Infusing Finetuning with Semantic Dependencies
Zhaofeng Wu♠ Hao Peng♠ Noah A. Smith♠♦
♠Paul G. Allen School of Computer Science & Engineering, University of Washington
♦Allen Institute for Artificial Intelligence
{zfw7,hapeng,nasmith}@cs.washington.edu
Abstract
For natural language processing systems, two
kinds of evidence support
the use of text
representations from neural language models
‘‘pretrained’’ on large unannotated corpora:
performance on application-inspired bench-
marks (Peters et al., 2018, inter alia), and
the emergence of syntactic abstractions in
those representations (Tenney et al., 2019,
inter alia). On the other hand, the lack of
grounded supervision calls into question how
well these representations can ever capture
meaning (Bender and Koller, 2020). We apply
novel probes to recent language models—
specifically focusing on predicate-argument
structure as operationalized by semantic de-
pendencies (Ivanova et al., 2012)—and find
that, unlike syntax, semantics is not brought
to the surface by today’s pretrained models.
We then use convolutional graph encoders
to explicitly incorporate semantic parses into
task-specific finetuning, yielding benefits to
natural language understanding (NLU) tasks
in the GLUE benchmark. This approach de-
monstrates the potential for general-purpose
(rather than task-specific) linguistic supervi-
sion, above and beyond conventional pretrain-
ing and finetuning. Several diagnostics help to
localize the benefits of our approach.1
1 Introduction
The past decade has seen a paradigm shift in how
NLP systems are built, summarized as follows:
• Before, general-purpose linguistic modules
(e.g., part-of-speech taggers, word-sense
disambiguators, and many kinds of parsers)
were constructed using supervised learning
from linguistic datasets. These were often
1https://github.com/ZhaofengWu/SIFT.
226
applied as preprocessing to text as part of
larger systems for information extraction,
question answering, and other applications.
• Today, general-purpose representation learn-
ing is carried out on large, unannotated
corpora—effectively a kind of unsupervised
learning known as ‘‘pretraining’’—and then
the representations are ‘‘finetuned’’ on
application-specific datasets using conven-
tional end-to-end neural network methods.
The newer paradigm encourages an emphasis
on corpus curation, scaling up pretraining, and
translation of end-user applications into trainable
‘‘tasks,’’ purporting to automate most of the la-
bor requiring experts (linguistic theory construc-
tion, annotation of data, and computational model
design). Apart from performance improvements
on virtually every task explored in the NLP lit-
erature, a body of evidence from probing studies
has shown that pretraining brings linguistic abs-
tractions to the surface, without explicit super-
vision (Liu et al., 2019a; Tenney et al., 2019;
Hewitt and Manning, 2019; Goldberg, 2019, inter
alia).
There are, however, reasons to pause. First,
some have argued from first principles that learn-
ing mappings from form to meaning is hard from
forms alone (Bender and Koller, 2020).2 Second,
probing studies have focused more heavily on
syntax than on semantics (i.e., mapping of forms
to abstractions of meaning intended by people
speaking in the world). Tenney et al. (2019)
noted that the BERT model (Devlin et al., 2019)
offered more to syntactic tasks like constituent and
dependency relation labeling than semantic ones
2In fact, Bender and Koller (2020) argued that this is
impossible for grounded semantics. Our probing analysis,
along with recent efforts (Kovaleva et al., 2019; Liu et al.,
2019a), suggests that modern pretrained models are poor at
surfacing predicate-argument semantics.
Transactions of the Association for Computational Linguistics, vol. 9, pp. 226–242, 2021. https://doi.org/10.1162/tacl a 00363
Action Editor: Benjamin Van Durme. Submission batch: 9/2020; Revision batch: 11/2020; Published 3/2021.
c(cid:4) 2021 Association for Computational Linguistics. Distributed under a CC-BY 4.0 license.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
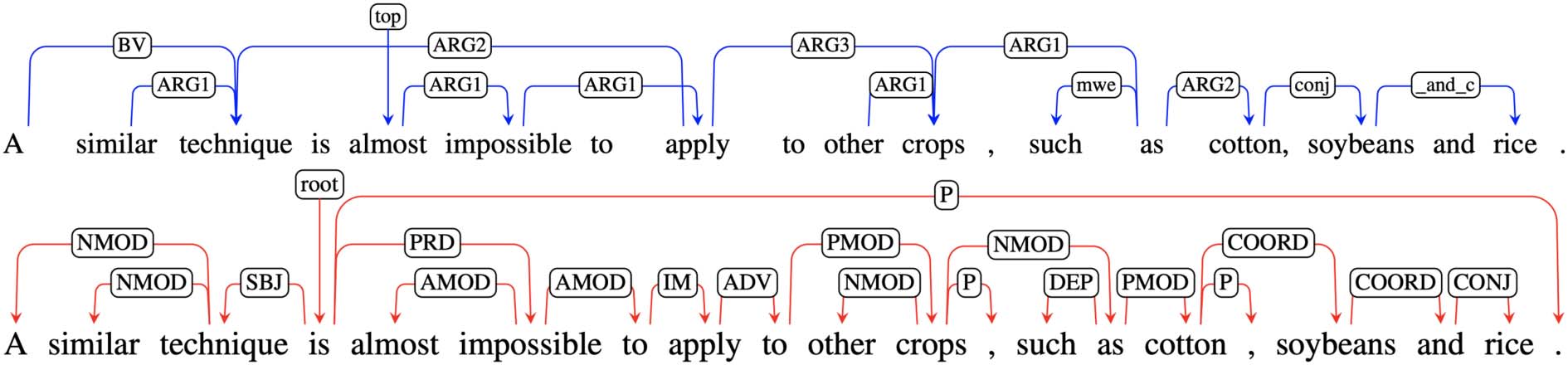
Figure 1: An example sentence in the DM (top, blue) and Stanford Dependencies (bottom, red) format, taken from
Oepen et al. (2015) and Ivanova et al. (2012).
like Winograd coreference and semantic proto-
role labeling. Liu et al. (2019a) showed that
pretraining did not provide much useful infor-
mation for entity labeling or coreference res-
olution. Kovaleva et al. (2019) found minimal
evidence that the BERT attention heads capture
FrameNet (Baker et al., 1998) relations. We extend
these findings in §3, showing that representations
from the RoBERTa model (Liu et al., 2019b)
are relatively poor at surfacing information for
a predicate-argument semantic parsing probe,
compared to what can be learned with finetuning,
or what RoBERTa offers for syntactic parsing.
The same pattern holds for BERT.
Based on that finding, we hypothesize that
semantic supervision may still be useful to tasks
targeting natural language ‘‘understanding.’’ In
§4, we introduce semantics-infused finetuning
(SIFT), inspired by pre-neural pipelines. Input
sentences are first passed through a semantic
dependency parser. Though the method can
accommodate any graph over tokens, our im-
plementation uses the DELPH-IN MRS-derived
dependencies, known as ‘‘DM’’ (Ivanova et al.,
2012), illustrated in Figure 1. The task architecture
learned during finetuning combines the pretrained
model (here, RoBERTa) with a relational graph
convolutional network (RGCN; Schlichtkrull
et al., 2018) that reads the graph parse. Though
the same graph parser can be applied at inference
time (achieving our best experimental results),
benefits to task performance are in evidence in
a ‘‘light’’ model variant without inference time
parsing and with the same inference cost as a
RoBERTa-only baseline.
We experiment with the GLUE benchmarks
(§5), which target many aspects of natural lan-
guage understanding (Wang et al., 2018). Our
model consistently improves over both base and
large-sized RoBERTa baselines.3 Our focus is not
on achieving a new state of the art, but we note
that SIFT can be applied orthogonally alongside
other methods that have improved over similar
baselines, such as Raffel et al. (2020) and Clark
et al. (2020), which used alternative pretraining
objectives, and Jiang et al. (2020), which proposed
an alternative finetuning optimization framework.
In §6, we use the HANS (McCoy et al., 2019)
and GLUE (Wang et al., 2018) diagnostics to
better understand where our method helps on
natural language inference tasks. We find that our
model’s gains strengthen when finetuning data is
reduced, and that our approach is more effective
than alternatives that do not use the full labeled
semantic dependency graph.
2 Predicate-Argument Semantics
as Dependencies
Though many formalisms and annotated datasets
have been proposed to capture various facets of
natural language semantics, here our focus is on
predicates and arguments evoked by words in
sentences. Our experiments focus on the DELPH-
IN dependencies formalism (Ivanova et al., 2012),
commonly referred to as ‘‘DM’’ and derived from
minimal recursion semantics (Copestake et al.,
2005) and head-driven phrase structure grammar
(Pollard and Sag, 1994). This formalism, illus-
trated in Figure 1 (top, blue) has the appealing
property that a sentence’s meaning is represented
as a labeled, directed graph. Vertices are words
(though not every word is a vertex), and 59 labels
are used to characterize argument and adjunct
relationships, as well as conjunction.
3RoBERTa-base and RoBERTa-large use the same pre-
training data and only differ in the number of parameters.
227
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Other semantic formalisms such as PSD (Hajic
et al., 2012), EDS (Oepen and Lønning, 2006), and
UCCA (Abend and Rappoport, 2013) also capture
semantics as graphs. Preliminary experiments
showed similar findings using these. Frame-based
predicate-argument representations such as those
found in PropBank (Palmer et al., 2005) and
FrameNet (Baker et al., 1998) are not typically cast
as graphs (rather as ‘‘semantic role labeling’’), but
see Surdeanu et al. (2008) for data transformations
and Peng et al. (2018b) for methods that help
bridge the gap.
Graph-based formalizations of predicate-
argument semantics, along with organized shared
tasks on semantic dependency parsing (Oepen
et al., 2014, 2015), enabled the development of
data-driven parsing methods following extensive
algorithm development for dependency syntax
(Eisner, 1996; McDonald et al., 2005). Even
before the advent of the pretraining-finetuning
labeled F1 scores above 0.9 were
paradigm,
achieved (Peng et al., 2017).
Some similarities between DM and dependency
syntax (e.g., the Stanford dependencies, illustrated
in Figure 1, bottom, red; de Marneffe et al.,
2006) are apparent: both highlight bilexical re-
lationships. However, semantically empty words
(like infinitival to) are excluded from the seman-
tic graph, allowing direct connections between
technique ←
semantically related pairs (e.g.,
apply, impossible → apply, and apply → crops,
all of which are mediated by other words in the
syntactic graph). DM analyses need not be trees
as in most syntactic dependency representations,4
so they may more directly capture the meaning of
many constructions, such as control.
3 Probing RoBERTa for
Predicate-Argument Semantics
The methodology known as ‘‘linguistic probing’’
seeks to determine the level to which a pretrained
model has rediscovered a particular linguistic ab-
straction from raw data (Shi et al., 2016; Adi et al.,
2017; Hupkes et al., 2018; Belinkov and Glass,
2019, inter alia). The procedure is:
1. Select an annotated dataset
that encodes
the theoretical abstraction of interest into a
predictive task, usually mapping sentences to
4The enhanced universal dependencies of Schuster and
Manning (2016) are a counterexample.
linguistic structures. Here we will consider
the Penn Treebank (Marcus et al., 1993)
converted to Stanford dependencies and the
DM corpus from CoNLL 2015’s shared task
18 (Oepen et al., 2015).5
2. Pretrain. We consider RoBERTa and BERT.
3. Train a full-fledged ‘‘ceiling’’ model with
finetuned representations. It can be seen as
proxy to the best performance one can get
with the pretrained representations.
4. Train a supervised ‘‘probe’’ model for the
task with the pretrained representations.
Importantly, the pretrained representations
should be frozen, and the probe model should
be lightweight with limited capacity, so that
its performance is attributable to pretraining.
We use a linear probe classifier.
5. Compare, on held-out data, the probe model
against the ceiling model. Through such a
comparison, we can estimate the extent to
which the pretrained model ‘‘already knows’’
how to do the task, or, more precisely, brings
relevant features to the surface for use by the
probing model.
Liu et al. (2019a) included isolated DM arc
prediction and labeling tasks and Tenney et al.
(2019) conducted ‘‘edge probing.’’ To our knowl-
edge, full-graph semantic dependency parsing has
not been formulated as a probe.
For both syntactic and semantic parsing, our
full ceiling model and our probing model are
based on the Dozat and Manning (2017, 2018)
parser that underlies many state-of-the-art systems
(Clark et al., 2018; Li et al., 2019, inter alia). Our
ceiling model contains nonlinear multilayer per-
ceptron (MLP) layers between RoBERTa/BERT
and the arc/label classifiers, as in the original
parser, and finetunes the pretrained representa-
tions. The probing model, trained on the same
data, freezes the representations and removes the
MLP layers, yielding a linear model with limited
capacity. We measure the conventionally reported
metrics: labeled attachment score for dependency
parsing and labeled F1 for semantic parsing,
as well as labeled and unlabeled exact match
scores. We follow the standard practice and use
5These are both derived from the same Wall Street Journal
the syntactic dependency
corpus and have similar size:
dataset has 39,832/2,416 training/test examples, while the
DM dataset has 33,964/1,410.
228
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Metrics
LAS/F1
LEM
UEM
Abs Δ
–13.5±0.2
–36.4±0.8
–46.3±0.7
Metrics
LAS/F1
LEM
UEM
Abs Δ
–17.6±0.1
–40.0±0.6
–50.2±0.6
PTB SD
Rel Δ
Ceiling
Probe
–14.2%±0.2
–72.4%±1.1
–73.2%±0.5
95.2±0.1
50.3±0.5
63.3±0.8
81.7±0.1
13.9±0.5
17.0±0.3
(a) Base.
PTB SD
Rel Δ
–18.5%±0.1
–77.2%±0.4
–77.4%±0.2
Ceiling
95.3±0.0
51.9±0.6
64.8±0.7
Probe
77.7±0.1
11.8±0.2
14.6±0.2
(b) Large.
Abs Δ
–23.5±0.1
–45.4±1.1
–48.8±1.0
CoNLL 2015 DM
Rel Δ
Ceiling
–24.9%±0.2
–93.5%±0.5
–92.8%±0.5
94.2±0.0
48.5±1.2
52.6±1.0
Abs Δ
–26.7±0.3
–46.6±1.1
–50.0±1.1
CoNLL 2015 DM
Rel Δ
–28.3%±0.3
–94.4%±0.1
–93.9%±0.2
Ceiling
94.4±0.1
49.3±1.1
53.2±1.0
Probe
70.7±0.2
3.1±0.2
3.8±0.2
Probe
67.7±0.2
2.7±0.0
3.3±0.1
Table 1: The RoBERTa-base (top) and RoBERTa-large (bottom) parsing results for the full ceiling
model and the probe on the PTB Stanford Dependencies (SD) test set and CoNLL 2015 in-domain test
set. We also report their absolute and relative differences (probe – full). The smaller the magnitude of
the difference, the more relevant content the pretrained model already encodes. We report the canonical
parsing metric (LAS for PTB dependency and labeled F1 for DM) and labeled/unlabeled exact match
scores (LEM/UEM). All numbers are mean ± standard deviation across three seeds.
the Chu-Liu-Edmonds algorithm (Chu and Liu,
1965; Edmonds, 1967) to decode the syntactic
dependency trees and greedily decode the seman-
tic graphs with local edge/label classification
decisions. See Appendix B for training details.
Comparisons between absolute scores on the
two tasks are less meaningful. Instead, we are
interested in the difference between the probe
(largely determined by pretrained representations)
and the ceiling (which benefits also from
to expect
finetuning). Prior work leads us
that
the semantic probe will exhibit a larger
difference than the syntactic one, signalling that
pretraining surfaces syntactic abstractions more
readily than semantic ones. This is exactly what
we see in Tables 1 across all metrics, for both
RoBERTa-base and RoBERTa-large, where all
relative differences (probe – full) are greater in
magnitude for parsing semantics than syntax.
Surprisingly, RoBERTa-large achieves worse
semantic and syntactic probing performance than
its base-sized counterpart across all metrics. This
suggests that
larger pretrained representations
do not necessarily come with better structural
information for downstream models to exploit. In
Appendix C, we also show that BERT-base shows
the same qualitative pattern.
4 Finetuning with Semantic Graphs
Given pretrained RoBERTa’s relative incapabil-
ity of surfacing semantic structures (§3) and the
229
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
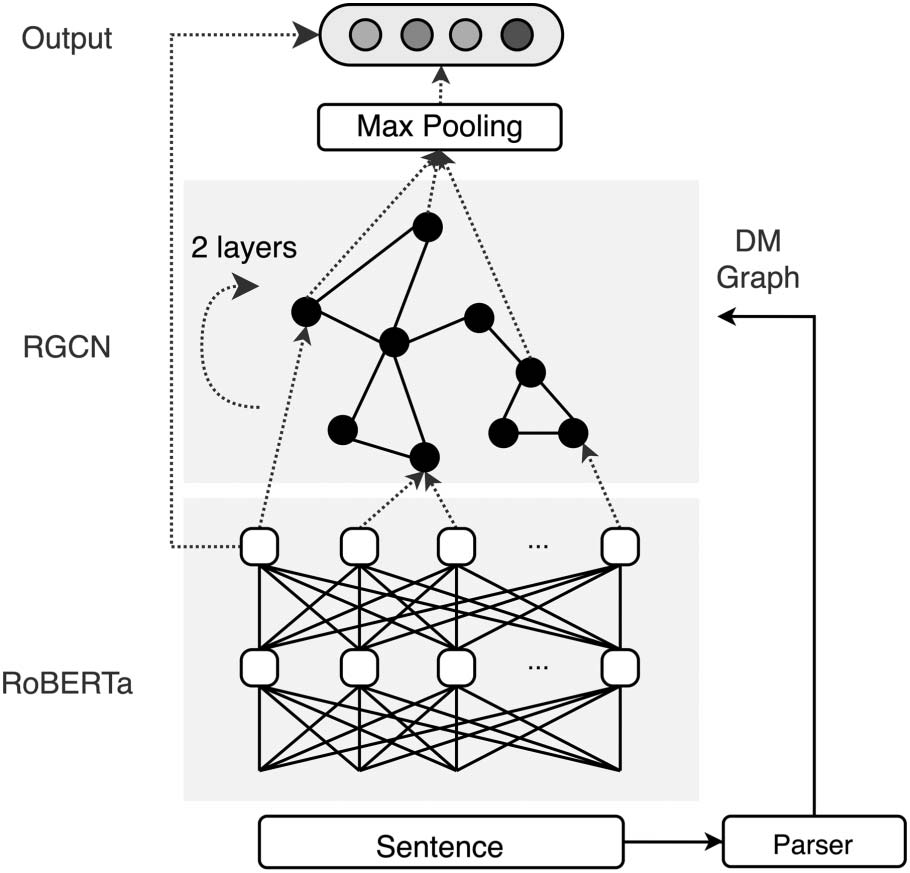
Figure 2: SIFT architecture. The sentence is first
contextualized using RoBERTa, and then parsed.
RGCN encodes the graph structures on top of
RoBERTa. We max-pool over the RGCN’s outputs
for onward computation.
importance of modeling predicate-argument se-
mantics (§2), we hypothesize that incorporating
such information into the RoBERTa finetuning
process should benefit downstream NLU tasks.
SIFT, briefly outlined in §4.1, is based on the
relational graph convolutional network (RGCN;
Schlichtkrull et al., 2018). §4.2 introduces a
lightweight variant of SIFT aiming to reduce test
time memory and runtime.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
and therefore has the same computational cost as
the RoBERTa baseline.
SIFT-Light learns two classifiers (or regres-
sors): (1) a main linear classifier on top of
RoBERTa fRoBERTa; (2) an auxiliary classifier
fRGCN based on SIFT. They are separately pa-
rameterized at the classifier level, but share the
same underlying RoBERTa. They are trained on
the same downstream task and jointly update
the RoBERTa model. At test time, we only use
fRoBERTa. The assumption behind SIFT-Light is
similar to the scaffold framework of Swayamdipta
et al. (2018): by sharing the RoBERTa parameters
between the two classifiers, the contextualized
representations steer towards downstream classi-
fication with semantic encoding. One key differ-
ence is that SIFT-Light learns with two different
architectures for the same task, instead of using
the multitask learning framework of Swayamdipta
et al. (2018). In §6.3, we find that SIFT-Light
outperforms a scaffold.
4.3 Discussion
Previous works have used GCN (Kipf and Welling,
2016), a similar architecture, to encode unlabeled
syntactic structures (Marcheggiani and Titov,
2017; Bastings et al., 2017; Zhang et al., 2020c,a,
inter alia). We use RGCN to explicitly encode
labeled semantic graphs. Our analysis shows that
it outperforms GCN, as well as alternatives such as
multitask learning with parameter-sharing (§6.3).
However, this comes with a cost. In RGCN, the
number of parameters linearly increases with the
number of relation types.6 In our experiments, on
top of the 125M RoBERTa-base parameters, this
adds approximately 3–118M parameters to the
model, depending on the hyperparameter settings
(see Appendix B). On top of RoBERTa-large,
this adds
which itself has 355M parameters,
6–121M additional parameters. The inference
runtime of SIFT is 1.41–1.79× RoBERTa’s with
the base size and 1.30–1.53× with the large size.
SIFT incorporates semantic information only
during finetuning. Recent evidence suggests
that structural information can be learned with
specially-designed pretraining procedures. For
example, Swayamdipta et al. (2019) pretrain with
syntactic chunking, requiring the entire pretraining
corpus to be parsed which is computationally
6In experiments we upper-bound the number of the pa-
rameters by imposing a low-rank constraint on the parameter
matrices by construction. See Appendix A.
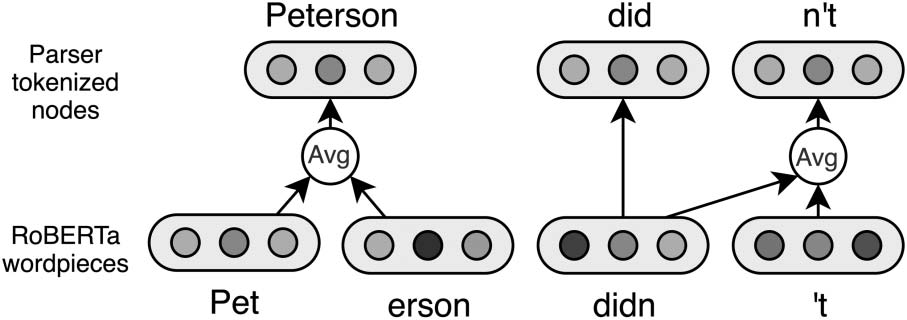
Figure 3: To get the representation of a node, we
average the vectors of the wordpieces it is aligned to.
4.1 SIFT
SIFT first uses an external parser to get
the
semantic analysis for the input sentence. Then
it contextualizes the input with a pretrained
RoBERTa model, the output of which is fed into
a graph encoder building on the semantic parse.
We use RGCN to encode the DM structures,
which are labeled graphs. The model is trained
end-to-end. Figure 2 diagrams this procedure.
RGCN. RGCN can be understood as passing
vector ‘‘messages’’ among vertices in the graph.
The nodes are initially represented with RoBERTa
token embeddings. At each RGCN layer, each
node representation is updated with a learned
composition function, taking as input the vector
representations of the node’s neighbors as well
itself. Each DM relation type is associated with
a separately parameterized composition function.
For tasks such as text classification or regression,
we max-pool over the final RGCN layer’s output
to obtain a sequence-level representation for
onward computation. Readers are referred to
Appendix A and Schlichtkrull et al. (2018) for
further details.
Note on Tokenization. RoBERTa uses byte-
pair encodings (BPE; Sennrich et al., 2016),
differing from the CoNLL 2019 tokenizer (Oepen
et al., 2019) used by the parser. To get each
token’s initial
representation for RGCN, we
average RoBERTa’s output vectors for the BPE
wordpieces that the token is aligned to (illustrated
in Figure 3).
4.2 SIFT-Light
Inspired by the scaffold model of Swayamdipta
et al. (2018), we introduce SIFT-Light, a light-
weight variant of SIFT that aims to reduce time
and memory overhead at test time. During infer-
ence it does not rely on explicit semantic structures
230
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
prohibitive at the scale of RoBERTa’s pretraining
dataset. With a distillation technique, Kuncoro
et al. (2020) bake syntactic supervision into
the pretraining objective. Despite better accuracy
on tasks that benefit from syntax,
they show
that the obtained syntactically-informed model
hurts the performance on other tasks, which
could restrict its general applicability. Departing
from these alternatives, SIFT augments general-
purpose pretraining with task-specific structural
finetuning, an attractively modular and flexible
solution.
5 Experiments
We next present experiments with SIFT to test
our hypothesis that pretrained models for nat-
ural language understanding tasks benefit from
explicit predicate-argument semantics.
5.1 Settings
We use the GLUE datasets, a suite of tests
targeting natural language understanding detailed
in Table 2 (Wang et al., 2018).7 Most are
classification datasets, while STS-B considers
regression. Among the classifications datasets,
MNLI has three classes while others have two;
CoLA and SST-2 classify single sentences while
the rest classify sentence pairs. We follow Dodge
et al. (2020) and Vu et al. (2020) and only report
development set results due to restricted GLUE
test set access.
We compare the following models:
• RoBERTa, both the base and large variants,
following Liu et al. (2019b).
• SIFT builds on pretrained RoBERTa, with 2
RGCN layers. To generate semantic graphs,
we use the semantic dependency parser by
Che et al. (2019) which held the first place in
the CoNLL 2019 shared task (Oepen et al.,
2019) with 92.5 labeled F1 for DM.8
• SIFT-Light (§4.2) is trained similarly to
SIFT, but does not rely on inference-time
parsing.
Data
CoLA
MRPC
QNLI
RTE
SST-2
STS-B
QQP
MNLI
Task
|Train|
|Dev.|
Acceptability
Paraphrase
Entailment
Entailment
Sentiment
Similarity
Paraphrase
Entailment
8.5K
2.7K
105K
2.5K
67K
5.8K
363K
392K
1K
409
5.5K
278
873
1.5K
40K
9.8K
Table 2: GLUE datasets and statistics. CoLA:
Warstadt et al. (2019); MRPC: Dolan and Brockett
(2005); SST-2: Socher et al. (2013); STS-B:
Cer et al. (2017); QQP: Csernai (2017); MNLI:
Williams et al. (2018); QNLI is compiled by
GLUE’s authors using Rajpurkar et al. (2016).
RTE is the concatenation of Dagan et al. (2005);
Bar-Haim et al. (2006); Giampiccolo et al. (2007);
Bentivogli et al. (2009).
• Syntax-infused finetuning is similar
to
the syntactic Universal
SIFT but uses
Dependencies parser (Straka, 2018; Straka
and Strakov´a, 2019) from the CoNLL 2019
shared task (Oepen et al., 2019). We include
this model to confirm that any benefits to
task performance are due specifically to the
semantic structures.
Hyperparameters are summarized in Appendix B.
Implementation Details. We run all models
across 3 seeds for the large datasets QNLI, MNLI,
and QQP (due to limited computational resources),
and 4 seeds for all others. As we do not aim for
state of the art, we do not use intermediate task
training, ensemble models, or re-formulate QNLI
as a ranking task as done by Liu et al. (2019b). For
sentence-pair classification tasks such as MNLI,
we use structured decomposable attention (Parikh
et al., 2016) and 2 additional RGCN layers to
further propagate the attended information (Chen
et al., 2017). The two graphs are separately max-
pooled to obtain the final representation. See
Appendix A for more details.
7Following Devlin et al. (2019), we do not report WNLI
results because it is hard to outperform the majority class
baseline using the standard classification finetuning routine.
8About half of the CoNLL 2019 evaluation set is out-
of-domain. Without gold semantic graph annotations for our
target datasets, this can be seen as a reasonable estimation of
the parser’s performance for our use case.
5.2 Main Findings
Tables 3 summarizes the GLUE development set
performance of the four aforementioned models
when they are implemented with RoBERTa-
base and RoBERTa-large. With RoBERTa-base
231
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Models
CoLA MRPC
RTE
SST-2
STS-B
QNLI
QQP
ID.
OOD.
Avg.
RoBERTa
63.1±0.9
90.1±0.8
79.0±1.6
94.6±0.3
91.0±0.0
93.0±0.3
91.8±0.1
87.7±0.2
87.3±0.3
86.4
SIFT
SIFT-Light
Syntax
64.8±0.4
64.1±1.3
63.5±0.6
90.5±0.7
90.3±0.5
90.4±0.5
81.0±1.4
80.6±1.4
80.9±1.0
95.1±0.4
94.7±0.1
94.7±0.5
91.3±0.1
91.2±0.1
91.1±0.2
93.2±0.2
92.8±0.3
92.8±0.2
91.9±0.1
91.7±0.0
91.8±0.0
87.9±0.2
87.7±0.1
87.9±0.1
87.7±0.1
87.6±0.1
87.7±0.1
87.0
86.7
86.7
MNLI
(a) Base.
MNLI
Models
CoLA MRPC
RTE
SST-2
STS-B
QNLI
QQP
ID.
OOD.
Avg.
RoBERTa
68.0±0.6
90.1±0.8
85.1±1.0
96.1±0.3
92.3±0.2
94.5±0.2
91.9±0.1
90.3±0.1
89.8±0.3
SIFT
Syntax
69.7±0.5
69.6±1.2
91.3±0.4
91.0±0.5
87.0±1.1
86.0±1.6
96.3±0.3
95.9±0.3
92.6±0.0
92.4±0.1
94.7±0.1
94.6±0.1
92.1±0.1
92.0±0.0
90.4±0.1
90.4±0.3
90.1±0.1
90.0±0.2
88.7
89.3
89.1
(b) Large.
Table 3: GLUE development set results with RoBERTa-base (top) and RoBERTa-large (bottom). We
report Matthews correlation for CoLA, Pearson’s correlation for STS-B, and accuracy for others. We
report mean ± standard deviation; for each bold entry, the mean minus standard deviation is no worse
than RoBERTa’s corresponding mean plus standard deviation.
(Table 3a), SIFT achieves a consistent improve-
ment over the baseline across the board, suggest-
ing that despite heavy pretraining, RoBERTa
still benefits from explicit semantic structural
information. Among the datasets, smaller ones
tend to obtain larger improvements from SIFT,
e.g., 1.7 Matthews correlation for CoLA and
2.0 accuracy for RTE, while the gap is smaller
on the larger ones (e.g., only 0.1 accuracy for
QQP). Moreover, SIFT-Light often improves
over RoBERTa, with a smaller gap, making
it a compelling model choice when latency is
prioritized. This shows that encoding semantics
using RGCN is not only capable of producing
better standalone output representations, but can
the finetuning of the RoBERTa-
also benefit
internal weights
sharing.
Finally, the syntax-infused model underperforms
SIFT across all tasks. It only achieves minor
improvements over RoBERTa, if not hurting per-
formance. These results provide evidence sup-
porting our hypothesis that incorporating semantic
structures is more beneficial to RoBERTa than
syntactic ones.
through parameter
We observe a similar trend with RoBERTa-
large in Table 3b, where SIFT’s absolute improve-
ments are very similar to those in Table 3a.
Specifically, both achieve an 0.6 accuracy im-
provement over RoBERTa, averaged across all
datasets. This indicates that the increase from
RoBERTa-base to RoBERTa-large added little to
surfacing semantic information.
6 Analysis and Discussion
In this
section, we first analyze in which
scenarios incorporating semantic structures helps
RoBERTa. We then highlight SIFT’s data effi-
ciency and compare it to alternative architectures.
We show ablation results for architectural deci-
sions in Appendix D. All analyses are conducted
on RoBERTa-base.
6.1 When Do Semantic Structures Help?
Using two diagnostic datasets designed for eval-
uating and analyzing natural language inference
models, we find that SIFT (1) helps guard the
model against frequent but invalid heuristics in
the data, and (2) better captures nuanced sentence-
level linguistic phenomena than RoBERTa.
Results on the HANS Diagnostic Data. We
first diagnose the model using the HANS dataset
(McCoy et al., 2019). It aims to study whether a
natural language inference (NLI) system adopts
three heuristics, summarized and exemplified in
Table 4. The premise and the hypothesis have
high surface form overlap, but the heuristics are
not valid for reasoning. Each heuristic has both
positive and negative (i.e., entailment and non-
entailment) instances constructed. Due to the high
surface similarity, many models tend to predict
‘‘entailment’’ for the vast majority of instances.
As a result, they often reach decent accuracy
on the entailment examples, but struggle on the
232
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Heuristic
Lexical
Overlap
Sub-
sequence
Constituent
Premise
Hypothesis
Label RoBERTa
SIFT
The banker near the judge saw the actor.
The judge by the actor stopped the banker.
The artist and the student called the judge.
The judges heard the actors resigned.
Before the actor slept, the senator ran.
If the actor slept, the judge saw the artist.
The banker saw the actor.
The banker stopped the actor.
The student called the judge.
The judges heard the actors.
The actor slept.
The actor slept.
E
N
E
N
E
N
98.3
68.1
99.7
25.8
99.3
37.9
98.9
71.0
99.8
29.5
98.8
37.6
Table 4: HANS heuristics and RoBERTa-base and SIFT’s accuracy. Examples are due to McCoy et al.
(2019). ‘‘E’’: entailment. ‘‘N’’: non-entailment. Bold font indicates better result in each category.
‘‘non-entailment’’ ones (McCoy et al., 2019), on
which we focus our analysis. The 30,000 test
examples are evenly spread among the 6 classes
(3 heuristics, 2 labels).
Table 4 compares SIFT against the RoBERTa
baseline on HANS. Both struggle with non-
entailment examples. SIFT yields improvements
on the lexical overlap and subsequence heuristics,
which we find unsurprising, given that semantic
analysis directly addresses the underlying dif-
ferences in meaning between the (surface-similar)
premise and hypothesis in these cases. SIFT
performs similarly to RoBERTa on the constituent
heuristic with a 0.3% accuracy difference for
the non-entailment examples. Here the hypothesis
corresponds to a constituent in the premise, and
therefore we expect its semantic parse to often be
a subgraph of the premise’s; accuracy hinges on
the meanings of the connectives (e.g., before and
if
in the examples), not on the structure of the
graphs.
Results on the GLUE Diagnostic Data.
GLUE’s diagnostic set (Wang et al., 2018) con-
tains 1,104 artificially curated NLI examples to
test a model’s performance on various linguis-
tic phenomena including predicate-argument
structure (e.g., ‘‘I opened the door.’’ entails ‘‘The
door opened.’’ but not ‘‘I opened.’’), logic (e.g.,
‘‘I have no pet puppy.’’ entails ‘‘I have no corgi
pet puppy.’’ but not ‘‘I have no pets.’’), lexical
semantics (e.g., ‘‘I have a dog.’’ entails ‘‘I have an
animal.’’ but not ‘‘I have a cat.’’), and knowledge
& common sense (e.g., ‘‘I went to the Grand
Canyon.’’ entails ‘‘I went to the U.S..’’ but not
‘‘I went to Antarctica.’’). Table 5 presents the
results in R3 correlation coefficient (Gorodkin,
2004). Explicit semantic dependencies help SIFT
perform better on predicate-argument structure
and sentence logic. On the other hand, SIFT
underperforms the baseline on lexical semantics
Phenomenon
RoBERTa
SIFT
Predicate Argument Structure
Logic
Lexical Semantics
Knowledge
43.5
36.2
45.6
28.0
44.6
38.3
44.8
26.3
Table 5: R3 correlation coefficient of RoBERTa-
base and SIFT on the GLUE diagnostic set.
and world knowledge. We would not expect
a benefit here, since semantic graphs do not
add lexical semantics or world knowledge; the
drop in performance suggests that some of what
RoBERTa learns is lost when it
is finetuned
through sparse graphs. Future work might seek
graph encoding architectures that mitigate this
loss.
6.2 Sample Efficiency
In §5.2, we observe greater improvements from
SIFT on smaller finetuning sets. We hypothesize
that the structured inductive bias helps SIFT more
when the amount of finetuning data is limited.
We test this hypothesis on MNLI by training
different models varying the amount of finetuning
data. We train all configurations with the same
three random seeds. As seen in Table 6, SIFT
offers larger improvements when less finetuning
data is used. Given the success of the pretraining
paradigm, we expect many new tasks to emerge
with tiny finetuning sets, and these will benefit the
most from methods like SIFT.
6.3 Comparisons to Other Graph Encoders
In this section we compare RGCN to some
commonly used graph encoders. We aim to study
whether or not (1) encoding graph labels helps,
and (2) explicitly modeling discrete structures is
necessary. Using the same experiment setting as
in §5.1, we compare SIFT and SIFT-Light to
233
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Fraction |Train| RoBERTa SIFT Abs Δ Rel Δ
ID.
OOD.
RoBERTa SIFT Abs Δ Rel Δ
100%
0.5%
0.2%
0.1%
392k
1,963
785
392
87.7
76.1
68.6
58.7
87.9
77.6
71.0
61.2
0.2
1.5
2.5
2.6
0.2%
1.9%
3.5%
4.2%
87.3
77.1
70.0
60.5
87.7
78.2
71.8
63.7
0.4
1.1
1.8
3.3
0.4%
1.4%
2.5%
5.1%
Table 6: RoBERTa-base and SIFT’s performance on the entire MNLI development sets and their
absolute and relative differences, with different numbers of finetuning instances randomly subsampled
from the training data.
MNLI
Models
CoLA MRPC RTE SST-2
STS-B QNLI QQP
ID. OOD. Avg.
RoBERTa
GCN
GAT
Hidden
Scaffold
SIFT
SIFT-Light
63.1
65.2
63.4
64.2
62.5
64.8
64.1
90.1
90.2
90.0
90.2
90.5
90.5
90.3
79.0
80.2
79.4
79.7
71.1
81.0
80.6
94.6
94.8
94.7
94.5
94.3
95.1
94.7
91.0
91.1
91.2
91.0
91.0
91.3
91.2
93.0
92.9
92.9
92.8
92.6
93.2
92.8
91.8
91.8
91.8
91.8
91.7
91.9
91.7
87.7
87.8
87.7
87.1
87.7
87.9
87.7
87.3
87.7
87.6
86.7
87.6
87.7
87.6
86.4
86.8
86.5
86.4
85.5
87.0
86.7
Table 7: GLUE development set results for different architectures for incorporating semantic information.
The settings and metrics are identical to Table 3a. All models use the base size variant.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
• Graph convolutional network (GCN; Kipf
and Welling, 2016). GCN does not encode
relations, but is otherwise the same as RGCN.
• Graph attention network (GAT; Veliˇckovi´c
et al., 2018). Similarly to GCN, it encodes
unlabeled graphs. Each node aggregates
representations of its neighbors using an
attention function (instead of convolutions).
• Hidden (Pang et al., 2019; Zhang et al.,
2020a). It does not explicitly encode struc-
tures, but uses the hidden representations
from a pretrained parser as additional fea-
tures to the classifier.
• Scaffold (Swayamdipta et al., 2018)
is
based on multitask learning.
It aims to
improve the downstream task performance
by additionally training the model on the DM
data with a full parsing objective.
To ensure fair comparisons, we use comparable
implementations for these models. We refer the
readers to the works cited for further details.
Table 7 summarizes the results, with SIFT hav-
ing the highest average score across all datasets.
234
Notably, the 0.2 average absolute benefit of SIFT
over GCN and 0.5 over GAT demonstrates the
benefit of including the semantic relation types
(labels). Interestingly, on the linguistic accept-
ability task—which focuses on well-formedness
and therefore we expect relies more on syntax
—GCN outperforms RGCN-based SIFT. GAT
underperforms GCN by 0.3 on average, likely
because the sparse semantic structures (i.e., small
degrees of each node) make attended message
passing less useful. Hidden does not on average
outperform the baseline, highlighting the bene-
fit of discrete graph structures (which it lacks).
Finally, the scaffold underperforms across most
tasks.
7 Related Work
Explicit
Linguistic
Information.
Using
Before pretrained contextualized representations
emerged, linguistic information was commonly
incorporated into deep learning models to im-
prove their performance including part of speech
(Sennrich and Haddow, 2016; Xu et al., 2016,
inter alia) and syntax (Eriguchi et al., 2017;
Chen et al., 2017; Miwa and Bansal, 2016, inter
alia). Nevertheless, recent attempts in incorpo-
rating syntax into pretrained models have little
success on NLU: Strubell et al. (2018) found
syntax to only marginally help semantic role
labeling with ELMo, and Kuncoro et al. (2020)
observed that incorporating syntax into BERT
conversely hurts the performance on some GLUE
NLU tasks. On the other hand, fewer attempts have
been devoted to incorporating sentential predicate-
argument semantics into NLP models. Zhang
et al. (2020b) embedded semantic role labels
from a pretrained parser to improve BERT.
However, these features do not constitute full
sentential semantics. Peng et al. (2018a) enhanced
a sentiment classification model with DM but
only used one-hop information and no relation
modeling.
Probing Syntax and Semantics in Models.
Many prior works have probed the syntactic
and semantic content of pretrained transformers,
typically BERT. Wallace et al. (2019) observed
that BERT displays suboptimal numeracy knowl-
edge. Clark et al. (2019) discovered that BERT’s
attention heads tend to surface syntactic relation-
ships. Hewitt and Manning (2019) and Tenney
et al. (2019) both observed that BERT embeds
a significant amount of syntactic knowledge.
Besides pretrained transformers, Belinkov et al.
(2020) used syntactic and semantic dependency
relations to analyze machine translation models.
8 Conclusion
We presented strong evidence that RoBERTa
and BERT do not bring predicate-argument se-
mantics to the surface as effectively as they
do for syntactic dependencies. This observation
motivates SIFT, which aims
to incorporate
explicit semantic structures into the pretraining-
finetuning paradigm. It encodes automatically
parsed semantic graphs using RGCN. In con-
trolled experiments, we find consistent benefits
language
across eight
understanding,
relative to RoBERTa and a
syntax-infused RoBERTa. These findings moti-
vate continued work on task-independent se-
mantic analysis, including training methods that
integrate it into architectures serving downstream
applications.
tasks targeting natural
Acknowledgments
The authors thank the anonymous reviewers for
feedback that improved the paper. We also thank
Stephan Oepen for help in producing the CoNLL
2019 shared task companion data, Yutong Li for
contributing to early experiments, and Elizabeth
Clark and Lucy Lin for their suggestions and
feedback. This research was supported in part
by a Google Fellowship to HP and NSF grant
1562364.
References
Omri Abend and Ari Rappoport. 2013. Universal
conceptual cognitive annotation (UCCA). In
Proceedings of ACL.
Yossi Adi, Einat Kermany, Yonatan Belinkov,
Ofer Lavi, and Yoav Goldberg. 2017. Fine-
grained analysis of sentence embeddings using
auxiliary prediction tasks. In Proceedings of
ICLR.
Collin F. Baker, Charles J. Fillmore, and John B.
Lowe. 1998. The Berkeley FrameNet project.
In Proceedings of ACL. DOI: https://doi
.org/10.3115/980845.980860
Roy Bar-Haim, Ido Dagan, Bill Dolan, Lisa
Ferro, and Danilo Giampiccolo. 2006. The
second PASCAL recognising textual entailment
challenge. Proceedings of the Second PASCAL
Challenges Workshop on Recognising Textual
Entailment.
Jasmijn Bastings, Ivan Titov, Wilker Aziz, Diego
Marcheggiani, and Khalil Sima’an. 2017.
Graph convolutional encoders for syntax-aware
In Proceedings
neural machine translation.
of EMNLP. DOI: https://doi.org/10
.18653/v1/D17-1209
Yonatan Belinkov, Nadir Durrani, Hassan Sajjad,
Fahim Dalvi, and James Glass. 2020. On
the linguistic representational power of neural
machine translation models. Computational
Linguistics, 46(1):1–52. DOI: https://doi
.org/10.1162/coli a 00367
Yonatan Belinkov and James Glass. 2019. Anal-
ysis methods in neural language processing:
A survey. Transactions of the Association for
Computational Linguistics, 7:49–72. DOI:
https://doi.org/10.1162/tacl a
00254
235
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Emily M. Bender and Alexander Koller. 2020.
Climbing towards NLU: On meaning, form, and
understanding in the age of data. In Proceed-
ings of ACL. DOI: https://doi.org/10
.18653/v1/2020.acl-main.463
Luisa Bentivogli, Ido Dagan, Hoa Trang Dang,
Danilo Giampiccolo, and Bernardo Magnini.
2009. The fifth PASCAL recognizing textual
entailment challenge. In Proceedings of TAC.
Daniel Cer, Mona Diab, Eneko Agirre, I˜nigo
Lopez-Gazpio,
and Lucia Specia. 2017.
SemEval-2017 task 1: Semantic textual simi-
larity multilingual and crosslingual focused
evaluation. In Proceedings of SemEval.
Wanxiang Che, Longxu Dou, Yang Xu, Yuxuan
Wang, Yijia Liu, and Ting Liu. 2019. HIT-SCIR
at MRP 2019: A unified pipeline for meaning
representation parsing via efficient training and
effective encoding. In Proceedings of MRP.
Qian Chen, Xiaodan Zhu, Zhenhua Ling, Si Wei,
Hui Jiang, and Diana Inkpen. 2017. Enhanced
In
LSTM for natural
Proceedings of ACL. DOI: https://doi
.org/10.18653/v1/P17-1152
language inference.
Yoeng-Jin Chu and Tseng-Hong Liu. 1965. On
the shortest arborescence of a directed graph.
Science Sinica, 14:1396–1400.
Kevin Clark, Urvashi Khandelwal, Omer Levy,
and Christopher D. Manning. 2019. What does
BERT look at? an analysis of BERT’s attention.
In Proceedings of the 2019 ACL Workshop
BlackboxNLP: Analyzing and Interpreting Neu-
ral Networks for NLP. DOI: https://doi
.org/10.18653/v1/W19-4828, PMID:
31709923
Kevin Clark, Minh-Thang Luong, Quoc V. Le,
and Christopher D. Manning. 2020. ELECTRA:
Pre-training text encoders as discriminators
rather than generators. In Proceedings of ICLR.
Kevin Clark, Minh-Thang Luong, Christopher D.
Manning, and Quoc Le. 2018. Semi-supervised
sequence modeling with cross-view training. In
Proceedings of EMNLP. DOI: https://doi
.org/10.18653/v1/D18-1217
Computation, 3(2–3):281–332. DOI: https://
doi.org/10.1007/s11168-006-6327-9
Korn´el Csernai. 2017. (accessed September 1,
2020). First Quora Dataset Release: Question
Pairs.
Ido Dagan, Oren Glickman, and Bernardo
Magnini. 2005. The PASCAL recognising tex-
tual entailment challenge. In Proceedings of
the First International Conference on Machine
Learning Challenges: Evaluating Predictive
Uncertainty Visual Object Classification, and
Recognizing Textual Entailment. DOI: https://
doi.org/10.1007/11736790 9
Marie-Catherine de Marneffe, Bill MacCartney,
and Christopher D. Manning. 2006. Generating
typed dependency parses from phrase structure
parses. In Proceedings of LREC.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Kristina Toutanova. 2019. BERT: Pre-training
of deep bidirectional transformers for language
understanding. In Proceedings of NAACL.
Jesse Dodge, Gabriel Ilharco, Roy Schwartz, Ali
Farhadi, Hannaneh Hajishirzi, and Noah Smith.
2020. Fine-tuning pretrained language models:
Weight initializations, data orders, and early
stopping. arXiv preprint arXiv:2002.06305.
William B. Dolan and Chris Brockett. 2005.
Automatically constructing a corpus of senten-
tial paraphrases. In Proceedings of the Third
International Workshop on Paraphrasing.
Timothy Dozat and Christopher D. Manning.
2017. Deep biaffine attention for neural depen-
dency parsing. In Proceedings of ICLR.
Timothy Dozat and Christopher D. Manning.
2018. Simpler but more accurate semantic
dependency parsing. In Proceedings of ACL.
DOI: https://doi.org/10.18653/v1
/P18-2077
Jack Edmonds. 1967. Optimum branchings.
Journal of Research of the National Bureau
of Standards, 71B:233–240. DOI: https://
doi.org/10.6028/jres.071B.032
Ann Copestake, Dan Flickinger, Carl Pollard, and
Ivan A Sag. 2005. Minimal recursion semantics:
An introduction. Research on Language and
Jason M. Eisner. 1996. Three new probabilis-
tic models for dependency parsing: An ex-
ploration. In Proceedings of COLING. DOI:
236
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
https://doi.org/10.3115/992628
.992688
.org/10.18653/v1/2020.acl-main.197,
PMCID: PMC7218724
Akiko Eriguchi, Yoshimasa Tsuruoka,
and
Kyunghyun Cho. 2017. Learning to parse and
translate improves neural machine translation.
In Proceedings of ACL. DOI: https://
doi.org/10.18653/v1/P17-2012
Danilo Giampiccolo, Bernardo Magnini,
Ido
Dagan, and Bill Dolan. 2007. The third PAS-
CAL recognizing textual entailment challenge.
In Proceedings of the ACL-PASCAL Workshop
on Textual Entailment and Paraphrasing. DOI:
https://doi.org/10.3115/1654536
.1654538
Yoav Goldberg. 2019. Assessing BERT’s syntac-
tic abilities. arXiv preprint arXiv:1901.05287.
Jan Gorodkin. 2004. Comparing two k-category
assignments by a k-category correlation coef-
ficient. Computational Biology and Chem-
istry, 28(5–6):367–374. DOI: https://doi
.org/10.1016/j.compbiolchem.2004
.09.006, PMID: 15556477
Jan Hajic, Eva Hajicov´a, Jarmila Panevov´a,
Petr Sgall, Ondrej Bojar, Silvie Cinkov´a,
Eva Fuc´ıkov´a, Marie Mikulov´a, Petr Pajas,
Jan Popelka, et al. 2012. Announcing Prague
Czech-English dependency treebank 2.0. In
Proceedings of LREC.
John Hewitt and Christopher D. Manning. 2019.
A structural probe for finding syntax in word
representations. In Proceedings of NAACL.
Dieuwke Hupkes, Sara Veldhoen, and Willem
Zuidema. 2018. Visualisation and ‘diagnostic
classifiers’ reveal how recurrent and recursive
neural networks process hierarchical structure.
In Proceedings of IJCAI.
Angelina Ivanova, Stephan Oepen, Lilja Øvrelid,
and Dan Flickinger. 2012. Who did what
to whom?: A contrastive study of syntacto-
semantic dependencies. In Proceedings LAW.
Thomas N. Kipf and Max Welling. 2016. Semi-
supervised classification with graph convolu-
tional networks. In Proceedings of ICLR.
Olga Kovaleva, Alexey Romanov, Anna Rogers,
and Anna Rumshisky. 2019. Revealing the dark
secrets of BERT. In Proceedings of EMNLP.
DOI: https://doi.org/10.18653/v1
/D19-1445
Adhiguna Kuncoro, Lingpeng Kong, Daniel
Fried, Dani Yogatama, Laura Rimell, Chris
Dyer, and Phil Blunsom. 2020. Syntactic struc-
ture distillation pretraining for bidirectional
encoders. arXiv preprint arXiv:2005.13482.
DOI: https://doi.org/10.1162/tacl
a 00345
Zuchao Li, Hai Zhao, Zhuosheng Zhang, Rui
Wang, Masao Utiyama, and Eiichiro Sumita.
2019. SJTU-NICT at MRP 2019: Multi-task
learning for end-to-end uniform semantic graph
parsing. In Proceedings of MRP.
Nelson F. Liu, Matt Gardner, Yonatan Belinkov,
Matthew Peters, and Noah A. Smith. 2019a.
Linguistic knowledge and transferability of
contextual representations. In Proceedings of
NAACL.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei
Du, Mandar Joshi, Danqi Chen, Omer Levy,
Mike Lewis, Luke Zettlemoyer, and Veselin
Stoyanov. 2019b. RoBERTa: A robustly opti-
mized BERT pretraining approach. arXiv
preprint arXiv:1907.11692.
Ilya Loshchilov and Frank Hutter. 2019. Decou-
pled weight decay regularization. In Proceed-
ings of ICLR.
Diego Marcheggiani and Ivan Titov. 2017.
Encoding sentences with graph convolutional
networks for semantic role labeling. In Pro-
ceedings of EMNLP. DOI: https://doi
.org/10.18653/v1/D17-1159
Haoming Jiang, Pengcheng He, Weizhu Chen,
Xiaodong Liu, Jianfeng Gao, and Tuo Zhao.
2020. SMART: Robust and efficient
fine-
tuning for pre-trained natural language models
through principled regularized optimization. In
Proceedings of ACL. DOI: https://doi
Mitchell P. Marcus, Beatrice Santorini, and
Mary Ann Marcinkiewicz. 1993. Building a
large annotated corpus of English: The Penn
Treebank. Computational Linguistics, 19(2):
313–330. DOI: https://doi.org.10
.21236/ADA273556
237
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Thomas McCoy, Ellie Pavlick, and Tal Linzen.
2019. Right for the wrong reasons: Diagnos-
ing syntactic heuristics in natural
language
In Proceedings of ACL. DOI:
inference.
https://doi.org/10.18653/v1/P19
-1334
Ryan McDonald, Fernando Pereira, Kiril Ribarov,
and Jan Hajiˇc. 2005. Non-projective depen-
dency parsing using spanning tree algorithms.
In Proceedings of NAACL. DOI: https://
doi.org/10.3115/1220575.1220641
Makoto Miwa and Mohit Bansal. 2016. End-to-
end relation extraction using LSTMs on se-
quences and tree structures. In Proceedings of
ACL. DOI: https://doi.org/10.18653
/v1/P16-1105
Stephan Oepen, Omri Abend,
Jan Hajic,
Daniel Hershcovich, Marco Kuhlmann, Tim
O’Gorman, Nianwen Xue, Jayeol Chun, Milan
Straka, and Zdenka Uresova. 2019. MRP
2019: Cross-framework meaning representation
parsing. In Proceedings of MRP.
Stephan Oepen, Marco Kuhlmann, Yusuke Miyao,
Daniel Zeman, Silvie Cinkova, Dan Flickinger,
Jan Hajic, and Zdenka Uresova. 2015. Semeval
2015 task 18: Broad-coverage semantic depen-
dency parsing. In Proceedings of SemEval.
Stephan Oepen, Marco Kuhlmann, Yusuke Miyao,
Daniel Zeman, Dan Flickinger, Jan Hajic,
Angelina Ivanova, and Yi Zhang. 2014.
SemEval 2014 task 8: Broad-coverage semantic
dependency parsing. In Proceedings SemEval.
Stephan Oepen and Jan Tore Lønning. 2006.
Discriminant-based MRS banking. In Proceed-
ings of LREC.
Martha Palmer, Daniel Gildea,
and Paul
Kingsbury. 2005. The proposition bank: An an-
notated corpus of semantic roles. Computa-
tional Linguistics, 31(1):71–106. DOI: https://
doi.org/10.1162/0891201053630264
attention model for natural language inference.
In Proceedings of EMNLP. DOI: https://
doi.org/10.18653/v1/D16-1244
Hao Peng, Sam Thomson, and Noah A. Smith.
2017. Deep multitask learning for semantic
dependency parsing. In Proceedings of ACL.
DOI: https://doi.org/10.18653/v1
/P17-1186
Hao Peng, Sam Thomson, and Noah A. Smith.
2018a. Backpropagating through structured
In Proceedings
argmax using a SPIGOT.
of ACL. DOI: https://doi.org/10
.18653/v1/P18-1173, PMID: 30080257
Hao Peng, Sam Thomson, Swabha Swayamdipta,
and Noah A. Smith. 2018b. Learning joint se-
mantic parsers from disjoint data. In Proceed-
ings of NAACL. DOI: https://doi.org/10
.18653/v1/N18-1135, PMCID: PMC6327562
Matthew E. Peters, Mark Neumann, Mohit Iyyer,
Matt Gardner, Christopher Clark, Kenton Lee,
and Luke Zettlemoyer. 2018. Deep contextu-
alized word representations. In Proceedings
of NAACL. DOI: https://doi.org/10
.18653/v1/N18-1202
Carl Pollard and Ivan A. Sag. 1994. Head-
Driven Phrase Structure Grammar. University
of Chicago Press.
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, Michael
Matena, Yanqi Zhou, Wei Li, and Peter J. Liu.
2020. Exploring the limits of transfer learning
with a unified text-to-text transformer. Journal
of Machine Learning Research, 21(140):1–67.
Pranav Rajpurkar,
Jian Zhang, Konstantin
Lopyrev, and Percy Liang. 2016. SQuAD:
100,000+ questions for machine comprehen-
sion of text. In Proceedings of EMNLP. DOI:
https://doi.org/10.18653/v1/D16
-1264
Deric Pang, Lucy H. Lin, and Noah A. Smith.
2019. Improving natural
language inference
with a pretrained parser. arXiv preprint
arXiv:1909.08217.
Ankur P. Parikh, Oscar T¨ackstr¨om, Dipanjan Das,
and Jakob Uszkoreit. 2016. A decomposable
Michael Schlichtkrull, Thomas N. Kipf, Peter
Bloem, Rianne Van Den Berg, Ivan Titov, and
Max Welling. 2018. Modeling relational data
with graph convolutional networks. In Euro-
pean Semantic Web Conference. DOI: https://
doi.org/10.1007/978-3-319-93417
-4 38
238
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Sebastian Schuster and Christopher D. Manning.
2016. Enhanced english universal dependen-
cies: An improved representation for natural
language understanding tasks. In Proceedings
of LREC.
Rico Sennrich and Barry Haddow. 2016. Linguis-
tic input features improve neural machine trans-
lation. In Proceedings of the First Conference
on Machine Translation. DOI: https://
doi.org/10.18653/v1/W16-2209
Rico Sennrich, Barry Haddow, and Alexandra
Birch. 2016. Neural machine translation of rare
words with subword units. In Proceedings ACL.
DOI: https://doi.org/10.18653/v1
/P16-1162
Xing Shi, Inkit Padhi, and Kevin Knight. 2016.
Does string-based neural MT learn source
syntax? In Proceedings of EMNLP. DOI:
https://doi.org/10.18653/v1/D16
-1159
Richard Socher, Alex Perelygin, Jean Wu, Jason
Chuang, Christopher D. Manning, Andrew Ng,
and Christopher Potts. 2013. Recursive deep
models for semantic compositionality over a
sentiment treebank. In Proceedings of EMNLP.
Milan Straka. 2018. UDPipe 2.0 prototype at
CoNLL 2018 UD shared task. In Proceedings
of the CoNLL 2018 Shared Task: Multilingual
to Universal De-
Parsing from Raw Text
pendencies. DOI: https://doi.org/10
.18653/v1/K19-2012
Milan Straka and Jana Strakov´a. 2019.
´UFAL
MRPipe at MRP 2019: UDPipe goes semantic
in the meaning representation parsing shared
task. In Proceedings of MRP.
Emma Strubell, Patrick Verga, Daniel Andor,
David Weiss, and Andrew McCallum. 2018.
Linguistically-informed self-attention for se-
In Proceedings of
mantic
EMNLP. DOI: https://doi.org/10
.18653/v1/D18-1548
labeling.
role
Swabha Swayamdipta, Matthew Peters, Brendan
Roof, Chris Dyer, and Noah A. Smith. 2019.
Shallow syntax in deep water. arXiv preprint
arXiv:1908.11047.
Swabha Swayamdipta, Sam Thomson, Kenton
Lee, Luke Zettlemoyer, Chris Dyer, and
Noah A. Smith. 2018. Syntactic scaffolds for
semantic structures. In Proceedings of EMNLP.
DOI: https://doi.org/10.18653/v1
/D18-1412
Ian Tenney, Patrick Xia, Berlin Chen, Alex Wang,
Adam Poliak, Thomas McCoy, Najoung Kim,
Benjamin Van Durme, Samuel R. Bowman,
Dipanjan Das, and Ellie Pavlick. 2019. What do
you learn from context? Probing for sentence
structure in contextualized word representa-
tions. In Proceedings of ICLR.
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa
Casanova, Adriana Romero, Pietro Lio, and
Yoshua Bengio. 2018. Graph attention net-
works. In Proceedings of ICLR.
Tu Vu, Tong Wang, Tsendsuren Munkhdalai,
Alessandro Sordoni, Adam Trischler, Andrew
Mattarella-Micke, Subhransu Maji, and Mohit
Iyyer. 2020. Exploring and predicting trans-
ferability across NLP tasks. In Proceedings
of EMNLP. DOI: https://doi.org/10
.18653/v1/2020.emnlp-main.635
Eric Wallace, Yizhong Wang, Sujian Li, Sameer
Singh, and Matt Gardner. 2019. Do NLP
models know numbers? Probing numeracy in
embeddings. In Proceedings of EMNLP. DOI:
https://doi.org/10.18653/v1/D19
-1534
Alex Wang, Amapreet Singh, Julian Michael,
Felix Hill, Omer Levy, and Samuel R.
Bowman. 2018. GLUE: A multi-task bench-
mark and analysis platform for natural language
In Proceedings of EMNLP.
understanding.
DOI: https://doi.org/10.18653/v1
/W18-5446
Mihai Surdeanu, Richard Johansson, Adam
Meyers, Llu´ıs M`arquez, and Joakim Nivre.
2008. The CoNLL 2008 shared task on joint
parsing of syntactic and semantic dependencies.
In Proceedings of CoNLL. DOI: https://
doi.org/10.3115/1596324.1596352
Alex Warstadt, Amanpreet Singh, and Samuel R.
Bowman. 2019. Neural network acceptability
judgments. Transactions of the Association for
Computational Linguistics, 7:625–641. DOI:
https://doi.org/10.1162/tacl a
00290
239
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Adina Williams, Nikita Nangia, and Samuel R.
Bowman. 2018. A broad-coverage challenge
corpus for sentence understanding through
inference. In Proceedings of NAACL. DOI:
https://doi.org/10.18653/v1/N18
-1101
Kun Xu, Siva Reddy, Yansong Feng, Songfang
Huang, and Dongyan Zhao. 2016. Question
answering on freebase via relation extraction
and textual evidence. In Proceedings of ACL.
DOI: https://doi.org/10.18653/v1
/P16-1220
Bo Zhang, Yue Zhang, Rui Wang, Zhenghua Li,
and Min Zhang. 2020a. Syntax-aware opinion
role labeling with dependency graph convolu-
tional networks. In Proceedings of ACL. DOI:
https://doi.org/10.18653/v1/2020
.acl-main.297
Zhuosheng Zhang, Yuwei Wu, Hai Zhao, Zuchao
Li, Shuailiang Zhang, Xi Zhou, and Xiang
Zhou. 2020b. Semantics-aware BERT for lan-
guage understanding. In Proceedings of AAAI.
DOI: https://doi.org/10.1609/aaai
.v34i05.6510
Zhuosheng Zhang, Yuwei Wu, Junru Zhou,
Sufeng Duan, Hai Zhao, and Rui Wang.
2020c. Sg-net: Syntax-guided machine reading
comprehension. In Proceedings of AAAI. DOI:
https://doi.org/10.1609/aaai.v34i05
.6511
A Detailed Model Architecture
In this section we provide a detailed illustration of
our architecture.
Graph Initialization Because RoBERTa’s BPE
tokenization differs from the Che et al. (2019)
semantic parser’s CoNLL 2019 tokenization, we
align the two tokenization schemes using character
level offsets, as illustrated in Figure 3. For each
node i, we find wordpieces [tj, · · · , tk] that it
aligns to. We initialize its node embedding by
averaging the vectors of these wordpiece followed
by an learned affine transformation and a ReLU
nonlinearity:
⎛
⎞
h(0)
i = ReLU
⎝We
1
k − j + 1
k(cid:4)
s=j
⎠
es
240
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 4: SIFT architecture for sentence pair tasks. Two
graphs are first separately encoded using RGCN, then
structured decomposable attention is used to capture
the inter-graph interaction. Additional RGCN layers are
used to further propagate the structured information.
Finally two vectors max-pooled from both graphs
are concatenated and used for onward computation.
RoBERTa and the external parser are suppressed for
clarity.
Here We is a learned matrix, and the e vectors are
the wordpiece representations. The superscript on
h denotes the layer number, with 0 being the input
embedding vector fed into the RGCN layers.
In each RGCN layer (cid:2), every
Graph Update
node’s hidden representation is propagated to its
direct neighbors:
h((cid:2)+1)
i
=
⎛
ReLU
⎝
(cid:4)
(cid:4)
r ∈ R
j ∈ N r
i
1
| N r
i |
W((cid:2))
r h((cid:2))
j + W((cid:2))
0 h((cid:2))
i
⎞
⎠
where R is the set of all possible relations
(i.e., edge labels; including inverse relations for
inverse edges that we manually add corresponding
to the original edges) and N r
i denotes vi’s
neighbors with relation r. Wr and W0 are
learned parameters representing a relation-specific
transformation and a self-loop transformation,
respectively. We also use the basis-decomposition
trick described in Schlichtkrull et al. (2018) to
reduce the number of parameters and hence the
memory requirement. Specifically, we construct B
basis matrices; where |R| > B, the transformation
of each relation is constructed by a learned linear
combination of the basis matrices. Each RGCN
layer captures the neighbors information that is
one hop away. We use (cid:2) = 2 RGCN layers for our
experiments.
Sentence Pair Tasks For sentence pair tasks, it is
crucial to model sentence interaction (Parikh et al.,
PTB SD
Metrics Abs Δ Rel Δ Full Probe
LAS/F1
LEM
UEM
–14.4% 94.6
–73.7% 48.6
–74.1% 60.3
–13.6
–35.8
–44.7
81.0
12.8
15.7
CoNLL 2015 DM
Abs Δ Rel Δ Full Probe
–23.2
–39.4
–42.0
–24.8% 93.6
–91.6% 43.0
–91.5% 45.9
70.4
3.6
3.9
Table 8: The BERT-base parsing results for the full ceiling model and the probing
model on the PTB Stanford Dependencies (SD) test set and CoNLL 2015 in-domain
test set. The metrics and settings are identical to Table 1 except only one seed is used.
MRPC STS-B ID. OOD.
MNLI
Full
– attention
– concat
90.5
90.1
90.2
91.3
91.2
91.0
87.9
87.9
87.8
87.7
87.7
87.6
Table 9: Ablation results on the development
sets of 3 GLUE datasets with a RoBERTa-base
backbone.
2016). We therefore use a similar structured de-
composable attention component to model the
interaction between the two semantic graphs. Each
node attends to the other graph’s nodes using
biaffine attention; its output is then concatenated
to its node representation calculated in its own
graph. Specifically, for two sentences a and b, we
obtain an updated representation h(cid:8)((cid:2)),a for a as
follows:
(cid:8)
, h((cid:2)),b
j
αi,j = biaffine
(cid:4)
˜h((cid:2)),a
i =
(cid:7)
h((cid:2)),a
i
αi,jh((cid:2)),b
j
(cid:9)
j
h(cid:8)(l),a = ReLU
Wα
[h((cid:2)),a
i
; ˜h((cid:2)),a
i
; h((cid:2)),a
i − ˜h((cid:2)),a
i
; h((cid:2)),a
i (cid:9) ˜h((cid:2)),a
i
(cid:10)
]
where Wα is a learned matrix, and (cid:9) denotes
the elementwise product. We do the same
operation to obtain the updated h(cid:8)((cid:2)),b. Inspired
by Chen et al. (2017), we add another (cid:2) RGCN
composition layers to further propagate the
attended representation. They result in additional
parameters and runtime cost compared to what
was presented in §4.3.
Graph Pooling The NLU tasks we experiment
with require one vector representation for each
instance. We max-pool over the sentence graph
(for sentence pair tasks, separately for the two
241
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
graphs whose pooled output are then concate-
nated), concatenate it with RoBERTa’s [CLS]
embedding, and feed the result into a layer nor-
malization layer (LN) to get the final output.
B Hyperparameters
Probing Hyperparameters. No hyperparame-
ter tuning is conducted for the probing experi-
ments. For the full models, we use intermediate
MLP layers with dimension 512 for arc projection
and 128 for label projection. The probing mod-
els do not have such layers. We minimize the
sum of the arc and label cross entropy losses for
both dependency and DM parsing. All models are
optimized with AdamW (Loshchilov and Hutter,
2019) for 10 epochs with batch size 8 and learning
rate 2 × 10−5.
Main Experiment Hyperparameters. For
SIFT, we use 2 RGCN layers for single-sentence
tasks and 2 additional composition RGCN layers
after the structured decomposable attention com-
ponent for sentence-pair tasks. The RGCN hidden
dimension is searched in {256, 512, 768},
the
number of bases in {20, 60, 80, 100}, dropout
between RGCN layers in {0, 0.2, 0.3}, and the
final dropout after all RGCN layers in {0, 0.1}.
the training loss is obtained
For SIFT-Light,
with 0.2lossRGCN +0.8lossRoBERTa. For all models,
the number of training epochs is searched in
{3, 10, 20} and the learning rate in {1 × 10−4, 2 ×
10−5}. We use 0.1 weight decay and 0.06 warmup
ratio. All models are optimized with AdamW with
an effective batch size of 32.
C BERT Probing Results
We replicate the RoBERTa probing experiments
described in §3 for BERT. We observe similar
trends where the probing model degrades more
from the full model for DM than dependency
syntax. This demonstrates that, like RoBERTa,
BERT also less readily surfaces semantic content
than syntax.
D Ablations
In this section we ablate two major architectural
choices: the sentence pair structured decompos-
able attention component and the use of a con-
catenated RoBERTa and RGCN representation
rather than only using the latter. We select 3
sentence-pair datasets covering different dataset
sizes and tasks with identical experimental setup
as §5.1. The ablation results in Table 9 show that
the full SIFT architecture performs the best.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
3
6
3
1
9
2
4
0
4
9
/
/
t
l
a
c
_
a
_
0
0
3
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
242