Categorical Metadata Representation for Customized Text Classification
Jihyeok Kim*1 Reinald Kim Amplayo*2
Kyungjae Lee1
Sua Sung1 Minji Seo1
Seung-won Hwang1
(* equal contribution)
1Yonsei University
zizi1532@yonsei.ac.kr
2University of Edinburgh
reinald.kim@ed.ac.uk
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
3
1
9
2
3
0
4
7
/
/
t
l
a
c
_
a
_
0
0
2
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
{lkj0509,dormouse,ggatalminji,seungwonh}@yonsei.ac.kr
Abstract
The performance of text classification has
improved tremendously using intelligently
engineered neural-based models, especially those
injecting categorical metadata as additional
information, e.g., using user/product informa-
tion for sentiment classification. This infor-
mation has been used to modify parts of the
model (e.g., word embeddings, attention mech-
anisms) such that results can be customized
according to the metadata. We observe that
current representation methods for categorical
metadata, which are devised for human con-
sumption, are not as effective as claimed in
popular classification methods, outperformed
even by simple concatenation of categorical
features in the final
layer of the sentence
encoder. We conjecture that categorical fea-
tures are harder to represent for machine use,
as available context only indirectly describes
the category, and even such context is often
scarce (for tail category). To this end, we pro-
pose using basis vectors to effectively incor-
porate categorical metadata on various parts
of a neural-based model. This additionally
decreases the number of parameters dramatic-
ally, especially when the number of categori-
cal features is large. Extensive experiments on
various data sets with different properties are
performed and show that through our method,
we can represent categorical metadata more
effectively to customize parts of the model,
including unexplored ones, and increase the
performance of the model greatly.
1
Introduction
Text classification is the backbone of most NLP
tasks: review classification in sentiment analysis
201
(Pang et al., 2002), paper classification in sci-
entific data discovery (Sebastiani, 2002), and
question classification in question answering (Li
and Roth, 2002), to name a few. While prior meth-
ods require intensive feature engineering, recent
methods enjoy automatic extraction of features
from text using neural-based models (Socher et al.,
2011) by encoding texts into low-dimensional
dense feature vectors.
This paper discusses customized text clas-
sification, generalized from personalized text
classification (Baruzzo et al., 2009), where we
customize classifiers based on possibly multiple
different known categorical metadata information
information for sentiment
(e.g., user/product
classification) instead of just the user information.
As shown in Figure 1, in addition to the text,
a customizable text classifier is given a list of
categories specific to the text to predict its class.
Existing works applied metadata information to
improve the performance of a model, such as
user and product (Tang et al., 2015) information
in sentiment classification, and author (Rosen-
Zvi et al., 2004) and publication (Joorabchi and
Mahdi, 2011) information in paper classification.
Towards our goal, we are inspired by the ad-
vancement in neural-based models, incorporat-
ing categorical information ‘‘as is’’ and injecting
it on various parts of the model such as in the
word embeddings (Tang et al., 2015), attention
mechanism (Chen et al., 2016; Amplayo et al.,
2018a) and memory networks (Dou, 2017).
these methods theoretically make use
Indeed,
of combined features from both textual and
categorical
features, which make them more
powerful than disconnected features. However,
metadata is generated for human understanding,
and thus we claim that these categories need
to be carefully represented for machine use to
Transactions of the Association for Computational Linguistics, vol. 7, pp. 201–215, 2019. Action Editor: Bo Pang.
Submission batch: 11/2018; Revision batch: 1/2019; Final submission: 2/2019; Published 4/2019.
c(cid:2) 2019 Association for Computational Linguistics. Distributed under a CC-BY 4.0 license.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
3
1
9
2
3
0
4
7
/
/
t
l
a
c
_
a
_
0
0
2
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 1: A high-level framework of models for the Customized Text Classification Task that inputs a text with n
tokens (e.g., review) and m categories (e.g., users, products) and outputs a class (e.g., positive/negative). Example
tasks are shown in the left of the figure.
improve the performance of the text classifier
effectively.
First, we empirically invalidate the results from
previous studies by showing in our experiments
on multiple data sets that popular methods using
metadata categories ‘‘as is’’ perform worse than
a simple concatenation of textual and categorical
feature vectors. We argue that this is because of
the difficulties of the model in learning optimized
dense vector representation of the categorical
features to be used by the classification model.
The reasons are two-fold: (a) categorical features
do not have direct context and thus rely solely
on classification labels when training the feature
vectors, and (b) there are categorical information
that are sparse and thus cannot effectively learn
optimal feature vectors.
Second, we suggest an alternative represen-
tation, using low-dimensional basis vectors to
mitigate the optimization problems of categorical
feature vectors. Basis vectors have nice properties
that can solve the issues presented here because
they (a) transform multiple categories into useful
combinations, which serve as mutual context to all
categories, and (b) intelligently initialize vectors,
especially of sparse categorical information, to
a suboptimal location to efficiently train them
further. Furthermore, our method reduces the
number of trainable parameters and thus is flex-
ible for any kinds and any number of available
categories.
We experiment on multiple classification tasks
with different properties and kinds of catego-
ries available. Our experiments show that while
customization methods using categorical infor-
mation ‘‘as is’’ do not perform as well as the
naive concatenation method, applying our pro-
posed basis-customization method makes them
much more effective than the naive method. Our
method also enables the use of categorical meta-
data to customize other parts of the model, such
as the encoder weights, that are previously un-
explored due to their high space complexity and
weak performance. We show that this unexplored
use of customization outperform popular and con-
ventional methods such as attention mechanism
when our proposed basis-customization method
is used.
202
2 Preliminaries
2.1 Problem: Customized Text Classification
The original text classification task is defined
as follows: Given a text W = {w1, w2, …, wn},
we are tasked to train a mapping function f (W )
to predict a correct class y ∈ {y1, y2, …, yp}
among the p classes. The customized text
classification task makes use of the categorical
to
metadata information attached on the text
customize the mapping function. In this paper,
we define categorical metadata as non-continuous
information that describes the text.1 An example
task is review sentiment classification with user
and product information as categorical metadata.
Formally, given a text t = {W, C}, where
W = {w1, w2, …, wn}, C = {c1, c2, …, cm}, wx
is the xth of the n tokens in the text, and cz is the
category label of the text on the zth category of
the m available categories, the goal of customized
text classification is to optimize a function fC(W )
to predict a label y, where fC(W ) is the classifier
dependent with C. In our example task, W is the
review text, and we have m = 2 categories where
c1 and c2 are the user and product information.
This is an interesting problem because of the
vast opportunities it provides. First, we are moti-
vated to use categorical metadata because exist-
ing work has shown that non-textual additional
information, such as POS tags (Go et al., 2009)
and latent topics (Zhao et al., 2017), can be used
as strong supplementary supervision to improve
the performance of text classification. Second,
while previously used additional information is
they are either domain-
found to be helpful,
dependent or very noisy (Amplayo et al., 2018b).
On the other hand, categorical metadata are
usually factual and valid information that are
either inherent (e.g., user/product information)
or human-labeled (e.g., research area). Finally,
the customized text classification task generalizes
the personalization problem (Baruzzo et al.,
2009), where instead of personalizing based on
single user information, we customize based on
1We limit our scope to texts with categorical metadata
information (product reviews, news articles, tweets, etc.),
which covers most of the texts on the Web. Texts without
metadata can use predicted categorical information, such as
topics from a topic model, which are commonly used (Zhao
et al., 2017; Chou et al., 2017). However, because the predic-
tion may be incorrect, performance gains cannot be guaran-
teed. We leave the investigation of this area in future work.
possibly multiple categories, which may or may
not include user information. This consequently
creates an opportunity to develop customizable
virtual assistants (Papacharissi, 2002).
2.2 Base Classifier: BiLSTM
We use a Bidirectional Long Short Term Memory
(BiLSTM) network (Hochreiter and Schmidhuber,
1997) as our base text classifier as it is proven to
work well on classifying text sequences (Zhou
et al., 2016). Although the methods that are
described here apply to other effective classifiers
as well, such as convolutional neural networks
(CNNs) (Kim, 2014) and hierarchical models
(Yang et al., 2016), we limit our experiments
to BiLSTM to cover more important findings.
Our BiLSTM classifier starts by encoding the
word embeddings using a forward and a back-
ward LSTM. The resulting pairs of vectors are
concatenated to get the final encoded word vec-
tors, as shown here:
wi ∈ W
−→
h i = LST Mf (wi,
←−
h i = LST Mb(wi,
−→
h i;
←−
h i]
hi = [
−→
h i−1)
←−
h i+1)
(1)
(2)
(3)
(4)
Next, we pool the encoded word vectors hi into
a text vector d using an attention mechanism
(Bahdanau et al., 2015; Luong et al., 2015), which
calculates importance scores using a latent context
vector x for all words, normalizes the scores using
softmax, and uses them to do weighted sum on
encoded word vectors, as shown:
ei = x(cid:6)hi
ai =
d =
(cid:2)
exp(ei)
j exp(ej)
(cid:3)
hi ∗ ai
(5)
(6)
(7)
i
Finally, we use a logistic regression classifier to
classify labels using learned weight matrix W (c)
and bias vector b(c):
y(cid:8) = W (c)d + b(c)
(8)
We can then train our classifier using any gradient
descent algorithm by minimizing the negative log
likelihood of the log softmax of predicted labels
y(cid:8) with respect to the actual labels y.
203
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
3
1
9
2
3
0
4
7
/
/
t
l
a
c
_
a
_
0
0
2
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
2.3 Baseline 1: Concatenated BiLSTM
To incorporate the categories into the classifier,
a simple and naive method is to concatenate the
categorical features with the text vector d. To do
this, we create embedding spaces for the dif-
ferent categories and get the category vectors
c1, c2, …, cm based on the category labels of text
d. We then use the concatenated vector as features
for the logistic regression classifier:
y(cid:8) = W (c)[d; c1; c2; …; cm] + b(c)
(9)
2.4 Baseline 2: Customized BiLSTM
Although the Concatenated BiLSTM easily makes
use of the categories as additional features for
the classifier, it is not able to leverage on the
possible low-level dependencies between textual
and categorical features.
There are different
levels of dependencies
between texts and categories. For example, when
predicting the sentiment of a review ‘‘The food is
very sweet,’’ given the user who wrote the review,
the classifier should give a positive label if the user
likes sweet foods and a negative label otherwise.
In this case, the dependency between the review
and the user is on the higher level, where we
look at relationships between the full text and the
categories. Another example is when predicting
the acceptance of a research paper given that the
research area is NLP, the classifier should focus
more on NLP words (e.g., language, text) rather
than less-related words (e.g., biology, chemistry).
In this case, the dependency between the research
paper and the research area is on the lower level,
where we look at relationships between segments
of text and the categories.
We present five levels of Customized BiLSTM,
which differ on the location where we inject the
categorical features, listed here from the highest
level to the lowest level of dependencies between
text and categories. The main idea is to impose
category-specific weights, rather than a single
weight at each level of the model:
1. Customize on the bias vector: At this level
of customization, we look at the general
biases the categories have towards the prob-
lem. As a concrete example, when classify-
ing the type of message a politician wrote,
he/she can be biased towards writing personal
messages than policy messages. Instead of
using a single bias vector b(c) in the logistic
regression classifier (Equation 8), we use
additional multiple bias vectors for each
category, as shown below. In fact, this is
in spirit essentially equivalent to concate-
nated BiLSTM (Equation 9), where the
derivation is:
y(cid:8) = Wdd + bc1 + … + bcm + b(c)
= Wdd + Wc1c1 + … + Wcmcm + b(c)
= W (c)[d; c1; c2; …; cm] + b(c)
2. Customize on the linear transformation:
At this level of customization, we look at
the text-level semantic biases the categories
have. As a concrete example, in the sentiment
classification task, the review ‘‘The food is
very sweet’’ can have a negative sentiment
if the user who wrote the review does
not like sweets. Instead of using a single
weight matrix W (c) in the logistic regres-
sion classifier (Equation 8), we use different
weight matrices for each category:
y(cid:8) = W (c)
c1
d + W (c)
c2
d + … + W (c)
cm d + b(c)
3. Customize on the attention pooling: At
this level of customization, we look at the
word importance biases the categories have.
A concrete example is, when classifying a
research paper, NLP words should be focused
more when the research area is NLP. Instead
of using a single context vector x when calcu-
lating the attention scores e (Equation 5),
we use different context vectors for each
category:
hi + … + x(cid:6)
cmhi
hi + x(cid:6)
ei = x(cid:6)
c2
c1
a = sof tmax(e)
(cid:3)
d =
i
hi ∗ ai
4. Customize on the encoder weights: At this
level of customization, we look at the word
contextualization biases the categories need.
A concrete example is, given the text ‘‘deep
learning for political message classifica-
tion’’, when encoding the word classifica-
tion, the BiLSTM should retain the semantics
of words political message more and forget
the semantics of other words more when
the research area is about politics. Instead of
204
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
3
1
9
2
3
0
4
7
/
/
t
l
a
c
_
a
_
0
0
2
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
using a single set of input, forget, output, and
memory cell weights for each LSTM (Equa-
tions 2 and 3), we use multiple sets of the
weights, one for each category:
⎤
⎡
⎤
⎡
⎢
⎢
⎢
⎣
gt
it
ft
ot
⎥
⎥
⎥
⎦ =
⎢
⎢
⎢
⎣
tanh
σ
σ
σ
⎥
⎥
⎥
⎦
(cid:10)
(cid:3)
(cid:11)
W (e)
ck
[wt; ht−1] + b
0
to those first responders and military personnel working to ensure our safety who are unable
to be with their families this holiday season. we are all thank you for your service and
dedication.
cs.CR (Cryptography and
Security)
Reject
Political Bias
Classification
Neutral
Personal
Partisan
Support
Table 5: Example texts from the AAPR data set (upper) and Political Media data set (lower) with a variable
category label (research field and political bias) that changes the classification label.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
3
1
9
2
3
0
4
7
/
/
t
l
a
c
_
a
_
0
0
2
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
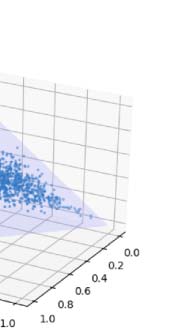
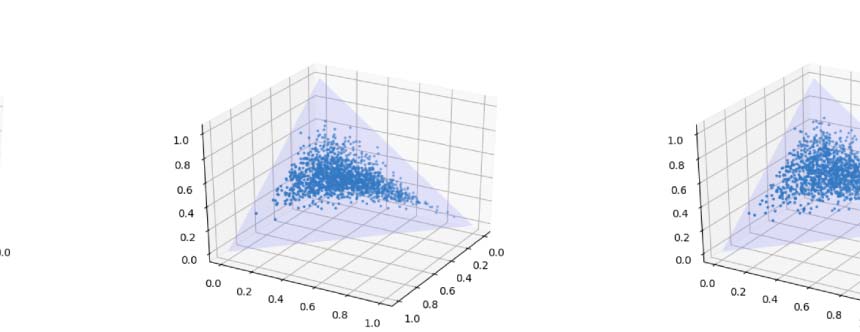
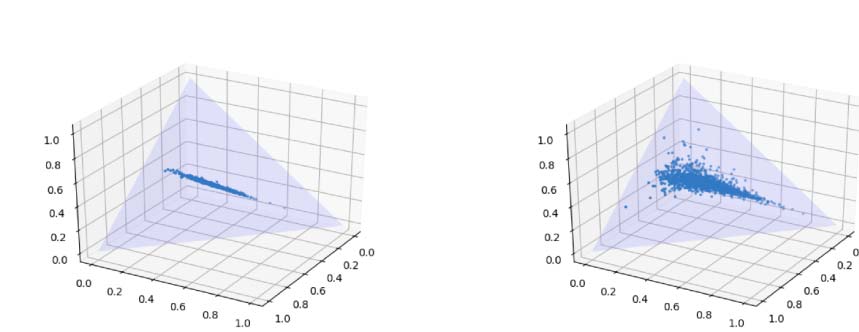
Figure 4: TSNE Visualization of the category vectors of Customized BiLSTM (first row) and Basis-Customized
BiLSTM (middle row), and the γ coefficients of the latter model (last row), when epoch is equal to 1, 2, 4, and
when training has finished (left to right).
We finally examine the performance of our
models when data contain cold-start entities (i.e.,
users/products may have zero or very few reviews)
using the Sparse80, subset of the Yelp 2013 data
set provided in Amplayo et al. (2018a). We com-
pare our models with three competing models:
NSC (Chen et al., 2016), which uses a hierarchi-
cal LSTM encoder coupled with customization
on the attention mechanism, BiLSTM+CSAA
(Amplayo et al., 2018a), which uses a BiLSTM
encoder with customization on a CSAA mecha-
nism, and HCSC (Amplayo et al., 2018a), which is
211
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
3
1
9
2
3
0
4
7
/
/
t
l
a
c
_
a
_
0
0
2
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 5: Accuracy per user/product review frequency on Yelp 2013 data set. The review frequency value f
represents the frequencies in the range [f, f + 10), except when f = 100, where it represents the frequencies in
the range [f, inf).
Models
NSC
BiLSTM+CSAA
HCSC
BiLSTM+encoder-basis-cust
BiLSTM+linear-basis-cust
BiLSTM+bias-basis-cust
BiLSTM+word-basis-cust
BiLSTM+attention-basis-cust
Accuracy
51.1
52.7
53.8
50.4
50.8
51.9
51.9
53.1
Table 6: Performance comparison of competing models
in the Yelp 2013 Sparse80 data set.
a combination of CNN and the BiLSTM encoder
with customization on CSAA.
Results are reported in Table 6, which provide
us two observations. First, the BiLSTM model
customized on the linear transformation matrix,
which performs the best on the original Yelp 2013
data set (see Table 3), obtains a very sharp decrease
in performance. We posit that this is because basis
customization is not able to handle zero-shot cold-
start entities, which are amplified in the Yelp 2013
Sparse80 data set. We leave extensions of basis for
zero-shot or cold-start, studied actively in machine
learning (Wang et al., 2019) and recommendation
domains (Sun et al., 2012), respectively. Inspired
by CSAA (Amplayo et al., 2018a), using similar
review texts for inferring the cold-start user (or
product), we expect to infer meta context, similarly
based on similar meta context, which may mitigate
the zero-shot cold-start problem. Second, despite
having no zero-shot learning capabilities, Basis-
Customized BiLSTM on the attention mechanism
performs competitively with HCSC and performs
better than BiLSTM+CSAA, which is Custom-
ized BiLSTM on attention mechanism with cold-
start awareness.
6 Conclusion
We presented a new study on customized text
classification, a task where we are given, aside
from the text, its categorical metadata informa-
tion, to predict the label of the text, customized by
the categories available. The issue at hand is that
these categorical metadata information are hardly
understandable and thus difficult to use by neural
machines. This,
therefore, makes neural-based
models hard to train and optimize to find a proper
categorical metadata representation. This issue is
very critical, in such a way that a simple concate-
nation of these categorical information provides
better performance than existing popular neural-
based methods. We propose solving this problem
by using basis vectors to customize parts of a clas-
sification model such as the attention mechanism
and the weight matrices in the hidden layers. Our
results show that customizing the weights using
the basis vectors boosts the performance of a basic
BiLSTM model, and also effectively outperforms
the simple yet robust concatenation methods. We
share the code and data sets used in our experi-
ments here: https://github.com/zizi1532/
BasisCustomize.
Acknowledgments
This work was supported by Microsoft Research
Asia and IITP/MSIT research grant (no. 2017-0-
01779).
212
References
Reinald Kim Amplayo, Jihyeok Kim, Sua Sung,
and Seung-won Hwang. 2018a. Cold-start
aware user and product attention for sentiment
classification. In Proceedings of the 56th An-
nual Meeting of the Association for Compu-
tational Linguistics (Volume 1: Long Papers),
pages 2535–2544. Association for Computa-
tional Linguistics.
Reinald Kim Amplayo, Kyungjae Lee, Jinyoung
Yeo, and Seung-won Hwang. 2018b. Trans-
lations as additional contexts for sentence clas-
sification. In Proceedings of the Twenty-Seventh
International Joint Conference on Artificial
Intelligence, IJCAI 2018, pages 3955–3961.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua
Bengio. 2015. Neural machine translation by
jointly learning to align and translate. In Pro-
ceedings of the 3rd International Conference
on Learning Representations, ICLR’15.
Andrea Baruzzo, Antonina Dattolo, Nirmala
Pudota, and Carlo Tasso. 2009. A general
framework for personalized text classification
and annotation. In Proceedings of the Workshop
on Adaptation and Personalization for Web 2.0,
AP WEB 2.0@UMAP.
Huimin Chen, Maosong Sun, Cunchao Tu, Yankai
Lin, and Zhiyuan Liu. 2016. Neural sentiment
classification with user and product atten-
tion. In Proceedings of the 2016 Conference
on Empirical Methods in Natural Language
Processing, pages 1650–1659. Association for
Computational Linguistics.
Po-Hao Chou, Richard Tzong-Han Tsai, and Jane
Yung-jen Hsu. 2017. Context-aware sentiment
propagation using LDA topic modeling on
chinese conceptnet. Soft Computing, 21(11):
2911–2921.
Zi-Yi Dou. 2017. Capturing user and product
information for document level sentiment anal-
ysis with deep memory network. In Proceed-
the 2017 Conference on Empirical
ings of
Methods in Natural Language Processing,
pages 521–526. Association for Computational
Linguistics.
Alec Go, Richa Bhayani, and Lei Huang. 2009.
Twitter sentiment classification using distant
supervision. CS224N Project Report, Stanford,
1(12).
Sepp Hochreiter and J¨urgen Schmidhuber. 1997.
Long short-term memory. Neural Computation,
9(8):1735–1780.
Arash Joorabchi and Abdulhussain E. Mahdi.
2011. An unsupervised approach to automatic
classification of scientific literature utilizing
bibliographic metadata. Journal of Information
Science, 37(5):499–514.
Yoon Kim. 2014. Convolutional neural networks
for sentence classification. In Proceedings of
the 2014 Conference on Empirical Methods
in Natural Language Processing (EMNLP),
pages 1746–1751. Association for Computa-
tional Linguistics.
Xuan Nhat Lam, Thuc Vu, Trong Duc Le,
and Anh Duc Duong. 2008. Addressing cold-
start problem in recommendation systems.
In Proceedings of
the 2nd International
Conference on Ubiquitous Information Man-
agement and Communication, ICUIMC 2008,
pages 208–211.
Fei-Fei Li, Robert Fergus, and Pietro Perona.
2006. One-shot learning of object categories.
IEEE Transactions on Pattern Analysis and
Machine Intelligence, 28(4):594–611.
Xin Li and Dan Roth. 2002. Learning question
In COLING 2002: The 19th
classifiers.
International Conference on Computational
Linguistics.
Rui Lin, Shujie Liu, Muyun Yang, Mu Li,
Ming Zhou, and Sheng Li. 2015. Hierarchical
recurrent neural network for document model-
ing. In Proceedings of the 2015 Conference
on Empirical Methods in Natural Language
Processing, pages 899–907. Association for
Computational Linguistics.
Yunfei Long, Mingyu Ma, Qin Lu, Rong
Xiang, and Chu-Ren Huang. 2018. Dual mem-
ory network model for biased product review
classification. In Proceedings of the 9th Work-
shop on Computational Approaches to Subjec-
tivity, Sentiment and Social Media Analysis,
pages 140–148. Association for Computational
Linguistics.
213
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
3
1
9
2
3
0
4
7
/
/
t
l
a
c
_
a
_
0
0
2
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
approaches
Thang Luong, Hieu Pham, and Christopher D.
to
Manning. 2015. Effective
attention-based neural machine translation. In
Proceedings of the 2015 Conference on Em-
pirical Methods in Natural Language Pro-
cessing, pages 1412–1421. Association for
Computational Linguistics.
Dehong Ma, Sujian Li, Xiaodong Zhang,
Houfeng Wang, and Xu Sun. 2017. Cas-
cading multiway attentions for document-level
sentiment classification. In Proceedings of the
Eighth International Joint Conference on Nat-
ural Language Processing (Volume 1: Long
Papers), pages 634–643. Asian Federation of
Natural Language Processing.
Tomas Mikolov, Kai Chen, Greg Corrado, and
Jeffrey Dean. 2013. Efficient estimation of
word representations in vector space. CoRR,
abs/1301.3781.
Bo
and
Pang, Lillian Lee,
Shivakumar
Vaithyanathan. 2002. Thumbs up? sentiment
classification using machine learning tech-
niques. In Proceedings of the 2002 Conference
on Empirical Methods in Natural Language
Processing (EMNLP 2002).
Zizi Papacharissi. 2002. The presentation of self
in virtual life: Characteristics of personal home
pages. Journalism & Mass Communication
Quarterly, 79(3):643–660.
Jeffrey
Socher,
Pennington, Richard
and
Christopher Manning. 2014. GloVe: Global
vectors for word representation. In Proceedings
of the 2014 Conference on Empirical Methods
in Natural Language Processing (EMNLP),
pages 1532–1543. Association for Computa-
tional Linguistics.
Matthew Peters, Mark Neumann, Mohit Iyyer,
Matt Gardner, Christopher Clark, Kenton Lee,
and Luke Zettlemoyer. 2018. Deep contex-
tualized word representations. In Proceedings
of the 2018 Conference of the North American
Chapter of the Association for Computational
Linguistics: Human Language Technologies,
Volume 1 (Long Papers), pages 2227–2237.
Association for Computational Linguistics.
Proceedings of the 4th International Confer-
ence on Learning Representations, ICLR’16.
Michal Rosen-Zvi, Thomas L. Griffiths, Mark
Steyvers, and Padhraic Smyth. 2004. The
author-topic model for authors and documents.
In UAI ’04, Proceedings of the 20th Confer-
ence in Uncertainty in Artificial Intelligence,
pages 487–494.
Fabrizio Sebastiani. 2002. Machine learning in
automated text categorization. ACM Computing
Surveys, 34(1):1–47.
Richard Socher, Jeffrey Pennington, Eric H.
Huang, Andrew Y. Ng, and Christopher D.
Manning. 2011. Semi-supervised recursive
autoencoders for predicting sentiment distri-
butions. In Proceedings of the 2011 Conference
on Empirical Methods in Natural Language
Processing, pages 151–161. Association for
Computational Linguistics.
Dong-ting Sun, Tao He, and Fu-hai Zhang. 2012.
Survey of cold-start problem in collaborative
filtering recommender system. Computer and
Modernization, 5:59–63.
Duyu Tang, Bing Qin, and Ting Liu. 2015.
Learning semantic representations of users and
products for document level sentiment classi-
fication. In Proceedings of the 53rd Annual
Meeting of the Association for Computational
Linguistics and the 7th International Joint
Conference on Natural Language Processing
(Volume 1: Long Papers), pages 1014–1023.
Association for Computational Linguistics.
Wei Wang, Vincent W. Zheng, Han Yu, and
Chunyan Miao. 2019. A survey of zero-shot
learning: Settings, methods, and applications.
ACM Transactions on Intelligent Systems and
Technology, 10(2):13:1–13:37.
Pengcheng Yang, Xu SUN, Wei Li, and Shuming
Ma. 2018. Automatic academic paper rating
based on modularized hierarchical convolu-
tional neural network. In Proceedings of the
56th Annual Meeting of the Association for
Computational Linguistics (Volume 2: Short
Papers), pages 496–502. Association for
Computational Linguistics.
Sachin Ravi and Hugo Larochelle. 2016. Optimi-
zation as a model for few-shot learning. In
Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong
He, Alex Smola, and Eduard Hovy. 2016.
214
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
3
1
9
2
3
0
4
7
/
/
t
l
a
c
_
a
_
0
0
2
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Hierarchical attention networks for document
classification. In Proceedings of the 2016 Con-
ference of the North American Chapter of the
Association for Computational Linguistics: Hu-
man Language Technologies, pages 1480–1489.
Association for Computational Linguistics.
Matthew D. Zeiler. 2012. ADADELTA: An adap-
tive learning rate method. CoRR, abs/1212.5701.
Peng Zhou, Zhenyu Qi, Suncong Zheng, Jiaming
Xu, Hongyun Bao, and Bo Xu. 2016. Text
classification improved by integrating bidi-
rectional LSTM with two-dimensional max
pooling. In Proceedings of COLING 2016,
the 26th International Conference on Com-
putational Linguistics: Technical Papers,
pages 3485–3495.
Rui Zhao, Kezhi Mao, Rui Zhao, and Kezhi
Mao. 2017. Topic-aware deep compositional
models for sentence classification. IEEE/ACM
Transactions on Audio, Speech and Languange
Processing, 25(2):248–260.
Pengcheng Zhu and Yujiu Yang. 2017. Parallel
multi-feature attention on neural sentiment
classification. In Proceedings of
the Eighth
International Symposium on Information and
Communication Technology, pages 181–188.
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
–
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
2
6
3
1
9
2
3
0
4
7
/
/
t
l
a
c
_
a
_
0
0
2
6
3
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
215