Transaktionen des Assoziation für Computer -Linguistik, Bd. 6, S. 529–541, 2018. Action Editor: Holger Schwenk.
Einreichungsstapel: 8/2017; Revisions -Stapel: 1/2018; Veröffentlicht 8/2018.
2018 Verein für Computerlinguistik. Unter einem cc-by verteilt 4.0 Lizenz.
C
(cid:13)
NeuralLatticeLanguageModelsJacobBuckmanLanguageTechnologiesInstituteCarnegieMellonUniversityjacobbuckman@gmail.comGrahamNeubigLanguageTechnologiesInstituteCarnegieMellonUniversitygneubig@cs.cmu.eduAbstractInthiswork,weproposeanewlanguagemod-elingparadigmthathastheabilitytoperformbothpredictionandmoderationofinforma-tionflowatmultiplegranularities:neurallat-ticelanguagemodels.Thesemodelscon-structalatticeofpossiblepathsthroughasen-tenceandmarginalizeacrossthislatticetocal-culatesequenceprobabilitiesoroptimizepa-rameters.Thisapproachallowsustoseam-lesslyincorporatelinguisticintuitions–in-cludingpolysemyandtheexistenceofmulti-wordlexicalitems–intoourlanguagemodel.ExperimentsonmultiplelanguagemodelingtasksshowthatEnglishneurallatticelanguagemodelsthatutilizepolysemousembeddingsareabletoimproveperplexityby9.95%rela-tivetoaword-levelbaseline,andthataChi-nesemodelthathandlesmulti-characterto-kensisabletoimproveperplexityby20.94%relativetoacharacter-levelbaseline.1IntroductionNeuralnetworkmodelshaverecentlycontributedto-wardsagreatamountofprogressinnaturallanguageprocessing.Thesemodelstypicallyshareacommonbackbone:recurrentneuralnetworks(RNN),whichhaveproventhemselvestobecapableoftacklingavarietyofcorenaturallanguageprocessingtasks(HochreiterandSchmidhuber,1997;Elman,1990).Onesuchtaskislanguagemodeling,inwhichweestimateaprobabilitydistributionoversequencesoftokensthatcorrespondstoobservedsentences(§2).Neurallanguagemodels,particularlymodelscon-ditionedonaparticularinput,havemanyapplica-tionsincludinginmachinetranslation(Bahdanauetal.,2016),abstractivesummarization(Chopraetal.,2016),andspeechprocessing(Gravesetal.,2013).dogs chased the small cat dogs chased the smallcatdogs chased thesmalldogs chasedthethe_smallthe_small_cat small_catdogs_chasedchasedchased_thedogs_chased_thechased_the_smallFigure1:Latticedecompositionofasentenceanditscor-respondinglatticelanguagemodelprobabilitycalculationSimilarly,state-of-the-artlanguagemodelsareal-mostuniversallybasedonRNNs,particularlylongshort-termmemory(LSTM)Netzwerke(Jozefowiczetal.,2016;Inanetal.,2017;Merityetal.,2016).Whilepowerful,LSTMlanguagemodelsusuallydonotexplicitlymodelmanycommonly-acceptedlinguisticphenomena.Asaresult,standardmod-elslacklinguisticallyinformedinductivebiases,po-tentiallylimitingtheiraccuracy,particularlyinlow-datascenarios(Adamsetal.,2017;KoehnandKnowles,2017).Inthiswork,wepresentanovelmodificationtothestandardLSTMlanguagemod-elingframeworkthatallowsustoincorporatesomevarietiesoftheselinguisticintuitionsseamlessly:neurallatticelanguagemodels(§3.1).Neurallat-ticelanguagemodelsdefinealatticeoverpossi-blepathsthroughasentence,andmaximizethemarginalprobabilityoverallpathsthatleadtogen-eratingthereferencesentence,asshowninFig.1.Dependingonhowwedefinethesepaths,wecanin-corporatedifferentassumptionsabouthowlanguageshouldbemodeled.Intheparticularinstantiationsofneurallatticelanguagemodelscoveredbythispaper,wefocusontwopropertiesoflanguagethatcouldpotentiallybeofuseinlanguagemodeling:theexistenceofmulti-wordlexicalunits(Zgusta,1967)(§4.1)andpoly-
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
0
3
6
1
5
6
7
6
2
8
/
/
T
l
A
C
_
A
_
0
0
0
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
530
semy(RavinandLeacock,2000)(§4.2).Neurallat-ticelanguagemodelsallowthemodeltoincorporatetheseaspectsinanend-to-endfashionbysimplyad-justingthestructureoftheunderlyinglattices.Werunexperimentstoexplorewhetherthesemodificationsimprovetheperformanceofthemodel(§5).Zusätzlich,weprovidequalitativevisualiza-tionsofthemodeltoattempttounderstandwhattypesofmulti-tokenphrasesandpolysemousem-beddingshavebeenlearned.2Background2.1LanguageModelsConsiderasequenceXforwhichwewanttocal-culateitsprobability.Assumewehaveavocabularyfromwhichwecanselectauniquelistof|X|tokensx1,x2,…,X|X|suchthatX=[x1;x2;…;X|X|],i.e.theconcatenationofthetokens(withanappro-priatedelimiter).Thesetokenscanbeeitheronthecharacterlevel(HwangandSung,2017;Lingetal.,2015)orwordlevel(Inanetal.,2017;Merityetal.,2016).Usingthechainrule,languagemodelsgen-erallyfactorizep(X)inthefollowingway:P(X)=p(x1,x2,…,X|X|)=|X|Yt=1p(xt|x1,x2,…,xt−1).(1)Notethatthisfactorizationisexactonlyinthecasewherethesegmentationisunique.Incharacter-levelmodels,itiseasytoseethatthispropertyismaintained,becauseeachtokenisuniqueandnon-overlapping.Inword-levelmodels,thisalsoholds,becausetokensaredelimitedbyspaces,andnowordcontainsaspace.2.2RecurrentNeuralNetworksRecurrentneuralnetworkshaveemergedasthestate-of-the-artapproachtoapproximatingp(X).Inparticular,theLSTMcell(HochreiterandSchmid-huber,1997)isaspecificRNNarchitecturewhichhasbeenshowntobeeffectiveonmanytasks,in-cludinglanguagemodeling(PressandWolf,2017;Jozefowiczetal.,2016;Merityetal.,2016;Inanetal.,2017).1LSTMlanguagemodelsrecursivelycal-1Inthiswork,weutilizeanLSTMwithlinkedinputandforgetgates,asproposedbyGreffetal.(2016).culatethehiddenandcellstates(htandctrespec-tively)giventheinputembeddinget−1correspond-ingtotokenxt−1:ht,ct=LSTM(ht−1,ct−1,et−1,θ),(2)thencalculatetheprobabilityofthenexttokengiventhehiddenstate,generallybyperforminganaffinetransformparameterizedbyWandb,followedbyasoftmax:P(xt|ht):=softmax(W∗ht+b).(3)3NeuralLatticeLanguageModels3.1LanguageModelswithAmbiguousSegmentationsToreiterate,thestandardformulationoflanguagemodelingintheprevioussectionrequiressplittingsentenceXintoauniquesetoftokensx1,…,X|X|.Ourproposedmethodgeneralizesthepreviousfor-mulationtoremovetherequirementofuniquenessofsegmentation,similartothatusedinnon-neuraln-gramlanguagemodelssuchasDupontandRosen-feld(1997)andGoldwateretal.(2007).Erste,wedefinesometerminology.Weusetheterm“token”,designatedbyxi,todescribeanyin-divisibleiteminourvocabularythathasnoothervocabularyitemasitsconstituentpart.Weusetheterm“chunk”,designatedbykiorxji,todescribeasequenceofoneormoretokensthatrepresentsaportionofthefullstringX,containingtheunitto-kensxithroughxj:xji=[xi,xi+1;…;xj].Wealsorefertothe“tokenvocabulary”,whichisthesubsetofthevocabularycontainingonlytokens,andtothe“chunkvocabulary”,whichsimilarlycontainsallchunks.NotethatwecanfactorizetheprobabilityofanysequenceofchunksKusingthechainrule,inpre-ciselythesamewayassequencesoftokens:P(K)=p(k1,k2,…,k|K|)=|K|Yt=1p(kt|k1,k2,…,kt−1).(4)Wecanfactorizetheoverallprobabilityofato-kenlistXintermsofitschunksbyusingthechainrule,andmarginalizingoverallsegmentations.ForanyparticulartokenlistX,wedefineasetofvalid
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
0
3
6
1
5
6
7
6
2
8
/
/
T
l
A
C
_
A
_
0
0
0
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
531
segmentationsS(X),suchthatforeverysequences∈S(X),X=[xs1−1s0;xs2−1s1;…;xs|S|S|S|−1].Thefactorizationis:P(X)=XSp(X,S)=XSp(X|S)P(S)=XS∈S(X)P(S)=XS∈S(X)|S|Yt=1p(xst−1st−1|xs1−1s0,xs2−1s1,…,xst−1−1st−2).(5)Notethat,bydefinition,thereexistsauniqueseg-mentationofXsuchthatx1,x2,…arealltokens,inwhichcase|S|=|X|.WhenonlythatoneuniquesegmentationisallowedperX,Scontainsonlythatoneelement,sosummationdropsout,andthereforeforstandardcharacter-levelandword-levelmodels,Eq.(5)reducestoEq.(4),asdesired.However,formodelsthatlicensemultiplesegmentationsperX,computingthismarginalizationdirectlyisgener-allyintractable.Forexample,considersegmentingasentenceusingavocabularycontainingallwordsandall2-wordexpressions.ThesizeofSwouldgrowexponentiallywiththenumberofwordsinX,meaningwewouldhavetomarginalizeovertril-lionsofuniquesegmentationsforevenmodestly-sizedsentences.3.2LatticeLanguageModelsToavoidthis,itispossibletore-organizethecom-putationsinalattice,whichallowsustodramati-callyreducethenumberofcomputationsrequired(DupontandRosenfeld,1997;Neubigetal.,2010).AllsegmentationsofXcanbeexpressedastheedgesofpathsthroughalatticeovertoken-levelpre-fixesofX:X<1,x<2,...,X.Theinfimumistheemptyprefixx<1;thesupremumisX;anedgefromprefixxandaddingittoourvocabulary.Ateachtimestep,wefirstuseourneuralnetworktocalculateascoreforeachchunkCinourvocabulary,includingthesentineltoken.Wedoasoftmaxacrossthesescorestoassignaprobabilitypmain(Ct+1|ht;θ)toeverychunkinourvocabulary,andalsoto.Fortokensequencesnotrepresentedinourchunkvocabulary,thisprobabilitypmain(Ct+1|ht;θ)=0.Next,theprobabilitymassassignedtothesentinelvalue,pmain(|ht;θ),isdistributedacrossallpossibletokenssequencesoflengthlessthanL,us-inganotherLSTMwithparametersθsub.SimilartoJozefowiczetal.(2016),thissub-LSTMisinitial-izedbypassinginthehiddenstateofthemainlatticeLSTMatthattimestep.Thisgivesusaprobabilityforeachsequencepsub(c1,c2,…,cL|ht;θsub).ThefinalformulaforcalculatingtheprobabilitymassassignedtoaspecificchunkCis:P(C|ht;θ)=pmain(C|ht;θ)+pmain(|ht;θ)psub(C|ht;θsub).4.2IncorporatingPolysemousTokens4.2.1MotivationAsecondshortcomingofcurrentlanguagemod-elingapproachesisthateachwordisassociatedwithonlyoneembedding.Forhighlypolysemouswords,asingleembeddingmaybeunabletorepresentallmeaningseffectively.Therehasbeenpastworkinwordembeddingswhichhasshownthatusingmultipleembeddingsforeachwordishelpfulinconstructingausefulrepre-sentation.AthiwaratkunandWilson(2017)repre-sentedeachwordwithamultimodalGaussiandis-tributionanddemonstratedthatembeddingsofthisformwereabletooutperformmorestandardskip-gramembeddingsonwordsimilarityandentailmenttasks.Similarly,Chenetal.(2015)incorporatestandardskip-gramtrainingintoaGaussianmixtureframeworkandshowthatthisimprovesperformanceonseveralwordsimilaritybenchmarks.Whenapolysemouswordisrepresentedusingonlyasingleembeddinginalanguagemodelingtask,themultimodalnatureofthetrueembeddingdistributionmaycausestheresultingembeddingtobebothhigh-varianceandskewedfromthepositionsofeachofthetruemodes.Thus,itislikelyusefultorepresenteachtokenwithmultipleembeddingswhendoinglanguagemodeling.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
0
3
6
1
5
6
7
6
2
8
/
/
T
l
A
C
_
A
_
0
0
0
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
535
4.2.2ModelingStrategyForourpolysemyexperiments,theunderlyinglat-ticesaremulti-lattices:latticeswhicharealsomulti-graphs,andcanhaveanynumberofedgesbetweenanygivenpairofnodes(Fig.2,d).Latticessetupinthismannerallowustoincorporatemultipleem-beddingsforeachword.Withinasinglesentence,anypairofnodescorrespondstothestartandendofaparticularsubsequenceofthefullsentence,andisthusassociatedwithaspecifictoken.Eachedgebetweenthemisauniqueembeddingforthatto-ken.Whilemanystrategiesforchoosingthenum-berofembeddingsexistintheliterature(Neelakan-tanetal.,2014),inthiswork,wechooseanumberofembeddingsEandassignthatmanyembeddingstoeachword.Thisensuresthatthemaximumin-degreeofanynodeinthelatticeD,isnogreaterthanE,givingusthetimeboundO(E|X|).Inthiswork,wedonotexploremodelsthatin-cludebothchunkvocabulariesandmultipleembed-dings.However,combiningthesetwotechniques,aswellasexploringother,morecomplexlatticestruc-tures,isaninterestingavenueforfuturework.5Experiments5.1DataWeperformexperimentsontwolanguages:EnglishandChinese,whichprovideaninterestingcontrastinlinguisticfeatures.4InEnglish,themostcommonbenchmarkforlanguagemodelingrecentlyisthePennTree-bank,specificallytheversionpreprocessedbyTom´aˇsMikolov(2010).Jedoch,thiscorpusislim-itedbybeingrelativelysmall,onlycontainingap-proximately45,000sentences,whichwefoundtobeinsufficienttoeffectivelytrainlatticelanguagemod-els.5Thus,weinsteadusedtheBillionWordCorpus(Chelbaetal.,2014).PastexperimentsontheBWCtypicallymodeledeverywordwithoutrestrictingthevocabulary,whichresultsinanumberofchallengesregardingthemodelingofopenvocabulariesthatareorthogonaltothiswork.Thus,wecreateapre-4Codetoreproducedatasetsandexperimentsisavailableat:http://github.com/jbuckman/neural-lattice-language-models5Experimentsusingmulti-wordunitsresultedinoverfitting,regardlessofnormalizationandhyperparametersettings.processedversionofthedatainthesamemannerasMikolov,lowercasingthewords,replacingnum-berswith
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
0
3
6
1
5
6
7
6
2
8
/
/
T
l
A
C
_
A
_
0
0
0
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
537
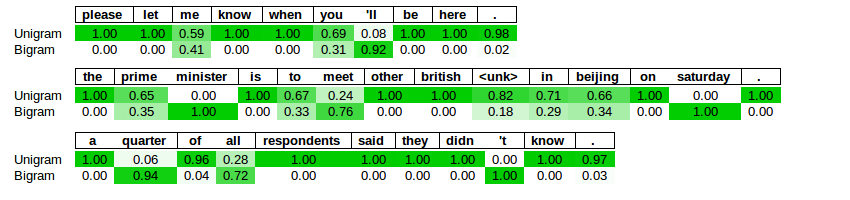
Figure3:Segmentationofthreesentencesrandomlysampledfromthetestcorpus,usingL=2.Greennumbersshowprobabilityassignedtotokensizes.Forexample,thefirstthreewordsinthefirstsentencehavea59%and41%chanceofbeing“pleaseletme”or“pleaseletme”respectively.Boxesaroundwordsshowgreedysegmentation.Table4:Comparisonofrandomly-selectedcontextsofseveralwordsselectedfromthevocabularyoftheBillionWordCorpus,inwhichthemodelpreferredoneembeddingovertheother.rock1rock2…atthe
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
0
3
6
1
5
6
7
6
2
8
/
/
T
l
A
C
_
A
_
0
0
0
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
538
textinwhichtheyappear.Insomecases,likeprofileandedition,oneofthetwoembeddingssimplycap-turesanidiosyncrasyofthetrainingdata.Additionally,forsomewords,suchasrodhaminTable4,thesystemalwaysprefersoneembedding.Thisispromising,becauseitmeansthatinfutureworkitmaybepossibletofurtherimproveaccu-racyandtrainingefficiencybyassigningmoreem-beddingstopolysemouswords,insteadofassigningthesamenumberofembeddingstoallwords.6RelatedWorkPastworkthatutilizedlatticesinneuralmodelsfornaturallanguageprocessingcentersaroundus-ingtheselatticesintheencoderportionofmachinetranslation.Suetal.(2016)utilizedavariationoftheGatedRecurrentUnit(GRU)thatoperatedoverlattices,andpreprocessedlatticesoverChi-nesecharactersthatallowedittoeffectivelyencodemultiplesegmentations.Additionally,Sperberetal.(2017)proposedavariationoftheTreeLSTMwiththegoalofcreatinganencoderoverspeechlatticesinspeech-to-text.Ourworktackleslanguagemod-elingratherthanencoding,andthusaddressestheissueofmarginalizationoverthelattice.AnotherrecentworkwhichmarginalizedovermultiplepathsthroughasentenceisLingetal.(2016).Theauthorstackletheproblemofcodegen-eration,wheresomecomponentsofthecodecanbecopiedfromtheinput,viaaneuralnetwork.Ourworkexpandsonthisbyhandlingmulti-wordtokensasinputtotheneuralnetwork,ratherthanpassinginonetokenatatime.Neurallatticelanguagemodelsimproveaccuracybyhelpingthegradientflowoversmallerpaths,pre-ventingvanishinggradients.Manyhierarchicalneu-rallanguagemodelshavebeenproposedwithasim-ilarobjective(Koutniketal.,2014;Zhouetal.,2017).Ourworkisdistinguishedfromthesebytheuseoflatenttoken-levelsegmentationsthatcap-turemeaningdirectly,ratherthansimplybeinghigh-levelmechanismstoencouragegradientflow.Chanetal.(2017)proposeamodelforpredict-ingcharactersatmultiplegranularitiesinthede-codersegmentofamachinetranslationsystem.Ourworkexpandsontheirsbyconsideringtheentirelat-ticeatonce,ratherthanconsideringaonlyasin-glepaththroughthelatticeviaancestralsampling.Thisallowsustotrainend-to-endwithoutthemodelcollapsingtoalocalminimum,withnoexplorationbonusneeded.Additionally,weproposeamorebroadclassofmodels,includingthoseincorporat-ingpolysemouswords,andapplyourmodeltothetaskofword-levellanguagemodeling,ratherthancharacter-leveltranscription.Concurrentlytothiswork,vanMerri¨enboeretal.(2017)haveproposedaneurallanguagemodelthatcansimilarlyhandlemultiplescales.Ourworkisdifferentiatedinthatitismoregeneral:utilizinganopenmulti-tokenvocabulary,proposingmultipletechniquesforhiddenstatecalculation,andhandlingpolysemyusingmulti-embeddinglattices.7FutureWorkInthefuture,wewouldliketoexperimentwithuti-lizingneurallatticelanguagemodelsinextrinsicevaluation,suchasmachinetranslationandspeechrecognition.Additionally,inthecurrentmodel,thenon-compositionalembeddingsmustbeselectedapriori,andmaybesuboptimal.Weareexploringtechniquestostorefixedembeddingsdynamically,sothatthenon-compositionalphrasescanbese-lectedaspartoftheend-to-endtraining.8ConclusionInthiswork,wehaveintroducedtheideaofaneurallatticelanguagemodel,whichallowsustomarginal-izeoverallsegmentationsofasentenceinanend-to-endfashion.InourexperimentsontheBillionWordCorpusandChineseGigaWordcorpus,wedemonstratedthattheneurallatticelanguagemodelbeatsanLSTM-basedbaselineatthetaskoflan-guagemodeling,bothwhenitisusedtoincorpo-ratemultiple-wordphrasesandmultiple-embeddingwords.Qualitatively,weobservedthatthelatentsegmentationsgeneratedbythemodelcorrespondwelltohumanintuitionaboutmulti-wordphrases,andthatthevaryingusageofwordswithmultipleembeddingsseemstoalsobesensible.AcknowledgementsTheauthorswouldliketothankHolgerSchwenk,KristinaToutanova,CindyRobinson,andallthere-viewersofthisworkfortheirinvaluablefeedback.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
0
3
6
1
5
6
7
6
2
8
/
/
T
l
A
C
_
A
_
0
0
0
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
539
ReferencesOliverAdams,AdamMakarucha,GrahamNeubig,StevenBird,andTrevorCohn.2017.Cross-lingualwordembeddingsforlow-resourcelanguagemodel-ing.InProceedingsofthe15thConferenceoftheEu-ropeanChapteroftheAssociationforComputationalLinguistics:Volume1,LongPapers,volume1,pages937–947.BenAthiwaratkunandAndrewWilson.2017.Multi-modalworddistributions.InProceedingsofthe55thAnnualMeetingoftheAssociationforComputationalLinguistics(Volume1:LongPapers),volume1,pages1645–1656.DzmitryBahdanau,JanChorowski,DmitriySerdyuk,PhilemonBrakel,andYoshuaBengio.2016.End-to-endattention-basedlarge-vocabularyspeechrecog-nition.InIEEEInternationalConferenceonAcous-tics,SpeechandSignalProcessing,pages4945–4949.IEEE.ColinBannardandDanielleMatthews.2008.Storedwordsequencesinlanguagelearning:Theeffectoffamiliarityonchildren’srepetitionoffour-wordcom-binations.PsychologicalScience,19(3):241–248.WilliamChan,YuZhang,QuocLe,andNavdeepJaitly.2017.Latentsequencedecompositions.5thInterna-tionalConferenceonLearningRepresentations.CiprianChelba,TomasMikolov,MikeSchuster,QiGe,ThorstenBrants,PhillippKoehn,andTonyRobinson.2014.Onebillionwordbenchmarkformeasuringprogressinstatisticallanguagemodeling.Interspeech.XinchiChen,XipengQiu,JingxiangJiang,andXuanjingHuang.2015.Gaussianmixtureembeddingsformul-tiplewordprototypes.CoRR,abs/1511.06246.SumitChopra,MichaelAuli,AlexanderMRush,andSEASHarvard.2016.Abstractivesentencesum-marizationwithattentiverecurrentneuralnetworks.NorthAmericanChapteroftheAssociationforCom-putationalLinguistics:HumanLanguageTechnolo-gies,pages93–98.PierreDupontandRonaldRosenfeld.1997.Latticebasedlanguagemodels.Technicalreport,DTICDoc-ument.ChrisDyer,AdhigunaKuncoro,MiguelBallesteros,andNoahASmith.2016.Recurrentneuralnetworkgram-mars.NorthAmericanChapteroftheAssociationforComputationalLinguistics:HumanLanguageTech-nologies,pages199–209.JeffreyL.Elman.1990.Findingstructureintime.Cog-nitivescience,14(2):179–211.YarinGalandZoubinGhahramani.2016.Atheoreti-callygroundedapplicationofdropoutinrecurrentneu-ralnetworks.InAdvancesinNeuralInformationPro-cessingSystems,pages1019–1027.SharonGoldwater,ThomasL.Griffiths,MarkJohnson,etal.2007.Distributionalcuestowordboundaries:Contextisimportant.InH.Caunt-Nulton,S.Kilati-late,andI.Woo,editors,BUCLD31:Proceedingsofthe31stAnnualBostonUniversityConferenceonLan-guageDevelopment,pages239–250.Somerville,Mas-sachusetts:CascadillaPress.AlexGraves,Abdel-rahmanMohamed,andGeoffreyHinton.2013.Speechrecognitionwithdeeprecurrentneuralnetworks.InIEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing,pages6645–6649.IEEE.KlausGreff,RupeshK.Srivastava,JanKoutn´ık,BasR.Steunebrink,andJ¨urgenSchmidhuber.2016.LSTM:Asearchspaceodyssey.IEEETransactionsonNeuralNetworksandLearningSystems.SeppHochreiterandJ¨urgenSchmidhuber.1997.Longshort-termmemory.NeuralComputation,9(8):1735–1780.KyuyeonHwangandWonyongSung.2017.Character-levellanguagemodelingwithhierarchicalrecurrentneuralnetworks.InIEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing,pages5720–5724.IEEE.HakanInan,KhashayarKhosravi,andRichardSocher.2017.Tyingwordvectorsandwordclassifiers:Alossframeworkforlanguagemodeling.5thInternationalConferenceonLearningRepresentations.EricJang,ShixiangGu,andBenPoole.2017.Categori-calreparameterizationwithGumbel-Softmax.5thIn-ternationalConferenceonLearningRepresentations.RafalJozefowicz,OriolVinyals,MikeSchuster,NoamShazeer,andYonghuiWu.2016.Exploringthelimitsoflanguagemodeling.arXiv:1602.02410.PhilippKoehnandRebeccaKnowles.2017.Sixchal-lengesforneuralmachinetranslation.InProceedingsoftheFirstWorkshoponNeuralMachineTranslation,pages28–39.JanKoutnik,KlausGreff,FaustinoGomez,andJuergenSchmidhuber.2014.AclockworkRNN.ProceedingsofMachineLearningResearch.WangLing,IsabelTrancoso,ChrisDyer,andAlanW.Black.2015.Character-basedneuralmachinetransla-tion.CoRR,abs/1511.04586.WangLing,EdwardGrefenstette,KarlMoritzHermann,Tom´aˇsKoˇcisk`y,AndrewSenior,FuminWang,andPhilBlunsom.2016.Latentpredictornetworksforcodegeneration.AssociationforComputationalLin-guistics.ChrisJMaddison,AndriyMnih,andYeeWhyeTeh.2017.Theconcretedistribution:Acontinuousrelax-ationofdiscreterandomvariables.5thInternationalConferenceonLearningRepresentations.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
0
3
6
1
5
6
7
6
2
8
/
/
T
l
A
C
_
A
_
0
0
0
3
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
540
StephenMerity,CaimingXiong,JamesBradbury,andRichardSocher.2016.Pointersentinelmixturemod-els.4thInternationalConferenceonLearningRepre-sentations.ArvindNeelakantan,JeevanShankar,RePassos,andAn-drewMccallum.2014.Efficientnonparametrices-timationofmultipleembeddingsperwordinvectorspace.InProceedingsofEMNLP.Citeseer.GrahamNeubig,MasatoMimura,ShinsukeMori,andTatsuyaKawahara.2010.Learningalanguagemodelfromcontinuousspeech.InINTERSPEECH,pages1053–1056.GrahamNeubig,ChrisDyer,YoavGoldberg,AustinMatthews,WaleedAmmar,AntoniosAnastasopoulos,MiguelBallesteros,DavidChiang,DanielClothiaux,TrevorCohn,etal.2017.DyNet:Thedynamicneuralnetworktoolkit.arXivpreprintarXiv:1701.03980.OfirPressandLiorWolf.2017.Usingtheoutputembed-dingtoimprovelanguagemodels.5thInternationalConferenceonLearningRepresentations.YaelRavinandClaudiaLeacock.2000.Polysemy:The-oreticalandComputationalApproaches.OUPOx-ford.RicoSennrich,BarryHaddow,andAlexandraBirch.2015.Neuralmachinetranslationofrarewordswithsubwordunits.AssociationforComputationalLin-guistics.AnnaSiyanova-Chanturia,KathyConklin,andNorbertSchmitt.2011.Addingmorefueltothefire:Aneye-trackingstudyofidiomprocessingbynativeandnon-nativespeakers.SecondLanguageResearch,27(2):251–272.MatthiasSperber,GrahamNeubig,JanNiehues,andAlexWaibel.2017.Neurallattice-to-sequencemod-elsforuncertaininputs.InProceedingsofthe2017ConferenceonEmpiricalMethodsinNaturalLan-guageProcessing,pages1380–1389.JinsongSu,ZhixingTan,DeyiXiong,andYangLiu.2016.Lattice-basedrecurrentneuralnet-workencodersforneuralmachinetranslation.CoRR,abs/1609.07730,ver.2.KaiShengTai,RichardSocher,andChristopherD.Man-ning.2015.Improvedsemanticrepresentationsfromtree-structuredlongshort-termmemorynetworks.As-sociationforComputationalLinguistics.Luk´aˇsBurgetJanHonzaCernockSanjeevKhudanpurTom´aˇsMikolov,MartinKarafi´at.2010.Recur-rentneuralnetworkbasedlanguagemodel.Pro-ceedingsofthe11thAnnualConferenceoftheInter-nationalSpeechCommunicationAssociation,pages1045–1048.BartvanMerri¨enboer,AmartyaSanyal,HugoLarochelle,andYoshuaBengio.2017.Multiscalesequencemodelingwithalearneddictionary.arXivpreprintarXiv:1707.00762.LadislavZgusta.1967.Multiwordlexicalunits.Word,23(1-3):578–587.HaoZhou,ZhaopengTu,ShujianHuang,XiaohuaLiu,HangLi,andJiajunChen.2017.Chunk-basedbi-scaledecoderforneuralmachinetranslation.Associa-tionforComputationalLinguistics.ALarge-ScaleExperimentsToverifythatourfindingsscaletostate-of-the-artlanguagemodels,wealsocomparedabaselinemodel,denselatticesofsize1and2,andamulti-latticewith2embeddingsperwordonthefullbyte-pairencodedBillionWordCorpus.Inthissetofexperiments,wetakethefullBil-lionWordCorpus,andapplybyte-pairencodingasdescribedbySennrichetal.(2015)toconstructavocabularyof10,000sub-wordtokens.OurmodelconsistsofthreeLSTMlayers,eachwith1500hid-denunits.Wetrainthemodelforasingleepochoverthecorpus,usingtheAdamoptimizerwithlearningrate.0001onaP100GPU.Weuseabatchsizeof40,andvariationaldropoutof0.1.The10,000sub-wordembeddingseachhaddimension600.Forlatticemodels,chunkvocabularieswereselectedbytakingthe10,000sub-wordsinthevocabularyandaddingthemostcommon10,000n-gramswith1