Transactions of the Association for Computational Linguistics, 1 (2013) 341–352. Action Editor: Mirella Lapata.
Submitted 12/2012; Überarbeitet 3/2013, 5/2013; Published 7/2013. C(cid:13)2013 Verein für Computerlinguistik.
341
WhatMakesWritingGreat?FirstExperimentsonArticleQualityPredictionintheScienceJournalismDomainAnnieLouisUniversityofPennsylvaniaPhiladelphia,PA19104lannie@seas.upenn.eduAniNenkovaUniversityofPennsylvaniaPhiladelphia,PA19104nenkova@seas.upenn.eduAbstractGreatwritingisrareandhighlyadmired.Readersseekoutarticlesthatarebeautifullywritten,informativeandentertaining.Yetinformation-accesstechnologieslackcapabil-itiesforpredictingarticlequalityatthislevel.Inthispaperwepresentfirstexperimentsonarticlequalitypredictioninthesciencejour-nalismdomain.Weintroduceacorpusofgreatpiecesofsciencejournalism,alongwithtypicalarticlesfromthegenre.Weimple-mentfeaturestocaptureaspectsofgreatwrit-ing,includingsurprising,visualandemotionalcontent,aswellasgeneralfeaturesrelatedtodiscourseorganizationandsentencestructure.Weshowthatthedistinctionbetweengreatandtypicalarticlescanbedetectedfairlyac-curately,andthattheentirespectrumofourfeaturescontributetothedistinction.1IntroductionMeasuresofarticlequalitywouldbehugelybene-ficialforinformationretrievalandrecommendationsystems.Inthispaper,wedescribeadatasetofNewYorkTimessciencejournalismarticleswhichwehavecategorizedforqualitydifferencesandpresentasystemthatcanautomaticallymakethedistinction.Sciencejournalismconveyscomplexscientificideas,entertainingandeducatingatthesametime.Considerthefollowingopeningofa2005articlebyDavidQuammenfromHarper’smagazine:Onemorningearlylastwinterasmallitemappearedinmylocalnewspaperannouncingthebirthofanextraordi-naryanimal.AteamofresearchersatTexasA&MUni-versityhadsucceededincloningawhitetaildeer.Neverdonebefore.Thefawn,knownasDewey,wasdevelopingnormallyandseemedtobehealthy.Hehadnomother,justasurrogatewhohadcarriedhisfetustoterm.Hehadnofather,justa“donor”ofallhischromosomes.HewasthegeneticduplicateofacertaintrophybuckoutofsouthTexaswhoseskincellshadbeenculturedinalaboratory.Oneofthosecellsfurnishedanucleusthat,transplantedandrejiggered,becametheDNAcoreofaneggcell,whichbecameanembryo,whichintimebe-cameDewey.Sohewaswildlife,inasense,andinan-othersenseelaboratelysynthetic.Thisisthesortofnews,quirkybutepochal,thatcancauseapersonwithamouth-fuloftoasttopauseandmarvel.Whatadumbidea,Imarveled.Thewritingisclearandwell-organizedbutthetextalsocontainscreativeuseoflanguageandacleverstory-likeexplanationofthescientificcon-tribution.Suchpropertiesmakesciencejournalismanattractivegenreforstudyingwritingquality.Sci-encejournalismisalsoahighlyrelevantdomainforinformationretrievalinthecontextofeducationalaswellasentertainingapplications.Articlequalitymeasurescanhugelybenefitsuchsystems.Priorworkindicatesthatthreeaspectsofarticlequalitycanbesuccessfullypredicted:A)whetheratextmeetstheacceptablestandardsforspelling(BrillandMoore,2000),grammar(TetreaultandChodorow,2008;RozovskayaandRoth,2010)anddiscourseorganization(Barzilayetal.,2002;Lap-ata,2003);B)hasatopicthatisinterestingtoapar-ticularuser.Forexample,content-basedrecommen-dationsystemsstandardlyrepresentuserinterestus-ingfrequentwordsfromarticlesinauser’shistoryandretrieveotherarticlesonthesametopics(Paz-
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
3
2
1
5
6
6
6
6
7
/
/
T
l
A
C
_
A
_
0
0
2
3
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
342
zanietal.,1996;MooneyandRoy,2000);andc)iseasytoreadforatargetreadership.Shorterwords(Flesch,1948),lesscomplexsyntax(SchwarmandOstendorf,2005)andhighcohesionbetweensen-tences(Graesseretal.,2004)typicallyindicateeas-ierandmore‘readable’articles.Lessunderstoodisthequestionofwhatmakesanarticleinterestingandbeautifullywritten.Anearlyandinfluentialworkonreadability(Flesch,1948)alsocomputedaninterestmeasurewiththehypoth-esisthatinterestingarticleswouldbeeasiertoread.Morerecently,McIntyreandLapata(2009)foundthatpeople’sratingsofinterestforfairytalescanbesuccessfullypredictedusingtoken-levelscoresre-latedtosyntacticitemsandcategoriesfromapsy-cholinguisticdatabase.Butlargescalestudiesofin-terestmeasuresforadulteducatedreadershavenotbeencarriedout.Further,therehavebeenlittleattemptstomeasurearticlequalityinagenre-specificsetting.Butitisreasonabletoexpectthatpropertiesrelatedtotheuniqueaspectsofagenreshouldcontributetothepredictionofqualityinthesamewaythatdomain-specificspellingandgrammarcorrection(CucerzanandBrill,2004;Baoetal.,2011;DaleandKilgar-riff,2010)techniqueshavebeensuccessful.Hereweaddresstheabovetwoissuesbydevelop-ingmeasuresrelatedtointerestingandwell-writtennaturespecificallyforsciencejournalism.Centraltoourworkisacorpusofsciencenewsarticleswithtwocategories:writtenbypopularjournalistsandtypicalarticlesinsciencecolumns(Section2).Weintroduceasetofgenre-specificfeaturesrelatedtobeautifulwriting,visualnatureandaffectivecontent(Section3)andshowthattheyhavehighpredictiveaccuracies,20%abovethebaseline,fordistinguish-ingourqualitycategories(Section4).Ourfinalsys-temcombinesthemeasuresforinterestandgenre-specificfeatureswiththoseproposedforidentifyingreadable,well-writtenandtopicallyinterestingarti-cles,givinganaccuracyof84%(Section5).2ArticlequalitycorpusOurcorpus1containschosenarticlesfromthelargerNewYorkTimes(NYT)corpus(Sandhaus,2008),thelattercontainingawealthofmetadataabouteach1Availablefromhttp://www.cis.upenn.edu/˜nlp/corpora/scinewscorpus.htmlarticleincludingauthorinformationandmanuallyassignedtopictags.2.1GeneralcorpusThearticlesintheVERYGOODcategoryincludeallcontributionstotheNYTbyauthorswhosewritingappearedin“TheBestAmericanScienceWriting”anthologypublishedannuallysince1999.Articlesfromthesciencecolumnsofleadingnewspapersarenominatedandexpertjournalistschooseasettheyconsiderexceptionaltoappearintheseanthologies.Thereare63NYTarticlesintheanthology(betweenyears1999and2007)thatarealsopartofthedigitalNYTcorpus;thesearticlesformtheseedsetoftheVERYGOODcategory.WefurtherincludeintheVERYGOODcategoryallothersciencearticlescontributedtoNYTbytheauthorsoftheseedexamples.SciencearticlesbyotherauthorsnotinourseedsetformtheTYPICALcategory.Weperformthisexpansionbyfirstcreat-ingarelevantsetofsciencearticles.Thereisnosinglemeta-datatagintheNYTwhichreferstoallthesciencearticles.Soweusethetopictagsfromtheseedarticlesasaninitialsetofresearchtags.Wethencomputetheminimalsetofresearchtagsthatcoverallbestarticles.Wegreedilyaddtagsintotheminimalset,ateachiterationchoosingthetagthatispresentinthemajorityofarticlesthatre-mainuncovered.Thisminimalsetcontains14tagssuchas‘MedicineandHealth’,‘Space’,‘Research’,‘Physics’and‘Evolution’.WecollectarticlesfromtheNYTwhichhaveatleastoneoftheminimalsettags.However,evenacursorymentionofaresearchtopicresultsinaresearch-relatedtagbeingassignedtothearticle.Sowealsouseadictionaryofresearch-relatedtermstodeterminewhetherthearticlepassesaminimumthresholdforresearchcontent.Wecreatedthisdic-tionarymanuallyanditcontainsthefollowingwordsandtheirmorphologicalvariants(total63items).Weusedourintuitionaboutafewcategoriesofre-searchwordstocreatethislist.Thecategoryisshownincapitallettersbelow.PEOPLE:Forscher,scientist,physicist,biologist,economist,anthropologist,environmentalist,linguist,professor,dr,studentPROCESS:discover,found,Experiment,arbeiten,finding,Studie,question,Projekt,discussTOPIC:biology,Physik,Chemie,anthropology,primatology
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
3
2
1
5
6
6
6
6
7
/
/
T
l
A
C
_
A
_
0
0
2
3
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
343
PUBLICATIONS:Bericht,published,journal,Papier,author,issueOTHER:menschlich,Wissenschaft,Forschung,Wissen,university,lab-oratory,labENDINGS:-ology-gist,-list,-mist,-uist,-phyTheitemsintheENDINGScategoryareusedtomatchwordsuffixes.Anarticleisconsideredscience-relatedifatleast10ofitstokensmatchthedictionaryandinaddition,atleast5uniquewordsfromthedictionaryarematched.Sincethetimespanofthebestarticlesis1999to2007,welimitourcol-lectiontothistimespan.Inaddition,weonlycon-siderarticlesthatareatleast500wordslong.Thisfilteredsetof23,709articlesformtherelevantsetofsciencejournalism.The63seedsamplesofgreatwritingwerecon-tributedbyabout40authors.Someauthorshavemultiplearticlesselectedforthebestwritingbookseries,supportingtheideathattheseauthorsproducehighqualitypiecesthatcanbeconsidereddistinctfromtypicalarticles.Separatingthearticlesfromtheseauthorsgivesus3,467extrasamplesofVERYGOODwriting.Intotal,theVERYGOODsethas3,530articles.Theremainingarticlesfromtherele-vantset,20,242,writtenbyabout3000otherauthorsformtheTYPICALcategory.2.2Topic-pairedcorpusThegeneralcorpusofsciencewritingintroducedsofarcontainsarticlesondiversetopicsincludingbi-ology,astronomy,religionandsports.TheVERYGOODandTYPICALcategoriescreatedaboveal-lowustostudywritingqualitywithoutregardtotopic.Howeveratypicalinformationretrievalsce-nariowouldinvolvecomparisonbetweenarticlesofthesametopic,i.e.relevanttothesamequery.Toinvestigatehowqualitydifferentiationcanbedonewithintopics,wecreatedanothercorpuswherewepairedarticlesofVERYGOODandTYPICALquality.ForeacharticleintheVERYGOODcategory,wecomputesimilaritywithallarticlesintheTYPICALset.Thissimilarityiscomputedbycomparingthetopicwords(computedusingaloglikelihoodratiotest(LinandHovy,2000))ofthetwoarticles.Weretainthemostsimilar10TYPICALarticlesforeachVERYGOODarticle.WeenumerateallpairsofVERYGOODwithmatchedupTYPICALARTICLES(10innumber)givingatotalof35,300pairs.Therearetwodistinguishingaspectsofourcor-pus.First,theaveragequalityofarticlesishigh.Theyareunlikelytohavespelling,grammarandba-sicorganizationproblemsallowingustoinvestigatearticlequalityratherthanthedetectionoferrors.Second,ourcorpuscontainsmorerealisticsamplesofqualitydifferencesforIRorarticlerecommen-dationcomparedtopriorwork,wheresystempro-ducedtextsandpermutedversionsofanoriginalar-ticlewereusedasproxiesforlowerqualitytext.2.3TasksWeperformtwotypesofclassificationtasks.Wedivideourcorpusintodevelopmentandtestsetsforthesetasksinthefollowingway.Anytopic:HerethegoalistoseparateoutVERYGOODversusTYPICALarticleswithoutregardtotopic.Thesettingroughlycorrespondstopickingoutaninterestingarticlefromanarchiveoraday’snewspaper.Thetestsetcontains3,430VERYGOODarticlesandwerandomlysample3,430articlesfromtheTYPICALcategorytocomprisethenegativeset.Sametopic:Hereweusethetopic-pairedVERYGOODandTYPICALarticles.ThegoalistopredictwhicharticleinthepairistheVERYGOODone.Thistaskisclosertoainformationretrievalsetting,wherearticlessimilarintopic(retrievedforauserquery)needtobedistinguishedforquality.Fortestset,weselected34,300pairs.Developmentdata:Werandomlyselected100VERYGOODarticlesandtheirpaired(10jede)TYPICALarticlesfromthetopic-normalizedcorpus.Overall,theseconstitute1,000pairswhichweusefordevelopingthesame-topicclassifier.Fromtheseselectedpairswetakethe100VERYGOODarticlesandsample100uniquearticlesfromtheTYPICALarticlesmakingupthepairs.These200articlesareusedtotunetheany-topicclassifier.3FacetsofsciencewritingInthissection,wediscusssixprominentfacetsofsciencewritingwhichwehypothesizedwillhaveanimpactontextquality.Thesearethepresenceofpassagesofhighlyvisualnature,people-orientedcontent,useofbeautifullanguage,sub-genres,sen-timentoraffect,andthedepthofresearchdescrip-tion.Severalotherpropertiesofsciencewritingcouldalsoberelevanttoqualitysuchastheuseof
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
3
2
1
5
6
6
6
6
7
/
/
T
l
A
C
_
A
_
0
0
2
3
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
344
humor,metaphor,suspenseandclarityofexplana-tionsandweplantoexploretheseinfuturework.Wedescribehowwecomputedfeaturesrelatedtoeachpropertyandtestedhowthesefeaturesaredis-tributedintheVERYGOODandTYPICALcategories.Todothisanalysis,werandomlysampled1,000ar-ticlesfromeachofthetwocategoriesasrepresenta-tiveexamples.Wecomputethevalueofeachfeatureonthesearticlesanduseatwo-sidedt-testtocheckifthemeanvalueofthefeatureishigherinoneclassofarticles.Ap-valuelessthan0.05istakentoin-dicatesignificantlydifferenttrendforthefeatureintheVERYGOODversusTYPICALarticles.Notethatourfeaturecomputationstepisnottunedforthequalitypredictiontaskinanyway.Ratherweaimtorepresenteachfacetasaccuratelyaspossible.Ideallywewouldrequiremanualanno-tationsforeachfacet(visuell,sentimentnatureetc.)toachievethisgoal.Atthistime,wesimplychecksomechosenfeatures’valuesonarandomcollectionofsnippetsfromourcorpusandcheckiftheybehaveasintendedwithoutresortingtotheseannotations.3.1VisualnatureofarticlesSometextscreateanimageinthereader’smind.Forexample,thesnippetbelowhasahighvisualeffect.Whenthesealionsapproachedclose,seeminglyascuriousaboutusaswewereaboutthem,theirbigbrowneyeswereencircledbylightfurthatlookedlikemakeup.Onesealionplayedwithaconchshellasifitwereaball.Suchvividdescriptionscanengageandentertainareader.Kosslyn(1980)foundthatpeoplespon-taneouslyformimagesofconcretewordsthattheyhearandusethemtoanswerquestionsorperformothertasks.Bookswrittenforstudentsciencejour-nalists(Blumetal.,2006;Stocking,2010)alsoem-phasizetheimportanceofvisualdescriptions.Wemeasurethevisualnatureofatextbycount-ingthenumberofvisualwords.Currently,theonlyresourceofimageryratingsforwordsistheMRCpsycholinguisticdatabase(Wilson,1988).Itcon-tainsalistof3,394wordsratedfortheirabilitytoinvokeanimage,sothelistcontainsbothwordsthatarehighlyvisualalongwithwordsthatarenotvisualatall.Withacutoffvalueweadopted,of4.5fortheGilhooly-Logieand350fortheBristolNorms2we2ThevisualwordsresourceinMRCcontainstwolists—obtain1,966visualwords.Sothecoverageofthatlexiconislikelytobelowforourcorpus.Wecollectalargersetofvisualwordsfromacor-pusoftaggedimagesfromtheESPgame(vonAhnandDabbish,2004).Thecorpuscontains83,904totalimagesand27,466uniquetags.Theaveragenumberoftagsperpictureis14.5.Thetagswerecollectedinagamesettingwheretwousersindivid-uallysawthesameimageandhadtoguesswordsrelatedtoit.Theplayersincreasedtheirscoreswhenthewordguessedbyoneplayermatchedthatoftheother.Duetothesimpleannotationmethod,thereisconsiderablenoiseandnon-visualwordsassignedastags.Soweperformedfilteringtofindhighpre-cisionimagewordsandalsogroupthemintotopics.WeuseLatentDirichletAllocation(Bleietal.,2003)toclusterimagetagsintotopics.Wetreateachpictureasadocumentandthetagsassignedtothepicturearethedocument’scontents.Weusesym-metricpriorssetto0.01forbothtopicmixtureandworddistributionwithineachtopic.Wefilteroutthe30mostcommonwordsinthecorpus,wordsthatap-pearinlessthanfourpicturesandimageswithfewerthanfivetags.Theremainingwordsareclusteredinto100topicswiththeStanfordTopicModelingToolbox3(Ramageetal.,2009).Wedidnottunethenumberoftopicsandchoosethevalueof100basedontheintuitionthatthenumberofvisualtopicsislikelytobesmall.Toselectcleanvisualclusters,wemaketheas-sumptionthatvisualwordsarelikelytobeclusteredwithothervisualterms.Topicsthatarenotvisualarediscardedaltogether.Weusethemanualan-notationsavailablewiththeMRCdatabasetode-terminewhichclustersarevisual.Foreachofthe100topicsfromthetopicmodel,weexaminethetop200wordswithhighestprobabilityinthattopic.Wecomputetheprecisionofeachtopicasthepro-portionofthese200wordsthatmatchtheMRClistofvisualwords(1,966wordsusingthecutoffmen-tionedabove).Onlythosetopicswhichhadapre-cisionofatleast25%wereretained,resultingin68visualtopics.Someexampletopics,withmanuallycreatedheadings,include:landscape.grass,mountain,Grün,hill,Blau,field,brown,sand,desert,dirt,landscape,skyGilhooly-LogieandBristolNorms.3http://nlp.stanford.edu/software/tmt/tmt-0.4/
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
3
2
1
5
6
6
6
6
7
/
/
T
l
A
C
_
A
_
0
0
2
3
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
345
jewellery.silver,Weiß,diamond,gold,necklace,Kette,ring,jewel,wedding,diamonds,jewelryshapes.round,ball,circles,logo,dots,square,dot,Kugel,glass,hole,oval,circleCombiningthese68topics,thereare5,347uniquevisualwordsbecausetopicscanoverlapinthelistofmostprobablewords.2,832wordsfromthissetarenotpresentintheMRCdatabase.Someexamplesofnewwordsinourlistare‘daffodil’,‘sailor’,‘hel-met’,‘postcard’,‘sticker’,‘carousel’,‘kayak’,and‘camouflage’.Forlaterexperimentsweconsiderthe5,347wordsasthevisualwordsetandalsokeeptheinformationaboutthetop200wordsinthe68selectedtopics.Wecomputetwoclassesoffeaturesonebasedonallvisualwordsandtheotheronvisualtopics.Weconsideronlytheadjectives,Adverbien,verbsandcommonnounsinanarticleascandidatewordsforcomputingvisualquality.Overallvisualuse:Wecomputethepropor-tionofcandidatewordsthatmatchthevisualwordlistastheTOTALVISUALfeature.Wealsocomputetheproportionsbasedonlyonthefirst200wordsofthearticle(BEGVISUAL),thelast200words(ENDVISUAL)andthemiddleregion(MIDVISUAL)asfeatures.Wealsodividethearti-cleintofiveequallysizedbinsofwordswhereeachbincapturesconsecutivewordsinthearticle.Withineachbinwecomputetheproportionofvisualwords.Wetreatthesevaluesasaprobabilitydistributionandcomputeitsentropy(ENTROPYVISUAL).Weexpectedthesepositionfeaturestoindicatehowtheplacementofvisualwordsisrelatedtoquality.Topic-basedfeatures:Wealsocomputewhatpro-portionofthewordsweidentifyasvisualmatchesthelistundereachtopic.Themaximumproportionfromasingletopic(MAXTOPICVISUAL)isafea-ture.Wealsocomputeagreedycoversetoftop-icsforthevisualwordsinthearticle.Thetopicthatmatchesthemostvisualwordsisaddedfirst,andthenexttopicisselectedbasedontheremain-ingunmatchedwords.Thenumberoftopicsneededtocover50%ofthearticle’svisualwordsistheTOPICCOVERVISUALfeature.Thesefeaturescap-turethemixofvisualwordsfromdifferenttopics.Disregardingtopicinformation,wealsocomputeafeatureNUMPICTURESwhichisthenumberofim-agesinthecorpuswhere40%oftheimage’stagsarematchedinthearticle.Wefound8featurestovarysignificantlybe-tweenthetwotypesofarticles.Thefea-tureswithsignificantlyhighervaluesinVERYGOODarticlesare:BEGVISUAL,ENDVISUAL,MAXTOPICVISUAL.Thefeatureswithsignifi-cantlyhighervaluesintheTYPICALarticlesare:TOTALVISUAL,MIDVISUAL,ENTROPYVISUAL,TOPICCOVERVISUAL,NUMPICTURES.ItappearsthatthesimpleexpectationthatVERYGOODarticlescontainmorevisualwordsoveralldoesnotholdtruehere.Howeverthegreatwrit-ingsampleshaveahigherdegreeofvisualcontentinthebeginningandendsofarticles.Goodarticlesalsohavelowerentropyforthedistributionofvi-sualwordsindicatingthattheyappearinlocalizedpositionsincontrasttobeingdistributedthroughout.Thetopic-basedfeaturesfurtherindicatethatfortheVERYGOODarticles,thevisualwordscomefromonlyafewtopics(comparedtoTYPICALarticles)andsomayevokeacoherentimageorscene.3.2TheuseofpeopleinthestoryWehypothesizedthatarticlescontainingresearchfindingsthatdirectlyaffectpeopleinsomeway,andthereforeinvolveexplicitreferencestopeopleinthestory,willmakeabiggerimpactonthereader.Forexample,themostfrequenttopicamongourVERYGOODsamplesis‘medicineandhealth’wherear-ticlesareoftenwrittenfromtheviewofapatient,doctororscientist.Anexampleisbelow.Dr.RemingtonwasborninReedville,Va.,in1922,toMaudandP.SheldonRemington,aschoolheadmaster.Charlesspenthisboyhoodchasingbutterfliesalongsidehisfather,alsoacol-lector.DuringhisgraduatestudiesatHarvard,hefoundedtheLepidopterists’Societywithanequallybutterfly-smittenunder-graduate,HarryClench.Weapproximatethisfacetbycomputingthenum-berofexplicitreferencestopeople,relyingonthreesourcesofinformationaboutanimacyofwords.Thefirstisnamedentity(NE)tags(PERSON,ORGANI-ZATIONandLOCATION)returnedbytheStanfordNErecognitiontool(Finkeletal.,2005).Wealsocreatedalistofpersonalpronounssuchas‘he’,‘my-self’etc.whichstandardlyindicateanimateentities(animatepronouns).Ourthirdresourcecontainsthenumberoftimesdifferentnounphrases(NP)werefollowedbyeachoftherelativepronouns‘who’,‘where’and‘which’.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
3
2
1
5
6
6
6
6
7
/
/
T
l
A
C
_
A
_
0
0
2
3
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
346
Thesecountsfor664,673nounphraseswerecol-lectedbyJiandLin(2009)fromtheGoogleNgramCorpus(Linetal.,2010).Weuseasimpleheuris-tictoobtainalistofanimate(googleanimate)andinanimatenouns(googleinanimate)fromthislist.TheheadofeachNPistakenasacandidatenoun.Ifthenoundoesnotoccurwith‘who’inanyofthenounphraseswhereitisthehead,thenitisinani-mate.Incontrast,ifitappearsonlywith‘who’inallnounphrases,itisanimate.Otherwise,foreachNPwherethenounisahead,wecheckwhetherthecountoftimesthenounphraseappearedwith‘who’isgreaterthaneachoftheoccurrencesof‘which’,‘where’and‘when’(takenindividually)withthatnounphrase.Iftheconditionholdsforatleastonenounphrase,thenounismarkedasanimate.Whencomputingthefeaturesforanarticle,weconsiderallnounsandpronounsascandidatewords.Ifthewordisapronounandappearsinourlistofan-imatepronouns,itisassignedan‘animate’labeland‘inanimate’otherwise.IfthewordisapropernounandtaggedwiththePERSONNEtag,wemarkitas‘animate’andifitisaORGANIZATIONorLO-CATIONtag,thewordis‘inanimate’.Forcommonnouns,wecheckitifappearsinthegoogleanimateandinanimatelists.Anymatchislabelledaccord-inglyas‘animate’and‘inanimate’.Notethatthisproceduremayleavesomenounswithoutanylabels.Ourfeaturesarecountsofanimatetokens(ANIM),inanimatetokens(INAMIN)andboththesecountsnormalizedbytotalwordsinthearticle(ANIMPROP,INANIMPROP).Threeofthesefea-tureshadsignificantlyhighermeanvaluesintheTYPICALcategoryofarticles:ANIM,ANIMPROP,INANIMPROP.Wefounduponobservationthatsev-eralarticlesthattalkaboutgovernmentpoliciesin-volvealotofreferencestopeoplebutareoftenintheTYPICALcategory.Thesefindingssuggestthatthe‘human’dimensionmightneedtobecomputednotonlybasedonsimplecountsofreferencestopeoplebutalsoinvolvefinerdistinctionsbetweenthem.3.3BeautifullanguageBeautifulphrasingandwordchoicecanentertainthereaderandleaveapositiveimpression.Multi-plestudiesintheeducationgenre(Diederich,1974;Spandel,2004)notethatwhenteachersandexpertadultreadersgradedstudentwriting,wordchoiceandphrasingalwaysturnoutasasignificantfactorsinfluencingtheraters’scores.Weimplementamethodfordetectingcreativelanguagebasedonasimpleideathatcreativewordsandphrasesaresometimesthosethatareusedinun-usualcontextsandcombinationsorthosethatsoundunusual.Wecomputemeasuresofunusuallanguagebothatthelevelofindividualwordsandforthecom-binationofwordsinasyntacticrelation.Wordlevelmeasures:Unusualwordsinanar-ticlearelikelytobethosewithlowfrequenciesinabackgroundcorpus.Weusethefullsetofarticles(notonlyscience)fromyear1996intheNYTcorpusasabackground(thesedonotover-lapwithourcorpusforarticlequality).Wealsoex-plorepatternsoflettersandphonemesequenceswiththeideathatunusualcombinationofcharactersandphonemescouldcreateinterestingwords.WeusedtheCMUpronunciationdictionary(Weide,1998)togetthephonemeinformationforwordsandbuilta4-grammodelofphonemesonthebackgroundcorpus.Laplacesmoothingisusedtocomputeprobabilitiesfromthemodel.However,theCMUdictionarydoesnotcontainphonemeinformationforseveralwordsinourcorpus.Sowealsocomputeanapproximatemodelusingthelettersinthewordsandobtainan-other4-grammodel.4Onlywordsthatarelongerthan4charactersareusedinbothmodelsandwefil-teroutpropernames,namedentitiesandnumbers.Duringdevelopment,weanalyzedthearticlesfromanentireyearofNYT,1997,withthethreemodelstoidentifyunusualwords.Belowisthelistofwordswithlowestfrequencyandthosewithhigh-estperplexityunderthephonemeandlettermodels.Lowfrequency.undersheriff,woggle,ahmok,hofman,volga,oceanaut,trachoma,baneful,truffler,acrimal,corvair,entomopterHighperplexity-phonememodel.showroom,yahoo,dossier,powwow,plowshare,oomph,chihuahua,iono-sphere,boudoir,superb,zaire,oeuvreHighperplexity-lettermodel.kudzu,muumuu,qi-pao,yugoslav,kohlrabi,iraqi,yaqui,yakuza,jujitsu,oeu-vre,yaohan,kaffiyehForcomputingthefeatures,weconsideronlynouns,verbs,adjectivesandadverbs.Wealsorequirethatthewordsareatleast5letterslong4Wefoundthathigherordern-gramsprovidedbetterpre-dictionsofunusualnatureduringdevelopment.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
3
2
1
5
6
6
6
6
7
/
/
T
l
A
C
_
A
_
0
0
2
3
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
347
anddonotcontainahyphen5.Threetypesofscoresarecomputed.FREQNYTistheaver-ageofwordfrequenciescomputedfromtheback-groundcorpus.Thesecondsetoffeaturesarebasedonthephonememodel.Wecomputetheaverageperplexityofwordsunderthemodel,AVRPHONEMEPERPALL.Inaddition,wealsoor-derthewordsinanarticlebasedondecreasingper-plexityvaluesandtheaverageperplexityofthetop10,20and30wordsinthislistareaddedasfea-tures(AVRPHONEMEPERP10,20,30).Weob-tainsimilarfeaturesfromthelettern-grammodel(AVRCHARPERPALL,AVRCHARPERP10,20,30).Inphonemefeatures,weignorewordsthatdonothaveanentryintheCMUdictionary.Wordpairmeasures:Nextweattempttodetectun-usualcombinationsofwords.Wedothiscalculationonlyforcertaintypesofsyntacticrelations–a)nounsandtheiradjectivemodifiers,B)verbswithadverbmodifiers,C)adjacentnounsinanounphraseandd)verbandsubjectpairs.Countsforco-occurrenceagaincomefromNYT1996articles.Thesyntacticrelationsareobtainedusingtheconstituencyandde-pendencyparsesfromtheStanfordparser(KleinandManning,2003;DeMarneffeetal.,2006).Toavoidtheinfluenceofpropernamesandnamedentities,wereplacethemwithtags(NNPforpropernamesandPERSON,ORG,LOCfornamedentities).Wetreatthewordsforwhichthedependencyholdsasa(auxiliaryword,mainword)pair.Foradjective-nounandadverb-verbpairs,theauxiliaryistheadjectiveoradverb;fornoun-nounpairs,itisthefirstnoun;andforverb-subjectpairs,theauxil-iaryisthesubject.Ourideaistocomputeusualnessscoresbasedonfrequencywithwhichaparticularpairofwordsappearsinthebackground.Specifically,wecomputetheconditionalproba-bilityoftheauxiliarywordgiventhemainwordasthescoreforlikelihoodofobservingthepair.Weconsiderthemainwordasrelatedtothearticletopic,soweusetheconditionalprobabilityofauxil-iarygivenmainwordandnottheotherwayaround.However,theconditionalprobabilityhasnoinfor-mationaboutthefrequencyoftheauxiliaryword.Soweapplyideasfrominterpolationsmoothing(Chen5Wenoticedthatinthisgenreseveralnewwordsarecreatedusinghyphentoconcatenatecommonwords.ADJ-NOUNADV-VERBhypoactiveNNPsuburbssaidplastickywomanintegralwaspsychogenicproblemscollectivedoyoplaittelevisionphysiologicallydosubminimallevelamuckrunehatcheryinvestmentillegitimatelyputNOUN-NOUNSUBJ-VERBspecificationtodayblogsaidauditorysystembriefersaidpalprogramshrsaidsteganographyprogramsknuckleheadsaidwastewatersystemlymphedemahaveautismconferencepermissionshaveTable1:Unusualword-pairsfromdifferentcategoriesandGoodman,1996)andcomputetheconditionalprobabilityasainterpolatedquantitytogetherwiththeunigramprobabilityoftheauxiliaryword.ˆp(aux|main)=λ∗p(aux|main)+(1−λ)∗p(aux)TheunigramandconditionalprobabilitiesarealsosmoothedusingLaplacemethod.WetrainthelambdavaluestooptimizedatalikelihoodusingtheBaumWelchalgorithmandusethepairsfromNYT1997yeararticlesasadevelopmentset.Thelambdavaluesacrossalltypesofpairstendedtobelowerthan0.5givinghigherweighttotheunigramproba-bilityoftheauxiliaryword.Basedonourobservationsonthedevelopmentset,wepickedacutoffof0.0001ontheproba-bility(0.001foradverb-verbpairs)andconsiderphraseswithprobabilitybelowthisvalueasun-usual.Foreachtestarticle,wecomputethenum-berofunusualphrases(totalforallcategories)asafeature(SURP)andalsothisvaluenormal-izedbytotalnumberofwordtokensinthearticle(SURPWD)andnormalizedbynumberofphrases(SURPPH).Wealsocomputefeaturesforindi-vidualpairtypesandineachcase,thenumberofunusualphrasesisnormalizedbythetotalwordsinthearticle(SURPADJNOUN,SURPADVVERB,SURPNOUNNOUN,SURPSUBJVERB).AlistofthetopunusualwordsunderthedifferentpairtypesareshowninTable1.Thesewerecom-putedonpairsfromarandomsetofarticlesfromourcorpus.Severalofthetoppairsinvolvehyphenatedwordswhichareunusualbythemselves,soweonlyshowinthetablethetopwordswithouthyphens.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
3
2
1
5
6
6
6
6
7
/
/
T
l
A
C
_
A
_
0
0
2
3
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
348
Mostofthesefeaturesaresignificantlydifferentbetweenthetwoclasses.ThosewithhighervaluesintheVERYGOODsetinclude:AVRPHONEMEPERPALL,AVRCHARPERP(ALL,10),SURP,SURPPH,SURPWD,SURPADJNOUN,SURPNOUNNOUN,SURPSUBJVERB.TheFREQNYTfeaturehashighervalueintheTYPICALclass.AllthesetrendsindicatethatunusualphrasesareassociatedwiththeVERYGOODcategoryofarticles.3.4Sub-genresThereareseveralsub-genreswithinsciencewriting(Stocking,2010):shortdescriptionsofdiscoveries,longerexplanatoryarticles,narratives,storiesaboutscientists,reportsonmeetings,reviewarticlesandblogposts.Naturally,someofthesesub-genreswillbemoreappealingtoreaders.Toinvestigatethisaspect,wecomputescoresforsomesub-genresofinterest—narrative,attributionandinterview.Narrativetextstypicallyhavecharactersandevents(Nakhimovsky,1988),sowelookforentitiesandpasttenseinthearticles.Wecountthenumberofsentenceswherethefirstverbinsurfaceorderisinthepasttense.Thenamongthesesentences,wepickthosewhichhaveeitherapersonalpronounorapropernounbeforethetargetverb(againinsurfaceorder).TheproportionofsuchsentencesinthetextistakenastheNARRATIVEscore.Wealsodevelopedameasuretoidentifythede-greetowhichthearticle’scontentisattributedtoex-ternalsourcesasopposedtotheauthor’sownstate-ments.Attributiontoothersourcesisfrequentinthenewsdomainsincemanycommentsandopin-ionsarenottheviewsofthejournalist(SemetkoandValkenburg,2000).Forsciencenews,attributionbe-comesmoreimportantsincetheresearchfindingswereobtainedbyscientistsandreportedinasecond-handmannerbythejournalists.TheATTRIBscoreistheproportionofsentencesinthearticlethathaveaquotesymbol,orthewords‘said’and‘says’.Wealsocomputeascoretoindicateifthearticleistheaccountofaninterview.ThereareeasycluesinNYTforthisgenrewithparagraphsintheinter-viewportionofthearticlebeginningwitheither‘Q.’(question)or‘A.’(Antwort).Wecountthetotalnum-berof‘Q.’and‘A.’prefixescombinedanddividethevaluebythetotalnumberofsentences(INTER-VIEW).Wheneitherthenumberof‘Q.’tagsiszeroor‘A.’tagsiszero,thescoreissettozero.AllthreescoresaresignificantlyhigherfortheTYPICALclass.3.5AffectivecontentSomearticles,forexamplethosedetailingresearchonhealth,crime,ethics,canprovokeemotionalre-actionsinreadersasshowninthesnippetbelow.Medicineisaconstanttrade-off,astruggletocurethedis-easewithoutkillingthepatientfirst.Chemotherapy,forexam-ple,involvespurposelypoisoningsomeone–butwiththeex-pectationthattheshort-terminjurywillbeoutweighedbytheeventualbenefits.Wecomputeaffect-relatedfeaturesusingthreelexicons.TheMPQA(Wilsonetal.,2005)andGen-eralInquirer(Stoneetal.,1966)givelistsofpositiveandnegativesentimentwords.Thethirdresourceisemotion-relatedwordsfromFrameNet(Bakeretal.,1998).Thesizesoftheselexiconare8,221,5,395,and653wordsrespectively.Wecomputethecountsofpositive,negative,polar,andemotionwords,eachnormalizedbythetotalnumberofcon-tentwordsinthearticle(POSPROP,NEGPROP,PO-LARPROP,EMOTPROP).Wealsoincludethepro-portionofemotionandpolarwordstakentogether(POLAREMOTPROP)andtheratiobetweencountofpositiveandnegativewords(POSBYNEG).ThefeatureswithhighervaluesintheVERYGOODclassareNEGPROP,POLARPROP,EMOTPOLARPROP.InTYPICALarticles,POSBYNEG,EMOTPROPhavehighervalues.VERYGOODarticleshavemoresentimentwords,mostlyskewedtowardsnegativesentiment.3.6AmountofresearchcontentForalayaudience,asciencewriterpresentsonlythemostrelevantfindingsandmethodsfromaresearchstudyandinterleavesresearchinformationwithde-tailsabouttherelevanceofthefinding,peoplein-volvedintheresearchandgeneralinformationaboutthetopic.Asaresult,thedegreeofexplicitresearchdescriptionsinthearticlesvariesconsiderably.Totesthowthisaspectisassociatedwithqual-ity,wecountreferencestoresearchmethodsandre-searchersinthearticle.Weusetheresearchdictio-narythatweintroducedinSection2asthesourceofresearch-relatedwords.Wecountthetotalnum-
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
3
2
1
5
6
6
6
6
7
/
/
T
l
A
C
_
A
_
0
0
2
3
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
349
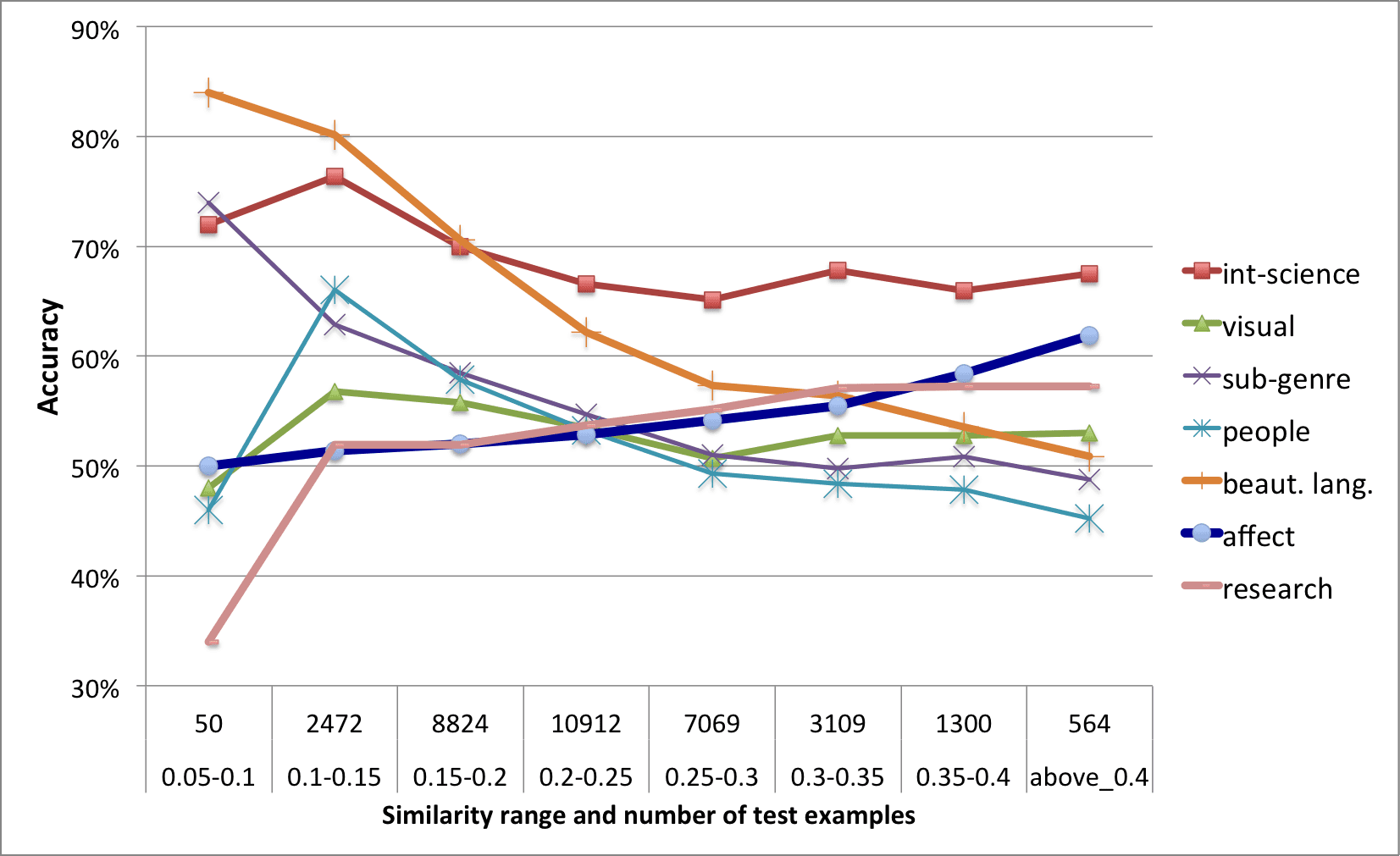
berofwordsinthearticlethatmatchthedictionary(RESTOTAL)andalsothenumberofuniquematch-ingwords(RESUNIQ).WealsonormalizethesecountsbythetotalwordsinthearticleandcreatefeaturesRESTOTALPROPandRESUNIQPROP.AllfourfeatureshavesignificantlyhighervaluesintheVERYGOODarticleswhichindicatethatgreatarticlesarealsoassociatedwithagreatamountofdirectresearchcontentandexplanations.4ClassificationaccuracyWetrainedclassifiersusingalltheabovefeaturesforforthetwosettings–‘any-topic’and‘same-topic’in-troducedinSection2.3.Thebaselinerandomaccu-racyinbothcasesis50%.WeuseaSVMclassi-fierwitharadialbasiskernel(RDevelopmentCoreTeam,2011)andparametersweretunedusingcrossvalidationonthedevelopmentdata.Thebestparameterswerethenusedtoclassifythetestsetina10foldcross-validationsetting.Wedi-videthetestsetinto10parts,trainon9partsandtestontheheld-outdata.Theaverageaccuraciesinthe10experimentsare75.3%accuracyforthe‘any-topic’setup,and68%accuracyforthetopic-paired‘same-topic’setup.Theseaccuraciesareconsider-ableimprovementsoverthebaseline.The‘same-topic’datacontainsarticlepairswithvaryingsimilarity.Soweinvestigatetherelationshipbetweentopicsimilarityandaccuracyofpredictionmorecloselyforthissetting.Wedividethearticlepairsintobinsbasedonthesimilarityvalue.Wecomputethe10-foldcrossvalidationpredictionsus-ingthedifferentfeatureclassesaboveandcollectthepredictedvaluesacrossallthefolds.Thenwecom-puteaccuracyofexampleswithineachbin.TheseresultsareplottedinFigure1.int-sciencereferstothefullsetoffeaturesandtheresultsfromthesixfeatureclassesarealsoindicated.Asthesimilarityincreases,thepredictiontaskbe-comesharder.Thecombinationofallfeaturesgives66%accuracyforpairsabove0.4similarityand74%whenthesimilarityislessthan0.15.Mostindivid-ualfeatureclassesalsoshowasimilartrend.Thisresultisunderstandablebecausearticlesonsimi-lartopicscouldexhibitsimilarproperties.Forex-ample,twoarticlesabout‘controversiessurround-ingvaccination’arelikelytohavesimilarlevelsofpeople-orientednatureorwritteninanarrativestyleFigure1:Accuracyonpairswithdifferentsimilarityinthesamewayastwospace-relatedarticlesarebothlikelytocontainhighvisualcontent.Therearehowevertwoexceptions—affectandresearch.Forthesefeatures,theaccuraciesimprovewithhighersimilarity;affectfeaturesgive51%forpairswithsimilarity0.1and62%forpairsabove0.4similar-ity,accuracyofresearchfeaturesgoesfrom52%to57%forthesamesimilarityvalues.Thisfindingil-lustratesthatevenarticlesonverysimilartopicscanbewrittendifferently,withthearticlesbytheexcel-lentauthorsassociatedwithgreaterdegreeofsenti-ment,anddeeperstudyoftheresearchproblem.5CombiningaspectsofarticlequalityWenowcompareandcombinethegenre-specificinterest-sciencefeatures(41total)withthosedis-cussedinworkonreadability,well-writtennature,interestandtopicclassification.Readability(16Merkmale):WetestthefullsetofreadabilityfeaturesstudiedinPitlerandNenkova(2008),involvingtoken-typeratio,wordandsen-tencelength,languagemodelfeatures,cohesionscoresandsyntacticestimatesofcomplexity.Well-writtennature(23Merkmale):Forwell-writtennature,weusetwoclassesoffeatures,bothrelatedtodiscourse.Oneistheprobabilitiesofdif-ferenttypesofentitytransitionsfromtheEntityGridmodel(BarzilayandLapata,2008)whichwecom-putewiththeBrownCoherenceToolkit(Elsneretal.,2007).Theotherclassoffeaturesarethosede-finedinPitlerandNenkova(2008)forlikelihoodsandcountsofexplicitdiscourserelations.Weiden-tifiedtherelationsfortextsinourcorpususingthe
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
3
2
1
5
6
6
6
6
7
/
/
T
l
A
C
_
A
_
0
0
2
3
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
350
AddDiscoursetool(PitlerandNenkova,2009).Interestingfiction(22Merkmale):arethoseintro-ducedbyMcIntyreandLapata(2009)forpredictinginterestratingsonfairytales.Theyincludecountsofsyntacticitemsandrelations,andtokencategoriesfromtheMRCpsycholinguisticdatabase.Wenor-malizeeachfeaturebythetotalwordsinthearticle.Content:featuresarebasedonthewordspresentinthearticles.Wordfeaturesarestandardincontent-basedrecommendationsystems(Pazzanietal.,1996;MooneyandRoy,2000)wheretheyareusedtopickoutarticlessimilartothosewhichauserhasalreadyread.Inourworkthefeaturesarethemostfrequentnwordsinourcorpusafterremovingthe50mostfrequentones.Theword’scountinthearticleisthefeaturevalue.Notethatwordfeaturesindicatetopicaswellasothercontentinthearticlesuchassentimentandresearch.Arandomsampleofthewordfeaturesforn=1000isshownbelowandreflectsthisaspect.“matter,Serie,wear,nation,ac-count,surgery,hoch,receive,remember,support,worry,enough,office,prevent,biggest,customer”.Table2comparestheaccuraciesofSVMclassi-fierstrainedonfeaturesfromdifferentclassesandtheircombinations.6Thereadability,well-writtennatureandinterestingfictionclassesprovidegoodaccuracies60%andabove.Thegenre-specificinteresting-sciencefeaturesareindividuallymuchstrongerthantheseclasses.Differentwritingas-pects(withoutcontent)areclearlycomplementaryandwhencombinedgive76%to79%accuracyforthe‘any-topic’taskand74%forthetopicpairstask.Thesimplebagofwordsfeaturesworkremark-ablywellgiving80%accuracyinbothsettings.Asmentionedbeforethesewordfeaturesareamixoftopicindicatorsaswellasothercontentofthear-ticles,ie.,theyalsoimplicitlyindicateanimacy,re-searchorsentiment.Butthehighaccuracyofwordfeaturesaboveallthewritingcategoriesindicatesthattopicplaysanimportantroleinarticlequality.However,despitethehighaccuracy,wordfeaturesarenoteasilyinterpretableindifferentclassesre-latedtowritingaswehavedonewithotherwritingfeatures.Further,thetotalsetofwritingfeaturesis6Forclassifiersinvolvingcontentfeatures,wedidnottunetheSVMparametersbecauseofthesmallsizeofdevelopmentdatacomparedtonumberoffeatures.DefaultSVMsettingswereusedinstead.FeaturesetAnyTopicSameInteresting-science75.368.0Readable65.563.0Well-written59.159.9Interesting-fiction67.962.8Readable+well-writ64.764.3Readable+well-writ+Int-fict71.070.3Readable+well-writ+Int-sci79.573.2Allwritingaspects76.774.7Content(500Wörter)81.779.4Content(1000Wörter)81.282.1Combination:Writing(alle)+Content(1000w)Infeaturevector82.6*84.0*Sumofconfidencescores81.684.9Oracle87.693.8Table2:Accuracyofdifferentarticlequalityaspectsonly102incontrastto1000wordfeatures.Inourinterest-sciencefeatureset,weaimedtohighlighthowwellsomeoftheaspectsconsideredimportanttogoodsciencewritingcanpredictqualityratings.Wealsocombinedwritingandwordfeaturestomixtopicwithwritingrelatedpredictors.Wedothecombinationinthreewaysa)wordandwritingfea-turesareincludedtogetherinthefeaturevector;B)twoseparateclassifiersaretrained(oneusingwordfeaturesandtheotherusingwritingones)andthesumofconfidencemeasuresisusedtodecideonthefinalclass;C)anoraclemethod:twoclassifiersaretrainedjustasinoption(B)butwhentheydisagreeontheclass,wepickthecorrectlabel.Theoraclemethodgivesasimpleupperboundontheaccuracyobtainablebycombination.Thesevaluesare87%for‘any-topic’andahigher93.8%for‘same-topic’.Theautomaticmethods,bothfeaturevectorcombi-nationandclassifiercombinationalsogivebetterac-curaciesthanonlythewordorwritingfeatures.Theaccuraciesforthefoldsfrom10foldcrossvalida-tioninthefeaturevectorcombinationmethodwerealsofoundtobesignificantlyhigherthanthosefromwordfeaturesonly(usingapairedWilcoxonsigned-ranktest).Thereforebothtopicandwritingfeaturesareclearlyusefulforidentifyinggreatarticles.6ConclusionOurworkisasteptowardsmeasuringoverallarti-clequalitybyshowingthecomplementarybenefitsofgeneralanddomain-specificwritingmeasuresaswellasindicatorsofarticletopic.Infutureweplantofocusondevelopmentofmorefeaturesaswellasbettermethodsforcombiningdifferentmeasures.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
3
2
1
5
6
6
6
6
7
/
/
T
l
A
C
_
A
_
0
0
2
3
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
351
ReferencesC.F.Baker,C.J.Fillmore,andJ.B.Lowe.1998.Theberkeleyframenetproject.InProceedingsofCOLING-ACL,pages86–90.Z.Bao,B.Kimelfeld,andY.Li.2011.Agraphap-proachtospellingcorrectionindomain-centricsearch.InProceedingsofACL-HLT,pages905–914.R.BarzilayandM.Lapata.2008.Modelinglocalcoher-ence:Anentity-basedapproach.ComputationalLin-guistics,34(1):1–34.R.Barzilay,N.Elhadad,andK.McKeown.2002.Inferringstrategiesforsentenceorderinginmulti-documentsummarization.JournalofArtificialIntel-ligenceResearch,17:35–55.D.M.Blei,A.Y.Ng,andM.I.Jordan.2003.Latentdirichletallocation.theJournalofmachineLearningresearch,3:993–1022.D.Blum,M.Knudson,andR.M.Henig,editors.2006.Afieldguideforsciencewriters:theofficialguideofthenationalassociationofsciencewriters.OxfordUniversityPress,NewYork.E.BrillandR.C.Moore.2000.Animprovederrormodelfornoisychannelspellingcorrection.InProceedingsofACL,pages286–293.S.F.ChenandJ.Goodman.1996.Anempiricalstudyofsmoothingtechniquesforlanguagemodeling.InProceedingsofACL,pages310–318.S.CucerzanandE.Brill.2004.Spellingcorrectionasaniterativeprocessthatexploitsthecollectiveknowledgeofwebusers.InProceedingsofEMNLP,pages293–300.R.DaleandA.Kilgarriff.2010.Helpingourown:textmassagingforcomputationallinguisticsasanewsharedtask.InProceedingsofINLG,pages263–267.M.C.DeMarneffe,B.MacCartney,andC.D.Man-ning.2006.Generatingtypeddependencyparsesfromphrasestructureparses.InProceedingsofLREC,vol-ume6,pages449–454.P.Diederich.1974.MeasuringGrowthinEnglish.Na-tionalCouncilofTeachersofEnglish.M.Elsner,J.Austerweil,andE.Charniak.2007.Auni-fiedlocalandglobalmodelfordiscoursecoherence.InProceedingsofNAACL-HLT,pages436–443.J.R.Finkel,T.Grenager,andC.Manning.2005.In-corporatingnon-localinformationintoinformationex-tractionsystemsbygibbssampling.InProceedingsofACL,pages363–370.R.Flesch.1948.Anewreadabilityyardstick.JournalofAppliedPsychology,32:221–233.A.C.Graesser,D.S.McNamara,M.M.Louwerse,andZ.Cai.2004.Coh-Metrix:Analysisoftextonco-hesionandlanguage.BehaviorResearchMethodsIn-strumentsandComputers,36(2):193–202.H.JiandD.Lin.2009.Genderandanimacyknowledgediscoveryfromweb-scalen-gramsforunsupervisedpersonnamedetection.InProceedingsofPACLIC.D.KleinandC.D.Manning.2003.Accurateunlexical-izedparsing.InProceedingsofACL,pages423–430.S.M.Kosslyn.1980.Imageandmind.HarvardUniver-sityPress.M.Lapata.2003.Probabilistictextstructuring:Experi-mentswithsentenceordering.InProceedingsofACL,pages545–552.C.LinandE.Hovy.2000.Theautomatedacquisitionoftopicsignaturesfortextsummarization.InProceed-ingsofCOLING,pages495–501.D.Lin,K.W.Church,H.Ji,S.Sekine,D.Yarowsky,S.Bergsma,K.Patil,E.Pitler,R.Lathbury,V.Rao,K.Dalwani,andS.Narsale.2010.Newtoolsforweb-scalen-grams.InProceedingsofLREC.N.McIntyreandM.Lapata.2009.Learningtotelltales:Adata-drivenapproachtostorygeneration.InPro-ceedingsofACL-IJCNLP,pages217–225.R.J.MooneyandL.Roy.2000.Content-basedbookrecommendingusinglearningfortextcategorization.InProceedingsofthefifthACMconferenceonDigitallibraries,pages195–204.A.Nakhimovsky.1988.Aspect,aspectualclass,andthetemporalstructureofnarrative.ComputationalLin-guistics,14(2):29–43,June.M.Pazzani,J.Muramatsu,andD.Billsus.1996.Syskill&Webert:Identifyinginterestingwebsites.InPro-ceedingsofAAAI,pages54–61.E.PitlerandA.Nenkova.2008.Revisitingreadabil-ity:Aunifiedframeworkforpredictingtextquality.InProceedingsofEMNLP,pages186–195.E.PitlerandA.Nenkova.2009.Usingsyntaxtodis-ambiguateexplicitdiscourseconnectivesintext.InProceedingsofACL-IJCNLP,pages13–16.RDevelopmentCoreTeam,2011.R:ALanguageandEnvironmentforStatisticalComputing.RFoundationforStatisticalComputing.D.Ramage,D.Hall,R.Nallapati,andC.D.Manning.2009.Labeledlda:Asupervisedtopicmodelforcreditattributioninmulti-labeledcorpora.InProceed-ingsofEMNLP,pages248–256.A.RozovskayaandD.Roth.2010.Generatingconfu-sionsetsforcontext-sensitiveerrorcorrection.InPro-ceedingsofEMNLP,pages961–970.E.Sandhaus.2008.Thenewyorktimesannotatedcor-pus.CorpusnumberLDC2008T19,LinguisticDataConsortium,Philadelphia.S.SchwarmandM.Ostendorf.2005.Readinglevelas-sessmentusingsupportvectormachinesandstatisticallanguagemodels.InProceedingsofACL,pages523–530.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
3
2
1
5
6
6
6
6
7
/
/
T
l
A
C
_
A
_
0
0
2
3
2
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
352
H.A.SemetkoandP.M.Valkenburg.2000.Framingeu-ropeanpolitics:Acontentanalysisofpressandtelevi-sionnews.Journalofcommunication,50(2):93–109.V.Spandel.2004.CreatingWritersThrough6-TraitWriting:AssessmentandInstruction.AllynandBa-con,Inc.S.H.Stocking.2010.TheNewYorkTimesReader:Sci-enceandTechnology.CQPress,WashingtonDC.P.J.Stone,J.Kirsh,andCambridgeComputerAsso-ciates.1966.TheGeneralInquirer:AComputerAp-proachtoContentAnalysis.MITPress.J.R.TetreaultandM.Chodorow.2008.Theupsanddownsofprepositionerrordetectionineslwriting.InProceedingsofCOLING,pages865–872.L.vonAhnandL.Dabbish.2004.Labelingimageswithacomputergame.InProceedingsofCHI,pages319–326.R.L.Weide.1998.Thecmupronunciationdictio-nary,release0.6.http://www.speech.cs.cmu.edu/cgi-bin/cmudict.T.Wilson,J.Wiebe,andP.Hoffmann.2005.Recogniz-ingcontextualpolarityinphrase-levelsentimentanal-ysis.InProceedingsofHLT-EMNLP,pages347–354.M.Wilson.1988.MRCpsycholinguisticdatabase:Machine-usabledictionary,version2.00.BehaviorResearchMethods,20(1):6–10.