Improving Statistical Machine
Translation by Adapting Translation
Models to Translationese
Gennadi Lembersky
University of Haifa, Israel
∗
∗∗
Noam Ordan
University of Haifa, Israel
Shuly Wintner
University of Haifa, Israel
†
Translation models used for statistical machine translation are compiled from parallel corpora
that are manually translated. The common assumption is that parallel texts are symmetrical:
The direction of translation is deemed irrelevant and is consequently ignored. Much research
in Translation Studies indicates that the direction of translation matters, however, as translated
language (translationese) has many unique properties. It has already been shown that phrase
tables constructed from parallel corpora translated in the same direction as the translation task
outperform those constructed from corpora translated in the opposite direction.
We reconfirm that this is indeed the case, but emphasize the importance of also using texts
translated in the “wrong” direction. We take advantage of information pertaining to the direction
of translation in constructing phrase tables by adapting the translation model to the special
properties of translationese. We explore two adaptation techniques: First, we create a mixture
model by interpolating phrase tables trained on texts translated in the “right” and the “wrong”
directions. The weights for the interpolation are determined by minimizing perplexity. Second,
we define entropy-based measures that estimate the correspondence of target-language phrases
to translationese, thereby eliminating the need to annotate the parallel corpus with information
pertaining to the direction of translation. We show that incorporating these measures as features
in the phrase tables of statistical machine translation systems results in consistent, statistically
significant improvement in the quality of the translation.
∗ Department of Computer Science, University of Haifa, 31905 Haifa, Israel.
E-mail: gennadi.lembersky@nice.com.
∗∗ Department of Computer Science, University of Haifa, 31905 Haifa, Israel.
E-mail: noam.ordan@gmail.com.
† Department of Computer Science, University of Haifa, 31905 Haifa, Israel.
E-mail: shuly@cs.haifa.ac.il.
Submission received: 23 June 2012; revised submission received: 13 November 2012; accepted for publication:
18 January 2013.
doi:10.1162/COLI a 00159
© 2013 Association for Computational Linguistics
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 39, Number 4
1. Introduction
Much research in translation studies indicates that translated texts have unique
characteristics that set them apart from original texts (Toury 1980; Gellerstam 1986;
Toury 1995). Known as translationese, translated texts (in any language) constitute a
genre, or a dialect, of the target language, which reflects both artifacts of the translation
process and traces of the original language from which the texts were translated.
Among the better-known properties of translationese are simplification and explicitation
(Blum-Kulka and Levenston 1983; Blum-Kulka 1986; Baker 1993): Translated texts tend
to be shorter, to have lower type/token ratio, and to use certain discourse markers
more frequently than original texts. Interestingly, translated texts are so markedly
different from original ones that automatic classification can identify them with very
high accuracy (Baroni and Bernardini 2006; van Halteren 2008; Ilisei et al. 2010; Koppel
and Ordan 2011).
Contemporary statistical machine translation (SMT) systems use parallel corpora to
train translation models that reflect source- and target-language phrase correspondences.
Typically, SMT systems ignore the direction of translation of the parallel corpus. Given
the unique properties of translationese, which operate asymmetrically from source to
target language, it is reasonable to assume that this direction may affect the quality
of the translation. Recently, Kurokawa, Goutte, and Isabelle (2009) showed that this is
indeed the case. They trained a system to translate between French and English (and
vice versa) using a French-translated-to-English parallel corpus, and then an English-
translated-to-French one. They find that in translating into French the latter parallel
corpus yields better results (in terms of higher BLEU scores), whereas for translating
into English it is better to use the former.
Typically, however, parallel corpora are not marked for direction. Therefore,
Kurokawa, Goutte, and Isabelle (2009) trained an SVM-based classifier to predict which
side of a bi-text is the origin and which one is the translation, and trained a translation
model by utilizing only the subset of the corpus that corresponds to the direction of the
task.
We use these results as our departure point, but improve them in two major ways.
First, we demonstrate that the other subset of the corpus, reflecting translation in the
“wrong” direction, is also important for the translation task, and must not be ignored;
second, we show that explicit information on the direction of translation of the par-
allel corpus, whether manually annotated or machine-learned, is not mandatory. This
is achieved by casting the problem in the framework of domain adaptation: We use
domain-adaptation techniques to direct the SMT system toward producing output that
better reflects the properties of translationese. We show that SMT systems adapted to
translationese produce better translations than vanilla systems trained on exactly the
same resources. We confirm these findings using automatic evaluation metrics, as well
as through a qualitative analysis of the results.
After reviewing related work in Section 2, we begin by replicating the results of
Kurokawa, Goutte, and Isabelle (2009) in Section 3. We then (Section 4) explain why
translation quality improves when the parallel corpus is translated in the “right” di-
rection. We do so by showing that the subset of the corpus that was translated in the
direction of the translation task (the “right” direction, henceforth source-to-target, or
S → T) yields phrase tables that are better suited for translation of the original language
than the subset translated in the reverse direction (the “wrong” direction, henceforth
target-to-source, or T → S). We use several statistical measures that indicate the better
quality of the phrase tables in the former case.
1000
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Lembersky, Ordan, and Wintner
Adapting Translation Models to Translationese
We then show (Section 5) that using the entire parallel corpus, including texts that
are translated both in the “right” and in the “wrong” direction, improves the quality
of the results. Next, we investigate several ways to improve the translation quality
by adapting a translation model to the nature of translationese, thereby making the
output of machine translation more similar to actual, human translation. Specifically,
we create two phrase tables, one for the S → T portion of the corpus, and one for the
T → S portion, and combine them into a mixture model using perplexity minimization
(Sennrich 2012) to set the model weights. We show that this combination significantly
outperforms a simple union of the two portions of the parallel corpus.
Furthermore, we show that the direction of translation used for producing the
parallel corpus can be approximated by defining several entropy-based measures that
correlate well with translationese, and, consequently, with translation quality. We use
the entire corpus, create a single, unified phrase table, and then use these measures,
and in particular cross-entropy, as a clue for selecting phrase pairs from this table. The
benefit of this method is that not only does it improve the translation quality, but it
also eliminates the need to directly predict the direction of translation of the parallel
corpus.
The main contribution of this work, therefore, is a methodology that improves
the quality of SMT by building translation models that are adapted to the nature of
translationese.1 To demonstrate the contribution of our methodology, we conduct in
Section 6 a thorough analysis of our results, both quantitatively and qualitatively. We
show that translations produced by our best-performing system indeed reflect some
well-known properties of translationese better than the output of baseline systems.
Furthermore, we provide several examples of SMT outputs that demonstrate in what
ways our adapted system generates better results.
2. Related Work
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
Kurokawa, Goutte, and Isabelle (2009) were the first to address the direction of
translation in the context of SMT. They found that a translation model based on the
S → T portion of the parallel corpus results in much better translation quality than a
translation model based on the T → S portion. We replicate these results here (Section 3),
and view them as a baseline. In taking direction into account, we are faced with two
major challenges. First, using only the “right” portion of the corpus results in discarding
potentially very useful data. In real-world scenarios this can be crucial, because the
proportion between the two portions of the corpus can vary greatly. In the Hansard
corpus, used by Kurokawa, Goutte, and Isabelle (2009), only 20% of the corpus is S → T.
We show that the T → S portion is also important for machine translation and thus
should not be discarded. Using information-theoretic measures, and in particular cross-
entropy, we gain statistically significant improvements in translation quality beyond the
results of Kurokawa, Goutte, and Isabelle (2009). The second challenge is to overcome
the need to (manually or automatically) classify parallel corpora according to direction.
We face this challenge by using an adaptation technique.
In previous work, we investigated the relations between translationese and machine
translation, focusing on the language model (LM) (Lembersky, Ordan, and Wintner
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
1 This article is a revised and much extended version of Lembersky, Ordan, and Wintner (2012a).
Extensions include experiments with several language pairs, in both directions; better adaptation
techniques; a new mixture model; and a detailed analysis of the results.
1001
Computational Linguistics
Volume 39, Number 4
2011, 2012b). We showed that LMs trained on translated texts yield better translation
quality than LMs compiled from original texts. We also showed that perplexity is a
good discriminator between original and translated texts. Importantly, we convincingly
demonstrated that the differences between translated and original texts are indeed due
to effects of translationese, and cannot be attributed to the domain or topic of the texts.
Whereas that work focused on the product of translation, namely, the language model,
the current study focuses on the process of translation, to wit, the translation model.
Our current work is closely related to research in domain-adaptation. In a typical
domain adaptation scenario, a system is trained on a large corpus of “general” (out-of-
domain) training material, with a small portion of in-domain training texts. In our case,
the translation model is trained on a large parallel corpus, of which some (generally
unknown) subset is “in-domain” (S → T), and some other subset is “out-of-domain”
(T → S). Most existing adaptation methods focus on selecting in-domain data from a
general domain corpus. In particular, perplexity is used to score the sentences in the
general-domain corpus according to an in-domain language model. Gao et al. (2002) and
Moore and Lewis (2010) apply this method to language modeling, and Foster, Goutte,
and Kuhn (2010) and Axelrod, He, and Gao (2011) apply this method to translation
modeling. Moore and Lewis (2010) suggest a slightly different approach, using cross-
entropy difference as a ranking function.
Domain adaptation methods are usually applied at the corpus level, whereas we
focus on an adaptation of the phrase table used for SMT. In this sense, our work follows
Foster, Goutte, and Kuhn (2010), who weigh out-of-domain phrase pairs according to
their relevance to the target domain. They use multiple features that help to distinguish
between phrase pairs in the general domain and those in the specific domain. We rely
on features that are motivated by the findings of translation studies, having established
their relevance through a comparative analysis of the phrase tables. In particular, we use
measures such as translation model entropy, inspired by Koehn, Birch, and Steinberger
(2009). Additionally, we apply the method suggested by Moore and Lewis (2010) using
perplexity ratio instead of cross-entropy difference.
Koehn and Schroeder (2007) suggest a method for adaptation of translation models.
They pass two phrase tables directly to the decoder using multiple decoding paths. As
we show in Section 5, the application of this method to our scenario does not result
in a clear contribution, and we are able to show better results using our proposed
method.
Finally, Sennrich (2012) proposes perplexity minimization as a way to set the
weights for translation model mixture for domain adaptation. We successfully apply
this method to the problem of adapting translation models to translationese, gaining
statistically significant improvements in translation quality.
3. Baseline Experiments
3.1 Europarl Experiments
The task we focus on in our experiments is translation from French to English (FR-
EN) and from English to French (EN-FR). To establish the robustness of our approach,
we also conduct experiments with other translation tasks, including German–English
(DE-EN), English–German (EN-DE), Italian–English (IT-EN), and English–Italian (EN-
IT). Our corpus is Europarl (Koehn 2005), specifically, portions collected over the years
1996–1999 and 2001–2009. This is a large multilingual corpus, containing sentences
1002
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Lembersky, Ordan, and Wintner
Adapting Translation Models to Translationese
translated from several European languages. In most cases the corpus is annotated with
the original language and the name of the speaker. For each language pair we extract
from the multilingual corpus two subsets, corresponding to the original languages in
which the sentences were produced. For example, in the case of FR-EN we extract
from our corpus all sentences produced in French and translated into English, and all
sentences produced in English and translated into French. All sentences are lowercased
and tokenized using Moses (Koehn et al. 2007). Sentences longer than 80 words are
discarded. Table 1 depicts the size of the subsets whose target language is English.
We use each subset to train two phrase-based statistical machine translation (PB-
SMT) systems (Koehn et al. 2007), translating in both directions between the languages
in each language pair. In other words, we train two PB-SMTs for each translation task,
each based on a parallel corpus produced and translated in a different direction. We
use GIZA++ (Och and Ney 2000) with grow-diag-final alignment, and extract phrases
of length up to 10 words. We prune the resulting phrase tables as in Johnson et al.
(2007), using at most 30 translations per source phrase and discarding singleton phrase
pairs.
We use all Europarl corpora between the years 1996–1999 and 2001–2009 to con-
struct English, German, French, and Italian 5-gram language models, using interpolated
modified Kneser-Ney discounting (Chen 1998) and no cut-off on all n-grams. We use a
specific symbol to mark out-of-vocabulary words (OOVs). The OOV rate is low, less
than 0.5%, and very similar in all our experiments. We use the portion of Europarl
collected over the year 2000 for tuning and evaluation. For each translation task we ran-
domly extract 1,000 parallel sentences for the tuning set and another set of 5,000 parallel
sentences for evaluation. These sentences are originally written in the translation task’s
source language and are translated into the translation task’s target language (in real-
world scenarios, the directionality of the test set is typically known). We use the MERT
algorithm (Och 2003) for tuning and BLEU (Papineni et al. 2002) as our evaluation
metric. We test the statistical significance of the differences between the results using
the bootstrap resampling method (Koehn 2004).
A word on notation: We use S → T when the translation direction of the parallel
corpus corresponds to the translation task and T → S when a corpus is translated in the
opposite direction to the translation task. For example, suppose the translation tasks are
English-to-French (E2F) and French-to-English (F2E). We use S → T when the French-
original corpus is used for the F2E task or when the English-original corpus is used for
the E2F task; and T → S when the French-original corpus is used for the E2F task or
when the English-original corpus is used for the F2E task.
Table 2 depicts the BLEU scores of the SMT systems. The data are consistent with
the findings of Kurokawa, Goutte, and Isabelle (2009): Systems trained on S → T parallel
Table 1
Europarl corpus size, in sentences and tokens.
Original language
#Sentence
#Tokens
FR-EN
DE-EN
IT-EN
French
English
German
English
Italian
English
168,818
134,318
200,037
129,309
69,270
125,640
4,995,397
3,441,120
5,571,202
3,283,298
2,535,225
3,389,736
1003
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 39, Number 4
Table 2
BLEU scores of the Europarl baseline systems.
Task
S → T
T → S
33.64
FR-EN
EN-FR
32.11
DE-EN 26.53
16.96
EN-DE
28.70
IT-EN
23.81
EN-IT
30.88
30.35
23.67
16.17
26.84
21.28
texts always outperform systems trained on T → S texts. The difference in BLEU score
can be as high as 3 points.
3.2 Hansard Experiments
The corpora used in the Europarl experiments are small (up to 200,000 sentences).
Also, the ratio between S → T and T → S materials varies greatly for different language
pairs. To mitigate these issues we use the Hansard corpus, containing transcripts of the
Canadian parliament from 1996–2007, as another source of parallel data. The Hansard is
a bilingual French–English corpus comprising approximately 80% English-original texts
and 20% French-original texts. Crucially, each sentence pair in the corpus is annotated
with the direction of translation.
To address the effect of corpus size, we compile six subsets of different sizes (250K,
500K, 750K, 1M, 1.25M, and 1.5M parallel sentences) from each portion (English-original
and French-original) of the corpus. Additionally, we use the devtest section of the
Hansard corpus to randomly select French-original and English-original sentences that
are used for tuning (1,000 sentences each) and evaluation (5,000 sentences each).
On these corpora we train twelve French-to-English and twelve English-to-French
PB-SMT systems using the Moses toolkit (Koehn et al. 2007). We use the same GIZA++
configuration and phrase table pruning as in the Europarl experiments. We also reuse
the English and French language models. French-to-English MT systems are tuned and
tested on French-original sentences and English-to-French systems on English-original
ones.
Table 3 depicts the BLEU scores of the Hansard systems. The data are consistent
with our previous findings: Systems trained on S → T parallel texts always outperform
Table 3
BLEU scores of the Hansard baseline systems.
Task: French-to-English
Task: English-to-French
Corpus subset
S → T
T → S
Corpus subset
S → T
T → S
34.35
35.21
36.12
35.73
36.24
36.43
31.33
32.38
32.90
33.07
33.23
33.73
250K
500K
750K
1M
1.25M
1.5M
27.74
29.15
29.43
29.94
30.63
29.89
26.58
27.19
27.63
27.88
27.84
27.83
250K
500K
750K
1M
1.25M
1.5M
1004
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Lembersky, Ordan, and Wintner
Adapting Translation Models to Translationese
Table 4
Statistic measures computed on the phrase tables: total size, in tokens (Total), the number of
unique source phrases (Source), and the average number of translations per source phrase
(AvgTran).
Task: French-to-English
Set
S → T
T → S
Total
Source AvgTran
Total
Source AvgTran
231K
250K
360K
500K
461K
750K
544K
1M
1.25M 619K
1.5M 684K
69K
86K
96K
103K
109K
114K
3.35
4.21
4.81
5.27
5.66
6.01
199K
317K
405K
479K
545K
602K
55K
69K
78K
85K
90K
94K
3.65
4.56
5.19
5.66
6.07
6.43
Task: English-to-French
Set
S → T
T → S
Total
Source AvgTran
Total
Source AvgTran
224K
250K
346K
500K
437K
750K
1M
513K
1.25M 579K
1.5M 635K
49K
61K
68K
74K
78K
81K
4.52
5.64
6.39
6.95
7.42
7.83
220K
334K
421K
489K
550K
603K
46K
57K
64K
69K
73K
76K
4.75
5.82
6.54
7.10
7.56
7.92
systems trained on T → S texts, even when the latter are much larger. For example,
a French-to-English SMT system trained on 250,000 S → T sentences outperforms a
system trained on 1,500,000 T → S sentences.
4. Phrase Tables Reflect Facets of Translationese
The baseline results suggest that S → T and T → S phrase tables differ substantially,
presumably due to the different characteristics of original and translated texts. In this
section we explain the better translation quality in terms of the better quality of the
respective phrase tables, as defined by a number of statistical measures. We first relate
these measures to the unique properties of translationese.
Translated texts tend to be simpler than original ones along a number of criteria.
Generally, translated texts are not as rich and variable as original ones, and, in particular,
their type/token ratio is lower. Consequently, we expect S → T phrase tables (which
are based on a parallel corpus whose source is original texts, and whose target is
translationese) to have more unique source phrases and a lower number of translations
per source phrase. A large number of unique source phrases suggests better coverage
of the source text, whereas a small number of translations per source phrase means a
lower phrase table entropy.
These expectations are confirmed, as the data in Table 4 show. We report the total
size of the phrase table in tokens (Total), the number of unique source phrases (Source),
and the average number of translations per source phrase (AvgTran), computed on the
1005
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 39, Number 4
24 phrase tables corresponding to our SMT systems.2 Evidently, S → T phrase tables
have more unique source phrases, but fewer translation options per source phrase.
This holds uniformly for all 24 tables.
These findings are consistent with our understanding of translationese. Translated
texts are not as rich as original ones; their type-to-token ratio is lower, and the variety
of syntactic structures is more limited. S → T phrase tables capture correspondences
between phrases written in the source language (original) and translated to the target
language (translated). Consequently, more different types in the source language corre-
spond to fewer types in the target language. For example, in the FR-EN S → T lexicon
trained on 1.5M sentences, the French word r´eduite (reduced) has 77 translations,
whereas in the T → S lexicon the same word has 143 translations. Moreover, in the
S → T lexicon the probability of the best translation, reduced, is 41.2%, whereas in the
T → S lexicon it is only 28.7%.
A well-established tool for assessing the quality of a phrase table involves entropy-
based measures. Phrase table entropy captures the amount of uncertainty involved in
choosing candidate translation phrases (Koehn, Birch, and Steinberger 2009). Given a
source phrase s and a phrase table T with translations t of s whose probabilities are
p(t | s), the entropy H of s is:
H(s) = −
(cid:1)
t∈T
p(t | s) × log2p(t | s)
(1)
To compute the phrase table entropy, Koehn, Birch, and Steinberger (2009) search
through all possible segmentations of the source sentence to find the optimal covering
set of test sentences that minimizes the average entropy of the source phrases in the
covering set. We refer to this measure as covering set entropy, or CovEnt.
We also propose a metric that assesses the quality of the source side of a phrase
table. This metric finds the minimal covering set of a given text in the source language
using source phrases from a particular phrase table, and outputs the average length of
a phrase in the covering set. This measure is referred to as covering set average length,
or CovLen.
Lembersky, Ordan, and Wintner (2011) show that perplexity distinguishes well
between translated and original texts. Moreover, perplexity can reflect the degree of
“relatedness” of a given phrase to original language or to translationese. Motivated
by this observation, we design a cross-entropy-based measure that assesses how well
each phrase table fits the properties of translationese. We then build language models
from translated texts, and compute the cross-entropy of each target phrase in the phrase
tables according to these language models.
Given a language model L, the cross-entropy of a text w = w1, w2, · · · wN is:
H(w, L) = − 1
N
N(cid:1)
i=1
log2L(wi)
(2)
Ideally, we would like to use only Hansard data for the language model, but as we
already used much of the Hansard data for training the translation model, we use
instead an adaptation of an external corpus (Europarl) to the Hansard domain. We
2 The phrase tables were pruned, retaining only phrases that are included in the evaluation set.
1006
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Lembersky, Ordan, and Wintner
Adapting Translation Models to Translationese
build language models of translated texts as follows. For English translationese, we
extract 170,000 French-original sentences from the English portion of Europarl, and
3,000 English-translated-from-French sentences from the Hansard corpus (disjoint from
the training, development, and test sets, of course). We use each corpus to train a
trigram language model with interpolated modified Kneser-Ney discounting and no
cut-off. All OOV words are mapped to a special token, (cid:8)unk(cid:9). Then, we interpolate
the Hansard and Europarl language models to minimize the perplexity of the target
side of the development set (λ = 0.58, the mixture weight of the Hansard corpus).
For French translationese, we use 270,000 sentences from Europarl and 3,000 sentences
from Hansard, λ = 0.81.
Similarly to covering set entropy, covering set cross-entropy (CovCrEnt) finds the
optimal covering set of test sentences that minimizes the weighted cross-entropy of the
source phrase in the covering set. Given a phrase table T and a language model L,
the weighted cross-entropy W for a source phrase s is:
W(s, L) = −
(cid:1)
t∈T
H(t, L) × p(t | s)
(3)
where H(t, L) is the cross-entropy of t according to a language model L.
Table 5 lists the entropy-based measures computed on our 24 phrase tables. Again,
the data meet our expectations: S → T phrase tables uniformly and unexceptionally
have lower entropy and cross-entropy, but higher covering set length.
So far, we have established the hypothesis that S → T phrase tables better reflect the
properties of translationese than T → S ones. But does this necessarily affect the quality
Table 5
Entropy-based measures computed on the phrase tables: covering set entropy (CovEnt),
covering set cross-entropy (CovCrEnt), and covering set average length (CovLen).
Task: French-to-English
S → T
T → S
CovEnt CovCrEnt CovLen CovEnt CovCrEnt CovLen
0.36
0.35
0.35
0.34
0.34
0.33
1.64
1.30
1.10
0.99
0.91
0.85
2.44
2.64
2.77
2.85
2.92
2.97
0.45
0.43
0.43
0.42
0.41
0.41
1.87
1.52
1.35
1.21
1.12
1.07
2.25
2.42
2.53
2.61
2.67
2.71
Task: English-to-French
S → T
T → S
CovEnt CovCrEnt CovLen CovEnt CovCrEnt CovLen
0.63
0.59
0.57
0.55
0.54
0.53
1.88
1.49
1.33
1.18
1.09
1.03
2.08
2.25
2.33
2.41
2.46
2.50
0.63
0.60
0.58
0.57
0.55
0.55
2.09
1.70
1.48
1.35
1.25
1.17
2.02
2.16
2.25
2.32
2.37
2.41
Set
250K
500K
750K
1M
1.25M
1.5M
Set
250K
500K
750K
1M
1.25M
1.5M
1007
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 39, Number 4
Table 6
Correlation of BLEU scores with phrase table statistical measures.
Measure
R2 (FR-EN) R2 (EN-FR)
CovEnt
CovCrEnt
CovLen
0.94
0.56
0.75
0.46
0.54
0.56
of the generated translations? To verify that, we measure the correlation between the
quality of the translation, as measured by BLEU (Table 3), with each of the entropy-
based metrics. We compute the correlation coefficient R2 (the square of Pearson’s
product-moment correlation coefficient) by fitting a simple linear regression model.
Table 6 lists the results; clearly, all three measures are strongly correlated with trans-
lation quality. Consequently, we use these measures as indicators of better translations,
more similar to translationese. Crucially, these measures are computed directly on the
phrase table, and do not require reference translations or meta-information pertaining
to the direction of translation of the parallel phrase.
5. Adaptation of the Translation Model to Translationese
We have thus established the fact that S → T phrase tables have an advantage over
T → S ones that stems directly from the different characteristics of original and trans-
lated texts. We have also identified three statistical measures that explain most of the
variability in translation quality. We now explore ways for taking advantage of the entire
parallel corpus, including translations in both directions, in light of these findings. Our
goal is to establish the best method to address the issue of different translation direction
components in the parallel corpus.
5.1 Baseline
As a simple baseline we take the union of the two subsets of the parallel corpus. This
gives the decoder an opportunity to select phrases from either subset of the corpus,
and MERT can be expected to optimize this selection process. For each translation
task in Section 3.1, we concatenate the S → T and the T → S subsets of the parallel
corpora and use the union to train an SMT system (henceforth UNION). We use the
same language and reordering models, Moses configuration, and the same tuning and
evaluation sets as in Section 3.1. Table 7 reports the results. The UNION systems, which
Table 7
Evaluation results of various ways for combining phrase tables.
System
FR-EN EN-FR DE-EN EN-DE
IT-EN EN-IT
S → T
UNION
MULTI-PATH
PPLMIN-1
PPLMIN-2
33.64
33.79
33.81
33.86
33.95
32.11
32.24
31.95
32.47
32.65
26.53
26.76
26.68
26.83
26.77
16.96
17.36
17.39
17.80
17.65
28.70
29.12
29.11
29.23
29.44
23.81
23.70
23.80
23.86
24.01
1008
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Lembersky, Ordan, and Wintner
Adapting Translation Models to Translationese
use twice as much training data as the S → T systems, outperform the S → T systems
for all language pairs except English-to-Italian. Only in three cases out of six (German-
to-English, English-to-German, and Italian-to-English), however, is the gain statistically
significant. Nevertheless, this indicates that the T → S subset contains useful material
that can (and does) contribute to translation quality.
We now look at ways to better utilize this portion. First, we train SMT systems
with two phrase tables using multiple decoding paths, and combine them in a log-
linear model, following Koehn and Schroeder (2007). The performance of this approach
(referred to as MULTI-PATH) is either lower or only slightly better than that of the
UNION systems (Table 7).
5.2 Perplexity Minimization
Next, we look at a linear interpolation of the translation models. We need a way to tune
the weights of the translation model components, and we use perplexity minimization,
following Sennrich (2012).
(cid:2)
Given n phrase tables, we are looking for a set of n weights λ = λ1, . . . , λn, such that
n
i=1 λi = 1, where λi is the interpolation weight of phrase table i. Then, given a phrase
pair (s, t), the linear interpolation of the n models is given by:
p(s | t; λ) =
n(cid:1)
i=1
λip(s | t)
(4)
To adapt an interpolated translation model to a specific (development) corpus, let ˜p(s, t)
be the observed, empirical probability of the pair (s, t) in the development corpus. This
is obtained by training a phrase table on the development corpus using the standard
methodology; the probability of the pair (s, t) is then extracted from the phrase table.
The cross entropy H of a translation model with probabilities p to a development corpus
with probabilities ˜p is defined as:
H = −
(cid:1)
s,t
˜p(s, t) × log2p(s | t)
To minimize the cross entropy, we look for a weight vector ˆλ such that:
ˆλ = arg min
−
λ
(cid:1)
s,t
˜p(s, t) × log2
(cid:4)
λip(s | t)
(cid:3)
n(cid:1)
i=1
(5)
(6)
Each feature of the standard SMT translation model (the phrase translation proba-
bilities p(t | s) and p(s | t), and the lexical weights lex(t | s) and lex(s | t)) is optimized
independently.
This technique is particularly appealing for us due to two reasons: first, Lembersky,
Ordan, and Wintner (2011) show that perplexity is a good differentiator between
original and translated texts; second, the perplexity is minimized with respect to some
development set. Consequently, if we use a S → T corpus for this purpose, we directly
adapt the interpolated phrase table to the qualities of the S → T translation models
as described in Section 4. We use this technique to interpolate two pairs of phrase
tables: we interpolate the S → T and the T → S models (we refer to this system as
1009
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 39, Number 4
PPLMIN-1) and we also interpolate the S → T with the UNION models (PPLMIN-2), as
a simple way of upweighting. Table 7 reports the results. In all cases, the interpolated
systems yield higher BLEU scores than the simple UNION systems. Although the
improvements are small (0.2–0.4 BLEU points), they are statistically significant in all
cases, except for German-English. Clearly, the interpolated systems outperform the
S → T systems by 0.2-0.7 BLEU points (statistically significant in all cases). PPLMIN-2
seems to be better than PPLMIN-1 in four out of six systems.
To verify that the improvement in translation quality is due to the adaptation
process rather than a quirk resulting from MERT instability, we use MultEval (Clark et
al. 2011). This is a script that takes machine translation hypotheses from several (in our
case, three) runs of an optimizer (MERT) and reports three popular metric scores: BLEU,
Meteor (Denkowski and Lavie 2011), and TER (Snover et al. 2006). Meteor and BLEU
scores are higher for better translations (↑), whereas TER is a lower-is-better measure (↓).
In addition, MultEval computes the ratio of output length to reference length (closer to
100% is better), as well as p-values (via approximate randomization). We use MultEval
to compare translation hypotheses of the UNION and PPLMIN-2 systems. Table 8
presents the results for French-to-English and English-to-French (other translation tasks
produce similar results). The improvement of the adapted systems is clear and robust.
5.3 Adaptation without Explicit Information on Directionality
A prerequisite for interpolating translation models, the method we advocate here, is
that the direction of translation of every sentence pair in the parallel corpus be known
in advance. When such information is not available, machine learning can automati-
cally classify texts as original or translated (Baroni and Bernardini 2006; van Halteren
Table 8
MultEval scores for UNION and PPLMIN-2 systems.
Metric
System
Avg
p-value
French-to-English
UNION
PPLMIN-2
BLEU ↑
METEOR ↑ UNION
PPLMIN-2
UNION
PPLMIN-2
UNION
PPLMIN-2
TER ↓
Length
33.7
33.9
35.7
35.8
49.7
49.5
99.4
99.5
English-to-French
UNION
PPLMIN-2
BLEU ↑
METEOR ↑ UNION
PPLMIN-2
UNION
PPLMIN-2
UNION
PPLMIN-2
TER ↓
Length
32.3
32.6
53.8
54.0
52.6
52.5
98.7
98.9
–
0.0001
–
0.0001
–
0.0001
–
0.0003
–
0.0001
–
0.0001
–
0.004
–
0.0001
1010
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Lembersky, Ordan, and Wintner
Adapting Translation Models to Translationese
2008; Ilisei et al. 2010; Koppel and Ordan 2011). Naturally, however, the quality of the
interpolation of translation models trained on classified (rather than annotated) data
is expected to decrease. In this section we establish an adaptation technique that does
not rely on explicit information pertaining to the direction of translation, but rather
uses perplexity-based measures to evaluate the “relatedness” of a specific phrase to an
original or a translated language “dialect.”
For the following experiments we use the Hansard corpus described in Section 3.2;
FO (French original) refers to subsets of the parallel corpus that were translated from
French to English, EO (English original) refers to texts translated from English to French.
We create three different mixtures of FO and EO: a balanced mix comprising 500K
sentences each of FO and EO (MIX), an EO-biased mix with 500K sentences of FO
and 1M sentences of EO (MIX-EO), and an FO-biased mix with 1M sentences of FO and
500K sentences of EO (MIX-FO). We use these corpora to train French-to-English and
English-to-French MT systems, evaluating their quality on the evaluation sets described
in Section 3.2. We use the same Moses configuration as well as the same language and
reordering models as in Section 3.2.
Now, we adapt the translation models by adding to each phrase pair in the phrase
tables an additional factor, as a measure of its fitness to the genre of translationese. The
factors are used as additional features in the phrase table. We experiment with two such
factors. First, we use the language models described in Section 4 to compute the cross-
entropy of each translation option according to this model. We add cross-entropy as an
additional score of a translation pair that can be tuned by MERT (we refer to this system
as CrEnt). Because cross-entropy is a “the lower the better” metric, we adjust the range
of values used by MERT for this score to be negative.
Second, following Moore and Lewis (2010), we define an adapting feature that not
only measures how close phrases are to translated language, but also how far they are
from original language, and use it as a factor in a phrase table (this system is referred to
as PplRatio). We build two additional language models of original texts as follows. For
original English, we extract 135,000 English-original sentences from the English portion
of Europarl, and 2,700 English-original sentences from the Hansard corpus. We train a
trigram language model with interpolated modified Kneser-Ney discounting on each
corpus and we interpolate both models to minimize the perplexity of the source side of
the development set for the English-to-French translation task (λ = 0.49). For original
French, we use 110,000 sentences from Europarl and 2,900 sentences from Hansard,
λ = 0.61. Finally, for each target phrase t in the phrase table we compute the ratio of
the perplexity of t according to the original language model Lo and the perplexity of t
with respect to the translated model Lt (see Section 4). In other words, the factor F is
computed as follows:
F(t) =
H(t, Lo)
H(t, Lt)
(7)
We apply these techniques to the French-to-English and English-to-French phrase
tables built from the concatenated corpora, and use each phrase table to train an SMT
system. We compare the performance of these systems to that of S → T, UNION, and
both PPLMIN systems. Table 9 summarizes the results.
All systems outperform the corresponding UNION systems. CrEnt systems show
significant improvements (p < 0.05) on balanced scenarios (MIX) and on scenarios
biased towards the S → T component (MIX-FO in the French-to-English task, MIX-
EO in English-to-French). PplRatio systems exhibit more consistent behavior, showing
1011
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 39, Number 4
Table 9
Adaption without classification results.
Task: French-to-English
System
MIX MIX-EO MIX-FO
S → T
UNION
PPLMIN-1
PPLMIN-2
CrEnt
PplRatio
35.21
35.27
35.46
35.75
35.54
35.59
35.21
35.36
35.59
35.65
35.45
35.78
35.73
35.94
36.26
36.20
36.75
36.22
Task: English-to-French
System
MIX MIX-FO MIX-EO
S → T
UNION
PPLMIN-1
PPLMIN-2
CrEnt
PplRatio
29.15
29.27
29.64
29.50
29.47
29.65
29.15
29.44
29.94
30.45
29.45
29.62
29.94
30.01
29.65
30.12
30.44
30.34
small, but statistically significant improvement (p < 0.05) in all scenarios. Additionally,
the new systems perform quite competitively compared to the interpolated systems,
winning in four out of six cases. Note again that all systems in the same column (except
S → T) are trained on exactly the same corpus and have exactly the same phrase tables.
The only difference is an additional factor in the phrase table that “encourages” the
decoder to select translation options that are closer to translated texts than to original
ones.
6. Analysis
We have demonstrated that SMT systems that are sensitive to the direction of translation
perform better. The superior quality of SMT systems that are adapted to translationese
is reflected in higher BLEU scores, but also in the scores of other automatic measures
for evaluating the quality of machine translation output. In this section we analyze the
better performance of translationese-adapted systems, both quantitatively and qualita-
tively, relating it to established insights in translation studies.
It may be claimed that translationese-aware systems perform better (in terms of
BLEU scores) not because of the properties of translated texts, but due to the closer
domain, genre, or topic of translated texts to those of the reference translations. In
our previous work (Lembersky, Ordan, and Wintner 2011, 2012b), we convincingly
demonstrated that this is not the case, by means of several experiments that abstracted
the texts away from specific words. Although these results are concerned with the
language model, we trust that they also hold for the translation model on which we focus
here.
Furthermore, improvements in BLEU scores that result from attention to transla-
tionese are consistent with human judgments. In other words, a machine translation
system that produces translations with higher BLEU scores by taking into account
1012
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Lembersky, Ordan, and Wintner
Adapting Translation Models to Translationese
the directionality of translation also produces translations that human judges prefer.
Although we have not conducted such experiments here, we have shown this corre-
lation in a previous work (Lembersky, Ordan, and Wintner 2012b) that focused on the
language model rather than on the translation model.
6.1 Quantitative Analysis
Is the output of translationese-adapted systems indeed more similar to translationese?
We begin with a set of properties of translationese that are easy to compute, and evaluate
the output of our translationese-adapted SMT systems in terms of these properties.
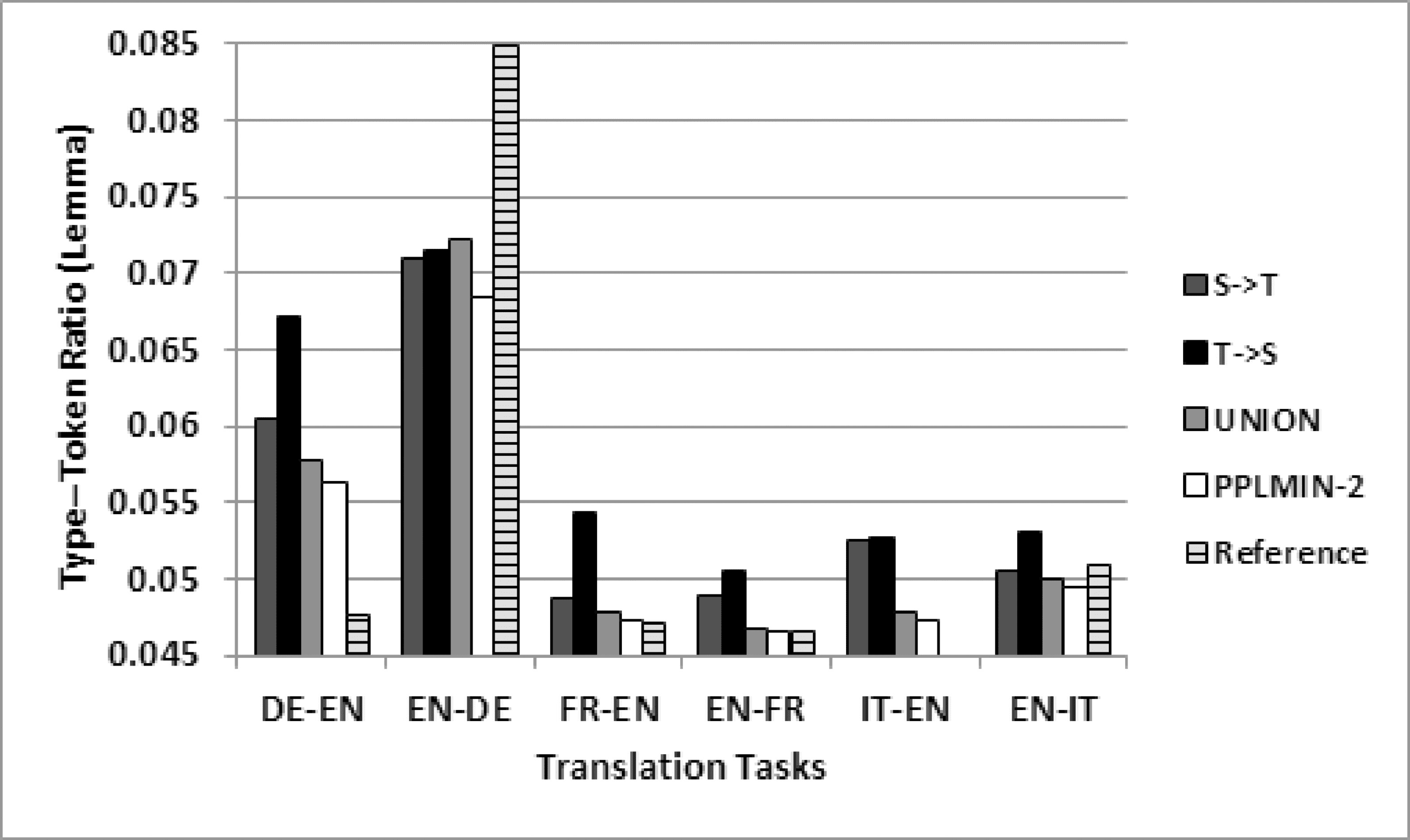
6.1.1 Type–Token Ratio. Translated texts have been shown to have lower type-to-token
ratio (TTR) than original ones (Al-Shabab 1996). Figure 1 compares the TTR of the trans-
lation outputs of S → T, T → S, UNION, and PPLMIN-2 systems. For comparison, we
also add the TTR of the reference translations for each task. To mitigate the effects of the
different morphological systems of the various languages, we compute the TTR in terms
of lemmas, rather than surface forms. Obviously, the TTR of S → T output is much lower
than T → S system. Recall that S → T systems produce markedly better translations
than T → S ones, so indeed there is a clear correspondence between the TTR of the
outputs and better translation quality. Figure 1 also compares the TTR of the outputs
produced from two combination systems, UNION and PPLMIN-2. The UNION outputs
are arbitrary: Their TTR is sometimes lower than the corresponding S → T system, but
sometimes higher than even the corresponding T → S system. In contrast, PPLMIN-2
systems (which are the best adapted systems) systematically produce outputs with the
lowest TTR, that is, outputs closest to translationese. As expected, reference translations
exhibit the lowest TTR in four out of the six tasks.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
1013
Figure 1
Type–token ratio in SMT translation outputs.
Computational Linguistics
Volume 39, Number 4
Figure 2
Numbers of singletons in SMT translation outputs.
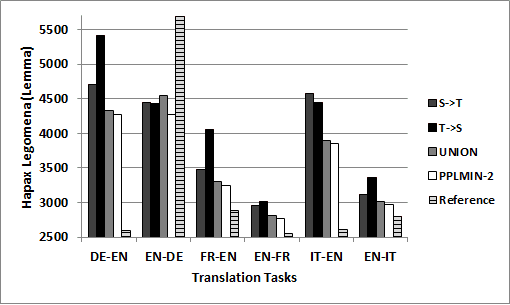
6.1.2 Singletons. A related property of translated texts is that they tend to exhibit a much
lower rate of words that occur only once in a text (hapax legomena) than original texts.
We thus count the number of singletons in the outputs of each of the SMT systems (and,
for comparison, the reference translations). The results, which are depicted in Figure 2,
are not totally conclusive, but are interesting nonetheless. Specifically, in all cases the
PPLMIN-2 system exhibits a lower number of singletons than the UNION system; and
in all systems except the English-Italian one, the number of singletons produced by the
PPLMIN-2 system is lowest. Reference translations exhibit the lowest rate of singletons
in five out of the six tasks.
6.1.3 Entropy. As another quantitative measure of the contribution of perplexity min-
imization as a method of adaptation, we list in Table 10 the values of the entropy-
based measures discussed in Section 4 on three types of SMT systems: those compiled
from S → T texts only, UNION, and PPLMIN-2 ones. Observe that the covering set
cross-entropy measure, designed to reflect the fitting of a phrase table’s target side to
translated texts, is significantly lower in PPLMIN-2 systems than in S → T and UNION
systems. This indicates that perplexity minimization improves the system’s fitness to
translationese. Interestingly, the PPLMIN-2 systems have better lexical coverage than
the UNION systems. Table 10 lists data for French-English and English-French, but
other language pairs exhibit similar behavior.
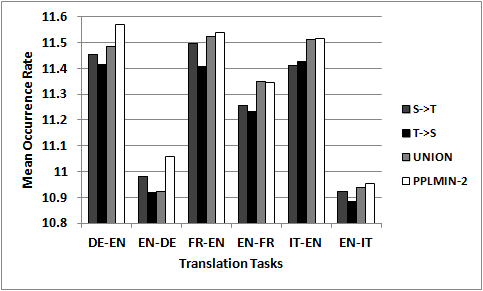
6.1.4 Mean Occurrence Rate. Original texts are known to be lexically richer than translated
ones; in particular, translationese uses more frequent and common words (Laviosa
1998). To assess the lexical diversity of a given text we define Mean Occurrence Rate
(MOR). MOR computes the average number of occurrences of tokens in the text with
1014
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Lembersky, Ordan, and Wintner
Adapting Translation Models to Translationese
Table 10
Entropy-based measures, computed on phrase tables of baseline and adapted SMT systems.
System
CovEnt CovCrEnt CovLen
FR-EN
EN-FR
S → T
T → S
UNION
PPLMIN-2
S → T
T → S
UNION
PPLMIN-2
0.43
0.45
0.43
0.43
0.64
0.66
0.61
0.61
2.39
2.77
2.20
2.14
3.47
3.52
3.09
2.99
2.24
2.03
2.34
2.35
2.01
1.99
2.17
2.18
respect to a large reference corpus. Consequently, sentences containing more frequent
words have higher MOR scores. More formally, given a reference corpus R with n word
· · · rn, let C(ri) be a number of occurrences of the word ri in the corpus R. Then
types r1
the MOR of a sentence S = s1
· · · sk is:
MOR(S) = 1
k
k(cid:1)
i=1
log(C(si))
(8)
∈ R. Otherwise, C(si) = α, where α is a pre-
C(si) is calculated from the corpus R if si
defined constant depending on the size of the reference corpus. In all our experiments
we use α = 0.5.
In order to establish the relation between the MOR measure and translation quality,
we compute MOR scores for each sentence of an SMT system output. Then, we sort the
output sentences based on their MOR scores, split the output into two parts—below and
above the median of MOR—and calculate BLEU score for each portion independently.
We perform these calculations on the outputs of UNION and PPLMIN-2 SMT systems
for all our translation tasks. We use the Europarl corpus (Koehn 2005) as a reference
for a list of occurrences. Table 11 depicts the results. In all cases, the bottom part
(below the median) of SMT outputs has significantly lower BLEU scores (up to 5 BLEU
points!) than the upper part, indicating that the MOR measure is a good (post factum)
differentiator between poor and good translations.
Table 11
BLEU scores computed on portions of UNION and PPLMIN-2 systems outputs below and above
the MOR median.
Task
DE-EN
EN-DE
FR-EN
EN-FR
IT-EN
EN-IT
UNION
PPLMIN-2
Bottom Upper Bottom Upper
24.05
16.06
31.48
28.97
26.07
21.57
28.72
18.78
35.49
34.83
31.75
25.79
24.10
16.42
31.85
29.30
26.43
21.97
28.71
18.82
35.49
35.58
31.97
25.99
1015
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 39, Number 4
Figure 3
Mean Occurrence Rate in SMT translation outputs.
We now compute the average MOR score on the outputs of all our SMT systems.
Figure 3 shows the results. In all cases (except Italian to English), S → T is better than
T → S; and in all systems except EN-FR, PPLMIN-2 is best.
6.2 Qualitative Analysis
Translation is sometimes described as an attempt
to strike a balance between
interference, the so-called inevitable marks left by the source language on the target
text, and standardization, the attempt of the translator to adapt the translation product
to the target language and culture, to break away from the source text towards a more
adequate text (Toury 1995). In order to study the effect of the adaptation qualitatively,
rather than quantitatively, we focus on several concrete examples. We compare transla-
tions produced by the UNION (henceforth baseline) and by the PPLMIN-2 (henceforth
adapted) French-English Europarl systems. We selected 200 sentences from the French-
English evaluation set for manual inspection, focusing on sentences in which the trans-
lations were significantly different from each other. Indeed, we find that the translations
are better adapted along several dimensions.
In the following sentences, the baseline follows a more literal translation, whereas
the adapted system creates a more adequate, standardized translation.
Source Monsieur le pr´esident, chers coll`egues, les tempˆetes qui ont ravag´e la france
dans la nuit des 26 et 27 d´ecembre ont fait, on l’a dit, 90 morts, 75 milliards de
francs,soit11milliardsd’euros,ded´egˆats.
Baseline Mr president, ladies and gentlemen, storms that have ravaged france during
thenightof26and27decemberwere,ashasbeensaid,90peopledead,75billion
francs,thatis,eur11billion,damage.
1016
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Lembersky, Ordan, and Wintner
Adapting Translation Models to Translationese
Adapted Mrpresident,ladiesandgentlemen,thestormswhichhavedevastatedfrance
during the night of 26 and 27 december were, as has been said, 90 people dead,
75billionfrancs,oreur11billion,damage.
Source Tout d’abord, je tiens `a saluer tous mes coll`egues maires, ´elus locaux, qui, au
quotidien,ontdˆurassurerlapopulation,organiserlasolidarit´e,coop´ereravecles
servicespublics.
Baseline First of all, I should like to pay tribute to all my colleagues, mayors,
local elected representatives, who, in their daily lives, have had to reassure the
population,organisesolidarity,cooperatewithpublicservices.
Adapted First of all, I should like to pay tribute to all my colleagues, mayors, local
elected representatives, who, on a daily basis, have had to reassure the popula-
tion,organisesolidarity,cooperatewithpublicservices.
Source Monsieurlepr´esident,jevousremerciedemelaisserconclure,etjerappellerai
simplementunemaxime:“lestueursens´eriesefonttoujoursprendreparlapolice
quandilsacc´el`erentlacadencedeleurscrimes”.
Baseline Mr president, thank you for allowing me to leave conclusion, and I would
like to remind you just a maxim: ‘the murderers in series are always take by the
policewhentheyacc´el`erentthepaceoftheircrimes’.
Adapted Mrpresident,thankyouforlettingmefinish,andIwouldliketoremindyou
just a maxim: ‘the murderers in series are always take by the police when they
acc´el`erentthepaceoftheircrimes’.
Note that the baseline is not necessarily incomprehensible, nor even “impossible”
in the target language; in the first example, it is clear what is meant by stormsthathave
ravaged France, and moreover, we find such expressions in a 1.5-G token-sized corpus
(Ferraresi et al. 2008); it is just half as likely as what is offered by the adapted system.
The second example, on the other hand, misses the point altogether, and the third one
is a clear case of interference, where the French laisserconclure is transferred verbatim
as leaveconclusion.
Another difference between the two systems is reordering. Sometimes, as in the two
following examples, the inability of the baseline system to reorder the words correctly
stems from interference:
Source Madamelapr´esidente,mescherscoll`egues,nouscroyions,jusqu’`apr´esent,que
l’unioneurop´eenne ´etait,selonlesdispositionsdestrait´esderomeetdeparisqui
avaient fond´e les communaut´es, devenues union, une association d’´etats libres,
ind´ependantsetsouverains.
Baseline Madam president, ladies and gentlemen, we croyions, up to now, that the
european union is, according to the provisions of the treaties of rome and paris
who had based the communities, become union, an association of states free,
independentandsovereign.
Adapted Madam president, ladies and gentlemen, we croyions, up to now, that the
europeanunionwas,accordingtotheprovisionsofthetreatiesofparisandrome
who had based communities, become union, an association of free, sovereign
andindependentstates.
Source La convention de lom´e b´en´eficie essentiellement `a quelques grands groupes
industriels ou financiers qui continuent ´a piller ces pays et perp´etuent leur
d´ependance ´economique,notammentdesanciennespuissancescoloniales.
Baseline Thelom´econventionhasmainlytoafewlargeindustrialgroupsorfinancial
whichcontinuetoplunderthosecountriesandperp´etuenttheireconomicdepen-
dence,inparticulartheformercolonialpowers.
1017
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 39, Number 4
Adapted The rom´e convention has mainly to a few large financial and industrial
groupswhichcontinuetoplunderthosecountriesandperpetuatetheireconomic
dependence,inparticulartheformercolonialpowers.
Additionally, the adapted system produces much better collocations. Compare the
“natural” expressions payahighprice and expresstheconcern with the baseline system
products:
Source Ces hommes et ces femmes qui bougent `a travers l’europe paient leur voiture,
leurstaxesnationales,leurpotcatalytique,leurstaxessurlescarburants,etpaient
doncd´ej`atr`escherleprixdelamagnifiquemachineetlalibert´edecirculer.
Baseline These men and women who are moving across europe are paying their car,
their national taxes, their catalytic converter, their taxes on fuel, and therefore
already pay very dearly for the price of the magnificent machine and freedom
ofmovement.
Adapted These men and women who are moving across europe pay their car, their
national taxes, their catalytic converter, their taxes on fuel, and therefore already
payahighpriceforthemagnificentmachineandfreedomofmovement.
Source Jeveuxdire ´egalementlesouciquej’aid’unebonnecoop´erationentreinterreg
etlefed,notammentpourlescara¨ıbesetl’oc´eanindien.
Baseline I would like to say to the concern that I have good cooperation between
interregandtheedf,particularlyforthecaribbeanandtheindianocean.
Adapted I also wish to express the concern that I have good cooperation between
interregandtheedf,particularlyforthecaribbeanandtheindianocean.
Last, there are a few cases of explicitation. Blum-Kulka (1986) observed the tendency
of translations to introduce to the target texts cohesive markers in order to render
implicit utterances more explicit. Koppel and Ordan (2011), who used function words to
discriminate between translated and non-translated texts, found that cohesive markers,
words such as in fact, however, moreover, and so forth, were among the top markers
of translationese, irrespective of source language and domain. And truly we find them
also over-represented in the adapted system:
Source Nous affirmons au contraire la n´ecessit´e politique de r´e´equilibrer les rapports
entrel’afriqueetl’unioneurop´eenne.
Baseline We say the opposite the political necessity to rebalance relations between
africaandtheeuropeanunion.
Adapted on the contrary, we maintain the political necessity of rebalancing relations
betweenafricaandtheeuropeanunion.
Source Cette mention semble alors contredire les explications linguistiques donn´ees
par l’office etlaisse craindre quel’erreur ne revˆete pas leseul caract`ere technique
quel’onsemblevouloirluidonner.
Baseline This note seems so contradict the explanations given by the language and
leaving office fear that the mistake revˆete do not only technical nature hat we
seemstowanttogiveit.
Adapted This note therefore seems to contradict the linguistic explanations given by
theofficeandfearthatleavesthemistakerevˆetedonotonlytechnicalnaturethat
weseemstowanttogiveit.
In (human) translation circles, translating out of one’s mother tongue is considered
unprofessional, even unethical (Beeby 2009). Many professional associations in Europe
urge translators to work exclusively into their mother tongue (Pavlovi´c 2007). The two
1018
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Lembersky, Ordan, and Wintner
Adapting Translation Models to Translationese
kinds of automatic systems built in this article reflect only partly the human situation,
but they do so in a crucial way. The S → T systems learn examples from many human
translators who follow the decree according to which translation should be made into
one’s native tongue. The T → S systems are flipped directions of humans’ input and
output. The S → T direction proved to be more fluent and accurate. This has to do
with the fact that the translators “cover” the source texts more fully, having a better
“translation model.”
7. Combining Translation and Language Models
When we experimented with translation models, we compiled language models from
corpora comprising original and translated texts. Our previous work (Lembersky,
Ordan, and Wintner 2011, 2012b), however, shows that language models compiled
from translated texts are better for machine translation than models trained on original
texts. In this section we examine whether these findings have a cumulative effect. In
other words, we test if an additional improvement in translation quality can be gained
by combining our findings for both the language and the translation model.
The tasks are translating French-to-English (FR-EN) and English-to-French (EN-
FR). We re-use the Europarl-based translation models of Section 3.1. We compile lan-
guage models from the French-English Hansard-based parallel corpora described in
Section 3.2. We use 1 million parallel sentence subsets. We train an original French LM
on the source side of the S → T corpus and we train the translated English LM on the
target side of the same corpus. In the same manner we compile the translated French LM
and the original English LM from the T → S corpus. All language models are 5-grams
with an interpolated modified Kneser-Ney discounting (Chen 1998). The vocabulary is
limited to tokens that appear twice or more in the reference set. All unknown words
are mapped to a special token. We tune and evaluate all SMT systems on two kinds of
reference sets: Europarl (Section 3.1) and Hansard (Section 3.2).
First, we use all possible combinations of translation and language models to train
four SMT systems for each translation task: T → S TM with original (O) LM, T → S TM
with translated (T) LM, S → T TM with O LM, and S → T TM with T LM. All systems
are tuned and evaluated on both the Europarl and the Hansard reference sets. Table 12
Table 12
Combining TMs and LMs: SMT system evaluation results.
FR-EN (EUROPARL)
FR-EN (HANSARD)
LM
O
T
LM
O
T
TM T → S
S → T
27.06
30.38
27.30
30.65
TM T → S
S → T
24.41
25.46
25.47
26.44
EN-FR (EUROPARL)
EN-FR (HANSARD)
LM
O
T
LM
O
T
TM T → S
S → T
22.33
25.11
22.71
24.94
TM T → S
S → T
15.88
17.08
16.34
17.48
1019
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 39, Number 4
Table 13
Adapting TMs and LMs: SMT system evaluation results.
FR-EN (EUROPARL)
FR-EN (HANSARD)
LM
Concat Adapt
LM
Concat Adapt
TM Concat
Adapt
30.76
31.06
30.69
31.13
TM Concat
Adapt
27.65
27.76
27.48
27.73
EN-FR (EUROPARL)
EN-FR (HANSARD)
LM
Concat Adapt
LM
Concat Adapt
TM Concat
Adapt
25.55
25.64
25.51
25.69
TM Concat
Adapt
18.69
18.65
18.46
18.68
shows the translation quality of the SMT systems in terms of BLEU. Both translation and
language models contribute to the translation quality, but it seems that the contribution
of the translation model is more significant. Even in the case of the Hansard reference
set, in the English-to-French translation task, the S → T TM (compiled from Europarl
texts) adds 1.2 BLEU points, and the T LM (compiled from Hansard texts) adds only
0.46 BLEU points.
Next, we perform a set of experiments to test whether a combination of the adap-
tation techniques described in Section 5 for the translation and language models can
further improve the translation quality. First, we build a baseline SMT system with
a translation model trained on a concatenation of S → T and T → S parallel corpora
and a language model compiled from a concatentation of translated and original texts.
Then, we build two other systems, one with an adapted translation model and one
with an adapted language model. Finally, we use the adapted translation and language
models to train yet another SMT system. We use the PPLMIN-2 method (Section 5) to
adapt the translation model and linear interpolation to adapt the language model. The
SMT systems are then tuned and evaluated on the Europarl and the Hansard reference
sets. The results, depicted in Table 13, show that SMT systems with an adapted TM
usually outperform the baseline systems. LM adaptation alone does not improve the
translation quality, but if combined with TM adaptation it produces the best results (but
not significantly better than just TM adaptation).
8. Conclusion
Phrase tables trained on parallel corpora that were translated in the same direction
as the translation task perform better than ones trained on corpora translated in the
opposite direction. Nonetheless, even “wrong” phrase tables contribute to the transla-
tion quality. We analyze both “correct” and “wrong” phrase tables, uncovering a great
deal of difference between them. We use insights from translation studies to explain
these differences; we then adapt the translation model to the nature of translationese.
We investigate several approaches to the adaptation problem. First, we use linear
interpolation to create a mixture model of S → T and T → S translation models. We
1020
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Lembersky, Ordan, and Wintner
Adapting Translation Models to Translationese
use perplexity minimization and an S → T reference set to determine the weights of
each model, thus directly adapting the model to the properties of translationese. We
show consistent and statistically significant improvements in translation quality on
three different language pairs (six translation tasks) using several automatic evaluation
metrics.
Furthermore, we incorporate information-theoretic measures that correlate well
with translationese into phrase tables as an additional score that can be tuned by MERT,
and show a statistically significant improvement in the translation quality over all
baseline systems. We also analyze the results qualitatively, showing that SMT systems
adapted to translationese tend to produce more coherent and fluent outputs than the
baseline systems. An additional advantage of our approach is that it does not require
an annotation of the translation direction of the parallel corpus. It is completely generic
and can be applied to any language pair, domain, or corpus.
Where this work focuses on improving the process of translation (i.e., the translation
model), our previous work (Lembersky, Ordan, and Wintner 2012b) focuses on improv-
ing the product of translation (i.e., the language model). We have shown preliminary
results in which both models were adapted to translationese; an open challenge is
finding the optimal combination of improving both process and product in a single
unified system.
Acknowledgments
We are grateful to Cyril Goutte, George
Foster, and Pierre Isabelle for providing us
with an annotated version of the Hansard
corpus. Alon Lavie has been instrumental in
stimulating some of the ideas reported in this
article, as well as in his long-term support
and advice. We benefitted greatly from
several constructive suggestions by the three
anonymous Computational Linguistics
referees. This research was supported by the
Israel Science Foundation (grant no. 137/06)
and by a grant from the Israeli Ministry of
Science and Technology.
References
Al-Shabab, Omar S. 1996. Interpretation
and the Language of Translation: Creativity
and Conventions in Translation. Janus,
Edinburgh.
Axelrod, Amittai, Xiaodong He, and Jianfeng
Gao. 2011. Domain adaptation via pseudo
in-domain data selection. In Proceedings
of the 2011 Conference on Empirical
Methods in Natural Language Processing,
pages 355–362, Edinburgh.
Baker, Mona. 1993. Corpus linguistics and
translation studies: Implications and
applications. In Gill Francis Mona Baker
and Elena Tognini-Bonelli, editors, Text
and Technology: In Honour of John Sinclair.
John Benjamins, Amsterdam,
pages 233–252.
Baroni, Marco and Silvia Bernardini.
2006. A new approach to the study of
Translationese: Machine-learning the
difference between original and translated
text. Literary and Linguistic Computing,
21(3):259–274.
Beeby, Alison. 2009. Direction of translation
(directionality). In Mona Baker and
Gabriela Saldanha, editors, Routledge
Encyclopedia of Translation Studies.
Routledge (Taylor and Francis),
New York, 2nd edition, pages 84–88.
Blum-Kulka, Shoshana. 1986. Shifts of
cohesion and coherence in translation. In
Juliane House and Shoshana Blum-Kulka,
editors, Interlingual and Intercultural
Communication Discourse and Cognition in
Translation and Second Language Acquisition
Studies, volume 35. Gunter Narr Verlag,
pages 17–35.
Blum-Kulka, Shoshana and Eddie A.
Levenston. 1983. Universals of lexical
simplification. In Claus Faerch and
Gabriele Kasper, editors, Strategies in
Interlanguage Communication. Longman,
pages 119–139.
Chen, Stanley F. 1998. An empirical study
of smoothing techniques for language
modeling. Technical report 10-98,
Computer Science Group, Harvard
University, Cambridge, MA.
Clark, Jonathan H., Chris Dyer, Alon
Lavie, and Noah A. Smith. 2011. Better
hypothesis testing for statistical machine
translation: Controlling for optimizer
1021
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 39, Number 4
instability. In Proceedings of the 49th Annual
Meeting of the Association for Computational
Linguistics: Human Language Technologies,
pages 176–181, Portland, OR.
Denkowski, Michael and Alon Lavie. 2011.
Meteor 1.3: Automatic metric for reliable
optimization and evaluation of machine
translation systems. In Proceedings of the
Sixth Workshop on Statistical Machine
Translation, pages 85–91, Edinburgh.
Ferraresi, Adriano, Silvia Bernardini, Picci
Giovanni, and Marco Baroni. 2008. Web
corpora for bilingual lexicography, a
pilot study of English/French collocation
extraction and translation. In Proceedings
of The International Symposium on Using
Corpora in Contrastive and Translation
Studies, pages 1–30, Hangzhou.
Foster, George, Cyril Goutte, and Roland
Kuhn. 2010. Discriminative instance
weighting for domain adaptation
in statistical machine translation.
In Proceedings of the 2010 Conference
on Empirical Methods in Natural
Language Processing, pages 451–459,
Stroudsburg, PA.
Gao, Jianfeng, Joshua Goodman, Mingjing
Li, and Kai-Fu Lee. 2002. Toward a
unified approach to statistical language
modeling for Chinese. ACM Transactions
on Asian Language Information Processing,
1:3–33.
Gellerstam, Martin. 1986. Translationese in
Swedish novels translated from English.
In Lars Wollin and Hans Lindquist,
editors, Translation Studies in Scandinavia.
CWK Gleerup, Lund, pages 88–95.
Ilisei, Iustina, Diana Inkpen, Gloria
Corpas Pastor, and Ruslan Mitkov.
2010. Identification of translationese:
A machine learning approach. In
Alexander F. Gelbukh, editor, Proceedings
of CICLing-2010: 11th International
Conference on Computational Linguistics
and Intelligent Text Processing,
volume 6008 of Lecture Notes in Computer
Science, pages 503–511. Springer.
Johnson, Howard, Joel Martin, George
Foster, and Roland Kuhn. 2007. Improving
translation quality by discarding most of
the phrasetable. In Proceedings of the Joint
Conference on Empirical Methods in Natural
Language Processing and Computational
Natural Language Learning
(EMNLP-CoNLL), pages 967–975, Prague.
Koehn, Philipp. 2004. Statistical significance
tests for machine translation evaluation. In
Proceedings of EMNLP 2004, pages 388–395,
Barcelona.
1022
Koehn, Philipp. 2005. Europarl: A parallel
corpus for statistical machine translation.
In Proceedings of the Tenth Machine
Translation Summit, pages 79–86,
Phuket Island.
Koehn, Philipp, Alexandra Birch, and Ralf
Steinberger. 2009. 462 machine translation
systems for Europe. In Proceedings of the
Twelfth Machine Translation Summit,
pages 65–72, Ottawa.
Koehn, Philipp, Hieu Hoang, Alexandra
Birch, Chris Callison-Burch, Marcello
Federico, Nicola Bertoldi, Brooke Cowan,
Wade Shen, Christine Moran, Richard
Zens, Chris Dyer, Ondrej Bojar, Alexandra
Constantin, and Evan Herbst. 2007.
Moses: Open source toolkit for statistical
machine translation. In Proceedings of the
45th Annual Meeting of the Association for
Computational Linguistics Companion
Volume Proceedings of the Demo and Poster
Sessions, pages 177–180, Prague.
Koehn, Philipp and Josh Schroeder.
2007. Experiments in domain adaptation
for statistical machine translation.
In Proceedings of the Second Workshop on
Statistical Machine Translation, StatMT ’07,
pages 224–227, Stroudsburg, PA.
Koppel, Moshe and Noam Ordan.
2011. Translationese and its dialects.
In Proceedings of the 49th Annual Meeting
of the Association for Computational
Linguistics: Human Language Technologies,
pages 1318–1326, Portland, OR.
Kurokawa, David, Cyril Goutte, and
Pierre Isabelle. 2009. Automatic
detection of translated text and its
impact on machine translation.
In Proceedings of MT-Summit XII,
pages 81–88, Ottawa.
Laviosa, Sara. 1998. Core patterns of lexical
use in a comparable corpus of English
lexical prose. Meta, 43(4):557–570.
Lembersky, Gennadi, Noam Ordan,
and Shuly Wintner. 2011. Language
models for machine translation: Original
vs. translated texts. In Proceedings of
the 2011 Conference on Empirical Methods
in Natural Language Processing,
pages 363–374, Edinburgh.
Lembersky, Gennadi, Noam Ordan,
and Shuly Wintner. 2012a. Adapting
translation models to translationese
improves SMT. In Proceedings of the
13th Conference of the European Chapter
of the Association for Computational
Linguistics, pages 255–265, Avignon.
Lembersky, Gennadi, Noam Ordan, and
Shuly Wintner. 2012b. Language models
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Lembersky, Ordan, and Wintner
Adapting Translation Models to Translationese
for machine translation: Original vs.
translated texts. Computational Linguistics,
38(4):799–825.
Moore, Robert C. and William Lewis.
2010. Intelligent selection of language
model training data. In Proceedings of
the ACL 2010 Conference, Short Papers,
pages 220–224, Stroudsburg, PA.
Och, Franz Josef. 2003. Minimum error rate
training in statistical machine translation.
In ACL ’03: Proceedings of the 41st Annual
Meeting on Association for Computational
Linguistics, pages 160–167, Morristown, NJ.
Och, Franz Josef and Hermann Ney. 2000.
Improved statistical alignment models.
In ACL ’00: Proceedings of the 38th Annual
Meeting on Association for Computational
Linguistics, pages 440–447, Morristown, NJ.
Papineni, Kishore, Salim Roukos, Todd
Ward, and Wei-Jing Zhu. 2002. BLEU:
a method for automatic evaluation of
machine translation. In ACL ’02:
Proceedings of the 40th Annual Meeting on
Association for Computational Linguistics,
pages 311–318, Morristown, NJ.
Pavlovi´c, Nataˇsa. 2007. Directionality in
translation and interpreting practice.
Report on a questionnaire survey in
Croatia. Forum, 5(2):79–99.
Sennrich, Rico. 2012. Perplexity
minimization for translation model
domain adaptation in statistical
machine translation. In Proceedings
of the 13th Conference of the European
Chapter of the Association for
Computational Linguistics,
pages 539–549, Avignon.
Snover, Matthew, Bonnie Dorr, Richard
Schwartz, Linnea Micciulla, and John
Makhoul. 2006. A study of translation
edit rate with targeted human annotation.
In Proceedings of the 7th Conference of the
Association for Machine Translation of the
Americas (AMTA-2006), pages 223–231,
Cambridge, MA.
Toury, Gideon. 1980. In Search of a Theory of
Translation. The Porter Institute for Poetics
and Semiotics, Tel Aviv University,
Tel Aviv.
Toury, Gideon. 1995. Descriptive Translation
Studies and Beyond. John Benjamins,
Amsterdam / Philadelphia.
van Halteren, Hans. 2008. Source
language markers in EUROPARL
translations. In COLING ’08: Proceedings
of the 22nd International Conference on
Computational Linguistics, pages 937–944,
Morristown, NJ.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
1023
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
3
9
4
9
9
9
1
8
0
2
2
3
4
/
c
o
l
i
_
a
_
0
0
1
5
9
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3