Narrative Question Answering with Cutting-Edge Open-Domain QA
Techniques: A Comprehensive Study
Xiangyang Mou∗
Chenghao Yang∗
Mo Yu∗
Bingsheng Yao
Xiaoxiao Guo
Saloni Potdar
Hui Su
Rensselaer Polytechnic Institute & IBM, Vereinigte Staaten
moux4@rpi.edu gflfof@gmail.com
Abstrakt
Recent advancements in open-domain ques-
tion answering (ODQA), das ist, finding an-
swers from large open-domain corpus like
Wikipedia, have led to human-level perfor-
mance on many datasets. Jedoch, progress
in QA over book stories (Book QA) lags de-
spite its similar task formulation to ODQA.
This work provides a comprehensive and
quantitative analysis about the difficulty of
Book QA: (1) We benchmark the research
on the NarrativeQA dataset with extensive
experiments with cutting-edge ODQA tech-
niques. This quantifies the challenges Book
QA poses, as well as advances the published
state-of-the-art with a ∼7% absolute improve-
ment on ROUGE-L. (2) We further analyze
the detailed challenges in Book QA through
human studies.1 Our findings indicate that
the event-centric questions dominate this task,
which exemplifies the inability of existing QA
models to handle event-oriented scenarios.
1
Einführung
Recent Question-Answering (QA) models have
achieved or even surpassed human performance
on many challenging tasks,
including single-
passage QA2 and open-domain QA (ODQA).3
Trotzdem, understanding rich context beyond
text pattern matching remains unsolved, espe-
∗Equal contribution. XM built the whole system, imple-
mented the data preprocessing pipeline, Hard EM ranker,
and all the reader modules, and conducted all the QA exper-
iments. CY implemented the unsupervised ICT ranker and
the first working version of FiD, and was responsible for the
final ranker module. MY is the corresponding author, WHO
proposed and led this project, built the ranker code base (until
the DS ranker), designed the question schema and conducted
its related experiments and analysis in Part II.
1https://github.com/gorov/BookQA.
2The SQuAD leaderboard (Rajpurkar et al., 2018):
rajpurkar.github.io/SQuAD-explorer.
3Wang et al. (2020); Iyer et al. (2020)’s results on
Quasar-T (Dhingra et al., 2017) and SearchQA (Dunn et al.,
2017).
cially answering questions on narrative elements
via reading books. One example is NarrativeQA
(Koˇcisk`y et al., 2018) (Figur 1). Since its first
release in 2017, there has been no significant im-
provement over the primitive baselines. In diesem
Papier, we study this challenging Book QA task
and shed light on the inherent difficulties.
Despite its similarity to standard ODQA tasks,4
das ist, both requiring finding evidence paragraphs
for inferring answers, the Book QA has certain
unique challenges (Koˇcisk`y et al., 2018): (1)
The narrative writing style of book stories dif-
fers from the formal texts in Wikipedia and news,
which demands a deeper understanding capability.
The flexible writing styles from different genres
and authors make the challenge severe; (2) Der
passages that depict related book plots and char-
acters share more semantic similarities than the
Wikipedia articles, which increases confusion in
finding the correct evidence to answer a question;
(3) The free-form nature of the answers necessi-
tates the summarization ability from the narrative
plots; (4) The free-form answers make it hard to
obtain fine-grained supervision at passage or span
levels; and finally (5) Different paragraphs usually
have logical relations among them.5
To quantify the aforementioned challenges, Wir
conduct a two-fold analysis to examine the gaps
between Book QA and the standard ODQA tasks.
Erste, we benchmark the Book QA performance
on the NarrativeQA dataset, with methods created
or adapted based on the ideas of state-of-the-art
ODQA methods (Wang et al., 2018A; Lin et al.,
2018; Lee et al., 2019; Min et al., 2019; Guu
4Historically, open-domain QA meant ‘‘QA on any do-
main/topic’’. More recently, the term has been restricted to
‘‘retrieval on a large pile of corpus’’ (Chen et al., 2017), Also
‘‘open-retrieval QA’’ seems a better term here. Jedoch, Zu
follow the recent terminology in the QA community, we still
use ‘‘open-domain QA’’ throughout this paper.
5We consider Challenge (5) more like an opportunity than
a challenge, and leave its investigation to future work.
1032
Transactions of the Association for Computational Linguistics, Bd. 9, S. 1032–1046, 2021. https://doi.org/10.1162/tacl a 00411
Action Editor: Hang Li. Submission batch: 12/20; Revision batch: 3/2021; Published 9/2021.
C(cid:4) 2021 Verein für Computerlinguistik. Distributed under a CC-BY 4.0 Lizenz.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
T
l
A
C
_
A
_
0
0
4
1
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
tion of recent ODQA advancements, but also re-
veals the unique challenges in Book QA with
quantitative measurements.
2 Related Work
Open-Domain QA ODQA aims at answering
questions from large open-domain corpora (z.B.,
Wikipedia). The recent work naturally adopts a
ranker-reader framework (Chen et al., 2017). Re-
cent success in this field mainly comes from
improvement in the following directions: (1) dis-
tantly supervised training of neural ranker models
(Wang et al., 2018A; Lin et al., 2018; Min et al.,
2019; Cheng et al., 2020) to select relevant evi-
dence passages for a question; (2) fine-tuning and
improving the pre-trained LMs, like ELMo (Peters
et al., 2018) and BERT (Devlin et al., 2019), as the
rankers and readers; (3) unsupervised adaptation
of pre-trained LMs to the target QA tasks (Lee
et al., 2019; Sun et al., 2019; Xiong et al., 2019A).
Book QA Previous works (Koˇcisk`y et al., 2018;
Tay et al., 2019; Frermann, 2019) also adopt a
ranker-reader pipeline. Jedoch, they have not
fully investigated the state-of-the-art ODQA tech-
niques. Erste, the NarrativeQA is a generative QA
task by nature, yet the application of the latest
pre-trained LMs for generation purposes, solch
as BART, is not well-studied. Zweite, lack of
fine-grained supervision on evidence prevents ear-
lier methods from training a neural ranking model,
thus they only use simple BM25 (Robertson et al.,
1995) based retrievers. An exception is Mou et al.
(2020), who construct pseudo distance supervi-
sion signals for ranker training. Another relevant
arbeiten (Frermann, 2019) uses book summaries as
an additional resource to train rankers. Jedoch,
this is different from the aim of the Book QA task
in answering questions solely from books, since in
a general scenario the book summary cannot an-
swer all questions about the book. Our work is the
first to investigate and compare improved training
algorithms for rankers and readers in Book QA.
3 Task Setup
3.1 Task Definition and Dataset
Following Koˇcisk`y et al. (2018), we define the
Book QA task as finding the answer A to a ques-
tion Q from a book, where each book contains
a number of consecutive and logically related
Figur 1: An example of Book QA. The content is
from the book An Ideal Husband (Wilde and Fornelli,
1916). The bottom contains a typical QA pair, und das
highlighted text is the evidence for deriving the answer.
et al., 2020; Karpukhin et al., 2020). We build a
state-of-the-art Book QA system with a retrieve-
and-read framework, which consists of a ranker
for retrieving evidence and a reader (d.h., QA
Modell) to predict answers given evidence. Für
the ranker model, we investigate different weakly
supervised or unsupervised methods for model
training with the lack of passage-level supervi-
sion. For the reader model, we fill up the missing
study and comparison among pre-trained genera-
tive models for Book QA, such as GPT-2 (Radford
et al., 2019) and BART (Lewis et al., 2019). Dann
we investigate approaches to adapt to the book
writing styles and to make use of more evidence
paragraphs. Infolge, our study gives a ∼7%
absolute ROUGE-L improvement over the pub-
lished state-of-the-art.
Zweite, we conduct human studies to quantify
the challenges in Book QA. Zu diesem Zweck, we design
a new question categorization schema based on the
types of reading comprehension or reasoning skills
required to provide the correct answers. Precisely,
we first define the basic semantic units, solch
as entities, event structures in the questions and
answers. The question category thus determines
the types of units and the relations between the
Einheiten. We annotate 1,000 questions accordingly
and discover the significantly distinctive statistics
of the NarrativeQA dataset from the other QA
datasets, mainly regarding the focus of event ar-
guments and relations between events. We further
give performance decomposition of our system
over the question categories, to show the detailed
types of challenges in a quantitative way.
Zusammenfassend, our comprehensive study not only
improves the state-of-the-art with careful utiliza-
1033
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
T
l
A
C
_
A
_
0
0
4
1
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
paragraphs C. The size |C| from different books
varies from a few hundred to thousands.
All our experiments are conducted on the Nar-
rativeQA dataset (Koˇcisk`y et al., 2018). It has a
collection of 783 books and 789 movie scripts
(we use the term books to refer to both of them),
each containing an average of 62K words. Addi-
tionally, each book has 30 question-answer pairs
generated by human annotators in free-form nat-
ural language. Hence the exact answers are not
guaranteed to appear in the books. NarrativeQA
provides two different settings, the summary set-
ting and the full-story setting. The former requires
answering questions from book summaries from
Wikipedia, and the latter requires answering ques-
tions from the original books, assuming that the
summaries do not exist. Our Book QA task corre-
sponds to the full-story setting, and we use both
names interchangeably.
Following Koˇcisk`y et al. (2018), we tokenize
the books with SpaCy,6 and split each book into
non-overlapping trunks of 200 tokens.
3.2 Baseline
Following the formulation of the open-domain
setting, we employ the dominating ranker-reader
pipeline that first utilizes a ranker model to select
the most relevant passages CQ to Q as evidence,
Figur 2: Characteristics of the compared systems.
†/‡ refers to generative/extractive QA systems, bzw-
aktiv. In addition to the standard techniques, Wang
et al. (2018A) use reinforcement learning to train the
ranker; Tay et al. (2019) use curriculum to train the
reader.
3.3 Metrics
Following previous works (Koˇcisk`y et al., 2018;
Tay et al., 2019; Frermann, 2019), wir gebrauchen
ROUGE-L (Lin, 2004) as the main metric for
both evidence retrieval and question answering.7
For completeness, Appendix A provides results
with other metrics used in the previous works, In-
cluding BLEU-1/4 (Papineni et al., 2002), Meteor
(Banerjee and Lavie, 2005), and the Exact Match
(EM) and F1 scores that are commonly used in
extractive QA.
CQ = top-k({P (Ci|Q)|∀ Ci ∈ C});
(1)
4 Analysis Part I: Experimental Study
and then a reader model to predict answer ˜A given
Q and CQ.
Our baseline QA systems consist of training
different base reader models (detailed in Sec. 4.1)
over the BM25 ranker. We also compare with
competitive public Book QA systems as base-
lines from several sources (Koˇcisk`y et al., 2018;
Frermann, 2019; Tay et al., 2019; Frermann, 2019;
Mou et al., 2020) under the Narrative full-story
setting, and a concurrent work (Zemlyanskiy et al.,
2021). As discussed in Section 2, Mou et al. (2020)
train a ranker with distant supervision (DS), Das
Ist, the first analyzed ranker method (Figur 3);
Frermann (2019) use exterior supervision from
the book summaries, which is considered unavail-
able by design of the Book QA task. Because the
summaries are written by humans, the system can
be viewed as benefiting from human comprehen-
sion of books. Figur 2 lists the details of our
compared systems.
6https://spacy.io/.
This section describes our efforts of applying or
adapting the latest open-domain QA ideas to im-
prove Book QA ranker/reader models. Figur 3
summarizes our inspected approaches. The exper-
imental results quantify the challenges in Book
QA beyond open-domain QA.
4.1 QA Reader
Base Reader Models We study the usage of
different pre-trained LMs on Book QA, einschließlich
BART (Lewis et al., 2019), GPT-2 (Radford et al.,
2019), T5 (Raffel et al., 2019), and BERT (Devlin
et al., 2019). The first three are generative readers
and can be directly trained with the free-form an-
swers as supervision. Speziell, during training
we treat Q ⊕ [SEP] ⊕ CQ as input to generate
answer A, Wo [SEP] is the special separation
token and ⊕ is the concatenation operator.
7For fair comparison, we lowercase the answers and
remove the punctuation, and use the open-source nlg-eval
library (Sharma et al., 2017).
1034
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
T
l
A
C
_
A
_
0
0
4
1
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Figur 3: Summary of our inspected approaches in Analysis Part I. *We directly apply the heuristics from
Mou et al. (2020) for Book QA.
For the extractive reader (BERT), we predict
the most likely span in CQ given the concatenation
of the question and the evidence Q ⊕ [SEP] ⊕ CQ.
Due to the generative nature of Book QA, Die
true answer may not have an exact match in the
Kontext. daher, we follow Mou et al. (2020) Zu
find the span S that has the maximum ROUGE-L
score with the ground truth A as the weak label,
subject to that A and S have the same length (d.h.,
|S| = |A|).
Method 1: Book Prereading Inspired by the
literature on the unsupervised adaptation of
pre-trained LMs (Sun et al., 2019; Xiong et al.,
2019A), we let the reader ‘‘preread’’ the training
books through an additional pre-training step prior
to fine-tuning with QA task. This technique helps
to better adapt to the narrative writing styles.
Speziell, we extract random passages from
all training books to build a passage pool. For each
training iteration, we mask random spans from
each passage, following the setting in Lewis et al.
(2019). The start positions of spans are sampled
from a uniform distribution without overlapping.
The length of each span is drawn from a Poisson
distribution with λ = 3. Each span is then replaced
by a single [mask] token regardless of the span
Länge. We mask 15% of the total tokens in each
passage. During the prereading stage, we use the
masked passage as the encoder input and the raw
passage as the decoder output to restore the raw
passage in the auto-regressive way.
Method 2: Fusion-in-Decoder Recently, Izacard
and Grave (2020) scale BART reader up to large
number of input paragraphs. The method, Fusion-
in-Decoder (FiD), first concatenates each para-
graph to the question to obtain a question-aware
encoded vector, then merges these vectors from all
paragraphs and feeds them to a decoder for answer
prediction. FiD reduces the memory and time costs
for encoding the concatenation of all paragraphs,
and improves on multiple ODQA datasets. FiD is
an interesting alternative for Book QA, since it
can be viewed as an integration of the ranker and
reader, with the ranker absorbed in the separated
paragraph encoding step.
FiD trades cross-paragraph interactions for en-
coding more paragraphs. The single encoded vec-
tor per passage works well for extractive ODQA
because the vector only needs to encode infor-
mation of candidate answers. Jedoch, in Book
QA, the answers may not be inferred from a sin-
gle paragraph and integration of multiple para-
graphs is necessary. daher, in our approach,
we concatenate the encoded vectors of all the
paragraphs, and rely on the decoder’s attention
over these vectors to capture the cross-paragraph
interactions.
4.2 Passage Ranker
Base Ranker Model Our ranker is a BERT-
based binary classifier fine-tuned for evidence re-
trieval. It estimates the likelihood of each passage
to be supporting evidence given a question Q.
Training the ranker models is difficult without
high-quality supervision. To deal with this prob-
lem, we investigate three approaches for creating
pseudo labels, including distant supervision, un-
supervised ranker training, and Hard EM training.
Method 1: Distant Supervision (DS) Das ist
the baseline approach from Mou et al. (2020). Es
constructs DS signals for rankers in two steps:
Erste, for each question Q, two BM25 rankers are
used to retrieve passages, one with Q as query
and the other with both Q and the true answer
A. Denoting the corresponding retrieval results as
1035
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
T
l
A
C
_
A
_
0
0
4
1
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
8 and CQ+A, the method samples the positive
Q from CQ ∩ CQ+A and the negative sam-
|/|C−
|
Q
CQ
samples C+
ples C−
for each question Q as a hyperparameter.
Q from the rest, with the ratio σ ≡ |C+
Q
Zweite, to enlarge the margin between the pos-
itive and negative samples, the method applies
a ROUGE-L filter upon the previous sampling
Q and C−−
results to get the refined samples, C++
Q :
(cid:3)
(cid:2)
C++
Q =
C−−
Q =
max
S⊂Ct,|S|=|A|
(cid:2)
max
S⊂Ct,|S|=|A|
Sim(S, A) > α, Ci ∈ C+
Q
(cid:3)
Sim(S, A) < β, Ci ∈ C−
Q
.
S is a span in Ci, Sim(·, ·) is ROUGE-L between
two sequences. α and β are hyperparameters.
Method 2: Unsupervised ICT Training In-
spired by the effectiveness of the Inverse Cloze
Task (ICT) (Lee et al., 2019) as an unsupervised
ranker training objective, we use it to pre-train our
ranker. The rationale is that we construct ‘‘pseudo-
question’’ q and ‘‘pseudo-evidence’’ b from the
same original passage p and aim at maximizing
the probability PICT(b|q) of retrieving b given q,
which is estimated using negative sampling as:
PICT(b|q) =
(cid:4)
exp (Sretr(b, q))
b(cid:11)∈B exp (Sretr (b(cid:11), q))
.
(2)
Sretr(·, q) is the relevance score between a para-
graph and the ‘‘pseudo-question’’ q. b(cid:11)
(cid:12)= b is
sampled from original passages other than p.
The selection of ‘‘pseudo-questions’’ is critical
to ICT training. To select representative questions,
we investigate several filtering methods, and fi-
nally develop a book-specific filter.9 Our method
selects the top-scored sentence in a passage as a
‘‘pseudo-question’’ in terms of its total of token-
wise mutual information against the correspond-
ing book. The details can be found in Appendix B.
Method 3: Hard EM Hard EM is an iterative
learning scheme. It was first introduced to ODQA
by Min et al. (2019), to find correct answer spans
that maximize the reader performance. Here we
adapt the algorithm to ranker training. Specifi-
cally, the hard EM can be achieved in two steps.
At step t, the E-step first trains the reader with
the current top-k selections CQ
t as input to update
its parameters Φt+1; then derives the new positive
t+1 that maximizes the reader Φt+1’s
passages C+
Q
8For simplicity, we use the notation CQ here.
9A unique filter is built for each book.
System
ROUGE-L
test
dev
Public Extractive Baselines
BiDAF (Koˇcisk`y et al., 2018)
6.33
6.22
R3 (Wang et al., 2018a)
11.40 11.90
DS-ranker + BERT (Mou et al., 2020) 14.76 15.49
15.15
BERT-heur (Frermann, 2019)
–
23.3
ReadTwice (Zemlyanskiy et al., 2021) 22.7
Public Generative Baselines
Seq2Seq (Koˇcisk`y et al., 2018)
13.29 13.15
AttSum∗ (Koˇcisk`y et al., 2018)
14.86 14.02
IAL-CPG (Tay et al., 2019)
17.33 17.67
DS-Ranker + GPT2 (Mou et al., 2020) 21.89 22.36
Our Book QA Systems
BART-no-context (baseline)
BM25 + BART reader (baseline)
Our best ranker + BART reader
Our best ranker + our best reader
repl ranker with oracle IR
16.86 16.83
23.16 24.47
25.83 26.95†
27.91 29.21†
37.75 39.32
Table 1: Overall QA performance (%) in Nar-
rativeQA Book QA setting. Oracle IR combines
question and true answers for BM25 retrieval.
We use an asterisk (*) to indicate the best results
reported in (Koˇcisk`y et al., 2018) with multi-
ple hyper-parameters on dev set. The dagger (†)
indicates significance with p-value < 0.01.
probability of predicting A (Eq. (3)). The M-step
updates the ranker parameter Θ (Eq. (4)):
C+
Q
t+1 = k- max
Ct∈C
P (A|Ci, Φt+1)
Θt+1 = arg max
Θ
P (C+
Q
t+1|Θt).
(3)
(4)
In practice, Min et al. (2019) find that initialized
with standard maximum likelihood training, the
Hard EM usually converges in 1–2 EM iterations.
5 Evaluation Part I: QA System Ablation
We evaluate the overall Book QA system, and the
individual modules on NarrativeQA.
Implementation Details: For rankers, we initial-
ize with bert-base-uncased. For readers, we use
bert-base-uncased, gpt2-medium, bart-large, and
T5-base. The readers use top-3 retrieved passages
as inputs, except for the FiD reader which uses
top-10, making the readers have comparable time
and space complexities.
5.1 Overall Performance of Book QA
We first show the positions of our whole sys-
tems on the NarrativeQA Book QA task. Table 1
1036
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
t
l
a
c
_
a
_
0
0
4
1
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
lists our results along with the state-of-the-art re-
sults reported in prior work (see Section 3.2 and
Figure 2 for reference). Empirically, our best
ranker is from the combination of heuristic distant
supervision and the unsupervised ICT training;
our best reader is from the combination of the
FiD model plus book prereading (with the top-10
ranked paragraphs as inputs). It is observed that
specifically designed pre-training techniques play
the most important role. Details of the best ranker
and reader can be found in the ablation study.
Overall, we significantly raise the bar on Narra-
tiveQA by 4.7% over our best baseline and 6.8%
over the best published one.10 But there is still
massive room for future improvement, compared
to the upperbound with oracle ranker. Our base-
line is better than all published results with simple
BM25 retrieval, showing the importance of reader
investigation. Our best ranker (see Section 5.2
for details) contributes to 2.5% of our improve-
ment over the baseline. Our best reader (see
Section 5.3 for details) brings an additional >2%
improvement compared to the BART reader.
We conduct a significance test for the results of
our best system. There is no agreement on the best
practice of the tests for natural language genera-
tion (Clark et al., 2011; Dodge et al., 2019). Wir
choose the non-parametric bootstrap test, Weil
it is a more general approach and does not as-
sume specific distributions over the samples. Für
bootstrapping, we sample 10K subsets, the size of
each is 1K. The small p-value (< 0.01) shows the
effectiveness of our best model.
As a final note, even the results with oracle IR
are far from perfect. It indicates the limitation of
text-matching-based IR; and further confirms the
challenge of evidence retrieval in Book QA.
5.2 Ranker Ablation
To dive deeper into the effects of our ranker train-
ing techniques in Sec. 4.2, we study the interme-
diate retrieval results and measure their cover-
age of the answers. The coverage is estimated on
the top-5 selections of a ranker from the baseline
BM25’s top-32 outputs, by both the maximum
ROUGE-L score of all the overlapped subse-
quences of the same length as the answer in the
retrieved passages; and a binary indicator of the
appearance of the answer in the passages (EM).
10Appendix A reports the full results, where we achieve
the best performance across all of the metrics.
IR Method
EM ROUGE-L
Baseline Rankers
BM25
18.99
BERT DS-ranker (Mou et al., 2020) 24.26
22.63
21.88
21.97
- ROUGE-L filtering
Repl BERT w/ BiDAF
Repl BERT w/ MatchLSTM
47.48
52.68
51.02
50.64
50.39
Our Rankers
BERT ICT-ranker
BERT DS-ranker
+ Hard EM
+ ICT pre-training∗
21.29
50.35
22.45
24.83
50.50
53.19
Oracle Conditions
Upperbound (BM25 top-32)
Oracle (BM25 w/ Q+A)
30.81
35.75
61.40
63.92
Table 2: Ranker performance (top-5) on dev set.
Asterisk (*) indicates our best ranker used in
Table 1.
Table 2 gives the ranker-only ablation. On one
hand, our best ranker improves both metrics. It also
significantly boosts the BART reader compared
to the DS-ranker (Mou et al., 2020), as shown in
Appendix A. On the other hand, on top of the
DS ranker, none of the other techniques can fur-
ther improve the two ranker metrics significantly.
The ICT unsupervised training brings significant
improvement over BM25. When adding to the
DS-ranker, it brings slight improvement and leads
to our best results. Hard EM (Min et al., 2019) does
not lead to improvements. Our conjecture is that
generative readers do not solely generate purely
matching-oriented signals, thus introducing noise
in matching-oriented ranker training.
The limited improvement and the low absolute
performance demonstrate the difficulty of retrieval
in Book QA. The gap between our best perfor-
mance and the upper-bound implies that there is a
large potential to design a more advanced ranker.
Additionally, we show how much useful infor-
mation our best ranker can provide to our readers
in the whole QA system. In our implementation,
the BART and FiD readers use top-3 and top-10
paragraphs from the ranker, respectively. The
top-3 paragraphs from our best ranker give the
answer coverage of 22.12% EM and 49.83%
ROUGE-L; and the top-10 paragraphs give
27.15% EM and 56.77% ROUGE-L. In compar-
ison, the BM25 baseline has 15.75%/43.44% for
top-3 and 24.08%/53.55% for top-10. Therefore,
our best ranker efficiently eases the limited-
passage bottleneck brought by the ranker and
1037
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
t
l
a
c
_
a
_
0
0
4
1
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
t
l
a
c
_
a
_
0
0
4
1
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 4: The definitions of semantic units (SUs). The underlined texts represent the recognized SUs of the types.
benefits BART reader much more, which is
consistent with our observations in Table 3,
Section 5.3.
5.3 Reader Ablation
Table 3 shows how the different reader techniques
in Section 4.1 contribute to the QA performance.
First, switching the BART reader to FiD gives
a large improvement when using the BM25 ranker
(2.8%), approaching the result of ‘‘our ranker
+ BART’’. This agrees with our hypothesis in
Section 4.1 Analysis 2, that FiD takes the roles
of both ranker and reader. Second, although the
above result shows that FiD’s ranking ability does
not add much to our best ranker, our cross-
paragraph attention enhancement still improves
FiD due to better retrieval results (0.5% improve-
ment over ‘‘our ranker + BART’’). Third, among
all the generative reader models, BART outper-
forms GPT-2 and T5 by a notable margin. Finally,
the book prereading brings consistent improve-
ments to both combinations; and the combination
of our orthogonal reader improvements finally
gives the best results. We also confirm that the
prereading helps decoders mostly, as only training
the decoder gives comparable results.
6 Analysis Part II: Human Study
This section conducts in-depth analyses of the
challenges in Book QA. We propose a new ques-
tion categorization scheme based on the types of
comprehension or reasoning skills required for
System
BM25 + BART reader (baseline)
+ BART-FiD reader
Our ranker + BART reader
+ BART-FiD reader
repl BART w/ GPT-2
repl BART w/ T5
+ book preread
+ BART-FiD Reader∗
+ book preread (decoder-only)
ROUGE-L
test
dev
23.16
25.95
25.83
26.27
22.22
20.57
26.82
27.91
26.51
24.47
–
26.95
–
–
–
–
29.21
–
Table 3: Ablation of our Reader Model. Asterisk
(*) indicates our best reader used in Table 1.
answering the questions; then conduct a human
study on 1,000 questions. Consequently, the model
performance per category provides further insights
of the deficiency in current QA models.
6.1 Question Categorization
There have been many different question catego-
rization schemes. Among them the most widely
used is intention-based, where an intention is de-
fined by the WH-word and its following word.
Some recent reasoning-focused datasets (Yang
et al., 2018; Xiong et al., 2019b) categorize intents
by the types of multi-hop reasoning or by the types
of required external knowledge beyond texts.
However, all these previous schemes do not rea-
sonably fit our analysis over narrative texts from
two aspects: (1) they only differentiate high-level
reasoning types, which is useful in knowledge
1038
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
t
l
a
c
_
a
_
0
0
4
1
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Figure 5: The definitions of question types. Note that sometimes the answer repeats parts of the question (like the
last two examples in the second block), and we ignore these parts when recognizing the SUs in answers.
base QA (i.e., KB-QA) but fails to pinpoint the
text-based evidence in Book QA; (2) they are usu-
ally entity-centric and overlook linguistic struc-
tures like events, while events play essential roles
in narrative stories. With this, we design a new
systematic schema to categorize the questions in
the NarrativeQA dataset.
Semantic Unit Definition We first identify a
minimum set of basic semantic units, each de-
scribing one of the most fundamental components
of a story. The set should be sufficient such that
(1) each answer can be uniquely linked to one se-
mantic unit, and (2) each question should contain
at least one semantic unit. Our final set contains
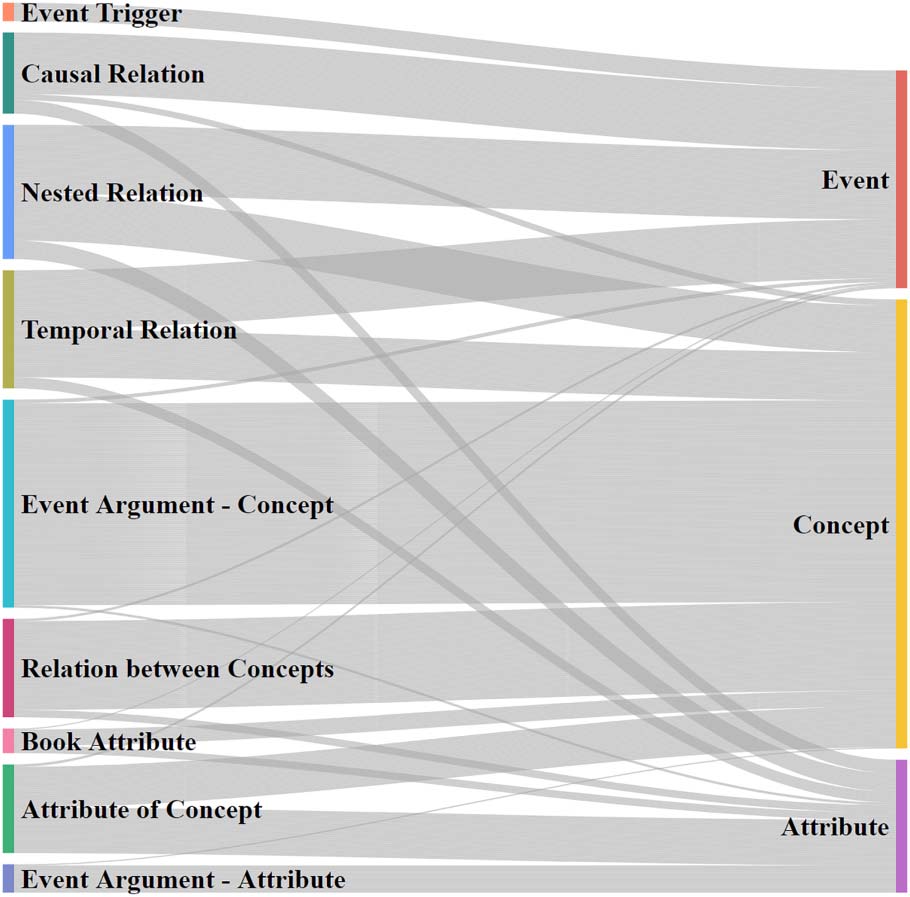
three main classes and nine subclasses (Figure 4).
We merge the two commonly used types in
the previous analysis, named entities and noun
phrases, into the Concept class. The Event class
follows the definition in ACE 2005 (Walker et al.,
2006). We also use a special sub-type ‘‘Book
Attribute’’ that represents the meta information or
the global settings of the book, such as the era and
the theme of the story in a book.
Question Type Definition On top of the seman-
tic units’ definition, each question can be catego-
rized as a query that asks about either a semantic
unit or a relation between two semantic units. We
use the difference and split all the questions into
nine types grouped in four collections (Figure 5).
• Concept questions that ask a Concept attri-
bute or a relation between two Concepts. The
most common types in most ODQA tasks
(e.g., TriviaQA) and the QA tasks require
multi-hop reasoning (e.g., ComplexQues-
tions and HotpotQA).
• Event-argument questions that ask parts of
an event structure. This type is less common
in the existing QA datasets, although some
of them contain a small portion of questions
in this class. The large ratio of these event-
centric questions demonstrates the unique-
ness of the NarrativeQA dataset.
• Event-relation questions that ask relations
(e.g., causal or temporal relations) between
two events or between an event and an at-
tribute (a state or a description). This type is
common in NarrativeQA, since events play
essential roles in story narrations. A partic-
ular type in this group is the relation that
one event serves as the argument of another
event (e.g., how-questions). It corresponds
to the common linguistic phenomenon of
(compositional) nested event structures.
• Global-attribute questions that ask Book
Attribute: As designed, it is also unique in
Book QA.
1039
Category
Simple Agreement(%) κ(%)
Question Type
SU Type
SU Sub Type
88.0
92.3
81.3
89.9
91.2
82.8
Table 4: Annotation agreement. SU: Semantic
Unit. ‘‘SU Type’’ and ‘‘SU Sub Type’’ are defined
in Figure 4.
with attribute-typed answers. This is because the
questions may ask the names of relations them-
selves, while some relation names are recognized
as description-typed attributes. (3) Most of Book
Attribute questions have concepts as answers, be-
cause they ask for the protagonists or the locations
where the stories occur.
Annotation Agreement A subset of 150 ques-
tions is used for quality checking, with each ques-
tion labeled by two annotators. Table 4 reports
both the simple agreement rates and the Fleiss
Kappa (Fleiss, 1971) κs. Our annotations reach
a high agreement, with around 90% for question
types and SU types and 80% for SU sub-types,
reflecting the rationality of our scheme.
6.3 Performance of Question Type
Classification on the Annotated Data
We conduct an additional experiment to study how
well a machine learning model can learn to clas-
sify our question types based on question surface
patterns. We use the RoBERTa-base model that
demonstrates superior on multiple sentence clas-
sification tasks. Since our labeled dataset is small,
we conduct a 10-fold cross validation on our la-
beled 1,000 instances. For each testing fold, we
randomly select another fold as the development
set and use the rest folds as training.
The final averaged testing accuracy is 70.2%.
Considering the inter-agreement rate of 88.0%,
this is a reasonable performance, with several rea-
sons for the gap: (1) Our training dataset is too
small and easy to overfit, evidenced by the per-
formance gap between the training accuracy and
development accuracy (∼100% versus 73.4%).
The accuracy can be potentially increased with
more training data. (2) Some of the ambiguous
questions require the contexts to determine their
types. During labeling, our human annotators are
allowed to read the answers for additional in-
formation, which leads to a higher upperbound
Figure 6: Visualization of the flow from the question
types to their expected answer types.
6.2 Annotation Details
Five annotators are asked to label the semantic unit
types and the question types on a total of 1,000
question-answer pairs. There can be overlapped
question categories for the same question. A major
kind of overlaps is between the three event com-
ponent types (trigger, argument - concept, argu-
ment - attribute) and the three event relation types
(causal, temporal, and nested). Therefore in the
guideline, when the question can be answered
with an event component, we ask the annotators
to check if the question requires the understand-
ing of event relations. If so, the question should
be labeled with the event relation types as these
are the more critical information for finding the
answers. Similarly, for the other rare cases of
category overlaps, we ask the annotators to label
the types that they believe are more important for
finding the answers.
Correlation Between Question and Answer
Types Figure 6 shows the ratios of answer types
under each question type via a flow diagram. Most
question types correspond to a single major an-
swer type, with a few exceptions: (1) Most of
the three event-relation questions have events as
answers. A small portion of them have concepts
or attributes as answers. This is either because
the answers are state/description attributes or be-
cause the answers are the arguments of one of the
related events queried by the questions. (2) The
Relation b/w Concepts type has some questions
1040
l
D
o
w
n
o
a
d
e
d
f
r
o
m
h
t
t
p
:
/
/
d
i
r
e
c
t
.
m
i
t
.
e
d
u
/
t
a
c
l
/
l
a
r
t
i
c
e
-
p
d
f
/
d
o
i
/
.
1
0
1
1
6
2
/
t
l
a
c
_
a
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
t
l
a
c
_
a
_
0
0
4
1
1
p
d
.
f
b
y
g
u
e
s
t
t
o
n
0
7
S
e
p
e
m
b
e
r
2
0
2
3
Question Type
Ratio(%)
QA ROUGE-L
Gen
Ext
Ranker
ROUGE-L
Relation b/w Concepts
Attribute of Concept
Event - Attribute
Event - Concept
Event - Trigger
Causal Relation
Temporal Relation
Nested Relation
Book Attribute
11.0
12.0
3.4
28.3
1.8
12.6
12.6
15.4
2.9
40.48
34.09
25.88
27.35
29.63
22.86
28.01
23.02
23.11
24.46
21.69
10.57
15.73
9.28
10.39
15.57
8.44
25.71
63.76
56.73
49.23
62.15
37.56
38.47
49.20
48.93
54.60
Table 5: Performance decomposition to question
types of our best generative system (Gen, the best
BART-based system), extractive system (Ext, the
best BERT-based system, i.e., our best ranker +
BERT reader), and ranker (BERT+ICT from
Table 2).
Figure 7: Error analysis of question-type classification.
We only list the major errors of each type (i.e., incorrect
predicted types that lead to >10% of the errors).
Answer Type
Ratio(%)
QA ROUGE-L Ranker
Gen
ROUGE-L
Ext
Leistung. (3) There is a small number of am-
biguous cases, on which humans can use world
knowledge whereas it is difficult for models to
employ such knowledge. daher, the current
accuracy can be potentially increased with a better
model architecture.
Error Analysis and Lessons Learned Figure 7
gives major error types, which verifies the rea-
sons discussed above. The majority of errors are
the confusion between Event Argument – Concept
and Nested Relation. The models are not accurate
on the two types for several reasons: (1) Some-
times the similar question surface forms can take
both concepts and events as an argument. In these
Fälle, the answers are necessary for determining
the question type. (2) According to our annotation
guideline, we encourage the annotators to label
event relations with higher priority, especially
when the answer is a concept but serves as an
argument of a clause. This increases the labeling
error rate between the two types. Another major
error type is labeling Causal Relation as Nest Re-
lation. This is mainly because some questions ask
causal relations in an implicit way, on which hu-
man annotators have the commonsense to identify
the causality but models do not. The third ma-
jor type is the failure in identifying the Attribute
of Concept and the Relation b/w Concepts cate-
gories. As the attributes can be associated to some
predicates, especially when they are descriptions,
the models confuse them with relations or events.
Concept – Entity
Concept – Common Noun
Concept – Book Specific
Ereignis – Expression
Ereignis – Name
Attribute – Zustand
Attribute – Numeric
Attribute – Description
Attribute – Book Attribute
35.3
16.9
4.3
25.1
2.8
4.2
4.7
6.1
0.6
26.76
31.53
39.68
24.62
24.79
38.75
33.57
26.13
27.91
18.59
12.90
26.53
11.50
5.54
17.03
24.44
11.15
19.88
66.79
51.03
65.54
39.40
42.88
53.82
57.31
41.70
52.78
Tisch 6: Performance decomposition to answer
types of our best generative/extractive systems
and ranker. Gen and Ext are the same systems as
in Table 5.
These observations provide insights on future
refinement of our annotation guidelines, if some-
one wishes to further enlarge the labeled data.
Zum Beispiel, the Nested Relation should be more
clearly defined with comprehensive examples pro-
vided. In this way,
the annotators can better
distinguish them from the other types, and can
better determine if the nested structure exists and
whether to label the Event Argument types. Simi-
larly, we could define clearer decision rules among
Beziehungen, attributes and events, to help annotators
distinguish Relation b/w Concepts, Attribute of
Concept, and Event Argument – Concept types.
7 Evaluation Part II: QA System
Performance Decomposition
Tisch 5 presents both the ratio of each question
type and our best generative and extractive per-
formance on it. The ratios reflect NarrativeQA’s
unique focus on events, as ∼75% of the questions
1041
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
T
l
A
C
_
A
_
0
0
4
1
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
are relevant to the events in book stories. Specif-
isch, ∼34% of the questions ask components of
event structures (d.h., arguments or triggers) Und
41% ask relations between events (note that these
questions may still require the understanding of
event structures). By comparison, the two dom-
inating types in the other QA datasets, Concept
Relation and Concept Attribute, only contribute to
a ratio of ∼23%. This agrees with human intuitions
on the unique challenges in book understanding.
Most Difficult Question Types: The performance
breakdown shows that all
three event-relation
types (Causal, Temporal, and Nested) are chal-
lenging to our QA systems. The Causal relation
is the most difficult type with the lowest QA
Leistung. The result confirms that the unique
challenge in understanding event relations is still
far from being well-handled by current machine
comprehension techniques, even with powerful
pre-trained LMs. Darüber hinaus, these types can also
be potentially improved by the idea of comple-
mentary evidence retrieval (Wang et al., 2018B;
Iyer et al., 2020; Mou et al., 2021) in ODQA.
Besides the three event-relation types, the Event
– Attribute and Event – Triggers are also challeng-
ing to the extractive system, because the answers
are usually long textual mentions of events or
states that are not extractable from the passages.
Challenging Types for the Reader: By checking
the performance gaps of the generative system and
the ranker, we can tell which types are difficult
mainly for the reader.11 The Event – Concept
type poses more challenges to the reader, gegeben
that the ranker can perform well on them but the
overall QA performance is low. These questions
are challenging mainly due to the current readers’
difficulty in understanding the event structures,
since their answers are usually extractable from
texts.
Breakdown Onto Answer Types: To better
understand the challenges of non-extractable an-
swers, we show the performance on each answer
type in Table 6. The answers are mostly extractable
when they are entities (including the book-specific
terms and numeric values). On these types the ex-
tractive systems perform better and the two sys-
System
Full Data Event-Only
test
test dev
dev
BERT+Hard EM
Masque
BART Reader (ours) 66.9 66.9 55.1
58.1 58.8
54.7
–
–
–
–
–
55.0
Tisch 7: ROUGE-L scores under NarrativeQA
summary setting. We list the best public extractive
model BERT+Hard EM (Min et al., 2019) Und
the best generative model Masque (Nishida et al.,
2019) for reference.
tems perform closer, compared to the other types.
Im Gegensatz, the answers are less likely to be ex-
tractable from the original passages when they
are events, Staaten, and descriptions. An interesting
observation is that the Common Noun Phrases
type is also challenging for the extractive system.
It indicates that these answers may not appear in
the texts with the exact forms, so commonsense
knowledge is required to connect their different
mentions.
Quantifying the Challenge of Event-Typed
Answers to the Reader: Tisch 6 zeigt, dass
the ranker performs poorly when the answers are
events and descriptions. This arouses a question
—whether the relatively lower QA performance
is mainly due to the ranker’s deficiency, or due to
the deficiency of both the ranker and the reader.
To answer this question, we conduct an exper-
iment in the summary setting of NarrativeQA, Zu
eliminate the effects of the ranker. We create a
subset of questions with event-typed answers if a
question has either of its two answers containing
a verb. This procedure results in a subset of 2,796
Und 8,248 QA pairs in validation and test sets,
jeweils. We train a BART reader with all
training data in the summary setting, and test on
both the full evaluation data and our event-only
subsets. Tisch 7 shows that the performance on
the event-only subsets is about 12% lower. Der
results confirm that questions with event-typed
answers are challenging for both the reader and
the ranker.
8 Abschluss
11Note that this analysis cannot confirm which types pose
challenges to the ranker. This is because for event answers
that are relatively longer and generative, there is a natural
disadvantage on our pseudo ranker ROUGE scores.
We conduct a comprehensive analysis on the Book
QA task, taking the representative NarrativeQA
dataset as an example. zuerst, we design the Book
1042
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
T
l
A
C
_
A
_
0
0
4
1
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
QA techniques by borrowing the wisdom from
the cutting-edge open-domain QA research and
demonstrate through extensive experiments that
(1) evidence retrieval in Book QA is difficult
even with the state-of-the-art pre-trained LMs,
due to the factors of rich writing style, recurrent
book plots and characters, and the requirement of
high-level story understanding; (2) our proposed
approaches that adapt pre-trained LMs to books,
especially the prereading technique for the reader
Ausbildung, are consistently helpful.
Zweitens, we perform a human study and find
Das (1) a majority of questions in Book QA
requires understanding and differentiating events
and their relations; (2) the existing pre-trained
LMs are deficient in extracting the inter- Und
intra-structures of the events in the Book QA. Solch
facts lead us towards the event understanding task
for future improvement over the Book QA task.
Danksagungen
This work is funded by RPI-CISL, a center in
IBM’s AI Horizons Network, and the Rensselaer-
IBM AI Research Collaboration (RPI-AIRC).
Verweise
Satanjeev Banerjee and Alon Lavie. 2005. Meteor:
An automatic metric for MT evaluation with
improved correlation with human judgments.
In Proceedings of the ACL 2005 Workshop,
pages 65–72.
Danqi Chen, Adam Fisch, Jason Weston, Und
Antoine Bordes. 2017. Reading Wikipedia to
answer open-domain questions. In Proceedings
of ACL 2017, pages 1870–1879. https://doi
.org/10.18653/v1/P17-1171
Hao Cheng, Ming-Wei Chang, Kenton Lee,
and Kristina Toutanova. 2020. Probabilistic
für
assumptions matter:
distantly-supervised document-level question
answering. arXiv preprint arXiv:2005.01898.
https://doi.org/10.18653/v1/2020.acl
-main.501
Improved models
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Und
Kristina Toutanova. 2019. BERT: Pre-training
of deep bidirectional transformers for language
Verständnis. In Proceedings of NAACL-HLT
2019, pages 4171–4186.
B. Dhingra, K. Mazaitis, and W. W. Cohen.
2017. Quasar: Datasets for question answering
by search and reading. arXiv preprint arXiv:
1707.03904.
Jesse Dodge, Suchin Gururangan, Dallas Card,
Roy Schwartz, and Noah A. Schmied. 2019. Show
your work: Improved reporting of experimen-
tal results. In Proceedings of EMNLP-IJCNLP
2019, pages 2185–2194. https://doi.org
/10.18653/v1/D19-1224
Matthew Dunn, Levent Sagun, Mike Higgins, V.
Ugur Guney, Volkan Cirik, and Kyunghyun
Cho. 2017. SearchQA: A new q&a dataset aug-
mented with context from a search engine. arXiv
preprint arXiv:1704.05179.
Joseph L. Fleiss. 1971. Measuring nominal scale
agreement among many raters. Psychological
Bulletin, 76(5):378. https://doi.org/10
.1037/h0031619
Lea Frermann. 2019. Extractive NarrativeQA with
heuristic pre-training. In Proceedings of the 2nd
MRQA Workshop, pages 172–182. https://
https://doi.org/10.18653/v1/D19-5823
Kelvin Guu, Kenton Lee, Zora Tung, Panupong
Pasupat, and Ming-Wei Chang. 2020. Realm:
Retrieval-augmented language model pre-
Ausbildung. arXiv preprint arXiv:2002.08909.
Srinivasan Iyer, Sewon Min, Yashar Mehdad, Und
Wen-tau Yih. 2020. Reconsider: Re-ranking
using span-focused cross-attention for open
domain question answering. arXiv preprint
arXiv:2010.10757.
Gautier
Izacard and Edouard Grave. 2020.
Leveraging passage retrieval with generative
models for open domain question answering.
arXiv preprint arXiv:2007.01282.
Jonathan H. Clark, Chris Dyer, Alon Lavie, Und
Noah A. Schmied. 2011. Better hypothesis testing
for statistical machine translation: Controlling
for optimizer instability. In Proceedings of ACL
2011, pages 176–181.
Vladimir Karpukhin, Barlas Oguz, Sewon Min,
Patrick Lewis, Ledell Wu, Sergey Edunov,
Danqi Chen, and Wen-tau Yih. 2020. Dense
passage
for open-domain ques-
tion answering. In Proceedings EMNLP 2020.
retrieval
1043
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
T
l
A
C
_
A
_
0
0
4
1
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
https://doi.org/10.18653/v1/2020.emnlp
-main.550
Tom´aˇs Koˇcisk`y, Jonathan Schwarz, Phil Blunsom,
Chris Dyer, Karl Moritz Hermann, G´abor
Melis, and Edward Grefenstette. 2018. Der
NarrativeQA reading comprehension challenge.
TACL, 6, 317–328. https://doi.org/10
.1162/tacl a 00023
Kenton Lee, Ming-Wei Chang, and Kristina
Toutanova. 2019. Latent retrieval for weakly
supervised open domain question answering.
Proceedings of ACL 2019.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer
Erheben, Ves Stoyanov, and Luke Zettlemoyer.
2019. BART: Denoising sequence-to-sequence
pre-training for natural language generation,
Übersetzung, and comprehension. arXiv preprint
arXiv:1910.13461. https://doi.org/10
.18653/v1/2020.acl-main.703
Chin-Yew Lin. 2004. ROUGE: A package for
automatic evaluation of summaries. In Text
Summarization Branches Out, pages 74–81,
Barcelona, Spanien. Association for Computa-
tional Linguistics.
Yankai Lin, Haozhe Ji, Zhiyuan Liu, Und
Maosong Sun. 2018. Denoising distantly su-
pervised open-domain question answering. In
Proceedings of ACL 2018, pages 1736–1745.
Sewon Min, Danqi Chen, Hannaneh Hajishirzi,
and Luke Zettlemoyer. 2019. A discrete hard
EM approach for weakly supervised question
answering. In Proceedings of EMNLP-IJCNLP
2019, pages 2844–2857. https://doi.org
/10.18653/v1/D19-1284
Kyosuke Nishida, Itsumi Saito, Kosuke Nishida,
Kazutoshi Shinoda, Atsushi Otsuka, Hisako
Asano, and Junji Tomita. 2019. Multi-style
generative reading comprehension. arXiv pre-
print arXiv:1901.02262. https://doi.org
/10.18653/v1/P19-1220
Kishore Papineni, Salim Roukos, Todd Ward,
and Wei-Jing Zhu. 2002. BLEU: A method for
automatic evaluation of machine translation. In
Proceedings of ACL 2002, pages 311–318.
Matthew Peters, Mark Neumann, Mohit Iyyer,
Matt Gardner, Christopher Clark, Kenton Lee,
and Luke Zettlemoyer. 2018. Deep contextu-
alized word representations. In Proceedings of
NAACL 2018, pages 2227–2237. https://
doi.org/10.18653/v1/N18-1202
Alec Radford, Jeffrey Wu, Rewon Child, David
Luan, Dario Amodei, and Ilya Sutskever. 2019.
Language models are unsupervised multitask
learners. OpenAI Blog, 1(8):9.
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, Michael
Matena, Yanqi Zhou, Wei Li, und Peter J. Liu.
2019. Exploring the limits of transfer learning
with a unified text-to-text transformer. arXiv
preprint arXiv:1910.10683.
Pranav Rajpurkar, Robin Jia, and Percy Liang.
2018. Know what you don’t know: Unanswer-
able questions for squad. In Proceedings of
ACL 2018, pages 784–789. https://doi.org
/10.18653/v1/P18-2124
Stephen E. Robertson, Steve Walker, Susan
Jones, Micheline M. Hancock-Beaulieu, Und
Mike Gatford. 1995. Okapi at trec-3. Nist Spe-
cial Publication Sp, 109:109.
Xiangyang Mou, Mo Yu, Shiyu Chang, Yufei
Feng, Li Zhang, and Hui Su. 2021. Comple-
mentary evidence identification in open-domain
question answering. arXiv preprint arXiv:2103
.11643.
Shikhar Sharma, Layla El Asri, Hannes Schulz,
and Jeremie Zumer. 2017. Relevance of unsu-
pervised metrics in task-oriented dialogue for
evaluating natural language generation. arXiv
preprint arXiv:1706.09799.
Xiangyang Mou, Mo Yu, Bingsheng Yao,
Chenghao Yang, Xiaoxiao Guo, Saloni
Potdar, and Hui Su. 2020. Frustratingly hard
evidence retrieval for qa over books. ACL Nuse
Workshop.
Kai Sun, Dian Yu, Dong Yu, and Claire Cardie.
2019. Improving machine reading comprehen-
sion with general reading strategies. In Pro-
ceedings of NAACL 2019, pages 2633–2643.
https://doi.org/10.18653/v1/N19-1270
1044
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
T
l
A
C
_
A
_
0
0
4
1
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Yi Tay, Shuohang Wang, Anh Tuan Luu, Jie
Fu, Minh C Phan, Xingdi Yuan, Jinfeng Rao,
Siu Cheung Hui, and Aston Zhang. 2019.
Simple and effective curriculum pointer-
generator networks for reading comprehension
over long narratives. In Proceedings of ACL
2019, pages 4922–4931. https://doi.org
/10.18653/v1/P19-1486
Christopher Walker, Stephanie Strassel, Julie
Medero, and Kazuaki Maeda. 2006. ACE 2005
multilingual training corpus. Linguistic Data
Konsortium, Philadelphia, 57:45.
Shuohang Wang, Mo Yu, Xiaoxiao Guo, Zhiguo
Wang, Tim Klinger, Wei Zhang, Shiyu
Chang, Gerry Tesauro, Bowen Zhou, and Jing
Jiang. 2018A. R3: Reinforced ranker-reader
for open-domain question answering. In AAAI
2018.
Shuohang Wang, Mo Yu, Jing Jiang, Wei Zhang,
Xiaoxiao Guo, Shiyu Chang, Zhiguo Wang,
Tim Klinger, Gerald Tesauro, and Murray
Campbell. 2018B. Evidence aggregation for
answer re-ranking in open-domain question
answering. In ICLR 2018.
Shuohang Wang, Luowei Zhou, Zhe Gan,
Yen-Chun Chen, Yuwei Fang, Siqi Sun, Yu
Cheng, and Jingjing Liu. 2020. Cluster-former:
Clustering-based sparse transformer for long-
range dependency encoding. arXiv preprint
arXiv:2009.06097.
Oscar Wilde and Guido Fornelli. 1916. An Ideal
Husband. Putnam.
Wenhan Xiong, Jingfei Du, William Yang Wang,
and Veselin Stoyanov. 2019A. Pretrained en-
cyclopedia: Weakly supervised knowledge-
pretrained language model. In International
Conference on Learning Representations.
Wenhan Xiong, Jiawei Wu, Hong Wang, Vivek
Kulkarni, Mo Yu, Shiyu Chang, Xiaoxiao
Guo,
and William Yang Wang. 2019B.
TweetQA: A social media focused question
answering dataset. In Proceedings of ACL
2019, pages 5020–5031. https://doi.org
/10.18653/v1/P19-1496
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua
Bengio, William Cohen, Ruslan Salakhutdinov,
and Christopher D Manning. 2018. HotpotQA:
A dataset for diverse, explainable multi-hop
question answering. In Proceedings of EMNLP
2018, pages 2369–2380. https://doi.org
/10.18653/v1/D18-1259
Yury Zemlyanskiy, Joshua Ainslie, Michiel de
Jong, Philip Pham, Ilya Eckstein, and Fei Sha.
2021. Readtwice: Reading very large docu-
ments with memories. arXiv preprint arXiv:
2105.04241. https://doi.org/10.18653/v1
/2021.naacl-main.408
A Full Results on NarrativeQA
Tisch 8 gives full results with different metrics.
B Details of ICT Training Data Creation
Our pilot study shows that uniformly sampling the
sentences and their source passages as ‘‘pseudo-
questions’’ (PQs) and ‘‘pseudo-evidences’’ (PEs)
does not work well. Such selected PQs have high
probability to be casual, Zum Beispiel, ‘‘Today is
sunny’’, thus are not helpful for ranker training.
To select useful PQs, we define the following
measure f (S, bj) to level the affinity between each
candidate sentence s and the book bj:
(cid:5)
F (S, bj) =
pmi(wik, bj)
(5)
wik∈s
where pmi(wk, bj) is the word-level mutual-
information between each word wik ∈ s and the
book bj. Intuitively, pmi(wk, bj) can be seen as
the ‘‘predictiveness’’ of the word wk with respect
to the book bj, and f (S, bj) measures the aggre-
gated ‘importance’’ for s. Folglich,
Die
sentence s with the highest f (S, bj) from each
passage pn will be selected as the PQ; the corre-
sponding pn with the PQ removed becomes the
positive sample; whereas the corresponding neg-
ative samples from the same book bj will be the
top-500 passages (exclusive of the source passage
pn) with the highest TF-IDF similarity scores to
the PQ.
During sampling, we filter out stopwords and
punctuation when computing f (S, bj). In movie
scripts, the instructive sentences like ‘‘SWITCH
THE SCENARIO’’ that have poor connections to
its source passages are also ignored. Endlich, Wir
require each PQ contain a minimum number of 3
non-stopwords.
1045
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
T
l
A
C
_
A
_
0
0
4
1
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
System
Bleu-1
Bleu-4
Meteor
ROUGE-L
EM
F1
BiDAF (Koˇcisk`y et al., 2018)
R3 (Wang et al., 2018A)
BERT-heur (Frermann, 2019)
DS-Ranker + BERT (Mou et al., 2020)
ReadTwice(E) (Zemlyanskiy et al., 2021)
BM25 + BERT Reader
+ HARD EM
+ ORQA
+ Oracle IR (BM25 w/ Q+A)
AttSum (top-20) (Koˇcisk`y et al., 2018)
IAL-CPG (Tay et al., 2019)
– curriculum
DS-Ranker + GPT2 (Mou et al., 2020)
BM25 + BART Reader
+ DS-Ranker
+ HARD EM
+ Our Ranker
+ Preread
+ FiD
+ FiD + Preread
+ Oracle IR (BM25 w/ Q+A)
BM25 + GPT-2 Reader
+ Our Ranker
+ Oracle IR (BM25 w/ Q+A)
BM25 + T5 Reader
+ Our Ranker
+ Oracle IR (BM25 w/ Q+A)
5.82/5.68
16.40/15.70
–/12.26
14.60/14.46
21.1/21.1
3.84/3.72
3.52/3.47
–/5.28
5.09/5.03
6.7/7.0
Public Extractive Baselines
0.22/0.25
0.50/0.49
–/2.06
1.81/1.38
3.6/4.0
Our Extractive QA Models
0.94/1.07
1.72/–
1.58/1.30
3.54/4.01
4.29/4.59
4.61/–
5.28/5.06
9.72/9.83
13.27/13.84
14.39/–
15.06/14.25
23.81/24.01
19.79/19.06
23.31/22.92
20.75/–
24.94/–
Public Generative Baselines
1.79/2.11
2.70/2.47
1.52/–
4.76/–
4.60/4.37
5.68/5.59
4.65/–
7.74/–
Our Generative QA Models
4.28/4.65
4.28/4.60
4.48/–
5.22/5.45
6.13/–
5.66/–
6.11/6.31
8.84/9.08
4.74/–
5.01/–
8.16/7.70
3.67/–
4.31/–
8.36/8.32
24.52/25.30
24.91/25.22
25.83/–
27.06/27.68
28.54/–
28.04/–
29.56/29.98
35.04/36.41
24.54/–
24.85/–
33.18/32.95
19.28/–
22.35/–
31.06/31.49
7.32/–
7.84/–
6.33/6.22
11.40/11.90
–/15.15
14.76/15.49
22.7/23.3
–
–
–
6.79/6.66
–/–
–
–
–
13.75/14.45
–/–
12.59/13.81
14.10/–
15.42/15.22
28.33/28.72 15.27/15.39
4.67/5.26
5.92/–
6.25/6.19
11.57/12.55
12.92/–
14.58/14.30
28.42/28.55
14.86/14.02
17.33/17.67
15.42/–
21.89/–
–
–
–
–
6.79/–
19.67/–
6.28/6.73
6.67/6.93
7.29/–
8.57/8.95
23.16/24.47
23.39/24.10
24.31/–
25.83/26.95
26.82/–
26.27/–
8.68/9.25
8.63/8.82
8.75/–
9.35/9.74
9.59/–
9.49/–
10.03/10.33 27.91/29.21 10.45/11.16
14.78/15.07 37.75/39.32 15.78/17.27
10.21/–
9.20/–
20.25/–
22.22/–
5.12/–
7.29/–
12.35/12.47 34.83/34.96 17.09/15.98
6.62/–
7.59/–
12.61/12.93 31.18/32.43 12.77/12.84
16.89/–
20.57/–
4.17/–
6.13/–
21.16/22.28
21.31/21.93
21.91/–
23.80/25.08
25.06/–
24.29/–
26.09/27.58
37.71/38.73
17.72/–
20.03/–
33.65/33.75
15.47/–
18.48/–
31.23/32.18
Tisch 8: Full results on NarrativeQA dev/test set (%) under the Book QA setting. We perform model
selection based on the ROUGE-L score on development set. DS is short for Distant Supervision in Sec. 4.2.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
4
1
1
1
9
6
3
9
9
7
/
/
T
l
A
C
_
A
_
0
0
4
1
1
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
1046