DATA PAPER
MDKB-Bot: A Practical Framework for Multi-Domain
Task-Oriented Dialogue System
Yadi Lao, Weijie Liu, Sheng Gao† & Si Li
Pattern Recognition and Intelligence System Laboratory, Beijing University of Posts and Telecommunications, Beijing 100876, China
Keywords: Dialogue system; Knowledge base; Natural language understanding; Slot filling; Natural language
generation
Citation: Y. Lao, W. Liu, S. Gao, & S. Li. MDKB-Bot: A practical framework for multi-domain task-oriented dialogue system.
Data Intelligence 1(2019), 176-186. doi: 10.1162/dint_a_00010
Received: August 27, 2018; Revised: November 30, 2018; Accepted: December 6, 2018
ABSTRACT
One of the major challenges to build a task-oriented dialogue system is that dialogue state transition
frequently happens between multiple domains such as booking hotels or restaurants. Recently, the encoder-
decoder model based on the end-to-end neural network has become an attractive approach to meet this
challenge. However, it usually requires a sufficiently large amount of training data and it is not flexible to
handle dialogue state transition. This paper addresses these problems by proposing a simple but practical
framework called Multi-Domain KB-BOT (MDKB-BOT), which leverages both neural networks and rule-
based strategy in natural language understanding (NLU) and dialogue management (DM). Experiments on
the data set of the Chinese Human-Computer Dialogue Technology Evaluation Campaign show that MDKB-
BOT achieves competitive performance on several evaluation metrics, including task completion rate and
user satisfaction.
1. INTRODUCTION
In the past decade, dialogue systems have become an attractive topic and they can be classified into
open-domain dialogue systems and task-oriented dialogue systems. One general approach to dialogue
system design is to treat it as a retrieval problem by learning the relevance matching score between user
queries and system responses. Inspired by the recent advances in deep learning, building an end-to-end
† Corresponding author: Sheng Gao (Email: gaosheng@bupt.edu.cn; ORCID: 0000-0003-1591-0595).
© 2019 Chinese Academy of Sciences Published under a Creative Commons Attribution 4.0 International (CC BY 4.0)
license
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
1
2
1
7
6
1
4
7
6
6
9
1
d
n
_
a
_
0
0
0
1
0
p
d
t
/
.
i
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
MDKB-Bot: A Practical Framework for Multi-Domain Task-Oriented Dialogue System
dialogue system has been a popular approach for its flexibility and extendibility. For example, encoder-
decoder models based on recurrent neural networks (RNNs) directly maximize the likelihood of the desired
responses when previous dialogue history data are available. However, two major drawbacks of those
systems are that multiple training corpora are required and generic responses such as “I do not know” are
likely to be generated. These drawbacks limit the generalization ability, especially for a task-oriented system
in which knowledge from multiple domains is needed to understand users’ underlying intents.
Compared to end-to-end approach, designing a task-oriented dialogue system as modularized pipeline
is feasible. And each essential component is trained individually, including 1) Natural Language
Understanding (NLU), to specify task domain and user intent and extract slot-value pairs, 2) Dialogue
Manager (DM), to keep tracking the dialogue state and guide users to achieve a desired goal, and 3) Natural
Language Generation (NLG), to generate responses. One of the challenges for a task-oriented dialogue
system is that dialogue state transition frequently happens between multiple domains. If earlier components
make mistakes in slot value extraction and errors are accumulated, the entire system’s functionality will be
severely impaired.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
To address the complex dialogue state transition problem, we adopt the architecture of modularized
pipeline and propose a multi-domain KB-BOT (MDKB-BOT), which leverages both rule extraction and
neural networks. We run the evaluation experiments on the data set of the Chinese Human-Computer
Dialogue Technology Evaluation Campaign and experimental results show that MDKB-BOT can robustly
fulfill the frequent changes of user intent among three domains (flight, train and hotel) and achieve
competitive scores based on human evaluation metrics.
2. RELATED WORK
As mentioned before, there have been a lot of research efforts in applying deep learning to task-oriented
dialogue systems. One of the most effective approaches is to build a modularized pipeline system by
connecting NLU, DM and NLG together. Traditional approach to NLU is to model domain classification/
intent detection as sentence classification while treating slot value pairs extraction as a sequence labeling
task. A desirable NLU system should not be sensitive to intent error and slot error, especially for slot filling.
For example, Xu and Sarikaya [1] applied a RNN to perform contextual domain classification and used a
triangular conditional random field (CRF) based on a convolutional neural network for intent detection and
slot filling. Jaech, Heck and Ostendorf [2] applied multi-task learning to achieve the goal to leverage
knowledge of source domains with rich data to improve the performance on the target domain with little
data. Bapna et al. [3] explored the role of context information in NLU via injecting previous dialogues into
a RNN based encoder and a memory network.
On the other hand, many attempts have been made to improve the architecture of DM. Recent research
indicates that reinforcement learning (DL) holds promise for planning a dialogue policy based on the current
dialogue state. Williams, Asadi and Zweig [4] proposed a model called Hybrid Code Networks (HCNs),
which is a mixture of supervised learning and reinforcement learning. HCNs select a dialogue action every
step by optimizing the reward for completing a task with policy gradient [5]. Faced with the sparse nature
Data Intelligence
177
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
1
2
1
7
6
1
4
7
6
6
9
1
d
n
_
a
_
0
0
0
1
0
p
d
.
t
/
i
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
MDKB-Bot: A Practical Framework for Multi-Domain Task-Oriented Dialogue System
of the reward signal in RL, Peng et al. [6] designed an end-to-end framework for hierarchical RL where a
MANAGER is used to choose current goal (like a specific domain task) and a WORKER is used to take
actions and help users finish the current subtask. Inspired by recent advances in RL, Mrksˇíc et al. [7]
introduced a belief tracker that can overcome the drawback of requiring a large amount of hand-crafted
lexicons to capture some of the linguistic variation in users’ language. Their Neural Belief Tracking (NBT)
models can reason over pre-trained word embeddings of system output, user utterance and candidate pairs
in databases.
As for NLG, most of the current work applied information retrieval technique to a large query-response
database, or used template-based methods with a set of rules to map frames to natural language or
generation models. Dusˇek and Jurcˇícˇek [8] encoded frames based on the syntax tree and used the seq2seq
model for generation.
3. PROPO SED FRAMEWORK
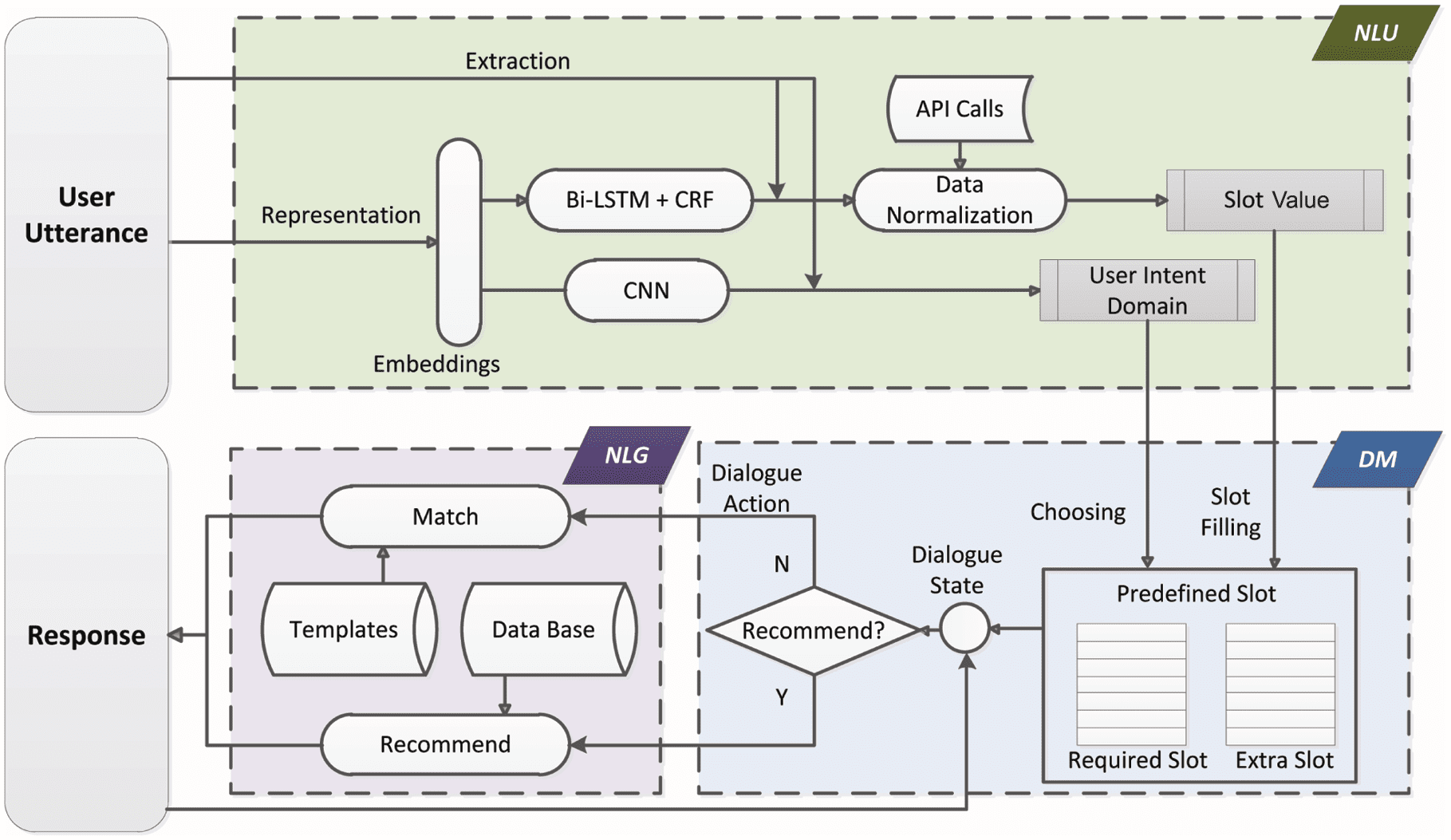
The proposed framework is illustrated in Figure 1, which includes NLU, DM and NLG. The implementation
of these components is described from Section 3.1 to Section 3.3.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
1
2
1
7
6
1
4
7
6
6
9
1
d
n
_
a
_
0
0
0
1
0
p
d
t
/
.
i
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Figure 1. The overall framework of the model consists of three components: (1) NLU module, which predicts
intent domain and gives slot value of user utterance, (2) DM module, which outputs the dialogue action to NLG
module, and (3) NLG module, which generates the fi nal response.
178
Data Intelligence
MDKB-Bot: A Practical Framework for Multi-Domain Task-Oriented Dialogue System
3.1 Natura l Language Understanding (NLU)
The main tasks for NLU involve domain classification, intent detection and slot filling as illustrated in
Figure 1.
3.1.1 Domain Classification
A convolutional neural network proposed by Kim [9] was adopted in domain classification. Let W ∈Rv*d
be the d dimensional word embedding table, where v is the vocabulary size. Then sentence semantic
representation of user query X ∈Rn*d is obtained by looking up each word in W, where n is the number
of words in this query. Then 1-D convolutional layer is adopted on X to extract n-gram features. However,
in a convolutional neural network (CNN) errors may happen in some cases containing several domains’
descriptions. For example, “The train is cheaper, but to save time, give me airline flight schedules and flight
timetables.” Thus, for our online model, some rule strategies are used to deal with this misclassification
problem by constructing a keyword list from both corpora and databases, e.g., city name list.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
1
2
1
7
6
1
4
7
6
6
9
1
d
n
_
a
_
0
0
0
1
0
p
d
t
.
/
i
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
3.1.2 Slot Fil ling
Slot filling is treated as a name entity recognition task where the popular bigin-in-out (BIO) format is
used for representing tags of each word in a query. Then Long Short-Term Memory (LSTM) scans the words
and outputs the representation:
f
k
i
k
o
k
~ =
c
k
s
= (
+
W x U h
k
k
f
f
s
= (
+
W x U h
i k
i k
+
+
−
1
−
1
b
f
),
b
i
),
s
= (
+
W x U h
o k
o k
+
−
1
b
o
),
tanh W x U h
c k
c k
(
+
+
−
1
b
c
),
c
k
=
f
k
c
− +
1
k
i
k
~
c
,k
h
k
=
o
k
tanh c
(
).
k
(1)
(2)
(3)
(4)
(5)
(6)
To enhance the ability to extract slot value pairs, a CRF network is connected to the output of LSTM or
bidirectional LSTM (BLSTM). Then the score of a sentence X along with a path of tags Y can be calculated
as the sum of the transition score A and the LSTM network score f:
S X Y
,
(
,
T
∑h
) =
(
[
A
]
Y
t
−
Y
,
t
1
+
[
f
J
]
Yt X
,
t
)
,
t
=1
where h is the trainable parameter of the LSTM network.
Data Intelligence
(7)
179
MDKB-Bot: A Practical Framework for Multi-Domain Task-Oriented Dialogue System
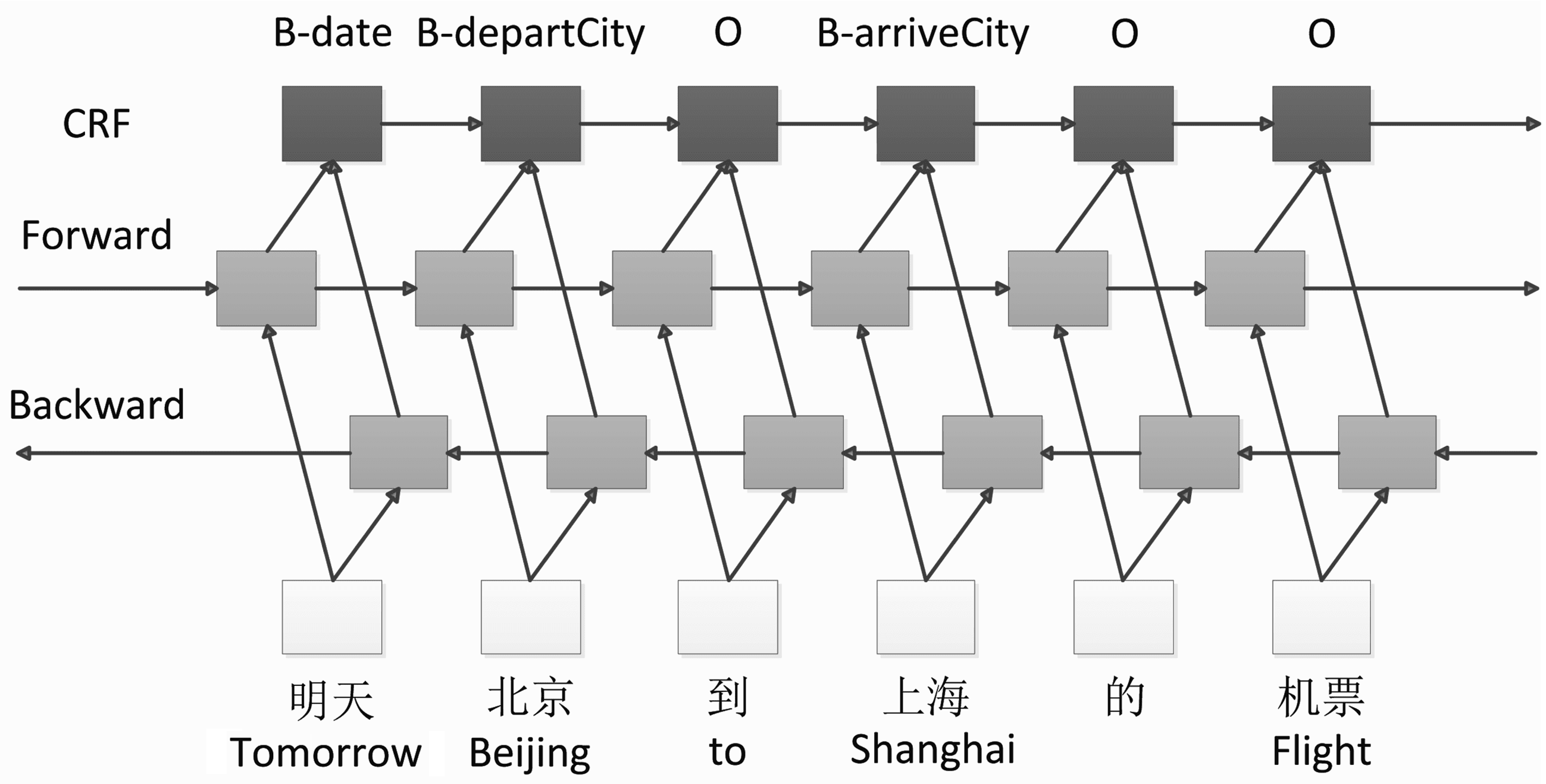
Figure 2 shows a bidirectional LSTM network enhanced with a CRF network on the top layer. For our
online model, we apply both keyword matching and BLSTM-CRF to avoid cases like diverse or nonstandard
expressions.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
Figure 2. BLSTM-CRF model for slot fi lling.
l
a
r
t
i
c
e
–
p
d
f
/
3.1.3 Intent Detection
Based on slots extracted from BLSTM-CRF, we update the maintained dialogue state template. Then user
intent is inferred by comparing the predefined dialogue template with the new state template.
3.2 Dialogue Manageme nt (DM)
/
/
/
1
2
1
7
6
1
4
7
6
6
9
1
d
n
_
a
_
0
0
0
1
0
p
d
t
/
.
i
After the NLU module, we obtain the output of NLU that includes the user intent domain and the slot
value of the current turn.
In order to avoid too many unnecessary turns of dialogue on some insignificant information for many
users, we divide all of the slots into two categories: required slots and extra slots. The required slots, like
users who do not care them, such as
slots necessary for booking, but if a user mentions extra slots in the dialogue, we will consider it while
retrieving the information from our data base.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
To regulate the dialogue course when our system interacts with users, DM module is then applied to
update the conversation state and the next dialogue action. We divide this module into three states. The
detailed procedures are described as follows.
180
Data Intelligence
MDKB-Bot: A Practical Framework for Multi-Domain Task-Oriented Dialogue System
•
•
•
Initial state At the beginning of the conversation, utterance with no explicit intention will be
considered a purposeless talk. After identifying a user’s intent, the system will turn into the slot filling
state. Note that the system will store the slot information even before domain prediction, and the
information will be distributed to the corresponding slot afterward.
Slot filling state The main task at this state is to interactively interact with the user to obtain the
required slot information for generating responses.
Recommendation state Our bot will list the results that can adapt to users’ demands by retrieval
and extraction of the data base. In case of failure, we set a series of strategies for similar
recommendations, such as: (1) remove the limitations of extra slots, (2) make appropriate adjustments
for the departure time, (3) change the cabin or train type, and (4) increase the price range. In addition,
users can change their requests and return to the slot filling state or recommendation state again.
Throughout the whole process of the dialogue, when the system finds that an intent cannot be completed,
it will prompt the user in time to avoid wasting time. For example, when a user wants to book a flight to
a city where no air service is available, it is unwise to continue the dialogue with the user, and the system
will recommend other means of traveling. A user can also change his or her intent anytime, and our system
will store the common information of slots automatically at the transformation process.
3.3 Natural Language Generation (NLG)
So far, we have obtained both the category of a user query’s intention and the next dialogue action each
turn, which guide the NLG module to generate natural language texts and replay the user’s query. Given
the user’s slots list, we convert it into the SQL statement, then retrieve from the date base which stores
information on trains, flights and accomendations, to check if there are eligible items for the user’s goal,
and match the appropriate template for replay.
Because of the shortage of the large-scale dialogue corpus in these domains, we generate the utterance
by the template-based NLG, which means we need to capture every case of different slot states to presuppose
the dialogue template. In this way, once the user dialogue actions are found in the predefined sentence
templates, we will replace the slot value with user history information. One advantage is that it can ensure
the controllability of the response given to users.
4. EXPERIMENTS
In th e Chinese Human-Computer Dialogue Technology Evaluation Campaign, a task-oriented dialogue
system is developed to help users book flights, trains and hotels.
Data Intelligence
181
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
1
2
1
7
6
1
4
7
6
6
9
1
d
n
_
a
_
0
0
0
1
0
p
d
.
/
t
i
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
MDKB-Bot: A Practical Framework for Multi-Domain Task-Oriented Dialogue System
4.1 Data Sets
Since o nly three databases are provided, we extend the data set of task 1 for domain classification and
rule extraction. We also annotate a 300-dialogue corpus (about 1,500 sentences for training) with slot labels
for evaluating LSTM-CRF and BLSTM-CRF models. Table 1 and Table 2 show the details of the data set.
Table 1. The statistics of training corpus for domain classifi cation.
#sentence
Train
533
Flight
510
Hotel
512
Others
588
Table 2. The statistics of training corpus for slot fi lling.
#label
Flight
15
Hotel
5
#sentence
Avg. sentence length
(word)
1,013
5.86
Train
13
4.2 Evaluation
For slot filling in NLU, the entity-level prediction F1 score of common name entity recognition is adopted.
However, dialogue evaluation still remains to be a difficult task. We use the evaluation metrics of the
Chinese Human-Computer Dialogue Technology Evaluation Campaign, including task completion rate, user
satisfaction score, dialogue naturalness, number of turns and robustness of uncovered cases.
5. DISCUSSION
Table 3 shows the results of slot filling. We compare the performance of LSTM-CRF and BLSTM-CRF
with unigram and unigram plus bigram separately. As illustrated, accuracy can increase by 1.7% when
considering word sequence order with BLSTM. Using bigram feature can be of help for LSTM-CRF, though
it is worse for BLSTM as the average length of bigram sequence is short. One possible way is to use character
embedding instead of word embedding.
Table 3. Comparison of labeling performance on NLU.
Feature
Unigram
Unigram + bigram
LSTM-CRF
85.93%
86.20%
BLSTM-CRF
87.63%
87.21%
Table 4 illustrates the performance of our system according to the evaluation metrics mentioned before.
Most of the metrics are annotated manually except for the average dialogue turn. our system obtained the
best score on user satisfaction, dialogue naturalness and boot ability due to the reasonable dialogue intent
transition template we predefined. But this leads to a decline in task performance, especially when the user
intent is not identified or the important slot value is not extracted correctly.
182
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
1
2
1
7
6
1
4
7
6
6
9
1
d
n
_
a
_
0
0
0
1
0
p
d
t
/
.
i
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
MDKB-Bot: A Practical Framework for Multi-Domain Task-Oriented Dialogue System
Table 4. Dialogue quality evaluation results between top 4 teams in the competition.
Metric
ShenSiKao
PuTaoWeiDu
MDKB-BOT
ChuMenWenWen
Completion rate
#turn
User satisfaction
Naturalness
Boot ability
6. CONCLUSION
31.75
64.53
0
-1
2
19.05
72.28
-1
1
3
19.05
78.72
0
1
3
11.11
71.39
-2
-1
3
In this paper, we proposed a simple but practical framework for multi-domain task-oriented dialogue
system. Our model leverages both neural network and rule-based strategy to handle the domain transition
problem. It achieves competitive results on the Chinese Human-Computer Dialogue Technology Evaluation
Campaign, especially for user-friendliness and utterance guidance metrics. For future work, we are going
to apply end-to-end neural networks to NLG based on the information extracted and maintained in NLU
and DM to improve the system performance.
AUTHOR CONTRIBUTIONS
Y. Lao (laoyadi@bupt.edu.cn) and W. Liu (liuweijie@bupt.edu.cn) are the leaders of the MDKB-Bot
system, who drew the whole framework of the system. S. Gao (gaosheng@bupt.edu.cn, corresponding
author) and S. Li (lisi@bupt.edu.cn) summarized the applications and drafted the paper. All authors
participated in the revision of the manuscript.
ACKNOWLEDGEMENTS
This work was supported by Beijing Natural Science Foundation (No. 4174098), National Natural Science
Foundation of China (No. 61702047) and the Fundamental Research Funds for the Central Universities
(No. 2017RC02).
REFERENCES
[1] P. Xu, & R. Sarikaya. Contextual domain classification in spoken language understanding systems using
recurrent neural network. In: IEEE International Conference on Acoustics, Speech and Signal Processing
(ICASSP), 2014, pp. 136–140. doi: 10.1109/ICASSP.2014.6853573.
[2] A. Jaech, L. Heck, & M. Ostendorf. Domain adaptation of recurrent neural networks for natural language
understanding. doi: 10.21437/Interspeech.2016-1598.
[3] A. Bapna, G. Tür, D. Hakkani-Tür, & L. Heck. Sequential dialogue context modeling for spoken language
understanding. In: Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, 2017,
pp. 103–114. doi: 10.18653/v1/W17-5514.
Data Intelligence
183
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
1
2
1
7
6
1
4
7
6
6
9
1
d
n
_
a
_
0
0
0
1
0
p
d
/
.
t
i
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
MDKB-Bot: A Practical Framework for Multi-Domain Task-Oriented Dialogue System
[4]
J.D. Williams, K. Asadi, & G. Zweig. Hybrid code networks: Practical and efficient end-to-end dialogue
control with supervised and reinforcement learning. arXiv preprint. arXiv: 1702.03274, 2017.
[5] R.J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning.
Machine learning 8(3-4)(1992), 229–256. doi: 10.1007/BF00992696.
[6] B. Peng, X. Li, L. Li, J. Gao, A. Celikyilmaz, S. Lee, & K.-F. Wong. Composite task-completion dialogue policy
learning via hierarchical deep reinforcement learning. In: Proceedings of the 2017 Conference on Empirical
Methods in Natural Language Processing, 2017, pp. 2221–2230. doi: 10.18653/v1/D17-1237.
[7] N. Mrksˇíc, D.O. Śeaghdha, T.-H. Wen, B. Thomson, & S. Young. Neural belief tracker: Data-driven dialogue
state tracking. arXiv preprint. arXiv:1606.03777, 2016.
[8] O. Dusˇek, & F. Jurcˇícˇek. Sequence-to-sequence generation for spoken dialogue via deep syntax trees and
strings. arXiv preprint. arXiv:1606.05491, 2016.
[9] Y. Kim. Convolutional neural networks for sentence classification. arXiv preprint. arXiv:1408.5882, 2014.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
1
2
1
7
6
1
4
7
6
6
9
1
d
n
_
a
_
0
0
0
1
0
p
d
t
.
/
i
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
184
Data Intelligence
MDKB-Bot: A Practical Framework for Multi-Domain Task-Oriented Dialogue System
AUTHOR BIOGRAPHY
Yadi Lao is currently a master student in Pattern Recognition and Intelligent
System Laboratory, School of Information and Communication Engineering,
Beijing University of Posts and Telecommunications. She received her
Bachelor Degree from Beijing University of Posts and Telecommunications in
2016. Her research interests include natural language processing and
reinforcement learning. She is the system designer of MDKB-Bot.
Weijie Liu is currently a master student in Pattern Recognition and Intelligent
System Laboratory, School of Information and Communication Engineering,
Beijing University of Posts and Telecommunications. He received his Bachelor
Degree from Central South University of Forestry and Technology in 2016.
His research interests include natural language processing and machine
reading comprehension. He is the system designer of MDKB-Bot.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
1
2
1
7
6
1
4
7
6
6
9
1
d
n
_
a
_
0
0
0
1
0
p
d
.
/
t
i
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Data Intelligence
185
MDKB-Bot: A Practical Framework for Multi-Domain Task-Oriented Dialogue System
Gao Sheng received his PhD Degree from the Sixth University of Paris,
France in 2011. He is now an associate professor in Pattern Recognition and
Intelligent System Laboratory, School of Information and Communication
Engineering, Beijing University of Posts and Telecommunications, member of
the Big Data Professional Committee of the Chinese Computer Society (CCF),
expert of the National Natural Science Foundation, and guest researcher of
the Sixth University of Paris, France. He was selected as the “Young Talents”
Program of Beijing and the “Star-casting Program” of Microsoft Asia Research
Institute. More than 30 papers have been published in international well-
known journals and conferences such as IEEE Transactions on Emerging
Topics in Computing, Knowledge-Based Systems, International Conference
on Data Mining and Knowledge Discovery (DMKD), AAAI Conference on
Artificial Intelligence, International World Wide Web Conference (WWW),
the Industrial Conference on Data Mining (ICDM), the European Conference
on Machine Learning (ECML) and European Conference on Information
Retrieval (ECIR). Research directions: machine learning and natural language
processing, information recommendation, social network analysis, etc.
Li Si received her PhD Degree in Signal and Information Processing from
Beijing University of Posts and Telecommunications in 2012. She is now
working as a lecturer in Pattern Recognition and Intelligent System Laboratory,
School of Information and Communication Engineering, Beijing University of
Posts and Telecommunications. Her research interests are natural language
processing and information extraction. She published many papers in Annual
Meeting of the Association for Computational Linguistics (ACL), International
Conference on Research on Development in Information Retrieval (SIGIR),
Conference on Empirical Methods in Natural Language Processing (EMNLP)
and other top-level conferences.
186
Data Intelligence
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
d
n
/
i
t
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
1
2
1
7
6
1
4
7
6
6
9
1
d
n
_
a
_
0
0
0
1
0
p
d
/
t
.
i
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3