CausaLM: Causal Model Explanation
Through Counterfactual Language Models
Amir Feder
Faculty of Industrial Engineering and
Management
Technion – Israel Institute of Technology
feder@campus.technion.ac.il
Nadav Oved
Faculty of Industrial Engineering and
Management
Technion – Israel Institute of Technology
nadavo@campus.technion.ac.il
Uri Shalit
Faculty of Industrial Engineering and
Management
Technion – Israel Institute of Technology
urishalit@technion.ac.il
Roi Reichart
Faculty of Industrial Engineering and
Management
Technion – Israel Institute of Technology
roiri@technion.ac.il
Understanding predictions made by deep neural networks is notoriously difficult, but also crucial
to their dissemination. As all machine learning–based methods, they are as good as their training
data, and can also capture unwanted biases. While there are tools that can help understand
whether such biases exist, they do not distinguish between correlation and causation, and might
be ill-suited for text-based models and for reasoning about high-level language concepts. A key
problem of estimating the causal effect of a concept of interest on a given model is that this
estimation requires the generation of counterfactual examples, which is challenging with existing
generation technology. To bridge that gap, we propose CausaLM, a framework for producing
causal model explanations using counterfactual language representation models. Our approach
is based on fine-tuning of deep contextualized embedding models with auxiliary adversarial tasks
derived from the causal graph of the problem. Concretely, we show that by carefully choosing
Submission received: 14 June 2020; revised version received: 9 February 2021; accepted for publication:
4 March 2021.
https://doi.org/10.1162/COLI a 00404
© 2021 Association for Computational Linguistics
Published under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International
(CC BY-NC-ND 4.0) license
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
auxiliary adversarial pre-training tasks, language representation models such as BERT can
effectively learn a counterfactual representation for a given concept of interest, and be used to
estimate its true causal effect on model performance. A byproduct of our method is a language
representation model that is unaffected by the tested concept, which can be useful in mitigating
unwanted bias ingrained in the data.1
1. Introduction
The rise of deep learning models (deep neural networks [DNNs]) has produced better
prediction models for a plethora of fields, particularly for those that rely on unstruc-
tured data, such as computer vision and natural language processing (NLP) (Peters
et al. 2018; Devlin et al. 2019). In recent years, variants of these models have dissem-
inated into many industrial applications, varying from image recognition to machine
translation (Szegedy et al. 2016; Wu et al. 2016; Aharoni, Johnson, and Firat 2019).
In NLP, they were also shown to produce better language models, and are being
widely used both for language representation and for classification in nearly every sub-
field (Tshitoyan et al. 2019; Gao, Galley, and Li 2018; Lee et al. 2020; Feder et al. 2020).
Although DNNs are very successful, this success has come at the expense of model
explainability and interpretability. Understanding predictions made by these models is
difficult, as their layered structure coupled with non-linear activations do not allow us
to reason about the effect of each input feature on the model’s output. In the case of text-
based models, this problem is amplified. Basic textual features are usually composed of
n-grams of adjacent words, but these features alone are limited in their ability to encode
meaningful information conveyed in the text. While abstract linguistic concepts, such as
topic or sentiment, do express meaningful information, they are usually not explicitly
encoded in the model’s input.2 Such concepts might push the model toward making
specific predictions, without being directly modeled and therefore interpreted.
Effective concept-based explanations are crucial for the dissemination of DNN-
based NLP prediction models in many domains, particularly in scientific applications to
fields such as healthcare and the social sciences that often rely on model interpretability
for deployment. Failing to account for the actual effect of concepts on text classifiers
can potentially lead to biased, unfair, misinterpreted and incorrect predictions. As
models are dependent on the data they are trained on, a bias existing in the data could
potentially result in a model that under-performs when this bias no longer holds in the
test set.
Recently, there have been many attempts to build tools that allow for DNN ex-
planations and interpretations (Ribeiro, Singh, and Guestrin 2016; Lundberg and Lee
2017), which have developed into a sub-field often referred to as Blackbox-NLP (Linzen
et al. 2019). These tools can be roughly divided into local explanations, where the effect
of a feature on the classifier’s prediction for a specific example is tested, and global
explanations, which measure the general effect of a given feature on a classifier. A
prominent research direction in DNN explainability involves utilizing network artifacts
such as attention mechanisms, which are argued to provide a powerful representation
tool (Vaswani et al. 2017) to explain how certain decisions are made (but see Jain and
Wallace [2019] and Wiegreffe and Pinter [2019] for a discussion of the actual explanation
1 Our code and data are available at: https://amirfeder.github.io/CausaLM/.
2 By concept, we refer to a higher level, often aggregated unit, compared to lower level, atomic input
features such as words. Some examples of linguistic concepts are sentiment, linguistic register, formality,
or topics discussed in the text. For a more detailed discussion of concepts, see Kim et al. (2018) and Goyal
et al. (2019a).
334
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
power of this approach). Alternatively, there have been attempts to estimate simpler,
more easily interpretable models around test examples or their hidden representa-
tions (Ribeiro, Singh, and Guestrin 2016; Kim et al. 2018).
Unfortunately, existing model explanation tools often rely on local perturbations
of the input and compute shallow correlations, which can result in misleading, and
sometimes wrong, interpretations. This problem arises, for example, in cases where two
concepts that can potentially explain the predictions of the model are strongly correlated
with each other. An explanation model that only considers correlations cannot indicate
if the first concept, the second concept, or both concepts are in fact the cause of the
prediction.
In order to illustrate the importance of causal and concept-based explanations, con-
sider the example presented in Figure 1, which will be our running example throughout
the paper. Suppose we have a binary classifier, trained to predict the sentiment con-
veyed in news articles. Say we hypothesize that the choice of adjectives is driving the
classification decision, something that has been discussed previously in computational
linguistics (Pang, Lee, and Vaithyanathan 2002). However, if the text is written about
a controversial figure, it could be that the presence of its name, or the topics that it
induces, are what is driving the classification decision, and not the use of adjectives. The
text in the figure is an example of such a case, where both adjectives and the mentioning
of politicians seem to affect one another, and could be driving the classifier’s prediction.
Estimating the effect of Donald Trump’s presence in the text on the predictions of the
model is also hard, as this presence clearly affects the choice of adjectives, the other
political figures mentioned in the text, and probably many additional textual choices.
Notice that an explanation model that only considers correlations might show that
the mention of a political figure is strongly correlated with the prediction, leading to
worries about the classifier having political bias. However, such a model cannot indicate
whether the political figure is in fact the cause of the prediction, or whether it is actually
the type of adjectives used that is the true cause of the classifier output, suggesting that
the classifier is not politically biased. This highlights the importance of causal concept-
based explanations.
A natural causal explanation methodology would be to generate counterfactual
examples and compare the model prediction for each example with its prediction for the
counterfactual. That is, one needs a controlled setting where it is possible to compute
President Trump did his best imitation of Ronald Reagan at the State of the Union
address, falling just short of declaring it Morning in America, the iconic imagery
and message of a campaign ad that Reagan rode to re-election in 1984. Trump
talked of Americans as pioneers and explorers; he lavished praise on members of
the military, several of whom he recognized from the podium; he optimistically
declared that the best is yet to come. It was a masterful performance – but behind
the sunny smile was the same old Trump: petty, angry, vindictive and deceptive.
He refused to shake the hand of House Speaker Nancy Pelosi, a snub she returned
in kind by ostentatiously ripping up her copy of the President’s speech at the
conclusion of the address, in full view of the cameras.
Figure 1
An example of a political commentary piece published at https://edition.cnn.com.
Highlighted in blue and red are names of political figures from the US Democratic and
Republican parties, respectively. Adjectives are highlighted in green.
335
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
the difference between an actual observed text, and what the text would have been had
a specific concept (e.g., a political figure) not existed in it. Indeed, there have been some
attempts to construct counterfactuals for generating local explanations. Specifically,
Goyal et al. (2019b) proposed changing the pixels of an image to those of another
image classified differently by the classifier, in order to compute the effect of those
pixels. However, as this method takes advantage of the spatial structure of images, it
is hard to replicate their process with texts. Vig et al. (2020) offered to use mediation
analysis to study which parts of the DNN are pushing toward specific decisions by
querying the language model. Although their work further highlights the usefulness of
counterfactual examples for answering causal questions in model interpretation, they
create counterfactual examples manually, by changing specific tokens in the original
example. Unfortunately, this does not support automatic estimation of the causal effect
that high-level concepts have on model performance.
Going back to our example (Figure 1), training a generative model to condition on
a concept, such as the choice of adjectives, and produce counterfactual examples that
only differ by this concept, is still intractable in most cases involving natural language
(see Section 3.3 for a more detailed discussion). While there are instances where this
seems to be improving (Semeniuta, Severyn, and Barth 2017; Fedus, Goodfellow, and
Dai 2018), generating a version of the example where a different political figure is
being discussed while keeping other concepts unaffected is very hard (Radford et al.
2018, 2019). Alternatively, our key technical observation is that instead of generating a
counterfactual text we can more easily generate a counterfactual textual representation,
based on adversarial training.
It is important to note that it is not even necessarily clear what the concepts are that
should be considered as the “generating concepts” of the text.3 In our example we only
consider adjectives and the political figure, but there are other concepts that generate
the text, such as the topics being discussed, the sentiment being conveyed, and others.
The number of concepts that would be needed and their coverage of the generated text
are also issues that we touch on below. The choice of such control concepts depends on
our model of the world, as in the causal graph example presented in Figure 2 (Section 3).
In our experiments we control for such concepts, as our model of the world dictates
both treated concepts and control concepts.4
In order to implement the above principles, in this article we propose a model
explanation methodology that manipulates the representation of the text rather than
the text itself. By creating a text encoder that is not affected by a specific concept
of interest, we can compute the counterfactual representation. Our explanation method,
which we name Causal Model Explanation through Counterfactual Language Models
(CausaLM), receives the classifier’s training data and a concept of interest as input,
and outputs the causal effect of the concept on the classifier in the test set. It does
that by pre-training an additional instance of the language representation model used
by the classifier, with an adversarial component designed to “forget” the concept of
choice, while keeping the other “important” (control) concepts represented. Following
3 Our example also sheds more light on the nature of a concept. For example, if we train a figure classifier
on the text after deleting the name of the political figure, it will probably still be able to classify the text
correctly according to the figure it discusses. Hence, a concept is a more abstract entity, referring to an
entire “semantic space/neighbourhood.”
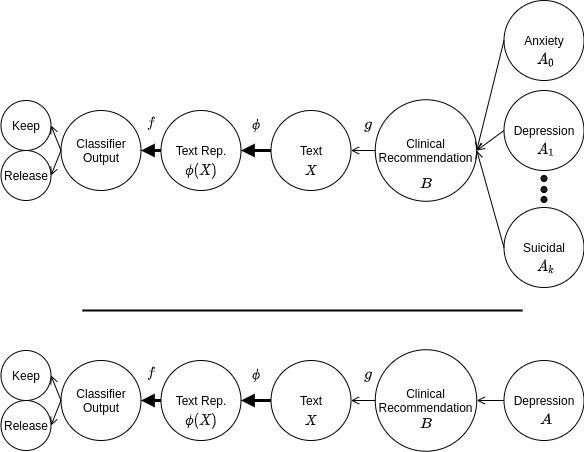
4 While failing to estimate the causal effect of a concept on a sentiment classifier is harmful, it pales in
comparison to the potential harm of wrongfully interpreting clinical prediction models. In Appendix A
we give an example from the medical domain, where the importance of causal explanations has already
been established (Zech et al. 2018).
336
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
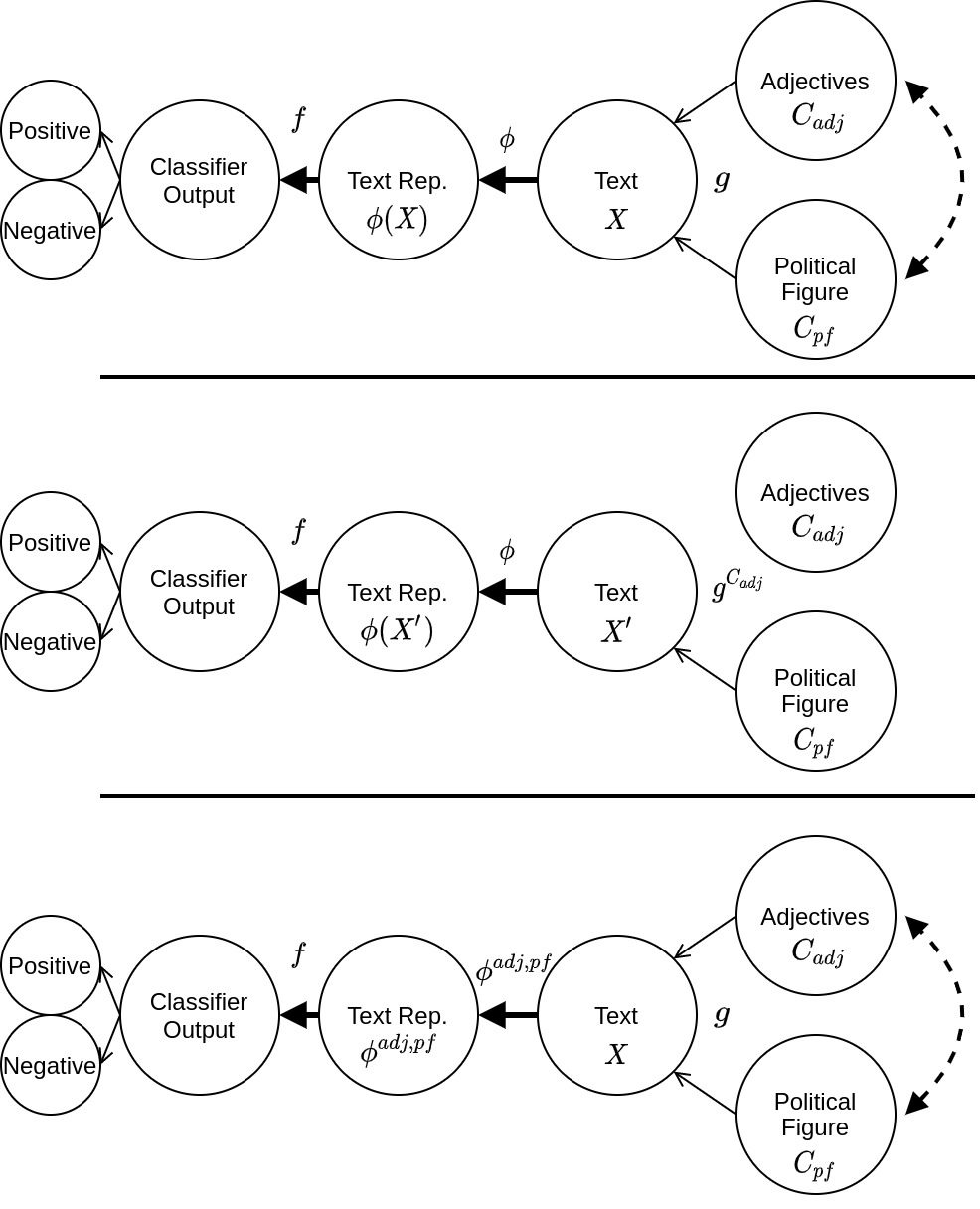
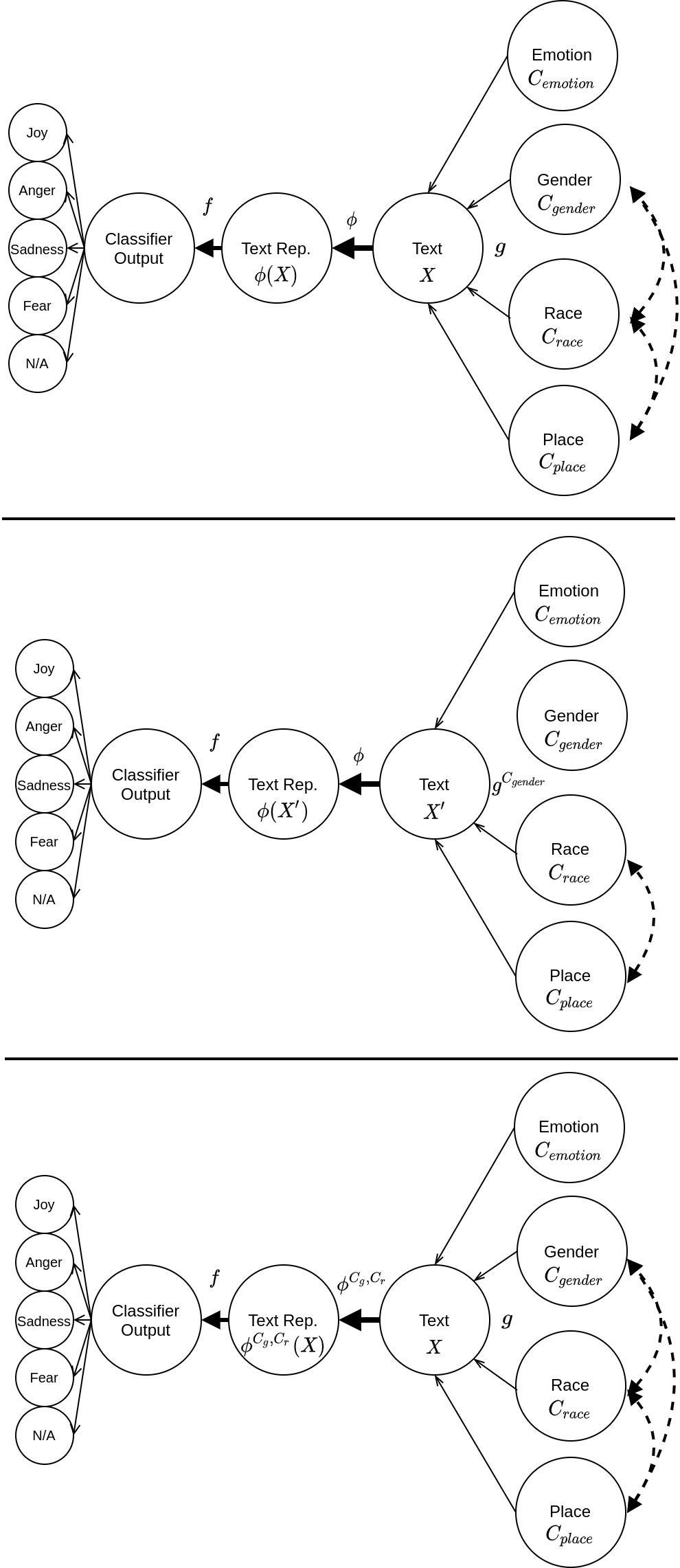
Figure 2
Three causal graphs relating the concepts of Adjectives and Political Figure, texts, their
representations, and classifier output. The top graph describes the original data-generating
process g. The middle graph describes the case of directly manipulating the text. In this case,
using the generative process gCadj allows us to generate a text X(cid:48) that is the same as X but does
not contain Adjectives. The bottom graph describes our approach, where we manipulate the
representation mechanism and not the actual text. The dashed edge indicates a possible hidden
confounder of the two concepts.
the additional training step, the representation produced by this counterfactual model
can be used to measure the concept’s effect on the classifier’s prediction for each test
example, by comparing the classifier performance with the two representations.
We start by diving into the link between causality and interpretability (Section 2).
We then discuss how to estimate causal effects from observational data using language
representations (Section 3): Defining the causal estimator (Section 3.1 and 3.2), dis-
cussing the challenges of producing counterfactual examples (Section 3.3), and, with
those options laid out, moving to describe how we can approximate counterfactual ex-
amples through manipulation of the language representation (Section 3.3). Importantly,
our concept-based causal effect estimator does not require counterfactual examples—it
works solely with observational data.
To test our method, we introduce in Section 4 four novel data sets, three of which
include counterfactual examples for a given concept. Building on those data sets, we
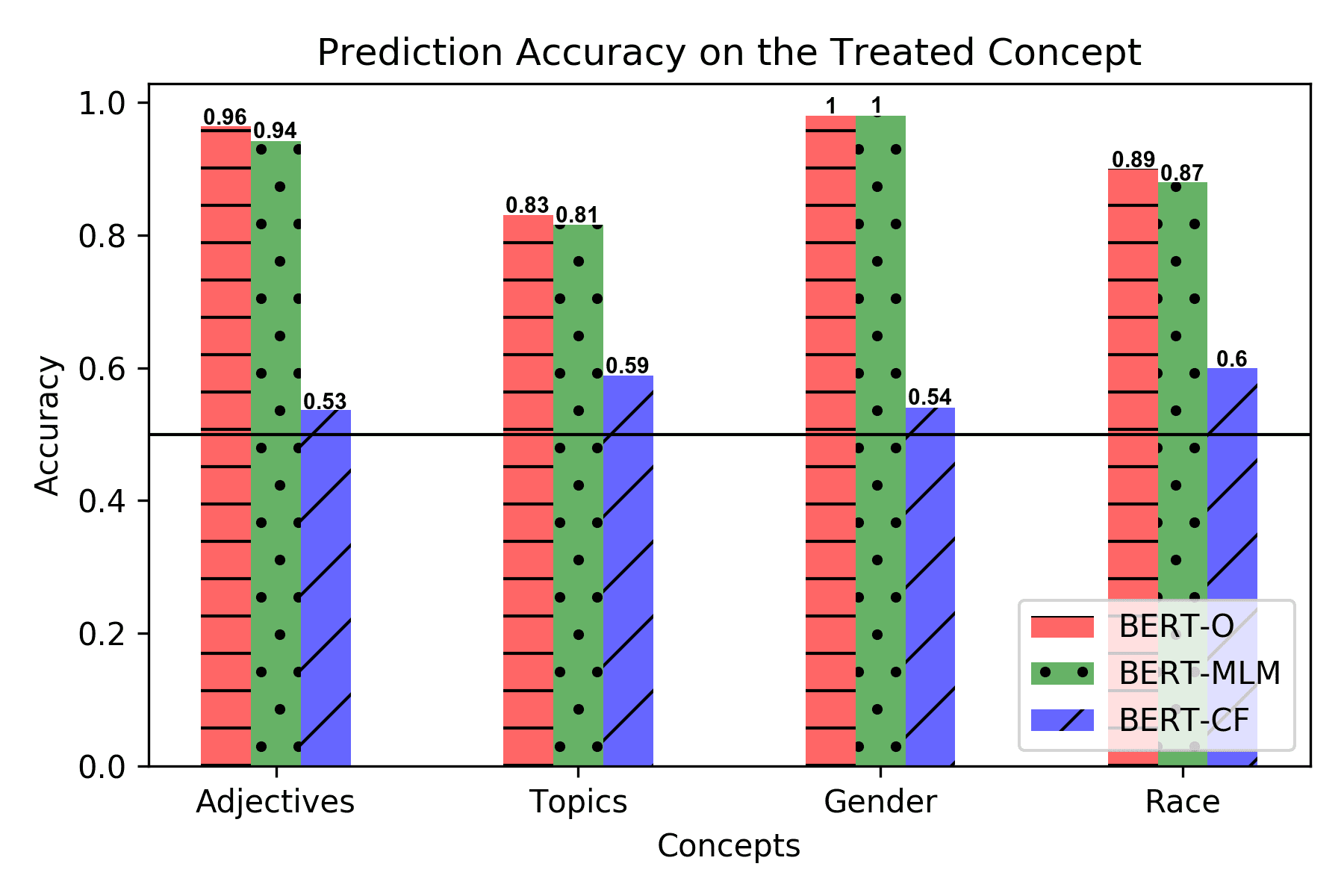
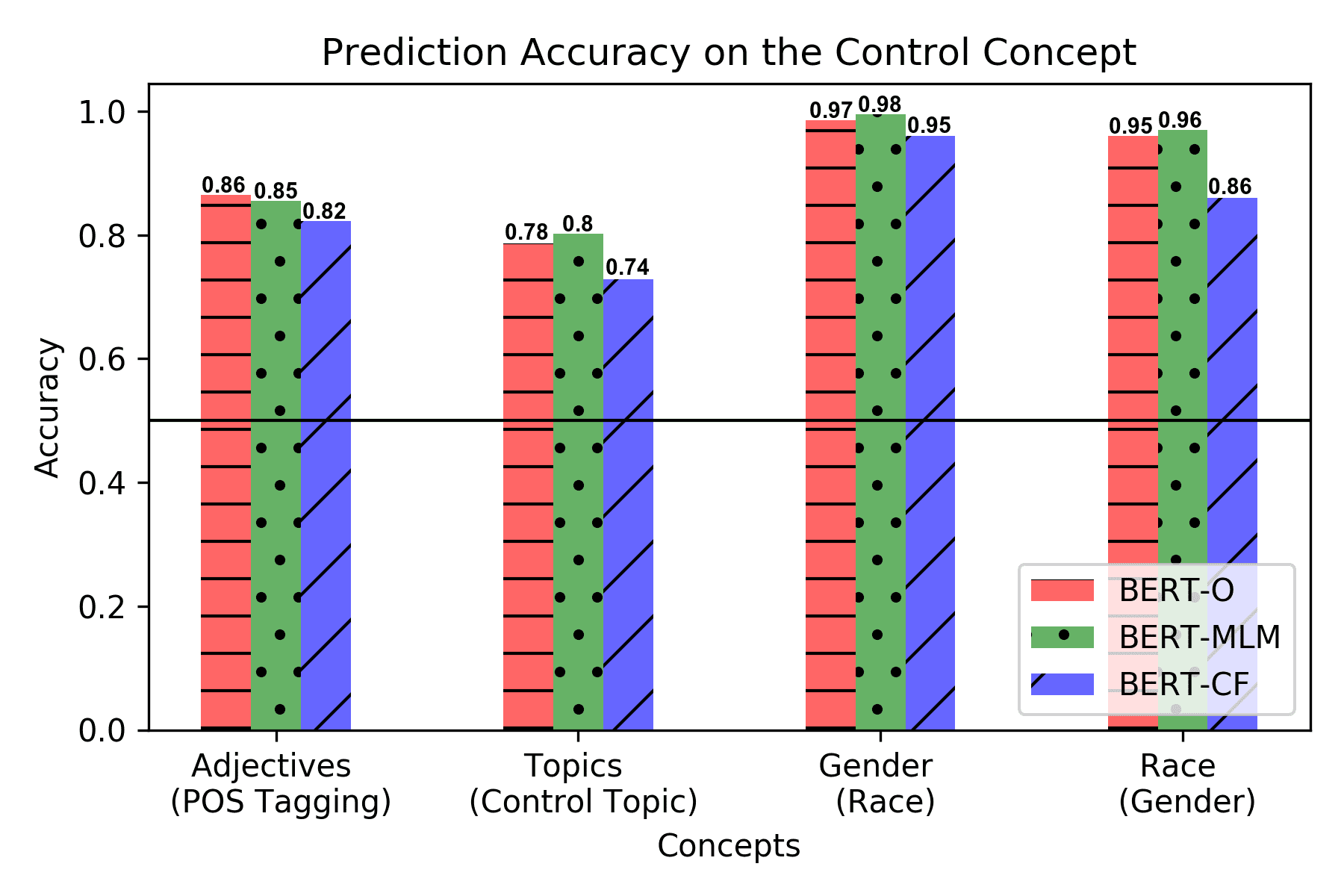
present in Section 5 four cases where a BERT-based representation model can be mod-
ified to ignore concepts, such as Adjectives, Topics, Gender, and Race, in various settings
involving sentiment and mood state classification (Section 5). To prevent a loss of
information on correlated concepts, we further modify the representation to remember
such concepts while forgetting the concept whose causal effect is estimated. Although
in most of our experiments we test our methods in controlled settings, where the true
causal concept effect can be measured, our approach can be used in the real world,
337
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
where such ground truth does not exist. Indeed, in our analysis we provide researchers
with tools to estimate the quality of the causal estimator without access to gold standard
causal information.
Using our newly created data sets, we estimate the causal effect of concepts on a
BERT-based classifier utilizing our intervention method and compare it with the ground
truth causal effect, computed with manually created counterfactual examples (Section 6).
To equip researchers with tools for using our framework in the real world, we provide
an analysis of what happens to the language representation following the intervention,
and discuss how to choose adversarial training tasks effectively (Section 6.2). As our
approach relies only on interventions done prior to the supervised task training stage, it
is not dependent on BERT’s specific implementation and can be applied whenever a pre-
trained language representation model is used. We also show that our counterfactual
models can be used to mitigate unwanted bias in cases where its effect on the classifier
can negatively affect outcomes. Finally, we discuss the strengths and limitations of our
approach, and propose future research directions at the intersection of causal inference
and NLP model interpretation (Section 7).
We hope that this research will spur more interest in the usefulness of causal
inference for DNN interpretation and for creating more robust models, within the NLP
community and beyond.
2. Previous Work
Previous work on the intersection of DNN interpretations and causal inference, specifi-
cally in relation to NLP, is rare. While there is a vast and rich literature on each of those
topics alone, the gap between interpretability, causality, and NLP is only now starting
to close (Vig et al. 2020). To ground our work in those pillars, we survey here previous
work in each. Specifically, we discuss how to use causal inference in NLP (Keith, Jensen,
and O’Connor 2020), and describe the current state of research on model interpretations
and debiasing in NLP. Finally, we discuss our contribution in light of the relevant work.
2.1 Causal Inference and NLP
There is a rich body of work on causality and on causal inference, as it has been at the
core of scientific reasoning since the writings of Plato and Aristotle (Woodward 2005).
The questions that drive most researchers interested in understanding human behavior
are causal in nature, not associational (Pearl 2009a). They require some knowledge or
explicit assumptions regarding the data-generating process, such as the world model we
describe in the causal graph presented in Figure 2. Generally speaking, causal questions
cannot be answered using the data alone, or through the distributions that generate
it (Pearl 2009a).
Even though causal inference is widely used in the life and social sciences, it has not
had the same impact on machine learning and NLP in particular (Angrist and Pischke
2008; Dorie et al. 2019; Gentzel, Garant, and Jensen 2019). This can mostly be attributed
to the fact that using existing frameworks from causal inference in NLP is challeng-
ing (Keith, Jensen, and O’Connor 2020). The high-dimensional nature of language does
not easily fit into the current methods, specifically as the treatment whose effect is being
tested is often binary (D’Amour et al. 2017; Athey et al. 2017). Recently, this seems to
be changing, with substantial work being done on the intersection of causal inference
and NLP (Tan, Lee, and Pang 2014; Fong and Grimmer 2016; Egami et al. 2018; Wood-
Doughty, Shpitser, and Dredze 2018; Veitch, Sridhar, and Blei 2019).
338
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
Specifically, researchers have been looking into methods of measuring other con-
founders via text (Pennebaker, Francis, and Booth 2001; Saha et al. 2019), or using text
as confounders (Johansson, Shalit, and Sontag 2016; De Choudhury et al. 2016; Roberts,
Stewart, and Nielsen 2018). In this strand of work, a confounder is being retrieved
from the text and used to answer a causal question, or the text itself is used as a
potential confounder, with its dimensionality reduced. Another promising direction is
causally driven representation learning, where the representation of the text is designed
specifically for the purposes of causal inference. This is usually done when the treatment
affects the text, and the model architecture is manipulated to incorporate the treatment
assignment (Roberts et al. 2014; Roberts, Stewart, and Nielsen 2018). Recently, Veitch,
Sridhar, and Blei (2019) added to BERT’s fine-tuning stage an objective that estimates
propensity scores and conditional outcomes for the treatment and control variables,
and used a model to estimate the treatment effect. As opposed to our work, they are
interested in creating low-dimensional text embeddings that can be used as variables
for answering causal questions, not in interpreting what affects an existing model.
While previous work from the causal inference literature used text to answer causal
questions, to the best of our knowledge we are the first (except for Vig et al. [2020])
that are using this framework for causal model explanation. Specifically, we build in
this research on a specific subset of causal inference literature, counterfactual analy-
sis (Pearl 2009b), asking causal questions aimed at inferring what would have been
the predictions of a given neural model had conditions been different. We present this
counterfactual analysis as a method for interpreting DNN-based models, to understand
what affects their decisions. By intervening on the textual representation, we provide a
framework for answering causal questions regarding the effect of low- and high-level
concepts on text classifiers without having to generate counterfactual examples.
Vig et al. (2020) also suggest using ideas from causality for DNN explanations, but
focus on understanding how information flows through different model components,
while we are interested in understanding the effect of textual concepts on classification
decisions. They are dependant on manually constructed queries, such as comparing the
language model’s probability for a male pronoun to that of a female, for a given masked
word. As their method can only be performed by manually creating counterfactual ex-
amples such as this query, it is exposed to all the problems involving counterfactual text
generation (see Section 3.3). Also, they do not compare model predictions on examples
and their counterfactuals, and only measure the difference between the two queries,
neither of which are the original text. In contrast, we propose a generalized method
for providing a causal explanation for any textual concept, and present data sets where
any causal estimator can be tested and compared to a ground truth. We also generate
a language representation that approximates counterfactuals for a given concept of
interest on each example, thus allowing for a causal model explanation without having
to manually create examples.
2.2 Model Interpretations and Debiasing in NLP
Model interpretability is the degree to which a human can consistently predict the
model’s outcome (Kim, Koyejo, and Khanna 2016a; Doshi-Velez and Kim 2017; Lipton
2018). The more easily interpretable a machine learning model is, the easier it is for
someone to comprehend why certain decisions or predictions have been made. An
explanation usually relates the feature values of an instance to its model prediction in a
humanly understandable way, usually referred to as a local explanation. Alternatively,
339
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
it can be composed of an estimation of the global effect of a certain feature on the
model’s predictions.
There is an abundance of recent work on model explanations and interpretations,
especially following the rise of DNNs in the past few years (Lundberg and Lee 2017;
Ribeiro, Singh, and Guestrin 2016). Vig et al. (2020) divide interpretations in NLP into
structural and behavioral methods. Structural methods try to identify the information
encoded in the model’s internal structure by using its representations to classify textual
properties (Adi et al. 2017; Hupkes, Veldhoen, and Zuidema 2018; Conneau et al. 2018).
For example, Adi et al. (2017) find that representations based on averaged word vectors
encode information regarding sentence length. Behavioral methods evaluate models on
specific examples that reflect an hypothesis regarding linguistic phenomena they cap-
ture (Sennrich 2017; Isabelle, Cherry, and Foster 2017; Naik et al. 2019). Sennrich (2017),
for example, discover that neural machine translation systems perform transliteration
better than models with byte-pair encoding segmentation, but are worse in terms of
capturing morphosyntactic agreement.
Both structural and behavioral methods generally do not offer ways to directly
measure the effect of the structure of the text or the linguistic concepts it manifests
on model outcomes. They often rely on token level analysis, and do not account for
counterfactuals. Still, there has been very little research in NLP on incorporating tools
from causal analysis into model explanations (Vig et al. 2020) (see above), something
that lies at the heart of our work. Moreover, there’s been, to the best of our knowledge,
no work on measuring the effect of concepts on models’ predictions in NLP (see Kim
et al. [2018] and Goyal et al. [2019a] for a discussion in the context of computer vision).
Closely related to model interpretability, debiasing is a rising sub-field that deals
with creating models and language representations that are unaffected by unwanted
biases that might exist in the data (Kiritchenko and Mohammad 2018; Elazar and
Goldberg 2018; Gonen and Goldberg 2019; Ravfogel et al. 2020). DNNs are as good
as the training data they are fed, and can often learn associations that are in direct pro-
portion to the distribution observed during training (Caliskan, Bryson, and Narayanan
2017). While debiasing is still an ongoing effort, there are methods for removing some of
the bias encoded in models and language representations (Gonen and Goldberg 2019).
Model debiasing is done through manipulation of the training data (Kaushik, Hovy,
and Lipton 2020), by altering the training process (Huang et al. 2020), or by changing
the model (Gehrmann et al. 2020).
Recently, Ravfogel et al. (2020) offered a method for removing bias from neural
representations, by iteratively training linear classifiers and projecting the representa-
tions on their null-spaces. Their method does not provide causal model explanation,
but instead reveals correlations between certain textual features and the predictions of
the model. Particularly, it does not account for control concepts as we do, which makes
it prone to overestimating the causal effect of the treatment concept (see Section 6 where
we empirically demonstrate this phenomenon).
Our work is the first to provide data sets where bias can be computed directly by
comparing predictions on examples and their counterfactuals. Comparatively, exist-
ing measures model bias using observational, rather than interventional, measures
(Rudinger, May, and Durme 2017; De-Arteaga et al. 2019; Davidson, Bhattacharya,
and Weber 2019; Swinger et al. 2019; Ravfogel et al. 2020). To compare methods for
causal model explanations, the research community would require data sets, like those
presented here, where we can intervene on specific textual features and test whether
candidate methods can estimate their effect. In the future we plan to develop richer,
more complex data sets that would allow for even more realistic counterfactual com-
parisons.
340
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
3. Causal Model Explanation
While usually in scientific endeavors causal inference is the main focus, we rely here on
a different aspect of causality—causal model explanation. That is, we attempt to esti-
mate the causal effect of a given variable (also known as the treatment) on the model’s
predictions, and present such effects to explain the observed behavior of the model.
Here we formalize model explanation as a causal inference problem, and propose a
method to do that through language representations.
We start by providing a short introduction to causal inference and its basic terminol-
ogy, focusing on its application to NLP. To ground our discussion within NLP, we follow
the Adjectives example from Section 1 and present in Figure 2 a causal diagram, a graph
that could describe the data-generating process of that example. Building on this graph,
we discuss its connection to Pearl’s structural causal model and the do-operator (Pearl
2009a). Typically, causal models are built for understanding real-world outcomes, while
model interpretability efforts deal with the case where the classification decision is the
outcome, and the intervention is on a feature present in the model’s input. As we are
the first, to the best of our knowledge, to propose a comprehensive causal framework
for model interpretations in NLP, we link between the existing literature in both fields.
3.1 Causal Inference and Language Representations
Confounding Factors and the do-operator. Continuing with the example from Section 1
(presented in Figure 1), imagine we observe a text X and have trained a model to
classify each example as either positive or negative, corresponding to the conveyed
sentiment. We also have information regarding the Political Figure discussed in the text,
and tags for the parts of speech in it. Given a set of concepts, which we hypothesize
might affect the model’s classification decision, we denote the set of binary variables
C = {Cj ∈ {0, 1} | j ∈ {0, 1, . . . , k}}, where each variable corresponds to the existence of
a predefined concept in the text, i.e., if Cj = 1 then the j-th concept appears in the text.
We further assume a pre-trained language representation model φ (such as BERT), and
wish to assert how our trained classifier f is affected by the concepts in C, where f is
a classifier that takes φ(X) as input and outputs a class l ∈ L. As we are interested in
the effect on the probability assigned to each class by the classifier f , we measure the
class probability of our output for an example X, and denote it for a class l ∈ L as zl.
When computing differences on all L classes, we use (cid:126)z( f (φ(X))), the vector of all zl
probabilities.
Computing the effect of a concept Cj on (cid:126)z(f (φ(X))) seems like an easy problem.
We can simply feed to our model examples with and without the chosen concepts,
and compute the difference between the average (cid:126)z(·) in both cases. For example, if
our concept of interest is positive Adjectives, we can feed the model with examples
that include positive Adjectives and examples that do not. Then, we can compare the
difference between the averaged (cid:126)z(·) in both sets and conclude that this difference is the
effect of positive Adjectives.
Now, imagine the case where the use of positive and negative Adjectives is associ-
ated with the Political Figure that is being discussed in the texts given to the model. An
obvious example is a case where a political commentator with liberal-leaning opinions is
writing about a conservative politician, or vice versa. In that case, it would be reasonable
to assume that the Political Figure being discussed would affect the text through other
concepts besides its identity. The author can then choose to express her opinion through
Adjectives or in other ways, and these might be correlated. In such cases, comparing
341
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
examples with and without positive Adjectives would result in an inaccurate measure-
ment of their effect on the classification decisions of the model.5
The problem with our correlated concepts is that of confounding. It is illustrated in
the top graph of Figure 2 using the example of Political Figure and Adjectives. In causal
inference, a confounder is a variable that affects other variables and the predicted label.
In our case, the Political Figure (Cpf ) being discussed in the texts is a confounder of the
Adjectives concept, as it directly affects both Cadj and X. As can be seen in this figure,
we can think of texts as originating from a list of concepts. While we plot only two,
Adjectives and Political Figure, there could be many concepts generating a text. We denote
the potential confoundedness of the concepts by dashed arrows, to represent that one
could affect the other or that they have a common cause.
Alternatively, if it was the case that a change of the Political Figure would not af-
fect the usage of Adjectives in the text, we could have said that Cadj and Cpf are not con-
founded. This is the case where we could intervene on Cadj, such as by having the author
write a text without using positive Adjectives, without inducing a text that contains a
different Political Figure. In causal terms, this is the case where:
(cid:126)z(f (φ(X)|do(Cadj))) = (cid:126)z( f (φ(X)|Cadj))
(1)
where do(Cadj) stands for an external intervention that compels the change of Cadj. In
contrast, the class probability distribution (cid:126)z(f (φ(X)|Cadj)) represents the distribution re-
sulting from a passive observation of Cadj, and rarely coincides with (cid:126)z( f (φ(X)|do(Cadj))).
Indeed, the passive observation setup relates to the probability that the sentiment is
positive given that positive adjectives are used. In contrast, the external intervention
setup relates to the probability that the sentiment is positive after all the information
about positive adjectives has been removed from a text that originally (pre-intervention)
conveyed positive sentiment.
Counterfactual Text Representations. The act of manipulating the text to change the Political
Figure being discussed or the Adjectives used in the text is derived from the notion of
counterfactuals. In the Adjectives example (presented in Figure 1), a counterfactual text is
such an instance where we intervene on one concept only, holding everything else equal.
It is the equivalent of imagining what could have been the text, had it been written about
a different Political Figure, or about the same Political Figure but with different Adjectives.
In the case of Adjectives, we can simply detect all of them in the text and change
them to a random alternative, or delete them altogether.6 For the concept highlighting
the Political Figure being discussed, this is much harder to do manually, as the chosen
figure induces the topics being described in the text and is hence likely to affect other
important concepts that generate the text.
Intervening on Adjectives as presented in the middle graph of Figure 2 relies on our
ability to create a conditional generative model, one that makes sure a certain concept
is or is not represented in the text. Because this is often hard to do (see Section 3.3),
we propose a solution that is based on the language representation φ(X). As shown
in the bottom causal graph of Figure 2, we assume that the concepts generate the
5 In fact, removing Adjectives does provide a literal measurement of their impact, but it does not provide a
measurement of the more abstract notion we are interested in (which is only partially expressed through
the Adjectives). Later we consider a baseline that does exactly this and demonstrate its shortcomings.
6 This would still require the modeler to control some confounding concepts, as Adjectives could be
correlated with other variables (such as some Adjectives used to describe a specific politician).
342
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
representation φ(X) directly. This approximation shares some similarities with the idea
of Process Control described in Pearl (2009a). While Pearl (2009a) presents Process Control
as the case of intervening on the process affected by the treatment, it is not discussed
in relation to language representations or model interpretations. Interventions on the
process that is generating the outcomes are also discussed in Chapter 4 of Bottou et al.
(2013), in the context of multi-armed bandits and reinforcement learning.
By intervening on the language representation, we attempt to bypass the process of
generating a text given that a certain concept should or should not be represented in
that text. We take advantage of the fact that modern NLP systems use pre-training to
produce a language representation, and generate a counterfactual language representa-
tion φC(X) that is unaffected by the existence of a chosen concept C. That is, we try to
change the language representation such that we get for a binary C:
(cid:126)z( f (φC(X))) = (cid:126)z( f (φC(X(cid:48))))
(2)
where X and X(cid:48) are identical for every generating concept, except for the concept C, on
which they might or might not differ. In Section 3.3, we discuss how we intervene in the
fine-tuning stage of the language representation model (BERT in our case) to produce
the counterfactual representation using an adversarial component.
We now formally define our causal effect estimator. We start with the definition of
the standard Average Treatment Effect (ATE) estimator from the causal literature. We next
formally define the causal concept effect (CaCE), first introduced in Goyal et al. (2019a) in
the context of computer vision. We then define the Example-based Average Treatment
Effect (EATE), a related causal estimator for the effect of the existence of a concept on
the classifier. The process required to calculate EATE is presented in the middle graph
of Figure 2, and requires a conditional generative model. In order to avoid the need in
such a conditional generative model, we follow the bottom graph of Figure 2 and use
an adversarial method, inspired by the idea of Process Control that was first introduced
by Pearl (2009b), to intervene on the text representation. We finally define the Textual
Representation-based Average Treatment Effect (TReATE), which is estimated using our
method, and compare it to the standard ATE estimator.7
3.2 The Textual Representation-based Average Treatment Effect (TReATE)
When estimating causal effects, researchers commonly measure the average treatment
effect, which is the difference in mean outcomes between the treatment and control
groups. Using do-calculus (Pearl 1995), we can define it in the following way:
Definition 1 (Average Treatment Effect (ATE))
The average treatment effect of a binary treatment T on the outcome Y is:
ATET = E (cid:2)Y|do(T = 1)(cid:3) − E (cid:2)Y|do(T = 0)(cid:3)
(3)
7 In Appendix B we discuss alternative causal graphs that describe different types of relationships between
the involved variables. We also discuss the estimation of causal effects in such cases and briefly touch on
the selection of the appropriate causal graph for a given problem.
343
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
Following the notations presented in the beginning of Section 3.1, we define the
following Structural Causal Model (SCM, Pearl (2009b)) for a document X:
(C0, C1, . . . , Ck) = h((cid:15)C)
X = g(C0, C1, . . . , Ck, (cid:15)X)
Cj ∈ {0, 1}, ∀j ∈ K
(4)
Where, as is standard in SCMs, (cid:15)C and (cid:15)X are independent variables. The function h is
the generating process of the concept variables from the random variable (cid:15)C and is not
the focus here. The SCM in Equation (4) makes an important assumption, namely, that it
is possible to intervene atomically on Cj, the treated concept (TC), while leaving all other
concepts untouched.
We denote expectations under the interventional distribution by the standard do-
(cid:2)·|do(Cj = a)(cid:3), where the subscript g indicates that this expectation
operator notation E
g
also depends on the generative process g. We can now use these expectations to define
CaCE:
Definition 2 (Causal Concept Effect (CaCE) (Goyal et al. 2019a))
The causal effect of a concept Cj on the class probability distribution (cid:126)z of the classifier f
trained over the representation φ under the generative process g is:
CaCECj
= (cid:104)E
g
(cid:2)(cid:126)z(cid:0) f (φ(X))(cid:1)|do(Cj = 1)(cid:3) − E
g
(cid:2)(cid:126)z(cid:0) f (φ(X))(cid:1)|do(Cj = 0)(cid:3)(cid:105)
(5)
where (cid:104)(cid:105) is the l1 norm: A summation over the absolute values of vector coordinates.8
CaCE was designed to test how a model would perform if we intervene and change
a value of a specific concept (e.g., if we changed the hair color of a person in a picture
from blond to black). Here we address an alternative case, where some concept exists
in the text and we aim to measure the causal effect of its existence on the classifier.
As can be seen in the middle causal graph of Figure 2, this requires an alternative data-
generating process gC0, which is not affected by the concept C0. Using gC0, we can define
another SCM that describes this relationship:
(C0, C1, . . . , Ck) = h((cid:15)C)
X(cid:48) = gC0 (C1, . . . , Ck, (cid:15)(cid:48)
Cj ∈ {0, 1}, ∀j ∈ K
X)
(6)
8 For example, for a three-class prediction problem, where the model’s probability class distribution for the
original example is (0.7, 0.2, 0.1), while for the counterfactual example it is (0.5, 0.1, 0.4), CaCECj is equal
to: |0.7 − 0.5| + |0.2 − 0.1| + |0.1 − 0.4| = 0.2 + 0.1 + 0.3 = 0.6.
344
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
where X(cid:48) is a counterfactual example generated by gC0 (C1 = c1, . . . , Ck = ck, (cid:15)(cid:48)
X). With
gC0, we want to generate texts that use (C1 = c1, . . . , Ck = ck) in the same way that g
does, but are as if C0 never existed. Using this SCM, we can compute the EATE:
Definition 3 (Example-based Average Treatment Effect (EATE))
The causal effect of a concept Cj on the class probability distribution (cid:126)z of the classifier f
under the generative processes g, gCj is:
EATECj
= (cid:104)E
g
Cj
(cid:2)(cid:126)z(cid:0) f (φ(X(cid:48)))(cid:1)(cid:3) − E
g
(cid:2)(cid:126)z(cid:0) f (φ(X))(cid:1)(cid:3)(cid:105)
(7)
Implementing EATE requires counterfactual example generation, as shown in the
middle graph of Figure 2. As this is often intractable in NLP (see Section 3.3), we do not
compute EATE here. We instead generate a counterfactual language representation, a
process which is inspired by the idea of Process Control introduced by Pearl (2009b) for
dynamic planning. This is the case where we can only control the process generating
φ(X) and not X itself.
Concretely, using the middle causal graph in Figure 2, we could have generated
two examples X1 = gC0 (C1 = c1, . . . , Ck = ck, (cid:15)X(cid:48) = (cid:15)x(cid:48) ) and X2 = gC0 (C1 = c1, . . . , Ck =
ck, (cid:15)X(cid:48) = (cid:15)x(cid:48) ) where C0 = 1 for X1 and C0 = 0 for X2, and have that X1 = X2 because the
altered generative process gC0 is not sensitive to changes in C0. Notice that we require
that gC0 would be similar to g in the way the concepts (C1, . . . , Ck) generate the text,
because otherwise any degenerate process will do. Alternatively, in the case where we
do not have access to the desired conditional generative model, we would like for the
¯X1 = g(C0 = 1, C1 = c1, . . . , Ck = ck, (cid:15)X = (cid:15)x) and ¯X2 = g(C0 = 0, C1 =
two examples
c1, . . . , Ck = ck, (cid:15)X = (cid:15)x), to have that φC0 ( ¯X1) = φC0 ( ¯X2). That is, we follow the bottom
graph from Figure 2, and intervene only on the language representation φ(X) such
that the resulting representation, φC0 (X), is insensitive to C0 and is similar to φ in the
way the concepts (C1, . . . , Ck) are represented. Following this intervention, we compute
the TReATE.
Definition 4 (Textual Representation-based Average Treatment Effect (TReATE))
The causal effect of a concept Cj, controlling for concept Cm, on the class probability
distribution (cid:126)z of the classifier f under the generative process g is:
TReATECj,Cm = (cid:104)E
g
(cid:2)(cid:126)z(cid:0) f (φ(X))(cid:1)(cid:3) − E
g
(cid:2)(cid:126)z(cid:0) f (φCj,Cm (X))(cid:1)(cid:3)(cid:105)
(8)
where {Cj, Cm} denotes the concept (or concepts) Cj whose effect we are estimating, and
Cm the potentially confounding concept (or concepts) we are controlling for. In order to
not overwhelm the notation, whenever we use only one concept in the superscript it is
the concept whose effect is being estimated, and not the confounders.
In our framework, we would like to use the tools defined here to measure the causal
effect of one or more concepts {C0, C1, · · · , Ck} on the predictions of the classifier f .
We will do that by measuring TReATE, which is a special case of the ATE defined in
Equation (3), where the intervention is performed via the textual representation. While
ATE is usually used to compute the effect of interventions in randomized experiments,
here we use TReATE to explain the predictions of a text classification model in terms
of concepts.
345
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
3.3 Representation-Based Counterfactual Generation
We next discuss the reason we choose to intervene through the language representation
mechanism, as an alternative to synthetic example generation. We present two existing
approaches for generating such synthetic examples and explain why they are often
implausible in NLP. We then introduce our approach, an intervention on the language
representation, designed to ignore a particular set of concepts while preserving the in-
formation from another set of concepts. Finally, we describe how to perform this inter-
vention using the counterfactual language representation.
Generating Synthetic Examples. Comparing model predictions on examples to the pre-
dictions on their counterfactuals is what allows the estimation of causal explanations.
Without producing a version of the example that does not contain the treatment (i.e.,
concept or feature of interest), it would be hard to ascertain whether the classifier is us-
ing the treatment or other correlated information (Kaushik, Hovy, and Lipton 2020). To
the best of our knowledge, there are two existing methods for generating counterfactual
examples: manual augmentation and automatic generation using generative models.
Manual augmentation can be straightforward, as one needs to manually change
every example of interest to reflect the absence or presence of a concept of choice. For
example, when measuring the effect of Adjectives on a sentiment classifier, a manual
augmentation could include changing all positive Adjectives into negative ones, or sim-
ply deleting all Adjectives. While such manipulations can sometimes be easily done with
human annotators, they are costly and time-consuming and therefore implausible for
large data sets. Also, in cases such as the clinical note example presented in Figure 13, it
would be hard to manipulate the text such that it uses a different writing style, making
it even harder to manually create the counterfactual text.
Using generative models has been recently discussed in the case of images (Goyal
et al. 2019a). In this article, Goyal et al. propose using a conditional generative model,
such as a conditional VAE (Lorberbom et al. 2019), to create counterfactual examples.
While in some cases, such as those presented in their article, it might be plausible to
generate counterfactual examples, in most cases in NLP it is still too hard to generate
realistic texts with conditional generative models (Lin et al. 2017; Che et al. 2017;
Subramanian et al. 2017; Guo et al. 2018). Also, for generating local explanations it is
required to produce a counterfactual for each example such that all the information
besides the concept of choice is preserved, something that is even harder than producing
two synthetic examples, one from each concept class, and comparing them.
As an alternative to manipulating the actual text, we propose to intervene on the
language representation. This does not require generating more examples, and therefore
does not depend on the quality of the generation process. The fundamental premise
of our method is that comparing the original representation of an example to this
counterfactual representation is a good approximation of comparing an example to
that of a synthetic counterfactual example that was properly manipulated to ignore the
concept of interest.
Interventions on Language Representation Models. Since the introduction of pre-trained
word-embeddings, there has been an explosion of research on choosing pre-training
tasks and understanding their effect (Jernite, Bowman, and Sontag 2017; Logeswaran
and Lee 2018; Ziser and Reichart 2018; Dong et al. 2019; Chang et al. 2019; Sun et al.
2019; Rotman and Reichart 2019). The goal of this process is to generate a representation
that captures valuable information for solving downstream tasks, such as sentiment
346
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
classification, entity recognition, and parsing. Recently, there has also been a shift in
focus toward pre-training contextual language representations (Liu et al. 2019; Yang
et al. 2019).
Contextual embedding models typically follow three stages: (1) Pre-training: where
a DNN (encoder) is trained on a massive unlabeled data set to solve self-supervised
tasks; (2) Fine-tuning: an optional step, where the encoder is further trained on different
tasks or data; and (3) Supervised task training: where task specific layers are trained on
labeled data for a downstream task of interest.
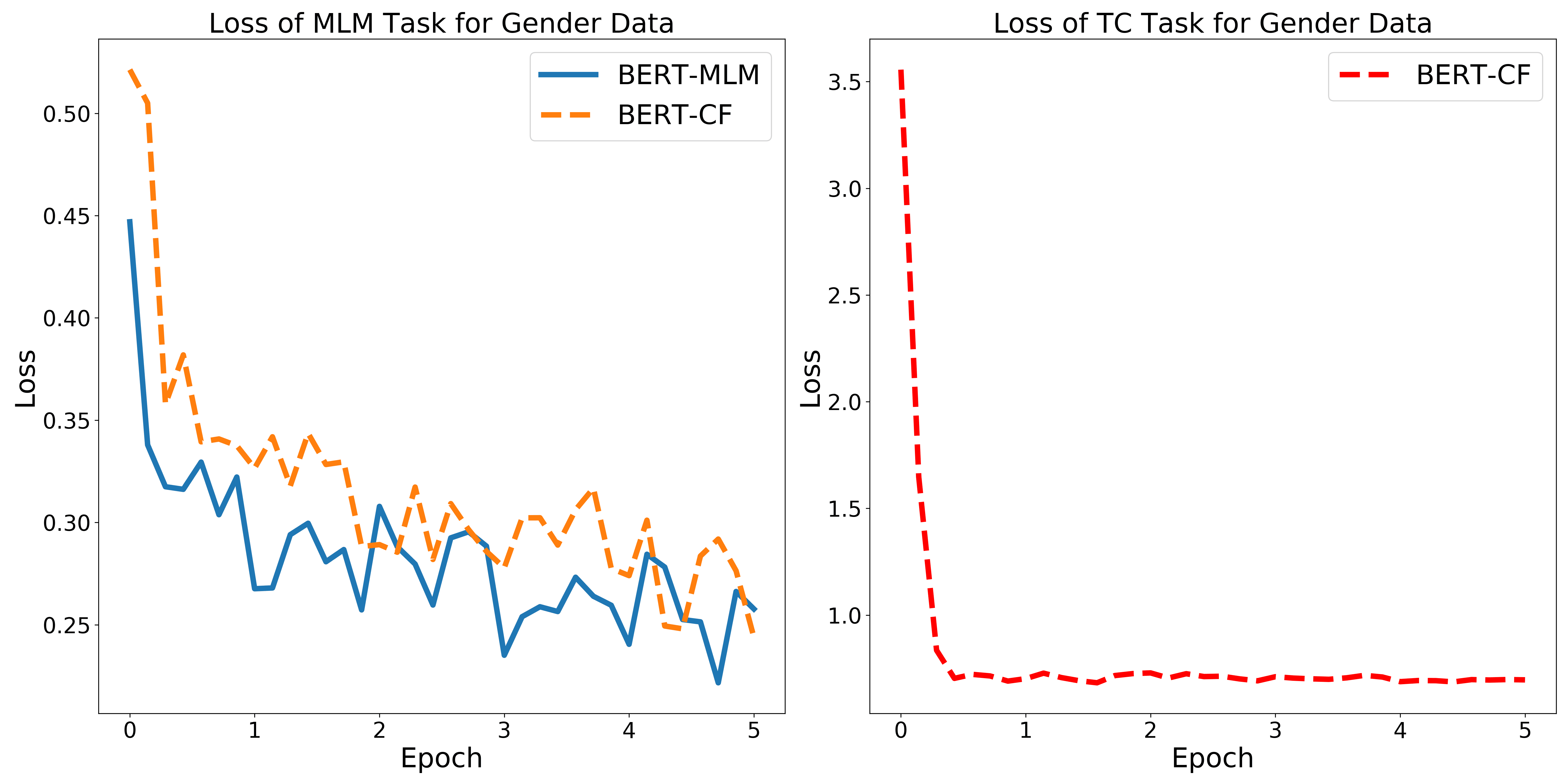
Our intervention is focused on Stage 2. In this stage, we continue training the en-
coder of the model on the tasks it was pre-trained on, but add auxiliary tasks, designed
to forget some concepts and remember others.9 In Figure 3 we present an example of our
proposed Stage 2, where we train our model to solve the original BERT’s Masked Lan-
guage Model (MLM) and Next Sentence Prediction (NSP) tasks, along with a Treated Concept
objective, denoted in the figure as TC. In order to preserve the information regarding
a potentially confounding concept, we use an additional task denoted in the figure as
CC, for Controlled Concept.
To illustrate our intervention, we can revisit the Adjectives example of Figure 1, and
consider a case where we want to test whether their existence in the text affects the
classification decision. To be able to estimate this effect, we traditionally would have to
produce for each example in the test set an equivalent example that does not contain
Adjectives. In terms of our intervention on the language representation, we should
be able to produce a representation that is unaffected by the existence of Adjectives,
meaning that the representation of a sentence that contains Adjectives would be identical
to that of the same sentence where Adjectives are excluded. Taking that to the fine-tuning
stage, we could use adversarial training to “forget” Adjectives.
Concretely, we add to BERT’s loss function a negative term for the target concept
and a positive term for each control concept we consider. As shown in Equation (9), in
the case of the example from Figure 1, this would entail augmenting the loss function
with two terms: adding the loss for the Political Figure classification PF (the CC head),
and subtracting that of the Is Masked Adjective (IMA) task (the TC head). As we are using
the IMA objective term in our Adjectives experiments (Section 5), and not only in the
running example, we describe the task below. For the Political Figure (PF) concept, we
could simply use a classification task where for each example we predict the political
orientation of the politician being discussed.10 With those tasks added to the loss func-
tion, we have that:
L(θbert, θmlm, θnsp, θcc, θtc) = 1
n
(cid:16) n
(cid:88)
i=1
Li
mlm(θbert, θmlm)
+
n
(cid:88)
i=1
Li
nsp(θbert, θnsp)
+
n
(cid:88)
i=1
Li
cc(θbert, θcc)
−λ
n
(cid:88)
i=1
Li
tc(θbert, θtc)
(cid:17)
(9)
where θbert denotes all of BERT’s parameters, except those devoted to θmlm, θnsp, θtc, and
θcc. λ is a hyperparameter which controls the relative weight of the adversarial task.
9 Continued pre-training has shown to be useful in NLP more generally (Gururangan et al. 2020; Gardner
et al. 2020).
10 For the CC objective, we can add any of the classification tasks suggested above for PF (CC), following
the definition of the world model (i.e., the causal graph) the researcher is assuming.
347
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
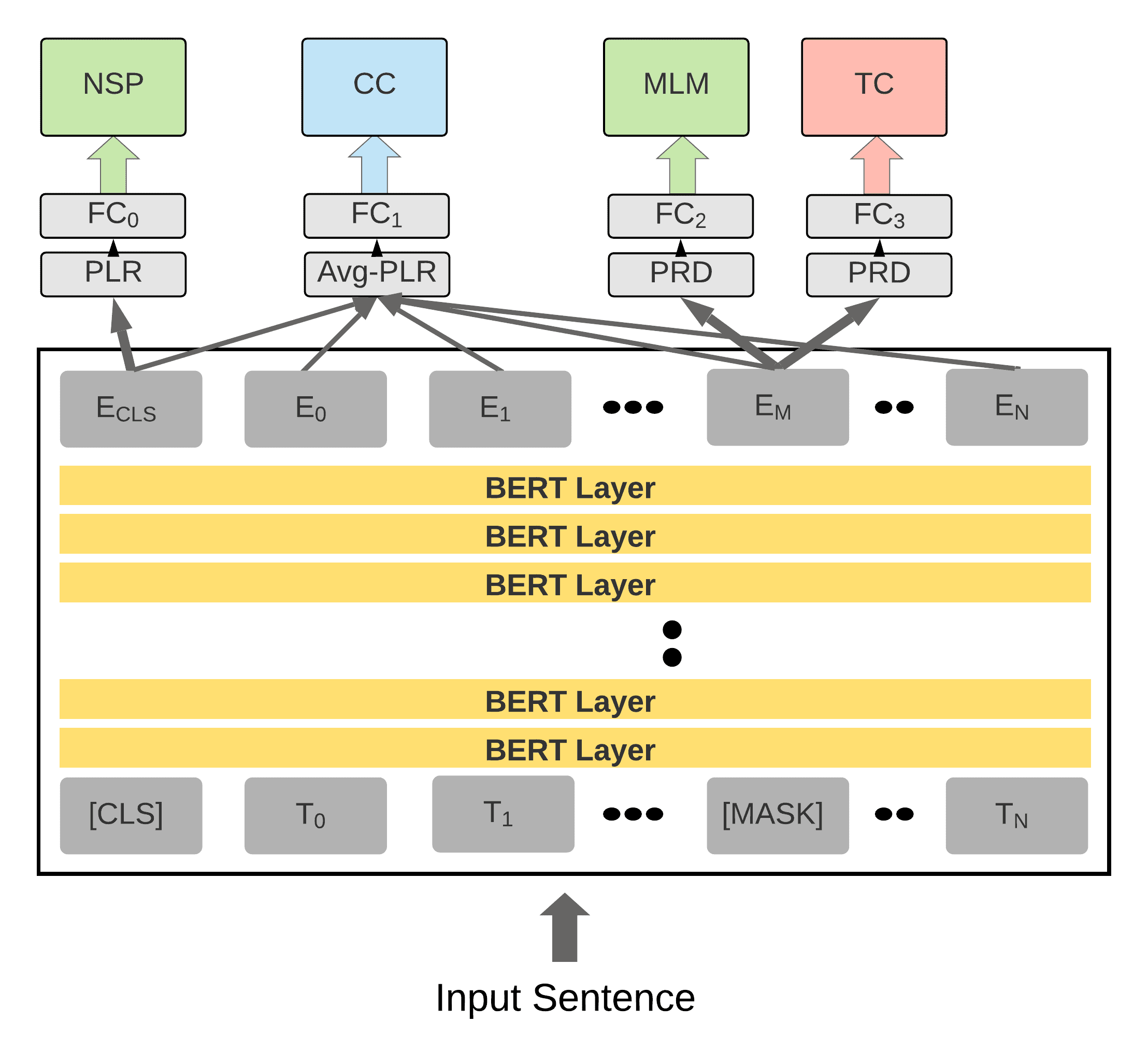
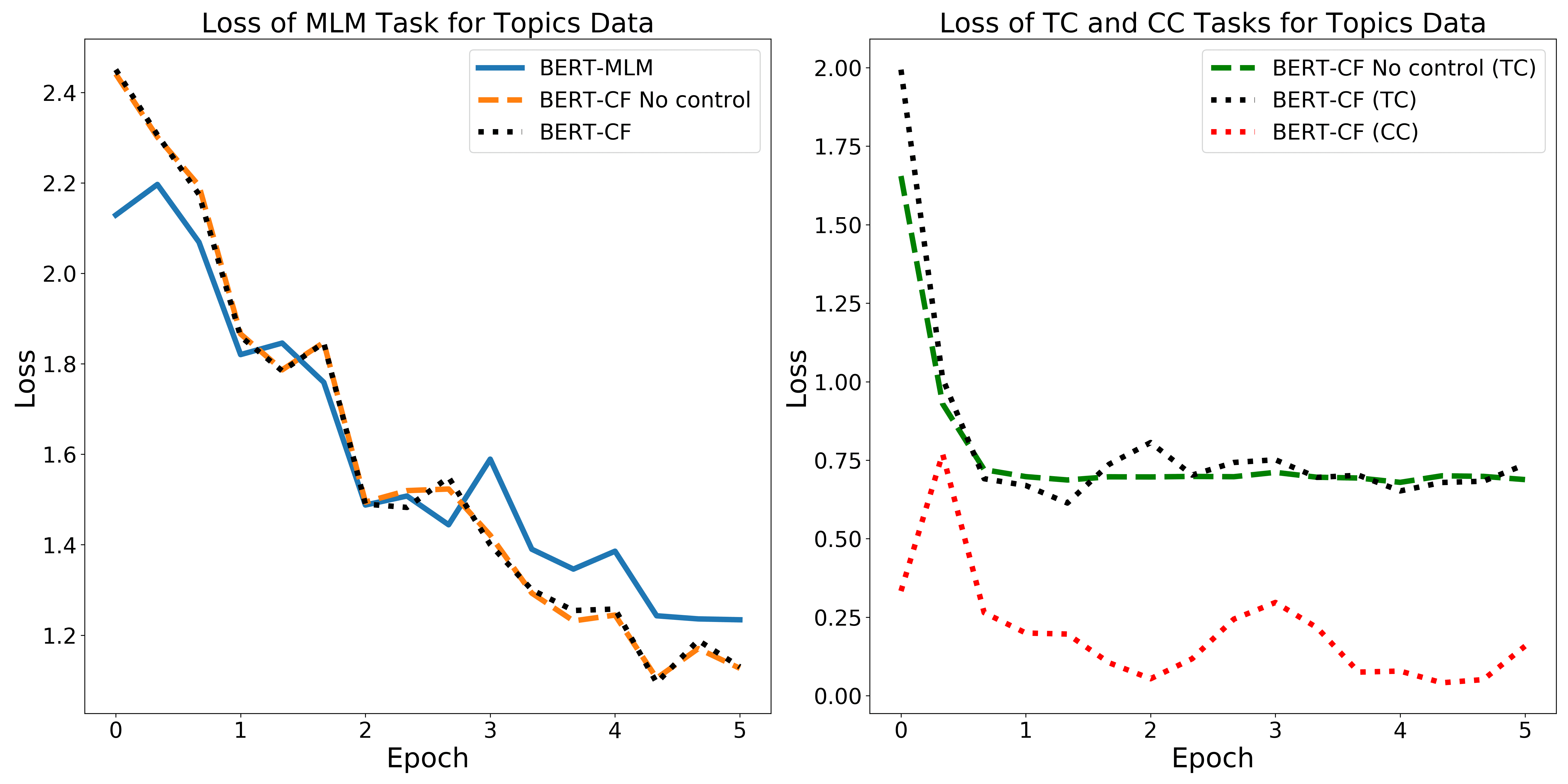
Figure 3
An illustration of our Stage 2 fine-tuning procedure for our counterfactual representation model
(BERT-CF). In this representative case, we add a task, named Treated Concept (TC), which is
trained adversarially. This task is designed to “forget” the effect of the treated concept, as in the
IMA adversarial task discussed in Section 5. To control for a potential confounding concept (i.e.,
to “remember” it), we add the Control Concept (CC) task, which predicts the presence of this
concept in the text, as in the PF task discussed below. PRD and PLR stand for BERT’s prediction
head and the pooler head, respectively, AVG − PLR for an average pooler head, FC is a fully
connected layer, and [MASK] stands for masked tokens embeddings. NSP and MLM are BERT’s
next prediction and masked language model objectives. The results of this training stage is our
counterfactual BERT-CF model.
One way of implementing the IMA TC head is inspired by BERT’s MLM head. That
is, masking Adjectives and Non-adjectives, then predicting whether the masked token
is an adjective. Following the gradient reversal method (Ganin et al. [2016], henceforth
DANN),11 we add this task with a layer that leaves the input unchanged during for-
ward propagation, yet reverses its corresponding gradients by multiplying them with a
negative scalar (−λ) during back propagation.
The core idea of DANN is to reduce the domain gap, by learning common represen-
tations that are indistinguishable to a domain discriminator (Ghosal et al. 2020). In our
model, we replace the domain discriminator with a discriminator that discriminates ex-
amples with the treated concept from examples that do not have that concept. Following
DANN, we optimize the underlying BERT representations jointly with classifiers oper-
ating on these representations: The task classifiers perform the main task of the model
11 See Equations 9–10 and 13–15 in Ganin et al. (2016).
348
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
(Lmlm, Lnsp, and Lcc in our objective) and the treatment concept classifier discriminates
between those masked tokens that are adjectives and those that are not (the Ltc term in
our objective). While the parameters of the classifiers (θmlm, θnsp, θcc, θtc) are optimized
in order to minimize their training error, the language encoder parameters (θbert) are
optimized in order to minimize the loss of the task classifiers (Lmlm, Lnsp, and Lcc) and
to maximize the loss of the treatment concept classifier (Ltc). Concretely in our case,
the parameters of the underlying language representation θbert are simultaneously opti-
mized in order to minimize the MLM, NSP, and PF loss functions and maximize the IMA
loss. Gradient reversal hence encourages an adjective-invariant language representation
to emerge. For more information about the adversarial multitask min-max optimization
dynamics, and the emergent concept-invariant language representations, see Xie et al.
(2017).
While the gradient reversal method is widely implemented throughout the domain
adaptation literature (Ramponi and Plank 2020), it has also been previously shown that
it can be at odds with the model’s main prediction objective (Elazar and Goldberg
2018). However, we implement it in our model’s training process in a different way
than in most previous literature. We use this method as part of the language model fine-
tuning stage, which is independent of and precedes the downstream prediction task’s
objective training. Therefore, our adversarial task’s objective is not directly at odds with
the downstream model’s prediction objective.
Having optimized the loss functions presented in Equation (9), we can now use
the resulting counterfactual representation model and compute the individual treatment
effect (ITE) on an example as follows. We compute the predictions of two different
models: One that uses the original BERT, that has not gone through our counterfactual
fine-tuning, and one that uses the counterfactual BERT model (BERT-CF). The Textual
Representation-based ITE (TRITE) is then the average of the absolute differences between
the probabilities assigned to the possible classes by these models. As TReATE is pre-
TReATE by
sented in Equation (8) in expectation form, we compute our estimated
(cid:92)TRITE for the set of all test-set examples, I:
summing over
(cid:92)
(cid:92)
TReATETC,CC = 1
|I|
1
|I|
(cid:88)
(cid:92)TRITE
i
TC,CC =
i∈I
(cid:88)
(cid:104)(cid:126)z(cid:0)f (φTC,CC(X = xi))(cid:1) − (cid:126)z(cid:0)f (φ(X = xi))(cid:1)(cid:105)
(10)
i∈I
where xi is the specific example, φ is the original language representation model, and
φTC,CC is the counterfactual BERT-CF representation model, where the intervention is
such that TC has no effect and CC is preserved. (cid:126)z(cid:0)f (φ(X))(cid:1) is the class probability dis-
tribution of the classifier f when using φ as the representation model for example X.
4. Data
When evaluating a trained classification model, we usually have access to a test set,
consisting of manually labeled examples that the model was not trained on, and can
hence be used for evaluation. Estimating causal effects is often harder in comparison,
as we do not have access to the ground truth. In the case of causal inference, we can
generally only identify effects if our assumptions on the data-generating process, such
as those presented in Figure 2, hold. This means that at the core of our causal model
349
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
explanation paradigm is the availability of a causal graph that encodes our assump-
tions about the world. Notice, however, that non-causal explanation methods that do
not make assumptions about the world are prone to finding arbitrary correlations, a
problem that we are aiming to avoid with our method.
To allow for ground-truth comparisons and to spur further research on causal infer-
ence in NLP, we propose here four cases where causal effects can be estimated. In three
out of those cases, we have constructed data sets with counterfactual examples so that
the causal estimators can be compared to the ground truth. We start here by introducing
the data sets we created and discuss the choices made in order to allow for proper
evaluation. Section 4.1 describes the sentiment analysis data with the Adjectives and
Topics concepts, while Section 4.2 describes the EEEC data set for mood classification
with the Gender and Race concepts. Section 5 presents the tasks for which we estimate
the causal effect, and the resulting experiments.12
4.1 Product and Movie Reviews
Following the running example of Section 1, we start by looking for prominent senti-
ment classification data sets. Specifically, we look for data sets where the domain entails
a rich description where Adjectives could play a vital role. With enough variation in
the structure and length of examples, we hope that Adjectives would have a significant
effect. Another key aspect is the number of training examples. To be able to amplify
the correlation between the treated concept (Adjectives) and the label, we need to be
able to omit some training examples. For instance, if we omit most of the positive texts
describing a Political Figure, we can create a correlation between the negative label and
that politician. We need a data set that will allow us to do that and still have enough
training data to properly train modern DNN classification models.
We also wish to estimate the causal effect of the concept of Topics on sentiment
classification (see Section 5 for an explanation on how we compute the topic distribu-
tion). To be able to observe the causal effect of Topics, some variation is required in the
Topics discussed in the texts. For that, we use data originating from several different
domains, where different, unrelated products or movies are being discussed. In this
section we focus on the description of the data set we have generated, and explain
how we manipulate the data in order to generate various degrees of concept-label
correlations.
Considering these requirements and the concepts for which we wish to estimate the The situation makes Now that it is all over, 5
causal effect on model performance, we choose to combine two data sets, spanning
five domains. The product data set we choose is widely used in the NLP domain
adaptation literature, and is taken from Blitzer, Dredze, and Pereira (2007). It contains
four different domains: Books, DVD, Electronics, and Kitchen Appliances. The movie data
set is the IMDb movie review data set, taken from Maas et al. (2011). In both data sets,
each example consists of a review and a rating (0–5 stars). Reviews with rating > 3
were labeled positive, those with rating < 3 were labeled negative, and the rest were
discarded because their polarity was ambiguous. The product data set is comprised of
1,000 positive and 1,000 negative examples for each of the four domains, for a total of
4,000 positive and 4,000 negative reviews. The Movies data set is comprised of 25,000
negative and 25,000 positive reviews. To construct our combined data set, we randomly
sample 1,000 positive and 1,000 negative reviews from the Movies data set and add these
12 Our data sets are available at: https://www.kaggle.com/amirfeder/causalm.
350
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
alongside the product data set reviews. Our final combined data set amounts to a total
of 10,000 reviews, balanced across all five domains and both labels.
We tag all examples in both data sets for the Part-of-Speech (PoS) of each word
with the automatic tagger available through spaCy,13 and use the predicted labels as
ground truth. For each example in the combined data set, we generate a counterfactual
example for Adjectives. That is, for each example we create another instance where we
delete all words that are tagged as Adjectives, such that for the example: “It’s a lovely
table,” the counterfactual example will be: “It’s a table.” Finally, we count the number of
Adjectives and other PoS tags, and create a variable indicating the ratio of Adjectives to
Non-adjectives in each example, which we use in Section 5 to bias the data.
For the Topic concepts, we train a Latent Dirichlet Allocation (LDA) topic model
(Blei, Ng, and Jordan 2003)14 on all the data in our combined data set and optimize the
number of topics for maximal coherence (Lau, Newman, and Baldwin 2014), resulting
in a set of T = 50 topics. For each of the five domains we then search for the treatment
concept topic tTC, which we define as the topic that is relatively most associated with that
domain, that is, the topic with the largest difference between the probability assigned
to examples from that domain and the probability assigned to examples outside of that
domain, using the following equation:
tTC(d) = arg max
t∈T
(cid:0) 1
|Id+|
(cid:88)
i∈Id+
t − 1
θi
|Id−|
(cid:88)
(cid:1)
θi
t
i∈Id−
(11)
where d is the domain of choice, t is a topic from the set of topics T, θt is the probability
of topic t, and Idomain is the set of examples for a given domain. Id+ is the set of examples
in domain d, and Id− the set of examples outside of domain d. After choosing tTC, we
exclude it from T and use the same process to choose tCC, our control concept topic.
For each Topic, we also compute the median probability on all examples, and define
a binary variable indicating for each example whether the Topic probability is above
or below its median. This binary variable can then be used for the TC and CC tasks
described in Section 5.
In Table 1 we present some descriptive statistics for all five domains, including the
Adjectives to Non-adjectives ratio and the median probability (θdomain) of the tTC(d) topic
for each domain. As can be seen in this table, there is a significant number of Adjectives
in each domain, but the variance in their number is substantial. Also, Topics are domain-
specific, with the most correlated topic tTC(d) for each domain being substantially more
visible in its domain compared with the others. In Table 2 we provide the top words for
all Topics, to show how they capture domain-specific information.
Our sentiment classification data allows for a natural setting for testing our methods
and hypotheses, but it has some limitations. Specifically, in the case of Topics, we cannot
generate realistic counterfactual examples and therefore compute ATEgt, the ground-
truth estimator of the causal effect. This is because creating counterfactual examples
would require deleting the topic from the text without affecting the grammaticality of
the text, something that cannot be done automatically. In the case of Adjectives, we are
hoping that removing Adjectives will not affect the grammaticality of the original text,
but are aware that this sometimes might not be the case. While this data provides a real-
world example of natural language, it is hard to automatically generate counterfactuals
13 https://spacy.io/.
14 Using the gensim library ( ˇReh ˚uˇrek and Sojka 2010).
351
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
-
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
Table 1
Descriptive statistics for the Sentiment Classification data sets. r(adj) denotes the ratio of
Adjectives to Non-adjectives in an example. θdomain is the mean probability of the topic that is most
observed in that domain, which will also serve as our treated topic. b, d, e, k, m are abbreviations
for Books, DVD, Electronics, Kitchen, and Movies.
Domain
Min. Med. # Max. #
r(adj)
r(adj)
r(adj)
Books
DVD
Electronics
Kitchen
Movies
0.0
0.0
0.0
0.0
0.0
0.135
0.138
0.136
0.142
0.138
0.444
0.425
0.461
0.500
0.666
σ of #
r(adj)
0.042
0.042
0.049
0.052
0.0333
θb
θd
θe
θk
θm
0.311
0.014
0.010
0.007
0.010
0.011
0.045
0.065
0.039
0.007
0.052
0.045
0.080
0.075
0.045
0.026
0.016
0.039
0.066
0.016
0.014
0.225
0.003
0.002
0.281
for it. To allow for a more accurate estimation of the ground truth effect, we would need
a data set where we can control the data-generating process.
4.2 The Enriched Equity Evaluation Corpus (EEEC)
Understanding and reducing gender and racial bias encapsulated in classifiers is a core
task in the growing literature of interpretability and debiasing in NLP (see Section 2).
There is an ongoing effort to both detect such bias and to mitigate its effect, which we
see from a causal perspective as a call for action. By offering a way to estimate the causal
effect of the Gender and Race concepts as they appear in the text, on classifiers, we enable
researchers to avoid using biased classifiers.
In order to evaluate the quality of our causal effect estimation method, we need a
data set where we can control test examples such that for each text we have a coun-
terfactual text that differs only by the Gender or Race of the person it discusses. We also
need to be able to control the data-generating process in the training set, so that we can
create such a bias for the model to pick up. A data set that offers such control exists, and
is called the Equity Evaluation Corpus (EEC) (Kiritchenko and Mohammad 2018).
It is a benchmark data set, designed for examining inappropriate biases in system
predictions, and it consists of 8,640 English sentences chosen to tease out Racial and
Gender related bias. Each sentence is labeled for the mood state it conveys, a task also
known as Profile of Mood States (POMS). Each of the sentences in the data set is composed
using one of eleven templates, with placeholders for a person’s name and the emotion
it conveys. For example, one of the original templates is: “
There is still a long way to go, but the situation makes
I made
The situation makes
foreseeable future
It is a mystery to me, but it seems i made
I made
It was totally unexpected, but
As
6
7
8
9
10
11 While it is still under construction, the situation makes
It is far from over, but so far i made
12
13 We went to the
14
15 While this is still under construction, the situation makes
16
17
18
19 While it is still under development, the situation makes
20
21
22 While we were at the
23
24
25
26 We were told that
Even though it is still under development, the situation makes
I have no idea how or why, but i made
I do not know why, but i made
30
31
32
33
787
490
286
1,145
598
1,114
691
1,218
1,504
598
400
531
891
550
335
1,131
312
1,188
261
492
1,092
648
483
285
468
1,168
1,164
1,164
1,156
728
1,128
1,152
1,156
34 While we were walking to the
1,156
events
The conversation with
35
36 While unsurprising, the conversation with
37
38
39
40
41
42
To our amazement, the conversation with
I
I talked to
1,192
748
1,164
844
580
580
580
580
CC probing tasks [Section 6.2]) and for each version of the data sets (Balanced, Gentle,
and Aggressive):
1.
Stage 2 fine-tuning on the training and development sets of the relevant
version of the data set (Balanced, Gentle, or Aggressive) to produce the
BERT-CF and BERT-MLM representation models. BERT-CF is trained
following the intervention methodology of Section 3.3, while BERT-MLM
is trained with standard MLM training as the original BERT model.
378
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
Table 12
Descriptive statistics comparing the EEC and Enriched EEC (EEEC) data sets.
Metric
EEC
EEEC
Full Data Size (# of Sentences)
Median Sentence Length (# of words)
# of Templates
# of Noise Sentences
# of Prefix Sentences
# of Suffix Sentences
# of Emotion Words
# of Female Names
# of Male Names
# of European Names
# of African-American Names
# of Places
9,840
6
11
0
0
0
40
10
10
10
10
10
33,738
14
42
13
21
16
55
10
10
10
10
10
2.
3.
Stage 3 supervised task training for a classifier based on BERT-O,
BERT-MLM, or BERT-CF, for the relevant downstream task (Sentiment,
POMS, TC, or CC probing).
Test our Stage 3 trained BERT-O, BERT-MLM, and BERT-CF–based
classifiers on the test set of the downstream task. Particularly, the causal
and baseline estimators are computed on the test sets.
In all our experiments we utilize the case-sensitive BERT-base pre-trained text rep-
resentation model (12 layers, 768 hidden vector size, 12 attention heads, 110M parame-
ters), trained on the BookCorpus (800M words) (Zhu et al. 2015) and Wikipedia (2, 500M
words) corpora. This model is publicly available along with its source code via the
Google Research GitHub repository.22
When training BERT-CF (Stage 2), we fine-tune all 12 layers of BERT. For the
downstream task classifier we use a fully connected layer that receives as input the
token representations produced by BERT’s top layer, as well as its CLS token. For INLP,
which requires a single representation vector as input, we provide the model with the
CLS token of the BERT-O’s top layer. The output produced by INLP for this vector is
then provided to the default classifier of that work, namely, logistic regression, in order
to compute the TReATE(O, INLP) estimator.
All our models use cross entropy as their loss function. We utilize the ADAM
optimization algorithm (Kingma and Ba 2015) with a learning rate of 1e−3, fuzz factor
of 1e−8, and no weight decay. We developed all our models and experimental pipelines
with PyTorch (Paszke et al. 2017), utilizing and modifying source code from Hugging-
Face’s Transformers (Wolf et al. 2019) and PyTorch Lightning (Falcon 2019) GitHub
repositories.23
22 https://github.com/google-research/bert.
23 https://github.com/huggingface/transformers, https://github.com/PyTorchLightning/pytorch
-lightning.
379
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
Table 13
The hyperparameters used in our experiments.
Hyperparameter
Random Seed
Sentiment maximum sequence length
POMS maximum sequence length
Stage 2 TC (adversarial) task λ
Stage 2 number of epochs
Stage 2 Sentiment batch size
Stage 2 POMS batch size
Stage 3 number of epochs
Stage 3 Sentiment batch size
Stage 3 POMS batch size
Stage 3 gradient accumulation steps
Stage 3 classifier dropout probability
#
212
384
32
1
5
6
24
50
128
200
4
0.1
Due to the extensive experimentation pipeline, which resulted in a large total num-
ber of experiments over many different combinations of data set versions and model
variations, we chose not to tune our hyperparameters. Table 13 details the hyperpara-
meters used for all our developed models in all experiments.
References
Adi, Yossi, Einat Kermany, Yonatan Belinkov,
Ofer Lavi, and Yoav Goldberg. 2017.
Fine-grained analysis of sentence
embeddings using auxiliary prediction
tasks. In 5th International Conference on
Learning Representations, ICLR 2017,
pages 1–13. Toulon.
Aharoni, Roee, Melvin Johnson, and Orhan
Firat. 2019. Massively multilingual neural
machine translation. In Proceedings of the
2019 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
NAACL-HLT 2019, pages 3874–3884.
Minneapolis, MN. https://doi.org/10
.18653/v1/N19-1388
Akbik, Alan, Duncan Blythe, and Roland
Vollgraf. 2018. Contextual string
embeddings for sequence labeling. In
Proceedings of the 27th International
Conference on Computational Linguistics,
pages 1638–1649. Santa Fe, NM.
Angrist, Joshua D. and J ¨orn-Steffen Pischke.
2008. Mostly Harmless Econometrics: An
Empiricist’s Companion. Princeton
University Press. https://doi.org/10
.2307/j.ctvcm4j72
Athey, Susan, Guido Imbens, Thai Pham, and
Stefan Wager. 2017. Estimating average
treatment effects: Supplementary analyses
and remaining challenges. American
Economic Review, 107(5):278–281. https://
doi.org/10.1257/aer.p20171042
380
Blei, David M., Andrew Y. Ng, and Michael I.
Jordan. 2003. Latent dirichlet allocation.
Journal of Machine Learning Research,
3:993–1022.
Blitzer, John, Mark Dredze, and Fernando
Pereira. 2007. Biographies, bollywood,
boom-boxes and blenders: Domain
adaptation for sentiment classification. In
Proceedings of the 45th Annual Meeting of the
Association for Computational Linguistics,
pages 440–447. Prague.
Bottou, L´eon, Jonas Peters,
Joaquin Qui ˜nonero Candela, Denis X.
Charles, Max Chickering, Elon Portugaly,
Dipankar Ray, Patrice Y. Simard, and Ed
Snelson. 2013. Counterfactual reasoning
and learning systems: The example of
computational advertising. The Journal of
Machine Learning Research, 14(1):3207–3260.
Boyd-Graber, Jordan L., Yuening Hu, and
David M. Mimno. 2017. Applications of
topic models. Foundations and Trends in
Information Retrieval, 11(2–3):143–296.
https://doi.org/10.1561/1500000030
Caliskan, Aylin, Joanna J. Bryson, and
Arvind Narayanan. 2017. Semantics
derived automatically from language
corpora contain human-like biases. Science,
356(6334):183–186. https://doi.org
/10.1126/science.aal4230, PubMed:
28408601
Chang, Ming-Wei, Kristina Toutanova,
Kenton Lee, and Jacob Devlin. 2019.
Language model pre-training for
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
hierarchical document representations.
CoRR, abs/1901.09128.
Che, Tong, Yanran Li, Ruixiang Zhang, R.
Devon Hjelm, Wenjie Li, Yangqiu Song,
and Yoshua Bengio. 2017. Maximum-
likelihood augmented discrete generative
adversarial networks. arXiv preprint
arXiv:1702.07983.
Conneau, Alexis, Germ´an Kruszewski,
Guillaume Lample, Lo¨ıc Barrault, and
Marco Baroni. 2018. What you can cram
into a single \$&!#* vector: Probing
sentence embeddings for linguistic
properties. In Proceedings of the 56th Annual
Meeting of the Association for Computational
Linguistics, pages 2126–2136. Melbourne.
https://doi.org/10.18653/v1/P18-1198
D’Amour, Alexander, Peng Ding, Avi Feller,
Lihua Lei, and Jasjeet Sekhon. 2017.
Overlap in observational studies with
high-dimensional covariates. arXiv preprint
arXiv:1711.02582.
Davidson, Thomas, Debasmita Bhattacharya,
and Ingmar Weber. 2019. Racial bias in
hate speech and abusive language
detection data sets. In Proceedings of the
Third Workshop on Abusive Language Online,
pages 25–35. https://doi.org/10.18653
/v1/W19-3504
De-Arteaga, Maria, Alexey Romanov,
Hanna M. Wallach, Jennifer T. Chayes,
Christian Borgs, Alexandra Chouldechova,
Sahin Cem Geyik, Krishnaram Kenthapadi,
and Adam Tauman Kalai. 2019. Bias in
bios: A case study of semantic
representation bias in a high-stakes setting.
In Proceedings of the Conference on Fairness,
Accountability, and Transparency,
pages 120–128. Atlanta, GA. https://
doi.org/10.1145/3287560.3287572
De Choudhury, Munmun, Emre Kiciman,
Mark Dredze, Glen Coppersmith, and
Mrinal Kumar. 2016. Discovering shifts
to suicidal ideation from mental health
content in social media. In Proceedings of
the 2016 CHI Conference on Human Factors
in Computing Systems, pages 2098–2110.
San Jose, CA. https://doi.org/10.1145
/2858036.2858207, PubMed: 29082385
Devlin, Jacob, Ming-Wei Chang, Kenton Lee,
and Kristina Toutanova. 2019. BERT:
Pre-training of deep bidirectional
transformers for language understanding.
In Proceedings of the 2019 Conference of the
North American Chapter of the Association for
Computational Linguistics: Human Language
Technologie, pages 4171–4186. Minneapolis,
MN.
Dong, Li, Nan Yang, Wenhui Wang, Furu
Wei, Xiaodong Liu, Yu Wang, Jianfeng
Gao, Ming Zhou, and Hsiao-Wuen Hon.
2019. Unified language model pre-training
for natural language understanding and
generation. In Advances in Neural
Information Processing Systems 32: Annual
Conference on Neural Information Processing
Systems 2019, pages 13042–13054.
VAncouver.
Dorie, Vincent, Jennifer Hill, Uri Shalit, Marc
Scott, Dan Cervone, and others. 2019.
Automated versus do-it-yourself methods
for causal inference: Lessons learned from
a data analysis competition. Statistical
Science, 34(1):43–68. https://doi.org
/10.1214/18-STS667
Doshi-Velez, Finale and Been Kim. 2017.
Towards a rigorous science of interpretable
machine learning. arXiv: Machine Learning.
Egami, Naoki, Christian J. Fong, Justin
Grimmer, Margaret E. Roberts, and
Brandon M. Stewart. 2018. How to make
causal inferences using texts. arXiv preprint
arXiv:abs/1802.02163.
Elazar, Yanai and Yoav Goldberg. 2018.
Adversarial removal of demographic
attributes from text data. In Proceedings of
the 2018 Conference on Empirical Methods in
Natural Language Processing, pages 11–21.
Brussels. https://doi.org/10.18653/v1
/D18-1002
Falcon, WA. 2019. Pytorch lightning. GitHub.
https://github.com/PyTorchLightning/
pytorch-lightning.
Feder, Amir, Danny Vainstein, Roni
Rosenfeld, Tzvika Hartman, Avinatan
Hassidim, and Yossi Matias. 2020. Active
deep learning to detect demographic traits
in free-form clinical notes. Journal of
Biomedical Informatics, vol. 107, 103436.
https://doi.org/10.1016/j.jbi.2020
.103436, PubMed: 32428572
Fedus, William, Ian J. Goodfellow, and
Andrew M. Dai. 2018. Maskgan: Better text
generation via filling in the
International Conference on Learning
Representations, pages 1–17. Vancouver.
Fong, Christian and Justin Grimmer. 2016.
. In
Discovery of treatments from text corpora.
In Proceedings of the 54th Annual Meeting
of the Association for Computational
Linguistics, pages 1600–1609. Berlin.
https://doi.org/10.18653/v1
/P16-1151
Ganin, Yaroslav, Evgeniya Ustinova, Hana
Ajakan, Pascal Germain, Hugo Larochelle,
Franc¸ois Laviolette, Mario Marchand, and
Victor S. Lempitsky. 2016. Domain-
adversarial training of neural networks.
The Journal of Machine Learning Research,
17:59:1–59:35.
Gao, Jianfeng, Michel Galley, and Lihong Li.
2018. Neural approaches to conversational
381
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
AI. In Proceedings of ACL 2018, pages 2–7.
Melbourne. https://doi.org/10.18653
/v1/P18-5002
Gardner, Matt, Yoav Artzi, Victoria Basmova,
Jonathan Berant, Ben Bogin, Sihao Chen,
Pradeep Dasigi, Dheeru Dua, Yanai Elazar,
Ananth Gottumukkala, Nitish Gupta,
Hannaneh Hajishirzi, Gabriel Ilharco,
Daniel Khashabi, Kevin Lin, Jiangming
Liu, Nelson F. Liu, Phoebe Mulcaire, Qiang
Ning, Sameer Singh, and others. 2020.
Evaluating models’ local decision
boundaries via contrast sets. In Proceedings
of the 2020 Conference on Empirical Methods
in Natural Language Processing: Findings,
Online, pages 1307–1323. https://doi.org
/10.18653/v1/2020.findings-emnlp.117
Gehrmann, Sebastian, Hendrik Strobelt,
Robert Kr ¨uger, Hanspeter Pfister, and
Alexander M. Rush. 2020. Visual
interaction with deep learning models
through collaborative semantic inference.
IEEE Transactions on Visualization and
Computer Graphics, 26(1):884–894.
https://doi.org/10.1109/TVCG.2019
.2934595, PubMed: 31425116
Gentzel, Amanda, Dan Garant, and David
Jensen. 2019. The case for evaluating
causal models using interventional
measures and empirical data. In Advances
in Neural Information Processing Systems,
pages 11717–11727. Vancouver.
Ghosal, Deepanway, Devamanyu Hazarika,
Abhinaba Roy, Navonil Majumder, Rada
Mihalcea, and Soujanya Poria. 2020.
Kingdom: Knowledge-guided domain
adaptation for sentiment analysis. In
Proceedings of the 58th Annual Meeting of the
Association for Computational Linguistics,
Online, pages 3198–3210. https://doi
.org/10.18653/v1/2020.acl-main.292
Gonen, Hila and Yoav Goldberg. 2019.
Lipstick on a pig: Debiasing methods
cover up systematic gender biases in word
embeddings but do not remove them. In
Proceedings of the 2019 Conference of the
North American Chapter of the Association for
Computational Linguistics: Human Language
Technologies, pages 609–614. Minneapolis,
MN.
Goyal, Yash, Amir Feder, Uri Shalit, and
Been Kim. 2019a. Explaining classifiers
with causal concept effect (cace). arXiv
preprint arXiv:abs/1907.07165.
Goyal, Yash, Ziyan Wu, Jan Ernst, Dhruv
Batra, Devi Parikh, and Stefan Lee. 2019b.
Counterfactual visual explanations. In
Proceedings of the 36th International
Conference on Machine Learning,
pages 2376–2384. Long Beach, California.
382
Guo, Jiaxian, Sidi Lu, Han Cai, Weinan
Zhang, Yong Yu, and Jun Wang. 2018. Long
text generation via adversarial training
with leaked information. In Thirty-Second
AAAI Conference on Artificial Intelligence,
pages 5141–5148. New Orleans, LA.
Gururangan, Suchin, Ana Marasovic,
Swabha Swayamdipta, Kyle Lo, Iz Beltagy,
Doug Downey, and Noah A. Smith. 2020.
Don’t stop pretraining: Adapt language
models to domains and tasks. In
Proceedings of the 58th Annual Meeting of the
Association for Computational Linguistics,
Online, pages 8342–8360. https://doi
.org/10.18653/v1/2020.acl-main.740
Huang, Po-Sen, Huan Zhang, Ray Jiang,
Robert Stanforth, Johannes Welbl, Jack
Rae, Vishal Maini, Dani Yogatama, and
Pushmeet Kohli. 2020. Reducing sentiment
bias in language models via counterfactual
evaluation. In Proceedings of the 2020
Conference on Empirical Methods in Natural
Language Processing: Findings, Online Event,
pages 65–83. https://doi.org/10
.18653/v1/2020.findings-emnlp.7
Hupkes, Dieuwke, Sara Veldhoen, and
Willem H. Zuidema. 2018. Visualisation
and ‘diagnostic classifiers’ reveal how
recurrent and recursive neural networks
process hierarchical structure. Journal of
Artificial Intelligence Research, 61:907–926.
https://doi.org/10.1613/jair.1.11196
Isabelle, Pierre, Colin Cherry, and George F.
Foster. 2017. A challenge set approach to
evaluating machine translation. In
Proceedings of the 2017 Conference on
Empirical Methods in Natural Language
Processing, pages 2486–2496. Copenhagen.
https://doi.org/10.18653/v1/D17-1263
Jain, Sarthak and Byron C. Wallace. 2019.
Attention is not explanation. In Proceedings
of the 2019 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
pages 3543–3556. Minneapolis, MN.
Jernite, Yacine, Samuel R. Bowman, and
David A. Sontag. 2017. Discourse-based
objectives for fast unsupervised sentence
representation learning. arXiv preprint
arXiv:abs/1705.00557.
Johansson, Fredrik D., Uri Shalit, and
David A. Sontag. 2016. Learning
representations for counterfactual
inference. In Proceedings of the 33nd
International Conference on Machine
Learning, pages 3020–3029. New York, NY.
Kaushik, Divyansh, Eduard H. Hovy, and
Zachary Chase Lipton. 2020. Learning the
difference that makes a difference with
counterfactually-augmented data. In 8th
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
International Conference on Learning
Representations, pages 1–17. Addis
Ababa.
Keith, Katherine A., David Jensen, and
Brendan O’Connor. 2020. Text and causal
inference: A review of using text to remove
confounding from causal estimates. In
Proceedings of the 58th Annual Meeting of the
Association for Computational Linguistics,
Online, pages 5332–5344. https://doi
.org/10.18653/v1/2020.acl-main.474
Kim, Been, Rajiv Khanna, and Oluwasanmi
O. Koyejo. 2016a. Examples are not
enough, learn to criticize! Criticism for
interpretability. In Advances in Neural
Information Processing Systems 29: Annual
Conference on Neural Information Processing
Systems, pages 2280–2288. Barcelona.
Kim, Been, Martin Wattenberg, Justin Gilmer,
Carrie Cai, James Wexler, Fernanda Viegas,
et al. 2016b. Interpretability beyond feature
attribution: Quantitative testing with
concept activation vectors (tcav). In
International Conference on Machine
Learning, pages 2668–2677. Barcelona.
Kingma, Diederik P. and Jimmy Ba. 2015.
Adam: A method for stochastic
optimization. In 3rd International Conference
on Learning Representations, pages 1–15.
San Diego, CA.
Kiritchenko, Svetlana and Saif Mohammad.
2018. Examining gender and race bias in
two hundred sentiment analysis systems.
In Proceedings of the Seventh Joint Conference
on Lexical and Computational Semantics,
pages 43–53. New Orleans, LA. https://
doi.org/10.18653/v1/S18-2005
Lau, Jey Han, David Newman, and Timothy
Baldwin. 2014. Machine reading tea leaves:
Automatically evaluating topic coherence
and topic model quality. In Proceedings of
the 14th Conference of the European Chapter of
the Association for Computational Linguistics,
pages 530–539. Gothenburg. https://doi
.org/10.3115/v1/E14-1056
Lee, Jinhyuk, Wonjin Yoon, Sungdong Kim,
Donghyeon Kim, Sunkyu Kim, Chan Ho
So, and Jaewoo Kang. 2020. BioBERT: A
pre-trained biomedical language
representation model for biomedical
text mining. Bioinformatics, 36(4):1234–1240.
https://doi.org/10.1093/bioinformatics
/btz682, PubMed: 31501885
Lin, Kevin, Dianqi Li, Xiaodong He,
Ming-Ting Sun, and Zhengyou Zhang.
2017. Adversarial ranking for language
generation. In Advances in Neural
Information Processing Systems,
pages 3155–3165, Long Beach, CA.
Linzen, Tal, Grzegorz Chrupała, Yonatan
Belinkov, and Dieuwke Hupkes, editors.
2019. Proceedings of the 2019 ACL Workshop
BlackboxNLP: Analyzing and Interpreting
Neural Networks for NLP. Florence.
Lipton, Zachary C. 2018. The mythos of
model interpretability. Communications of
ACM, 61(10):36–43. https://doi.org
/10.1145/3233231
Liu, Yinhan, Myle Ott, Naman Goyal, Jingfei
Du, Mandar Joshi, Danqi Chen, Omer
Levy, Mike Lewis, Luke Zettlemoyer, and
Veselin Stoyanov. 2019. RoBERTa: A
robustly optimized BERT pretraining
approach. arXiv preprint arXiv:1907
.11692.
Logeswaran, Lajanugen and Honglak Lee.
2018. An efficient framework for learning
sentence representations. In 6th
International Conference on Learning
Representations, pages 1–15. Vancouver.
Lorberbom, Guy, Tommi S. Jaakkola,
Andreea Gane, and Tamir Hazan. 2019.
Direct optimization through arg max for
discrete variational auto-encoder. In
Advances in Neural Information Processing
Systems, pages 6200–6211. Vancouver.
Lundberg, Scott M. and Su-In Lee. 2017. A
unified approach to interpreting model
predictions. In Advances in Neural
Information Processing Systems,
pages 4765–4774. Long Beach, CA.
Maas, Andrew L., Raymond E. Daly, Peter T.
Pham, Dan Huang, Andrew Y. Ng, and
Christopher Potts. 2011. Learning word
vectors for sentiment analysis. In the 49th
Annual Meeting of the Association for
Computational Linguistics: Human Language
Technologies, pages 142–150. OR.
Naik, Aakanksha, Abhilasha Ravichander,
Carolyn Penstein Ros´e, and Eduard H.
Hovy. 2019. Exploring numeracy in word
embeddings. In Proceedings of the 57th
Conference of the Association for
Computational Linguistics, pages 3374–3380.
Florence.
Oved, Nadav, Amir Feder, and Roi Reichart.
2020. Predicting in-game actions from
interviews of NBA players. Computational
Linguistics, 46(3):667–712.
Pang, Bo, Lillian Lee, and Shivakumar
Vaithyanathan. 2002. Thumbs up?
Sentiment classification using machine
learning techniques. In Proceedings of the
2002 Conference on Empirical Methods in
Natural Language Processing, pages 79–86.
Philadelphia, PA.
Paszke, Adam, Sam Gross, Soumith
Chintala, Gregory Chanan, Edward Yang,
383
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
Zachary DeVito, Zeming Lin, Alban
Desmaison, Luca Antiga, and Adam Lerer.
2017. Automatic differentiation in PyTorch.
In NIPS-W, pages 1–4. Long Beach, CA.
Pearl, Judea. 1995. Causal diagrams for
empirical research. Biometrika,
82(4):669–688. https://doi.org/10
.1093/biomet/82.4.669
Pearl, Judea. 2009a. Causal inference in
statistics: An overview. Statistics Surveys,
3:96–146. https://doi.org/10.1214
/09-SS057
Pearl, Judea. 2009b. Causality. Cambridge
University Press.
Pennebaker, James W., Martha E. Francis,
and Roger J. Booth. 2001. Linguistic inquiry
and word count: LIWC 2001. http://
downloads.liwc.net.s3.amazonaws.com
/LIWC2015 OperatorManual.pdf.
Peters, Matthew E., Mark Neumann, Mohit
Iyyer, Matt Gardner, Christopher Clark,
Kenton Lee, and Luke Zettlemoyer. 2018.
Deep contextualized word representations.
In Proceedings of the 2018 Conference of the
North American Chapter of the Association for
Computational Linguistics: Human Language
Technologies, pages 2227–2237.
New Orleans, LA. https://doi.org
/10.18653/v1/N18-1202
Radford, Alec, Karthik Narasimhan, Tim
Salimans, and Ilya Sutskever. 2018.
Improving language understanding with
unsupervised learning, Technical report,
OpenAI.
Radford, Alec, Jeffrey Wu, Rewon Child,
David Luan, Dario Amodei, and Ilya
Sutskever. 2019. Language models are
unsupervised multitask learners. OpenAI
Blog, 1(8):9.
Ramponi, Alan and Barbara Plank. 2020.
Neural unsupervised domain adaptation
in NLP – A survey. In Proceedings of the 28th
International Conference on Computational
Linguistics, pages 6838–6855. Barcelona.
https://doi.org/10.18653/v1/2020
.coling-main.603
Ravfogel, Shauli, Yanai Elazar, Hila Gonen,
Michael Twiton, and Yoav Goldberg. 2020.
Null it out: Guarding protected attributes
by iterative nullspace projection. In
Proceedings of the 58th Annual Meeting of the
Association for Computational Linguistics,
Online, pages 7237–7256. https://doi
.org/10.18653/v1/2020.acl-main.647
ˇReh ˚uˇrek, Radim and Petr Sojka. 2010.
Software framework for topic modelling
with large corpora. In Proceedings of the
LREC 2010 Workshop on New Challenges for
NLP Frameworks, pages 45–50. Valletta,
Malta. http://is.muni.cz/publication
/884893/en
384
Ribeiro, Marco T ´ulio, Sameer Singh, and
Carlos Guestrin. 2016. Why should I trust
you?: Explaining the predictions of any
classifier. In Proceedings of the 22nd ACM
SIGKDD International Conference on
Knowledge Discovery and Data Mining,
pages 1135–1144. San Francisco, CA.
https://doi.org/10.1145/2939672
.2939778
Roberts, Margaret E., Brandon M. Stewart,
and Richard A. Nielsen. 2018. Adjusting
for confounding with text matching.
American Journal of Political Science,
64:887–903.
Roberts, Margaret E., Brandon M. Stewart,
Dustin Tingley, Christopher Lucas, Jetson
Leder-Luis, Shana Kushner Gadarian,
Bethany Albertson, and David G. Rand.
2014. Structural topic models for
open-ended survey responses.
American Journal of Political Science,
58(4):1064–1082. https://doi.org/10
.1111/ajps.12103
Rotman, Guy and Roi Reichart. 2019. Deep
contextualized self-training for low
resource dependency parsing. Transactions
of the Association for Computational
Linguistics, 7:695–713.
Rudinger, Rachel, Chandler May, and
Benjamin Van Durme. 2017. Social bias in
elicited natural language inferences. In
Proceedings of the First ACL Workshop on
Ethics in Natural Language Processing,
EthNLP@EACL, Valencia, Spain, April 4,
2017, pages 74–79. Valencia. https://
doi.org/10.18653/v1/w17-1609.
Saha, Koustuv, Benjamin Sugar, John Torous,
Bruno D. Abrahao, Emre Kiciman, and
Munmun De Choudhury. 2019. A social
media study on the effects of psychiatric
medication use. In Proceedings of the
International AAAI Conference on Web
and Social Media, pages 440–451.
Munich.
Sari, Yunita, Mark Stevenson, and Andreas
Vlachos. 2018. Topic or style? Exploring
the most useful features for authorship
attribution. In Proceedings of the 27th
International Conference on Computational
Linguistics, pages 343–353. Santa Fe,
New Mexico.
Semeniuta, Stanislau, Aliaksei Severyn,
and Erhardt Barth. 2017. A hybrid
convolutional variational autoencoder for
text generation. In Proceedings of the 2017
Conference on Empirical Methods in Natural
Language Processing, pages 627–637.
Copenhagen. https://doi.org/10.18653
/v1/d17-1066
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Feder et al.
CausaLM
Sennrich, Rico. 2017. How grammatical is
character-level neural machine
translation? Assessing MT quality with
contrastive translation pairs. In Proceedings
of the 15th Conference of the European Chapter
of the Association for Computational
Linguistics, pages 376–382. Valencia.
https://doi.org/10.18653/v1/e17-2060
Subramanian, Sandeep, Sai Rajeswar, Francis
Dutil, Chris Pal, and Aaron C. Courville.
2017. Adversarial generation of natural
language. In Proceedings of the 2nd
Workshop on Representation Learning for
NLP, 241–251. Vancouver. https://doi
.org/10.18653/v1/W17-2629
Sun, Chi, Xipeng Qiu, Yige Xu, and Xuanjing
Huang. 2019. How to fine-tune BERT for
text classification? arXiv preprint
arXiv:1905.05583. https://doi.org
/10.1007/978-3-030-32381-3 16
Swinger, Nathaniel, Maria De-Arteaga, Neil
Thomas Heffernan IV, Mark D. M.
Leiserson, and Adam Tauman Kalai. 2019.
What are the biases in my word
embedding? In Proceedings of the 2019
AAAI/ACM Conference on AI, Ethics, and
Society, pages 305–311. Honolulu, HI.
https://doi.org/10.1145/3306618
.3314270
Szegedy, Christian, Vincent Vanhoucke,
Sergey Ioffe, Jonathon Shlens, and
Zbigniew Wojna. 2016. Rethinking the
inception architecture for computer vision.
In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition,
pages 2818–2826. Las Vegas, NV.
https://doi.org/10.1109/CVPR.2016
.308
Tan, Chenhao, Lillian Lee, and Bo Pang.
2014. The effect of wording on message
propagation: Topic- and author-controlled
natural experiments on Twitter. In
Proceedings of the 52nd Annual Meeting of the
Association for Computational Linguistics,
pages 175–185. Baltimore, MD. https://
doi.org/10.3115/v1/p14-1017
Tshitoyan, Vahe, John Dagdelen, Leigh
Weston, Alexander Dunn, Ziqin Rong,
Olga Kononova, Kristin A. Persson,
Gerbrand Ceder, and Anubhav Jain. 2019.
Unsupervised word embeddings capture
latent knowledge from materials science
literature. Nature, 571(7763):95–98.
https://doi.org/10.1038/s41586-019
-1335-8, PubMed: 31270483
need. In Advances in Neural Information
Processing Systems 30: Annual Conference on
Neural Information Processing Systems,
pages 5998–6008. Long Beach, CA.
Veitch, Victor, Dhanya Sridhar, and David M.
Blei. 2019. Using text embeddings for
causal inference. arXiv preprint
arXiv:abs/1905.12741.
Vig, Jesse, Sebastian Gehrmann, Yonatan
Belinkov, Sharon Qian, Daniel Nevo, Yaron
Singer, and Stuart M. Shieber. 2020.
Investigating gender bias in language
models using causal mediation analysis. In
Advances in Neural Information Processing
Systems 33: Annual Conference on Neural
Information Processing Systems, virtual.
Wiegreffe, Sarah and Yuval Pinter. 2019.
Attention is not not explanation. In
Proceedings of the 2019 Conference on
Empirical Methods in Natural Language
Processing and the 9th International Joint
Conference on Natural Language Processing,
pages 11–20, Hong Kong. https://doi
.org/10.18653/v1/D19-1002
Wolf, Thomas, Lysandre Debut, Victor Sanh,
Julien Chaumond, Clement Delangue,
Anthony Moi, Pierric Cistac, Tim Rault,
R´emi Louf, Morgan Funtowicz, and
Jamie Brew. 2019. Huggingface’s
Transformers: State-of-the-art natural
language processing. ArXiv,
abs/1910.03771.
Wood-Doughty, Zach, Ilya Shpitser, and
Mark Dredze. 2018. Challenges of using
text classifiers for causal inference. In
Proceedings of the 2018 Conference on
Empirical Methods in Natural Language
Processing, pages 4586–4598. Brussels.
https://www.aclweb.org/anthology
/D18-1488/.
Woodward, James. 2005. Making Things
Happen: A Theory Of Causal Explanation.
Oxford University Press.
Wu, Yonghui, Mike Schuster, Zhifeng Chen,
Quoc V. Le, Mohammad Norouzi,
Wolfgang Macherey, Maxim Krikun, Yuan
Cao, Qin Gao, Klaus Macherey, Jeff
Klingner, Apurva Shah, Melvin Johnson,
Xiaobing Liu, Lukasz Kaiser, Stephan
Gouws, Yoshikiyo Kato, Taku Kudo,
Hideto Kazawa, Keith Stevens, and others.
2016. Google’s neural machine translation
system: Bridging the gap between
human and machine translation. arXiv
preprint arXiv:1609.08144.
Vaswani, Ashish, Noam Shazeer, Niki
Xie, Qizhe, Zihang Dai, Yulun Du, Eduard H.
Parmar, Jakob Uszkoreit, Llion Jones,
Aidan N. Gomez, Lukasz Kaiser, and Illia
Polosukhin. 2017. Attention is all you
Hovy, and Graham Neubig. 2017.
Controllable invariance through
adversarial feature learning. In Advances in
385
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
Computational Linguistics
Volume 47, Number 2
Neural Information Processing Systems 30:
Annual Conference on Neural Information
Processing Systems, pages 585–596. Long
Beach, CA.
Yang, Zhilin, Zihang Dai, Yiming Yang, Jaime
G. Carbonell, Ruslan Salakhutdinov, and
Quoc V. Le. 2018. Variable generalization
performance of a deep learning model to
detect pneumonia in chest radiographs:
A cross-sectional study. In Advances in
Neural Information Processing Systems 32:
Annual Conference on Neural Information
Processing Systems, pages 5754–5764.
Vancouver.
Zech, John R., Marcus A. Badgeley, Manway
Liu, Anthony B. Costa, Joseph J. Titano,
and Eric Karl Oermann. 2018. Variable
generalization performance of a deep
learning model to detect pneumonia in
chest radiographs: A cross-sectional study.
PLoS Medicine, 15(11):e1002683. https://
doi.org/10.1371/journal.pmed.1002683,
PubMed: 30399157
Zhu, Yukun, Ryan Kiros, Richard S. Zemel,
Ruslan Salakhutdinov, Raquel Urtasun,
Antonio Torralba, and Sanja Fidler. 2015.
Aligning books and movies: Towards
story-like visual explanations by watching
movies and reading books. In 2015 IEEE
International Conference on Computer Vision,
pages 19–27. Santiago. https://doi.org
/10.1109/ICCV.2015.11
Ziser, Yftah and Roi Reichart. 2018. Pivot
based language modeling for improved
neural domain adaptation. In Proceedings of
the 2018 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
pages 1241–1251. New Orleans, Louisiana.
https://doi.org/10.18653/v1/n18-1112
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
c
o
l
i
/
l
a
r
t
i
c
e
–
p
d
f
/
/
/
/
4
7
2
3
3
3
1
9
3
8
1
0
7
/
c
o
l
i
_
a
_
0
0
4
0
4
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
8
S
e
p
e
m
b
e
r
2
0
2
3
386