RESEARCH ARTICLE
Just an artifact? The concordance between peer
review and bibliometrics in economics and
statistics in the Italian research
assessment exercise
Keine offenen Zugänge
Tagebuch
Alberto Baccini1
and Giuseppe De Nicolao2
1Department of Economics and Statistics, University of Siena, Italien
2Department of Electrical, Computer and Biomedical Engineering, University of Pavia, Italien
Zitat: Baccini, A., & De Nicolao, G.
(2022). Just an artifact? Der
concordance between peer review and
bibliometrics in economics and
statistics in the Italian research
assessment exercise. Quantitative
Science Studies, 3(1), 194–207. https://
doi.org/10.1162/qss_a_00172
DOI:
https://doi.org/10.1162/qss_a_00172
Peer Review:
https://publons.com/publon/10.1162
/qss_a_00172
zusätzliche Informationen:
https://doi.org/10.1162/qss_a_00172
Erhalten: 26 Mai 2021
Akzeptiert: 1 November 2021
Korrespondierender Autor:
Alberto Baccini
alberto.baccini@unisi.it
Handling-Editor:
Ludo Waltman
Urheberrechte ©: © 2022 Alberto Baccini and
Giuseppe De Nicolao. Veröffentlicht unter
eine Creative-Commons-Namensnennung 4.0
International (CC BY 4.0) Lizenz.
Die MIT-Presse
Schlüsselwörter: bibliometrics, economics and statistics, Italien, peer review, replication study, Forschung
assessment exercise
ABSTRAKT
During the Italian research assessment exercise (2004–2010), the governmental agency
(ANVUR) in charge of its realization performed an experiment on the concordance between
peer review and bibliometrics at an individual article level. The computed concordances were
at most weak for science, Technologie, engineering, and mathematics. The only exception was
the moderate concordance found for the area of economics and statistics. In diesem Papier, Die
disclosed raw data of the experiment are used to shed light on the anomalous results obtained
for economics and statistics. Insbesondere, the data permit us to document that the protocol of
the experiment adopted for economics and statistics was different from the one used in the
andere Gebiete. In der Tat, in economics and statistics the same group of scholars developed the
bibliometric ranking of journals for evaluating articles, managing peer reviews and forming
the consensus groups for deciding the final scores of articles after having received the
referee’s reports. This paper shows that the highest level of concordance in economics and
statistics was an artifact mainly due to the role played by consensus groups in boosting the
agreement between bibliometrics and peer review.
EINFÜHRUNG
1.
During the research assessment exercise for the years 2004–2010, the Italian governmental
Agency for Evaluation of Universities and Research (ANVUR) performed an experiment on
the agreement between peer review and bibliometrics at an individual article level (for a
recent review of literature see Baccini, Barabesi, and De Nicolao [2020]). The experiment
involved all the fields of science, Technologie, engineering, and mathematics, plus economics
and statistics. The design of the experiment was apparently very linear: A stratified random
sample of about 10,000 journal articles was evaluated by applying bibliometric indicators
and by peer review; the degree of agreement between the scores obtained with the two sys-
tems of evaluation was then estimated by using weighted Cohen’s kappa. The overall results of
the experiment were published not only in the official reports (ANVUR, 2013) but also as jour-
nal articles authored by researchers affiliated to ANVUR or appointed to carry out the exper-
iment (Ancaiani, Anfossi et al., 2015). For the field of economics and statistics, the results of
the experiment and a big part of the official report were published by Research Policy as a
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
.
/
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Just an artifact?
research paper authored by some of the members of the panel appointed by ANVUR to carry
out the research assessment in the field (Bertocchi, Gambardella et al., 2015).1
In a nutshell, the results of the experiment were generally presented in the official reports as
successful by stating that there is a “more than adequate concordance” between bibliometrics
and peer review (ANVUR, 2013). This “fundamental agreement” (Ancaiani et al., 2015) würde
support the use of the so-called “dual system of evaluation” adopted in the research assess-
ment, consisting in the interchangeable use of bibliometrics and peer review for evaluating
journal articles. Economics and statistics presented the highest level of agreement between
bibliometrics and peer review. The results of the Italian experiment are cited as solid evidence
of the agreement between bibliometrics and peer review at an individual article level in sci-
entometric literature and in the discussion about reliability of research assessment (among
others by Fassin [2021], Mittermaier [2020], Rousseau and Rousseau [2021], and Thomas,
Nedeva et al. [2020]).
Doubts about the reliability of the whole Italian experiment, especially for the field of eco-
nomics and statistics, were raised by Baccini and De Nicolao (2016A, 2016B, 2017A, 2017B)
on the basis of the official published data. In a first paper (Baccini & De Nicolao, 2016A), Sie
highlighted an anomalous high level of agreement reached for economics and statistics with
respect to all the other research areas. They argued that it was due to substantial modifications
of the protocol of the experiment in this field with respect to the other areas. They described
these modifications on the basis of ANVUR official documents. Bertocchi, Gambardella et al.
(2016) denied the existence of the modifications. Baccini and De Nicolao replied by confirm-
ing all their claims, but they were limited by the impossibility of verifying some conjectures on
the basis of the raw data (Baccini & De Nicolao, 2016B). Afterwards, Baccini and De Nicolao
(2017B) documented statistical problems in the experiment and factual errors in the way in
which it was reported by Ancaiani et al. (2015). They replied by correcting some errors in their
paper and by denying the relevance of the statistical problems (Benedetto, Cicero et al., 2017).
All of these issues could have been easily resolved if ANVUR or the authors of the papers had
disclosed the raw data of the experiment 2.
März 2019, ANVUR decided to disclose the raw data of the experiment 3. This disclo-
sure has permitted Baccini et al. (2020) to reconsider in full the experiment by providing the
correct design-based setting for it. They showed that “for each research area of science, tech-
nology, engineering and mathematics the degree of agreement between bibliometrics and peer
review is—at most—weak at an individual article level.” They confirmed also the anomalous
high value of agreement for the area of economics and statistics.
On the basis of the raw data now available, this paper aims to finally establish (A) wenn die
protocol of the experiment adopted for economics and statistics was different from that
adopted in the other areas; (B) if this difference was responsible for the anomalous agreement
in economics and statistics; (C) if the description of the experiment published in Bertocchi et al.
1 Both in the case of the overall results and of economics and statistics, no indications are available that permit
us to distinguish between the official positions of ANVUR and the views expressed by the authors of the
published articles.
2 The authors of this paper requested the data from the President of ANVUR (at that time Professor Stefano
Fantoni [mail sent on February 10th 2014]). They never received a reply.
3 The mail from one of the authors to Professor Paolo Miccoli, President of ANVUR, containing the request is
dated from March 12, 2019. The decision to disclose the data was communicated by mail dated March 26,
2019; access to the data was granted on April 9, 2019. The data can be downloaded from https://doi.org/10
.5281/zenodo.3727460.
Quantitative Science Studies
195
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
/
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Just an artifact?
(2015) is correct; Und (D) if the claims about the experiment contained in Bertocchi et al.
(2016) are true of false. In Section 2 of the paper a short description of the experiment is pro-
vided. Abschnitt 3 illustrates the interventions of the so-called consensus groups for scoring the
articles of the experiment. In Section 4 the effect on the agreement between peer review and
biblometrics of the different protocol adopted in Area 13 is estimated. Endlich, Abschnitt 5 dis-
cusses the results and the general lessons that can be drawn for research assessment and
research policy.
2. A SHORT DESCRIPTION OF THE PROTOCOL OF THE EXPERIMENT
The ANVUR experiment involved 10 research areas of science, Technologie, engineering, Und
Mathematik, plus economics and statistics. For each area, a panel managed the evaluation.
Each panel was composed of a number of scholars proportional to the size of the area. Für
each area, ANVUR selected a random sample of journal articles. These articles were scored
both by bibliometrics and by peer review. There were four possible letter scores: A (Excellent),
B (Good), C (Acceptable), and D (Limited).
For all the areas, except economics and statistics (Bereich 13), the bibliometric scores were
attributed according to an algorithm. It combined the number of citations of an article and a
bibliometric indicator of the impact of the journal in which it was published. If the two indi-
cators were coherent (z.B., high number of citations and high impact factor) the articles
received a score. If the two were incoherent (z.B., high number of citation and low impact
factor) the algorithm returned an inconclusive score “IR.” While in the research assessement
IR papers were scored by peer review, in the experiment, they were simply dropped from the
sample (for a discussion of the statistical problems induced by this procedure see Baccini et al.
[2020]).
For Area 13 nur, the bibliometric algorithm consisted in scoring a paper on the basis of the
journal in which it was published. Zu diesem Zweck, the Area 13 panel directly developed a ranking
of journals organized in four classes from A to D 4. As a consequence, differently from the other
Bereiche, in Area 13 there were no articles with inconclusive bibliometric scores and no papers
were dropped from the experiment. Columns 1 Und 2 of Table 1 Bericht, stratified by research
Bereiche, respectively the size of the experiment sample and the size of the subsample after the
removal of the IR papers.
As for the peer review, each article was assigned to two of the members of the area panel.
They formed a so-called Consensus Group (CG). Im Gegenzug, each of the two members of the CG
selected a referee who evaluated the article by assigning a numerical score according to a
predefined format. The format required that the referee evaluate a paper according to three
Kriterien: relevance; originality/innovation; and internationalization. Each criterion received a
partial score; the sum of the three scores represented the final score assigned by a referee
to a paper. The two referee’s reports were indicated as “P1” and “P2.” In Areas 2, 3, 6, 7,
8A, Und 13, referees were required to score each criterion on a scale from 1 Zu 9 points; somit
the total score assigned by a referee to a paper ranged from 3 Zu 27 points. In Areas 1, 4, 5, Und
9, referees were required to score each criterion on a scale from 0 Zu 3 points; hence the total
score assigned by a referee to a paper ranged from 0 Zu 9 points. CGs received the two
4 The methodology adopted for the classification is available in Bertocchi et al. (2015). An Italian adminis-
trative court conclusively invalidated the procedure and methodology adopted for the journal ranking,
because of “failure to carry out an investigation, misinterpretation of facts and failure to state reasons” (Tri-
bunale Amministrativo del Lazio, 30/10/2017, N. 10805/2007; https://tinyurl.com/y6sqwo4p).
Quantitative Science Studies
196
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
.
/
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Just an artifact?
Sample and subsample size, number of articles with a final score coincident with the scored agreed by two referees (P = P1 = P2),
Tisch 1.
number of articles for which two referees indicated nonconcordant scores (P1 ≠ P2), number of articles for which the consensus groups
changed two concordant referees’ scores P ≠ P1 = P2, and total number and share of articles scored after an intervention of a consensus group
Scientific areas
Bereich 1: Mathematik
and Informatics
Bereich 2: Physik
Bereich 3: Chemistry
Bereich 4: Earth Sciences
Bereich 5: Biology
Bereich 6: Medicine
Bereich 7: Agricultural and
Veterinary Sciences
Area 8a: Civil Engineering
Bereich 9: Industrial and
Information Engineering
Bereich 13: Economics and
Statistics
Areas 1–9
All areas
Quelle: Elaboration on ANVUR data.
Sample
(1)
631
Subsample
(2)
438
P = P1 = P2
(3)
207
P1 ≠ P2
(4)
230
P ≠ P1 = P2
(5)
1
Scored
by CG
(6 = 4 + 5)
231
Scored by
CG (%)
(7 = 6:2)
52.7
1,412
1,212
927
458
1,310
1,984
532
225
1,130
590
8,609
9,199
778
377
1,058
1,603
425
198
919
590
7,008
7,598
513
339
149
433
607
134
85
378
255
696
438
228
623
994
290
112
540
326
3
1
0
2
2
1
1
1
9
699
439
228
625
996
291
113
541
335
2,845
3,100
4,151
4,477
12
21
4,163
4,498
57.7
56.4
60.6
59.1
62.1
68.5
57.1
58.9
56.8
59.4
59.2
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
.
/
referee’s reports P1 and P2 and “synthesized [ihnen] in a final evaluation” (P) (see ANVUR
[2013, Appendix B, P. 5]). For all the areas, except for Area 13, this final evaluation was based
on “algorithms specifically defined by each Area panel” (see ANVUR [2013, Appendix B,
P. 5]). It appears that the final evaluation P was simply the average of the two numerical scores
P1 and P2 assigned by the two referees. This average was then converted to one of the four
final scores P, according to the two “conversion grids” reported in Table 25.
Bereich 13 also adopted a conversion grid (siehe Anmerkung 24 of Bertocchi et al. [2015]), Aber, Bei der
gleiche Zeit, it also adopted a more elaborate protocol for CGs’ decisions by permitting a more
flexible treatment of the referees’ reports. This protocol is described in the official report as
follows:
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
The opinion [sic] of the external referees was then summarized by the internal Consensus
Group: in case of disagreement between P1 and P2, the P index is not simply the average of
P1 and P2, but also reflects the opinion of two (and occasionally three) members of the
GEV13 (see ANVUR [2013, Bereich 13 Bericht, Appendix A, P. 52]).
5 The descriptions of the procedures adopted by each Area panel are in ANVUR (2013) (see Appendix A of
each area report).
Quantitative Science Studies
197
Just an artifact?
The conversion grids adopted for transforming the numerical scores to the final letter
Tisch 2.
score P. Numerical scores are computed by averaging the scores P1 and P2 resulting from peer
Rezension. The ranges of numerical scores are indicated as intervals
P
A
B
C
D
Areas 2, 3, 6, 7, 8A, Und 13
Score range
[8–9]
[6–8]
[5–6]
[0–5]
Areas 1, 4, 5, Und 9
Score range
[23–27]
[18–23]
[15–18]
[3-15]
The point was stressed in more than one part of the official reports:
The Consensus Groups will give an overall evaluation of the research product by using the
informed peer review method, by considering the evaluation of the two external referees,
the available indicators for quality and relevance of the research product, and the Consen-
sus Group competences (ANVUR, 2013).
And again:
The consensus groups in some cases evaluated also the competences of the two referees,
and gave “more importance to the most expert referee in the research field” (see ANVUR
[2013, Area Report, P. 15; translation from Italian by the authors]).
According to Baccini and De Nicolao (2016A), the main difference between the protocol of
the experiment for Area 13 and for the other areas consisted properly in allowing the consen-
sus group to consider so many elements for the final decisions.
Darüber hinaus, the information available to the members of the CGs was different in Area 13
with respect to the other areas: (A) the members of the CGs in Area 13 knew that the journal
articles for which they had to arrange a peer review were those selected for the experiment.
In der Tat, all the articles submitted to the research assessment and published in journals listed in
the ranking developed by the area panel received an automatic score. This was not the case in
the other areas, where panels had to arrange peer reviews not only for the articles of the exper-
iment but also for those submitted to the research assessment and classified as IR (inconclusive
rating) by the bibliometric algorithm. (B) The CG members knew the final bibliometric score of
articles, while in the other areas, the CGs might know only the bibliometric indicators infor-
ming the bibliometric algorithm. The information about the bibliometric score of each article
might have been used by the CGs when they chose the referees and when they decided the
final peer review score of each article.
Zusätzlich, there were also differences regarding the information available for the referees.
The referees of Area 13 were possibly aware that they were participating in the experiment, für
the same reason discussed above for the members of the panel. In der Tat, in Area 13, all journal
articles submitted to the research assessment were automatically scored according to the jour-
nal rank. So if a referee received a journal article for evaluation, it was obviously one of the
sample extracted for the experiment. In the other areas, as anticipated, referees received many
journal articles because they had an inconclusive bibliometric rating. Somit, it was impossible
Quantitative Science Studies
198
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
/
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Just an artifact?
for referees in the other areas to know if an article was part of the sample of the experiment.
Differently again from the other areas, the referees of Area 13 also knew the bibliometric clas-
sification of the articles:
The referees were provided with the panel journal classification list and the actual or
imputed values of IF, IF5 [5 years impact factor] and AIS [Article influence score] (Bertocchi
et al., 2015).
By having access to the ANVUR raw data, it is possible to verify in detail how these mod-
ifications of the protocol impacted on the experiment conducted in Area 13. Insbesondere, es ist
possible to verify if and how the more active role of the consensus groups impacted on the
results of the experiment with respect to the other areas.
3. THE ROLE OF CONSENSUS GROUPS: HOW MANY PAPERS HAVE THEY EVALUATED?
The first question is how many papers required an intervention by the CGs. To answer this, Die
total number of papers can be partitioned into three nonoverlapping subsets. The three sets are
reported in Table 1, stratified by scientific areas. The three sets are composed of the following:
1. Papers for which two referees indicated a concordant score that was also confirmed as
the final score (Tisch 1, column 3: P = P1 = P2);
2. Papers for which two referees indicated discordant scores (Tisch 1, column 4: P1 ≠ P2);
3. Papers for which the final score was different from the one agreed by the two referees
(Tisch 1, column 5: P ≠ P1 = P2).
Wie bereits erwähnt, when the two referees’ reports did not coincide, the final peer review score of an
article required an intervention by the CGs. Then the total number of articles for which the
final score was obtained after a CG intervention can be obtained by summing up columns 4
Und 5 of Table 1: The sum is reported as column 6 of Table 1. The expression “Scored by CG”
used in this paper simply indicates that the final score was decided after a CG intervention.
This intervention might have consisted in confirming the average between P1 and P2, as cal-
culated by the algorithm; or in deciding the final letter score by modifying the scores indicated
by the referees.
In the whole experiment, the share of papers finally requiring a CG intervention was
59.2% of the sample. In Area 13 this share was 56.8%, only a little lower than the average.
From this point of view, on the whole, in Area 13, CGs did not intervene more actively than
in the other areas. dennoch, Bereich 13 shows the highest number of articles for which CGs
changed a concordant score of the two referees. In Area 13 CGs changed a concordant
score of the two referees for nine articles out of 590, representing 1.52% of the total articles
in the area sample. In all the other areas, CGs changed just 16 articles out of 7,598, repre-
senting 0.16% of the total experiment sample. This may be considered as a first clue to the
attitude of the Area 13 panel to intervene in scoring papers more actively than the panels of
the other areas.
Tisch 1 finally shows that Baccini and De Nicolao (2016A) even underestimated the num-
ber of 326 papers scored after a CG intervention in Area 13. Bertocchi et al. (2016) had con-
tested this estimate by stating the following:
one could argue that at most 15 Papiere (nicht 326) were evaluated the panel itself.
Quantitative Science Studies
199
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
/
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Just an artifact?
How is it possible to have this very big misalignment on a basic fact? Bertocchi et al. limited
their attention to 15 articles for which they argued that the CGs
effectively graded the paper. This occurred when (ich) the two reports were so different that
one referee assigned the minimum score (D) and the other the maximum score (A), Und (ii)
the CGs disagreed on the arithmetic average of the score (the default solution). (Bertocchi
et al., 2016)
This very restrictive claim about the intervention of the CGs is at odds with official reports
and Bertocchi et al.’s own description of the experiment (Bertocchi et al., 2015). Tisch 1 finally
shows that it is also strictly falsified by the data, because in addition to the 15 articles for which
the referees were in maximum disagreement, as we have seen, CGs “directly graded” nine
other papers for which the two referees indicated a concordant score6.
It remains to clarify how invasive the interventions of the consensus groups were in defining
the final score P. The most invasive CG intervention consisted obviously in changing a score
agreed by two reviewers. But CGs might have adopted a less invasive strategy by assigning a
final P score without applying rigidly the “conversion grid” reported in Table 2. If ANVUR had
disclosed the numerical scores of the referees’ reports instead of P1 and P2 only, it would be
possible to trace precisely the intervention of the CGs by comparing the score P with the aver-
age of the numerical scores attributed by two referees. In every case, the disclosed data permit
us to show that CGs, especially in Area 13, graded some articles outside the rules as defined in
the official reports.
In der Tat, it is possible to roughly define for the final scores P lower and upper bounds within
which CG interventions respect the rules of the assessment by considering the conversion grid
adopted in each area. Lower bounds for CG decisions are computed as follows. The first step
consisted in calculating the minimum average associated with each possible combination of
P1 and P2. Consider, Zum Beispiel, that a first referee assigns a score P1 = A and a second
referee a score P2 = B. The minimum average is calculated under the hypothesis that both
reviewers assigned the minimum numerical score to the paper: The first referee judged the
paper as A by assigning a numerical score of 23; while Referee 2 judged the paper as B by
assigning the minimum numerical score of 18. daher, the minimum possible average for a
paper judged A by one referee and B by the other is (23 + 18)/2 = 20.5, corresponding in the
conversion grid to a final score B. Somit, to respect the rules of the assessment, the final score
P of a paper receiving P1 = A and P2 = B should be A or B. Upper bounds are analogously
computed. The maximum average can be calculated by considering that both referees assign
the maximum scores for A and B, jeweils 27 and a bit less than 23. Therefore the max-
imum possible average for a paper judged A by one referee and B by the other is (27 + 23)/2 =
25, corresponding in the conversion grid to the letter score A. This is the upper bound for the
CG decision. Table A1 in the Supplementary material reports the upper and lower bounds
computed for the two conversion grids adopted in different areas. Note that in the case of
P1 = A and P2 = C the final letter score P is necessarily B because the minimum possible
average is (23 + 15)/2 = 19 and the maximum possible average is (27 + 18)/2 = 22.5, and both
numerical scores correspond to the letter score B; analogously for P1 = A and P2 = D the upper
6 Insbesondere: Four papers, concordantly scored B by two referees, were classified as A by the CGs; zwei
papers respectively scored C and D by two concordant referees were finally classified as B by the CGs;
and three papers concordantly scored D by referees were classified C by the CGs.
Quantitative Science Studies
200
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
.
/
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Just an artifact?
Tisch 3. Number of papers scored by consensus groups out of the bounds of the research
assessment, as reported in the Table A1 of Supplementary material. The percentage is calculated
over the total number of papers requiring the intervention of the consensus groups (Tisch 1, column
beschriftet: “Scored by CG”)
Final P score
Bereich 1: Mathematics and Informatics
Bereich 2: Physik
Bereich 3: Chemistry
Bereich 4: Earth Sciences
Bereich 5: Biology
Bereich 6: Medicine
Bereich 7: Agricultural and Veterinary Sciences
Area 8a: Civil Engineering
Bereich 9: Industrial and Information Engineering
Bereich 13: Economics and Statistics
Areas 1–9
All areas
Quelle: Elaboration on ANVUR data.
A
0
0
0
0
0
6
2
0
0
16
8
24
B
0
0
1
0
1
2
0
1
1
3
6
9
C
1
D
0
Total
1
3
0
0
3
2
0
0
0
4
9
13
3
0
1
0
1
0
0
0
0
5
5
6
1
1
4
11
2
1
1
23
28
51
%
0.43
0.86
0.23
0.44
0.64
1.10
0.69
0.88
0.18
6.87
0.67
1.13
bound is P = B, because the maximum average score is (27 + 15)/2 = 21 corresponding to a
letter score B.
Tisch 3 reports the number of papers scored by CGs out of the bounds of Table A1 (d.h., Die
number of papers scored not respecting the declared rules of the assessment). The consensus
groups of Areas 1–9 did not respect the bounds for 28 out of 4,163 Papiere (0.67%). In Area 13
the consensus groups did not respect the bounds for 23 out of 335 Papiere (6.87%). The major-
ity of these papers received a final score P = A. This is a second clue indicating that in Area 13
consensus groups have a more active attitude in deciding the final letter score P, with respect
to the other areas.
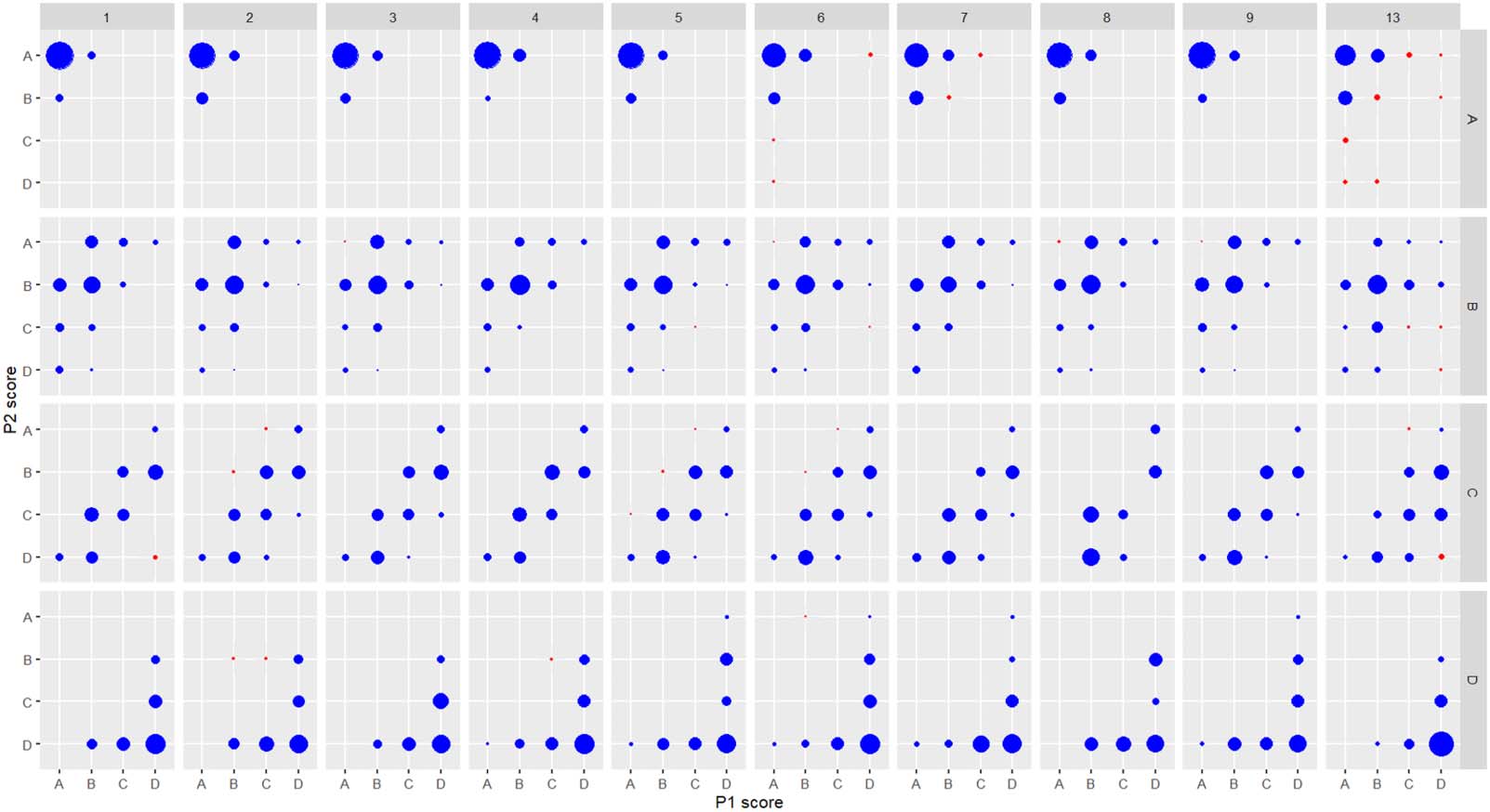
Allgemeiner, Figur 1 permits us to visually compare the interventions of CGs in decid-
ing the final score of a paper in the different areas of the experiment. The graph is organized in
40 facets representing 10 Bereiche (columns) and the four final P-scores (rows). Each panel rep-
resents the scores P1 (x-axis) and P2 (y-axis) in a given area for a given final peer review score
P. The size of each point indicates the proportion of articles finally scored P in the given area.
Blue points indicates articles scored by respecting the declared bounds of the assessment,
while red points indicates articles scored not respecting the bounds. Tables A5.1 and A5.2
of the Supplementary material report the data used to create Figure 1.
Consider the top left panel. In Area 1 (Mathematics and Informatics) most of the articles
with a final P-score A in the experiment were concordantly classified as A by the two reviewers
P1 and P2; a few of these articles were also scored A by one of the referees and B by the other.
No article scored less than B by one of the referee was finally scored A by the CG. Consider
now the top right panel. In Area 13, there were many papers scored less than B by one of the
two referees that were finally classified as A by the CGs. It is apparent that CGs scored A some
Quantitative Science Studies
201
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
/
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Just an artifact?
Figur 1. Visual comparison of the interventions of CGs in deciding the final score of a paper in the different areas of the experiment. Der
graph is faceted according to 10 disciplinary areas (columns) and the four final P scores (A, B, C, D). Each panel represents the scores attributed
by P1 (x-axis) and P2 (y-axis) in a given area for a given final peer review score P. The size of each point indicates the proportion of articles
finally scored P in the given area. Blue points indicate articles with a final score respecting the bounds of the assessment as reported in Table A1;
red points indicate articles for which CGs did not respect the bounds.
papers for which concordantly the two referees had indicated a score B and also some papers
for which no referee indicated a score A. From visual inspection of the Figure 1 it is apparent
that the CGs of Area13 behave differently from those in the other areas, by adopting greater
flexibility than in the other areas in the conversion of the referees’ scores P1 and P2 to the final
score P.
In sum, the consensus groups of Area 13 managed a share of papers similar to all the other
Bereiche. The data documented that they had a more active attitude both in modifying the scores
agreed by the referees and in scoring the papers outside the bounds defined in the rules of the
research assessment. Darüber hinaus, they tended to interpret more flexibly than in the other areas
the rules for converting the referees’ reports to the final P score.
4. HOW MUCH OF THE AGREEMENT BETWEEN PEER REVIEW AND BIBLIOMETRICS WAS
INDUCED BY CG DECISIONS?
On the basis of ANVUR data, it is now possible to shed light also on the central question about
the experiment: How much of the agreement between peer review and bibliometrics
depended on the decisions of the CGs (d.h., how much of the agreement was induced by
the scores defined by the members of the panel). From Table A1, it is evident that even while
respecting the bounds, CGs had a good margin of flexibility in deciding the final score P. Für
Beispiel, after having received two discordant peer review reports indicating P1 = B and P2 =
D, a CG can decide a final P score B or C or D, perhaps in accordance with the bibliometric
Punktzahl.
To measure the role of CGs’ decisions in determining the agreement between peer review
and bibliometrics, it is possible to build two indicators.
Quantitative Science Studies
202
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
.
/
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Just an artifact?
Tisch 4.
total papers scored by consensus groups, stratified according to final P scores
Percentage of papers scored by consensus groups in agreement with bibliometrics over
Bereich
Bereich 1: Mathematics and Informatics
Bereich 2: Physik
Bereich 3: Chemistry
Bereich 4: Earth Sciences
Bereich 5: Biology
Bereich 6: Medicine
Bereich 7: Agricultural and Veterinary Sciences
Area 8a: Civil Engineering
Bereich 9: Industrial and Information Engineering
Bereich 13: Economics and Statistics
Areas 1–9
All areas
Quelle: Elaboration on ANVUR data.
A
73.3
83.1
75.6
71.4
70.6
69.2
86.4
92.3
89.7
81.0
78.5
78.9
B
14.7
19.6
22.6
18.6
19.2
27.2
9.2
4.6
13.4
29.5
18.8
19.3
C
20.0
10.3
5.3
8.3
8.1
4.6
0.0
4.8
11.3
29.4
7.5
9.5
D
21.3
26.3
25.6
41.3
38.4
44.8
62.8
28.6
6.6
65.5
36.7
38.7
Total
20.8
24.6
24.1
23.2
24.8
27.8
20.6
17.7
17.6
45.4
23.7
25.3
The first indicator, reported in Table 4, is the percentage of CG decisions that produced a
final score in agreement with the bibliometric score. It is calculated as the ratio between the
number of papers scored by CGs in agreement with bibliometrics and the total number of
papers scored by CGs. In Area13, GCs attributed a score in agreement with bibliometrics
für 45.4% of the papers scored by CGs (152 papers out of 335). In the other nine areas, Das
share ranges from a minimum of 17.6% in Area 9 to a maximum of 27.9% in Area 6. Im
other nine areas taken together, CGs attributed a score in agreement with bibliometrics for
nur 23.7% of the papers scored by CGs (986 concordant papers out of 4,163). The agreement
induced by CG decisions was anomalous with respect to the other areas mainly for the subset
of articles scored less than A. This indicates that in Area 13 consensus groups’ interventions
boosted the agreement between peer review and bibliometrics for the set of papers receiving a
final score less than A. Insbesondere, in Area 13 the share of concordant C papers was almost
three times as much as in the other areas; and the share of concordant D papers was a bit less
than double with respect to the other areas.
The second indicator, reported in Table 5, is the share of papers for which the agreement
between peer review and bibliometrics was due to the decisions of the CG. It is computed as
the ratio between between the number of papers scored by CGs in agreement with biblio-
metrics and the total number of papers for which there is agreement between peer review
and bibliometrics. In Area 13 there were 311 papers for which peer review and bibliometrics
were in agreement; für 152 of these papers (d.h., for a share of 48.9%), the final peer review
score was decided by the CGs. In the other nine areas the share was of 39.5% nur (986
papers out of 2,857). The anomaly of Area 13 was concentrated in the group of papers scored
A: in Area 13 CGs directly scored more than half (51 out of 98, das ist 52%) of the concordant
papers against one fifth (241 out of 1,160, das ist 20.8%) of the other areas. This second indi-
cator shows that more than half of the papers scored as excellent by both bibliometrics and
Quantitative Science Studies
203
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
/
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Just an artifact?
Percentage of papers scored by consensus groups in agreement with bibliometrics, über
Tisch 5.
total number of papers with concordant peer review and bibliometrics, stratified according to final P
scores
Bereich
Bereich 1: Mathematics and Informatics
A
9.6
B
61.3
C
100.0
D
38.5
Total
26.8
Bereich 2: Physik
Bereich 3: Chemistry
23.4
57.1
85.0
54.1
19.1
56.6
83.3
47.6
Bereich 4: Earth Sciences
16.1
42.1
85.7
53.1
Bereich 5: Biology
Bereich 6: Medicine
16.8
49.5
80.0
49.6
28.8
64.9
93.3
49.2
Bereich 7: Agricultural and Veterinary Sciences
34.5
50.0
0.0
61.4
Area 8a: Civil Engineering
27.9
60.0
100.0
44.4
Bereich 9: Industrial and Information Engineering
17.2
59.7
80.0
26.7
Bereich 13: Economics and Statistics
52.0
55.4
82.1
32.2
Areas 1–9
All areas
Quelle: Elaboration on ANVUR data.
20.8
56.9
85.9
49.7
23.2
56.8
84.7
46.7
38.9
35.9
42.4
38.9
48.9
47.2
34.5
31.0
48.9
39.5
40.5
peer review received the final P score after an intervention of the member of the Area 13
panel.
5. DISCUSSION AND CONCLUSION
The results of the experiment performed by ANVUR during the Italian research assessment
exercise VQR 2004–2010 have a central role in the ongoing discussion about the agreement
between peer review and bibliometrics. In der Tat, it is probably the most extensive experiment
conducted so far for verifying the concordance between peer review and bibliometrics. Es ist
results were presented as indicating a “fundamental agreement” between peer review and bib-
liometrics in science, Technologie, engineering, Mathematik, and especially in economics and
Statistiken. Despite the early critics of the reliability of the whole experiment, the results are
currently cited (Fassin, 2021; Mittermaier, 2020; Rousseau & Rousseau, 2021; Thomas
et al., 2020) as indicating solid evidence of good agreement between peer review and biblio-
metrics at an individual article level. Eigentlich, when the results of the experiments were rep-
licated in the correct inferential setting, they showed that for science, Technologie, engineering,
and mathematics the degree of agreement between bibliometrics and peer review was at most
weak at an individual article level (Baccini et al., 2020). The only exception was economics
and statistics, where the agreement was moderate.
This work aimed to finally test whether this anomalous result for economics and statistics
was due to a substantial modification of the protocol of the experiment with respect to that
adopted in the other areas, as suggested by Baccini and De Nicolao (2016A, 2016B, 2017A,
2017B).
The data eventually disclosed by ANVUR reveal that the official report published by
ANVUR, the text collated from it and published by Research Policy, as well as the “final”
Quantitative Science Studies
204
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
.
/
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Just an artifact?
description provided in Bertocchi et al. (2016), contain partial or even incorrect descriptions of
the protocol of the experiment conducted in Area 13.
Insbesondere, in Area 13, the CGs decided the final score of 335 papers out of a total of 590.
Diese 335 enthalten 326 papers for which the two referees were in disagreement, and nine
papers that CGs scored by modifying the concordant score suggested by two reviewers. Dort-
Vordergrund, the raw data directly and conclusively falsify the statement by Bertocchi et al. (2016) Das
in Area 13 “at most 15 papers” were evaluated by CGs.
The raw data also show that for 6.87% of the papers, the Area 13 CGs did not respect the
upper and lower bounds for scoring articles stated in the official reports and in Bertocchi et al.
(2015, 2016). In the other nine areas, the share of scores not respecting the declared bounds
was just 0.67%.
Darüber hinaus, the ANVUR data show that CGs played a major role in boosting the agreement
reached in the experiment of Area 13. In Area 13, 45.4% of the scores given by the CGs
agreed with bibliometrics, against a 23.7% in the other areas. Insbesondere, among the papers
with a concordant A score between peer review and bibliometrics, as much as 52% had been
scored by the CGs against 20.8% for the other areas.
In sum, the disclosed raw data of the experiment document that the moderate agreement
between bibliometrics and peer review in economics and statistics was an anomalous result
produced by the active intervention of the members of the consensus groups in charge of syn-
thesizing peer review reports (ANVUR, 2017).
This conclusion is corroborated by the results of a second experiment, conducted by
ANVUR during the national research assessment VQR 2011–2014. In this second experiment,
the protocol “excluded the intervention” of the consensus groups in the definition of the final
peer review P scores, which were instead computed by an algorithm in all the areas (sehen
ANVUR [2017, Appendix B, P. 8 Notiz 4]). The replication of the results of this second exper-
iment in the correct inferential setting showed that “when an identical protocol was adopted
for all the areas, the agreement for Area 13 was only slightly larger, but still comparable with
the other areas” (Baccini et al., 2020). Genauer, in the second experiment, the degree
of agreement between bibliometrics and peer review is generally even lower than in the first
eins, by indicating that the agreement between peer review and bibliometrics at the level of
individual articles is at most weak in all the considered research areas (Baccini et al., 2020).
In a nutshell, in Area 13 a group of scholars was called to develop a bibliometric ranking of
journals for attributing a bibliometric score to articles published in these journals. This same
group of scholars was called also to manage peer reviews for the papers published in these
journals. Endlich, they formed the consensus groups for deciding the final peer review scores of
articles after having received the referee reports. Zu diesem Zweck, the consensus groups had not
only flexible margins for their decisions but also the freedom to deviate from the rules of
the experiment fixing the bounds for scoring articles. Given all these premises, it is hardly sur-
prising that in economics and statistics, the agreement between bibliometric and peer review
reached a level not recorded in any other area considered in the Italian experiment.
Eigentlich, the decisions of the panel for economics and statistics simply confirmed and
strengthened the bibliometric assessment methods it had developed. Recall that for economics
and statistics, only the bibliometric score of an article was defined on the basis of the journal
ranking developed by the panel. As a consequence, a high level of agreement would indicate
that the ranking of journals developed by the panel was a good proxy of the quality of articles
as revealed by reviewers in their reports. Insbesondere, the choices of the consensus groups
Quantitative Science Studies
205
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
/
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Just an artifact?
delimited the set of excellent documents. If the experiment shows that the articles rated as
excellent by peer review are those published in journals rated as excellent by the panel, A
clean and simple criterion of excellence could finally be established: Excellent articles are
those and only those hosted by a restricted set of supposedly excellent journals.
On a more general level, the evidence of good agreement would justify the use of journal
ranking instead of peer review for evaluating papers in economics and statistics. In der Tat, Die
results of the experiment were used to produce policy advice about research evaluation for an
international audience (see for example Bertocchi, Gambardella et al. [2014]). The good
agreement and the consequent policy advice were especially welcome in economics, a schol-
arly environment particularly fascinated by journal rankings (Heckman & Moktan, 2020). Es ist
well known that the use of journal rankings tends to reinforce existing hierarchies within
disciplines (Corsi, D’Ippoliti, & Zacchia, 2019; Heckman & Moktan, 2020; Stockhammer,
Dammerer, & Kapur, 2021) Und, gleichzeitig, reduce pluralism of research. A growing
Literatur (Lee, Pham, & Gu, 2013; Corsi et al., 2019; D’Ippoliti, 2021) suggests that the reduc-
tion of pluralism in economics cannot be considered as just an unintended consequence of
research assessment (Rousseau & Rousseau, 2021).
Zusammenfassend, in light of the raw data disclosed by ANVUR, the current interpretation of the
Italian experiment on peer review and bibliometrics agreement should be revised and be rea-
ligned with the available evidence. The first Italian experiment showed that peer review and
bibliometrics have less than weak agreement at an individual article level for the fields of sci-
enz, Technologie, engineering, and mathematics (Baccini et al., 2020). Darüber hinaus, the higher
level of agreement in economics and statistics appears to be simply an artifact of the experi-
ment protocol adopted by the group in charge of evaluating economics and statistics. Somit,
the results of the Italian experiment cannot be considered as solid evidence of a special agree-
ment between peer review and journal ranking, even for the fields of economics and statistics.
ACKNOWLEDGMENTS
Grants from the Institute for New Economic Thinking are gratefully acknowledged. Thanks to
the reviewers for their careful comments.
BEITRÄGE DES AUTORS
Alberto Baccini: Konzeptualisierung, Methodik, Formal Analysis, Schreiben – Originalentwurf,
Schreiben – Rezension & Bearbeitung. Giuseppe De Nicolao: Konzeptualisierung, Methodik, Formal
Analyse, Schreiben – Originalentwurf, Schreiben – Rezension & Bearbeitung.
COMPETING INTERESTS
The authors have no competing interests.
FUNDING INFORMATION
Alberto Baccini is the recipient of grants by the Institute For New Economic Thinking Grant
Institute For New Economic Thinking Grant ID INO17-00015 and INO19-00023.
DATA AVAILABILITY
The raw data used in the article can be downloaded from https://doi.org/10.5281/zenodo
.3727460.
Quantitative Science Studies
206
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
.
/
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Just an artifact?
VERWEISE
Ancaiani, A., Anfossi, A. F., Barbara, A., Benedetto, S., Blasi, B., …
Sileoni, S. (2015). Evaluating scientic research in Italy: The 2004–10
research evaluation exercise. Research Evaluation, 24(3), 242–255.
https://doi.org/10.1093/reseval/rvv008
ANVUR. (2013). Rapporto finale. valutazione della qualità della
ricerca 2004–2010 (Tech. Rep.).
ANVUR. (2017). Valutazione della qualità della ricerca 2011–2014.
rapporto finale (Tech. Rep.).
Baccini, A., Barabesi, L., & De Nicolao, G. (2020). On the agree-
ment between bibliometrics and peer review: Evidence from the
Italian research assessment exercises. PLOS ONE, 15(11),
e0242520. https://doi.org/10.1371/journal.pone.0242520,
PubMed: 33206715
Baccini, A., & De Nicolao, G. (2016A). Do they agree? Bibliometric
evaluation versus informed peer review in the Italian research
assessment exercise. Scientometrics, 108(3), 1651–1671.
https://doi.org/10.1007/s11192-016-1929-y
Baccini, A., & De Nicolao, G. (2016B). Reply to the comment of
Bertocchi et al. Scientometrics, 108(3), 1675–1684. https://doi
.org/10.1007/s11192-016-2055-6
Baccini, A., & De Nicolao, G. (2017A). Errors and secret data in the
Italian research assessment exercise. A comment to a reply. RT. A
Journal on Research Policy and Evaluation, 5(1). https://doi.org
/10.13130/2282-5398/8872
Baccini, A., & De Nicolao, G. (2017B). A letter on Ancaiani et al.
‘Evaluating scientific research in Italy: The 2004–10 research
evaluation exercise’. Research Evaluation, 26(4), 353–357.
https://doi.org/10.1093/reseval/rvx013
Benedetto, S., Cicero, T., Malgarini, M., & Nappi, C. (2017). Reply
to the letter on Ancaiani et al. ‘Evaluating scientific research in
Italien: The 2004–10 research evaluation exercise’. Research Eval-
uation, 26(4), 358–360. https://doi.org/10.1093/reseval/rvx017
Bertocchi, G., Gambardella, A., Jappelli, T., Nappi, C. A., & Peracchi,
F. (2014). Assessing Italian research quality: A comparison between
bibliometric evaluation and informed peer review. www.voxeu.org.
Bertocchi, G., Gambardella, A., Jappelli, T., Nappi, C. A., & Peracchi,
F. (2015). Bibliometric evaluation vs. informed peer review: Evi-
dence from Italy. Research Policy, 44(2), 451–466. https://doi.org
/10.1016/j.respol.2014.08.004
Bertocchi, G., Gambardella, A., Jappelli, T., Nappi, C. A., & Peracchi,
F. (2016). Comment to: Do they agree? Bibliometric evaluation
versus in formed peer review in the Italian research assessment
exercise. Scientometrics, 108, 349–353. https://doi.org/10.1007
/s11192-016-1965-7
Corsi, M., D’Ippoliti, C., & Zacchia, G. (2019). Diversity of back-
grounds and ideas: The case of research evaluation in econom-
ics. Research Policy, 48(9), 103820. https://doi.org/10.1016/j
.respol.2019.103820
D’Ippoliti, C. (2021). Many-citedness: Citations measure more than
just scientific quality. Journal of Economic Surveys, 35(5), 1271–1301.
https://doi.org/10.1111/joes.12416
Fassin, Y. (2021). Does the Financial Times FT50 journal list
select the best management and economics journals? Sciento-
metrics, 126(7), 5911–5943. https://doi.org/10.1007/s11192
-021-03988-X
Heckman, J. J., & Moktan, S. (2020). Publishing and promotion
in economics: The tyranny of
Journal of Eco-
nomic Literature, 58(2), 419–470. https://doi.org/10.1257/jel
.20191574
the top five.
Lee, F. S., Pham, X., & Gu, G. (2013). The UK Research Assessment
Exercise and the narrowing of UK economics. Cambridge Journal
of Economics, 37(4), 693–717. https://doi.org/10.1093/cje
/bet031
Mittermaier, B. (2020). Peer review and bibliometrics. In R. Ball
(Ed.), Handbook bibliometrics (S. 77–90). Berlin/Boston: Von
Gruyter Saur. https://doi.org/10.1515/9783110646610-009
Rousseau, S., & Rousseau, R. (2021). Bibliometric techniques and
their use in business and economics research. Journal of Eco-
nomic Surveys, 35(5), 1428–1451. https://doi.org/10.1111/joes
.12415
Stockhammer, E., Dammerer, Q., & Kapur, S. (2021). The Research
Excellence Framework 2014, journal ratings and the marginalisa-
tion of heterodox economics. Cambridge Journal of Economics,
45(2), 243–269. https://doi.org/10.1093/cje/beaa054
Thomas, D. A., Nedeva, M., Tirado, M. M., & Jacob, M. (2020).
Changing research on research evaluation: A critical literature
review to revisit the agenda. Research Evaluation, 29(3), 275–288.
https://doi.org/10.1093/reseval/rvaa00818
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
/
e
D
u
Q
S
S
/
A
R
T
ich
C
e
–
P
D
l
F
/
/
/
/
3
1
1
9
4
2
0
0
8
2
9
6
Q
S
S
_
A
_
0
0
1
7
2
P
D
/
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Quantitative Science Studies
207