Morphology Without Borders: Clause-Level Morphology
Omer Goldman
Bar Ilan University, Israel
omer.goldman@gmail.com
Reut Tsarfaty
Bar Ilan University, Israel
reut.tsarfaty@biu.ac.il
Abstrakt
Morphological tasks use large multi-lingual
datasets that organize words into inflection
tables, which then serve as training and eval-
uation data for various tasks. Jedoch, A
closer inspection of these data reveals pro-
found cross-linguistic inconsistencies, welche
arise from the lack of a clear linguistic and
operational definition of what is a word, Und
which severely impair the universality of the
derived tasks. To overcome this deficiency, Wir
propose to view morphology as a clause-level
phenomenon, rather than word-level. Es ist ein-
chored in a fixed yet inclusive set of features,
that encapsulates all functions realized in a
saturated clause. We deliver MIGHTYMORPH,
a novel dataset for clause-level morphology
Abdeckung 4 typologically different languages:
English, Deutsch, Turkish, and Hebrew. Wir
use this dataset
to derive 3 clause-level
morphological tasks: inflection, reinflection
and analysis. Our experiments show that the
clause-level tasks are substantially harder than
the respective word-level tasks, while hav-
ing comparable complexity across languages.
Außerdem, redefining morphology to the
clause-level provides a neat
interface with
contextualized language models (LMs) Und
allows assessing the morphological knowl-
edge encoded in these models and their usabil-
ity for morphological tasks. Taken together,
this work opens up new horizons in the
study of computational morphology, leaving
ample space for studying neural morphology
cross-linguistically.
1
Einführung
Morphology has long been viewed as a funda-
mental part of NLP, especially in cross-lingual
settings—from translation (Minkov et al., 2007;
Chahuneau et al., 2013) to sentiment analy-
Schwester (Abdul-Mageed et al., 2011; Amram et al.,
2018)—as languages vary wildly in the extent
to which they use morphological marking as a
means to realize meanings.
Recent years have seen a tremendous devel-
opment in the data available for supervised mor-
phological tasks, mostly via UniMorph (Batsuren
et al., 2022), a large multi-lingual dataset that
provides morphological analyses of standalone
Wörter, organized into inflection tables in over
170 languages. In der Tat, UniMorph was used in all
of SIGMORPHON’s shared tasks in the last de-
cade (Cotterell et al., 2016; Pimentel et al., 2021
Unter anderem).
Such labeled morphological data rely heavily
on the notion of a ‘word’, as words are the ele-
ments occupying the cells of the inflection tables,
and subsequently words are used as the input or
output in the morphological tasks derived from
these tables. Jedoch, a closer inspection of the
data in UniMorph reveals that it is inherently in-
consistent with respect to how words are defined.
Zum Beispiel, it is inconsistent with regards to the
inclusion or exclusion of auxiliary verbs such as
‘‘will’’ and ‘‘be’’ as part of the inflection tables,
and it is inconsistent in the features words in-
flect for. A superficial attempt to fix this problem
leads to the can of worms that is the theoreti-
cal linguistic debate regarding the definition of
the morpho-syntactic word, where it seems that
a coherent cross-lingual definition of words is
nowhere to be found (Haspelmath, 2011).
Relying on a cross-linguistically ill-defined
concept in NLP is not unheard of, but it does
have its price here: It undermines the perceived
universality of the morphological tasks, and skews
annotation efforts as well as models’ accuracy in
favor of those privileged languages in which mor-
phology is not complex. To wit, wenngleich
English and Turkish exhibit comparably complex
systems of tense and aspect marking, pronounced
using linearly ordered morphemes, English is
said to have a tiny verbal paradigm of 5 Formen
in UniMorph while Turkish has several hundred
forms per verb.
Darüber hinaus, although inflection tables have a
superficially similar structure across languages,
1455
Transactions of the Association for Computational Linguistics, Bd. 10, S. 1455–1472, 2022. https://doi.org/10.1162/tacl a 00528
Action Editor: Richard Sproat. Submission batch: 4/2022; Revision batch: 8/2022; Published 12/2022.
C(cid:2) 2022 Verein für Computerlinguistik. Distributed under a CC-BY 4.0 Lizenz.
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
We thus present MIGHTYMORPH, a novel data-
set for clause-level inflectional morphology, cov-
ering 4 typologically different languages: English,
Deutsch, Turkish, and Hebrew. We sample data
from MIGHTYMORPH for 3 clause-level morphol-
ogical tasks: inflection, reinflection, and analysis.
We experiment with standard and state-of-the-
art models for word-level morphological tasks
(Silfverberg and Hulden, 2018; Makarov and
Clematide, 2018; Peters and Martins, 2020) Und
show that clause-level
tasks are substantially
harder compared to their word-level counterparts,
cross-linguistic
while
complexity.
exhibiting comparable
Operating on the clause level also neatly in-
terfaces morphology with general-purpose pre-
trained language models, such as T5 (Raffel et al.,
2020) and BART (Lewis et al., 2020), to harness
them for morphological tasks that were so far
considered non-contextualized. Using the multi-
lingual pre-trained model mT5 (Xue et al., 2021)
on our data shows that complex morphology is
still genuinely challenging for such LMs. Wir
conclude that our redefinition of morphological
tasks is more theoretically sound, crosslingually
more consistent, and lends itself to more sophis-
ticated modeling, leaving ample space to test the
ability of LMs to encode complex morphological
phenomena.
The contributions of this paper are manifold.
Erste, we uncover a major inconsistency in the
current setting of supervised morphological tasks
in NLP (§2). Zweite, we redefine morphologi-
cal inflection to the clause level (§3) and deliver
MIGHTYMORPH, a novel clause-level morphologi-
cal dataset reflecting the revised definition (§4).
We then present data for 3 clause-level morpho-
logical tasks with strong baseline results for all
languages, that demonstrate the profound chal-
lenge posed by our new approach to contempo-
rary models (§5).
2 Morphological Essential Preliminaries
2.1 Morphological Tasks
Morphological tasks in NLP are typically devided
into generation and analysis tasks. In both cases,
the basic morphological structure assumed is an
inflection table. The dimensions of an inflection
table are defined by a set of attributes (gen-
der, number, Fall, usw.) and their possible values
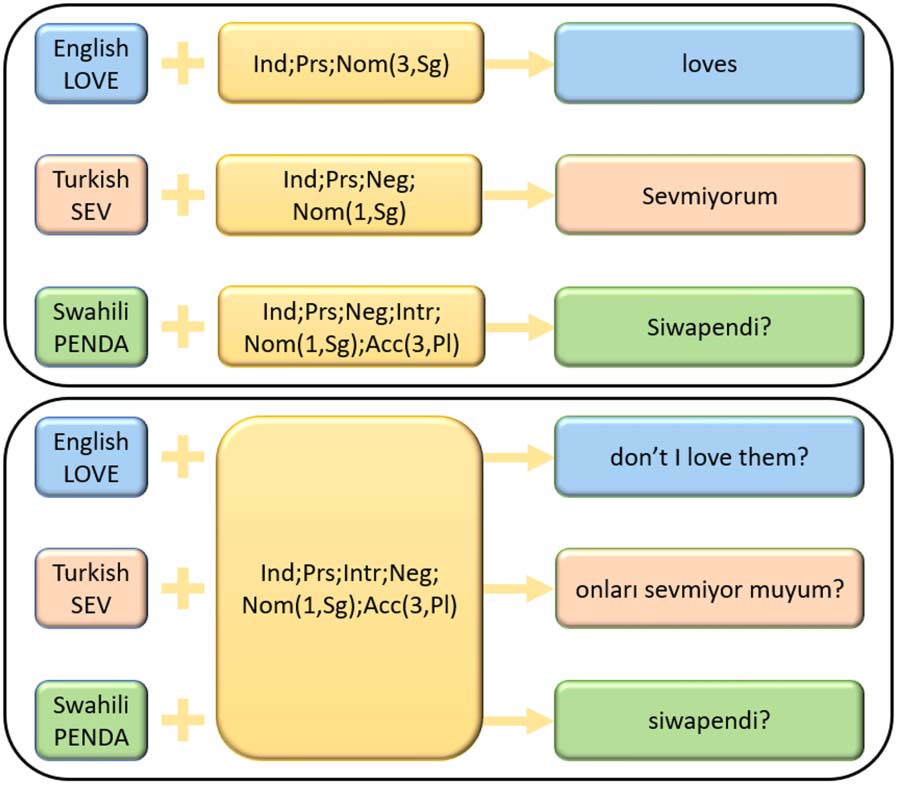
Figur 1: In word-level morphology (top), inflection
scope is defined by ‘wordhood’, and lexemes are
inflected to different sets of features in the bundle
depending on language-specific word definitions. In
our proposed clause-level morphology (bottom) inflec-
tion scope is fixed to the same feature bundle in all
languages, regardless of white-spaces.
they are in fact built upon language-specific sets
of features. Infolge, models are tasked with ar-
bitrarily different dimensions of meaning, guided
by each language’s orthographic tradition (z.B.,
the abundance of white-spaces used) rather than
the set of functions being realized. In this work
we set out to remedy such cross-linguistic incon-
sistencies, by delimiting the realm of morphology
by the set of functions realized, rather than the
set of forms.
Concretely, in this work we propose to rein-
troduce universality into morphological tasks by
side-stepping the issue of what is a word and
giving up on any attempt to determine consistent
word boundaries across languages. Stattdessen, we an-
chor morphological tasks in a cross-linguistically
consistent set of inflectional features, welches ist
equivalent to a fully saturated clause. Dann, Die
lexemes in all languages are inflected to all le-
gal feature combinations of this set, regardless of
the number of ‘words’ or ‘white spaces’ needed
to realize its meaning. Under this revised defini-
tion, the inclusion of the Swahili form ‘siwapendi’
for the lexeme penda inflected to the following
Merkmale: PRS;NEG;NOM(1,SG);ACC(3,PL), entails the
inclusion of the English form ‘I don’t love them’,
bearing the exact same lexeme and features (sehen
Figur 1).
1456
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
lexeme=PENDA
PRS;DECL;NOM(2,SG)
ACC(1,SG)
ACC(1,PL)
ACC(2,SG,RFLX)
ACC(2,PL)
ACC(3,SG)
ACC(3,PL)
IND
POS
unanipenda
unatupenda
unajipenda
unawapendeni
unampenda
unawapenda
lexeme=LOVE
PRS;DECL;NOM(2,SG)
ACC(1,SG)
IND
POS
you love me
ACC(1,PL)
you love us
IND;PERF
POS
NEG
NEG
hunipendi
hutupendi
hujipendi
huwapendini
humpendi
huwapendi
umenipenda
umetupenda
umejipenda
umewapendeni
umempenda
umewapenda
(A) Swahili inflection table
IND;PERF
hujanipenda
hujatupenda
hujajipenda
hujawapendeni
hujampenda
hujawapenda
COND
POS
ungenipenda
ungetupenda
ungejipenda
ungewapendeni
ungempenda
ungewapenda
NEG
usingenipenda
usingetupenda
usingejipenda
usingewapendeni
usingempenda
usingewapenda
COND
NEG
you don’t
love me
you don’t
love us
POS
you have
loved me
you have
loved us
NEG
you haven’t
loved me
you haven’t
loved us
POS
you would
love me
you would
love us
ACC(2,SG,RFLX)
you love
yourself
you don’t
love yourself
you have
loved yourself
you haven’t
loved yourself
you would
love yourself
ACC(2,PL)
you love y’all
ACC(3,SG)
ACC(3,PL)
you love him
you love them
you don’t
love y’all
you don’t
love him
you have
loved y’all
you have
loved him
you haven’t
loved y’all
you haven’t
loved him
you don’t
love them
you have
love them
(B) English inflection table
you haven’t
love them
you would
love y’all
you would
love him
you would
love them
NEG
you wouldn’t
love me
you wouldn’t
love us
you wouldn’t
love yourself
you wouldn’t
love y’all
you wouldn’t
love him
you wouldn’t
love them
Tisch 1: A fraction of a clause-level inflection table, in both English and Swahili. The tables are
completely aligned in terms of meaning, but differ in the number of words needed to realize each cell.
In der Praxis, we did not inflect English clauses for number in 2nd person, so we did not use the y’all
pronoun and it is given here for the illustration.
(z.B., Geschlecht:{masculine,feminine,neuter}). A spe-
cific attribute:value pair defines an inflectional
feature (fortan, a feature) and a specific
combination of features is called an inflectional
feature bundle (Hier, a feature bundle). An in-
flection table includes, for a given lexeme li,
an exhaustive list of m inflected word-forms
{wli
}M
j=0, corresponding to all available feature
bj
bundles {bj}M
j=0. See Table 1a for a fraction of
an inflection table in Swahili. A paradigm in a
Sprache (verbal, nominal, Adjektiv, usw.) is a set
of inflection tables. The set of inflection tables
for a given language can be used to derive labeled
data for (mindestens) 3 different tasks, inflection,
reinflection, and analysis.1
In morphological inflection (1A), the input is a
lemma li and a feature bundle bj that specifies
the target word-form. The output is the inflected
word-form wli
realizing the feature bundle. Ex-
bj
reichlich (1B) is an example in the French verbal
paradigm for the lemma finir, inflected to an in-
dicative IND future tense FUT with a 1st person
singular subject 1;SG.
(1)
A. (cid:3)li, bj(cid:4) (cid:5)→ wli
bj
B. (cid:3) finir, IND;FUT;1;SG(cid:4) (cid:5)→ finirai
The morphological inflection task is in fact a
specific version of a more general task, welches ist
called morphological reinflection. In the general
Fall, the source of inflection can be any form
rather than only the lemma. Speziell, a source
word-form wli
from some lexeme li is given as
bj
input accompanied by its own feature bundle bj,
and the model reinflects it to a different feature
bundle bk, resulting in the word wli
(2A). In
bk
(2B) we illustrate for the same French lemma
finir, a reinflection from the indicative present
tense with a first person singular subject ‘finis’ to
the subjunctive past and second person singular
‘finisses’.
1The list of tasks mentioned above is of course not ex-
haustive; other tasks may be derived from labeled inflec-
tion tables, z.B., the Paradigm Cell Completion Problem
(Ackerman et al., 2009; Cotterell et al., 2017).
(2)
A. (cid:3)bj, wli
bj
(cid:4), (cid:3)bk,
(cid:4) (cid:5)→ wli
bk
B.
(cid:3) IND;PRS;1;SG, finis (cid:4),
(cid:4)
(cid:3) SBJV;PST;2;SG,
(cid:5)→ finisses
1457
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Morphological inflection and reinflection are
generation tasks, in which word forms are gener-
ated from feature specifications. In the opposite
Richtung, morphological analysis is a task where
word-forms are the input, and models map them
to their lemmas and feature bundles (3A). This task
is in fact an inverted version of inflection, as can
be seen in (3), which are the exact inverses of (1).
(3)
(cid:5)→ (cid:3)li, bj(cid:4)
A. wli
bj
B. finirai (cid:5)→ (cid:3)finir, IND;FUT;1;SG(cid:4)
2.2 UniMorph
The most significant source of inflection tables
for training and evaluating all of the aforemen-
tioned tasks is UniMorph2 (Sylak-Glassman et al.,
2015; Batsuren et al., 2022), a large inflectional-
morphology dataset covering over 170 languages.
For each language the data contains a list of
lexemes with all their associated feature bundles
and the words realizing them. Formally, jeden
entry in UniMorph is a triplet (cid:3)l,B,w(cid:4) mit
lemma l, a feature bundle b, and a word-form
w. The tables in UniMorph are exhaustive, Das
Ist, the data generally does not contain partial ta-
bles; their structure is fixed for all lexemes of
the same paradigm, and each cell is filled in
with a single form, unless that form doesn’t ex-
ist in that language.3 The data is usually crawled
from Wiktionary4 or from some preexisting finite-
state automaton. The features for all languages
are standardized to be from a shared inventory
of features, but every language makes use of a
different subset of that inventory.
languages. Zum Beispiel,
So far, the formal definition of UniMorph seems
cross-linguistically consistent. Jedoch, a closer
inspection of UniMorph reveals an inconsistent
definition of words, which then influences the
dimensions included in the inflection tables in
anders
the Finnish
phrase ‘olen ajatellut’ is considered a single word,
even though it contains a white-space. Es ist in-
cluded in the relevant inflection table and anno-
tated as ACT;PRS;PRF;POS;IND;1;SG. Likewise, Die
Albanian phrase ‘do t¨e mendosh’ is also consid-
ered a single word, labeled as IND;FUT;1;PL. In
Kontrast, the English equivalents have thought
and will think, corresponding to the exact same
2https://unimorph.github.io.
3In cases of overabundance, d.h., availability of more than
one form per cell, only one canonical form occupies the cell.
4https://www.wiktionary.org.
feature-bundles and meanings, are absent from
UniMorph, and their construction is considered
purely syntactic.
This overall
inconsistency encompasses the
inclusion or exclusion of various auxiliary verbs
as well as the inclusion of particles, clitics, light
verb constructions, and more. The decision on
what or how much phenomena to include is done
in a per-language fashion that is inherited from
the specific language’s grammatical traditions and
sources. In der Praxis, it is quite arbitrary and taken
without any consideration of universality. Tatsächlich,
the definition of inflected words can be inconsis-
tent even in closely related languages in the same
language family, Zum Beispiel, the Arabic definite
article is included in the Arabic nominal para-
digm, while the equivalent definite article is ex-
cluded for Hebrew nouns.
One possible attempted solution could be to
define words by white-spaces and strictly exclude
any forms with more than one space-delimited
word. Jedoch, this kind of solution will severely
impede the universality of any morphological task
as it would give a tremendous weight to the
orthographic tradition of a language and would
be completely inapplicable for languages that
do not use a word-delimiting sign like Mandarin
Chinese and Thai. Andererseits, a decades-
long debate about a space-agnostic word defini-
tion have failed to result in any workable solution
(see Section 6).
We therefore suggest to proceed in the oppo-
site, far more inclusive, Richtung. We propose
not to try to delineate ‘words’, but rather a con-
sistent feature set to inflect lexemes for, regard-
less of the number of ‘words’ and white spaces
needed to realize it.
3 The Proposal: Word-Free Morphology
In this work we extend inflectional morphology,
Daten, and tasks, to the clause level. We define an
inclusive cross-lingual set of inflectional features
{bj} and inflect lemmas in all languages to the
same set, no matter how many white-spaces have
to be used in the realized form. By doing so, Wir
reintroduce universality into morphology, equat-
ing the treatment of languages in which clauses
are frequently expressed with a single word with
those that use several of them. Figur 1 exem-
plifies how this approach induces universal treat-
languages, als
ment for typologically different
1458
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
lexemes are inflected to the same feature bundles
in all of them.
The Inflectional Features Our guiding princi-
ple in defining an inclusive set of features is the
inclusion of all feature types expressed at word
level in some language. This set essentially de-
fines a saturated clause.
Concretely, our universal feature set contains
the obvious tense, aspect, und Stimmung (TAM) fea-
tures, as well as negation, interrogativity, and all
argument-marking features such as: person, num-
ber, Geschlecht, Fall, formality, and reflexivity. TAM
features are obviously included as the hallmark
of almost any inflectional system, particularly in
most European languages, negation is expressed
at the word level in many Bantu languages (Wilkes
and Nkosi, 2012; Mpiranya, 2014), and interrog-
ativity—in, Zum Beispiel, Inuit (Webster, 1968)
and to a lesser degree in Turkish.
Perhaps more important (and less familiar) Ist
the fact that in many languages multiple argu-
ments can be marked on a single verb. Zum Beispiel-
reichlich, agglutinating languages like Georgian and
Basque show poly-personal agreement, Wo
the verb morphologically indicates features of
multiple arguments, above and beyond the subject.
Zum Beispiel:
(4)
A. Georgian:
Trans: ‘‘we will let you go’’
IND;FUT;NOM(1,PL);ACC(2,SG)
B. Spanish: d´ımelo
Trans: ‘‘tell it to me’’
IMP;NOM(2,SG);ACC(3,SG,NEUT);DAT(1,SG)
C. Basque: dakarkiogu
Trans: ‘‘we bring it to him/her’’
IND;PRS;ERG(1,PL);ABS(3,SG);DAT(3,SG)
Following Anderson’s (1992) feature layering
Ansatz, we propose the annotation of argu-
ments to be done as complex features, das ist,
features that allow a feature set as their value.5
Also, the Spanish verb form d´ımelo (übersetzt:
‘tell it to me’), Zum Beispiel, will be tagged as
IMP;NOM(2,SG);ACC(3,SG,NEUT);DAT(1,SG).
For languages that do not mark the verb’s argu-
ments by morphemes, we use personal pronouns
to realize the relevant feature-bundles, for exam-
Bitte, the bold elements in the English translations
In (4). Treating pronouns as feature realizations
keeps the clauses single-lexemed for all languages,
whether argument incorporating or not. To keep
the inflected clauses single-lexemed in this work,
we also limit the forms to main clauses, avoiding
subordination.
Although we collected the inflectional features
empirically and bottom–up, the list we ended up
with corresponds to Anderson’s (1992, P. 219)
suggestion for clausal inflections: ‘‘[for VP:] aux-
iliaries, tense markers, and pronominal elements
representing the arguments of the clause; Und
determiners and possessive markers in NP’’.
Daher, our suggested feature set is not only di-
verse and inclusive in practice, it is also theoreti-
cally sound.6
To illustrate, Tisch 1 shows a fragment of
a clause-level
inflection table in Swahili and
its English equivalent. It shows that while the
Swahili forms are expressed with one word, their
English equivalents express the same feature
bundles with several words. Including the exact
same feature combinations, while allowing for
multiple ‘word’ expressions in the inflections,
finally makes the comparison between the two
languages straightforward, and showcases the
comparable complexity of clause-level morphol-
ogy across languages.
The Tasks To formally complement our pro-
posal, We amend the task definitions in Section 2
to refer to forms in general f li
rather than
bj
words wli
bj
:
(5) Clause-Level Morphological Tasks
A. inflection
(cid:3)li, bj(cid:4) (cid:5)→ f li
bj
B. reinflection (cid:3)bj, f li
(cid:4), (cid:3)bk,
bj
(cid:5)→ (cid:3)li, bj(cid:4)
C. Analyse
f li
bj
(cid:4) (cid:5)→ f li
bk
See Table 2 for detailed examples of these tasks
for all the languages included in this work.
5This is reminiscent of feature structures in Unification
Grammars (Shieber, 2003) such as GPSG, HPSG, and LFG
(Gazdar et al., 1989; Pollard and Sag, 1994; Bresnan et al.,
2015).
6Our resulted set may still be incomplete, but the principle
holds: When adding a new language with new word-level
Merkmale, these features will be realized for all languages.
1459
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Tisch 2: Examples for the data format used for the inflection, reinflection, and analysis tasks.
4 The MIGHTYMORPH Benchmark
We present MIGHTYMORPH, the first multilingual
clause-level morphological dataset. Like Uni-
Morph, MIGHTYMORPH contains inflection tables
with entries of the form of lemma,
Merkmale,
bilden. The data can be used to elicit training sets
for any clause-level morphological task.
The data covers four languages from three lan-
guage families: English, Deutsch, Turkish, Und
Hebrew.7 Our selection covers languages clas-
sified as isolating, agglutinative, and fusional.
The languages vary also in the extent they uti-
lize morpho-syntactic processes: from the ablaut
extensive Hebrew to no ablauts in Turkish; aus
fixed word order in Turkish to the meaning-
conveying word-order in German. Our data for
least 500 inflec-
each language contains at
tion tables.
Our data is currently limited to clauses con-
structed from verbal lemmas, as these are typical
clause heads. Reserved for future work is the ex-
pansion of the process described below to nomi-
nal and adjectival clauses.
4.1 Data Creation
The data creation process, for any language, can
be characterized by three conceptual compo-
nen: (ich) Lexeme Sampling, (ii) Periphrastic
Construction, Und (iii) Argument Marking. Wir
describe each of the different phases in turn.
As a running example, we will use the English
verb receive.
Lexeme Sampling. To create MIGHTYMORPH,
we first sampled frequently used verbs from
UniMorph. We assessed the verb usage by the
position of the lemma in the frequency-ordered
vocabulary of the FastText word vectors (Grave
et al., 2018).8 We excluded auxiliaries and any
lemmas frequent due to homonymy with non-
verbal lexemes.
7For Hebrew, we annotated a vocalized version in addi-
8https://fasttext.cc/docs/en/crawl-vectors
tion to the commonly used unvocalized forms.
.html.
1460
Periphrastic Constructions We expanded each
verb’s word-level inflection table to include all pe-
riphrastic constructions using a language-specific
rule-based grammar we wrote and the inflection
tables of any relevant auxiliaries. Das ist, Wir
constructed forms for all possible TAM combina-
tions expressible in the language, regardless of the
number of words used to express this combina-
tion of features. Zum Beispiel, when constructing
the future perfect form with a 3rd person singu-
lar subject for the lexeme receive, equivalent to
IND;FUT;PRF;NOM(3,SG), we used the past partici-
ple from the UniMorph inflection table received
and the auxiliaries will and have to construct will
have received.
Argument Marking At first, we added the pro-
nouns that the verb agrees with, unless a pro-drop
applies. For all languages in our selection, das Verb
agrees only with its subject. A place-holder was
then added to mark the linear position of the rest
of the arguments. So the form of our example is
now he will have received ARGS.
In order to obtain a fully saturated clause, Aber
also not to over-generate redundant arguments—
Zum Beispiel, a transitive clause for an intransitive
verb—an exhaustive list of frames for each verb
is needed. The frames are lists of cased arguments
that the verb takes. Zum Beispiel, the English
verb receive has 2 frames, {NOM, ACC} Und {NOM,
ACC, ABL}, where an accusative argument indi-
cates theme and the an ablative argument marks
the source. When associating verbs with their
arguments we did not restrict ourselves to the
distinction between intransitive, transitive, und in-
transitive verbs, we allow arguments of any case.
We treated all argument types equally and anno-
tated them with a case feature, whether expressed
with an affix, an adposition, or a coverb. Daher,
English from you, Turkish senden, and Swahili
kutoka kwako are all tagged with an ablative case
feature ABL(2,SG).
For each frame we exhaustively generated all
suitably cased pronouns without regarding the
semantic plausibility of the resulted clause. Also
the clause he will have received you from it is in
the inflection table since it is grammatical—even
though it sounds odd. Im Gegensatz, he will have
received is not in the inflection table, as it is strictly
ungrammatical, missing (mindestens) one obligatory
Streit.
Vor allem, we excluded adjuncts from the pos-
sible frames, defined here as argument-like ele-
ments that can be added to all verbs without
regards to their semantics, like beneficiary and
location.
We manually annotated 500 verbs in each lan-
guage with a list of frames, each listing 0 or more
arguments. This is the only part of the annotation
process that required manual treatment of indi-
vidual verbs.9 It was done by the authors, mit
the help of a native speaker or a monolingual
dictionary.10
We built an annotation framework that de-
lineates the different stages of the process. Es
includes an infrastructure for grammar description
and an interactive frame annotation component.
Given a grammar description, the system handles
the sampling procedure and constructs all rele-
vant periphrastic constructions while leaving an
additional-arguments place-holder. After receiv-
ing the frame-specific arguments from the user,
the system completes the sentence by replacing
the place holder with all prespecified pronouns
for the frame. The framework can be used to
speed up the process of adding more languages to
MIGHTYMORPH.11 Using this framework, we have
been able to annotate 500 verb frames in about 10
hours per language on average.
4.2 The Annotation Schema
Just as our data creation builds on the word-level
inflection tables of UniMorph and expands
ihnen, so our annotation schema is built upon
UniMorph’s.
In der Praxis, due to the fact that some languages
do use a single word for a fully saturated clause,
we could simply apply the UniMorph annotation
guidelines (Sylak-Glassman, 2016) both as an in-
ventory of features and as general guidelines for
the features’ usage. Adhering to these guidelines
ensures that our approach is able to cover es-
sentially all languages covered by UniMorph. In
addition, we extended the schema with the lay-
ering mechanism described in Section 3 und von
9 Excluding the manual work that may have been put in
constructing the UniMorph inflection tables to begin with.
10For German we used Duden dictionary, and for Turkish
we used the T¨urk Dil Kurumu dictionary.
11The data and annotation scripts are available at
https://github.com/omagolda/mighty morph
tagging tool.
1461
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Table size Feat set size Feats per form Form length
UM MM
UM MM UM MM UM MM
Ing
Deu
Heb
Hebvoc
Tur
5 450
29 512
29 132
29 132
703 702
6
12
13
13
25
32
43
25
25
30
2.8
4.62
4.46
4.46
7.87
12.75
12.67
13.55
13.55
11.95
6.84
9.18
5.20
9.80
17.81
29.63
31.28
20.47
32.02
28.71
Tisch 3: Comparison of statistics over the 4
languages common to UniMorph (UM) Und
MIGHTYMORPH (MM). In all cases, the values for
MIGHTYMORPH are more uniform across languages.
Guriel et al. (2022), and officially adopted as part
of the UniMorph schema by Batsuren et al. (2022).
See Table 4 for a detailed list of features used.
4.3 Data Analysis
The MIGHTYMORPH benchmark represents inflec-
tional morphology in four typologically diverse
languages, yet the data is both more uniform
across languages and more diverse in the fea-
tures realized for each language, compared with
the de facto standard word-level morphological
annotations.
Tisch 3 compares aggregated values between
UniMorph and MIGHTYMORPH across languages:
the inflection table size,12 the number of unique
features used, the average number of features per
bilden, and the average form-length in characters.
We see that MIGHTYMORPH is more cross-
lingually consistent than UniMorph on all four
comparisons: The size of the tables is less varied,
so English no longer has extraordinarily small
tables; the sets of features that were used per lan-
guage are very similar, due to the fact that they all
come from a fixed inventory; and finally, Formen
in all languages are of similar character length
and are now described by feature bundles whose
feature length are also highly similar. The residual
variation in all of these values arises only from
true linguistic variation. Zum Beispiel, Hebrew
does not use features for aspects as Hebrew does
not express verbal aspect at all. This is a strong
empirical indication that applying morphologi-
cal annotation to clauses reintroduces universality
into morphological data.
Zusätzlich,
the bigger inflection tables in
MIGHTYMORPH include phenomena more diverse,
12Since the table size is dependent on the transitivity of the
verb, the clause level is compared to an intransitive table.
like word-order changes in English,
lexeme-
dependent perfective auxiliary in German, Und
partial pro-drop in Hebrew. Daher, models trying
to tackle clause-level morphology will need to
address these newly added phenomena. We con-
clude that our proposed data and tasks are more
universal than the previously studied word-level
morphology.
5 Experimente
Goal We set out to assess the challenges and op-
portunities presented to contemporary models by
clause-level morphological tasks. To this end we
experimented with the 3 tasks defined in Section 3:
inflection, reinflection, and analysis, all executed
both at the word-level and the clause-level.
Splits For each task we sampled from 500 In-
flection tables 10,000 examples (pairs of examples
in the case of reinflection). Wir verwendeten 80% of the
examples for training and the rest was divided
between the validation and test sets. We sampled
the same number of examples from each table
Und, following Goldman et al. (2022), we split the
data such that the lexemes in the different sets are
disjoint. Also, 400 lexemes are used in the train set,
Und 50 are for each of the validation and test sets.
Models As baselines, we applied contemporary
models designed for word-level morphological
tasks (fortan: word-level models). The appli-
cation of word-level models will allow us to assess
the difficulty of the clause-level tasks comparing
to their word-level counterparts. Diese Modelle
generally handle characters as input and output,
and we applied them to clause-level tasks straight-
forwardly by treating white-space as yet another
character rather than a special delimiter. Für
each language and task we trained a separate
model for 50 Epochen. The word-level models we
trained are:
• LSTM: An LSTM encoder-decoder with
attention, by Silfverberg and Hulden (2018).
• TRANSDUCE: A neural transducer predicting
actions between the input and output strings,
by Makarov and Clematide (2018).
• DEEPSPIN: An RNN-based system using
sparsemax instead of softmax, by Peters and
Martins (2020).
1462
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Attribute
Tense
Mood
Aspect
Non-locative Cases
Locative Cases
Sentence Features
Argument
Features
Person
Nummer
Gender
Misc.
Wert
PST(Vergangenheit),PRS(present),FUT(future)
IND(indicative) IMP(imperative) SBJV(subjunctive) INFR
†(necessitative) COND(conditional) QUOT(quotative)
NEC
†(inferential)
HAB(habitual) PROG(progressive) PRF(perfekt) PRSP(prospective)
NOM(nominative) ACC(accusative) DAT(dative) GEN(genitive) COM(comitative) BEN(benefactive)
†(perlative)
†(general locative) ABL(ablative) ALL(allative) ESS(essive) APUD(apudessive) PERL
†(against) AT(bei, general vicinity) ON(An) IN(In) VON
†(um)
LOC
CIRC(near) ANTE(in front) CONTR
NEG(negative) Q(interrogative)
1(1st person) 2(2nd person) 3(3rd person)
SG(singular) PL(plural)
MASC(masculine) FEM(feminine) NEUT(neuter)
FORM(formal) RFLX
†(reflexive)
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Tisch 4: A list of all features used in constructing the data for the 4 languages in MIGHTYMORPH. Upon
addition of new languages the list would expand. Features not taken from Sylak-Glassman (2016) Sind
marked with †.
All models were developed for word-level inflec-
tion. TRANSDUCE is the SOTA for low-resourced
morphological inflection (Cotterell et al., 2017),
and DEEPSPIN is the SOTA in the general setting
(Goldman et al., 2022). We modified TRANSDUCE
to apply to reinflection, while only the generally
designed LSTM could be used for all tasks.
In contrast with word-level tasks, the exten-
sion of morphological tasks to the clause-level
introduces context of a complete sentence, welche
provides an opportunity to explore the benefits of
pre-trained contextualized LMs. Success of such
models on many NLP tasks calls for investigat-
ing their performance in our setting. We thus
used the following pretrained text-to-text model as
an advanced modeling alternative for our clause-
level tasks:
• MT5: An encoder-decoder transformer-based
Modell, pretrained by Xue et al. (2021)
MT5’s input and output are tokens provided by
the model’s own tokenizer; the morphological
features were used as a prompt and were added
to the model’s vocabulary as new tokens with
randomly initialized embeddings.13
13As none of the models were designed to deal with
hierarchical feature structures, the features’ strings were
flattened before training and evaluation. Zum Beispiel,
the bundle IND;PRS;NOM(1,SG);ACC(2,PL)
is replaced with
IND;PRS;NOM1;NOMSG;ACC2;ACCPL.
5.1 Results and Analysis
Tisch 5 summarizes the results for all models
and all tasks, for all languages. When averaged
across languages, the results for the inflection
task show a drop in performance for the word-
inflection models (LSTM, DEEPSPIN, and TRANSDUCE)
on clause-level tasks, indicating that the clause-
level task variants are indeed more challenging.
This pattern is even more pronounced in the re-
sults for the reinflection task which seems to be
the most challenging clause-level task, presum-
ably due to the need to identify the lemma in
the sequence, in addition to inflecting it. Im
analysis task, the only word-level model, LSTM,
actually performs better on the clause level than
on the word level, but this seems to be the effect
one outlier language, nämlich, unvocalized He-
brew, where analysis models suffer from the lack
of diacritization and extreme ambiguity.
Moving from words to clauses introduces con-
Text, and we hypothesized that this would enable
contextualized pretrained LMs to shine. Wie-
immer, on all tasks MT5 did not prove itself to be
a silver bullet. That said, the strong pretrained
model performed on par with the other mod-
els on the challenging reinflection task—the only
task involving complete sentences on both in-
put and output—in accordance with the model’s
pretraining.
In terms of languages, the performance of the
word-level models seems correlated across lan-
guages, with notable under-performance over all
tasks in German. Im Gegensatz, MT5 seems to be
1463
Average
Ing
Deu
Heb
Hebvocalized
Tur
word
clause word
clause word
clause word
clause word
clause word
clause
LSTM
inflec.
DEEPSPIN
TRANSDUCE
MT5
LSTM
reinflec.
TRANSDUCE
MT5
LSTM
MT5
Analyse
NA
84.7
70.0
±1.1 ±1.2
89.4
71.8
±0.8 ±0.5
78.9
86.7
±0.5 ±0.4
51.9
±1.1
45.4
73.2
±1.6 ±9.4
44.5
75.1
±0.5 ±0.8
45.2
±1.8
64.4
62.0
±0.9 ±1.1
42.8
±1.2
NA
NA
70.0
NA
NA
NA
91.7
68.5
60.0
71.7
90.8
76.6
99.4
86.1
90.7
80.4
78.4
64.5
40.0
78.2
85.4
71.5
82.5
97.5
81.1
90.9
47.5
93.1
89.4
57.7
±3.3
31.0
70.7
±1.7
62.7
86.0
81.6
±1.8 ±3.8 ±4.7 ±4.0 ±1.6 ±0.6 ±1.1 ±1.2 ±0.9 ±2.1
87.3
82.7
±2.8 ±1.5 ±0.5 ±0.5 ±0.2 ±0.7 ±2.0 ±0.7 ±2.1 ±1.6
97.2
86.8
±0.4 ±1.1 ±2.5 ±1.3 ±0.6 ±0.8 ±0.5 ±1.1 ±0.1 ±0.5
48.7
±1.7
71.1
78.2
±6.3 ±2.5 ±3.5 ±1.7 ±1.6 ±29.8 ±1.9 ±36.4 ±2.2 ±1.2
72.5
82.7
±1.1 ±0.4 ±0.5 ±0.3 ±1.2 ±2.2 ±1.5 ±1.8 ±1.1 ±2.7
37.5
±7.0
84.4
81.6
±0.4 ±2.2 ±2.2 ±0.6 ±1.3 ±1.4 ±3.6 ±2.2 ±0.7 ±4.5
46.0
±4.5
54.2
±2.0
25.7
73.6
±3.1
79.5
29.7
±1.9
74.8
30.8
±4.2
57.7
48.0
±3.3
30.6
34.2
±1.4
31.4
45.1
±2.7
69.0
±1.2
48.0
±3.3
34.2
±1.4
53.5
34.6
84.7
67.1
85.2
49.2
73.3
80.7
35.5
81.5
41.5
85.6
68.4
34.8
77.2
NA
NA
NA
NA
NA
NA
NA
NA
NA
NA
NA
NA
6.1
Tisch 5: Word and clause results for all tasks, Modelle, and languages, stated in terms of exact match
accuracy in percentage. Over clause tasks, for every language and task the best performing system is in
bold, in cases that are too close to call, in terms of standard deviations, all best systems are marked.
Results are averaged over 3 runs with different initializations and training data order.
somewhat biased towards the western languages,
English and German, especially in the generation
tasks, inflection, and reinflection.
Data Sufficiency To illustrate how much la-
beled data should suffice for training clause-
morphology models, let us first note that the
least) zwei
nature of morphology provides (bei
ways to increase the amount of information
available for the model. One is to increase the
absolute number of sampled examples to larger
training sets, while using the same number of
inflection tables; alternatively, the number of in-
flection tables can be increased for a fixed size
of the training set, increasing not the size but the
variation in the set. The former is especially easy
in languages with larger inflection tables, Wo
each table can provide hundreds or thousands of
inflected forms per lexeme, but the lack of variety
in lexemes may lead to overfitting. To examine
which dimension is more important for the over-
all success in the tasks, we tested both.
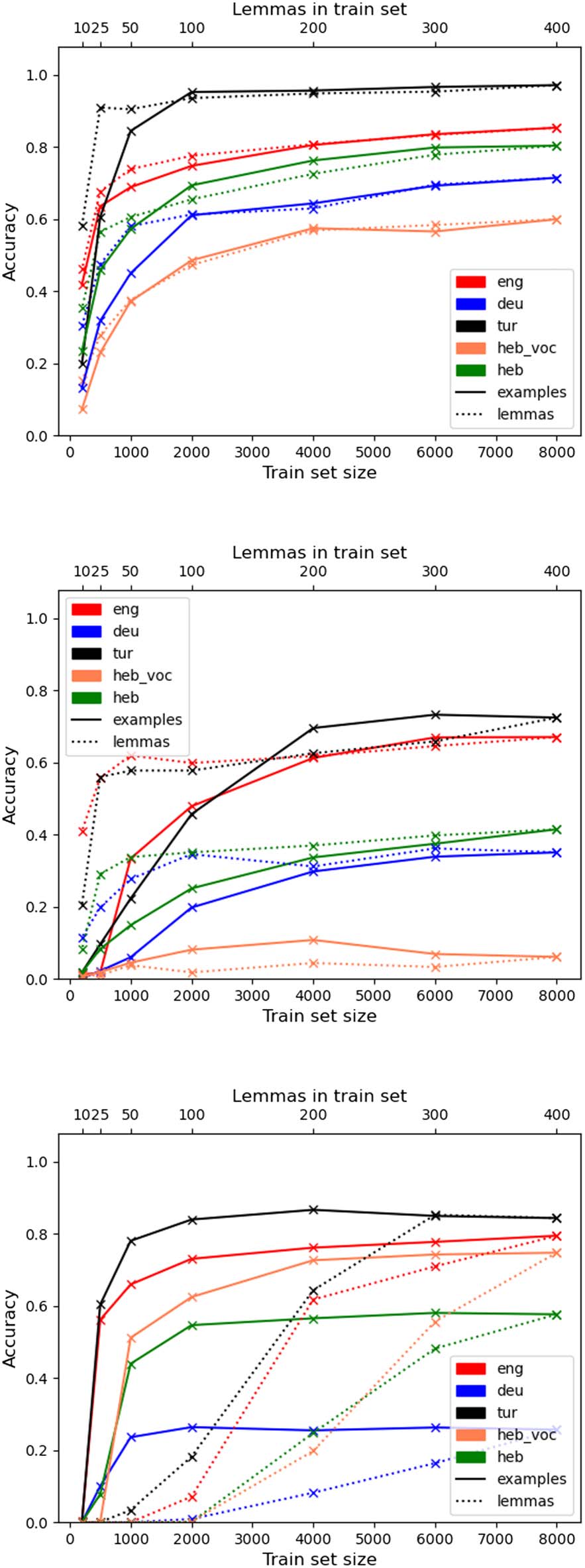
The resulting curves are provided in Figure 2. In
each sub-figure, the solid lines are for the results
as the absolute train set size is increased, Und
the dashed lines are for increasing the number of
lexemes in the train set while keeping the absolute
size of the train set fixed.
The resulting curves show that the balance be-
tween the options is different for each task. Für
inflection (Figure 2a), increasing the size and
the lexeme-variance of the training set produce
similar trends, indicating that one dimension can
compensate for the other. The curves for reinflec-
tion (Figure 2b) show that for this task the number
of lexemes used is more important than the size
of the training set, as the former produces steeper
curves and reaches better performance with rel-
atively little number of lexemes added. Auf der
andererseits, the trend for analysis (Figure 2c) Ist
the other way around, with increased train set
size being more critical than increased lexeme-
variance.
6 Related Work
6.1 Wordhood in Linguistic Theory
The quagmire surrounding words and their demar-
cation is long-standing in theoretical linguistics.
Tatsächlich, no coherent word definition has been pro-
vided by the linguistic literature despite many
attempts. Zum Beispiel, Zwicky and Pullum
(1983) enumerate 6 anders, sometimes contra-
dictory, ways to discern between words, clitics,
and morphemes. Haspelmath (2011) Namen 10
criteria for wordhood before concluding that no
1464
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
the prosodic word (Hall, 1999)
Beispiel,
Ist
defined in phonology and phonetics indepen-
dently of the morphological word (Bresnan and
Mchombo, 1995). And in general, many different
notions of a word can be defined (z.B., Packard,
2000 for Chinese).
Jedoch, the definition of morpho-syntactic
words is inherently needed for the contemporary
division of labour in theoretical linguistics, als es
defines the boundary between morphology, Die
grammatical module in charge of word construc-
tion, and syntax, that deals with word combina-
tion (Dixon and Aikhenvald, 2002). Alternative
theories do exist, including ones that incorpo-
rate morphology into the syntactic constituency
trees (Halle and Marantz, 1993), and others that
expand morphology to periphrastic constructions
(Ackerman and Stump, 2004) or to phrases in
allgemein (Anderson, 1992). In this work we follow
that latter theoretical thread and expand morpho-
logical annotation up to the level of full clauses.
This approach is theoretically leaner and requires
less decisions that may be controversial, zum Beispiel-
reichlich, regarding morpheme boundaries, leer
morphemes, and the like.
The definition of words is also relevant to histor-
ical linguistics, where the common view considers
items on a spectrum between words and affixes.
Diachronically, items move mostly towards the
affix end of the scale in a process known as gram-
maticalization (Hopper and Traugott, 2003) while
occasional opposite movement is also possible
(Norde et al., 2009). Jedoch, here as well it is
difficult to find precise criteria for determining
when exactly an item moved to another category
on the scale, despite some extensive descrip-
tions of the process (z.B., Joseph, 2003 for Greek
future construction).
The vast work striving for cross-linguistically
consistent definition of morpho-syntactic words
seems to be extremely Western-biased, as it as-
pires to find a definition for words that will
roughly coincide with those elements of text
separated by white-spaces in writing of Western
languages, rendering the endeavour particularly
problematic for languages with orthographies
that do not use white-spaces at all, like Chinese
whose grammatical tradition contains very lit-
tle reference to words up until the 20th century
(Duanmu, 1998).
Figur 2: Learning curves for the best performing
model on each task. Solid lines are for increasing train
set sizes while dashed lines are for using more lexemes.
cross-linguistic definition of this notion can cur-
rently be found.
Darüber hinaus, words may be defined differently
in different areas of theoretical linguistics. Für
In this work we wish to bypass this theoretical
discussion as it seems to lead to no workable word
1465
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
definition, and we therefore define morphology
without the need of word demarcation.
7 Limitations and Extensions of
Clause-Level Morphology
6.2 Wordhood in Language Technology
The concept of words has been central to NLP
from the very establishment of the field, as most
models assume tokenized input (z.B., Richens
and Booth, 1952; Winograd, 1971). Jedoch, Die
lack of a word/token delimiting symbol in some
languages prompted the development of more
sophisticated tokenization methods, supervised
(Xue, 2003; Nakagawa, 2004) oder
statistical
(Schuster and Nakajima, 2012), mostly for east
Asian languages.
Statistical
tokenization methods also found
their way to NLP of word-delimiting languages,
albeit for different reasons like dealing with
unattested words and unconventional spelling
(Sennrich et al., 2016; Kudo, 2018). Noch, tokens
produced by these methods are sometimes as-
sumed to correspond to linguistically defined
Einheiten, mostly morphemes (Bostrom and Durrett,
2020; Hofmann et al., 2021).
Zusätzlich, the usage of words as an orga-
nizing notion in theoretical linguistics, separating
morphology from syntax, led to the alignment of
NLP research according to the same subfields,
with resources and models aimed either at syntac-
tic or morphological tasks. Zum Beispiel, syntactic
models usually take their training data from
Universal Dependencies (UD; de Marneffe et al.,
2021), where syntactic dependency arcs connect
words as nodes while morphological features
characterize the words themselves, although some
works have experimented with dependency pars-
ing of nodes other than words, be it chunks
(Abney, 1991; Buchholz et al., 1999) or nuclei
(B¯arzdin¸ ˇs et al., 2007; Basirat and Nivre, 2021).
Jedoch, in these works as well, the predicate-
argument structure is still opaque in agglutinative
languages where the entire structure is expressed
in a single word.
Here we argue that questions regarding the cor-
rect granularity of input for NLP models will
continue to haunt the research, at least until a
thorough reference is made to the predicament
surrounding these questions in theoretical linguis-
Tics. We proposed that given the theoretic state
of affairs, a technologically viable word-free sol-
ution for computational morpho-syntax is desired,
and this work can provide a stepping-stone for
such a solution.
Our revised definition of morphology to dis-
regard word boundaries does not (and is not
intended to) solve all existing problems with
morphological annotations in NLP of course.
Here we discuss some of the limitations and
opportunities of this work for the future of mor-
pho(syntactic) models in NLP.
The Derivation-inflection Divide. Our defini-
tion or clause-level morphology does not solve
the long-debated demarcation of boundary be-
tween inflectional and derivational morphology
(z.B., Scalise, 1988). Speziell, we only refered
here to inflectional features, Und, like UniMorph,
did not provide a clear definition of what counts as
inflectional vs. derivational. Jedoch, we suggest
here that the lack of a clear boundary between in-
flectional and derivational morphology is highly
similar to the lack of definition for words that
operate as the boundary between morphology and
syntax. In der Tat, in the theoretical linguistics lit-
erature, some advocate a view that posits no
boundary between inflectional and derivational
morphology (Bybee, 1985). Although this ques-
tion is out of scope for this work, we conjecture
that this similar problem may require a similar
solution to ours, that will define a single frame-
work for the entire inflectional–derivational mor-
phology continuum without positing a boundary
between them.
Overabundance. Our shift to clause-level mor-
phology does not solve the problem of over-
abundance, where several forms are occupying
the same cell
in the paradigm (Zum Beispiel,
non-mandatory pro-drop in Hebrew). As the prob-
lem exists also in word-level morphology, Wir
followed the same approach and constructed only
one canonical form for each cell. Jedoch, for a
greater empirical reach of our proposal, a further
extension of the inflection table is conceivable, Zu
accommodate sets of forms in every cell, eher
than a single one.
Implications to Syntax. Our solution for an-
notating morphology at the clause level blurs
the boundary between morphology and syntax
as it is often presupposed in NLP, and thus has
implications also for syntactic tasks. Some previ-
ous studies indeed emphasized the cross-lingual
1466
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
inconsistency in word definition from the syn-
tactic perspective (Basirat and Nivre, 2021).
Our work points to a holistic approach for
morpho-syntactic annotation in which clauses are
consistently tagged in a morphology-style anno-
Station, leaving syntax for inter-clausal operations.
Daher, we suggest that an extension of the ap-
proach taken here is desired in order to realize a
single morpho-syntactic framework. Speziell,
our approach should be extended to include: mor-
phological annotation for clauses with multiple
lexemes; realization of morphological features
of more clause-level characteristics (z.B., types
of subordination and conjunction); and annota-
tion of clauses in recursive structures. Diese sind
all fascinating research directions that extend the
present contribution, and we reserve them for
future work.
Polysynthetic Languages. As a final note, Wir
wish to make the observation that a unified
morpho-syntactic system, whose desiderata are
laid out
is essen-
in the previous paragraph,
tial for providing a straightforward treatment of
some highly polysynthetic languages, specific-
ally those that employ noun incorporation to reg-
ularly express some multi-lexemed clauses as a
single word.
the Yupik clause
Zum Beispiel, consider
Mangteghangllaghyugtukut
translated We want
to make a house14 containing 3 lexemes. Its treat-
ment with the current syntactic tools is either
non-helpful, as syntax only characterizes inter-
word relations, or requires ad hoc morpheme seg-
mentation not used in other types of languages.
Umgekehrt, resorting to morphological tools will
also provide no solution, due to the lexeme–
inflection table paradigm that assumes single-
lexemed words. With a single morpho-syntactic
Rahmen, we could annotate the example above
by incorporating the lemmas into their respective
positions on the nested feature structure we used
in this work, ending up with something similar to
yug;IND;ERG(1;PL);COMP(ngllagh;ABS(-mangtegha;
INDEF)). Daher, an annotation of this kind can
expose the predicate-argument structure of the
sentence while also being naturally applicable to
other languages.
Equipped with these extensions, our approach
could elegantly deal with polysynthetic languages
14Example adopted from Yupik UD (Park et al., 2021).
and unlock a morpho-syntactic modeling ability
that is most needed for low-resourced languages.
8 Conclusions
In this work we expose the fundamental
In-
in contemporary computational
consistencies
morphology, nämlich, the inconsistency of word-
hood across languages. To remedy this, Wir
deliver MIGHTYMORPH, the first labeled dataset
for clause-level morphology. We derive training
and evaluation data for the clause-level inflec-
tion, reinflection and analysis tasks. Our data
analysis shows that the complexity of these tasks
is more comparable across languages than their
word-level counterparts. This reinforces our as-
sumption that redefinition of morphology to the
clause-level reintroduces universality into com-
putational morphology. Darüber hinaus, we showed
that standard (Re)inflection models struggle on
the clause-level compared to their performance
on word-level tasks, and that the challenge is not
trivially solved, even by contextualized pretrained
LMs such as MT5. In the future we intend to further
expand our framework for more languages, Und
to explore more sophisticated models that take
advantage of the hierarchical structure or better
utilize pretrained LMs. Darüber hinaus, future work is
planned to expand the proposal and benchmark
to the inclusion of derivational morphology, Und
to a unified morpho-syntactic framework.
Danksagungen
We would like to thank the TACL anonymous
reviewers and the action editor for their insight-
ful suggestions and remarks. Diese Arbeit wurde sup-
ported funded by an ERC-StG grant from the
European Research Council, grant number 677352
(NLPRO), and by an innovation grant by the
Ministry of Science and Technology (MOST)
0002214, for which we are grateful.
Verweise
In Proceedings of
Muhammad Abdul-Mageed, Mona Diab, Und
Mohammed Korayem. 2011. Subjectivity and
sentiment analysis of Modern Standard Ara-
the 49th Annual
bic.
Meeting of the Association for Computational
Linguistik: Human Language Technologies,
pages 587–591, Portland, Oregon, USA. Asso-
ciation for Computational Linguistics.
1467
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Steven P. Abney. 1991. Parsing by chunks.
In Principle-based parsing, pages 257–278,
https://doi.org/10.1007
Springer.
/978-94-011-3474-3_10
Farrell Ackerman, James P. Blevins, and Robert
Malouf. 2009. Parts and wholes: Patterns of
relatedness in complex morphological systems
and why they matter. Analogy in Grammar:
Form and Acquisition, 54:82. https://doi
.org/10.1093/acprof:oso/9780199547548
.003.0003
Farrell Ackerman and Gregory Stump. 2004.
Paradigms and periphrastic expression: A study
in realization-based lexicalism. Projecting
Morphology, pages 111–157.
Adam Amram, Anat Ben David, and Reut
Tsarfaty. 2018. Representations and architec-
tures in neural sentiment analysis for morpho-
logically rich languages: A case study from
Modern Hebrew. In Proceedings of the 27th
International Conference on Computational
Linguistik, pages 2242–2252, Santa Fe, Neu
Mexiko, USA. Association for Computational
Linguistik.
Stephen R. Anderson.
1992. A-morphous
62. Cambridge University
https://doi.org/10.1017
Morphology,
Drücken Sie.
/CBO9780511586262
Guntis B¯arzdin¸ ˇs, Normunds Gr¯uz¯ıtis, Gunta
Neˇspore, and Baiba Saul¯ıte. 2007. Dependency-
based hybrid model of syntactic analysis for
the languages with a rather free word order. In
Proceedings of the 16th Nordic Conference
of Computational Linguistics
(NODALIDA
2007), pages 13–20, Tartu, Estonia. Universität
of Tartu, Estonia.
Ali Basirat and Joakim Nivre. 2021. Syntactic
nuclei in dependency parsing – a multilingual
the 16th
In Proceedings of
exploration.
Conference of the European Chapter of the
Verein für Computerlinguistik:
Main Volume, pages 1376–1387, Online.
Verein für Computerlinguistik.
https://doi.org/10.18653/v1/2021
.eacl-main.117
Ryskina, Sabrina J. Mielke, Elena Budianskaya,
Charbel El-Khaissi, Tiago Pimentel, Michael
Gasser, William Lane, Mohit Raj, Matt Coler,
Jaime Rafael Montoya Samame, Delio
Siticonatzi Camaiteri, Esa´u Zumaeta Rojas,
Didier L´opez Francis, Arturo Oncevay,
Juan L´opez Bautista, Gema Celeste Silva
Villegas, Lucas Torroba Hennigen, Adam
Ek, David Guriel, Peter Dirix, Jean-Philippe
Bernardy, Andrey
Scherbakov, Aziyana
Bayyr-ool, Antonios Anastasopoulos, Roberto
Zariquiey, Karina Sheifer, Sofya Ganieva,
Hilaria Cruz, Ritv´an Karah´oˇga,
Stella
Markantonatou, George Pavlidis, Matvey
Plugaryov, Elena Klyachko, Ali Salehi, Candy
Angulo, Jatayu Baxi, Andrew Krizhanovsky,
Natalia Krizhanovskaya, Elizabeth Salesky,
Clara Vania, Sardana Ivanova, Jennifer White,
Rowan Hall Maudslay, Josef Valvoda, Ran
Zmigrod, Paula Czarnowska, Irene Nikkarinen,
Aelita Salchak, Brijesh Bhatt, Christopher
Straughn, Zoey Liu, Jonathan North Washington,
Yuval Pinter, Duygu Ataman, Marcin Wolinski,
Totok Suhardijanto, Anna Yablonskaya, Niklas
Stoehr, Hossep Dolatian, Zahroh Nuriah,
Shyam Ratan, Francis M. Tyers, Edoardo M.
Ponti, Grant Aiton, Aryaman Arora, Richard
J. Hatcher, Ritesh Kumar, Jeremiah Young,
Daria Rodionova, Anastasia Yemelina,
Taras Andrushko,
Igor Marchenko, Polina
Mashkovtseva, Alexandra Serova, Emily
Prud’hommeaux, Maria Nepomniashchaya,
Fausto Giunchiglia, Eleanor Chodroff, Mans
Hulden, Miikka Silfverberg, Arya D. McCarthy,
David Yarowsky, Ryan Cotterell, Reut
Tsarfaty, and Ekaterina Vylomova. 2022.
Unimorph 4.0: Universal morphology. In Pro-
ceedings of the 13th Language Resources and
Evaluation Conference.
Kaj Bostrom and Greg Durrett. 2020. Byte pair
encoding is suboptimal for language model
the Association
pretraining. In Findings of
für Computerlinguistik: EMNLP 2020,
pages 4617–4624, Online. Association for
Computerlinguistik. https://doi.org
/10.18653/v1/2020.findings-emnlp.414
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Khuyagbaatar Batsuren, Omer Goldman, Salam
Khalifa, Nizar Habash, Witold Kiera´s,
G´abor Bella, Brian Leonard, Garrett Nicolai,
Kyle Gorman, Yustinus Ghanggo Ate, Maria
Joan Bresnan, Ash Asudeh, Ida Toivonen, Und
Stephen Wechsler. 2015. Lexical-Functional
Syntax. John Wiley & Sons. https://doi
.org/10.1002/9781119105664
1468
Joan Bresnan and Sam A. Mchombo. 1995.
The lexical integrity principle: Evidence from
Bantu. Natural Language & Linguistic Theory,
13(2):181–254. https://doi.org/10.1007
/BF00992782
Robert M. W. Dixon and Alexandra Y.
Aikhenvald. 2002. Word: a typological frame-
arbeiten. Word: A Cross-Linguistic Typology,
pages 1–41. https://doi.org/10.1017
/CBO9780511486241.002
Sabine Buchholz, Jorn Veenstra, and Walter
Daelemans. 1999. Cascaded grammatical re-
In 1999 Joint SIGDAT
lation assignment.
Conference on Empirical Methods in Natural
Language Processing and Very Large Corpora.
Joan L. Bybee. 1985. Morphology: A study of the
relation between meaning and form, Volumen 9.
John Benjamins Publishing. https://doi
.org/10.1075/tsl.9
Victor Chahuneau, Eva Schlinger, Noah A.
Schmied, and Chris Dyer. 2013. Translating into
morphologically rich languages with synthetic
phrases. In Proceedings of the 2013 Confer-
ence on Empirical Methods in Natural Lan-
guage Processing, pages 1677–1687, Seattle,
Washington, USA. Association for Computa-
tional Linguistics.
Ryan Cotterell, Christo Kirov,
John Sylak-
Glassman, G´eraldine Walther, Ekaterina
Vylomova, Patrick Xia, Manaal Faruqui,
Sandra K¨ubler, David Yarowsky,
Jason
Eisner, and Mans Hulden. 2017. CoNLL-
SIGMORPHON 2017 shared task: Universal
morphological reinflection in 52 languages.
In Proceedings of the CoNLL SIGMORPHON
2017 Shared Task: Universal Morphological
Reinflection, pages 1–30, Vancouver. Associ-
ation for Computational Linguistics. https://
doi.org/10.18653/v1/K17-2001
Ryan Cotterell, Christo Kirov,
John Sylak-
Glassman, David Yarowsky, Jason Eisner,
and Mans Hulden. 2016. The SIGMORPHON
2016 shared task—Morphological
reinflec-
tion. In Proceedings of
the 14th SIGMOR-
PHON Workshop on Computational Research
in Phonetics, Phonology, and Morphology,
pages 10–22, Berlin, Deutschland. Association for
Computerlinguistik. https://doi
.org/10.18653/v1/W16-2002
San Duanmu. 1998. Wordhood in Chinese. In
New approaches to Chinese word formation,
pages 135–196, De Gruyter Mouton.
Gerald Gazdar, Ewan Klein, Geoffrey Pullum,
and Ivan Sag. 1989. Generalized phrase
structure grammar. Philosophical Review,
98(4):556–566. https://doi.org/10.2307
/2185122
Omer Goldman, David Guriel, and Reut Tsarfaty.
2022.
inflection:
(un)solving morphological
Lemma overlap artificially inflates models’
Leistung. In Proceedings of the 60th An-
nual Meeting of the Association for Computa-
tional Linguistics, Dublin, Ireland. Association
für Computerlinguistik. https://doi
.org/10.18653/v1/2022.acl-short.96
Edouard Grave, Piotr Bojanowski, Prakhar
Gupta, Armand Joulin, and Tomas Mikolov.
2018. Learning word vectors for 157 languages.
In Proceedings of the Eleventh International
Conference on Language Resources and Evalu-
ation (LREC 2018), Miyazaki, Japan. European
Language Resources Association (ELRA).
David Guriel, Omer Goldman, and Reut Tsarfaty.
2022. Morphological reinflection with multiple
arguments: An extended annotation schema
and a georgian case study. In Proceedings of
the 60th Annual Meeting of the Association
für Computerlinguistik, Dublin, Ireland.
Verein für Computerlinguistik.
https://doi.org/10.18653/v1/2022
.acl-short.21
T. Alan Hall. 1999. The phonological word: A
Rezension. Studies on the Phonological Word,
174(1):22. https://doi.org/10.1075
/cilt.174.02hal
Morris Halle and Alec Marantz. 1993. Distrib-
uted morphology and the pieces of inflection.
The View from Building 20, pages 111–176.
Marie-Catherine de Marneffe, Christopher D.
Manning, Joakim Nivre, and Daniel Zeman.
2021. Universal dependencies. Rechnerisch
Linguistik, 47(2):255–308. https://doi
.org/10.1162/coli_a_00402
Martin Haspelmath. 2011. The indeterminacy of
word segmentation and the nature of morphol-
ogy and syntax. Folia Linguistica, 45(1):31–80.
https://doi.org/10.1515/flin.2011
.002
1469
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Valentin Hofmann, Janet Pierrehumbert, Und
Hinrich Sch¨utze. 2021. Superbizarre is not
superb: Derivational morphology improves
BERT’s interpretation of complex words. In
Proceedings of the 59th Annual Meeting of
the Association for Computational Linguistics
and the 11th International Joint Conference
on Natural Language Processing (Volumen
1: Long Papers), pages 3594–3608, Online.
Verein für Computerlinguistik.
https://doi.org/10.18653/v1/2021
.acl-long.279
Paul J. Hopper and Elizabeth Closs Traugott.
2003. Grammaticalization. Cambridge Univer-
sity Press. https://doi.org/10.1017
/CBO9781139165525
Brian D. Joseph. 2003. Morphologization from
syntax. Handbook of Historical Linguistics,
pages 472–492. https://doi.org/10.1002
/9780470756393.ch13
Taku Kudo. 2018. Subword regularization: Ich bin-
proving neural network translation models
with multiple subword candidates. In Pro-
ceedings of
the 56th Annual Meeting of
the Association for Computational Linguis-
Tics (Volumen 1: Long Papers), pages 66–75,
Melbourne, Australia. Association for Compu-
tational Linguistics. https://doi.org/10
.18653/v1/P18-1007
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad,
Abdelrahman Mohamed,
Omer Levy, Veselin Stoyanov, and Luke
Zettlemoyer. 2020. BART: Denoising sequence-
to-sequence pre-training for natural language
Generation, Übersetzung, and comprehension. In
Proceedings of the 58th Annual Meeting of
the Association for Computational Linguis-
Tics, pages 7871–7880, Online. Association for
Computerlinguistik. https://doi.org
/10.18653/v1/2020.acl-main.703
Peter Makarov and Simon Clematide. 2018.
Neural transition-based string transduction for
limited-resource setting in morphology. In Pro-
ceedings of the 27th International Conference
on Computational Linguistics, pages 83–93,
Santa Fe, New Mexico, USA. Association for
Computerlinguistik.
Einat Minkov, Kristina Toutanova, and Hisami
Suzuki. 2007. Generating complex morphol-
ogy for machine translation. In Proceedings
of the 45th Annual Meeting of the Association
of Computational Linguistics, pages 128–135,
Prague, Czech Republic. Association for Com-
putational Linguistics.
Fid`ele Mpiranya. 2014. Swahili Grammar and
Workbook. Routledge. https://doi.org
/10.4324/9781315750699
Tetsuji Nakagawa. 2004. Chinese and Japanese
word segmentation using word-level and
In COLING
character-level
Information.
2004: Proceedings of the 20th International
Conference on Computational Linguistics,
pages 466–472, Genf, Schweiz. COLING.
https://doi.org/10.3115/1220355
.1220422
Muriel Norde et al. 2009. Degrammaticalization.
Oxford University Press. https://doi.org
/10.1093/acprof:oso/9780199207923
.001.0001
Jerome L. Packard. 2000. The Morphology of
Chinese: A Linguistic and Cognitive Approach.
Cambridge University Press. https://doi
.org/10.1017/CBO9780511486821
Hyunji Park, Lane Schwartz, and Francis Tyers.
2021. Expanding Universal Dependencies
for polysynthetic languages: A case of St.
Lawrence Island Yupik. In Proceedings of the
First Workshop on Natural Language Process-
ing for Indigenous Languages of the Americas,
pages 131–142, Online. Association for Com-
putational Linguistics. https://doi.org/10
.18653/v1/2021.americasnlp-1.14
Ben Peters and Andr´e F. T. Martins. 2020. Eins-
size-fits-all multilingual models. In Proceed-
the 17th SIGMORPHON Workshop
ings of
on Computational Research in Phonetics, Pho-
nology, and Morphology, pages 63–69, Online.
Verein für Computerlinguistik.
https://doi.org/10.18653/v1/2020
.sigmorphon-1.4
Tiago Pimentel, Maria Ryskina, Sabrina J. Mielke,
Shijie Wu, Eleanor Chodroff, Brian Leonard,
Garrett Nicolai, Yustinus Ghanggo Ate, Salam
Khalifa, Nizar Habash, Charbel El-Khaissi,
Omer Goldman, Michael Gasser, William Lane,
Matt Coler, Arturo Oncevay, Jaime Rafael
Montoya Samame, Gema Celeste Silva
1470
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
Villegas, Adam Ek, Jean-Philippe Bernardy,
Andrey Shcherbakov, Aziyana Bayyr-ool,
Karina Sheifer, Sofya Ganieva, Matvey
Plugaryov, Elena Klyachko, Ali Salehi,
Andrew Krizhanovsky, Natalia Krizhanovsky,
Clara Vania, Sardana Ivanova, Aelita Salchak,
Christopher Straughn, Zoey Liu, Jonathan
North Washington, Duygu Ataman, Witold
Kiera´s, Marcin Woli´nski, Totok Suhardijanto,
Niklas
Shyam
Stoehr, Zahroh Nuriah,
Ratan, Francis M. Tyers, Edoardo M. Ponti,
Grant Aiton, Richard J. Hatcher, Emily
Prud’hommeaux, Ritesh Kumar, Mans Hulden,
Botond Barta, Dorina Lakatos, G´abor Szolnok,
´Acs, Mohit Raj, David Yarowsky,
Judit
Ryan Cotterell, Ben Ambridge, and Ekaterina
Vylomova. 2021. Sigmorphon 2021 geteilt
task on morphological reinflection: Generali-
zation across languages. In Proceedings of the
18th SIGMORPHON Workshop on Compu-
tational Research in Phonetics, Phonology,
and Morphology, pages 229–259, Online.
Verein für Computerlinguistik.
https://doi.org/10.18653/v1/2021
.sigmorphon-1.25
Carl Pollard and Ivan A. Sag. 1994. Kopf-
Driven Phrase Structure Grammar. Universität
of Chicago Press.
Colin Raffel, Noam Shazeer, Adam Roberts,
Katherine Lee, Sharan Narang, Michael
Matena, Yanqi Zhou, Wei Li, und Peter J. Liu.
2020. Exploring the limits of transfer learning
with a unified text-to-text transformer. Zeitschrift
of Machine Learning Research, 21(140):1–67.
Richard H. Richens and A. Donald Booth. 1952.
Some methods of mechanized translation. In
Proceedings of the Conference on Mechanical
Translation.
Sergio Scalise. 1988. Inflection and derivation.
Linguistik, 26(4):561–582. https://doi
.org/10.1515/ling.1988.26.4.561
Mike Schuster and Kaisuke Nakajima. 2012.
Japanese and Korean voice search. In 2012
IEEE International Conference on Acous-
Tics, Speech and Signal Processing (ICASSP),
pages 5149–5152. IEEE. https://doi.org
/10.1109/ICASSP.2012.6289079
Rico Sennrich, Barry Haddow, and Alexandra
Birch. 2016. Neural machine translation of
rare words with subword units. In Proceedings
of the 54th Annual Meeting of the Associa-
tion for Computational Linguistics (Volumen 1:
Long Papers), pages 1715–1725, Berlin,
Deutschland. Association for Computational Lin-
guistics. https://doi.org/10.18653
/v1/P16-1162
Stuart M. Shieber. 2003. An Introduction to
Unification-Based Approaches to Grammar.
Microtome Publishing.
Miikka Silfverberg and Mans Hulden. 2018.
An encoder-decoder approach to the paradigm
Die
cell filling problem. In Proceedings of
2018 Conference on Empirical Methods in Nat-
ural Language Processing, pages 2883–2889,
Brussels, Belgien. Association for Computa-
tional Linguistics. https://doi.org/10
.18653/v1/D18-1315
John Sylak-Glassman. 2016. The composition
and use of the universal morphological fea-
ture schema (unimorph schema). Technisch
Bericht, Department of Computer Science, Johns
Hopkins University.
John Sylak-Glassman, Christo Kirov, David
Yarowsky, and Roger Que. 2015. A language-
independent feature schema for inflectional
morphology. In Proceedings of the 53rd An-
nual Meeting of the Association for Compu-
tational Linguistics and the 7th International
Joint Conference on Natural Language Process-
ing (Volumen 2: Short Papers), pages 674–680,
Peking, China. Association for Computational
Linguistik. https://doi.org/10.3115
/v1/P15-2111
Donald Humphry Webster. 1968. Let’s learn
Eskimo. Summer Institute of Linguistics.
Arnett Wilkes and Nikolias Nkosi. 2012. Com-
plete Zulu Beginner to Intermediate Book and
Audio Course: Learn to Read, Write, Speak
and Understand a New Language with Teach
Yourself . Hachette UK.
Terry Winograd. 1971. Procedures as a rep-
resentation for data in a computer program
for understanding natural language. Technisch
Bericht, Project MAC, MIT.
Linting Xue, Noah Constant, Adam Roberts,
Mihir Kale, Rami Al-Rfou, Aditya Siddhant,
Aditya Barua, and Colin Raffel. 2021. mT5:
A massively multilingual pre-trained text-to-
text transformer. In Proceedings of the 2021
1471
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
the North American Chap-
Conference of
the Association for Computational
ter of
Linguistik: Human Language Technologies,
pages 483–498, Online. Association for Com-
putational Linguistics.
Nianwen Xue. 2003. Chinese word segmentation
as character tagging. In International Jour-
nal of Computational Linguistics & Chinese
Language Processing, Volumen 8, Nummer 1,
Februar 2003: Special Issue on Word For-
mation and Chinese Language Processing,
pages 29–48.
Arnold M. Zwicky and Geoffrey K. Pullum.
1983. Cliticization vs. inflection: English n’t.
Language, 59(3):502–513. https://doi.org
/10.2307/413900
l
D
Ö
w
N
Ö
A
D
e
D
F
R
Ö
M
H
T
T
P
:
/
/
D
ich
R
e
C
T
.
M
ich
T
.
e
D
u
/
T
A
C
l
/
l
A
R
T
ich
C
e
–
P
D
F
/
D
Ö
ich
/
.
1
0
1
1
6
2
/
T
l
A
C
_
A
_
0
0
5
2
8
2
0
6
5
9
4
2
/
/
T
l
A
C
_
A
_
0
0
5
2
8
P
D
.
F
B
j
G
u
e
S
T
T
Ö
N
0
7
S
e
P
e
M
B
e
R
2
0
2
3
1472