Transaktionen des Assoziation für Computer -Linguistik, 2 (2014) 435–448. Action Editor: Sharon Goldwater.
Submitted 8/2014; Überarbeitet 10/2014; Veröffentlicht 10/2014. C
(cid:13)
2014 Verein für Computerlinguistik.
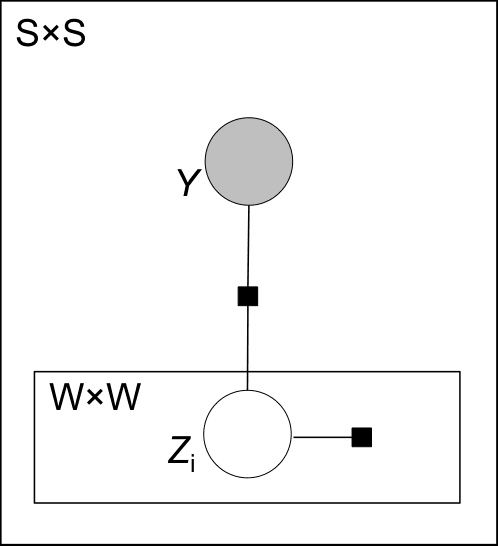
ExtractingLexicallyDivergentParaphrasesfromTwitterWeiXu1,AlanRitter2,ChrisCallison-Burch1,WilliamB.Dolan3andYangfengJi41UniversityofPennsylvania,Philadelphia,Pa,USA{xwe,ccb}@cis.upenn.edu2TheOhioStateUniversity,Columbus,OH,USAritter.1492@osu.edu3MicrosoftResearch,Redmond,WA,USAbilldol@microsoft.com4GeorgiaInstituteofTechnology,Atlanta,GA,USAjiyfeng@gatech.eduAbstractWepresentMULTIP(Multi-instanceLearn-ingParaphraseModel),anewmodelsuitedtoidentifyparaphraseswithintheshortmes-sagesonTwitter.Wejointlymodelpara-phraserelationsbetweenwordandsentencepairsandassumeonlysentence-levelannota-tionsduringlearning.Usingthisprincipledla-tentvariablemodelalone,weachievetheper-formancecompetitivewithastate-of-the-artmethodwhichcombinesalatentspacemodelwithafeature-basedsupervisedclassifier.Ourmodelalsocaptureslexicallydivergentpara-phrasesthatdifferfromyetcomplementprevi-ousmethods;combiningourmodelwithpre-viousworksignificantlyoutperformsthestate-of-the-art.Inaddition,wepresentanovelan-notationmethodologythathasallowedustocrowdsourceaparaphrasecorpusfromTwit-ter.Wemakethisnewdatasetavailabletotheresearchcommunity.1IntroductionParaphrasesarealternativelinguisticexpressionsofthesameorsimilarmeaning(BhagatandHovy,2013).Twitterengagesmillionsofusers,whonat-urallytalkaboutthesametopicssimultaneouslyandfrequentlyconveysimilarmeaningusingdiverselinguisticexpressions.Theuniquecharacteristicsofthisuser-generatedtextpresentsnewchallengesandopportunitiesforparaphraseresearch(Xuetal.,2013b;Wangetal.,2013).Formanyapplications,likeautomaticsummarization,firststorydetection(Petrovi´cetal.,2012)andsearch(Zanzottoetal.,2011),itiscrucialtoresolveredundancyintweets(e.g.oscarnom’ddoc↔Oscar-nominateddocu-mentary).Inthispaper,weinvestigatethetaskofdetermin-ingwhethertwotweetsareparaphrases.Previousworkhasexploitedapairofsharednamedentitiestolocatesemanticallyequivalentpatternsfromre-latednewsarticles(Shinyamaetal.,2002;Sekine,2005;ZhangandWeld,2013).ButshortsentencesinTwitterdonotoftenmentiontwonamedentities(Ritteretal.,2012)andrequirenontrivialgeneral-izationfromnamedentitiestootherwords.Forex-ample,considerthefollowingtwosentencesaboutbasketballplayerBrookLopezfromTwitter:◦ThatboyBrookLopezwithadeep3◦brooklopezhita3andimisseditAlthoughthesesentencesdonothavemanywordsincommon,theidenticalword“3”isastrongindicatorthatthetwosentencesareparaphrases.Wethereforeproposeanoveljointword-sentenceapproach,incorporatingamulti-instancelearningassumption(Dietterichetal.,1997)thattwosen-tencesunderthesametopic(wehighlighttopicsinbold)areparaphrasesiftheycontainatleastonewordpair(wecallitananchorandhighlightwithunderscores;thewordsintheanchorpairneednotbeidentical)thatisindicativeofsententialpara-phrase.Thisat-least-one-anchorassumptionmightbeineffectiveforlongorrandomlypairedsentences,butholdsupbetterforshortsentencesthataretem-porallyandtopicallyrelatedonTwitter.Moreover,ourmodeldesign(seeFigure1)allowsexploitationofarbitraryfeaturesandlinguisticresources,suchaspart-of-speechfeaturesandanormalizationlex-
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
436
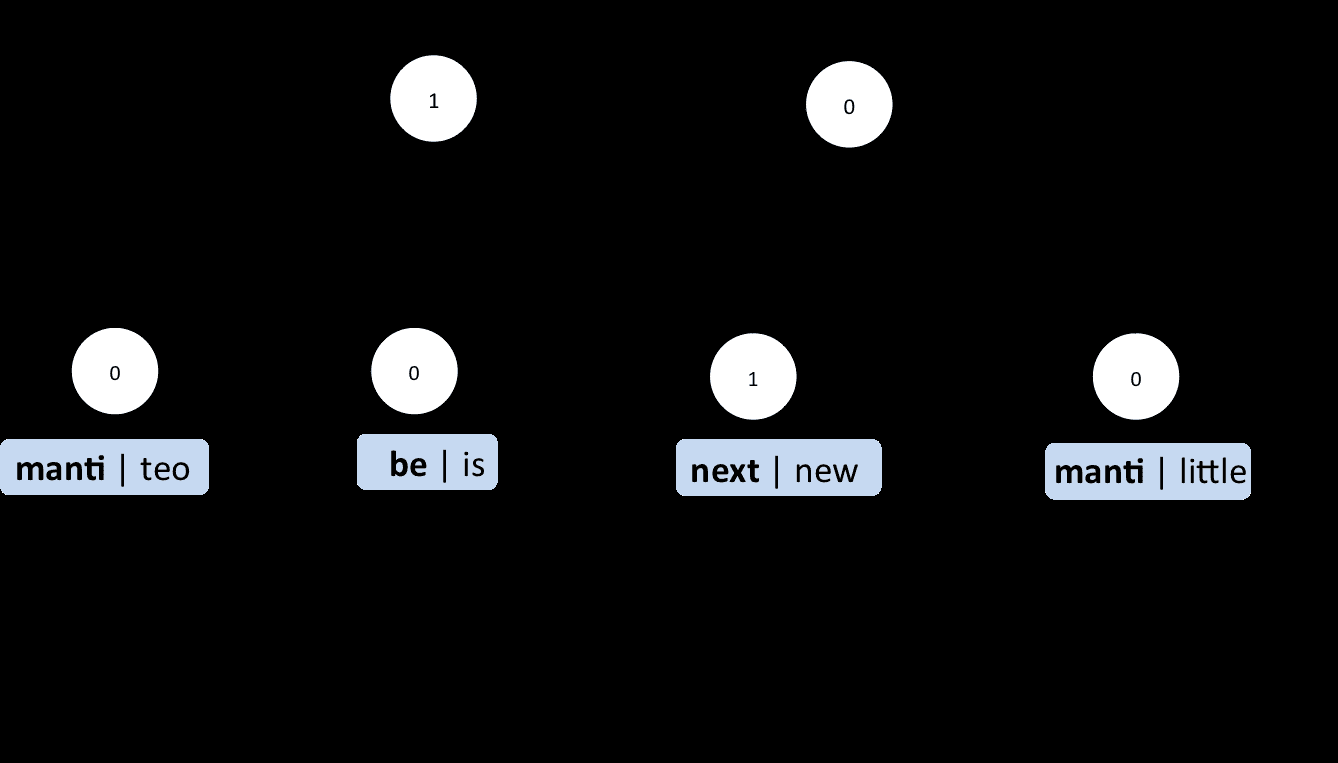
(A)(B)Figure1:(A)aplaterepresentationoftheMULTIPmodel(B)anexampleinstantiationofMULTIPforthepairofsentences“MantibouttobethenextJuniorSeau”and“TeoisthelittlenewJuniorSeau”,inwhichanewAmericanfootballplayerMantiTe’owasbeingcomparedtoafamousformerplayerJuniorSeau.Only4outofthetotal6×5wordpairs,z1-z30,areshownhere.icon,todiscriminativelydeterminewordpairsasparaphrasticanchorsornot.Ourgraphicalmodelisamajordeparturefrompopularsurface-orlatent-similaritymethods(Wanetal.,2006;GuoandDiab,2012;JiandEisenstein,2013,andothers).Ourapproachtoextractpara-phrasesfromTwitterisgeneralandcanbecom-binedwithvarioustopicdetectingsolutions.Asademonstration,weuseTwitter’sowntrendingtopicservice1tocollectdataandconductexperiments.Whilehavingaprincipledandextensibledesign,ourmodelaloneachievesperformanceonparwithastate-of-the-artensembleapproachthatinvolvesbothlatentsemanticmodelingandsupervisedclassi-fication.Theproposedmodelalsocapturesradicallydifferentparaphrasesfrompreviousapproaches;acombinedsystemshowssignificantimprovementoverthestate-of-the-art.Thispapermakesthefollowingcontributions:1)Wepresentanovellatentvariablemodelforparaphraseidentification,thatspecificallyac-commodatestheveryshortcontextanddi-vergentwordinginTwitterdata.Weexper-imentallycompareseveralrepresentativeap-proachesandshowthatourproposedmethod1MoreinformationaboutTwitter’strends:https://support.twitter.com/articles/101125-faqs-about-twitter-s-trendsyieldsstate-of-the-artresultsandidentifiesparaphrasesthatarecomplementarytoprevi-ousmethods.2)WedevelopanefficientcrowdsourcingmethodandconstructaTwitterParaphraseCorpusofabout18,000sentencepairs,asafirstcommontestbedforthedevelopmentandcomparisonofparaphraseidentificationandsemanticsimilar-itysystems.Wemakethisdatasetavailabletotheresearchcommunity.22JointWord-SentenceParaphraseModelWepresentanewlatentvariablemodelthatjointlycapturesparaphraserelationsbetweensentencepairsandwordpairs.Itisverydifferentfrompreviousap-proachesinthatitsprimarydesigngoalandmotiva-tionistargetedtowardsshort,lexicallydiversetextonthesocialweb.2.1At-least-one-anchorAssumptionMuchpreviousworkonparaphraseidentificationhasbeendevelopedandevaluatedonaspecificbenchmarkdataset,theMicrosoftResearchPara-phraseCorpus(Dolanetal.,2004),whichisde-2Thedatasetandcodearemadeavailableat:SemEval-2015sharedtaskhttp://alt.qcri.org/semeval2015/task1/andhttps://github.com/cocoxu/twitterparaphrase/
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
437
CorpusExamplesNews◦Revenueinthefirstquarteroftheyeardropped15percentfromthesameperiodayearearlier.◦WiththescandalhangingoverStewart’scompany,revenueinthefirstquarteroftheyeardropped15percentfromthesameperiodayearearlier.(DolanandBrockett,2005)◦TheSenateSelectCommitteeonIntelligenceispreparingablisteringreportonprewarintelligenceonIraq.◦AmericanintelligenceleadinguptothewaronIraqwillbecriticizedbyapow-erfulUSCongressionalcommitteeduetoreportsoon,officialssaidtoday.◦CanKlayThompsonwakeup◦CmonKlayneedutogetitgoingTwitter(ThisWork)◦EzekielAnsahwearing3Dglasseswoutthelens◦WaitEzekielansahiswearing3dmovieglasseswiththelensesknockedout◦MarriageequalitylawpassedinRhodeIsland◦CongratstoRhodeIslandbecomingthe10thstatetoenactmarriageequalityTable1:Representativeexamplesfromparaphrasecorpora.Theaveragesentencelengthis11.9wordsinTwittervs.18.6inthenewscorpus.rivedfromnewsarticles.Twitterdataisverydif-ferent,asshowninTable1.Weobservethatamongtweetspostedaroundthesametimeaboutthesametopic(e.g.anamedentity),sententialparaphrasesareshortandcanoftenbe“anchored”bylexicalparaphrases.Thisintuitionleadstotheat-least-one-anchorassumptionwestatedintheintroduction.Theanchorcouldbeawordthetwosentencesshareincommon.Italsocouldbeapairofdifferentwords.Forexample,thewordpair“nextknew”intwotweetsaboutanewplayerMantiTe’otoafa-mousformerAmericanfootballplayerJuniorSeau:◦MantibouttobethenextJuniorSeau◦TeoisthelittlenewJuniorSeauFurthernotethatnoteverywordpairofsimilarmeaningindicatessentence-levelparaphrase.Forexample,theword“3”,sharedbytwosentencesaboutmovie“IronMan”thatreferstothe3rdse-quelofthemovie,isnotaparaphrasticanchor:◦IronMan3wasbrilliantfun◦IronMan3tonightseewhatthisislikeTherefore,weuseadiscriminativemodelattheword-leveltoincorporatevariousfeatures,suchaspart-of-speechfeatures,todeterminehowprobableawordpairisaparaphraseanchor.2.2Multi-instanceLearningParaphraseModel(MULTIP)Theat-least-one-anchorassumptionnaturallyleadstoamulti-instancelearningproblem(Dietterichetal.,1997),wherethelearneronlyobserveslabelsonbagsofinstances(i.e.sentence-levelparaphrasesinthiscase)insteadoflabelsoneachindividualin-stance(i.e.wordpair).Weformallydefineanundirectedgraphicalmodelofmulti-instancelearningforparaphraseidentifica-tion–MULTIP.Figure1showstheproposedmodelinplateformandgivesanexampleinstantiation.Themodelhastwolayers,whichallowsjointrea-soningbetweensentence-levelandword-levelcom-ponents.Foreachpairofsentencessi=(si1,si2),thereisanaggregatebinaryvariableyithatrepresentswhethertheyareparaphrases,andwhichisobservedinthelabeledtrainingdata.LetW(sik)bethesetofwordsinthesentencesik,excludingthetopicnames.Foreachwordpairwj=(wj1,wj2)∈W(si1)×W(si2),thereexistsalatentvariablezjwhichdenoteswhetherthewordpairisaparaphraseanchor.Intotaltherearem=|W(si1)|×|W(si2)|wordpairs,andthuszi=z1,z2,…,zj,…,zm.Ourat-least-one-anchorassumptionisrealizedbyadeterministic-orfunction;thatis,ifthereexistsatleastonejsuchthatzj=1,thenthesentencepair
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
438
isaparaphrase.Ourconditionalparaphraseidentificationmodelisdefinedasfollows:P(zi,yi|wi;θ)=mYj=1φ(zj,wj;θ)×σ(zi,yi)=mYj=1exp(θ·f(zj,wj))×σ(zi,yi)(1)wheref(zj,wj)isavectoroffeaturesextractedforthewordpairwj,θistheparametervector,andσisthefactorthatcorrespondstothedeterministic-orconstraint:σ(zi,yi)=1ifyi=true∧∃j:zj=11ifyi=false∧∀j:zj=00otherwise(2)2.3LearningTolearntheparametersoftheword-levelparaphraseanchorclassifier,θ,wemaximizelikelihoodoverthesentence-levelannotationsinourparaphrasecorpus:θ∗=argmaxθP(j|w;θ)=argmaxθYiXziP(zi,yi|wi;θ)(3)Aniterativegradient-ascentapproachisusedtoestimateθusingperceptron-styleadditiveupdates(Collins,2002;Liangetal.,2006;ZettlemoyerandCollins,2007;Hoffmannetal.,2011).WedefineanupdatebasedonthegradientoftheconditionalloglikelihoodusingViterbiapproximation,asfollows:∂logP(j|w;θ)∂θ=EP(z|w,j;θ)(Xif(zi,wi))−EP(z,j|w;θ)(Xif(zi,wi))≈Xif(z∗i,wi)−Xif(z0i,wi)(4)wherewedefinethefeaturesumforeachsentencef(zi,wi)=Pjf(zj,wj)overallwordpairs.Thesetwoaboveexpectationsareapproximatedbysolvingtwosimpleinferenceproblemsasmaxi-mizations:z∗=argmaxzP(z|w,j;θ)y0,z0=argmaxy,zP(z,j|w;θ)(5)Input:atrainingset{(si,yi)|i=1…N},whereiisanindexcorrespondingtoaparticularsentencepairsi,andyiisthetraininglabel.1:initializeparametervectorθ←02:fori←1tondo3:extractallpossiblewordpairswi=w1,w2,…,wmandtheirfeaturesfromthesentencepairsi4:endfor5:forl←1tomaximumiterationsdo6:fori←1tondo7:(y0i,z0i)←argmaxyi,ziP(zi,yi|wi;θ)8:ify0i6=yithen9:z∗i←argmaxziP(zi|wi,yi;θ)10:θ←θ+f(z∗i,wi)−f(z0i,wi)11:endif12:endfor13:endfor14:returnmodelparametersθFigure2:MULTIPLearningAlgorithmComputingbothz0andz∗areratherstraightfor-wardunderthestructureofourmodelandcanbesolvedintimelinearinthenumberofwordpairs.Thedependenciesbetweenzandyaredefinedasdeterministic-orfactorsσ(zi,yi),whichwhensat-isfieddonotaffecttheoverallprobabilityofthesolution.Eachsentencepairisindependentcon-ditionedontheparameters.Forz0,itissufficienttoindependentlycomputethemostlikelyassign-mentz0iforeachwordpair,ignoringthedetermin-isticdependencies.y0iisthensetbyaggregatingallz0ithroughthedeterministic-oroperation.Sim-ilarly,wecanfindtheexactsolutionforz∗,themostlikelyassignmentthatrespectsthesentence-leveltraininglabely.Forapositivetrainingin-stance,wesimplyfinditshighestscoredwordpairwτbytheword-levelclassifier,thensetz∗τ=1andz∗j=argmaxx∈0,1φ(X,wj;θ)forallj6=τ;foranegativeexample,wesetz∗i=0.Thetimecom-plexityofbothinferencesforonesentencepairisO(|W(S)|2),Wo|W(S)|2isthenumberofwordpairs.Inpractice,weuseonlinelearninginsteadofopti-mizingthefullobjective.Thedetailedlearningalgo-rithmispresentedinFigure2.FollowingHoffmannetal.(2011),weuse50iterationsintheexperiments.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
439
2.4FeatureDesignAttheword-level,ourdiscriminativemodelallowsuseofarbitraryfeaturesthataresimilartothoseinmonolingualwordalignmentmodels(MacCartneyetal.,2008;ThadaniandMcKeown,2011;Yaoetal.,2013a,B).Butunlikediscriminativemono-lingualwordalignment,weonlyusesentence-leveltraininglabelsinsteadofword-levelalignmentannotation.Foreverywordpair,weextractthefollowingfeatures:StringFeaturesthatindicatewhetherthetwowords,theirstemmedformsandtheirnormalizedformsarethesame,similarordissimilar.WeusedtheMorphastemmer(Minnenetal.,2001),3Jaro-Winklerstringsimilarity(Winkler,1999)andtheTwitternormalizationlexiconbyHanetal.(2012).POSFeaturesthatarebasedonthepart-of-speechtagsofthetwowordsinthepair,specifyingwhetherthetwowordshavesameordifferentPOStagsandwhatthespecifictagsare.WeusetheTwitterPart-Of-SpeechtaggerdevelopedbyDerczynskietal.(2013).Weaddnewfine-grainedtagsforvariationsoftheeightwords:“a”,“be”,“do”,“have”,“get”,“go”,“follow”and“please”.Forexample,weuseatagHAforwords“have”,“has”and“had”.TopicalFeaturesthatrelatetothestrengthofaword’sassociationtothetopic.Thisfeatureidentifiesthepopularwordsineachtopic,e.g.“3”intweetsaboutbasketballgame,“RIP”intweetsaboutacelebrity’sdeath.WeuseG2log-likelihood-ratiostatistic,whichhasbeenfrequentlyusedinNLP,asameasureofwordassociations(Dunning,1993;Moore,2004).Thesignificantscoresarecomputedforeachtrendonanaverageofabout1500sentencesandconvertedtobinaryfeaturesforeverywordpair,indicatingwhetherthetwowordsarebothsignificantornot.Ourtopicalfeaturesarenovelandwerenotusedinpreviouswork.FollowingRiedeletal.(2010)andHoffmannetal.(2011),wealsoincor-porateconjunctionfeaturesintooursystemforbet-teraccuracy,namelyWord+POS,Word+TopicalandWord+POS+Topicalfeatures.3https://github.com/knowitall/morpha3Experiments3.1DataItisnontrivialtogatheragold-standarddatasetofnaturallyoccurringparaphrasesandnon-paraphrasesefficientlyfromTwitter,sincethisrequirespairwisecomparisonoftweetsandfacesaverylargesearchspace.Tomakethisannotationtasktractable,wedesignanovelandefficientcrowdsourcingmethodusingAmazonMechanicalTurk.Ourentiredatacollectionprocessisde-tailedinSection§4,withseveralexperimentsthatdemonstrateannotationqualityandefficiency.Intotal,weconstructedaTwitterParaphraseCor-pusof18,762sentencepairsand19,946uniquesen-tences.Thetraininganddevelopmentsetconsistsof17,790sentencepairspostedbetweenApril24thandMay3rd,2014from500+trendingtopics(ex-cludinghashtags).OurparaphrasemodelanddatacollectionapproachisgeneralandcanbecombinedwithvariousTwittertopicdetectingsolutions(Diaoetal.,2012;Ritteretal.,2012).Asademonstra-tion,weuseTwitter’sowntrendsservicesinceitiseasilyavailable.Twittertrendingtopicsarede-terminedbyanunpublishedalgorithm,whichfindswords,phrasesandhashtagsthathavehadasharpincreaseinpopularity,asopposedtooverallvol-ume.Weusecase-insensitiveexactmatchingtolo-catetopicnamesinthesentences.Eachsentencepairwasannotatedby5differentcrowdsourcingworkers.Forthetestset,weob-tainedbothcrowdsourcedandexpertlabelson972sentencepairsfrom20randomlysampledTwittertrendingtopicsbetweenMay13thandJune10th.Ourdatasetismorerealisticandbalanced,contain-ing79%non-paraphrasesvs.34%inthebenchmarkMicrosoftParaphraseCorpusofnewsdata.Asnotedin(DasandSmith,2009),thelackofnaturalnon-paraphrasesintheMSRcorpuscreatesbiastowardscertainmodels.3.2BaselinesWeusefourbaselinestocomparewithourproposedapproachforthesententialparaphraseidentificationtask.Forthefirstbaseline,wechooseasuper-visedlogisticregression(LR)baselineusedbyDasandSmith(2009).Itusessimplen-gram(alsoinstemmedform)overlappingfeaturesbutshowsvery
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
440
MethodF1PrecisionRecallRandom0.2940.2080.500WTMF(GuoandDiab,2012)*0.5830.5250.655LR(DasandSmith,2009)**0.6300.6290.632LEXLATENT0.6410.6630.621LEXDISCRIM(JiandEisenstein,2013)0.6450.6640.628MULTIP0.7240.7220.726HumanUpperbound0.8230.7520.908Table2:PerformanceofdifferentparaphraseidentificationapproachesonTwitterdata.*Anenhancedversionthatusesadditional1.6millionsentencesfromTwitter.**ReimplementationofastrongbaselineusedbyDasandSmith(2009).competitiveperformanceontheMSRcorpus.Thesecondbaselineisastate-of-the-artunsu-pervisedmethod,WeightedTextualMatrixFactor-ization(WTMF),4whichisspeciallydevelopedforshortsentencesbymodelingthesemanticspaceofbothwordsthatarepresentinandabsentfromthesentences(GuoandDiab,2012).Theorigi-nalmodelwaslearnedfromWordNet(Fellbaum,2010),OntoNotes(Hovyetal.,2006),Wiktionary,theBrowncorpus(FrancisandKucera,1979).Weenhancethemodelwith1.6millionsentencesfromTwitterassuggestedbyGuoetal.(2013).JiandEisenstein(2013)presentedastate-of-the-artensemblesystem,whichwecallLEXDIS-CRIM.5Itdirectlycombinesbothdiscriminatively-tunedlatentfeaturesandsurfacelexicalfeaturesintoaSVMclassifier.Specifically,thelatentrepresenta-tionofapairofsentences~v1and~v2isconvertedintoafeaturevector,[~v1+~v2,|~v1−~v2|],byconcatenatingtheelement-wisesum~v1+~v2andabsolutedifferent|~v1−~v2|.Wealsointroduceanewbaseline,LEXLATENT,whichisasimplifiedversionofLEXDISCRIMandeasytoreproduce.Itusesthesamemethodtocom-binelatentfeaturesandsurfacefeatures,butcom-binestheopen-sourcedWTMFlatentspacemodelandthelogisticregressionmodelfromabovein-stead.ItachievessimilarperformanceasLEXDIS-CRIMonourdataset(Table2).4ThesourcecodeanddataforWTMFisavailableat:http://www.cs.columbia.edu/˜weiwei/code.html5TheparsingfeaturewasremovedbecauseitwasnothelpfulonourTwitterdataset.3.3SystemPerformanceForevaluationofdifferentsystems,wecomputeprecision-recallcurvesandreportthehighestF1measureofanypointonthecurve,onthetestdatasetof972sentencepairsagainsttheexpertlabels.Ta-ble2showstheperformanceofdifferentsystems.OurproposedMULTIP,aprincipledlatentvariablemodelalone,achievescompetitiveresultswiththestate-of-the-artsystemthatcombinesdiscriminativetrainingandlatentsemantics.InTable2,wealsoshowtheagreementlevelsoflabelsderivedfrom5non-expertannotationsonMe-chanicalTurk,whichcanbeconsideredasanup-perboundforautomaticparaphraserecognitiontaskperformedonthisdataset.Theannotationqualityofourcorpusissurprisinglygoodgiventhefactthatthedefinitionofparaphraseisratherinexact(BhagatandHovy,2013);theinter-rateragreementbetweenexpertannotatorsonnewsdataisonly0.83asre-portedbyDolanetal.(2004).F1PrecRecallMULTIP0.7240.7220.726-Stringfeatures0.5090.4480.589-POSfeatures0.4960.3500.851-Topicalfeatures0.7150.6940.737Table3:Featureablationbyremovingeachindivid-ualfeaturegroupfromthefullset.Toassesstheimpactofdifferentfeaturesonthemodel’sperformance,weconductfeatureablationexperiments,removingonegroupoffeaturesatatime.TheresultsareshowninTable3.Bothstring
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
441
Para?SentencePairfromTwitterMULTIPLEXLATENTYES◦ThenewCirocflavorhasarrivedrank=12rank=266◦CirocgotanewflavorcominoutYES◦RobertoMancinigetsthebootfromManCityrank=64rank=452◦RobertoMancinihasbeensackedbyManchesterCitywiththeBluessayingYES◦Iwanttowatchthepurgetonightrank=136rank=11◦IwanttogoseeThePurgewhowantstocomewithNO◦SomebodytooktheMarlinsto20inningsrank=8rank=54◦Anyonewhostayed20inningsforthemarlinsNO◦WORLDOFJENKSISONAT11rank=167rank=9◦WorldofJenksismyfavoriteshowontvTable4:Examplesystemoutputs;rankisthepositioninthelistofallcandidateparaphrasepairsinthetestsetorderedbymodelscore.MULTIPdiscoverslexicallydivergentparaphraseswhileLEXLATENTprefersmoreoverallsentencesimilarity.Underlinemarksthewordpair(S)withhighestestimatedprobabilityasparaphrasticanchor(S)foreachsentencepair.0.00.20.40.60.81.00.00.20.40.60.81.0RecallPrecisionMULTIPLEXLATENT0.00.20.40.60.81.00.00.20.40.60.81.0RecallPrecisionMULTIP−PELEXLATENTFigure3:Precisionandrecallcurves.OurMULTIPmodelaloneachievescompetitiveperformancewiththeLEXLATENTsystemthatcombineslatentspacemodelandfeature-basedsupervisedclassifier.Thetwoapproacheshavecomplementarystrengths,andachievessignificantimprovementwhencombinedtogether(MULTIP-PE).andPOSfeaturesareessentialforsystemperfor-mance,whiletopicalfeaturesarehelpfulbutnotascrucial.Figure3presentsprecision-recallcurvesandshowsthesensitivityandspecificityofeachmodelincomparison.Inthefirsthalfofthecurve(abrufen<0.5),MULTIPmodelmakesbolderandlessac-curatedecisionsthanLEXLATENT.However,thecurveforMULTIPmodelismoreflatandshowscon-sistentlybetterprecisionatthesecondhalf(recall>0.5)aswellasahighermaximumF1score.Thisre-sultreflectsourdesignconceptofMULTIP,whichisintendedtopickupsententialparaphraseswithmoredivergentwordingsaggressively.LEXLATENT,asacombinedsystem,considerssentencefeaturesinbothsurfaceandlatentspaceandismoreconserva-tive.Table4furtherillustratesthisdifferencewithsomeexamplesystemoutputs.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
442
3.4ProductofExperts(MULTIP-PE)OurMULTIPmodelandprevioussimilarity-basedapproacheshavecomplementarystrengths,soweexperimentwithcombiningMULTIP(Pm)andLEXLATENT(Pl)throughaproductofexperts(Hinton,2002):P(j|s1,s2)=Pm(j|s1,s2)×Pl(j|s1,s2)PyPm(j|s1,s2)×Pl(j|s1,s2)(6)TheresultingsystemMULTIP-PEprovidescon-sistentlybetterprecisionandrecallovertheLEXLATENTmodel,asshownontherightinFigure3.TheMULTIP-PEsystemoutperformsLEXLATENTsignificantlyaccordingtoapairedt-testwithρlessthan0.05.OurproposedMUL-TIPtakesadvantageofTwitter’sspecificpropertiesandprovidescomplementaryinformationtoprevi-ousapproaches.Previously,DasandSmith(2009)hasalsousedaproductofexpertstocombinealex-icalandasyntax-basedmodeltogether.4ConstructingTwitterParaphraseCorpusWenowturntodescribingourdatacollectionandannotationmethodology.Ourgoalistoconstructahighqualitydatasetthatcontainsrepresentativeex-amplesofparaphrasesandnon-paraphrasesinTwit-ter.SinceTwitterusersarefreetotalkaboutany-thingregardinganytopic,arandompairofsen-tencesaboutthesametopichasalowchance(lessthan8%)ofexpressingthesamemeaning.Thiscausestwoproblems:A)itisexpensivetoobtainparaphrasesviamanualannotation;B)non-expertannotatorstendtoloosenthecriteriaandaremorelikelytomakefalsepositiveerrors.Toaddressthesechallenges,wedesignasimpleannotationtaskandintroducetwoselectionmechanismstoselectsentenceswhicharemorelikelytobeparaphrases,whilepreservingdiversityandrepresentativeness.4.1RawDatafromTwitterWecrawlTwitter’strendingtopicsandtheirassoci-atedtweetsusingpublicAPIs.6AccordingtoTwit-ter,trendsaredeterminedbyanalgorithmwhich6MoreinformationaboutTwitter’sAPIs:https://dev.twitter.com/docs/api/1.1/overviewexpert=0 expert=1expert=2expert=3expert=4expert=5turk=0turk=1turk=2turk=3turk=4turk=5Figure4:Aheat-mapshowingoverlapbetweenexpertandcrowdsourcingannotation.Theinten-sityalongthediagonalindicatesgoodreliabilityofcrowdsourcingworkersforthisparticulartask;andtheshiftabovethediagonalreflectsthedifferencebetweenthetwoannotationschemas.Forcrowd-sourcing(turk),thenumbersindicatehowmanyan-notatorsoutof5pickedthesentencepairaspara-phrases;0,1areconsiderednon-paraphrases;3,4,5areparaphrases.Forexpertannotation,all0,1,2arenon-paraphrases;4,5areparaphrases.Medium-scoredcasesarediscardedintrainingandtestinginourexperiments.identifiestopicsthatareimmediatelypopular,ratherthanthosethathavebeenpopularforlongerperiodsoftimeorwhichtrendonadailybasis.Wetokenizeandspliteachtweetintosentences.74.2TaskDesignonMechanicalTurkWeshowtheannotatoranoriginalsentence,thenaskthemtopicksentenceswiththesamemean-ingfrom10candidatesentences.Theoriginalandcandidatesentencesarerandomlysampledfromthesametopic.Foreachsuch1vs.10question,weob-tainbinaryjudgementsfrom5differentannotators,payingeachannotator$0.02perquestion.Onaver-age,eachquestiontakesoneannotatorabout30∼45secondstoanswer.4.3AnnotationQualityWeremoveproblematicannotatorsbycheckingtheirCohen’sKappaagreement(ArtsteinandPoe-7WeusethetoolkitdevelopedbyO’Connoretal.(2010):https://github.com/brendano/tweetmotif
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
443
Reggie MillerAmberRobert WoodsCandiceThe ClippersRyuJeff GreenHarvickMilwaukeeKlayHuckMorningMomma DeeDortmundRonaldoNetflixGWBDwight HowardFacebookU.S.0.00.20.40.60.8filteredrandomPercentage of Positive JudgementsTrending TopicsFigure5:Theproportionofparaphrases(percentageofpositivevotesfromannotators)varygreatlyacrossdifferenttopics.AutomaticfilteringinSection4.4roughlydoublestheparaphraseyield.sio,2008)withotherannotators.Wealsocomputeinter-annotatoragreementwithanexpertannotatoron971sentencepairs.Intheexpertannotation,weadopta5-pointLikertscaletomeasurethedegreeofsemanticsimilaritybetweensentences,whichisdefinedbyAgirreetal.(2012)asfollows:5:Completelyequivalent,astheymeanthesamething;4:Mostlyequivalent,butsomeunimportantdetailsdiffer;3:Roughlyequivalent,butsomeimportantinforma-tiondiffers/missing.2:Notequivalent,butsharesomedetails;1:Notequivalent,butareonthesametopic;0:Ondifferenttopics.Althoughthetwoscalesofexpertandcrowd-sourcingannotationaredefineddifferently,theirPearsoncorrelationcoefficientreaches0.735(two-tailedsignificance0.001).Figure4showsaheat-maprepresentingthedetailedoverlapbetweenthetwoannotations.Itsuggeststhatthegradedsimi-larityannotationtaskcouldbereducedtoabinarychoiceinacrowdsourcingsetup.4.4AutomaticSummarizationInspiredSentenceFilteringWefilterthesentenceswithineachtopictose-lectmoreprobableparaphrasesforannotation.Ourmethodisinspiredbyatypicalprobleminextractivesummarization,thatthesalientsentencesarelikelyredundant(paraphrases)andneedtoberemovedintheoutputsummaries.WeemploythescoringmethodusedinSumBasic(NenkovaandVander-wende,2005;Vanderwendeetal.,2007),asimplebutpowerfulsummarizationsystem,tofindsalientsentences.Foreachtopic,wecomputetheprobabil-ityofeachwordP(wi)bysimplydividingitsfre-quencybythetotalnumberofallwordsinallsen-tences.Eachsentencesisscoredastheaverageoftheprobabilitiesofthewordsinit,i.e.Salience(S)=Xwi∈sP(wi)|{wi|wi∈s}|(7)Wethenrankthesentencesandpicktheoriginalsentencerandomlyfromtop10%salientsentencesandcandidatesentencesfromtop50%topresenttotheannotators.Inatrialexperimentof20topics,thefilteringtechniquedoubletheyieldofparaphrasesfrom152to329outof2000sentencepairsoverna¨ıveran-domsampling(Figure5andFigure6).WealsousePINC(ChenandDolan,2011)tomeasurethequal-ityofparaphrasescollected(Figure7).PINCwasdesignedtomeasuren-gramdissimilaritybetweentwosentences,andinessenceitistheinverseofBLEU.Ingeneral,thecaseswithhighPINCscoresincludemorecomplexandinterestingrephrasings.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
444
543210100200300400randomfilteredMABNumber of Annotators Judging as Paraphrases (out of 5)Number of Sentence Pairs (out of 2000)Figure6:Numbersofparaphrasescollectedbydif-ferentmethods.Theannotationefficiency(3,4,5areregardedasparaphrases)issignificantlyim-provedbythesentencefilteringandMulti-ArmedBandits(MAB)basedtopicselection.5432100.750.800.850.900.951.00randomfilteredMABNumber of Annotators Judging as Paraphrases (out of 5)PINC (lexical dissimilarity)Figure7:PINCscoresofparaphrasescollected.ThehigherthePINC,themoresignificantthere-wording.Ourproposedannotationstrategyquadru-plesparaphraseyield,whilenotgreatlyreducingdiversityasmeasuredbyPINC.4.5TopicSelectionusingMulti-ArmedBandits(MAB)AlgorithmAnotherapproachtoincreasingparaphraseyieldistochoosemoreappropriatetopics.Thisispartic-ularlyimportantbecausethenumberofparaphrasesvariesgreatlyfromtopictotopicandthusthechancetoencounterparaphrasesduringannotation(Fig-ure5).WetreatthistopicselectionproblemasavariationoftheMulti-ArmedBandit(MAB)prob-lem(Robbins,1985)andadaptagreedyalgorithm,thebounded(cid:15)-firstalgorithm,ofTran-Thanhetal.(2012)toaccelerateourcorpusconstruction.Ourstrategyconsistsoftwophases.Inthefirstexplorationphase,wededicateafractionoftheto-talbudget,(cid:15),toexplorerandomlychosenarmsofeachslotmachine(trendingtopiconTwitter),eachmtimes.Inthesecondexploitationphase,wesortalltopicsaccordingtotheirestimatedproportionofparaphrases,andsequentiallyannotated(1−(cid:15))Bl−mearmsthathavethehighestestimatedrewarduntilreachingthemaximuml=10annotationsforanytopictoinsuredatadiversity.Wetunetheparametersmtobe1and(cid:15)tobebe-tween0.35∼0.55throughsimulationexperiments,byartificiallyduplicatingasmallamountofrealan-notationdata.WethenapplythisMABalgorithminthereal-world.Weexplore500randomtopicsandthenexploited100ofthem.Theyieldofpara-phrasesrisesto688outof2000sentencepairsbyusingMABandsentencefiltering,a4-foldincreasecomparedtoonlyusingrandomselection(Figure6).5RelatedWorkAutomaticParaphraseIdentificationhasbeenwidelystudied(AndroutsopoulosandMalakasiotis,2010;MadnaniandDorr,2010).TheACLWikigivesanexcellentsummaryofvarioustechniques.8Manyrecenthigh-performanceapproachesusesys-temcombination(DasandSmith,2009;Madnanietal.,2012;JiandEisenstein,2013).Forexam-ple,Madnanietal.(2012)combinesmultiplesophis-ticatedmachinetranslationmetricsusingameta-classifier.AnearlierattemptonTwitterdataisthatofXuetal.(2013B).Theylimitedthesearchspacetoonlythetweetsthatexplicitlymentionasamedateandasamenamedentity,howeverthereremainaconsiderableamountofmislabelsintheirdata.9Zanzottoetal.(2011)alsoexperimentedwithSVMtreekernelmethodsonTwitterdata.Departingfromthepreviouswork,weproposealatentvariablemodeltojointlyinferthecorre-spondencebetweenwordsandsentences.Itisre-latedtodiscriminativemonolingualwordalignment(MacCartneyetal.,2008;ThadaniandMcKeown,8http://aclweb.org/aclwiki/index.php?title=Paraphrase_Identification_(State_of_the_art)9ThedataisreleasedbyXuetal.(2013B)bei:https://github.com/cocoxu/twitterparaphrase/
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
445
2011;Yaoetal.,2013a,B),butdifferentinthattheparaphrasetaskrequiresadditionalsentencealign-mentmodelingwithnowordalignmentdata.OurapproachisalsoinspiredbyFungandCheung’s(2004A;2004B)workonbootstrappingbilingualpar-allelsentenceandwordtranslationsfromcompara-blecorpora.MultipleInstanceLearning(Dietterichetal.,1997)hasbeenusedbydifferentresearchgroupsinthefieldofinformationextraction(Riedeletal.,2010;Hoffmannetal.,2011;Surdeanuetal.,2012;Ritteretal.,2013;Xuetal.,2013a).Theideaistoleveragestructureddataasweaksupervisionfortaskssuchasrelationextraction.Thisisdone,forexample,bymakingtheassumptionthatatleastonesentenceinthecorpuswhichmentionsapairofen-tities(e1,e2)participatinginarelation(R)expressestheproposition:R(e1,e2).CrowdsourcingParaphraseAcquisition:Buzeketal.(2010)andDenkowskietal.(2010)focusedspecificallyoncollectingparaphrasesoftexttobetranslatedtoimprovemachinetranslationquality.ChenandDolan(2011)gatheredalarge-scalepara-phrasecorpusbyaskingMechanicalTurkworkerstocaptiontheactioninshortvideosegments.Sim-ilarly,Burrowsetal.(2012)askedcrowdsourcingworkerstorewriteselectedexcerptsfrombooks.Lingetal.(2014)crowdsourcedbilingualparalleltextusingTwitterasthesourceofdata.Incontrast,wedesignasimplecrowdsourcingtaskrequiringonlybinaryjudgementsonsentencescollectedfromTwitter.Thereareseveraladvantagesascomparedtoexistingwork:A)thecorpusalsocoversaverydiverserangeoftopicsandlinguisticexpressions,especiallycolloquiallanguage,whichisdifferentfromandthuscomplementspreviousparaphrasecorpora;B)theparaphrasecorpuscol-lectedcontainsarepresentativeproportionofbothnegativeandpositiveinstances,whilelackofgoodnegativeexampleswasanissueinthepreviousre-search(DasandSmith,2009);C)thismethodisscal-ableandsustainableduetothesimplicityofthetaskandreal-time,virtuallyunlimitedtextsupplyfromTwitter.6ConclusionsThispaperintroducedMULTIP,ajointword-sentencemodeltolearnparaphrasesfromtempo-rallyandtopicallygroupedmessagesinTwitter.Whilesimpleandprincipled,ourmodelachievesperformancecompetitivewithastate-of-the-arten-semblesystemcombininglatentsemanticrepresen-tationsandsurfacesimilarity.Bycombiningourmethodwithpreviousworkasaproduct-of-expertsweoutperformthestate-of-the-art.Ourlatent-variableapproachiscapableoflearningword-levelparaphraseanchorsgivenonlysentenceannotations.Becauseourgraphicalmodelismodularandex-tensible(forexampleitshouldbepossibletore-placethedeterministic-orwithotheraggregators),weareoptimisticthisworkmightprovideapathtowardsweaklysupervisedwordalignmentmodelsusingonlysentence-levelannotations.Inaddition,wepresentedanovelandefficientannotationmethodologywhichwasusedtocrowd-sourceauniquecorpusofparaphrasesharvestedfromTwitter.Wemakethisresourceavailabletotheresearchcommunity.AcknowledgmentsTheauthorwouldliketothankeditorSharonGold-waterandthreeanonymousreviewersfortheirthoughtfulcomments,whichsubstantiallyimprovedthispaper.WealsothankRalphGrishman,SameerSingh,YoavArtzi,MarkYatskar,ChrisQuirk,AniNenkovaandMitchMarcusfortheirfeedback.Thismaterialisbasedinpartonresearchspon-soredbytheNSFundergrantIIS-1430651,DARPAunderagreementnumberFA8750-13-2-0017(theDEFTprogram)andthroughaGoogleFacultyRe-searchAwardtoChrisCallison-Burch.TheU.S.Governmentisauthorizedtoreproduceanddis-tributereprintsforgovernmentalpurposes.TheviewsandconclusionscontainedinthispublicationarethoseoftheauthorsandshouldnotbeinterpretedasrepresentingofficialpoliciesorendorsementsofDARPAortheU.S.Government.YangfengJiissupportedbyaGoogleFacultyResearchAwardawardedtoJacobEisenstein.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
446
ReferencesAgirre,E.,Diab,M.,Cer,D.,andGonzalez-Agirre,A.(2012).Semeval-2012task6:Apilotonse-mantictextualsimilarity.InProceedingsoftheFirstJointConferenceonLexicalandComputa-tionalSemantics(*SEM).Androutsopoulos,I.andMalakasiotis,P.(2010).Asurveyofparaphrasingandtextualentailmentmethods.JournalofArtificialIntelligenceRe-search,38.Artstein,R.andPoesio,M.(2008).Inter-coderagreementforcomputationallinguistics.Compu-tationalLinguistics,34(4).Bhagat,R.andHovy,E.(2013).Whatisapara-phrase?ComputationalLinguistics,39(3).Burrows,S.,Potthast,M.,andStein,B.(2012).Paraphraseacquisitionviacrowdsourcingandmachinelearning.TransactionsonIntelligentSystemsandTechnology(ACMTIST).Buzek,O.,Resnik,P.,andBederson,B.B.(2010).ErrordrivenparaphraseannotationusingMe-chanicalTurk.InProceedingsoftheWorkshoponCreatingSpeechandLanguageDatawithAma-zon’sMechanicalTurk.Chen,D.L.andDolan,W.B.(2011).Collectinghighlyparalleldataforparaphraseevaluation.InProceedingsofthe49thAnnualMeetingoftheAs-sociationforComputationalLinguistics(ACL).Collins,M.(2002).DiscriminativetrainingmethodsforhiddenMarkovmodels:Theoryandexperi-mentswithperceptronalgorithms.InProceed-ingsoftheConferenceonEmpiricalMethodsonNaturalLanguageProcessing(EMNLP).Das,D.andSmith,N.A.(2009).Paraphraseidenti-ficationasprobabilisticquasi-synchronousrecog-nition.InProceedingsoftheJointConferenceofthe47thAnnualMeetingoftheAssociationforComputationalLinguisticsandthe4thInter-nationalJointConferenceonNaturalLanguageProcessingoftheAsianFederationofNaturalLanguageProcessing(ACL-IJCNLP).Denkowski,M.,Al-Haj,H.,andLavie,A.(2010).Turker-assistedparaphrasingforEnglish-Arabicmachinetranslation.InProceedingsoftheWork-shoponCreatingSpeechandLanguageDatawithAmazon’sMechanicalTurk.Derczynski,L.,Ritter,A.,Clark,S.,andBontcheva,K.(2013).Twitterpart-of-speechtaggingforall:Overcomingsparseandnoisydata.InProceed-ingsoftheRecentAdvancesinNaturalLanguageProcessing(RANLP).Diao,Q.,Jiang,J.,Zhu,F.,andLim,E.-P.(2012).Findingburstytopicsfrommicroblogs.InPro-ceedingsofthe50thAnnualMeetingoftheAsso-ciationforComputationalLinguistics(ACL).Dietterich,T.G.,Lathrop,R.H.,andLozano-P´erez,T.(1997).Solvingthemultipleinstanceprob-lemwithaxis-parallelrectangles.ArtificialIntel-ligence,89(1).Dolan,B.,Quirk,C.,andBrockett,C.(2004).Un-supervisedconstructionoflargeparaphrasecor-pora:Exploitingmassivelyparallelnewssources.InProceedingsofthe20thInternationalConfer-enceonComputationalLinguistics(COLING).Dolan,W.andBrockett,C.(2005).Automaticallyconstructingacorpusofsententialparaphrases.InProceedingsofthe3rdInternationalWorkshoponParaphrasing.Dunning,T.(1993).Accuratemethodsforthestatis-ticsofsurpriseandcoincidence.ComputationalLinguistics,19(1).Fellbaum,C.(2010).WordNet.InTheoryandAp-plicationsofOntology:ComputerApplications.Springer.Francis,W.N.andKucera,H.(1979).Browncorpusmanual.BrownUniversity.Fung,P.andCheung,P.(2004A).Miningvery-non-parallelcorpora:Parallelsentenceandlexiconex-tractionviabootstrappingandEM.InProceed-ingsoftheConferenceonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP).Fung,P.andCheung,P.(2004B).Multi-levelboot-strappingforextractingparallelsentencesfromaquasi-comparablecorpus.InProceedingsoftheInternationalConferenceonComputationalLin-guistics(COLING).Guo,W.andDiab,M.(2012).Modelingsentencesinthelatentspace.InProceedingsofthe50th
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
447
AnnualMeetingoftheAssociationforComputa-tionalLinguistics(ACL).Guo,W.,Li,H.,Ji,H.,andDiab,M.(2013).Link-ingtweetstonews:Aframeworktoenrichshorttextdatainsocialmedia.InProceedingsofthe51thAnnualMeetingoftheAssociationforCom-putationalLinguistics(ACL).Er,B.,Cook,P.,andBaldwin,T.(2012).Auto-maticallyconstructinganormalisationdictionaryformicroblogs.InProceedingsoftheConfer-enceonEmpiricalMethodsonNaturalLanguageProcessingandComputationalNaturalLanguageLearning(EMNLP-CoNLL).Hinton,G.E.(2002).Trainingproductsofexpertsbyminimizingcontrastivedivergence.NeuralComputation,14(8).Hoffmann,R.,Zhang,C.,Ling,X.,Zettlemoyer,L.S.,andWeld,D.S.(2011).Knowledge-basedweaksupervisionforinformationextractionofoverlappingrelations.InProceedingsofthe49thAnnualMeetingoftheAssociationforComputa-tionalLinguistics(ACL).Hovy,E.,Marcus,M.,Palmer,M.,Ramshaw,L.,andWeischedel,R.(2006).OntoNotes:the90%solution.InProceedingsoftheHumanLanguageTechnologyConference-NorthAmericanChap-teroftheAssociationforComputationalLinguis-ticsAnnualMeeting(HLT-NAACL).Ji,Y.andEisenstein,J.(2013).Discriminativeimprovementstodistributionalsentencesimilar-ity.InProceedingsoftheConferenceonEm-piricalMethodsinNaturalLanguageProcessing(EMNLP).Liang,P.,Bouchard-Cˆot´e,A.,Klein,D.,andTaskar,B.(2006).Anend-to-enddiscriminativeapproachtomachinetranslation.InProceedingsofthe21stInternationalConferenceonComputationalLin-guisticsandthe44thannualmeetingoftheAsso-ciationforComputationalLinguistics(COLING-ACL).Ling,W.,Marujo,L.,Dyer,C.,Alan,B.,andIsabel,T.(2014).Crowdsourcinghigh-qualityparalleldataextractionfromTwitter.InProceedingsoftheNinthWorkshoponStatisticalMachineTrans-lation(WMT).MacCartney,B.,Galley,M.,andManning,C.(2008).Aphrase-basedalignmentmodelfornaturallanguageinference.InProceedingsoftheConferenceonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP).Madnani,N.andDorr,B.J.(2010).Generatingphrasalandsententialparaphrases:Asurveyofdata-drivenmethods.ComputationalLinguistics,36(3).Madnani,N.,Tetreault,J.,andChodorow,M.(2012).Re-examiningmachinetranslationmet-ricsforparaphraseidentification.InProceedingsoftheConferenceoftheNorthAmericanChapteroftheAssociationforComputationalLinguistics-HumanLanguageTechnologies(NAACL-HLT).Minnen,G.,Carroll,J.,andPearce,D.(2001).Ap-pliedmorphologicalprocessingofenglish.Natu-ralLanguageEngineering,7(03).Moore,R.C.(2004).Onlog-likelihood-ratiosandthesignificanceofrareevents.InProceedingsoftheConferenceonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP).Nenkova,A.andVanderwende,L.(2005).Theim-pactoffrequencyonsummarization.Technicalreport,MicrosoftResearch.MSR-TR-2005-101.O’Connor,B.,Krieger,M.,andAhn,D.(2010).Tweetmotif:Exploratorysearchandtopicsum-marizationforTwitter.InProceedingsofthe4thInternationalAAAIConferenceonWeblogsandSocialMedia(ICWSM).Petrovi´c,S.,Osborne,M.,andLavrenko,V.(2012).Usingparaphrasesforimprovingfirststorydetec-tioninnewsandTwitter.InProceedingsoftheConferenceoftheNorthAmericanChapteroftheAssociationforComputationalLinguistics-Hu-manLanguageTechnologies(NAACL-HLT).Riedel,S.,Yao,L.,andMcCallum,A.(2010).Mod-elingrelationsandtheirmentionswithoutlabeledtext.InProceedignsoftheEuropeanConferenceonMachineLearningandPrinciplesandPracticeofKnowledgeDiscoveryinDatabases(ECML-PKDD).Ritter,A.,Mausam,Etzioni,O.,andClark,S.(2012).OpendomaineventextractionfromTwit-ter.InProceedingsofthe18thInternationalCon-
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
1
9
4
1
5
6
6
9
2
3
/
/
T
l
A
C
_
A
_
0
0
1
9
4
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
448
ferenceonKnowledgeDiscoveryandDataMin-ing(SIGKDD).Ritter,A.,Zettlemoyer,L.,Mausam,andEtzioni,O.(2013).Modelingmissingdataindistantsuper-visionforinformationextraction.TransactionsoftheAssociationforComputationalLinguistics(TACL).Robbins,H.(1985).Someaspectsofthesequen-tialdesignofexperiments.InHerbertRobbinsSelectedPapers.Springer.Sekine,S.(2005).AutomaticparaphrasediscoverybasedoncontextandkeywordsbetweenNEpairs.InProceedingsofthe3rdInternationalWorkshoponParaphrasing.Shinyama,Y.,Sekine,S.,andSudo,K.(2002).Au-tomaticparaphraseacquisitionfromnewsarticles.InProceedingsofthe2ndInternationalConfer-enceonHumanLanguageTechnologyResearch(HLT).Surdeanu,M.,Tibshirani,J.,Nallapati,R.,andMan-ning,C.D.(2012).Multi-instancemulti-labellearningforrelationextraction.InProceedingsofthe50thAnnualMeetingoftheAssociationforComputationalLinguistics(ACL).Thadani,K.andMcKeown,K.(2011).Optimalandsyntactically-informeddecodingformonolingualphrase-basedalignment.InProceedingsofthe49thAnnualMeetingoftheAssociationforCom-putationalLinguistics-HumanLanguageTech-nologies(ACL-HLT).Tran-Thanh,L.,Stein,S.,Rogers,A.,andJennings,N.R.(2012).Efficientcrowdsourcingofun-knownexpertsusingmulti-armedbandits.InPro-ceedingsoftheEuropeanConferenceonArtificialIntelligence(ECAI).Vanderwende,L.,Suzuki,H.,Brockett,C.,andNenkova,A.(2007).BeyondSumBasic:Task-focusedsummarizationwithsentencesimplifica-tionandlexicalexpansion.InformationProcess-ing&Management,43.Wan,S.,Dras,M.,Dale,R.,andParis,C.(2006).Usingdependency-basedfeaturestotakethe“para-farce”outofparaphrase.InProceedingsoftheAustralasianLanguageTechnologyWork-shop.Wang,L.,Dyer,C.,Black,A.W.,andTrancoso,ICH.(2013).Paraphrasing4microblognormaliza-tion.InProceedingsoftheConferenceonEm-piricalMethodsonNaturalLanguageProcessing(EMNLP).Winkler,W.E.(1999).Thestateofrecordlink-ageandcurrentresearchproblems.Technicalre-port,StatisticalResearchDivision,U.S.CensusBureau.Xu,W.,Hoffmann,R.,Zhao,L.,andGrishman,R.(2013A).Fillingknowledgebasegapsfordistantsupervisionofrelationextraction.InProceedingsofthe51stAnnualMeetingoftheAssociationforComputationalLinguistics(ACL).Xu,W.,Ritter,A.,andGrishman,R.(2013B).Gath-eringandgeneratingparaphrasesfromTwitterwithapplicationtonormalization.InProceed-ingsoftheSixthWorkshoponBuildingandUsingComparableCorpora(BUCC).Yao,X.,VanDurme,B.,Callison-Burch,C.,andClark,P.(2013A).Alightweightandhighperfor-mancemonolingualwordaligner.InProceedingsofthe49thAnnualMeetingoftheAssociationforComputationalLinguistics(ACL).Yao,X.,VanDurme,B.,andClark,P.(2013B).Semi-markovphrase-basedmonolingualalign-ment.InProceedingsoftheConferenceonEm-piricalMethodsonNaturalLanguageProcessing(EMNLP).Zanzotto,F.M.,Pennacchiotti,M.,andTsiout-siouliklis,K.(2011).LinguisticredundancyinTwitter.InProceedingsoftheConferenceonEm-piricalMethodsinNaturalLanguageProcessing(EMNLP).Zettlemoyer,L.S.andCollins,M.(2007).On-linelearningofrelaxedCCGgrammarsforpars-ingtologicalform.InProceedingsofthe2007JointConferenceonEmpiricalMethodsinNatu-ralLanguageProcessingandComputationalNat-uralLanguageLearning(EMNLP-CoNLL).Zhang,C.andWeld,D.S.(2013).Harvestingparal-lelnewsstreamstogenerateparaphrasesofeventrelations.InProceedingsoftheConferenceonEmpiricalMethodsinNaturalLanguageProcess-ing(EMNLP).