LETTER
A tipping point for open citation data
B. Ian Hutchins
a n o p e n a c c e s s
j o u r n a l
Citation: Hutchins, B. I. (2021). A
tipping point for open citation data.
Quantitative Science Studies, 2(2),
433–437. https://doi.org/10.1162/qss_c
_00138
DOI:
https://doi.org/10.1162/qss_c_00138
ABSTRACT
Open citation data can improve the transparency and robustness of scientific portfolio analysis,
improve science policy decision-making, stimulate downstream commercial activity, and
increase the discoverability of scientific articles. Once sparsely populated, public-domain
citation databases crossed a threshold of one billion citations in February 2021. Shortly
thereafter, the threshold of one billion public domain citations from the Crossref database alone
was crossed. As the relative advantage of withholding data in closed databases has diminished
with the flood of public domain data, this likely constitutes an irreversible change in the citation
data ecosystem. The successes of this movement can guide future open data efforts.
1. BACKGROUND
Science builds on the knowledge of past discoveries to advance the frontier of research. The
spread of new knowledge, and the provenance of that information, is documented in the
scientific citation graph. For this reason, the citations are often used in studies of knowledge
flow, scientific attribution, and research assessment. Access to this information can improve
discoverability, stimulate entrepreneurship, and advance basic and applied research in infor-
mation networks (Dugan, Fenner et al., 2017). However, for decades, the main sources of
citation data were confined by licensing restrictions from commercial providers.
The landscape has recently shifted toward open citation data. Databases such as Semantic
Scholar, The Lens, Microsoft Academic, and Digital Science’s Dimensions have indexed cita-
tions from the literature and released them at no cost on web services or in bulk under rela-
tively permissive licenses. However, the most permissive license is a public domain license.
Importantly, two large and explicitly public domain platforms have been developed: COCI,
the OpenCitations Index of Crossref open DOI-to-DOI Citations (Peroni & Shotton, 2020)
and NIH-OCC, the National Institutes of Health Open Citation Collection (Hutchins, Baker
et al., 2019). COCI indexes public citation data from Crossref (Heibi, Peroni, & Shotton,
2018) that many publishers opened up in response to the Initiative for Open Citations
(Dugan et al., 2017). The NIH-OCC, which I spearheaded as senior data scientist while work-
ing at NIH, is a merger of several citation databases, plus references parsed with machine
learning from crawled full text articles (Hutchins et al., 2019). NIH-OCC citations are distrib-
uted through the iCite web service (iCite, 2021) and as database snapshots (Hutchins &
Santangelo, 2019). These platforms have permanently released restriction-free citation data
Copyright: © 2021 B. Ian Hutchins.
Published under a Creative Commons
Attribution 4.0 International
(CC BY 4.0) license.
The MIT Press
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
q
s
s
/
a
r
t
i
c
e
–
p
d
l
f
/
/
/
/
2
2
4
3
3
1
9
3
0
7
4
7
q
s
s
_
c
_
0
0
1
3
8
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
A tipping point for open citation data
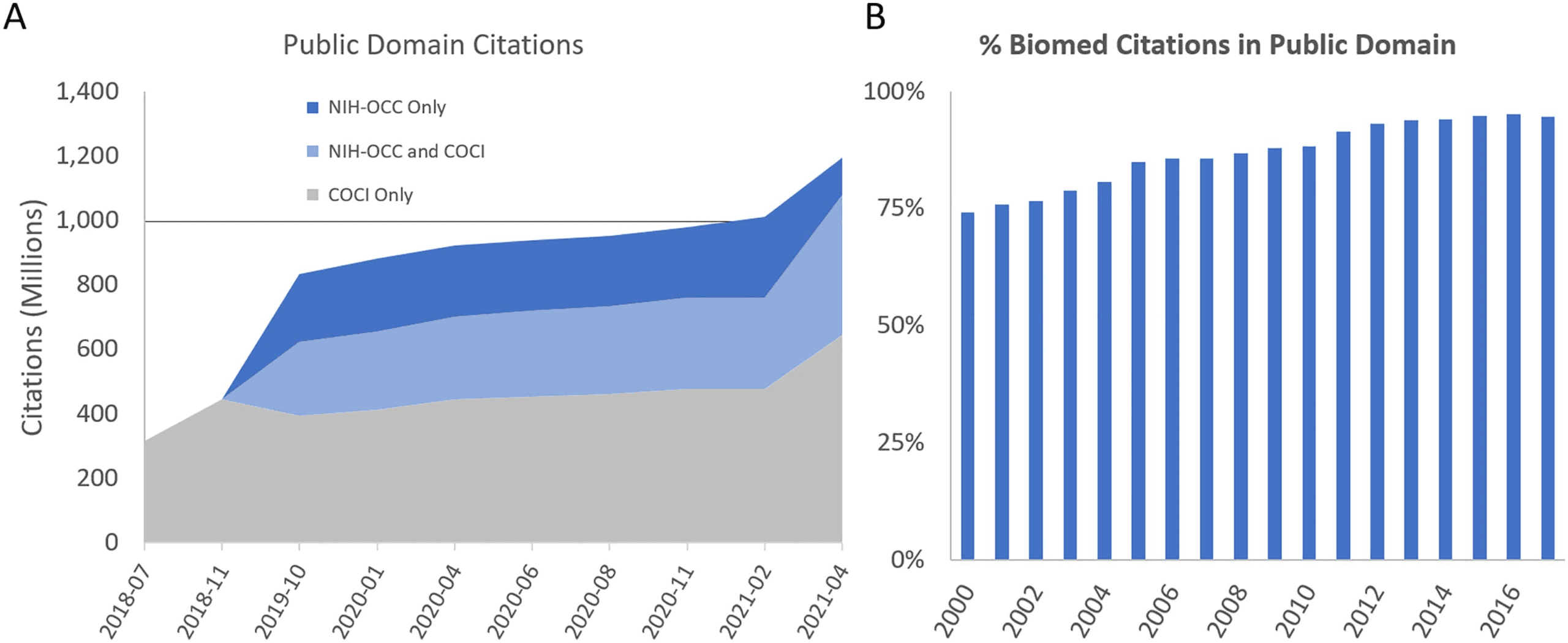
to the public, and when combined, recently hit the major milestone of over one billion cita-
tions in the public domain (Figure 1A). The next COCI update is expected to have this many
citations from Crossref alone, following ingestion of references recently opened in Crossref by
Elsevier (Plume, 2020) and the American Chemical Society (Clinton, 2021).
What fraction of citations does this represent? One estimate of the upper bound puts
Elsevier’s share of Crossref references at approximately 30%. Other data sources accounted
for 60% of the total already, so public domain citation coverage for articles with Crossref
Digital Object Identifiers may exceed 90% of the total (Dugan et al., 2017; Molteni, 2017;
Waltman, 2020). Checking the Crossref application programming interface at the time of writ-
ing indicates that 88% reference-containing documents are open. Notably, the fraction when
looking at journal articles only is higher, with 92% having opened their references.
However, this accounting overestimates the fraction of all citations that are publicly avail-
able, as many print-only articles precede widespread indexing in Crossref, or publishers have
not yet supplied reference information for the digital articles that are included. Here, a compar-
ison of the biomedical literature may be instructive, as PubMed broadly indexes both digital and
print-only articles. The PubMed Knowledge Graph is another source of citation information that
uses Web of Science as a source of biomedical references (Xu, Kim et al., 2020), and contains
references for many such historical print-only articles. Combining the references from the NIH
Open Citation Collection and the PubMed Knowledge Graph shows that 86% of this union is
explicitly public domain. While this estimate applies specifically to the biomedical literature, it
can anchor expectations for coverage in other fields as well. Thus, the reality of citation coverage
aligns closely with expectations even when accounting for print-only articles.
Importantly, in recent years, over 95% of references are explicitly public domain (Figure 1B),
demonstrating nearly complete public domain coverage of recent papers. This result reinforces
estimates that over 85% of Crossref citations are entering into the public domain.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
q
s
s
/
a
r
t
i
c
e
–
p
d
l
f
/
/
/
/
2
2
4
3
3
1
9
3
0
7
4
7
q
s
s
_
c
_
0
0
1
3
8
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Figure 1.
(A) Unique and overlapping citations in the public domain NIH-OCC and COCI databases. Unique public domain citations now
total 1.2 billion, 46% of which are biomedical PubMed-to-PubMed citations. Black line, 1 billion citations. The final data point (2021-04) is
estimated from a cache of open references from the Crossref API (the corresponding COCI data set is still being generated at the time of
writing). (B) Fraction of biomedical citations that are in the public domain, by publication year.
Quantitative Science Studies
434
A tipping point for open citation data
2. AN IRREVERSIBLE STATE OF AFFAIRS
When citation indexing first began, it was a laborious affair. Information extraction and
processing for the Science Citation Index took teams in excess of 100 operators to generate
regular database updates (Garfield, 1979). A lack of public investment necessitated that
databases be paywalled to finance operation. Closed-access data became the norm and this
persisted for decades.
Despite an explosion in the number of scientific articles published each year, the burden of
indexing citations has fallen dramatically. This situation makes a prediction about the future of
open citation data: that this open data ecosystem likely constitutes an irreversible change. In
other words, a tipping point has been reached. It is now unlikely that the situation will revert to
a closed data ecosystem, for three related reasons.
First, the increased availability of data as journals open up access to their articles (Piwowar,
Priem, & Orr, 2019), combined with these advances in hardware, open-source software, and
improved algorithms, have made large-scale citation processing tractable even to small teams
(Hutchins et al., 2019; Jefferson, Jaffe et al., 2018). Second, there are multiple, overlapping
public domain citation data providers (NIH, Crossref, and OpenCitations). These account
for over 85% of citation data going forward, and ensure that the data ecosystem is resilient
to recissions by any one provider. For example, Microsoft announced recently that its
Academic Graph will be retired at the end of 2021 (Microsoft Academic, 2021).
Overlapping portfolios in this context is a feature, not a bug. Finally, public domain licensing
guarantees that citation data are permanently available without restriction, meaning that new
providers can redistribute the existing base of public domain citations even if the previous
providers shut down.
The competitive benefits of closing access to citation data diminish with each new citation
released to the public domain, but the benefits of open data remain. Going forward, citation
data is almost completely public domain (Figure 1). In this environment, the benefits of open
data overwhelm the rapidly decaying costs, even to publishers that previously monetized ac-
cess to their citation data (Plume, 2020).
3. ADDITIONAL BENEFITS
The scientometrics community called on publishers and funding agencies to open citation
data, noting that this would improve the transparency and reproducibility of scientometric
analyses (Singh Chawla, 2019; Sugimoto, Waltman et al., 2017). As such analyses are used
for science policy, this will improve decision-making as well. Opening citation data also
improves discoverability of research articles, as readers can follow citations to more recent
relevant work.
Public domain citation data excel in certain applications compared to other permissive li-
censes. The first is in downstream entrepreneurship and stimulating commercial activity.
Public domain citation data do not even need to be reviewed for licensing suitability, and
can be immediately federated into commercial applications (Dimensions, 2019). Other li-
censes must be reviewed carefully, as they may contain no-commercial-use restrictions.
Even some licenses that permit commercial use might exclude monetizing the redistribution
of data, which could prohibit commercial curation or data cleaning. Public domain data, in
contrast, are well suited for stimulating all kinds of downstream economic activity.
A second area in which public domain licenses excel is in improving science policy.
Because my professional experience lies with the U.S. federal government, I will focus on that
Quantitative Science Studies
435
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
q
s
s
/
a
r
t
i
c
e
–
p
d
l
f
/
/
/
/
2
2
4
3
3
1
9
3
0
7
4
7
q
s
s
_
c
_
0
0
1
3
8
p
d
/
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
A tipping point for open citation data
perspective, although other countries may face similar constraints. Permissive licenses targeted
toward academics and research institutions may contain indemnification clauses, which
render such data sets unusable in many circumstances by the U.S. federal government. This
is in part due to restrictions in the Antideficiency Act (O’Connell, 2014); such clauses often
function as a no-government-use license. Perversely, this can drive U.S. federal agencies to
source data from closed providers, reducing the transparency and robustness of the analyses
used in science policy decision-making. Public domain data are a powerful remedy for this
situation.
4. CONCLUSION
The broad coverage of public domain citation data means that these resources are well suited
for use in scientometric analyses that traditionally used proprietary data. This community has
uniquely contributed to the development of public domain citation data, and I exhort its mem-
bers to transition from using proprietary citation data to using these comprehensive public do-
main data sources in their projects as much as possible. This will reduce dependence on
closed data sources, increase the number of researchers using and contributing to open cita-
tion efforts, and improve the reproducibility of these projects. Additionally, I would encourage
members of the community to contribute their support to other open science movements, such
as the Initiative for Open Abstracts (Duce, Hendricks et al., 2020). The utility of open citation
data will be multiplied when article text, author metadata, institutional linkages, and article
classifications are also made open.
The successful movement toward public domain citation data can offer guidance for other
open access efforts. First, identify the important gatekeepers of the current data sources.
Explore win-win value propositions such as discoverability and reproducibility, and clearly artic-
ulate the benefits of open access. Second, build a network of open access providers. U.S. science
funding agencies aspire to data transparency and can be powerful allies in this respect. Data
acquired by U.S. agencies under the “Unlimited Rights in Data” clauses of the Federal
Acquisition Regulations and disseminated to the public can ensure their permanent open re-
lease. Finally, work toward a comprehensive release of open data. Incentives for participants
in the data ecosystem will lean in favor of contributing to open data initiatives as more data
are opened up and the remaining competitive value of closed data diminishes. If structured well,
opening data is irreversible, so the advantages to withholding data will give way while the
benefits of open data remain strong.
ACKNOWLEDGMENTS
I thank Nees Jan van Eck for providing the Crossref bulk data for estimating the number of
citations available in the 2021-05 COCI release. I also thank the NIH Office of Portfolio
Analysis for providing regular iCite database snapshots containing the NIH-OCC.
COMPETING INTERESTS
The author spearheaded the NIH-OCC as senior data scientist while working at NIH.
FUNDING INFORMATION
Support for this work was provided by the Office of the Vice Chancellor for Research and
Graduate Education at the University of Wisconsin-Madison with funding from the
Wisconsin Alumni Research Foundation.
Quantitative Science Studies
436
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
q
s
s
/
a
r
t
i
c
e
–
p
d
l
f
/
/
/
/
2
2
4
3
3
1
9
3
0
7
4
7
q
s
s
_
c
_
0
0
1
3
8
p
d
.
/
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
A tipping point for open citation data
DATA AVAILABILITY
iCite NIH Open Citation Collection data are available at Figshare (https://doi.org/10.35092
/yhjc.c.4586573). The raw data supporting the analysis in Figure 1B can be found at
Figshare (https://doi.org/10.6084/m9.figshare.14544405). The Crossref data set used for the
2021-04 data point is available at Zenodo (https://doi.org/10.5281/zenodo.4748336). The
PubMed Knowledge Graph data can be accessed at the University of Texas (https://er.tacc
.utexas.edu/datasets/ped).
REFERENCES
Clinton, A. (2021). ACS Publications signs DORA. ACS Axial.
https://axial.acs.org/2021/02/18/acs-publications-signs-dora/
Dimensions. (2019). Where are citations in Dimensions coming
from? Digital Science. https://dimensions.freshdesk.com/support
/solutions/articles/23000018849-where-are-citations-in
-dimensions-coming-from
Duce, H., Hendricks, G., Kramer, B., Larivière, V., Maccallum, C. J.,
… Waltman, L. (2020). Initiative for Open Abstracts. https://i4oa
.org/
Dugan, J., Fenner, M., Gerlach, J., MacCallum, C., Mietchen, D., …
Taraborelli, D. (2017). Initiative for Open Citations. https://i4oc
.org
Garfield, E. (1979). The design and production of a citation index.
In Citation indexing – Its theory and application in science, tech-
nology and humanities. Chichester: John Wiley & Sons.
Heibi, I., Peroni, S., & Shotton, D. (2018). COCI CSV dataset of all the
citation data. Figshare. https://doi.org/10.6084/m9.figshare.6741422
Hutchins, B. I., Baker, K. L., Davis, M. T., Diwersy, M. A., Haque, E.,
… Santangelo, G. M. (2019). The NIH Open Citation Collection: A
public access, broad coverage resource. PLOS Biology, 17(10),
e3000385. https://doi.org/10.1371/journal.pbio.3000385,
PubMed: 31600197
Hutchins, B. I., & Santangelo, G. M. (2019). iCite Database
Snapshots (NIH Open Citation Collection). Figshare. https://doi
.org/10.35092/yhjc.c.4586573
iCite. (2021). iCite: A powerful web application that provides a
panel of bibliometric information for scientific publications.
https://icite.od.nih.gov/
Jefferson, O. A., Jaffe, A., Ashton, D., Warren, B., Koellhofer, D., …
Jefferson, R. A. (2018). Mapping the global influence of published
research on industry and innovation. Nature Biotechnology, 36(1),
31–39. https://doi.org/10.1038/nbt.4049, PubMed: 29319684
Microsoft Academic. (2021). Next steps for Microsoft Academic –
Expanding into new horizons. https://www.microsoft.com/en-us
/research/project/academic/articles/microsoft-academic-to
-expand-horizons-with-community-driven-approach/
Molteni, M. (2017). Tearing down science’s citation paywall, one
link at a time. Wired Magazine. https://www.wired.com/2017/04
/tearing-sciences-citation-paywall-one-link-time/
O’Connell, S. M. (2014). Contractual indemnification by the
Federal Government. Law School Student Scholarship, 279.
Peroni, S., & Shotton, D. (2020). OpenCitations, an infrastructure
organization for open scholarship. Quantitative Science
Studies, 1(1), 428–444. https://doi.org/10.1162/qss_a_00023
Piwowar, H., Priem, J., & Orr, R. (2019). The future of OA: A large-
scale analysis projecting open access publication and reader-
ship. bioRxiv, 795310. https://doi.org/10.1101/795310
Plume, A. (2020). Advancing responsible research assessment.
https://www.elsevier.com/connect/advancing-responsible
-research-assessment
Singh Chawla, D. (2019). Open-access row prompts editorial board
of Elsevier journal to resign. Nature. https://doi.org/10.1038
/d41586-019-00135-8
Sugimoto, C. R., Waltman, L., Larivière, V., van Eck, N. J., Boyack,
K. W., … de Rijcke, S. (2017). Open citations: A letter from the
scientometric community to scholarly publishers. https://www
.issi-society.org/open-citations-letter/
Waltman, L. (2020). Q&A about Elsevier’s decision to open its cita-
tions. https:// leidenmadtrics.nl/articles/q-a-about-elseviers
-decision-to-open-its-citation
Xu, J., Kim, S., Song, M., Jeong, M., Kim, D., Kang, J., … Ding, Y.
(2020). Building a PubMed knowledge graph. Scientific Data, 7(1),
205. https://doi.org/10.1038/s41597-020-0543-2, PubMed:
32591513
Quantitative Science Studies
437
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
/
e
d
u
q
s
s
/
a
r
t
i
c
e
–
p
d
l
f
/
/
/
/
2
2
4
3
3
1
9
3
0
7
4
7
q
s
s
_
c
_
0
0
1
3
8
p
d
/
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3