Data-to-text Generation with Variational Sequential Planning
Ratish Puduppully and Yao Fu and Mirella Lapata
Institute for Language, Cognition and Computation
School of Informatics, University of Edinburgh
10 Crichton Street, Edinburgh EH8 9AB, UK
r.puduppully@sms.ed.ac.uk yao.fu@ed.ac.uk mlap@inf.ed.ac.uk
Abstract
We consider the task of data-to-text genera-
tion, which aims to create textual output from
non-linguistic input. We focus on generating
long-form text, that is, documents with mul-
tiple paragraphs, and propose a neural model
enhanced with a planning component respon-
sible for organizing high-level information in
a coherent and meaningful way. We infer
latent plans sequentially with a structured vari-
ational model, while interleaving the steps of
planning and generation. Text is generated by
conditioning on previous variational decisions
and previously generated text. Experiments on
two data-to-text benchmarks (ROTOWIRE and
MLB) show that our model outperforms strong
baselines and is sample-efficient in the face
of limited training data (e.g., a few hundred
instances).
1
Introduction
Data-to-text generation refers to the task of gener-
ating textual output from non-linguistic input such
as database tables, spreadsheets, or simulations of
physical systems (Reiter and Dale, 1997, 2000;
Gatt and Krahmer, 2018). Recent progress in
this area (Mei et al., 2016; Lebret et al., 2016;
Wiseman et al., 2017) has been greatly facil-
itated by the very successful encoder-decoder
neural architecture (Sutskever et al., 2014) and the
development of large scale datasets. ROTOWIRE
(Wiseman et al., 2017) and MLB (Puduppully
et al., 2019b) constitute such examples. They both
focus on the sports domain, which has histori-
cally drawn attention in the generation community
(Barzilay and Lapata, 2005; Tanaka-Ishii et al.,
1998; Robin, 1994) and consider the problem of
generating long target texts from database records.
Figure 1 (reproduced from Puduppully and
Lapata, 2021) provides a sample from the MLB
dataset, which pairs human written summaries
697
(Table C in Figure 1) with major league baseball
game statistics. These are mostly scores (collec-
tively referred to as box score) which summarize
the performance of teams and players, for ex-
ample, batters, pitchers, or fielders (Table A in
Figure 1) and a play-by-play description of the
most important events in the game (Table B in
Figure 1). Game summaries in MLB are relatively
long (540 tokens on average) with multiple para-
graphs (15 on average). The complexity of the
input and the length of the game summaries pose
various challenges to neural models which, de-
spite producing fluent output, are often imprecise,
prone to hallucinations, and display poor con-
tent selection (Wiseman et al., 2017). Attempts to
address these issues have seen the development
of special-purpose modules that keep track of
salient entities (Iso et al., 2019; Puduppully et al.,
2019b), determine which records (see the rows in
Tables A and B in Figure 1) should be mentioned
in a sentence and in which order (Puduppully et al.,
2019a; Narayan et al., 2020), and reconceptualize
the input in terms of paragraph plans (Puduppully
and Lapata, 2021) to facilitate document-level
planning (see Table D in Figure 1).
Specifically, Puduppully and Lapata (2021) ad-
vocate the use of macro plans for improving
the organization of document content and struc-
ture. A macro plan is a sequence of paragraph
plans, and each paragraph plan corresponds to a
document paragraph. A macro plan is shown in
Table E (Figure 1). Examples of paragraph plans
are given in Table D where
verbalizes records pertaining to entities and
Top/Bottom side of an inning. Verbalizations are
sequences of record types followed by their val-
ues. Document paragraphs are shown in Table C
and have the same color as their corresponding
plans in Table E. During training, Puduppully and
Transactions of the Association for Computational Linguistics, vol. 10, pp. 697–715, 2022. https://doi.org/10.1162/tacl a 00484
Action Editor: Ehud Reiter. Submission batch: 10/2021; Revision batch: 3/2021; Published 6/2022.
c(cid:2) 2022 Association for Computational Linguistics. Distributed under a CC-BY 4.0 license.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 1: Example from the MLB dataset reproduced from Puduppully and Lapata (2021) with the authors’
permission. Table A is typically referred to as box score. It summarizes the data of the game per team and player.
Table B reports statistics pertaining to innings or play-by-play scores. Table C contains the game summary.
Paragraphs in Table C are separated with
delimiters. Table D contains paragraph plans obtained from
Tables A and B. Paragraph plans in the first column correspond to a single entity or event. Paragraph plans in
the second column describe combinations of entities or events.
to entities and
correspond to paragraphs in Table C. Table E contains the macro plan for the document in Table C. A macro plan
is a sequence of paragraph plans. Plan-document correspondences are highlighted using the same color.
Lapata (2021) learn to predict a macro plan from a
pool of paragraph plans, and produce a game sum-
mary based on it. Continuing with our example
in Figure 1, plan (E) is obtained from paragraph
plans (D), to give rise to game summary (C).
The intermediate macro plan renders genera-
tion more interpretable (differences in the output
can be explained by differences in macro plan-
ning). It also makes modeling easier, the input is
no longer a complicated table but a sequence of
paragraph plans, which in turn allows us to treat
data-to-text generation as a sequence-to-sequence
learning problem. Nevertheless, decoding to a
long document remains challenging for at least
two reasons. Firstly, the macro plan may be en-
coded as a sequence but a very long one (more
than 3,000 tokens), which the decoder has to attend
to at each time step in order to generate a sum-
mary token-by-token. Secondly, the prediction of
the macro plan is conditioned solely on the input
(i.e., pool of paragraph plans (D) in Figure 1) and
does not make use of information present in the
summaries. We hypothesize that planning would
be more accurate were it to consider information
available in the table (and corresponding para-
graph plans) and the generated summary, more so
because the plans are coarse-grained and there is
a one-to-many relationship between a paragraph
plan and its realization. For example, we can see
that the plan for
two very different realizations in the summary in
Figure 1 (see first and third paragraph).
698
chronological order. However, another ordering
might have been equally plausible, for example,
describing innings where the highest runs are
scored first or innings that are important in flip-
ping the outcome of the match. In the face of
such diversity, there may never be enough data
to learn an accurate global plan. It is easier to
select a paragraph plan from the pool once some
of the summary is known, and different plans
can be predicted for the same input. In addition,
the proposed model is end-to-end differentiable
and gradients for summary prediction also inform
plan prediction.
Our contributions can be summarized as fol-
lows: (1) We decompose data-to-text generation
into sequential plan selection and paragraph gener-
ation. The two processes are interleaved and gen-
eration proceeds incrementally. We look at what
has been already generated, make a plan on what
to discuss next, realize the plan, and repeat; (2) in
contrast to previous models (Puduppully et al.,
2019a; Puduppully and Lapata, 2021), where
content plans are monolithic and determined in ad-
vance, our approach is more flexible, it simplifies
modeling (we do not need to learn alignments be-
tween paragraph plans and summary paragraphs),
and leads to sample efficiency in low resource
scenarios; (3) our approach scales better for tasks
involving generation of
long multi-paragraph
texts, as we do not need to specify the document
plan in advance; and (4) experimental results on
English and German ROTOWIRE (Wiseman et al.,
2017; Hayashi et al., 2019), and MLB (Puduppully
et al., 2019b) show that our model is well-suited to
long-form generation and generates more factual,
coherent, and less repetitive output compared to
strong baselines.
We share our code and models in the hope of
being useful for other tasks (e.g., story generation,
summarization).1
2 Related Work
A long tradition in natural language generation
views content planning as a central component
to identifying important content and structuring
it appropriately (Reiter and Dale, 2000). Earlier
work has primarily made use of hand-crafted con-
tent plans with some exceptions that pioneered
1https://github.com/ratishsp/data2text
-seq-plan-py.
Figure 2: Conceptual sequence of interleaved plan-
ning and generation steps. The paragraph plan and its
corresponding paragraph have the same color.
In this work, we present a model which inter-
leaves macro planning with text generation (see
Figure 2 for a sketch of the approach). We begin
by selecting a plan from a pool of paragraph plans
(see Table D in Figure 1), and generate the first
paragraph by conditioning on it. We select the next
plan by conditioning on the previous plan and the
previously generated paragraph. We generate the
next paragraph by conditioning on the currently
selected plan, the previously predicted plan, and
generated paragraph. We repeat this process until
the final paragraph plan is predicted. We model
the selection of paragraph plans as a sequential
latent variable process, which we argue is in-
tuitive since content planing is inherently latent.
Contrary to Puduppully and Lapata (2021), we do
not a priori decide on a global macro plan. Rather,
our planning process is incremental and as a result
less rigid. Planning is informed by generation and
vice versa, which we argue should be mutually
beneficial (they are conditioned on each other).
During training, the sequential latent model can
better leverage the summary to render paragraph
plan selection more accurate and take previous
decisions into account. We hypothesize that the
interdependence between planning and generation
allows the model to cope with diversity. In gen-
eral, there can be many ways in which the input
table can be described in the output summary, that
is, different plans give rise to equally valid game
summaries. The summary in Figure 1 (Table C)
focuses on the performance of Brad Keller, who is
a high scoring pitcher (first three paragraphs). An
equally plausible summary might have discussed
a high scoring batter first (e.g., Ryan O’Hearn).
Also notice that the summary describes innings in
699
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
learning-based approaches. For instance, Duboue
and McKeown (2001) learn ordering constraints
on the content plan, while Kan and McKeown
(2002) learn content planners from semantically
annotated corpora, and Konstas and Lapata (2013)
predict content plans using grammar rules whose
probabilities are learned from training data.
More recently, there have been attempts to
equip encoder-decoder models (Bahdanau et al.,
2015; Wiseman et al., 2017) with content plan-
ning modules. Puduppully et al. (2019a) introduce
micro planning: They first learn a content plan
corresponding to a sequence of records, and then
generate a summary conditioned on it. Narayan
et al. (2020) treat content selection as a task
similar to extractive summarization. Specifically,
they post-process Pudupully et al.’s (2019a)
micro-plans with special tokens identifying the
beginning and end of a sentence. Their model
first extracts sentence plans and then verbalizes
them one-by-one by conditioning on previously
generated sentences. Moryossef et al. (2019b,a)
propose a two-stage approach that first predicts
a document plan and then generates text based
on it. The input to their model is a set of RDF
(cid:3)Subject, Object, Predicate(cid:4) tuples. Their docu-
ment plan is a sequence of sentence plans where
each sentence plan contains a subset of tuples in a
specific order. Text generation is implemented us-
ing a sequence-to-sequence model enhanced with
attention and copy mechanisms (Bahdanau et al.,
2015). They evaluate their model on the WebNLG
dataset (Gardent et al., 2017), where the outputs
are relatively short (24 tokens on average).
Our approach is closest
to Puduppully and
Lapata (2021), who advocate macro planning as
a way of organizing high-level document content.
Their model operates over paragraph plans that
are verbalizations of the tabular input and pre-
dicts a document plan as a sequence of paragraph
plans. In a second stage, the summary is generated
from the predicted plan making use of atten-
tion enriched with a copy mechanism. We follow
their formulation of content planning as para-
graph plan prediction. Our model thus operates
over larger content units compared to related work
(Puduppully et al., 2019a; Narayan et al., 2020)
and performs the tasks of micro- and macro-
planning in one go. In contrast to Puduppully
and Lapata (2021), we predict paragraph plans
and their corresponding paragraphs jointly in an
incremental fashion. Our approach is reminiscent
of psycholinguistic models of speech production
(Levelt, 1993; Taylor and Taylor, 1990; Guhe,
2020), which postulate that different levels of pro-
cessing (or modules) are responsible for language
generation; these modules are incremental, each
producing output as soon as the information it
needs is available and the output is processed
immediately by the next module.
We assume that plans form a sequence of
paragraphs, which we treat as a latent variable
and learn with a structured variational model.
Sequential latent variables (Chung et al., 2015;
Fraccaro et al., 2016; Goyal et al., 2017) have
previously found application in modeling atten-
tion in sequence-to-sequence networks (Shankar
and Sarawagi, 2019), document summarization
(Li et al., 2017), controllable generation (Li and
Rush, 2020; Fu et al., 2020), and knowledge-
grounded dialogue (Kim et al., 2020). In the
context of data-to-text generation, latent variable
models have been primarily used to inject diver-
sity in the output. Shao et al. (2019) generate a
sequence of groups (essentially a subset of the
input) which specifies the content of the sentence
to be generated. Their plans receive no feedback
from text generation, they cover a small set of in-
put items, and give rise to relatively short docu-
ments (approximately 100 tokens long). Ye et al.
(2020) use latent variables to disentangle the
content from the structure (operationalized as tem-
plates) of the output text. Their approach gen-
erates diverse output output by sampling from
the template-specific sample space. They apply
their model to single-sentence generation tasks
(Lebret et al., 2016; Reed et al., 2018).
3 Model
Following Puduppully and Lapata (2021), we as-
sume that at training time our model has access
to a pool of paragraph plans E (see Table D in
Figure 1), which represent a clustering of records.
We explain how paragraph plans are created from
tabular input in Section 4. Given E, we aim to gen-
erate a sequence of paragraphs y = [y1, . . . , yT ]
that describe the data following a sequence of
chosen plans z = [z1, . . . , zT ]. Let yt denote a
paragraph, which can consist of multiple sen-
tences, and T the count of paragraphs in a
summary. With a slight abuse of notation, super-
scripts denote indices rather than exponentiation.
So, yt
i refers to the i-th word in the t-th paragraph.
700
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 3: Model workflow. Solid arrows show dependencies between random variables. Dashed arrows show the
computation graph whose backbone consists of an LSTMtext and an LSTMplan. Note that the variational model
and the generative model are tied closely with the shared LSTM. To generate long documents, the model observes
what has been already generated, decides on a plan about what to discuss next, uses this plan to guide next stage
generation, and repeats until the end.
A plan z = [z1, . . . , zT ] is a list of discrete vari-
ables where zt = j means that we choose the j-th
item from pool E of candidate plans to guide the
generation of paragraph yt.
Generation with Latent Plans The core tech-
nique of our model is learning the sequence of
latent plans that guides long document genera-
tion. We consider a conditional generation setting
where the input E is a set of paragraph plans
and the output y1:T are textual paragraphs ver-
balizing the selected sequence z = z1:T . Our
goal is to induce variables z that indicate which
paragraphs are being talked about and in which
order. Similar to previous work (Li and Rush,
2020; Fu et al., 2020), we model this process as
a conditional generative model that produces both
y and z and factorizes as:
pθ(y, z|E) =
(cid:2)
pθ(zt|y
7
this using the shorthand
paragraph plan for an event is the verbalization of
the players in the event followed by the verbaliza-
tion of play-by-plays. Candidate paragraph plans
703
RW
MLB
DE-RW
Vocab Size
# Tokens
# Instances
# Paragraphs
# Record Types
Avg Records
Avg Length
Avg Plan length
723
11.3K 38.9K
9.5K
1.5M 14.3M 234K
4.9K 26.3K
399K 47.7K
39
628
337.1
10.6
7K
39
628
323.6
9.5
53
565
542.1
15.1
Table 1: Dataset statistics for ROTOWIRE (RW),
MLB, and German ROTOWIRE (DE-RW). Vo-
cabulary size, number of tokens, number of
instances (i.e., table-summary pairs), number of
paragraphs, number of record types, average num-
ber of records, average summary length, average
macro plan length measured in terms of number
of paragraphs.
E are obtained by enumerating entities and events
and their combinations (see Table D in Figure 1).
Oracle macro plans are obtained by matching the
mentions of entities and events in the gold sum-
mary with the input table. We make use of these
oracle macro plans during training. The versions
of MLB and ROTOWIRE released by Puduppully
and Lapata (2021) contain paragraph delimiters
for gold summaries; we preprocessed the German
ROTOWIRE in a similar fashion.
Table 1 also shows the average length of the
macro plan in terms of the number of paragraph
plans it contains. This is 10.6 for ROTOWIRE, 15.1
for MLB, and 9.5 for German RotoWire.
Training Configuration We train our model
with the AdaGrad optimizer
(Duchi et al.,
2011) and tune parameters on the development
set. We use a learning rate of 0.15. We learn a
joint subword vocabulary (Sennrich et al., 2016)
for paragraph plans and summaries with 6K
merge operations for ROTOWIRE, 16K merge op-
erations for MLB, and 2K merge operations for
German ROTOWIRE. The model is implemented
on a fork of OpenNMT-py (Klein et al., 2017).
For efficiency, we batch using summaries in-
stead of individual paragraphs. Batch sizes for
MLB, ROTOWIRE, and German-ROTOWIRE are
8, 5, and 1, respectively. We set λ to 2 in
Equation (18). In Equation (19), c is 1/100000
for MLB, 1/50000 for ROTOWIRE, and 1/30000
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
for German-ROTOWIRE. We set the temperature
of Gumbel-Softmax to 0.1.
During inference in MLB, similar to Puduppully
and Lapata (2021), we block the repetition of
paragraph plan bigrams (i.e., we disallow the rep-
etition of (zt, zt+1)) and select the paragraph plan
with the next higher probability in Equation (8).
In addition, we block consecutive repetitions, and
more than two repetitions of a unigram. Dur-
ing training we observed high variance in the
length of paragraphs yt, since the same plan can
result in a shorter or longer paragraph. For ex-
ample,
paragraphs (first and third paragraph) with dif-
ferent lengths in Figure 1. We found that this
encourages the model
to be conservative and
generate relatively short output. We control the
paragraph length (Fan et al., 2018) by creating
discrete bins, each containing approximately an
equal number of paragraphs. During training, we
prepend the embedding of the bin to the current
plan rt
z (see Equation (11)). For inference, bins
are tuned on the validation set.
We run inference for 15 paragraphs on
ROTOWIRE and German ROTOWIRE, and for
20 paragraphs on MLB; we stop when the model
predicts the end of paragraph plan token EOP.
Unlike previous work (Wiseman et al., 2017;
Puduppully et al., 2019a,b, inter alia), we do
not make use of truncated Back Propagation
Through Time (Williams and Peng, 1990), as
we incrementally generate paragraphs instead of
long documents.
System Comparisons We compared our model
with: (1) a Template-based generator which cre-
ates a document consisting of template sentences.
We used Wiseman et al.’s (2017) system on
ROTOWIRE and Puduppully et al.’s (2019b) system
on MLB. They are both similar in that they de-
scribe team scores followed by player specific
statistics and a concluding statement. In MLB, the
template additionally describes play-by-play de-
tails. We also created a template system for Ger-
man ROTOWIRE following a similar approach. (2)
ED+CC, the best performing model of Wiseman
et al. (2017). It consists of an encoder-decoder
model equipped with attention and copy mecha-
nisms. (3) NCP+CC, the micro planning model
of Puduppully et al. (2019a). It first creates a
content plan by pointing to input records through
the use of Pointer Networks (Vinyals et al., 2015).
The content plan is then encoded with a BiL-
STM and decoded using another LSTM with an
attention and copy mechanism. (4) ENT,
the
entity model of Puduppully et al. (2019b). It
creates entity-specific representations which are
updated dynamically. At each time step during
decoding, their model makes use of hierarchical
attention by attending over entity representa-
tions and the records corresponding to these.
(5) MACRO,
the two-stage planning model
of Puduppully and Lapata (2021), which first
makes use of Pointer Networks (Vinyals et al.,
2015) to predict a macro plan from a set of candi-
date paragraph plans. The second stage takes the
predicted plan as input and generates the game
summary with a sequence-to-sequence model en-
hanced with attention and copy mechanisms. In
addition, we compare with a variant of Macro
enhanced with length control (+Bin).
5 Results
Our experiments were designed to explore how the
proposed model compares to related approaches
which are either not enhanced with planning mod-
ules or non-incremental. We also investigated the
sample efficiency of these models and the quality
of the predicted plans when these are available.
The majority of our results focus on automatic
evaluation metrics. We also follow previous
work (Wiseman et al., 2017; Puduppully et al.,
2019a,b; Puduppully and Lapata, 2021) in eliciting
judgments to evaluate system output.
5.1 Automatic Evaluation
output
evaluate model
We
using BLEU
(Papineni et al., 2002) with the gold summary as
a reference. We also report model performance
against the Information Extraction (IE) metrics of
Wiseman et al. (2017) which are defined based
on the output of an IE model which extracts entity
(team and player names) and value (numbers)
pairs from the summary and predicts the type of
relation between them.
Let ˆy be the gold summary and y be the model
output. Relation Generation (RG) measures the
precision and count of relations obtained from y
that are found in the input table. Content Selec-
tion (CS) measures the precision, recall, and F-
measure of relations extracted from y also found
in ˆy. And Content Ordering (CO) measures the
704
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
complement of the Damerau-Levenshtein dis-
tance between relations extracted from y and ˆy.
Higher values are better for RG Precision, CS
F-measure, CO, and BLEU. We reuse the IE model
from Puduppully et al. (2019a) for ROTOWIRE,
Puduppully and Lapata (2021) for MLB, and
Hayashi et al. (2019) for German ROTOWIRE. Our
computation of IE metrics for all systems includes
duplicate records (Puduppully and Lapata, 2021).
In addition to IE-based metrics, we report the
number of errors made by systems according
to Number (incorrect number in digits, number
spelled in words, etc.), Name (incorrect names
of teams, players, days of week, etc.), and Word
(errors in usage of words) following the classifi-
cation of Thomson and Reiter (2020). We detect
such errors automatically using the system of
Kasner et al. (2021), which scored best against
gold standard human annotations of the same type
(Thomson and Reiter, 2021). We only report these
metrics for English ROTOWIRE, since error an-
notations (for automatic metric learning) are not
available for other datasets. Moreover, with regard
to Word errors, we only report errors for incor-
rect usage of the word double-double.3 We found
such errors to be detected reliably, in contrast to
Word errors as a whole for which the precision
of the system of Kasner et al. (2021) is ∼50%.
Lower values are better for the Number, Name,
and double-double errors. We note metrics such as
RG precision, Number, Name, and double-double
errors directly compute the accuracy of the gener-
ation model. Metrics such as CS, CO, and BLEU
measure how similar model output is against a
reference summary. Thus, CS, CO, and BLEU
measure generation accuracy indirectly under the
assumption that gold summaries are accurate.
MLB Dataset Table 2 summarizes our results
on MLB. Our sequential planning model (Seq-
Plan) has the highest RG P among neural mod-
els and performs best in terms of CS F, CO,
and BLEU. The variant of Macro with length
control (+Bin) performs comparably or worse
than Macro.
To examine the importance of latent sequential
planning, we also present a variant of our model
that uniformly samples a plan from the pool E
instead of Equation (8) (see row w(ith) Uniform
3A double-double occurs when a player scores 10 points
or more in two record types: points, rebounds, assists, steals,
and blocked shots.
MLB
RG
CS
CO
#
P% P% R% F% DLD%
BLEU
Templ
62.3 99.9 21.6 55.2 31.0
11.0
4.12
ED+CC
NCP+CC
ENT
Macro
+Bin
32.5 91.3 27.8 40.6 33.0
19.6 81.3 44.5 44.1 44.3
23.8 81.1 40.9 49.5 44.8
. . . .30.8 . . . .94.4 40.8 54.9 . . . .46.8
31.2 93.7 38.3 52.4 44.2
SeqPlan
28.9 95.9 . . . .43.3 . . . .53.5 47.8
w Uniform 18.5 90.9 36.5 30.6 33.3
w Oracle
27.6 95.9 42.5 50.4 46.1
28.6 95.9 41.4 50.8 45.6
2-Stage
17.1
21.9
20.7
21.8
. . . . .
21.6
22.7
14.5
22.0
21.3
9.68
9.68
11.50
12.62
. . . . . .
12.32
14.29
10.30
13.13
13.96
Table 2: MLB results (test set); relation genera-
tion (RG) count (#) and precision (P%), content
selection (CS) precision (P%), recall (R%), and
F-measure (F%), content ordering (CO) as com-
plement of normalized Damerau-Levenshtein dis-
tance (DLD%), and BLEU. Highest and . . . . . . .
second
highest generation models are highlighted.
. . . . . . .
in Table 2). This version obtains lower values
compared to SeqPlan across all metrics under-
scoring the importance of sequential planning.
We also present two variants of SeqPlan: (a) one
that makes use of oracle (instead of predicted)
plans during training to generate yt; essentially, it
replaces zt with z∗ in Equation (12) (row w(ith)
Oracle in Table 2); and (b) a two-stage model
that trains the planner (Equation (15)) and gen-
erator (Equation (12)) separately (row 2-stage in
Table 2)—in this case, we use greedy decod-
ing to sample zt from Equation (15) instead of
Gumbel-Softmax and replace zt with z∗ in Equa-
tion (12). Both variants are comparable to SeqPlan
in terms of RG P but worse in terms of CS F, CO,
and BLEU.
Furthermore, we evaluate the accuracy of the
inferred plans by comparing them against oracle
plans, using the CS and CO metrics (computed
over the entities and events in the plan).4 Table 4
shows that SeqPlan achieves higher CS F and
CO scores than Macro. Again, this indicates that
planning is beneficial, particularly when taking
the table and the generated summary into account.
4To compute the accuracy of macro plans, entities and
events from the model’s plan need to be compared against
entities and events in the oracle macro plan. Puduppully and
Lapata (2021) obtained the entities and events for the oracle
macro plan by extracting these from reference summaries.
We noted that this includes coreferent or repeat mentions of
entities and events within a paragraph. We instead extract
entities and events directly from the oracle macro plan.
705
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
RW
RG
CS
CO
#
P% P% R% F% DLD%
BLEU
Templ
54.3 99.9 27.1 57.7 36.9
13.1
8.46
WS-2017
ED+CC
NCP+CC
ENT
RBF-2020
Macro
+Bin
34.1 75.1 20.3 36.3 26.1
35.9 82.6 19.8 33.8 24.9
40.8 87.6 28.0 51.1 36.2
32.7 . . . .91.7 34.7 48.5 40.5
44.9 89.5 23.9 47.0 31.7
42.1 97.6 34.1 57.8 42.9
61.0 97.2 26.8 66.1 38.2
SeqPlan
. . . .46.7 97.6 . . . .30.6 . . . .57.4 . . . .39.9
w Uniform 22.0 80.2 18.2 19.6 18.9
w Oracle
50.4 97.2 29.0 59.1 38.9
53.4 97.5 28.5 61.3 38.9
2-stage
DE-RW
RG
CS
#
P% P% R% F% DLD%
Templ
54.4 99.9 17.2 63.0 27.1
11.6
ED+CC
NCP+CC
ENT
RBF-2020
Macro
+Bin
6.7 18.8
. . . .24.8 59.3
9.9
17.7 52.5 11.3 . . . .25.7 15.7
17.4 . . . .64.7 . . . .13.3 24.0 . . . .17.1
0.6
0.4
1.1
0.2
5.1 21.0
8.3
7.9 20.0 11.3
4.0
30.2 49.7
20.4 55.0
6.8
9.6
. . . .9.8
0.3
6.1
8.1
SeqPlan
13.8 91.8 38.0 38.4 38.2
21.2
12.4
12.0
15.8
16.6
14.3
17.7
15.8
16.7
. . . . .
6.0
16.8
16.1
CO
14.19
14.99
16.50
16.12
17.16
15.46
16.48
16.26
. . . . . .
8.61
16.32
16.61
BLEU
7.32
5.09
. . . .7.29
6.52
2.29
5.15
6.18
8.65
Table 3: Evaluation on ROTOWIRE (RW) and Ger-
man ROTOWIRE (DE-RW) test sets; relation gener-
ation (RG) count (#) and precision (P%), content
selection (CS) precision (P%), recall (R%), and
F-measure (F%), content ordering (CO) as com-
plement of normalized Damerau-Levenshtein dis-
tance (DLD%), and BLEU. Highest and . . . . . . .
second
highest generation models are highlighted.
. . . . . . . .
English and German ROTOWIRE Results on
ROTOWIRE are presented in Table 3 (top). In ad-
dition to Templ, ED+CC, NCP+CC, and ENT,
we compare with the models of Wiseman et al.
(2017) (WS-2017) and Rebuffel et al. (2020)
(RBF-2020). WS-2017 is the best performing
model of Wiseman et al. (2017). Note that ED+CC
is an improved re-implementation of WS-2017.
RBF-2020 represents the current state-of-the-art
on ROTOWIRE, and is composed of a Transformer
encoder-decoder architecture (Vaswani et al.,
2017) with hierarchical attention on entities and
their records. The models of Saleh et al. (2019),
Iso et al. (2019), and Gong et al. (2019) are not
comparable as they make use of information ad-
ditional to the table such as previous/next games
or the author of the game summary. The model of
706
Narayan et al. (2020) is also not comparable as it
relies on a pretrained language model (Rothe et al.,
2020) to generate the summary sentences.
Table 3 (bottom) shows our results on German
ROTOWIRE. We compare against NCP+CC’s entry
in the WNGT 2019 shared task5 (Hayashi et al.,
2019), and our implementation of Templ, ED+
CC, ENT, Macro, and RBF-2020. Saleh et al.
(2019) are not comparable as they pretrain on 32M
parallel and 420M monolingual data. Likewise,
Puduppully et al. (2019c) make use of a jointly
trained multilingual model by combining ROTO-
WIRE with German ROTOWIRE.
We find that SeqPlan achieves highest RG P
among neural models, and performs on par with
Macro (it obtains higher BLEU but lower CS F and
CO scores). The +Bin variant of Macro performs
better on BLEU but worse on other metrics. As
in Table 2, w Uniform struggles across metrics
corroborating our hypothesis that latent sequential
planning improves generation performance. The
other two variants (w Oracle and 2-Stage) are
worse than SeqPlan in RG P and CS F, comparable
in CO, and slightly higher in terms of BLEU.
On German, our model is best across metrics,
achieving an RG P of 91.8% which is higher by
42% (absolute) compared to Macro. In fact, the
RG P of SeqPlan is superior to Saleh et al. (2019),
whose model is pretrained with additional data
and is considered state of the art (Hayashi et al.,
2019). RG# is lower mainly because of a bug in
the German IE that is excludes number records.
RG# for NCP+CC and Macro is too high because
the summaries contain considerable repetition.
The same record will repeat at least once with
NCP+CC and three times with Macro, whereas
only 7% of the records are repeated with SeqPlan.
Table 4 evaluates the quality of the plans in-
ferred by our model on the ROTOWIRE dataset.
As can be seen, SeqPlan is slightly worse than
Macro in terms of CS F and CO. We believe this
is because summaries in ROTOWIRE are somewhat
formulaic, with a plan similar to Templ: an open-
ing statement is followed by a description of the
top scoring players, and a conclusion describing
the next match. Such plans can be learned well by
Macro without access to the summary. MLB texts
show much more diversity in terms of length, and
5We thank Hiroaki Hayashi for providing us with the
output of the NCP+CC system.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Datasets
Macro
SeqPlan
Macro
SeqPlan
Macro
SeqPlan
B
L
M
W
R
W
R
–
E
D
CS
CO
P% R% F% DLD%
27.0
73.6
27.1
74.4
45.9
51.1
56.5
60.6
81.5
79.1
86.8
73.1
62.7
61.6
34.2
60.8
70.9
69.3
49.0
66.4
36.3
35.5
30.1
31.0
Table 4: Evaluation of macro planning stage (test
set); content selection (CS) precision (P%), re-
call (R%), and F-measure (F%), content ordering
(CO) as complement of normalized Damerau-
Levenshtein distance (DLD%).
Templ
WS-2017
ED+CC
NCP+CC
ENT
RBF-2020
Macro
SeqPlan
Number Name
3.05*
0.08*
double-double
0.00*
13.01*
8.11*
7.89*
5.89*
6.20*
2.57
2.70
9.66*
8.29*
7.76*
7.24*
8.39*
4.60*
6.56
0.36*
0.31*
0.14
0.15
0.41*
0.18
0.20
Table 5: Number, Name, and double-double
(Word) errors per example. Systems significantly
different from SeqPlan are marked with an as-
terisk * (using a one-way ANOVA with posthoc
Tukey HSD tests; p ≤ 0.05).
the sequencing of entities and events. The learn-
ing problem is also more challenging, supported
by the fact that the template system does not do
very well in this domain (i.e., it is worse in BLEU,
CS F, and CO compared to ROTOWIRE). In Ger-
man ROTOWIRE, SeqPlan plans achieve higher
CS F and CO than Macro.
Table 5 reports complementary automatic met-
rics on English ROTOWIRE aiming to assess the
factuality of generated output. We find that Templ
has the least Number, Name, and double-double
errors. This is expected as it simply reproduces
facts from the table. SeqPlan and Macro have
similar Number errors, and both are significantly
better than other neural models. SeqPlan has sig-
nificantly more Name errors than Macro, and
significantly fewer than other neural models. In-
707
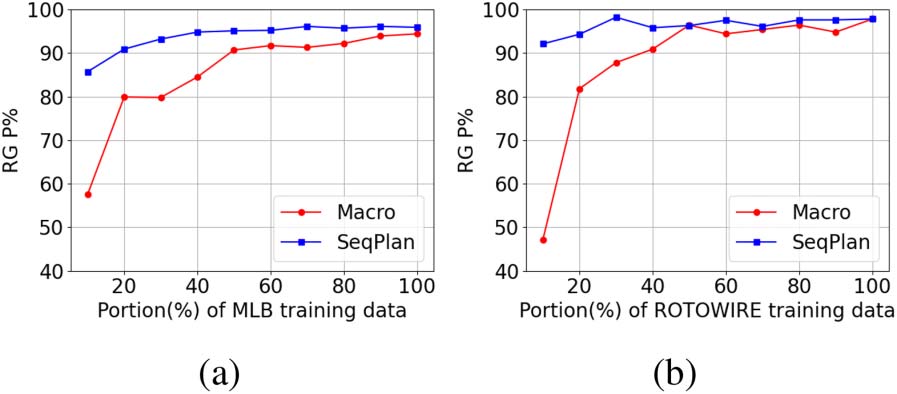
Figure 4: Sample efficiency for (a) MLB and (b)
ROTOWIRE datasets. SeqPlan and Macro are trained
on different portions (%) of the training dataset and
performance is measured with RG P%.
spection of Name errors revealed that these are
mostly due to incorrect information about next
games. Such information is not part of the in-
put and models are prone to hallucinate. SeqPlan
fares worse as it attempts to discuss next games
for both teams while Macro focuses on one team
only. In terms of double-double errors, SeqPlan is
comparable to Macro, ENT, and NCP+CC, and
significantly better than WS-2017, ED+CC, and
RBF-2020.
5.2 Sample Efficiency
We also evaluated whether SeqPlan is more
sample-efficient in comparison to Macro, by ex-
amining how RG P varies with (training) data
size. As shown in Figure 4, the difference be-
tween SeqPlan and Macro is more pronounced
when relatively little data is available. For exam-
ple, with 10% of training data, RG P for SeqPlan
on MLB is 85.7% and 92.1% on ROTOWIRE. In con-
trast, Macro obtains 57.5% on MLB and 47.1% on
ROTOWIRE. As more training data becomes avail-
able, the difference in RG P decreases. The slope
of increase in RG P for Macro is higher for
ROTOWIRE than MLB. We hypothesize that this
is because MLB has longer summaries with more
paragraphs, and it is thus more difficult for Macro
to learn alignments between paragraph plans and
text paragraphs in the game summary.
5.3 Human Evaluation
We used the Amazon Mechanical Turk crowd-
sourcing platform for our judgment elicitation
study. To ensure consistent ratings (van der Lee
et al., 2019), we required that raters have com-
least
pleted at
98% approval rate. Participants were restricted to
English-speaking countries (USA, UK, Canada,
least 1,000 tasks, and have at
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Australia, Ireland, or New Zealand) and were al-
lowed to provide feedback or ask questions. Raters
were paid an average of $0.35 for each task, en-
suring that the remuneration is higher than the
minimum wage per hour in the United States. We
compared SeqPlan with Gold, Templ, ED+CC,
and Macro; we did not compare against ENT,
as previous work (Puduppully and Lapata, 2021)
has shown that it performs poorly against Macro.
For ROTOWIRE, we additionally compared against
RBF-2020.
Supported and Contradicted Facts Our first
eliciation study provided raters with box scores
(and play-by-plays in the case of MLB), along
with sentences randomly extracted from game
summaries. We asked them to count supported and
contradicting facts (ignoring hallucinations). Par-
ticipants were given a cheatsheet to help them
understand box score and play-by-play statistics
as well as examples of sentences with the correct
count of supported and contradicting facts. This
evaluation was conducted on 40 summaries (20
for each dataset), with four sentences per sum-
mary, each rated by three participants. For MLB,
this resulted in 300 tasks (5 systems × 20 sum-
maries × 3 raters) and for ROTOWIRE in 360 (6
systems × 20 summaries × 3 raters). Altogether,
we had 177 participants. The agreement between
raters using Krippendorff’s α for supported facts
and contradicting facts was 0.43.
Table 6 (columns #Supp and #Contra) presents
our results. Lower is better for contradicting facts.
In case of supporting facts, the count should nei-
ther be too high nor too low. A high count of
supporting facts indicates indicates poor content
selection. A low count of supporting facts with
a high count of contradicting facts indicates low
accuracy of generation.
Templ achieves the lowest count of contradict-
ing facts and the highest count of supported facts
for both the datasets. This is no surprise as it
essentially regurgitates facts (i.e., records) from
the table. On MLB, all systems display a com-
parable count of supported facts (differences are
not statistically significant), with the exception
of Templ, which contains significantly more. In
terms of contradicting facts, SeqPlan performs on
par with Macro, Gold, and Templ, and is sig-
nificantly better than ED+CC. On ROTOWIRE, in
terms of supported facts, SeqPlan performs on
par with the other neural models, is significantly
MLB
#Supp #Contra Gram
Coher
Concis
Gold
Templ
ED+CC
Macro
SeqPlan
3.59
4.21*
3.42
3.76
3.68
21.67
0.14
29.17
14.17
0.04 −58.33* −48.33*
9.17
0.72* −32.50* −18.33* −48.33*
22.50
0.25
2.50
0.19
37.50
31.67
15.00
22.50
42.67*
ROTOWIRE #Supp #Contra Gram
3.63*
Gold
7.57*
Templ
ED+CC
3.92
RBF-2020 5.08
4.00
Macro
4.84
SeqPlan
Coher
Concis
40.67
28.00
−57.33* −55.33* −34.67*
4.00 −14.67* −13.33
−0.67
1.33
6.00
10.00
7.33
0.67
10.67
20.67
4.00
0.07
0.08
0.91*
0.67*
0.27
0.17
Table 6: Average number of supported (#Supp)
and contradicting (#Contra) facts in game sum-
maries and best-worst scaling evaluation for
Coherence (Coher), Conciseness (Concis), and
Grammaticality (Gram). Lower is better for con-
tradicting facts; higher is better for Coherence,
Conciseness, and Grammaticality. Systems sig-
nificantly different from SeqPlan are marked with
an asterisk * (using a one-way ANOVA with post
hoc Tukey HSD tests; p ≤ 0.05).
higher than Gold, and significantly lower than
Templ. In terms of contradicting facts, SeqPlan
performs on par with Macro, Gold, and Templ, and
significantly better than ED+CC and RBF-2020.
Coherence, Grammaticality, and Conciseness
In our second study, raters were asked to choose
the better summary from a pair of summaries based
on Coherence (Is the summary well structured and
well organized and does it have a natural ordering
of the facts?), Conciseness (Does the summary
avoid unnecessary repetition including whole sen-
tences, facts or phrases?), and Grammaticality
(Is the summary written in well-formed En-
glish?). For this study, we required that the raters
be able to comfortably comprehend summaries
of NBA/MLB games. We obtained ratings using
Best-Worst scaling (Louviere and Woodworth,
1991; Louviere et al., 2015), an elicitation para-
digm shown to be more accurate than Likert
scales. The score for a system is obtained by the
number of times it is rated best minus the number
of times it is rated worst (Orme, 2009). Scores
range between −100 (absolutely worst) and +100
(absolutely best); higher is better. We assessed 40
summaries from the test set (20 for each dataset).
Each summary pair was rated by three participants.
708
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
For MLB, we created 1,800 tasks (10 system
pairs × 20 summaries × 3 raters × 3 dimensions)
and 2,700 for ROTOWIRE (15 pairs of systems × 20
summaries × 3 raters × 3 dimensions). Altogether,
377 raters participated in this task. The agree-
ment between the raters using Krippendorff’s α
was 0.49.
On MLB, SeqPlan is significantly more coher-
ent than ED+CC and Templ, and is comparable
with Gold and Macro. A similar picture emerges
with grammaticality. SeqPlan is as concise as
Gold, Macro, and Templ, and significantly better
than ED+CC. On ROTOWIRE, SeqPlan is signif-
icantly more coherent than Templ and ED+CC,
but on par with Macro, RBF-2020, and Gold.
In terms of conciseness, SeqPlan is compara-
ble to Gold, Macro, RBF-2020, and ED+CC,
and significantly better than Templ. In terms of
grammaticality, SeqPlan is comparable to Macro,
RBF-2020, and ED+CC, significantly better than
Templ, and significantly worse than Gold.
6 Discussion
In this work, we proposed a novel sequential la-
tent variable model for joint macro planning and
generation. Key in our approach is the creation of
a latent plan in a sequential manner, while inter-
leaving the prediction of plans and the generation
of corresponding paragraphs. We proposed to de-
construct monolithic long document generation
into smaller units (paragraphs, in our case), which
affords flexibility and better communication be-
tween planning and generation. Taken together,
the results of automatic and human evaluation
suggest that SeqPlan performs best in terms of
factuality and coherence, it generates diverse, and
overall fluent, summaries, and is less data-hungry
compared with strong systems like Macro and
NCP+CC. As SeqPlan does not have to learn
alignments between the macro plan and the output
text, it is better suited for long-form generation.
Potential applications include summarizing books
(Kry´sci´nski et al., 2021), where the output can
be longer than 1,000 tokens, or generating finan-
cial reports (Kogan et al., 2009; H¨andschke et al.,
2018), where the output exceeds 9,000 tokens.
Existing approaches for long-form generation
summarize individual paragraphs independently
(Kry´sci´nski et al., 2021) or adopt a hierarchical
approach (Wu et al., 2021), where summaries of
ST. LOUIS – The St. Louis Cardinals have been waiting for
their starting rotation.
Skip Schumaker drove in the go-ahead
run with a double in the ninth inning, and the Cardinals beat the
Milwaukee Brewers 4–3 on Wednesday night to avoid a three-game
sweep.
The Cardinals have won four of five, and have won
four in a row.
The Cardinals have won four of five, including
a three-game sweep by the Brewers.
Brian Barton led off
the ninth with a pinch-hit double off Derrick Turnbow (0–1) and
moved to third on Cesar Izturis’ sacrifice bunt. Schumaker drove in
Barton with a double down the left-field line.
Ryan Braun,
who had two hits, led off the eighth with a double off Ryan Franklin
(1–1). Braun went to third on a wild pitch and scored on Corey Hart’s
triple into the right-field corner.
Albert Pujols was intentionally
walked to load the bases with one out in the eighth, and Guillermo
Ankiel flied out. Troy Glaus walked to load the bases for Kennedy,
who hit a sacrifice fly off Guillermo Mota.
Ryan Franklin (1–1)
got the win despite giving up a run in the eighth. Ryan Braun led
off with a double and scored on Corey Hart’s one-out triple.
Jason Isringhausen pitched a perfect ninth for his seventh save in
nine chances. He has converted his last six save opportunities and has
n’t allowed a run in his last three appearances.
The Brewers
lost for the seventh time in eight games.
Wainwright allowed
two runs and four hits in seven innings. He walked four and struck
out six.
Brewers manager Ron Roenicke was ejected by home
plate umpire Bill Miller for arguing a called third strike.
The
Cardinals took a 2–0 lead in the third. Albert Pujols walked with two
outs and Rick Ankiel walked. Glaus then lined a two-run double into
the left-field corner.
The Brewers tied it in the third. Jason
Kendall led off with a double and scored on Rickie Weeks’ double.
Ryan Braun’s RBI single tied it at 2.
Villanueva allowed two
runs and three hits in seven innings. He walked four and struck
out one.
Table 7: Predicted macro plan (top) and gener-
ated output from our model. Transitions between
paragraph plans are shown using →. Paragraphs
are separated with
delimiters. Entities and
events in the summary corresponding to the macro
plan are boldfaced.
paragraphs form the basis of chapter summaries
which in turn are composed into a book summary.
Table 7 gives an example of SeqPlan output.
We see that the game summary follows the macro
plan closely. In addition, the paragraph plans and
the paragraphs exhibit coherent ordering. Manual
inspection of SeqPlan summaries reveals that a
major source of errors in MLB relate to atten-
tion diffusing over long paragraph plans. As an
example, consider the following paragraph pro-
duced by SeqPlan ‘‘Casey Kotchman had three
hits and three RBIs, including a two-run double
in the second inning that put the Angels up 2–0.
Torii Hunter had three hits and drove in a run.’’
In reality, Torii Hunter had two hits but the model
incorrectly generates hits for Casey Kotchman.
709
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
The corresponding paragraph plan is 360 tokens
long and attention fails to discern important to-
kens. A more sophisticated encoder, for example,
based on Transformers (Vaswani et al., 2017),
could make attention more focused. In ROTOWIRE,
the majority of errors involve numbers (e.g., team
attributes) and numerical comparisons. Incorpo-
rating pre-executed operations such as min, max
(Nie et al., 2018) could help alleviate these errors.
Finally, it is worth mentioning that although
the template models achieve highest RG precision
for both MLB and ROTOWIRE (Tables 2 and 3),
this is mainly because they repeat facts from the
table. Template models score low against CS F,
CO, and BLEU metrics. In addition, they obtain
lowest scores in Grammaticality and Coherence
(Table 6), which indicates that they are poor at
selecting records from the table and ordering them
correctly in a fluent manner.
Acknowledgments
We thank the Action Editor, Ehud Reiter, and
the anonymous reviewers for their constructive
feedback. We also thank Parag Jain for helpful dis-
cussions. We acknowledge the financial support
of the European Research Council (award num-
ber 681760, ‘‘Translating Multiple Modalities
into Text’’).
References
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua
Bengio. 2015. Neural machine translation by
jointly learning to align and translate. In 3rd
International Conference on Learning Repre-
sentations, ICLR 2015, San Diego, CA, USA,
May 7–9, 2015, Conference Track Proceedings.
Regina Barzilay and Mirella Lapata. 2005. Col-
lective content selection for concept-to-text
generation. In Proceedings of Human Lan-
guage Technology Conference and Conference
on Empirical Methods in Natural Language
Processing, pages 331–338, Vancouver, British
Columbia, Canada. Association for Computa-
tional Linguistics. https://doi.org/10
.3115/1220575.1220617
Samy Bengio, Oriol Vinyals, Navdeep Jaitly,
and Noam Shazeer. 2015. Scheduled sam-
pling for sequence prediction with recurrent
neural networks. In Proceedings of the 28th
International Conference on Neural Informa-
tion Processing Systems – Volume 1, NIPS’15,
pages 1171–1179, Cambridge, MA, USA.
MIT Press.
Junyoung Chung, Kyle Kastner, Laurent Dinh,
Kratarth Goel, Aaron C. Courville, and Yoshua
Bengio. 2015. A recurrent latent variable model
for sequential data. In Advances in Neural
Information Processing Systems, volume 28.
Curran Associates, Inc.
Carl Doersch. 2016. Tutorial on variational auto-
encoders. CoRR, abs/1606.05908.
Pablo A. Duboue and Kathleen R. McKeown.
2001. Empirically estimating order constraints
for content planning in generation. In Pro-
the 39th Annual Meeting of
ceedings of
the Association for Computational Linguistics,
pages 172–179, Toulouse, France. Association
for Computational Linguistics.
John C. Duchi, Elad Hazan, and Yoram Singer.
2011. Adaptive subgradient methods for online
learning and stochastic optimization. Journal
of Machine Learning Research, 12:2121–2159.
Angela Fan, David Grangier, and Michael Auli.
2018. Controllable abstractive summarization.
the 2nd Workshop on
In Proceedings of
Neural Machine Translation and Generation,
pages 45–54, Melbourne, Australia. Associa-
tion for Computational Linguistics.
Marco Fraccaro, Søren Kaae Sønderby, Ulrich
Paquet, and Ole Winther. 2016. Sequential neu-
ral models with stochastic layers. In Advances
in Neural Information Processing Systems,
volume 29. Curran Associates, Inc.
Yao Fu, Chuanqi Tan, Bin Bi, Mosha Chen,
Yansong Feng, and Alexander Rush. 2020.
Latent template induction with Gumbel-CRFS.
In Advances in Neural Information Process-
ing Systems, volume 33, pages 20259–20271.
Curran Associates, Inc.
Claire Gardent, Anastasia Shimorina, Shashi
Narayan, and Laura Perez-Beltrachini. 2017.
Creating training corpora for NLG micro-
planners. In Proceedings of the 55th Annual
Meeting of
the Association for Computa-
tional Linguistics (Volume 1: Long Papers),
pages 179–188, Vancouver, Canada. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/P17-1017
710
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Albert Gatt and Emiel Krahmer. 2018. Survey of
the state of the art in natural language gen-
eration: Core tasks, applications and evalua-
tion. Journal of Artificial Intelligence Research,
61:65–170. https://doi.org/10.1613
/jair.5477
Sebastian Gehrmann, Yuntian Deng,
and
Alexander Rush. 2018. Bottom-up abstractive
the 2018
summarization. In Proceedings of
Conference on Empirical Methods in Natu-
ral Language Processing, pages 4098–4109,
Brussels, Belgium. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/D18-1443
Heng Gong, Xiaocheng Feng, Bing Qin, and
Ting Liu. 2019. Table-to-text generation with
effective hierarchical encoder on three dimen-
sions (row, column and time). In Proceedings
of the 2019 Conference on Empirical Meth-
ods in Natural Language Processing and the
9th International Joint Conference on Natu-
ral Language Processing (EMNLP-IJCNLP),
pages 3143–3152, Hong Kong, China. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/D19-1310
Anirudh Goyal, Alessandro Sordoni, Marc-
Alexandre Cˆot´e, Nan Rosemary Ke, and Yoshua
Bengio. 2017. Z-forcing: Training stochastic
recurrent networks. In Advances in Neural
Information Processing Systems, volume 30.
Curran Associates, Inc.
Markus Guhe. 2020. Incremental Conceptual-
ization for Language Production. Psychol-
ogy Press. https://doi.org/10.4324
/9781003064398
Sebastian G. M. H¨andschke, Sven Buechel,
Jan Goldenstein, Philipp Poschmann, Tinghui
Duan, Peter Walgenbach, and Udo Hahn. 2018.
A corpus of corporate annual and social respon-
sibility reports: 280 million tokens of balanced
organizational writing. In Proceedings of the
First Workshop on Economics and Natural Lan-
guage Processing, pages 20–31, Melbourne,
Australia. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/W18-3103
Hiroaki Hayashi, Yusuke Oda, Alexandra Birch,
Ioannis Konstas, Andrew Finch, Minh-Thang
Luong, Graham Neubig, and Katsuhito Sudoh.
2019. Findings of the third workshop on neural
generation and translation. In Proceedings of
the 3rd Workshop on Neural Generation and
Translation, pages 1–14, Hong Kong. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/D19-5601
Hayate Iso, Yui Uehara, Tatsuya Ishigaki,
Hiroshi Noji, Eiji Aramaki, Ichiro Kobayashi,
Yusuke Miyao, Naoaki Okazaki, and Hiroya
Takamura. 2019. Learning to select, track, and
generate for data-to-text. In Proceedings of the
57th Annual Meeting of the Association for
Computational Linguistics, pages 2102–2113,
Florence, Italy. Association for Computational
Linguistics. https://doi.org/10.18653
/v1/P19-1202
Eric Jang, Shixiang Gu, and Ben Poole. 2017.
Categorical reparametrization with Gumble-
softmax. In International Conference on Learn-
ing Representations (ICLR 2017). OpenReview
.net.
Min-Yen Kan and Kathleen R. McKeown. 2002.
Corpus-trained text generation for summa-
rization. In Proceedings of the International
Natural Language Generation Conference,
pages 1–8, Harriman, New York, USA. Asso-
ciation for Computational Linguistics.
Zdenˇek Kasner, Simon Mille, and Ondˇrej Duˇsek.
2021. Text-in-context: Token-level error detec-
tion for table-to-text generation. In Proceedings
of the 14th International Conference on Nat-
ural Language Generation, pages 259–265,
Aberdeen, Scotland, UK. Association for
Computational Linguistics.
Byeongchang Kim, Jaewoo Ahn, and Gunhee
Kim. 2020. Sequential latent knowledge se-
lection for knowledge-grounded dialogue. In
International Conference on Learning Repre-
sentations. https://doi.org/10.1145
/3459637.3482314
Diederik P. Kingma and Max Welling. 2014.
Auto-encoding variational Bayes. In 2nd In-
ternational Conference on Learning Represen-
tations, ICLR 2014, Banff, AB, Canada, April
14–16, 2014, Conference Track Proceedings.
Guillaume Klein, Yoon Kim, Yuntian Deng, Jean
Senellart, and Alexander Rush. 2017. Open-
NMT: Open-source toolkit for neural machine
711
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
translation. In Proceedings of ACL 2017, Sys-
tem Demonstrations, pages 67–72, Vancouver,
Canada. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/P17-4012
Shimon Kogan, Dimitry Levin, Bryan R.
Routledge, Jacob S. Sagi, and Noah A. Smith.
2009. Predicting risk from financial reports with
regression. In Proceedings of Human Language
Technologies: The 2009 Annual Conference of
the North American Chapter of the Association
for Computational Linguistics, pages 272–280,
Boulder, Colorado. Association for Computa-
tional Linguistics. https://doi.org/10
.3115/1620754.1620794
Ioannis Konstas and Mirella Lapata. 2013. In-
ducing document plans for concept-to-text
generation. In Proceedings of the 2013 Con-
ference on Empirical Methods in Natural Lan-
guage Processing, pages 1503–1514, Seattle,
Washington, USA. Association for Computa-
tional Linguistics.
Wojciech Kry´sci´nski, Nazneen Rajani, Divyansh
Agarwal, Caiming Xiong, and Dragomir Radev.
2021. Booksum: A collection of datasets for
long-form narrative summarization.
R´emi Lebret, David Grangier, and Michael
Auli. 2016. Neural text generation from struc-
tured data with application to the biography do-
main. In Proceedings of the 2016 Conference
on Empirical Methods in Natural Language
Processing, pages 1203–1213, Austin, Texas.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/D16
-1128
Chris van der Lee, Albert Gatt, Emiel van
and Emiel
Miltenburg, Sander Wubben,
Krahmer. 2019. Best practices for the human
evaluation of automatically generated text. In
Proceedings of
the 12th International Con-
ference on Natural Language Generation,
pages 355–368, Tokyo, Japan. Association for
Computational Linguistics.
Willem J. M. Levelt. 1993. Speaking: From
Intention to Articulation, volume 1. MIT Press.
https://doi.org/10.7551/mitpress
/6393.001.0001
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer
Levy, Veselin Stoyanov, and Luke Zettlemoyer.
2020. BART: Denoising sequence-to-sequence
pre-training for natural language generation,
translation, and comprehension. In Proceed-
ings of
the
Association for Computational Linguistics,
pages 7871–7880, Online. Association for
Computational Linguistics. https://doi
.org/10.18653/v1/2020.acl-main.703
the 58th Annual Meeting of
Piji Li, Wai Lam, Lidong Bing, and Zihao
Wang. 2017. Deep recurrent generative de-
coder for abstractive text summarization. In
Proceedings of the 2017 Conference on Em-
pirical Methods in Natural Language Process-
ing, pages 2091–2100, Copenhagen, Denmark.
Association for Computational Linguistics.
Xiang Lisa Li and Alexander Rush. 2020.
Posterior control of blackbox generation. In
Proceedings of the 58th Annual Meeting of
the Association for Computational Linguistics,
pages 2731–2743, Online. Association for
Computational Linguistics.
Jordan J. Louviere, Terry N. Flynn, and Anthony
Alfred John Marley. 2015. Best-Worst Scaling:
Theory, Methods and Applications. Cambridge
University Press. https://doi.org/10
.1017/CBO9781107337855
Jordan J. Louviere and George G. Woodworth.
1991. Best-Worst Scaling: A Model for the
Largest Difference Judgments. University of
Alberta: Working Paper.
Chris J. Maddison, Andriy Mnih, and Yee
Whye Teh. 2017. The concrete distribution:
relaxation of discrete ran-
A continuous
dom variables. In International Conference
on Learning Representations (ICLR 2017).
OpenReview.net.
Hongyuan Mei, Mohit Bansal, and Matthew
R. Walter. 2016. What
to talk about and
how? Selective generation using LSTMs with
coarse-to-fine alignment. In Proceedings of
the 2016 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
pages 720–730, San Diego, California. Associ-
ation for Computational Linguistics.
Amit Moryossef, Yoav Goldberg, and Ido
Dagan. 2019a. Improving quality and effi-
ciency in plan-based neural data-to-text gener-
ation. In Proceedings of the 12th International
712
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Conference on Natural Language Generation,
pages 377–382, Tokyo, Japan. Association for
Computational Linguistics. https://doi
.org/10.18653/v1/W19-8645
Amit Moryossef, Yoav Goldberg, and Ido Dagan.
2019b. Step-by-step: Separating planning from
realization in neural data-to-text generation.
In Proceedings of
the 2019 Conference of
the North American Chapter of the Associ-
ation for Computational Linguistics: Human
Language Technologies, Volume 1 (Long and
Short Papers), pages 2267–2277, Minneapolis,
Minnesota. Association for Computational
Linguistics.
Shashi Narayan, Joshua Maynez, Jakub Adamek,
Daniele Pighin, Blaz Bratanic, and Ryan
McDonald. 2020. Stepwise extractive summa-
rization and planning with structured transform-
ers. In Proceedings of the 2020 Conference on
Empirical Methods in Natural Language Pro-
cessing (EMNLP), pages 4143–4159, Online.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/2020
.emnlp-main.339
Feng Nie, Jinpeng Wang, Jin-Ge Yao, Rong Pan,
and Chin-Yew Lin. 2018. Operation-guided
neural networks for high fidelity data-to-text
generation. In Proceedings of the 2018 Con-
ference on Empirical Methods in Natural Lan-
guage Processing, pages 3879–3889, Brussels,
Belgium. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/D18-1422
Bryan Orme. 2009. Maxdiff analysis: Simple
counting, individual-level logit, and HB. Saw-
tooth Software.
Kishore Papineni, Salim Roukos, Todd Ward,
and Wei-Jing Zhu. 2002. BLEU: A method for
automatic evaluation of machine translation.
In Proceedings of the 40th Annual Meeting of
the Association for Computational Linguistics,
pages 311–318, Philadelphia, Pennsylvania,
USA. Association for Computational Linguistics.
https://doi.org/10.3115/1073083
.1073135
Ratish Puduppully, Li Dong, and Mirella Lapata.
2019a. Data-to-text generation with content se-
lection and planning. In Proceedings of the 33rd
AAAI Conference on Artificial Intelligence.
Honolulu, Hawaii. https://doi.org/10
.1609/aaai.v33i01.33016908
Ratish Puduppully, Li Dong, and Mirella Lapata.
2019b. Data-to-text generation with entity
modeling. In Proceedings of the 57th Annual
Meeting of the Association for Computational
Linguistics, pages 2023–2035, Florence, Italy.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/P19
-1195
Ratish Puduppully and Mirella Lapata. 2021.
Data-to-text generation with macro planning.
Transactions of the Association for Computa-
tional Linguistics, abs/2102.02723. https://
doi.org/10.1162/tacl a 00381
Ratish Puduppully,
Jonathan Mallinson, and
Mirella Lapata. 2019c. University of Edin-
burgh’s submission to the document-level
generation and translation shared task. In Pro-
ceedings of
the 3rd Workshop on Neural
Generation and Translation, pages 268–272,
Hong Kong. Association for Computational
Linguistics. https://doi.org/10.18653
/v1/D19-5630
Cl´ement Rebuffel, Laure Soulier, Geoffrey
Scoutheeten, and Patrick Gallinari. 2020. A hi-
erarchical model for data-to-text generation. In
European Conference on Information Retrieval,
pages 65–80. Springer. https://doi.org
/10.1007/978-3-030-45439-5_5
Lena Reed, Shereen Oraby, and Marilyn Walker.
2018. Can neural generators for dialogue
learn sentence planning and discourse structur-
ing? In Proceedings of the 11th International
Conference on Natural Language Genera-
tion, pages 284–295, Tilburg University, The
Netherlands. Association for Computational
Linguistics. https://doi.org/10.18653
/v1/W18-6535
Ehud Reiter and Robert Dale. 1997. Building
applied natural language generation systems.
Natural Language Engineering, 3(1):57–87.
https://doi.org/10.1017/S13513249
97001502
Ehud Reiter and Robert Dale. 2000. Build-
ing Natural Language Generation Systems,
Cambridge University Press, New York, NY.
https://doi.org/10.1017/CBO978051
1519857
713
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Danilo Jimenez Rezende, Shakir Mohamed, and
Daan Wierstra. 2014. Stochastic backprop-
agation and approximate inference in deep
generative models. In Proceedings of the 31th
International Conference on Machine Learn-
ing, ICML 2014, Beijing, China, 21–26 June
2014, volume 32 of JMLR Workshop and
Conference Proceedings, pages 1278–1286.
JMLR.org.
Jacques Robin. 1994. Revision-based generation
of Natural Language Summaries providing his-
torical Background. Ph.D.
thesis, Columbia
University.
Sascha Rothe, Shashi Narayan, and Aliaksei
Severyn. 2020. Leveraging pre-trained check-
points for sequence generation tasks. Trans-
actions of the Association for Computational
Linguistics, 8:264–280. https://doi.org
/10.1162/tacl_a_00313
Fahimeh
Ioan
Saleh, Alexandre Berard,
Calapodescu, and Laurent Besacier. 2019. Na-
ver Labs Europe’s systems for the document-
level generation and translation task at WNGT
the 3rd Work-
2019.
shop on Neural Generation and Translation,
pages 273–279, Hong Kong. Association for
Computational Linguistics. https://doi
.org/10.18653/v1/D19-5631
In Proceedings of
Abigail See, Peter J. Liu, and Christopher D.
to the point: Summa-
Manning. 2017. Get
rization with pointer-generator networks. In
Proceedings of the 55th Annual Meeting of
the Association for Computational Linguistics
(Volume 1: Long Papers), pages 1073–1083,
Vancouver, Canada. Association for Computa-
tional Linguistics.
Rico Sennrich, Barry Haddow, and Alexandra
Birch. 2016. Neural machine translation of rare
words with subword units. In Proceedings of
the 54th Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long
Papers), pages 1715–1725, Berlin, Germany.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/P16
-1162
the Thirty-First AAAI Conference on Arti-
ficial Intelligence, February 4-9, 2017, San
Francisco, California, USA, pages 3295–3301.
AAAI Press.
Shiv Shankar and Sunita Sarawagi. 2019. Pos-
terior attention models for sequence to se-
quence learning. In International Conference
on Learning Representations. https://doi
.org/10.18653/v1/D18-1065
Zhihong Shao, Minlie Huang, Jiangtao Wen,
Wenfei Xu, and Xiaoyan Zhu. 2019. Long and
diverse text generation with planning-based hi-
erarchical variational model. In Proceedings
of the 2019 Conference on Empirical Meth-
ods in Natural Language Processing and the
9th International Joint Conference on Natu-
ral Language Processing (EMNLP-IJCNLP),
pages 3257–3268, Hong Kong, China. Associa-
tion for Computational Linguistics. https://
doi.org/10.18653/v1/D19-1321
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le.
2014. Sequence to sequence learning with neu-
ral networks. In Advances in Neural Informa-
tion Processing Systems 27, pages 3104–3112.
Curran Associates, Inc.
Kumiko Tanaka-Ishii, Koiti Hasida, and Itsuki
Noda. 1998. Reactive content selection in the
generation of real-time soccer commentary. In
36th Annual Meeting of the Association for
Computational Linguistics and 17th Interna-
tional Conference on Computational Linguis-
tics, Volume 2, pages 1282–1288, Montreal,
Quebec, Canada. Association for Computa-
tional Linguistics. https://doi.org/10
.3115/980691.980778
M. Martin Taylor and Insup Taylor. 1990. Book re-
views: Speaking: From intention to articulation.
Computational Linguistics, 16(1).
Craig Thomson and Ehud Reiter. 2020. A gold
standard methodology for evaluating accu-
racy in data-to-text systems. In Proceedings
of the 13th International Conference on Nat-
ural Language Generation, pages 158–168,
Dublin, Ireland. Association for Computational
Linguistics.
Iulian Vlad Serban, Alessandro Sordoni, Ryan
Lowe, Laurent Charlin, Joelle Pineau, Aaron C.
Courville, and Yoshua Bengio. 2017. A hierar-
chical latent variable encoder-decoder model
for generating dialogues. In Proceedings of
Craig Thomson and Ehud Reiter. 2021. Gen-
eration challenges: Results of the accuracy
evaluation shared task. In Proceedings of the
14th International Conference on Natural Lan-
guage Generation, pages 240–248, Aberdeen,
714
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Scotland, UK. Association for Computational
Linguistics.
Ashish Vaswani, Noam Shazeer, Niki Parmar,
Jakob Uszkoreit, Llion Jones, Aidan N. Gomez,
Łukasz Kaiser, and Illia Polosukhin. 2017,
Attention is all you need.
In I. Guyon,
U. V. Luxburg, S. Bengio, H. Wallach, R.
Fergus, S. Vishwanathan, and R. Garnett,
editors, Advances in Neural Information Pro-
cessing Systems 30, pages 5998–6008. Curran
Associates, Inc.
Oriol Vinyals, Meire Fortunato, and Navdeep
Jaitly. 2015, Pointer networks. In C. Cortes, N.
D. Lawrence, D. D. Lee, M. Sugiyama, and R.
Garnett, editors, Advances in Neural Informa-
tion Processing Systems 28, pages 2692–2700.
Curran Associates, Inc.
Ronald J. Williams and Jing Peng. 1990. An effi-
cient gradient-based algorithm for on-line train-
ing of recurrent network trajectories. Neural
Computation, 2(4):490–501. https://doi
.org/10.1162/neco.1990.2.4.490
Sam Wiseman, Stuart Shieber, and Alexander
Rush. 2017. Challenges in data-to-document
generation. In Proceedings of the 2017 Con-
ference on Empirical Methods in Natural
Language Processing,
2253–2263,
Copenhagen, Denmark. Association for Com-
putational Linguistics. https://doi.org
/10.18653/v1/D17-1239
pages
Jeff Wu, Long Ouyang, Daniel M. Ziegler,
Nisan Stiennon, Ryan Lowe, Jan Leike, and
Paul F. Christiano. 2021. Recursively sum-
marizing books with human feedback. CoRR,
abs/2109.10862.
In Proceedings of
Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong
He, Alex Smola, and Eduard Hovy. 2016.
Hierarchical attention networks for document
the 2016
classification.
Conference of the North American Chapter
the Association for Computational Lin-
of
guistics: Human Language Technologies,
pages 1480–1489, San Diego, California.
Association for Computational Linguistics.
https://doi.org/10.18653/v1/N16
-1174
Rong Ye, Wenxian Shi, Hao Zhou, Zhongyu Wei,
and Lei Li. 2020. Variational template machine
for data-to-text generation. In International
Conference on Learning Representations.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
8
4
2
0
2
9
9
5
4
/
/
t
l
a
c
_
a
_
0
0
4
8
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
715