail-
able under permissive licensing, and covers a broad
range of topics. Although Wikipedia currently
supports more than 260 languages,1 several low-
resource languages have relatively few articles
containing well structured sentences. Moreover,
translating a few hundred sentences for several
thousand different language pairs would be in-
feasible, at the very least because of the lack of
qualified translators that can read both the source
and target.
Instead, we opted to source all sentences from
three locations in English Wikimedia, while con-
sidering a broad set of topics that could be of
general interest regardless of the native language
of the reader. In particular, we collected a third
of the sentences from Wikinews,2 which is a
collection of international news articles, a third
1https://en.wikipedia.org/wiki/Wikipedia
:Multilingual statistics.
2https://en.wikinews.org/wiki/Main Page.
523
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
from Wikijunior,3 which is a collection of age-
appropriate nonfiction books for children from
birth to age 12, and a third from WikiVoyage,4
which is a travel guide with a collection of articles
about travel tips, food, and destinations around
the globe. By translating the same set of English
sentences in more than hundred languages, we
enable evaluation of multilingual MT with the
caveat that source sentences not in English are
produced by human translators. While translation-
ese (or overly literal or awkward translations) has
known idiosyncrasies (Zhang and Toral, 2019),
we conjecture that these effects are rather mar-
ginal when evaluating models in low-resource
languages, where current MT systems produce
many severe mistakes. Another downside to this
English-centric translation approach is a possi-
ble artificial increase of the differences between
two dialects of the same language. For example,
Catalan translations of Spanish sentences are very
close to the original source sentences. However,
translating from English to Spanish and English
to Catalan can produce Spanish and Catalan sen-
tences that are no longer so similar. We believe the
benefits of many-to-many evaluation, which sup-
ports the measurement of traditionally neglected
regionally relevant pairs such as Xhosa-Zulu,
Vietnamese-Thai, and Spanish-Aymara, largely
outsize the risk of evaluating translationese.
Sentence Selection. The sentence process con-
sisted of selecting an article at random from each
domain, and then selecting between 3 and 5 con-
tiguous sentences, avoiding segments with very
short or malformed sentences. We selected one
paragraph per document, from either the begin-
ning, middle, or end of the article. For each sen-
tence, we extracted the URL, topic, and noted
Boolean flags to indicate whether the sentence
contained entities linked to other Wikipedia pages
and images.
Several contiguous sentences are extracted from
the same article and we also provide the corre-
sponding URL. Additional document-level context
can be accessed through this provided metadata
when translating each sentence. On average, we
select 3.5 contiguous sentences per article, pro-
viding assessment possibilities beyond single sen-
tences. However, we note that compared to the
document-level evaluation datasets in WMT 2018
3https://en.wikibooks.org/wiki/Wikijunior.
4https://en.wikivoyage.org/wiki/Main Page.
to 2020 for Russian and German, FLORES-101
does not contain translations of full documents.
On the other hand, FLORES-101 covers a much
wider array of domains and topics, facilitated by
translating a far greater number of articles and
fewer sentences per article. Further, the metadata
for each sentence in FLORES-101 is provided, and
thus the full English document could be used
in studies of document-level translation. Overall,
we find this a reasonable compromise between
evaluating beyond sentence-level context while
creating a diverse evaluation dataset.
Finally, with the additional meta-data provided
in FLORES-101, we also enable evaluation of mul-
timodal machine translation as users can access
images through the metadata. Around two-thirds
of all articles chosen for translation contain im-
ages (see Table 3), allowing the incorporation of
both text and image content for evaluation.
3.2 Translation Guidelines
We describe how translators were selected and
detail the guidelines provided to translators.
Translator Selection Translators are required
to be native speakers and educated in the target
language. They must also have a high level of flu-
ency (C1-C2) in English. Translators are required
to have at least two to three years of translation ex-
perience in the relevant language pair if they have
an academic degree in translation or linguistics and
three to five years of translation experience if they
do not have any relevant academic qualification.
Translators are also required to to be an experi-
enced, generalist translator and/or familiar with
United States and international news, current af-
fairs, politics, sports, and so forth. Translators also
undergo a translation test every 18 months to as-
sess their translation quality. In addition to having
the necessary translation skills, FLORES trans-
lators must be able to communicate effectively
in English.
Instructions for Translation Translators were
instructed to translate source data as informa-
tive, neutral, and standardized content. Assistance
from any machine translation was strictly pro-
hibited and translators were advised to translate
localized in the target language as appropriate
for content in the informative domain. Particular
guidance was made on translating named enti-
ties, in which proper nouns were to be translated
524
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
ISO 639-3
Language
Family
Subgrouping
Script
afr
amh
ara
hye
asm
ast
azj
bel
ben
bos
bul
mya
cat
ceb
zho
zho
hrv
ces
dan
nld
est
tgl
fin
fra
ful
glg
lug
kat
deu
ell
guj
hau
heb
hin
hun
isl
ibo
ind
gle
ita
jpn
jav
kea
kam
kan
kaz
khm
kor
kir
lao
lav
lin
lit
luo
ltz
mkd
msa
mal
mlt
mri
Afrikaans
Amharic
Arabic
Armenian
Assamese
Asturian
Azerbaijani
Belarusian
Bengali
Bosnian
Bulgarian
Burmese
Catalan
Cebuano
Chinese (Simpl)
Chinese (Trad)
Croatian
Czech
Danish
Dutch
Estonian
Filipino (Tagalog)
Finnish
French
Fula
Galician
Ganda
Georgian
German
Greek
Gujarati
Hausa
Hebrew
Hindi
Hungarian
Icelandic
Igbo
Indonesian
Irish
Italian
Japanese
Javanese
Kabuverdianu
Kamba
Kannada
Kazakh
Khmer
Korean
Kyrgyz
Lao
Latvian
Lingala
Lithuanian
Luo
Luxembourgish
Macedonian
Malay
Malayalam
Maltese
M¯aori
Indo-European
Afro-Asiatic
Afro-Asiatic
Indo-European
Indo-European
Indo-European
Turkic
Indo-European
Indo-European
Indo-European
Indo-European
Sino-Tibetan
Indo-European
Austronesian
Sino-Tibetan
Sino-Tibetan
Indo-European
Indo-European
Indo-European
Indo-European
Uralic
Austronesian
Uralic
Indo-European
Atlantic-Congo
Indo-European
Atlantic-Congo
Kartvelian
Indo-European
Indo-European
Indo-European
Afro-Asiatic
Afro-Asiatic
Indo-European
Uralic
Indo-European
Atlantic-Congo
Austronesian
Indo-European
Indo-European
Japonic
Austronesian
Indo-European
Atlantic-Congo
Dravidian
Turkic
Austro-Asiatic
Koreanic
Turkic
Kra-Dai
Indo-European
Atlantic-Congo
Indo-European
Nilo-Saharan
Indo-European
Indo-European
Austronesian
Dravidian
Afro-Asiatic
Austronesian
Latin
Ge’ez
Arabic
Armenian
Bengali
Latin
Latin
Cyrillic
Bengali
Latin
Cyrillic
Myanmar
Latin
Latin
Han
Han
Latin
Latin
Latin
Latin
Latin
Latin
Latin
Latin
Latin
Latin
Latin
Georgian
Latin
Greek
Gujarati
Latin
Hebrew
Devanagari
Latin
Latin
Latin
Latin
Latin
Latin
Han, Hiragana, Katakana
Latin
Latin
Latin
Telugu-Kannada
Cyrillic
Khmer
Hangul
Cyrillic
Lao
Latin
Latin
Latin
Latin
Latin
Cyrillic
Latin
Malayalam
Latin
Latin
Germanic
Afro-Asiatic
Afro-Asiatic
Other IE
Indo-Aryan
Romance
Turkic
Balto-Slavic
Indo-Aryan
Balto-Slavic
Balto-Slavic
Sino-Tibetan+Kra-Dai
Romance
Austronesian
Sino-Tibetan+Kra-Dai
Sino-Tibetan+Kra-Dai
Balto-Slavic
Balto-Slavic
Germanic
Germanic
Uralic
Austronesian
Uralic
Romance
Nilotic+Other AC
Romance
Bantu
Other
Germanic
Other IE
Indo-Aryan
Afro-Asiatic
Afro-Asiatic
Indo-Aryan
Uralic
Germanic
Nilotic+Other AC
Austronesian
Other IE
Romance
Other
Austronesian
Romance
Bantu
Dravidian
Turkic
Austro-Asiatic
Other
Turkic
Sino-Tibetan+Kra-Dai
Balto-Slavic
Bantu
Balto-Slavic
Nilotic+Other AC
Germanic
Balto-Slavic
Austronesian
Dravidian
Afro-Asiatic
Austronesian
525
Bitext
w/ En
570K
339K
25.2M
977K
43.7K
124K
867K
42.4K
2.16M
187K
10.3M
283K
5.77M
484K
37.9M
37.9M
42.2K
23.2M
10.6M
82.4M
4.82M
70.6K
15.2M
289M
71K
1.13M
14.4K
1.23M
216M
23.7M
160K
335K
6.64M
3.3M
16.3M
1.17M
145K
39.1M
329K
116M
23.2M
1.49M
5.46K
50K
155K
701K
398K
7.46M
566K
153K
4.8M
21.1K
6.69M
142K
3.41M
1.13M
968K
497K
5.82M
196K
Mono
Data
26.1M
3.02M
126M
25.4M
738K
—
41.4M
24M
57.9M
15.9M
235M
2.66M
77.7M
4.11M
209M
85.2M
144M
124M
344M
230M
46M
107M
377M
428M
531K
4.22M
537K
31.7M
417M
201M
9.41M
5.87M
208M
104M
385M
37.5M
693K
1.05B
1.54M
179M
458M
24.4M
178K
181K
13.1M
35.6M
8.87M
390M
2.02M
2.47M
68.4M
336K
111M
239K
—
28.8M
77.5M
24.8M
—
—
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
ISO 639-3
Language
Family
Subgrouping
Script
mar
mon
npi
nso
nob
nya
oci
ory
orm
pus
fas
pol
por
pan
ron
rus
srp
sna
snd
slk
slv
som
ckb
spa
swh
swe
tgk
tam
tel
tha
tur
ukr
umb
urd
uzb
vie
cym
wol
xho
yor
zul
Marathi
Mongolian
Nepali
Northern Sotho
Norwegian
Nyanja
Occitan
Oriya
Oromo
Pashto
Persian
Polish
Portuguese (Brazil)
Punjabi
Romanian
Russian
Serbian
Shona
Sindhi
Slovak
Slovenian
Somali
Sorani Kurdish
Spanish (Latin America)
Swahili
Swedish
Tajik
Tamil
Telugu
Thai
Turkish
Ukrainian
Umbundu
Urdu
Uzbek
Vietnamese
Welsh
Wolof
Xhosa
Yoruba
Zulu
Indo-European
Mongolic
Indo-European
Atlantic-Congo
Indo-European
Atlantic-Congo
Indo-European
Indo-European
Afro-Asiatic
Indo-European
Indo-European
Indo-European
Indo-European
Indo-European
Indo-European
Indo-European
Indo-European
Atlantic-Congo
Indo-European
Indo-European
Indo-European
Afro-Asiatic
Indo-European
Indo-European
Atlantic-Congo
Indo-European
Indo-European
Dravidian
Dravidian
Kra-Dai
Turkic
Indo-European
Atlantic-Congo
Indo-European
Turkic
Austro-Asiatic
Indo-European
Atlantic-Congo
Atlantic-Congo
Atlantic-Congo
Atlantic-Congo
Indo-Aryan
Other
Indo-Aryan
Bantu
Germanic
Bantu
Romance
Indo-Aryan
Afro-Asiatic
Indo-Aryan
Indo-Aryan
Balto-Slavic
Romance
Indo-Aryan
Romance
Balto-Slavic
Balto-Slavic
Bantu
Indo-Aryan
Balto-Slavic
Balto-Slavic
Afro-Asiatic
Indo-Aryan
Romance
Bantu
Germanic
Indo-Aryan
Dravidian
Dravidian
Sino-Tibetan+Kra-Dai
Turkic
Balto-Slavic
Bantu
Indo-Aryan
Turkic
Austro-Asiatic
Other IE
Nilotic+Other AC
Bantu
Nilotic+Other AC
Bantu
Devanagari
Cyrillic
Devanagari
Latin
Latin
Latin
Latin
Oriya
Latin
Perso-Arabic
Perso-Arabic
Latin
Latin
Gurmukhi
Latin
Cyrillic
Cyrillic
Latin
Perso-Arabic
Latin
Latin
Latin
Arabic
Latin
Latin
Latin
Cyrillic
Tamil
Telugu-Kannada
Thai
Latin
Cyrillic
Latin
Perso-Arabic
Latin
Latin
Latin
Latin
Latin
Latin
Latin
Bitext
w/ En
109K
555K
19.6K
13.8K
10.9M
932K
5.11K
5K
162K
293K
6.63M
40.9M
137M
142K
31.9M
127M
7.01M
877K
21.8K
10.5M
5.42M
358K
305K
315M
349K
54.8M
544K
992K
381K
10.6M
41.2M
5.44M
217K
630K
—
32.1M
826K
86.9K
130K
171K
123K
Mono
Data
14.4M
20.4M
17.9M
612K
338M
—
—
2.47M
752K
12M
611M
256M
340M
5.02M
391M
849M
35.7M
—
314K
174M
74.7M
14.1M
7.98M
379M
35.8M
580M
—
68.2M
17.2M
319M
128M
357M
142K
28M
7.54M
992M
12.7M
676K
995K
1.59M
994K
Table 1: 101 Languages in FLORES-101. We include the ISO 639-3 code, the language family, and
script. Next to each language family, we include more fine-grained subgrouping information. We also
include the amount of resources available in OPUS (for bitext with English) and cc100 (for monolingual
data) at the time this report was written. The parallel datasets were used to train the baseline described
in §5, the monolingual datasets were only used to calculate SentencePiece, see Section §5.
in the most commonly used form in the target
language and when such equivalent terms did
not exist, transliteration in the target language
was advised. Translators were also advised to
translate abbreviations and idiomatic expressions
to their best knowledge for how these terms and
phrases usually appear in the target language, find-
ing equivalents rather than literal word-for-word
translations. Gender neutral pronouns were also
advised to be used when 3rd person pronouns are
ambiguous in the source text.
3.3 Translation and Evaluation
Obtaining high translation quality in low-resource
languages is difficult because the translation job
relies on the skill of a small set of translators. If one
translator is not perfectly fluent or uses a different
local convention for that language, this could
526
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 1: Depiction of Overall Translation Workflow.
render the quality of the dataset insufficient or in-
consistent for that language. Here, we describe the
process we followed with our Language Service
Providers (LSPs) for translation and evaluation.
with major or critical errors, 2% of the reviewed
sample with critical errors, and 3% with unnatural
translation errors. We summarize in Table 4 the
overall statistics around the translation process.
Translation Quality Score. How do we know
if the translations are good enough to include in
FLORES-101, and how do we know when a language
has completed translation? Twenty percent of the
dataset is sampled and reviewed, this is the same
set of sentences across all languages, which allows
us to compare quality. Each sentence-translation
pair in the sampled data is assessed by a language-
specific reviewer. We assess quality through a
Translation Quality Score per language on a 0
to 100 scale, determined based on the number of
identified errors by the evaluation LSPs. The fol-
lowing errors are examined: grammar, punctua-
tion, spelling, capitalization, addition or omission
of information, mistranslation, unnatural transla-
tion, untranslated text, and register. Each error is
also associated with a severity level:minor, major
or critical. Based on pilots, we set the acceptable
score to 90%.
Translation Workflow. The overall translation
workflow is depicted in Figure 1. For each lan-
guage, all source sentences are sent to a certain
translation LSP. Once sentences are translated,
the data is sent to different translators within the
LSP for editing and then moves on to automated
quality control steps. If any of the checks fail,
the LSP has to re-translate until all verification
is passed. Afterwards, translations are sent to an
evaluation LSP that performs quality assessment,
providing a translation quality score and construc-
tive linguistic feedback both on the sentence and
language levels. If the score is below 90%, trans-
lations together with the assessment report are
sent back to the translation LSP for re-translation.
Languages scoring above our quality threshold of
90% have an average 15% of the reviewed sample
4 FLORES-101 At a Glance
In this section, we analyze FLORES-101. We pro-
vide a high-level comparison of FLORES-101 with
existing benchmarks, then discuss the sentences,
languages, and translation quality in detail.
4.1 Comparison with Existing Benchmarks
We compare FLORES-101 with several existing
benchmarks, summarized in Table 2. FLORES-101
combines large language coverage with topic
diversity, support for many-to-many evaluation,
and high quality human translations (e.g., pro-
duced with no automatic alignment). Further,
FLORES-101 adds document-level evaluation and
support multimodal translation evaluation through
provided metadata.
4.2 Sentences in FLORES-101
Table 3 provides an overview of FLORES-101. The
total dataset translates 3001 sentences into 101 lan-
guages. On average, sentences contain around 20
words. These sentences originate from 1,175 dif-
ferent articles in three domains: WikiNews, Wiki-
Junior, and WikiVoyage. On average, 3 sentences
are selected from each document, and then doc-
uments are divided into dev, devtest, and test
sets. The articles are rich in metadata: 40% of
articles contain hyperlinks to other pages, and
66% of articles contain images. We manually
classify the content of the sentences into one of
10 broader topics, and display the distribution.
Overall, most sentences are about world travel
(sourced from WikiVoyage), though there are also
a large number of sentences about science, poli-
tics, and crime.
527
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Table 2: Comparison of Various Evaluation Benchmarks. We compare FLORES-101 to a variety
of popular, existing translation benchmarks, indicating language coverage, topic diversity, whether
many-to-many translation is supported, if the translations are manually aligned by humans, and if the
tasks of document-level translation or multimodal translation are supported.
Number of Sentences
Average Words per Sentence
Number of Articles
Average Number of Sentences per Article
% of Articles with Hyperlinked Entities
% of Articles with Images
Evaluation Split
dev
devtest
test
Domain
WikiNews
WikiJunior
WikiVoyage
Sub-Topic
Crime
Disasters
Entertainment
Geography
Health
Nature
Politics
Science
Sports
Travel
# Articles
281
281
280
# Articles
309
284
249
# Articles
155
27
28
36
27
17
171
154
154
505
3001
21
842
3.5
40
66
# Sentences
997
1012
992
# Sentences
993
1006
1002
# Sentences
313
65
68
86
67
45
341
325
162
1529
Table 3: Statistics of FLORES-101.
4.3 Languages in FLORES-101
We summarize all languages in FLORES-101 in
Table 1. Our selected languages cover a large
percentage of people globally, with a large diver-
sity of scripts and families. Many languages are
spoken by millions, despite being considered low-
resource in the research community. In Table 1, we
estimate resource level by reporting the amount
of data available in OPUS, a public repository for
multilingual data. The majority of languages have
bilingual data through English and monolingual
data, though a number of languages have less than
100K sentences through English. Many have no
528
# of Languages requiring Re-translation
Avg # of Re-translations
Max # of Re-translations
Avg # of Days to Translate 1 language
Avg # of Days to Re-Translate
Avg # of Days for 1 language
Shortest Turnaround (days) for 1 language
Longest Turnaround (days) for 1 language
45
1
3
26
35
61
31
89
Table 4: Statistics of FLORES-101 Translation
Workflow.
monolingual data available, making them truly
low-resource.
4.4 Translation Quality
The translation quality score across all languages
is depicted in Figure 2. All 101 languages in
FLORES-101 meet our threshold of 90% quality.
Overall, about 50% of languages have fairly high
quality (above 95%), with few near the 90%
threshold boundary. Even low-resource languages
like Lao and Zulu can score well on the qual-
ity metric. The largest error category across all
languages was mistranslation, a broad category
that generally notes that the source text was not
translated faithfully and the translation has ren-
dered an incorrect meaning in the target language.
Error categories with few errors include register,
grammar, and punctuation.
5 Multilingual Evaluation
Automatic evaluation of translation quality is
an active research field. Each year, the WMT
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 2: Translation Quality Score across Languages. We require the final translation quality score to be above
90% before the translation is of sufficient quality to include in FLORES-101.
Metrics shared task seeks to determine the met-
rics that better correlate with human evaluations
(Mathur et al., 2020). While many metrics have
been proposed through the years, most have
not gained traction in the community.5 In fact,
99% of MT publications in the last decade
still report BLEU, and 74% do so exclusively
(Marie et al., 2021). Through the years, researchers
continue to use BLEU to compare different mod-
els. As a result, the community has developed
strong intuitions on the significance of the ef-
fects when looking at BLEU. Unfortunately, using
word-level BLEU as-is is suboptimal in a multilin-
gual context, as n-gram overlap heavily depends
on the particular tokenization used, which is not
well defined in many low-resource languages.
5.1 The Challenge of Multilingual Evaluation
Making BLEU comparable by using equivalent
tokenization schemes has been challenging for
the translation community. It has been partially
addressed by sacrebleu (Post, 2018) which
allows specifying evaluation signatures that take
tokenization into account. For example, sacre-
bleu uses the standardized NIST tokenizer6 as
a default.
However, the picture is not so simple when
looking into multilingual evaluation. For instance,
some languages like Hindi and Japanese already
have custom tokenizers that are used when com-
puting BLEU, although these appear scattered
in various publication footnotes. For many other
languages, tokenizers do not exist and English
rules are applied as a default. While English to-
kenization rules might operate reasonably well
for European languages, they do not extend to
global support. For example, white-space tok-
enization is insufficient for some languages like
Burmese or Khmer, which do not segment words
5In the past 10 years, only RIBES and chrF++ have been
used more than twice in MT publications (Marie et al., 2021).
6https://bit.ly/3CoGWma.
with white space. Other languages like Arabic are
morphologically rich, and encode more meaning
into a single word through the use of clitics.7
In short, there is no standard for universal tok-
enization and developing tokenizers for each lan-
guage of interest is a challenging effort (Dossou
and Emezue, 2021; Li et al., 2021) that is dif-
ficult to scale.
an
like
automatic
Ideally, we would
evaluation process that
is robust, simple, and
applicable to any language without the need to
specify any particular tokenizer, as this will make
it easier for researchers to compare against each
other. We would like our automatic evaluation
to also support future languages—as translation
quality continues to improve, the community will
naturally produce models for more and more
languages.
5.2 SentencePiece BLEU
Towards this goal, we propose to use BLEU over
text tokenized with a single language-agnostic and
publicly available fixed SentencePiece subword
model. We call this evaluation method spBLEU,
for brevity. It has the benefit of continuing to use a
metric that the community is familiar with, while
addressing the proliferation of tokenizers.
For this, we have trained a SentencePiece
(SPM) tokenizer (Kudo and Richardson, 2018)
with 256,000 tokens using monolingual data
(Conneau et al., 2020; Wenzek et al., 2019) from
all the FLORES-101 languages. SPM is a system
that learns subword units based on training data,
and does not require tokenization. The logic is not
dependent on language, as the system treats all sen-
tences as sequences of Unicode. Given the large
amount of multilingual data and the large number
of languages, this essentially provides a universal
tokenizer, that can operate on any language.
7This has incentivized the creation of BLEU variants
(Bouamor et al., 2014) that rely on morphological analyzers.
529
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Training SPM. One challenge is that
the
amount of monolingual data available for dif-
ferent languages is not the same—an effect that
is extreme when considering low-resource lan-
guages. Languages with small quantities of data
may not have the same level of coverage in sub-
word units, or an insufficient quantity of sentences
to represent a diverse enough set of content.
To address the low resource languages, first we
extend monolingual data of lowest 80 resource lan-
guages to 60 Common Crawl snapshots. We then
perform temperature sampling (Arivazhagan et al.,
2019) with temperature = 5.0 so that low-resource
languages are well represented. The SPM model
is trained on a combined total of 100M sampled
sentences based on the temperature sampling prob-
ability mentioned above. We use a character cov-
erage value of 0.9995 following Fan et al. (2020)
to have sufficient representation of character-
based languages. For FLORES-101 languages, the
max unknown token rate with our SPM model is
3.8% for Tagalog, with all other languages below
1%, indicating good coverage for low resource
languages from the trained tokenizer. In the future
if a new language is added to FLORES-101 and this
tokenizer does not support its script, we can add
new tokens to encode it as desired.
Computing spBLEU. Given this SPM-tokenizer,
we compute BLEU by tokenizing the system out-
put and the reference, and then calculate BLEU
in the space of sentence-pieces. SpBLEU is inte-
grated into sacrebleu for ease of use8 as the
spm tokenizer.
5.3 Experiments and Analysis
In this section we evaluate spBLEU to understand
its properties. Particularly, we want to verify that it
preserves the intuitions that researchers have built
over years using BLEU. To do so, we contrast its
results to languages where mosestokenizer
is used as the default; and when custom tokenizers
are used. Secondly, we verify that spBLEU offers
similar results to other metrics that are tokenizer-
independent such as chrF++ (Popovi´c, 2017).
Note that a rigorous assessment of any automatic
metric requires the measurement of correlation
with respect to human evaluations. However, to
date, such annotations are only available for a
handful of languages, most of which are high-
8https://github.com/mjpost/sacrebleu.
Lang
French
Italian
Spanish
Hindi
Tamil
Chinese
Correlation
spBLEU v. BLEU
Correlation
spBLEU v. chrF++
0.99
0.99
0.99
0.99
0.41
0.99
0.98
0.98
0.98
0.98
0.94
0.98
Table 5: Spearman Correlation of spBLEU,
BLEU, and chrF++. We evaluate on three sets of
languages (En-XX). Models evaluated are derived
from our baselines (discussed in Section 6). In the
top section, we evaluate languages that often use
the standard mosestokenizer. In the bottom
section, we evaluate languages that have their own
custom tokenization.
resource. Obtaining human evaluations for a large
proportion of languages covered in FLORES101 is
costly and time-consuming. Moreover, the conclu-
sions of a partial study focused on high-resource
languages might not generalize well to other lan-
guages. Therefore, we defer the in-depth evalua-
tion of the best metric for multilingual evaluation
to future work, once the adequate data is available.
spBLEU Correlates with BLEU. First, we ex-
amine the correlation between spBLEU and BLEU
across various languages where the mosesto-
kenizer is widely used. We examine Spanish,
Italian, and French. As shown in Table 5 (top),
spBLEU correlates well (0.99) with BLEU on
these languages. In the bottom section, we show
the correlation for Chinese, Hindi, and Tamil
where custom tokenizers are needed.9 We observe
a high correlation (0.99) for Hindi and Chinese,
and a weaker correlation (0.41) for Tamil.10
spBLEU Has a Strong Correlation with chrF++.
Next, we compare how well spBLEU tracks
against another well vetted tokenizer-independent
metric: chrF++. In Table 5 we observe that both
metrics are highly correlated across target lan-
guages ranging from 0.94 to 0.98. This is con-
sistent across all the 101×100 language pairs
9Chinese is
supported by mosetokenizer with
special rules. Hindi and Tamil have a popularly used
tokenizer in the community from IndicNLP (https://
anoopkunchukuttan.github.io/indic nlp library/).
10We hypothesize that a weaker correlation for Tamil
might be due to the agglutinative nature of the language,
which spBLEU handles more similarly to chrF++.
530
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
6.1 Data Splits
FLORES-101 is divided into dev, devtest, and
test. The dev set is meant to be used for hyper-
parameter tuning. The devtest is meant to be used
for testing purposes during the development phase.
The test set will not be released, but is available via
a publicly available evaluation server,11 while the
dev and devtest are publicly downloadable. The
primary motivation for keeping the test set avail-
able only through an evaluation server is to gua-
rantee equivalent assessment of models and reduce
overfitting to the test set. Further, as the dataset
is many-to-many, if the source sentences are re-
leased, the target sentences would also be released.
6.2 Baselines
We evaluate three baselines:
• M2M-124: Fan et al.
(2020) created a
Many-to-Many translation model, but did not
have full coverage of FLORES-101. We ex-
tended their model by supplementing OPUS
data. We trained two different sizes of models
with 615M and 175M parameters.
• OPUS-100: Zhang et al. (2020) trained mul-
tilingual machine translation models on an
English-centric OPUS dataset with language-
aware layers and random online backtransla-
tion (RoBT). We evaluate the 24-layer model
with backtranslation with 254M parameters.
• Masakhane: The Maskhane Participatory
Research effort, focusing on African lan-
guages, has developed and open-sourced for
the community various machine translation
models (Nekoto et al., 2020; Abbott and
Martinus, 2019).
6.3 Generation
We generate from all models with beam size 5,
setting the max generation length to 200. Given the
large number of directions covered in FLORES-101,
we do not tune the beam size, length penalty, or
minimum/maximum generation length.
6.4 Results
Figure 3: Scatterplot of spBLEU against chrF++ for
101×100 language pairs in FLORES-101 devtest. Each
point represents the score of the translation for a given
language pair. To illustrate the behavior of evaluation
into the same target language (e.g., XX-> zho), we use
different color shades for each target language. Target
language groupings can be observed as streaks that
extend from left to right. We can observe a high-degree
of global correlation (0.94) between the chrF++ and
metrics, although different trends with strong local
correlation can be observed for individual languages
like Chinese (zho), Japanese (jpn), and Korean (kor).
supported by FLORES-101. In Figure 3, we plot
chrF++ vs. spBLEU scores resulting from trans-
lating between all languages in FLORES. We
observe that there is a strong, linear relationship
between the two metrics (Pearson correlation of
0.94). Notably,
languages like Chinese,
Korean, and Japanese behave differently than the
rest, yet the relationship between the two metrics
remains locally strong.
target
Takeaway. Overall, we conclude that spBLEU
functions fairly similarly to BLEU, especially on
languages that usually default to the moses-
tokenizer. Moreover, spBLEU exhibits a
strong correlation to the tokenization-independent
chrF++, across a myriad of language pairs, yet
has the advantage of keeping the familiarity of
BLEU. In short, spBLEU combines the familiar-
ity of BLEU with the generalizability of chrF++.
For the vast majority of languages without custom
tokenizers, spBLEU provides the ability to quan-
tify performance in the same way, with a single
tokenization model. In the rest of the work, we
use spBLEU to evaluate model performance.
6 Evaluating Baselines on FLORES-101
In this section, we present the evaluation of three
baseline models on FLORES-101.
We compare the performance of various models
across several axes, analyzing the effect of lan-
guages, data, and domain.
11https://dynabench.org/flores.
531
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
c
i
t
a
i
s
A
–
o
r
f
A
7
4.20
6.39
8.32
3.28
3.04
9.48
3.64
1.60
8.25
4.68
3.55
5.13
n
a
i
s
e
n
o
r
t
s
u
A
6
6.82
11.50
12.29
5.70
4.56
14.25
5.27
3.10
12.74
7.45
5.24
c
i
v
a
l
S
–
o
t
l
a
B
14
10.93
13.78
22.81
6.29
7.21
22.56
8.56
2.76
20.70
10.58
9.35
8.08
12.32
n
a
i
d
i
v
a
r
D
4
1.21
2.08
3.25
1.16
2.34
3.26
2.01
0.43
2.41
2.29
1.24
1.97
c
i
n
a
m
r
e
G
9
11.95
15.53
21.67
7.40
7.66
26.09
8.81
3.48
22.43
10.84
8.81
13.15
u
t
n
a
B
10
2.31
3.48
3.48
2.37
1.44
4.17
1.60
1.45
3.22
2.29
1.61
2.49
n
a
y
r
A
–
o
d
n
I
14
3.43
4.69
6.82
2.16
3.62
6.89
3.70
0.79
6.04
4.10
2.96
4.11
C
A
r
e
h
t
O
+
c
i
t
o
l
i
N
5
0.93
1.45
0.89
1.37
0.39
1.40
0.42
0.95
1.15
0.67
0.58
0.93
e
c
n
a
m
o
R
10
11.70
14.95
21.75
7.16
7.31
23.53
8.66
3.48
24.44
11.05
9.14
13.01
i
a
D
–
a
r
K
+
b
i
T
–
o
n
i
S
4
3.66
5.78
7.31
2.77
2.73
7.98
3.26
1.29
6.96
5.10
3.13
4.54
c
i
k
r
u
T
5
2.73
4.13
5.87
1.95
2.04
6.24
2.36
0.81
5.46
3.20
2.38
3.38
Avg
5.44
7.61
10.41
3.78
3.85
11.44
4.39
1.83
10.35
5.66
4.36
Num Languages:
Afro-Asiatic
Austronesian
Balto-Slavic
Bantu
Dravidian
Germanic
Indo-Aryan
Nilotic+Other AC
Romance
Sino-Tib+Kra-Dai
Turkic
Avg
Table 6: Many-to-Many Performance on Family Groups. We display the spBLEU on the devtest of
FLORES-101 for the M2M-124 615M parameter model. Each cell represents the average performance for
translating from all the languages in the source group (row) into the each language of the target group
(column). We highlight in gray the cells that correspond to within-group evaluation. In bold we show
the best performance per target group and underline the best performance per source group.
Very Low
Low
Medium
High
< 100K (100K, 1M) (1M, 100M) >100M
# Langs
15
40
Very Low
Low
Medium
High
Avg
1.6
2.0
3.8
4.3
2.9
2.3
2.74
5.4
5.8
4.1
38
7.0
8.5
19.1
21.7
14.1
6
9.1
10.3
23.4
27.3
17.6
Table 7: Many-to-Many Performance by avail-
able Bitext through English. We show spBLEU
on devtest for M2M-124 615M parameter model.
spBLEU is worse for low-resource languages
compared to high resource languages, and trans-
lating into low-resource languages is harder than
translating out of them.
6.4.1 Findings From All Directions
English-Centric Translation. Performance of
translation into English is strong, with only a few
languages with spBLEU below 10. Performance
out of English is worse. Performance is heavily
correlated with amount of training data, which
we discuss in greater detail later. We note that
the construction of FLORES-101 is English-centric
in and of itself, as the same set of sentences are
translated from English into all languages. This
can affect the performance of non-English-centric
Num Sentences
English ←
English →
Chinese ←
Chinese →
Spanish ←
Spanish →
Hindi ←
Hindi →
Arabic ←
Arabic →
Many-to-Many
News
993
20.64
16.85
11.57
10.02
14.91
11.67
14.33
10.88
8.39
9.81
8.56
Junior
1006
20.67
16.67
9.66
9.93
13.80
10.96
14.15
10.86
8.23
10.31
7.97
Voyage
1002
19.41
15.48
9.55
9.57
13.23
10.37
13.84
10.11
7.74
9.54
7.59
Avg
20.24
16.33
10.26
9.84
13.98
11.00
14.11
10.62
8.12
9.88
Table 8: Many-to-Many Performance by
Domain. We show spBLEU on three partitions
of the FLORES-101 devtest according to the origi-
nating domains. We compute the corpus spBLEU
for each language in each domain, and then
average across languages.
directions, because languages that are similar to
each other may have been translated differently
if they were not translated out of English. For
example, the sentence construction of Lao when
translating from Thai to Lao may look different
compared to English to Thai and English to Lao.
Many-to-Many Translation. Across non-English-
centric directions, performance requires improve-
ment—translation in and out of most African
532
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
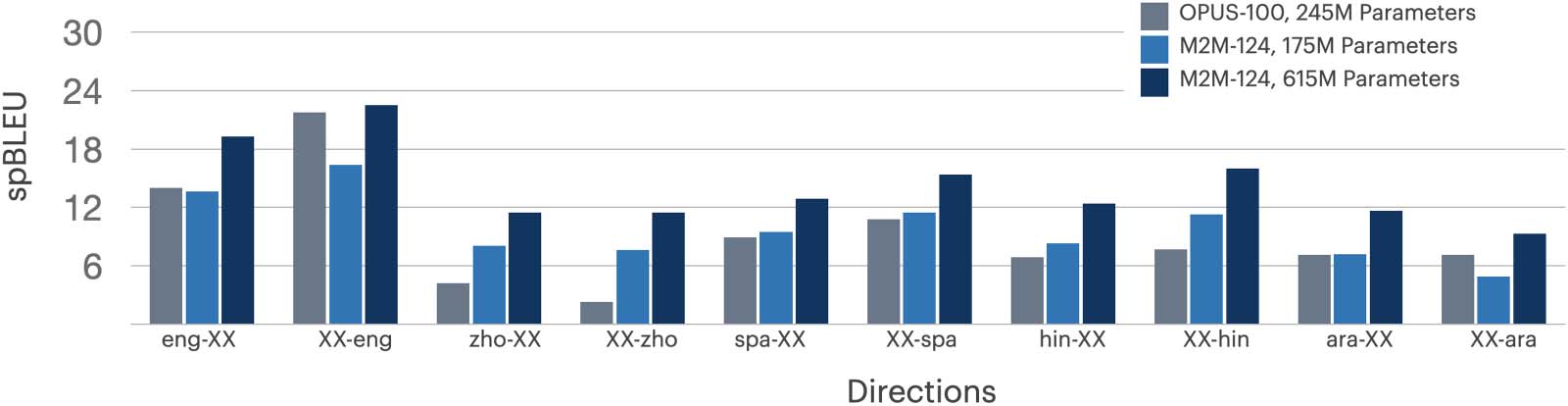
Figure 4: Comparison between OPUS-100 and M2M-124 on several one-to-many and many-to-one translation
tasks using five languages: English, Chinese, Spanish, Hindi, and Arabic. Because the open-source OPUS-100
model covers only 80 languages of FLORES-101, we restrict the evaluation to only these languages.
Figure 5: Full results of M2M-124 Models on several one-to-many and many-to-one translation tasks using five
languages: English, Chinese, Spanish, Hindi, and Arabic.
languages, for example, struggles to reach 5
spBLEU. In contrast, translation into many Eu-
ropean languages, even low-resource languages
such as Occitan, has much better performance
(over 10 spBLEU for many directions). This result
highlights the importance of both the amount of
data and transfer learning from related languages.
For instance, translation to and from Occitan can
naturally borrow from related high-resource lan-
guages like French, Italian, and Spanish. How-
ever, the same cannot be said about most African
languages, for which related languages are also
low resource and difficult to translate.
Performance by Language Family. We group
languages into eleven general families and report
in Table 6 the average spBLEU for translating
from and into each family. Our results indicate
that Bantu, Dravidian, Indo-Aryan, and Nilotic
are the language families where M2M-124 strug-
gles the most, attaining an average spBLEU be-
low 5 points. Even translation within the language
family (see values in the diagonal) is poor. In
general, Germanic, Romance, and Balto-Slavic
are the language families that yield the largest
spBLEU scores (above 10 spBLEU points in
average). Overall, many-to-many translation re-
quires improvement.
Performance by Resource Level. Performance
is often closely tied to the amount (and quality)
of training data. Certain language families have
much less data. For example, almost every sin-
gle African language is considered a low-resource
translation direction. We classify languages into
four bins based on resource level of bitext
with English: high-resource languages, with more
than 100M sentences, mid-resource with between
1M and 100M sentences, low-resource with be-
tween 100K and 1M sentences, and finally very
low-resource with less than 100K sentences. Our
results are summarized in Table 7. As hypothe-
sized, performance increases with greater quantity
of training data, in a clear pattern. spBLEU in-
creases moving from left to right, as well as
from top to bottom. Even translation between
high-resource and low-resource languages is still
quite low, indicating that lack of training data
strongly limits performance.
Performance by Domain. We analyze whether
certain domains are more difficult to translate
than others. We report results of translating in and
out of five languages, namely, English, Chinese,
Spanish, Hindi, and Arabic, as well as the aver-
age across all of the 10,000 possible directions.
The results in Table 8 demonstrate that the factor
533
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Masakhane M2M-124
English → Yoruba
English → Zulu
English → Swahili
English → Shona
English → Nyanja
English → Luo
2.04
11.85
22.09
8.19
2.19
5.33
2.17
3.89
26.95
11.74
12.9
3.37
Table 9: spBLEU of Masakhane-MT. We eval-
uate models on translating from English to six
different African languages. We compare against
the M2M-124 615M parameter model.
that affects quality the most is the language we
translate in and out of rather than domain. Over-
all, WikiNews is the easiest with slightly higher
spBLEU, and WikiVoyage is the hardest domain.
6.4.2 Comparison of Various Systems
Comparison with OPUS-100. We evaluate
OPUS-100 (Zhang et al., 2020) with 254M
parameters and the two versions of M2M-124
(Fan et al., 2020) with 175 and 615M parameters.
We calculate spBLEU in and out of five languages:
English, Chinese, Spanish, Hindi, and Arabic. Re-
sults are shown in Figure 4. Note that OPUS-100
only covers 80 languages in FLORES-101, so this
figure is on the subset of 80 languages covered by
all models, for comparability. We see a consistent
trend across models and directions: The larger
M2M-124 has the best performance, followed by
the smaller M2M-124 and OPUS-100.
We display results of M2M-124 175M param-
eters and 615M parameters on the full set of
FLORES-101 languages (see Figure 5). Comparing
results with Figure 4, it is evident that the average
performance in these language groupings has de-
creased, indicating that the additional languages
in FLORES-101 are likely very difficult. We see the
same consistent trend that the larger M2M-124
model has stronger performance.
Comparison with Masakhane. The compari-
son with OPUS-100 compares M2M-124 with
another multilingual model. However, various
researchers in the low-resource translation com-
munity have developed models for specific lan-
guages, which could produce specialized models
with higher quality. We evaluate models from
English to the following languages: Yoruba, Zulu,
Swahili, Nyanja, Shona, and Luo. Results are
shown in Table 9. We observe that for two
languages—Zulu and Luo—Masakhane’s open
sourced models have stronger performance on
FLORES-101 than the M2M-124 model. The re-
maining languages we assess have similar or worse
performance than M2M-124.
7 Conclusion
The potential
to develop translation for lan-
guages globally is hindered by lack of reli-
able, high-quality evaluation. We create and
open-source FLORES-101, a benchmark with 101
languages. It supports many-to-many evaluation,
meaning all 10,100 directions can be evalu-
ated. Unlike many other datasets, FLORES-101 is
professionally translated, including human evalu-
ation during dataset creation. Beyond translation,
FLORES-101 can be used to evaluate tasks such
as sentence classification, language identification,
and domain adaptation.
References
Jade Abbott and Laura Martinus. 2019. Bench-
marking neural machine translation for South-
In Proceedings of
ern African languages.
the 2019 Workshop on Widening NLP,
pages 98–101, Florence, Italy. Association for
Computational Linguistics.
David I. Adelani, Dana Ruiter, Jesujoba O.
Alabi, Damilola Adebonojo, Adesina Ayeni,
Mofe Adeyemi, Ayodele Awokoya,
and
Cristina Espa˜na-Bonet. 2021. Menyo-20k: A
multi-domain english-yor\ub\’a corpus for
machine translation and domain adaptation.
arXiv preprint arXiv:2103.08647.
ˇZeljko Agi´c and Ivan Vuli´c. 2019. JW300: A
wide-coverage parallel corpus for low-resource
languages. In Proceedings of the 57th Annual
Meeting of the Association for Computational
Linguistics, pages 3204–3210, Florence, Italy.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/P19
-1310
Roee Aharoni, Melvin Johnson, and Orhan Firat.
2019. Massively multilingual neural machine
translation. In Proceedings of the 2019 Confer-
ence of the North American Chapter of the
534
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Association for Computational Linguistics:
Human Language Technologies, Volume 1
(Long and Short Papers), pages 3874–3884,
Minneapolis, Minnesota. Association
for
Computational Linguistics.
Felermino D. M. A. Ali, Andrew Caines, and
Jaimito L. A. Malavi. 2021. Towards a parallel
corpus of Portuguese and the Bantu language
Emakhuwa of Mozambique. arXiv preprint
arXiv:2104.05753.
Antonios Anastasopoulos, Alessandro Cattelan,
Zi-Yi Dou, Marcello Federico, Christian
Federmann, Dmitriy Genzel,
Franscisco
Guzm´an, Junjie Hu, Macduff Hughes, Philipp
Koehn, Rosie Lazar, Will Lewis, Graham
Neubig, Mengmeng Niu, Alp ¨Oktem, Eric
Paquin, Grace Tang, and Sylwia Tur. 2020.
Tico-19: The translation initiative for covid-
19. In EMNLP Workshop on NLP-COVID.
https://doi.org/10.18653/v1/2020
.nlpcovid19-2.5
Naveen Arivazhagan, Ankur Bapna, Orhan Firat,
Dmitry Lepikhin, Melvin Johnson, Maxim
Krikun, Mia Xu Chen, Yuan Cao, George
Foster, Colin Cherry, Wolfgang Macherey,
Zhifeng Chen, and Yonghui Wu. 2019. Mas-
sively multilingual neural machine translation
in the wild: Findings and challenges. arXiv
preprint arXiv:1907.05019.
Allahsera Auguste Tapo, Michael Leventhal,
Sarah Luger, Christopher M. Homan, and
Marcos Zampieri. 2021. Domain-specific MT for
low-resource languages: The case of Bambara-
French. arXiv e-prints, arXiv–2104.
Mikko Aulamo, Sami Virpioja, Yves Scherrer,
and J¨org Tiedemann. 2021. Boosting neural ma-
chine translation from finnish to northern S´ami
with rule-based backtranslation. NoDaLiDa
2021, page 351.
Lo¨ıc Barrault, Magdalena Biesialska, Ondˇrej Bojar,
Marta R. Costa-juss`a, Christian Federmann,
Yvette Graham, Roman Grundkiewicz, Barry
Haddow, Matthias Huck, Eric Joanis, Tom
Kocmi, Philipp Koehn, Chi-kiu Lo, Nikola
Ljubeˇsic, Christof Monz, Makoto Morishita,
Masaaki Nagata, Toshiaki Nakazawa, Santanu
Pal, Matt Post, and Marcos Zampieri. 2020a.
Findings of the 2020 conference on machine
the
translation (wmt20). In Proceedings of
Fifth Conference on Machine Translation,
pages 1–55, Online. Association for Compu-
tational Linguistics. https://doi.org/10
.18653/v1/W19-5301
Lo¨ıc Barrault, Magdalena Biesialska, Ondˇrej Bojar,
Marta R. Costa-juss`a, Christian Federmann,
Yvette Graham, Roman Grundkiewicz, Barry
Haddow, Matthias Huck, Eric Joanis, Tom
Kocmi, Philipp Koehn, Chi-kiu Lo, Nikola
Ljubeˇsi´c, Christof Monz, Makoto Morishita,
Masaaki Nagata, Toshiaki Nakazawa, Santanu
Pal, Matt Post, and Marcos Zampieri. 2020b.
the 2020 conference on ma-
Findings of
chine translation (wmt20). In Proceedings of
the Fifth Conference on Machine Translation,
pages 1–55. https://doi.org/10.18653
/v1/W19-5301
Lo¨ıc Barrault, Ondˇrej Bojar, Marta R. Costa-Juss`a,
Christian Federmann, Mark Fishel, Yvette
Graham, Barry Haddow, Matthias Huck,
Philipp Koehn, Shervin Malmasi, et al. 2019.
Findings of the 2019 conference on machine
the
translation (wmt19). In Proceedings of
Fourth Conference on Machine Translation
(Volume 2: Shared Task Papers, Day 1),
pages 1–61. https://doi.org/10.18653
/v1/W19-5301
Ondˇrej Bojar, Christian Federmann, Mark Fishel,
Yvette Graham, Barry Haddow, Matthias Huck,
Philipp Koehn, and Christof Monz. 2018. Find-
ings of the 2018 conference on machine trans-
lation (wmt18). In Proceedings of the Third
Conference on Machine Translation, volume 2,
272–307. https://doi.org/10
pages
.18653/v1/W18-6401
Ondˇrej Bojar, Chatterjee Rajen, Christian
Federmann, Yvette Graham, Barry Haddow,
Matthias Huck, Philipp Koehn, Qun Liu,
Varvara Logacheva, Christof Monz, Matteo
Negri, Matt Post, Raphael Rubino, Lucia
Specia, and Marco Turchi. 2017. Findings of
the 2017 conference on machine translation
(wmt17). In Second Conference on Machine
Translation, pages 169–214. The Association
for Computational Linguistics. https://
doi.org/10.18653/v1/W17-4717
Houda Bouamor, Hanan Alshikhabobakr,
Behrang Mohit, and Kemal Oflazer. 2014.
A human judgement corpus and a metric
535
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
for Arabic MT evaluation. In Proceedings of
the 2014 Conference on Empirical Methods
in Natural Language Processing (EMNLP),
pages 207–213, Doha, Qatar. Association for
Computational Linguistics. https://doi
.org/10.3115/v1/D14-1026
Shweta Chauhan, Shefali Saxena, and Philemon
Daniel. 2021. Monolingual and parallel cor-
pora for Kangri low resource language. arXiv
preprint arXiv:2103.11596.
Christos Christodouloupoulos and Mark Steedman.
2015. A massively parallel corpus: The bible in
100 languages. Language Resources and Eval-
uation, 49(2):375–395. https://doi.org
/10.1007/s10579-014-9287-y, PubMed:
26321896
Alexis Conneau, Kartikay Khandelwal, Naman
Goyal, Vishrav Chaudhary, Guillaume Wenzek,
Francisco Guzm´an, ´Edouard Grave, Myle Ott,
Luke Zettlemoyer, and Veselin Stoyanov.
2020. Unsupervised cross-lingual representa-
tion learning at scale. In Proceedings of the
58th Annual Meeting of the Association for
Computational Linguistics, pages 8440–8451.
https://doi.org/10.18653/v1/2020
.acl-main.747
Chenchen Ding, Masao Utiyama, and Eiichiro
Sumita. 2016. Similar southeast Asian lan-
guages: Corpus-based case study on Thai-
Laotian and Malay-Indonesian. In Proceedings
of
the 3rd Workshop on Asian Translation
(WAT2016), pages 149–156.
Bonaventure F. P. Dossou and Chris C. Emezue.
2020. Ffr v1. 1: FonFrench neural machine
translation. arXiv preprint arXiv:2006.09217.
Bonaventure F. P. Dossou and Chris C. Emezue.
2021. Crowdsourced phrase-based tokenization
for low-resourced neural machine translation:
The case of Fon language. arXiv preprint
arXiv:2103.08052.
Abteen Ebrahimi, Manuel Mager, Arturo
Oncevay, Vishrav Chaudhary, Luis Chiruzzo,
Angela Fan, John Ortega, Ricardo Ramos,
Annette Rios,
Ivan Vladimir, Gustavo A.
Gim´enez-Lugo, Elisabeth Mager, Graham
Neubig, Alexis Palmer, Rolando A. Coto
Solano, Ngoc Thang Vu, and Katharina Kann.
2021. AmericasNLI: Evaluating zero-shot nat-
language understanding of pretrained
ural
multilingual models in truly low-resource lan-
guages. arXiv preprint arXiv:2104.08726.
Ignatius Ezeani, Paul Rayson,
Ikechukwu
Onyenwe, Chinedu Uchechukwu, and Mark
Hepple. 2020. Igbo-English machine transla-
tion: An evaluation benchmark. arXiv preprint
arXiv:2004.00648.
Angela Fan, Shruti Bhosale, Holger Schwenk,
Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal,
Mandeep Baines, Onur Celebi, Guillaume
Wenzek, Vishrav Chaudhary, Naman Goyal,
Tom Birch, Vitaliy Liptchinsky, Sergey Edunov,
Edouard Grave, Michael Auli, and Armand
Joulin. 2020. Beyond English-centric multi-
lingual machine translation. arXiv preprint
arXiv:2010.11125.
Fagbohungbe,
Wilhelmina Nekoto, Vukosi Marivate, Tshinondiwa
Matsila, Timi Fasubaa, Tajudeen Kolawole,
Solomon Oluwole
Taiwo
Akinola, Shamsuddee Hassan Muhammad,
Salomon Kabongo, Salomey Osei, Sackey
Freshia, Rubungo Andre Niyongabo, Ricky
Macharm, Perez Ogayo, Orevaoghene Ahia,
Musie Meressa, Mofe Adeyemi, Masabata
Mokgesi-Selinga, Lawrence Okegbemi, Laura
Jane Martinus, Kolawole Tajudeen, Kevin
Degila, Kelechi Ogueji, Kathleen Siminyu,
Julia Kreutzer, Jason Webster, Jamiil Toure
Ali, Jade Abbott, Iroro Orife, Ignatius Ezeani,
Idris Abdulkabir Dangana, Herman Kamper,
Hady Elsahar, Goodness Duru, Ghollah Kioko,
Espoir Murhabazi, Elan van Biljon, Daniel
Whitenack, Christopher Onyefuluchi, Chris
Emezue, Bonaventure Dossou, Blessing
Sibanda, Blessing Itoro Bassey, Ayodele
Olabiyi, Arshath Ramkilowan, Alp ¨Oktem,
Adewale Akinfaderin, and Abdallah Bashir.
2020. Participatory research for low-resourced
machine translation: A case study in african
languages. arXiv preprint arXiv:2010.02353.
Markus Freitag and Orhan Firat. 2020. Com-
plete multilingual neural machine translation.
In Proceedings of
the Fifth Conference on
Machine Translation, pages 550–560, Online.
Association for Computational Linguistics.
Andargachew Mekonnen Gezmu, Andreas
N¨urnberger, and Tesfaye Bayu Bati. 2021.
Extended parallel corpus for Amharic-English
machine translation. arXiv preprint arXiv:
2104.03543.
536
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Francisco Guzm´an, Peng-Jen Chen, Myle Ott,
Juan Pino, Guillaume Lample, Philipp Koehn,
Vishrav Chaudhary, and Marc’Aurelio Ranzato.
2019. The FLORES evaluation datasets for
low-resource machine translation: Nepali–
English and Sinhala–English. In Proceedings
of the 2019 Conference on Empirical Meth-
ods in Natural Language Processing and the
9th International Joint Conference on Natu-
ral Language Processing (EMNLP-IJCNLP),
pages 6098–6111, Hong Kong, China. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/D19-1632
M. Johnson, M. Schuster, Q. V. Le, M. Krikun,
Y. Wu, Z. Chen, N. Thorat, F. Viagas, M.
Wattenberg, G. Corrado, M. Hughes, and J.
Dean. 2016. Google’s multilingual neural ma-
chine translation system: Enabling zero-shot
translation. In Transactions of the Association
for Computational Linguistics. https://doi
.org/10.1162/tacl a 00065
Philipp Koehn. 2005. In Europarl: A paral-
lel corpus for statistical machine translation.
Citeseer.
Sai Koneru, Danni Liu, and Jan Niehues. 2021.
Unsupervised machine translation on Dravidian
languages. arXiv preprint arXiv:2103.15877.
Taku Kudo and John Richardson. 2018. Sentence-
piece: A simple and language independent sub-
word tokenizer and detokenizer for neural text
processing. arXiv preprint arXiv:1808.06226.
https://doi.org/10.18653/v1/D18-2012
Garry Kuwanto, Afra Feyza Aky¨urek, Isidora
Chara Tourni, Siyang Li, and Derry Wijaya.
2021. Low-resource machine translation for
low-resource languages: Leveraging compar-
able data, code-switching and compute re-
sources. arXiv preprint arXiv:2103.13272.
Yachao Li, Jing Jiang, Jia Yangji, and Ning
Ma. 2021. Finding better subwords for Tibetan
neural machine translation. Transactions on
Asian and Low-Resource Language Informa-
tion Processing, 20(2):1–11. https://doi
.org/10.1145/3448216
Chaitanya Malaviya, Graham Neubig, and Patrick
Littell. 2017. Learning language representa-
In Proceed-
tions for
typology prediction.
ings of
the 2017 Conference on Empirical
Methods in Natural Language Processing,
pages 2529–2535. https://doi.org/10
.18653/v1/D17-1268
Benjamin Marie, Atsushi Fujita, and Raphael
Rubino. 2021. Scientific credibility of machine
translation research: A meta-evaluation of 769
papers. CoRR, abs/2106.15195. https://doi
.org/10.18653/v1/2021.acl-long.566
Nitika Mathur, Johnny Wei, Markus Freitag,
Qingsong Ma, and Ondˇrej Bojar. 2020. Results
of the wmt20 metrics shared task. In Pro-
ceedings of the Fifth Conference on Machine
Translation, pages 688–725, Online. Associa-
tion for Computational Linguistics.
El Moatez Billah Nagoudi, Wei-Rui Chen,
Muhammad Abdul-Mageed,
and Hasan
Cavusogl. 2021. Indt5: A text-to-text trans-
former for 10 indigenous languages. arXiv
preprint arXiv:2104.07483.
Evander Nyoni and Bruce A Bassett. 2021.
Low-resource neural machine translation for
southern African languages. arXiv preprint
arXiv:2104.00366.
In Proceedings of
Maja Popovi´c. 2017. chrf++: words helping
the
character n-grams.
Second Conference on Machine Translation,
Volume 2: Shared Task Papers, pages 612–618,
Copenhagen, Denmark. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/W17-4770
Matt Post. 2018. A call for clarity in reporting
BLEU scores. arXiv preprint arXiv:1804.08771.
https://doi.org/10.18653/v1/W18
-6319
Hammam Riza, Michael Purwoadi, Teduh
Uliniansyah, Aw Ai Ti, Sharifah Mahani
Aljunied, Luong Chi Mai, Vu Tat Thang,
Nguyen Phuong Thai, Vichet Chea, Sethserey
Sam, Sopheap Seng, K. Soe, K. Nwet, M.
Utiyama, and Chenchen Ding. 2016. Intro-
duction of the Asian language treebank. In
2016 Conference of The Oriental Chapter
of International Committee for Coordination
and Standardization of Speech Databases
and Assessment Techniques (O-COCOSDA),
pages 1–6. IEEE. https://doi.org/10
.1109/ICSDA.2016.7918974
537
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
J¨org Tiedemann. 2018. Emerging language spaces
learned from massively multilingual corpora.
In Digital Humanities in the Nordic Countries
DHN2018, pages 188–197. CEUR Workshop
Proceedings.
J¨org Tiedemann. 2020. The Tatoeba Translation
Challenge – Realistic data sets for low resource
and multilingual MT. In Proceedings of the
Fifth Conference on Machine Translation,
pages 1174–1182, Online. Association for
Computational Linguistics.
Guillaume Wenzek, Marie-Anne Lachaux, Alexis
Conneau, Vishrav Chaudhary,
Francisco
Guzm´an, Armand Joulin, and Edouard Grave.
2019. Ccnet: Extracting high quality mono-
lingual datasets from web crawl data. arXiv
preprint arXiv:1911.00359.
translation. In Proceedings of
Biao Zhang, Philip Williams, Ivan Titov, and
Improving massively
Rico Sennrich. 2020.
multilingual neural machine translation and
the
zero-shot
58th Annual Meeting of the Association for
Computational Linguistics, pages 1628–1639,
Online. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/2020.acl-main.148
Mike Zhang and Antonio Toral. 2019. The ef-
fect of translationese in machine translation test
sets. In Proceedings of the Fourth Conference
on Machine Translation (Volume 1: Research
Papers), pages 73–81, Florence, Italy. Associ-
ation for Computational Linguistics. https://
doi.org/10.18653/v1/W19-5208
Holger Schwenk, Vishrav Chaudhary, Shuo Sun,
Hongyu Gong, and Francisco Guzm´an. 2021.
WikiMatrix: Mining 135M parallel sentences
in 1620 language pairs from Wikipedia. In
Proceedings of
the
the Association for
European Chapter of
Computational Linguistics: Main Volume,
pages 1351–1361, Online. Association for
Computational Linguistics. https://doi
.org/10.18653/v1/2021.eacl-main
.115
the 16th Conference of
Holger Schwenk, Guillaume Wenzek, Sergey
Edunov, Edouard Grave, Armand Joulin, and
Angela Fan. 2019. CCMatrix: Mining billions
of high-quality parallel sentences on the web.
arXiv preprint arXiv:1911.04944.
for
technology development
Stephanie Strassel and Jennifer Tracey. 2016.
LORELEI language packs: Data, tools, and
in
resources
low resource languages. In Proceedings of
the Tenth International Conference on Lan-
guage Resources and Evaluation (LREC’16),
pages 3273–3280, Portoroˇz, Slovenia. Euro-
pean Language Resources Association (ELRA).
Ye Kyaw Thu, Win Pa Pa, Masao Utiyama,
Andrew Finch, and Eiichiro Sumita. 2016. In-
troducing the Asian language treebank (ALT).
In Proceedings of
the Tenth International
Conference on Language Resources and Eval-
uation (LREC’16), pages 1574–1578, Portoroˇz,
Slovenia. European Language Resources Asso-
ciation (ELRA).
538
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
7
4
2
0
2
0
6
9
9
/
/
t
l
a
c
_
a
_
0
0
4
7
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3