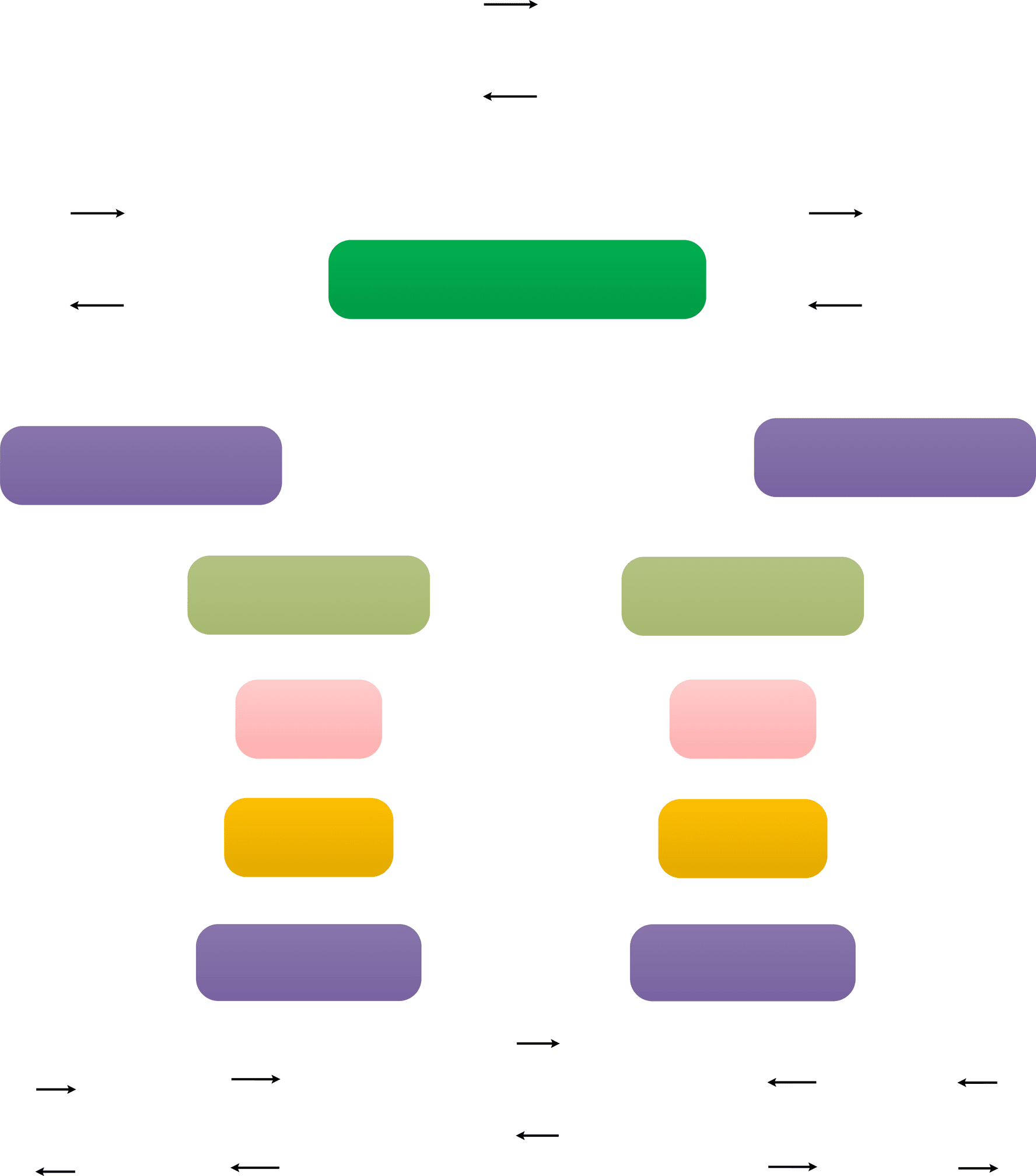Synchronous Bidirectional Neural Machine Translation
Long Zhou1,2,
Jiajun Zhang1,2∗, Chengqing Zong1,2,3
1National Laboratory of Pattern Recognition, CASIA, Peking, China
2University of Chinese Academy of Sciences, Peking, China
3CAS Center for Excellence in Brain Science and Intelligence Technology, Shanghai, China
{long.zhou, jjzhang, cqzong}@nlpr.ia.ac.cn
Abstrakt
Existing approaches to neural machine trans-
lation (NMT) generate the target
Sprache
sequence token-by-token from left to right.
Jedoch, this kind of unidirectional decod-
ing framework cannot make full use of the
target-side future contexts which can be pro-
duced in a right-to-left decoding direction,
and thus suffers from the issue of unbal-
anced outputs. In diesem Papier, we introduce
a synchronous bidirectional–neural machine
Übersetzung (SB-NMT) that predicts its outputs
using left-to-right and right-to-left decoding
simultaneously and interactively, um zu
leverage both of the history and future in-
formation at the same time. Konkret, Wir
first propose a new algorithm that enables syn-
chronous bidirectional decoding in a single
Modell. Dann, we present an interactive decod-
ing model in which left-to-right (right-to-left)
generation does not only depend on its pre-
viously generated outputs, but also relies on
future contexts predicted by right-to-left (links-
to-right) decoding. We extensively evaluate
the proposed SB-NMT model on large-scale
NIST Chinese-English, WMT14 English-
Deutsch, and WMT18 Russian-English trans-
lation tasks. Experimental results demonstrate
that our model achieves significant improve-
ments over the strong Transformer model
von 3.92, 1.49, Und 1.04 BLEU points, bzw-
aktiv, and obtains the state-of-the-art per-
formance on Chinese-English and English-
German translation tasks.1
1
Einführung
Neural machine translation has significantly im-
proved the quality of machine translation in recent
Jahre (Sutskever et al., 2014; Bahdanau et al.,
2015; Zhang and Zong, 2015; Wu et al., 2016;
Gehring et al., 2017; Vaswani et al., 2017). Recent
approaches to sequence-to-sequence learning typ-
ically leverage recurrence (Sutskever et al., 2014),
convolution (Gehring et al., 2017), or attention
(Vaswani et al., 2017) as basic building blocks.
Typically, NMT adopts the encoder-decoder
architecture and generates the target translation
from left to right. Despite their remarkable suc-
Prozess, NMT models suffer from several weak-
nesses (Koehn and Knowles, 2017). One of the
most prominent issues is the problem of unbal-
anced outputs in which the translation prefixes are
better predicted than the suffixes (Liu et al., 2016).
We analyze translation accuracy of the first and
last 4 tokens for left-to-right (L2R) and right-to-
links (R2L) directions, jeweils. Wie gezeigt in
Tisch 1, the statistical results show that L2R per-
forms better in the first 4 tokens, whereas R2L
translates better in terms of the last 4 tokens.
This problem is mainly caused by the left-to-
right unidirectional decoding, which conditions
each output word on previously generated out-
puts only, but leaving the future information from
target-side contexts unexploited during transla-
tion. The future context is commonly used in
reading and writing in human cognitive process
∗Corresponding author.
com/wszlong/sb-nmt.
1The source code is available at https://github.
91
Transactions of the Association for Computational Linguistics, Bd. 7, S. 91−105, 2019. Action Editor: George Foster.
Submission batch: 8/2018; Revision batch: 10/2018; Published 4/2019.
C(cid:13) 2019 Verein für Computerlinguistik. Distributed under a CC-BY 4.0 Lizenz.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
5
6
1
9
2
3
6
6
5
/
/
T
l
A
C
_
A
_
0
0
2
5
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
Modell
L2R
R2L
Der Erste 4 tokens
40.21%
35.67%
The last 4 tokens
35.10%
39.47%
Tisch 1: Translation accuracy of the first 4 tokens
and last 4 tokens in NIST Chinese-English translation
tasks. L2R denotes left-to-right decoding and R2L
means right-to-left decoding for conventional NMT.
(Xia et al., 2017), and it is crucial to avoid under-
Übersetzung (Tu et al., 2016; Mi et al., 2016).
To alleviate the problems, existing studies usu-
ally used independent bidirectional decoders for
NMT (Liu et al., 2016; Sennrich et al., 2016A).
Most of them trained two NMT models with left-
to-right and right-to-left directions, jeweils.
they translated and re-ranked candidate
Dann,
translations using two decoding scores together.
More recently, Zhang et al. (2018) vorgeführt
an asynchronous bidirectional decoding algo-
rithm for NMT, which extended the conventional
encoder-decoder framework by utilizing a back-
ward decoder. Jedoch, these methods are more
complicated than the conventional NMT frame-
work because they require two NMT models or
decoders. Außerdem, the L2R and R2L de-
coders are independent from each other (Liu et al.,
2016), or only the forward decoder can utilize
information from the backward decoder (Zhang
et al., 2018). It is therefore a promising direction
to design a synchronous bidirectional decoding
algorithm in which L2R and R2L generations can
interact with each other.
Entsprechend, we propose in this paper a novel
Rahmen (SB-NMT) that utilizes a single de-
coder to bidirectionally generate target sentences
simultaneously and interactively. Wie gezeigt in
Figur 1, two special labels ((cid:104)l2r(cid:105) Und (cid:104)r2l(cid:105)) bei
the beginning of the target sentence guide trans-
lating from left to right or right to left, und das
decoder in each direction can utilize the previ-
ously generated symbols of bidirectional decod-
ing when generating the next token. Taking L2R
decoding as an example, at each moment, the gen-
eration of the target word (z.B., y3) does not only
rely on previously generated outputs (y1 and y2)
of L2R decoding, but also depends on previously
predicted tokens (yn and yn−1) of R2L decod-
ing. Compared with the previous related NMT
Modelle, our method has the following advan-
tages: 1) We use a single model (one encoder and
one decoder) to achieve the decoding with left-
Figur 1: Illustration of the decoder in the synchronous
bidirectional NMT model. L2R denotes left-to-right
decoding guided by the start token (cid:104)l2r(cid:105) and R2L
means right-to-left decoding indicated by the start
token (cid:104)r2l(cid:105). SBAtt is our proposed synchronous bi-
Die
directional attention (see § 3.2). Zum Beispiel,
generation of y3 does not only rely on y1 and y2, Aber
also depends on yn and yn−1 of R2L.
to-right and right-to-left generation, which can
be processed in parallel. 2) Via the synchronous
bidirectional attention model (SBAtt, §3.2), unser
proposed model is an end-to-end joint framework
and can optimize bidirectional decoding simulta-
neously. 3) Compared with two-phase decoding
scheme in previous work, our decoder is faster and
more compact, using one beam search algorithm.
Konkret, we make the following contribu-
tions in this paper:
• We propose a synchronous bidirectional
NMT model
that adopts one decoder to
generate outputs with left-to-right and right-
to-left directions simultaneously and interac-
aktiv. To the best of our knowledge, this is
the first work to investigate the effectiveness
of a single NMT model with synchronous
bidirectional decoding.
• Extensive experiments on NIST Chinese-
English, WMT14 English-German and WMT18
Russian-English translation tasks demon-
strate that our SB-NMT model obtains
significant
improvements over the strong
Transformer model by 3.92, 1.49, Und 1.04
BLEU points, jeweils. Insbesondere, unser
approach separately establishes the state-of-
the-art BLEU score of 51.11 Und 29.21 An
Chinese-English and English-German trans-
lation tasks.
2 Hintergrund
In diesem Papier, we build our model based on the
powerful Transformer (Vaswani et al., 2017) mit
92
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
5
6
1
9
2
3
6
6
5
/
/
T
l
A
C
_
A
_
0
0
2
5
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
Figur 2: (links) Scaled Dot-Product Attention. (Rechts)
Multi-Head Attention.
an encoder-decoder framework, where the en-
coder network first transforms an input sequence
of symbols x = (x1, x2, …, xn) to a sequence
of continues representations z = (z1, z2, …, zn),
from which the decoder generates an output se-
quence y = (y1, y2, …, ym) one element at a time.
Insbesondere, relying entirely on the multi-head
attention mechanism, the Transformer with beam
search algorithm achieves the state-of-the-art
results for machine translation.
Multi-head attention allows the model to jointly
attend to information from different representa-
tion subspaces at different positions. It operates
on queries Q, keys K, and values V . For multi-
head intra-attention of encoder or decoder, all of
Q, K, V are the output hidden-state matrices of
the previous layer. For multi-head inter-attention
of the decoder, Q are the hidden states of the pre-
vious decoder layer, and K-V pairs come from
the output (z1, z2, …, zn) of the encoder.
Formally, multi-head attention first obtains h
different representations of (Qi, Ki, Vi). Specif-
isch, for each attention head i, we project the
hidden-state matrix into distinct query, key, Und
value representations Qi = QW Q
, Ki = KW K
,
ich
ich
Vi = V W V
, jeweils. Then we perform scaled
ich
dot-product attention for each representation,
concatenate the results, and project the concate-
nation with a feed-forward layer.
MultiHead(Q, K, V ) = Concati(headi)W O
, V W V
ich )
headi = Attention(QW Q
ich , KW K
ich
(1)
Figur 3: Illustration of the standard beam search
algorithm with beam size 4. The black blocks denote
the ongoing expansion of the hypotheses.
Scaled dot-product attention can be described
as mapping a query and a set of key-value pairs
to an output. Konkret, we can then multiply
query Qi by key Ki to obtain an attention weight
Matrix, which is then multiplied by value Vi
for each token to obtain the self-attention token
representation. As shown in Figure 2, scaled dot-
product attention operates on a query Q, a key K,
and a value V as:
Attention(Q, K, V ) = Softmax
(cid:19)
(cid:18) QKT
√
dk
V
(2)
where dk is the dimension of the key. For the sake
of brevity, we refer the reader to Vaswani et al.
(2017) for more details.
Standard Beam Search Given the trained
model and input sentence x, we usually employ
beam search or greedy search (beam size = 1)
to find the best translation (cid:98)y = argmaxyP (j|X).
Beam size N is used to control the search space
by extending only the top-N hypotheses in the
current stack. As shown in Figure 3, the blocks
represent the four best token expansions of the
previous states, and these token expansions are
sorted top-to-bottom from most probable to least
probable. We define a complete hypothesis as
a hypothesis which outputs EOS, where EOS
is a special target token indicating the end of
Satz. With the above settings, the translation
y is generated token-by-token from left to right.
3 Our Approach
where W Q
ich
projection matrices.
, W K
ich
, W V
ich
, and W O are parameter
In diesem Abschnitt, we will introduce the approach of
synchronous bidirectional NMT. Our goal is to
93
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
5
6
1
9
2
3
6
6
5
/
/
T
l
A
C
_
A
_
0
0
2
5
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
design a synchronous bidirectional beam search
Algorithmus (§3.1) which generates tokens with
both L2R and R2L decoding simultaneously and
interactively using a single model. The central
module is the synchronous bidirectional atten-
tion (SBAtt, see §3.2). By using SBAtt, the two
decoding directions in one beam search process
can help and interact with each other, and can
make full use of the target-side history and future
information during translation. Dann, we apply
our proposed SBAtt to replace the multi-head
intra-attention in the decoder part of Transformer
Modell (§3.3), and the model is trained end-to-end
by maximum likelihood using stochastic gradient
descent (§3.4).
3.1 Synchronous Bidirectional Beam Search
Figur 4 illustrates the synchronous bidirectional
beam search process with beam size 4. With two
special start tokens which are optimized during
the training process, we let half of the beam
keep decoding from left to right guided by the
label (cid:104)l2r(cid:105), and allow the other half beam to
decode from right to left, indicated by the label
(cid:104)r2l(cid:105). Wichtiger, via the proposed SBAtt
(§3.2) Modell, L2R (R2L) generation does not only
depend on its previously generated outputs, Aber
also relies on future contexts predicted by R2L
(L2R) decoding.
Beachten Sie, dass (1) at each time step, we choose the
best items of the half beam from L2R decoding
and the best items of the half beam from R2L
decoding to continue expanding simultaneously;
(2) L2R and R2L beams should be thought of
as parallel, with SBAtt computed between items
of 1-best L2R and R2L, items of 2-best L2R and
R2L, and so on2; (3) the black blocks denote
the ongoing expansion of the hypotheses, Und
decoding terminates when the end-of-sentence
flag EOS is predicted;
in our decoding
Algorithmus,
the complete hypotheses will not
participate in subsequent SBAtt, and the L2R
hypothesis attended by R2L decoding may change
at different time steps, while the ongoing partial
hypotheses in both directions of SBAtt always
share the same length; (5) finally, we output the
(4)
2We also did experiments in which all of L2R hypotheses
attend to the 1-best R2L hypothesis, and all
the R2L
hypotheses attend to the 1-best L2R hypothesis. The results
of the two schemes are similar. For the sake of simplicity, Wir
employed the previous scheme.
94
Figur 4: The synchronous bidirectional decoding of
our model. (cid:104)l2r(cid:105) Und (cid:104)r2l(cid:105) are two special labels, welche
indicate the target-side translation direction in L2R and
R2L modes, jeweils. Our model can decode with
both L2R and R2L directions in one beam search by
using SBAtt, simultaneously and interactively. SBAtt
means the synchronous bidirectional attention (§3.2)
performed between items of L2R and R2L decoding.
translation result with highest probability from
all complete hypotheses. Intuitively, our model
is able to choose from L2R output or R2L out-
put as final hypothesis according to their model
probabilities, and if an R2L hypothesis wins, Wir
reverse the tokens before presenting it.
3.2 Synchronous Bidirectional Attention
Instead of multi-head intra-attention which pre-
vents future information flow in the decoder to
preserve the auto-regressive property, we propose
a synchronous bidirectional attention (SBAtt)
mechanism. With the two key modules of syn-
chronous bidirectional dot-product attention (§3.2.1)
and synchronous bidirectional multi-head atten-
tion (§3.2.2), SBAtt is capable of capturing and
combining the information generated by L2R and
R2L decoding.
3.2.1 Synchronous Bidirectional
Dot-Product Attention
Figur 5 shows our particular attention Syn-
chronous Bidirectional Dot-Product Attention
←−
Q ]),
(SBDPA). The input consists of queries ([
←−
←−
V ]) welche sind
K ]), and values ([
keys ([
all concatenated by forward (L2R) states and
backward (R2L) Staaten. The new forward state
←−
−→
H can be obtained by
H and backward state
−→
V ;
−→
Q ;
−→
K ;
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
5
6
1
9
2
3
6
6
5
/
/
T
l
A
C
_
A
_
0
0
2
5
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
where λ is a hyper-parameter decided by the
performance on development set.3
−→
H is equal to
−→
H history
Nonlinear Interpolation
in the conventional attention mechanism, Und
−→
H f uture means the attention information between
current hidden state and generated hidden states
of the other decoding. In order to distinguish
two different information sources, we present a
nonlinear interpolation by adding an activation
function to the backward hidden states:
−→
H =
−→
H history + λ ∗ AF (
−→
H f uture)
(5)
where AF denotes activation function, wie zum Beispiel
tanh or relu.
Gate Mechanism We also propose a gate mech-
anism to dynamically control
the amount of
information flow from the forward and backward
contexts. Konkret, we apply a feed-forward
−→
H f uture to
gating layer upon
enrich the nonlinear expressiveness of our model:
−→
H history as well as
−→
H history;
rt, zt = σ(W g[
−→
H history + zt (cid:12)
−→
H = rt (cid:12)
−→
H f uture])
−→
H f uture
(6)
Wo (cid:12) denotes element-wise multiplication. Via
this gating layer, it is able to control how much
past information can be preserved from previous
context and how much reversed information can
be captured from backward hidden states.
Similar to the calculation of forward hidden
←−
H i can be
−→
H i, the backward hidden states
Staaten
computed as follows.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
5
6
1
9
2
3
6
6
5
/
/
T
l
A
C
_
A
_
0
0
2
5
6
P
D
.
←−
H history = Attention(
←−
H f uture = Attention(
←−
H = Fusion(
←−
H history,
←−
K ,
−→
K ,
←−
V )
−→
V )
←−
Q ,
←−
Q ,
←−
H f uture)
(7)
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
where Fusion(·) is the same as introduced in
←−
H can be cal-
Equations 4–6. Beachten Sie, dass
culated in parallel. We refer to the whole proce-
dure formulated in Equation 3 and Equation 7 als
SBDPA(·).
−→
H and
−→
H ;
[
←−
H ] = SBDPA([
←−
Q ;
−→
Q ], [
←−
K ;
−→
K ], [
←−
V ;
−→
V ])
(8)
3Note that we can also set λ to be a vector and learn
λ during training with standard back-propagation, and we
remain it as future exploration.
95
Figur 5: Synchronous bidirectional attention model
based on scaled dot-product attention. It operates on
forward (L2R) and backward (R2L) queries Q, keys K,
values V.
synchronous bidirectional dot-product attention.
−→
H , it can be calcu-
For the new forward state
lated as:
−→
H history = Attention(
−→
H f uture = Attention(
−→
H history,
−→
H = Fusion(
−→
Q ,
−→
Q ,
−→
K ,
←−
K ,
−→
V )
←−
V )
−→
H f uture)
(3)
−→
H history is obtained by using conven-
Wo
tional scaled dot-product attention as introduced
in Gleichung 2, and its purpose is to take ad-
vantage of previously generated tokens, nämlich
−→
H f uture using
history information. We calculate
−→
Q ) and backward key-value pairs
forward query (
←−
←−
V ), which attempts at making use of future
K ,
(
information from R2L decoding as effectively as
possible in order to help predict the current to-
ken in L2R decoding. The role of Fusion(·) (Grün
−→
H history and
block in Figure 5) is to combine
−→
H f uture by using linear interpolation, nonlinear
interpolation, or gate mechanism.
−→
H history and
−→
H f uture
Linear Interpolation
have different importance to prediction of cur-
−→
H history and
rent word. Linear interpolation of
−→
H f uture produces an overall hidden state:
−→
H =
−→
H history + λ ∗
−→
H f uture
(4)
3.2.2 Synchronous Bidirectional
Multi-Head Attention
Multi-head attention consists of h attention
heads, each of which learns a distinct attention
function to attend to all of the tokens in the
sequence, where mask is used for preventing
leftward information flow in decoder. Compared
with the multi-head attention, our inputs are the
concatenation of forward and backward hidden
Staaten. We extend standard multi-headed attention
by letting each head attend to both forward and
backward hidden states, combined via SBDPA(·):
MultiHead([
= Concat([
←−
K ;
←−
Q ;
−→
H 1;
−→
Q ], [
←−
H 1], …, [
−→
K ], [
−→
H h;
←−
V ;
−→
V ])
←−
H h])W O
(9)
−→
H i;
←−
Und [
H i] can be computed as follows, welche
is the biggest difference from conventional multi-
head attention:
−→
H i;
[
←−
H i] = SBDPA([
−→
K ]W K
ich
←−
K ;
[
, [
←−
Q ;
←−
V ;
−→
Q ]W Q
ich ,
−→
V ]W V
ich )
(10)
, W V
, W K
ich
where W Q
i and W O are parameter pro-
ich
jection matrices, which are the same as standard
multi-head attention introduced in Equation 1.
3.3
Integrating Synchronous Bidirectional
Attention into NMT
We apply our synchronous bidirectional attention
to replace the multi-head intra-attention in the
decoder, as illustrated in Figure 6. The neural
encoder of our model is identical to that of the
standard Transformer model. From the source
tokens, learned embeddings are generated which
are then modified by an additive positional
encoding. The encoded word embeddings are
then used as input to the encoder which consists
of N blocks each containing two layers: (1) A
multi-head attention layer (MHAtt), Und (2) A
position-wise feed-forward layer (FFN).
Ist
The bidirectional decoder of our model
extended from the standard Transformer decoder.
For each layer in the bidirectional decoder, Die
lowest sub-layer is our proposed synchronous
bidirectional attention network, and it also uses
residual connections around each of the sublayers,
followed by layer normalization:
d = LayerNorm(sl−1 + SBAtt(sl−1, sl−1, sl−1))
sl
(11)
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
2
5
6
1
9
2
3
6
6
5
/
/
T
l
A
C
_
A
_
0
0
2
5
6
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
8
S
e
P
e
M
B
e
R
2
0
2
3
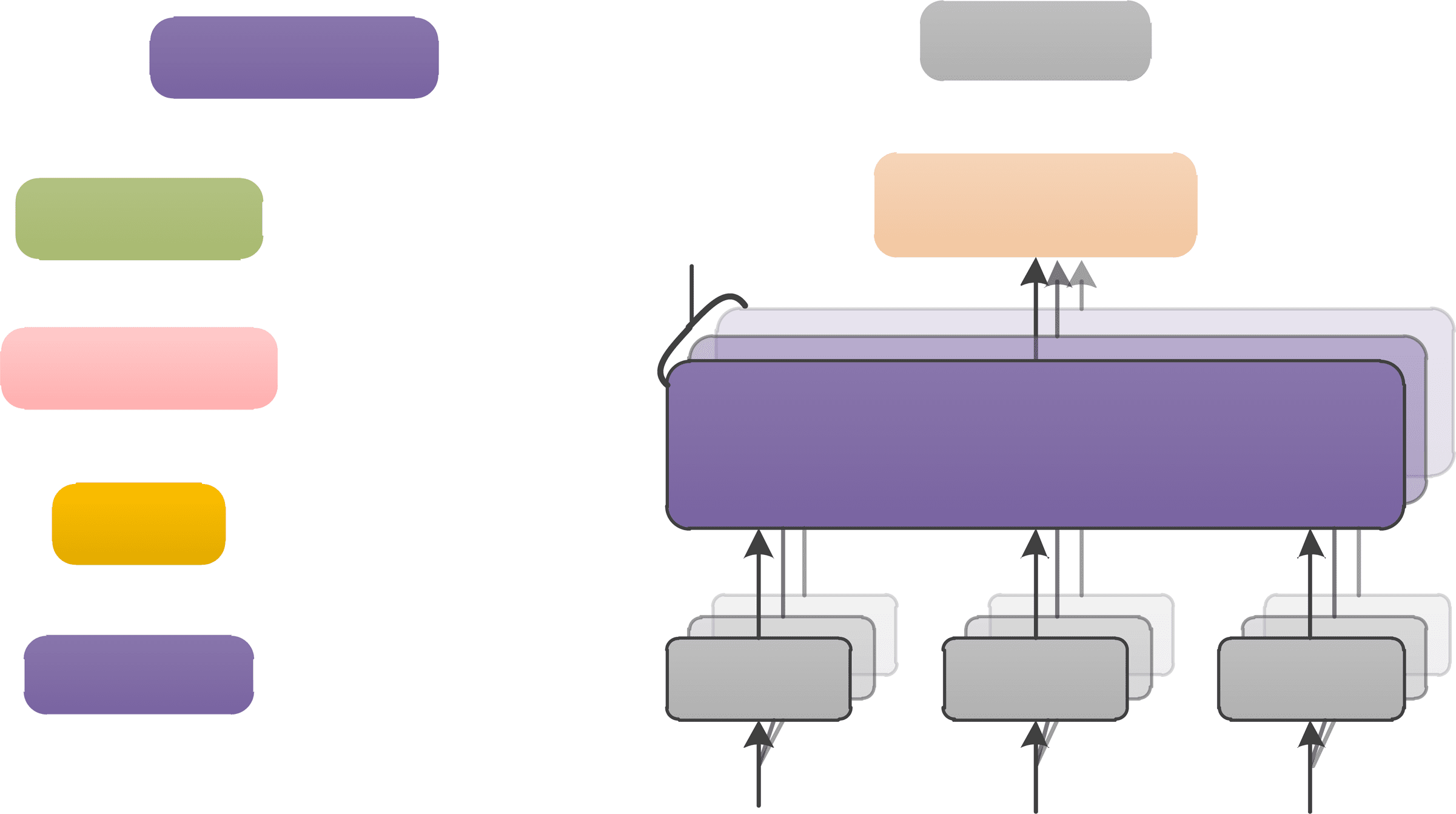
Figur 6: The new Transformer architecture with the
proposed synchronous bidirectional multi-head atten-
tion network, namely SBAtt. The input of decoder is
concatenation of forward (L2R) sequence and back-
ward (R2L) sequence. Note that all bidirectional
information flow in decoder runs in parallel and only
interacts in synchronous bidirectional attention layer.
where l denotes layer depth, and subscript d
means the decoder-informed intra-attention rep-
resentation. SBAtt is our proposed synchronous
bidirectional attention, and sl−1
Zu
[−→s l−1; ←−s l−1] containing forward and backward
hidden states. Zusätzlich, the decoder stacks an-
other two sub-layers to seek translation-relevant
source semantics to bridge the gap between the
source and target language:
is equal
e = LayerNorm(sl
sl
sl = LayerNorm(sl
D + MHAtt(sl
e + FFN(sl
e))
D, hN , hN ))
(12)
where MHAtt denotes the multi-head attention in-
troduced in Equation 1, and we use e to denote
the encoder-informed inter-attention representa-
tion; hN is the source top layer hidden state, Und
FFN means feed-forward networks.
Endlich, we use a linear transformation and
softmax activation to compute the probability of
the next tokens based on sN = [−→s N ; ←−s N ],
96
namely the final hidden states of forward and
backward decoding:
P(−→y j|−→y