Unsupervised Learning of KB Queries in Task-Oriented Dialogs
Dinesh Raghu∗1,2, Nikhil Gupta†3, and Mausam1
1IIT Delhi, Neu-Delhi, Indien
2IBM Research, Neu-Delhi, Indien
3LimeChat, Gurgaon, Indien
diraghu1@in.ibm.com, nikhil@limechat.ai, mausam@cse.iitd.ac.in
Abstrakt
1 Einführung
Task-oriented dialog (TOD) systems often
need to formulate knowledge base (KB) que-
ries corresponding to the user intent and use
the query results to generate system responses.
Existing approaches require dialog datasets to
explicitly annotate these KB queries—these
annotations can be time consuming, and ex-
pensive. In Beantwortung, we define the novel prob-
lems of predicting the KB query and training
the dialog agent, without explicit KB query
annotation. For query prediction, we propose
a reinforcement learning (RL) baseline, welche
rewards the generation of those queries whose
KB results cover the entities mentioned in sub-
sequent dialog. Further analysis reveals that
correlation among query attributes in KB can
significantly confuse memory augmented pol-
icy optimization (MAPO), an existing state of
the art RL agent. Um das zu erwähnen, we improve
the MAPO baseline with simple but impor-
tant modifications suited to our task.
To train the full TOD system for our setting, Wir
propose a pipelined approach: it independently
predicts when to make a KB query (query po-
sition predictor), then predicts a KB query at
the predicted position (query predictor), Und
uses the results of predicted query in subse-
quent dialog (next response predictor). Über-
alle, our work proposes first solutions to our
novel problem, and our analysis highlights the
research challenges in training TOD systems
without query annotation.
∗D. Raghu is an employee at IBM Research. This work
was carried out as part of PhD research at IIT Delhi.
†This work was done while Nikhil Gupta was a graduate
student at IIT Delhi.
374
Task-oriented dialog (TOD) systems converse
with users to accomplish specific tasks such as
restaurant reservation (Henderson et al., 2014B),
movie ticket booking (Li et al., 2017), or bus
enquiry (Raux et al., 2005). In addition to the
ability to converse, it is crucial for TOD systems
to learn to formulate knowledge base (KB) Abfragen
based on user needs, and generate responses using
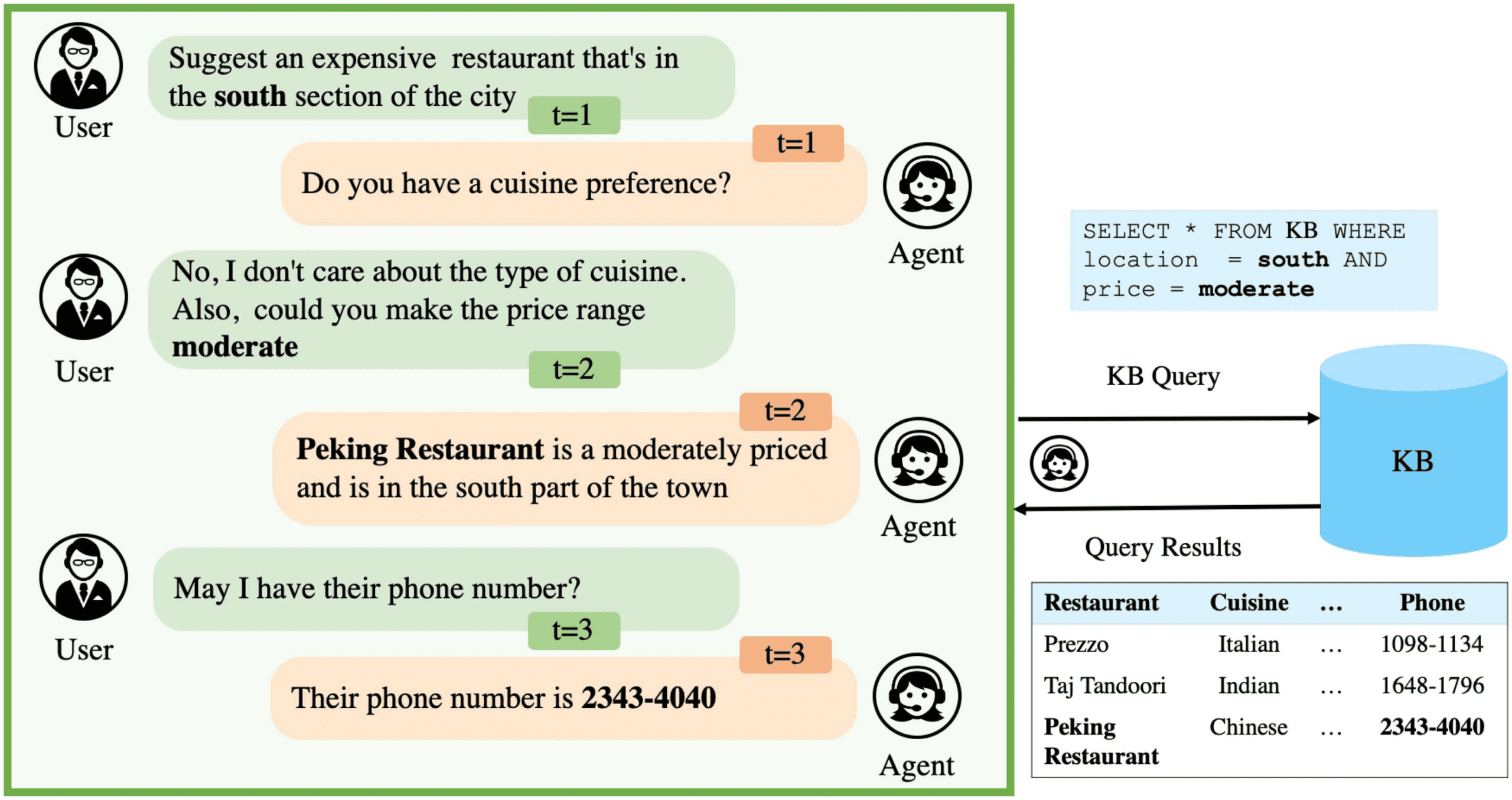
the query results. An example TOD is shown in
Figur 1, where during the conversation (at turn
2), the agent queries the KB based on the user
needs, and then suggests the Peking Restaurant
based on the retrieved results. Existing end-to-end
approaches (Bordes and Weston, 2017; Madotto
et al., 2018; Reddy et al., 2019) learn to formulate
KB queries using manually annotated queries.
In real-world scenarios, human agents chat with
users on messaging platforms. When the need to
query the KB arises, the agent fires the query on
a back-end KB application and uses the retrieved
results to compose a response back on the mes-
saging platform. The dialogs retrieved from these
the user and the agent
platforms contain just
utterances, but the KB queries typically go un-
documented. As existing approaches require KB
annotations, they have to be manually annotated,
which is expensive and hinders scalability. To
eliminate the need for such annotations, we define
the novel problem of training a TOD system with-
out explicit KB query annotation. A key subtask
of such a system is the unsupervised prediction of
KB queries.
While there is no explicit query annotation, Wir
observe that dialog data still offers weak super-
vision to induce KB queries—all the entities used
by the agent in subsequent dialog should be re-
In
turned by the correct query. Zum Beispiel,
Figur 1, the correct query should retrieve Peking
Restaurant and its phone number. This suggests a
Transactions of the Association for Computational Linguistics, Bd. 9, S. 374–390, 2021. https://doi.org/10.1162/tacl a 00372
Action Editor: Hang Li. Submission batch: 8/2020; Revision batch: 11/2020; Published 4/2021.
C(cid:13) 2021 Verein für Computerlinguistik. Distributed under a CC-BY 4.0 Lizenz.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Figur 1: Example of a training task-oriented dialog. At turn 2, the agent first queries the KB based on the user
requirement and then responds based on the retrieved results.
reinforcement learning (RL) formulation for query
prediction, not unlike similar tasks in Question
Answering (QA) (Artzi and Zettlemoyer, 2013)
and conversational QA (Yu et al., 2019). Wie-
immer, there is one key difference between TOD
and QA settings—in TOD only a few entities from
the query results are used in subsequent dialog,
whereas in QA all correct answers are provided
at training time. This makes defining the reward
function more challenging for our setting.
Our problem is further exacerbated by the issue
of correlated attributes. Query attributes in TOD
may exhibit significant correlation, like in the
restaurant domain, cuisine and price range are of-
ten correlated. Zum Beispiel, most Japanese res-
taurants in a KB may be in expensive price range.
Infolge, presence and absence of expensive
price range in the query could retrieve almost the
same set of KB entities and hence similar rewards.
This can confuse the weakly supervised query pre-
dictor. To counter this issue we present a baseline
solution for KB query prediction by extending an
existing policy optimization technique, Erinnerung
augmented policy optimization (MAPO; Liang
et al., 2018). Experiments show that our proposed
modification significantly improves the query
prediction accuracy.
To train a full TOD system without KB query
annotation, we propose a pipelined solution. It uses
three main components: (1) query position predic-
tor predicts when a query must be made, (2) query
predictor predicts the query at the turn predicted by
position predictor, Und (3) next response predictor
generates next utterance based on dialog context,
and predicted query’s results. We train these com-
ponents in a curriculum, due to the pipeline nature
of the system. We find that overall our system
obtains good dialog performance, and also learns
to generalize to entities unseen during training.
We conclude with novel research challenges
highlighted by our paper. Insbesondere, we notice
that even fully supervised TOD systems (trained
with KB query annotation) suffer a significant loss
in performance when they are evaluated with the
protocol of using their own predicted queries and
its query results (instead of using gold queries and
gold results) in subsequent dialog. We believe that
designing TOD systems with high performance
under this evaluation protocol is the key next step
towards making end-to-end TOD systems useful
in real applications. We release all our resources
for further research—training data, evaluation
Code, and code for TOD systems.1
2 Hintergrund & Related Work
Our work is on task-oriented dialogs and is closely
related to the task of semantic parsing. We briefly
discuss related work in both areas. Our query
predictor is an extension of MAPO (Liang et al.,
2018), which we describe in detail.
Task Oriented Dialogs: TOD systems are of
two main types: traditional spoken dialog systems
1https://github.com/dair-iitd/mb-mapo.
375
(SDS) and end-to-end TOD systems. SDS (Wen
et al., 2017; Williams et al., 2017) use hand-crafted
states and state annotations on every utterance
in the dialogs—a significant human supervision.
End-to-end TOD systems (Reddy et al., 2019;
Wu et al., 2019; Raghu et al., 2019) do not require
state annotations but just the KB query annota-
tionen. There exist approaches (Chen et al., 2013,
2015) to induce state annotations in SDS, aber wir
are the first to induce query annotations in end-to-
end TOD systems. TOD systems cannot be learned
with just the state annotations, additional state to
KB query mapping/annotation is required. Aber
no further annotations are needed to learn TOD
system when query annotations are available.
We build on recent architectures, which use
memory networks to store previous utterances and
query results, and a generative copy decoder to
construct the agent utterances (Madotto et al.,
2018; Reddy et al., 2019; Raghu et al., 2019). Ein
alternative approach maintains the entire KB in its
neural model, bypassing the need for KB queries
entirely (Dhingra et al., 2017; Eric et al., 2017).
Bedauerlicherweise, such approaches can only work
with small KBs. Im Gegensatz, our approach is scal-
able and does not impose restrictions on KB size.
Semantic Parsing: Semantic parsing is the
task of mapping natural language text to a logical
bilden (or program) (Zelle and Mooney, 1996;
Zettlemoyer and Collins, 2005). To alleviate the
need for gold program annotations, weakly super-
vised approaches have been proposed (Artzi and
Zettlemoyer, 2013; Berant et al., 2013; Pasupat
and Liang, 2015; Neelakantan et al., 2017; Haug
et al., 2018). These weakly supervised approaches
solve two main problems: (1) exploring large
search space to find correct logical programs and
(2) spurious program problem—where the policy
learns an incorrect program that fetches the cor-
rect answer. To explore large search space better,
Guu et al. (2017) used randomized beam search,
Liang et al. (2017) and MAPO used systematic
suchen. There exists several approaches to over-
come the spurious query problem: crowd sourcing
(Pasupat and Liang, 2016), spreading the probabil-
ity mass over multiple reward earning programs
(Guu et al., 2017), clustering similar natural
language inputs and using their abstract represen-
tations (Goldman et al., 2018), and using overlap
between the text spans in input and the generated
Programme (Wang et al., 2019; Dasigi et al., 2019;
Misra et al., 2018). MAPO samples from a buffer
376
of systematically explored reward earning pro-
grams based on their likelihood in the current pol-
icy (Liang et al., 2018) to tackle the spurious
program problem. Our query prediction approach
follows this literature, except in a dialog setting.
As our approach is an extension of MAPO, Wir
inherit the ability to effectively tackle the two
issues.
These methods use an RL formalism, in which a
logical form (query, in our case) a is predicted by
an RL-policy πθ(A|C). Hier, θ are the parameters
of the RL agent, and c is the input, Zum Beispiel, A
question (in our case, a dialog context). The policy
πθ is trained by maximizing the expected reward:
OER = Ea∼πθ(A|C)R(A|C, j) = Ea∼πθ(A)R(A)
where R is the reward function and y is the
gold answer for c. For simplicity, we drop the
dependence of πθ and R on c and y. REINFORCE
(Williams, 1992) can be used to estimate the
gradient of the expected reward. Using N queries
sampled i.i.d. from the current policy, the gradient
estimate can be expressed as:
∇θOER =
1
N
N
X
k=1
∇θlogπθ(ak)R(ak)
(1)
When the search space is large and the rewards
are sparse, relying on just the on-policy samples
often leads to poor search space exploration. To
overcome this, search is added on top of policy
Proben (Liang et al., 2017). We build on MAPO,
which uses systematic exploration to identify non-
zero reward queries for each training data and
stores them in a memory buffer B. The expected
reward is computed as a weighted sum of two
expectations: one over the queries inside the buffer
B and the other over the remaining queries:
OER = X
a ∈ B
= πBE
πθ(A)R(A) + X
πθ(A)R(A)
a ∈ A − B
θ (A)R(A)+(1 − πB)E
a∼π+
a∼π−
θ (A)R(A)
(2)
where A is the set of all possible queries,
πB = Pa ∈ B πθ(A) is total probability of all
queries in the buffer, and π+
θ (A) are the
normalized probability distributions inside and
outside the buffer respectively. The gradient of
the first term is estimated exactly by enumerating
all queries in the buffer, while the gradients of
θ (A) and π−
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
the second term is estimated as in Equation 1 von
sampling i.i.d queries from the current policy and
rejecting them if they are present in the buffer B.
A randomly initialized policy is likely to assign
small probabilities to the queries in the buffer, Und
hence negligible contribution to the gradient esti-
mation. To ensure queries in the buffer contribute
significantly to the gradient estimates, MAPO
clips πB to α. The modified gradient estimate is
∇θOc
ER = πc
B
E
a∼π+
+ (1 − πc
θ (A)∇θlogπθ(A)R(A)
B)E
a∼π−
θ (A)∇θlogπθ(A)R(A)
(3)
where πc
B = max(πB, α). When the training
begins, α > πB resulting in gradient estimates
biased towards the queries in the buffer. Once the
policy stabilizes, πB gets larger than α and the
estimates becomes unbiased.
Experience Replay: Experience replay (Lin,
1992) stores past experience in a buffer and reuses
that to stabilize training and improve sample effi-
ciency. Prioritized experience replay (Schaul et al.,
2016) assigns priorities to the experiences and
samples them based on the priorities to efficiently
learn using them. MAPO and our approach use
replay buffers that store non-zero reward queries.
These queries include both past experiences and
queries identified using systematic search. Der
sampling strategy is similar to prioritized expe-
rience replay, where the priorities are defined by
the probability of the query in the current policy.
3 Task Definition & Baseline System
We first define our novel task of learning TOD
system using unannotated dialogs – we name it
uTOD. We then describe the KB query predictor in
detail. Endlich, we describe our proposed baseline
uTOD system, which uses the KB query predictor.
3.1 Problem Definition
1 , cs
1, cu
M, cs
2, . . . , cu
We represent a dialog d between a user u and an
agent s as {cu
2 , cs
M} where m
denotes the number of turns in the dialog. Unser
goal is to train a uTOD system, welche, for all
turns i, takes the partial dialog-so-far {cu
1, . . . ,
cu
i−1, cu
i−1, cs
ich } as input and predicts the next sys-
tem response ˆcs
ich . Such a uTOD system is trained by
the training data D comprising complete dialogs
{dj}| D|
j=1, and an associated knowledge base KB.
1 , cs
377
System responses in a dialog often use certain
entities from KB. To accomplish this, a uTOD
system can fire an appropriate query a to KB
and fetch the query results Ea, and use those to
generate its response. No explicit supervision is
provided on the gold queries, at either training or
test time. Das ist, a uTOD system neither knows
which query was fired to KB, nor knows when it
was fired. In this work we assume that the system
can make only one KB query per dialog. Unser
overall uTOD baseline uses a pipeline of multiple
components: a query position predictor, a query
predictor, and a next response predictor.
3.2 KB Query Predictor
1, cu
2 , cs
1 , cs
2, . . . , cu
We first assume that we have access to the specific
turn number q, 1 ≤ q ≤ m, where a KB query
gets fired by the system (an assumption we relax
in the next section). Daher, formally, we are given
the dialog context c = {cu
Q }, Und
KB, and the goal of query predictor is to output a
that appropriately captures the user intent. Wir gebrauchen
the term subsequent dialog to refer to all utterances
that follow the KB query–{cs
M}. In
Figur 1, the subsequent dialog starts from the
second agent utterance. Let Es be the set of
KB entities present in the subsequent dialog. In
Figur 1, Es = {Peking Restaurant, 2343-4040}.
We train the query predictor using RL, by pro-
viding feedback based on the predicted query’s
ability to retrieve the entities in Es.
q+1, . . . , cs
Q, cu
Our proposed baseline follows the literature
on semantic parsing with weak supervision using
RL, and treats the query prediction as equivalent
to learning policy πθ(A|C) that takes the dialog
context c as the input and generates a KB query
a = a1a2 · · · aT . The KB query is a sequence of
T actions, where each action is a word predicted
by the query predictor. For a given context, Die
set of all possible actions is a union of a set of
keywords2 in the SQL query language, set of field
names in KB, the set of all words in the context c
und ein
The query is generated auto-regressively as:
πθ(A|C) =
T
Y
t=1
πθ(bei|a1:t−1, C)
(4)
As the environment is deterministic, at each time
T, the RL state can be fully defined by the dialog
context c and the actions predicted so far a1:t−1.
2{SELECT, *, =, FROM, AND, WHERE}.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
RL gradients can be computed using REIN-
FORCE or the MAPO algorithm.
ing aspects of our task, and our improved baseline,
multi buffer MAPO, to resolve those issues.
The policy network is implemented with a stan-
dard encoder-decoder architecture for TOD sys-
Systeme. The context is encoded using a multi-hop
memory encoder (Sukhbaatar et al., 2015) with a
bag of sequences memory (Raghu et al., 2019). In
the bag of sequences memory, the context is rep-
resented as a set of utterances and each utterance
as a sequence of words. Each utterance is encoded
using a bi-directional GRU (Cho et al., 2014).
The KB query is generated one word at a time
by a copy-augmented sequence decoder (Gu et al.,
2016). The search space is the output space of
this variable length, copy-augmented sequence
decoder. At each time step, the decoder computes
a copy distribution over words in the dialog con-
text and a generate distribution over words KB
field names and SQL keywords. Endlich, a soft
gate (Siehe et al., 2017) is used to combine the
two distributions and a word is sampled from the
combined distribution. By allowing only copying
words from the dialog context to the values in
the SQL WHERE clauses, we reduce the decod-
er’s ability to predict spurious queries. Following
Ghazvininejad et al. (2016), we use beam search
guided by the SQL grammar to generate only
syntactically correct queries.
3.2.1 Reward Functions
We now describe a vanilla reward function
considered for training the RL agent. For a given
(C, Es) pair, the query a is predicted using c and
the reward is computed using Es. Since partial
query isn’t meaningful, the reward is computed
only at time t = T , when the complete query is
generated.
Let Ea be the set of entities retrieved by the
query a, then the reward at time T must ensure
that all entities present in the subsequent dialog are
retrieved by the query. Darüber hinaus, the query should
be penalized for retrieving more than required
entities. This can be operationalized as follows:
R(A|C, Es) = 11recall(Es, Ea)=1.prec(Es, Ea) (5)
The recall based indicator ensures that all entities
are retrieved, and precision penalizes retrieval of
a large number of entities. While a reasonable
first solution, our initial experiments showed that
MAPO with this reward function does not achieve
satisfactory results. We now discuss the challeng-
3.2.2 Multi Buffer MAPO (mB-MAPO)
Our problem can become particularly challenging
if KB has correlated attributes. To understand
Das, consider two types of KB queries: (1) partial
intent query and (2) complete intent query. A par-
tial query is one that is partially correct, nämlich,
captures a part of the user’s intent, and does not
include any incorrect clauses. A complete query
contains all (und nur) correct clauses expressed
in the intent. Zum Beispiel (A) in Table 1, the first
two queries are complete ones, whereas rest are
partial. Query 4 in column (B) is a spurious query
that can retrieve the same result as the complete
intent query. This spurious query is not a partial
query, as it does not capture any of the user
needs. Our query decoder allows only words to
be copied from the context when predicting the
query, thus reducing the policy network’s ability
to learn spurious queries.
Because of the nature of weak supervision in
uTOD (we get to see only a subset of entities
in subsequent dialog), it is possible that multiple
queries can achieve non-zero rewards for a dialog
Kontext. It is further possible that a specific par-
tial query can achieve non-zero rewards in many
the query ‘‘price=
dialog contexts. Example,
moderate’’ fetches non-zero rewards for both in-
tents in Table 1. Such phenomena can confuse an
RL agent, to the extent that it may end up incor-
rectly learning a single partial query as the best
query for many contexts.
This problem is further exacerbated if some
query attributes in KB are correlated. Zum Beispiel
(A) in Table 1, let us assume that KB has 8 chinese
restaurants out of which 7 have moderate price
range, das ist, cuisine and price range are highly
correlated. Hier, results of the partial query ‘‘cui-
sine=chinese” would contain only one additional
restaurant compared to the complete query. As a
Ergebnis, they will receive almost the same reward
during training. This could potentially get extreme
in certain cases, where presence or absence of an
attribute makes no difference, giving little signal
to an RL agent. As the number of attributes in
an intent increases, the problem can get harder
and harder. In our preliminary experiments using
MAPO with reward from Equation 5, the RL
agent often produced partial queries leading to
further errors in subsequent dialog.
378
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
User
Intent
(A)
user needs a restaurant that serves
Chinese with moderate price range
(B)
user needs a Japanese restaurant
in moderate price range
KB
Queries
1. cuisine=chinese AND price=moderate
2. price=moderate AND cuisine=chinese
3. cuisine=chinese
4. price=moderate
1. cuisine=japanese AND price=moderate
2. price=moderate AND cuisine=japanese
3. cuisine=japanese
4. phone=98232-66789
Tisch 1: Summary of dialogs and a few examples of non-zero reward KB queries for the corresponding
dialogs. For simplicity, the SELECT clauses are removed from the KB queries.
In our datasets intents can be described by
SELECT queries with multiple WHERE clauses;
daher, every partial query is a prefix of some
complete query (z.B., query 3 in Table 1). Upon
further analysis of model behavior, we observed
that MAPO often maintained both partial prefix
queries and complete queries, but still learned a
model to output the partial ones.
To understand this surprising observation, Wir
first note that auto-regressive decoders, due to
probability multiplication at every decode step,
generally prefer shorter grammatical sentences
(partial prefix query in our case) to longer ones.
This is particularly likely to happen when the
decoder gets randomly initialized at the start of
Ausbildung. A partial query in the buffer that is as-
signed a high probability makes a higher contribu-
tion in the gradient estimation. Darüber hinaus, Weil
of correlated attributes, this query may have a
fairly high reward. This results in the model be-
lieving it to be a good query, and changing the
parameters to increase its probability further. Der
only way RL can break out of this vicious cycle is if
the complete query is explored often—however,
MAPO’s in-buffer sampling probabilities are
to network-assigned probabilities,
proportional
leading to an ineffective in-buffer exploration.
This issue is general, but gets extreme in our
problem due to a combination of (1) real-valued
(not just 0/1) rewards, (2) prefix queries getting
high rewards due to correlated attributes, Und (3)
prefix queries getting sampled more often due to
decoder’s bias in favoring shorter queries.
In Beantwortung, our proposed baseline extends
MAPO to maintain multiple buffers, so that com-
plete intent queries with high rewards can be
prioritized over other queries during gradient esti-
mation. We use two buffers with MAPO: a buffer
Bh to store all queries with the highest reward
for a dialog context and a buffer Bo to store all
other queries whose rewards are non-zero and
less than the highest. The expected reward is now
computed as:
379
OER = X
a ∈ Bh
πθ(A)R(A) + X
a ∈ Bo
πθ(A)R(A)
+ X
πθ(A)R(A)
a ∈ A−(Bh∪Bo)
= πBh
E
a∼πh+
θ (A)R(A) + πBoE
a∼π−
a∼πo+
θ (A)R(A)
θ (A)R(A)
(6)
+ (1 − πBh − πBo)E
and π−
θ , πo+
θ
where πh+
θ are the normalized prob-
ability distributions of queries in Bh, queries in
Bo, and all other queries, jeweils. πBh =
Pa ∈ Bh πθ(A) and πBo = Pa ∈ Bo πθ(A) are the
total probabilities assigned by the policy πθ of all
queries in Bh and Bo respectively. As the complete
intent queries mostly have the highest rewards for
a given context, they are placed in Bh, and as the
partial prefix queries usually have rewards less
than the complete queries, they are placed in the
other buffer Bo. To ensure that all non-zero reward
queries are explored, each buffer is made to con-
tribute to the gradient estimation. To ensure that
each buffer contributes significantly to the gradi-
ent estimation, we clip πBh using max(πBh, αh)
and πBo using min(max((1 − πc
Bh)αo, πBo), (1 −
πc
Bh)). αh and αo are hyperparameters whose
value can be between 0 Und 1. αh ensures that
the highest reward buffer gets assigned a certain
weight during gradient estimation. αo ensures that
the queries in Bo are assigned at least a certain
fraction of probability mass unused by the queries
in Bh. The estimator is biased when the training
starts, and can becomes unbiased when πBh > αh
and πBo > (1 − πBh))αo. Based on the clipped
probabilities, the gradients are estimated as:
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
∇θOc
E
ER = πc
Bh
+πc
Bo
Bh − πc
E
Bo)E
a∼πh+
a∼πo+
θ (A)∇θlogπθ(A)R(A)
θ (A)∇θlogπθ(A)R(A)
θ (A)∇θlogπθ(A)R(A)
a∼π−
+(1 − πc
Endlich, if a new query is found that has a higher
reward than queries in Bh, then the buffers are
(7)
Figur 2: The architecture of the uTOD system.
updated: That query is added to Bh, and all other
queries in that buffer are removed and added
to Bo. The proposed approach can be used for
estimating the policy gradients for any deter-
ministic environments with discrete actions and
non-binary rewards.
3.3 uTOD System
We now describe the remaining parts of the uTOD
system that learns to predict the next response
using unannotated dialogs. The system has three
main components: (1) query position predictor, (2)
query predictor (as described in the previous sec-
tion), Und (3) next response predictor. The system
architecture is shown in Figure 2. The position pre-
dictor is a binary classifier that decides whether the
KB query is to be predicted at the given turn or not.
The query predictor generates a KB query at the
turn predicted by the position predictor. Endlich,
the next response predictor takes the dialog con-
text along with the query results (if a KB query has
been made) and predicts the next system response.
In order to train the position predictor, each train
dialog must be annotated with the turn at which the
KB query is to be made. As there are no gold labels
verfügbar, we heuristically provide this supervi-
sion. We identify the turn (˜q) at which the agent
response contains a KB entity that was never seen
in the dialog context. We mark ˜q as the heuristic
label for training position predictor.3 For example,
in Abbildung 1, t = 2 is the turn at which the agent
response contains a KB entity Peking Restaurant
that was never used in the dialog context.
The position predictor takes the dialog context
as input and encodes it using a multi-hop memory
3This heuristic labeling matched 80% of gold labels in
our datasets.
encoder, as described in Section 3.2. The encoder
output is then passed through a linear layer fol-
lowed by sigmoid function to generate the prob-
ability of the binary label. At training time, KB
query predictor learns to generate KB queries at
the turns (˜q) annotated by the heuristic. Während
test time, a query is generated at the turn (ˆq)
predicted by the position predictor.
The query predictor can be seen as annotating
all the train dialogs with KB queries. Daher, nach
this annotation, any existing end-to-end TOD sys-
tem can be used for next response prediction. Für
our experiments, we use BoSsNet as the under-
lying response predictor (Raghu et al., 2019).
BoSsNet takes as input (ich) the dialog context and
(ii) the ground truth KB query results (während
both train and test) to generate the response.
As we assume the ground truth KB queries are
nicht verfügbar, we use the results of the predicted
query results instead.
Since our system uses a pipeline of compo-
nen, it is trained in a training curriculum, welche
is divided into three phases. In phase-1, the query
predictor is trained. Once each train dialog is
annotated with KB queries, the next response
predictor is trained in phase-2. Endlich, in phase-3
the position predictor is trained. We train the
position predictor after the response predictor as
we observed that initializing the position pre-
dictor encoder with the weights of the response
predictor encoder yields better position prediction
Leistung.
4 Experimental Setup
We now describe the datasets used, the compar-
ison algorithms and the evaluation metrics for our
Aufgabe. We release all software and datasets from
our experimental setup for further research.
380
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
CamRest
DSTC2
Train Dialogs
Val Dialogs
Test Dialogs
Avg. NEIN. of turns
Rows/Fields in KB
Vocab Size
406
135
135
4.06
110/8
1215
1279
324
1051
7.94
108/8
958
Tisch 2: Statistics of CamRest and DSTC2
datasets.
4.1 Datasets
We perform experiments on two task-oriented
dialog datasets from the restaurant reservation
Domain: CamRest (Wen et al., 2016) and DSTC2
(Henderson et al., 2014A). CamRest676 is a human
human dialog dataset with having just one KB
query annotated in them. DSTC2 is a human-bot
dialog dataset. We filtered the dialogs from this
dataset that had more than one KB query. Tisch 2
summarizes the statistics of the two datasets. Als
CamRest and DSTC2 are originally designed for
dialog state tracking, we use the versions that are
suitable for end-to-end learning, made available
by Raghu et al. (2019) and Bordes and Weston
(2017), jeweils. Both these datasets have KB
query annotations. We remove these annotations
from the training dialogs to create datasets for our
Aufgabe. We use these annotations for evaluating the
performance of various algorithms.
4.2 Comparison Baselines
We compare various gradient estimation tech-
niques to train the policy network (defined in
Abschnitt 3.2) for the task of KB query prediction
as follows.
REINFORCE (Williams, 1992): uses on-policy
samples to estimate the gradient as in Equation 1,
with the reward function defined in Equation 5.
BS-REINFORCE (Guu et al., 2017): uses all
the queries generated by beam search to estimate
the gradients. The reward for each query is a
product of the reward defined in Equation 5 Und
the likelihood of the query in the current policy.
RBS-REINFORCE (Guu et al., 2017): uses all
the queries generated by ǫ-greedy randomized
beam search (RBS) to estimate the gradients. Bei
every time step, RBS samples a random continu-
ation as opposed to a highest scoring continuation
with a probability ǫ.
MAPO (Liang et al., 2018): uses on-policy sam-
ples and a buffer of non-zero reward queries to
estimate the gradients. It uses the reward function
defined in Equation 5.
mB-MAPO: the proposed approach, multi buffer
MAPO, which uses a buffer with highest reward
queries and a buffer with other non-zero reward
queries to estimate the gradients. This algorithm
uses the reward function defined in Equation 5.
SL: uses the gold KB queries as direct supervi-
sion. We train the policy network proposed in
Abschnitt 3.2 with cross entropy loss.
SL+RL: we combine weak supervision using RL
as a secondary source of knowledge on top of
supervised cross entropy loss for better training.
This is analogous to the benefits of additional prior
Wissen (z.B., as constraints) on top of super-
vision for small datasets (Nandwani et al., 2019).
In our experiments, total loss = Cross-Entropy
−λ.OER. Gleichung 6 is used for computing
OER.
We also compare the full uTOD dialog engines,
built using these RL approaches for query predic-
tion; we name them uTODREINFORCE, uTODMAPO,
and uTODmMAPO. We also compare these to a
fully supervised TOD system that uses KB query
annotations during training (aTOD). We report
two variants of the aTOD system based on the
supervised query predictors used: aTODSL and
aTODSL+RL.
4.3 Evaluation Metrics
As we have gold annotations, we evaluate the KB
query predictor and position predictor separately,
in addition to the overall TOD system. KB query
predictors are evaluated based on accuracy—the
fraction of dialogs where the gold KB queries are
predicted. We also report two other metrics: total
reward and the PIQ ratio—the fraction of dialogs
where a partial intent query was outputted, das ist,
the predicted query captured only a subset of gold
query attributes.
A query position predictor’s performance is
also measured using accuracy. The predictor is
considered correct only if it predicts 1 at the turn at
which query is made and 0 for all turns before that.
We also compute turn difference as the absolute
difference between the turn at which the classifier
predicts true and the turn corresponding to the
gold label in the annotated dialog. The smaller the
average turn difference, the better is the classifier.
381
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
The next response prediction is evaluated based
on its ability to match the gold responses at every
turn. We use standard metrics of BLEU (Papineni
et al., 2002) and entity F1 to measure the similarity
between predicted and gold responses. Entity F1
is the average of F1 scores computed for each
response. We also report Entity F1 KB for entities
that can only be copied from the KB results, Zu
emphasize importance of using query results in
subsequent dialog.
We note that our setup for evaluating dialog
engines looks similar to supervised TOD systems,
but has a subtle but important difference. In stan-
dard supervised dialog evaluations, for a given
turn, the full dialog context is provided and the
system is evaluated on correctly predicting the
next utterance. Daher, even if the system made an
incorrect query at an earlier turn, the subsequent
turns will be shown correct query and correct KB
query results.
Jedoch, since our goal is to assess the response
prediction without query annotation, we remove
such annotation from the test dialogs also. Das ist,
for the test dialogs subsequent to making the query,
all responses are generated based on the predicted
KB queries at predicted position ˆq and their query
results. This makes the evaluation much more
realistic, but also quite challenging for current
dialog engines. This is the key reason why aTOD
performance in Table 5 is much lower than results
reported in the BossNet paper (Raghu et al., 2019).
We perform two human evaluation experiments
to compare (1) informativeness – the ability to
effectively use the results to generate responses
and convey the information requested by the user,
Und (2) grammar – ability to generate gram-
matically correct and fluent responses. Both the
dimensions were annotated on a scale of (0–2).
As the primary focus of our work is to evaluate
the ability of a TOD system to effectively use the
annotated query results, we only collect judge-
ments for responses that occur after the KB query.
We sampled 100 random dialog-context from
CamRest dataset and collected judgments from 2
judges for 4 Systeme, nämlich, uTODREINFORCE,
uTODMAPO, uTODmB−MAPO, and aTOD. Wir
collected a total of 1600 labels from the judges.
4.4 Implementation Details
We implemented our system using TensorFlow
(Abadi et al., 2016). We identify hyperparameters
based on the evaluation of the held-out validation
sets. We sample word embedding, hidden layer,
and cell sizes (es) aus {32, 64, 128, 256, 512},
learning rates (lr) aus {10−3, 25 × 10−4, 5 ×
10−4, 10−4}, αo and λ from increments of 0.1
zwischen [0.1, 0,9], ǫ from {0.05, 0.1, 0.15, 0.2},
and αh from increments of 0.1 zwischen [0.5, 0,9].
The hyper-parameters that (αh, αo, λ, ǫ, es, lr)
achieved the best validation rewards were (0.5,
0.1, 0, 0.15, 256, 5×10−4) Und (0.6, 0.1, 0.1, 0.15,
256, 25 × 10−4) for DSTC2 and CamRest, bzw-
aktiv. As our response predictor is BossNet, Wir
used the best performing hyper-parameters re-
ported by Raghu et al. (2019) for each dataset.
Total accumulated validation rewards is used as
a early stopping criteria for training the query
predictor and BLEU for the training the response
predictor.
5 Experimente
Our experiments evaluate three research questions:
1. Query Predictor Performance: How does the
performance of mB-MAPO compare to other
gradient estimation techniques?
2. Query Position Predictor Performance: Wie
does the proposed position predictor perform
on the two datasets?
3. Next Response Predictor Performance: Wie
do responses from TOD systems trained with
unannotated dialogs compare to the ones
trained with KB query annotated dialogs?
5.1 Query Predictor Performance
To measure the query predictor performance, Wir
generate the KB queries at the gold position during
train and test. We only use the gold queries during
test to measure the performance. Tisch 3 Berichte
the KB query prediction accuracy, PIQ ratio, Und
total test rewards achieved by various gradient
estimation techniques. mB-MAPO significantly
outperforms MAPO on both datasets. The perfor-
mance gain comes from mB-MAPO’s ability to
address correlated attributes in KB and the fre-
quent sampling of highest reward queries from the
buffer to prevent the policy from learning common
partial intent queries. Compared to MAPO, mB-
MAPO reduces the PIQ ratio by 55% on DSTC2
Und 54% on CamRest, and achieves considerably
higher rewards.
The failure of REINFORCE highlights that
using just the on-policy samples to estimate policy
382
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
REINFORCE
BS-REINFORCE
RBS-REINFORCE
MAPO
mB-MAPO
SL
SL+RL
Accuracy
PIQ Ratio
DSTC2
0.00
0.00
0.00
0.25±0.01
0.68±0.03
0.78±0.02
0.78±0.02
CamRest
0.00
0.00
0.002±0.005
0.10±0.01
0.62±0.03
0.59±0.06
0.66±0.04
DSTC2
0.00
0.00
0.00
0.61±0.01
0.06±0.03
0.09±0.02
0.09±0.02
CamRest
0.00
0.004±0.008
0.02±0.05
0.54±0.05
0.09±0.02
0.09±0.03
0.09±0.03
Total Test Rewards
CamRest
DSTC2
0.00
0.00
0.01±0.03
0.00
0.24±0.26
0.00
77.13±3.6 11.8±0.5
169.98±7.6 23.4±1.1
175.9±2.7 21.7±1.4
175.9±2.7 23.7±1.3
Tisch 3: Accuracy of KB query prediction of mB-MAPO and other algorithms on CamRest and DSTC2
An 10 runs. Partial intent query (PIQ) ratio is the fraction of partial intent queries predicted.
gradients is inadequate for exploring large combi-
natorial search spaces with sparse rewards. Beide
MAPO and mB-MAPO use queries in the buffer,
which are explored using systematic search. Diese
guide the policy towards the parts of the search
space that are likely to yield non-zero rewards.
We notice that, überraschenderweise, mB-MAPO achieves
slightly better accuracy than even the supervised
(SL) baseline on CamRest dataset. Further analy-
sis reveals that on this dataset, supervised learner
achieves a train accuracy of 95%, while mB-
MAPO achieves only 75% (but higher test accu-
racy). This suggests that the supervised learner is
overfitting, which is conceivable since CamRest
is a relatively small dataset (406 train dialogs, sehen
Tisch 2). Because mB-MAPO is learning with
weak supervision, it is solving a much harder
Problem, which makes it harder to overfit. More-
über, sometimes mB-MAPO may simply learn
partial intent queries if they generalize better.
This added flexibility helps avoid overfitting in
the small dataset. Our error analysis reveals that
25% of queries generated by supervised learner
had non-entity words as values in the WHERE
clause. Zum Beispiel,‘‘please” was predicted as a
cuisine. This shows the model has learned to pick
up spurious signals to predict certain attributes. In
Kontrast, nur 11% Zu 13% of the queries predicted
by MAPO and mB-MAPO exhibited this problem.
To prevent the supervised learner from overfitting,
SL+RL combines the weak supervision using RL
as a secondary source of knowledge on top of
cross entropy loss. This increased the accuracy by
7 points and percent of queries with non-entity
words reduced from 25% Zu 11%.
Andererseits, compared to supervised
learner, mB-MAPO is 10 accuracy points lower
on DSTC2. The difference in performance can be
attributed to two factors. Erste, DSTC2 is a larger
dataset, which enables supervised learner to train
well. Zweite, in this dataset, es gibt 12% von
dialogs where overconstrained queries (those that
have even more attributes than the gold) fetch bet-
ter rewards than the gold. Zum Beispiel, in Table 1
Beispiel (A), say the query ‘‘cuisine=chinese AND
price=moderate AND location=west” fetches all
the entities mentioned in subsequent dialog. Sogar
though it has one additional attribute compared to
the actual user intent (or gold query), it will likely
contain fewer unused entities than the gold query.
Thus mB-MAPO will assign a higher reward to
this overconstrained query, and will encourage the
training to output this. This confuses mB-MAPO,
leading to a significant performance gap from
supervised learner.
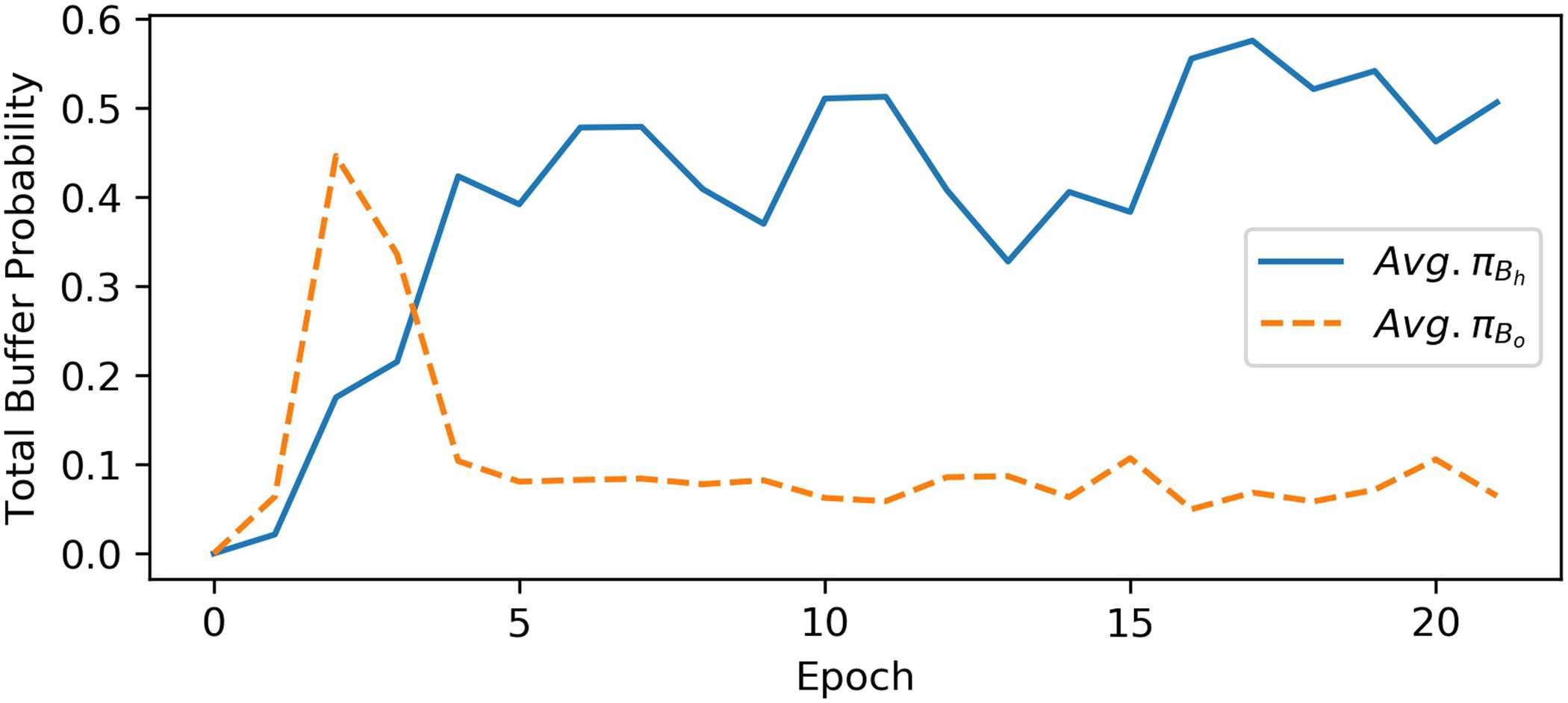
Dynamics of the Total Buffer Probabilities:
πBh and πBo are the sum of probabilities of all the
queries in buffers Bh and Bo, jeweils. Wir
now discuss the dynamics of πBh and πBo during
Ausbildung. We define average πBh and average πBo
as the average of total buffer probabilities across
all the examples in train. Figur 3 shows the aver-
age πBh and average πBo after each train epoch
on DSTC2. Queries in Bo are typically shorter
(partial queries) compared to the queries in Bh
and so they get assigned a higher probabilities
when the policy is randomly initialized. Somit
during initial epochs average πBo is higher than
average πBh. But as the training proceeds, Die
policy learns to assign higher probability to the
(longer) queries in Bh as a result of clipping the
buffer probabilities defined by αh. The gradients
are biased towards the queries in Bh during the
first few epochs, but as the policy converges we
can see that the average πBh reaches close to αh
(0.5 for DSTC2) making the gradient estimates
unbiased.
383
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
model since it has to decide between whether to
make a query or request a re-affirmation.
5.3 TOD System Performance
To study the TOD system performance, we neither
use the gold positions nor the gold queries. Wir
use the heuristic defined in Section 3.3 to label
the positions. These labelled positions are used
to train the position predictor and as the position
at which the query predictor generates the query
during train. At test time, the query predictor
generates the query at the predicted position.
We study the performance of uTOD systems
(next response prediction) trained using the dia-
logs whose queries were predicted by various
query prediction algorithms. For this evaluation,
test dialogs are first divided into (Kontext, Re-
sponse) pairs. The system predicts a response
for each turn and the predicted response is com-
pared with the gold response. When predicting
responses in the subsequent dialog, the results of
the predicted query are appended to the context.
For the aTOD system, results from gold queries
are used during train, and the results of predicted
queries are used during test.
Entities in responses can be divided into two
types: context entities and KB entities. Context
entities are present in the dialog context. Zum Beispiel-
reichlich, in Abbildung 1, agent utterance in turn 2 hat
two context entities (‘‘moderate’’ and ‘‘south’’)
and one KB entity (‘‘Peking Restaurant’’). Für
the response to contain the correct KB entity, alle
of position predictor, query predictor, and next
response predictor must work together. To assess
Das, we report KB Entity F1, which judges the
match between gold and predicted KB entities
used in the utterance.
Tisch 5 shows the performance of various TOD
systems on two datasets. We see that the uTOD
system trained using mB-MAPO is only a few
points lower than aTOD system. This underscores
the value of our gradient computation scheme.
mB-MAPO is significantly better than MAPO;
our analysis reveals that MAPO frequently returns
partial queries which have a larger set of results
—this confuses the response predictor, reduzierend
KB Entity F1 substantially.
Most entities predicted by REINFORCE are just
context entities copied from the context and their
contribution dominates the entity F1 (alle) Punktzahl.
As REINFORCE fails completely in generating
Figur 3: Dynamics of total buffer probabilities πBh
and πBo while training on DSTC2.
Accuracy
ATD
CamRest
DSTC2
w/o PT w/ PT w/o PT w/ PT
0.56
2.20
0.54
0.28
0.47
0.21
0.72
2.26
Tisch 4: Position predictor performance with and
without pre-training (PT). ATD = average turn
difference.
5.2 Query Position Predictor Performance
To study the performance of the query position
predictor, we use the gold positions to train the
classifier and to measure the performance during
test. Tisch 4 shows the accuracy and the average
turn differences for the task of query position pre-
diction. The predictor is evaluated in two settings:
one initialized with random weights (w/o PT) Und
one with the encoder network pre-trained for the
task of response prediction (w/ PT). The response
prediction tasks helps the network identify parts
of dialog context that are crucial for generating
the response. This additional information helps
improve the accuracy by 7 points on both datasets.
The overall performance for CamRest is accept-
able, since average turn difference is less than
1. The errors are due to natural variations in the
policy followed by the agent (human in the Wiz-
ard of Oz study)—sometimes the agent fires the
query before all possible attributes are specified
by the user, and at other times, the agent requests
for missing attributes and only then fires a query.
Jedoch, performance in DSTC2 is somewhat
limited. In addition to natural agent policy vari-
ations, there are artifacts of speech data, Weil
DSTC2 are speech transcripts of human-bot con-
versations. For exmaple, the bot often re-confirms
an already specified attribute to reduce speech
recognition errors. As DSTC2 dataset uses tran-
scripts and not actual speech, this re-affirmation
is redundant, but is still present. This confuses the
384
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Ent. F1
KB
0.11±0.01
0.14±0.01
0.21±0.02
0.24±0.02
0.24±0.02
DSTC2
Ent. F1
Alle
0.36±0.02
0.36±0.01
0.38±0.02
0.41±0.02
0.41±0.02
BLEU
51.52±0.91
46.27±1.63
47.52±1.27
48.35±1.58
48.35±1.58
Ent. F1
KB
0.02±0.01
0.14±0.01
0.23±0.02
0.25±0.03
0.29±0.03
CamRest
Ent. F1
Alle
0.34±0.02
0.31±0.03
0.35±0.02
0.36±0.02
0.41±0.02
BLEU
15.09±0.56
12.90±0.75
13.11±0.86
13.80±1.04
14.68±0.85
uTODREINFORCE
uTODMAPO
uTODmB−MAPO
aTODSL
aTODSL+RL
Tisch 5: Performance of various uTOD systems and aTOD system on 10 runs.
uTODREINFORCE
uTODMAPO
uTODmB−MAPO
aTODSL+RL
DSTC2
CamRest
0.02±0.01
0.08±0.01
0.17±0.02
0.20±0.01
0.00±0.00
0.10±0.01
0.21±0.02
0.28±0.02
Tisch 6: KB entity F1 achieved by various TOD
systems on OOV test set.
Info.
Grammar
uTODREINFORCE
uTODMAPO
uTODmB−MAPO
aTODSL+RL
0.20
0.36
0.64
1.08
0.89
1.18
1.38
1.39
Tisch 7: Human evaluations on CamRest.
correct queries, the response predictor is forced
to memorize the KB entities rather than inferring
them from the query results. This results in very
low KB entity F1. As the dialog context often
has no query results, the system’s only objective
becomes generation of good language. Due to
Das, it achieves a higher BLEU score compared
to other systems.
Human Evaluation: We report the human evalua-
tion4 results on 100 random context-response pairs
for CamRest dataset in Table 7. uTODmB−MAPO
outperforms other uTOD baselines on both infor-
mativeness and grammar. It was surprising to see
uTODREINFORCE perform poorly on grammar. Fur-
ther investigation showed that often the responses
generated were missing entities that made them
look incomplete. Zum Beispiel, the response ‘‘is a
restaurant in the moderate part of town . would you
like their phone number’’ has a missing restaurant
name at the start of the sentence. We measure the
inter-annotator agreement using Cohen’s Kappa
(κ) (Cohen, 1960). The agreement was substantial
for informativeness (κ = 0.62) and moderate
(κ = 0.45) for grammar.
Disentanglement Study: TOD systems can
learn to predict KB entities in the response either
by inferring (copying) them from the query results
or memorizing (Erstellen) ihnen. Only systems
that learns to copy them from the results will
generalize to entities unseen during train. To test
this ability to generalize, we follow Raghu et al.
(2019) and construct an OOV test set (and a corre-
sponding KB) such that it contains entities unseen
during train. Tisch 6 shows KB entity F1 of var-
ious TOD systems on this OOV test set. The low
numbers for uTODREINFORCE confirm that it mem-
orizes KB entities. uTODmB−MAPO achieves best
scores, and is 3–7 points short of supervised TOD.
Qualitative Example We qualitatively com-
pare the performance of various TOD systems
using the example shown in Table 8. The example
demonstrates the ability of uTODmB−MAPO to
generate the correct query and use the KB results
to generate an appropriate response. uTODMAPO
generates a partial query that has a larger set
of results—this confuses the response predictor,
and hence an incorrect restaurant is copied in the
response. uTODREINFORCE fails to generate a valid
query and so the response predictor generates a
random restaurant memorized during train. Der
response generated by all approaches contain the
correct context entities (cheap and south), but only
responses of uTODmB−MAPO and uTODSL contain
the appropriate KB entity requested by the user.
6 Diskussion & Research Challenges
4We used two in-house (non-author) judges. One was an
expert in dialog systems and the other was a novice.
We now discuss novel research questions identi-
fied in this research.
385
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
KB Results (Restaurant | Food | Bereich | Pricerange)
nandos | portuguese | south | cheap
the lucky star | chinese | south | cheap
User-1
Gold
uTODREINFORCE
uTODMAPO
uTODmB−MAPO
aTODSL+RL
hello, i am looking for a cheap restaurant on the south side of town .
SELECT * FROM KB WHERE area = south AND pricerange = cheap
there is a place called nandos that specializes in portuguese food on the south side of town .
SELECT * FROM table WHERE area = i
chiquito restaurant bar is cheap in the south of town . would you like their phone number
SELECT * FROM table WHERE pricerange = cheap
the missing sock is a cheap restaurant in the south . would you like their phone number
SELECT * FROM table WHERE area = south AND pricerange = cheap
nandos are portuguese in the south south would you like their phone number
SELECT * FROM table WHERE area = south AND pricerange = cheap
the lucky star is a cheap restaurant in the south south would you like their phone number
Tisch 8: Queries and responses generated by uTODmB−MAPO and other TOD systems on a dialog from
CamRest. For simplicity, only the fields used in the dialog are mentioned in the KB results. Entities are
italicized.
Training
Q.Position Query
Predictor
Predicted
Oracle
Predicted
Oracle
Predictor
Predicted
Predicted
Oracle.
Oracle
Ent. F1
KB
0.24±0.02
0.32±0.04
0.32±0.03
0.38±0.03
DSTC2
Ent. F1
Alle
0.41±0.02
0.40±0.02
0.41±0.03
0.41±0.02
BLEU
48.35±1.58
48.52±1.31
48.94±1.80
49.79±1.80
Ent. F1
KB
0.29±0.03
0.32±0.02
0.37±0.04
0.39±0.04
CamRest
Ent. F1
Alle
0.41±0.02
0.40±0.02
0.44±0.03
0.45±0.03
BLEU
14.68±0.85
14.17±0.70
14.63±0.82
14.84±0.94
Tisch 9: Performance gap for supervised TOD systems when trained in different evaluation settings.
Can we train an end-to-end differentiable uTOD
System? Our proposed approach for uTOD uses a
pipeline of three components trained separately,
which can lead to cascading errors. We believe
that a single end-to-end neural architecture will
likely obtain superior performance. Aber, this is a
technical challenge, since it will require one model
to make two discrete decisions: when to query
and what to query, complicating the RL problem.
Can we bridge the gap between aTOD per-
formance with and without oracle queries at test
Zeit? Our work exposes a critical weakness of
fully supervised TOD systems. When evaluated in
a setting where the TOD system only has access
to its own predicted query and that query’s results,
the overall performance drops drastically. Tisch 9
shows the performance of our aTOD system,
where at test time, both for query position and the
query, the system prediction is used (Prediction)
or the gold value is used (Oracle). We observe
that using oracle values gets 14-point KB Entity
F1 gains over predicted values. Since our setting
is very realistic to assess the usability of current
dialog systems, this result highlights the research
challenge of improving supervised TOD systems
in our setting. We also emphasize the importance
of KB Entity F1 as an important metric—it better
assesses the value offered to the end user, gegeben
that these datasets contain mostly informational
tasks.
Can we design a uTOD system to handle dialogs
that require more than one query per dialog? Unser
current work makes the assumption of a single
query per dialog. This is because most supervised
TOD datasets also make only one query per dia-
log. Given that our task is harder than those, Es
was important to define it such that existing ML
machinery of TOD can feasibly learn our task. Bei
die selbe Zeit, extending the task definition and
creating datasets for the multiple queries per dia-
log case is straightforward. An important future
research challenge will be to design an end-to-end
dialog system that can handle a variable number
of KB queries in a single dialog, without explicit
386
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
query (or query position) annotation. We believe
that this is best studied only after substantial pro-
gress on our specific task definition.
7 Abschluss
We define the novel problem of learning TOD
systems without explicit KB query annotation and
the associated subtask of unsupervised prediction
of KB queries. We also propose first baseline
solutions for these tasks. Our best query predic-
tion baseline extends the existing RL approach
MAPO to include multiple query buffers at train-
ing time. We also present a pipeline architecture
that trains different components in a curriculum
to obtain the final TOD system. Our detailed eval-
uation shows that our approaches achieve much
better performance than simpler baselines, obwohl
there is some gap when compared to supervised
approaches. We study the results further to iden-
tify research challenges for future research. Wir
will release all resources for use by the research
Gemeinschaft.
Danksagungen
We thank Gaurav Pandey, Danish Contractor,
Dhiraj Madan, Sachindra Joshi, and the anony-
mous reviewers for their comments on an earlier
version of this paper. This work is supported by
IBM AI Horizons Network grant, an IBM SUR
award, grants by Google, Bloomberg, and 1MG,
a Visvesvaraya faculty award the Government of
Indien, and the Jai Gupta chair fellowship by IIT
Delhi. We thank the IIT Delhi HPC facility for
computational resources.
Verweise
Mart´ın Abadi, Paul Barham, Jianmin Chen,
Zhifeng Chen, Andy Davis, Jeffrey Dean,
Matthieu Devin, Sanjay Ghemawat, Geoffrey
Irving, Michael Isard, and et al. 2016. Ten-
sorflow: A system for large-scale machine
learning. In 12th {USENIX} Symposium on
Operating Systems Design and Implementation
({OSDI} 16), pages 265–283.
1:49–62. DOI: https://doi.org/10.1162
/tacl a 00209
Jonathan Berant, Andrew Chou, Roy Frostig,
and Percy Liang. 2013. Semantic parsing on
Freebase from question-answer pairs. In Pro-
ceedings of the 2013 Conference on Empirical
Methods in Natural Language Processing,
pages 1533–1544, Seattle, Washington, USA.
Verein für Computerlinguistik.
Antoine Bordes and Jason Weston. 2017. Learn-
ing end-to-end goal-oriented dialog. In Interna-
tional Conference on Learning Representations.
Yun-Nung Chen, William Yang Wang, Anatole
Gershman, and Alexander I. Rudnicky. 2015.
Matrix factorization with knowledge graph prop-
agation for unsupervised spoken language un-
derstanding. In Proceedings of the 53rd Annual
Meeting of the Association for Computational
Linguistics and the 7th International Joint
Conference on Natural Language Processing
(Volumen 1: Long Papers), pages 483–494.
Yun-Nung Chen, William Yang Wang, Und
Alexander I. Rudnicky. 2013. Unsupervised
induction and filling of semantic slots for spo-
ken dialogue systems using frame-semantic
parsing. In 2013 IEEE Workshop on Auto-
matic Speech Recognition and Understanding,
pages 120–125. IEEE. DOI: https://doi
.org/10.1109/ASRU.2013.6707716
Kyunghyun Cho, Bart van Merrienboer, Caglar
Gulcehre, Dzmitry Bahdanau, Fethi Bougares,
Holger Schwenk, and Yoshua Bengio. 2014.
Learning phrase representations using rnn
encoder–decoder for statistical machine trans-
lation. In Proceedings of the 2014 Conference
on Empirical Methods in Natural Language
Processing (EMNLP), pages 1724–1734. Asso-
ciation for Computational Linguistics.
Jacob Cohen. 1960. A coefficient of agreement for
nominal scales. Educational and Psychological
Measurement, 20(1):37–46. DOI: https://
doi.org/10.1177/001316446002000104
Yoav Artzi and Luke Zettlemoyer. 2013. Weakly
supervised learning of semantic parsers for
mapping instructions to actions. Transactions of
the Association for Computational Linguistics,
Pradeep Dasigi, Matt Gardner, Shikhar Murty,
Luke Zettlemoyer, and Eduard Hovy. 2019.
Iterative search for weakly supervised semantic
parsing. In Proceedings of the 2019 Conference
387
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
of the North American Chapter of the Asso-
ciation for Computational Linguistics: Human
Language Technologies, Volumen 1 (Long and
Short Papers), pages 2669–2680, Minneapolis,
Minnesota. Association for Computational Lin-
guistics. DOI: https://doi.org/10.18653
/v1/N19-1273
Bhuwan Dhingra, Lihong Li, Xiujun Li, Jianfeng
Gao, Yun-Nung Chen, Faisal Ahmed, and Li
Deng. 2017. Towards end-to-end reinforce-
ment learning of dialogue agents for infor-
mation access. In Proceedings of
the 55th
Annual Meeting of the Association for Compu-
tational Linguistics (Volumen 1: Long Papers),
pages 484–495. DOI: https://doi.org
/10.18653/v1/P17-1045
Mihail Eric, Lakshmi Krishnan, Francois Charette,
and Christopher D. Manning. 2017. Key-value
retrieval networks for task-oriented dialogue.
In Dialog System Technology Challenges,
Saarbr¨ucken, Deutschland, August 15-17, 2017,
pages 37–49.
Marjan Ghazvininejad, Xing Shi, Yejin Choi, Und
Kevin Knight. 2016. Generating topical poetry.
In Proceedings of
Die 2016 Conference on
Empirical Methods in Natural Language Pro-
Abschließen, pages 1183–1191. DOI: https://
doi.org/10.18653/v1/D16-1126
Omer Goldman, Veronica Latcinnik, Ehud Nave,
Amir Globerson, and Jonathan Berant. 2018.
Weakly supervised semantic parsing with
abstract examples. In Proceedings of the 56th
Annual Meeting of the Association for Compu-
tational Linguistics (Volumen 1: Long Papers),
pages 1809–1819, Melbourne, Australia. Asso-
ciation for Computational Linguistics. DOI:
https://doi.org/10.18653/v1/P18
-1168
Jiatao Gu, Zhengdong Lu, Hang Li, and Victor
Ö. K. Li. 2016. Incorporating copying mecha-
nism in sequence-to-sequence learning.
In
Proceedings of the 54th Annual Meeting of
the Association for Computational Linguistics
(Volumen 1: Long Papers), pages 1631–1640.
Verein für Computerlinguistik.
Kelvin Guu, Panupong Pasupat, Evan Liu, Und
Percy Liang. 2017. From language to programs:
Bridging reinforcement learning and maximum
likelihood. In Proceedings of
Die
marginal
55th Annual Meeting of the Association for
Computerlinguistik (Volumen 1: Long
Papers), pages 1051–1062.
Till Haug, Octavian-Eugen Ganea, and Paulina
Grnarova. 2018. Neural multi-step reasoning
for question answering on semi-structured ta-
bles. In European Conference on Information
Retrieval, pages 611–617. Springer. DOI:
https://doi.org/10.1007/978-3-319
-76941-7 52
Matthew Henderson, Blaise Thomson,
Und
Jason D. Williams. 2014A. The second dialog
state tracking challenge. In Proceedings of the
15th Annual Meeting of the Special Interest
Group on Discourse and Dialogue (SIGDIAL),
pages 263–272. DOI: https://doi.org
/10.3115/v1/W14-4337
Matthew Henderson, Blaise Thomson,
Und
Steve Young. 2014B. Word-based dialog state
tracking with re-current neural networks. In
In Proceedings of the 15th Annual Meeting of
the Special Interest Group on Discourse and
Dialogue (SIGDIAL), pages 292–299. DOI:
https://doi.org/10.3115/v1/W14
-4340
Xiujun Li, Yun-Nung Chen, Lihong Li, Jianfeng
Gao, and Asli Celikyilmaz. 2017. End-to-end
task-completion neural dialogue systems. In
Proceedings of the Eighth International Joint
Conference on Natural Language Processing,
pages 733–743. Asian Federation of Natural
Language Processing.
Chen Liang, Jonathan Berant, Quoc Le, Kenneth
D. Forbus, and Ni Lao. 2017. Neural symbolic
machines: Learning semantic parsers on free-
base with weak supervision. In Proceedings of
the 55th Annual Meeting of the Association
für Computerlinguistik (Volumen 1: Long
Papers), pages 23–33. DOI: https://doi
.org/10.18653/v1/P17-1003
Chen Liang, Mohammad Norouzi,
Jonathan
Berant, Quoc V. Le, and Ni Lao. 2018. Memory
augmented policy optimization for program
synthesis and semantic parsing. In Advances
in Neural Information Processing Systems,
pages 9994–10006.
388
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Long-Ji Lin. 1992. Self-improving reactive agents
based on reinforcement learning, planning and
teaching. Mach. Learn., 8(3–4):293–321. DOI:
https://doi.org/10.1007/BF00992699
A. Madotto, C. S. Wu, and P. Fung. 2018.
Mem2seq: Effectively incorporating knowl-
edge bases into end-to-end task-oriented dialog
Systeme. In Proceedings of 56th Annual Meet-
the Association for Computational
ing of
Linguistik. Association for Computational
Linguistik. DOI: https://doi.org/10
.18653/v1/P18-1136
Dipendra Misra, Ming-Wei Chang, Xiaodong He,
and Wen-tau Yih. 2018. Policy shaping and gen-
eralized update equations for semantic parsing
from denotations. In Proceedings of the 2018
Conference on Empirical Methods in Natural
Language Processing, pages 2442–2452. DOI:
https://doi.org/10.18653/v1/D18
-1266
Yatin Nandwani, Abhishek Pathak, Mausam,
and Parag Singla. 2019. A primal dual for-
mulation for deep learning with constraints.
In Advances in Neural Information Processing
Systeme 32: Annual Conference on Neural
Information Processing Systems 2019, NeurIPS
2019, 8-14 Dezember 2019, Vancouver, BC,
Kanada, pages 12157–12168.
Arvind Neelakantan, Quoc V. Le, Mart´ın Abadi,
Andrew McCallum, and Dario Amodei. 2017.
Learning a natural
language interface with
neural programmer. In 5th International Con-
ference on Learning Representations, ICLR
2017, Toulon, Frankreich, April 24-26, 2017, Con-
ference Track Proceedings. OpenReview.net.
Kishore Papineni, Salim Roukos, Todd Ward,
and Wei-Jing Zhu.
2002. BLEU: A
method for automatic evaluation of machine
Übersetzung. In Proceedings of the 40th Annual
Meeting on Association for Computational
Linguistik, pages 311–318. Association for
Computerlinguistik. DOI: https://
doi.org/10.3115/1073083.1073135
Panupong Pasupat and Percy Liang. 2015. Com-
positional semantic parsing on semi-structured
the 53rd Annual
tables. In Proceedings of
Meeting of the Association for Computational
Linguistics and the 7th International Joint
Conference on Natural Language Processing
(Volumen 1: Long Papers), pages 1470–1480,
Peking, China. Association for Computational
Linguistik. DOI: https://doi.org/10
.3115/v1/P15-1142
Panupong Pasupat and Percy Liang. 2016.
Inferring logical forms from denotations. In
Proceedings of the 54th Annual Meeting of
the Association for Computational Linguistics
(Volumen 1: Long Papers), pages 23–32, Berlin,
Deutschland. Association for Computational Lin-
guistics. DOI: https://doi.org/10.18653
/v1/P16-1003
Dinesh Raghu, Nikhil Gupta, and Mausam. 2019.
Disentangling language and knowledge in task-
oriented dialogs. In Proceedings of the 2019
Conference of the North American Chapter of
the Association for Computational Linguistics:
Human Language Technologies, Volumen 1
(Long and Short Papers), pages 1239–1255.
Antoine Raux, Brian Langner, Dan Bohus,
Alan W. Black, and Maxine Esk´enazi. 2005.
Let’s go public! Taking a spoken dialog system
to the real world. In INTERSPEECH.
Revanth Gangi Reddy, Danish Contractor, Dinesh
Raghu, and Sachindra Joshi. 2019. Multi-
level memory for task oriented dialogs. In
Verfahren der 2019 Conference of the
North American Chapter of the Association for
Computerlinguistik: Human Language
Technologies, Volumen 1 (Long and Short
Papers), pages 3744–3754. DOI: https://
doi.org/10.18653/v1/N19-1375
Tom Schaul, John Quan, Ioannis Antonoglou,
and David Silver. 2016. Prioritized experience
replay. In International Conference on Learn-
ing Representations, Puerto Rico.
Abigail See, Peter J. Liu, and Christopher D.
to the point: Summa-
Manning. 2017. Get
rization with pointer-generator networks. In
Proceedings of the 55th Annual Meeting of
the Association for Computational Linguistics
(Volumen 1: Long Papers), pages 1073–1083.
Verein für Computerlinguistik.
Sainbayar Sukhbaatar, Arthur Szlam,
Jason
Weston, and Rob Fergus. 2015. End-to-end
memory networks. In Advances in Neural Infor-
mation Processing Systems, pages 2440–2448.
389
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Bailin Wang, Ivan Titov, and Mirella Lapata.
2019. Learning semantic parsers from deno-
tations with latent structured alignments and
abstract programs. In Proceedings of the 2019
Conference on Empirical Methods in Natural
Language Processing and the 9th International
Joint Conference on Natural Language Pro-
Abschließen (EMNLP-IJCNLP), pages 3765–3776.
DOI: https://doi.org/10.18653/v1
/D19-1391, PMID: 31933765
T. H. Wen, D. Vandyke, N. Mrkˇs´ıc, M. Gaˇs´ıc,
L. M. Rojas-Barahona, P. H. Su, S. Ultes,
and S. Jung. 2017. A network-based end-
to-end trainable task-oriented dialogue system.
In 15th Conference of the European Chapter
of the Association for Computational Linguis-
Tics, EACL 2017-Proceedings of Conference,
Volumen 1, pages 438–449. DOI: https://doi
.org/10.18653/v1/E17-1042, PMCID:
PMC5677129
Tsung-Hsien Wen, Milica Gasic, Nikola Mrkˇsi´c,
Lina M. Rojas Barahona, Pei-Hao Su, Stefan
Ultes, David Vandyke, and Steve Young.
2016. Conditional generation and snapshot
learning in neural dialogue systems. In EMNLP,
pages 2153–2162, Austin, Texas. ACL.
Jason D. Williams, Kavosh Asadi, and Geoffrey
Zweig. 2017. Hybrid code networks: practical
and efficient end-to-end dialog control with
In
supervised and reinforcement
Proceedings of the 55th Annual Meeting of
the Association for Computational Linguis-
Tics (Volumen 1: Long Papers), Volumen 1,
pages 665–677. DOI: https://doi.org/10
.18653/v1/P17-1062, PMID: 28243779
learning.
Ronald J. Williams. 1992. Simple statistical
gradient-following algorithms for connectionist
learning. Machine learning,
reinforcement
8(3-4):229–256. DOI: https://doi.org
/10.1007/BF00992696
Chien-Sheng Wu, Richard Socher, and Caiming
Xiong. 2019. Global-to-local memory pointer
networks for task-oriented dialogue. In Pro-
ceedings of the International Conference on
Learning Representations (ICLR).
Tao Yu, Rui Zhang, Heyang Er, Suyi Li, Eric
Xue, Bo Pang, Xi Victoria Lin, Yi Chern
Bräunen, Tianze Shi, Zihan Li, Youxuan Jiang,
Michihiro Yasunaga, Sungrok Shim, Tao Chen,
Alexander Fabbri, Zifan Li, Luyao Chen,
Yuwen Zhang, Shreya Dixit, Vincent Zhang,
Caiming Xiong, Richard Socher, Walter S.
Lasecki, and Dragomir Radev. 2019. CoSQL: A
conversational text-to-SQL challenge towards
cross-domain natural
language interfaces to
databases. In Proceedings of the 2019 Con-
ference on Empirical Methods in Natural
Language Processing and the 9th International
Joint Conference on Natural Language Pro-
Abschließen (EMNLP-IJCNLP), pages 1962–1979.
DOI: https://doi.org/10.18653/v1
/D19-1204
John M. Zelle and Raymond J. Mooney. 1996.
Learning to parse database queries using
inductive logic programming. In Proceedings
von
the Thirteenth National Conference on
Artificial Intelligence – Volumen 2, AAAI’96,
pages 1050–1055. AAAI Press.
Luke S. Zettlemoyer and Michael Collins. 2005.
Learning to map sentences to logical form:
Structured classification with probabilistic
categorial grammars. In Proceedings of
Die
Twenty-First Conference on Uncertainty in
Artificial Intelligence, UAI’05, pages 658–666,
Arlington, Virginia, USA. AUAI Press.
390
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
3
7
2
1
9
2
4
2
0
7
/
/
T
l
A
C
_
A
_
0
0
3
7
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3